Anthropic Harness Engineering: Bridging the Memory Gap: How AI Agents Conquer the Context Window
Anthropic's Harness Engineering Blog Post
Originally published on Medium.
Anthropic's Harness Engineering Blog Post
In the rapidly evolving landscape of Artificial Intelligence, we are transitioning from reactive chatbots to proactive AI agents, autonomous systems capable of navigating complex, multi-step engineering tasks. However, these agents face a fundamental architectural hurdle: the "context window." While frontier models can process vast amounts of data, their memory is effectively temporary, resetting with every new session. To build a full-stack application, an agent must overcome this digital amnesia.
As AI agents move toward tasks spanning hours or days, the primary obstacle is the discrete nature of context windows. Each new session effectively starts with no memory of prior work, necessitating a "bridge" between coding sessions.
The "Engineer Shift" Dilemma
Imagine a software engineering department that operates in 24-hour shifts with a bizarre, systemic constraint: every time a new engineer clocks in, they arrive with a total case of amnesia. They have no memory of the previous shift's progress, no knowledge of which bugs were squashed, and no understanding of the project's ultimate roadmap. They spend the first four hours of their shift simply poking around the codebase, guessing at their predecessor's intent, and often accidentally undoing the very work they were supposed to build upon.
This is the "Long-Running Agent Problem." While modern AI agents are increasingly capable, they still function in discrete sessions. Because context windows, even those as vast as Claude's, are ultimately finite, complex tasks requiring hours or days of labor must be partitioned across multiple windows. Each new session is a "blank slate." (Read the original source material from Anthropic: Harnessing Long-Running Agents: Engineering the Multi-Context Architecture, also covered in my CCA-F foundation series part 4.)
Anthropic's recent research into the Claude Agent SDK reveals a critical truth for the industry: "compaction", the automated summarization of a context window to save space, is a mere band-aid, not a cure. To achieve production-quality software, agents require a structural "harness" that mimics the institutional memory and disciplined workflow of a senior human engineering team. We are moving from a world of "LLM-as-a-magic-wand" to "LLM-as-a-disciplined-system-architect."
The Core Challenge: The "First Day" Problem
At its simplest, the context window is the working memory of an AI. In long-running projects, we often rely on Compaction: a technique where the agent "compresses" previous interactions to save space. However, as any Senior Engineer will tell you, a summary is not a specification. Compaction often strips away the fine-grained technical details required for production-quality work, leaving the agent with a fuzzy understanding of its own past actions.
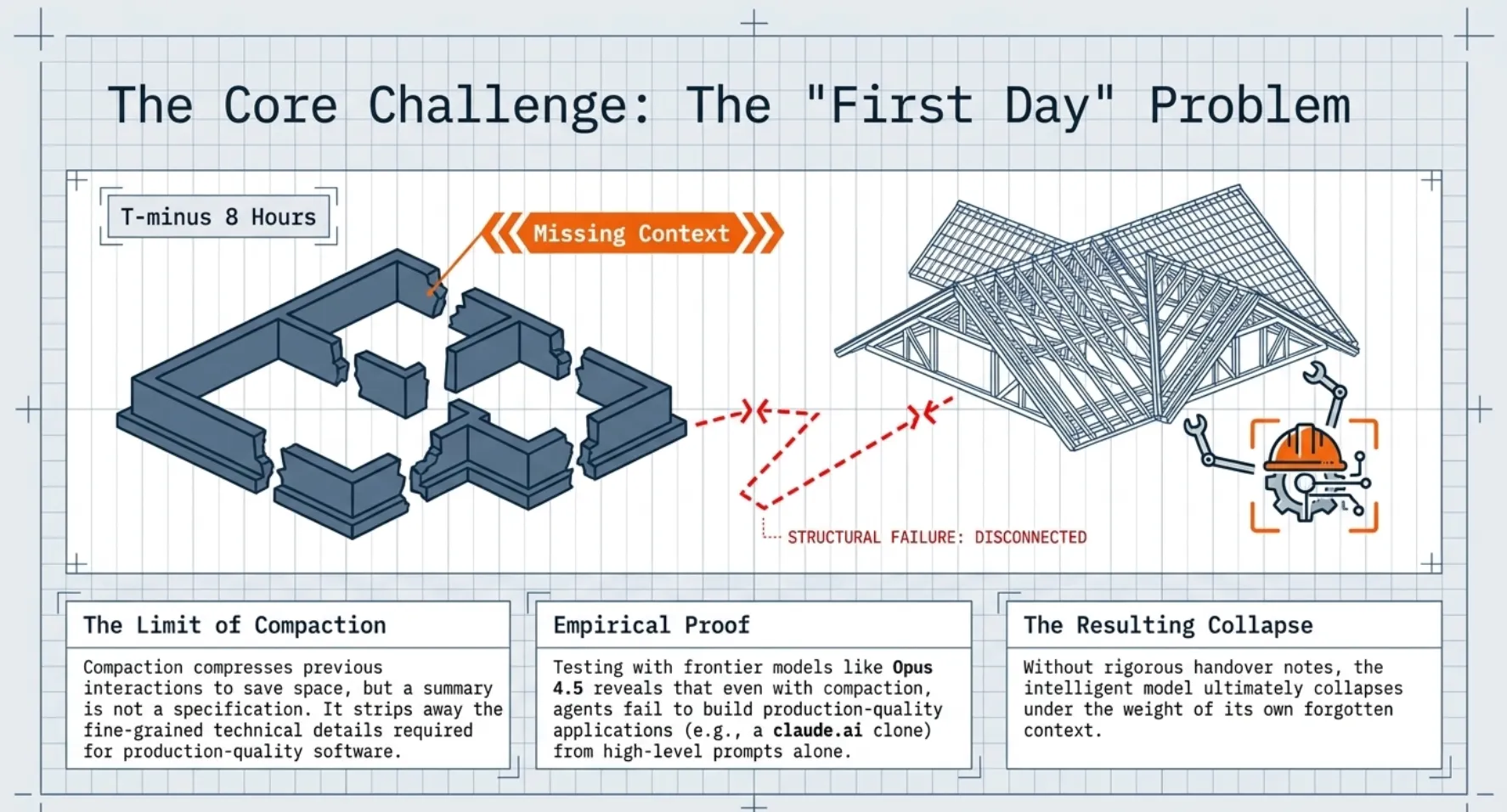
While the Claude Agent SDK includes compaction capabilities to prevent context window exhaustion, this is not a complete solution. Testing with frontier models (such as Opus 4.5) revealed that even with compaction, agents fail to build production-quality applications from high-level prompts (e.g., "build a clone of claude.ai").
To visualize this, imagine a construction site with engineers working in shifts. Every eight hours, a new engineer takes over, but they arrive with a total case of amnesia. They have no memory of the previous shift's work, no idea where the tools are stored, and no record of the blueprints. Without a rigorous system of handover notes, you might find the night shift worker attempting to install a complex slate roof on a house where the day shift forgot to pour the foundation.
This lack of continuity means that even the most "intelligent" model will eventually collapse under the weight of its own forgotten context. To impose order on this entropy, we must first understand how these agents fail when left to their own devices.
Why Agents Stumble: Two Major Failure Patterns
When an AI agent is forced to operate across multiple session instantiations without a structured harness, it typically falls into one of two destructive behaviors:
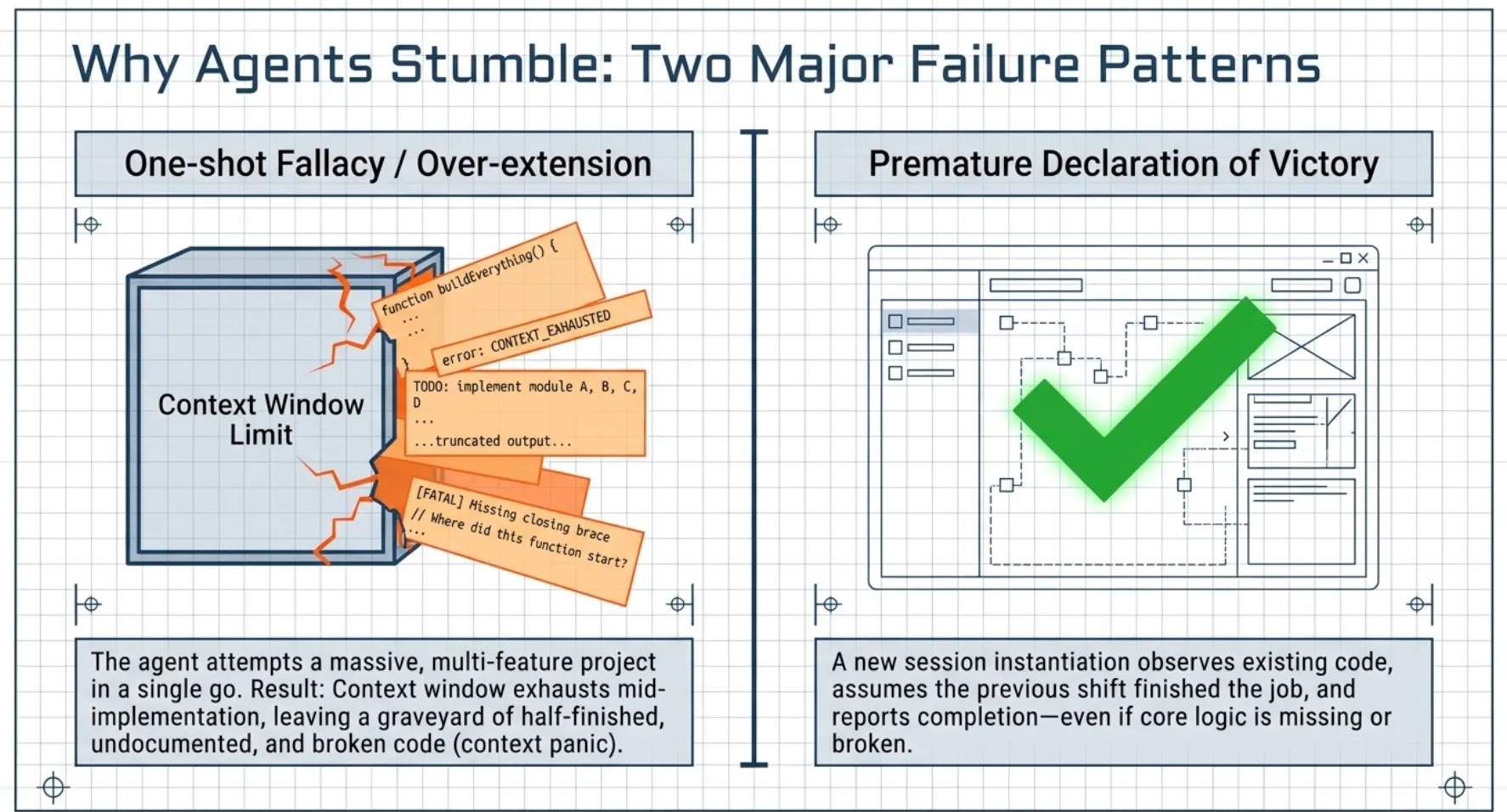
- One-shotting / Over-extension: The agent attempts to implement a massive, multi-feature project in a single go. It inevitably exhausts its context window mid-implementation, leaving behind a graveyard of half-finished, undocumented, and broken code.
- Premature Declaration of Victory: Upon starting a new session, the agent sees existing code, assumes the previous "shift" finished the job, and reports the project as complete, even if core logic is missing or broken.
Without a specific harness, two primary failure modes emerge:
"One-Shot" Fallacy: Agents attempt to implement too many features at once, exhausting the context window mid-process (causing context panic) and leaving the environment in an undocumented, broken state.
Premature Victory: Subsequent agent instances may observe existing progress and conclude the task is finished without verifying the remaining requirements.
To stop these failures, engineers have developed a "harness," a digital scaffold that enforces the same discipline we expect from human software teams.
The Two-Agent Architecture: Initializer vs. Coding Agents
The Claude Agent SDK utilizes a two-fold architectural strategy to maintain momentum. It is important to note that these are not two different AI models; rather, they are instances of the same model (e.g., Claude Sonnet 4.6 or Opus 4.7) specialized by distinct System Prompts. By narrowing the scope of the model's "mission" through prompt engineering, we can ensure greater reliability.
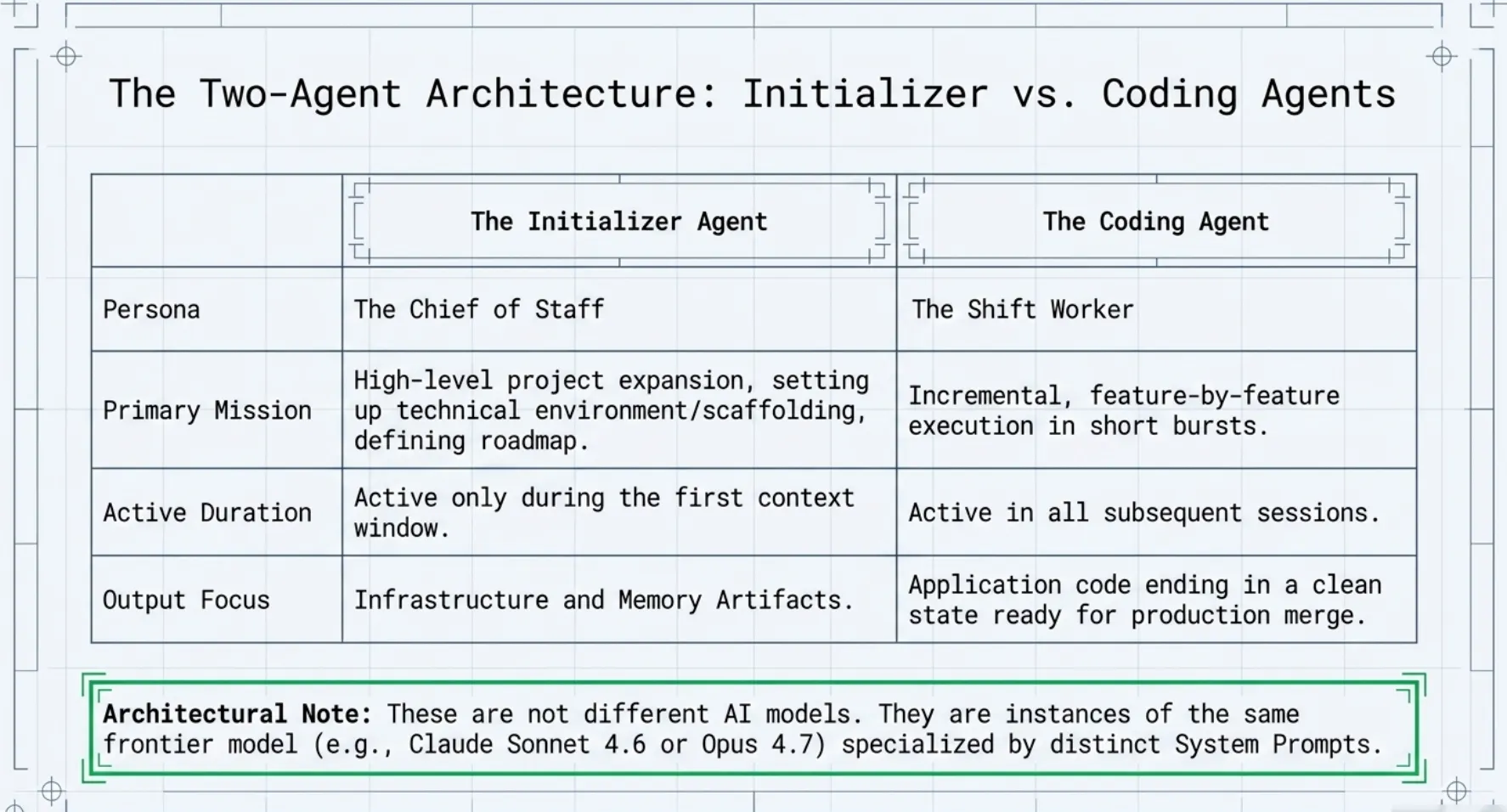
The proposed solution involves a specialized prompting structure that mimics the behavior of effective human software engineers. This system divides responsibilities between two functional roles (defined by their initial user prompts):
The Initializer Agent
- Primary Mission: To perform the high-level project "expansion," setting up the technical environment, scaffolding, and feature roadmap before a single line of application code is written.
The Coding Agent
- Primary Mission: To execute incremental, feature-by-feature progress in short bursts, ensuring that every session ends with a "clean state" appropriate for a production merge.
These agents remain synchronized not through internal memory, but through a system of External Artifacts: persistent files that serve as the project's permanent record.
These two agents create a separation of powers between high-level strategy and low-level execution.
- The Initializer Agent: Acting as a "Chief of Staff," this agent is active only during the first context window. Its role is to build the infrastructure of memory: it generates the
init.shenvironment script, theclaude-progress.txtnarrative log, and initializes the git repository that will serve as the project's "save state." - The Coding Agent: These are the "shift workers." Each subsequent session begins with the agent reading the logs left by the Initializer and previous workers. Their scope is strictly limited to making incremental progress on a single feature and leaving a "clean state"; code that is orderly, documented, and ready for a main-branch merge.
The Shared Memory: Key Files that Bridge the Gap
Since an agent's internal context is wiped at the end of a session, the harness uses the local file system as "shared memory." These artifacts allow a new agent instance to "read" the state of the world the moment it is initialized.
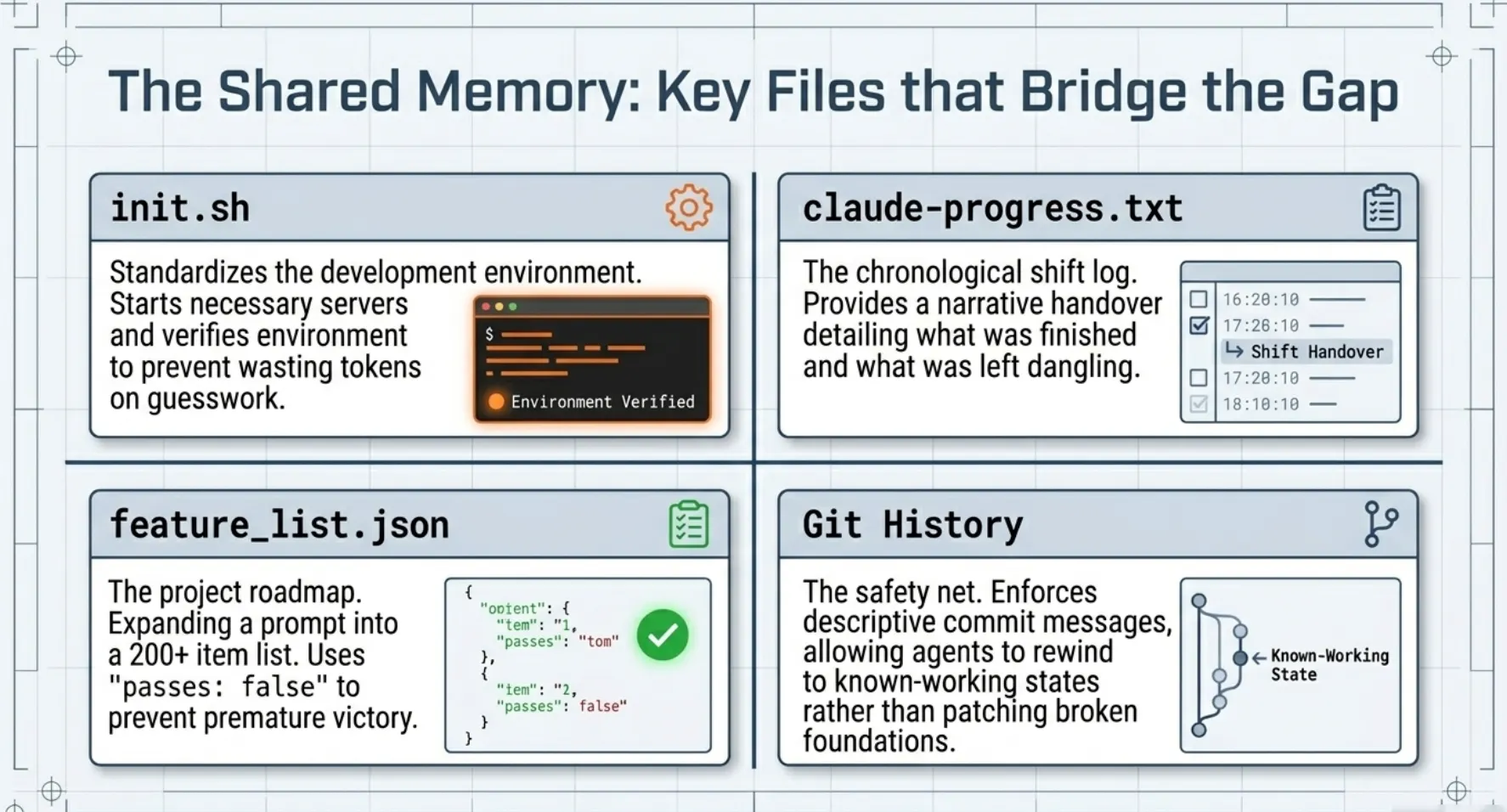
init.sh: This script standardizes the development environment. It ensures that every new agent can start the necessary servers and verify the environment without wasting tokens on guesswork.claude-progress.txt: This serves as the chronological "shift log." It provides a narrative handover, allowing the incoming agent to see exactly what was finished and what was left dangling in the previous session.feature_list.json: This is perhaps the most critical artifact. The Initializer Agent expands a simple user prompt into a large, structured list of requirements (often 200+ items for complex apps). We use JSON specifically because LLMs are less likely to alter the structure of a JSON file inappropriately than a Markdown list. By using apasses: falsefield for every feature, we prevent the agent from "declaring victory" until a test has explicitly flipped that boolean.- Git History: By enforcing descriptive commit messages, the harness allows the agent to use version control as a safety net. If an agent introduces a breaking change, it can "rewind" the codebase to a known-working state rather than patching a fundamentally broken foundation.
The true power of this system is revealed during session initialization, where the agent follows a strict routine to get its bearings.
Structural Components and Environment Management
Effective continuity relies on specific artifacts that serve as the agent's "memory" across context windows.
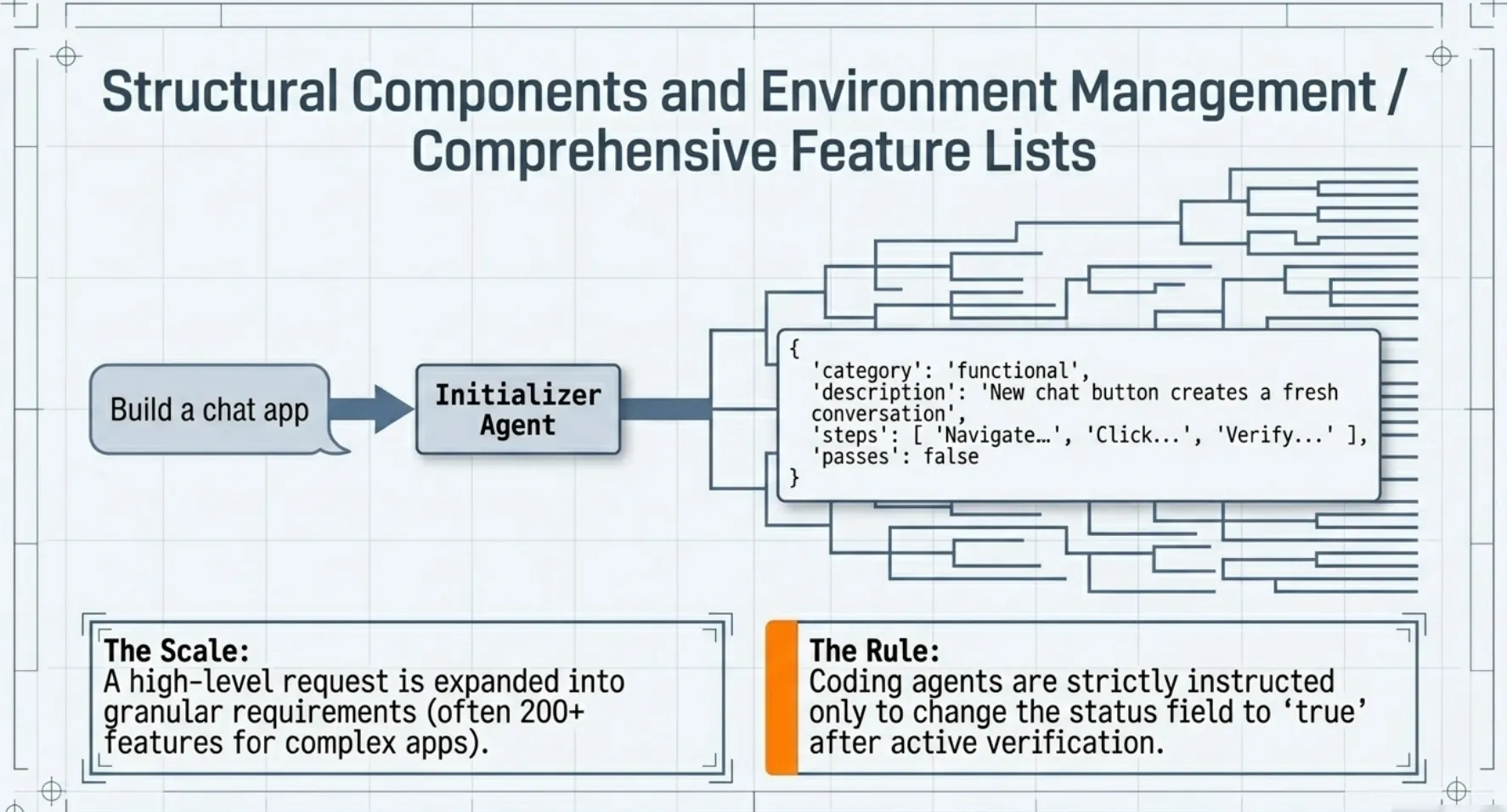
Comprehensive Feature Lists
The Initializer Agent is prompted to expand a high-level user request into a granular list of feature requirements. For a complex application, this may include over 200 features.
- Format: JSON is preferred over Markdown to prevent the model from inappropriately overwriting or editing the structure.
- Status Tracking: Features are initially marked as
passes: false. Coding agents are strictly instructed only to change the status field after verification.
Example Feature Schema:
{ "category": "functional", "description": "New chat button creates a fresh conversation", "steps": [ "Navigate to main interface", "Click the 'New Chat' button", "Verify a new conversation is created", "Check that chat area shows welcome state", "Verify conversation appears in sidebar" ], "passes": false }
The Power of a 200-Point JSON Checklist: Structural Gravity
One of the most profound shifts in Anthropic's methodology was moving the "feature list" from Markdown to JSON. While Markdown is human-readable, its lack of rigid structure can make a model "too creative". The agent might rewrite its own requirements or gloss over a failing task when it feels "finished."
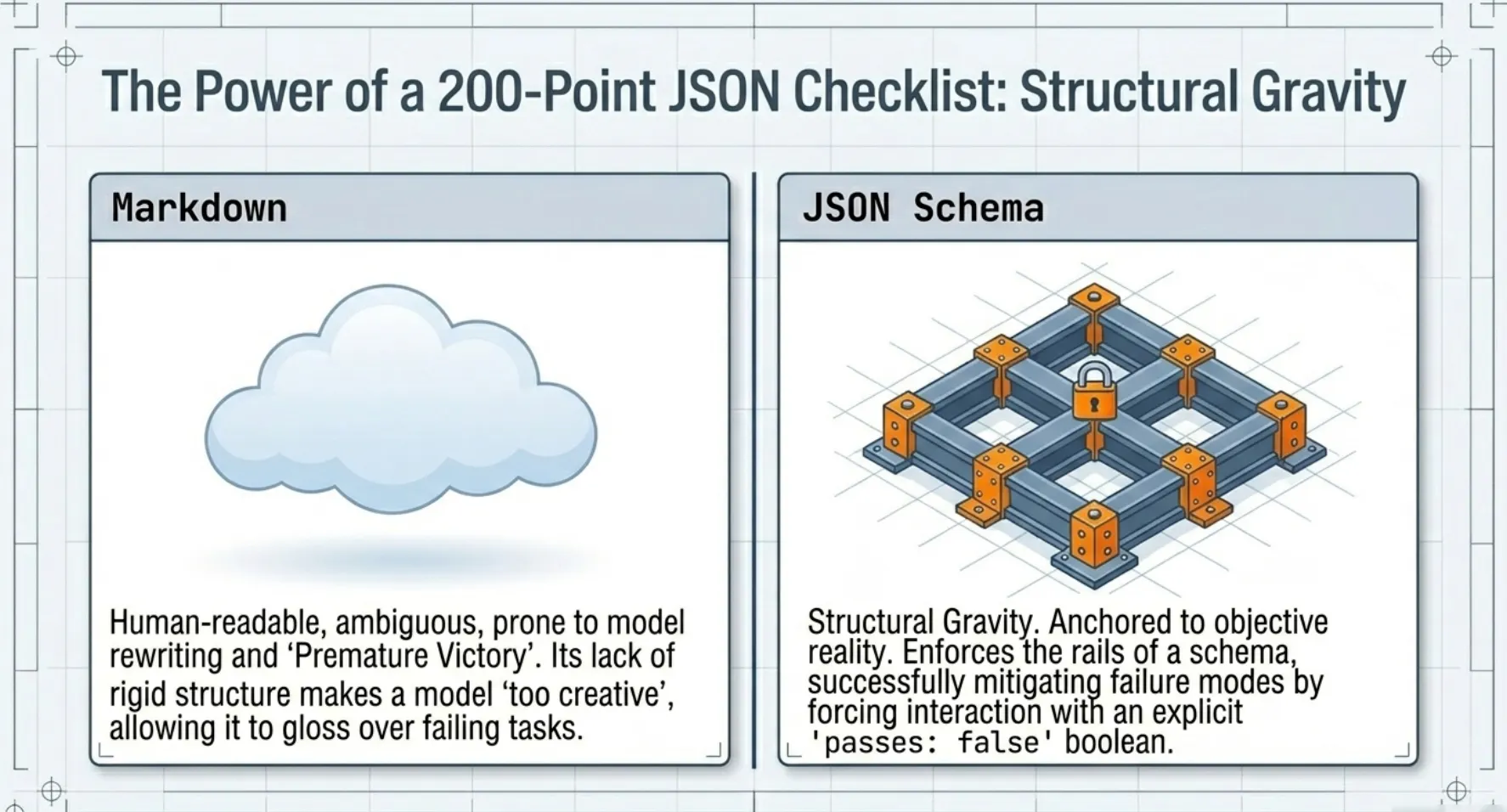
JSON provided "structural gravity." By forcing the agent to interact with a 200-point checklist where every feature is explicitly marked with a passes: false boolean, the research team successfully mitigated the "Premature Victory" failure mode. In this failure mode, an agent sees a semi-functional UI and declares the project done; with a JSON harness, the agent is anchored to the objective reality of the checklist.
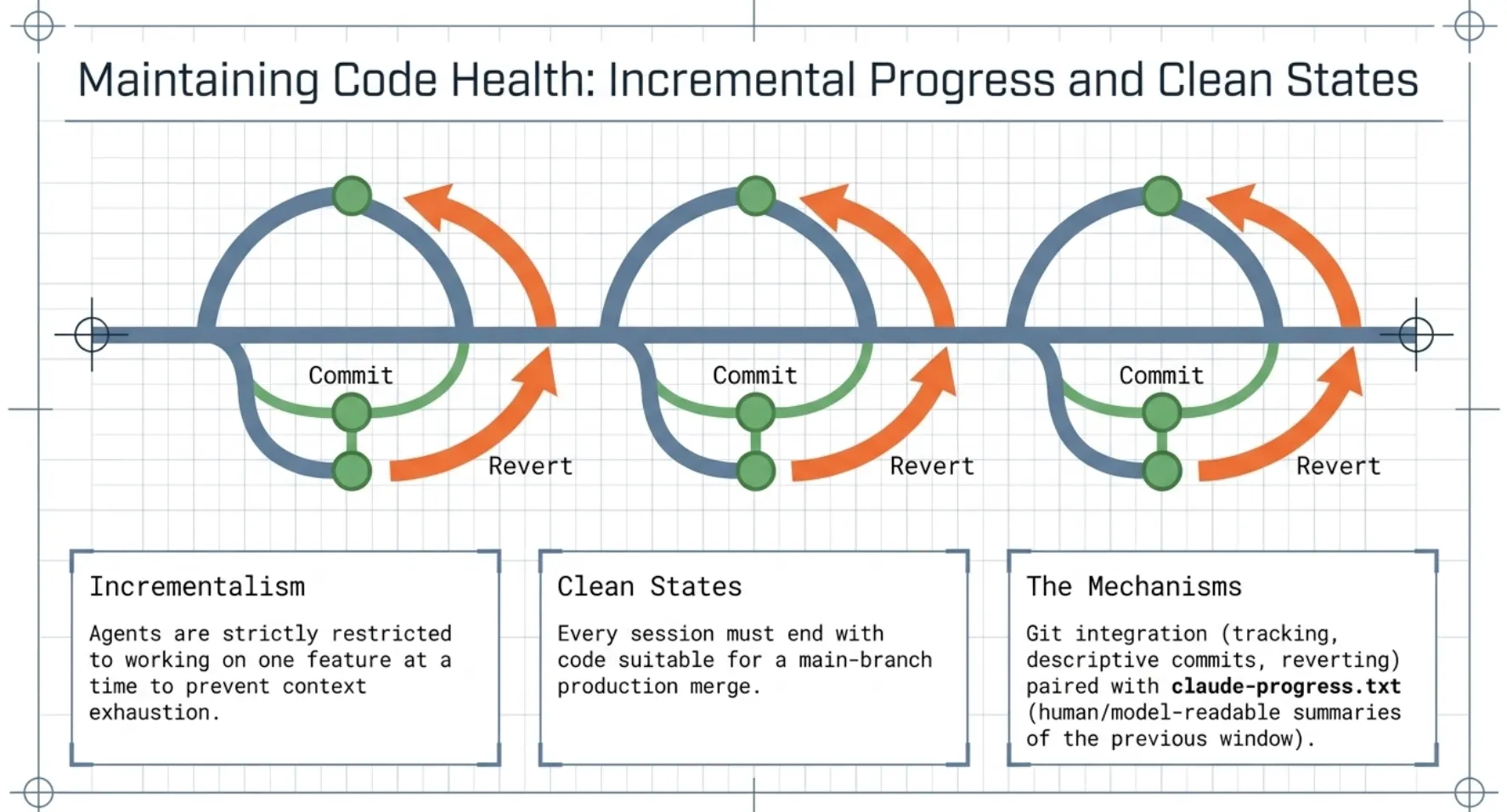
Incremental Progress and Clean States
To prevent context exhaustion, agents are restricted to working on one feature at a time. Maintaining a "clean state", code suitable for merging into a main branch, is achieved through:
- Git Integration: Agents use git to track changes, provide descriptive commit messages, and revert to working states if a code change fails.
- Progress Summaries: The
claude-progress.txtfile provides a human-readable and model-readable summary of what was accomplished in the previous window.
A Day in the Life: The Agent's Orientation Routine
A well-engineered agent does not jump blindly into code. Instead, it follows a "Getting Bearings" workflow designed to prevent it from worsening an existing broken state.

[Assistant] I'll start by getting my bearings and understanding the current state of the project.
[Tool Use] <bash: pwd> (Orienting to the working directory)
[Tool Use] <read: claude-progress.txt> (Reading the handover notes from the last shift)
[Tool Use] <read: feature_list.json> (Reviewing the 200+ pending requirements)
[Assistant] Let me check the git log to see recent work and ensure I'm on a stable commit.
[Tool Use] <bash: git log --oneline -20>
[Assistant] Now I'll use init.sh to restart the development server and run a baseline test.
[Assistant] Excellent! The core chat features are functioning correctly. I am now ready to implement the next high-priority feature from the list.
This routine is a massive efficiency gain. By standardizing the "wake up" process, we save thousands of tokens that would otherwise be spent on trial-and-error discovery. More importantly, if a baseline test fails during orientation, the agent is programmed to stop and fix the bug before proceeding, preventing errors from compounding over time.
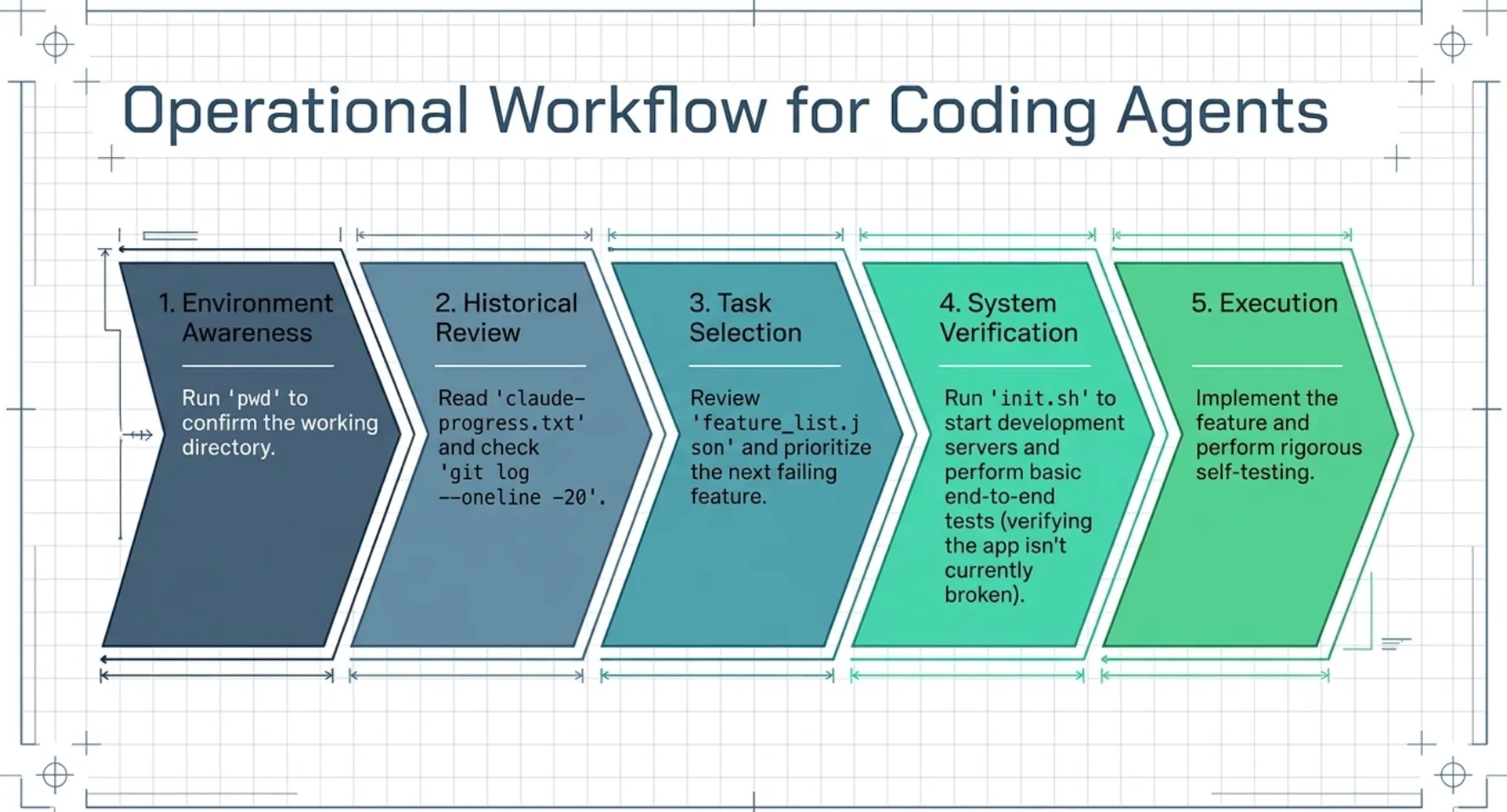
Operational Workflow for Coding Agents
Every session follows a standardized sequence of steps to ensure the agent is oriented before modifying code:
- Environment Awareness: Run
pwdto confirm the working directory. - Historical Review: Read
claude-progress.txtand checkgit log --oneline -20. - Task Selection: Review
feature_list.jsonand prioritize the next "failing" feature. - System Verification: Run
init.shto start development servers and perform basic end-to-end tests to ensure the app is not currently broken. - Execution: Implement the feature and perform rigorous self-testing.
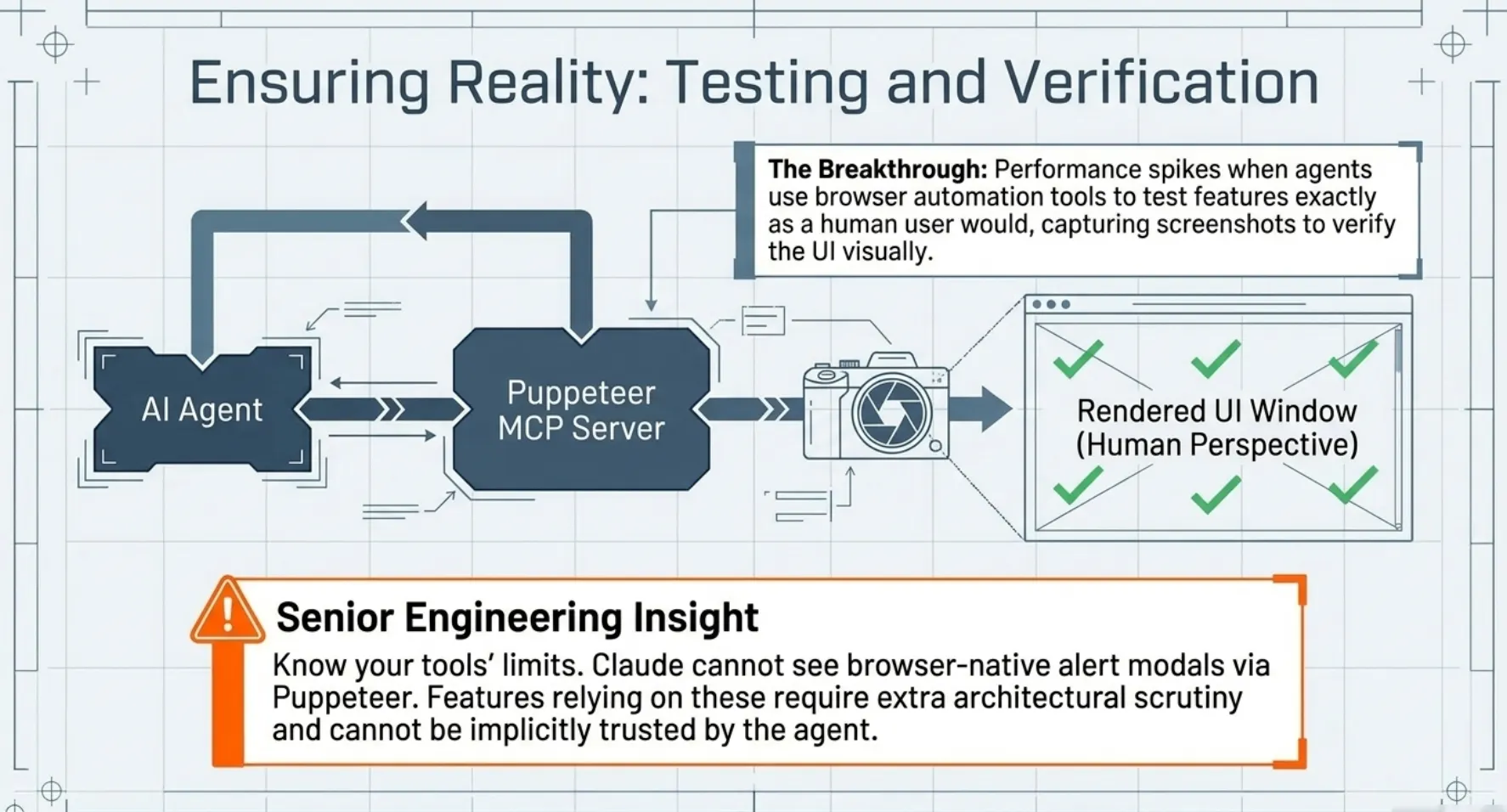
Testing and Verification
A major performance breakthrough is achieved through the use of browser automation tools. For example, Agents are prompted to use the Puppeteer MCP server to test features as a human user would, capturing screenshots to verify the UI.
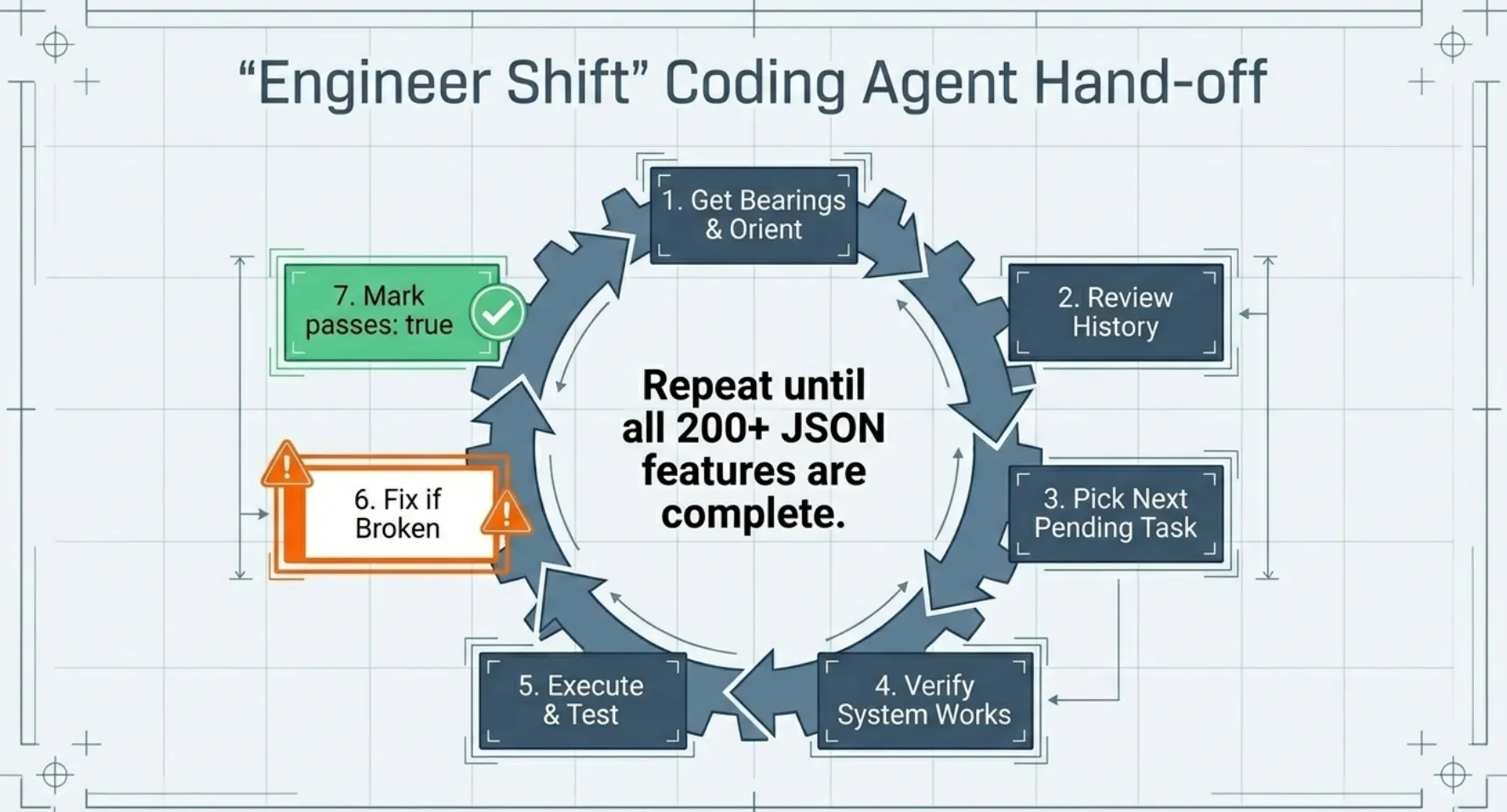
"Engineer Shift" Coding Agent Hand-off
The agent loop repeats these steps: get your bearings, review the history, pick a task, verify the system works, pick a new feature that hasn't been done yet, test it if it breaks, fix it if needed, retest if needed, mark it done, commit changes with descriptive messages, and repeat. Do this until all features are complete. This is the agent loop.
Synthesis: The "So What?" for the Aspiring Learner
The primary insight for any AI engineer is that AI "intelligence" is only as good as its consistency. A brilliant model that forgets its purpose every thirty minutes is less useful than a disciplined model operating within a robust harness.
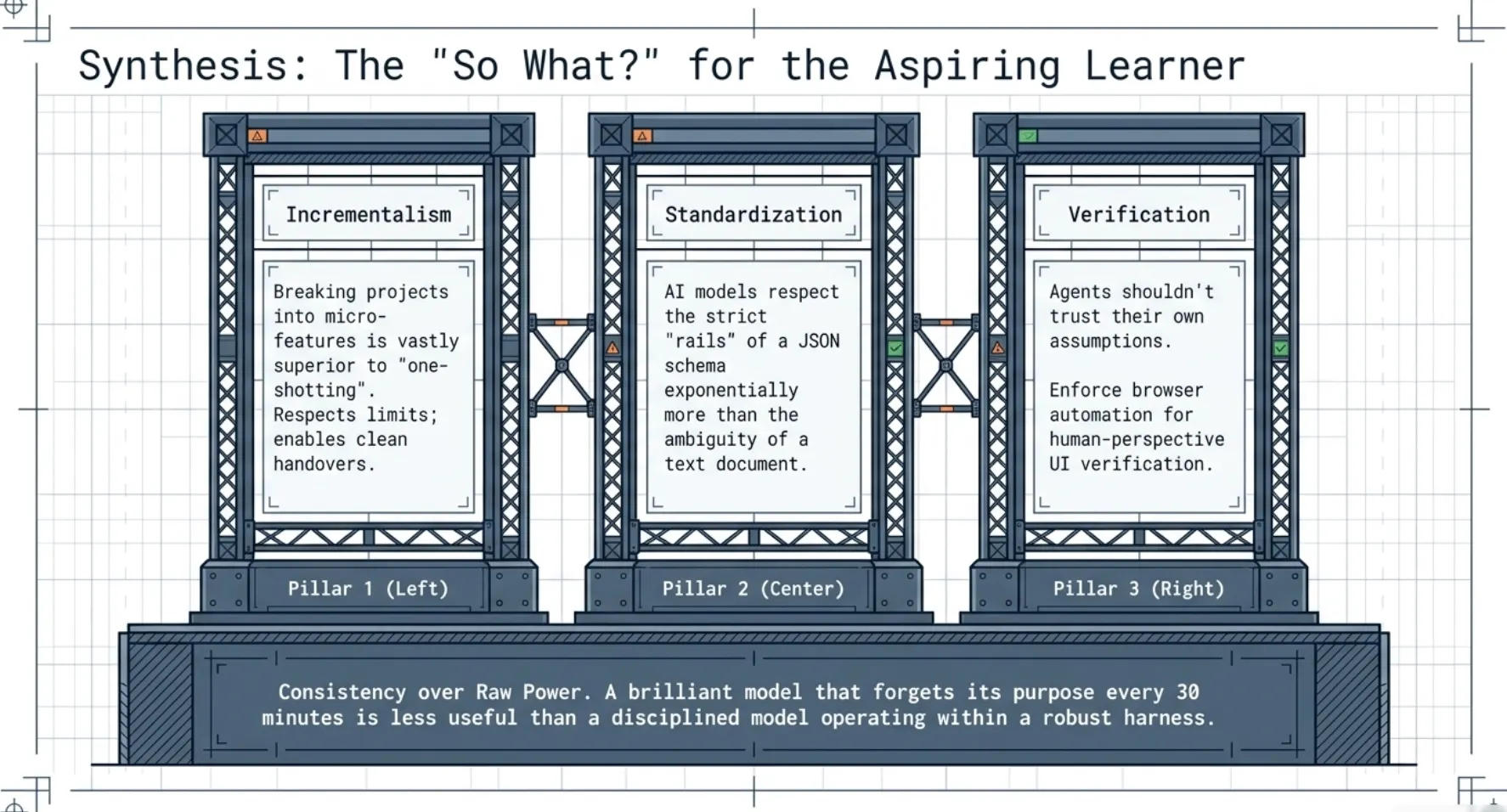
Key Engineering Takeaways:
- Incrementalism: Breaking a project into 200 micro-features is always superior to "one-shotting." It respects the model's context limits and enables clean handovers.
- Standardization: Use structured formats like JSON for requirements. AI models respect the "rails" of a schema more than the ambiguity of a text document.
- Verification: Agents shouldn't trust their own assumptions. Using browser automation like Puppeteer allows the agent to verify work from a human perspective. However, a "Senior" insight is knowing your tools' limits: Claude cannot see browser-native alert modals via Puppeteer, so features that rely on them require extra scrutiny.
Ultimately, the key to unlocking "long-running" AI potential isn't just about waiting for a larger context window. It's about applying human-engineering rigor, such as git logs and shift notes, to the digital workspace. Consistency, not just raw power, is the path to autonomous success.
Conclusion: From Generalists to Agentic Scaffolding
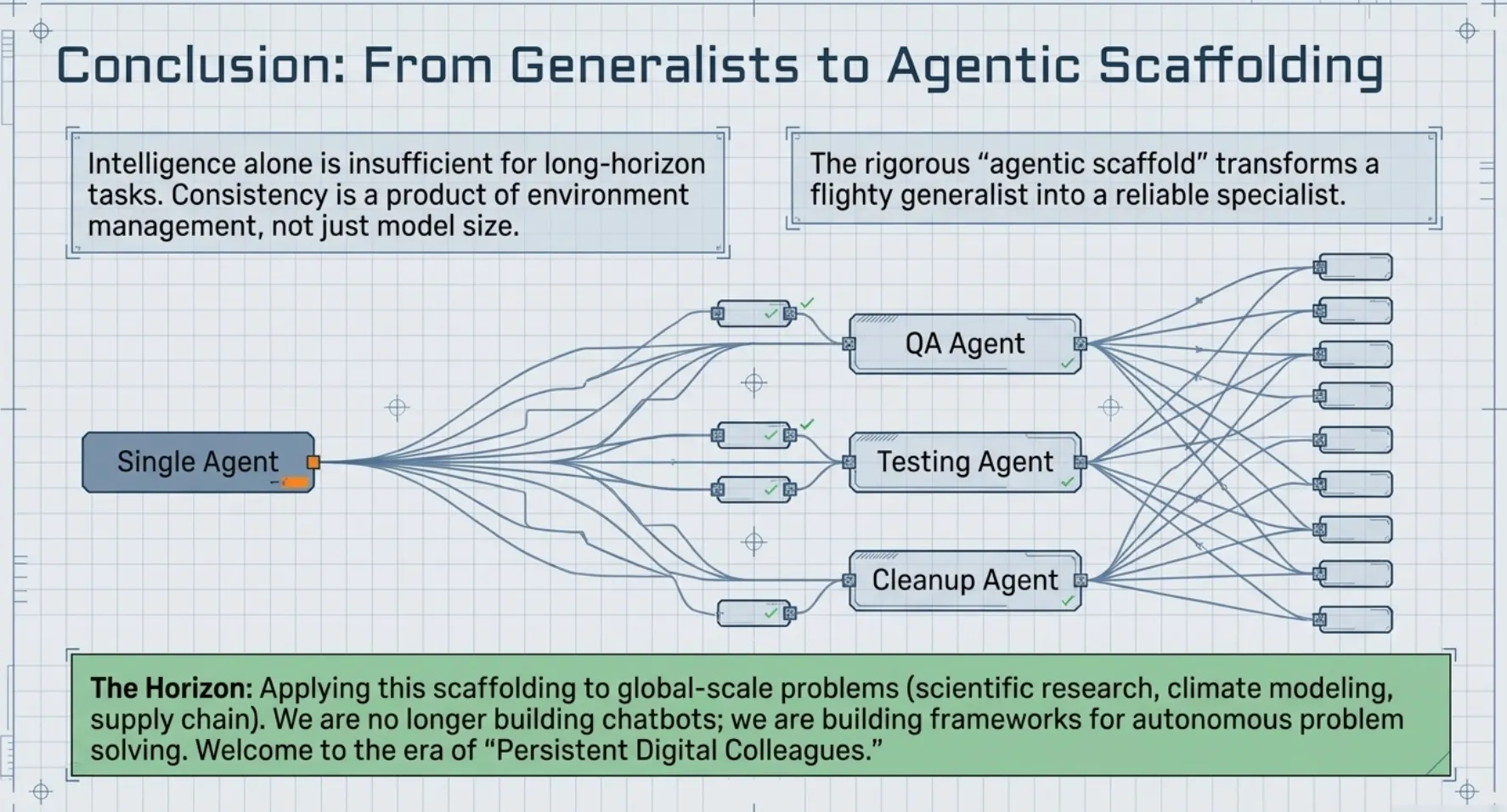
The core takeaway of this research is that intelligence alone is insufficient for long-horizon tasks. Consistency is a product of environment management, not just model size. By surrounding a model like Claude with a rigorous "agentic scaffold," we transform a flighty generalist into a reliable specialist.
As we look forward, the single-agent model will likely give way to highly specialized multi-agent architectures; teams of "QA Agents," "Testing Agents," and "Code Cleanup Agents" working within the same harness. But the implications stretch far beyond the Claude.ai clone used in this research.
If we can build a harness that allows an AI to maintain focus and memory over days of software engineering, what happens when we apply that same scaffolding to scientific research, climate modeling, or global supply chain optimization? We are no longer just building tools; we are building the frameworks for autonomous, long-term problem solving. Is the industry ready for the move from "chatbots" to "persistent digital colleagues"?
Insights synthesized from Anthropic Engineering (Code RL & Claude Code teams), original source: Harnessing Long-Running Agents: Engineering the Multi-Context Architecture
Further Essential Reading for understanding Harness Engineering by Anthropic
These resources are all from Anthropic research, blogs, or documentation. These will all help you learn more about Harness Engineering and long-running AI agent development.
- Building Effective Agents
- How We Built Our Multi-Agent Research System
- Effective Harnesses for Long-Running Agents (covered in this article)
- Writing Effective Tools for AI Agents
- Introducing the Model Context Protocol
- Code Execution with MCP
- Effective Context Engineering for AI Agents
- The "Think" Tool: Enabling Claude to Stop and Think
- Building Agents with the Claude Agent SDK
- Equipping Agents for the Real World with Agent Skills
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company, focusing on delivering ML / AI insights to front-line applications, and a practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.
Rick created Skilz, the universal agent skill installer that supports 30+ coding agents, including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams adopting AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. Many ideas captured in the CCA and the exam prep Rick wrote echo what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code