Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
How Anthropic solved the context window boundary problem for long-running agentic coding tasks
Originally published on Medium.
 Harness Engineering: Two-agent harness architecture with Initializer and Coding Agent, JSON feature list anchor, git checkpoints, Anthropic coding patterns
Harness Engineering: Two-agent harness architecture with Initializer and Coding Agent, JSON feature list anchor, git checkpoints, Anthropic coding patterns
How Anthropic solved the context window boundary problem for long-running agentic coding tasks
Series: “Harness Engineering”
Summary: Anthropic’s harness engineering patterns solve the context window boundary for long-running AI coding tasks. Two-agent architecture, feature lists, and commit discipline form an integrated system that prevents both premature completion and context collapse.
Why does the same model that writes a flawless 200-line function forget what it was building halfway through a 2,000-line feature?
The answer is the context window boundary. It is the single hardest problem in agentic coding today.
Anthropic’s research team tackled it head-on. Their paper on best practices for agentic coding (outlined in Anthropic’s 2025–2026 engineering posts on context engineering and harnesses for long-running agents) does not describe a theoretical framework. It describes what Anthropic learned from watching Claude build real software, failing in specific ways, and then engineering the harness to prevent those failures from recurring.
The result is a set of harness engineering patterns that have become the blueprint for Anthropic’s own long-running coding agents and heavily influenced third-party harnesses. If you have used Claude Code, Cursor with Claude, or any Claude-powered coding agent, you have experienced these patterns. Most people just do not know they are there.
💡 Source: This article was inspired by the harness engineering thread and article by Rohit, which assembled the evidence that harness design drives agent performance more than model selection.
The Context Window Boundary: The Hard Problem
Let me be direct about what makes long-running coding tasks fundamentally different from short ones. It is not complexity. It is not intelligence. It is memory.
A context window is not infinite. Current frontier models have windows ranging from 128K to 200K tokens. That sounds like a lot until you consider what a real coding session looks like. Every file the agent reads goes into the window. Every command output. Every error message. Every conversation turn. A single large codebase exploration can consume 50K tokens before the agent writes its first line of code.
For short tasks (fix this bug, write this function, refactor this class), the context window is more than sufficient. The agent reads the relevant files, understands the problem, writes the fix, and finishes. The entire task fits comfortably in memory.
But for long-running tasks (build this feature end-to-end, implement this API with tests, create this multi-component system), the math stops working. The agent needs to hold the feature specification, the existing codebase context, the code it has already written, the errors it has encountered, and its current plan all in the same window. By hour two, something has to give.
Anthropic identified this as the core engineering challenge. Not as a model limitation to be solved with bigger windows, but as an environmental constraint to be managed with better harness design. Their approach: if you cannot make the window bigger, make the agent’s relationship with the window smarter.
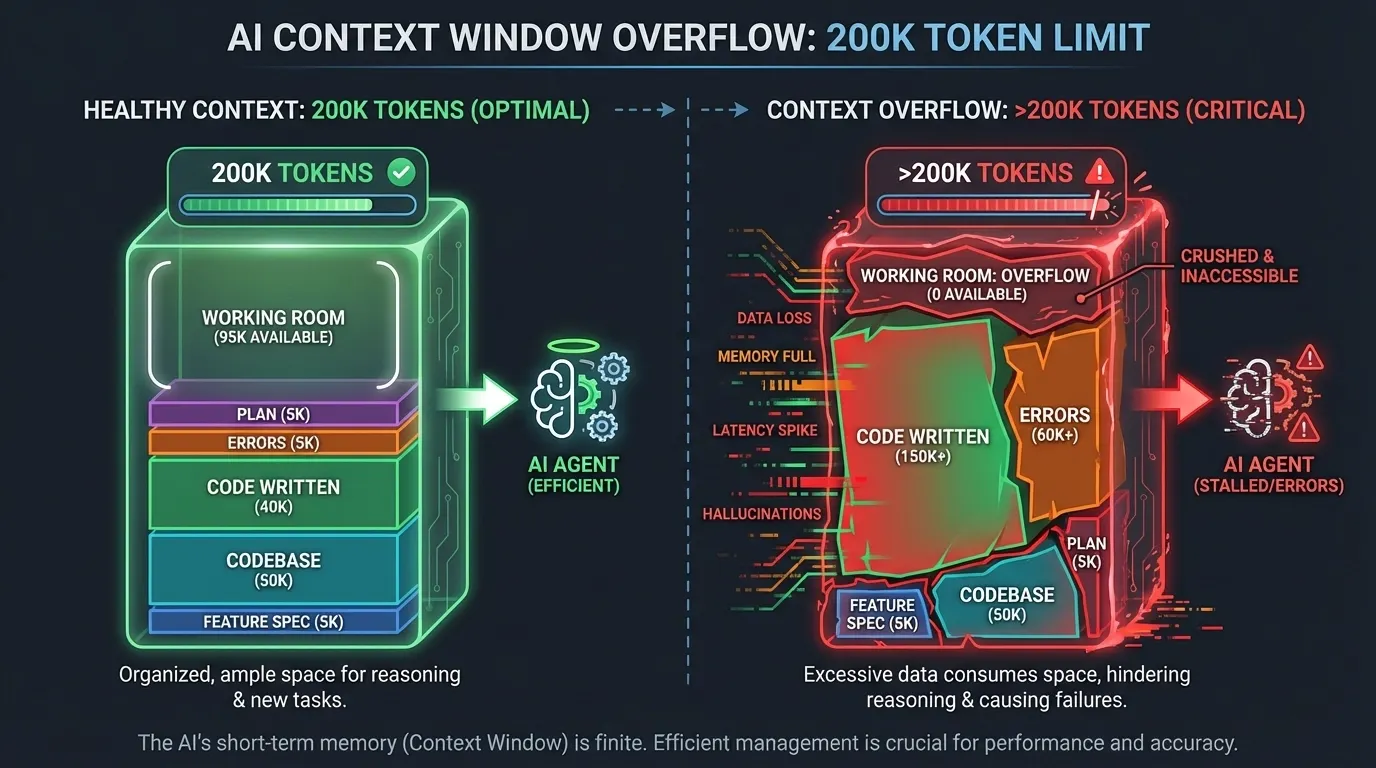 Harness Engineering: Context window overflow: healthy token distribution at session start versus overflowed context at hour two where code and errors consume all working room
Harness Engineering: Context window overflow: healthy token distribution at session start versus overflowed context at hour two where code and errors consume all working room
Two Failure Patterns That Kill Agent Projects
Before diving into Anthropic’s solutions, it is worth understanding exactly how agents fail at long tasks. Not in theory. In practice. Anthropic documented two dominant failure modes that accounted for the vast majority of long-task failures in agentic coding.
Failure Pattern 1: Building Everything at Once
The first failure pattern is the ambitious agent. Given a feature spec with ten requirements, it tries to implement all ten simultaneously. It writes hundreds of lines of code across multiple files before running a single test.
Why is this catastrophic? Because when something goes wrong (and something always goes wrong), the agent has no idea where the failure originated. Did the authentication middleware break the route handler, or did the database migration create a schema mismatch? The agent has changed so many things at once that debugging becomes a combinatorial explosion.
Human developers know this pattern. It is the “I’ll just refactor the whole thing” impulse. Experienced developers resist it. They work in small increments, testing frequently, building confidence one piece at a time. Junior developers (and unharnessed agents) try to hold the entire system in their head and build it all at once.
The result is predictable. The agent spends 80% of its token budget debugging interconnected failures rather than building features. By the time it untangles one issue, it has forgotten the details of another. Context window exhaustion turns a solvable problem into an impossible one.
Failure Pattern 2: Premature Completion
The second failure pattern is the opposite extreme. Instead of building everything at once, the agent declares victory too early. It implements the happy path, skips edge cases, ignores error handling, and announces “Done!” with a codebase that works for exactly one input.
This pattern is especially insidious because it looks like success. The agent produces working code. Tests pass (the ones the agent wrote, anyway). The feature appears to function. But the first time a real user sends an unexpected input, or the network hiccups, or the database returns null instead of an empty array, everything falls apart.
Premature completion is a cognitive bias, not a capability limitation. The model can absolutely handle edge cases. It just has a strong prior toward “the code compiles and the tests pass, therefore I am done.” Without external verification pressure, the agent satisfies its own completion criteria and moves on.
Both failure patterns share a root cause: the agent lacks the environmental structure to manage long-running work effectively. The model is capable. The harness is missing.
For a deep dive into what happens when the harness is missing in production, see The 9% Disaster: What Anthropic’s Harness Design Paper Teaches Us About Building Autonomous AI.
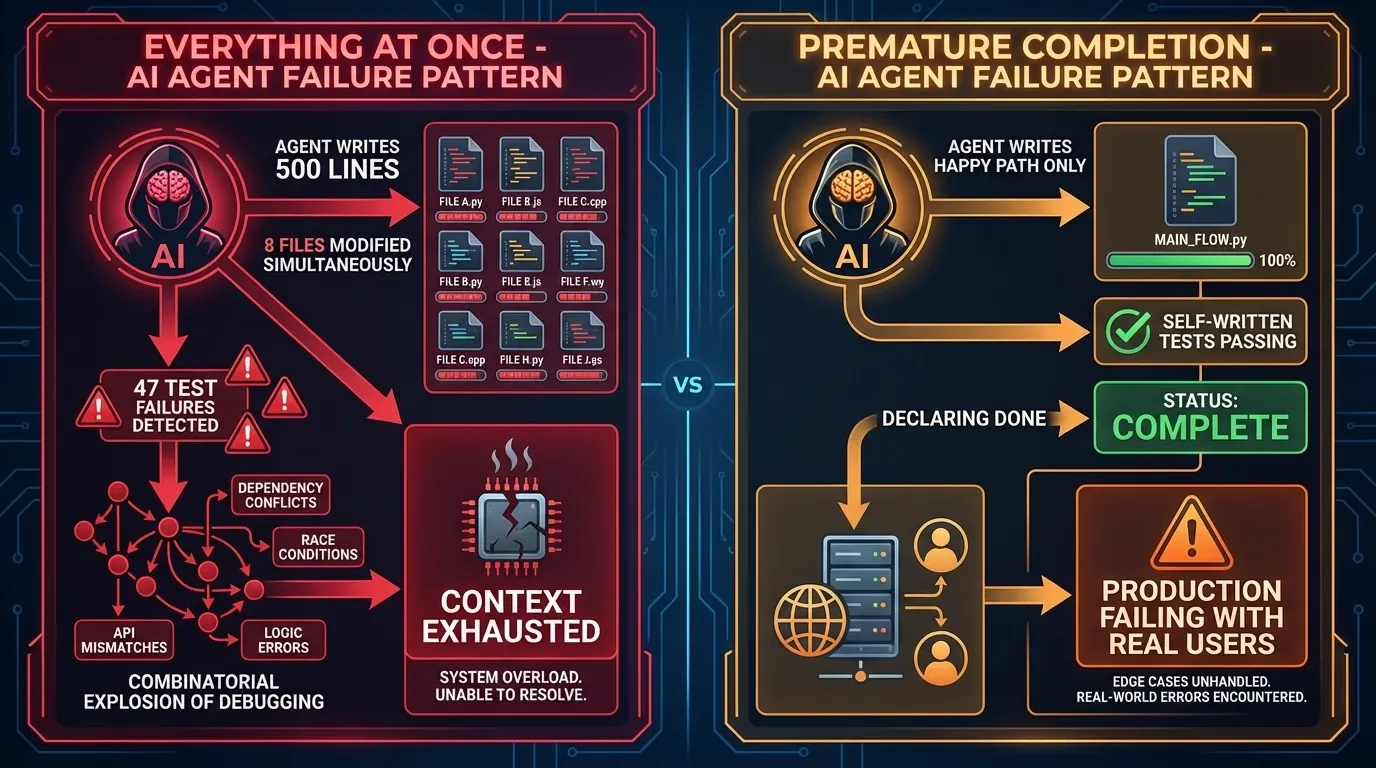 Harness Engineering: Two agent failure patterns: building everything at once leads to combinatorial debugging explosion, while premature completion skips edge cases and fails in production
Harness Engineering: Two agent failure patterns: building everything at once leads to combinatorial debugging explosion, while premature completion skips edge cases and fails in production
The Two-Agent Architecture
Anthropic’s harness uses an initializer agent that decomposes a product spec into tasks, and a coding agent that implements those tasks one feature at a time. Not two models. Two agents with different roles, different contexts, and different responsibilities.
This distinction matters. You do not need two API keys or two model subscriptions. You need two separate sessions with two separate context windows, each focused on a different phase of the work. The separation is architectural, not financial.
The Initializer Agent
The first agent, the Initializer, runs before any coding begins. Its job is planning and specification, not implementation. The Initializer:
- Reads the feature specification or user request
- Analyzes the existing codebase to understand conventions, patterns, and architecture
- Generates a detailed feature list with specific, testable requirements
- Creates skeleton test files that define what “done” means
- Writes a startup script that subsequent coding sessions can use to re-establish context
The Initializer has a fundamentally different relationship with the context window than the Coding Agent. It needs to see the big picture: the full feature spec, the codebase structure, the architectural patterns. But it does not need to hold implementation details. Its context is broad but shallow.
Once the Initializer finishes, its output becomes the specification that drives everything else. The Initializer’s context is then discarded. This is intentional. The planning context and the implementation context have different requirements, and trying to keep both alive in the same window is exactly how agents run out of memory.
The Coding Agent
The second agent, the Coding Agent, takes the Initializer’s output and builds the feature incrementally. It has a different context profile: narrow but deep. It needs to understand the specific files it is working on, the specific tests it needs to pass, and the specific feature list item it is currently implementing.
The Coding Agent does not need to understand the full feature spec at every moment. It needs to understand the current task, the current tests, and the current codebase state. The feature list acts as a persistent anchor that keeps the agent oriented even as its working context shifts from file to file.
This two-agent split is not just architectural convenience. It is a direct response to the context window boundary problem. By separating planning from implementation, Anthropic ensures that neither agent has to hold both in memory simultaneously. Each agent gets the right context for its specific role.
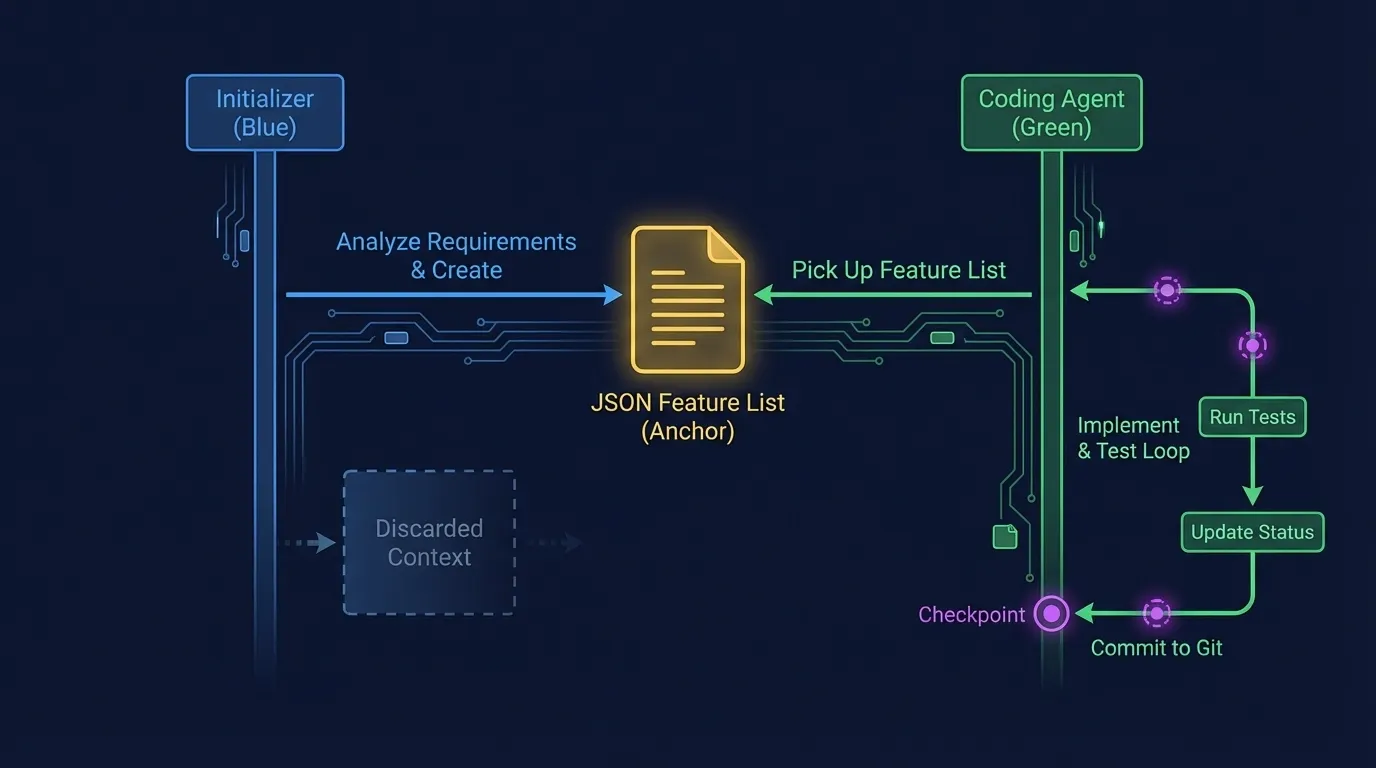 Harness Engineering: Two-agent sequence: Initializer analyzes requirements and creates JSON feature list, then Coding Agent iterates through features with test verification and git commits
Harness Engineering: Two-agent sequence: Initializer analyzes requirements and creates JSON feature list, then Coding Agent iterates through features with test verification and git commits
The Feature List as Cognitive Anchor
The feature list deserves its own section because it is the most underrated pattern in Anthropic’s harness engineering. On the surface, it looks like a simple TODO list. In practice, it is the mechanism that prevents both failure patterns: building everything at once and premature completion.
Why JSON, Not Markdown
Anthropic advocates using structured, machine-readable progress artifacts (often JSON) instead of ad-hoc Markdown checklists, so agents can reliably resume work across sessions.
Markdown lists are ambiguous. Is a checked item done or just partially done? Are sub-items required or optional? When the agent reads a Markdown list, it has to interpret the format, and that interpretation varies between sessions.
JSON is unambiguous. Each feature is a structured object with explicit fields:
{
"features": [
{
"id": "F1",
"title": "User authentication endpoint",
"status": "complete",
"requirements": [
"POST /auth/login accepts email and password",
"Returns JWT token on success",
"Returns 401 with error message on failure",
"Rate limits to 5 attempts per minute per IP"
],
"tests": ["test_auth_login_success", "test_auth_login_failure", "test_auth_rate_limit"],
"files": ["src/auth/routes.py", "src/auth/middleware.py", "tests/test_auth.py"]
},
{
"id": "F2",
"title": "User profile CRUD",
"status": "in_progress",
"requirements": [
"GET /profile returns current user data",
"PUT /profile updates user fields",
"DELETE /profile soft-deletes the account"
],
"tests": ["test_profile_get", "test_profile_update", "test_profile_delete"],
"files": ["src/profile/routes.py", "tests/test_profile.py"]
}
]
}
Look at what this structure does for the agent. It knows F1 is complete, so it does not touch it. It knows F2 is in progress, so that is where it starts. It knows exactly which tests must pass for F2 to be done, and it knows which files are involved. There is no ambiguity. No interpretation required.
The JSON feature list acts as external memory that survives across context window resets. When a coding session ends and a new one begins, the agent reads this file and immediately knows where it is. The entire project state fits in a structure small enough to read in seconds.
The engineering lesson: structured state that survives between sessions is more valuable than any amount of in-session reasoning. Build your harness to externalize state into durable, parseable formats.
Inviolable Tests
The second critical aspect of the feature list is its connection to tests. Anthropic’s pattern requires that each feature has associated tests defined before implementation begins. In a harness like Anthropic’s, you treat those tests as inviolable: the agent isn’t allowed to change them just to make them pass.
This constraint seems strict. It is. But it dramatically reduces the premature completion problem in practice. The agent cannot declare a feature “done” by writing a test that only checks the happy path. The tests were defined during initialization, when the full specification was in context. They cover edge cases, error conditions, and integration points that the Coding Agent might otherwise skip.
If the agent cannot modify the tests, and the tests represent the real requirements, then the only way to “finish” is to actually satisfy the requirements. The feature list plus inviolable tests creates a closed-loop verification system that does not depend on the agent’s self-assessment.
This matters because agent self-assessment is unreliable. The model will tell you it is done when the code compiles and the obvious tests pass. The inviolable test constraint forces it to satisfy an external definition of “done” that was written before it started, not by the agent trying to finish.
Incremental Progress: Every Session Ends with a Commit
The third major pattern in Anthropic’s harness engineering addresses what happens when the context window fills up and the agent needs to start a new session.
In a naive implementation, this is a disaster. The agent loses its entire working context. It does not remember what files it modified, what approach it was taking, what bugs it encountered and fixed. The new session starts cold, and the agent often duplicates work or contradicts decisions made in the previous session.
Anthropic’s pattern: in practice, the most robust harnesses follow Anthropic’s lead and end each coding session with a small, test-passing commit.
This is not just “save your work.” It is a structural constraint that shapes how the agent approaches each task. If you know you must commit working code at the end of every session, you cannot leave things in a half-broken state. You cannot start a massive refactor without a plan for leaving the codebase functional at each checkpoint.
The commit discipline enforces several beneficial behaviors:
Small, testable increments. The agent naturally gravitates toward changes that can be completed and tested within a single session. Instead of “implement the entire authentication system,” it targets “implement the login endpoint with basic validation.” This directly prevents the building-everything-at-once failure pattern.
Resumable state. When a new session starts, the agent can run git log and git diff to understand exactly what has been done and what remains. The commit messages, combined with the feature list, provide enough context for the new session to pick up where the old one left off.
Rollback safety. If a session goes badly and the agent gets confused, you can git reset to the last good commit and try again. Without commit discipline, a confused agent can corrupt the codebase in ways that are hard to undo.
Progress visibility. The human supervising the agent can review commits to understand what is happening. Each commit is a checkpoint that can be reviewed, approved, or redirected. This turns an opaque “agent is working” status into a transparent progress trail.
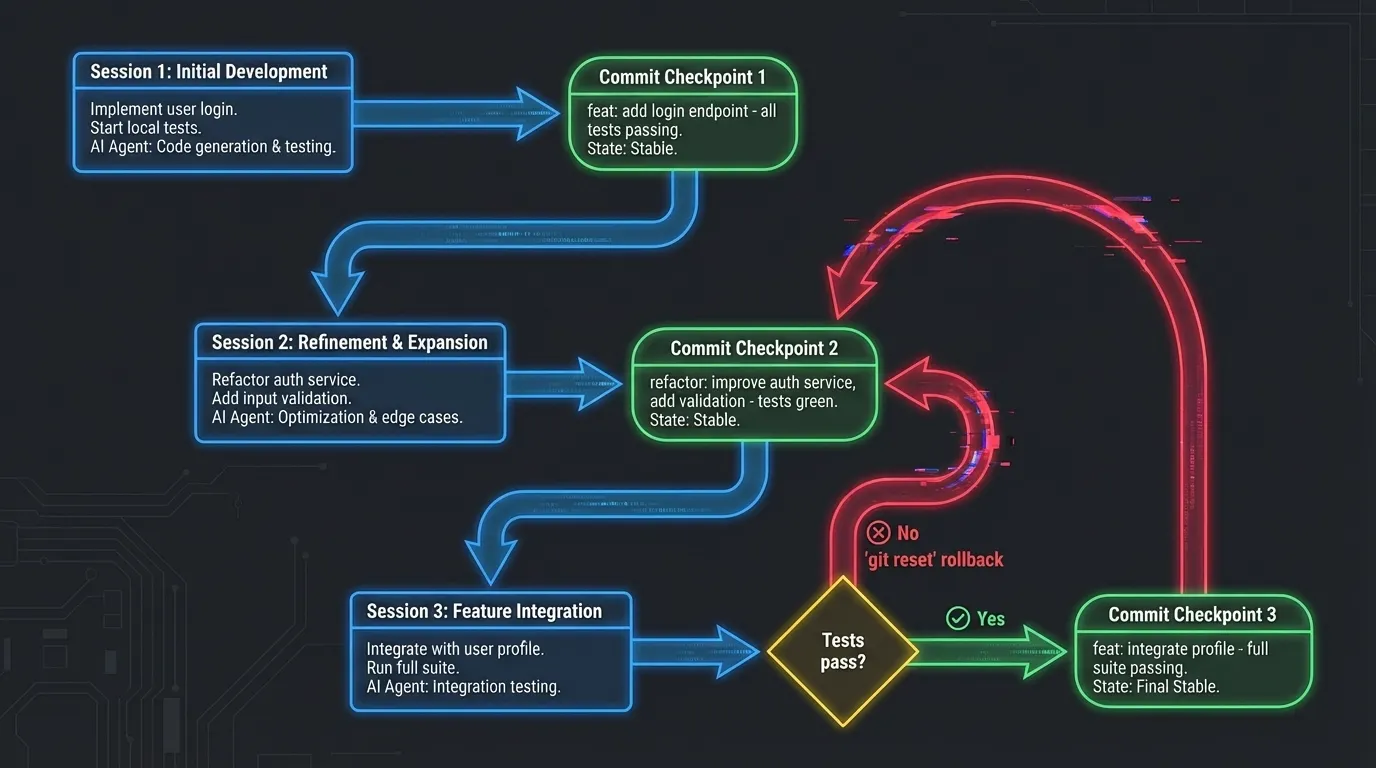 Harness Engineering: Commit discipline flow: each coding session produces a tested commit checkpoint, with git reset rollback safety when tests fail
Harness Engineering: Commit discipline flow: each coding session produces a tested commit checkpoint, with git reset rollback safety when tests fail
Testing via Browser Automation
For web applications, Claude-based coding agents increasingly pair these harness patterns with browser-automation MCPs like Playwright MCP for end-to-end web tests.
The rationale is straightforward. Unit tests verify that individual functions work correctly. But many bugs live in the integration layer: the button that does not trigger the right API call, the form that submits but does not update the UI, the authentication flow that works in isolation but breaks when combined with navigation.
Playwright MCP gives the agent access to a real browser. The agent can navigate to pages, click buttons, fill forms, and verify that the UI behaves correctly. This is end-to-end testing from the agent’s perspective, and it catches an entire category of bugs that unit tests miss.
The integration with the harness is key. The agent does not just run Playwright tests randomly. The tests are defined in the feature list, linked to specific requirements, and run as part of the verification step before each commit. Browser automation is not a separate tool. It is part of the harness’s verification pipeline.
This pattern also solves a subtle problem with LLM-generated code. Models are good at writing code that is syntactically correct and logically sound in isolation. They are less good at predicting how components will interact in a running system. Browser automation provides ground truth about system behavior that no amount of code review can substitute for.
The engineering lesson: verification quality determines completion quality. If your agent can only run unit tests, it will only achieve unit-test-level confidence. Give it end-to-end verification and it can achieve production-level confidence.
Standardized Startup Sequences
The final pattern in Anthropic’s harness engineering addresses token efficiency at the start of each session. Every coding session begins with a startup phase where the agent establishes context: reading the feature list, checking the current state of the codebase, understanding what tests pass and which fail, reviewing recent commits.
In a naive implementation, this startup phase consumes a significant chunk of the context window. The agent reads the entire feature list, opens multiple files to understand the codebase state, runs the full test suite, and reviews several commits. By the time it has established context, it has consumed 20–30% of its available window on orientation alone.
Anthropic’s solution is the standardized startup sequence: a scripted series of commands that efficiently establish session context with minimal token waste.
The startup sequence typically includes:
- Read the feature list JSON to understand overall progress
- Run git log --oneline -10 to see recent commits
- Run the test suite to identify what currently passes and fails
- Read the specific files related to the next incomplete feature
- Check for any TODO or FIXME markers left by previous sessions
This sequence is deterministic. It runs the same way every time. The agent does not need to figure out how to establish context. The harness provides a script that does it efficiently.
The token savings are significant. For example, a well-designed startup sequence consumes 5–10% of the context window instead of 20–30%. That extra 15–20% of available context translates directly into more room for actual coding work. Over a multi-session feature build, those savings compound.
But the benefit goes beyond token efficiency. The standardized startup also prevents a subtle failure mode: inconsistent context establishment. Without a startup script, the agent might explore different files in different sessions, building inconsistent mental models of the codebase. The standardized sequence ensures every session starts from the same foundation.
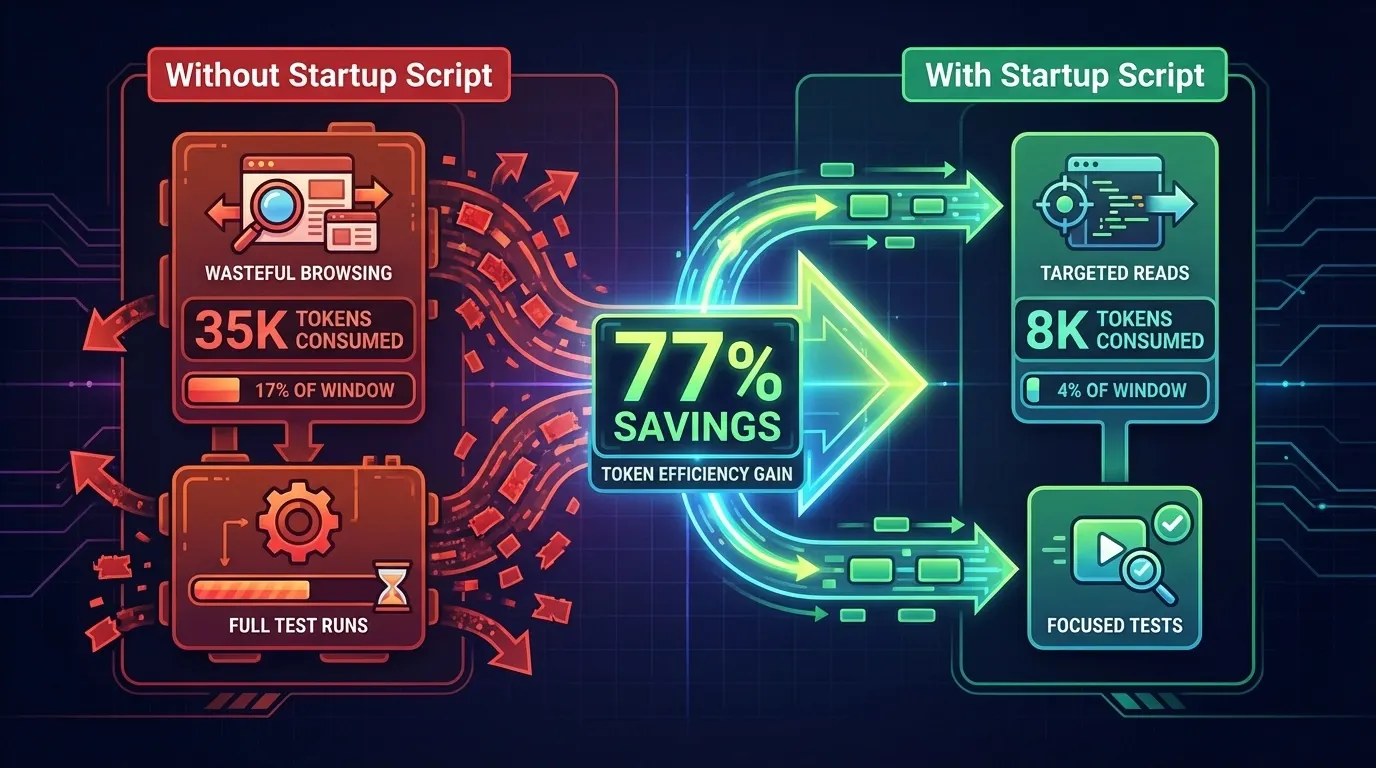 Harness Engineering: Startup script token savings: without a script consumes 35K tokens at 17% of window, with a script consumes only 8K tokens at 4% of window
Harness Engineering: Startup script token savings: without a script consumes 35K tokens at 17% of window, with a script consumes only 8K tokens at 4% of window
Putting It All Together: The Full Harness
Let me connect these patterns into the complete picture. Anthropic’s harness engineering is not a collection of independent tricks. It is an integrated system where each pattern reinforces the others.
The two-agent architecture separates planning from implementation, ensuring each phase gets the right context without overloading a single window.
The feature list bridges the two agents, providing a persistent specification that survives across sessions and prevents both premature completion and overambitious building.
The inviolable tests create a closed-loop verification system that does not depend on the agent’s self-assessment.
The commit discipline enforces incremental progress, provides rollback safety, and enables session resumption.
The browser automation extends verification beyond unit tests to catch integration-level bugs.
The standardized startup minimizes the token cost of session initialization, leaving more room for productive work.
Remove any one of these patterns and the system degrades. Remove the feature list and the agent loses its anchor. Remove the commit discipline and sessions cannot resume cleanly. Remove the inviolable tests and premature completion returns. The patterns are interdependent by design.
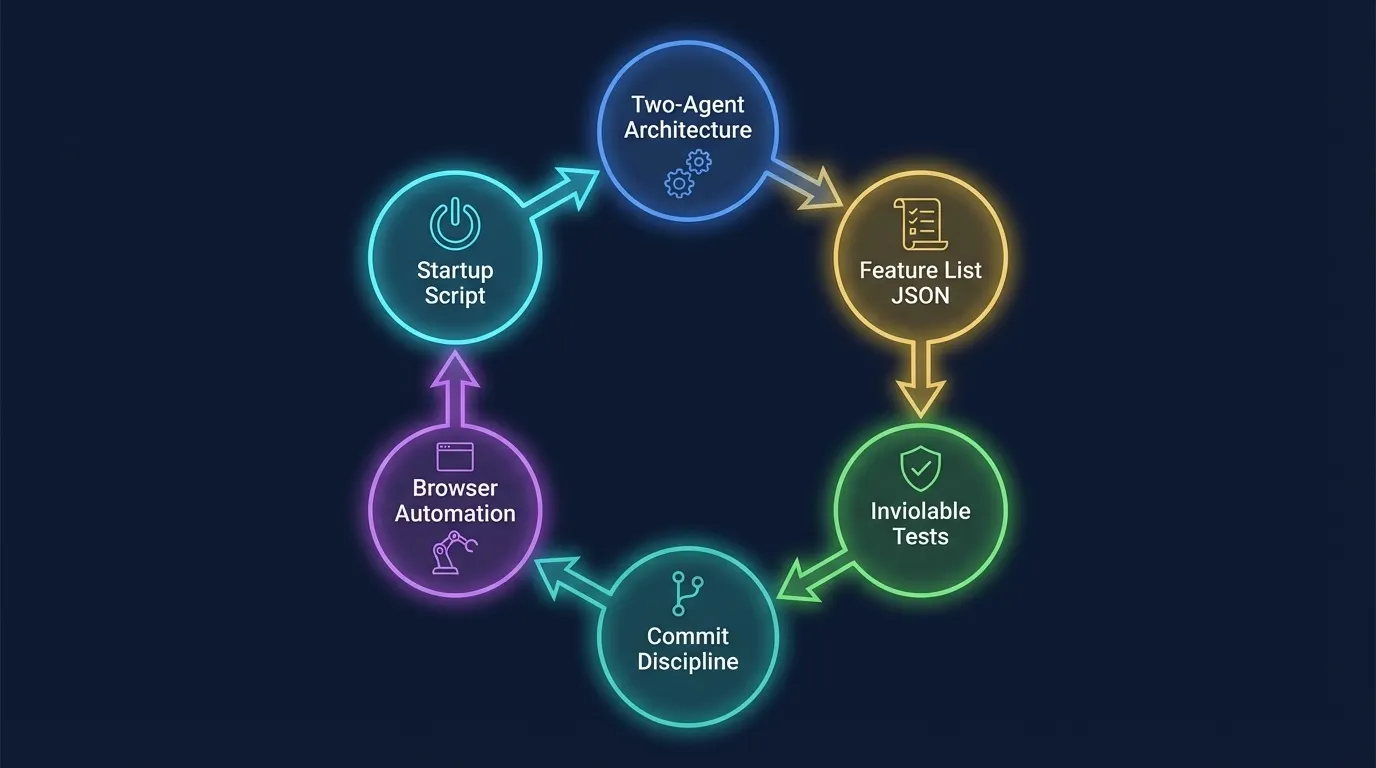 Complete harness engineering cycle: six interdependent patterns forming an integrated system from two-agent architecture through feature list, tests, commits, browser automation, and startup scripts
Complete harness engineering cycle: six interdependent patterns forming an integrated system from two-agent architecture through feature list, tests, commits, browser automation, and startup scripts
Why This Is Harness Engineering, Not Prompt Engineering
I want to draw a clear line here because the distinction matters.
Prompt engineering would be telling the model: “Please work incrementally, test frequently, and do not declare victory too early.” That might help. For one session. Maybe.
Harness engineering is building a system where the model cannot skip incremental progress (commit discipline), cannot declare premature victory (inviolable tests), and cannot lose track of the plan (feature list as persistent state). The model does not need to “remember” these practices. The harness enforces them structurally.
This is the same distinction that the SWE-agent paper (Part 3 of this series) demonstrated with its agent-computer interface. You can ask the model to write better search queries, or you can cap search results at 50 so it has to write better queries. One approach relies on the model’s cooperation. The other relies on the environment’s constraints.
As Anthropic’s posts and Rohit’s “harness is everything” thread argue, the harness—the environment and protocols around the model—often matters more than the specific model choice for long-running work.
The question is not whether your model is capable enough. The question is whether your harness is demanding enough.
For a deeper look at the distinction between these two disciplines, see Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS.
Practical Applications for Your Own Agents
You do not need to be Anthropic to apply these harness engineering patterns. Here is how each one translates to your own agent setups:
If you want to understand the real-world cost of skipping these patterns, see Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage.
Split planning from execution. If your agent is building anything that takes more than one session, use a separate planning step. Have one agent (or one session) analyze the requirements and generate a structured plan. Then hand that plan to the execution sessions as their specification.
Use JSON specifications, not prose. When you give an agent a task, structure it as JSON with explicit fields for requirements, acceptance criteria, and test definitions. The agent will follow structured specs more reliably than prose descriptions. This is not about being formal. It is about being unambiguous.
Make tests inviolable. Write your acceptance tests before the agent starts coding. Tell the agent it cannot modify them. This single constraint eliminates an enormous category of “the agent thinks it is done but it is not” failures.
Enforce commit checkpoints. If your agent modifies code, require it to commit working code at defined intervals. This is trivially implementable with a pre-completion hook that runs the test suite and blocks the commit if tests fail.
Script your startup sequences. If your agent runs in multiple sessions, create a deterministic startup script that establishes context efficiently. Do not rely on the agent to figure out where it left off. A five-step script that reads the feature list, checks git log, and runs failing tests will outperform an agent trying to reconstruct context from scratch every time.
Add browser testing for web projects. If your agent builds web applications, give it Playwright or a similar browser automation tool. Unit tests are necessary but not sufficient for verifying web application behavior.
Treat session boundaries as first-class engineering problems. The most expensive moment in a multi-session agent project is the session restart. Every token you spend re-establishing context is a token not spent building features. Design the session boundary explicitly and the rest of the workflow improves.
Looking Ahead
Anthropic’s harness engineering patterns address the context window boundary problem, the fundamental constraint on long-running agentic tasks. But they were designed primarily for single-developer, single-feature workflows.
In Part 5 of this series, we will look at how LangChain took similar principles and applied them to competitive benchmarks, discovering that middleware hooks, self-verification loops, and loop detection could vault an agent from outside the Top 30 to the Top 5 on Terminal Bench 2.0. Where Anthropic solved the session-boundary problem, LangChain solved the within-session effectiveness problem. Together, they define the state of the art in harness engineering for coding agents.
Read the full LangChain story: LangChain’s Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0.
Discussion Questions
- Anthropic’s two-agent architecture intentionally discards the Initializer’s context after the planning phase. What does this tell you about treating context window space as a resource to be managed rather than accumulated?
- The inviolable test constraint prevents the agent from modifying tests to make them pass. Have you encountered situations in human development workflows where similar constraints (immutable acceptance criteria, locked test suites) improved outcomes? What made them work or fail?
- The feature list JSON pattern treats external structured state as more reliable than the agent’s in-context memory. Where else in your systems could you replace in-context reasoning with durable external state to improve reliability across session boundaries?
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.
References
Anthropic. “Effective Context Engineering for AI Agents.” Anthropic Engineering Blog, 28 Sept 2025. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
Anthropic. “Effective Harnesses for Long-Running Agents.” Anthropic Engineering Blog, 25 Nov 2025. https://www.anthropic.com/engineering/effective-harnesses-for-long-running-agents
Anthropic. “Harness Design for Long-Running Application Development.” Anthropic Engineering Blog, 23 Mar 2026. https://www.anthropic.com/engineering/harness-design-long-running-apps
Anthropic. “Building Effective AI Agents.” Anthropic Research, 18 Dec 2024. https://www.anthropic.com/research/building-effective-agents
Rohit Karelia. “The Harness Is Everything.” X (Twitter) Thread, 16 Mar 2026. https://x.com/rohit4verse/status/2033945654377283643
Nate. “Get the Cheat Code on Long-Running AI Agents—Here’s What Anthropic and Others Learned.” Nate’s Newsletter, 8 Dec 2025. https://natesnewsletter.substack.com/p/i-read-everything-google-anthropic
ZenML. “Long-Running Agent Harness for Multi-Context Software Development.” 2025. https://www.zenml.io/llmops-database/long-running-agent-harness-for-multi-context-software-development
Joshua Berkowitz. “How Anthropic Builds Smarter Long-Running AI Agents Inspired by Human Engineering.” 3 Dec 2025. https://joshuaberkowitz.us/blog/news-1/how-anthropic-builds-smarter-long-running-ai-agents-inspired-by-human-engineering-1926
Paddo. “Agent Harnesses: From DIY Patterns to Product.” 27 Nov 2025. https://paddo.dev/blog/agent-harnesses-from-diy-to-product
Microsoft. “playwright-mcp.” GitHub Repository. https://github.com/microsoft/playwright-mcp
Morph. “Playwright MCP: How AI Coding Agents Control the Browser.” 27 Feb 2026. https://www.morphllm.com/playwright-mcp