Architecting Production-Grade Agents through LLM Orchestration and Agentic Loops
Domain 1 Study Guide for CCA-F with examples in Claude Agent SDK
Originally published on Medium.
Domain 1 Study Guide for CCA-F with examples in Claude Agent SDK
Empowering developers to stop "coaxing" LLMs and start architecting a high-performance, autonomous workforce.
Summary: Discover how to transform flaky, prompt-driven LLM experiments into rock-solid production systems by mastering agentic loops, deterministic orchestration, and structured data handoffs. We cover the core concepts, stop-reason payloads, hub-and-spoke coordination, context isolation, hooks for normalization, parallel wave execution, and session management (resume, fork, fresh starts), and provides concrete Python examples using Claude's Agent SDK. By the end, you'll see why explicit, deterministic architecture beats "super-agent" prompting and how to build reliable, scalable AI workflows that actually get work done.
Domain 1: Agentic Architecture & Orchestration
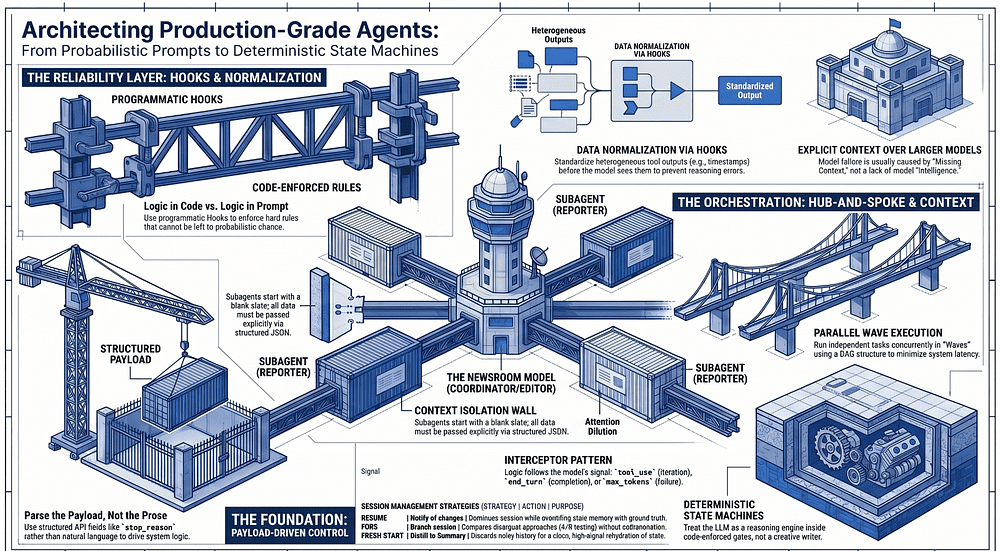
In the current AI landscape, the "chatbot" is a deceptive interface. For engineers building production-grade systems, the chat window is an illusion that masks the real engine of automation: the agentic loop. Moving from experimental prompts to reliable systems requires a fundamental shift in perspective. We must stop treating Large Language Models (LLMs) as creative writers and start treating them as reasoning engines within a deterministic state machine.
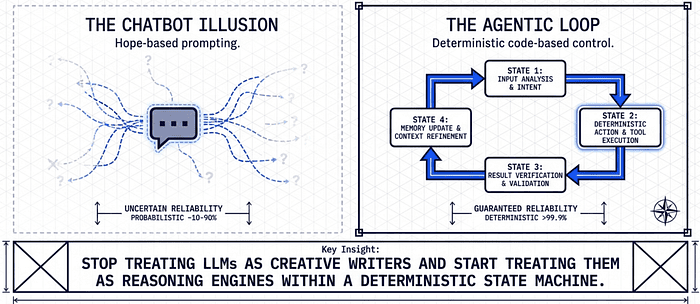
Traditional "hope-based" prompting fails in professional settings because it is inherently probabilistic. To achieve reliability, we must wrap the model in an orchestration layer that enforces safety, manages state, and handles execution. This is the shift from "prompt engineering" to "agentic architecture" and "harness engineering".
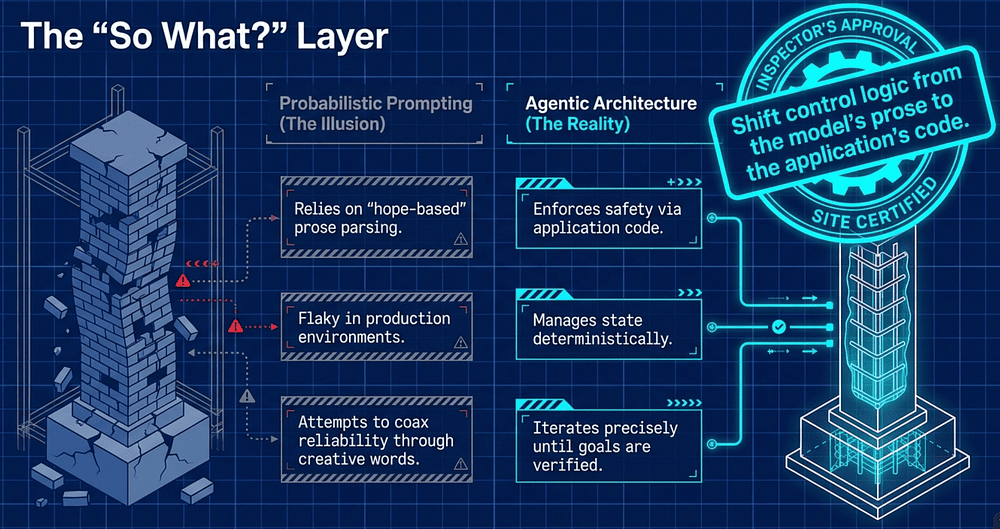
The "So What?" Layer: Agentic loops transform LLMs from passive responders into autonomous workers. By moving the control logic from the model's prose to the application's code, we create a system that doesn't just "talk" about a task, but iterates until a goal is verified and complete. The heart of this transformation is the payload-driven agentic loop.
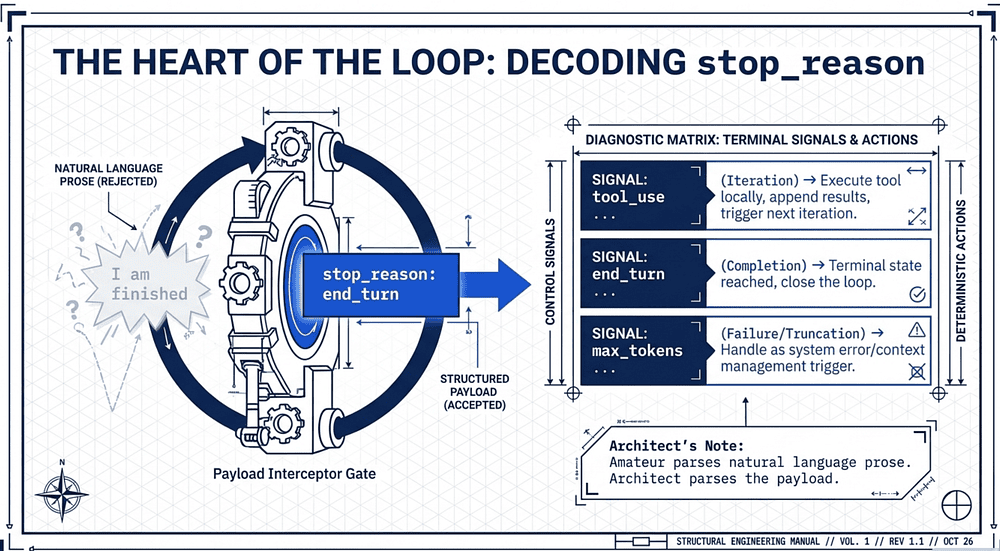
The Heart of the Loop: Decoding stop_reason
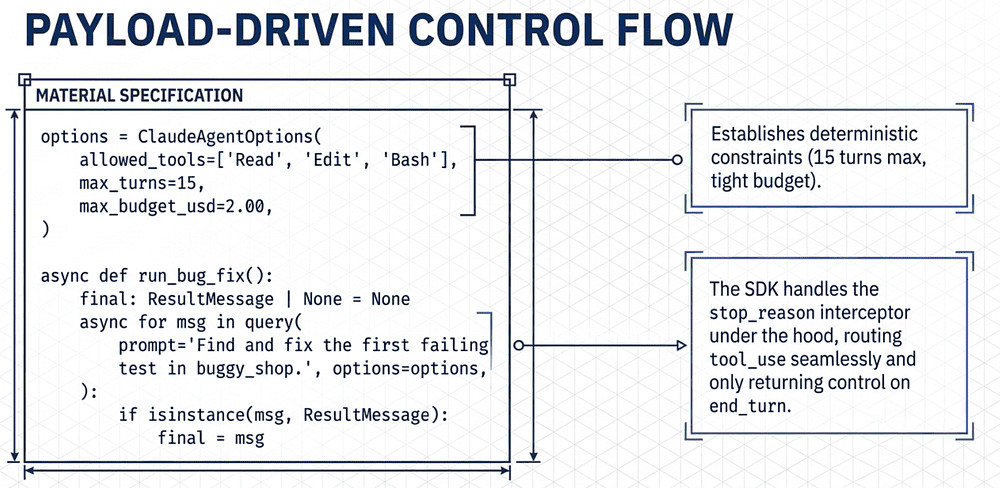
An agentic loop is not a conversation; it is a deterministic state machine. Its progression is governed not by the text Claude generates, but by specific fields in the API payload; most critically, the stop_reason.
Payload-Driven Control Flow
The application logic follows a strict interceptor pattern based on the model's signal:
tool_use(Iteration): The model requests an action. The application executes the tool locally, appends the results to the history, and triggers the next iteration. Everytool_usemust be answered with a matchingtool_resultto maintain state integrity.end_turn(Completion): The model signals it has reached a terminal state. The loop closes.max_tokens(Failure/Truncation): A non-normal completion where the output was truncated. Architects must handle this as a system error or a trigger for context management, not a successful task end.
The "So What?" Layer: A common anti-pattern is parsing natural language, e.g., reading the assistant's prose for phrases like "I am finished" to determine loop termination. This is a recipe for catastrophic system failure.
Stop reason handling: continue only on tool_use. Treat end_turn as normal completion. Treat max_tokens, refusal (stop_reason="stop" with no tool call), stop-sequence triggers, SDK execution errors, and budget or turn exhaustion as non-normal exits requiring explicit handling — not silent continuation. The exam tests whether you can distinguish these cases. Professional orchestration "parses the payload, not the prose." By relying on stop_reason, you ensure the system's control flow is driven by structured data, making it immune to the model's creative interpretation of its own status.
Example using stop_reason to check for end_turn using Claude Agent SDK
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions, ResultMessage
class AgentRunError(RuntimeError):
"""Raised when the agent loop does not complete successfully."""
# Set up agent.
options = ClaudeAgentOptions(
allowed_tools=["Read", "Edit", "Bash"],
max_turns=15,
max_budget_usd=2.00,
)
async def run_bug_fix():
final: ResultMessage | None = None
async for msg in query(
prompt="Find and fix the first failing test in buggy_shop.",
options=options,
):
if isinstance(msg, ResultMessage):
final = msg
if final is None:
raise AgentRunError("Loop ended without a ResultMessage: transport-level failure")
# Branch on the payload, not the text.
match final.subtype:
case "success":
# stop_reason on success tells us *how* the model concluded.
if final.stop_reason == "end_turn":
print(f"Fix complete:\n{final.result}")
elif final.stop_reason == "max_tokens":
# Terminal output was truncated; don't trust `result`.
raise AgentRunError("Output truncated mid-sentence. Re-run with smaller scope.")
elif final.stop_reason == "refusal":
raise AgentRunError("Model refused the task. Escalate to a human.")
else:
raise AgentRunError(f"Unexpected stop_reason on success: {final.stop_reason}")
case "error_max_turns":
raise AgentRunError(f"Turn budget exhausted after {final.num_turns} turns.")
case "error_max_budget_usd":
raise AgentRunError(f"Budget exhausted at ${final.total_cost_usd:.2f}.")
case "error_during_execution":
raise AgentRunError("Transport or tool failure: see logs.")
case other:
raise AgentRunError(f"Unhandled result subtype: {other}")
asyncio.run(run_bug_fix())
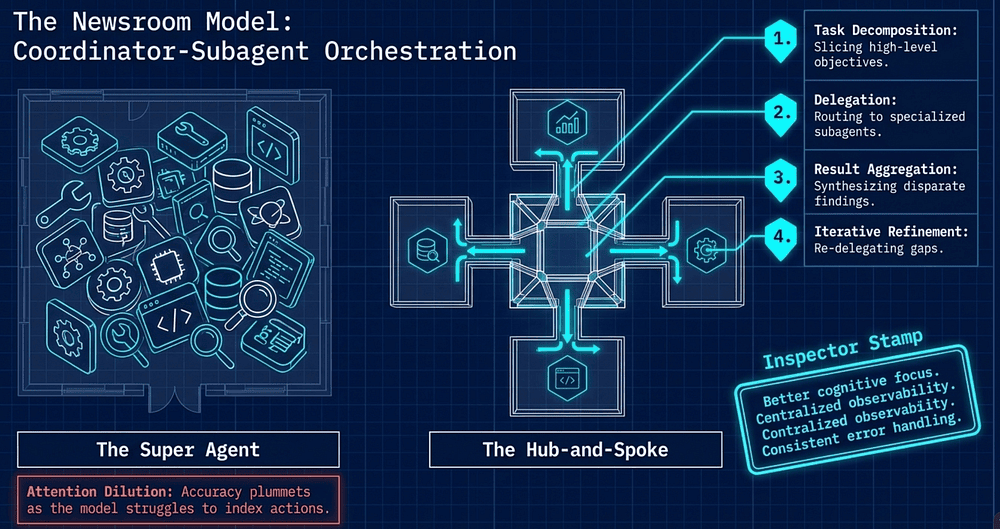
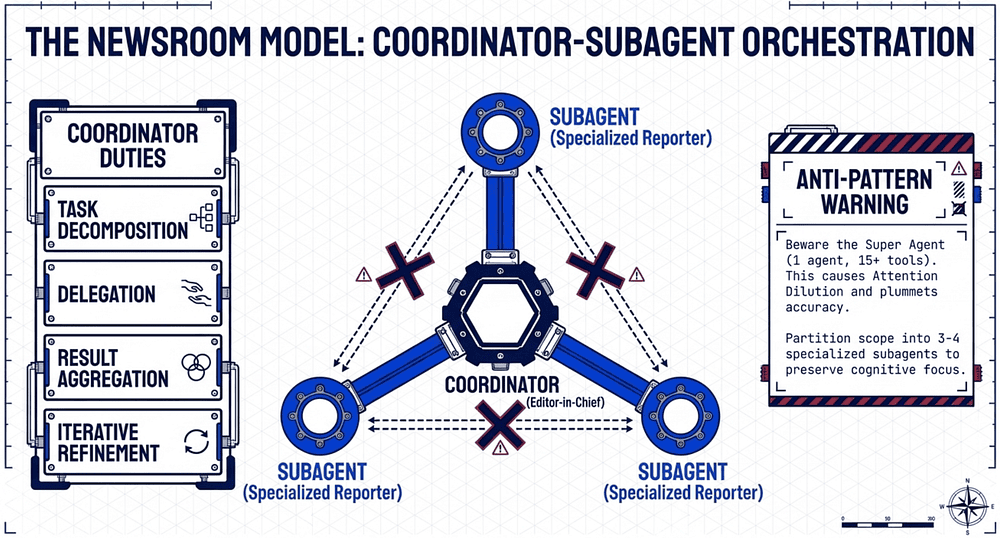
The Newsroom Model: Coordinator-Subagent Orchestration
To manage complexity, we deploy the Hub-and-Spoke architecture. We ground this in the "Newsroom" metaphor: the Coordinator acts as the Editor-in-Chief, while specialized Subagents act as Reporters.
In this model, reporters never communicate with each other directly. All information, error handling, and routing flow through the Coordinator. This ensures centralized observability and consistent error handling across the entire system.
The Coordinator's Responsibilities
- Task Decomposition: Slicing a high-level objective into distinct, manageable subtasks.
- Delegation: Selecting the right specialized subagent based on the task's requirements.
- Result Aggregation: Synthesizing disparate findings into a unified output.
- Iterative Refinement: Evaluating synthesis for gaps and re-delegating targeted queries until quality criteria are met.
The "So What?" Layer: Beware the "Super Agent" anti-pattern; a single agent equipped with 15+ tools. This leads to "attention dilution," where accuracy plummets as the model struggles to index its available actions. A superior architect partitions scope into 3-4 specialized subagents. This provides better "cognitive" focus and prevents the model from being overwhelmed by irrelevant tool context.
Let's cover a brief example of the Newsroom Model: a coordinator running a research-grade investigation of why buggy_shop's checkout is broken, with three specialized reporters and a refinement loop.
Coordinator prompt design: define the goal, evidence requirements, coverage criteria, and escalation or refinement rules. Avoid over-prescribing every step unless the workflow is intentionally fixed. A prompt that defines output quality (return findings with source and confidence) outperforms one that micromanages execution steps, because the coordinator can adapt when subagents return partial results or fail.
Coordinator-Subagent Orchestration: Claude Agent SDK Example
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions, AgentDefinition, ResultMessage
options = ClaudeAgentOptions(
# The coordinator gets the Agent tool; reporters do not (no spoke-to-spoke comms).
allowed_tools=["Agent", "Read", "Bash"],
agents={
# --- The Reporters (spokes) ---
"code-reporter": AgentDefinition(
description="Investigates application code. Read-only.",
prompt=(
"You are a code reporter. Given a module name, return: "
"(1) what it does in 2 sentences, (2) suspicious functions, "
"(3) recent edits (git log -5). Be terse. Do not propose fixes."
),
tools=["Read", "Grep", "Bash"],
),
"test-reporter": AgentDefinition(
description="Investigates failing tests and fixtures. Read-only.",
prompt=(
"You are a test reporter. Given a test path, return: "
"(1) which tests fail and their assertion messages, "
"(2) what fixtures they depend on, (3) any shared setup. "
"Be terse. Do not propose fixes."
),
tools=["Read", "Bash", "Grep"],
),
"schema-reporter": AgentDefinition(
description="Investigates data models and recent migrations. Read-only.",
prompt=(
"You are a schema reporter. Given a models module, return: "
"(1) the relevant Pydantic models, (2) recent schema changes "
"in the last 10 commits, (3) any field-type mismatches you notice."
),
tools=["Read", "Grep", "Bash"],
),
},
)
# The coordinator prompt encodes the four responsibilities explicitly.
coordinator_prompt = """You are the Editor-in-Chief investigating why buggy_shop's checkout tests fail.
You don't write code: you direct reporters.
YOUR RESPONSIBILITIES:
1. DECOMPOSE: Break the question into distinct angles (code behavior, test surface, data shape). One angle per reporter.
2. DELEGATE: Dispatch reporters IN A SINGLE TURN so they run in parallel:
- code-reporter -> target: buggy_shop.checkout
- test-reporter -> target: tests/test_checkout.py
- schema-reporter -> target: buggy_shop.models
Pass each reporter only the context it needs. Reporters do not talk to each other; everything routes through you.
3. AGGREGATE: When all three return, synthesize their findings into a single root-cause hypothesis with supporting evidence from each report.
4. REFINE: Critically review your synthesis. If any of these are true:
- A reporter's findings contradict another's
- The root cause doesn't explain all observed test failures
- You're relying on a guess where a fact would do
then dispatch a TARGETED follow-up reporter with a specific question. Stop when the synthesis is internally consistent and evidence-backed.
Output: a one-paragraph root cause + a bulleted evidence list citing which reporter supplied each fact."""
async def main():
async for msg in query(prompt=coordinator_prompt, options=options):
if isinstance(msg, ResultMessage) and msg.subtype == "success":
print(msg.result)
asyncio.run(main())
Each subagent in the agents dict is an AgentDefinition. The three fields matter for the exam: description tells the coordinator when to choose this subagent (routing logic); prompt defines the subagent's role, output expectations, and scope boundaries; tools is the least-privilege capability set — a reporter that only needs to read files should not have Edit or Bash. Giving a subagent fewer tools than it could theoretically use is not a limitation; it is an architectural constraint that makes the system auditable and safe to parallelize.
How the four responsibilities map to code
Decomposition lives in the coordinator's prompt; it's instructed to slice the question into three distinct angles, each matched to an available reporter's description. The model picks who handles what based on those descriptions.
Delegation happens through the Agent tool. The coordinator emits three Agent calls in a single turn ("IN A SINGLE TURN" is doing real work here; it's the difference between parallel and serial execution). Each reporter gets a fresh context window containing only the targeted prompt the coordinator wrote for it. They run concurrently because they're read-only.
Aggregation is structural, not magical: each reporter's final message comes back to the coordinator as a tool result. The coordinator's context window now holds three concise summaries instead of dozens of file reads. It synthesizes a unified root cause from those summaries.
Iterative refinement is the prompt's third move. The coordinator self-critiques against three concrete failure modes (contradiction, unexplained evidence, guesswork) and is licensed to dispatch additional reporters if needed. The loop continues until the synthesis is consistent. The model decides when to stop; the prompt defines what "good enough" means.
Why the hub-and-spoke shape matters
Notice what reporters can't do:
- They don't have the
Agenttool, so they can't spawn each other. - They don't see each other's outputs; only the coordinator does.
- They don't have
EditorWrite, so a confused reporter can't damage the repo.
This is the architectural payoff of the Newsroom Model. Every fact in the final report passes through one observable, auditable point. If the synthesis is wrong, you can read the coordinator's transcript and see exactly which reporter supplied which claim. If a reporter hallucinates, the blast radius is bounded: it ends up as one input in the coordinator's aggregation, where contradiction with the other two reporters will likely flag it during the refinement step.
The alternative, reporters chatting peer-to-peer, looks more "agentic" but loses centralized observability and turns every error into a debugging nightmare across N parallel transcripts. The Editor-in-Chief constraint isn't a limitation; it's what makes the system legible.
Dynamic Agent Selection: Not Every Query Needs All Reporters
The Newsroom example dispatches three reporters every time. In production, the coordinator should analyze the query before deciding which subagents to invoke. A narrow test failure may only need test-reporter and code-reporter. A schema-related failure adds schema-reporter. An ambiguous or broad research question may expand the pool further. Always running all subagents wastes tokens, increases latency, and introduces irrelevant context into the aggregation step.
The coordinator should also avoid the overly narrow decomposition failure mode: if three subagents all investigate visual arts under 'creative industries,' the final report will miss music, film, and writing. That is not a subagent failure — it is a coordinator decomposition failure. The coordinator must scope subtasks broadly.
Dynamic selection also applies across domains. When a user says "I was double charged, my shipment is late, and I need to change my email," the coordinator does not send all three complaints to a single agent. It decomposes the request into three independent investigations: a billing subagent, a shipping subagent, and an account-profile subagent. Each runs in parallel. The coordinator synthesizes a single unified response. This is multi-concern decomposition, and it directly maps to the customer support scenario on the CCA-F exam.
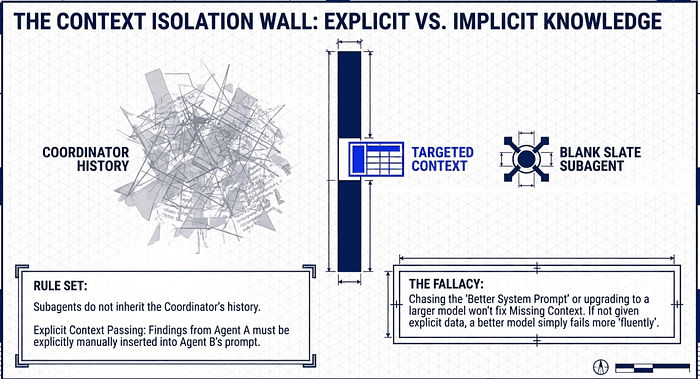
The Context Isolation Wall: Explicit vs. Implicit Knowledge
The most important rule in multi-agent systems is Context Isolation. Subagents do not inherit the Coordinator's history; they start with a blank slate.
Mechanics of Explicit Passing
To spawn a subagent, the Coordinator uses the Task tool (now renamed to Agent tool but for the test still Task). This requires the Coordinator's allowedTools to include "Task" and each subagent to be defined via a clear AgentDefinition (specifying prompts and tool restrictions).
- Explicit Context Passing: Findings from Agent A must be manually inserted into the
Taskprompt for Agent B. - Structured Data Handoffs: Use JSON to separate content from metadata (e.g., source URLs, page numbers). This preserves source attribution as information moves through the hierarchy.
The "So What?" Layer: When a subagent fails, developers often chase the "Better System Prompt" fallacy or upgrade to a larger model (e.g., switching from Haiku to Sonnet). However, the root cause is almost always "Missing Context." A more powerful model cannot reason about data it was never given. If the Coordinator doesn't explicitly forward the policy or the data, the subagent will fail; it will just fail more "fluently."
Explicit Context Passing Example using Claude Agent SDK
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions, AgentDefinition, ResultMessage
...
# Define a subagent.
options = ClaudeAgentOptions(
agents={
"bug-fixer": AgentDefinition(
description="Fixes a single failing test given full context up front.",
prompt=(
"You fix exactly one failing test. Read only the file you are told to "
"read, make the minimum edit, and report the diff. Do not explore."
),
tools=["Read", "Edit", "Bash"],
model="sonnet",
)
}
)
# Everything the subagent needs is in this prompt
# it sees nothing else from the parent.
# We pass what it needs to its context for the subagent.
# Failing test, error and suspect file are passed.
prompt = f"""Use the bug-fixer agent.
Failing test: {FAILING_TEST}
Error: {ERROR}
File to edit: {SUSPECT_FILE}
Constraint: do not modify the test. Run `pytest {FAILING_TEST}` to confirm the fix."""
...
async for msg in query(prompt=prompt, options=options):
if isinstance(msg, ResultMessage):
print(msg.result)
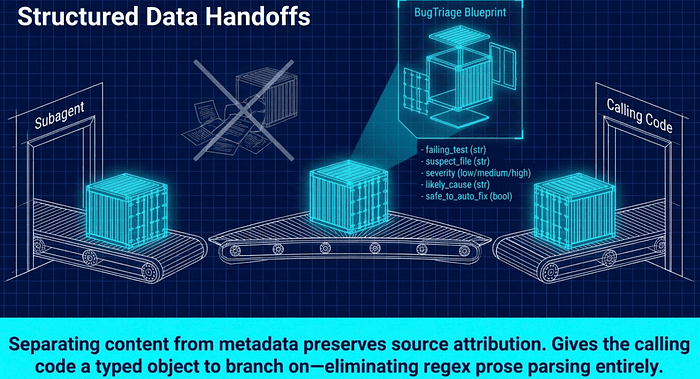
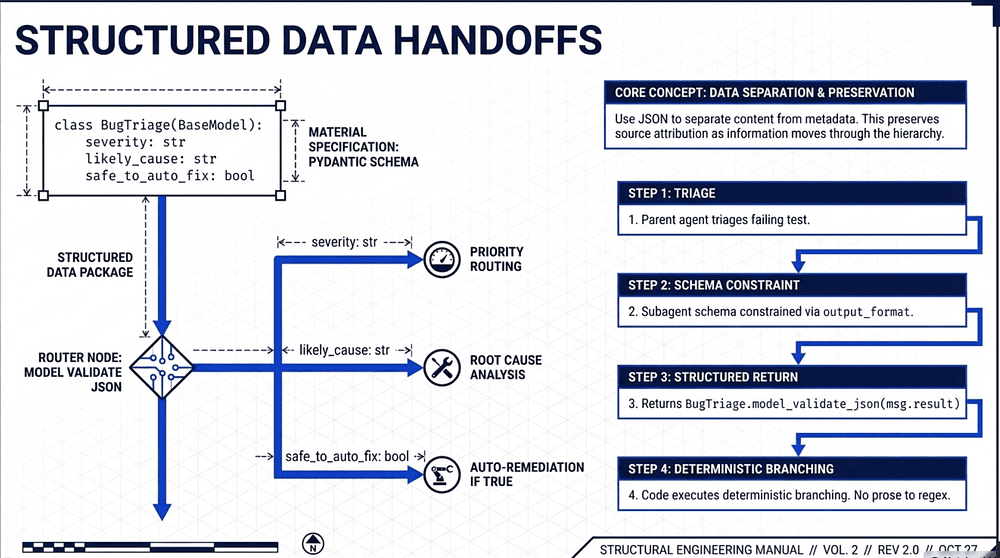
Structured Data Handoffs Example
The parent agent triages a failing-test report and hands back typed JSON the calling code can route on; no prose parsing.
Python (Pydantic) example of Structured Data Handoff
import asyncio
from pydantic import BaseModel
from claude_agent_sdk import query, ClaudeAgentOptions, ResultMessage
# This class defines the structured handoff.
class BugTriage(BaseModel):
failing_test: str
suspect_file: str
severity: str # "low" | "medium" | "high"
likely_cause: str
safe_to_auto_fix: bool
# Define the subagent, and specify the output format uses json schema from
# BugTriage.
options = ClaudeAgentOptions(
allowed_tools=["Read", "Bash", "Grep"],
output_format={
"type": "json_schema",
"schema": BugTriage.model_json_schema(),
},
)
prompt = "Run the buggy-shop test suite, pick the first failure, and triage it."
...
# Invoke subagent
async for msg in query(prompt=prompt, options=options):
if isinstance(msg, ResultMessage) and msg.result:
# The structured data is passed back.
triage = BugTriage.model_validate_json(msg.result)
if triage.safe_to_auto_fix and triage.severity != "high":
autoFix(triage.suspect_file)
else:
escalate(triage.likely_cause)
The agent can still use any tools it needs mid-run (grep, read, pytest). The structured output only constrains the final message, giving the calling code a typed object to branch on instead of prose to regex.
Determinism vs. Probabilistic Control: The Power of Hooks
When subagents investigate the same question from different sources and return conflicting claims, the coordinator must not silently pick one. Preserve both with source and confidence metadata: { "claim": "Revenue grew 12%", "source": "audited annual report", "confidence": "high" } vs { "claim": "Revenue grew 18%", "source": "press release", "confidence": "medium" }. The coordinator then applies a conflict-resolution policy (prefer audited sources) or requests a targeted follow-up investigation before synthesizing the final answer.
Architects must decide where logic lives: in the prompt (probabilistic) or in the code (deterministic). Reliable systems use Hooks, programmatic interceptors, to enforce rules that cannot be left to chance.

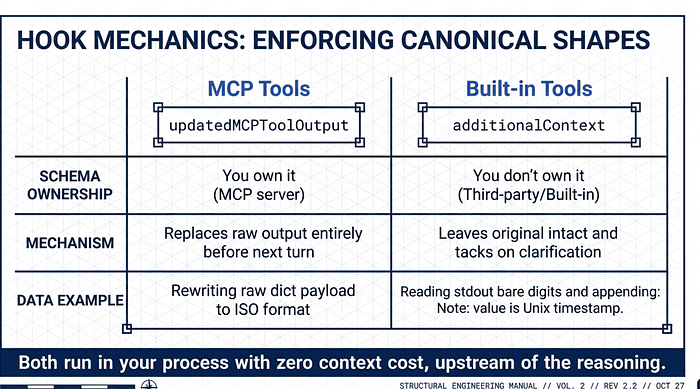
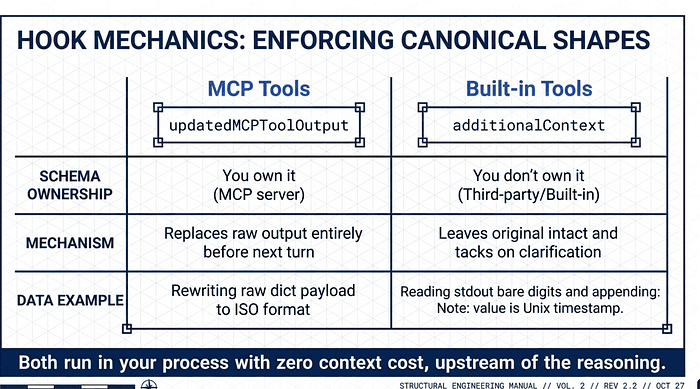
Normalization via PostToolUse
Hooks are vital for "Data Normalization." When multiple tools return heterogeneous data (e.g., different timestamp formats), the model's reasoning suffers.
- For MCP Tools, the
updatedMCPToolOutputfield allows the hook to replace the raw output entirely with a normalized version. - For Built-in Tools, we use
additionalContextto append clarified data.
The "So What?" Layer: Normalization prevents "Attention Dilution." By standardizing Unix vs. ISO timestamps programmatically before the model sees them, you free the LLM to focus on reasoning rather than parsing data formats.
Using Tool Hooks and MCP Hooks to normalize dates
import asyncio
from datetime import datetime, timezone
from typing import Any
from claude_agent_sdk import query, ClaudeAgentOptions, HookMatcher, HookContext
def _to_iso(ts: Any) -> str:
"""Coerce Unix seconds, Unix millis, or ISO strings to a single ISO format."""
if isinstance(ts, (int, float)):
# Heuristic: millis if it looks too big to be seconds.
seconds = ts / 1000 if ts > 10_000_000_000 else ts
return datetime.fromtimestamp(seconds, tz=timezone.utc).isoformat()
return datetime.fromisoformat(str(ts).replace("Z", "+00:00")).isoformat()
# Hook 1: MCP tool
# replace the raw output entirely.
async def normalize_mcp_orders(
input_data: dict[str, Any],
tool_use_id: str | None,
context: HookContext
) -> dict[str, Any]:
raw = input_data["tool_response"] # whatever the MCP server returned
# e.g. raw == {"orders": [{"id": "A1", "created_at": 1731024000}, ...]}
normalized = {
"orders": [
{**o, "created_at": _to_iso(o["created_at"])}
for o in raw.get("orders", [])
]
}
return {
"hookSpecificOutput": {
"hookEventName": "PostToolUse",
"updatedMCPToolOutput": normalized, # model sees this, not `raw`
}
}
# Hook 2: Built-in tool
# append a clarifying note alongside the output.
async def annotate_bash_timestamps(
input_data: dict[str, Any],
tool_use_id: str | None,
context: HookContext
) -> dict[str, Any]:
# We can't rewrite Bash output, but we can tell the model how to read it.
# e.g. `date +%s` returned "1731024000"
stdout = str(input_data["tool_response"].get("stdout", "")).strip()
note = ""
if stdout.isdigit():
note = f"Note: the value {stdout} is a Unix timestamp ({_to_iso(int(stdout))})."
return {
"hookSpecificOutput": {
"hookEventName": "PostToolUse",
"additionalContext": note, # appended to the tool result the model sees
}
}
options = ClaudeAgentOptions(
allowed_tools=["Bash", "mcp__orders__list_recent"],
# mcp_servers=... # MCP server wiring omitted
hooks={
"PostToolUse": [
HookMatcher(matcher="mcp__orders__list_recent", hooks=[normalize_mcp_orders]),
HookMatcher(matcher="Bash", hooks=[annotate_bash_timestamps]),
],
},
)
...
async for _ in query(
prompt="List recent orders and tell me which were placed today.",
options=options,
):
... # message handling omitted
Let's walk through the code a bit.
imports: query runs the agent loop, ClaudeAgentOptions carries config including hooks, HookMatcher pairs a tool-name pattern with callbacks, and HookContext is a reserved third argument every hook must accept.
The _to_iso helper: Pure utility that swallows three timestamp dialects: Unix seconds, Unix millis, and ISO strings, and emits one canonical ISO-8601 UTC string. The > 10_000_000_000 check distinguishes millis from seconds (anything that large can't be seconds without being centuries in the future). Both hooks call it.
Hook 1, normalize_mcp_orders: Every PostToolUse callback receives input_data (with tool_name, tool_input, tool_response), a tool_use_id, and a context. This hook pulls tool_response, rebuilds each order with its created_at replaced by the ISO form, and returns it under updatedMCPToolOutput; an MCP-only field that tells the SDK to substitute the tool result before the next turn. The model never sees the raw payload.
Hook 2, annotate_bash_timestamps: Same signature, different strategy. You can't wholesale-replace built-in tool output, so this one reads stdout, checks if it's a bare digit string (the giveaway for date +%s), and returns a one-line translation via additionalContext. The SDK appends that note to the tool result the model sees. The original 1731024000 is still there, now accompanied by its ISO equivalent so the model doesn't have to do timestamp math. An empty string is a clean no-op when there's nothing to annotate.
Wiring: The hooks dict is keyed by event name; the value is a list of HookMatchers. Matchers filter by tool name only; finer filtering (file paths, command shape) happens inside the callback. MCP tool names follow mcp__<server>__<action> exactly; typos fail silently.
The dividing line:
- You own the schema (your MCP server) ->
updatedMCPToolOutputenforces one canonical shape. - You don't own the schema (built-in tools, third-party APIs) ->
additionalContextleaves the original intact and tacks on the clarification the model would otherwise have to derive.
Note: additionalContext works on PostToolUse hooks regardless of whether the tool is MCP or built-in. The matcher mcp__orders__list_recent could just as easily return additionalContext instead of (or alongside) updatedMCPToolOutput. The asymmetry is one-directional: additionalContext is universal, updatedMCPToolOutput is MCP-only. So for an MCP tool you have a real choice; for a built-in tool you don't. Both run in your process with zero context cost, upstream of the reasoning.

PreToolUse Guards and Human Handoff: When Prompting Is Not Enough
Hooks give you two intervention points: PostToolUse transforms and normalizes results after a tool executes, while PreToolUse intercepts the action before it executes. For enforcement logic — identity verification, refund thresholds, or blocking unsafe actions — PreToolUse is the right layer. A prompt instruction alone cannot enforce a hard rule; a PreToolUse guard can block the call entirely and redirect Claude to an escalation path.
Consider a customer support agent. The agent may call get_customer to look up the caller, then call process_refund if a billing issue is confirmed. A PostToolUse hook normalizes the customer record format. A PreToolUse guard enforces the policy: refunds are only allowed after identity is verified, and only up to the approved limit.
The guard_refund function below shows the pattern:
When the guard blocks a refund — because verification failed or the amount exceeds policy — the agent should not silently stop. It should produce a structured handoff for human review:
{
"customer_id": "cust_123",
"verified": true,
"issue_summary": "Customer reports duplicate billing",
"root_cause": "Two payment attempts captured",
"steps_attempted": ["lookup_order", "check_billing_events"],
"refund_amount": 49.99,
"recommended_action": "Manager approval required before refund"
}
This structured handoff is the difference between a production-grade agent and a toy demo. The coordinator passes all context — what it tried, what it learned, what it recommends — so a human can act immediately without re-investigating from scratch.
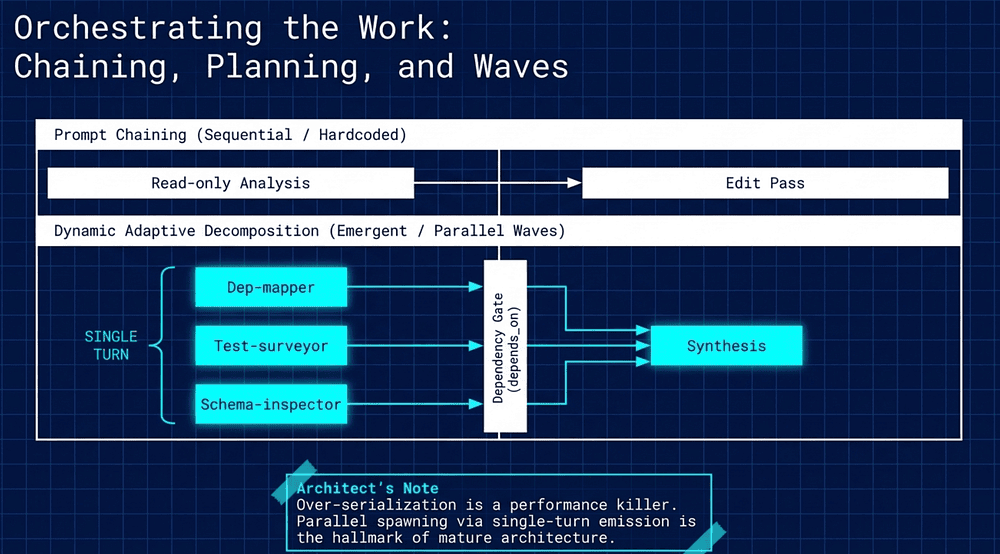
Orchestrating the Work: Chaining, Planning, and Waves
Not all workflows are equal. We categorize them by the predictability of their path:
Prompt Chaining (Sequential): A fixed, known pipeline (e.g., local file analysis followed by a global integration pass).
Dynamic Adaptive Decomposition (Emergent): The plan emerges as discoveries are made (e.g., investigating an unknown legacy codebase).
Use this decision table to pick the right pattern:
- Predictable, same steps every time -> Fixed sequential pipeline / prompt chaining.
- Open-ended investigation -> Dynamic adaptive decomposition.
- Large code review -> Per-file local passes + cross-file integration pass.
- Independent subtasks with dependencies -> Parallel waves / DAG-style orchestration.
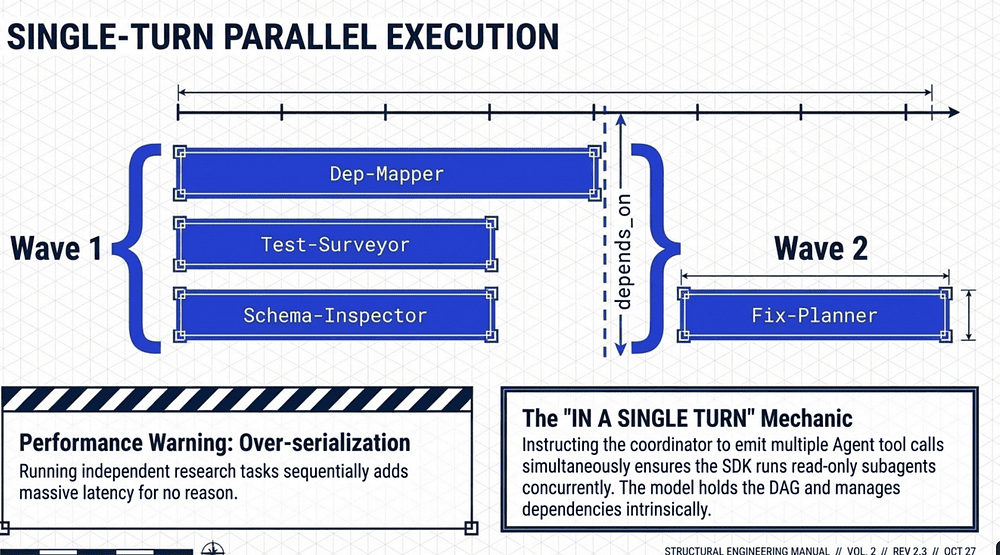
Wave Ordering and Parallel Execution
To minimize latency, independent tasks should run in "Waves" using a Directed Acyclic Graph (DAG) structure.
Parallel Spawning: The Coordinator emits multiple Task (note Task was renamed to Agent) tool calls in a single turn.
Dependency Logic: We use depends_on to ensure Wave 2 only begins once Wave 1's prerequisites are satisfied.
The "So What?" Layer: "Over-serialization" is a performance killer. Running independent research tasks one-by-one is an amateur mistake. Parallel spawning via single-turn emission is the hallmark of a mature, efficient agentic architecture.
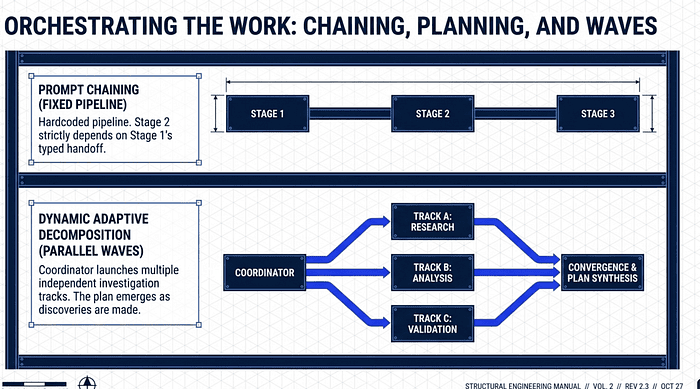
1. Prompt Chaining: fixed, known pipeline
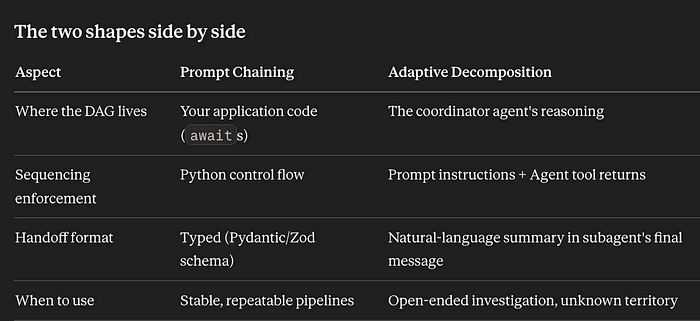
A two-stage pipeline where stage 2 strictly depends on stage 1's output. The path is hardcoded in your application code, not negotiated by the model. Each query() call is one stage; the typed handoff between them is the structured output from stage 1.
import asyncio
from pydantic import BaseModel
from claude_agent_sdk import query, ClaudeAgentOptions, ResultMessage
class FailureReport(BaseModel):
failing_tests: list[str]
suspect_files: list[str]
# --- Wave 1: local file analysis (constrained, read-only) ---
async def stage_analyze() -> FailureReport:
opts = ClaudeAgentOptions(
allowed_tools=["Read", "Bash", "Grep"],
output_format={"type": "json_schema", "schema": FailureReport.model_json_schema()},
)
async for msg in query(prompt="Run pytest; list failing tests and suspect files.", options=opts):
if isinstance(msg, ResultMessage) and msg.subtype == "success":
return FailureReport.model_validate_json(msg.result)
raise RuntimeError("analysis stage failed")
# --- Wave 2: global integration pass, gated on Wave 1's typed output ---
async def stage_fix(report: FailureReport) -> None:
prompt = (
f"Fix these failing tests: {report.failing_tests}\n"
f"Likely files: {report.suspect_files}\n"
"Run pytest after each edit until all pass."
)
opts = ClaudeAgentOptions(allowed_tools=["Read", "Edit", "Bash"])
async for _ in query(prompt=prompt, options=opts):
...
async def main():
report = await stage_analyze() # Wave 1
await stage_fix(report) # Wave 2, strictly after Wave 1
asyncio.run(main())
The pipeline shape is in your code: await enforces the sequencing, the Pydantic schema enforces the contract between stages, and each stage gets a different tool set (read-only first, edit-capable second). The model never decides whether to skip ahead.
2. Dynamic Adaptive Decomposition with Parallel Waves
The plan emerges as discoveries are made. The coordinator agent spawns independent subagents in a single turn: one Agent (was called Task when test was created so test still refers to it as Task) tool call per investigation track, and then they run concurrently. Wave 2 only fires after Wave 1's subagents return summaries the coordinator can reason about.
import asyncio
from claude_agent_sdk import query, ClaudeAgentOptions, AgentDefinition, ResultMessage
options = ClaudeAgentOptions(
allowed_tools=["Agent", "Read", "Grep", "Bash"],
agents={
# Wave 1: independent investigators (read-only, safe to parallelize)
"dep-mapper": AgentDefinition(
description="Map module dependencies. Read-only.",
prompt="Identify imports and call sites for the named module. Return a summary.",
tools=["Read", "Grep"],
),
"test-surveyor": AgentDefinition(
description="Survey failing tests and their fixtures. Read-only.",
prompt="List failing tests, their fixtures, and shared setup. Return a summary.",
tools=["Read", "Bash", "Grep"],
),
"schema-inspector": AgentDefinition(
description="Inspect data models and migrations. Read-only.",
prompt="Summarize the relevant Pydantic models and any recent schema changes.",
tools=["Read", "Grep"],
),
# Wave 2: synthesizer: depends on all three Wave 1 outputs
"fix-planner": AgentDefinition(
description="Synthesize investigation results into a concrete fix plan.",
prompt="Given dependency, test, and schema summaries, propose a minimal fix plan.",
tools=["Read"],
),
},
)
# The coordinator decides which investigations to launch based on what it finds.
# The instruction to spawn in parallel is what produces single-turn multi-Agent emission.
prompt = """Investigate why buggy_shop's checkout tests are failing.
You don't yet know the cause.
Wave 1: spawn these three subagents IN A SINGLE TURN so they run in parallel:
- dep-mapper (target: buggy_shop.checkout)
- test-surveyor (target: tests/test_checkout.py)
- schema-inspector (target: buggy_shop.models)
Wave 2: ONLY after all three return, invoke fix-planner with their combined summaries.
Then apply the plan."""
async def main():
async for msg in query(prompt=prompt, options=options):
if isinstance(msg, ResultMessage):
print(msg.result)
asyncio.run(main())
The key mechanics:
Parallel spawning is achieved by instructing the coordinator to emit multiple Agent tool calls in one turn. The SDK runs read-only subagents concurrently: dep-mapper, test-surveyor, and schema-inspector all execute simultaneously, not sequentially.
Dependency logic ("Wave 2 only after Wave 1") is expressed in the prompt itself. The model holds the DAG; it doesn't fire fix-planner until it has all three summaries in hand to pass as that subagent's prompt context.
Why this is adaptive: the coordinator might decide mid-run that schema-inspector returned nothing relevant and spawn a fourth investigator instead, or skip Wave 2 entirely if Wave 1 already revealed the cause. The plan isn't hardcoded. The plan emerges.
Over-serialization watch: in the second example, if the coordinator emits the three Wave 1 Agent calls across three separate turns instead of one, you've just added two round trips of latency for no reason. The phrase "IN A SINGLE TURN" in the prompt is doing real work. This phrase is the difference between concurrent and serial execution. For high-stakes workflows you can enforce this with a PreToolUse hook that tracks Agent calls.
When a subagent fails, it should not just return an error string. Return a structured error payload so the coordinator can decide: retry, delegate to a fallback agent, or proceed with explicit coverage gaps.
Example:
{
"success": false,
"error_type": "timeout",
"attempted_query": "checkout schema migrations",
"partial_results": ["Found Order model but migration query timed out"],
"retryable": true,
"recommended_next_step": "Retry with narrower date range"
}
A coordinator that receives this can make an informed decision. A coordinator that receives "Error: timeout" cannot.
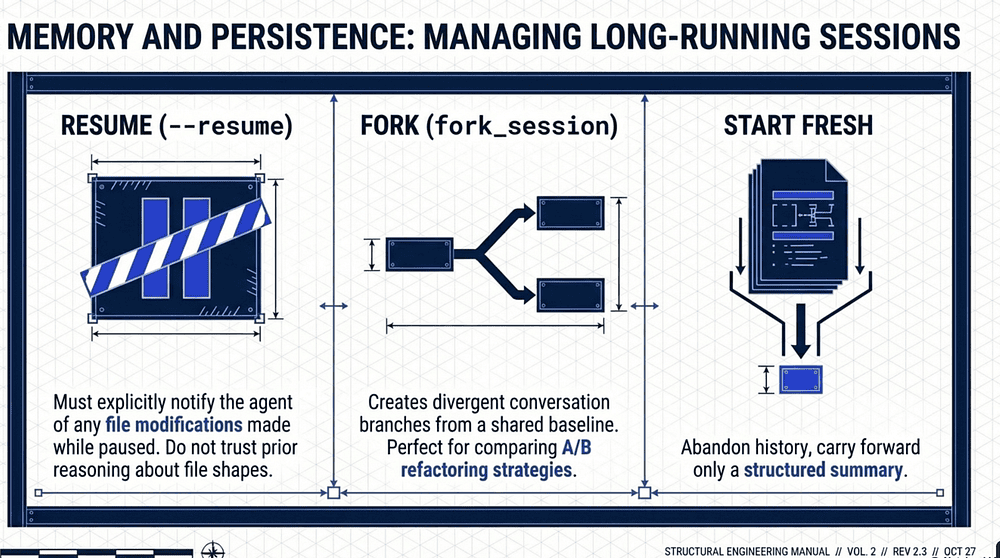
Memory and Persistence: Managing Long-Running Sessions
As sessions grow, conversation history degrades and tool results become "stale." State management is a strategic necessity.
Resume (--resume): Continuing a session. Critical: When resuming, you must explicitly notify the agent of any file modifications that occurred while it was paused. Without this, the agent will reason based on stale memory of the code state.
Fork (fork_session): Creating branches from a shared baseline to compare divergent approaches (e.g., two different refactoring strategies).
Start Fresh with Summary: Abandoning the history for a new session, carrying only a structured summary of the current state.
The "So What?" Layer There is a common misconception that "more context is always better." In reality, a clean session with a tight, high-signal summary often outperforms a bloated, resumed session carrying "Stale Context"; old reasoning that no longer applies to the project's current state.

Let's go over some examples in Claude Agent SDK to drive the points home with these three small examples staged around the bug-fix agent: one for each pattern.
1. Resume with stale-state notification
The agent finished analysis, you went to lunch, your colleague pushed a refactor, now you want the agent to continue with the new reality. Resuming without telling it what changed is the trap: it will edit against the file layout from before lunch.
import asyncio
import subprocess
from claude_agent_sdk import ClaudeAgentOptions, ResultMessage, query
async def resume_with_diff(session_id: str) -> None:
# Capture what changed on disk while the session was paused.
diff = subprocess.check_output(
["git", "diff", "--stat", "HEAD@{1}"],
text=True,
)
# Hand the agent the delta BEFORE it acts on its stale mental model.
prompt = f"""Resuming. The repo changed while you were paused:
{diff}
Re-read any files in the diff before continuing your fix.
Do not trust your prior reasoning about their contents."""
async for msg in query(
prompt=prompt,
options=ClaudeAgentOptions(
# Notice we are passed a session ID.
resume=session_id,
allowed_tools=["Read", "Edit", "Bash"],
),
):
if isinstance(msg, ResultMessage) and msg.subtype == "success":
print(msg.result)
asyncio.run(resume_with_diff("01HXYZ..."))
The instruction "do not trust your prior reasoning" is doing real work. The session history still claims cart.py has a certain shape; the prompt is overriding that memory with ground truth.
2. Fork to compare two refactoring strategies
Same baseline analysis, two divergent approaches, no contamination between them. Each fork is its own session ID. You can resume either one independently later.
import asyncio
from claude_agent_sdk import ClaudeAgentOptions, ResultMessage, query
async def fork(base_id: str, strategy: str) -> str | None:
forked_id = None
async for msg in query(
prompt=f"Refactor the discount logic using this approach: {strategy}",
options=ClaudeAgentOptions(
resume=base_id,
fork_session=True, # New session ID, history copied from base.
allowed_tools=["Read", "Edit", "Bash"],
),
):
if isinstance(msg, ResultMessage):
forked_id = msg.session_id
return forked_id
async def main() -> None:
base_id = "01HXYZ..." # Session that did the upfront analysis.
a, b = await asyncio.gather(
fork(base_id, "extract a Discount strategy class"),
fork(base_id, "inline the logic and add a comment"),
)
print(f"Strategy A: {a}\nStrategy B: {b}")
# Compare diffs, pick a winner, discard the loser's session.
asyncio.run(main())
Caveat the SDK is explicit about: forking branches the conversation, not the filesystem. Both forks edit the same files on disk and will clobber each other. For real A/B work, run each fork in a separate worktree or use file checkpointing; but the session-branching mechanic stands on its own.
Let's cover a tight A/B example using the cleaner of the two approaches, git worktrees.

A/B with git worktrees: Each fork edits a physically separate copy of the repo. No clobbering, results trivially diff-able, losing fork discarded with rm -rf.
import asyncio
import subprocess
from pathlib import Path
from claude_agent_sdk import ClaudeAgentOptions, ResultMessage, query
REPO = Path("/path/to/buggy_shop")
BASE_BRANCH = "main"
def make_worktree(name: str) -> Path:
"""Create an isolated working copy on its own branch."""
path = REPO.parent / f"buggy_shop-{name}"
subprocess.run(
[
"git", "-C", str(REPO),
"worktree", "add", "-b", f"ab/{name}",
str(path), BASE_BRANCH,
],
check=True,
)
return path
async def run_strategy(base_id: str, name: str, strategy: str) -> tuple[str | None, Path]:
workdir = make_worktree(name)
forked_id = None
async for msg in query(
prompt=f"Refactor the discount logic. Approach: {strategy}",
options=ClaudeAgentOptions(
resume=base_id,
fork_session=True, # Branch the conversation.
cwd=str(workdir), # And branch the filesystem.
allowed_tools=["Read", "Edit", "Bash"],
),
):
if isinstance(msg, ResultMessage):
forked_id = msg.session_id
return forked_id, workdir
async def main() -> None:
base_id = "01HXYZ..." # Session that did the upfront analysis.
(id_a, dir_a), (id_b, dir_b) = await asyncio.gather(
run_strategy(base_id, "strategy-class", "extract a Discount strategy class"),
run_strategy(base_id, "inline-comment", "inline the logic and add a comment"),
)
# Compare results.
for name, directory in [("A", dir_a), ("B", dir_b)]:
diff = subprocess.check_output(
["git", "-C", str(directory), "diff", "--stat", BASE_BRANCH],
text=True,
)
print(f"--- Fork {name} ({directory.name}) ---\n{diff}")
# Pick winner: merge winner's branch, remove loser's worktree.
# subprocess.run(
# ["git", "-C", str(REPO), "worktree", "remove", str(dir_b)],
# check=True,
# )
asyncio.run(main())
Three things doing the real work:
fork_session=True branches the conversation, each agent inherits the baseline analysis but builds a separate transcript.
cwd=str(workdir) branches the filesystem, each agent's Edit/Write calls land in a different directory, so they can't see or overwrite each other's changes.
asyncio.gather runs both forks concurrently. The two strategies finish in the time the slower one takes, not the sum of both.
The result is two independent worlds: two session IDs, two working directories, two diffs against main. Merge the winner, git worktree remove the loser.
3. Start fresh with a structured summary
The "more context is always better" trap. After 40 turns the session has tool results from files that have since been rewritten, dead-end hypotheses the agent backed out of, and partial reasoning from before a key discovery. Carrying all of that forward dilutes attention. Better: extract a tight summary, discard the history, start clean.
import asyncio
from pydantic import BaseModel
from claude_agent_sdk import ClaudeAgentOptions, ResultMessage, query
class SessionSummary(BaseModel):
root_cause: str
files_modified: list[str]
tests_passing: list[str]
tests_still_failing: list[str]
open_questions: list[str]
# --- Step 1: distill the stale session into a typed summary ---
async def distill(old_session_id: str) -> SessionSummary:
opts = ClaudeAgentOptions(
resume=old_session_id,
output_format={
"type": "json_schema",
"schema": SessionSummary.model_json_schema(),
},
max_turns=1, # No exploration; just report state.
)
async for msg in query(
prompt="Summarize current state for handoff.",
options=opts,
):
if isinstance(msg, ResultMessage) and msg.subtype == "success":
return SessionSummary.model_validate_json(msg.result)
raise RuntimeError("Session summary was not returned.")
# --- Step 2: start a brand-new session, seed it with only the summary ---
async def restart(summary: SessionSummary) -> None:
prompt = f"""Continuing work on buggy_shop. Prior session has been discarded; here is the high-signal state:
Root cause identified: {summary.root_cause}
Already modified: {summary.files_modified}
Now passing: {summary.tests_passing}
Still failing: {summary.tests_still_failing}
Open questions: {summary.open_questions}
Pick up from here. Read files fresh; do not assume prior context."""
async for msg in query(
prompt=prompt,
options=ClaudeAgentOptions(
allowed_tools=["Read", "Edit", "Bash"],
),
):
if isinstance(msg, ResultMessage) and msg.subtype == "success":
print(msg.result)
async def main() -> None:
summary = await distill("01HXYZ...")
await restart(summary)
asyncio.run(main())
The new session has ~300 tokens of curated state instead of 40 turns of accumulated noise. The agent re-reads files on demand, which is cheaper than carrying stale memories of them.
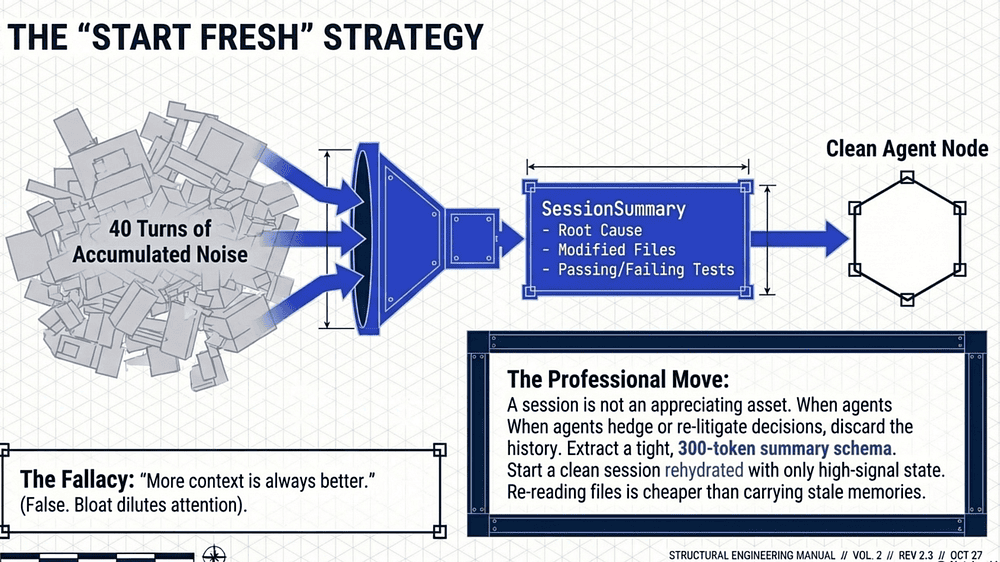
The contrarian take to internalize: a session isn't an asset that automatically appreciates with length. Past a certain point, usually signaled by the agent re-litigating decisions, hedging on file contents, or contradicting itself; the cheapest fix is to throw the history away and rehydrate from a typed summary. "More context is always better" is the amateur move; the right context, in the right amount, at the right time is the professional one.
Conclusion: Building for Reliability
Domain 1 Coverage Checklist: 1.1 Agentic loops -- covered (stop_reason, state machine pattern). 1.2 Coordinator-subagent -- covered (Newsroom model, hub-and-spoke). 1.3 Invocation/context/spawning -- covered (explicit context passing, AgentDefinition). 1.4 Enforcement/handoff -- covered (PreToolUse guards, structured handoff JSON). 1.5 Hooks -- covered (PostToolUse normalization, PreToolUse blocking). 1.6 Decomposition -- covered (decision table, dynamic selection, multi-concern, overly narrow failure mode). 1.7 Session state -- covered (resume, fork, fresh start with summary).
The transition from "prompting" to "architecting" is defined by a single philosophy: Let Claude reason dynamically, but make the orchestration layer responsible for the state, safety, and structure.
The Architect's Principles:
Deterministic beats Probabilistic: Use hooks and gates for hard rules, not just prompts.
Explicit beats Implicit: Never assume a subagent knows the Coordinator's history; pass data explicitly and structurally.
Decomposition beats Consolidation: Specialized agents with focused toolsets outperform monolithic "super agents."
Reliability is not found in the perfect prompt; it is built into the orchestration. It is time to move from being a prompt engineer to becoming an agentic architect.
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company, focusing on delivering ML / AI insights to front-line applications, and a practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company
Rick created Skilz, the universal agent skill installer that supports 30+ coding agents, including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams adopting AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. Many ideas captured in the CCA and the exam prep Rick wrote echo what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code