CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
Claude Certified Architect Multi-Agent Research: Hub-and-Spoke Design, Context Isolation, and Why the Super Agent Anti-Pattern Fails Every Time — CCA Scenario Deep Dive
Originally published on Medium.

Claude Certified Architect Multi-Agent Research: Hub-and-Spoke Design, Context Isolation, and Why the Super Agent Anti-Pattern Fails Every Time — CCA Scenario Deep Dive
Master the CCA Multi-Agent Research scenario: hub-and-spoke design, context isolation, super agent anti-pattern, and silent failures. Covers 60% of exam weight. Ready to ace the CCA exam? Dive into the world of multi-agent systems! Discover why the hub-and-spoke design is your secret weapon and learn how to avoid the super agent anti-pattern that trips up even the best candidates. Don't miss out on mastering the crucial concepts that make up 60% of the exam weight! #CCAExam #MultiAgentSystems
Summary: Mastering the Multi-Agent Research System scenario is crucial for the CCA exam, covering 60% of the exam weight. Key concepts include the hub-and-spoke architecture, where a coordinator manages specialized subagents, and the importance of context isolation, ensuring subagents do not inherit context from the coordinator. The super agent anti-pattern, which involves overloading a single agent with too many tools, is discouraged in favor of distributing 4–5 focused tools across specialized agents. Additionally, structured error handling is essential to avoid silent failures that compromise reliability.
Claude Certified Architect Multi-Agent Research — Hub-and-Spoke Design, Context Isolation, and Why the Super Agent Anti-Pattern Fails Every Time
CCA Exam: The Scenario That Tests Everything
If there is one scenario on the CCA exam that separates strong candidates from average ones, it is the Multi-Agent Research System.
Why? Because it draws from the three heaviest exam domains simultaneously. Agentic Architecture & Orchestration carries 27% of the total exam weight. Tool Design & MCP Integration adds another 18%. Context Management & Reliability contributes 15%. Combined, those three domains represent 60% of the exam. This one scenario touches all of them.
The mental models you build here do not just apply to research systems. They apply to almost every multi-agent architecture question on the exam. The coordinator pattern, context isolation, tool scoping, error handling . These concepts show up across scenarios. Master them here, and you have a framework for answering questions you have never seen before.
Let's break it down.
💡 Series note: This is Article 4 of the CCA Exam series. Context degradation from Article 3 and context isolation here are variations on the same core idea: attention is finite and scope determines quality. If you have not read Article 3, the per-file pass pattern and the coordinator pattern covered there are the direct single-session equivalents of what multi-agent context isolation does at the system level.
Context degradation and context isolation are key concepts: attention is finite and scope determines quality.
Series Navigation
- Article 1: Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam by Spillwave written by Rick Hightower*.
- Article 2: Customer Support Resolution Agent — Agentic loops, escalation design, confidence calibration by Spillwave written by Rick Hightower
- Article 3: Code Generation with Claude Code — Context degradation, CLAUDE.md hierarchy, CI/CD integration
- Article 4: Multi-Agent Research System: Hub-and-spoke design, context isolation, tool scoping (you are here)
- Article 5: Claude Code for CI/CD — Using Claude Code headless in your CI/CD workflows
- Article 6: CCA Exam — Structured Data Extraction
- This series is a work in progress with 8 total articles.
Scenario Setup
The Multi-Agent Research System scenario typically presents you with a system that gathers information from multiple sources, synthesizes findings, and produces a structured research report.
The architecture includes:
- A coordinator agent that receives the research query and orchestrates the work
- Multiple specialized subagents, each focused on a specific research task:
- Web Researcher: searches the web, fetches pages, extracts text
- Document Analyzer: parses documents, extracts sections, identifies claims
- Data Extractor: queries databases, transforms data, validates schemas
- Fact Checker: verifies claims, cross-references sources, scores reliability
- Report Writer: outlines, writes, and formats the final report
The coordinator decomposes the research query, delegates subtasks to the appropriate subagents, aggregates their results, resolves contradictions, and produces the final output.
Key constraints the CCA exam builds questions around:
- Sources may be unreliable or unavailable
- Subagents may fail (timeouts, parsing errors, API outages)
- Results must be cited and verified
- The coordinator must handle contradictory findings from different subagents
Every question in this scenario maps to a decision: how do you decompose tasks, how do you handle failures, and how do you manage context across agents?
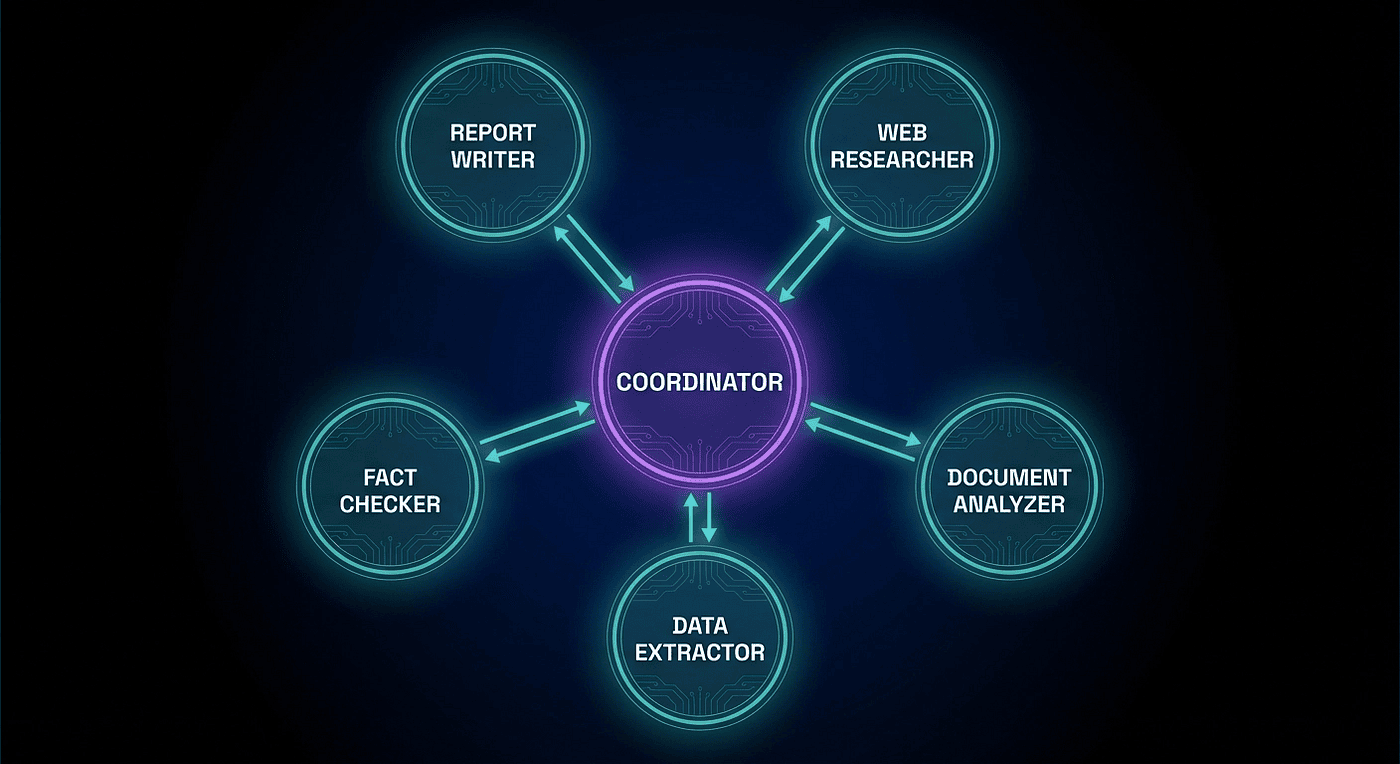
CCA Exam: Hub-and-Spoke Architecture: The Coordinator Pattern
How the Pattern Works
The Multi-Agent Research System follows a hub-and-spoke model. The coordinator sits at the hub. The specialized subagents are the spokes.
Think of it as a newsroom. The editor (coordinator) receives a story assignment, breaks it into beats, and sends reporters (subagents) out to cover each one. The political reporter covers the policy angle. The financial reporter covers the funding trail. The investigative reporter works their sources. None of them know what the others are writing. They each do their job, file their story, and the editor assembles the pieces into a coherent whole.
The key insight is that the spokes do not talk to each other. They talk to the hub, and only to the hub. The web researcher does not coordinate with the fact checker. The document analyzer does not share notes with the data extractor. All coordination flows through the coordinator. This is not a limitation. It is what makes the system trustworthy and predictable.
The flow looks like this:
- Coordinator receives the research query and creates a task plan
- Coordinator delegates specific subtasks to the appropriate subagents
- Subagents execute their tasks independently (they work in isolation from each other)
- Subagents return structured results to the coordinator
- Coordinator aggregates, resolves contradictions, and produces the final output
This pattern provides clean separation of concerns. The web researcher does not need to know about document parsing. The fact checker does not need to know about report formatting. Each agent excels at its specialty because its scope is narrow and well-defined.
💡 CCA Exam Tip: When a CCA exam question asks about the correct architecture for a multi-agent system:
✅ Look for the option that has a single coordinator delegating to specialized subagents.
🚫 If an answer option describes subagents that communicate directly with each other or share context automatically, that is the distractor.
The hub-and-spoke pattern keeps coordination centralized.
Context Isolation: The Critical CCA Concept
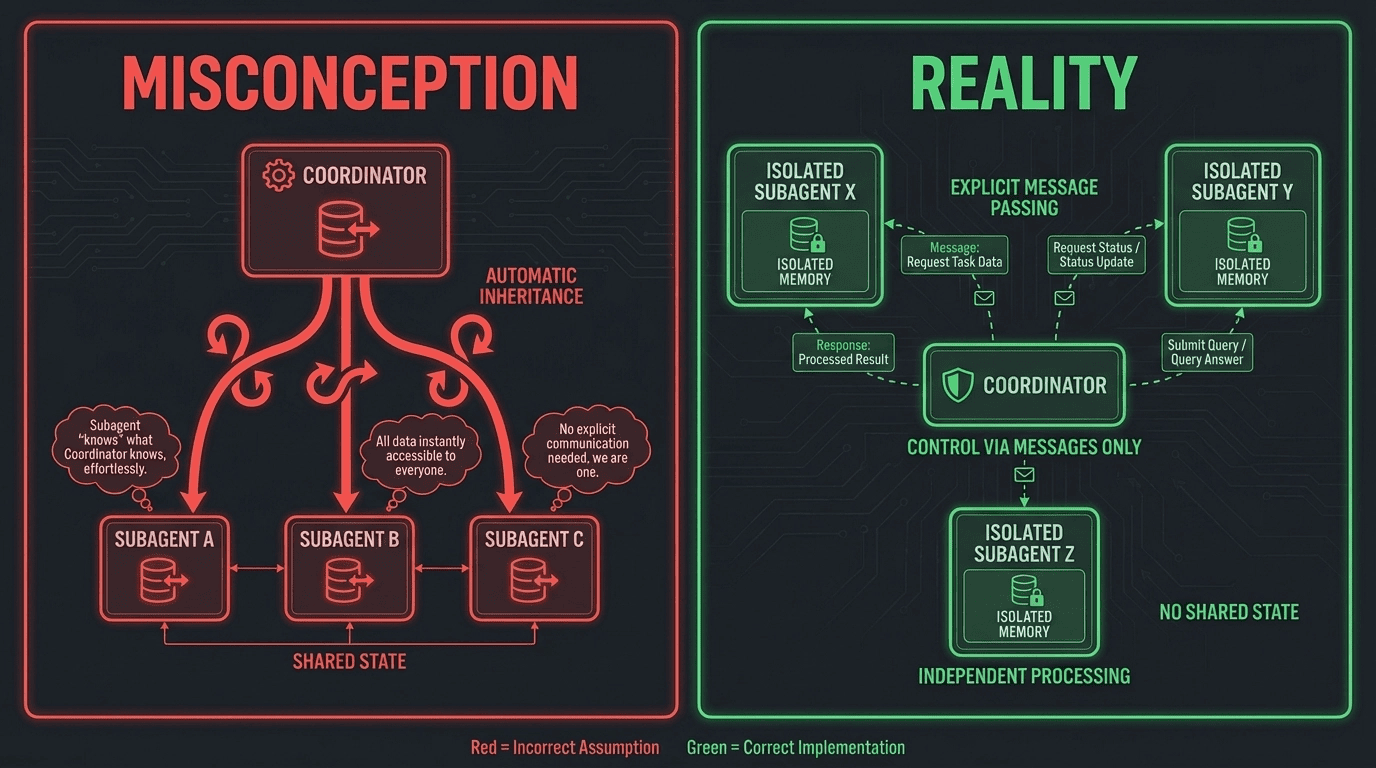
Here is the concept that trips up more candidates than any other in this scenario: subagents do NOT inherit context from the coordinator.
This surprises developers who come from a background in threaded or shared-memory programming. In a multi-threaded application, threads can read from the same memory. You set a variable in one thread, another thread can see it. That mental model does not transfer to multi-agent systems.
In a multi-agent system, each agent is its own independent context. There is no shared memory. There is no background inheritance. When the coordinator spawns a subagent, that subagent starts with a completely blank slate. It does not see the coordinator's conversation history. It does not see the task plan the coordinator built. It does not see the results that other subagents have already returned. It sees only what was explicitly handed to it in the delegation message.
Here is a concrete example of how this breaks in practice. Imagine a coordinator has a rule in its context: "All citations must use APA format." The coordinator builds a task plan, delegates a research task to the Document Analyzer, and gets back results with MLA citations. The coordinator is confused. It told the agent about APA format. Or did it?
It did not. It had APA format in its own context. It never explicitly included that requirement in the delegation message it sent to the Document Analyzer. The subagent had no way to know.
The exam question pattern looks like this:
❓ "The coordinator sends a research task to a subagent, but the subagent produces results that contradict the coordinator's instructions. What is the most likely root cause?"
✅ The answer: the coordinator did not explicitly pass the relevant context. The subagent had no visibility into the coordinator's plan or constraints. It only knew what was explicitly included in the task delegation.
💡 CCA Exam Tip: Any question where a subagent produces results that "should have followed the coordinator's instructions" is testing context isolation.
✅ The answer is always that the instructions were in the coordinator's context but never explicitly forwarded.
🚫 Subagents do not inherit.
Subagents receive only what you explicitly send.
Context Forking and Explicit Context Passing
When the coordinator spawns a subagent, it "forks" a subset of its context. But forking here does not mean cloning. It means the coordinator deliberately selects which pieces of context the subagent needs and passes only those.
The subagent gets:
- The specific task description
- Relevant constraints and requirements
- The expected output format
- Any context needed to do its job
The subagent does NOT get:
- The coordinator's full conversation history
- Results from other subagents (unless explicitly passed)
- The overall research plan (unless explicitly passed)
- Any prior context that was not deliberately included
Results flow back to the coordinator as structured output, not as shared context. The coordinator then integrates those results into its own context and decides what to do next.
This is the pattern the CCA exam calls explicit context passing. Nothing is implicit. Nothing is inherited. Everything a subagent knows must be deliberately sent to it.
💡 CCA Exam Tip: The phrase "explicit context passing" is the correct-answer language for this domain.
✅ When you see answer options about context in multi-agent systems, the one that emphasizes explicit, deliberate passing of context is correct.
🚫 Options that describe automatic inheritance or shared state are always wrong.
This connects to Article 3: the focused per-file pass pattern works because each session gets only the context it needs, nothing more. Context isolation in multi-agent systems is the same discipline applied at the system level rather than the session level.
Subagents do NOT inherit context from the coordinator
The Super Agent Anti-Pattern
What It Looks Like
Someone decides that instead of building five specialized subagents, they will create one powerful agent with all the tools attached:
🛑 "Just give the research agent access to web search, document parsing, data extraction, fact checking, report writing, email, Slack, database queries, file system access, calendar lookup, spreadsheet editing…" — Wrong! Anti-Pattern!
Before you know it, the agent has 18 tools. On paper, it can do everything. In practice, it does everything poorly.
This is the super agent anti-pattern, and the CCA exam tests it explicitly with the exact numbers: 18 tools fails, 4–5 tools works.
Why the Super Agent Fails: The Attention Tax
Understanding why 18 tools fails requires the same attention-is-finite insight from Article 2 on context degradation.
When an agent evaluates a task, it does not magically know which tool to use. It reads every tool description in its context window to select the right one. With 18 tools, a significant portion of the model's attention budget goes to evaluating 18 descriptions and determining which one applies. That is attention spent on bookkeeping instead of on the actual task.
More tools equals more problems with attention budget. More time paying attention to tools then job at hand — the task you need done!
Worse, as tool count increases, the descriptions start to blur. When you have search_web, search_internal_docs, search_database, search_archive, and search_knowledge_base all in the same context, the model must parse fine distinctions between five similar-sounding tools every time it needs to find information. Misrouting is not a matter of the model being "bad at tools." It is a predictable consequence of cognitive load.
Here is the comparison the CCA exam is built around:
Agent with 18 tools:
- Each tool selection requires evaluating 18 options
- Similar tools create ambiguity and misrouting
- Task-irrelevant tools consume attention on every single decision
- Output: inconsistent, wrong-tool usage, degraded quality
Agents with 4–5 focused tools each:
- Each tool selection requires evaluating 4–5 options
- Each tool is meaningfully distinct within its domain
- Every tool present is relevant to the current task
- Output: accurate tool selection, consistent quality
This is not a small difference. It is the difference between a system you can rely on and one that produces unpredictable results. The improvement comes purely from reorganizing tools across specialized agents, not from any change to the underlying model.
The exam's official guidance is specific: keep 4–5 tools per agent. This is not a soft recommendation. It is the exam-correct answer.
Think of it like a restaurant menu. A focused 15-item menu lets the kitchen excel at every dish. A 200-item menu means the kitchen is spread too thin, and nothing is exceptional. The best restaurants in the world are narrow specialists. Claude agents work the same way.
💡 CCA Exam Tip: The super agent question is one of the most reliable on the CCA exam. It will describe an agent with many tools that frequently selects the wrong one.
The answer choices will include:
🚫 "improve tool descriptions" — WRONG!
🚫 "add a tool-selection preprocessing step" — WRONG!
✅ "decompose into specialized subagents with 4–5 tools each" — CORRECT!
The improvement is architectural, not descriptive.
👷 Analogy — Show Truck vs Work Truck
Having 18 tools is like bringing a show truck to a construction site.
- It has oversized tires, chrome everything, perfect paint
- It looks powerful, but it's optimized for display, not work
- Loaded with every bell and whistle, but the winch and tow setup just block you when you're trying to haul what matters.
- When it's time to haul lumber, you hesitate
- You're thinking about scratches, not the job
Meanwhile, the guy with the beat-up work truck:
- Knows exactly what it does
- Uses it without hesitation
- Gets the job done faster
While you are putting in cinder blocks gently so you don't scratch your laminated truck liner, they are hurling in rubish with rusted nails with no worries — no cognitive load. No deciding how to avoid hitting your spot lights on the low clearance tree-line.
And those oversized tires? If you're not off-roading, they're not capability; they're compensation. Like wearing a 10-gallon cowboy hat with no ranch.
Point: More capability ≠ more effectiveness. Too many tools shift focus from doing the work to managing the tools.
The Correct Pattern: 4–5 Focused Tools Per Agent
The solution is to distribute tools across specialized subagents. Each agent gets a tightly scoped set relevant to its specialty:
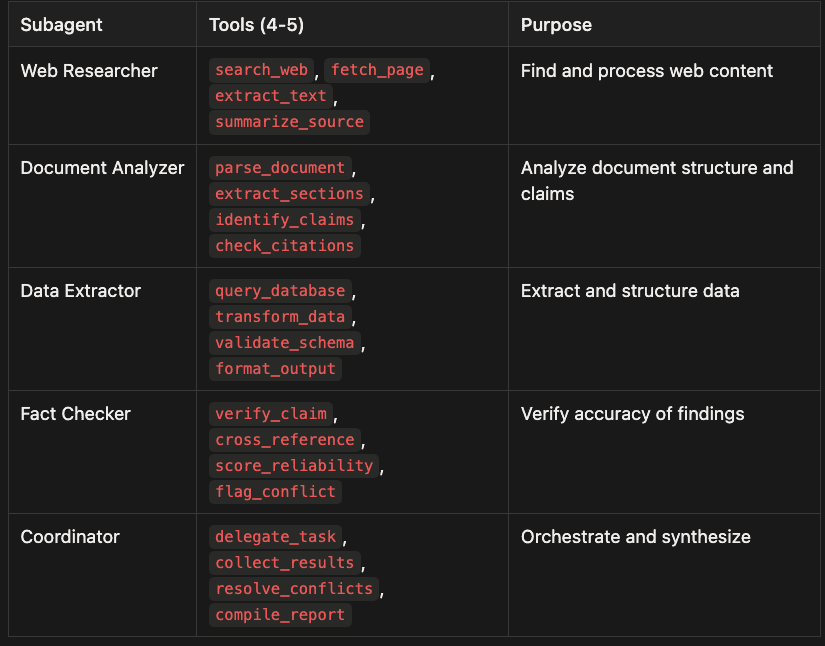
Web Researcher
- Tools:
search_web,fetch_page,extract_text,summarize_source - Purpose: Find and process web content
Document Analyzer
- Tools:
parse_document,extract_sections,identify_claims,check_citations - Purpose: Analyze document structure and claims
Data Extractor
- Tools:
query_database,transform_data,validate_schema,format_output - Purpose: Extract and structure data
Fact Checker
- Tools:
verify_claim,cross_reference,score_reliability,flag_conflict - Purpose: Verify accuracy of findings
Coordinator
- Tools:
delegate_task,collect_results,resolve_conflicts,compile_report - Purpose: Orchestrate and synthesize
Notice the coordinator itself has tools. It is not just a prompt router. It has tools for delegation, collection, conflict resolution, and report compilation. But even the coordinator stays within the 4–5 tool budget.
Notice also that each agent's tools are meaningfully distinct from each other within the same agent. The Web Researcher has four tools that represent a natural workflow: search, fetch, extract, summarize. No two tools are easily confused with each other. That distinctness is part of what makes selection reliable.
Avoid super agent anti-pattern 18 tools fails, 4–5 tools works. 18 tools too much divided attention.
🏗️ Analogy: Specialized Crews vs One Guy With Every Tool
The correct pattern: 4–5 focused tools per agent.
Think of it like building a house.
You don't send one person with 18 tools to do everything:
- Pour the foundation
- Frame the structure
- Run electrical
- Install plumbing
- Inspect the work
Even if that person technically has all the tools, they're constantly switching context:
- Am I doing framing or electrical right now?
- Which tool applies here?
- What's the standard for this step?
Most of their time isn't spent building; it's spent deciding how to build.
Instead, real construction works like this:
- Foundation crew → concrete tools, leveling, forms
- Framers → saws, nail guns, structure
- Electricians → wiring, circuits, code compliance
- Plumbers → pipes, flow, fittings
- Inspectors → validation, standards, safety
- Architect / GC → coordination, sequencing, final output
Each crew:
- Has a small, focused toolset
- Operates in a clear phase of work
- Doesn't confuse its tools with another crew's tools
🔁 Mapping to Agents
- Web Researcher → search → fetch → extract → summarize
- Document Analyzer → parse → structure → identify → validate
- Data Extractor → query → transform → validate → format
- Fact Checker → verify → cross-reference → score → flag
- Coordinator (General Contractor) → delegate → collect → resolve → compile
⚠️ Anti-Pattern: The "Super Agent"
A single agent with 18 tools is like:
- One worker trying to be framer + electrician + plumber + inspector
- Carrying every tool on their belt
- Stopping constantly to decide what role they're playing
Result:
- Slower execution
- More mistakes
- Misapplied tools
- Cognitive overload
CCA Exam: Silent Subagent Failures: The Hidden Killer
The Anti-Pattern: Swallowing Errors
Here is a failure mode that produces some of the worst outcomes in multi-agent systems: a subagent fails, but the coordinator never finds out.
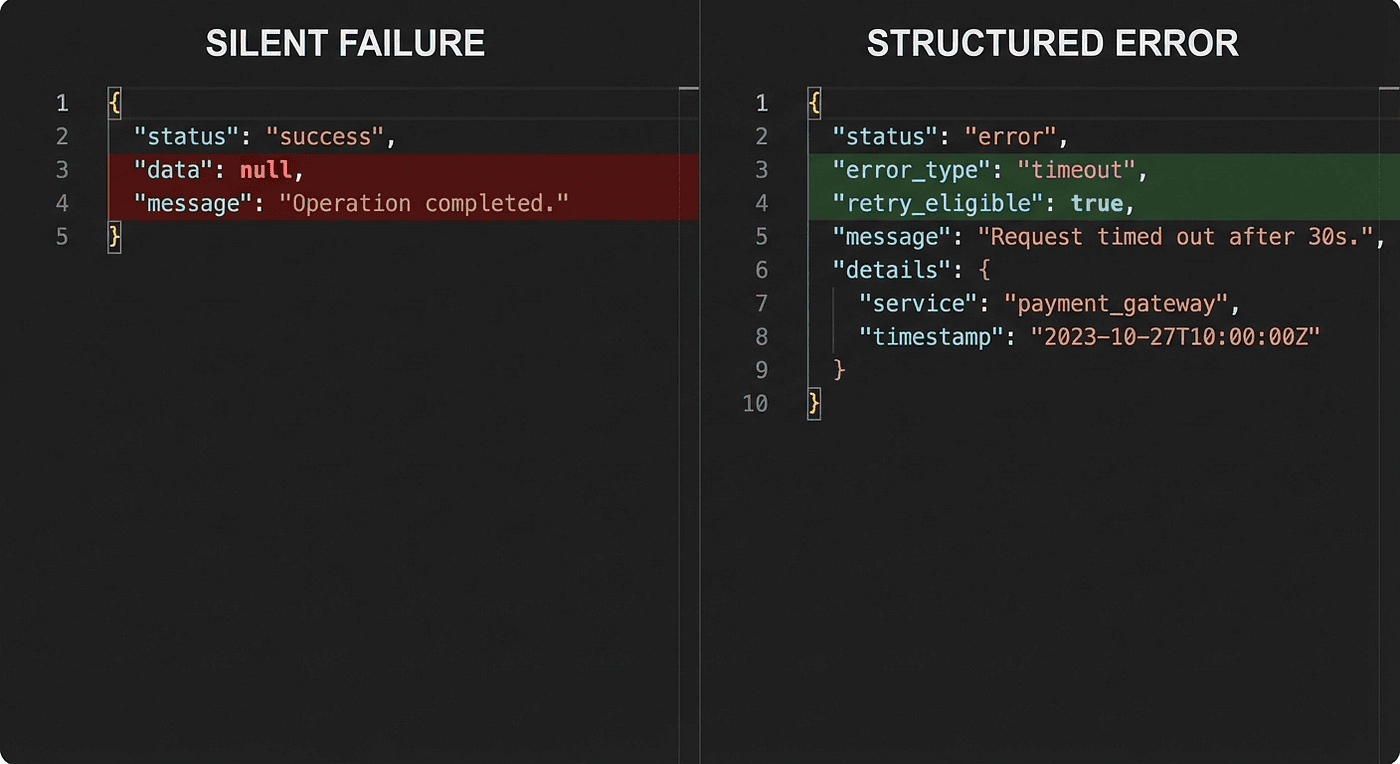
A Web Researcher subagent tries to fetch a source. The API times out after 30 seconds. The subagent has error handling code, so it catches the exception and returns { "status": "success", "data": null }. Clean, no crash. The coordinator receives this, interprets it as "no relevant data found from this source," and moves on. After all, "success" with null data could reasonably mean the source had nothing useful.
The final research report looks complete. It has findings, citations, and a confident conclusion. But it is missing critical data from a source that was unavailable, not irrelevant. One of those sources was a government database that contained the only direct evidence contradicting the report's main finding. Nobody knows it was skipped. Nobody can tell from the output.
This is the silent failure anti-pattern. The coordinator cannot distinguish between "no relevant data exists" and "the subagent failed to retrieve data."
Why Silent Failures Undermine Multi-Agent Reliability
The consequences cascade in ways that are hard to detect until damage is done:
- The coordinator makes synthesis decisions based on incomplete data
- Missing sources create systematic bias in the final report (the report reflects only the sources that happened to be available)
- The end user reads a report that appears thorough but has blind spots they cannot see
- In production, this creates liability risk when research reports omit contradictory evidence that was simply unreachable, not nonexistent
The CCA exam frames this as a reliability problem. Systems that fail silently cannot be trusted, because you never know whether you are looking at a complete result or a partial one. And partial results presented as complete results are worse than explicit failures, because at least an explicit failure tells you something went wrong.
Don't trust systems that fail silently. You never know if you are looking at a complete or incomplete work product
Offering a work product as complete when there are missing facts due to steps that failed is almost a type of hallucination. Unless you note it.
Correct Pattern: Structured Error Context
The fix is straightforward: subagents must return structured error information when something goes wrong. Not just "success" or "failure." Structured context that tells the coordinator what happened, why, and what options exist.
Here is what a proper error response looks like:
{ "status": "error", "error_type": "timeout", "source": "api.example.com", "attempted_at": "2026-03-23T14:30:00Z", "retry_eligible": true, "partial_data": null, "fallback_available": false }
Compare that to the silent failure version:
{ "status": "success", "data": null }
The first response gives the coordinator a decision tree. The second gives the coordinator a lie.
With structured error context, the coordinator can:
- Retry eligible failures (timeouts, rate limits) before concluding the source is unavailable
- Flag gaps in the report explicitly ("Source X was unavailable")
- Adjust confidence in findings that depend on the missing source
- Include transparency notes in the final output: "This report does not include data from Source X, which was unreachable during research."
The final report should explicitly note what it does not cover. A report that says "we could not reach Source X" is more trustworthy than one that silently omits it. Transparency about limitations is a feature, not a weakness.
💡 CCA Exam Tip: The silent failure question presents a scenario where a report is missing data from a source that encountered an error.
The answer choices will include
🚫 "increase timeout duration"; addressing symptoms, not the root problem
🚫 "add retry logic"; partially helpful but not the core fix
✅ "require structured error context from subagents" (correct).
The reason retry logic alone is insufficient: even after retries fail, the coordinator still needs to know the failure happened so it can flag the gap in the report.
This connects to the Context Management & Reliability domain: systems must degrade gracefully and transparently. Silent failures violate both principles.
CCA Exam: MCP Integration in Multi-Agent Systems
MCP Configuration for Multi-Agent Systems
The Model Context Protocol (MCP) provides the infrastructure for how agents discover and use tools. In a multi-agent system, MCP configuration determines which tools each agent can access.
Key configuration points:
.mcp.jsonat project level: Shared tool servers available to all agents. Committed to version control.- Subagent-specific MCP servers: Each subagent can connect to specialized MCP servers for its domain (a web research MCP server, a document parsing MCP server, etc.).
MCP defines three primitives that show up in the CCA exam:

MCP Primitives:
Tools:
- What It Is: Executable functions an agent can invoke
- Research System Example: search_web, parse_document, verify_claim
Resources:
- What It Is: Data schemas and catalogs agents can query
- Research System Example: document catalog, source reliability database
Prompts:
- What It Is: Templates for common operations
- Research System Example: research query template, citation format template
The exam tests whether you know the difference between MCP tools, resources, and prompts. Tools are actions. Resources are data. Prompts are templates. Mixing them up (exposing data as a tool, or an action as a resource) is a common exam distractor.
💡 CCA Exam Tip: The MCP primitives question is a vocabulary test.
Tools are things the agent does (verbs).
Resources are things the agent reads (nouns).
Prompts are templates the agent uses (patterns).
If a question describes a source reliability database that agents can query for information, that is a Resource, not a Tool.
If it describes a function that verifies a specific claim, that is a Tool.
Tool Descriptions as Routing
In a multi-agent system, tool descriptions become the primary routing mechanism. The coordinator decides which subagent to delegate to based on which agent's tools match the task.
If tool descriptions are ambiguous, tasks get misrouted. A tool called process_data could mean anything. A tool called extract_structured_fields_from_pdf_document is unambiguous.
Best practice for tool descriptions: include what the tool does AND what it does not do. For example:
✅
search_web: Searches the public web for information matching a query. Returns URLs, titles, and snippets. Does NOT fetch full page content (usefetch_pagefor that). Does NOT search private databases or internal documents.
The above description is a good tool description because it describes what the tool does and also what it does NOT do.
Negative descriptions prevent misuse. When Claude knows what a tool does not do, it can route more accurately. Without negative bounds, Claude may try to use search_web to search internal documents and get unexpected results or errors, because the tool's description never told it that was out of scope.
💡 Exam Tip: The tool description question will present a scenario where a tool is being called with inputs it was not designed to handle.
✅ The correct answer involves adding negative bounds to the description ("does NOT…").
🚫 The distractor is usually "add validation logic inside the tool."
Validation helps but does not fix the routing problem. The agent should never attempt the wrong call in the first place.
Task Decomposition Strategies
How the Coordinator Decomposes Research Queries
Task decomposition is the coordinator's primary job. A complex research query gets broken into independent, parallelizable subtasks wherever possible.
The key decisions:
- Identify independent tasks: Web search and document analysis can run in parallel because they do not depend on each other
- Identify dependencies: Fact checking cannot start until claims are extracted. Report writing cannot start until conflict resolution is done.
- Design the task graph: Which subtasks run in parallel? Which run sequentially? What is the critical path?
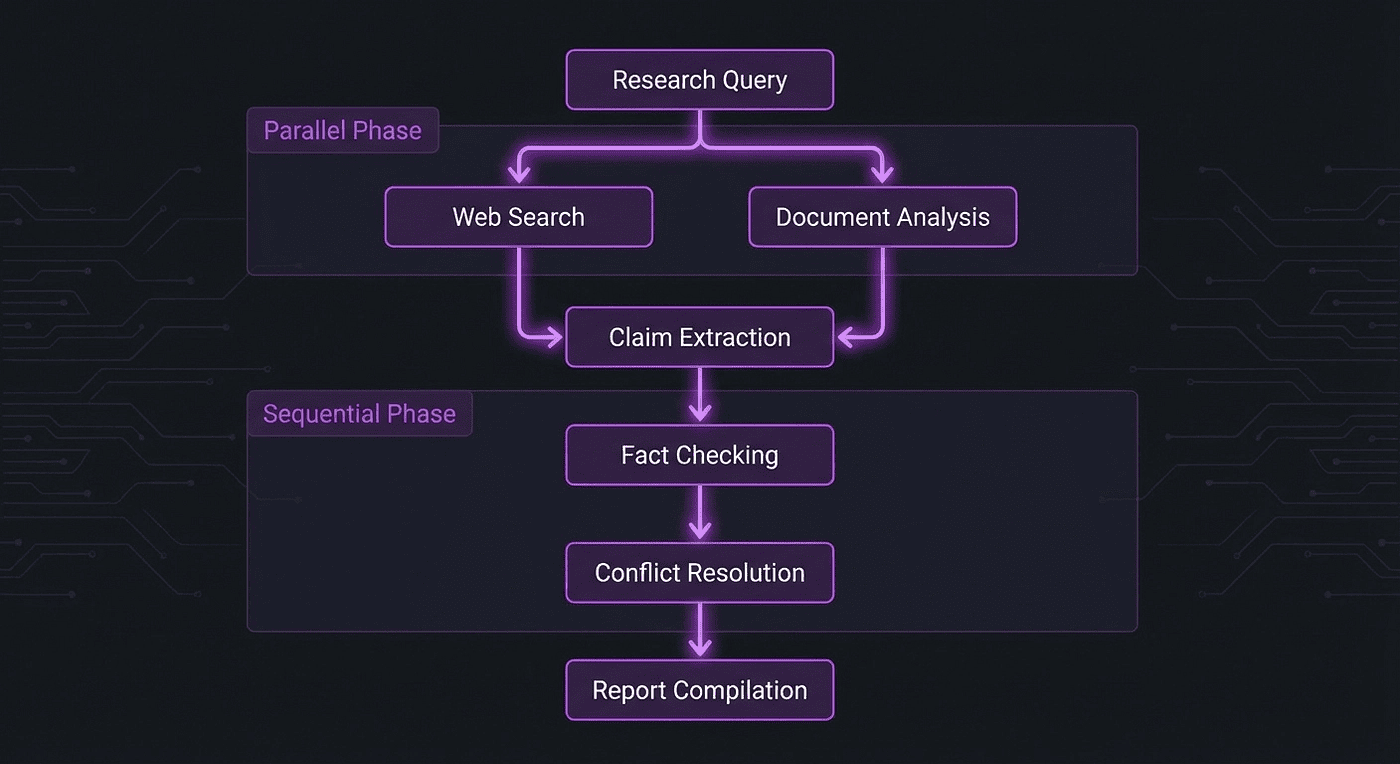
Here is a typical task decomposition for a research query:
- Parallel phase: Web search + Document analysis (independent, run simultaneously)
- Sequential phase: Claim extraction (depends on results from phase 1)
- Sequential phase: Fact checking (depends on extracted claims)
- Sequential phase: Conflict resolution (depends on fact-checking results)
- Final phase: Report compilation (depends on resolved findings)
The agentic loop that drives this: plan, delegate, collect, evaluate, re-delegate if needed, synthesize.
💡 Exam Tip: Task decomposition questions will ask whether two subtasks should run in parallel or sequentially. The answer depends on data dependencies.
If Subtask B needs output from Subtask A, they run sequentially.
If they can work from independent inputs, they run in parallel.
"Web search" and "document parsing" are the canonical parallel pair.
"Fact checking" and "report writing" are always sequential, because fact checking must complete before a credible report can be written.
Validation and Conflict Resolution
Multiple subagents will sometimes return contradictory findings. Source A says one thing; Source B says the opposite. The coordinator needs a strategy for handling this.
Common approaches the CCA exam expects you to know:
- Source reliability ranking: Weight findings by the reliability score of their source
- Majority consensus: If three sources agree and one disagrees, go with the majority (but flag the dissent)
- Flag for human review: When contradictions involve high-stakes claims, escalate rather than auto-resolve
Validation-retry loops also apply here. If a subagent's results fail quality checks (missing citations, inconsistent formatting, low confidence scores), the coordinator re-delegates with more specific instructions. This is the same validation-retry pattern from the Prompt Engineering domain, applied to multi-agent orchestration.
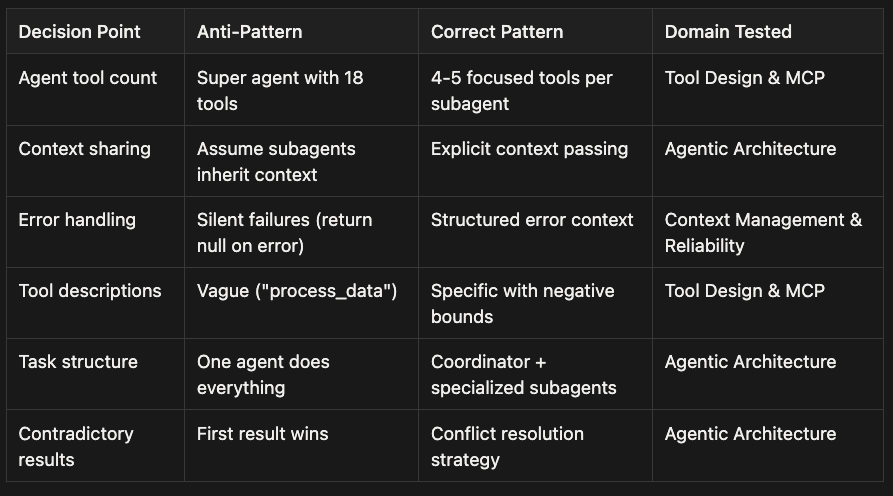
Anti-Pattern vs Correct Pattern Summary
Let's cover decision points one by one
Agent tool count:
- Anti-Pattern: Super agent with 18 tools
- Correct Pattern: 4–5 focused tools per subagent
- Too much cognitive load, agent can pick the wrong tool or not use a tool
Context sharing:
- Anti-Pattern: Assume subagents inherit context
- Correct Pattern: Explicit context passing
- If key decisions or facts are in the coordinator and it does not pass this to the subagent, the subagent will not know and will not perform correctly.
Error handling:
- Anti-Pattern: Silent failures (return null on error)
- Correct Pattern: Structured error context
- The coordinator can't make informed decisions without information about the error. Is there a workaround? Is the system down? Is this a retry-able error?
Tool descriptions:
- Anti-Pattern: Vague ("process_data")
- Correct Pattern: Specific with negative bounds
- Agents can't pick the right tool unless the description is clear and the boundaries are set. Good descriptions say what the tool does and what it does not do, reducing confusion with similar tools.
Task structure:
- Anti-Pattern: One agent does everything
- Correct Pattern: Coordinator + specialized subagents
- A single agent handling every step becomes the equivalent of one worker trying to be the architect, framer, electrician, plumber, and inspector all at once. Coordinators and specialists reduce context switching, improve reliability, and let each agent stay focused on a narrow type of work.
Contradictory results:
- Anti-Pattern: First result wins
- Correct Pattern: Conflict resolution strategy
- Disagreement is not noise to ignore; it is a signal to investigate. A good multi-agent system treats contradictions as something to resolve through source comparison, confidence scoring, retries, or escalation — not as something to discard by whichever answer arrived first.
Exam Question Walkthrough
Let's work through three representative questions.
Question 1: Context Isolation
❓ "A coordinator agent has specific instructions about required citation format. The coordinator delegates a research task to a subagent. The subagent returns results with incorrect citation formatting. What is the most likely root cause?"
A.) The subagent's model does not support the required citation format
B.) The coordinator's instructions were ambiguous
C.) The citation format requirements were not explicitly passed to the subagent
D.) The subagent's tools do not support citation formatting
✅ Answer: C. This is the context isolation question. Subagents do not inherit the coordinator's context. If the coordinator has citation formatting rules in its context but does not explicitly include them in the task delegation, the subagent has no knowledge of those requirements.
🚫 Option B is the most tempting distractor because ambiguous instructions are a real problem, but the question specifies the coordinator had "specific instructions," pointing to a passing problem, not an ambiguity problem. The instructions existed. They just were not sent.
Question 2: Tool Overload
❓ "A research agent is configured with 18 tools covering web search, document parsing, data extraction, fact checking, report writing, email, and database access. The agent frequently selects the wrong tool for the current task. What is the recommended architectural change?"
A.) Improve tool descriptions to help the model differentiate between tools
B.) Add a tool-selection pre-processing step that filters available tools per query
C.) Decompose into specialized subagents with 4–5 focused tools each
D.) Switch to a model with better tool selection capabilities
✅ Answer: C. The exam-correct answer is to decompose into focused subagents. With 18 tools, a significant portion of the model's attention is spent evaluating irrelevant tool descriptions on every decision. This creates cognitive overload and increases misrouting. Breaking the system into specialized agents with 4–5 tools each reduces attention fragmentation and improves reliability.
🚫 Option A is the most tempting distractor because better descriptions do help, but only at the margins. They do not fix the structural problem of too many tools competing for attention.
🚫 Option B adds complexity without addressing root cause.
🚫 Option D incorrectly assumes a model limitation when the issue is architectural.
Question 3: Silent Failure
❓ "A multi-agent research system produces a report on a controversial topic. After review, a critical contradictory source is missing from the report. Investigation reveals the subagent responsible for that source encountered an API timeout. What architectural change would prevent this issue?"
A.) Increase the timeout duration for subagent API calls
B.) Add a retry mechanism with exponential backoff
C.) Require subagents to return structured error context so the coordinator can flag data gaps
D.) Add a validation step that checks report completeness against a source list
✅ Answer: C. The core issue is not the timeout itself, but the lack of visibility into the failure. Without structured error context, the coordinator cannot distinguish between "no relevant data found" and "source unavailable." Structured error reporting enables informed decisions such as retrying, substituting sources, or flagging incomplete results.
🚫 Option B is the most tempting distractor because retries are a best practice, but they do not eliminate failures. When retries are exhausted, the system still needs error transparency.
🚫 Option A only reduces frequency, not impact.
🚫 Option D is a useful safeguard, but it is secondary and does not address the root cause of silent failures.
Study Checklist
Before you consider this scenario mastered, verify you can confidently answer yes to each of these:
- ✅ I can draw the hub-and-spoke architecture with coordinator and subagents
- ✅ I can explain that subagents do NOT inherit coordinator context
- ✅ I can describe the "newsroom" mental model: spokes report to hub, not to each other
- ✅ I know the explicit context passing pattern (what to pass, what not to pass)
- ✅ I can explain why 18 tools on one agent degrades selection reliability
- ✅ I know the correct tool budget: 4–5 focused tools per agent
- ✅ I can explain the attention cost of evaluating irrelevant tool descriptions
- ✅ I can design subagent tool sets for a research system
- ✅ I can explain the silent failure anti-pattern and its consequences
- ✅ I can describe a structured error response schema with all key fields
- ✅ I know why structured error context is more important than retry logic alone
- ✅ I know the three MCP primitives: tools (actions), resources (data), prompts (templates)
- ✅ I can explain why tool descriptions need negative bounds ("does NOT…")
- ✅ I can decompose a research query into parallel and sequential subtasks
- ✅ I know the coordinator's conflict resolution strategies
Discussion Questions
These questions push past recall into the reasoning the CCA tests.
- A team is debating whether to build a single "super researcher" agent with 15 tools or five specialized subagents with 3–4 tools each. A teammate argues that the single agent is easier to maintain because there is less coordination overhead. How would you explain why the coordination overhead of the hub-and-spoke design is actually lower than the attention tax paid by the super agent?
- Your multi-agent research system produces a report that contradicts a key finding from last quarter. You suspect a subagent silently failed during the research run. What changes to the subagent error response schema would let you audit past runs and determine whether a silent failure occurred?
- A subagent is correctly returning structured error context, but the coordinator is treating all errors the same way, it flags them and moves on. What fields in the error response would allow the coordinator to make smarter decisions: retry a timeout, escalate a parsing failure, and skip a permanently unavailable source?
Conclusion
The Multi-Agent Research System scenario is where the CCA exam's biggest ideas converge: a hub-and-spoke coordinator, strict context isolation, disciplined tool scoping, and reliability through transparent failure handling. If you remember only one rule, make it this: nothing is shared unless you explicitly pass it. Build around that reality, keep each agent focused, and require structured error context so the system stays trustworthy even when sources and tools fail.
The Multi-Agent Research System scenario is arguably the most comprehensive on the CCA exam because it draws from the three heaviest domains: Agentic Architecture (27%), Tool Design & MCP (18%), and Context Management & Reliability (15%). Together, that is 60% of the exam weight. The patterns you learned will show up in questions across every scenario, not just this one. These patterns are across domains:
- context isolation,
- focused tool sets,
- structured error handling, and
- explicit context passing
You now have the complete framework for all three deep-dive scenarios. The concepts overlap and reinforce each other: context degradation from Article 3 connects to context isolation here. The coordinator pattern appears in both code generation and multi-agent research. Anti-patterns like silent failures and the super agent trap are variations on the same theme: scope your work, make failures visible, and never assume context is shared automatically.
Good luck on the exam.
#CCAExam #MultiAgentSystems #AnthropicCertification #AIEngineering #AgenticArchitecture #MCP #ExamPrep #LLMEngineering #ContextIsolation
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.