CCA Exam Prep: Structured Data Extraction
Structured Data Extraction for High-Reliability Pipelines: Mastering JSON Schema and Retry Loops
Originally published on Medium.
 Claude Certified Architect: CCA Exam Prep: Structured Data Extraction
Claude Certified Architect: CCA Exam Prep: Structured Data Extraction
Structured Data Extraction for High-Reliability Pipelines: Mastering JSON Schema and Retry Loops
🚀 Ready to ace the CCA exam? Discover how to build high-reliability data extraction pipelines with our latest article on JSON schema validation and retry loops! Avoid common pitfalls and ensure your data is always clean and actionable. Dive in now! 🌟 #CCA #DataExtraction #ClaudeCertifiedArchitect
Summary: The article focuses on structured data extraction for the CCA exam, emphasizing the importance of a three-layer reliability model: structural reliability through JSON schema enforcement, semantic reliability via programmatic validation, and recovery mechanisms like retry loops. It highlights common pitfalls candidates face, such as relying solely on prompts for JSON output, and stresses the need for high-reliability pipelines that ensure clean, valid data extraction from unstructured sources. The piece also discusses specific strategies for schema enforcement using the Anthropic SDK, including tool-forcing and Pydantic models.
JSON Schema Validation, Retry Loops, and High-Reliability Pipelines
This is article six in an eight-part series preparing you for the Claude Certified Architect (CCA) Foundations exam. If you have been following along, you already understand the exam format, the five competency domains, and four of the six production scenarios. Now we tackle the scenario that trips up more candidates than any other: Structured Data Extraction.
 Master Claude structured data extraction for the CCA exam. Learn the 3-layer reliability model, JSON schema enforcement, and retry loops for production pipelines
Master Claude structured data extraction for the CCA exam. Learn the 3-layer reliability model, JSON schema enforcement, and retry loops for production pipelines
Here is why it trips people up. Data extraction looks simple on the surface. You hand Claude a document, ask for JSON back, and it works. It works 90% of the time. Then your pipeline crashes at 3 AM because the other 10% is unparseable garbage. Or worse, it silently writes bad data into your production database and nobody notices until a customer calls.
The CCA exam tests whether you understand that gap between “works in my demo” and “works in production.” This article walks you through the three-layer reliability model the exam rewards, the anti-patterns it punishes, and the exact patterns you need to fix unparseable JSON from LLM outputs and pick the right answer under time pressure.
This scenario draws from three exam domains:
- Prompt Engineering and Structured Output (20%),
- Context Management and Reliability (15%), and
- Agentic Architecture and Orchestration (27%).
Nail this material and you are covering significant ground across the exam. We cover the domains in the 1st article in the series and then deep dive in the follow up articles.
Series Navigation
- Article 1:* Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam* by Spillwave written by Rick Hightower.**
- Article 2: Customer Support Resolution Agent — Agentic loops, escalation design, confidence calibration** by Spillwave written by **Rick Hightower
- Article 3: Code Generation with Claude Code — Context degradation, CLAUDE.md hierarchy, CI/CD integration
- Article 4: Multi-Agent Research System: Hub-and-spoke design, context isolation, tool scoping
- Article 5: Claude Code for CI/CD— Using Claude Code headless in your CI/CD workflows
- Article 6: Structured Data Extraction (you are here)
- This series is a work in progress with 8 total articles.
What the Exam Actually Tests
The Structured Data Extraction scenario drops you into a production context. You are building high-reliability pipelines that pull structured data from unstructured sources: invoices, emails, server logs, meeting transcripts, customer feedback. The extracted data feeds downstream systems like databases, APIs, and dashboards. These systems expect clean, valid, correctly typed data every single time.
The exam probes specific decision points:
- How do you guarantee Claude returns valid JSON, not JSON-with-commentary? This is the structural reliability question.
- How do you validate that the extracted data is actually correct? This is the semantic reliability question.
- What happens when extraction fails? This is the recovery and escalation question.
- How do you handle edge cases? Missing fields, ambiguous data, conflicting information in the source document.
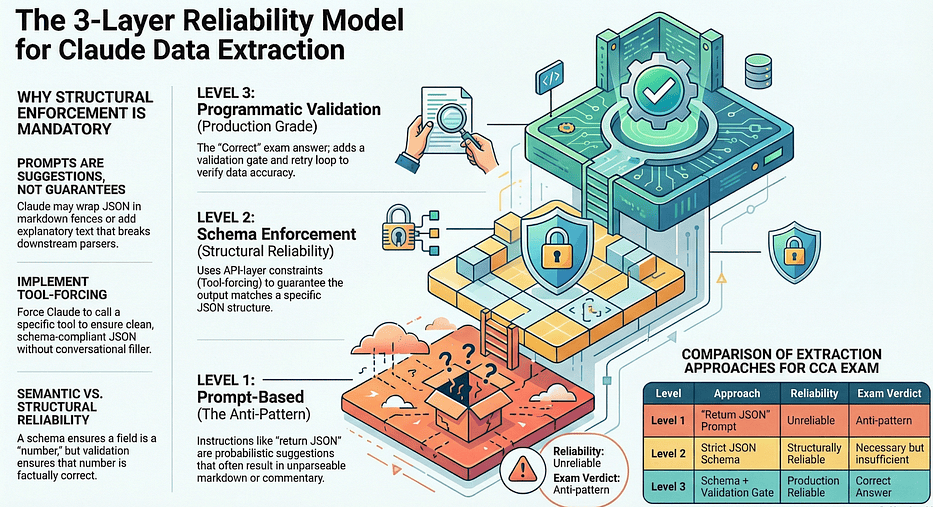
Every question in this scenario tests whether you understand the distinction between three levels of extraction reliability:

 Three-layer reliability model: prompt guidance, schema enforcement, programmatic validation
Three-layer reliability model: prompt guidance, schema enforcement, programmatic validation
The exam consistently rewards Level 3 answers. If a question asks about improving an extraction pipeline and the answer choices include both “add more emphasis to the JSON instruction” and “add programmatic validation with error feedback,” you pick the programmatic validation every single time.
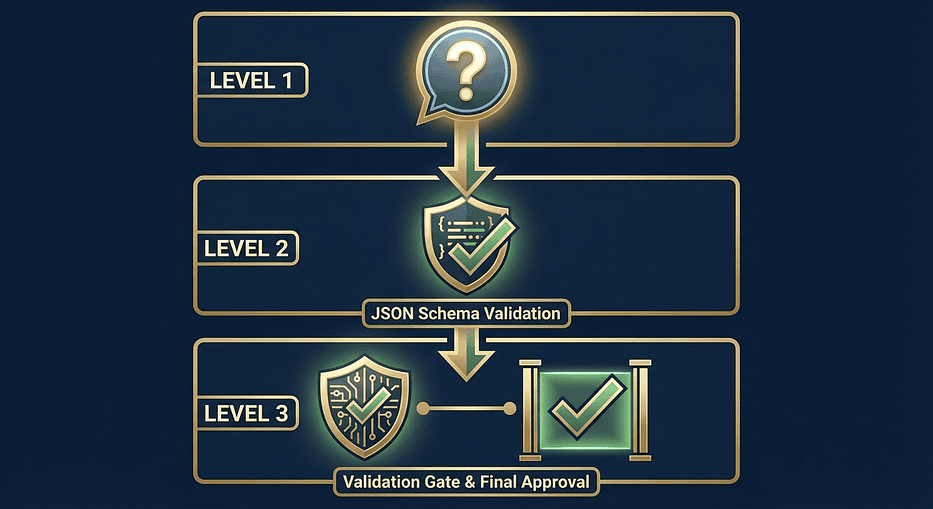
Why the Three Layers Are Inevitable, Not Optional
Let me walk you through why these three layers exist in the order they do. Once you understand the reasoning, you will never confuse them again.
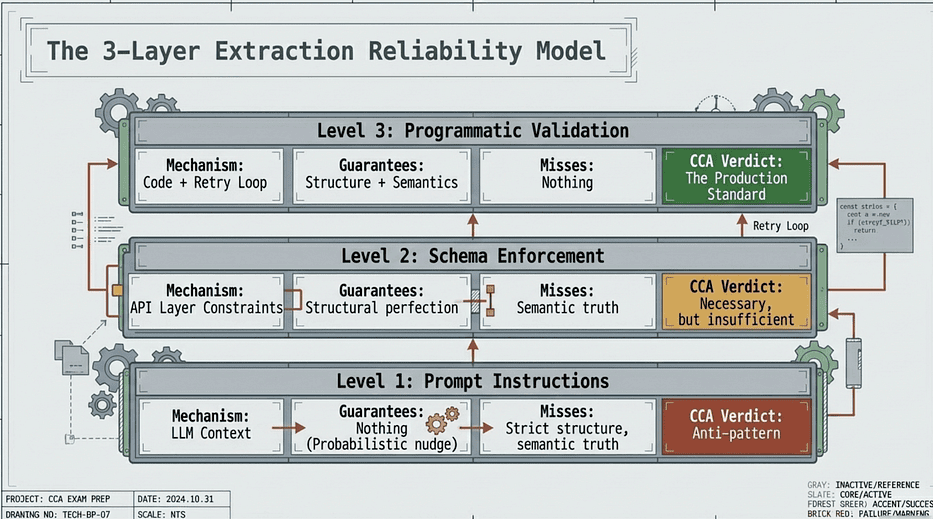 CCA Exam: 3-Layer Extraction Reliability Model
CCA Exam: 3-Layer Extraction Reliability Model
The problem that makes Level 1 fail. You write “Always return valid JSON” in your system prompt. This is a natural instinct. You are giving Claude a clear instruction. Claude is excellent at following instructions. But here is the thing: Claude is a probabilistic language model, not a deterministic parser. Every token it generates is a sample from a probability distribution over possible next tokens.
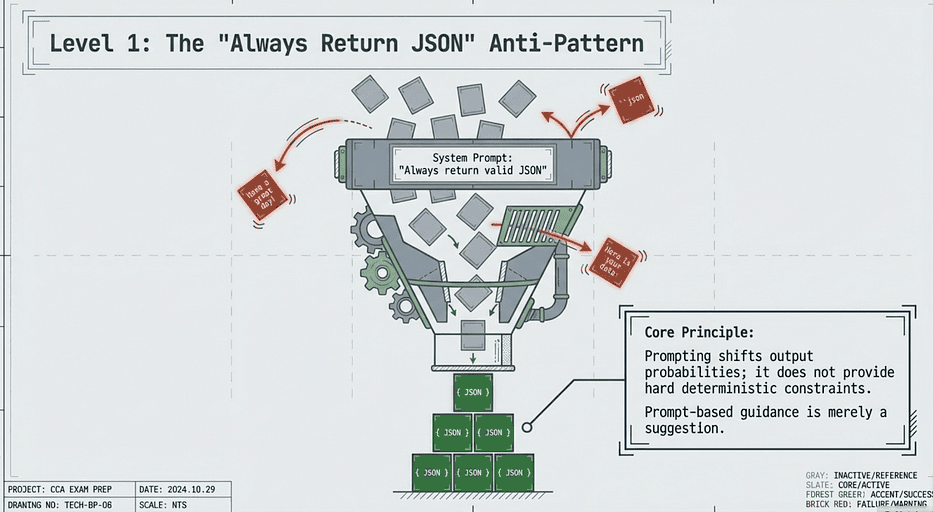 CCA — Claude Certification Exam — Relying on Prompting for JSON
CCA — Claude Certification Exam — Relying on Prompting for JSON
The instruction “return JSON” shifts that distribution strongly toward JSON-shaped output. It does not eliminate all other possibilities. There remains some probability mass on “Here is the JSON you requested:” followed by your actual data. There remains some probability mass on wrapping the JSON in triple-backtick fences. There remains some probability mass on adding a closing pleasantry. You cannot prompt that probability to zero. Level 1 fails not because the instruction is bad, but because instructions are probabilistic guides, not hard constraints.
The problem that Level 1 failure reveals. Once you accept that prompts cannot guarantee structure, you look for a mechanism that can. That mechanism exists at the API layer. When you define a JSON schema and force Claude to populate a tool call, the API enforces structural conformance before the response ever reaches your code. The probability argument becomes irrelevant because the generation is constrained. This is Level 2, and it solves exactly the problem Level 1 cannot.
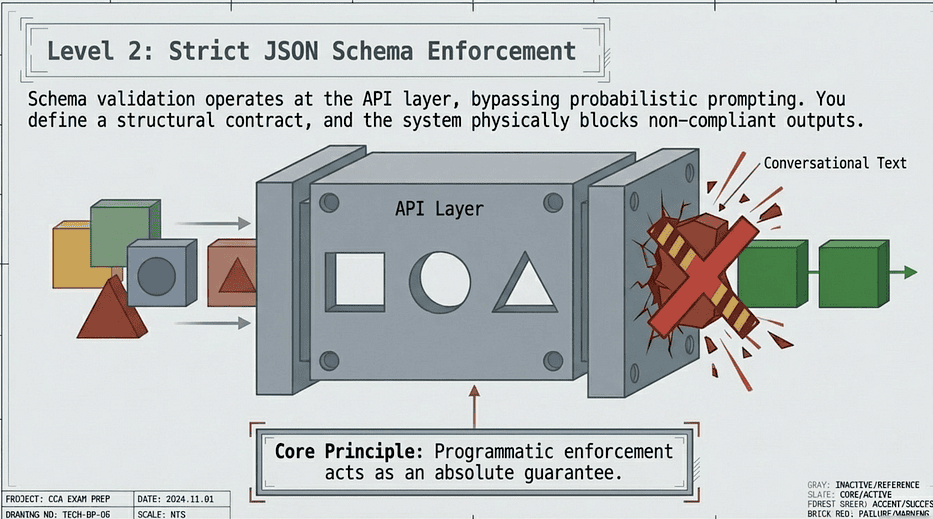 Claude Certified Architect Exam: Level 2 — Strict JSON Schema Enforcement
Claude Certified Architect Exam: Level 2 — Strict JSON Schema Enforcement
The problem Level 2 leaves unsolved. Schema enforcement guarantees structure. It says nothing about meaning. Your schema can require a total field of type number and you will always get a number. But nothing in the schema checks whether that number equals the sum of the line items. Nothing checks whether the date field contains a real calendar date versus an impossible value like February 31st. Nothing checks whether the vendor name matches any vendor in your system. Structure and semantics are different problems. Level 2 solves structure. Level 3 adds the programmatic validation that checks semantics.
That is why the three layers exist in this order. Each one solves a problem the previous layer cannot touch.
- Level 1 addresses what Claude should do.
- Level 2 enforces what Claude must return (schema).
- Level 3 verifies whether what Claude returned is actually correct (semantic). Skip any layer and you have a gap that will surface in production.
 Claude Certified Architect Exam: Level 3 Tests Semantic meaning, something Level 2 cannot. Semantic vs Structure
Claude Certified Architect Exam: Level 3 Tests Semantic meaning, something Level 2 cannot. Semantic vs Structure
💡 Exam Tip: The Layer Sequencing Question
If the exam asks “in what order should these reliability mechanisms be applied,” the answer follows the same logic:
✅ 1) structural enforcement first,
✅ 2) semantic validation second,
✅ 3) retry-with-feedback third.
🚩 Don’t validate semantics before enforcing structure. This is doing expensive semantic checks on data that might not even parse.
🚩 Don’t retry without specifying a reason for the retry. An answer that retries without specific feedback is blind retrying.
💡 The layers are ordered this way because each one depends on the previous one succeeding first.
The Anti-Pattern: “Always Return JSON”
Let me describe the mistake candidates make so you can spot it immediately on exam day.
The anti-pattern looks like this: you add “Always return your response as valid JSON” to the system prompt, test it a few times, see it working, and move on. Maybe you add a few-shot example of the JSON format you want. Maybe you bold the instruction. Maybe you add “IMPORTANT: Only return JSON, no other text.”
 CCA — Claude Certification Exam — Relying on Prompting for JSON — Problems
CCA — Claude Certification Exam — Relying on Prompting for JSON — Problems
This feels like the right move. It is not. Here is why that approach fails, and the exam tests every single one of these failure modes:
Claude wraps JSON in markdown code fences. You asked for JSON, and Claude helpfully returns it inside triple-backtick fences with a json language tag. Your JSON parser chokes on the backticks.
Claude adds explanatory text. “Here is the extracted data:” followed by the JSON, followed by “Let me know if you need any changes.” Your parser fails or, worse, silently captures garbage.
Claude returns valid JSON that does not match your schema. The JSON parses fine, but there is an extra field you did not expect, a missing required field, or a string where you needed a number. Your downstream system breaks on type mismatches.
Claude hallucinates field values. The source document says “payment pending” and Claude extracts "status": "completed" because that seemed like a reasonable value. The JSON is structurally valid. The data is wrong.
Under context pressure, Claude truncates or malforms JSON. When the source document is long and complex, the output occasionally gets cut off or the closing braces get mangled.
None of these failure modes can be fixed by adding more emphasis to the prompt. The instruction “IMPORTANT: ONLY return JSON” is still a probabilistic nudge. You are trying to solve a determinism problem with a suggestion.
Here is the exam question pattern to look out for:
❓ “Your extraction pipeline works 90% of the time but occasionally produces unparseable output. What is the BEST improvement?”
- 🚩 Wrong: “Add more emphasis to the JSON instruction in the system prompt.” Still prompt-based. Still a suggestion.
- 🚩** Wrong**: “Use a larger context window.” Does not solve the structural problem.
- Wrong: “Add few-shot examples of the expected JSON format.” Helps, but still a suggestion. Claude can still deviate.
- Correct: “Use strict JSON schema enforcement with programmatic validation.”
Burn this into your memory:
✅** prompt-based guidance is a suggestion**
✅** programmatic enforcement is a guarantee.**
The exam returns to this principle over and over across multiple domains.
💡 Exam Tip: Spotting the “Always Return JSON” Trap
💡 The exam will present this trap in multiple forms. Watch for answer choices that include any of these phrases:
🚩 Add to the system prompt that Claude must only return JSON
🚩 Add few-shot examples of the expected JSON format
🚩 Emphasize the output format requirements in the prompt
🚩 Instruct Claude to double-check its JSON before responding
All of these are Level 1 answers. They add more words to a suggestion. They cannot turn a probabilistic nudge into a structural guarantee. The moment you see the problem framed as “output is sometimes invalid or malformed,” the correct answer involves schema enforcement at the API level, not stronger prompt language.
💡 Exam Tip: Spotting the “prompt layer or the code layer” Trap
A useful gut-check on exam day: ask yourself whether the proposed solution operates at the prompt layer or the code layer. Prompt layer solutions cannot fix structural reliability. Code layer solutions can.
Strict JSON Schema Validation with the Anthropic SDK
JSON schema validation is the bridge between “Claude usually returns JSON” and “Claude always returns valid JSON.” It operates at the API layer, not the prompt layer, which is why it works.
What Schema Enforcement Does
When you define a JSON schema and enforce it at the API level, you are telling the system: only accept output that conforms to this exact structure. Claude is constrained to produce output matching your schema. You do not get JSON wrapped in explanations. You do not get missing required fields. You do not get wrong types. The structural guarantee is absolute.
How It Works in Practice
For the CCA exam, you need to understand two approaches to schema enforcement with the native Anthropic SDK:
Approach 1: Tool-forcing. You define a tool whose input_schema matches the data structure you want, then use tool_choice to force Claude to call that specific tool. The tool does not actually do anything; it is a schema enforcement mechanism disguised as a tool.
import anthropic
client = anthropic.Anthropic()
# Tool defines Toolname and includes JSON schema validation
extraction_tool = {
"name": "extract_invoice",
"description": "Extract structured invoice data from the document",
"input_schema": {
"type": "object",
"properties": {
"vendor_name": {
"type": "string",
"description": "Name of the vendor or supplier"
},
"invoice_date": {
"type": "string",
"description": "Invoice date in YYYY-MM-DD format"
},
"line_items": {
"type": "array",
"items": {
"type": "object",
"properties": {
"description": {"type": "string"},
"quantity": {"type": "number"},
"unit_price": {"type": "number"}
},
"required": ["description", "quantity", "unit_price"]
}
},
"total": {
"type": "number",
"description": "Total invoice amount"
},
"currency": {
"type": "string",
"enum": ["USD", "EUR", "GBP", "CAD", "AUD"]
}
},
"required": ["vendor_name", "invoice_date", "line_items",
"total", "currency"]
}
}
# Claude API call to create passes tool def which has JSON schema.
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=[extraction_tool], # <------ Use tool that uses schema
tool_choice={"type": "tool", "name": "extract_invoice"},
messages=[{
"role": "user",
"content": f"Extract the invoice data from this document:\n\n"
f"{document_text}"
}]
)
# The extracted data is in the tool call input
extracted = response.content[0].input
The key line is tool_choice={"type": "tool", "name": "extract_invoice"}. This forces Claude to call the extract_invoice tool, which means the output must conform to the tool's input_schema. No markdown wrappers. No explanatory text. Just clean, schema-compliant JSON.
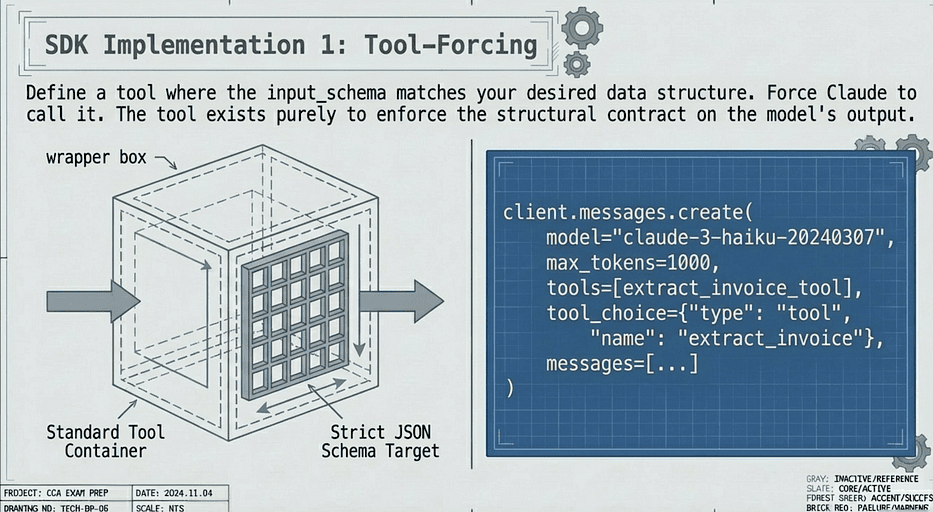 CCA Exam: Tool Forcing
CCA Exam: Tool Forcing
Approach 2: client.messages.parse() with Pydantic. This is a higher-level approach that uses Pydantic models directly:
from pydantic import BaseModel
from typing import List
# Pydantic type enforces schema rules
class LineItem(BaseModel):
description: str
quantity: float
unit_price: float
class Invoice(BaseModel):
vendor_name: str
invoice_date: str
line_items: List[LineItem]
total: float
currency: str
# Notice Claude API call to parse uses Pydantic type
response = client.messages.parse(
model="claude-sonnet-4-6",
output_format=Invoice, # <----- Pydantic type passed to enforce schema
messages=[{
"role": "user",
"content": f"Extract the invoice data:\n\n{document_text}"
}]
)
extracted = response.parsed_output # Typed Pydantic Invoice object
Important exam distinction: with_structured_output() is a LangChain method, not a native Anthropic SDK method. If you see a question asking about the native Anthropic SDK and with_structured_output() is an answer choice, that is a distractor. The native SDK uses tool-forcing or client.messages.parse().
 CCA Exam: Use client.messages.parse(..), don’t confuse with LangChain with_structured_output()
CCA Exam: Use client.messages.parse(..), don’t confuse with LangChain with_structured_output()
💡 Exam Tip: The SDK Method Distractor
⚠ The exam will mix Anthropic SDK methods with LangChain methods in answer choices, expecting you to know which belong where.
🚩 — with_structured_output() belongs to LangChain. It is not an Anthropic SDK method. - tool_choice={"type": "tool", "name": "..."} belongs to the Anthropic SDK. This is the tool-forcing pattern. - client.messages.parse() belongs to the Anthropic SDK (beta). This is the Pydantic-based approach.
🚩 If a question says “using the native Anthropic SDK” and one of the answer choices mentions with_structured_output(), eliminate that choice immediately.
Schema Design Considerations the Exam Tests
The exam may show you a schema and ask what is wrong with it or what edge cases it would miss.
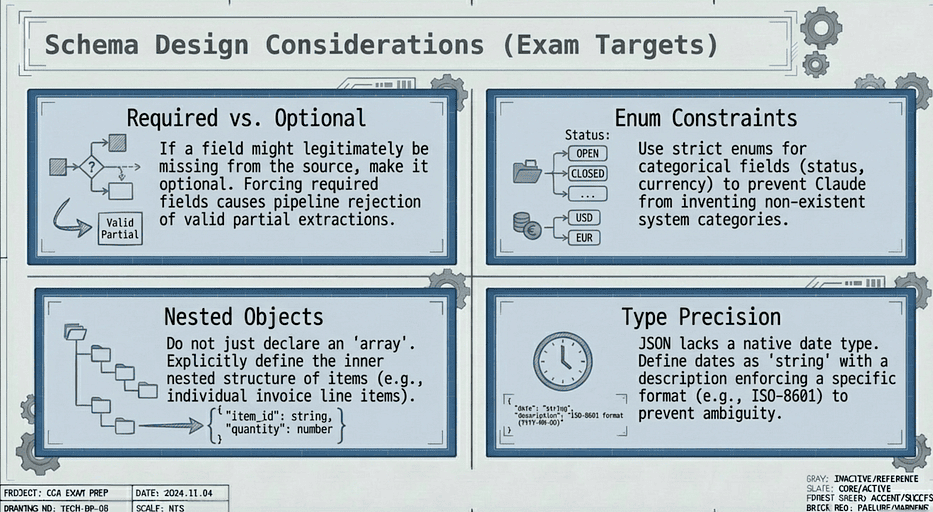 CCA Exam: Schema Design Considerations
CCA Exam: Schema Design Considerations
Know these patterns:
- Required vs. optional fields: If a field might legitimately be missing from the source document, make it optional. If it must always be present, make it required. Getting this wrong means your pipeline either rejects valid extractions or accepts incomplete ones.
- Enum constraints: For categorical fields (status, currency, category), use enums. This prevents Claude from inventing category names that do not exist in your system.
- Nested objects and arrays: Line items on an invoice, addresses on a contact record. The schema must define the inner structure, not just say “array.”
- Type precision: A “total” field should be
number, notstring. A "date" field should bestringwith a description specifying the format (since JSON Schema does not have a native date type).
The Exam Trap: Schema in the Prompt Only
Here is the anti-pattern the exam tests: you describe the schema in the prompt text (“Return a JSON object with fields vendor_name (string), total (number)…”) but do not use schema enforcement at the API level. Claude sees the schema description and usually follows it. But “usually” is not “always,” and the exam knows the difference.
🚫** Anti-pattern**: Schema described in prompt text only.
✅** Correct pattern**: Schema defined in code and enforced at the API level.
For Claude Code specifically, you can use the --json-schema flag:
claude -p "Extract invoice data from this text: ..." \
--output-format json \
--json-schema '{"type":"object","properties":{"vendor_name":{"type":"string"},"total":{"type":"number"}},"required":["vendor_name","total"]}'
Programmatic Validation Gates
Schema enforcement guarantees structure. It does not guarantee correctness. This distinction is where many candidates lose points.
Why Schema Enforcement Alone Is Not Enough
Consider an invoice extraction where the schema requires a total field of type number and a line_items array. Schema enforcement guarantees you get both fields with the right types. But it does not check whether the total actually equals the sum of the line items. It does not check whether the date is a real date versus "yesterday." It does not check whether the vendor name matches any known vendor in your system.
Schema validates structure. Validation gates check semantics.
Think of it this way: a perfectly formatted check is not the same as a check that will clear. The format is necessary. It is not sufficient.
The Validation Gate Pattern
Here is the pattern the exam rewards:
def validate_invoice(extracted: dict) -> tuple[bool, list[str]]:
"""Validate extracted invoice data against business rules."""
errors = []
# Check date format
try:
datetime.strptime(extracted["invoice_date"], "%Y-%m-%d")
except ValueError:
errors.append(
f"invoice_date '{extracted['invoice_date']}' "
f"is not a valid YYYY-MM-DD date"
)
# Check line items sum matches total
computed_total = sum(
item["quantity"] * item["unit_price"]
for item in extracted["line_items"]
)
if abs(computed_total - extracted["total"]) > 0.01:
errors.append(
f"total is {extracted['total']} but line items "
f"sum to {computed_total}"
)
# Check total is positive
if extracted["total"] <= 0:
errors.append(
f"total must be positive, got {extracted['total']}"
)
# Check vendor against known vendors (optional)
if extracted["vendor_name"] not in KNOWN_VENDORS:
errors.append(
f"unknown vendor '{extracted['vendor_name']}' "
f"- may need manual review"
)
return (len(errors) == 0, errors)
Step 1: Claude extracts data with schema enforcement.
Step 2: Your programmatic validator checks business rules.
Step 3: Pass or fail.
If fail, you have specific error messages ready for the retry loop.
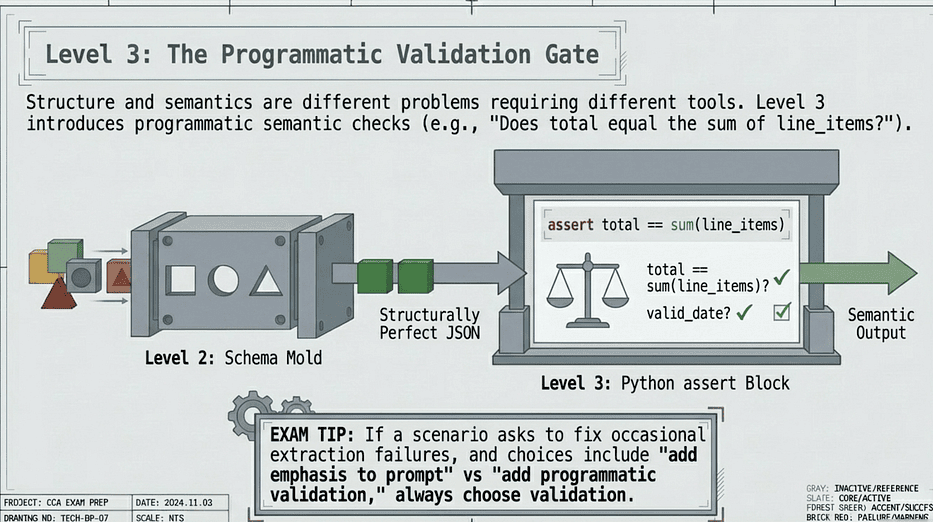 CCA — Programmatic Validation Gate for Semantic Validation
CCA — Programmatic Validation Gate for Semantic Validation
The CCA Exam Trap: Trusting LLM Confidence
Here is an anti-pattern the exam explicitly tests. You ask Claude to self-report its confidence: “On a scale of 1–10, how confident are you in this extraction?” Claude says 9. You accept the extraction.
This is wrong. LLM-generated confidence scores are not reliable enough for production decisions. Claude might say it is 90% confident in an extraction that is completely wrong, or 60% confident in one that is perfect. The calibration between stated confidence and actual accuracy is not tight enough to use as a validation mechanism.
🚫** Anti-pattern**: Trust Claude’s self-reported confidence scores.
✅** Correct pattern**: External programmatic validation that checks actual data quality.
The CCA exam frames this as:
“Your team proposes having Claude rate its extraction confidence and only flagging low-confidence results for review. What is the problem with this approach?”
The answer is that LLM confidence scores are poorly calibrated and cannot replace programmatic validation.
💡** Exam Tip: The Confidence Score Red Herring**
Confidence score answers appear frequently in extraction questions because they sound reasonable. After all, if Claude knows it made a mistake, why not ask it to say so?
The problem is that Claude does not reliably know when it has made a mistake. A hallucinated vendor name looks just as confident to the model as a correctly extracted one. A date that slipped to “last Thursday” instead of the actual date may generate high confidence. The model cannot see the ground truth.
Whenever an answer choice involves asking Claude to rate, score, or assess its own extraction quality, treat it as a trap. Programmatic validation does not ask Claude anything. It independently verifies the extracted data against rules your code enforces. That is the answer the exam wants.
Claude Certified Architect: The Validation-Retry Feedback Loop
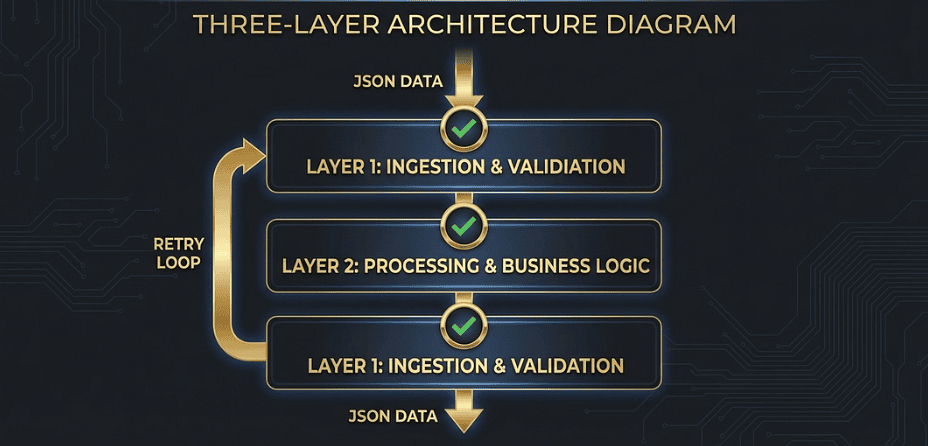
This is the complete pattern the exam rewards. It combines everything we have covered into a production-grade extraction pipeline. Once you have this loop in your head as a single coherent unit, the exam questions about it become easy.
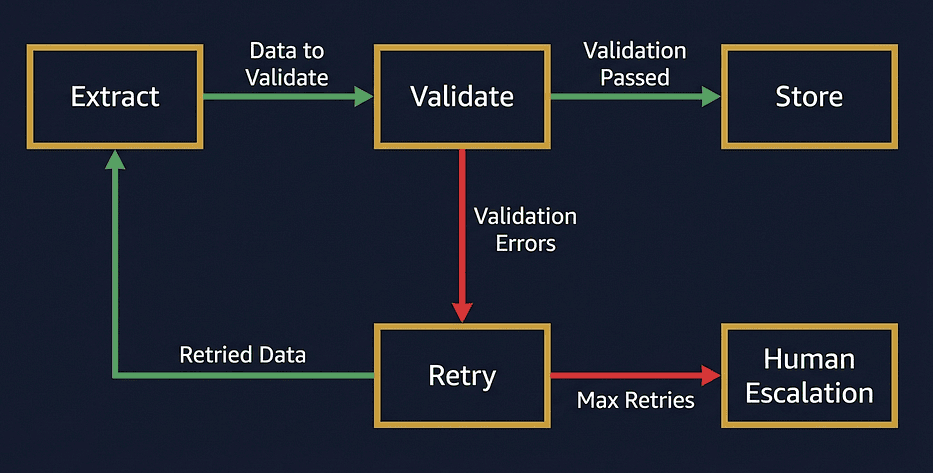 Claude Certified Architect — Validation-Retry Feedback Loop — Structured Data Extraction
Claude Certified Architect — Validation-Retry Feedback Loop — Structured Data Extraction
The Full Loop
Extract --> Validate --> [Pass] --> Store
--> [Fail] --> Feedback --> Retry --> Validate
--> [Max retries] --> Human Escalation
Here is what each step does:
- Extract: Claude processes the source document with JSON schema enforcement (tool-forcing or
messages.parse()). - Validate: Your programmatic validator checks both structure and business rules.
- Feedback: If validation fails, you send specific error messages back to Claude. Not “try again.” Specific: “The total was 150.00 but the line items sum to 175.00. Please re-examine the source document and correct the total or the line item amounts.”
- Retry: Claude re-extracts with the original document plus the error feedback in context. It now knows what went wrong and can correct it.
- Gate: After a bounded number of retries (typically 2–3), escalate to human review.
Why Feedback Matters: The Difference Between Blind and Informed Retry
This is one of the most important distinctions the exam tests. Think of it like debugging. When a compiler tells you “line 47, undeclared variable,” you know exactly where to look. When it tells you “something went wrong,” you start guessing. Claude is in the same position on a retry.
🚫 Blind retry (anti-pattern):
“That was wrong, try again.”
Claude has no idea what was wrong. It might make the same mistake. It might make a different mistake. This is barely better than not retrying at all. You are spending tokens on a coin flip.
✅ Informed retry (correct pattern):
“The invoice_date field contained ‘last Tuesday’ but we need a date in YYYY-MM-DD format. The source document mentions March 15, 2026 in the header. Please re-extract with the correct date.”
Claude now has specific, actionable correction guidance. It knows which field failed, what the current value was, what the expected format is, and where to look in the source document for the right value.
The quality of your feedback message determines whether retries converge. Specific error messages that reference the validation logic convert most retry attempts into successful extractions. Generic “try again” messages burn tokens and produce random variation.
The exam tests this directly: “Your extraction pipeline retries on failure but the retry rarely fixes the problem. What should you change?” The answer is to include specific validation error messages in the retry prompt.
Specific error messages that reference the validation logic convert most retry attempts into successful extractions.
Generic “try again” messages burn tokens and produce random variation.
💡 Exam Tip: Making the Retry Loop Stick
A simple way to remember the three types of retry loops:
🚫 Blind retry = “Try again.” (Claude guesses what went wrong — always wrong on the exam)
✅ Informed retry = “Here is what failed and why.” (Claude knows what to fix)
✅ Bounded retry = “After N attempts, a human takes over.” (The loop cannot run forever)
The exam tests all three.
🚫 Blind retry is always wrong
🚫 Informed retry loop without a bound is also wrong
The only correct pattern is informed retry + bounded attempts + human escalation.
If you see an answer like:
🚫 “Retry until success”
🚫 “Keep retrying until validation passes”
Eliminate it immediately!
Production systems require a finite exit condition.
Unbounded retry loops are a reliability failure waiting to happen.
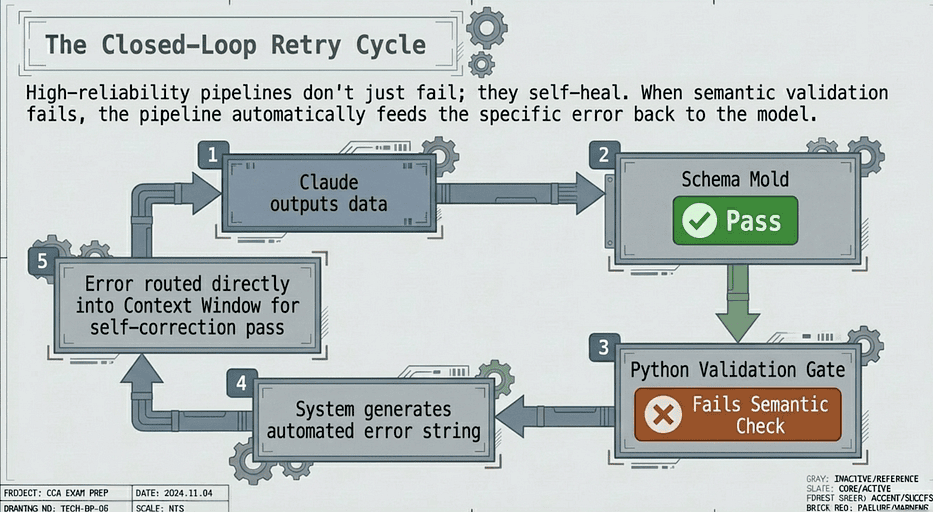 CCA Exam: Closed-Loop Retry Cycle
CCA Exam: Closed-Loop Retry Cycle
Claude Certified Architect: Bounded Retries and Human Escalation
The retry loop must be bounded. This is a reliability principle that crosses into the **Agentic Architecture domain **and we cover this in detail in other articles in this series.
🚫** Anti-pattern**: Infinite retry loop that keeps trying until it works. This burns tokens without converging and can loop forever on genuinely ambiguous documents.
✅ Correct pattern: Set a maximum retry count (2–3 attempts), then escalate.
MAX_RETRIES = 3 # Bounded retries
def extract_with_validation(document_text: str) -> dict:
"""Extract data with validation-retry loop."""
messages = [{
"role": "user",
"content": f"Extract invoice data:\n\\n{document_text}"
}]
# Retry only MAX_RETRIES
for attempt in range(MAX_RETRIES):
# Extract with schema enforcement
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=[extraction_tool], # <---- JSON Schema Validation
tool_choice={"type": "tool", "name": "extract_invoice"},
messages=messages
)
# Extracted is structurally correct and conforms to schema
extracted = response.content[0].input
# Now test that response is semantically valid
# Does it follow business rules or patterns not testable by JSON schema
is_valid, errors = validate_invoice(extracted)
if is_valid:
return extracted
# Build specific feedback for retry
error_feedback = "Validation failed:\\n" + "\n".join(
f"- {e}" for e in errors
)
error_feedback += (
"\nPlease re-examine the source document "
"and correct these issues."
)
# Add the failed attempt and feedback to conversation
messages.append({
"role": "assistant",
"content": response.content
})
messages.append({
"role": "user",
"content": error_feedback
})
# Max retries exceeded: escalate
escalate_to_human(
document=document_text,
last_extraction=extracted,
errors=errors,
attempts=MAX_RETRIES
)
return None
The escalation function should pass the human reviewer everything they need: the original document, the last extraction attempt, the validation errors, and how many attempts were made. This is the “human-in-the-loop” pattern the exam rewards in the Context Management and Reliability domain.
**Does that look correct? It is close, but it missed some key points. **The code listing forgot a critical step. Can you spot it? Did you catch it? If not, review it again, and see where it went wrong, and then let’s review how to fix it.
Why the “Happy Path Only” Retry Loop Fails the Exam
On the surface, this looks good: bounded retries, semantic validation, human escalation. Under exam conditions, this will not get full credit, because it only handles soft failures (semantic errors) and assumes the hard parts never break.
Here is what this code assumes without checking:
- The API call always succeeds.
response.contentis always a non-empty list.response.content[0]is always atool_useblock.- That block always has an
.inputattribute. .inputis always a JSON object that already conforms to the schema.
Those are exactly the assumptions that fail in production. As written, if the tool schema is invalid, the tool call fails, Claude returns text instead of a tool call, or the response shape changes, this function throws an exception before it ever reaches validate_invoice. It never retries. It never escalates. The “retry loop” only works when everything is already perfect.platform.claude+2
In CCA exam language: this pattern validates semantics but lets transport, tool, and schema failures crash the pipeline. That is a partial reliability pattern, not a complete one.
The Correct Pattern: Handle Hard Failures Before Semantic Validation
The corrected version adds just enough structure to cover the full reliability stack without turning into a framework:
python
MAX_RETRIES = 3 # Bounded retries
# Correct version
def extract_with_validation(document_text: str) -> dict | None:
"""Extract data with validation-retry loop and schema-safe retries."""
messages = [{
"role": "user",
"content": f"Extract invoice data:\n\n{document_text}",
}]
last_extraction = None
last_errors = []
for attempt in range(1, MAX_RETRIES + 1):
try: # <--- Call I/O and schema tool validation schema in try block
# 1) Call Claude with schema-enforced tool use
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
tools=[extraction_tool], # <--- JSON scheme enforced tool call
tool_choice={"type": "tool", "name": "extract_invoice"},
messages=messages,
)
# 2) Defensive checks on the response shape
if not response.content:
raise ValueError("Claude returned no content.")
block = response.content[0]
if getattr(block, "type", None) != "tool_use":
raise ValueError(
"Claude did not return the expected tool_use block."
)
if not hasattr(block, "input"):
raise ValueError("Tool block missing input payload.")
extracted = block.input
# 3) Optional: light JSON shape sanity check
if not isinstance(extracted, dict):
raise TypeError(
"Tool input payload was not a JSON object."
)
last_extraction = extracted
except Exception as e:
# Any API / schema / shape problem lands here
last_errors = [f"Attempt {attempt} failed: {e}"]
if attempt == MAX_RETRIES:
escalate_to_human(
document=document_text,
last_extraction=last_extraction,
errors=last_errors,
attempts=attempt,
)
return None
messages.append({
"role": "user",
"content": (
"The previous extraction attempt failed due to an API "
f"or JSON schema issue:\n- {e}\n\n"
"Please call ONLY the extract_invoice tool and return a "
"valid JSON object that matches the tool schema."
),
})
continue
# 4) Only now do we run semantic validation
# At this point, we know we have a valid dict that conforms
# to JSON schema in tool definition.
is_valid, errors = validate_invoice(extracted)
if is_valid:
return extracted
last_errors = errors
if attempt == MAX_RETRIES:
escalate_to_human(
document=document_text,
last_extraction=last_extraction,
errors=last_errors,
attempts=attempt,
)
return None
error_feedback = (
"Validation failed:\n" + "\n".join(f"- {e}" for e in errors)
)
error_feedback += (
"\nPlease re-examine the source document and correct these "
"issues."
)
messages.append({
"role": "assistant",
"content": response.content,
})
messages.append({
"role": "user",
"content": error_feedback,
})
return None
Notice what changed:
- Hard failures are handled explicitly.
- Any JSON schema problem on the return side (e.g., malformed tool input, missing
.input, wrong type) is caught by thetry/exceptaroundclient.messages.createand theresponse.contentchecks. - API errors, tool failures, and bad response shapes no longer crash the function.platform.claude+2
**2) The retry loop now covers both layers. **The loop retries on:
- Transport / API / schema / shape failures (hard failures in the
exceptblock). - Semantic failures (soft failures from
validate_invoice). This matches the exam’s reliability story: you must be robust to both “the call broke” and “the call succeeded but the data is wrong.”
3) Escalation always has context.
last_extractionandlast_errorsare tracked so that even- if the first attempt fails structurally, the final call to
escalate_to_humancan pass a meaningful error report instead of crashing on an undefined variable.
In exam terms: the second listing implements the full “Extract → Validate → Retry → Escalate” loop the scenario describes, not just the “Validate” step.
The principle to burn in:
The CCA exam rewards retry loops that handle both execution failures and validation failures. A loop that retries only when semantic checks fail, but crashes on tool or schema errors, is not a complete reliability pattern.
💡 Example CCA Exam Code is not production code
In the examples, we catch a broad Exception to keep the control flow easy to follow and to avoid over‑focusing on SDK‑specific error types. In production, it’s usually better to narrow this to more specific exceptions (for example, anthropic.APIError for API failures, ValueError for bad response shapes, TypeError for type mismatches), but only once you’ve confirmed which errors your stack actually raises and how you want to handle each class. Early in development or in teaching code, a single broad except can be acceptable for clarity, as long as you eventually tighten it up before shipping. Not all exceptions are retryable.
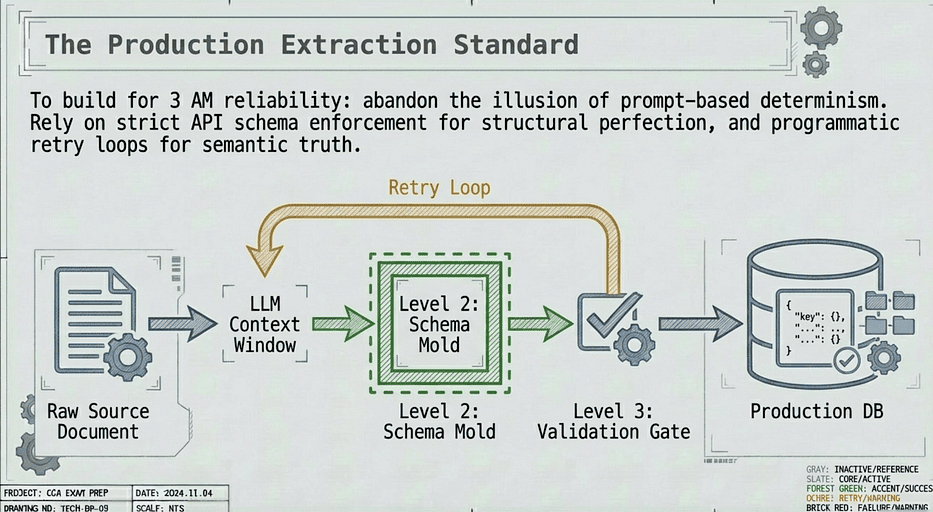 CCA: Production Extraction Standard. Retry Loop.
CCA: Production Extraction Standard. Retry Loop.
The “Lost in the Middle” Problem
One more consideration the exam tests, pulled from the Context Management domain. When your source document is long (tens of thousands of tokens), Claude’s attention is strongest at the beginning and end of the context window. Key data buried in the middle of a long document may get less attention, leading to extraction errors.
Claude’s attention is strongest at the beginning and end of the context window. Key data buried in the middle … may get less attention, leading to extraction errors.
The mitigation: chunk long documents, extract from each chunk independently, then merge and deduplicate the results. This is especially relevant for multi-page invoices, long legal documents, or concatenated email threads.
Exam question pattern: “Your extraction pipeline works well on short documents but accuracy drops on documents longer than 50 pages. What is the most likely cause and fix?”
Answer: The “lost in the middle” effect. Chunk the documents and extract from chunks.
The mitigation: chunk long documents, extract from each chunk independently, then merge and deduplicate the results.
Connecting to Other CCA Concepts
The Structured Data Extraction scenario does not exist in isolation. The exam tests how it connects to other domains.
Claude Certified Architect: MCP Integration
Extraction pipelines in production often use MCP tools to access source documents and write results to downstream systems. The exam tests whether you understand tool scoping here:
- Correct: 4–5 focused extraction tools (extract_invoice, extract_receipt, extract_contract, validate_extraction, store_result).
- Anti-pattern: One monolithic
extract_anythingtool with 15 schema definitions that Claude has to choose between.
Remember the rule: 4–5 tools per agent, distribute the rest to specialized subagents. If your extraction pipeline handles 10 document types, do not give one agent 10 extraction tools. Create specialized subagent extractors and a coordinator that routes documents to the right subagent. The multi-agent coordinator-subagent pattern is covered in depth in Article 7: Multi-Agent Orchestration.
CCA: Agentic Patterns
Complex extraction workflows use the coordinator-subagent pattern:
- Coordinator: Manages the document queue, routes documents to the right extractor, aggregates results.
- Subagents: Specialized extractors for invoices, receipts, contracts, and other document types. Each has 4–5 tools and domain-specific validation rules.
- Critical rule: Subagents do not inherit context automatically. The coordinator must explicitly pass each subagent the document it needs to process.
This is covered in detail in the Multi-Agent Orchestration.
CCA: Batch API for Bulk Extraction
If the exam asks: “You need to extract data from 5,000 invoices. Which API approach?” The answer is the Message Batches API.
- 50% cost discount versus standard API calls
- Most batches complete within 1 hour, with a 24-hour maximum processing window
- Up to 100,000 requests per batch
- Perfect for: nightly processing runs, bulk document migration, historical data extraction
🚫** Anti-pattern**: Processing 5,000 documents through the real-time API one at a time.
✅ Correct pattern: Batch API for non-blocking bulk extraction, real-time API only for user-facing blocking workflows.
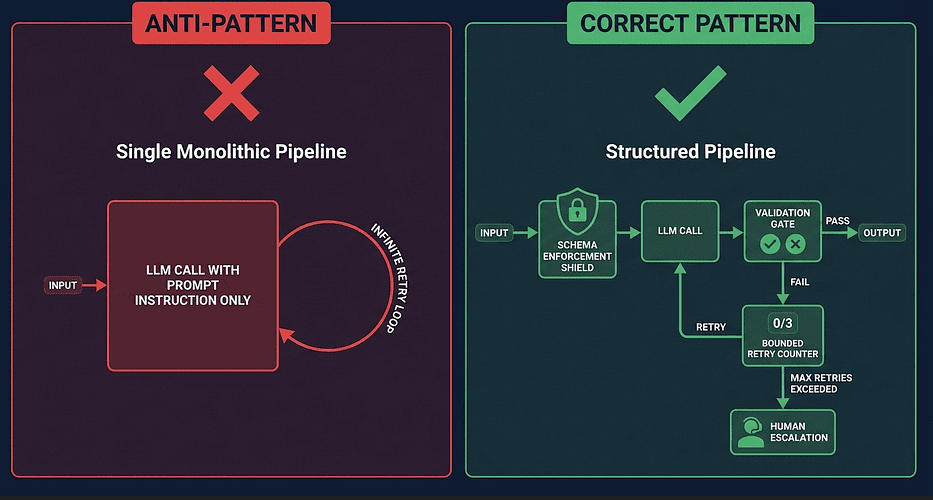
💡CCA Exam Strategy: Data Extraction Questions
When you see a data extraction question, run through this decision framework:
“Output is sometimes invalid JSON”
✅ You need schema enforcement, not more prompt instructions. Look for answers mentioning JSON schema, tool-forcing, or --json-schema.
“Output structure is correct but values are wrong”
✅ You need a programmatic validation gate. Look for answers mentioning business rule validation, programmatic checks, or post-extraction verification.
“Extraction fails and retry does not fix it”
✅ You need specific error feedback in the retry loop. Look for answers mentioning validation error messages passed back to Claude.
“Extraction pipeline needs to scale to thousands of documents”
✅ You need the Batch API. Look for answers mentioning Message Batches, 50% discount, or non-blocking processing.
“Accuracy drops on long documents”
✅ You need document chunking. Look for answers mentioning chunking, splitting, or the “lost in the middle” effect.
Practice Question Walkthrough
Question: Invoice Extraction Reliability ❓
Your team built an invoice extraction pipeline using Claude. The system prompt instructs Claude to “always return valid JSON matching the invoice schema.” Testing shows 92% accuracy, but 8% of extractions either produce unparseable JSON or contain incorrect totals. The pipeline is going into production next month. A teammate suggests adding few-shot examples of correct JSON output to the prompt. What is the BEST improvement?
A.) Add few-shot examples as the teammate suggests
B.) Increase the context window to give Claude more room
C.) Add strict JSON schema enforcement with programmatic validation of business rules and a retry loop with specific error feedback
D.) Have Claude rate its confidence and flag low-confidence extractions for review
✅ Answer: C. This is the classic “prompting vs. controls” question. The issue is not just formatting. The system has two distinct failure modes: unparseable JSON and incorrect totals. The best answer is the one that addresses both with deterministic safeguards.
Option A is the main distractor because it sounds useful, and it probably would improve formatting somewhat. But it is still prompt-based. Claude can still drift from the schema, and few-shot examples do nothing to guarantee arithmetic correctness.
Option B is wrong because context window size is not the problem. More context does not make JSON generation more reliable, and it does not fix incorrect totals. It is unrelated to the root cause.
Option D is tempting because it sounds operationally mature, but it is the confidence-score trap. LLM self-rated confidence is poorly calibrated. A model can be highly confident and still return bad totals. Confidence scoring may help with triage, but it is not the best primary control for production reliability.
Option C is correct because it closes the loop programmatically. Schema enforcement prevents invalid JSON from reaching downstream systems. Business-rule validation catches incorrect totals. A retry loop with targeted feedback such as “total was X but line items sum to Y” gives Claude a chance to repair the specific defect.
Notice how this question combines two symptoms to make answer C feel heavier than necessary. That is deliberate. When an exam question presents multiple failure modes, the correct answer is usually the one that solves all of them, not the one that partially improves one of them.
💡 Exam Tip: The “Combined Failure Mode” Signal
When a question describes two distinct problems in the same scenario (for example, structural and semantic failures), that is your signal.
The correct answer will address both problems, not just one.
The exam deliberately includes answer choices that fix only part of the issue. These are distractors. They sound reasonable because they do help — just not enough.
Do not pick a partial solution.
In the example above:
🚫 Few-shot examples (A) help with unparseable output but do nothing for incorrect totals
🚫 Confidence scoring (D) addresses neither problem reliably
✅ Only answer C solves both failure modes by enforcing structure and validating correctness with a retry loop
If you see multiple symptoms, choose the answer that eliminates all of them, not the one that improves just one
Key Takeaways for Exam Day
 CCA Exam: Prompt-based JSON is never the complete answer. Any answer that relies solely on prompt instructions for structured output is a distractor. In the words of Admiral Ackbar: “It’s a trap”.
CCA Exam: Prompt-based JSON is never the complete answer. Any answer that relies solely on prompt instructions for structured output is a distractor. In the words of Admiral Ackbar: “It’s a trap”.
- The three-layer model is not arbitrary. Each layer solves a problem the previous layer cannot: Level 1 guides Claude, Level 2 constrains structure, Level 3 verifies correctness. The layers are ordered this way because each one depends on the previous one succeeding.
- Prompt-based JSON is never the complete answer. Any answer that relies **solely on prompt instructions **for structured output is a distractor. In the words of Admiral Ackbar: “It’s a trap”. Prompts are probabilistic nudges. The exam rewards enforcement mechanisms.
- Tool-forcing is the native SDK pattern. Define a tool with your schema, force Claude to call it with
tool_choice. Thewith_structured_output()method belongs to LangChain, not the Anthropic SDK. - Validation must be programmatic. Do not trust Claude’s self-reported confidence. Check dates, ranges, sums, and cross-references with external code.
- Retries must be informed and bounded. Pass specific validation errors back to Claude. Set a maximum retry count (2–3). Escalate to human review after max retries. Blind retries waste tokens. Unbounded retries break systems.
- Batch API for bulk extraction. If the question involves thousands of documents and no real-time requirement, the answer is the Message Batches API.
- Chunk long documents. The “lost in the middle” effect is real. If extraction accuracy drops on long documents, chunk and extract per chunk.
Next up in the series: Article 7 — Practice Exam Walkthrough, where everything from all six scenario articles comes together for a simulated exam experience.
Discussion Questions
- The three-layer reliability model treats schema enforcement and semantic validation as separate concerns. In your own production pipelines, have you found cases where the boundary between structural and semantic validation blurs? How did you decide which layer owned the check?
- The article argues that LLM confidence scores are too poorly calibrated to use as a validation mechanism. Do you think there are any scenarios where a self-assessed confidence score is a useful signal, even if not a decision gate? Where would you draw the line between useful signal and false assurance?
- The bounded retry pattern caps retries at 2–3 attempts and then escalates to a human. In a high-volume extraction pipeline processing tens of thousands of documents per day, what factors would you use to decide the right retry ceiling, and how would you design the human escalation queue to stay manageable?
Continue the Series
- Previous: CCA Exam Prep: CI/CD with Claude Code — Pipeline automation, deployment patterns, Claude Code in production workflows
- Next: CCA Exam Prep: Multi-Agent Orchestration — Coordinator-subagent design, context passing, tool scoping at scale
- Full series overview: CCA Exam Prep: Introduction and Exam Format
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.