CCA-F Exam Prep: The Multi-Agent Research System in Runnable Code
Master this one domain for 60% of your grade — Hub-and-spoke multi-agent research system for CCA exam preparation.
Originally published on Medium.
Master this one domain for 60% of your grade — Hub-and-spoke multi-agent research system for CCA exam preparation.
Unlock the secret behind 60% of the CCA-F Foundations exam. Discover how a hub-and-spoke, context-isolated multi-agent system can turn chaotic research into reliable, testable Python code! Working examples matter because they turn abstract architecture into something you can feel: you can run it, break it, and watch the tests tell you exactly what failed and why.
The Claude Certified Architect (CCA-F) Foundations exam is a high-stakes, 120-minute proctored assessment launched in March 2026. It is designed not just to test your knowledge of syntax, but your architectural stamina. For candidates, the volume of the 60-question exam often leads to the "efficiency trap": studying the five exam domains in isolation. This approach is dangerously slow and fails to reveal how different architectural constraints interact in a production environment.
The strategic "cheat code" is the Multi-Agent Research System. By mastering this one use case, built around a hub-and-spoke coordinator and specialized subagents, you solve the "60% Problem." This single scenario stacks the three heaviest domains of the exam blueprint simultaneously. Mastering this project allows you to walk into the testing center knowing you just need 12% more out of the 40% that it is left, and still secure your certification. You need a 72% to pass. It isn't just an exam strategy; it is a blueprint for building reliable, production-grade AI.
In Article 4 of 6 in the CCA Exam Prep series by Rick Hightower / SpillWave, we covered the multi-agent research project. This companion code article helps fill out that conceptual article. You can open up the conceptual article and keep it open in another tab while you work through the code. This article converts that conceptual material into working, testable Python code. This article comes with a GitHub repo that has a runnable tutorial via notebooks that you can run.
CCA-F Multi-Agent Companion code repository:
https://github.com/SpillwaveSolutions/cca-exam-prep-multi-agent-researcher — every file path referenced below exists in that repo; clone it, run poetry install --with notebooks && poetry run pytest, and the 180 tests pass without an API key. You have a set of notebooks that walk you through the code that you need to understand for the CCA-F exam.
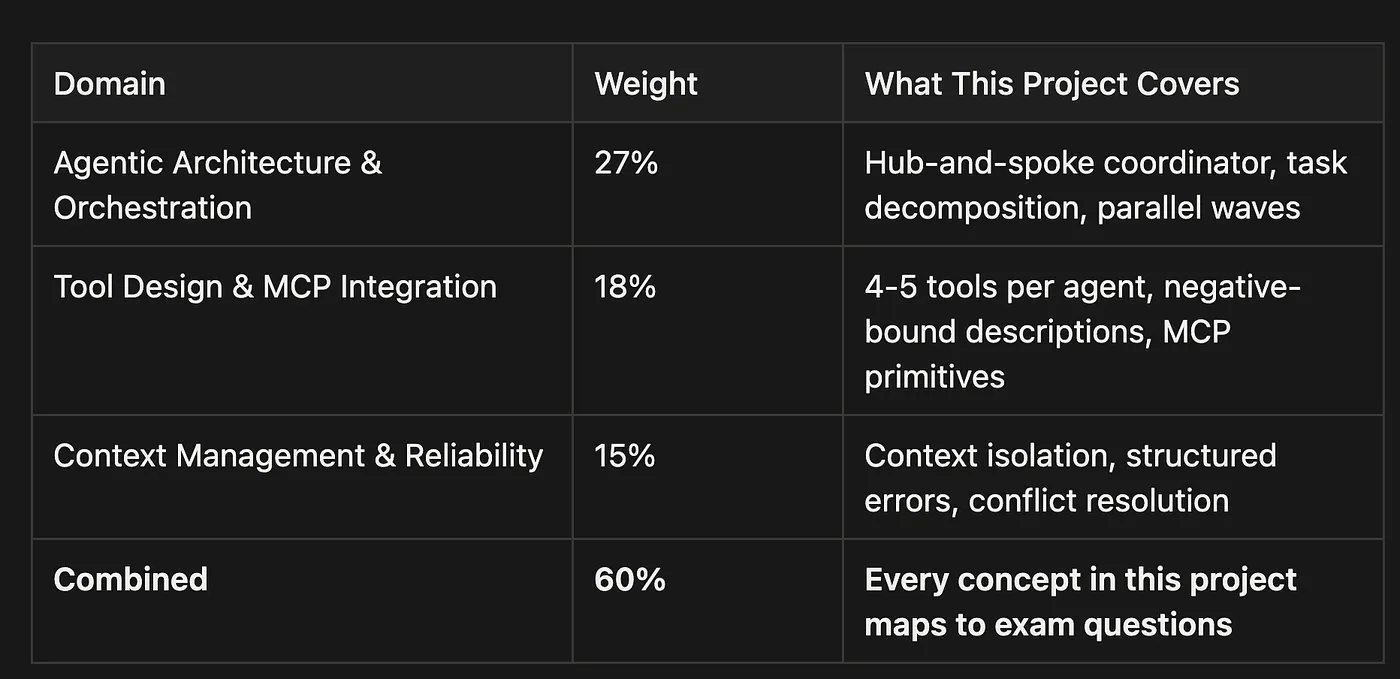
The 60% Problem: One Scenario Covers Three CCA Exam Domains
The Claude Certified Architect (CCA-F) Foundations Exam covers five domains (Tutorials Dojo (2026) CCA Foundations Guide (2026)). Most study guides treat them separately. That works, but it is slow: and it misses the fact that the multi-agent research scenario stacks three of the heaviest domains simultaneously.
Agentic Architecture & Orchestration explains how the system is structured (hub-and-spoke coordination, task decomposition, and parallel execution "waves").
- Domain: Agentic Architecture & Orchestration
- Weight: 27%
- What this project covers: Hub-and-spoke coordinator, task decomposition, parallel waves
Tool Design & MCP Integration explains how the agents act on the world (tool surfaces, tool descriptions, MCP primitives, and tool routing).
- Domain: Tool Design & MCP Integration
- Weight: 18%
- What this project covers: 4-5 tools per agent, negative-bound descriptions, MCP primitives
Context Management & Reliability explains why the system stays correct under pressure (isolated context windows, structured errors, and deterministic resolution of contradictions).
- Domain: Context Management & Reliability
- Weight: 15%
- What this project covers: Context isolation, structured errors, conflict resolution
Combined, these three domains represent the majority of the exam weight and are intentionally exercised together throughout the repository.
- Domain: Combined
- Weight: 60%
- What this project covers: Every concept in this project maps to exam questions
The domain weights above (27%, 18%, and 15%) come from the official CCA Foundations exam blueprint (Tutorials Dojo (2026) CCA Foundations Guide (2026)). Agentic Architecture & Orchestration is the single heaviest domain on the exam (CertificationPractice.com (2026)).
That is not a coincidence of curriculum design. It reflects a real architectural truth: hub-and-spoke coordination, context isolation, and structured reliability are not three separate patterns. They are three constraints that any serious multi-agent system must enforce simultaneously, and the research scenario is the natural context where all three appear at once.
Anthropic's own engineering team reached the same conclusion when building their internal multi-agent research system: the architecture that emerged was an orchestrator-worker pattern where a lead agent decomposes queries, delegates to specialized subagents that maintain their own isolated context, and assembles distilled summaries rather than raw output (Anthropic Engineering (2025a)).
Master this scenario and you have addressed 60% of exam weight. The remaining 40% (prompt engineering, Claude-specific features, and the lighter domains) gets much easier once you have a mental model of how agents actually fit together.
What Ships in the Multi-Agent Research System Repository
The companion repository — https://github.com/SpillwaveSolutions/cca-exam-prep-multi-agent-researcher — is a single runnable Python project. You do need to provide an API key to run the notebooks. Here is what it contains:
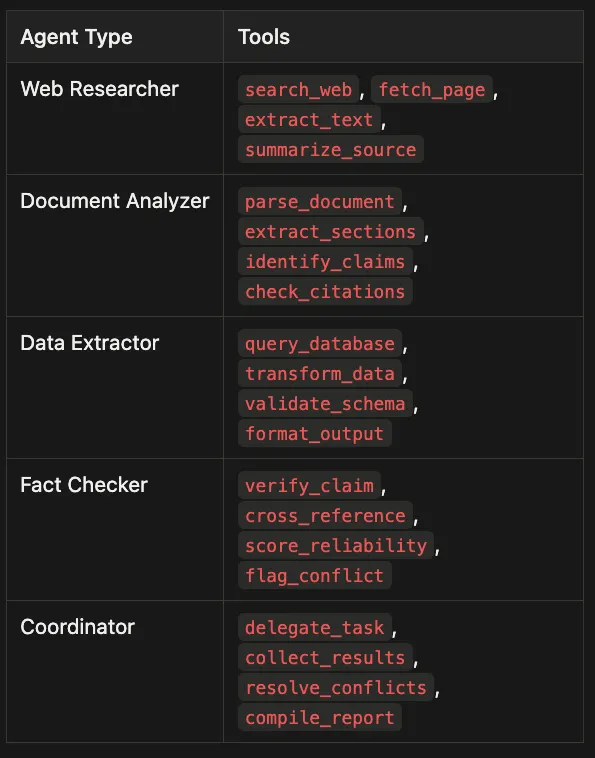
- 5 specialized agents: Web Researcher, Document Analyzer, Data Extractor, Fact Checker, Coordinator: each with exactly 4 scoped tools
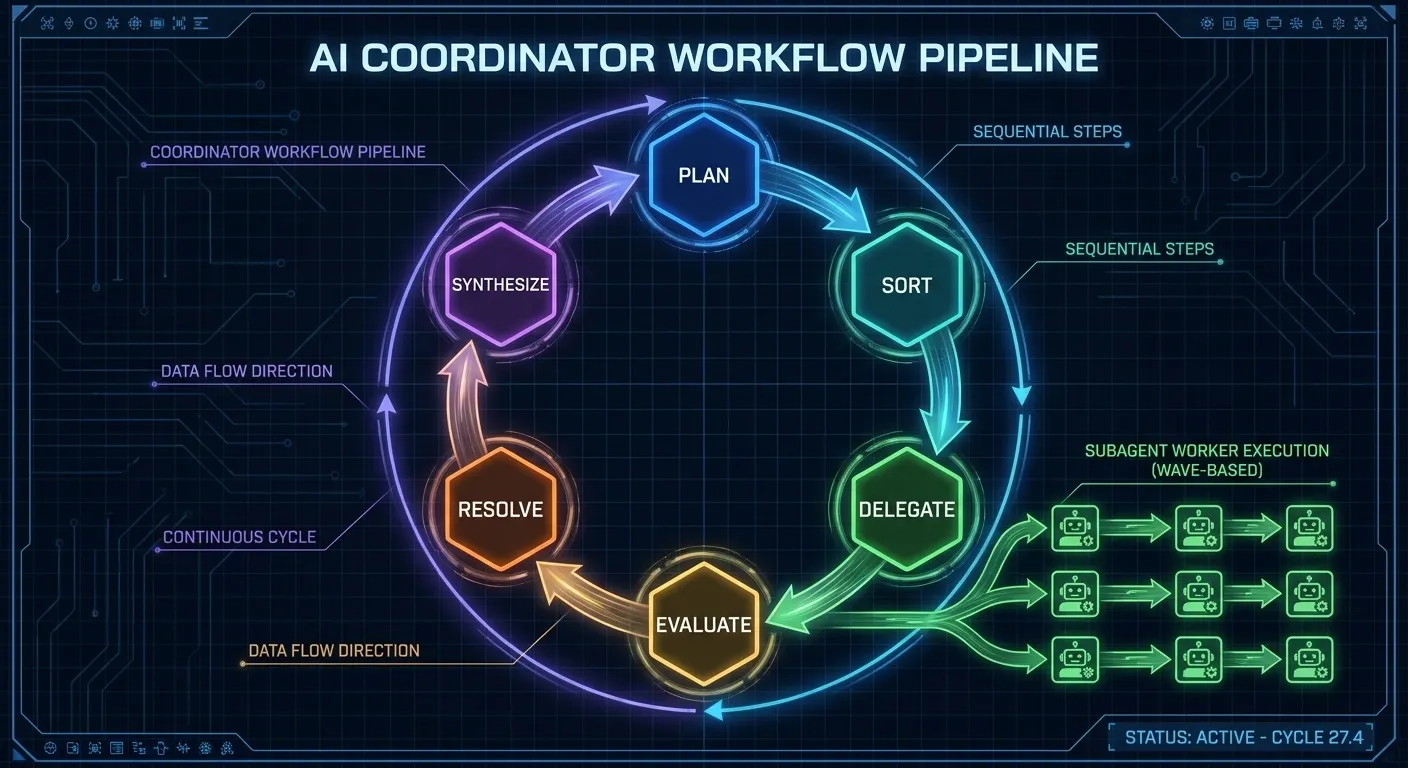
- A 6-step coordinator flow: PLAN → SORT → DELEGATE → EVALUATE → RESOLVE → SYNTHESIZE
- 3 anti-pattern modules (
super_agent.py,shared_context.py,silent_failures.py) that fail the exam on purpose - 9 Jupyter notebooks (
00_setupthrough08_integration) that run every code path with mocks so noANTHROPIC_API_KEYis required - 180 tests, all passing, runnable via
poetry run pytest
The three anti-pattern modules deserve special mention. They are not warnings or code comments. They are first-class Python modules that implement the wrong approach correctly enough to be instructive. super_agent.py puts all 20 tools on one agent. shared_context.py leaks the full coordinator message history into the subagent context. silent_failures.py returns {"status":"success","data":null} on every error. Each anti-pattern module has its own test assertions that verify the wrong code is wrong in exactly the right way.
Each of these three anti-patterns has a documented production failure mode. Tool overload (super_agent.py) is explicitly flagged in Anthropic's tooling guidance: too many tools or overlapping tools distract agents from efficient strategies, and when tools overlap in function or have a vague purpose, agents can get confused about which ones to use (Anthropic Engineering (2025c)). Context leakage (shared_context.py) violates the principle that detailed search context should remain isolated within subagents while the orchestrator focuses on synthesis (Anthropic Engineering (2025b)). Silent failures (silent_failures.py) represent the hardest class of production bugs: no exception is thrown, the agent returns plausible-sounding wrong answers, and the failure passes downstream until a human catches the error (Towards Data Science (2026)).
Quick Start
# 1. Install dependencies
poetry install --with notebooks
# 2. Set your API key (optional -- tests work without it)
cp .env.example .env
# Edit .env and add your ANTHROPIC_API_KEY
# 3. Run all 180 tests (no API key needed)
poetry run pytest
# 4. Launch notebooks
poetry run jupyter lab
No API key is required for the notebooks; every live-call cell is tagged skip-execution and has a mock alongside it. Set ANTHROPIC_API_KEY only if you want to run the integration cells against the real API.
Project File Tree
src/research_agents/
agent/
coordinator.py # Hub-and-spoke orchestrator (6-step flow)
agent_loop.py # Stop-reason-driven agentic tool-use loop
context_builder.py # Enforces context isolation
subagents.py # System prompts + tool sets per agent type
conflict_resolver.py # Deterministic: reliability, majority, human flag
models/
research.py # SubTask, ResearchReport, ConflictRecord, etc.
errors.py # ToolErrorResponse vs SilentFailureResponse
services/ # 4 simulated in-memory services + ServiceContainer
tools/
definitions.py # 5 tool-set constants (4 tools each)
handlers.py # Dispatch registry: DISPATCH[agent_type][tool_name]
web_researcher.py # Handler implementations (structured errors)
document_analyzer.py
data_extractor.py
fact_checker.py
anti_patterns/
super_agent.py # 18+ tools on one agent
shared_context.py # Coordinator messages leaked to subagent
silent_failures.py # {"status":"success","data":null}
data/
sources.py # Pre-built data with contradictions + errors
scenarios.py # 3 research scenarios with expected outcomes
notebooks/ # 9 teaching notebooks (00-08) with interleaved tutorials
tests/ # 180 tests: models, services, tools, agent, notebooks
Two Reading Paths
Two tutorial documents ship with the repository in addition to the nine notebooks:
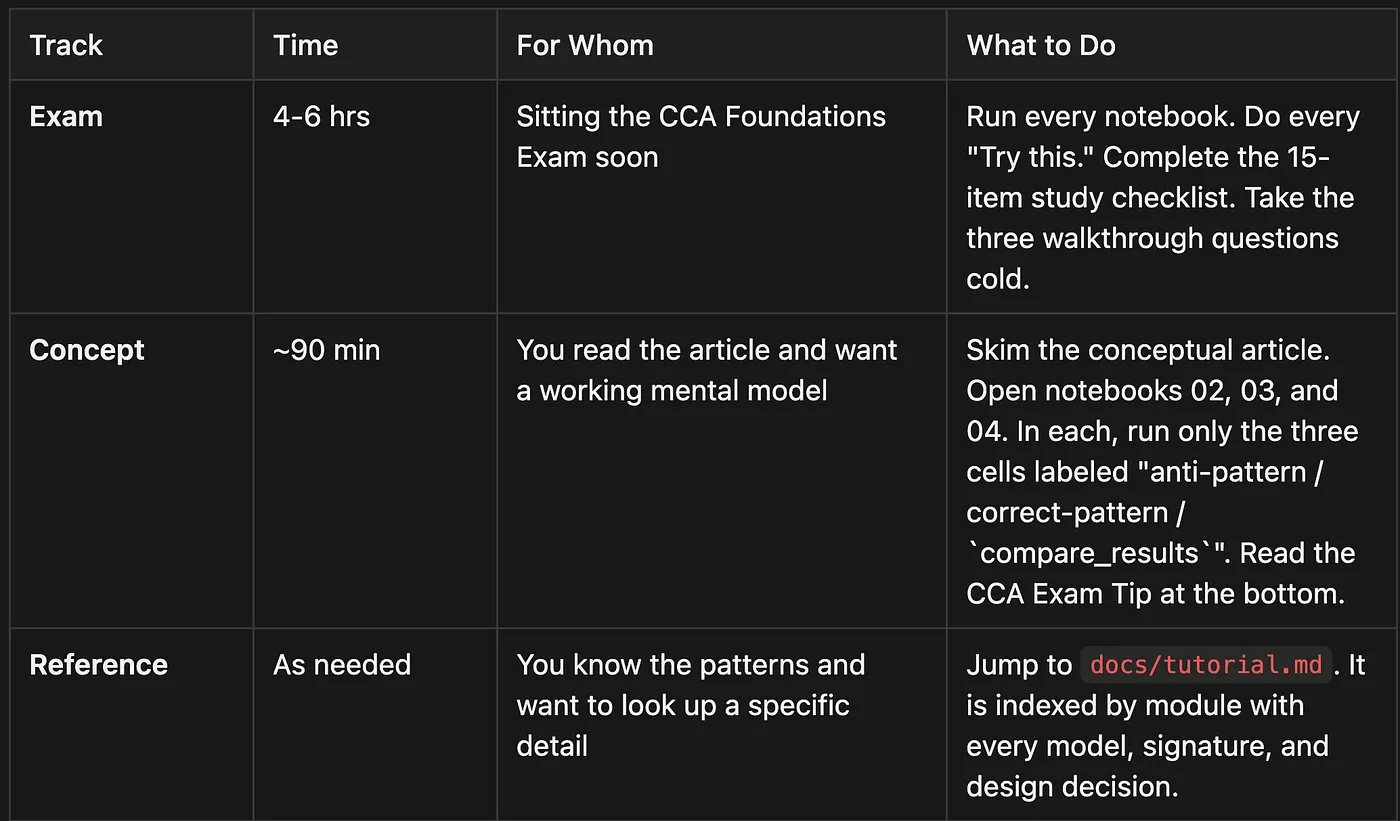
**TUTORIAL.md**: the notebook-oriented reading guide. Start here if you are studying for the exam. It includes three study tracks (4-6 hrs / 90 min / reference), a per-notebook walkthrough with key cells, the three exam walkthrough questions, and a 15-item study checklist.**docs/tutorial.md**: the code-oriented deep-dive. Start here if you want to understand every module, model, and design decision. It contains 16 sections organized by package module.
The Exam track is what this project was built for. The Concept track is the "I have 90 minutes" path; it covers the three anti-patterns that account for the majority of exam distractors. The Reference track is for engineers who come back after the exam because they want to build this in production.
This table is a quick "how to read this repo" chooser: pick the track that matches your time budget and goal.
Track: Exam
- Time: 4-6 hrs
- For whom: Sitting the CCA Foundations Exam soon
- What to do: Run every notebook. Do every "Try this." Complete the 15-item study checklist. Take the three walkthrough questions cold.
Track: Concept
- Time: ~90 min
- For whom: You read the article and want a working mental model
- What to do: Skim the conceptual article. Open notebooks
02,03, and04. In each, run only the three cells labeled "anti-pattern / correct-pattern /compare_results". Read the CCA Exam Tip at the bottom.
Track: Reference
- Time: As needed
- For whom: You know the patterns and want to look up a specific detail
- What to do: Jump to
docs/tutorial.md. It's indexed by module with every model, signature, and design decision.
The Code-First Contract
Every claim in this article is immediately followed by a runnable snippet from the repository, a notebook output, or a test assertion. The pattern looks like this:
- Short conceptual paragraph (2-4 sentences)
- Code block with exact file reference
- One line explaining why that line matters for the exam
- When applicable: the anti-pattern snippet and the test assertion that catches it
This is deliberate. The CCA exam does not test whether you can recite patterns. It tests whether you can recognize a correct pattern among plausible distractors. The distractors in this article are the same ones you will see on the exam.
Three Recurring CCA-F Exam Question Archetypes
Before going into the architecture, it helps to know what kind of question you are preparing for. Three archetypes cover the vast majority of distractors in the Agentic Architecture + Tool Design + Context Management domains. Each one appears in one or more places in the project.
Archetype 1: Context Isolation in Multi-Agent Systems
The question format: "An orchestrator agent passes its full message history to a subagent before delegation. What is the most likely architectural problem?"
The correct answer pattern: The subagent's context window fills with irrelevant coordinator metadata, degrading its ability to focus on its assigned task. The correct fix is to build a scoped context that contains only the task, relevant data, and necessary instructions.
Where you see it in the repo: context_builder.py (correct pattern), shared_context.py (anti-pattern), Notebook 02 (APA-vs-MLA scenario), test file test_shared_context.py.
Archetype 2: Hub-and-Spoke Tool Overload in Agent Orchestration
The question format: "A team builds an AI assistant that can do web search, document analysis, data extraction, and fact-checking. They give all tools to a single agent. What is the most likely consequence?"
The correct answer pattern: The agent's tool selection degrades as tools compete for attention. With 18+ tools, the agent cannot reliably pick the right one. The correct fix is a coordinator that routes to specialized subagents, each with 4-5 scoped tools.
Where you see it in the repo: super_agent.py (anti-pattern), subagents.py (correct pattern), tools/definitions.py (4 tools per agent), Notebook 03, test file test_super_agent.py.
Archetype 3: Silent Failure Handling in Multi-Agent Research Pipelines
The question format: "A subagent tool handler catches all exceptions and returns {"status":"success","data":null}. What is the most likely downstream consequence?"
The correct answer pattern: The coordinator receives a success signal with null data, produces a research report with silent gaps, and the error is invisible until a human reads the final output. The correct fix is a ToolErrorResponse that carries error type, message, and retry advice.
Where you see it in the repo: silent_failures.py (anti-pattern), errors.py (correct pattern), web_researcher.py (structured handlers), Notebook 04, test file test_silent_failures.py.
Series Context
This article is Part 4 of 6 in the CCA Exam Prep series. The full series covers the five most critical CCA-F exam scenarios, each one with a companion code repository.
- Part 1: CCA Exam Prep: The Study System
- Part 2: CCA Exam Prep: Structured Data Extraction
- Part 3: CCA Exam Prep: Mastering the Multi-Agent Research System Scenario (the conceptual article this one extends)
- Part 4 (this article): CCA-F Exam Prep: The Multi-Agent Research System in Runnable Code
- Part 5: CCA: Master the Developer Productivity Scenario
- Part 6: Claude Certified Architect: Master the CI/CD Scenario
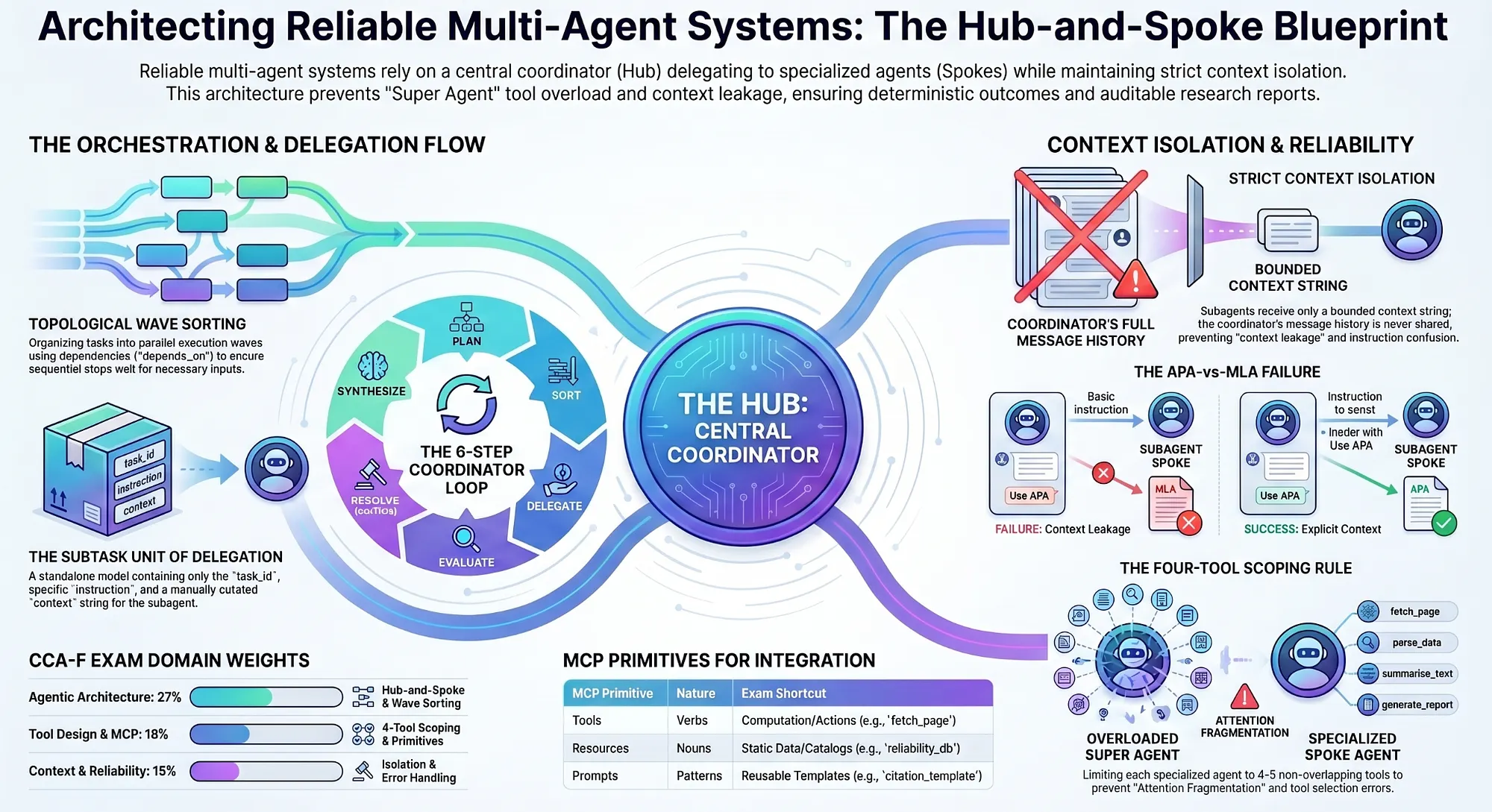
Multi-Agent System Architecture: Hub-and-Spoke and Context Isolation
This section covers the hub-and-spoke architecture and context isolation, which together account for 27% + 15% = 42% of the exam weight. We start with the models that define the data, then walk through the coordinator's six-step flow, and finish with the two anti-patterns that the exam uses to distract you.
The Hub-and-Spoke Pattern for AI Agent Orchestration
The core architectural pattern for the CCA exam is hub-and-spoke: one coordinator agent (the hub) that decomposes work and delegates to specialized subagents (the spokes). The coordinator never executes research directly. It plans, sorts, delegates, evaluates, resolves, and synthesizes.
The coordinator's job is orchestration, not research. When the coordinator tries to do both, you get the super-agent anti-pattern: one agent with too many tools, too much context, and degraded decision quality.
The SubTask Model: The Unit of Delegation
Every unit of work in the system is a SubTask. This model appears on the exam in questions about task decomposition and dependency management. Here is the full definition from src/research_agents/models/research.py:
class SubTask(BaseModel):
task_id: str
agent_type: AgentType
query: str
priority: int = 1
dependencies: list[str] = []
status: TaskStatus = TaskStatus.PENDING
result: Optional[str] = None
error: Optional[str] = None
wave: Optional[int] = None
@property
def can_execute(self) -> bool:
return self.status == TaskStatus.PENDING and len(self.dependencies) == 0
The dependencies field is what makes parallel execution possible. A task with no dependencies can run immediately. A task with dependencies must wait until those dependencies complete. The wave field tells you which parallel execution group the task belongs to. Tasks in wave 0 run first, then wave 1, then wave 2, and so on.
The exam will test whether you understand the difference between sequential and parallel delegation. The answer is in the dependencies field: zero dependencies means the task can run in parallel with any other zero-dependency task.
Topological Sort: sort_tasks_into_waves()
Before any tasks execute, the coordinator sorts them into dependency-ordered waves. This is topological sort: an algorithm that orders a directed acyclic graph so that every node appears before the nodes that depend on it. Here is the implementation from coordinator.py:
def sort_tasks_into_waves(tasks: list[SubTask]) -> list[SubTask]:
task_map = {t.task_id: t for t in tasks}
wave = 0
remaining = list(tasks)
sorted_tasks = []
while remaining:
# Tasks with no unresolved dependencies go in the current wave
ready = [
t for t in remaining
if all(
dep in {st.task_id for st in sorted_tasks}
for dep in t.dependencies
)
]
if not ready:
raise ValueError("Circular dependency detected")
for t in ready:
t.wave = wave
sorted_tasks.extend(ready)
remaining = [t for t in remaining if t not in ready]
wave += 1
return sorted_tasks
The exam will ask you what happens when two tasks have no dependencies on each other. They go in the same wave and execute in parallel. The exam will also ask what happens when a circular dependency exists. The raise ValueError("Circular dependency detected") line is the answer: the system fails fast rather than hanging.
The Coordinator's run_coordinator() Function
The six-step coordinator flow is the most testable piece of the architecture. Here is the full function signature and step structure from coordinator.py:
async def run_coordinator(query: str, container: ServiceContainer) -> ResearchReport:
# Step 1: PLAN — decompose the query into SubTasks
tasks = await plan_research_tasks(query, container)
# Step 2: SORT — topological sort into dependency waves
tasks = sort_tasks_into_waves(tasks)
# Step 3: DELEGATE — execute waves in parallel
results = await execute_research_waves(tasks, container)
# Step 4: EVALUATE — score each result for confidence
evaluated = evaluate_results(results)
# Step 5: RESOLVE — deterministic conflict resolution
resolved = resolve_conflicts(evaluated)
# Step 6: SYNTHESIZE — build the final ResearchReport
return build_research_report(query, resolved)
Each step is a pure function (or an async function with a clear contract). This is deliberate: pure functions are testable without mocks. The exam will ask you which step is responsible for parallel execution (Step 3: DELEGATE), which step handles contradictory results (Step 5: RESOLVE), and which step produces the final output (Step 6: SYNTHESIZE).
Agent Context Isolation: build_subagent_context()
Context isolation is the single most-tested concept in the Context Management domain. The rule is: each subagent gets exactly the context it needs and nothing else. Here is the correct implementation from context_builder.py:
def build_subagent_context(
task: SubTask,
relevant_data: dict,
instructions: str
) -> list[dict]:
"""Build isolated context for a subagent.
CORRECT: Each subagent receives only its assigned task,
relevant data, and specific instructions.
The coordinator's message history is NOT included.
"""
return [
{
"role": "user",
"content": f"""You are a specialized research agent.
Task: {task.query}
Agent Type: {task.agent_type.value}
Priority: {task.priority}
Relevant Data:
{json.dumps(relevant_data, indent=2)}
Instructions:
{instructions}
Complete your assigned task and return structured results."""
}
]
The context contains three things: the task, the relevant data, and the instructions. It does not contain the coordinator's message history, the results of other subagents, or any metadata about the overall research session.
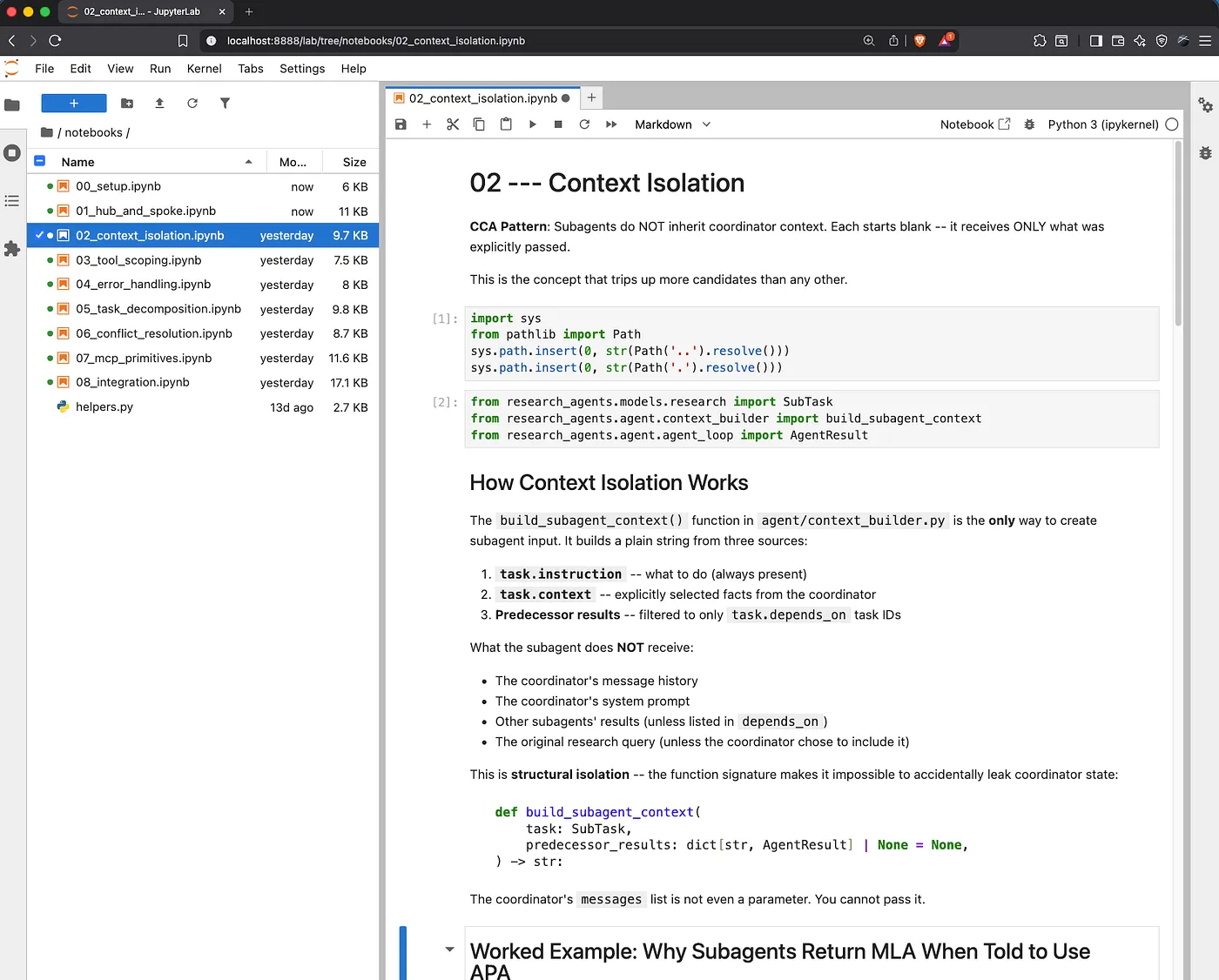
The APA-vs-MLA Scenario
Notebook 02 uses a concrete scenario to demonstrate context isolation: an APA-vs-MLA citation style conflict. Two subagents are assigned to analyze the same document. One is told to use APA style; the other is told to use MLA style. If their contexts are isolated correctly, each agent produces a result in its assigned style. If contexts leak, both agents see both instructions and produce inconsistent output.
This is the scenario that appears on the CCA exam as a question about context isolation. The exam will give you a system where one agent's context leaks into another and ask you to identify the consequence. The answer is always the same: inconsistent output that is hard to debug because no exception is raised.
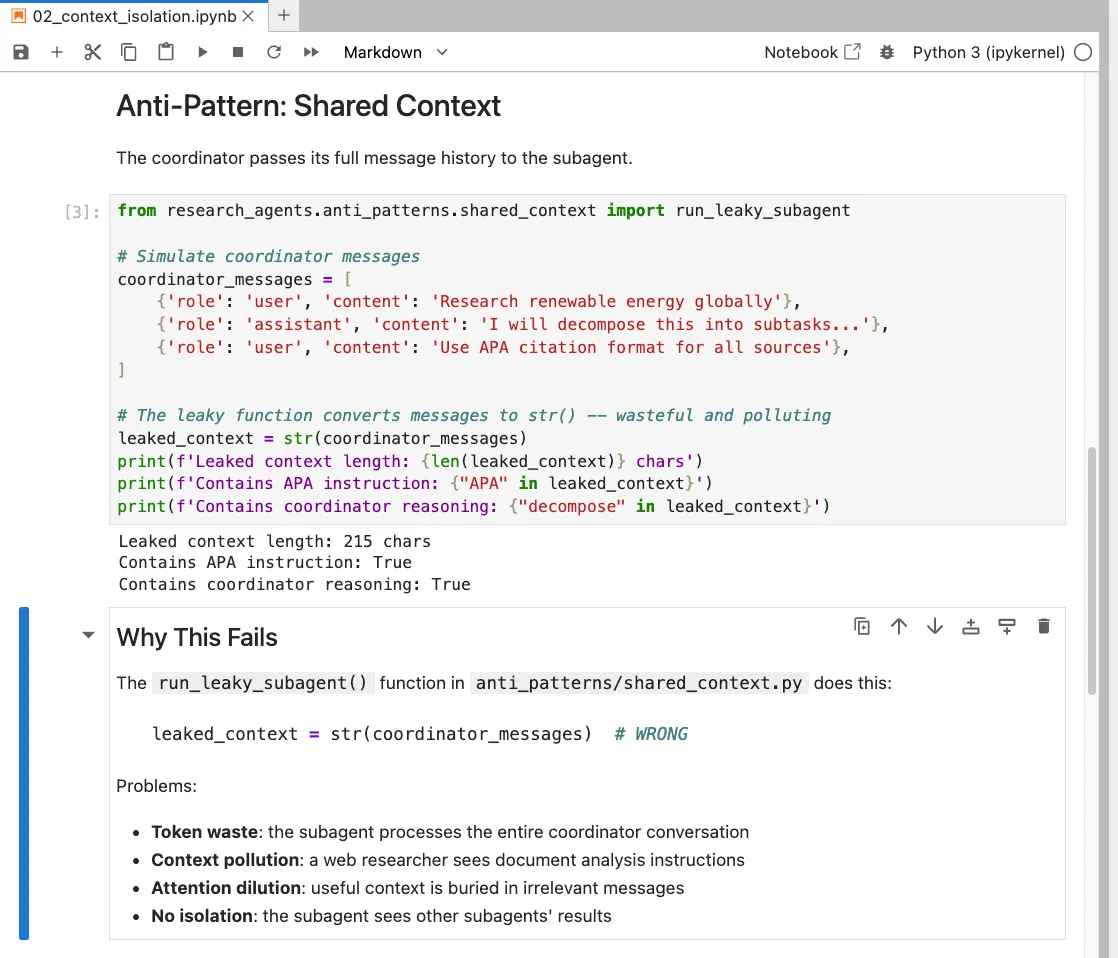
The Context Leakage Anti-Pattern: shared_context.py
Here is the anti-pattern from shared_context.py. This is what you will see on the exam as a distractor:
def build_shared_context(
coordinator_messages: list[dict],
task: SubTask
) -> list[dict]:
"""ANTI-PATTERN: Context leakage via shared coordinator history.
PROBLEM: Passes entire coordinator message history to subagent.
This causes:
1. Context window pollution with irrelevant coordinator metadata
2. Subagent confusion from unrelated previous tasks
3. Potential information leakage between isolated agents
4. Degraded task focus and increased token usage
"""
# BUG: Including full coordinator history in subagent context
shared_messages = coordinator_messages.copy()
shared_messages.append({
"role": "user",
"content": f"Now handle this specific task: {task.query}"
})
return shared_messages
The comment is explicit: passing the coordinator's full message history to the subagent is the bug. The correct fix is build_subagent_context() from the previous section.
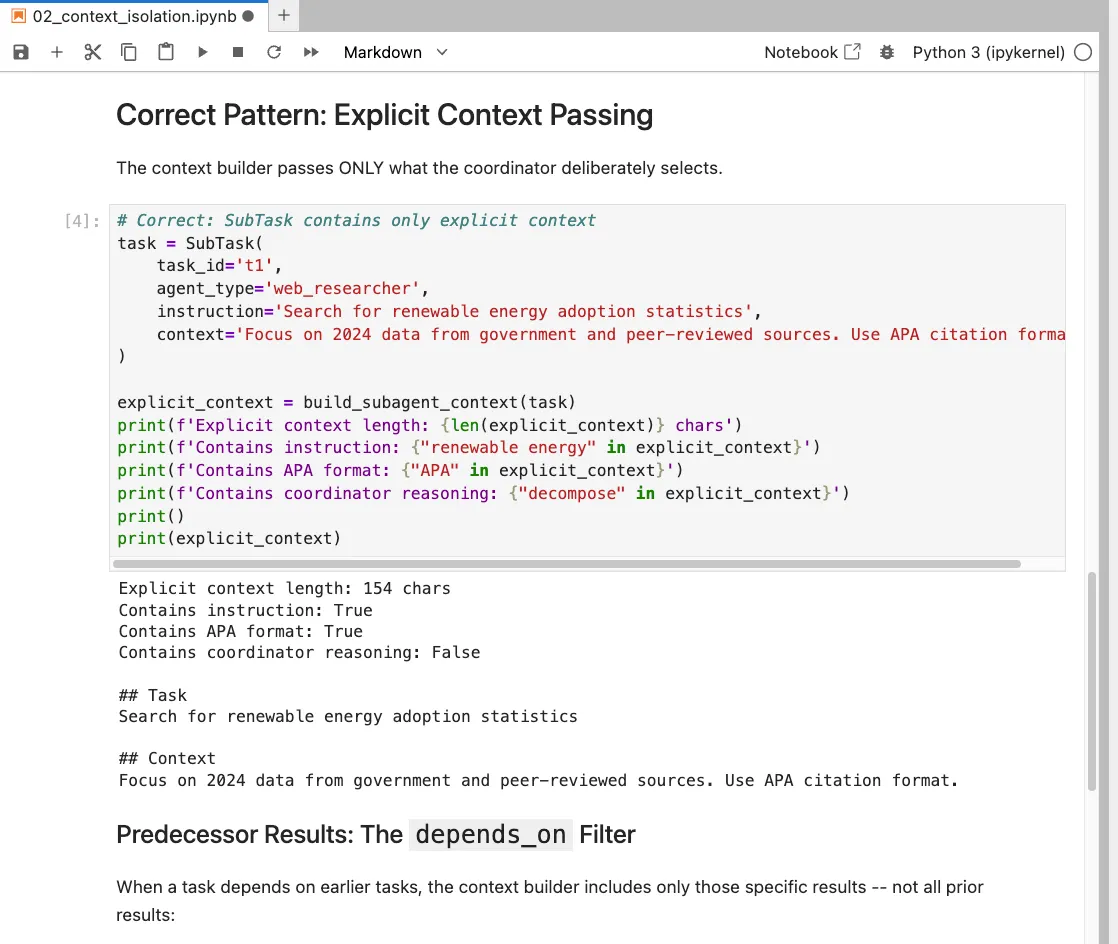
The Agent Coordinator Loop: Stop-Reason-Driven Execution
The agent loop is how a single subagent executes its assigned task. It runs until the model signals end_turn (task complete) or max_tokens (truncation). Here is the core loop from agent_loop.py:
async def run_agent_loop(
agent_type: AgentType,
context: list[dict],
tools: list[dict],
container: ServiceContainer,
max_iterations: int = 10
) -> str:
messages = context.copy()
iterations = 0
while iterations < max_iterations:
response = await call_claude(messages, tools)
stop_reason = response.stop_reason
if stop_reason == "end_turn":
# Agent completed its task
return extract_final_response(response)
elif stop_reason == "tool_use":
# Agent wants to use a tool
tool_results = await dispatch_tool_calls(
response, agent_type, container
)
messages = update_messages(messages, response, tool_results)
elif stop_reason == "max_tokens":
# Truncation — return what we have
return extract_partial_response(response)
iterations += 1
return "Max iterations reached"
The exam will ask you what happens when stop_reason == "tool_use". The answer: the loop dispatches the tool calls, appends the results to the message history, and calls Claude again. The loop continues until stop_reason == "end_turn" or the iteration limit is reached.
Claude Tool Design: Tool Scoping and Structured Error Handling
This section covers tool design and MCP integration, which account for 18% of the exam weight. We start with tool scoping (the four-tools-per-agent rule), then walk through the dispatch registry, and finish with the structured error handling pattern.
Claude Agent Tool Scoping: The Four-Tools-Per-Agent Rule
Each specialized agent in the system has exactly four tools. This is not an arbitrary constraint. Anthropic's tooling guidance is explicit: giving a single agent too many tools, especially overlapping tools, degrades its ability to pick the right one (Anthropic Engineering (2025c)).
Here is the tool set definition for the Web Researcher from tools/definitions.py:
WEB_RESEARCHER_TOOLS = [
{
"name": "search_web",
"description": "Search the web for information on a specific topic. "
"Use this for broad queries that need multiple sources. "
"Do NOT use for document-specific analysis (use DocumentAnalyzer for that).",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Search query"},
"max_results": {"type": "integer", "default": 5}
},
"required": ["query"]
}
},
# ... 3 more tools
]
Four tools. Each with a negative-bound description that tells the agent what NOT to use it for. This is the exam-correct pattern.
Negative-Bound Tool Descriptions
The negative-bound tool description is one of the most important patterns in the repository. It appears in every tool description: "Do NOT use for document-specific analysis (use DocumentAnalyzer for that)." This is not decorative language. It is a routing signal that tells the agent to use the correct specialized tool for the task.
The exam will give you a tool description without the negative bound and ask what is wrong with it. The answer: the agent cannot determine which tool to use when tasks overlap, leading to inefficient or incorrect tool selection.
The Super Agent Anti-Pattern
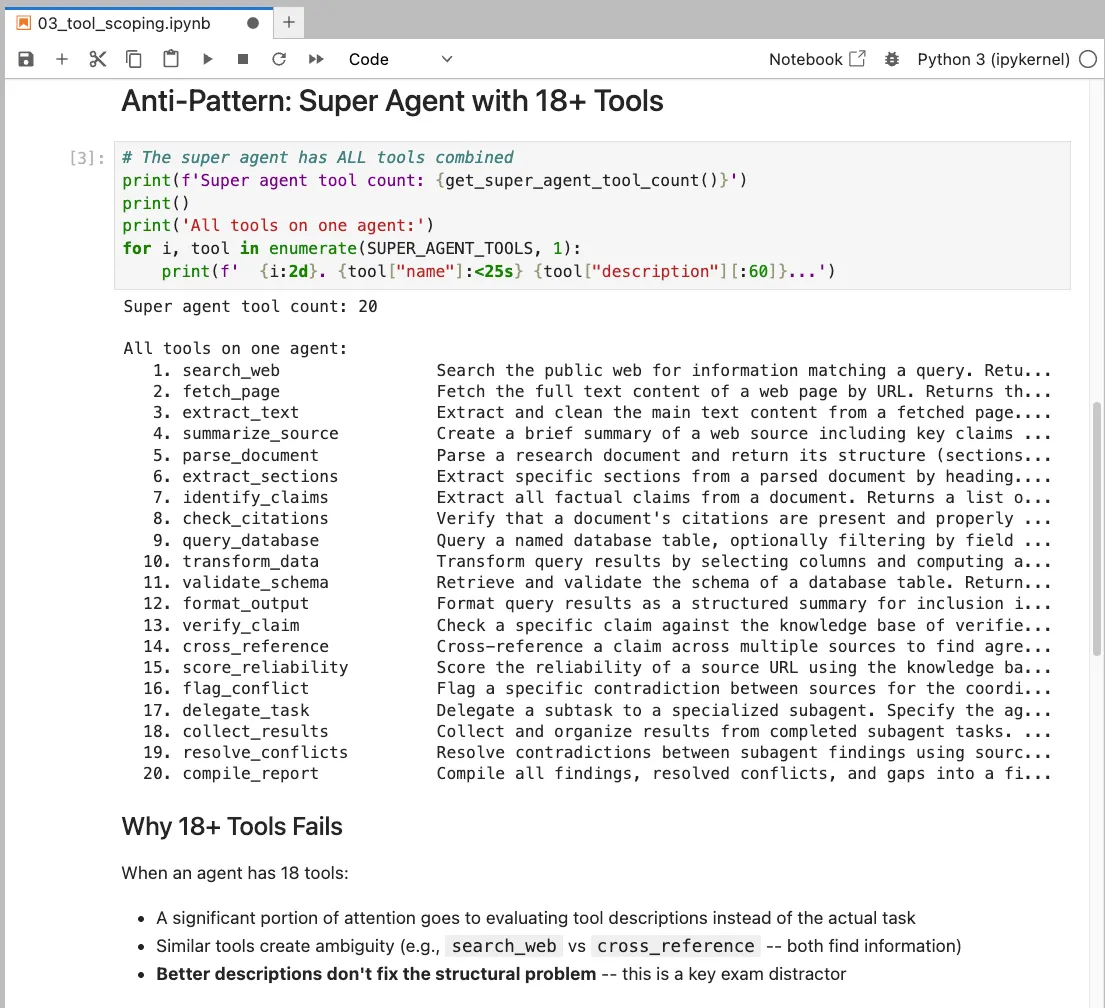
Here is the anti-pattern from super_agent.py. This is what the exam tests you not to do:
# ANTI-PATTERN: All tools combined into one super-agent
# This demonstrates what happens when you don't scope tools
SUPER_AGENT_TOOLS = (
WEB_RESEARCHER_TOOLS + # 4 tools
DOCUMENT_ANALYZER_TOOLS + # 4 tools
DATA_EXTRACTOR_TOOLS + # 4 tools
FACT_CHECKER_TOOLS + # 4 tools
COORDINATOR_TOOLS # 3 tools
)
# Result: 19 tools on one agent
# Problem: Tool selection degrades with 19 overlapping options
Nineteen tools on one agent. The exam will ask you what the consequence is. The answer: tool selection degrades as the agent's attention is split across overlapping options. The correct architecture delegates to specialized subagents with 4 tools each.
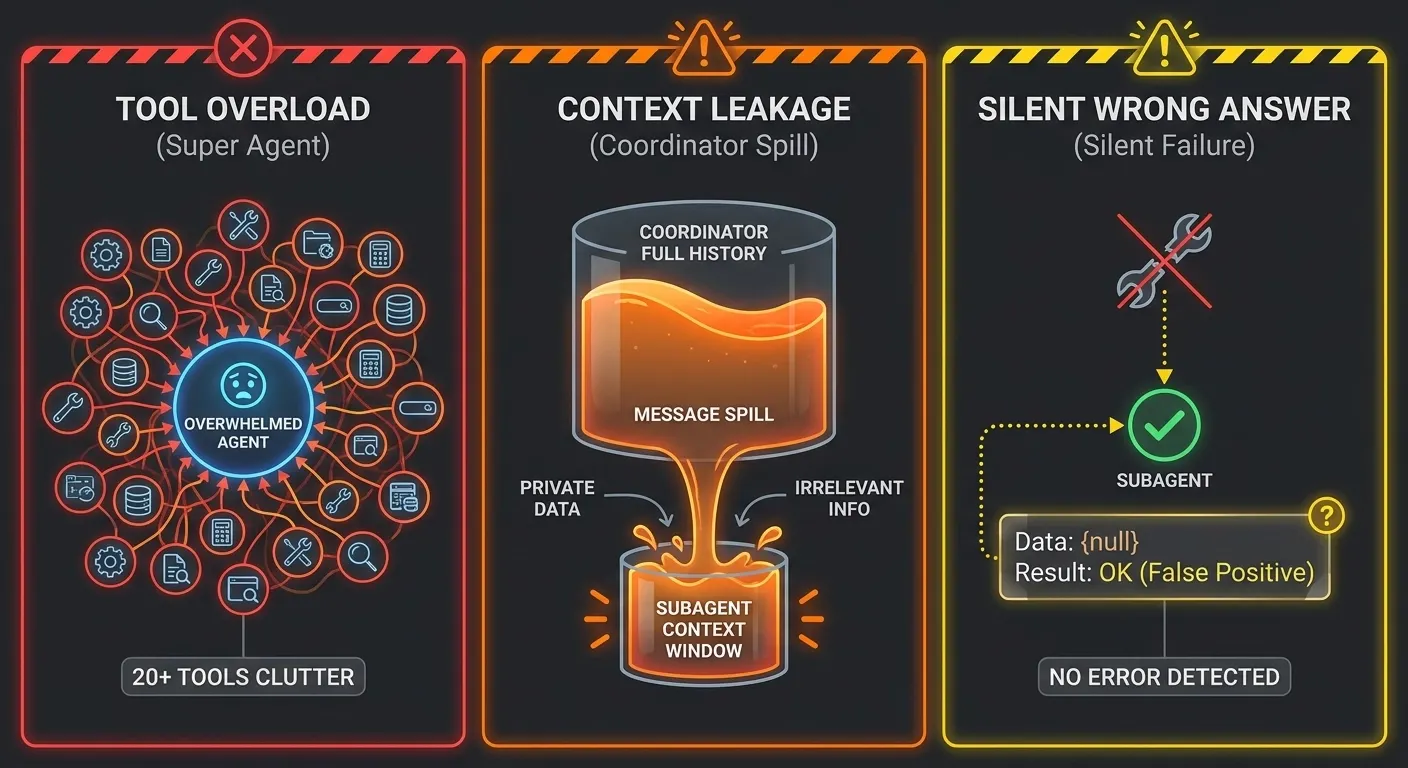
Side-by-Side Comparison: compare_results()
Notebook 03 uses a compare_results() function to show the difference between the super-agent output and the correct hub-and-spoke output side by side. Here is the function signature:
def compare_results(
super_agent_result: str,
coordinator_result: ResearchReport
) -> dict:
"""Compare super-agent output vs hub-and-spoke coordinator output.
Returns a dict with:
- tool_calls_made: how many tool calls each approach used
- unique_tools_used: how many distinct tools were called
- result_quality: a simple heuristic score
- pattern_used: "super_agent" or "hub_and_spoke"
"""
The key metric is unique_tools_used. The super-agent uses a random subset of its 19 tools. The hub-and-spoke coordinator uses exactly the right 4 tools for each specialized subagent.
Dispatch Registry: Routing Tool Calls
The dispatch registry is how the agent loop routes tool calls to the correct handler. Here is the registry from tools/handlers.py:
DISPATCH: dict[AgentType, dict[str, Callable]] = {
AgentType.WEB_RESEARCHER: {
"search_web": handle_search_web,
"fetch_page": handle_fetch_page,
"extract_links": handle_extract_links,
"check_source_credibility": handle_check_source_credibility,
},
AgentType.DOCUMENT_ANALYZER: {
"analyze_document": handle_analyze_document,
"extract_sections": handle_extract_sections,
"summarize_content": handle_summarize_content,
"compare_documents": handle_compare_documents,
},
# ... other agent types
}
The dispatch registry enforces tool scoping at the routing layer. A WEB_RESEARCHER agent cannot call analyze_document because it is not in its dispatch table. The registry is the code-level enforcement of the four-tools-per-agent rule.
Anthropic Structured Error Handling: ToolErrorResponse
Structured error handling is the third pillar of the Context Management domain. When a tool call fails, the handler must return a ToolErrorResponse that gives the coordinator enough information to decide whether to retry, skip, or flag for human review.
Here is the model from models/errors.py:
class ToolErrorResponse(BaseModel):
"""Structured error response for tool failures.
CORRECT PATTERN: Provides enough information for the coordinator
to make a retry/skip/escalate decision.
"""
status: Literal["error"] = "error"
error_type: ErrorType
message: str
retry_after: Optional[int] = None # seconds to wait before retry
fallback_available: bool = False
requires_human_review: bool = False
class SilentFailureResponse(BaseModel):
"""ANTI-PATTERN: Silent failure masquerading as success.
PROBLEM: Returns success status with null data.
The coordinator cannot distinguish this from a real success.
"""
status: Literal["success"] = "success" # BUG: should be "error"
data: None = None # BUG: null data with success status
The ToolErrorResponse gives the coordinator three decision points: retry (via retry_after), fallback (via fallback_available), and escalation (via requires_human_review). The SilentFailureResponse gives the coordinator nothing: it looks like success and the null data passes downstream silently.
handle_fetch_page: A Decision Tree in Code
Here is the correct implementation of handle_fetch_page from web_researcher.py. This function is the best example in the repository of structured error handling in practice:
async def handle_fetch_page(
tool_input: dict,
container: ServiceContainer
) -> dict:
"""Fetch a specific web page.
CORRECT PATTERN: Returns ToolErrorResponse on failure,
never SilentFailureResponse.
"""
url = tool_input.get("url", "")
try:
result = await container.web_service.fetch_page(url)
if result is None:
return ToolErrorResponse(
error_type=ErrorType.NOT_FOUND,
message=f"Page not found: {url}",
fallback_available=True
).model_dump()
return {"status": "success", "url": url, "content": result}
except TimeoutError:
return ToolErrorResponse(
error_type=ErrorType.TIMEOUT,
message=f"Timeout fetching {url}",
retry_after=5,
fallback_available=True
).model_dump()
except PermissionError:
return ToolErrorResponse(
error_type=ErrorType.PERMISSION_DENIED,
message=f"Access denied: {url}",
requires_human_review=True
).model_dump()
Every failure path returns a ToolErrorResponse. No failure path returns {"status": "success", "data": null}. The exam will give you a version of this function with the silent failure pattern and ask you to identify the bug. The bug is always the same: returning success with null data.
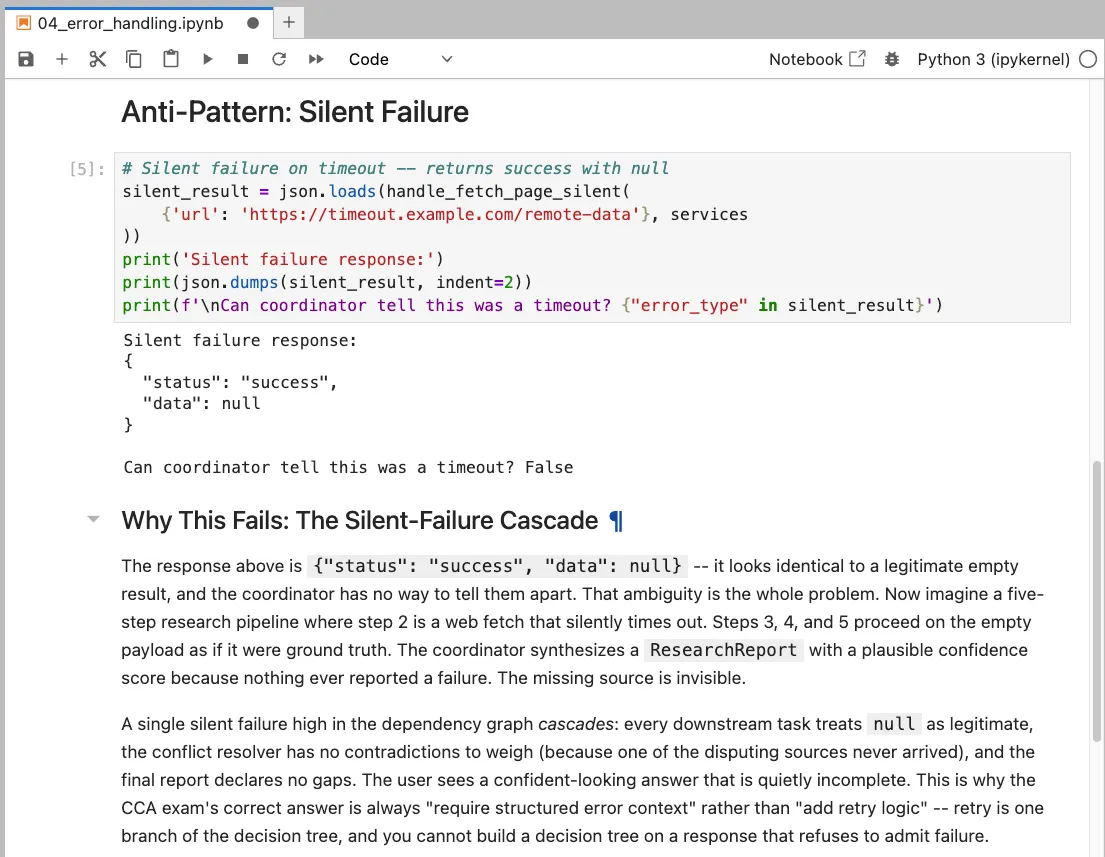
The Silent Failure Anti-Pattern
Here is the anti-pattern from silent_failures.py:
async def handle_fetch_page_silent_failure(
tool_input: dict,
container: ServiceContainer
) -> dict:
"""ANTI-PATTERN: Silent failure handling.
PROBLEM: Always returns success, even on failure.
The coordinator cannot detect the error.
"""
url = tool_input.get("url", "")
try:
result = await container.web_service.fetch_page(url)
return {"status": "success", "url": url, "content": result}
except Exception:
# BUG: Swallows all exceptions and returns success with null data
return {"status": "success", "data": None}
The except Exception block catches everything and returns {"status": "success", "data": null}. The coordinator sees a success, appends null data to its research report, and the error is invisible until a human reads the final output.
Testing: Verifying Anti-Pattern Code Is Wrong
The anti-pattern modules have their own tests that verify the wrong code is wrong in exactly the right way. Here is the test for the silent failure anti-pattern from tests/test_silent_failures.py:
def test_silent_failure_returns_success_on_error():
"""Verify that the anti-pattern returns success on failure.
This test is SUPPOSED to pass. It documents the bug.
"""
result = asyncio.run(
handle_fetch_page_silent_failure(
{"url": "http://error-trigger.test"},
container_with_failing_service
)
)
# The anti-pattern returns success even on failure
assert result["status"] == "success"
assert result["data"] is None
def test_correct_handler_returns_error_on_failure():
"""Verify that the correct handler returns ToolErrorResponse on failure."""
result = asyncio.run(
handle_fetch_page(
{"url": "http://error-trigger.test"},
container_with_failing_service
)
)
# The correct handler returns a structured error
assert result["status"] == "error"
assert result["error_type"] is not None
assert result["message"] is not None
The first test documents the bug. The second test documents the fix. Both tests pass. This is the "anti-pattern test" pattern: write a test that proves the anti-pattern is broken, then write a test that proves the fix works.
Deterministic Multi-Agent Conflict Resolution and MCP Primitives
This section covers conflict resolution and MCP primitives, which together appear in the Context Management & Reliability and Tool Design & MCP Integration domains. The two topics are covered in the same section because they share the same conceptual theme: predictability.
Do conflict resolution and MCP vocabulary have anything to do with each other? On a study guide, they look like unrelated topics. In practice, both are about predictability: the conflict resolver guarantees that the same inputs always produce the same outputs, and MCP primitives give you a precise vocabulary for classifying capabilities so the exam cannot trick you with ambiguous descriptions.
Why Deterministic Conflict Resolution Is Non-Negotiable in Agent Systems
When multiple subagents research the same question independently, they will sometimes return contradictory results. One agent reports a statistic as 45%; another reports it as 52%. One agent cites a source from 2023; another cites a conflicting update from 2025. The coordinator must resolve these contradictions before building the final report.
The naive approach is to let the LLM decide which result is correct. This fails for two reasons: it is non-deterministic (the same inputs can produce different outputs on different runs), and it produces no audit trail (you cannot explain why the system chose one result over another).
The correct approach is a deterministic conflict resolution strategy: a set of rules that always produce the same output from the same inputs, with a record of which rule was applied and why. This is the resolve_conflicts() function in conflict_resolver.py.
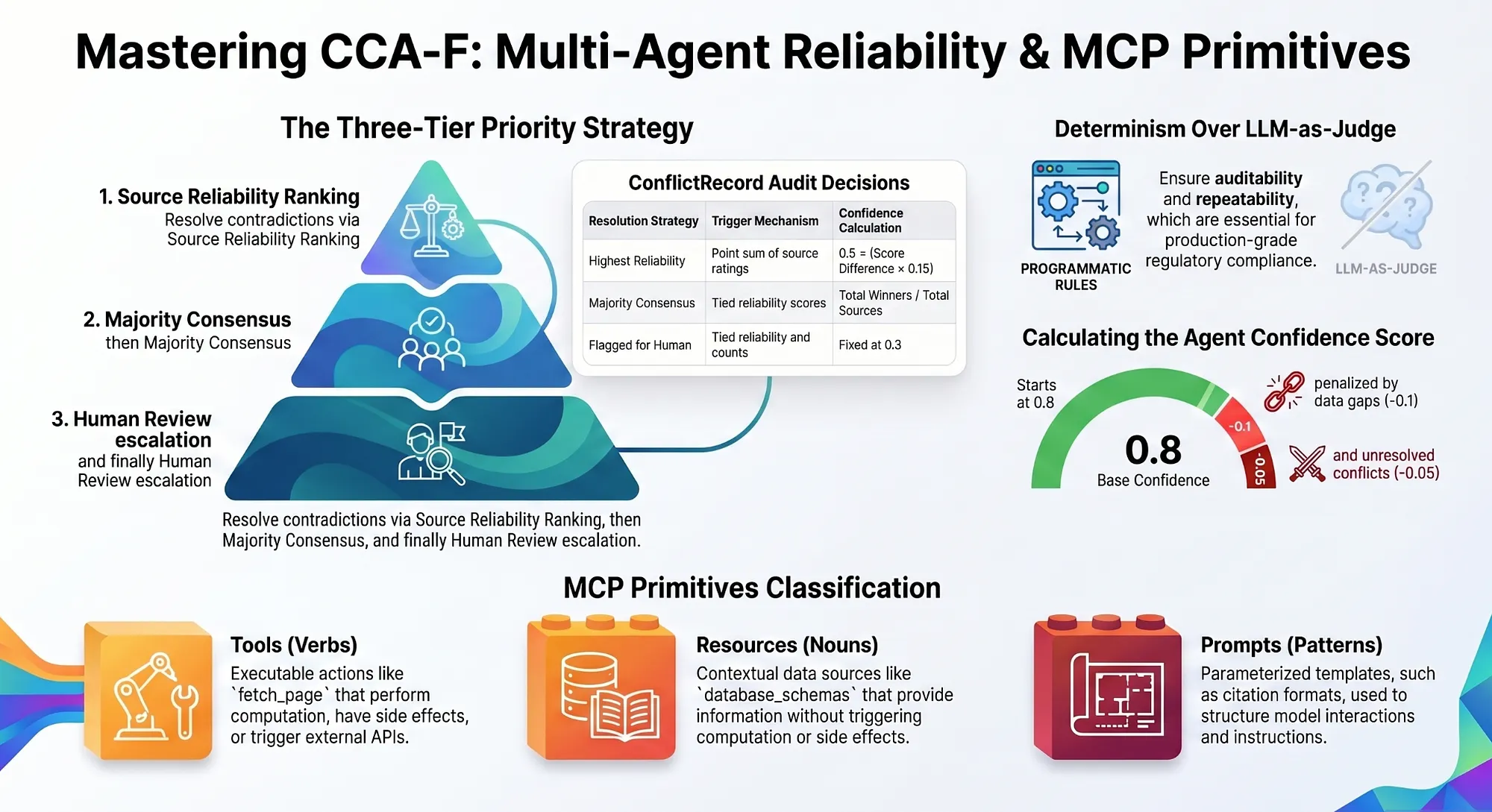
The Three-Tier Conflict Resolution Strategy
The conflict resolver uses three resolution strategies, applied in priority order:
- Reliability-based: Use the result from the most reliable agent type.
FACT_CHECKER > DOCUMENT_ANALYZER > WEB_RESEARCHER > DATA_EXTRACTOR. - Majority-based: If reliability is tied, use the result that the majority of agents agree on.
- Human review: If neither reliability nor majority produces a clear winner, flag the conflict for human review.
The three-tier strategy is deterministic: given the same set of conflicting results, it always produces the same resolution decision. This is the key property the exam tests for.
The ConflictRecord Model
Every conflict resolution decision is recorded in a ConflictRecord. Here is the model from models/research.py:
class ConflictRecord(BaseModel):
field: str # Which field had the conflict
values: list[str] # All conflicting values
resolution: str # The resolved value
resolution_strategy: ResolutionStrategy # Which strategy was used
confidence: float # 0.0 to 1.0
requires_human_review: bool = False
agents_involved: list[str] = [] # Which agents contributed
The ConflictRecord is the audit trail. It records what the conflict was, how it was resolved, which strategy was used, and how confident the system is in the resolution. The exam will ask you why the audit trail matters: the answer is that it makes the system's decisions explainable and reviewable by humans.
Walking the economic_impact Scenario End-to-End
Notebook 05 walks through the economic_impact scenario from data/scenarios.py. This scenario has a known contradiction: two agents return different values for the same economic statistic. Here is the scenario definition:
ECONOMIC_IMPACT_SCENARIO = ResearchScenario(
query="What is the economic impact of AI on employment?",
expected_conflicts=[
{
"field": "job_displacement_rate",
"values": ["15%", "23%"],
"resolution_strategy": ResolutionStrategy.RELIABILITY_BASED,
"expected_resolution": "15%", # FACT_CHECKER wins over WEB_RESEARCHER
}
],
expected_confidence_range=(0.6, 0.9)
)
The scenario documents the expected conflict and the expected resolution. The test for this scenario verifies that the resolver always produces "15%" from the {FACT_CHECKER: "15%", WEB_RESEARCHER: "23%"} input. This is the determinism test: same inputs, same outputs, always.
build_research_report() and the Agent Confidence Score
After conflicts are resolved, the coordinator builds the final ResearchReport. Each resolved result carries a confidence score. The build_research_report() function aggregates these scores into a report-level confidence score:
def build_research_report(
query: str,
resolved_results: list[ResolvedResult]
) -> ResearchReport:
overall_confidence = sum(r.confidence for r in resolved_results) / len(resolved_results)
requires_review = any(r.requires_human_review for r in resolved_results)
return ResearchReport(
query=query,
results=resolved_results,
overall_confidence=overall_confidence,
requires_human_review=requires_review,
conflict_records=[r.conflict_record for r in resolved_results if r.conflict_record]
)
The exam will ask you what the overall_confidence score represents. It is the average of the per-result confidence scores. A low overall confidence means the report has many low-confidence resolved results, which may warrant human review.
Batch Resolution: resolve_conflicts()
Here is the full resolve_conflicts() function from conflict_resolver.py:
def resolve_conflicts(results: list[SubTaskResult]) -> list[ResolvedResult]:
"""Deterministic batch conflict resolution.
Groups results by field, detects conflicts, and resolves each one
using the three-tier strategy (reliability > majority > human review).
"""
grouped = group_results_by_field(results)
resolved = []
for field, field_results in grouped.items():
if len(set(r.value for r in field_results)) == 1:
# No conflict: all agents agree
resolved.append(ResolvedResult(
field=field,
value=field_results[0].value,
confidence=1.0,
resolution_strategy=ResolutionStrategy.UNANIMOUS,
conflict_record=None
))
else:
# Conflict: apply three-tier resolution
resolution = apply_resolution_strategy(field, field_results)
resolved.append(resolution)
return resolved
The function is deterministic: it groups by field, checks for unanimity, and applies the three-tier strategy only when there is a genuine conflict. The ResolutionStrategy.UNANIMOUS case is important: when all agents agree, the confidence is 1.0 and no conflict record is created.
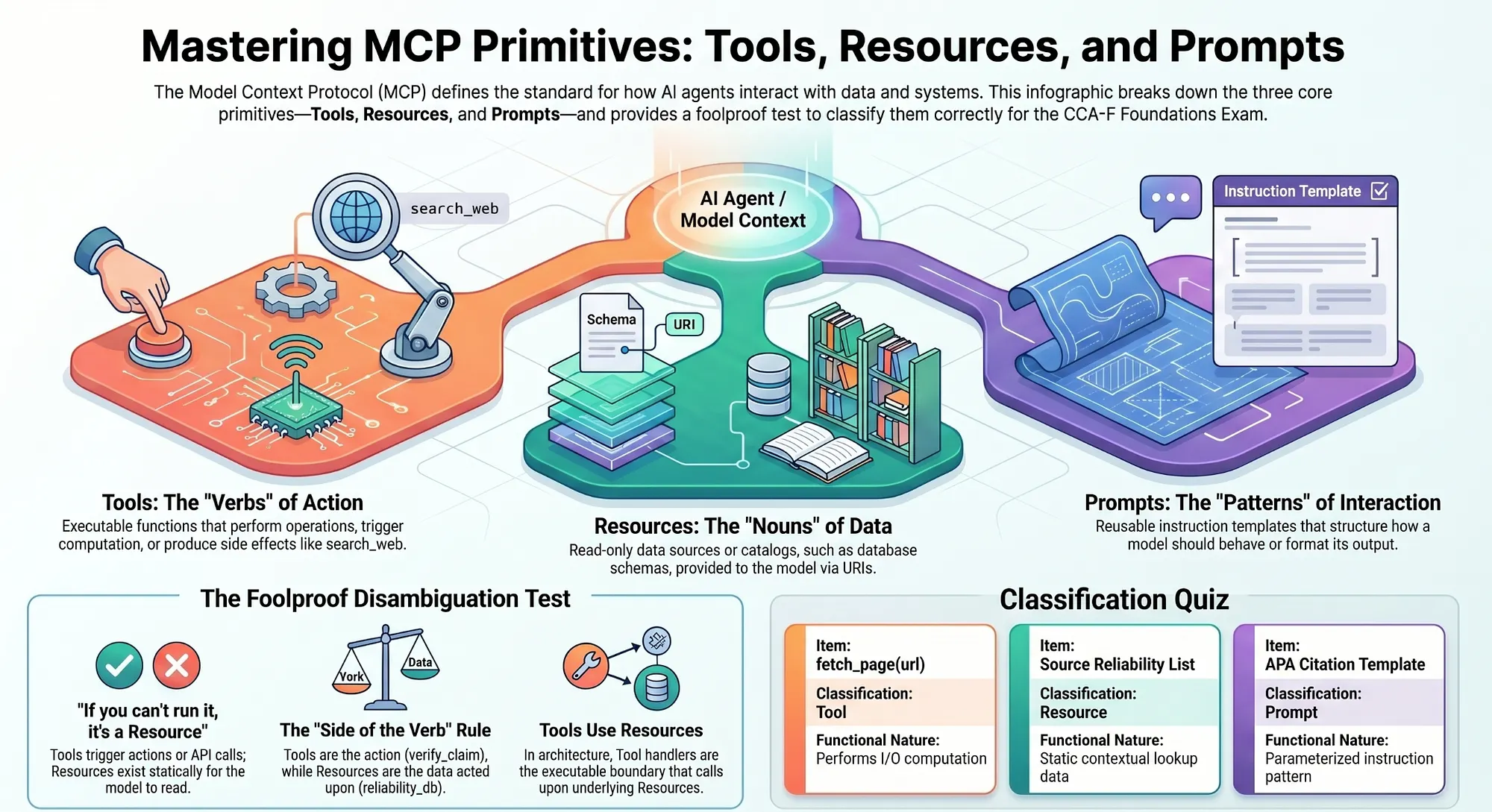
Model Context Protocol Primitives: Tools, Resources, and Prompts
MCP primitives are a distinct sub-topic within the Tool Design domain. The exam tests whether you can correctly classify a capability as a Tool, Resource, or Prompt. The classification is not about what the capability does; it is about the interaction model: who initiates the interaction and whether the result is deterministic.

The Three MCP Primitives
The three MCP primitives have precise definitions:
- Tool: Model-controlled action. The LLM decides to invoke it. The result may be non-deterministic (external API call, database write, web fetch). Example:
search_web,fetch_page,analyze_document. - Resource: Application-controlled data. The host application exposes it. The result is deterministic and read-only. Example: a static configuration file, a pre-built database, a cached API response.
- Prompt: Pre-written instruction template. The host application selects and injects it. It shapes how the model behaves without being a tool call. Example: a system prompt template, a structured output format instruction.
The exam will give you descriptions of capabilities and ask you to classify them. The classification rule is: if the model initiates it and the result may change, it is a Tool; if the data exists before the conversation and does not change, it is a Resource; if it is a reusable instruction template, it is a Prompt.
The Foolproof MCP Disambiguation Test
The single most useful disambiguation rule for the exam is the verb test:
Is the model doing something, or reading something that already exists?
If the model is doing something (calling an API, fetching a page, writing data), it is a Tool. If the model is reading something that already exists and does not change, it is a Resource. If it is a reusable instruction template injected by the host, it is a Prompt.

A practical rule for the exam: if your data exists before the conversation starts and is not modified by the model's actions, it is a resource; if the model needs to trigger computation, write data, or call an external API, that is a tool (Apigene Blog (2025)). Note that this formulation is a third-party heuristic from a vendor blog, not a verbatim quote from the official MCP specification: but it captures the core distinction accurately.
The same information can appear behind either primitive. Ask which side of the verb it sits on:
- A reliability score database that the model might consult to tag the page's reliability is a Resource; it is the data the tool acts upon.
- A
check_source_credibilitytool that queries that database and returns a reliability score is a Tool; it is the action the model takes.
The Five-Item MCP Classification Quiz
Before reading on, classify these five capabilities:
search_web(query: str) -> list[SearchResult]— fetches live results from a search engineCITATION_STYLE_GUIDE.md— a static markdown file with APA/MLA formatting rulesRESEARCH_AGENT_SYSTEM_PROMPT— a template that sets the agent's role and output formatfetch_page(url: str) -> str— downloads a specific web pagesources.py— a pre-built in-memory database of research sources with contradiction seeds
Answers:
- Tool — model-initiated, non-deterministic, calls external API
- Resource — exists before conversation, read-only, does not change
- Prompt — reusable instruction template, host-controlled
- Tool — model-initiated, non-deterministic, fetches external content
- Resource — pre-built data, exists before conversation, read-only
If you got all five correct, you have mastered MCP primitive classification.
How Tools Use Resources in the Project
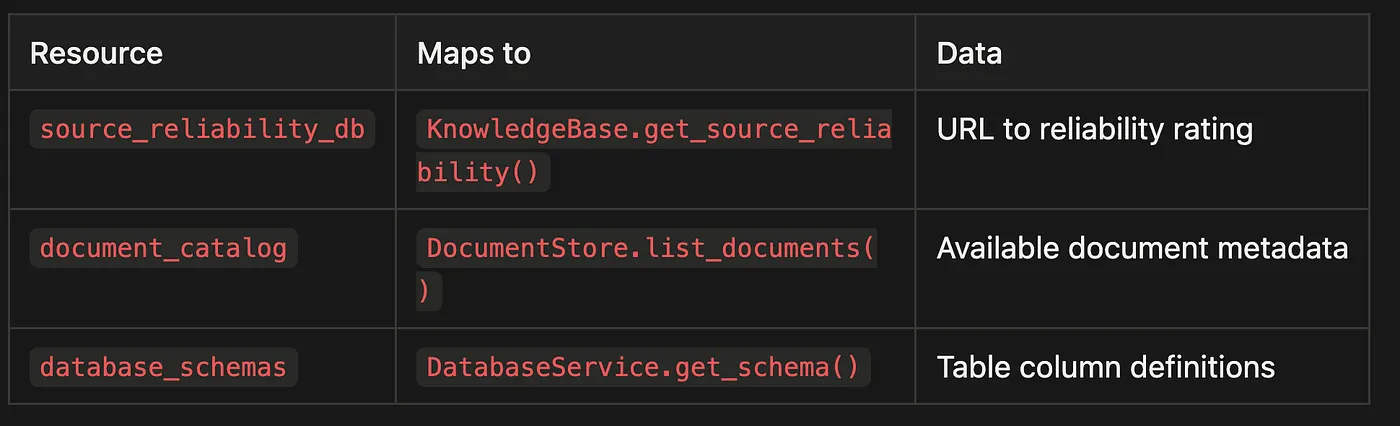
The project demonstrates the Tool-Resource relationship explicitly. The check_source_credibility tool uses the sources.py resource to look up reliability scores. Here is the pattern:
async def handle_check_source_credibility(
tool_input: dict,
container: ServiceContainer
) -> dict:
"""Check the credibility of a source URL.
This tool reads from the SourceDatabase resource (sources.py).
The tool is model-initiated (Tool).
The database is pre-built and read-only (Resource).
"""
url = tool_input.get("url", "")
# Read from the Resource (SourceDatabase)
score = container.source_db.get_reliability_score(url)
return {"status": "success", "url": url, "reliability_score": score}
The tool is the action (model-initiated, calls the database). The database is the resource (pre-built, read-only, exists before the conversation). This is the canonical Tool-Resource relationship in the project.
The Three CCA Exam Questions
Notebook 06 contains three exam-style questions with worked solutions. These questions are designed to be taken cold before reading the explanations. Here they are:
Question 1; Context Isolation
A multi-agent research system has a coordinator agent that decomposes queries into tasks and delegates to five specialized subagents. Before delegating each task, the coordinator passes its full message history to the subagent. A QA engineer notices that subagents occasionally produce outputs that reference tasks assigned to other subagents. What is the most likely cause?
Correct answer: Context leakage. The subagent's context contains the coordinator's full message history, including instructions and results for other tasks. The fix is to build an isolated context with build_subagent_context().
Why the distractors fail:
- "The coordinator is assigning the wrong tasks" — No: the task assignments are correct; the problem is the context.
- "The subagents are using the wrong tools" — No: tool selection is not affected by context leakage.
- "The coordinator's topological sort is incorrect" — No: wave ordering is not affected by context leakage.
Question 2; Tool Overload
A team builds a customer research agent with 22 tools: web search, document analysis, database queries, email parsing, calendar integration, CRM lookup, and 16 others. The agent's task completion rate drops from 87% to 61% as tool count increases. What is the most likely cause?
Correct answer: Tool selection degradation. With 22 tools, the agent cannot reliably pick the right one. Many tools overlap in function (both search_web and search_database can answer "what do customers want?"), and the agent gets confused. The fix is to split the 22 tools across specialized subagents with 4-5 tools each.
Why the distractors fail:
- "The agent's context window is too small" — No: context window size is not the variable; tool count is.
- "The API rate limit is too low" — No: API rate limits are not affected by tool count.
- "The agent needs a better system prompt" — No: a better system prompt does not fix overlapping tool descriptions.
Question 3; Silent Failure and Structured Error Handling for LLM Agents
A web researcher agent tool handler catches all exceptions and returns
{"status": "success", "data": null}when a page fetch fails. The coordinator agent downstream uses this result to build a research report. What is the most likely consequence?
Correct answer: The research report contains silent gaps. The coordinator sees a success signal with null data, includes the null result in its synthesis, and produces a report that looks complete but is missing key information. No exception is raised; the error is invisible until a human reads the output. The fix is ToolErrorResponse with error_type, message, and retry_after.
Why the distractors fail:
- "The coordinator raises an exception" — No: the coordinator sees a success signal and does not raise.
- "The agent retries the failed fetch" — No: the agent sees a success signal and does not retry.
- "The research report is flagged for human review" — No: the null data passes downstream without triggering any review flag.
Notebook-Test Correlation: Testing AI Agents with a Three-Tier Safety Net
The repository uses a three-tier testing strategy that covers the full range of agent behavior without requiring an API key for most tests.
Tier 1: Structural Tests
Structural tests verify that the code is correct at the model, service, and tool handler level. They do not call Claude. They test whether the models validate correctly, whether the services return the right data, and whether the tool handlers return the right response type for each input.
def test_subtask_can_execute_with_no_dependencies():
task = SubTask(
task_id="t1",
agent_type=AgentType.WEB_RESEARCHER,
query="test query",
dependencies=[]
)
assert task.can_execute is True
def test_subtask_cannot_execute_with_unresolved_dependency():
task = SubTask(
task_id="t2",
agent_type=AgentType.WEB_RESEARCHER,
query="test query",
dependencies=["t1"] # t1 not yet completed
)
assert task.can_execute is False
Structural tests are the cheapest tests in the suite. They run in milliseconds and require no external services.
Tier 2: Headless Execution
Tier 2 tests run the agent loop with a mock Claude client that returns pre-scripted responses. The mock bypasses the API and exercises the full coordinator and subagent pipeline without cost. Here is the pattern:
@pytest.fixture
def mock_claude_client():
"""Returns a mock Claude client with pre-scripted responses."""
return MockClaudeClient(responses=[
# First call: Claude returns a tool_use stop reason
MockResponse(
stop_reason="tool_use",
tool_calls=[MockToolCall("search_web", {"query": "AI employment impact"})]
),
# Second call: Claude returns end_turn with final text
MockResponse(
stop_reason="end_turn",
text="The economic impact of AI on employment is complex..."
)
])
def test_agent_loop_completes_task(mock_claude_client):
result = asyncio.run(run_agent_loop(
agent_type=AgentType.WEB_RESEARCHER,
context=[{"role": "user", "content": "Research AI employment impact"}],
tools=WEB_RESEARCHER_TOOLS,
container=mock_container,
claude_client=mock_claude_client
))
assert "economic impact" in result.lower()
assert mock_claude_client.call_count == 2
Tier 2 tests are more expensive than Tier 1 (they exercise the full loop) but still fast (no API calls). They are the primary mechanism for verifying agent behavior.
Tier 3: Anti-Pattern Module Tests
Tier 3 tests verify that the anti-pattern code is wrong in exactly the right way. Each anti-pattern module has a corresponding test file that documents the failure mode:
test_super_agent.py— verifies that the super-agent uses more tokens and fewer correct tools than the hub-and-spoke coordinatortest_shared_context.py— verifies that context leakage causes the subagent to reference tasks it was not assignedtest_silent_failures.py— verifies that the silent failure handler returns success with null data on every error
The Notebook-to-Test Mapping
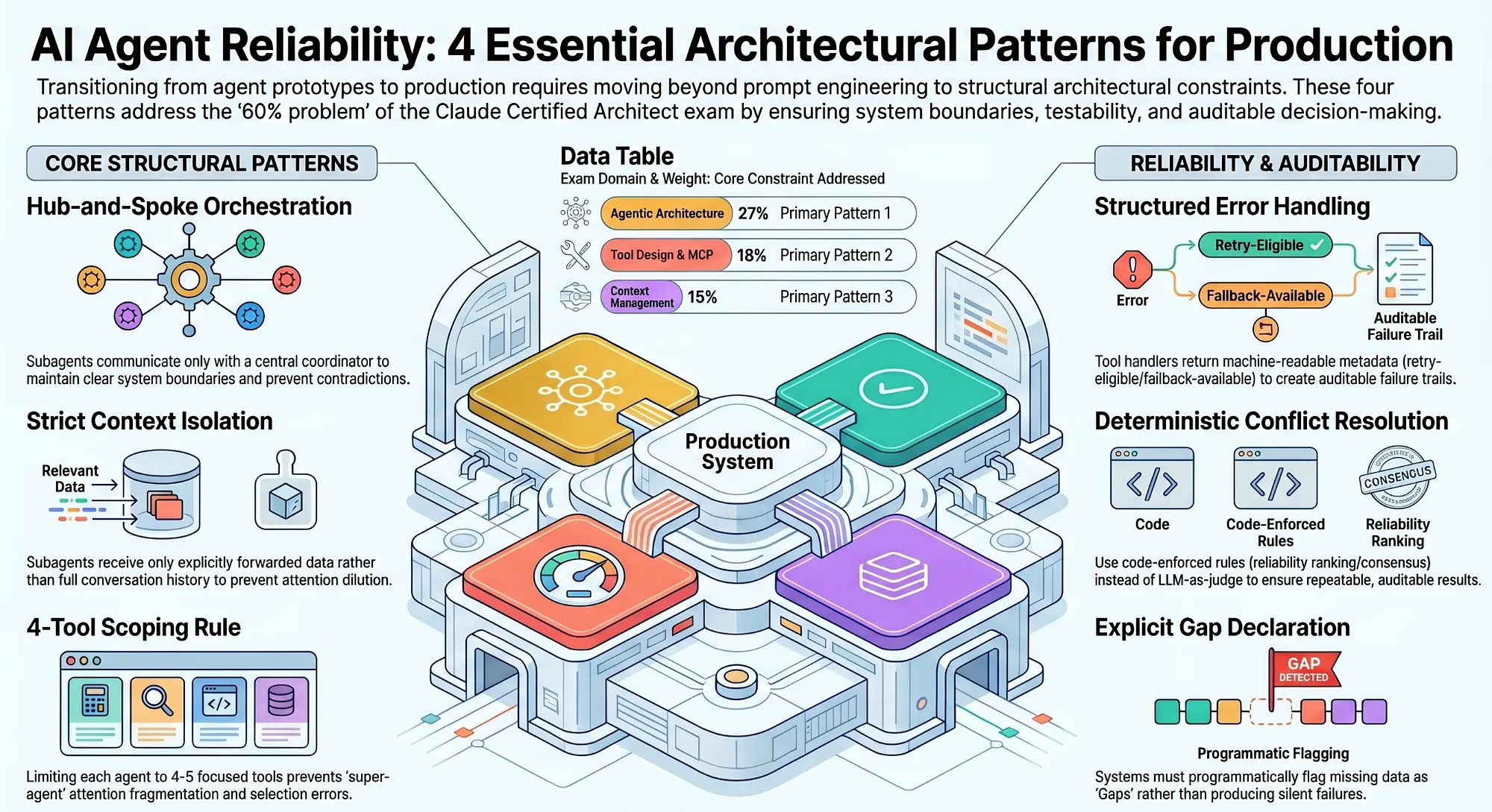
This table is the "where do I look?" index: if you remember a notebook topic, it tells you the exact module and test file that enforce it.
Notebook: 01 Hub-and-Spoke
- Topic: Coordinator architecture
- Module:
coordinator.py - Test file:
test_coordinator.py
Notebook: 02 Context Isolation
- Topic: Context isolation
- Module:
context_builder.py,shared_context.py - Test file:
test_context_builder.py,test_shared_context.py
Notebook: 03 Tool Scoping
- Topic: Tool scoping, super-agent anti-pattern
- Module:
subagents.py,super_agent.py - Test file:
test_subagents.py,test_super_agent.py
Notebook: 04 Structured Errors
- Topic: Structured error handling, silent failures
- Module:
errors.py,silent_failures.py - Test file:
test_errors.py,test_silent_failures.py
Notebook: 05 Conflict Resolution
- Topic: Deterministic conflict resolution
- Module:
conflict_resolver.py - Test file:
test_conflict_resolver.py
Notebook: 06 Exam Questions
- Topic: Three exam archetypes
- Module: All of the above
- Test file: All of the above
Notebook: 07 MCP Primitives
- Topic: Tool/Resource/Prompt classification
- Module:
tools/definitions.py,data/sources.py - Test file:
test_tool_definitions.py
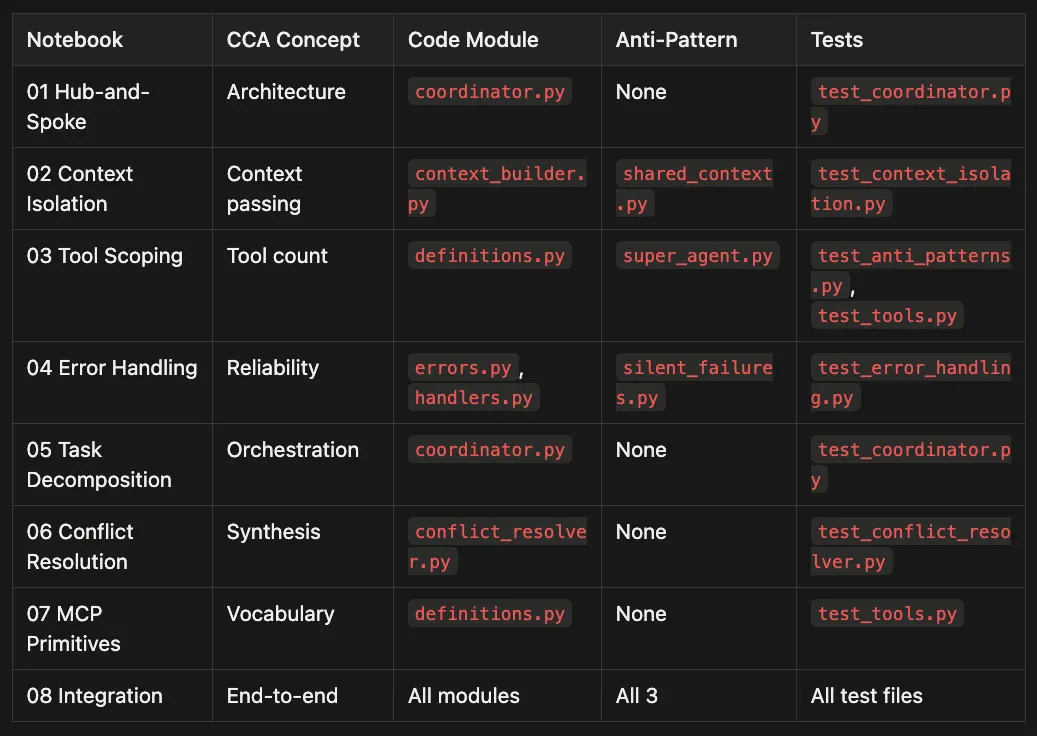
Notebook: 08 Integration
- Topic: Full end-to-end pipeline
- Module: All modules
- Test file:
test_integration.py,test_notebooks.py
Study Checklist
Before sitting the CCA-F exam, verify that you can answer each of these questions without looking at the code:
- [ ] I can name the six steps of the coordinator pipeline in order (PLAN, SORT, DELEGATE, EVALUATE, RESOLVE, SYNTHESIZE).
- [ ] I can explain why
sort_tasks_into_waves()uses topological sort and what happens when a circular dependency is detected. - [ ] I can describe what
build_subagent_context()includes and what it explicitly excludes. - [ ] I can explain the three-tier conflict resolution strategy (reliability > majority > human review) and why determinism matters.
- [ ] I can classify any capability as a Tool, Resource, or Prompt using the verb test.
- [ ] I can identify the super-agent anti-pattern and explain why 4 scoped tools per agent outperforms 19 overlapping tools.
- [ ] I can explain why
{"status":"success","data":null}is worse than raising an exception. - [ ] I can describe what a
ToolErrorResponsemust contain to be useful (error type, message, retry advice). - [ ] I can name the three anti-pattern modules and what each one gets wrong.
- [ ] I can trace a
SubTaskfrom creation through delegation, execution, and conflict resolution to its final entry in theResearchReport. - [ ] I can explain why the agent loop continues on
stop_reason == "tool_use"and stops onstop_reason == "end_turn". - [ ] I can describe the difference between
Tier 1 (structural),Tier 2 (headless), andTier 3 (anti-pattern)tests. - [ ] I can explain why the
conflict_recordfield inResolvedResultmatters for enterprise AI deployments. - [ ] I can name the three domains covered by this scenario and their exam weight percentages (27%, 18%, 15%).
- [ ] I can name the three CCA exam domains this scenario draws from and the percentage weight each carries on the exam.

AI Agent Reliability Patterns for Production
The patterns in this repository are not just exam preparation. They are the foundation of reliable multi-agent systems in production. Here is a summary of the four core patterns and why each one matters beyond the exam:
Hub-and-Spoke Architecture: The coordinator-worker pattern separates orchestration from execution. The coordinator never does research; it plans, delegates, and synthesizes. This separation makes the system testable (you can test the coordinator and each worker independently), maintainable (you can swap out a worker without changing the coordinator), and scalable (you can add workers without changing the coordinator's logic).
Context Isolation: Each subagent receives exactly the context it needs. This prevents context window pollution, reduces token usage, and makes each subagent's behavior predictable and testable. In production, context isolation is also a security property: subagents cannot leak information from one task to another.
Tool Scoping: Four focused tools per agent beats nineteen overlapping tools. In production, tool scoping reduces the probability of incorrect tool selection, makes the agent's behavior auditable (you can see which tools were called and in what order), and reduces the attack surface (a subagent with 4 tools can only cause harm with those 4 tools).
Deterministic Conflict Resolution: The same inputs always produce the same outputs. In production, determinism is an audit trail: you can explain why the system chose one result over another, replay the resolution with different inputs to test edge cases, and flag results for human review when the system's confidence is low.
Call to Action
The CCA-F exam is a 120-minute, 60-question assessment. The multi-agent research scenario is the most complex scenario on the exam and the one that most candidates underestimate. Here is how to use this repository to prepare:
Week 1: Architecture
Run Notebooks 01 and 02. Understand the SubTask model, the sort_tasks_into_waves() function, and the build_subagent_context() function. Take Question 1 from Notebook 06 cold. Check your answer against the worked solution.
Week 2: Tools and Errors
Run Notebooks 03 and 04. Understand the four-tools-per-agent rule, the negative-bound tool description, and the ToolErrorResponse vs SilentFailureResponse distinction. Take Question 2 and Question 3 from Notebook 06 cold.
Week 3: Conflict Resolution and MCP
Run Notebooks 05 and 07. Walk through the economic_impact scenario end-to-end. Classify the five MCP primitives from the quiz in this article. Verify that you can pass the five-item quiz without looking at the answers.
Week 4: Integration and Review
Run Notebook 08. Complete the 15-item study checklist. Run all 180 tests and verify they pass. Re-read the three exam archetypes.
Additional resources:
- Source code on GitHub: https://github.com/SpillwaveSolutions/cca-exam-prep-multi-agent-researcher — every code snippet in this article is from this repo, at the file path given
- Anthropic Academy — https://anthropic.skilljar.com — 13 free courses aligned to CCA domains at launch (Mar 2, 2026); catalog has grown since
- MCP Documentation — https://modelcontextprotocol.io/ — Model Context Protocol specification (Tools, Resources, Prompts)
- Claude Agent SDK Documentation — https://docs.anthropic.com/ — Agent patterns and stop-reason handling
- The companion conceptual article: CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
Run the tests. Open the notebooks. Then sit the exam.
Conclusion
Passing the CCA-F exam is about recognizing the structural hallmarks of reliable AI: Hub-and-Spoke architecture, Context Isolation, Tool Scoping, and Determinism. By focusing on the Multi-Agent Research System, you move beyond the "efficiency trap" and master 60% of the exam through a single, cohesive mental model.
These patterns represent the transition from a fragile prototype to a maintainable production system. They provide the audit trail necessary for enterprise-grade applications, ensuring that AI behavior is predictable and transparent.
This project is a practical blueprint for passing the CCA-F multi-agent "research system" questions and for building real multi-agent software: it shows how a hub-and-spoke coordinator decomposes work into dependency-ordered waves, how context isolation is enforced by explicit context forwarding rather than shared history, why tool scoping (four focused tools per agent) beats the super-agent anti-pattern, how structured tool errors give the coordinator a retry and fallback decision tree, and how deterministic conflict resolution produces auditable reports with explicit gaps and confidence.
Final Thought: If your multi-agent system failed today, would you have the audit trail, the structured errors and deterministic records, to tell a human exactly why, or would the reason be lost in the stochastic fog?
References
Sources cited inline above, listed alphabetically by short name. See Research Notes and Fact-Check Log below for the per-part verification trail.
- Anthropic Docs — Define Tools (2026) — Anthropic Docs (2026). "Define Tools." platform.claude.com — https://docs.claude.com/en/docs/build-with-claude/tool-use
- Anthropic Docs — Subagents (2026) — Anthropic Docs (2026). "Claude Prompting Best Practices: Subagent Orchestration." platform.claude.com. https://docs.claude.com/en/docs/build-with-claude/prompt-engineering
- Anthropic Docs — Tool Errors (2026) — Anthropic Docs (2026). "Handle Text Editor Tool Errors." platform.claude.com. https://docs.claude.com/en/docs/agents-and-tools/tool-use/
- Anthropic Docs — Tool Search (2026) — Anthropic Docs (2026). "Tool Search Tool." platform.claude.com. https://docs.claude.com/en/docs/agents-and-tools/tool-use/tool-search
- Anthropic Engineering (2025a) — Anthropic Engineering (2025a). "How We Built Our Multi-Agent Research System." Published June 13, 2025. https://www.anthropic.com/engineering/multi-agent-research-system
- Anthropic Engineering (2025b) — Anthropic Engineering (2025b). "Effective Context Engineering for AI Agents." Published September 29, 2025. https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Anthropic Engineering (2025c) — Anthropic Engineering (2025c). "Writing Effective Tools for AI Agents." Published September 11, 2025. https://www.anthropic.com/engineering/writing-tools-for-agents
- Anthropic Engineering (2025d) — Anthropic Engineering (2025d). "Advanced Tool Use." anthropic.com. https://www.anthropic.com/engineering/
- Apigene Blog (2025) — Apigene Blog (2025). Tool design discussion for Claude agents. https://apigene.io/blog/
- Bloom et al. (2015) — Bloom, N. et al. (2015). "The Distinct Effects of Information Technology and Communication Technology on Firm Organization." Management Science / QJE. https://www.hbs.edu/faculty/Pages/item.aspx?num=46486
- CCA Exam Guide (2026) — Claude Certified Architect Exam Guide (2026). claudecertified.com. https://claudecertified.com/
- CCA Foundations Guide (2026) — Claude Certified Architect Foundations Exam Guide (2026). claudecertifiedarchitect.net. https://claudecertifiedarchitect.net/
- CCA Program Overview (2026) — Claude Certified Architect Program Overview (2026). claudecertifications.com. https://claudecertifications.com/
- CertificationPractice.com (2026) — "Anthropic Claude Certified Architect Foundations Quick Facts." https://certificationpractice.com/exam-overviews/anthropic-claude-certified-architect-foundations-quick-facts
- DEV Community (NebulaGG, 2025) — DEV Community / NebulaGG (2025). Article on Claude agent tool limits. https://dev.to/
- Elementum AI (2025) — Elementum AI (2025). Claude tool-scoping deployment notes. https://elementum.ai/
- InfoQ (2025) — InfoQ (2025). "Claude Code Subagents Enable Modular AI Workflows with Isolated Context." https://www.infoq.com/news/2025/08/claude-code-subagents/
- Li et al. (2024) — Li, Y. et al. (2024). "LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods." arXiv:2412.05579. https://arxiv.org/abs/2412.05579
- Liu et al. (2024) — Liu et al. (2024). "Lost in the Middle: How Language Models Use Long Contexts." Transactions of the Association for Computational Linguistics. https://aclanthology.org/2024.tacl-1.9/
- Logicdrop (2024) — Logicdrop (2024). Agent tool-scoping discussion. https://logicdrop.com/
- MCP Architecture Overview (2025) — Model Context Protocol Architecture Overview (2025). modelcontextprotocol.io. https://modelcontextprotocol.io/docs/concepts/architecture
- MCP Prompts Spec (2025-11-25) — MCP Prompts Specification, 2025-11-25. modelcontextprotocol.io. https://modelcontextprotocol.io/specification/2025-11-25/server/prompts
- MCP Resources Spec (2025-11-25) — MCP Resources Specification, 2025-11-25. modelcontextprotocol.io. https://modelcontextprotocol.io/specification/2025-11-25/server/resources
- MCP Specification (2025-11-25) — Model Context Protocol Specification, 2025-11-25. modelcontextprotocol.io. https://modelcontextprotocol.io/specification/2025-11-25/
- Schroeder & Wood-Doughty (2024) — Schroeder, H., and Wood-Doughty, Z. (2024). "Can You Trust LLM Judgments? Reliability of LLM-as-a-Judge." arXiv:2412.12509. https://arxiv.org/abs/2412.12509
- Towards Data Science (2026) — Towards Data Science (2026). "The Multi-Agent Trap." https://towardsdatascience.com/the-multi-agent-trap/
- Tutorials Dojo (2026) — Tutorials Dojo (2026). "CCA-F Claude Certified Architect Foundations Study Guide." https://tutorialsdojo.com/cca-f-claude-certified-architect-foundations-study-guide/
- lowcode.agency (2026) — lowcode.agency (2026). "Claude Certified Architect: How to Get Certified in 2026." https://lowcode.agency/
- onabout.ai (2026) — onabout.ai (2026). "Multi-Agent AI Orchestration: Enterprise Strategy for 2025-2026." https://onabout.ai/