Choosing Your Agent Harness: An Architectural Comparison of Claude Managed Agents, LangChain Deep Agents, and the OpenAI Agents SDK
Claude Managed Agents vs. LangChain Deep Agents vs. OpenAI Agents SDK to guide your AI agent harness decision.
Originally published on Medium.

Claude Managed Agents vs. LangChain Deep Agents vs. OpenAI Agents SDK to guide your AI agent harness decision.
Discover why the AI agent harness is the next big battlefield in tech -- and which framework will give your team the decisive edge.
The AI model is no longer the product. The harness is. As agentic systems move from chat to long-horizon autonomy, the decisive architectural choice becomes the layer that runs the loop between reasoning and execution: sandboxing, tool routing, state, credentials, and multi-agent delegation.
This article compares three competing answers to that problem, Claude Managed Agents, Managed LangChain Deep Agents, and the OpenAI Agents SDK, across architecture, security boundaries, economics, and strategic lock-in. The goal is not to crown a winner. It is to help engineering leaders pick the harness that matches their constraints today, and their migration path tomorrow.
Key takeaways
- Harness ownership is the real build-vs-buy decision. Managed harnesses maximize speed, but trade away auditability and sovereignty.
- Anthropic Claude Managed Agents offers the fastest path to production, but it comes with meaningful lock-in and a research-preview gap around multi-agent orchestration, memory, and outcomes evaluation.
- LangChain Deep Agents provides the most flexible open-source orchestration (LangGraph), including durable execution and deep nesting, but the pragmatic road to production typically runs through LangSmith Deployments, which reintroduces platform dependence and seat-based costs.
- OpenAI Agents SDK is a middle ground: a developer-owned harness with native sandbox support, explicit handoffs, guardrails, and portable environment manifests, yielding more predictable economics at scale when you already operate your own infrastructure.
- The market is converging on standards. Protocols like Agent Skills, MCP and conventions like AGENTS.md are reducing switching costs, making "own the harness" a more realistic long-term posture.
Part 1: The Harness Is the New Agentic Control Plane
The Shift from Conversational AI to Autonomous Agentic Infrastructure
The model isn't the product anymore. The harness is.
For the first few years of large language model deployments, the model was everything. Swap the model, change the product. But something shifted. Long-horizon tasks, filesystem access, multi-agent coordination: these aren't model features. They're infrastructure features. The layer that manages all of it, the orchestration layer running the loop between the model's reasoning and the actual execution of work, that's the harness. And right now, the harness is where the real architectural decisions get made.
Early LLM deployments were simple request-response cycles. Today's frontier is long-horizon autonomy: AI Agents operating inside complex execution environments, manipulating filesystems, and coordinating across multiple specialized sub-agents. Three major players have staked out distinct positions in this space: Anthropic with Claude Managed Agents, LangChain with Deep Agents, and OpenAI with its upgraded Agents SDK. Each one encodes a different answer to the same question: how much infrastructure should you own, and how much should you hand off?
These three frameworks represent different positions on the build-vs-buy spectrum, each offering a different balance of deployment speed, security, and architectural control. Anthropic's Claude Managed Agents is a fully hosted, sovereign infrastructure approach that abstracts the entire execution stack. LangChain's Deep Agents pitches itself as the open-source, model-agnostic alternative, though it has a complicated relationship between its MIT-licensed library and its proprietary commercial platform. The OpenAI Agents SDK occupies a genuine middle ground: a model-native harness that stays developer-managed while adding native sandbox support. Understanding the trade-offs between these systems is what this article is about.
Why the Agent Harness Is the New Agentic Control Plane
Think about a simple chatbot. The model is everything; swap the model and the product changes completely. Now think about a long-horizon agentic AI deployment. The model is one component inside a larger system. The harness manages the agent loop: the cycle of reasoning, tool selection, execution, result observation, and next-step planning. The harness decides which credentials the agent can access, which sandboxes get spun up for code execution, how session state persists across network failures, and how multi-agent delegation gets coordinated.
That's why your choice of harness determines your long-term trade-offs across security, cost, model flexibility, and operational control. Delegate the harness entirely to a managed vendor and you gain speed, but you surrender auditability. Own the harness entirely and you gain sovereignty, but you take on real infrastructure engineering. The build-vs-buy decision between those poles is exactly what this article addresses.
Introducing the Three Agent Orchestration Frameworks
Anthropic Claude Managed Agents collapses the entire external orchestration layer into a fully hosted platform. It virtualizes four primitives, Agent, Environment, Session, and Event, into a turnkey execution stack. You define what the agent is and what tools it can use; Anthropic provisions, manages, and scales everything else. Fastest time-to-market of the three frameworks, no question. The catch: significant vendor lock-in, and several enterprise-critical features (outcomes, multiagent orchestration, and memory) are still gated behind a research preview as of April 2026.
LangChain Deep Agents markets itself as the open-source, model-agnostic alternative. Built on the MIT-licensed LangGraph library, it gives you fine-grained control over AI Agents orchestration: a planning tool (write_todos), sub-agents with isolated contexts, a virtual filesystem as shared workspace, and automatic context summarization. The framework itself is genuinely free. Moving to production, however, runs through the proprietary LangSmith Deployment platform (formerly LangGraph Platform, renamed October 2025), creating a "paradox of openness" where the harness is free but productionization is not.
OpenAI Agents SDK sits in the middle: a code-first, developer-owned harness with native sandbox support, a portable Manifest abstraction for environment blueprints, and a credential isolation architecture where secrets are injected into ephemeral sandbox workers and never exposed to the model's context. No platform-layer fees beyond model tokens and your chosen compute costs, which means, for teams with existing cloud infrastructure, the economics at scale are genuinely predictable.
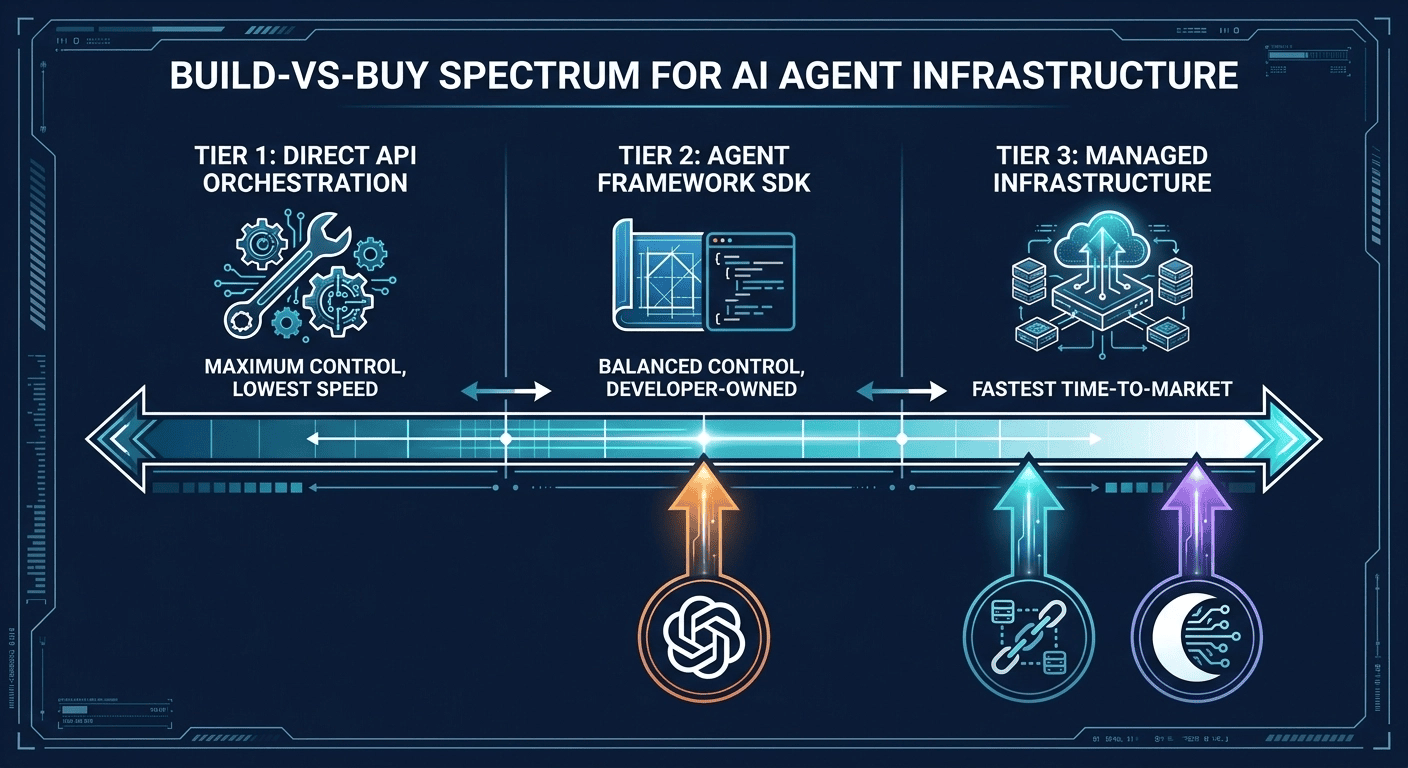
The Build-vs-Buy Spectrum for Agentic Infrastructure
Here's how the market breaks down:
- Tier 1: Direct API Orchestration (Build): You use standard API clients and build every infrastructure layer yourself: loops, state management, sandboxing, and security proxies. Maximum control, minimum speed-to-market. Right for teams with deep distributed systems expertise and requirements no existing framework satisfies.
- Tier 2: Agent Frameworks (where the OpenAI SDK lives): A standardized agent harness with developer-managed infrastructure. You get blueprints and an engine; you choose where it runs. Optimized for compliance, model flexibility, and cost-efficiency.
- Tier 3: Managed Agent Infrastructure (where Anthropic and LangChain live): The entire execution stack goes to a vendor. Fastest time-to-market. Highest vendor lock-in. Platform-specific fees that can strain unit economics at high volume.
The rest of this article examines each framework's architecture, security model, economic structure, and strategic fit in depth, then synthesizes those findings into a decision framework for engineering leaders navigating this spectrum.
Part 2: Anthropic Claude Managed Agents: Sovereign Infrastructure and Its Gaps
The Sovereign AI Infrastructure Approach
Anthropic built Claude Managed Agents around a simple premise: the external orchestration layer is what breaks in production, so let them manage it. The core philosophy is to decouple the "brain" (the reasoning model) from the "hands" (the execution environments), so that as models evolve, the underlying interfaces for tool interaction and session management stay stable. This is designed for long-horizon tasks that run for minutes or hours, requiring multiple asynchronous tool calls and secure, stateful environments.
Virtualizing the Claude Agent Harness and Sandbox Architecture
The architecture virtualizes three core components: the session, the harness, and the sandbox. The session is a persistent, server-side record of the entire interaction history; state is maintained even if the client disconnects or the execution environment fails. The harness is the persistent loop managing communication between Claude and the infrastructure, routing tool calls and handling event orchestration. The sandbox is a secure, isolated container where Claude executes code, edits files, and interacts with the operating system.
This decoupling creates a critical security boundary. In traditional agent architectures, the credentials used to call the AI model often live in the same environment where the model executes generated code. Anthropic's managed approach keeps sensitive tokens in a secure vault, unreachable from the sandbox. When Claude needs to call a tool, it goes through a dedicated proxy; the proxy fetches the necessary credentials and executes the call on the agent's behalf. The "thinking" process and the "execution" process never share a credential space. That structural separation is what mitigates prompt injection attacks that would otherwise try to exfiltrate API keys from the agent's environment.
The Four Primitives
The platform exposes four canonical abstractions that together make up the managed execution stack:
Agent: The static definition of the model, system prompt, tools, MCP servers, and skills. This defines who the agent is and what it's permitted to do.
Environment: A configured cloud container template with pre-installed packages. This is the world the agent inhabits, including its OS and dependencies.
Session: A running instance of an agent within an environment. This is the living task, persisting the event log and filesystem state across the full run.
Event: A message unit (user turn, tool result, status update) exchanged via SSE. This is how the application communicates with the managed agent in real time.
The platform handles infrastructure complexity, container provisioning, network access rules, and credential rotation automatically. When a session starts, Anthropic provisions a fresh container from the environment template. If the container fails, the harness catches the error and reinitializes a new container from the same recipe. Compute resources are treated as ephemeral; the agent's mission is not.
Claude Managed Agents Pricing Model: Active Runtime Economics
Anthropic's pricing for Managed Agents adds something new on top of standard token billing: a session-based runtime fee of 8 US cents ($0.08) per active session-hour. The meter runs to the millisecond, but only while the session's status is "running." Idle time, when the agent is waiting for your response or a human-in-the-loop confirmation, doesn't count.
Model usage is still billed at standard rates ($5 per million input tokens and $25 per million output tokens for Claude Opus 4.7).
Here's how the billing layers stack:
- Model Tokens: Standard API rates ($5/$25 MTok for Opus 4.7), measured by total input/output volume per turn.
- Session Runtime: $0.08 per session-hour, billed to the millisecond during "running" status.
- Tool-Triggered Costs: $10 per 1,000 web searches, applied as a surcharge for specialized server-side tool use.
- Prompt Caching: 0.1x to 2x multipliers applied to input tokens based on cache hits and writes.
Note on prompt caching: Cache reads are billed at 0.1x the base input rate; 5-minute cache writes at 1.25x; 1-hour cache writes at 2x.
Important caveat for Opus 4.7 workloads: Claude Opus 4.7 ships with a new tokenizer that may generate up to 35% more tokens for identical input text compared to Opus 4.6. Per-token rates are unchanged, but effective costs on the same prompts can increase 0% to 35% depending on content type, with structured data, code, and non-English text most affected. Teams migrating from Opus 4.6 should re-benchmark token consumption before projecting costs.
For a standard one-hour coding session consuming 50,000 input tokens and 15,000 output tokens, the total cost comes to about $0.705. The session runtime fee is roughly 11% of that; model tokens account for the other 89%. For sporadic, high-value workloads, say, an agent running 10 minutes to solve a complex engineering problem, this model is quite efficient ($0.013 in runtime). The numbers change fast for high-volume AI Agents running 24/7: $57.60 per month per agent in runtime alone, before touching token costs. At that scale, a move toward self-hosted infrastructure with fixed compute costs starts making economic sense.
The Research Preview Gap: Unfulfilled Architectural Promises
Here's the honest read on Claude Managed Agents' current state: several of the most important features aren't shipped yet. Multi-agent orchestration, stateful memory, and agent outcomes evaluation are all behind a gated research preview. The core product is stable. The advanced architectural patterns that enterprise "swarm" architectures require? Not yet generally available.
The multi-agent orchestration feature, when you get access, allows a coordinator agent to delegate work to specialized sub-agents. The catch: sub-agents are limited to a single level of delegation. They cannot spawn further sub-agents. That reflects Anthropic's focus on reliability over complexity, but it limits the platform for highly nested workflows that other frameworks handle without restriction.
Memory is also in research preview. AI Agents can carry learnings, project conventions and prior mistakes, across sessions using persistent memory stores. Without it, everything the agent learns evaporates when the session ends. The current implementation caps each individual memory at 100KB (roughly 25,000 tokens), nudging you toward many small, focused files rather than one large context object. That's a deliberate design choice to maximize prompt cache hit rates, but it means you're managing the granularity of memory yourself.
Research preview status by feature:
- Multi-agent Orchestration: Limited to one level of delegation; flat graph only.
- Persistent Memory Stores: Ephemeral by default; 100KB cap per memory.
- Agent Outcomes Evaluation: Restricted ability for agents to judge completion.
All three require a separate access request. Teams must apply for research preview enrollment.
Vendor Lock-In: The Strategic Cost of Convenience
The lock-in is real, and you should think carefully about it. When you use Claude Managed Agents, agent execution happens in an environment you don't control. Session data lives in Anthropic's infrastructure. VentureBeat has noted the platform "gives enterprises a new one-stop shop but raises vendor lock-in risk": that's a fair summary of the trade-off.
For regulated industries, finance, healthcare, and government, storing session data in a single-vendor proprietary database is often a non-starter. No publicly documented BYOC (Bring Your Own Cloud) option exists for Claude Managed Agents at any tier; the platform runs exclusively through Anthropic's infrastructure, as far as current documentation shows. Enterprise teams should verify private-deployment options directly with Anthropic's sales team before finalizing this assessment.
The calculus is simple: if speed-to-market dominates everything else, and the Claude model family meets all your functional requirements today, this is the fastest path to a working production agent. But if data sovereignty, multi-agent complexity, or model flexibility is a first-class requirement, the Research Preview Gap and lock-in profile make this platform a real strategic risk right now.
Part 3: LangChain Deep Agents: The Paradox of Open-Source Agent Orchestration
LangChain Agents as an Open-Source Alternative: Opportunities and Tensions
LangChain Deep Agents is positioned as the open alternative to proprietary model-vendor ecosystems. Built on the MIT-licensed LangGraph library, it's designed for "deep" work: tasks that require planning over long horizons, managing a filesystem as a shared workspace, and delegating to sub-agents with isolated contexts. The harness is yours. The model is your choice.
The commercial tension, however, is real. The harness is free. Productionizing that harness is not. Understanding this paradox is essential before committing to LangChain Deep Agents as a strategic platform.
LangChain Deep Agents: Planning Core and Multi-Agent Orchestration
Why "Deep" Agents? The name comes from a distinction between "shallow" agents, which call tools in a reactive loop, and "deep" agents, which plan, reason, and manage their own state over time. The architecture rests on four pillars: a planning tool (write_todos), sub-agents for isolated context, a filesystem as shared workspace, and automatic context management via summarization.
That write_todos tool is deceptively important. It gives the AI agent a visible todo list, decomposing complex objectives into actionable steps. During long-running tasks, the agent doesn't lose track of the goal; it keeps checking the list. The framework also instructs the agent to update its memory files before responding: a pattern the official documentation states explicitly: "Learning from feedback is a main priority. Updating memory must be the first action before responding to the user." Knowledge accumulates across sessions rather than evaporating at the end of each run.
Four Architectural Pillars of LangGraph Agent Orchestration
- Orchestration via LangGraph: Low-level control over state, transitions, and loops.
- Planning via
write_todos: Decomposition of long-horizon tasks into manageable steps. - State Management via Checkpointers: Durable execution with the ability to replay from any prior state.
- Memory via Namespaces: Granular scoping of data for users, agents, and organizations.
Using a filesystem as a shared workspace lets AI Agents work across multiple files, similar to how a developer uses a project directory. When SummarizationMiddleware is enabled (an opt-in component, not active by default in a bare deepagents install), it automatically fires once token usage crosses approximately 85% of max_input_tokens, and tool outputs exceeding 20,000 tokens are automatically offloaded to the filesystem. The agent gets a compressed history; the raw data stays accessible on disk.
Sub-agents get isolated contexts; each one sees only the slice of the task it needs, preventing context pollution between concurrent workstreams. The nesting model differs from Anthropic's managed platform: Claude Code subagents each run in isolated context windows with custom system prompts and independent permissions, but cannot recursively spawn further subagents. LangGraph, by contrast, supports arbitrarily nested subgraph compositions. For highly nested workflows, that distinction matters.
Stateful LangChain Agents: State and Memory Architecture
Deep Agents handle memory through "namespaces"; scoped storage managing different levels of visibility and persistence.
User Scope: Private memory for a specific user. Personal preferences and data stay isolated per user, identified via user_id in the namespace factory configuration.
Assistant Scope: Shared instructions or knowledge specific to one agent instance, allowing an agent to develop its own specialized expertise over time. Identified via a developer-defined namespace key (conventionally an assistant_id string, though this is not a reserved or canonical API field; official LangMem template variables are {langgraph_user_id} and {org_id}).
Global/Org Scope: Shared policies or reference data accessible across all users and agents in an organization. Achievable via custom namespace factory configuration (e.g., ("org", org_id, "shared_context")), though not a first-class named scope in the published API. Treating this scope as read-only is an architectural convention, not an API-enforced constraint.
The Storage Architecture
Under the hood, the storage treats memory like a virtual filesystem: ephemeral working state goes to a Checkpointer (e.g., MemorySaver, PostgresSaver, RedisSaver), and long-term learnings route to a BaseStore implementation (e.g., InMemoryStore, PostgresStore, RedisStore). You wire both together via graph.compile(checkpointer=..., store=...), giving an agent both a "scratchpad" for intermediate work and a "vault" for persistent knowledge:
Checkpointer(e.g.,InMemorySaver,PostgresSaver,RedisSaver): Short-term, per-thread persistence: the agent's working memory during a single session.BaseStore(e.g.,InMemoryStore,PostgresStore,RedisStore): Cross-session storage: knowledge that persists between runs.graph.compile(checkpointer=..., store=...): Routes writes to the appropriate backend based on namespace and scope.
This architecture is what enables "Durable Execution": every step gets checkpointed, and if a task is interrupted by a network failure or a human-in-the-loop pause, the agent picks up exactly where it left off. LangChain calls this "Time Travel": the ability to inspect, branch, and replay from any prior checkpoint state. It's genuinely useful for debugging complex, multi-step workflows.
Self-Healing LangGraph Pipelines: A Strategic Differentiator
One of LangChain's most compelling capabilities is integration with self-healing deployment pipelines. The idea is straightforward: use an autonomous coding agent, such as Open SWE, to detect production regressions, triage them, and open a Pull Request with a fix. A pipeline detects the Docker build failure; the agent writes the patch.
This capability emerges naturally from the "deep" architecture. Because the AI agent can plan over multiple steps, manage files, and delegate to sub-agents, you can assign it the meta-task of fixing its own deployment environment. For teams that need full filesystem access, multi-step CI integration, and automated PR generation as part of remediation, LangChain's open architecture offers a much more configurable path than managed platforms that restrict agent access to filesystems and repositories.
Open-Source LLM Agent Orchestration: Commercial Realities of LangSmith
Here's the paradox stated plainly. The LangChain framework is MIT-licensed. Moving a Deep Agent from local prototype to production-ready system means using LangSmith Deployments (formerly LangGraph Platform, renamed October 2025): a proprietary SaaS deployment server that handles multi-tenant scaling, authentication, and infrastructure provisioning that production agents require.
LangSmith Deployments starts at $39 per seat per month for the "Plus" tier. On top of the subscription, teams pay usage-based fees for agent runs and uptime, plus LLM token costs. For a team of five, the base subscription alone is $195 per month (5 seats x $39), before any actual usage. The total cost of production deployment ends up several times higher than the framework's $0 license fee.
Pricing by tier:
- Developer (Free): MIT-licensed library only. Local prototyping, no production deployment features.
- Plus ($39/user/month): Managed cloud deployment. Moderate production scaling.
- Enterprise (Custom pricing): Hybrid/self-hosted VPC. High-compliance and high-scale deployments.
True self-hosted or BYOC (Bring Your Own Cloud) deployment modes are only available at the Enterprise tier, leaving smaller teams dependent on LangChain's managed cloud for production features. For many developers, this feels like trading one proprietary ecosystem for another: albeit one with more model flexibility.
LangChain Agents vs. Managed Platforms: The Paradox in Summary
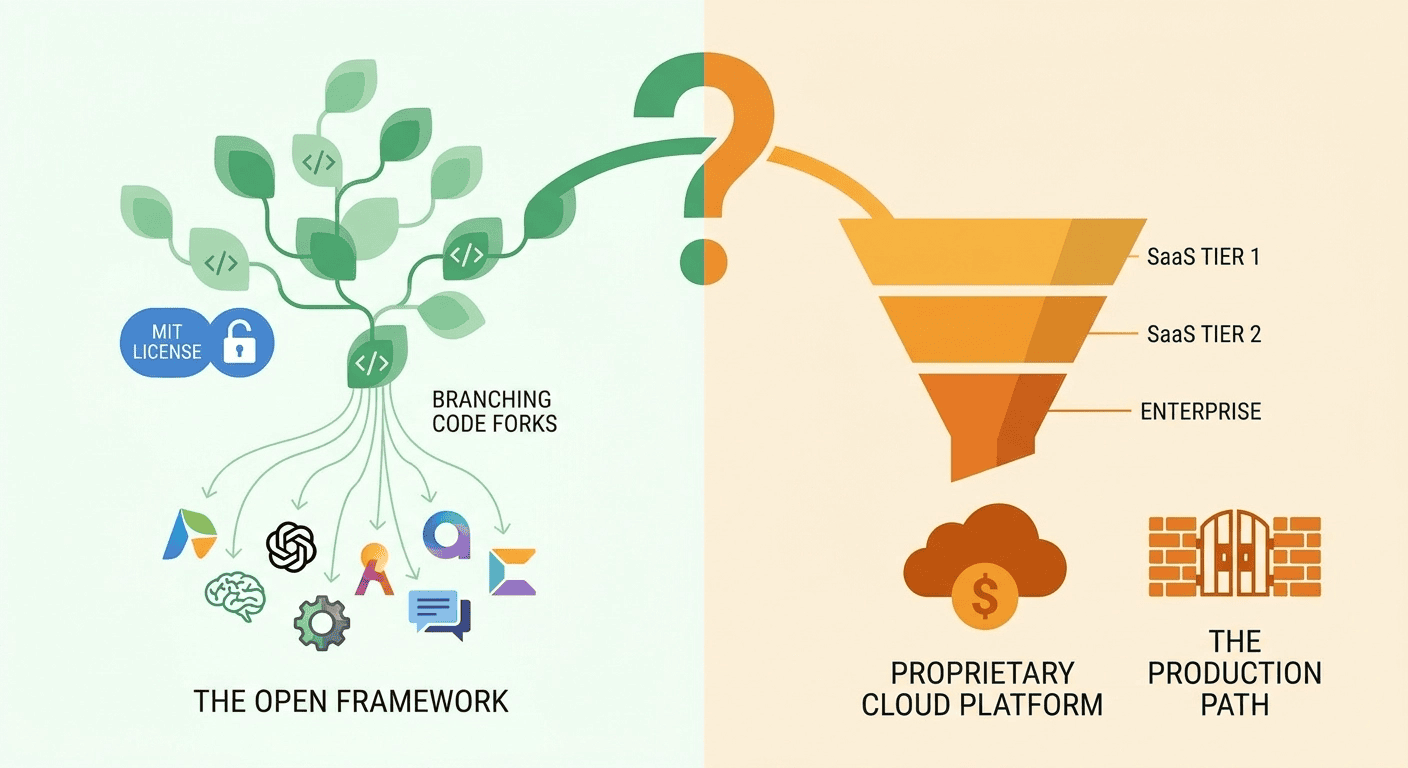
The "paradox of openness" in LangChain Deep Agents can be stated simply: the framework's MIT license gives you unlimited flexibility to build and modify the harness, but the economics of production deployment push most teams toward proprietary LangSmith Deployments infrastructure. The framework is model-agnostic by design; the platform is commercial by necessity.
For teams with the engineering capacity to self-host at Enterprise tier, LangChain Deep Agents offers the most control of the three frameworks examined here: full LangGraph access, deepest multi-agent nesting, broadest model support, and true BYOC deployment. For teams without that capacity, the effective cost and lock-in profile start to look a lot like the managed platforms LangChain positions itself against.
Part 4: OpenAI Agents SDK: The Model-Native Middle Ground
OpenAI Agents SDK: Beyond Short-Turn Conversations
OpenAI moved past the Assistants API's short-turn limitations with a serious upgrade. The new Agents SDK is designed for long-horizon tasks and secure computer environments. It sits between raw API access and fully managed platforms; you own the harness, but you get the primitives to build with.
The evolution matters. Earlier OpenAI SDKs were optimized for short conversations. This iteration introduces a full agent loop: inspect files, run shell commands, work across multiple turns and models. Rather than abstracting the harness away from you (as Anthropic does), the SDK makes the harness explicit, composable, and fully under your control. Released in March 2025 as the production-ready successor to Swarm (OpenAI's earlier experimental multi-agent framework), the SDK formally introduced three core primitives: Agents, Handoffs, and Guardrails: with Tracing and Sessions as additional built-in capabilities. OpenAI has formally deprecated the Assistants API, with a sunset date of August 26, 2026.
Upgrading the Agent Loop for Long-Horizon Autonomy
The SDK introduces the SandboxAgent, which runs against a live sandbox session managed by a Runner. The big architectural shift is native support for "specialist collaboration" via handoffs. A "Manager" agent delegates specific sub-tasks to "Specialist" agents, each with its own tools and instructions. Unlike Claude Managed Agents, currently limited in delegation depth, the OpenAI SDK supports complex, branching orchestration patterns that you manage entirely in code.
Core SDK Components
Runner: Manages the execution loop and event streaming. Full developer control via code-first implementation.
SandboxAgent: Defines the agent persona and sandbox requirements. Configured via the portable Manifest abstraction.
Handoffs: The mechanism for delegating tasks between AI Agents. Explicit handoff descriptions make every delegation point a named, traceable event in the execution log.
Guardrails: Validation hooks that run on input or output. Customizable callback logic lets teams enforce content policies, schema compliance, or business-logic constraints without rebuilding the core loop.
The Runner handles the fundamental orchestration loop: model inference, tool call dispatch, result collection, and loop continuation until a terminal condition is reached. It also handles event streaming, so you can surface real-time progress to users or monitoring infrastructure during long-horizon runs.
Handoffs are the multi-agent delegation mechanism. A handoff is an explicit, described transfer of control from one SandboxAgent to another, not a hidden internal call. That explicitness matters for auditability. Guardrails run in parallel with agent execution and fail fast when checks don't pass, though tool guardrails don't apply to handoff calls themselves, which run through the SDK's separate handoff pipeline.
OpenAI Agents SDK Security: Harness and Compute Separation
The SDK separates the "harness" (control plane) from the "compute" (execution plane) as a first-class security principle. Authentication, billing, and audit logs stay in trusted harness infrastructure. The sandbox handles untrusted code execution. As OpenAI's documentation puts it directly: "Separating harness and compute helps keep credentials out of environments where model-generated code executes."
Autonomous Agent Credential Isolation Architecture
Here's where the credential isolation architecture gets interesting. The SDK doesn't expose credentials to the model via system prompts or instructions. Instead, secrets live in a secure vault, a Cloudflare Durable Object, or a provider like Runloop with state-snapshotting for long-running secure workflows, and get injected directly into the ephemeral sandbox worker only when needed. The model never "sees" the secret. It requests a secure action; the infrastructure provides the authentication. Clean separation.
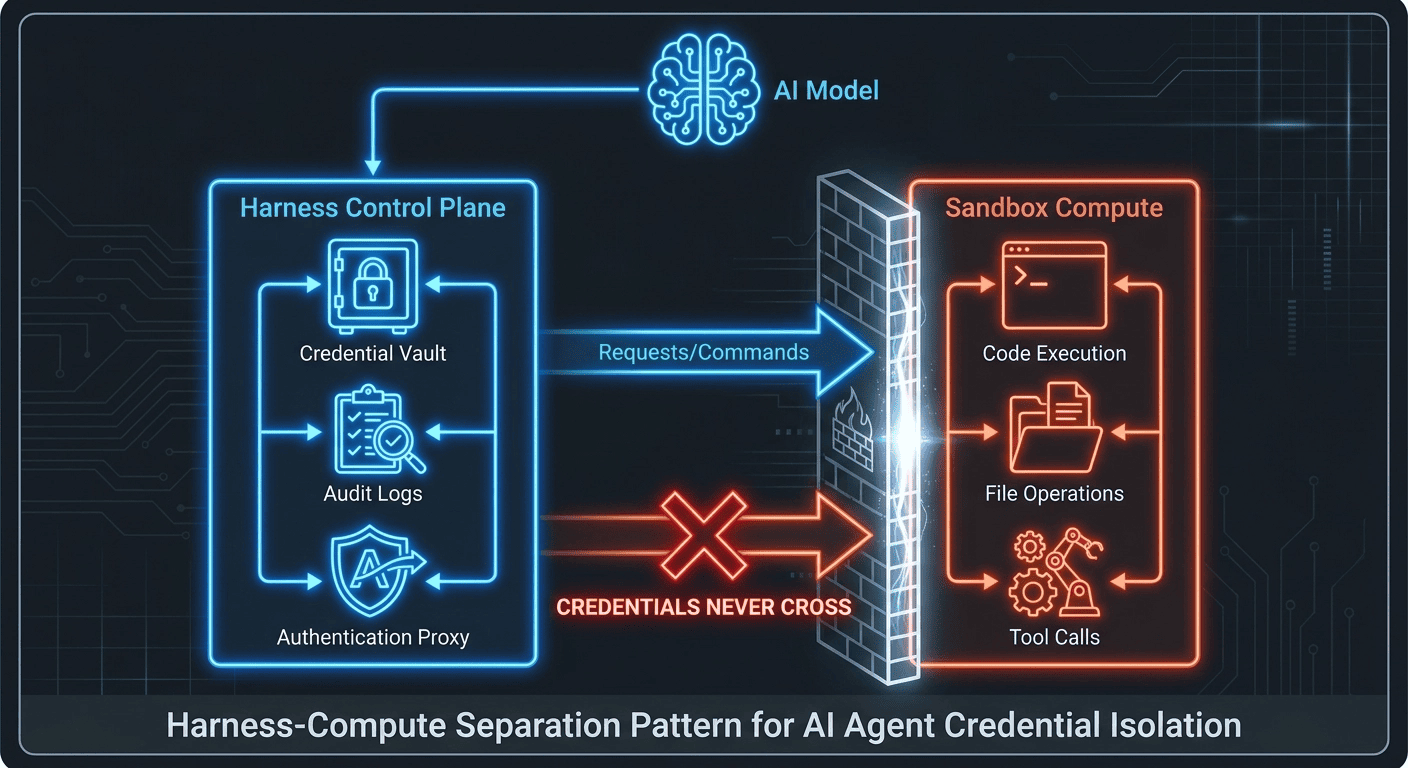
This isolation reduces the blast radius of a potential compromise. An attacker who compromises the sandbox through code execution is still contained within that isolated environment; no access to the parent application's primary tokens. The credential isolation architecture is a harness-level design enforced through harness-sandbox separation, not a feature of any single sandbox provider.
Portability via the OpenAI Agent Manifest Abstraction
Environment drift between local development and production is one of those problems that kills engineer productivity slowly. OpenAI's "Manifest" abstraction solves it. A Manifest is a portable blueprint: a structured description of the agent's workspace specifying files, directories, Git repos, environment variables, users, groups, and mounts. Build on your laptop using a local Docker container; deploy to a high-performance cloud sandbox with minimal code changes. The Manifest is the contract between the harness and the sandbox: any provider that honors the contract is a valid execution target.
Developers can bring their own sandbox or use built-in support for a wide range of providers:
- Docker (local development)
- E2B (cloud sandboxes)
- Modal (serverless compute)
- Runloop (developer cloud with state-snapshotting for long-horizon workflows)
- Cloudflare (edge execution with Durable Objects)
- Vercel (serverless functions)
- Daytona (cloud development environments)
- Blaxel (agent infrastructure)
Agentic AI Capability Matrix
Key capabilities across the SDK's native support and sandbox provider integrations:
- Filesystem access:
ApplyPatchandViewImagenatively; extendable to local, R2, S3, GCS, and Azure Blob via provider mounts. - Shell execution: Command execution with input natively; Docker, E2B, Modal, and Runloop as compute backends.
- Secret injection:
Manifest.environmentfor ephemeral secrets; HashiCorp Vault and Cloudflare SecretsVault for enterprise-grade credential management. - Context trimming: Compaction built into the SDK; model-native context management keeps long runs from hitting hard limits.
Context compaction is a practical feature for long-horizon tasks where context windows saturate. Rather than failing when you hit the limit, the SDK compacts earlier portions of the conversation into summaries, keeping AI Agents running on tasks that span hundreds of steps. OpenAI's own recommendation: use compaction "as a default long-run primitive, not an emergency fallback." Don't wait until you're near the limit; start compacting from the beginning of long runs.
Manifests also support mounting files from storage providers including AWS S3, Google Cloud Storage, Azure Blob Storage, and Cloudflare R2: making it straightforward to bring data in from wherever your team already stores it.
The Middle Ground Proposition
The SDK's philosophy in one sentence: "We give you the engine and the blueprints. You choose the garage." That stands in direct contrast to Anthropic's "We give you the whole car, maintained by us" and LangChain's "We give you the engine for free, but our garage is the only production-ready option."
No platform fees beyond model tokens and sandbox compute means predictable economics at scale. Organizations with mature cloud infrastructure, those already running Docker or Kubernetes clusters, get a clean, professionally designed harness that fits their existing practices: typed code, isolated compute, credential vaults, and portable environment definitions, without the platform tax.
For enterprise engineering teams that need cost predictability at high volume, developer-owned harness semantics, and sandbox portability across cloud providers, this is the strongest long-term position of the three frameworks.
Part 5: Strategic Synthesis: Navigating the Build-vs-Buy AI Agent Architecture Spectrum
The Fundamental Choice in AI Agent Architecture
Choosing between Claude Managed Agents, LangChain Deep Agents, and the OpenAI Agents SDK isn't just a model performance decision. It's a decision about who owns the agentic stack and the data it generates. Each framework encodes a different answer to that question. And once you've committed to a harness, switching is expensive.
To navigate this choice well, you need two things: a clear view of where each framework sits on the deployment abstraction spectrum, and a decision matrix that maps your organizational constraints to the right fit.
Tiered Classification of AI Agent Deployment Architectures
The market for agent deployment breaks into three tiers of abstraction.
Tier 1: Direct API Orchestration (Build)
You use standard API clients (the basic OpenAI or Anthropic Message APIs) and build every infrastructure layer yourself: loops, state management, sandboxing, and security proxies. Highest control. Lowest speed-to-market. Right for teams with deep distributed systems expertise and requirements no existing framework satisfies.
Tier 2: Agent Frameworks (The OpenAI Agents SDK Position)
A standardized harness with primitives, but infrastructure stays in your hands. The OpenAI Agents SDK is the clear example of this tier. It gives you the blueprints (Manifests) and the engine (the agent loop) while you choose where to run it. The Manifest is a structured, portable workspace description, files, directories, Git repos, environment variables, users, groups, and mounts, giving you a consistent interface from local prototype to production without rewriting environment configuration for each target. Optimized for compliance, model flexibility, and cost-efficiency.
Tier 3: Managed Agent Infrastructure (Anthropic and LangChain)
The entire execution stack goes to a vendor. Anthropic and LangChain (via LangSmith Deployments) are here. Fastest time-to-market. Highest vendor lock-in. Platform fees that can make unit economics painful at very high volumes.
Enterprise AI Agent Deployment Decision Matrix: Six Strategic Drivers
Selecting the right framework requires a balance of speed, control, and cost. Here's how the three frameworks score against the six drivers that matter most to enterprise engineering leaders.
Speed to Market
- Claude Managed Agents: Highest; zero infrastructure code required.
- LangChain Deep Agents: High; managed cloud handles deployment.
- OpenAI Agents SDK: Medium; code-first harness requires setup.
Model Flexibility
- Claude Managed Agents: None; Claude model family only.
- LangChain Deep Agents: Highest; any tool-calling model.
- OpenAI Agents SDK: High; optimized for OpenAI, but extensible.
Data Sovereignty
- Claude Managed Agents: Low; Anthropic-managed infrastructure.
- LangChain Deep Agents: Medium; LangChain-managed by default.
- OpenAI Agents SDK: High; developer-managed infrastructure.
Cost at Small Scale
- Claude Managed Agents: Competitive; usage-based pricing.
- LangChain Deep Agents: Expensive; $39/seat base plus usage fees.
- OpenAI Agents SDK: Lowest; token and sandbox compute only.
Cost at High Scale
- Claude Managed Agents: High; $0.08/hr per agent compounds fast.
- LangChain Deep Agents: Variable; agent runs and uptime fees accumulate.
- OpenAI Agents SDK: Predictable; fixed compute costs at scale.
Customization Depth
- Claude Managed Agents: Low; harness is a black box.
- LangChain Deep Agents: Highest; full LangGraph control.
- OpenAI Agents SDK: High; extensible hooks at every layer.
Framework-Specific Fit Patterns for Enterprise AI Agent Deployment
The decision matrix translates into three distinct organizational fit profiles.
When Claude Managed Agents Wins
Organizations focused on rapid prototyping of internal tools or single-purpose assistants will find the convenience of Claude Managed Agents hard to beat, despite the lock-in. The 8-cent-per-hour runtime fee is negligible for high-value engineering tasks where human-in-the-loop oversight is the primary bottleneck. If speed-to-market dominates all other concerns, and the Claude model family meets all your functional requirements today, this is the fastest path to a working production agent.
The calculus changes sharply as scale increases, as multi-agent complexity becomes necessary, or as the Research Preview Gap becomes a blocking constraint. Teams building long-horizon "swarm" architectures today should treat this platform's multi-agent and memory features as future options, not current capabilities.
When LangChain Deep Agents Wins
Consulting firms and product builders that must stay model-agnostic to serve different client needs will naturally gravitate toward LangChain Deep Agents. The ability to swap between Claude, GPT-4, and open-source models without rebuilding the core orchestration logic is a significant strategic advantage. For teams with the engineering capacity to self-host at Enterprise tier, LangChain offers the deepest multi-agent nesting, broadest model support, most flexible memory architecture, and true BYOC deployment.
LangGraph's durable execution model, combined with LangSmith's observability, enables resilient AI Agents pipelines that persist through failures and resume from checkpoints: a genuine differentiator that managed platforms can't replicate. For DevOps-intensive workloads, this operational integration can justify the platform complexity.
When the OpenAI Agents SDK Wins for Enterprise Teams
Enterprise engineering teams with existing, high-scale infrastructure, those already running large Docker or Kubernetes clusters, will see the OpenAI Agents SDK as the most natural fit. It's a clean way to build AI Agents that aligns with professional software engineering practices: typed code, isolated compute, credential vaults, and portable environment definitions, without adding the platform tax of managed offerings. For teams that need cost predictability at high volume, developer-owned harness semantics, and sandbox portability across cloud providers, this is the strongest long-term position.
Economic Model Comparison at Scale
Each framework's economic model breaks down at a different point.
Session-hour billing (Anthropic) favors sporadic, high-value tasks: engineering assistance, research synthesis, one-off complex automation. At $0.08/session-hour, a 10-minute task costs $0.013 in runtime. Continuous operation (24/7) costs $57.60/agent/month in runtime alone, before token costs.
Seat + usage fees (LangChain) suits small teams with moderate volume. The $39/seat/month base is expensive for solo developers or small teams. Teams with predictable, low-frequency workloads can manage costs; high-frequency multi-step pipelines accumulate deployment fees rapidly. LangSmith's deployment billing charges per agent run and uptime; development deployments at $0.005/run plus $0.0007/minute; production deployments at $0.0036/minute.
Token + sandbox compute (OpenAI) yields the most predictable costs at high scale. No platform fees; only model tokens (market rate) and sandbox compute (provider rate). For teams already paying for cloud compute, the harness itself adds zero marginal cost.
Future Outlook: Toward Standardized Agentic AI Protocols and Open Build-vs-Buy Options
As the field matures, the "Research Preview" features of today, multi-agent coordination and persistent cross-session memory, will become table stakes for all frameworks. Two standardization initiatives are already pushing this direction.
MCP (Model Context Protocol): Anthropic donated MCP to neutral governance, acknowledging that tool connectivity standards can't stay proprietary. MCP governance is now stewarded by the Agentic AI Foundation (AAIF), established in December 2025 under the Linux Foundation with founding contributions from Anthropic, OpenAI, and Block, along with other Platinum members including AWS, Bloomberg, Cloudflare, Google, and Microsoft. With 146 member organizations as of February 2026, AAIF is the first credible attempt at a cross-vendor tool connectivity standard for Agentic AI systems.
AGENTS.md: The AGENTS.md specification, now stewarded by AAIF, gives a standardized way to describe AI coding agent behavior and constraints: think of it as a README for your agent's rulebook. Originally developed as an open convention for AI coding tools, AGENTS.md has been adopted by more than 60,000 open-source projects and frameworks including Codex, Cursor, Devin, GitHub Copilot, and VS Code. As more frameworks adopt AGENTS.md, the switching cost between harnesses drops, reducing the lock-in premium of any single managed platform.
Both trends point toward convergence: the harness primitives, session, sandbox, memory, and multi-agent delegation, will commoditize across frameworks. The differentiator will shift from "which primitives does this platform support" to "which execution model fits our operational constraints."
The Likely Hybrid Winner in the Agentic AI Architecture Race
What wins in the long run? The framework that best balances developer "magic", automatic loops and sandboxes, with enterprise "boring" infrastructure: auditability, VPC isolation, and predictable costs. Anthropic and LangChain lead the Managed Infrastructure tier today. The OpenAI Agents SDK's trajectory suggests the future may favor a hybrid model: managed execution environments paired with developer-owned, code-first harnesses.
Here's the key insight: the "hands" are becoming a commodity. Compute environments, sandbox providers, tool execution infrastructure: these will be interchangeable. The "harness": the orchestration logic, the security model, the session persistence layer: that's where strategic control lives.
Organizations that own their harness today are best positioned to adapt as execution environments commoditize, models evolve, and standards emerge. Organizations that delegate their harness to a vendor are betting that their vendor's strategic interests will permanently align with their own.
That bet may pay off. But it is a bet, and the architecture of the harness is where it is placed.
This article compared three Agentic AI orchestration frameworks, Claude Managed Agents, LangChain Deep Agents, and the OpenAI Agents SDK, across architecture, security, economics, and strategic fit. All technical references verified as of April 20, 2026.
About the Author

Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.

He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code