Claude Agent SDK: The Coordinator That Forgets to Check Its Work: Iterative Refinement Loops in Multi-Agent Systems
CCA-F Exam Prep, Domain 1.6: The Named Pattern Behind the EVALUATE Step
Originally published on Medium.

CCA-F Exam Prep, Domain 1.6: The Named Pattern Behind the EVALUATE Step
There is a kind of multi-agent system that looks impressive in a demo and disappoints in production. It plans well. It delegates correctly. It runs subagents in parallel. It synthesizes their results into a clean report. And then it ships that report to the user without ever asking whether the report is actually any good.
The CCA-F exam tests this failure mode directly, by name, in Domain 1.6. Here is the question, almost verbatim from a practice set:
Question: A literature-review coordinator runs its plan once and returns whatever the subagents produced. Reviewers complain of thin coverage and missing rebuttals. Which addition is the named Domain 1.6 pattern?
A. Increase the synthesis subagent's max_tokens so it can elaborate more
B. Spawn more subagents per wave to broaden the initial sweep of sources
C. Run synthesis a second time with identical inputs for consistency
D. Add an EVALUATE step that scores synthesis and triggers refinement
The answer is D. But the value is not in picking D; it is in understanding why every other answer is a different shape of the same mistake, and what the EVALUATE step actually looks like when you build it in real Claude Agent SDK code.
This article walks the question, the wrong answers, the named pattern, and a working implementation.
The Phrase That Gives Away the Answer
The question stem contains two diagnostic phrases that, once you see them, make D inevitable.
The first is "runs its plan once and returns whatever the subagents produced." That is the inverse description of a feedback loop. The coordinator is operating as a one-shot pipeline: plan, delegate, synthesize, ship. There is no point in that flow where the coordinator stops and asks, "Is this synthesis good enough?" That missing question is the named pattern.
The second is "named Domain 1.6 pattern." This is exam shorthand. It is telling you that the answer is not a generic improvement; it is a specific labeled architecture from the CCA curriculum. The labels matter. The exam will reward you for recognizing the specific shape, not for proposing something that sounds reasonable.
Once you read both phrases together, the question collapses to: "What labeled pattern adds a feedback loop to a one-shot coordinator?" The answer is the iterative refinement loop. EVALUATE plus targeted re-delegation is its mechanical core.
The Six-Step Coordinator Pipeline
The CCA curriculum describes the iterative refinement loop as a six-step pipeline. Most one-shot coordinators implement steps 1, 2, 3, and 6. The named pattern adds steps 4 and 5, and crucially, adds a back-edge from step 6 to step 3.
1. PLAN Decompose the query into SubTasks with depends_on
2. SORT Topological sort into parallel execution waves
3. DELEGATE Build explicit context, run subagents with scoped tools
4. EVALUATE Score the synthesis against coverage and quality criteria
5. RESOLVE Deterministic conflict resolution (not LLM judgment)
6. SYNTHESIZE Compile findings; if EVALUATE flagged gaps, loop to 3
The shape of the loop, with the back-edge that turns hub-and-spoke into iterative refinement, looks like this:
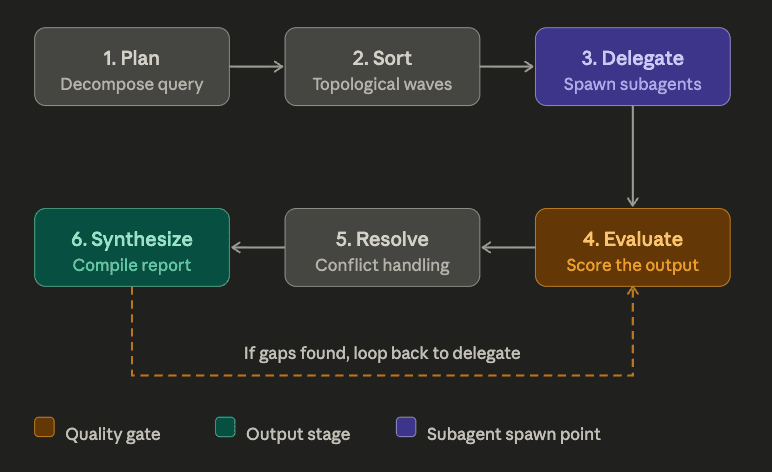
The EVALUATE step is a quality gate, not a vibe check. It scores the synthesized output against explicit criteria: coverage of required subtopics, presence of citations, presence of counterarguments, conflict counts, and any other dimensions the domain cares about. When EVALUATE finds a gap, the coordinator does not start over. It generates targeted refinement subtasks aimed at the specific gap: not "search again," but "search for criticisms of the methodology in Paper X" or "find papers that dispute the central claim of Paper Y."
Those targeted subtasks go back through DELEGATE. Their results merge into the existing synthesis. EVALUATE runs again. The loop continues until coverage is sufficient or a max-iteration bound is hit.
That loop is what separates the iterative refinement pattern from plain hub-and-spoke. Hub-and-spoke fans out, aggregates, synthesizes, and ships. Iterative refinement does all of that and then asks whether the synthesis earned the right to be shipped.
Why Each Wrong Answer Is Wrong
The three distractors are designed to catch three common confusions, and each one is worth understanding because the same confusions show up in real system design, not just on exams.
A. Increase max_tokens so the synthesis can elaborate more. This confuses output capacity with input information. The synthesis is thin because the researchers did not find enough relevant material, not because the synthesizer ran out of room to write. More tokens on the synthesizer does nothing about gaps in the research findings. It is like giving a journalist a larger word count limit when the problem is that their sources did not know the full story.
B. Spawn more subagents per wave to broaden the initial sweep. This is the "more is better" distractor. It treats coverage gaps as a quantity problem rather than a targeting problem. Throwing more researchers at the same initial query might widen the sweep, but it does not address the specific gaps that the first wave missed. The iterative refinement loop narrows subsequent queries based on what the evaluation found missing. More initial agents is noise; targeted refinement is signal.
C. Run synthesis a second time with identical inputs for consistency. This conflates consistency with quality. Running the same synthesis twice with the same inputs does not improve coverage. It produces two versions of the same incomplete result. Consistency is about reducing variance in outputs; quality is about the correctness and completeness of those outputs. The second run has no new information to draw on.
All three wrong answers share the same flaw. They treat the symptom (thin output) without addressing the cause (no mechanism for detecting and filling specific gaps). The EVALUATE step is the mechanism that identifies the specific gap. The targeted re-delegation is what fills it.
What the Pattern Looks Like in Claude Agent SDK Code
Before reading the code, it helps to see the architecture it implements. The coordinator owns state and runs the loop. The subagents are stateless workers.
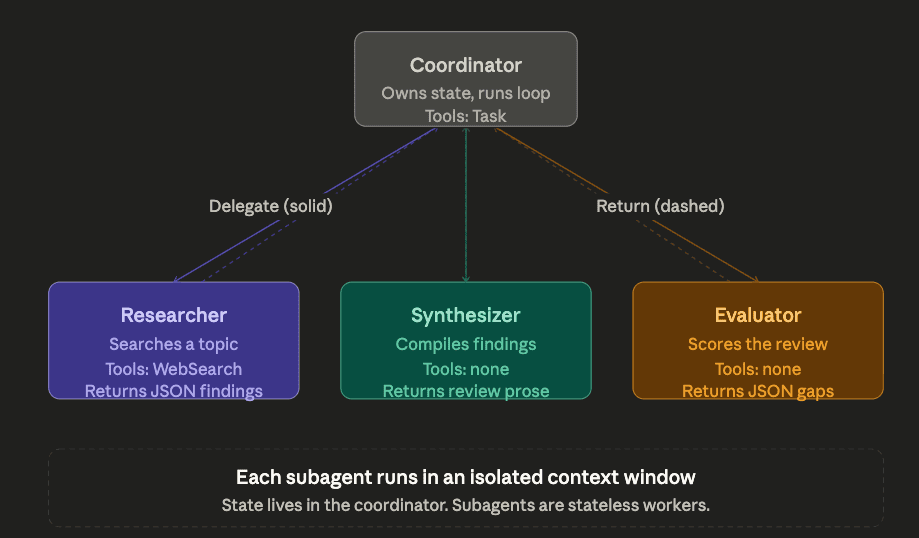
Here is the iterative refinement loop written as a coordinator using the Claude Agent SDK. It is not a full multi-agent harness; it is the minimum code that demonstrates the named pattern in working form.
import asyncio
import json
from claude_agent_sdk import (
query,
ClaudeAgentOptions,
AgentDefinition,
ResultMessage,
)
options = ClaudeAgentOptions(
allowed_tools=["Task", "WebSearch", "Read"],
agents={
"researcher": AgentDefinition(
description="Searches for papers on a specific topic.",
prompt=(
"You search the web for academic papers and research on the given topic. "
"Return a structured summary of what you found, including titles, key claims, "
"and any notable counterarguments. Be specific."
),
tools=["WebSearch"],
model="sonnet",
),
"synthesizer": AgentDefinition(
description="Compiles research findings into a literature review.",
prompt=(
"You receive a JSON list of research findings and compile them into a "
"coherent literature review. Cover every topic in the inputs. "
"Flag any gaps you notice."
),
tools=[],
model="sonnet",
),
"evaluator": AgentDefinition(
description=(
"Scores a literature review against coverage and "
"quality criteria. Returns JSON."
),
prompt=(
"You receive a literature review and evaluate it against these dimensions: "
"subtopic_coverage (0-1), counterargument_coverage (0-1), citation_density (0-1). "
"Return JSON with keys: scores (dict), gaps (list of specific missing topics), "
"pass (bool, true if all scores >= 0.7). Be precise about what is missing."
),
tools=[],
model="sonnet",
),
},
)
async def run_refinement_loop(
initial_query: str,
initial_topics: list[str],
max_iterations: int = 3,
):
findings: list[dict] = []
synthesis: str = ""
# DELEGATE: Initial research wave
for topic in initial_topics:
delegate_prompt = (
f"Use the researcher agent to investigate this topic "
f"for a literature review on '{initial_query}': {topic}"
)
async for msg in query(delegate_prompt, options=options):
if isinstance(msg, ResultMessage):
findings.append({"topic": topic, "result": msg.result})
# SYNTHESIZE: First draft
synthesis = await synthesize(initial_query, findings)
# EVALUATE + REFINE loop
for iteration in range(max_iterations):
evaluation = await evaluate(initial_query, synthesis)
print(f"Iteration {iteration + 1}: scores={evaluation['scores']}, pass={evaluation['pass']}")
if evaluation["pass"]:
break
# Targeted re-delegation based on evaluator gaps
for gap_query in evaluation["gaps"]:
delegate_prompt = (
f"Use the researcher agent to fill this specific "
f"gap in a literature review on '{initial_query}': {gap_query}"
)
async for msg in query(delegate_prompt, options=options):
if isinstance(msg, ResultMessage):
findings.append({"topic": gap_query, "result": msg.result})
# RE-SYNTHESIZE with accumulated findings
synthesis = await synthesize(initial_query, findings)
else:
print(f"Max iterations ({max_iterations}) reached without passing evaluation.")
return synthesis
async def synthesize(topic: str, findings: list[dict]) -> str:
prompt = (
f"Use the synthesizer agent to compile these research findings "
f"into a literature review on '{topic}':\n\n"
f"{json.dumps(findings, indent=2)}"
)
async for msg in query(prompt, options=options):
if isinstance(msg, ResultMessage):
return msg.result
return ""
async def evaluate(topic: str, synthesis: str) -> dict:
prompt = (
f"Use the evaluator agent to score this literature review "
f"on '{topic}' and identify gaps:\n\n{synthesis}"
)
async for msg in query(prompt, options=options):
if isinstance(msg, ResultMessage):
try:
return json.loads(msg.result)
except json.JSONDecodeError:
return {"pass": False, "gaps": [], "scores": {}}
return {"pass": False, "gaps": [], "scores": {}}
asyncio.run(
run_refinement_loop(
initial_query="The cultural impact of streaming media",
initial_topics=[
"effects on traditional broadcast TV viewership",
"changes in music discovery and consumption",
"impact on film distribution and theatrical releases",
"effects on local and regional content production",
],
)
)
A few things worth pointing out about this implementation, because they map directly to exam concepts.
Note the latest versions of the Claude Agent SDK use Agent as the tool name instead of Task. The Task tool is deprecated in the latest version.
The evaluator is a separate subagent, not a function call. This matters because the exam tests whether you understand that the evaluation step requires the same kind of reasoning capability as the research and synthesis steps. A hard-coded scoring function cannot detect semantic gaps in a literature review. A subagent can.
The refinement subtasks are targeted, not generic. Notice that when the evaluator finds gaps, it emits specific query strings in the gaps field. Those strings become the prompts for the next research wave. The coordinator is not re-running "search for papers on streaming media." It is running "search for papers on counterarguments to the claim that streaming democratizes music discovery" or whatever the evaluator identified as missing.
The loop is bounded. max_iterations=3 is the safety bound. Without it, a stubborn quality gate could trigger an infinite loop of researcher invocations and synthesis passes. Bounded loops are non-negotiable in agent systems. Every loop in the Claude Agent SDK pattern library has an explicit termination condition.
The state lives in the coordinator, not in the subagents. The findings list accumulates across iterations in the coordinator's Python scope. The subagents are stateless. They receive their full context in each prompt and return their output. The coordinator is the one tracking what has been found and what remains to be found.
How to Tell the Iterative Refinement Loop Apart From Its Cousins
The exam will put closely related patterns next to each other and test whether you can pick the right one. Three patterns are in the same neighborhood.
Evaluator-optimizer is the same structural idea (closed feedback loop with explicit scoring) applied to a single generative agent rather than a multi-agent coordinator. It improves a single output through repeated refinement without decomposing the work into subtasks. If the question describes one agent refining its own output, that is evaluator-optimizer, not iterative refinement loop.
Hub-and-spoke is one-shot fan-out and aggregation, no feedback. It is the pattern the question's coordinator currently uses before the fix. If a coordinator fans out, aggregates, synthesizes, and ships without any scoring step, that is hub-and-spoke. The presence or absence of EVALUATE is the only structural difference between hub-and-spoke and iterative refinement loop.
Dynamic adaptive decomposition is the pattern where the coordinator picks the next subtask based on prior results, but there is no explicit evaluation gate and no synthesized output being scored. It is adaptive because the plan evolves, but it is not iterative refinement because there is no quality threshold that has to be passed before the output ships.
If you see all three elements together (explicit evaluation gate, synthesized output, targeted re-work), that is the Domain 1.6 pattern. If any one of those three elements is missing, you are looking at a cousin.
The One-Line Takeaway
Coordinators are loops, not pipelines. The CCA exam reliably distinguishes candidates who treat multi-agent systems as fixed graphs from candidates who understand that quality-sensitive systems require feedback.
If the question stem describes a coordinator that "runs once and returns whatever came back," and the answer choices include anything with the word EVALUATE or "quality gate" or "targeted refinement," that answer is almost certainly correct. The exam is testing whether you can read the shape of the architecture.
Build coordinators that check their work. Build evaluators that emit structured gap reports. Build refinement subtasks that target those gaps specifically. That is the pattern.
Code Walkthrough: The Iterative Refinement Loop in Claude Agent SDK
A block-by-block reading of the coordinator that implements the Domain 1.6 named pattern.
This walkthrough takes the iterative refinement loop implementation and reads it top to bottom. Each block of code is explained in terms of what it does, why it is structured that way, and how it maps to the CCA curriculum concepts. If you already understand the pattern at the architecture level, this walkthrough fills in the implementation details.
Block 1: Imports and What They Bring In
import asyncio
import json
from claude_agent_sdk import (
query,
ClaudeAgentOptions,
AgentDefinition,
ResultMessage,
)
Four things are coming in from the SDK, and each one earns its place.
query is the entry point for invoking the agent system. It is an async generator. You iterate over it and receive a stream of message objects. The last one is usually the result.
ClaudeAgentOptions is the configuration object that tells the SDK how the agent is allowed to behave. It carries the tool list, the subagent registry, and other behavioral constraints.
AgentDefinition is how you define a subagent the coordinator can invoke. It bundles a description that explains what the subagent does (visible to the coordinator's planning), a system prompt (visible to the subagent itself), a tool list (what the subagent can call), and a model specification. The distinction between Task (deprecated) and Agent (current) in allowed_tools maps to the same underlying capability: spawning a named subagent.
ResultMessage is one of several message types that query yields. It is the one that carries the final text output from a completed agent invocation. You filter for it with isinstance(msg, ResultMessage).
asyncio and json are standard library. We need asyncio because the SDK is async-native. We need json because we are going to serialize findings into prompts and deserialize evaluator output out of prompts.
Block 2: Subagent Definitions
options = ClaudeAgentOptions(
allowed_tools=["Task", "WebSearch", "Read"],
agents={
"researcher": AgentDefinition(...),
"synthesizer": AgentDefinition(...),
"evaluator": AgentDefinition(...),
},
)
This is where the architecture is declared. Three things stand out.
First, allowed_tools=["Task", "WebSearch", "Read"] is the coordinator's tool list. The "Task" entry is mandatory. Without it, the coordinator cannot invoke any subagents. "WebSearch" and "Read" are included because the coordinator might call those tools directly in some implementations, though in this one it delegates all research to the researcher subagent.
Second, the agents dictionary is where the three named subagents are registered. The keys, which are "researcher", "synthesizer", and "evaluator", are the names the coordinator uses to invoke each subagent in its prompts. The coordinator will write "Use the researcher agent to investigate..." and the SDK will route that invocation to the matching AgentDefinition.
Third, there are three subagents, not one. This is the core architectural decision. A naive implementation would have one general-purpose subagent do all three jobs: search, synthesize, and evaluate. Splitting them into three specialized subagents is what makes the evaluation step independent and reliable. The evaluator cannot be biased by having done the synthesis itself.
Block 3: The Researcher Subagent
"researcher": AgentDefinition(
description="Searches for papers on a specific topic.",
prompt=(
"You search the web for academic papers and research on the given topic. "
"Return a structured summary of what you found, including titles, key claims, "
"and any notable counterarguments. Be specific."
),
tools=["WebSearch"],
model="sonnet",
),
The researcher is the simplest of the three. Its job is narrow. Take a topic, search the web, and return findings.
The description is what the coordinator sees when deciding whether to invoke this agent. It is short and specific. The exam tests this distinction: the description is the agent's interface to the coordinator; the prompt is the agent's internal operating instructions. They serve different audiences.
The prompt is the system prompt the researcher operates under. Three things stand out. The prompt tells the agent what inputs to expect (a topic), what tools to use (implied by the tool list), and what format to return (structured summary with specific fields). The specificity of the output format matters because the synthesizer will receive this output as input. Structured output from the researcher makes the synthesizer's job simpler.
The line tools=["WebSearch"] is tight scoping. The researcher has exactly one tool, the one it needs. It cannot read files, cannot invoke other subagents, cannot take any action other than searching the web. Minimal tool scope is a security and reliability practice the exam labels as "least privilege."
The line model="sonnet" picks the model tier. Sonnet is the working choice for most subagents. It is strong enough for web search and summarization without the latency and cost of Opus.
Block 4: The Synthesizer Subagent
"synthesizer": AgentDefinition(
description="Compiles research findings into a literature review.",
prompt=(
"You receive a JSON list of research findings and compile them into a "
"coherent literature review. Cover every topic in the inputs. "
"Flag any gaps you notice."
),
tools=[],
model="sonnet",
),
The synthesizer takes a pile of research findings and produces prose. Two design choices are worth dwelling on.
The first is that tools=[] is an empty tool list. The synthesizer has zero tools. It cannot search, cannot read files, and cannot invoke other subagents. This is intentional. The synthesizer's job is reasoning and writing, not information gathering. Giving it tools would introduce the possibility of it going off and finding more information when it should be synthesizing what the coordinator gave it. Empty tool lists are not laziness; they are scope enforcement.
The second is that the prompt has two specific instructions worth noticing. The phrase "cover every topic in the inputs" is an explicit completeness requirement. The phrase "flag any gaps you notice" is asking the synthesizer to do a primitive form of self-evaluation. This is not the EVALUATE step; it is the synthesizer flagging what it cannot cover given the inputs. The EVALUATE step is where those flags are scored against explicit criteria.
Block 5: The Evaluator Subagent
"evaluator": AgentDefinition(
description=(
"Scores a literature review against coverage and "
"quality criteria. Returns JSON."
),
prompt=(
"You receive a literature review and evaluate it against these dimensions: "
"subtopic_coverage (0-1), counterargument_coverage (0-1), citation_density (0-1). "
"Return JSON with keys: scores (dict), gaps (list of specific missing topics), "
"pass (bool, true if all scores >= 0.7). Be precise about what is missing."
),
tools=[],
model="sonnet",
),
This is the heart of the named pattern. Without this subagent, you have hub-and-spoke. With this subagent, you have iterative refinement loop.
The evaluator's job has three parts that the prompt makes explicit. First, the evaluator scores the synthesis on named dimensions. Second, it identifies specific gaps, not general complaints but actionable queries the coordinator can use to spawn targeted researchers. Third, it returns a pass/fail determination based on whether all scores clear a threshold.
Three things make this evaluator effective.
The scoring dimensions are subtopic_coverage, counterargument_coverage, and citation_density. These are named, which means the coordinator can log them, track improvement across iterations, and make decisions based on which specific dimension is failing. An evaluator that returns "this is incomplete" is less useful than one that returns "counterargument coverage is 0.2."
The output is structured, not prose. JSON with named keys, specifically scores, gaps, and pass, is what makes the coordinator's branching logic possible. The coordinator does evaluation["pass"] to check whether to continue. It does evaluation["gaps"] to get the targeted queries. Structured evaluator output is load-bearing; prose output would require parsing.
The evaluator has no tools. It does not search and it does not read files. It only reads the synthesis the coordinator hands it. This is the clean separation of concerns that makes the pattern work: the researcher gathers, the synthesizer compiles, the evaluator judges.
Block 6: The Coordinator Loop, Signature and State
async def run_refinement_loop(
initial_query: str,
initial_topics: list[str],
max_iterations: int = 3,
):
findings: list[dict] = []
synthesis: str = ""
The coordinator is a Python async function with three parameters and two pieces of state.
The initial_query parameter is the overall research topic, for example "The cultural impact of streaming media." It is what ties all the research together and what the synthesizer uses to compile the review.
The initial_topics parameter is the PLAN step's output. In a more sophisticated coordinator, this list would be generated dynamically by a planner subagent. In this implementation, it is passed in as a parameter to keep the focus on the refinement loop, not the planning step.
The max_iterations=3 parameter is the safety bound on the refinement loop. Without this, a stubborn quality gate could trigger endless iterations. Three is a reasonable default for most use cases. The exam will test whether you recognize that unbounded loops are a correctness hazard in agent systems.
The two state variables, findings and synthesis, live in the coordinator's Python scope and persist across iterations of the loop. This is the state management model the CCA curriculum describes: the coordinator holds state; the subagents are stateless. findings grows as each researcher returns results. synthesis is overwritten with each new synthesis pass. Both persist across the EVALUATE loop.
Block 7: The Initial Delegation Wave
for topic in initial_topics:
delegate_prompt = (
f"Use the researcher agent to investigate this topic "
f"for a literature review on '{initial_query}': {topic}"
)
async for msg in query(delegate_prompt, options=options):
if isinstance(msg, ResultMessage):
findings.append({"topic": topic, "result": msg.result})
This is the DELEGATE step from the six-step pipeline. For each topic in the plan, the coordinator spawns a researcher subagent, collects the result, and appends it to the findings list.
A few things happen here that are worth being precise about.
The delegate_prompt is the subagent's full context. Notice the structure. It names the agent to use, with the phrase "Use the researcher agent to investigate...". This phrasing is what tells the coordinator's underlying model to invoke the researcher AgentDefinition rather than a generic tool call. The coordinator and subagent communicate through prompt text, not through function signatures.
The loop is sequential in the code, but the SDK can parallelize. In a more performance-oriented implementation, you would asyncio.gather all the researcher invocations to run them concurrently. Sequential execution here keeps the control flow readable for the walkthrough. The CCA exam may test the difference between sequential delegation (simpler, slower) and parallel delegation (SORT step's output drives concurrent waves).
The line async for msg in query(...) is how you consume the stream. The query function yields a series of message objects. Intermediate messages carry partial output, tool calls, and other events. ResultMessage is the final one. Filtering with isinstance(msg, ResultMessage) gives you the completed result without processing intermediate events.
The line findings.append({"topic": topic, "result": msg.result}) is where state accumulates. Each researcher's result gets stored with the topic that prompted it. This structure lets the synthesizer know which topic each finding came from, and lets the coordinator later add new findings from targeted refinement without losing the original context.
Block 8: The Initial Synthesis
synthesis = await synthesize(initial_query, findings)
One line, one purpose. Take all the accumulated findings and produce the first draft of the literature review. The synthesize helper packages the findings into a prompt and invokes the synthesizer subagent. The result is stored in synthesis, which will be evaluated in the next step.
This is the SYNTHESIZE step of the six-step pipeline. At this point in the flow, the coordinator has not yet done EVALUATE. The synthesis is a first draft. It may be complete. It may have gaps. The evaluator will determine which.
Block 9: The Refinement Loop, the Heart of the Pattern
for iteration in range(max_iterations):
evaluation = await evaluate(initial_query, synthesis)
print(f"Iteration {iteration + 1}: scores={evaluation['scores']}, pass={evaluation['pass']}")
if evaluation["pass"]:
break
# Targeted refinement based on evaluator gaps
for gap_query in evaluation["gaps"]:
delegate_prompt = (
f"Use the researcher agent to fill this specific "
f"gap in a literature review on '{initial_query}': {gap_query}"
)
async for msg in query(delegate_prompt, options=options):
if isinstance(msg, ResultMessage):
findings.append({"topic": gap_query, "result": msg.result})
synthesis = await synthesize(initial_query, findings)
This block is the named Domain 1.6 pattern made concrete. Walk it step by step.
The outer for iteration in range(max_iterations) is the bounded loop. Bounded loops are non-negotiable in agent systems. The exam tests this directly. An unbounded refinement loop is a correctness hazard, not just a performance hazard.
The line evaluation = await evaluate(...) is the EVALUATE step. The coordinator hands the current synthesis to the evaluator subagent and waits for a structured JSON response. The evaluator scores the synthesis, identifies gaps, and returns a pass/fail verdict.
The line if evaluation["pass"]: break is the exit condition. If the evaluator says the synthesis is good enough, the loop terminates early. The final synthesis value is the result. If the evaluator never passes within max_iterations, the loop finishes naturally and the best synthesis available is returned.
The targeted refinement subtasks are where the pattern differs from re-running the pipeline. Look closely at this part:
for gap_query in evaluation["gaps"]:
delegate_prompt = (
f"Use the researcher agent to fill this specific "
f"gap in a literature review on '{initial_query}': {gap_query}"
)
The coordinator is not re-running the initial wave of researchers. It is spawning new researchers with new prompts derived from the evaluator's gap list. Each gap_query is a specific, targeted question the evaluator identified as missing from the synthesis. The new findings are appended to the existing findings list, not replacing it.
This is the key distinction the exam tests. Wrong answer C, "run synthesis a second time with identical inputs," cannot improve coverage because the inputs do not change. The iterative refinement loop changes the inputs by adding targeted new findings before re-synthesizing.
The line synthesis = await synthesize(initial_query, findings) at the end of the iteration is the RE-SYNTHESIZE step. The synthesizer now has the original findings plus the targeted gap-filling findings. The new synthesis incorporates everything.
The else: print(...) uses Python's for...else construction, which runs when the loop completes without hitting break. In other words, it runs when max_iterations is exhausted without the evaluator passing. This is the "max iterations reached" warning path. It does not change the return value; it just logs that the loop ran to its bound without satisfying the quality gate.
Block 10: The synthesize Helper
async def synthesize(topic: str, findings: list[dict]) -> str:
prompt = (
f"Use the synthesizer agent to compile these research findings "
f"into a literature review on '{topic}':\n\n"
f"{json.dumps(findings, indent=2)}"
)
async for msg in query(prompt, options=options):
if isinstance(msg, ResultMessage):
return msg.result
return ""
A small helper that packages findings into a synthesizer invocation. Two design choices are worth noting.
The line json.dumps(findings, indent=2) is how the findings get into the synthesizer's prompt. Structured data, serialized as readable JSON, is easier for the synthesizer to parse than a flat concatenation of strings. The indent=2 makes the JSON readable in the prompt, which the synthesizer processes as text.
The function returns the first ResultMessage.result it sees. This works because, for our purposes, each query call resolves to one final result. The return inside the async for loop exits as soon as the result arrives. The return "" at the end is the empty-result safety case.
Block 11: The evaluate Helper
async def evaluate(topic: str, synthesis: str) -> dict:
prompt = (
f"Use the evaluator agent to score this literature review "
f"on '{topic}' and identify gaps:\n\n{synthesis}"
)
async for msg in query(prompt, options=options):
if isinstance(msg, ResultMessage):
try:
return json.loads(msg.result)
except json.JSONDecodeError:
return {"pass": False, "gaps": [], "scores": {}}
return {"pass": False, "gaps": [], "scores": {}}
This has a similar shape to synthesize, but with one important difference. The result gets parsed as JSON before being returned.
The line json.loads(msg.result) converts the evaluator's text output into a Python dict that the coordinator can branch on. This is why the evaluator's prompt specifies a JSON output format. The coordinator needs to do evaluation["pass"] and evaluation["gaps"]; it cannot do those operations on a string.
The fallback {"pass": False, "gaps": [], "scores": {}} is the safety case for when the evaluator does not return valid JSON. The default is conservative: pass: False means the coordinator will try another refinement iteration rather than shipping an unevaluated synthesis. Conservative defaults in safety cases are a pattern the exam tests explicitly.
This is also where you would use the SDK's structured output feature, the output_format option with a Pydantic schema, if you wanted the SDK to enforce the JSON structure rather than relying on the evaluator's prompt compliance. That is the more robust production approach; json.loads with a fallback is the simpler demonstration approach.
Block 12: The Entry Point
asyncio.run(
run_refinement_loop(
initial_query="The cultural impact of streaming media",
initial_topics=[
"effects on traditional broadcast TV viewership",
"changes in music discovery and consumption",
"impact on film distribution and theatrical releases",
"effects on local and regional content production",
],
)
)
The function asyncio.run is the standard way to invoke an async function from sync code, such as a top-level script. It creates an event loop, runs the coroutine to completion, and closes the loop.
The example query is a deliberate echo of one of the exam questions in the practice materials. The "cultural impact of streaming media" topic was chosen because it has multiple subtopics, natural counterarguments, and a large enough literature to make coverage evaluation meaningful.
This is the pattern's payoff. The coordinator's initial plan was incomplete, and a one-shot pipeline would have shipped whatever the first wave of researchers found. The iterative refinement loop detects the gaps, fills them with targeted research, and re-synthesizes until the quality bar is cleared or the iteration limit is hit.
How the Code Maps to the Six-Step Pipeline
Pulling all of that back up to the curriculum vocabulary:

The thing that is load-bearing, the thing that makes this iterative refinement rather than hub-and-spoke, is the back-edge from RE-SYNTHESIZE to DELEGATE when the evaluator returns pass: False. That back-edge, and the targeted gap_query strings that carry information across it, is the named pattern.
The Mental Model to Carry Forward
Reading the code as a whole, the pattern is:
- Plan and delegate an initial wave of work.
- Synthesize what comes back.
- Evaluate the synthesis against explicit, structured criteria.
- If the evaluation passes, ship. If it fails, the evaluator emits targeted gap queries.
- Delegate new work, specifically aimed at the gaps, not a re-run of the original wave.
- Re-synthesize with old and new findings folded in.
- Loop, bounded.
What this looks like across an actual run, with the evaluator's verdicts visible at each stage:
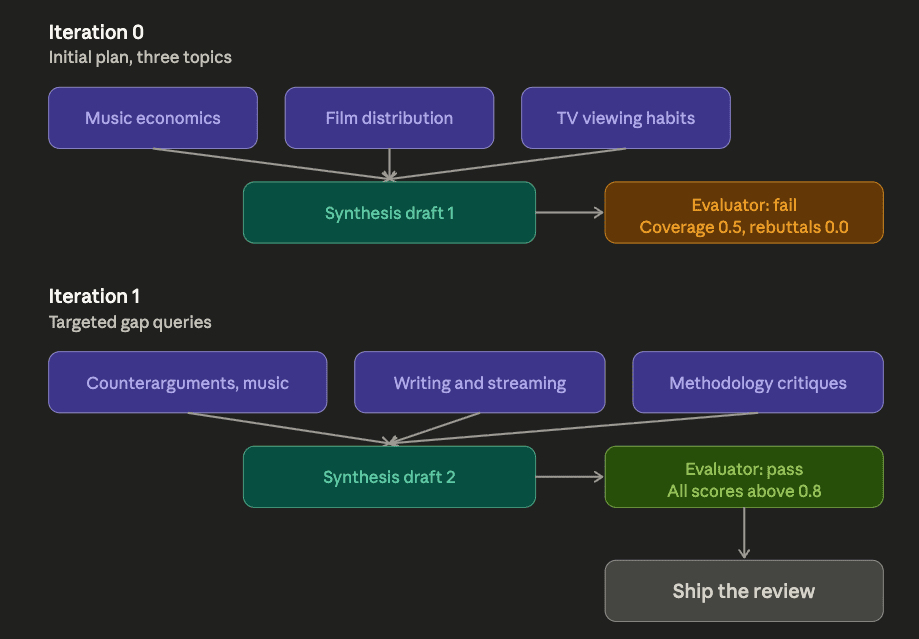
That is the pattern. The Python is just the scaffolding that makes it executable. Once you can read the code and see the six steps, the exam questions that describe the pattern become recognizable at a glance.
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company, focusing on delivering ML / AI insights to front-line applications, and a practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.
Rick created Skilz, the universal agent skill installer that supports 30+ coding agents, including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams adopting AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. Many ideas captured in the CCA and the exam prep Rick wrote echo what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code