Claude Certified Architect (CCA-F) Exam Prep: The Gap Closer: Everything the Other Articles Missed
Closing the hidden CCA-F exam gaps: essential patterns, tools, and reliability strategies for Claude Code agents.
Originally published on Medium.
Closing the hidden CCA-F exam gaps: essential patterns, tools, and reliability strategies for Claude Code agents.

Unlock the hidden 15 high-value Claude Certified Architect CCA-F exam gaps that other guides miss. Master session tricks, tool selection, and quality patterns to boost your score and avoid costly surprises.
Summary: Let's fills the CCA exam prep gaps our series has not covered yet, spanning 15 high-value topics across all five domains: PostToolUse normalization hooks, resume vs. fresh-session strategies, prompt chaining vs. adaptive decomposition, built-in tool selection (grep, glob, read, write, edit, bash), and MCP resources as content catalogs. It also covers configuration mechanics (@-file inclusion, .claude/rules/ YAML path globs, and skill frontmatter keys like context: fork, allowed-tools, and argument-hint) plus advanced patterns such as the Explore subagent, iterative refinement (few-shot examples, TDD, interview pattern, batch vs. sequential fixing), self-validating schema fields (detected_pattern, calculated_total, conflict_detected), independent review instances, calibrated human-review workflows, temporal provenance with content-type-appropriate rendering, and crash-recovery manifests. Each gap lists the exam skill, the right approach, common traps, and citations as a concise cheat sheet to boost your score.
This material is in addition to the other articles in the series.
Articles in the CCA-F Exam Series:
- Claude Certified Architect: The Complete Guide to Passing the CCA-F Foundations Exam
- CCA-F Exam Prep: Mastering the Multi-Agent Research System Scenario
- Claude Code Subagents and Main Agent Coordination: A Complete Guide to AI Agent Delegation Patterns
- CCA-F Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA-F Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA-F Exam Prep: Structured Data Extraction
- CCA-F: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA-F Exam Prep: Mastering the Customer Support Resolution Agent Scenario (Full code examples with runnable notebooks)
- CCA-F Exam Prep: The Multi-Agent Research System in Runnable Code (Full code examples with runnable notebooks)
The 15 High-Value CCA Exam Topics Hiding in the Exam Guide
The pass score is 720 out of 1,000. Most candidates who fall short do not lose points on the headline concepts. They lose them on 15 specific task statements that the popular study guides treat as secondary details or skip entirely. These are the questions where even well-prepared candidates stall, because the topics sound narrow until one appears in an answer choice and you realize you have no sharp mental model for it.
Work through the earlier articles in this CCA exam prep series, and you have the big drumbeat concepts down: programmatic enforcement beats prompt-based guidance, subagents do not inherit context, tool descriptions drive routing, 4-5 tools per agent, lost in the middle, bounded retry with informed feedback. In this series' assessment, that covers roughly 75-80% of the exam surface area.
This article covers the remaining 20-25%. These are the specific named patterns, task statements, and skills the official CCA Foundations Exam Guide calls out that the other articles in this series do not cover, or cover only in passing. None of this is filler. Every topic here maps to at least one task statement in the exam blueprint, and several map to entire task statements that got skipped.
About the CCA Foundations Exam: The Claude Certified Architect — Foundations certification launched on March 12, 2026 as Anthropic's first official technical credential. The exam consists of 60 multiple-choice questions in 120 minutes, is proctored and taken without AI assistance, and requires a scaled score of 720/1,000 to pass. It covers five weighted domains in the official numbering: Domain 1 Agentic Architecture & Orchestration (27%), Domain 2 Tool Design & MCP Integration (18%), Domain 3 Claude Code Configuration & Workflows (20%), Domain 4 Prompt Engineering & Structured Output (20%), and Domain 5 Context Management & Reliability (15%). Preparation courses are free through Anthropic Academy on Skilljar; the standard exam fee is $99. [1, 2]
If you are taking the exam in the next two weeks, read this article twice. These are the questions where even prepared candidates lose points, because the topics sound minor until you see them in an answer choice and realize you do not have a sharp mental model for them.
How to Use This Article
Each section below follows the same structure: the gap, the exam signal, the correct pattern, and the trap. For the highest-value gaps, read sections 1, 2, 6, 9, 10, and 13 first. The rest fill in narrower skills that can each still appear as a single question.
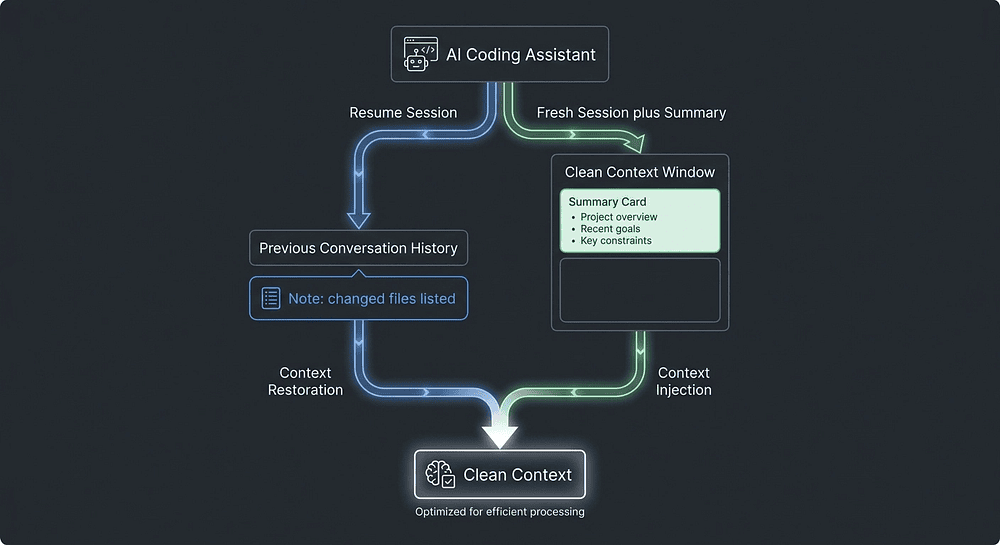
Gap 3: Session Management: --resume vs. Fresh Session with Summary (Domain 1.7)
What the Other CCA Study Guides Cover
fork_session for parallel exploration is well covered. The rest of session management is not.
fork_sessionin brief: Claude Code's/forkcommand spawns a parallel branch from the current session. Each fork runs as a subagent in its own context window and can be cost-optimized via theCLAUDE_CODE_FORK_SUBAGENT=1environment variable, which lets additional children reuse the shared prompt cache prefix. Because a fork's system prompt and tool definitions are identical to the parent's, its first request reuses the parent's prompt cache, making forking cheaper than spawning a fresh subagent for tasks that need the same context. Note:CLAUDE_CODE_FORK_SUBAGENT=1takes effect only in interactive sessions; forked subagents cannot themselves spawn further forks. Third-party sources quote 'roughly a 10x cost reduction per additional child'; official Claude Code docs confirm cache reuse savings without specifying a multiplier. [4, 3]
Three Session Management Skills the CCA Exam Tests
1. Named session resumption with --resume <session-name>. You give sessions explicit names when you start them. Later, you resume by name to continue a specific prior conversation. This differs from forking, which creates a branch from a shared baseline.
Flag reference: Use
--name(short form-n) at startup to assign a human-readable name:claude --name "auth-refactor". Resume that session later withclaude --resume "auth-refactor"(short form-r). From the official CLI reference:--namesets a display name shown in/resumeand the terminal title;--resumeaccepts either a session ID or a session name, or shows an interactive picker when called without an argument.
2. Informing a resumed session about file changes. The model in a resumed session has tool results, and file reads from the prior session in its context. If files changed between sessions, those results are stale. Explicitly tell the resumed session which files have changed since the last session, so it knows to re-read rather than trust memory.
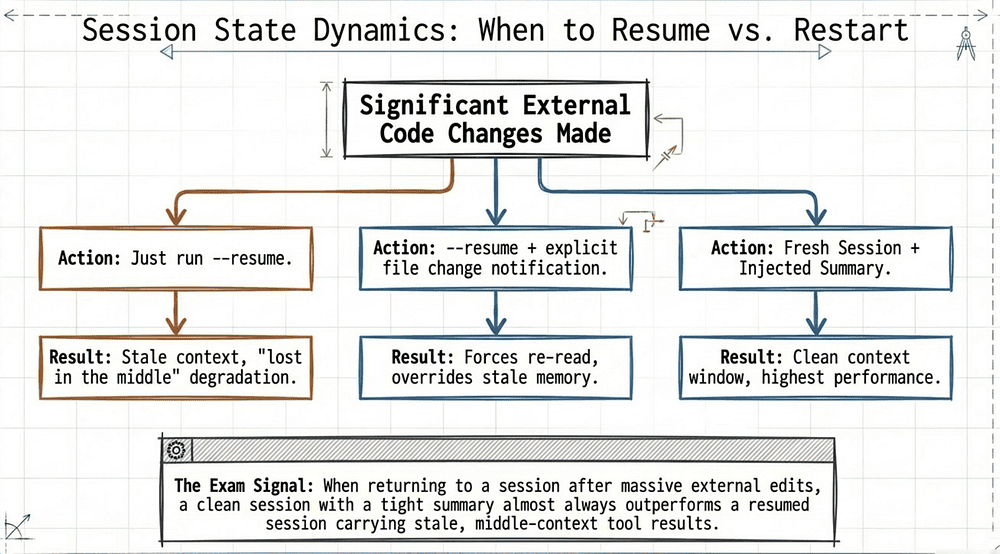
3. Knowing when to use --resume vs. start fresh with a summary. This is the judgment call the exam cares about. Resume a session when the prior context is mostly still valid, and you want continuity. Start a fresh session with an injected summary when prior tool results are stale, the context has drifted, or the earlier session ran long and quality degraded. A clean, fresh session with a tight summary often outperforms a resumed session carrying stale context.
Why stale context degrades quality: This connects directly to the "lost in the middle" finding. Liu et al. (2024) demonstrated that LLM performance follows a U-shaped curve relative to context position: relevant information placed in the middle of a long context window causes significant performance degradation compared to information at the beginning or end, even on models explicitly designed for long contexts. A resumed session with accumulated stale tool results pushes the useful signal toward the middle of an increasingly large context. [8]
The Exam Signal
When a question describes a developer returning to work after significant code changes, the answer is almost never "resume the prior session." It is either "start fresh with a summary of what was decided" or "resume and explicitly list the changed files."
Gap 4: Claude Agent Task Decomposition Patterns by Name (Domain 1.6)
What the Other Articles Cover
Parallel vs. sequential task dependencies, and why web search and document analysis are the canonical parallel pair.
Task Decomposition Patterns Underweighted in Other Guides
The exam guide names two distinct decomposition patterns and tests them as named concepts. Know them by name.
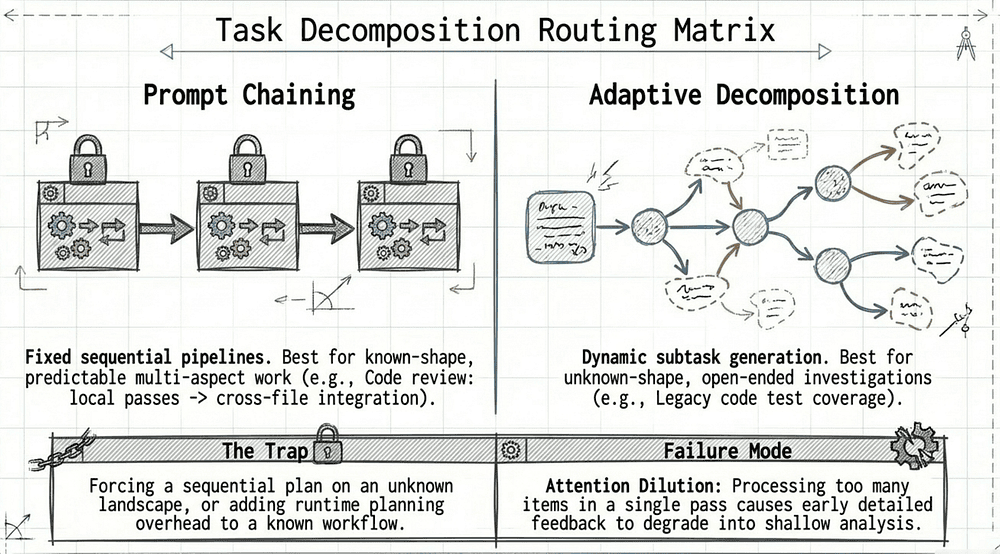
Prompt chaining is a sequential decomposition approach for predictable, multi-aspect work. The canonical example: a large code review is broken into per-file local analysis passes, followed by a separate cross-file integration pass. Each step has a known shape. You chain the outputs together.
Dynamic adaptive decomposition handles open-ended investigations where you cannot fully plan in advance. The canonical example: "add comprehensive tests to a legacy codebase." You cannot list the subtasks in advance. The correct approach is to first map structure, identify high-impact areas, and then generate a prioritized plan that adapts as dependencies are discovered.
Both patterns appear in Anthropic's "Building Effective Agents" reference and are explicitly named and contrasted in the CCA Foundations Exam Guide under Domain 1, Task Statement 1.6 (Task Decomposition Strategies). The official description: fixed sequential pipelines (prompt chaining) are best for predictable, structured tasks providing consistency and reliability; dynamic adaptive decomposition generates subtasks based on discoveries at each step, with the plan evolving as new information emerges. [9, 10]
Attention dilution failure mode: The CCA exam guide also identifies a specific failure mode associated with incorrect decomposition: processing too many items in a single pass creates inconsistent analysis depth, manifesting as detailed early feedback degrading to shallow later analysis, identical patterns flagged differently across files, and missed obvious bugs in later items. The structural fix is a multi-pass architecture. [10]
The Decision Rule
- Known shape, predictable multi-aspect work → prompt chaining (fixed sequence).
- Unknown shape, open-ended investigation → dynamic adaptive decomposition (plan evolves with findings).
The Exam Signal
When a question describes a multi-step workflow, look for whether the steps are predictable. "Review each file, then check cross-file integration" is prompt chaining. "Explore this codebase and improve test coverage" is an adaptive prompt. Choosing prompt chaining for an open-ended investigation means forcing a plan that does not yet exist. Choosing adaptive decomposition for a known-shape workflow adds unnecessary runtime planning.
Gap 9: Claude Plan Mode and the Explore Subagent (Domain 3.4)
What the Other Articles Cover
Plan mode for complex architectural work. Direct execution for single-file bug fixes.
What They Miss: The Explore Subagent
The Explore subagent is not just another name for plan mode. It is a separate tool entirely.
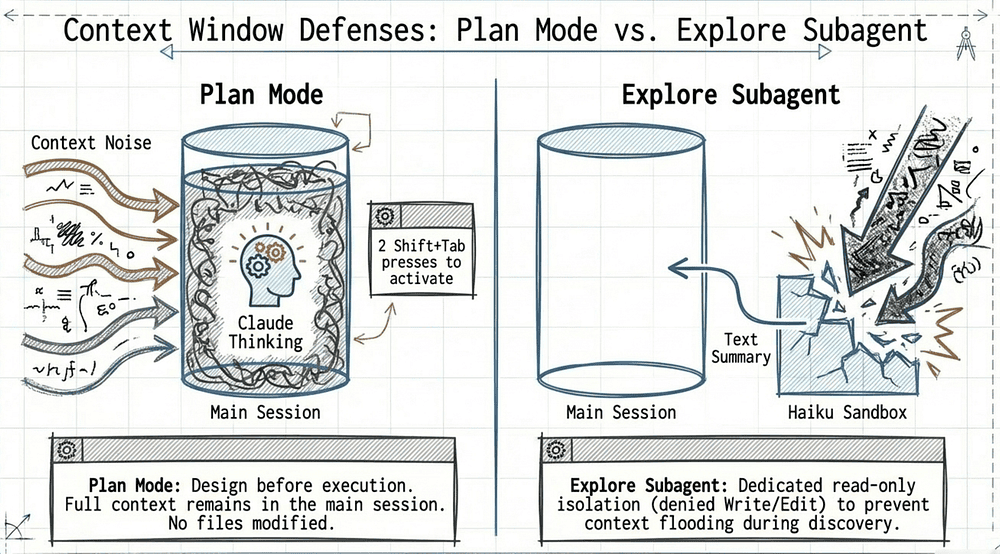
The Explore subagent isolates verbose discovery output. Plan mode helps you investigate before committing to changes. The Explore subagent is different: it performs noisy codebase discovery and returns a summary, keeping the main session's context clean.
From the Claude Code documentation: "Use one [a subagent] when a side task would flood your main conversation with search results, logs, or file contents you won't reference again: the subagent does that work in its own context and returns only the summary." The Explore subagent is read-only (it is denied access to Write and Edit tools) and runs on Haiku by default. It is optimized for speed and cost, designed to search and understand a codebase without making changes. Each subagent runs in its own context window with a custom system prompt, specific tool access, and independent permissions. [39]
Plan mode activation: Plan mode activates by pressing Shift+Tab, which cycles through permission modes in this order: default → acceptEdits → plan. Reaching plan mode requires pressing Shift+Tab twice from the default mode. Auto mode (the autonomous execution setting) is not part of this default cycle and is a separate opt-in feature available only on Max, Team, Enterprise, or API plans (not Pro). Plan mode prevents file modifications and tool executions while Claude maps an approach. When Claude needs to understand the codebase during plan mode, it delegates to the Plan subagent, which prevents infinite subagent nesting while still gathering necessary context. [59]
When to Use the Claude Explore Subagent
In a multi-phase task, Phase 1 requires reading many files to understand the codebase. If that reading happens in the main session, the context fills with file contents, and later phases suffer from context degradation. Delegate the reading to an Explore subagent instead, get back a summary, and proceed in the main session with room to breathe.
The Combined Plan Mode and Explore Pattern
A plan-mode approach for investigation combined with direct execution for implementation is a common answer. Example: plan mode to map out a library migration affecting 45 files, then execute the plan to apply it. The exam rewards candidates who can separate "design" from "do."
The Exam Signal
When a question describes a multi-phase task where early exploration is filling up context, the Explore subagent appears as an answer. It is not the same as plan mode. Know the difference.
Key distinction for exam answers: Plan mode = Claude itself investigates, no file modifications, full context still in main session. Reach it with two Shift+Tab presses from default (default → acceptEdits → plan). Explore subagent = separate agent with its own context window, read-only (denied Write and Edit access), returns a summary, protects main session context.
Research Notes
Sources consulted for Part 1:
- AI.cc; CCA-F Exam Guide 2026 · https://www.ai.cc/blogs/claude-certified-architect-foundations-cca-f-exam-guide-2026/ · CCA exam format, domain weights, launch date, passing score
- LowCode Agency: How to Become Claude Certified Architect · https://www.lowcode.agency/blog/how-to-become-claude-certified-architect · CCA exam proctored format corroboration
- Claude Code Docs; CLI Reference · https://code.claude.com/docs/en/cli-reference ·
--nameand--resumeflag definitions, short forms, official behavior - ClaudeLog: What is the — resume Flag · https://claudelog.com/faqs/what-is-resume-flag-in-claude-code/ ·
--resumeflag behavior,-rshort form - Pillitteri; Claude Code — continue and — resume · https://pasqualepillitteri.it/en/news/366/claude-code-continue-resume-guide · Named session resumption, restores full conversation history
- ClaudeFa.st; Sub-Agent Best Practices · https://claudefa.st/blog/guide/agents/sub-agent-best-practices ·
fork_sessionparallel patterns, CLAUDE_CODE_FORK_SUBAGENT env var - BuildThisNow; Fork Subagents in Claude Code · https://www.buildthisnow.com/blog/guide/mechanics/claude-code-fork-subagent ·
/forkcommand behavior, interactive-only constraint, no nested forks - Liu et al.; "Lost in the Middle: How Language Models Use Long Contexts" · https://aclanthology.org/2024.tacl-1.9/ · U-shaped performance curve, significant degradation at middle-context positions
- Anthropic; Building Effective Agents · https://www.anthropic.com/research/building-effective-agents · Prompt chaining and dynamic decomposition as canonical patterns
- ClaudeCertificationGuide.com; 1.6 Task Decomposition Strategies · https://claudecertificationguide.com/learn/1-agentic-architecture/1-6-human-in-the-loop · Domain 1.6 task statement, attention dilution failure mode
- Claude Code Docs; Create Custom Subagents · https://code.claude.com/docs/en/sub-agents · Explore subagent definition, Haiku default, read-only (denied Write/Edit), context preservation
- Claude Code Docs: Choose a Permission Mode · https://code.claude.com/docs/en/permission-modes · Plan mode activation cycle (default → acceptEdits → plan), two Shift+Tab presses to reach plan; auto mode only on Max/Team/Enterprise/API plans
- GetAIPerks; Claude Code Plan Mode Complete Guide 2026 · https://www.getaiperks.com/en/articles/claude-code-plan-mode · Plan mode overview, Plan subagent behavior
- ClaudeLog; Plan Mode · https://claudelog.com/mechanics/plan-mode/ · Plan mode overview, Explore subagent context savings
- GitHub; Piebald-AI claude-code-system-prompts · https://github.com/Piebald-AI/claude-code-system-prompts · Built-in subagent prompts (Plan/Explore/Task) confirmation
Part 1 covered session management and orchestration patterns. Part 2 moves into the tool architecture layer: the hook and resource patterns that prior study materials either skip entirely or treat as secondary details. These are not minor footnotes. Each anchors a separate task statement.
Three tool architecture gaps trip up CCA exam candidates on exam day: PostToolUse hooks for data normalization, built-in tool selection strategy, and MCP Resources as content catalogs. Each section follows the same structure used throughout this series — what prior study materials cover, what the exam actually tests, and which answer choices are deliberate traps.
Gap 1: Claude Code PostToolUse Hooks for Data Normalization (Domain 1.5)
What Prior CCA Study Guides Cover About PostToolUse Hooks
The existing articles cover hooks as a compliance mechanism: blocking refunds above $500, redacting PII before audit log writes, and enforcing tool ordering. This is correct — and it is only half of what the exam tests.
What They Miss
The exam guide explicitly separates two hook use cases:
- Tool call interception: block or redirect outgoing calls based on policy (well covered).
- PostToolUse data normalization: transform incoming tool results before the model sees them (not covered).
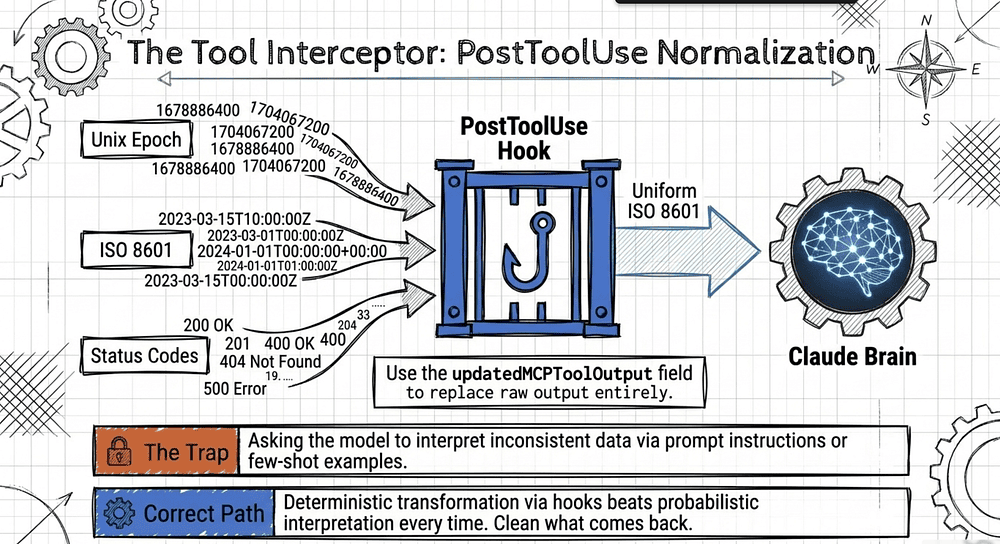
The specific skill the guide names: "Implementing PostToolUse hooks to normalize heterogeneous data formats (Unix timestamps, ISO 8601, numeric status codes) from different MCP tools before the agent processes them."
Why This Matters in Production
Picture your AI agent with three MCP tools from three different backend systems:
lookup_orderreturns timestamps as Unix epoch integers.get_customerreturns timestamps as ISO 8601 strings.get_shipmentreturns timestamps as numeric status codes (1 = pending, 2 = shipped, 3 = delivered) plus a separate date field in MM/DD/YYYY.
The model encounters three different formats and must reason about what "January 15" means in each. That reasoning consumes tokens and introduces errors. When a customer asks, "When did I place my order?", the model must determine whether 1705276800 is in seconds, milliseconds, or something else.
Never show the model the raw heterogeneous format. A PostToolUse hook intercepts each tool result, normalizes the timestamps to ISO 8601, translates status codes to human-readable strings, and hands the cleaned result to the model. Deterministic transformation beats probabilistic interpretation every time.
According to the official Claude Agent SDK documentation, PostToolUse fires immediately after a tool completes successfully, giving the hook a chance to append context or transform output before Claude processes the result in its next turn [11]. The hook callback receives tool_name, tool_input (the arguments sent to the tool), tool_response (the tool's output), and tool_use_id [11]. The return shape for appending context is:
{ "hookSpecificOutput": { "hookEventName": "PostToolUse", "additionalContext": "normalized data for Claude" } }
For MCP tools specifically, a second field — updatedMCPToolOutput — replaces the tool's raw output entirely rather than appending to it [12]:
{ "hookSpecificOutput": { "hookEventName": "PostToolUse", "updatedMCPToolOutput": "normalized replacement output" } }
The updatedMCPToolOutput applies only to MCP tool calls (tools matching the mcp__<server>__<tool> naming pattern) and is documented in the hooks reference [12]. Note that community reports indicate the field's behavior can vary by SDK version: the Claude Agent SDK Python repository has tracked issues where returning the field triggers runtime errors depending on the installed version. Verify against your own Agent SDK version before relying on it in production. [61] An analogous updatedToolOutput field for built-in tools (Bash, Read, Write, etc.) is in active development but is not yet documented as stable [18].
Note that additionalContext may not reliably surface for MCP tool calls. GitHub issue #24788 (filed February 2026, open as of March 2026) documents that additionalContext works for native built-in tools but can fail silently for MCP tools; updatedMCPToolOutput is the reliable path for MCP output replacement [17].
The Exam Signal
When a question describes an AI agent confused by data format inconsistencies across tools, the wrong answers include:
- Add format descriptions to the system prompt
- Use few-shot examples showing how to interpret each format
- Instruct the model to always normalize timestamps before using them
The correct answer is a PostToolUse hook that normalizes results before the model sees them. Deterministic transformation beats probabilistic interpretation.
The Mental Model
Hooks intercept in two directions. Pre-execution hooks guard what goes out. Post-execution hooks clean what comes back [11]. Both are deterministic. Both beat prompt instructions. Know which direction the question is asking about.
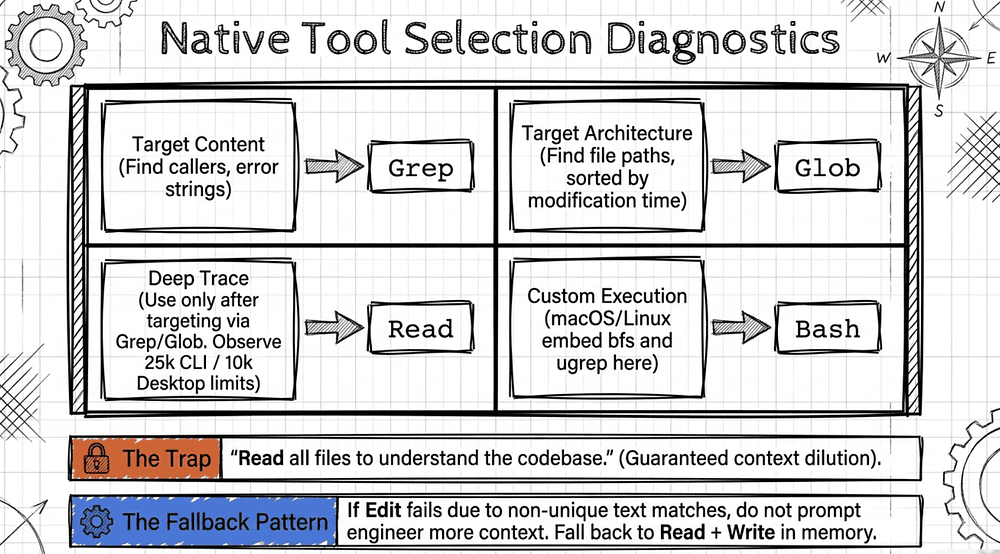
Gap 2: Claude Code Built-In Tool Selection: Read, Write, Edit, Bash, Grep, Glob (Domain 2.5)
What Prior CCA Study Guides Cover About Built-In Tool Selection
The existing articles treat built-in tools abstractly. You know they exist. You know Claude Code uses them. You do not have a sharp sense of when to pick which one.
What the Exam Tests
This is an entire task statement with specific skills. Candidates who have never considered built-in tool selection are surprised on exam day.
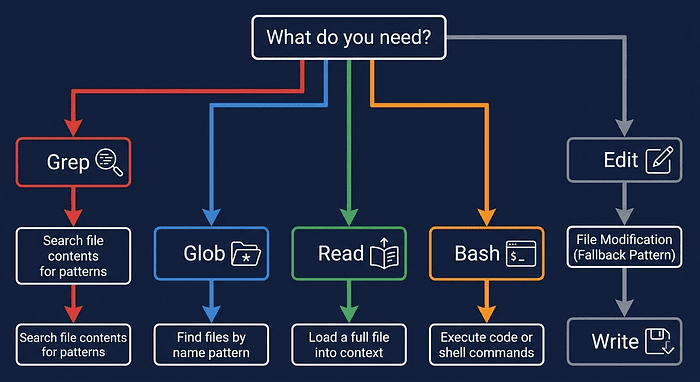
Grep vs Glob vs Read vs Bash: CCA Exam Tool Selection Distinctions
Grep searches the contents of files for patterns [15]. Use it to find:
- All callers of a function (
grep -r "functionName(") - Locations of a specific error message in the codebase
- Every file that imports a particular module
Glob matches file paths by pattern [15]. Use it to find:
- All test files regardless of directory (
**/*.test.tsx) - Every Terraform file (
terraform/**/*) - All Python files under a specific package
Per the official tool documentation, Glob returns matching file paths sorted by modification time, making it the right choice when you know the file pattern but not the location [15].
Read loads a file into context. Use it when you need to see the whole file, not just matches. Read supports text files up to a token limit (25,000 tokens on the CLI build; 10,000 tokens on the Desktop app), with offset and limit parameters for reading specific portions of larger files. Read also supports images, PDFs, and Jupyter notebooks [15, 19, 20].
Write creates a new file or completely overwrites an existing one.
Edit modifies targeted sections of a file using unique text matching. Edit fails with an error when the target string is not found or appears more than once in the file. To handle non-unique matches, provide a larger string with more surrounding context to make the match unique, or use replace_all to change every instance [15].
Bash executes shell commands. Use it for anything that needs to actually run code, not just read files.
Note on platform variants: As of 2026, native macOS and Linux builds of Claude Code replace the separate Glob and Grep tools with embedded
bfsandugrepexposed through the Bash tool. Windows and npm-installed builds keep the standard Glob and Grep built-ins. Official documentation still presents both as normal built-in tools without a platform caveat [16].
The Fallback Pattern of the Exam Tests
When Edit fails due to non-unique text matches, use Read + Write as a fallback. Read the whole file, make the modification in memory, and write the whole file back. Do not try to make Edit work with more context; fall through to the reliable path instead.
Claude Code Incremental Exploration Pattern (CCA Exam-Tested)
For understanding an unfamiliar codebase, the exam rewards this sequence:
- Grep for entry points, route definitions, or the main class you were told about.
- Read those specific files to follow imports and trace flows.
- Glob when you need to find all instances of a file type.
- Do not read every file upfront. That fills context with noise.
For tracing function usage across wrapper modules: first identify all exported names, then search for each name across the codebase. This is the pattern that generalizes.
The Exam Signal
When a question describes exploring or modifying a codebase, watch for answer choices that say "Read all files first to understand the codebase." That is the trap. The correct answer involves targeted search first, then reading only what matters.
Gap 5: MCP Resources as Content Catalogs (Domain 2.4)
What Prior CCA Study Guides Cover About MCP Resources
CCA exam study materials cover the Tools vs. Resources vs. Prompts vocabulary. Tools are actions. Resources are data. Prompts are templates.
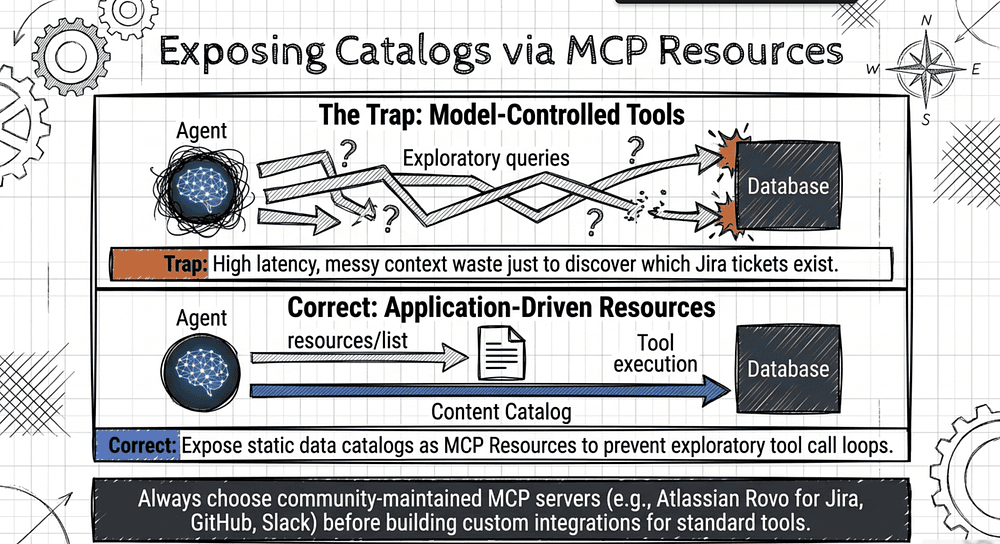
MCP Resources: Application-Driven Access vs. Model-Controlled Tools
The exam tests a specific use pattern for Resources: exposing content catalogs to reduce exploratory tool calls.
The MCP specification defines Resources as a standardized way for servers to expose data that provides context to language models, such as files, database schemas, or application-specific information [13]. A key architectural distinction: Resources follow an application-driven access pattern (the spec's exact terminology). Unlike tools, which are model-controlled, the specification states that tools are "designed to be model-controlled, meaning that the language model can discover and invoke tools automatically" — Resources require explicit client-side management, with host applications determining how to incorporate context [13]. Clients discover available resources through a resources/list request, then fetch specific content with resources/read [13].
Examples the guide calls out:
- Issue summaries: a list of open Jira tickets with ID, title, and status.
- Documentation hierarchies: the structure of an internal docs site.
- Database schemas: table names and columns without the full data.
These map directly to the MCP spec's described use cases: files, database schemas, and application-specific information [13].
Why This Matters
Without a content catalog, an AI agent asks "what tickets are open?" and must call a search tool, then another, then another to determine what it can query. With a Resource exposing the catalog, the agent sees the available data up front and can decide which tool call actually matters. Fewer round-trips. Cleaner context.
The Related Skill
The exam also tests: choose existing community MCP servers over custom implementations for standard integrations (e.g., Jira). Know when to use community-maintained servers for common integrations and when to reserve custom server work for team-specific workflows that nothing off-the-shelf covers.
This is well-founded. Anthropic and the MCP community maintain pre-built servers for GitHub, Slack (8 tools in the reference implementation, now housed in servers-archived), Git, Google Drive, PostgreSQL, and Puppeteer [21]. For Jira specifically, the official Atlassian Rovo MCP server (generally available since February 4, 2026) enables interaction with Jira epics and issues, Confluence pages, and Rovo semantic search across both [22]. Community directories now index over 12,000 MCP servers across categories such as database, cloud, automation, and communication [23].
The Exam Signal
When a question describes an AI agent making too many exploratory tool calls before finding the data it needs, look for "expose the data catalog as an MCP Resource." When a question asks about integrating with Jira, GitHub, Slack, or similar common systems, the answer is rarely "build a custom MCP server."
Research Notes
Sources consulted for Part 2:
- Anthropic Agent SDK; Hooks Reference · https://code.claude.com/docs/en/agent-sdk/hooks · PostToolUse hook behavior, firing sequence,
additionalContextinsidehookSpecificOutput,tool_responsefield name,tool_use_id, PreToolUse vs PostToolUse directionality - Anthropic Claude Code: Hooks Reference · https://code.claude.com/docs/en/hooks · Hook event names, matcher patterns,
updatedMCPToolOutput(confirmed documented field for MCP output replacement) - MCP Official Specification: Resources (normative, 2025-11-25) · https://modelcontextprotocol.io/specification/2025-11-25/server/resources · Resources definition,
resources/listandresources/readprotocol, application-driven access pattern - MCP Official Specification: Tools (2025-11-25) · https://modelcontextprotocol.io/specification/2025-11-25/server/tools · Model-controlled tools definition
- Claude Code Tools Reference · https://code.claude.com/docs/en/tools-reference · Glob sort order, Read token limits, Edit error behavior
- Anthropic Claude Code GitHub: Issue #51781 · Platform-specific Glob/Grep behavior
- Anthropic Claude Code GitHub: Issue #24788 · PostToolUse
additionalContextfailing silently for MCP tool calls - Anthropic Claude Code GitHub: Issue #32105 ·
updatedToolOutputfor built-in tools in active development - Anthropic Claude Code GitHub: Issue #40357 · Read tool token limits (25k tokens CLI / 10k tokens Desktop)
- modelcontextprotocol/servers-archived (GitHub) · Reference MCP server list
- Atlassian Rovo MCP Server (GA February 4, 2026) · Official Atlassian MCP server
- PulseMCP Server Directory · https://www.pulsemcp.com/servers · MCP ecosystem size (12,000+ servers as of April 2026)
Part 2 covered MCP tools, resources, and hook behaviors. Part 3 moves into Claude configuration architecture: the CLAUDE.md modular patterns, rules directories, and skill frontmatter keys that the exam tests in Domain 3.1. These organizational details rarely appear in introductory overviews, but they account for a meaningful slice of CCA questions on agent setup and context scoping.
Three Claude agent configuration patterns appear frequently in CCA exam questions: modular CLAUDE.md organization using @-file inclusion, path-scoped rules via .claude/rules/ with YAML glob patterns, and skill frontmatter keys (context: fork, allowed-tools, argument-hint) that control execution context and tool access.
Gap 6: CLAUDE.md @-File Inclusion and .claude/rules/ for Modular Agent Configuration (Domain 3.1)
What the Other Articles Cover
The CLAUDE.md hierarchy (managed/org, project, user, local) is well covered. Why team rules go at the project level is well covered.
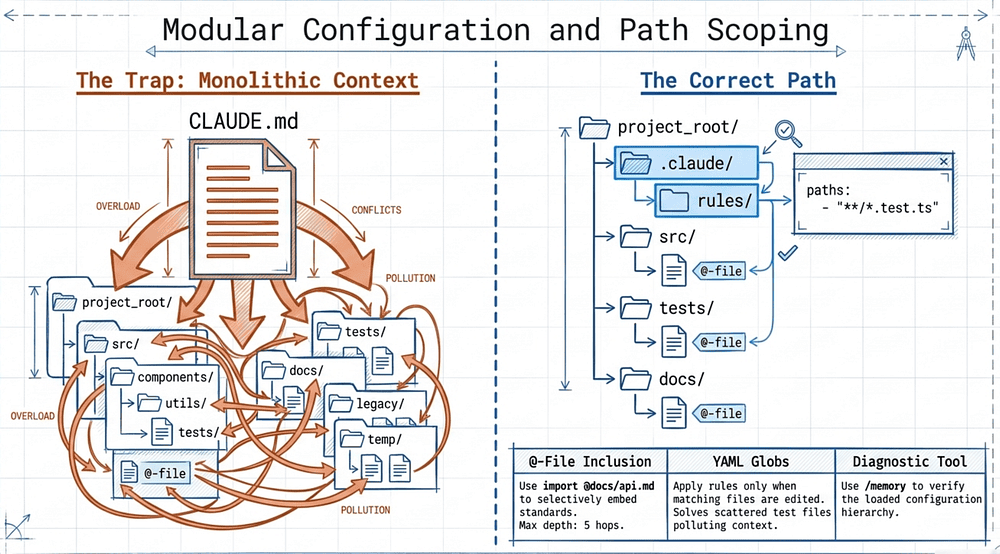
What They Miss
Two specific organizational patterns on the exam:
@-file inclusion syntax for modular CLAUDE.md. Instead of one monolithic file, you embed inline file references directly in the CLAUDE.md text [24]:
# Project Standards
git workflow @docs/git-instructions.md
testing standards @./standards/testing.md
api conventions @./standards/api-conventions.md
Each package can selectively import only the standards its maintainer actually cares about. The syntax is an inline @path reference embedded in the surrounding text, not a standalone @import directive. Both relative and absolute paths are supported; relative paths resolve from the importing file's location. [24]
Official wording: "CLAUDE.md files can import additional files using
@path/to/importsyntax. Imported files are expanded and loaded into context at launch alongside the CLAUDE.md that references them."; [24]
The .claude/rules/ directory as an alternative to monolithic CLAUDE.md. Split topic-specific rule files into .claude/rules/testing.md, .claude/rules/api-conventions.md, etc. [24]. These can be loaded together or conditionally via path scoping (see Gap 7). The official example structure:
your-project/
├── .claude/
│ ├── CLAUDE.md # Main project instructions
│ └── rules/
│ ├── code-style.md # Code style guidelines
│ ├── testing.md # Testing conventions
│ └── security.md # Security requirements
Official note: "Rules without
pathsfrontmatter are loaded at launch with the same priority as.claude/CLAUDE.md."; [24]
Import depth limit: Imported files can recursively import other files, with a maximum depth of five hops. [24]
The /memory Command for CLAUDE.md Hierarchy Debugging
When behavior is inconsistent across sessions, use /memory to verify which memory files are actually loaded. This is the diagnostic tool for CLAUDE.md hierarchy issues. [24]
Official wording: "The
/memorycommand lists all CLAUDE.md, CLAUDE.local.md, and rules files loaded in your current session... Run/memoryto verify your CLAUDE.md and CLAUDE.local.md files are being loaded. If a file isn't listed, Claude can't see it."; [24]
The Exam Signal
When a question describes a large CLAUDE.md file that is getting unwieldy, or a team where different packages have different conventions, the answer involves either @-file inclusion for selective inclusion or splitting into .claude/rules/ files. "Put everything in one CLAUDE.md" is the wrong answer when the context implies scale.
Gap 7: .claude/rules/ with YAML paths Globs for Path-Scoped Agent Rules (Domain 3.3)
What the Other Articles Cover
Subdirectory CLAUDE.md files are mentioned. Path-specific rules are not.
What the Exam Tests: YAML Path Globs and Context Scoping
This is its own task statement. The skill is creating .claude/rules/ files with YAML frontmatter that scopes them to specific file patterns [24]:
---
paths:
- "**/*.test.tsx"
- "**/*.test.ts"
---
# Testing Conventions
All tests must use Vitest, not Jest. Test files live next to the code they test.
The rule loads only when Claude is editing a file that matches the glob. [24] Two benefits:
- Reduces context noise: API conventions do not get loaded when editing a test file.
- Handles files that span multiple directories (test files live everywhere in a typical codebase; a subdirectory CLAUDE.md cannot cover them all).
Official wording: "Path-scoped rules trigger when Claude reads files matching the pattern, not on every tool use."; [24]
Brace expansion is also supported for matching multiple extensions in one pattern [24]:
---
paths:
- "src/**/*.{ts,tsx}"
- "lib/**/*.ts"
- "tests/**/*.test.ts"
---
Official glob pattern reference [24]:
**/*.ts; All TypeScript files in any directorysrc/**/*; All files undersrc/directory*.md; Markdown files in the project rootsrc/components/*.tsx; React components in a specific directory
The Decision Rule: Path Rules vs. Subdirectory CLAUDE.md
- Files cluster in one directory (e.g., all API code in
src/api/) → subdirectory CLAUDE.md works. - Files spread across the codebase by type (e.g., test files next to source files) → path-specific rules in
.claude/rules/with glob patterns. [24]
The Exam Signal
The official exam guide's sample questions include one targeting this exact trap: a codebase where React components, API handlers, database models, and test files are scattered across the tree. The trap answer is "put a CLAUDE.md in each subdirectory." The correct answer is .claude/rules/ with glob patterns, because the test files do not sit in one directory.
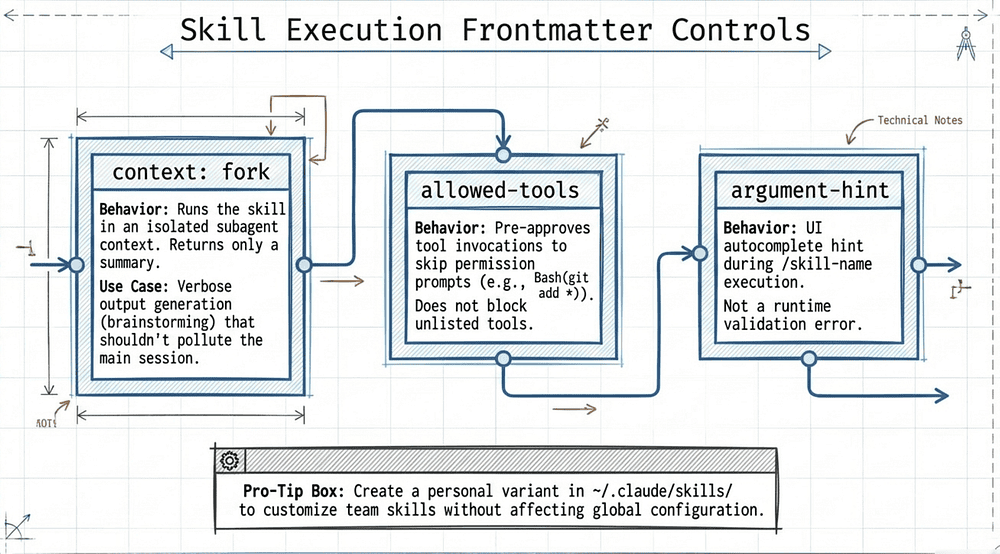
Gap 8: Skill Frontmatter: context: fork, allowed-tools, argument-hint (Domain 3.2)
What the Other Articles Cover
Skills as reusable workflow encodings. Project-scoped vs. user-scoped skill locations.
Skill Frontmatter Keys the Exam Tests by Name
Three specific frontmatter keys appear in answer choices:
context: fork: runs the skill in an isolated subagent context [25]. The subagent lacks access to the main conversation history (sans what was passed via arguments), so the skill's content serves as its sole prompt. Results are summarized and returned to the main conversation, so verbose intermediate output does not accumulate in the main session. Use this when the skill produces verbose output (codebase analysis, brainstorming) that the main session does not need to retain in full.
Official wording: "Add
context: forkto your frontmatter when you want a skill to run in isolation. The skill content becomes the prompt that drives the subagent. It won't have access to your conversation history."; [25]Corollary from the docs: "Results are then summarized and returned to the main conversation."; [26]
The allowed-tools field: pre-approves which tools the skill can invoke during execution, skipping permission prompts for those tools [25]. Use this to scope down a skill that should only read files, or to prevent destructive actions in skills with a narrow purpose. Note: allowed-tools grants pre-approval for listed tools but does not block access to other tools. The field accepts a space-separated list of tool names and supports Bash subcommand patterns for fine-grained shell scoping (e.g., Bash(git add *) runs git add without approving all Bash commands). [25]
Official wording: "The
allowed-toolsfield grants permission for the listed tools while the skill is active, so Claude can use them without prompting you for approval. It does not restrict which tools are available: every tool remains callable, and your permission settings still govern tools that are not listed."; [25] (emphasis added)Corollary from the docs: "To block a skill from using certain tools, add deny rules in your permission settings instead."; [25]
The argument-hint field: shows a hint in the autocomplete UI when a developer types /skill-name, indicating what arguments are expected [25]. The hint appears during tab completion, not as a runtime error or prompt when arguments are missing.
Official wording: "Hint shown during autocomplete to indicate expected arguments. Example:
[issue-number]or[filename] [format]."; [25]
The Personal Variant Pattern for User-Scoped Skill Customization
To customize a team skill for yourself without affecting teammates, create a personal variant in ~/.claude/skills/ with a different name. Your version lives at the user level. The team version stays untouched. [25]
Official scope table; personal skills path:
~/.claude/skills/<skill-name>/SKILL.md; "Applies to: All your projects." [25]
Priority rule: "When skills share the same name across levels, higher-priority locations win: enterprise > personal > project."; [25]
The Exam Signal
When a question shows a skill that produces verbose exploration output, derailing the main session, the answer includes context: fork. When a question describes a skill that should have a tight tool scope, the answer includes allowed-tools. These are distractors only if you do not know the frontmatter keys.
Research Notes
Sources consulted for Part 3:
- Claude Code Docs — Memory · https://code.claude.com/docs/en/memory · @-file inclusion syntax; relative-path resolution;
.claude/rules/directory; YAMLpathsfrontmatter;/memorycommand; 5-hop import depth limit - Claude Code Docs — Skills · https://code.claude.com/docs/en/skills ·
context: forksemantics;allowed-toolsbehavior;argument-hintautocomplete hint; personal skill scoping; priority order - Claude Code Docs — Slash Commands · https://code.claude.com/docs/en/slash-commands ·
context: forkresult-return behavior ("summarized and returned to the main conversation")
Configuration mechanics are one layer. The runtime layer is another. Part 4 shifts to the quality and validation patterns that govern how a Claude Code workflow performs: iterative refinement techniques, structured field design, and independent review architectures, all tested by name in domains 3.5, 4.4, and 4.6. Get these right, and you earn points that most candidates leave on the table.
Three quality and validation patterns the CCA exam tests by name: iterative refinement techniques for Claude Code workflows, structured validation field design, and independent review instance architecture. These gaps separate candidates who understand system-level quality from those who know only basic validation loops. Each section maps directly to CCA exam domains 3.5, 4.4, and 4.6.
Gap 10: Iterative Refinement Patterns for Claude Code (Domain 3.5)
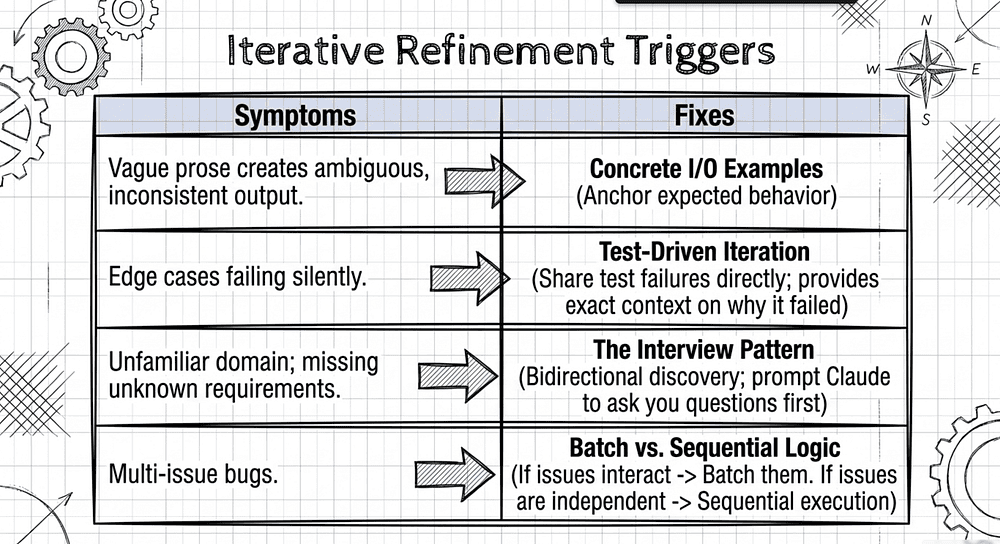
What the Other Articles Cover
Validation-retry loops with specific error feedback. Bounded retries.
What the Exam Tests by Name
Four refinement techniques with specific triggering conditions:
Concrete input/output examples. When prose descriptions of a transformation produce inconsistent results, the fix is not "write a better prompt." Show 2-3 concrete examples of input and expected output instead. This works when natural language is ambiguous; examples anchor the expected behavior. [27] [28] Few-shot prompting, providing a small number of representative input/output pairs, consistently outperforms pure prose instructions for specialized or nuanced tasks where the model might not grasp specific requirements from description alone. [29]
Test-driven iteration. Write the test suite first, covering expected behavior, edge cases, and performance requirements. Then iterate by sharing test failures. The model sees what failed and why, not a vague "please improve the code." [30] [31] Research on TDD workflows with Claude Code confirms that "running tests with Claude allows it to interpret failures and error messages to guide fixes, and using test failures feeds the LLM context exactly on how and why the app fails." [32]
The interview pattern. Have Claude ask you questions before implementing. This surfaces considerations you have not thought about: cache invalidation strategies, failure modes, and edge cases specific to your domain. You answer the questions, then Claude implements with the added context. This is especially valuable in unfamiliar domains where you do not know what you do not know. [33] This technique reflects a broader shift in Agentic AI from top-down specification ("tell it once, it builds") to bidirectional discovery, in which the model uses clarifying questions to uncover requirements you did not know you had. [33]
Batching vs. sequential issue fixing. This one trips people up.
- Interacting problems (fixing one affects the others) → address all of them in a single detailed message so the model sees the full picture.
- Independent problems (fixes do not interact) → iterate sequentially, fixing one at a time. (/batch)
The wrong move is batching independent issues (the model spreads attention too thin) or sequencing interacting issues (each fix breaks the previous one). [35] [34]
The Exam Signal
When a question describes vague prose instructions producing inconsistent output, the answer is concrete I/O examples, not more detailed prose. When a question describes an unfamiliar domain where the developer does not know the right questions, the answer is the interview pattern. When a question describes multiple issues, check whether they interact to determine batch vs. sequential.
Gap 11: Self-Correcting Schema Design for Extraction Agents (Domain 4.4)

What the Other Articles Cover
Semantic validation gates. Validation-retry loops. Tracking validation errors. All of that treats validation as a separate step that runs after extraction.
What They Miss: Validation Built Into the Schema Itself
The exam tests a deeper pattern. Instead of extracting a flat value and then validating it, you design the schema so that problems surface as part of the extraction. The model does the work of flagging discrepancies inline, without a second pass.
Three concrete realizations of this pattern show up in exam answer choices. The specific field names vary, but the shape is the same: the schema captures enough detail that inconsistencies become visible in the output itself.
Trigger metadata on structured findings. When a code review agent flags an issue, the finding includes metadata about which rule, pattern, or code construct triggered it. Call the field detected_pattern, rule_id, or trigger: the shape matters more than the name. A typical shape:
{
"severity": "major",
"detected_pattern": "broad_except_Exception",
"file": "services/billing.py",
"line": 147,
"message": "Bare except swallows all errors."
}
Later, when you analyze which findings developers dismissed, you group by detected_pattern. If broad_except_Exception has a 90% dismissal rate, that pattern is generating false positives in your codebase and you tune it down. Without the field, every dismissed finding is just noise; you have no way to improve signal.
Dual-value capture for arithmetic consistency. For invoice extraction, instead of extracting just total, extract both the value as stated in the document and the value derived from the line items:
{
"vendor": "ACME Corp.",
"stated_total": 1247.50,
"line_items_sum": 1142.50,
"discrepancy_flag": true
}
The model fills both fields during extraction. If they disagree, the flag surfaces automatically. No separate arithmetic-validation pass is needed because the schema itself forces the model to perform the check inline. This is a direct application of "have the model do the math while it's looking at the document," the same principle that makes chain-of-thought prompts more accurate on arithmetic tasks.
Conflict flags for inconsistent source data. When a document contains contradictory values: a date written two ways, a total that contradicts itself, a vendor name that changes between header and footer, the extraction captures both and flags the conflict rather than silently picking one:
{
"invoice_date": "2026-03-14",
"invoice_date_alt": "2026-04-14",
"conflict_detected": true,
"conflict_fields": ["invoice_date"]
}
The downstream system; or a human reviewer; decides how to reconcile. The model's job is to surface the ambiguity, not to resolve it on the user's behalf.
The Pattern
Each of these is a self-correcting schema. The schema forces the model to surface problems during extraction, rather than hiding them in a single flat value that looks plausible but is wrong. The exam tests whether you can recognize this pattern shape when it appears, not whether you've memorized any specific field name.
Think of it this way: a naive schema asks "what is the total?" A self-correcting schema asks, "What does the document say the total is, and does that match the sum of the line items?" The second prompt is structurally harder to answer incorrectly, because the model has to show its work.
The Exam Signal
- When a question describes an extraction pipeline producing plausible-looking but incorrect values, look for answers that extract both a stated value and a derived check value. The trap is a single-field schema with a post-hoc validator.
- When a question describes developers dismissing findings, look for answers about tracking which patterns or rules triggered each finding. The trap is "improve the prompt" without instrumentation to tell you which prompt change helped.
- When a question describes ambiguous source data, look for schemas that capture both competing values plus a conflict flag. The trap is schemas that force the model to pick one value, silently.
The underlying principle: design schemas so the model's own output surfaces the problems, instead of demanding a second-pass validator to discover them. This is consistent with broader structured-extraction best practices around schema-driven validation and LLM-as-a-judge post-checks, where richer schemas consistently outperform flat ones on accuracy and reliability. [47]
Gap 12: Independent Review Instance vs. Self-Review in Claude Code (Domain 4.6)
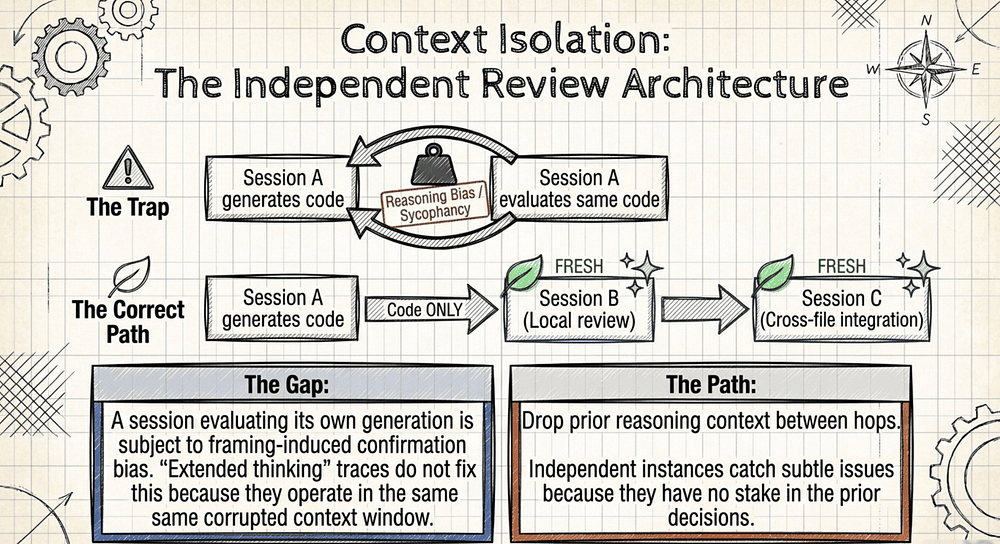
What the Other Articles Cover
Multi-pass review (per-file + cross-file integration). Splitting large reviews to avoid attention dilution.
What Is Missing
A distinct principle: independent instance review beats self-review.
Why Independent Review Instances Outperform Self-Review
A Claude session that generates code carries the reasoning context that led to it. Asking that same session to review its own work is asking it to question decisions it has already committed to. The reasoning bias is real and documented.
This is where Agentic AI system design diverges sharply from single-agent thinking. Multiple independent lines of research converge on this point. First, LLM-assisted security code review research shows that framing and prior context in the review prompt cause substantial confirmation bias: when a code change is framed as "bug-free," vulnerability detection rates drop by 16-93% across tested models, demonstrating how susceptible LLM reviewers are to the context loaded before they evaluate code. [36] A session that generates code loads the same reasoning context into subsequent review, creating analogous framing conditions. Second, multi-agent debate research has found that LLM agents exhibit both sycophancy and self-bias when reasoning in shared context; while sycophancy (uncritically adopting peer views) dominates in most model-dataset combinations, self-bias (stubborn adherence to prior outputs) emerges as a significant factor in certain configurations. [38] A code-generating session that subsequently reviews its own output occupies an analogous single-context position where prior reasoning commitments can resist revision. Third, confirmation bias in chain-of-thought reasoning skews both the reasoning process and the use of rationales for answer prediction. [37]
Extended thinking; Claude's visible step-by-step reasoning trace is not a documented remedy for this bias, and there is no published Anthropic claim that it resolves same-session self-review bias. The reasoning traces unfold within the same context window that already carries the prior commitments, so the underlying framing-bias and self-bias dynamics persist. Self-review instructions ("now critically evaluate your output") are similarly insufficient as a remedy, consistent with the confirmed framing-bias and sycophancy/self-bias research above.
The fix is a second independent Claude instance with no prior reasoning context. It sees only the code and the review criteria. It catches subtle issues the generator missed because it has no stake in the prior decisions. This parallels findings from TDD multi-agent research: "When everything runs in one context window, the test writer's analysis bleeds into the implementer's thinking, and the implementer's code exploration pollutes the refactorer's evaluation." Context isolation is the structural solution. [32]
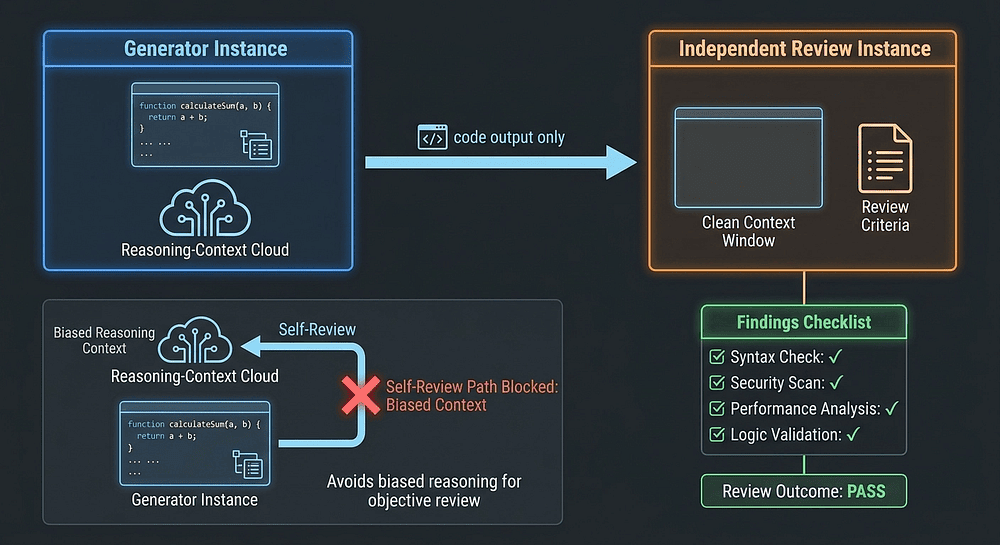
The Combined Multi-Instance Review Pattern
For large multi-file generation, the pattern that scales from the self-review principle is a chain of independent instances, not a single reviewer doing everything. A typical shape:
- Session A generates the code.
- Fresh Session B reviews each file for local issues: correctness, style, obvious bugs: with no knowledge of the generation context.
- Fresh Session C runs the cross-file integration pass: interface contracts, import cycles, architectural drift: with no knowledge of either prior session.
- Optionally, a fourth pass where the model self-reports confidence alongside each finding, which helps a human reviewer triage the list.
Each hop drops the prior reasoning context so it cannot bias what comes next. The exam does not name this specific three-session chain in the public guide, but the underlying principle; that context isolation between generation and review improves review quality; is what the scenario questions expect you to apply. It flows directly from the framing-bias and sycophancy/self-bias research cited above and from Anthropic's own guidance that subagents run in their own context window with independent permissions. [39]
The Exam Signal
When a question describes code quality issues that self-review is not catching, the answer involves a separate review instance, not better self-review prompting. When a question invites extended thinking to make self-review work, that is the trap.
Research Notes
Sources consulted for Part 4:
- Prompting Guide; Few-Shot Prompting · https://www.promptingguide.ai/techniques/fewshot · Concrete I/O examples vs. prose instructions
- DataCamp; Few-Shot Prompting Tutorial · https://www.datacamp.com/tutorial/few-shot-prompting · Few-shot outperforms prose for specialized tasks
- The New Stack; Claude Code and TDD · https://thenewstack.io/claude-code-and-the-art-of-test-driven-development/ · Test-driven iteration with Claude
- ResearchGate; Tests as Prompt (TDD Benchmark) · https://www.researchgate.net/publication/391742058 · TDD benchmark for LLM code generation
- alexop.dev; Custom TDD Workflow with Claude Code · https://alexop.dev/posts/custom-tdd-workflow-claude-code-vue/ · TDD context isolation rationale
- Developers Digest; Claude Code Interview Mode · https://www.developersdigest.tech/blog/claude-code-interview-mode · Interview pattern technique; agentic AI bidirectional discovery shift
- Anthropic; Prompting Best Practices (Claude 4) · https://platform.claude.com/docs/en/build-with-claude/prompt-engineering/claude-4-best-practices · Batching vs. sequential, examples
- Claude Code Docs; Best Practices · https://code.claude.com/docs/en/best-practices · Batching vs. sequential issue fixing
- arxiv:2603.18740 · https://arxiv.org/html/2603.18740v1 · Framing-induced confirmation bias drops detection rates 16-93%
- ACL Findings 2025 · https://aclanthology.org/2025.findings-acl.195.pdf · Confirmation bias in chain-of-thought reasoning
- arxiv:2510.07517 · https://arxiv.org/html/2510.07517v3 · Self-bias in multi-agent shared-context reasoning
Those are the quality and validation patterns for domains 3.5, 4.4, and 4.6. Part 5 closes the remaining Domain 5 gaps: human review workflows, field-level confidence calibration, provenance tracking for temporal data, and multi-agent crash recovery. These are the patterns that separate candidates who pass comfortably from those who land on the edge of the cutoff. If you have been taking practice exams and stalling out around 700, the next section is where your points are hiding.
Three full gaps: human review workflows with field-level confidence calibration, information provenance for temporal data, and crash-recovery manifests for multi-agent systems; plus four specific singleton topics the exam has been known to test by name.
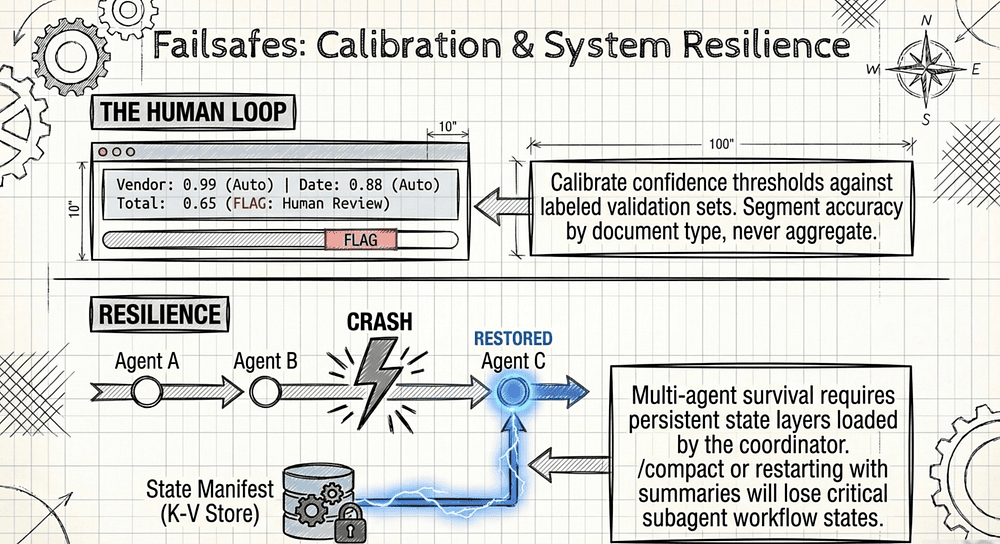
Gap 13: Human Review Workflows: Stratified Sampling and Field-Level Confidence Calibration (Domain 5.5)
What the Other Articles Cover
The confidence-score trap: LLM self-reported confidence is poorly calibrated [40, 41]. Do not use it as your sole gatekeeper.
What Is Entirely Missing
The positive side of this task statement. The exam tests how to actually design human review workflows properly.
The Four Skills for Human Review Workflow Design
1. Stratified random sampling of high-confidence extractions. High confidence does not mean correct. Pull a stratified random sample of high-confidence extractions, have humans label them, and measure the actual error rate. Watch for novel error patterns that did not appear in your training set. If even 5% of "high confidence" extractions are wrong, your confidence threshold is mis-calibrated; empirical studies of uncalibrated LLMs report expected calibration error (ECE) between roughly 7% and 18% across benchmark tasks, so the real rate is often worse than your threshold suggests. [42, 43]
2. Field-level confidence scores, not overall confidence. Instead of "this extraction is 90% confident," assign each field its own confidence score: vendor_name: 0.95, total: 0.70, invoice_date: 0.88. Low-confidence fields route to human review; high-confidence fields in the same document can be auto-processed. This captures where the model is uncertain, not just an aggregate. Modern extraction frameworks such as GLiNER return character offsets and per-field confidence scores as first-class outputs, demonstrating that field-level granularity is a standard production pattern [46].
3. Calibrate confidence thresholds against labeled validation sets. Model confidence is a signal, not a calibrated probability. Map model confidence to actual accuracy using a labeled holdout set [44]. "Model confidence 0.8 corresponds to 92% actual accuracy" gives you a review routing threshold you can defend. Without calibration, you are guessing. Post-hoc calibration methods such as Platt scaling (logistic regression fit on held-out scores) and isotonic regression (preferred for datasets with more than 1,000 examples) are the canonical tools for this mapping [45, 44].
4. Analyze accuracy by document type and field segment. Aggregate accuracy hides problems. Your pipeline reports 97% overall accuracy. That sounds great until you break it down by document type: 99% on invoices, 98% on receipts, 73% on credit memos. The aggregate metric masks a failure mode on a specific document type. Before you reduce human review, verify consistent performance across all segments.
The Exam Signal
When a question describes an extraction system with "97% accuracy overall" that still has quality problems, the answer involves segmenting accuracy by document type and field. When a question describes routing to human review, the answer involves field-level confidence calibrated on a labeled set, not self-reported overall confidence.
The Exam Trap
Do not conflate this with the confidence-score trap from earlier articles. The prior articles say "do not use self-reported confidence as your only gate." This section says "when human review is the design, field-level confidence calibrated on labeled data is a legitimate routing signal." The difference is calibration and specificity.
Gap 14: Information Provenance: Temporal Data and Content-Type Rendering (Domain 5.6)
What the Other Articles Cover
Claim-source mappings in structured output. Conflict annotation rather than arbitrary selection.
What They Miss
Publication and collection dates. Require subagents to include publication dates or data collection dates in structured outputs. Conflicting statistics are often temporal differences, not contradictions. A source saying "unemployment is 3.7%" and another saying "unemployment is 4.1%" may both be correct if they are from different months. Without dates, the coordinator sees a contradiction. With dates, it sees temporal evolution.
Content-type appropriate rendering. Different findings render appropriately for their content type:
- Financial data → tables.
- News and narrative findings → prose.
- Technical findings with multiple discrete items → structured lists.
The trap is converting everything to a uniform format (all prose, all tables, all bullets). That destroys the signal in the presentation. A financial comparison rendered as prose hides the numbers; a news narrative rendered as a table strips the context.
The Exam Signal
When a question describes a synthesis system that produces reports flattening different types of findings, the answer involves rendering content appropriately for its type. When a question describes apparent "contradictions" in research outputs, look for temporal metadata as the fix.
Gap 15: Crash-Recovery Manifests for Multi-Agent Systems (Domain 5.4)
What the Other Articles Cover
Scratchpad files for persisting findings across context boundaries. /compact for reducing context in long sessions.
What They Miss
Structured state persistence via crash-recovery manifests for multi-agent systems. This is a specific pattern the exam names.
How Multi-Agent Crash Recovery with Manifests Works
Each agent in your multi-agent system exports its state to a known location (a file or a key-value store) on a schedule or at significant events. The coordinator maintains a manifest of agent states. On crash recovery or session resume, the coordinator loads the manifest and injects each agent's last known state into its prompt before resuming work.
This mirrors industry practice in durable workflow frameworks. LangGraph, for example, includes a built-in persistence layer with checkpointing that snapshots the entire graph state at each superstep; when agent nodes fail, the system can be re-invoked with the same thread ID to resume from the last successful checkpoint without re-executing completed nodes [48, 49]. The same checkpoint-at-each-superstep pattern applies directly to multi-agent Claude Code pipelines, with state written to a manifest file or key-value store rather than a graph database.
Why State Persistence Matters for Production Agent Systems
Without manifests, a crashed multi-agent workflow restarts from zero. Hours of subagent work are lost. With manifests, each agent picks up where it left off; findings, error state, and partial results intact.
The Exam Signal for Crash Recovery
When a question describes a long-running multi-agent system that needs to survive crashes or session timeouts, the answer involves structured state export and a coordinator-loaded manifest. Not "just use /compact." Not "restart with a summary." A durable state layer that each agent reads and writes to.
Smaller Specific Items the CCA Exam Singles Out
These are not full task statements, but each can show up as a single question.
Multiple customer matches require clarification, not heuristics. When get_customer returns three people with the same name, the agent asks for additional identifiers (order number, email, ZIP code). It does not pick the one with the most recent account activity, the most orders, or any other heuristic. Heuristic selection causes misidentified accounts. Clarification is the only correct pattern.
Escalate on policy gaps, not just policy complexity. The standard escalation triggers are explicit customer requests, inability to progress, and policy exceptions or gaps. The "policy gap" case is underweighted: when the customer asks something your policy does not address, that is not a hard case. It is a case where the policy is silent. Example: competitor price matching when your policy only addresses your own-site adjustments. Escalate. Do not try to infer a policy.
Batch submission frequency from SLA constraints. If your SLA is 30 hours and batch processing can take up to 24 hours, submit batches every 6 hours (or tighter) to meet the SLA. The arithmetic: SLA budget minus maximum batch processing time equals submission frequency ceiling. 30-24 = 6 hours. Memorize the math.
load_document instead of fetch_url. Generic tools (fetch_url, search_anything) are replaced with constrained alternatives (load_document, which validates the URL is a document, and search_papers, which only hits the academic index). The pattern generalizes: replace generic tools with purpose-specific ones that enforce preconditions. [53, 54]
Scoped cross-role tools for high-frequency needs. When a subagent frequently needs a capability beyond its primary role, giving it a scoped version of the tool is better than routing everything through the coordinator. Example: the synthesis agent gets a verify_fact tool for simple lookups; complex verification still routes through the coordinator to the web search agent. This reduces round-trips without blowing up the tool budget. Anthropic's subagent docs describe this directly: subagents run in their own context window with specific tool access and independent permissions, and "if you keep all tools selected, the subagent inherits all tools available to the main conversation": the correct move is to deselect every tool the role does not need. [39, 52]
Quick Reference: All 15 CCA Exam Gaps Mapped to Domains
All 15 gaps, grouped by domain:
Domain 1: Agentic Architecture & Orchestration (27%)
- Gap 1: PostToolUse hooks for normalization (1.5)
- Gap 3:
--resumeand fresh-with-summary (1.7) - Gap 4: Prompt chaining vs. adaptive decomposition (1.6)
Domain 2: Tool Design & MCP Integration (18%)
- Gap 2: Built-in tool selection (2.5)
- Gap 5: MCP resources as content catalogs (2.4)
Domain 3: Claude Code Configuration & Workflows (20%)
- Gap 6:
@-file inclusion and.claude/rules/(3.1) - Gap 7:
.claude/rules/with YAML paths (3.3) - Gap 8: Skill frontmatter keys (3.2)
- Gap 9: Explore subagent (3.4)
- Gap 10: Iterative refinement patterns (3.5)
Domain 4: Prompt Engineering & Structured Output (20%)
- Gap 11:
detected_pattern,calculated_total,conflict_detected(4.4) - Gap 12: Independent review instance (4.6)
Domain 5; Context Management & Reliability (15%)
- Gap 13: Stratified sampling and field-level confidence (5.5)
- Gap 14: Temporal data and content-type rendering (5.6)
- Gap 15: Crash-recovery manifests (5.4)
The five-domain structure is confirmed by the official CCA exam guide [55, 51]. Domain 5 (Context Management & Reliability) explicitly covers confidence calibration, long-context handoffs, and resilience patterns: the three themes this article fills in.
If you can speak confidently to each row above, you have closed the gaps the rest of the series left open.
CCA Exam-Day Decision Heuristics for Domain 5 Topics
A few heuristics that help when these specific topics come up on exam day:
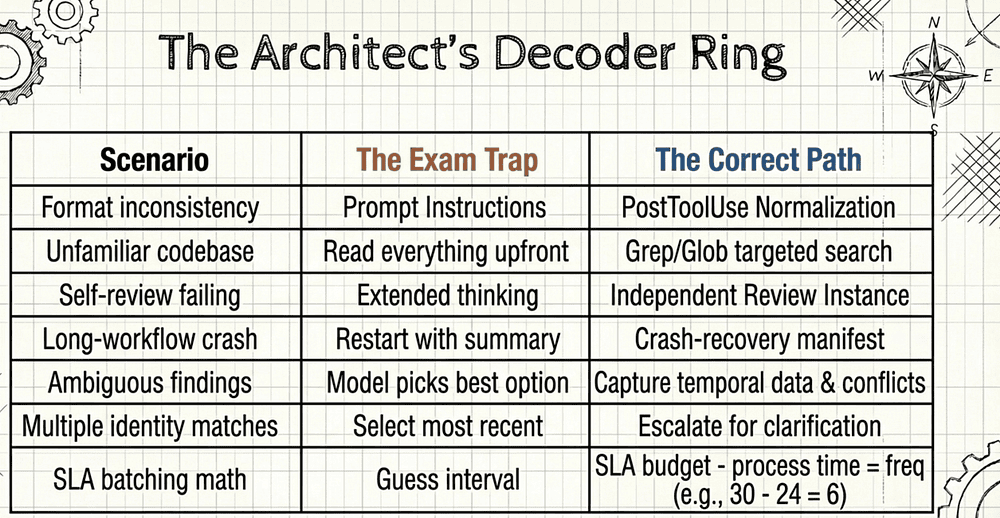
Data format inconsistency across tools → PostToolUse normalization. Not prompt instructions. PostToolUse hooks fire immediately after a tool executes and can append additional context for Claude to consider or block further processing. For MCP tools specifically, they can also replace the tool output entirely before Claude processes it [12].
Finding things in a codebase → start with Grep for content or Glob for paths. Not "Read everything."
Coming back to a session after code changes → decide if prior context is still valid. Resume with explicit change notification, or start fresh with a summary. The --resume flag in Claude Code restores the entire message history and tool state from a named or ID-referenced session; when a session is too large to reload in full, it offers to resume from a summary instead [50].
Multi-directory file types like tests or configs → .claude/rules/ with globs. Not subdirectory CLAUDE.md.
Self-review not catching issues → independent instance. Not extended thinking.
Aggregate metrics masking problems → segmentation. By document type, by field, by any axis, the aggregate hides.
"Contradictions" in research output → temporal metadata first. Many "contradictions" are just different dates.
Long-running multi-agent workflow that needs resilience → crash-recovery manifests. Not "just retry." Research on AI agent resilience consistently identifies checkpoint-based state export as the production-grade approach [48, 49].
Closing Thought

These topics are not glamorous. They are not the headline mental models like "programmatic enforcement beats prompt-based guidance" or "subagents do not inherit context." They are the narrower skills the exam guide lists as distinct task statements, which means the exam is free to write questions around them.
Candidates who skip these gaps can still pass. The headline concepts cover enough surface area. But missing them is where you lose the margin that separates 720 (pass) from 850+ (comfortable pass). If you are on the edge after your first practice exam, come back to this article. These are the points you can still pick up.
Every point between 720 and 850 comes from a candidate who knew the answer to a question most people guessed on. These 15 gaps are your answer keys.
Good luck on exam day.
Research Notes
Sources consulted for Part 5:
- Geng et al., "A Survey of Confidence Estimation and Calibration in Large Language Models" (NAACL 2024) · https://aclanthology.org/2024.naacl-long.366.pdf · LLM self-reported confidence poorly calibrated claim
- Chhikara, "Mind the Confidence Gap" (arXiv, Feb 2025) · https://arxiv.org/abs/2502.11028 · LLM overconfidence / miscalibration
- Niculescu-Mizil & Caruana, "Predicting Good Probabilities With Supervised Learning" (ICML 2005) · https://www.cs.cornell.edu/~alexn/papers/calibration.icml05.crc.rev3.pdf · Platt scaling and isotonic regression
- scikit-learn, "Probability Calibration" (v1.8, 2025) · https://scikit-learn.org/stable/modules/calibration.html · Calibrating model confidence on labeled holdout sets
- SAS Data Science Blog, "The rise of small language models for information extraction" (Dec 2025) · https://blogs.sas.com/content/subconsciousmusings/2025/12/17/ · Field-level confidence scores as production pattern
- eunomia.dev, "Checkpoint/Restore Systems: Evolution, Techniques, and Applications in AI Agents" (May 2025) · https://eunomia.dev/blog/2025/05/11/ · Checkpoint-based crash recovery for multi-agent systems
- Indium Tech, "7 State Persistence Strategies for Long-Running AI Agents in 2026" · https://www.indium.tech/blog/ · State persistence manifest pattern
- Anthropic, "Claude Code Hooks Reference" (code.claude.com, 2026) · https://code.claude.com/docs/en/hooks · PostToolUse hook behavior
- Anthropic, "Claude Code Common Workflows" (code.claude.com, 2026) · https://code.claude.com/docs/en/common-workflows ·
--resumeflag, session continuation - claudecertifications.com · https://claudecertifications.com · CCA exam five-domain structure
References
- AI.cc, "Claude Certified Architect (CCA-F) 2026: Exam Guide & Prep Strategy" (2026)
- LowCode Agency, "Claude Certified Architect: How to Get Certified in 2026" (2026)
- ClaudeFa.st, "Sub-Agent Best Practices" (2026)
- BuildThisNow, "Fork Subagents in Claude Code" (2026)
- Anthropic, "Claude Code CLI Reference" (2026)
- ClaudeLog, "What is the — resume Flag in Claude Code?" (2026)
- Pillitteri, "Claude Code — continue and — resume Guide" (2026)
- Liu et al., "Lost in the Middle: How Language Models Use Long Contexts", Transactions of the Association for Computational Linguistics, vol. 12, pp. 157-173 (2024). DOI: 10.1162/tacl_a_00638
- Anthropic, "Building Effective Agents" (2024)
- ClaudeCertificationGuide.com, "1.6 Task Decomposition Strategies" (2026)
- Anthropic, "Agent SDK Hooks Reference" (2026)
- Anthropic, "Claude Code Hooks Reference" (2026)
- Model Context Protocol, "Resources Specification (2025-11-25)" (2025)
- Model Context Protocol, "Tools Specification (2025-11-25)" (2025)
- Anthropic, "Claude Code Tools Reference" (2026)
- Anthropic, Claude Code GitHub Issue #51781: Platform-specific Glob/Grep behavior (2026)
- Anthropic, Claude Code GitHub Issue #24788: PostToolUse additionalContext failing for MCP tools (2026)
- Anthropic, Claude Code GitHub Issue #32105: updatedToolOutput for built-in tools (2026)
- Anthropic, Claude Code GitHub Issue #40357: Read tool token limits (2026)
- Anthropic, Claude Code GitHub Issue #14888: Read tool support for images, PDFs, Jupyter notebooks (2026)
- Model Context Protocol, "servers-archived: Reference MCP Servers (archived)" (2026)
- Atlassian, "Atlassian Rovo MCP Server is now GA" (2026)
- PulseMCP, "MCP Server Directory" (2026)
- Anthropic, "Claude Code Memory" documentation (2026)
- Anthropic, "Claude Code Skills" documentation (2026)
- Anthropic, "Claude Code Slash Commands" documentation (2026)
- DAIR.AI, "Few-Shot Prompting", Prompt Engineering Guide (2025)
- PromptHub, "The Few Shot Prompting Guide" (2025)
- DataCamp, "Few-Shot Prompting: Examples, Theory, Use Cases" (2025)
- The New Stack, "Claude Code and the Art of Test-Driven Development" (2025)
- Cheshta et al., "Tests as Prompt: A Test-Driven-Development Benchmark for LLM Code Generation", arXiv:2505.09027 (2025)
- alexop.dev, "Forcing Claude Code to TDD: An Agentic Red-Green-Refactor Loop" (2025)
- Developers Digest, "Interview Mode: Let Claude Code Ask the Questions First" (2025)
- Anthropic, "Prompting Best Practices (Claude 4)" (2026)
- Anthropic, "Claude Code Best Practices" (2026)
- "Measuring and Exploiting Confirmation Bias in LLM-Assisted Security Code Review", arXiv:2603.18740 (2026)
- Wan, Jia, Li, "Unveiling Confirmation Bias in Chain-of-Thought Reasoning", Findings of ACL 2025, pp. 3788-3804 (2025)
- "When Identity Skews Debate: Anonymization for Bias-Reduced Multi-Agent Reasoning", arXiv:2510.07517 (2025)
- Anthropic, "Create Custom Subagents", Claude Code Documentation (2026)
- Geng et al., "A Survey of Confidence Estimation and Calibration in Large Language Models", NAACL 2024, pp. 6577-6595 (2024)
- Chhikara, "Mind the Confidence Gap: Overconfidence, Calibration, and Distractor Effects in Large Language Models", arXiv:2502.11028 (2025)
- Yang et al., ECE calibration error benchmarks (2023)
- Zhou et al., "SteerConf: Calibrating LLM Confidence with Semantic Steering", arXiv:2503.02863 (2025)
- scikit-learn, "Probability Calibration", scikit-learn documentation (2025)
- Niculescu-Mizil & Caruana, "Predicting Good Probabilities With Supervised Learning", ICML 2005, pp. 625-632 (2005)
- SAS Data Science Blog, "The Rise of Small Language Models for Information Extraction" (December 2025)
- "Structured Data Extraction best practices; De Jure schema research" (2026)
- eunomia.dev, "Checkpoint/Restore Systems: Evolution, Techniques, and Applications in AI Agents" (May 2025)
- Indium Tech, "7 State Persistence Strategies for Long-Running AI Agents in 2026" (2026)
- Anthropic, "Claude Code Common Workflows" (2026)
- claudecertifications.com, "Claude Certified Architect Exam Guide" (2026)
- Anthropic, "Effective Context Engineering for AI Agents", Engineering Blog (2025)
- CertSafari, "Anthropic Claude Certified Architect — Foundations" (2026)
- Tutorials Dojo, "CCA-F Claude Certified Architect Foundations Study Guide" (2026)
- Anthropic, "CCA Foundations Exam Guide" (official) (2026)
- ClaudeLog, "Plan Mode" (2026)
- GetAIPerks, "Claude Code Plan Mode Complete Guide 2026" (2026)
- GitHub / Piebald-AI, "claude-code-system-prompts" (2026)
- Anthropic, "Claude Code Permission Modes" documentation (2026)
- Anthropic Academy, CCA Foundations preparation courses (Skilljar) (2026)
- Anthropic, Claude Agent SDK Python Issue #781 (2026)
Related Articles in this CCA-F Series
If this article sparked ideas you want to follow further, these pieces cover the patterns directly:
- Claude Certified Architect: The Complete Guide to Passing the CCA-F Foundations Exam
- CCA-F Exam Prep: Mastering the Multi-Agent Research System Scenario
- Claude Code Subagents and Main Agent Coordination: A Complete Guide to AI Agent Delegation Patterns
- CCA-F Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA-F Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA-F Exam Prep: Structured Data Extraction
- CCA-F: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA-F Exam Prep: Mastering the Customer Support Resolution Agent Scenario (Full code examples with runnable notebooks)
- CCA-F Exam Prep: The Multi-Agent Research System in Runnable Code (Full code examples with runnable notebooks)
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.
He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA-F) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code