Claude Certified Architect Practice Exam: 60 Questions with Detailed Explanations
A full-length CCA practice exam covering all 5 domains and 6 scenarios, with explanations that teach you why every wrong answer is wrong
Originally published on Medium.
A full-length CCA practice exam covering all 5 domains and 6 scenarios, with explanations that teach you why every wrong answer is wrong

Unlock your potential with the ultimate CCA practice exam! Dive into 60 comprehensive questions that cover all domains and scenarios, complete with detailed explanations to help you master the Claude Certified Architect Foundations exam. Get ready to transform your study sessions!
-
Timed pass first (120 minutes) — answer without looking at explanations.
-
Score yourself.
-
Review every explanation.
-
Identify weak domains.
-
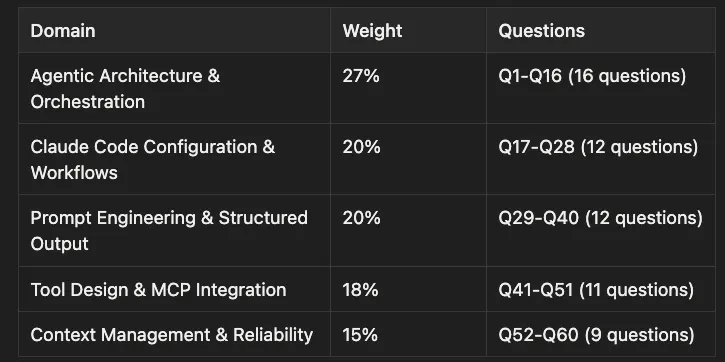
Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam The series opener and exam roadmap. It covers the CCA Foundations format, domain weights, scenario types, and a practical study plan for passing on the first try.
-
Claude Certified Architect — Exam Prep: Mastering the Customer Support Resolution Agent Scenario A deep dive into the customer support scenario, focused on escalation rules, compliance workflows, and why deterministic business logic beats model self-confidence in production support systems.
-
CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario Focuses on code-generation questions from the exam, especially context degradation, CLAUDE.md hierarchy, large-codebase refactoring, and CI/CD-safe Claude Code usage.
-
CCA Exam Prep: Structured Data Extraction Covers high-reliability extraction pipelines, including JSON schema enforcement, semantic validation, retry loops, and the exam’s preference for programmatic guarantees over prompt-only approaches.
-
CCA Exam Prep: Mastering the Multi-Agent Research System Scenario Explains the multi-agent research scenario through hub-and-spoke orchestration, context isolation, tool scoping, explicit context passing, and failure handling patterns that the CCA exam heavily tests.
-
Claude Certified Architect: Master the CI/CD scenario for the CCA Foundations Exam This article focuses on the CI/CD scenario in the CCA series, covering the flags and pipeline patterns that matter in production. It explains why -p, — bare, and structured JSON output are central to passing exam questions about non-interactive automation, validation loops, and reliable pipeline behavior.
-
CCA: Master the Developer Productivity scenario for the Claude Certified Architect exam This piece covers the Developer Productivity scenario, with emphasis on CLAUDE.md hierarchy, MCP configuration, tool scoping, and team workflow design. It frames developer productivity as a multi-domain CCA topic and highlights the exam’s preference for programmatic enforcement, clear configuration boundaries, and disciplined agent design.
A team is building a customer support system using Claude Agent SDK. The design calls for one primary agent that receives all customer requests, determines the category (billing, returns, account issues), and then delegates specialized handling to purpose-built agents that each have their own tool sets and system prompts. The primary agent then combines the results before responding to the customer.
Which architectural pattern does this design describe?
A) Pipeline orchestration with sequential handoffs
B) Peer-to-peer multi-agent collaboration
C) Coordinator-subagent pattern with task delegation
D) Single-agent with dynamic tool loading
The coordinator-subagent pattern is the most heavily tested multi-agent pattern. Know it cold: one coordinator, multiple specialized subagents, synthesis step before final response.
An architect is debugging a Claude Agent SDK application. The agent receives a user query, generates a response that includes a tool call, and then the application needs to decide what to do next. The API response has a stop_reason field.
What does a stop_reason of “tool_use” indicate? A) The agent wants to invoke a tool and is waiting for the tool result before continuing
B) The agent has finished processing and the tool was used successfully
C) The tool execution failed and the agent is requesting a retry
D) The agent has exceeded its maximum tool call limit
Memorize the agentic loop: generate → tool_use stop → execute tool → return result → generate again → end_turn. stop_reason signals the model’s intent for the next step.
A multi-agent research system has a coordinator agent conducting a detailed conversation about quantum computing. The coordinator delegates a subtask (finding recent papers on quantum error correction) to a research subagent using the Claude Agent SDK’s Agent tool.
What context does the research subagent have access to?
A) The full conversation history between the coordinator and the user
B) A summarized version of the conversation history, automatically generated by the SDK
C) The conversation history plus the coordinator’s system prompt
D) Only the prompt string passed through the Agent tool, plus its own system prompt and tool definitions
Exam Trap: Many assume subagents inherit context. They do not. The only channel is the prompt string passed to the Agent tool. Explicitly include any needed context (file paths, decisions, error messages).
A team needs to build an agent that processes customer refund requests:
(1) validate order exists,
(2) check refund policy,
(3) calculate refund amount,
(4) initiate refund in payment system.
Which decomposition approach is most appropriate? A) Create four separate subagents, one for each step, coordinated by a parent agent
B) Use a single agent with four tools, one for each step, since the tasks are sequential and share context
C) Create two subagents (validation + policy check, calculation + payment)
D) Use the Batch API to process all four steps simultaneously
Not every workflow needs subagents. Save them for independent, parallelizable work. Sequential + shared context → single agent with focused tools.
A customer support coordinator delegates a billing dispute to a billing subagent. The subagent encounters an authentication error but returns only: “I was unable to complete the analysis.” The coordinator then tells the customer: “Your billing dispute has been reviewed and no action is needed.”
What is the root cause of this failure? A) The subagent failed silently, and the coordinator lacked the context to detect the failure and respond appropriately
B) The coordinator agent’s system prompt does not include instructions for handling billing disputes
C) The billing system API needs a longer timeout configuration
D) The coordinator should be using the Batch API for billing operations
Exam Trap: The exam often presents silent failures as a “prompt problem.” It is a design failure in subagent error reporting. No coordinator-side prompt engineering fully compensates.
An architect is building an agent with five tools. For most interactions the agent decides tool use freely, but for one workflow it must always call validate_input first.
How should tool_choice be configured? A) Use tool_choice: “none” for general and tool_choice: “any” for validation
B) Use tool_choice: “any” for general and tool_choice: “auto” for validation
C) Use tool_choice: “required” for both and rely on system prompt
D) Use tool_choice: “auto” for general interactions and tool_choice: {“type”: “tool”, “name”: “validate_input”} for the forced validation workflow
- “auto” = model decides
- “any”/”required” = must use a tool (model picks)
- {“type”:”tool”,”name”:”X”} = must use tool X
- “none” = no tools allowed
A research coordinator has a 15-turn conversation on market trends. The user asks: “What if we assumed the opposite market conditions?” The team wants to explore this alternative without losing the existing thread.
Which approach correctly implements this using the Claude Agent SDK? A) Create a new session with an empty history and summarize the original conversation
B) Copy the full message history array into a new API call manually
C) Use fork_session=True in ClaudeAgentOptions to create a branched copy of the current session
D) Use context: fork as a parameter in the Agent tool
Use fork_session=True with the resume parameter for parallel exploration while preserving exact history.
A system must research a topic across three independent dimensions (academic papers, industry reports, news coverage), each requiring different tools. Results need synthesis into a unified report.
Which architecture is most appropriate? A) A coordinator agent with three specialized subagents (one per dimension), each with 3 tools, that run independently before synthesis
B) A single agent with all nine tools that processes each dimension sequentially
C) Three independent agents writing to a shared database, with a final agent reading to produce the report
D) A sequential pipeline where each agent passes findings to the next
Exam Trap: Pipelines look “structured” but hurt performance on independent tasks. Use coordinator + parallel subagents for speed and flexibility.
A customer support agent has attempted resolution three times on a rare edge case it cannot handle. The agent self-reports “85% confident” the issue is resolved.
What should the system do next? A) Trust the 85% confidence and close the ticket
B) Retry a fourth time with additional prompt instructions
C) Escalate to a human agent, providing full interaction history and attempted tools
D) Switch to a model with a larger context window
Bounded retry (2–3 attempts) then escalate. Never use self-reported confidence as the sole criterion.
A research agent currently has 4 tools. The team wants to add capabilities for patent searching, regulatory lookup, financial data, and social media monitoring.
What is the best approach? A) Add all four new tools (total 8)
B) Add the four tools and improve descriptions
C) Create two new specialized subagents (patent/regulatory and financial/social) with 2 tools each; keep original agent as coordinator with its 4 tools
D) Replace with one agent having all 8 tools + few-shot examples
Exam Trap: Few-shot examples demonstrate output format/quality, not tool execution order.
An architect must enforce that an agent never processes PII before it has been anonymized by a preprocessing tool.
Which enforcement approach is most reliable? A) System prompt + few-shot examples showing correct order
B) Create a single combined anonymize_and_process tool
C) Use tool_choice to force anonymize_data first, then switch to auto
D) Register a PreToolUse hook on process_request that verifies anonymization and blocks if not completed
Exam Trap: Prompt + few-shot sounds robust. It is still probabilistic. Security-critical rules require programmatic enforcement (hooks).
A returns agent retries indefinitely during API outages (47 retries in one case). Leadership wants a better design.
Which design correctly implements bounded retry with escalation? A) Maximum of 10 retries with exponential backoff, then generic error to customer
B) Maximum of 2–3 retries with specific error feedback on each retry, then escalate to human with full context
C) Maximum of 5 retries, increasing context window each time
D) Remove retries entirely and escalate on first failure
Magic number across domains: 2–3 retries with specific feedback. Goldilocks range — not too few, not too many.
A coordinator delegates to three subagents in parallel. Subagent B fails silently and returns “I could not complete the research.”
Where does the coordinator’s conversation state live, and what is the impact of Subagent B’s silent failure? A) State lives in a shared database; coordinator can query error logs
B) State lives in each subagent’s conversation; coordinator reads all sessions
C) State lives in the coordinator’s conversation; coordinator cannot distinguish failure from “no results found” without structured error reporting
D) State is managed by the SDK’s built-in state store
Coordinator sees only final subagent output. Design subagents to return structured status (success/failure/partial + details).
A system uses tool_choice: “any” in its API calls. A user sends: “Hello, how are you today?”
What will happen? A) The model is forced to call one of its available tools
B) The model responds with a friendly greeting
C) The model throws an error
D) The model responds “I cannot help with that”
Use “any” only when every request genuinely requires a tool call. Prefer “auto” for mixed conversational/tool workflows.
An organization is training its team on effective AI collaboration. The framework covers: knowing when/what to delegate, writing clear task descriptions, exercising discernment on outputs, and practicing diligence in verification.
What is this framework called? A) The DACI framework
B) The RACI matrix adapted for AI
C) The Four Pillars of Prompt Engineering
D) The AI Fluency framework: Delegation, Description, Discernment, Diligence
Know the 4 D’s cold. The Description–Discernment loop is particularly emphasized.
A team is setting up Claude Code for a new project. They want to define coding standards, preferred libraries, and project-specific conventions that will apply to everyone who works on the repository.
Where should they place the CLAUDE.md file?
A) In ~/.claude/CLAUDE.md so it applies to all team members
B) In the project root as ./CLAUDE.md or ./.claude/CLAUDE.md so it is shared via source control
C) In /etc/claude-code/CLAUDE.md for system-wide enforcement
D) In each team member’s home directory as ~/CLAUDE.md
Project CLAUDE.md = repo root or .claude/ (shared, versioned). User CLAUDE.md = ~/.claude/ (personal, local).
A developer has the following CLAUDE.md files: organization managed, project, user, and local.
Which describes the CLAUDE.md hierarchy correctly? A) User-level always overrides project-level
B) All four levels are loaded and combined; the managed/org level cannot be overridden
C) Only the project-level file is loaded
D) The most recently modified file takes priority
Exam Trap: Many miss CLAUDE.local.md (gitignored local overrides).
A team adds Claude Code to their GitHub Actions workflow. The pipeline hangs indefinitely at the Claude Code step.
What is the most likely cause? A) Claude Code is running in interactive mode and the -p flag was not used
B) The ANTHROPIC_API_KEY environment variable is not set
C) The CI runner does not have enough memory
D) Claude Code requires a GUI terminal
Pipeline hanging in CI = missing -p flag. This is the single most common CI/CD trap.
A team needs consistent, reproducible behavior across all CI runners.
Which flag should they add?
A) — deterministic
B) — no-context
C) — bare
D) — reproducible
— bare is Anthropic’s primary recommendation for CI/CD pipelines.
A team has a complex code review checklist.
When should they use a custom skill (.claude/skills/code-review/SKILL.md) instead of adding instructions to CLAUDE.md? A) Skills and CLAUDE.md are interchangeable
B) Use a skill when the instructions are task-specific and do not need to be in context for every session
C) Use CLAUDE.md for long instructions and skills for short instructions
D) Skills are only for slash commands
Skills = on-demand, task-specific.
CLAUDE.md = always-loaded, broadly applicable.
A team has a shared PostgreSQL MCP server and each developer has a personal GitHub MCP server.
Where should each MCP server be configured? A) Both in .mcp.json
B) The PostgreSQL server in CLAUDE.md
C) Both in ~/.claude.json
D) The PostgreSQL server in .mcp.json (project level) and the GitHub server in ~/.claude.json (user level)
.mcp.json = project/shared/committed.
~/.claude.json = user/personal/never committed.
A CI pipeline needs to extract results programmatically using jq.
Which approach produces machine-parseable output? A) Use claude -p and parse plain text with regex
B) Use claude -p with — output-format json
C) Use a prompt instruction “return as JSON”
D) Use — format structured
— output-format json for machine-parseable output.
Never rely on “return JSON” in the prompt for pipelines.
A CI pipeline needs Claude Code to return a specific structure with passed (boolean), failures (array), and summary (string).
Which approach guarantees schema compliance? A) Include the schema in the prompt
B) Use — output-format json then validate in post-processing
C) Use — output-format json — json-schema “{…}”
D) Use — output-format json and add few-shot examples
Generation-time enforcement ( — json-schema) prevents failures.
Post-generation validation only detects them.
A tech lead wants to enforce TypeScript strict mode, functional React components, and Zod validation for the entire team, versioned with the project.
Which CLAUDE.md configuration is correct? A) Each developer adds these rules to ~/.claude/CLAUDE.md
B) The tech lead adds these rules to the organization-managed location
C) The tech lead adds these rules to ./CLAUDE.md in the project repository
D) The tech lead emails the rules to each developer
Team coding standards = project-level CLAUDE.md (./CLAUDE.md).
Personal preferences = user-level (~/.claude/CLAUDE.md).
An architect is designing a GitHub Actions workflow where Claude Code performs three tasks on every pull request: security review, test generation, and code style remediation.
Which pipeline design is correct? A) A single Claude Code call with all three tasks in one prompt
B) Three separate Claude Code calls, each with — bare -p and task-specific — json-schema
C) A single Claude Code call in interactive mode
D) Three parallel calls without the -p flag
CI/CD best practice:
— bare -p “prompt” — allowedTools “…” — json-schema “…”
for each separate concern.
A developer argues that adding “Please return your response as JSON” to the prompt is equivalent to using — output-format json.
Is this correct? A) Yes, both approaches produce identical, reliable JSON output
B) Yes, but the flag is faster
C) No, prompt-based JSON is actually more reliable
D) No, prompt-based JSON may include markdown or extra text while the flag provides a guaranteed JSON envelope
Programmatic flags ( — output-format, — json-schema) are always more reliable than prompt instructions for structured output.
A new developer joins a project that has ./CLAUDE.md, .mcp.json, and skills. The developer also has personal MCP servers.
What should the developer configure? A) Add their personal MCP servers to ~/.claude.json and optionally set personal preferences in ~/.claude/CLAUDE.md
B) Nothing; all configuration is automatic
C) Copy the project .mcp.json and add personal servers
D) Edit the project .mcp.json to add personal servers
Project config loads automatically; personal MCP servers require manual setup in ~/.claude.json.
A team uses Claude’s structured output feature with a JSON schema to extract invoice data.
What does strict JSON schema enforcement guarantee? A) The extracted values will be factually correct
B) The output will be valid JSON
C) The output will conform to the specified structure but does not guarantee semantic accuracy
D) Both structural compliance and semantic accuracy
Schema = structure guarantee.
Validation = semantic guarantee.
You need both layers for reliable extraction.
A system prompt includes “Always return your response as valid JSON.” Approximately 15% of responses include markdown or extra text.
What is the correct fix? A) Make the instruction more emphatic
B) Use programmatic enforcement through — json-schema or tool_choice
C) Add few-shot examples showing raw JSON
D) Switch to a more capable model
“Always return JSON” in the prompt is the classic trap. Escalate to programmatic enforcement.
An extraction pipeline retries when validation fails with the generic message “The output was invalid. Please try again.”
What is the most effective improvement? A) Replace the generic error message with specific feedback
B) Increase the retry count to 10
C) Switch to a larger model for retries
D) Skip the retry and escalate on first failure
Specific feedback is the key variable in retry loop effectiveness.
A developer includes three few-shot examples and believes they also control the order in which the model calls tools.
Which statement is correct? A) Few-shot examples effectively control both output format and tool execution order
B) Few-shot examples are deprecated in favor of JSON schema
C) Few-shot examples are only useful for simple tasks
D) Few-shot examples demonstrate output format and quality, but do not reliably control tool execution order
Few-shot = format and quality demonstration. Tool ordering = programmatic enforcement.
A team needs to analyze 5,000 code files for security vulnerabilities as part of a nightly audit.
Which processing approach is most cost-effective? A) Process through the real-time API with parallel requests
B) Use the Message Batches API for 50% cost savings
C) Process files sequentially through Claude Code with -p flag
D) Use the Batch API with Zero Data Retention
Exam Trap: Batch API and Zero Data Retention are mutually exclusive.
Schema enforcement produces correct structure, but extracted values sometimes have wrong totals or misspellings.
Which approach addresses this gap? A) Add a semantic validation layer with cross-referencing and business rule checks
B) Use a more restrictive JSON schema
C) Switch to a larger model
D) Add more few-shot examples
Schema enforces structure. Business rules enforce semantics. You always need both layers.
An architect must ensure amounts never exceed $1,000,000.
Three proposals:
A) Add to the system prompt
B) Use a PostToolUse hook
C) Use a JSON schema with “maximum”: 1000000Which is most reliable? A) A alone
B) B and C combined
C) C alone
D) All three
Ranking: prompt (lowest) < schema < programmatic hooks.
Use multiple programmatic layers.
A data extraction pipeline retries when validation fails.
What is the recommended maximum retry count before escalation? A) 1 retry
B) 5–7 retries
C) 2–3 retries with specific feedback
D) Unlimited retries
2–3 retries is the universal bounded retry range across CCA domains.
Initial prompt: “Review this code for security issues.” Reviews are inconsistent.
What is the most effective improvement? A) Restructure with specific categories, severity levels, and required output format
B) Add “Be very thorough and detailed”
C) Add 10 few-shot examples
D) Switch to Claude Opus 4.6
Inconsistent output = vague prompt.
Consistent output = structured prompt with specific categories and output requirements.
A 50-page contract extraction system has high error rates on pages 20–30 while edges are accurate.
What is this problem called and what is the correct mitigation? A) Context overflow — use larger context window
B) Attention decay — repeat instructions
C) Token exhaustion — use prompt caching
D) The “lost in the middle” effect — split into smaller chunks and merge results
Larger context window does NOT fix “lost in the middle.” Correct fix is always chunking + merging.
A developer needs typed Pydantic objects from the Claude API.
Which approach provides the strongest type guarantees? A) System prompt + manual parsing
B) client.messages.parse() with Pydantic model and structured-outputs beta header
C) Regular messages.create() + JSON.parse()
D) Batch API with JSON schema
client.messages.parse() with Pydantic returns a fully typed object with compile-time and runtime validation.
messages.parse() + Pydantic = strongest types (beta). tool_choice with structured tool = strongest stable option.
The pipeline produces 98% schema-compliant JSON, but 12% of records have incorrect values.
What does this indicate? A) The JSON schema needs to be more restrictive
B) The model is hallucinating — replace with rule-based extraction
C) Schema ensures structural correctness but not semantic accuracy; add semantic validation layer
D) 12% error rate is acceptable
98% structural + 12% semantic errors = your schema is working; your validation layer is missing.
The Model Context Protocol (MCP) defines three core primitives.
Which answer correctly names all three? A) Functions, Variables, and Callbacks
B) Actions, Data, and Templates
C) Endpoints, Schemas, and Handlers
D) Tools, Resources, and Prompts
Memorize exact names: Tools, Resources, Prompts.
An MCP server provides search capability and full text of static API reference.
Which primitive for each? A) Both as Tools
B) Search as Tool, API reference as Resource
C) Both as Resources
D) Search as Prompt, reference as Resource
Tools = actions/dynamic.
Resources = data/persistent.
This boundary is heavily tested.
Two tools have vague descriptions and 25% of requests are routed incorrectly.
Root cause and fix? A) Tool descriptions are the primary routing mechanism; rewrite them to be specific
B) Fine-tune the model
C) Add keyword-based routing layer
D) Combine the two tools
Every tool description should include:
what it does,
when to use it, and
how it differs from similar tools.
An agent has 18 tools and frequently selects the wrong one.
Recommended solution? A) Improve descriptions of all 18 tools
B) Reduce to 4–5 tools per agent by using specialized subagents
C) Remove least-used tools
D) Add few-shot examples
The 4–5 tool limit is one of the most consistent principles in this domain.
Where is project-level MCP server configuration stored? A) In ~/.claude.json
B) In CLAUDE.md as text
C) In .mcp.json at the project root
D) In ~/.mcp/config.json
.mcp.json = project/shared/committed.
A developer has a personal GitHub API token. A teammate asks to add it to the project .mcp.json.
Why is this a problem? A) It is not a problem
B) The token would be committed to source control
C) .mcp.json does not support authentication
D) Performance issue
Personal tokens go in ~/.claude.json, never in .mcp.json.
Team needs shared PostgreSQL/Sentry servers and each developer’s personal GitHub server.
Correct configuration? A) All in .mcp.json with placeholders
B) Shared in .mcp.json, personal in ~/.claude.json
C) All in ~/.claude.json with setup script
D) Shared as CLAUDE.md instructions
Shared = .mcp.json. Personal = ~/.claude.json.
A subagent calls an MCP tool that returns 503 error but returns only “I was unable to complete the research.”
What is wrong and how to improve? A) Return structured error information (tool name, error type, retryable?, partial results)
B) Retry indefinitely
C) Coordinator should call the tool directly
D) MCP tool should handle all retries internally
Subagents must return: tool name, error type, retryability, partial results.
When is a Resource more appropriate than a Tool for API reference documentation? A) When data changes frequently
B) When the data is too large for context
C) When the client needs to execute an action
D) When the data is relatively static, fits in context, and benefits from persistent availability
Resources = static + fits context + persistent benefit. Tools = dynamic/actions.
An agent with 15 tools has 30% misrouting.
Most effective redesign? A) Rewrite descriptions
B) Split into coordinator + five specialized subagents (3 tools each)
C) Remove API tools
D) Add a separate classification model
15 tools + high misrouting = split into subagents with 4–5 tools each.
A subagent’s MCP tool fails but the subagent fabricates a plausible summary.
What design change prevents this? A) PostToolUse hook that validates tool responses
B) PreToolUse hook to check availability
C) Increase retry count
D) Give coordinator direct access to all tools
Exam Trap:
PreToolUse prevents the call but not substitution.
PostToolUse detects what actually happened.
A support agent processes long account histories but misses issues in the middle.
What is this phenomenon called? A) Context overflow
B) Token truncation
C) The “lost in the middle” effect
D) Recency bias
“Lost in the middle” affects accuracy, not capacity.
All content is present.
A code review agent struggles with large PRs. Teammate suggests larger context window.
Is this the correct solution? A) Yes
B) No — larger window does not fix attention distribution
C) Yes if 10x larger
D) No because it is slower
More capacity ≠ better attention. Chunking is the correct fix.
Pipeline uses Claude’s self-reported confidence for routing to human review.
What is the problem? A) LLM confidence is not reliably calibrated
B) Nothing — confidence is reliable
C) Confidence only works for classification
D) Thresholds are too high
Never use LLM self-reported confidence as primary gatekeeper. Use programmatic validation.
A support agent uses the same 4,000-token system prompt for 10,000 daily requests.
What cost savings does Prompt Caching provide? A) 50% reduction on all calls
B) Zero savings
C) 90% reduction on all tokens
D) 90% reduction on cache reads (25% premium on writes)
Prompt Caching (90% read savings)
vs
Batch API (50% discount, high latency).
An engineer suggests using Message Batches API for all support interactions to save 50%.
Why is this problematic? A) Does not support conversation history
B) Customer support is blocking/real-time; Batch API has no SLA (up to 24h)
C) Only supports English
D) Maximum 100 requests per batch
Batch API = non-blocking/offline.
Real-time API = user-facing/blocking workflows.
Medical claims system occasionally extracts wrong procedure code.
Most effective reliability layer? A) Ask Claude to double-check
B) Use second model and compare
C) Programmatic cross-referencing against known database
D) Add more prompt detail
For critical fields, validate programmatically against authoritative sources.
A 50-turn conversation exists. User wants to explore two alternative strategies simultaneously while preserving full history.
Correct approach? A) Use fork_session=True twice
B) Two new sessions with summary
C) Process sequentially in same session
D) Use Message Batches API
Fork sessions for parallel exploration with shared exact history.
What improves observability in agentic systems? A) Logs and metrics
B) Larger models
C) More tools
D) Longer prompts
You can’t fix what you can’t see.
What is the key principle for reliable agentic systems? A) Perfect prompts
B) System design + layered safeguards
C) Larger models
D) More data
Reliability is engineered, not prompted. Build defense in depth.