Claude Certified Architect -- Exam Prep: Mastering the Customer Support Resolution Agent Scenario
Dominate the Claude Certification Exam: Navigating Customer Support Challenges with Confidence
Originally published on Medium.
🚀 Ready to conquer the Claude Certified Architect (CCA) Exam? Dive into the ultimate guide on mastering the Customer Support Resolution Agent scenario! Uncover the pitfalls that trip up most candidates and learn how to leverage escalation logic and compliance workflows to your advantage. Don’t let common traps derail your success — read more to ensure you’re fully prepared! 📚✨ #CAExamPrep #CustomerSupport #AIArchitecture
Summary: The Customer Support Resolution Agent scenario on the CCA exam tests candidates on escalation logic, compliance workflows, and tool design. Key pitfalls include relying on self-reported confidence scores for escalation decisions, which can lead to costly errors. Instead, deterministic business rules should guide these decisions. The scenario emphasizes the importance of programmatic enforcement for compliance and cost optimization through techniques like Prompt Caching, rather than using the Batch API for live support. Effective tool design limits agents to 4–5 focused tools to maintain accuracy and reduce risk, while structured summaries enhance context management during long support sessions.
Escalation Logic, Compliance Workflows, and the Anti-Patterns That Trip Up Most Candidates
Why This Scenario Is the Hardest
Of the six production scenarios on the Claude Certified Architect (CCA) Foundations exam, the Customer Support Resolution Agent catches the most people off guard. Not because the technology is exotic, but because the scenario feels familiar. Everyone has dealt with customer support. Everyone thinks they know how it works.
That familiarity is the trap.
You walk into a question about support agents and your brain says “I know this.” But the exam is not testing your general intuition about support systems. It is testing your precise knowledge of Anthropic’s recommended architectural patterns. And in this scenario, the patterns that seem intuitively correct are often exactly wrong.
This scenario tests your understanding across multiple competency domains simultaneously: Agentic Architecture (27%), Tool Design (18%), and Context Management and Reliability (15%). It weaves together escalation logic, compliance enforcement, financial authorization, and cost optimization into a single coherent system. Get any one of those wrong and the errors cascade into the others.
Here is what makes this scenario especially dangerous on exam day: the wrong answers look like reasonable engineering decisions. “Use the model’s confidence score to decide when to escalate” sounds smart. “Move support requests to the Batch API to cut costs” sounds efficient. Both are wrong. The exam is designed to test whether you know why.
TRAPS:
🛑 “Use the model’s confidence score to decide when to escalate” — WRONG
🛑 “Move support requests to the Batch API to cut costs”. — WRONG
🛑 “Use the model’s confidence score to decide when to escalate” — WRONG
🛑 “Move support requests to the Batch API to cut costs”. — WRONG
Think of this article as a conversation with someone who already took the exam and is telling you exactly where the landmines are. Every decision point, every trap, every correct pattern: laid out before you sit down to take the test.
If you are preparing for the CCA Foundations exam and want to master the Customer Support Resolution Agent scenario, you are in the right place. For the full exam overview, domain weights, and the complete four-week study plan, start with Article 1: The Complete CCA Foundations Guide.
Claude Certified Architect Series Navigation
- Article 1: Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- Article 2: Customer Support Resolution Agent — Agentic loops, escalation design, confidence calibration
- Article 3: Code Generation with Claude Code — Context degradation, CLAUDE.md hierarchy, CI/CD integration
- Article 4: Multi-Agent Research System: Hub-and-spoke design, context isolation, tool scoping (you are here)
- Article 5: Claude Code for CI/CD — Using Claude Code headless in your CI/CD workflows
- Article 6: CCA Exam — Structured Data Extraction
- This series is a work in progress with 8 total articles.
CCA Exam: The Scenario Setup for Customer Support
The typical exam framing goes something like this: you are designing a customer support agent powered by Claude that handles tier-1 through tier-3 issues. The agent receives customer inquiries via chat, looks up account information, consults policy documents, processes certain actions (like refunds), and escalates complex issues to human agents.
The key actors in the system are:
- Customer: initiates the interaction, expects timely resolution
- Claude Support Agent: the AI agent handling the conversation in real time
- Policy Engine: contains deterministic business rules for refunds, escalation thresholds, and compliance requirements
- Financial System: processes refunds and adjustments within authorized limits
- Escalation Queue: routes issues to human agents with full context
- Audit Log: records every action for compliance and review
A typical interaction flow: a customer contacts support about a billing dispute. The agent retrieves the customer’s profile and history, checks the refund policy for the disputed amount, determines whether it has authority to resolve the issue or needs to escalate, takes the appropriate action, and logs everything.
The exam questions zero in on the decision points within that flow.
- How does the agent decide to escalate? How does it enforce compliance?
- Which API handles the real-time interaction?
- How do you optimize costs without breaking the workflow?
Each of those questions has a wrong answer that sounds right, and the rest of this article explains how to tell the difference.
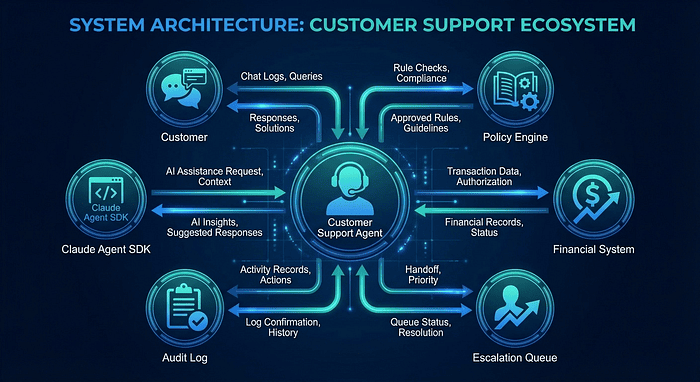
CCA Exam: Customer Support Agent architecture showing central agent connected to Policy Engine, Financial System, Escalation Queue, Audit Log, and Customer
Escalation Logic: Deterministic vs. Probabilistic
This is the single most important concept in the Customer Support scenario. Get this wrong and you will miss multiple questions. Get it right and a whole category of exam traps becomes transparent.
CCA Exam: The Self-Reported Confidence Trap
Here is the anti-pattern the exam loves to test: the agent encounters a complex customer issue and reports that it is “85% confident” in its proposed resolution. The question asks what should determine whether the agent handles the issue or escalates to a human.
The wrong answer that sounds right: “Set a confidence threshold of 80% and escalate when the agent’s confidence falls below it.”
🛑 Set a confidence threshold of 80% and escalate when the agent’s confidence falls below it. — WRONG
That answer sounds like engineering best practice. You are using the model’s own output to make a routing decision. You are data-driven. You are adaptive. And you will get this question wrong if you choose it.
Here is why.
LLM-generated confidence scores are not calibrated the way statistical model probability outputs are calibrated. When Claude says “I am 85% confident,” that number is not calculated from a probability distribution over possible outputs. The model is generating text that resembles a confidence assessment. There is no guarantee that 85% stated confidence corresponds to 85% actual accuracy. Research consistently shows that LLMs exhibit overconfidence in the high-confidence range (90–100%), where stated confidence significantly exceeds actual accuracy.
But the deeper problem is architectural. You are asking the same system that might be wrong to tell you how likely it is to be wrong. That is like asking a student to grade their own test. Even if they are occasionally accurate, you would never build a production financial workflow around it.
And this scenario has financial consequences. A wrong routing decision does not just produce a bad response. It can result in an unauthorized refund, a regulatory violation, or a compliance failure. The stakes make the calibration problem fatal.
🚩 Exam Tip: Any answer choice that mentions “confidence score,” “self-reported confidence,” “model certainty,” or “if the agent is uncertain, escalate” as a routing mechanism is almost certainly wrong. When you see those words in an answer choice, treat it as a red flag and eliminate it before reading the rest of the option.
Correct Pattern: Programmatic Threshold Logic
The right answer is always deterministic business rules evaluated programmatically. Escalation decisions should be based on structured data the model does not get to override:
- Dollar amount: refund greater than $500 requires human review
- Account action: account closure, subscription cancellation always escalate
- Customer tier: VIP customers route to priority queue regardless of issue complexity
- Issue type: legal complaints, regulatory inquiries always escalate
- Policy lookup: the policy engine contains the rule for this specific scenario
These rules live in code. They execute as programmatic hooks (PostToolUse callbacks in the Claude Agent SDK) that fire after the agent proposes an action. The agent proposes a resolution. The programmatic layer validates it against business rules before executing it.
The mental model the exam tests: programmatic enforcement is always stronger than prompt-based guidance for business rules. You can put “always escalate refunds over $500” in the system prompt, and it will work most of the time. But “most of the time” is not good enough when real money is on the line. The programmatic hook catches it every time, with zero exceptions.
What the wrong answer looks like on the exam: the question describes a support agent escalating based on a “confidence threshold set in the system prompt.” The trap is that this looks like the correct approach because you are using both programmatic thresholds (a number) and a policy (escalate when below). The problem is that the threshold is based on self-reported confidence. The correct answer separates the two: use deterministic business rules (dollar amounts, account flags, issue categories) enforced in code, not confidence scores enforced in prompts.
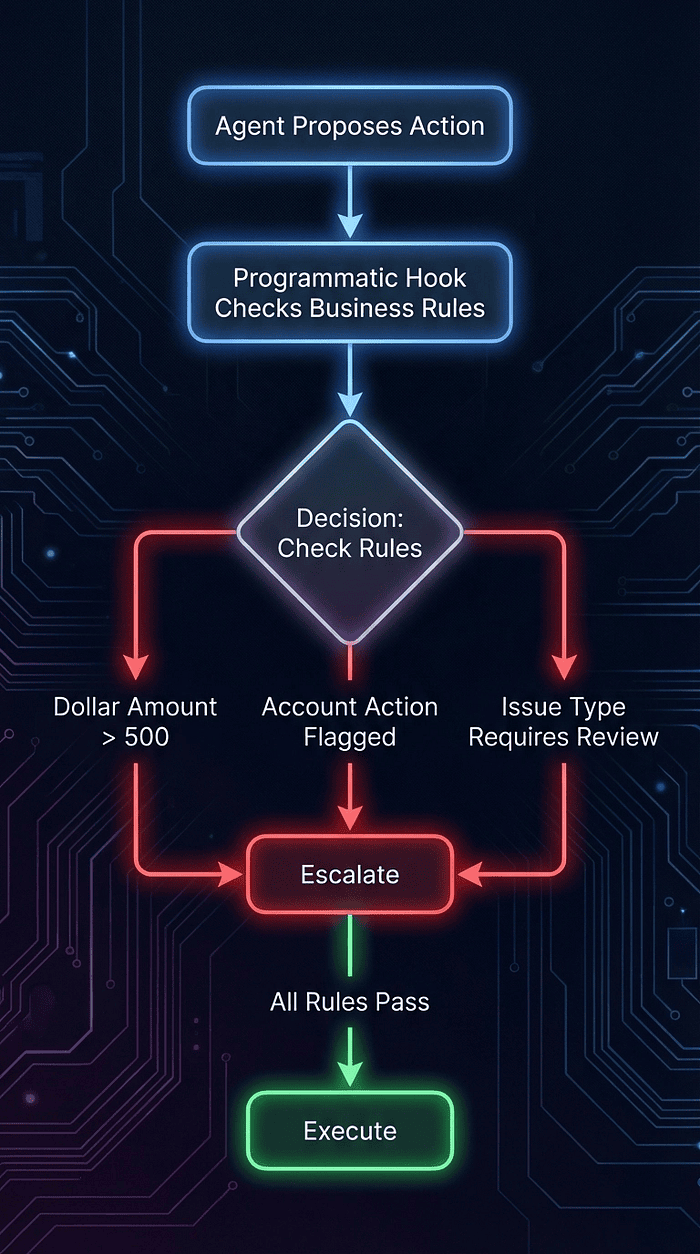
CCA Exam: Escalation decision flow: agent proposes action, programmatic hook checks business rules, three deterministic branches lead to escalation or execution
Compliance Workflows and Financial Consequences
The Customer Support scenario is unique among the six exam scenarios because it has direct financial consequences. A wrong decision by the agent can result in unauthorized refunds, regulatory violations, or compliance failures. The exam tests whether you understand that this changes everything about how you design the system.
Why Compliance Cannot Be Prompt-Based
Consider PCI-DSS requirements for handling payment card data. You cannot “ask Claude to be careful with credit card numbers.” That is not a compliance strategy. That is a hope.
Compliance requirements demand deterministic enforcement:
- Payment data must never appear in logs (programmatic redaction, not “please don’t log sensitive data”)
- Refund authorization must follow a defined approval chain (programmatic validation, not “check if the amount is within limits”)
- Customer identity verification must follow a specific protocol (structured workflow, not “make sure you verify the customer”)
- Every financial action must have an audit trail (programmatic logging, not “remember to log everything”)
Each of these is enforced through code. The system prompt can describe the rules so Claude understands the context, but the actual enforcement happens in the application layer surrounding the agent.
What the wrong answer looks like on the exam: the question asks how to ensure PCI compliance in a customer support agent. One answer says “include detailed PCI compliance requirements in the system prompt so the agent follows them.” Another says “implement programmatic data redaction and audit logging in the application layer, with the system prompt providing context about why these rules exist.” The first answer sounds thorough. It is wrong. Prompts are guidance. Code is enforcement.

Anthropic CCA Exam: Prompt only guidance wrong. Code enforcement correct.
The exam pattern is consistent: when a question asks how to ensure compliance in a customer support agent, any answer that relies solely on prompt engineering is wrong. The correct answer always involves programmatic enforcement with prompts providing context.
Real-Time API vs. Batch API: The Cost Optimization Trap
This is the second major anti-pattern the exam tests, and it catches a surprising number of candidates, including experienced engineers who know both APIs well.
The trap in full: a question describes a customer support system where API costs are high. It proposes moving support interactions to the Message Batches API to achieve 50% cost savings. This sounds like smart engineering. You are cutting costs in half without changing the model or the prompts. What is the problem?
The problem is catastrophic: the Batch API has a processing window of up to 24 hours. There is no formal SLA with guaranteed response times. Most batches complete within an hour, but the system is designed for non-blocking, asynchronous workloads. A customer waiting in a chat window cannot wait an hour. They certainly cannot wait 24 hours. Using the Batch API for live customer support is not a cost optimization. It is an architectural failure that breaks the fundamental contract with your users.
What the wrong answer looks like on the exam: “To reduce API costs for the high-volume customer support system, migrate interactions to the Message Batches API. This achieves 50% cost reduction while maintaining the same model quality.” The answer is attractive because it names a real API, cites a real cost savings percentage, and makes an accurate statement about model quality. All three facts are true. The answer is still wrong because it ignores the fundamental incompatibility between 24-hour processing windows and live customer support.
Here is the decision framework to use on any API selection question:
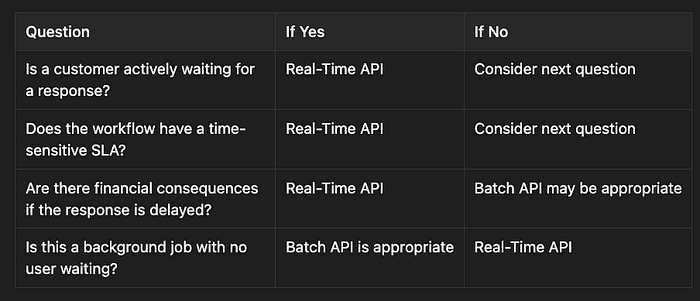
Anthropic CCA: Decision flow
Let’s review the key points in the table:
Is a customer actively waiting for a response? When a customer is in a live chat or phone call, they expect immediate responses. The Real-Time API provides responses within seconds; the only viable option. The Batch API’s 24-hour processing window creates unacceptable user experience. If no customer is waiting, proceed to the next question.
Does the workflow have a time-sensitive SLA? Some workflows have contractual requirements for response within specific timeframes (e.g., one-hour initial response). These demand the Real-Time API’s predictable speed. If there’s no time-sensitive SLA, continue to the next question. You can only use the Batch API if the SLA is greater than 24 hours.
Are there financial consequences if the response is delayed? Delays in refunds, payment disputes, or account adjustments can cause late fees, interest charges, or regulatory penalties. These require the Real-Time API to minimize financial risk. Without financial consequences or immediate users waiting, the Batch API becomes viable for cost optimization.
Is this a background job with no user waiting? This defines appropriate Batch API use cases: nightly audit reports, post-interaction quality scoring, bulk ticket analysis, compliance log reviews, and training data generation. These workloads are cost-sensitive, asynchronous, and have no waiting users. The Batch API’s 50% cost reduction is ideal here. If someone is waiting, use the Real-Time API.
The key insight: cost optimization cannot compromise user experience or compliance requirements. The Batch API is powerful for cost savings, but only for the right workloads. Using it for live customer interactions is an architectural failure.
💡 Exam Tip:
Know when to use Batch API: background jobs only (nightly audit reports, post-interaction quality scoring, compliance log analysis, bulk ticket classification).
Live customer interactions always require Real-Time API.
Know when to use Batch API: background jobs only (nightly audit reports, post-interaction quality scoring, compliance log analysis, bulk ticket classification).
Live customer interactions always require Real-Time API.
Token Economics: The Right Way to Cut Costs
So if you cannot use the Batch API to reduce costs for live support, what do you do? The answer is Prompt Caching. This is the cost optimization the exam expects you to recommend.
In a customer support agent, certain context gets repeated with every single interaction:
- The compliance rulebook (company refund policies, escalation procedures)
- The product catalog (product descriptions, pricing, known issues)
- The escalation policy document (tier definitions, routing rules)
These documents might total 50,000–100,000 tokens. Without caching, you pay full price for those tokens on every customer interaction. With Prompt Caching, you pay full price once and get up to a 90% cost reduction on subsequent requests that reuse the same cached prefix.
The math matters for exam questions. If your support agent handles 10,000 interactions per day and each interaction includes 80,000 tokens of policy context, Prompt Caching saves you roughly 90% on those 800 million repeated tokens daily. That savings is larger than the 50% from the Batch API, and it works with the Real-Time API, so customers keep getting immediate responses.
Exam Tip:
💡 For cost optimization in customer support systems, choose Prompt Caching (90% savings on repeated tokens, real-time compatible).
🛑 Avoid the Batch API trap; despite 50% savings, its 24-hour processing window breaks user-facing workflows.
✅ Prompt cache can be cheaper than Batch API and is still Real-Time.
💡 For cost optimization in customer support systems, choose Prompt Caching (90% savings on repeated tokens, real-time compatible).
🛑 Avoid the Batch API trap; despite 50% savings, its 24-hour processing window breaks user-facing workflows.
✅ Prompt cache can be cheaper than Batch API and is still Real-Time.
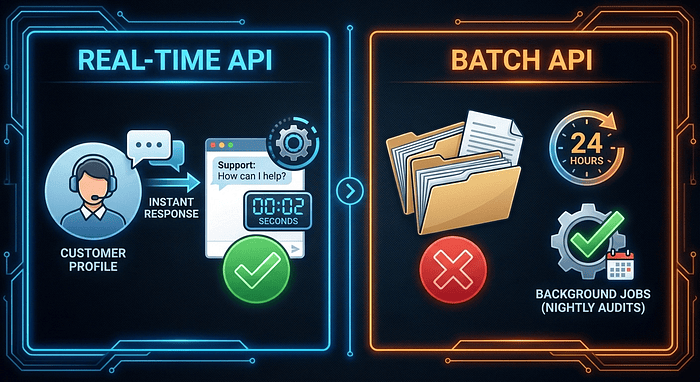
Anthropic CCA Exam: Real-Time API vs Batch API comparison: left panel shows instant chat response for live support, right panel shows 24-hour processing for background jobs
Tool Design for the Support Agent
Domain 4 (Tool Design and MCP Integration) accounts for 18% of the exam, and the Customer Support scenario is one of the primary places it gets tested. This domain trips up more candidates than the weight suggests.
The Focused Tool Set
The correct architecture gives the support agent 4–5 focused tools, each with a clear, unambiguous description:
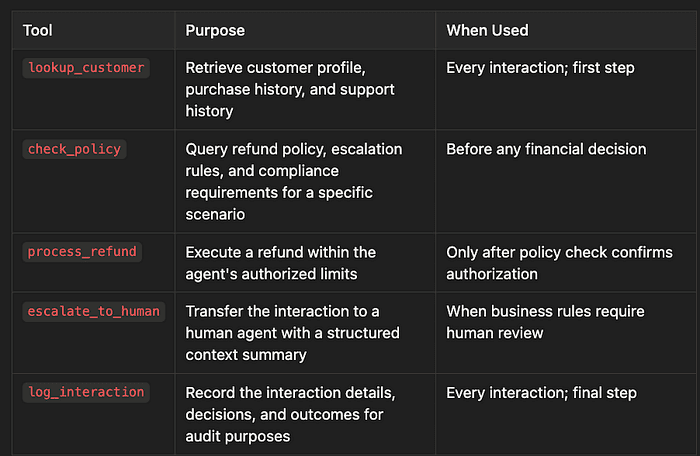
- lookup_customer - Retrieve customer profile, purchase history, and support history - Every interaction; first step
- check_policy - Query refund policy, escalation rules, and compliance requirements for a specific scenario - Before any financial decision
- process_refund - Execute a refund within the agent's authorized limits - Only after policy check confirms authorization
- escalate_to_human - Transfer the interaction to a human agent with a structured context summary - When business rules require human review
- log_interaction - Record the interaction details, decisions, and outcomes for audit purposes - Every interaction; final step
The tool descriptions matter as much as the tool functionality. Claude uses tool descriptions as the primary routing mechanism to decide which tool to call.
A vague description like “handles customer stuff” will lead to misrouting. A precise description like “Retrieve the customer’s profile including purchase history, support ticket history, and account tier. Requires customer_id as input. Returns structured JSON with profile data.” gives Claude exactly the information it needs to select the right tool at the right time.
✅ Exam Tip:
When a support agent calls the wrong tool, the answer depends on tool count.
With 4–5 tools, fix descriptions.
With 12+ tools, reduce count or split into subagents.
Improving descriptions on a 12-tool agent doesn’t solve the selection reliability problem.
When a support agent calls the wrong tool, the answer depends on tool count.
With 4–5 tools, fix descriptions.
With 12+ tools, reduce count or split into subagents.
Improving descriptions on a 12-tool agent doesn’t solve the selection reliability problem.
Anti-Pattern: The Swiss Army Agent
The exam tests the inverse problem as well: giving the support agent too many tools. Imagine a support agent with 15 tools including billing management, shipping tracking, inventory lookup, HR policy queries, marketing campaign management, and product roadmap access.
This fails for two distinct reasons, and the exam expects you to know both:
Reason 1, Tool selection accuracy degrades. With 15+ tools, Claude must evaluate more options per turn, and the probability of selecting the wrong tool increases. Anthropic’s official guidance is 4–5 tools per agent. This is not a soft recommendation. It is the number at which selection reliability is maintained.
Reason 2, Scope creep creates security and compliance risk. A support agent with access to HR policies and marketing campaign data has capabilities it should never exercise. The principle of least privilege applies to AI agents exactly as it applies to human users. An agent that can access HR data can accidentally (or via prompt injection) expose that data to a customer.
The correct pattern when you need more than 5 tools: a coordinator agent handles the conversation and routes to specialized subagents for billing, shipping, or account management. Each subagent has its own 4–5 tools scoped to its domain.

CCA Exam: Calling the right tool. 4–5 tools. Split large agents into smaller agents, 12+ tools — need to be three agents
What the wrong answer looks like on the exam: “The support agent occasionally selects the wrong tool from its 12-tool set. The best fix is to improve the tool descriptions to make each tool more clearly distinguishable.” This answer is partially correct (description quality matters) but addresses the symptom, not the cause. The correct answer is to reduce the tool set to 4–5 focused tools and move the remaining capabilities to specialized subagents.
💡 Exam Tip:
✅ If a question describes an agent with 12 or more tools and asks what to change, the answer is to reduce tool count or split into subagents.
🛑 The answer is never “add more tools” or “write better descriptions as the primary fix for a tool count problem.”
✅ If a question describes an agent with 12 or more tools and asks what to change, the answer is to reduce tool count or split into subagents.
🛑 The answer is never “add more tools” or “write better descriptions as the primary fix for a tool count problem.”
Context Management in Long Support Sessions
Domain 5 (Context Management and Reliability) is 15% of the exam, and customer support sessions are one of the hardest contexts to manage. A single support interaction can accumulate thousands of tokens: the initial complaint, multiple policy lookups, back-and-forth clarifications, previous resolution attempts, and internal notes.
The Lost-in-the-Middle Problem
Research on large language models has documented the “lost in the middle” effect: models pay more attention to information at the beginning and end of the context window, and less attention to information buried in the middle. While Claude’s architecture has improved significantly on this (scoring 76% on long-context retrieval benchmarks, up from 18% in earlier versions), the fundamental challenge remains real at production scale.
In a customer support session, this manifests in a specific way. The customer’s initial complaint is at the beginning of the context (high attention). The most recent exchange is at the end (high attention). But the policy lookup result from three turns ago that contains the critical refund threshold? That is in the middle. The agent might give it less weight.
What the wrong answer looks like on the exam: “To ensure the agent correctly applies the $500 refund limit, include that limit prominently in the system prompt.” This sounds right and is partially correct (system prompt is good placement), but it misses the more important design consideration: the policy engine check should happen programmatically through a tool call, not through the agent’s recollection of something in its context. The system prompt provides context; the tool call enforces the rule.

Anthropic CCA Exam: Use programmatic hooks, do not rely on prompt logic alone
Correct Patterns for Context Management
Structured summaries at context boundaries: rather than letting the raw conversation grow unbounded, periodically insert a structured summary that restates the critical facts. Place the customer’s tier, the active policies, the refund limits, and the current resolution status at the beginning of each new turn. This keeps critical information out of the “lost in the middle” zone.
System prompt for persistent rules; user messages for session context: the system prompt is the right place for rules that never change (escalation thresholds, compliance requirements, the agent’s identity and capabilities). The user message sequence carries the session-specific context (this customer’s history, this specific dispute).
Structured escalation handoff: when the agent escalates to a human, do not pass the raw conversation transcript. Pass a structured summary:
{
"customer_id": "CUS-12345",
"customer_tier": "VIP",
"issue_type": "billing_dispute",
"disputed_amount": 750.00,
"agent_findings": "Policy allows refund but amount exceeds agent authority",
"escalation_reason": "refund_amount_exceeds_limit",
"recommended_action": "approve_refund",
"conversation_summary": "Customer disputed charge from March 15. Agent verified charge is valid but customer has VIP status with 100% satisfaction guarantee. Refund of $750 exceeds the $500 agent limit.",
"turns_elapsed": 6
}
This structured handoff ensures the human agent gets exactly what they need without wading through six turns of conversation. It also keeps the context compact and positions critical information where it will receive appropriate attention from the next reader, human or AI.
What the wrong answer looks like on the exam: “When escalating to a human agent, pass the complete conversation transcript so the human has full context.” This sounds thorough. It is wrong. The complete transcript is long, unstructured, and buries the critical information in a sea of back-and-forth. The human agent has to read all of it to find the relevant facts. The structured JSON summary extracts exactly what matters and puts it at the top.
💡 Exam Tip:
When a question asks about escalation handoff design, look for answers that include structured JSON or key-value summaries.
Answers that describe passing the “full conversation history” or “complete interaction transcript” are the wrong answers for this question type.
When a question asks about escalation handoff design, look for answers that include structured JSON or key-value summaries.
Answers that describe passing the “full conversation history” or “complete interaction transcript” are the wrong answers for this question type.
Exam Question Walkthrough
Here are three representative question patterns. These are not actual exam questions, but they reflect the decision patterns the exam tests. Work through each one yourself before reading the analysis.
Question 1: Escalation Routing
A customer support agent built with Claude handles refund requests. The agent reports 92% confidence in its ability to resolve a $600 refund. What should determine whether the agent processes the refund or escalates?
A) “Set a confidence threshold of 90% and only escalate when confidence falls below the threshold.”
B) “Apply deterministic business rules: the $600 amount exceeds the $500 agent authority limit, so escalate regardless of confidence.”
C) “Allow the agent to proceed since 92% confidence is above the typical threshold for financial decisions.”
D) “Improve the system prompt to clarify escalation rules so the agent applies them consistently.”
Correct answer: B
Why A is wrong: the confidence score is irrelevant. A $600 refund exceeds agent authority regardless of how confident the agent is. Even at 99% confidence, the business rule is absolute. This tests Domain 1 (Agentic Architecture).
Why C is wrong: same problem as A, stated more directly. No confidence level overrides a business rule.
Why D is wrong: the system prompt is not the right enforcement mechanism for financial authorization rules. Programmatic hooks enforce them reliably. System prompts provide context.
Why B is correct: the business rule ($600 exceeds the $500 limit) is deterministic. It does not depend on the agent’s confidence. The programmatic enforcement fires after the agent’s proposal and applies the rule unconditionally.
Question 2: Cost Optimization
A customer support system using the Real-Time API processes 50,000 interactions daily, each including 80,000 tokens of repeated policy context. The team wants to reduce API costs significantly. What is the best approach?
A) “Migrate customer support interactions to the Message Batches API for 50% cost savings.”
B) “Reduce the policy context from 80,000 tokens to 20,000 tokens through summarization.”
C) “Implement Prompt Caching for the repeated policy documents to achieve up to 90% cost reduction on cached tokens while maintaining real-time response.”
D) “Use a smaller model for policy lookups and reserve the full model for complex issues.”
Correct answer: C
Why A is wrong: the Batch API has a processing window of up to 24 hours. Customers in a live chat workflow cannot wait. This is the most common wrong answer for cost optimization questions in this scenario.
Why B might help but is not the best answer: summarizing context reduces token count but may lose important policy details. It is an engineering tradeoff, not an architectural best practice.
Why D might help in some systems but is not the best answer here: two-model routing adds complexity and the question is specifically about the repeated context cost, which caching addresses directly.
Why C is correct: Prompt Caching addresses the specific problem (80,000 tokens repeated across 50,000 daily interactions) with the best cost savings (90%) while preserving the real-time response the workflow requires.
Question 3: Tool Count
A customer support agent has 12 tools available, including customer lookup, refund processing, shipping tracking, inventory management, HR policy queries, and marketing campaign access. The agent occasionally selects the wrong tool. What is the best improvement?
A) “Improve the tool descriptions to make each tool more clearly distinguishable from the others.”
B) “Add a tool selection validation step that asks Claude to confirm its tool choice before executing.”
C) “Reduce the agent’s tool set to 4–5 focused customer support tools and move the remaining capabilities to specialized subagents.”
D) “Increase the model’s context window to give it more space to evaluate tool options.”
Correct answer: C
Why A is a trap: improving descriptions helps with a well-scoped tool set. It does not fix the fundamental problem that 12 tools exceed the recommended 4–5, and it does not address that the agent should never have access to HR policies or marketing campaigns in the first place. Better descriptions on a 12-tool agent do not eliminate the selection accuracy degradation from tool count alone.
Why B adds complexity without fixing the root cause: a validation step makes the agent slower and more expensive. It does not solve the selection reliability problem.
Why D is wrong: a larger context window does not improve tool selection accuracy. It may even make it worse by giving the model more room to deliberate between incorrect options.
Why C is correct: it addresses both problems. Reducing to 4–5 tools restores selection accuracy. Moving billing, shipping, and HR to subagents eliminates scope creep and applies least privilege.
Anti-Pattern vs. Correct Pattern Summary
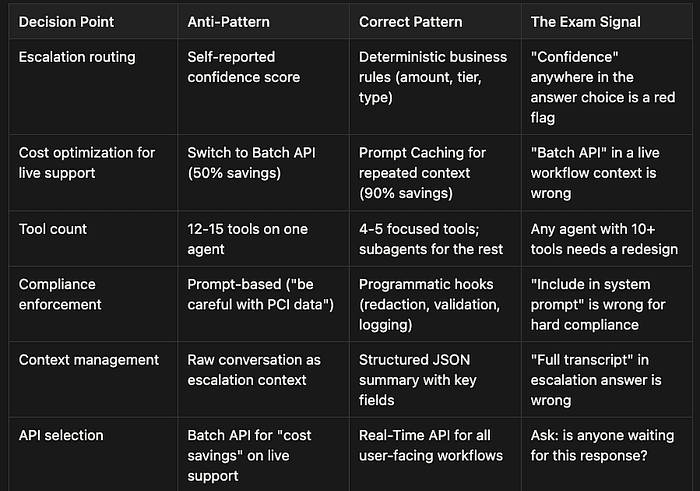
Anthropic CCA Exam: Anti-Pattern vs. Correct Pattern Summary
Quick Review for CCA Exam: Decision Patterns at a Glance
Before diving into the detailed domain breakdown, here’s a condensed review of the core decision patterns this scenario tests. Each row represents a critical architectural choice where most candidates pick the plausible-sounding wrong answer.
Escalation Routing
Anti-Pattern: Using self-reported confidence scores to decide whether the agent can handle a request. An agent reporting 92% confidence on a $600 refund sounds reliable, but confidence scores are not calibrated for authorization decisions.
Correct Pattern: Apply deterministic business rules based on dollar amount, customer tier, and issue type. If the refund exceeds the $500 agent authority limit, escalate regardless of confidence.
The Exam Signal: Any answer choice that mentions “confidence threshold” or “confidence score” as the primary routing mechanism is wrong. Look for answers that reference specific dollar limits, tier checks, or policy boundaries.
Cost Optimization for Live Support
Anti-Pattern: Switching to the Message Batches API to achieve 50% cost savings. This sounds fiscally responsible but breaks the real-time requirement — customers in live chat cannot wait up to 24 hours for a response.
Correct Pattern: Implement Prompt Caching for repeated policy context. This delivers up to 90% cost reduction on cached tokens while maintaining real-time response capability.
The Exam Signal: “Batch API” in any live, user-facing workflow context is the wrong answer. The exam tests whether you understand the latency tradeoff. If anyone is waiting for the response, you cannot use batching.
Tool Count
Anti-Pattern: Giving a single agent 12–15 tools covering customer support, billing, HR policies, and marketing access. This exceeds the recommended 4–5 tool limit and degrades selection accuracy.
Correct Pattern: Scope each agent to 4–5 focused tools. Create specialized subagents for billing, shipping, and HR queries. This improves tool selection reliability and applies least privilege principles.
The Exam Signal: When you see an agent with 10+ tools, the correct answer will involve redesigning the architecture with subagents. Answers that suggest “improving tool descriptions” without reducing tool count are traps.
Compliance Enforcement
Anti-Pattern: Including compliance instructions in the system prompt: “Be careful with PCI data” or “Always redact SSNs before logging.” Prompts provide guidance but do not enforce rules.
Correct Pattern: Enforce compliance through programmatic hooks in the application layer — redaction functions, validation checks, structured logging with automatic PII removal.
The Exam Signal: For hard compliance requirements (PCI, HIPAA, data retention), any answer that says “include in the system prompt” is wrong. Look for answers describing programmatic enforcement, pre-processing, or post-processing hooks.
Context Management
Anti-Pattern: Passing the raw conversation transcript when escalating to a human agent. This sounds thorough — the human gets “full context” — but it buries critical information in unstructured text.
Correct Pattern: Generate a structured JSON summary with key fields: customer ID, tier, issue type, disputed amount, escalation reason, and recommended action. Place this at the top of the escalation payload.
The Exam Signal: Answers that describe passing the “complete conversation history” or “full interaction transcript” are wrong. Look for structured summaries, key-value pairs, or JSON schemas.
API Selection
Anti-Pattern: Choosing the Batch API for cost savings on live support interactions. The 50% cost reduction is real, but the processing window makes it incompatible with synchronous workflows.
Correct Pattern: Use the Real-Time API for all user-facing workflows where someone is waiting for a response. Reserve the Batch API for background tasks like nightly report generation or bulk data processing.
The Exam Signal: Ask yourself: is anyone waiting for this response? If yes, the Batch API is wrong. The exam tests your ability to match API capabilities to latency requirements.
These six decision patterns account for the majority of the points in this scenario. Memorize the anti-pattern, the correct pattern, and the exam signal for each. When you see a question, identify which pattern it’s testing and apply the correct architectural choice.
Domains Tested in This Scenario
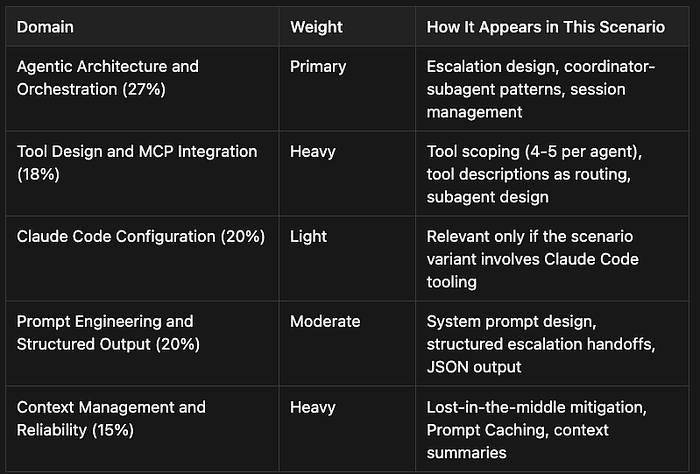
CCA Exam: Domains Tested with the Customer Scenario
- Agentic Architecture and Orchestration (27%) — Primary — Escalation design, coordinator-subagent patterns, session management
- Tool Design and MCP Integration (18%) — Heavy — Tool scoping (4–5 per agent), tool descriptions as routing, subagent design
- Claude Code Configuration (20%) — Light — Relevant only if the scenario variant involves Claude Code tooling
- Prompt Engineering and Structured Output (20%) — Moderate — System prompt design, structured escalation handoffs, JSON output
- Context Management and Reliability (15%) — Heavy — Lost-in-the-middle mitigation, Prompt Caching, context summaries
Study Checklist
Before you sit for the exam, make sure you can answer each of these without hesitation. These are not trivia questions. They are the core decision patterns this scenario tests.
✅ Why is self-reported confidence unreliable for escalation decisions? (not calibrated; overconfidence at high confidence range; circular reasoning)
✅ What should determine escalation instead? (deterministic business rules: dollar amount, customer tier, issue type, account actions)
✅ Why is the Batch API wrong for live customer support? (up to 24-hour processing window; no formal SLA; customers cannot wait)
✅ What is the correct cost optimization for repeated context? (Prompt Caching; up to 90% reduction; real-time compatible)
✅ How many tools should one agent have? (4–5)
✅ What do you do when you need more than 5 tools? (specialized subagents, each with their own 4–5 tools)
✅ Where should compliance rules be enforced? (programmatic hooks in application layer; not in prompts)
✅ What is the “lost in the middle” effect and how do you mitigate it? (models attend less to middle of context; place critical info at start or end; use structured summaries)
✅ What does a proper escalation handoff look like? (structured JSON with key fields; not raw conversation transcript)
✅ What goes in the system prompt vs. user messages? (persistent rules and compliance context in system prompt; session-specific context in user messages)
Discussion Questions
- The exam distinguishes sharply between confidence-based routing and deterministic rule-based routing. Have you built production systems that initially used confidence scores and had to migrate to deterministic rules? What was the failure that triggered the change?
- Prompt Caching versus the Batch API is framed as an obvious choice in this article, but in a real system with mixed workloads (some live, some background), how would you architect the cost optimization layer to use both appropriately?
- The structured escalation handoff JSON shown in this article includes turns_elapsed as a field. What other fields would you add for a high-stakes financial support scenario, and why would each field matter to the human agent receiving the escalation?
What’s Next
This article covered the Customer Support Resolution Agent scenario in depth. The next articles in this series tackle the remaining scenarios:
- Article 1: CCA Exam Prep: The Complete Overview covers exam format, domains, and study strategy
- Article 3: Code Generation with Claude Code scenario deep dive
- Article 4: Multi-Agent Research System scenario deep dive
Each scenario has its own set of traps and correct patterns. The good news: the mental models transfer. Once you internalize “programmatic enforcement beats prompt-based guidance” and “deterministic rules beat model self-assessment,” you will see those patterns everywhere on the exam.
Study the escalation flow diagram until you can draw it from memory. On exam day, when you see a question about a support agent’s confidence score, you will know exactly what to do: ignore the confidence score and check the business rules.
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.