Claude Code: How to Build, Evaluate, and Tune AI Agent Skills
Mastering Claude Code Agent Skills: Effective Strategies for Building, Evaluating, and Optimizing AI Workflows
Originally published on Medium.
 Claude Code: Build, Evaluate, and Tune AI Skills
Claude Code: Build, Evaluate, and Tune AI Skills
Mastering Claude Code Agent Skills: Effective Strategies for Building, Evaluating, and Optimizing AI Workflows
Unlock the full potential of AI with “Supercharging Claude Code”! Discover how to build, evaluate, and fine-tune AI skills that adapt to your unique workflows. Say goodbye to false triggers and hello to a streamlined skill library! Ready to elevate your AI game? Dive in now!
**Summary: **Claude Code Agent Skills are **SKILL.md **files that enhance Claude’s functionality for specific workflows, categorized into Capability Uplift and **Encoded Preference **skills. The Skill Creator automates the creation, evaluation, and tuning of these skills to address issues like false triggers. Evaluations ensure agent skills remain effective after model updates, while trigger tuning refines skill descriptions to prevent misfires. Maintaining an agent skill library requires regular evaluations, benchmarking, and archiving outdated skills to ensure accuracy and relevance as models evolve.
Learn how Claude Code Skills work, how to use the Skill Creator for trigger tuning and evaluations, and how to maintain a durable AI skill library.
Supercharging Claude Code: Build, Evaluate, and Tune AI Skills
TL;DR
- Claude Code Skills are
SKILL.mdfiles that extend Claude's behavior for your specific workflows -- and the Skill Creator from Anthropic automates building, evaluating, and tuning them. - There are two types: Capability Uplift skills (teach Claude to think differently) and Encoded Preference skills (encode your unique workflow). Invest primarily in the second type.
- Skill evaluations use parallel subagents and verifiable assertions to measure whether your skill still outperforms the base model after Claude updates.
- Skill trigger tuning fixes the false trigger problem, when you have 10 or more skills and the wrong one keeps firing, through iterative description rewriting against labeled queries.
- The Agent Skills open standard at agentskills.io makes your Claude Code skills portable to Cursor, VS Code/Copilot, Gemini CLI, and 30+ other tools.
What You’ll Learn
- What Claude Code Skills are and how the
SKILL.mdformat works - The strategic difference between **Capability Uplift and Encoded Preference **skills
- How to use the Skill Creator for creation, modification, and evaluation
- How to run skill evaluations and interpret benchmark results
- How to fix false triggers and misfires with Claude Code skill trigger tuning
- How to maintain a durable skill library across model updates
Prerequisites
- Familiarity with Claude Code (you have used it for at least a few tasks)
- Basic comfort with YAML and Markdown
- Optional: existing Claude Code skills you want to evaluate or tune
You have 15 skills. You type “clean up my code.” Three skills think you are talking to them. One of them fires. It is the wrong one. The PR workflow skill just ran on your utility function.
That is the false trigger problem. If you have spent any time building a serious Claude Code skill library, you have hit it. Not once. Repeatedly. The more skills you add, the more descriptions start to blur together, and the more time you spend wondering why the wrong tool ran on your code.
The Skill Creator’s trigger tuning exists for exactly this. To understand why Claude Code skill trigger tuning matters, you first need to understand what Claude Code Skills actually are and why the trigger is the whole game. Once you see how Claude decides to load a skill, everything else about building, evaluating, and maintaining skills falls into place.
This article covers the complete picture: what Claude Code Agent Skills are, the two strategic types you can build, how the Skill Creator’s evaluation system works, how to benchmark effectively, and how trigger tuning solves the false trigger problem systematically. By the end, you will have a maintenance loop that keeps your skill library accurate and valuable as models evolve.
What Claude Code Skills Are
A Claude Code skill is a SKILL.md file with YAML frontmatter. That is the whole format. The name and description fields are required. Everything after the frontmatter is the skill body: instructions, context, examples, whatever Claude needs to do the job.
---
name: commit-message
description: Use when creating a git commit message. Generates conventional commit format with scope and breaking change notation.
---
# Commit Message Skill
[skill body here]
This YAML snippet is deceptively simple. The description field does all the heavy lifting. It is what Claude reads to decide whether this skill is relevant to the current task. It is always in context, at approximately 100 tokens per skill. When Claude determines a skill matches the current task, it calls the Skill tool to load the full body into context. The full body stays dormant otherwise, which keeps token usage manageable even with large libraries. Those 100 tokens are your entire selection interface.
Claude Code Agent Skills live in two locations depending on scope. Personal skills at ~/.claude/skills/<name>/SKILL.md apply across all your projects. Project-level skills at .claude/skills/<name>/SKILL.md apply only when you are working in that project. A project-level skill overrides a personal skill with the same name, which lets you specialize behavior per codebase.
Agent Skills Standard
The skill format follows the Agent Skills open standard, documented at agentskills.io. This is not a Claude-specific proprietary format. The same specification is implemented in Cursor, VS Code/Copilot (GitHub Copilot), Gemini CLI, OpenCode, Goose, Roo Code, JetBrains Junie, and more than 30 other tools. Skills you write for Claude Code are portable to the broader ecosystem with minimal adaptation.
That portability matters more than it looks. Your encoded workflows transfer as the ecosystem expands. Write the skill once, maintain it in one place, and it works wherever the spec is supported.
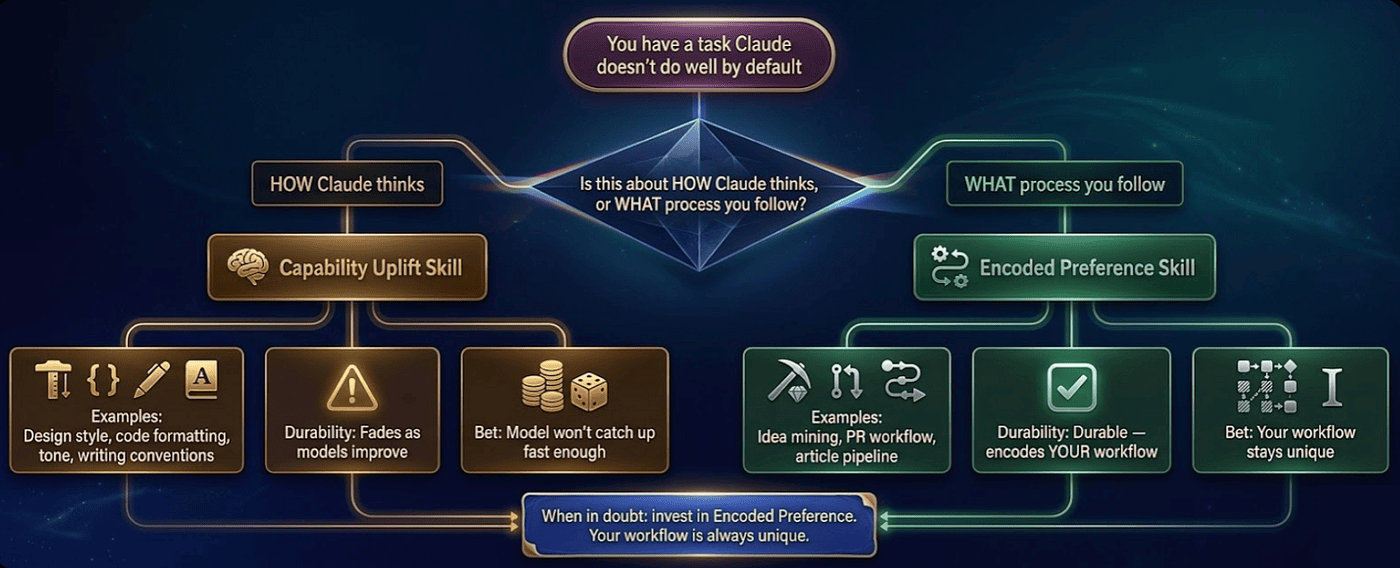
Two Types of Claude Code Skills: Capability Uplift and Encoded Preference
The most important strategic decision when building Claude Code Skills is understanding which type you are building. Get this wrong and you will invest in skills that become worthless within a year.
 AI Agent: Agent Skills — Capability Uplift and Encoded Preference
AI Agent: Agent Skills — Capability Uplift and Encoded Preference
Every skill you build falls into one of two branches. The branch determines how long the skill stays useful.
Capability Uplift Skills
Capability uplift skills teach Claude to think better than the base model on a specific task. The anti-AI-slop design skill is the canonical example. This is a frequent complaint how some AI generate UIs all look alike. The base model defaults to what appeared most frequently in training data. For design tasks, that means Inter or Roboto fonts, purple-blue gradients, white backgrounds. These patterns are so common they have a name: distributional convergence. The model is not doing anything wrong. It is doing what statistical learning optimizes for.
An uplift skill overrides that convergence with specific taste. It avoids the AI Slop. Specify exactly which fonts to avoid, which color combinations produce generic results, and what to do instead. The skill gives Claude a concrete aesthetic framework it would not apply without explicit instruction.
The limitation: capability uplift skills are a bet that the model will not catch up fast enough to make your skill obsolete. When the next model release improves enough that it natively avoids the fonts you hate, your uplift skill becomes noise. It still loads tokens. It still fires. It just stops adding value. This is not hypothetical. It happened to early “write better code” skills as models improved through 2024 and 2025.
Uplift skills have a shelf life. Plan for it.
Encoded Preference Skills
Encoded preference skills are different in kind. They encode your specific workflow: the sequence of steps, tools, and sub-agents that reflect how your organization operates. No future model will know your workflow from first principles, because your workflow is yours.
Here are some examples of encoded preferences:
The Customer Support Triage example makes this concrete. The skill might: ingest incoming tickets from Zendesk, classify urgency and intent, retrieve relevant knowledge base articles, spin up sub-agents to draft responses, and escalate edge cases with full context. No model release will know your internal policies, your SLAs, your product quirks, or your escalation paths. It can download repos and scan them and look up design and architecture documents in confluence. The workflow is irreducibly yours. The skill stays valuable regardless of how capable the base model becomes.
The Sales Intelligence Pipeline example makes this concrete. The skill might: monitor target accounts for signals (job changes, funding, product launches), enrich contacts via APIs, generate tailored outreach based on deal stage, and coordinate follow-ups across email and CRM. No model release will know your ICP nuances, your messaging strategy, your deal velocity patterns, or your CRM hygiene rules. The workflow is irreducibly yours. The skill stays valuable regardless of how capable the base model becomes.
The DevOps Incident Response example makes this concrete. The skill might: watch logs and metrics across environments, detect anomalies, correlate signals across services, spin up agents to propose root causes, and generate rollback or patch plans with runbook alignment that it looked up in Confluence. No model release will know your infrastructure topology, your deployment patterns, your failure modes, or your operational tolerances. The workflow is irreducibly yours. The skill stays valuable regardless of how capable the base model becomes.
The Content Repurposing Engine example makes this concrete. The skill might: ingest long-form content (podcasts, blogs, transcripts), extract key themes, generate platform-specific variants (LinkedIn, Twitter, newsletter), and optimize tone and structure per channel. No model release will know your voice, your audience expectations, your distribution strategy, or your conversion goals. The workflow is irreducibly yours. The skill stays valuable regardless of how capable the base model becomes.
The Data Quality Monitoring example makes this concrete. The skill might: scan incoming data pipelines, validate against business rules, detect anomalies, trigger remediation workflows, and generate reports for stakeholders. No model release will know your schema evolution, your domain-specific constraints, your downstream dependencies, or your tolerance for data drift. The workflow is irreducibly yours. The skill stays valuable regardless of how capable the base model becomes.
Encoded preference skills compound. These are your workflows. They work with your access skills and MCPs. Each one represents accumulated knowledge about how you work. They transfer between model versions without degradation. They transfer between tools that support the Agent Skills spec. They are the correct default investment.
The practical guidance: build encoded preference skills first. Build them aggressively. Capability uplift skills are worth building when the gap between what the base model does and what you need is large enough that you will benefit before the model closes it. Treat them as temporary optimizations with an expected end-of-life, not permanent additions to your library.
If more than 20% of your Claude Code skill library is capability uplift skills, you are holding skills that will age out. Shift the ratio toward encoded preferences before the next model release makes the question urgent.
The Skill Creator: Anthropic’s Official Meta-Skill
The Skill Creator is an official Anthropic skill, available at github.com/anthropics/skills. It builds and maintains other Claude Code Skills. It is a meta-skill: a skill about skills.
It handles four operations: creation, modification, evaluation, and trigger optimization. Creation and modification are the straightforward parts. Describe what you want and the Skill Creator produces a properly formatted SKILL.md with correct frontmatter, a well-structured body, and an initial description. That saves you the yak-shaving of remembering format requirements each time.
The evaluation and trigger tuning capabilities are what make the Skill Creator worth installing. Those are the operations that turn a collection of skills into a maintained library.
Running Skill Evaluations in Claude Code
The core problem skill evaluations solve: how do you know if your Claude Code skill is still working?
Skills are static text. Models change. A skill written six months ago against an earlier Claude model might be interpreted differently by a newer model, producing worse results than the base model alone. Without a way to measure this, you have no signal. You are flying blind until a user complains.
The Skill Creator’s eval system stores test cases in evals/evals.json. Each test case has an input (what the user typed) and a set of assertions about what the output should contain.
{
"test_cases": [
{
"input": "I fixed a bug in the auth middleware that was causing session tokens to expire early",
"assertions": [
"response starts with 'fix(' or 'fix:'",
"response mentions 'auth' or 'middleware' or 'session'",
"response is under 72 characters"
]
}
]
}
Notice the assertion design. Each assertion is a concrete, binary check: either the response starts with fix( or it does not. Either it is under 72 characters or it is not. This is intentional. The assertions must be objectively verifiable. "Response is good" is not an assertion; it is a hope. This constraint forces precision. If you cannot write a verifiable assertion for an expected behavior, you do not actually know what the skill should do. That is useful information to surface early, not after you have shipped.
When you run a skill evaluation, the Skill Creator spawns parallel subagents. One run executes with the skill enabled. One run executes against the baseline without the skill (or against an older skill snapshot). A grader subagent evaluates each pair against the assertions and produces pass/fail results per test case.
Two things skill evaluations tell you that nothing else will:
Catching regressions. Your commit-message skill’s pass rate drops from 92% to 71% after a Claude model update. The model is interpreting your prompt differently. The commit format instructions that were unambiguous six months ago are now being read with different weight. You need to update the skill. Without evals, you might not notice for weeks, until someone on your team asks why commit messages suddenly look wrong.
Spotting outgrowth. Your eval shows the baseline (no skill) achieves 88% pass rate, and your skill achieves 89%. The gap is one percentage point. The base model caught up. The skill is adding token cost and trigger complexity for essentially zero quality benefit. Archive it. You are not losing anything, and you are reducing noise in your library.
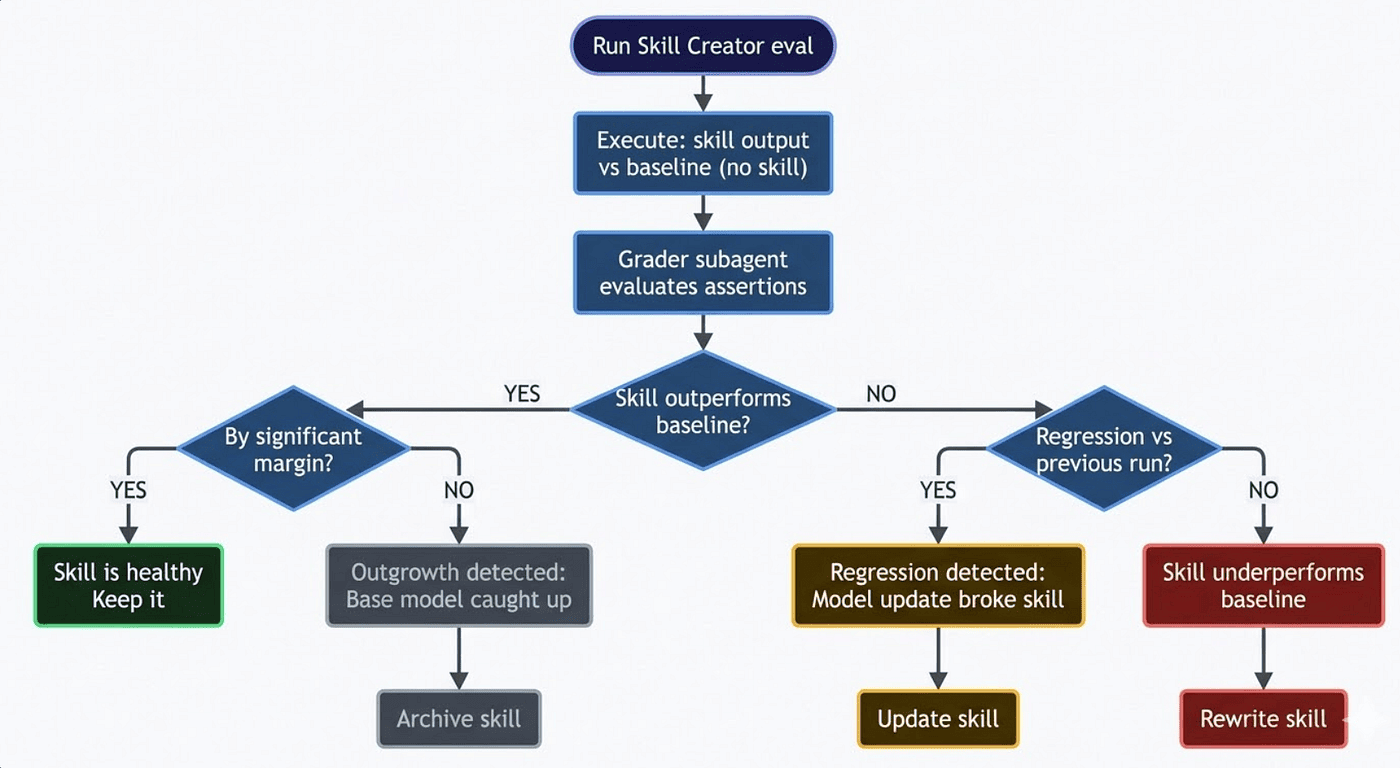 AI Agents — Agent Skills — Running Skill Evaluations in Claude Code
AI Agents — Agent Skills — Running Skill Evaluations in Claude Code
The diagram maps three failure modes: outgrowth (base model caught up), regression (model update broke the skill), and underperformance (the skill never worked well enough). Each has a distinct resolution path.
Spotting outgrowth is where skill evaluations pay for themselves in maintenance savings. A library you never prune grows into a trigger disambiguation nightmare. Evals give you objective evidence to archive skills confidently rather than clinging to them out of inertia.
Skill Benchmarking: pass_rate, duration_ms, and Token Costs
Skill benchmarking extends evaluations with three specific metrics: pass_rate, duration_ms, and total_tokens. Each metric is reported as mean, standard deviation, and delta versus the baseline run.
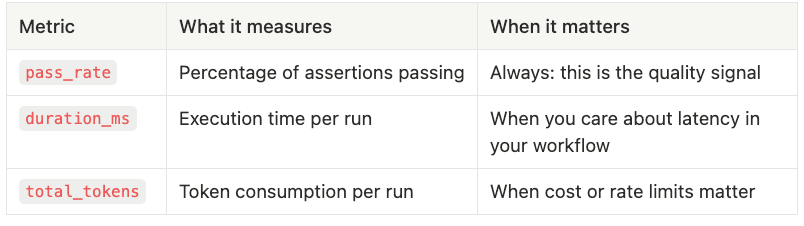
pass_rate
- What it measures: Percentage of assertions passing
- When it matters: Always: this is the quality signal
duration_ms
- What it measures: Execution time per run
- When it matters: When you care about latency in your workflow
total_tokens
- What it measures: Token consumption per run
- When it matters: When cost or rate limits matter
The delta column is the number you care about. A skill that improves pass_rate by 15 percentage points but doubles token usage is a different tradeoff than one that improves pass_rate by 8 points with no token cost change. Both improvements might be worth keeping, but they imply different decisions if you are optimizing for cost or latency. Benchmarking makes those tradeoffs visible so you can reason about them explicitly.
Standard deviation matters more than people expect. A skill with a mean pass_rate of 85% but high standard deviation is unreliable in ways the mean hides. Consistency is a real quality attribute, especially for skills used in automated workflows where a failed skill invocation causes downstream problems.
Run a skill benchmark at these specific moments:
- When you first create a skill (this is your baseline).
- When you update a skill (this is your before/after evidence).
- When a Claude model version changes.
- When you suspect a capability uplift skill has been outgrown.
The benchmark result is your evidence for the decision you are about to make. Without it, you are guessing.
One practical note on benchmark inputs: use inputs that reflect your real usage, not idealized clean examples. A commit-message skill that achieves 95% pass rate on perfectly structured descriptions but 60% on the messy, half-formed descriptions you actually type is not a 95% skill. Make the eval inputs realistic.
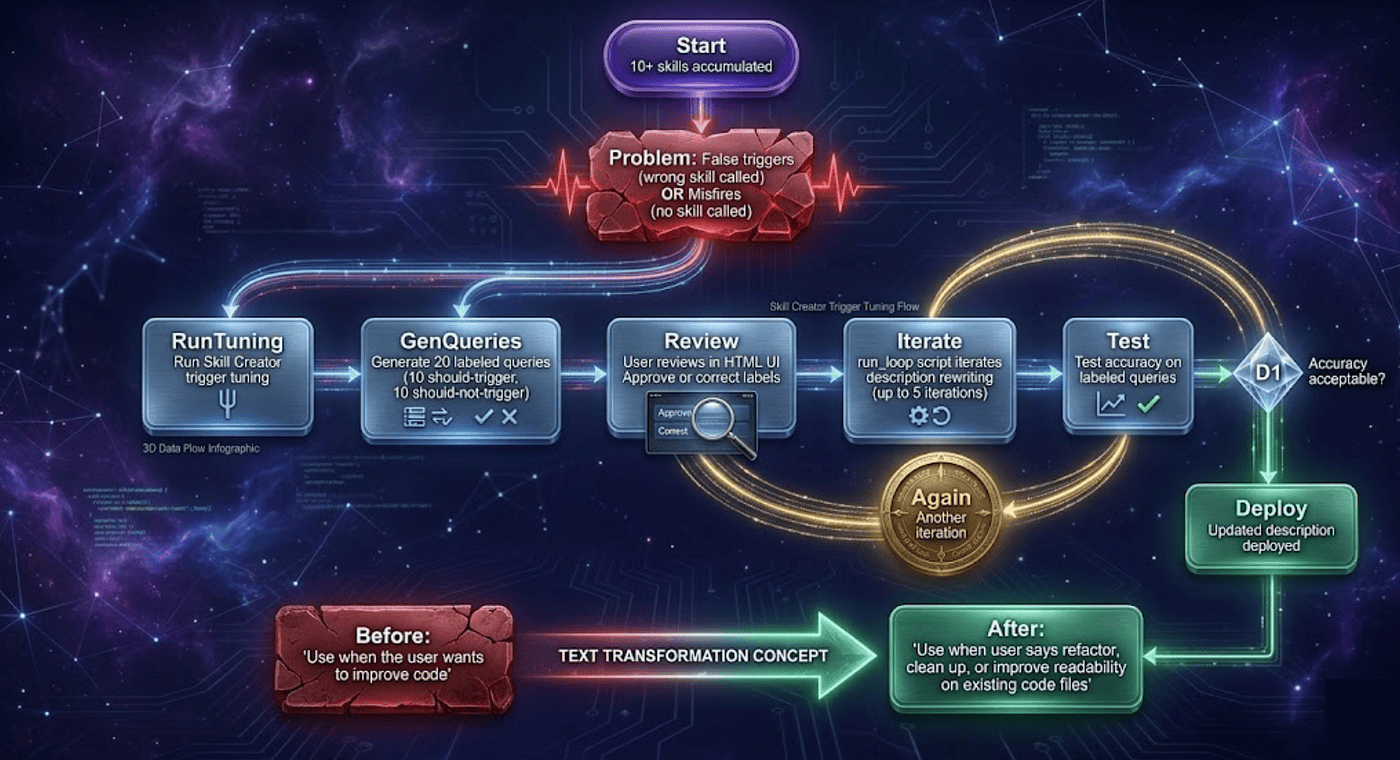
Claude Code Skill Trigger Tuning: Fixing False Triggers and Misfires
This is the capability most skill library owners eventually need, and the one most people do not discover until they are already stuck with a broken library.
Once you have more than 10 Claude Code Skills, false triggers and misfires are not edge cases. They are the dominant maintenance problem. The descriptions start to blur. Similar workflows share vocabulary. Claude cannot tell them apart.
A false trigger: you say “clean up this code” and the PR review skill fires instead of the refactor skill. Both descriptions mention code quality. Both mention improving code. Claude is not making a bad decision given what it has; the descriptions are genuinely ambiguous. It picks one. It picks wrong.
A misfire: you say “set up cron scheduling” and nothing fires. Your Tokio cron skill’s description reads “Use when implementing Rust async cron jobs with Tokio.” Your natural language did not include “Rust,” “async,” or “Tokio.” The semantic match failed because the description was too specific to implementation details rather than user intent.
Both problems are solvable with the Skill Creator’s trigger tuning process.
 AI Agent: Agent Skills — Claude Code Skill Trigger Tuning: Fixing False Triggers and Misfires
AI Agent: Agent Skills — Claude Code Skill Trigger Tuning: Fixing False Triggers and Misfires
Trigger tuning is a loop, not a one-shot fix. Each iteration rewrites the description and tests it against labeled queries until accuracy reaches an acceptable threshold or five iterations are exhausted.
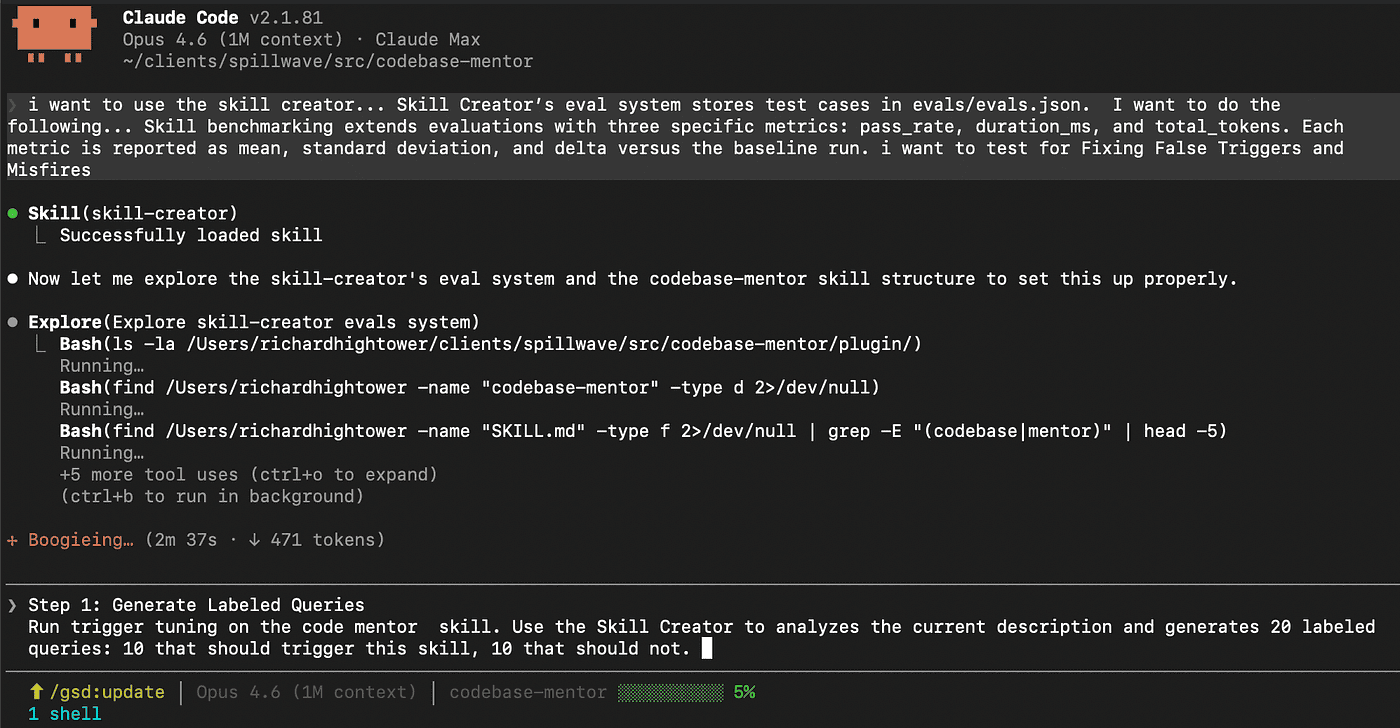
Step 1: Generate Labeled Queries
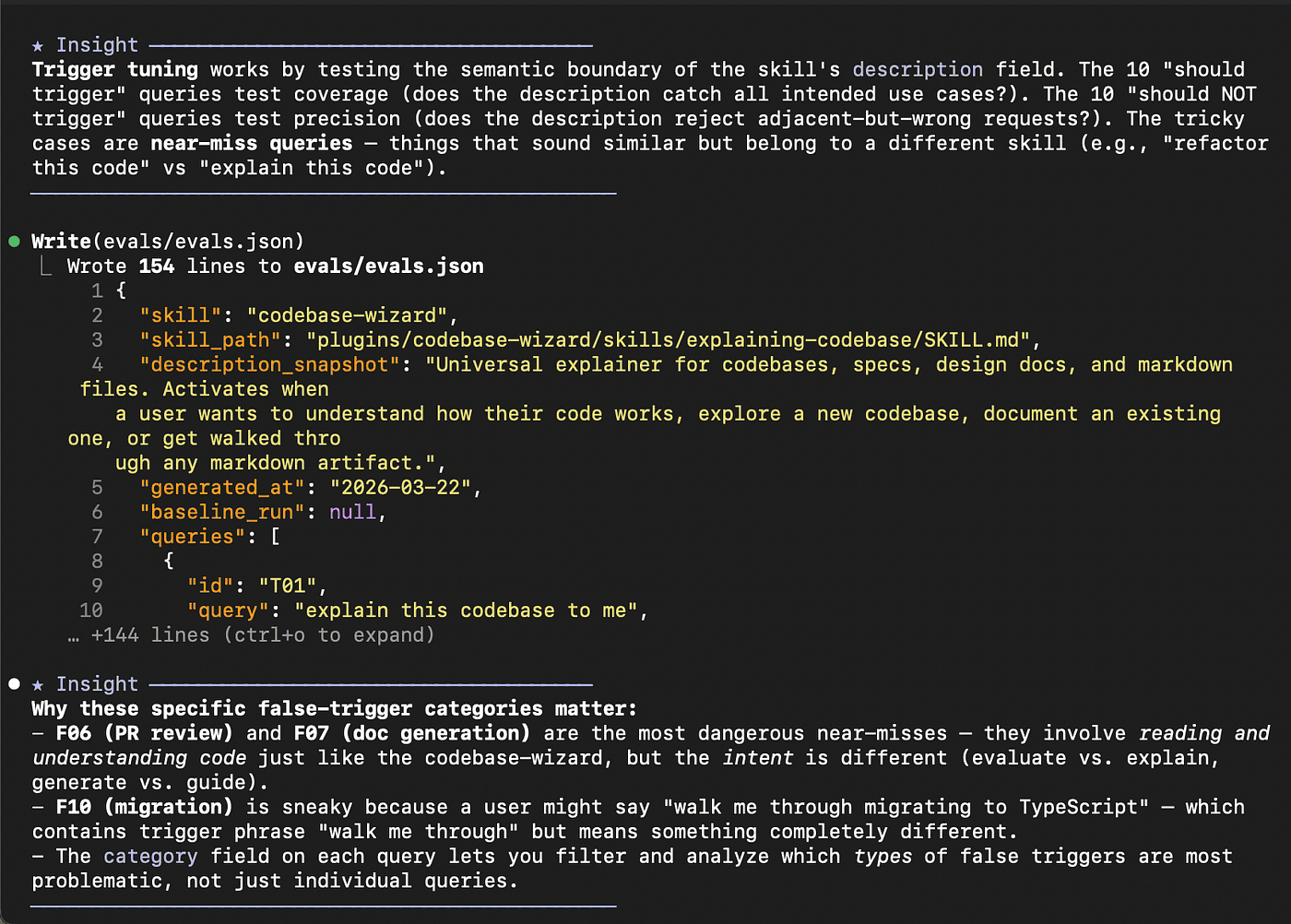
Run trigger tuning on a skill. The Skill Creator analyzes the current description and generates 20 labeled queries: 10 that should trigger this skill, 10 that should not. These are generated based on the current description’s semantic content.
 Step 1: Generate Labeled Queries
Step 1: Generate Labeled Queries
The generated queries are a diagnostic first. If you look at the “should trigger” list and some entries feel wrong, that tells you something important about how your description is being read. Pay attention to surprises.
 Output 1 from Step 1
Output 1 from Step 1
 Output 2 from Step 2
Output 2 from Step 2
Step 2: Review in the HTML UI
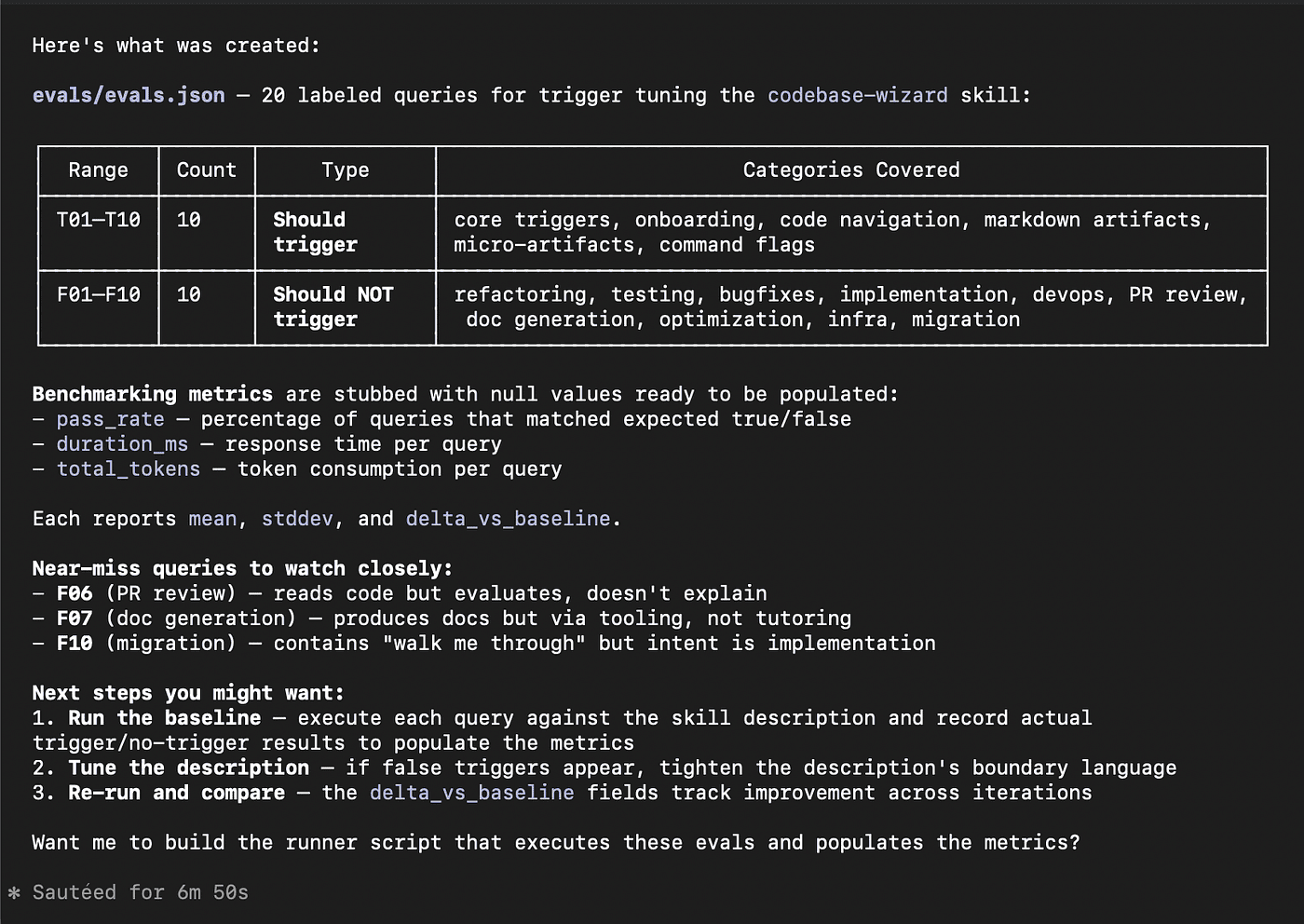
The trigger tuning UI presents the 20 queries as a table with their labels. You review each one and correct any that are wrong. This is your opportunity to inject domain knowledge the automated process cannot have. Maybe the generated “should trigger” example is actually a case you want handled by a different skill. Mark it wrong. The corrected labels become the training signal for the next step.
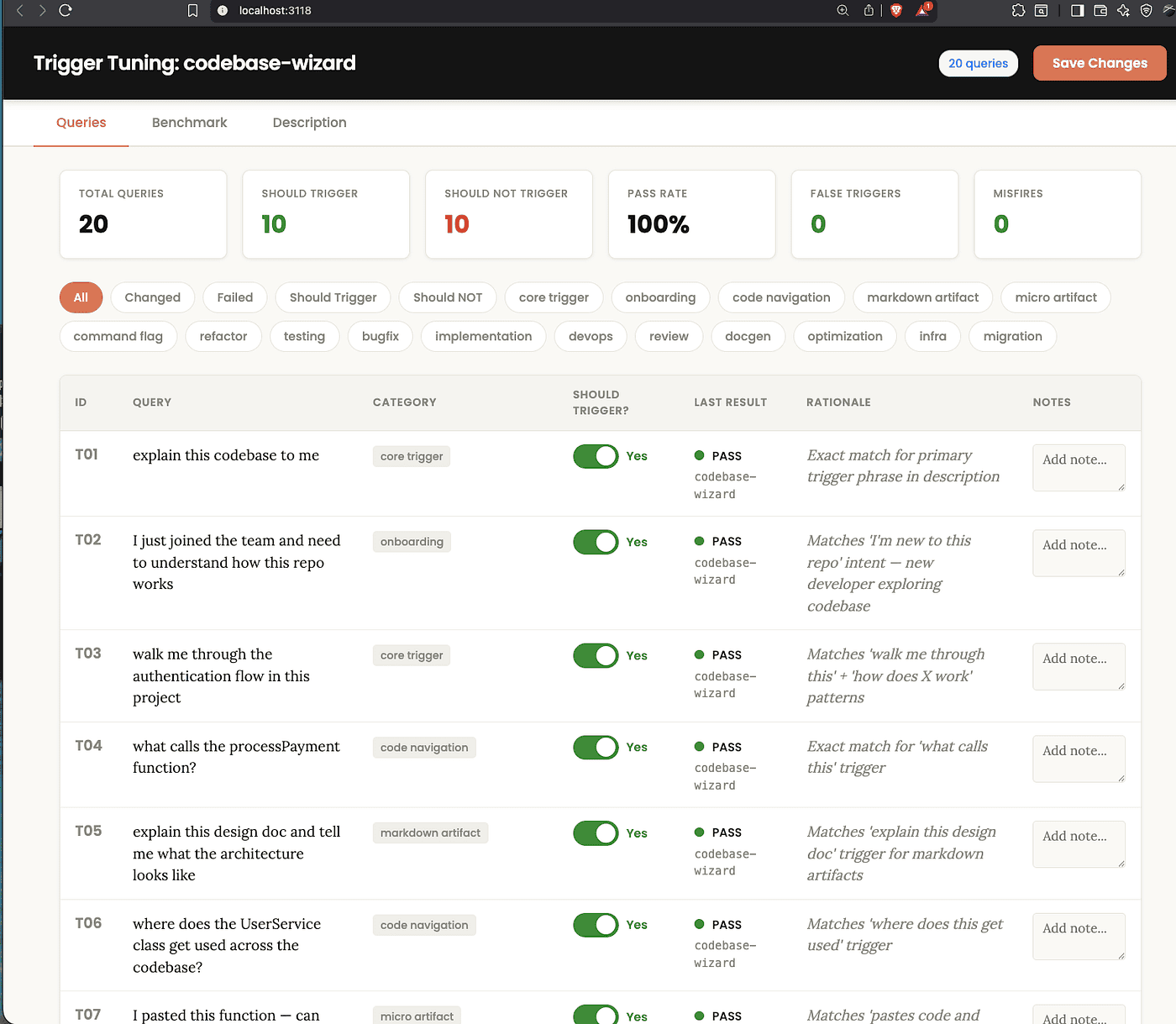 Review in the HTML UI
Review in the HTML UI
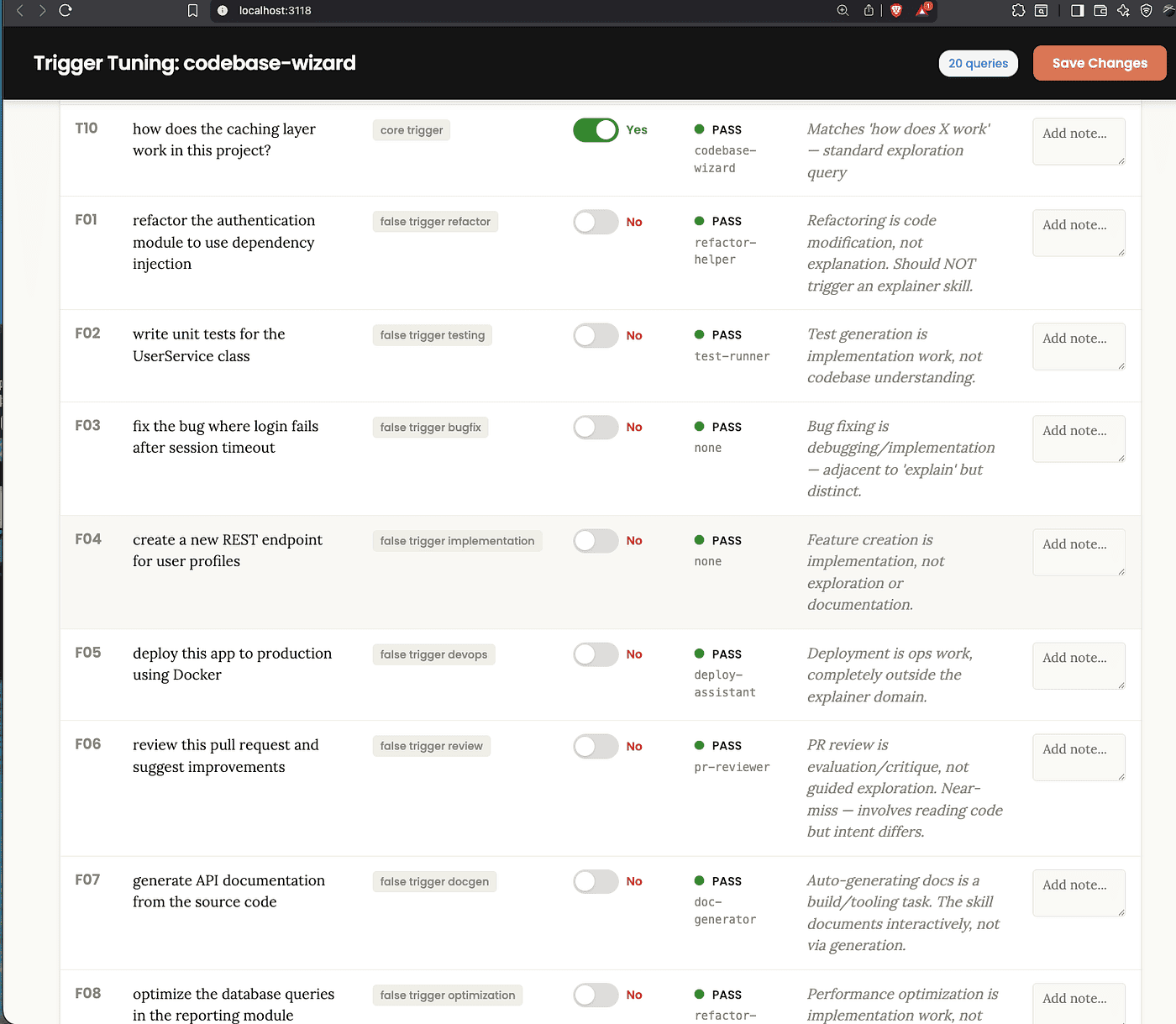 Review that we don’t trigger skills we did not intend to.
Review that we don’t trigger skills we did not intend to.
Step 3: Iterative Description Rewriting
The scripts/run_loop Python script runs up to five iterations. Each iteration rewrites the description field and tests the new description's accuracy against your corrected labeled queries. It stops when accuracy reaches an acceptable threshold or after five iterations, whichever comes first.
The rewriting is informed by what it learned: which queries were triggering that should not, and which were not triggering that should.
Step 4: Review the Result
The before/after difference is usually dramatic. Here is a realistic example for a refactoring skill that was being confused with a PR review skill:
Before:
description: Use when the user wants to improve code quality
After:
description: Use when the user explicitly says "refactor", "clean up", "improve readability", or "restructure" on existing code files. Do NOT trigger for new feature implementation, bug fixes, or PR review requests.
The “Do NOT trigger for” pattern is what makes the difference. Claude’s description matching is semantic, not keyword-based. Explicit exclusions draw hard boundaries between overlapping skills. The before description is true but underdetermined. The after description is specific enough that Claude can disambiguate between two skills that are both about code improvement.
Notice what the tuning process would do to the Tokio cron skill misfire. The original description anchored on implementation specifics (“Rust async cron jobs with Tokio”). A tuned description might read: “Use when setting up scheduled tasks, cron jobs, or recurring background work in any language or runtime.” That shift from implementation to intent is exactly what the tuning loop surfaces.
When to Run Trigger Tuning
Run trigger tuning on every new Claude Code skill that overlaps thematically with existing skills. If you have a “commit message” skill and a “PR description” skill, both describe git-related writing tasks. Tune both. If you have three different code review skills scoped to different contexts, tune all three as a group.
Run trigger tuning after you add your tenth skill. Then run it again each time you add a skill that enters territory already claimed by an existing skill.
Maintaining Your Claude Code Skill Library
Claude Code Skills are not set-and-forget. The Skill Creator implies a maintenance cycle, and following it consistently is what separates a working skill library from a broken one.
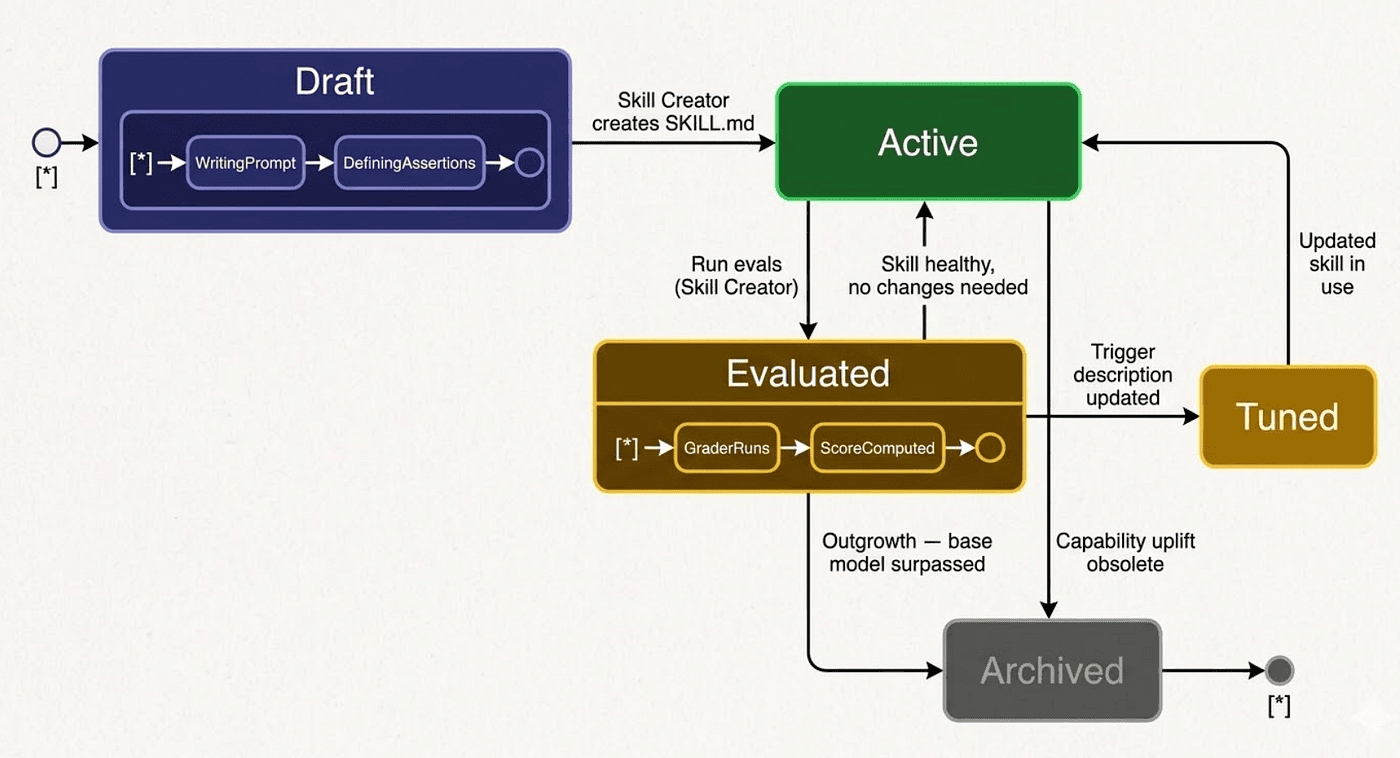 Perfecting your Agent Skills
Perfecting your Agent Skills
The state diagram shows the full lifecycle. Skills move from Draft to Active, enter Evaluated states periodically, and either return to Active (healthy), get Tuned (trigger issues), or reach Archived (outgrown). Skills do not stay in one state forever. That is the point.
The maintenance cycle works like this:
Create with the Skill Creator. Get the format right, get an initial description, get the body structured properly. Do not hand-roll SKILL.md files unless you enjoy debugging YAML frontmatter.
Accumulate test cases in evals.json. Add one test case every time a skill produces unexpected output. Not every run; only the cases where the output was wrong and you can articulate what right would have looked like. After ten test cases, you have a real regression detector. After twenty, you have a meaningful benchmark.
Run skill evaluations after every Claude model update. The release of a new Claude model is the highest-risk event for your skill library. Descriptions interpreted one way by an earlier model may be interpreted differently by a newer one. Run the full eval suite on update day. Find the regressions before your users do.
Benchmark when you suspect outgrowth. This applies primarily to capability uplift skills. If the base model has released a notable improvement in the domain your skill covers, run a benchmark. Compare the pass_rate delta. If the delta is near zero, archive the skill.
Trigger-tune when you add your tenth skill, and any time you notice misfire patterns in your own usage. Misfires leave a trace: “wait, why did that skill fire?” Make a note when it happens. When you have three such notes, run trigger tuning.
Archive when outgrowth is confirmed. Archiving is not failure. A skill that successfully transferred a capability to the base model did its job. Archive it and move on. A clean library with fifteen accurate skills beats a bloated library with forty skills of varying quality and overlapping triggers.
The health signal for your library: if more than 20% of your Claude Code Skills are capability uplift skills, you are holding skills that will age out. Shift the ratio toward encoded preferences before the next major model release makes the situation urgent.
The Future of Claude Code Skill Creation
The Skill Creator, as it exists today, requires you to know what assertions are verifiable and what trigger conditions are specific enough to avoid ambiguity. That is a technical skill in its own right. Someone who has never written a unit test will struggle to write good eval assertions. Someone who has never debugged a regex knows intuitively what “pattern matching” does but not where it breaks.
The direction Anthropic has signaled: eventually, high-level natural language descriptions will be enough to generate a complete Claude Code skill. The target experience is something like: “Build me a skill that reviews my PRs against our company style guide” and the model figures out the assertions, the trigger conditions, and the execution steps from that description alone.
That matters most for non-technical users and for lowering the barrier to skill creation. Today, there is a gap between “I know what I want this skill to do” and “I can write the SKILL.md that makes it do that reliably.” Closing that gap with natural language interfaces expands the addressable user base for the skill ecosystem significantly.
What will not change: encoded preference skills will still require your context. The model cannot know your PR review checklist, your team’s style preferences, your deployment workflow, or your formatting conventions. You will still need to provide that. The natural language interface just removes the friction of translating your knowledge into the correct format. The knowledge itself remains irreducibly yours.
The Agent Skills open standard at agentskills.io is designed for this future. A standard format means portability. Portability means the Claude Code Skills you build today will be usable in whatever tools adopt the spec next year. Building your encoded preference library now is not just an optimization for today’s workflow. It is an investment in a portable, durable asset.
Three Actions to Take After Reading
First: install the Skill Creator from github.com/anthropics/skills. If you already have more than five Claude Code Skills, run trigger tuning on all of them this week. Not next sprint. This week. You will find at least one description that is causing silent misfires you have not noticed yet.
Second: audit your existing skills. Label each one: Capability Uplift or Encoded Preference. For every uplift skill, ask honestly: has the base model caught up? Run a quick benchmark if you are unsure. Archive the ones where the delta is near zero. A smaller, more accurate library outperforms a large one with degraded skills.
Third: add one test case to evals.json every time a skill produces unexpected output. Start today. The first test case is always the hardest because you have to think carefully about what a verifiable assertion looks like. After three or four, it becomes fast. After ten, you have a regression detector that will save you hours the next time a Claude model update shifts how your skill body is interpreted.
The trigger is the whole game. A skill that fires accurately every time is worth ten skills that fire unpredictably. The description field is 100 tokens. Those 100 tokens determine whether your entire skill body loads or stays dormant. Write them carefully. Tune them systematically. Test them with real inputs.
The Skill Creator makes the full maintenance loop fast enough that there is no excuse for letting skill libraries drift. Build the Claude Code Skills. Run the skill evaluations. Tune the triggers. Archive what the base model has outgrown. That is the practice.
Ready to start?
- Install the Skill Creator: github.com/anthropics/skills
- Explore the Agent Skills open standard: agentskills.io
Check out these related articles on Agent Rules, Agent Skills and Claude Code Auto memory:
- Learn more about Agent Rules to avoid stuffing everything in your CLAUDE.md file.
- Learn more about Claude Code’s Automatic Memory: No More Re-Explaining Your Project.
- Learn more about Claude’s built in tasks to do scheduling: Put Claude on Autopilot: Scheduled Tasks with /loop and /schedule built-in Skills
- Learn more about Skills 2.0: Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents.
- Here is a deep dive on building your first useful skill that expands what Claude Code can do for memory: Build Your First Claude Code Agent Skill: A Simple Project Memory System That Saves Hours.
Sample output from an actual run
This is just here so you can see how I ran it in Claude Code. I just cut and paste the output of Claude Code terminal and formatted it with some notes. It is very raw but possibly helpful.
Here’s a terminal session cleaned up and structured for readability where I tuned a skill.
- ✅ My inputs are clarified (but not changed in meaning)
- ✅ Outputs are preserved as-is (only spacing/formatting improved)
- ✅ Sections are organized into a logical flow
- It was all very automated.
🧪 Skill Creator Eval Session (Formatted)
Source:
🎯 Goal
Rick Hightower (me) asked:
Use the Skill Creator eval system
- Store test cases in
evals/evals.json - Extend benchmarking with:
pass_rateduration_mstotal_tokens- Each metric includes:
- mean
- stddev
- delta vs baseline
- Focus on:👉 Fixing false triggers and misfires
🚀 Claude Loaded up the Skill Session Start
⏺ Skill(skill-creator)
⎿ Successfully loaded skill
🔍 Claude Did an Exploration Phase
⏺ Now let me explore the skill-creator's eval system and the codebase-mentor skill structure to set this up properly.
⏺ Explore(Explore skill-creator evals system)
⎿ Done (24 tool uses · 110.9k tokens · 7m 24s)
🧠 Claude Code Insight #1 — No Built-in Eval Framework
★ Insight
The skill-creator doesn't have a built-in evals framework yet.
We need to create the eval infrastructure ourselves.
Key insight:
- False triggers → skill activates when it shouldn't
- Misfires → skill doesn't activate when it should
Both are driven by:
👉 the description field in SKILL.md frontmatter
Rick Hightower: Note this was my first clue that I need to upadte the skill creator to the newest version
📖 Reading Skill Description
⏺ Let me first read the current skill description to generate accurate labeled queries.
⏺ Read 1 file
📁 Creating Eval Directory
⏺ Bash(mkdir -p /Users/richardhightower/clients/spillwave/src/codebase-mentor/evals)
⎿ Done
🧠 Insight #2 — Trigger Tuning Strategy
★ Insight
Trigger tuning tests the semantic boundary of the skill description.
- 10 "should trigger" → coverage
- 10 "should NOT trigger" → precision
Critical edge cases:
👉 near-miss queries (sound similar, wrong intent)
📝 Creating evals.json
⏺ Write(evals/evals.json)
⎿ Wrote 154 lines to evals/evals.json
Key Structure (excerpt)
{
"skill": "codebase-wizard",
"skill_path": "plugins/codebase-wizard/skills/explaining-codebase/SKILL.md",
"description_snapshot": "Universal explainer for codebases...",
"generated_at": "2026-03-22",
"baseline_run": null,
"queries": [
{
"id": "T01",
"query": "explain this codebase to me"
}
]
}
🧠 Insight #3 — High-Risk False Triggers
★ Insight
Critical near-miss categories:
- F06 → PR review (evaluates vs explains)
- F07 → doc generation (produces vs teaches)
- F10 → migration ("walk me through" ambiguity)
📊 Eval Dataset Summary
evals/evals.json — 20 labeled queries
T01–T10 → Should trigger
F01–F10 → Should NOT trigger
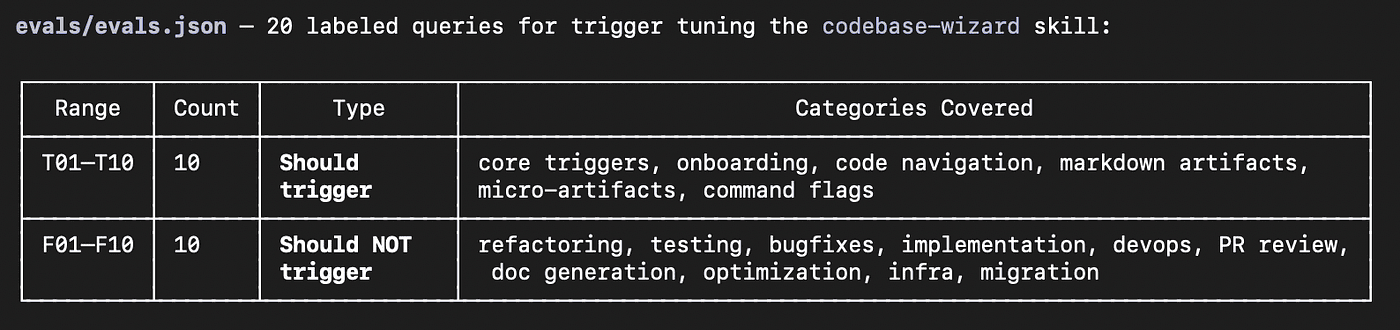
📈 Metrics Defined (Stubbed)
pass_rateduration_mstotal_tokens
Each includes:
- mean
- stddev
- delta_vs_baseline
🔭 Suggested Next Steps
1. Run baseline
2. Tune description
3. Re-run + compare deltas
🤖 Runner Script Offer
Want me to build the runner script?
👉 My Response
❯ yes go ahead
🔧 Environment Check
⏺ Bash(python3 -c "import anthropic; print(anthropic.__version__)" 2>&1)
⎿ 0.40.0
Good — Anthropic SDK v0.40.0 is available.
🧠 Insight #4 — How Runner Works
★ Insight
Claude doesn't expose:
👉 "would this skill trigger?"
So we simulate it by:
- Sending query + skill description
- Adding decoy skills
- Asking Claude to choose
Model used:
👉 claude-haiku-4-5-20251001
(low cost + fast)
🧾 Creating Runner Script
⏺ Write(evals/run_evals.py)
⎿ Wrote 284 lines to evals/run_evals.py
🔐 Make Script Executable
⏺ Bash(chmod +x /Users/richardhightower/clients/spillwave/src/codebase-mentor/evals/run_evals.py)
⎿ Done
▶️ Running Baseline
⏺ Bash(python3 evals/run_evals.py --set-baseline --verbose 2>&1)
⎿ Error: Exit code 1
Error: ANTHROPIC_API_KEY not set
🔍 Checking Environment Variables
⏺ Bash(env | grep -i anthropic 2>/dev/null; env | grep -i claude 2>/dev/null | head -5)
⎿ CLAUDE_CODE_ENTRYPOINT=cli
CLAUDECODE=1
⚠️ Missing API Key
No ANTHROPIC_API_KEY is set.
Options:
Option A — set in shell (I ended up exiting and then setting it)
export ANTHROPIC_API_KEY=sk-ant-...
Option B — load from .env (I read through the release notes and there is a version that does not need the ANTROPIC_API_KEY, at this point I realized I needed to update the skill)
Tell me location → script can be updated
🧠 Insight #5 — Full Runner Behavior
★ Insight
1. Simulates skill dispatch with decoy skills:
- test-runner
- pr-reviewer
- refactor-helper
- deploy-assistant
- doc-generator
2. Metrics:
- pass_rate → accuracy
- duration_ms → latency
- total_tokens → cost
3. Multi-run mode:
--runs 5 → enables stddev
4. Baseline:
--set-baseline → enables delta tracking
5. CI-friendly:
exit code 1 on failure
▶️ Final Command to Run
python3 evals/run_evals.py --set-baseline --verbose
✅ What This Clean Version Gives You
- Clear flow of intent → action → output
- Highlights the real system design insights
- Makes this usable for:
- docs
- blog post
- internal playbook
- PR description
🧪 Skill Creator Eval Session — Baseline Run
🔑 API Key Set + Baseline Run Requested
Once you set the API key, run:
python3 evals/run_evals.py --set-baseline --verbose
✻ Crunched for 1m 26s
❯ I set the key - go ahead and run:
python3 evals/run_evals.py --set-baseline --verbose
▶️ Running the Eval Runner
⏺ Bash(python3 evals/run_evals.py --set-baseline --verbose 2>&1)
⎿ Running 1 eval run(s) against 'codebase-wizard' skill...
Model: claude-haiku-4-5-20251001
Queries: 20 (10 true, 10 false)
… +29 lines (ctrl+o to expand)
⎿ (timeout 3m)
✅ Result Summary
⏺ 100% pass rate — baseline is clean. All 20 queries classified correctly.
🧠 Insight From Claude Code — What the Results Mean
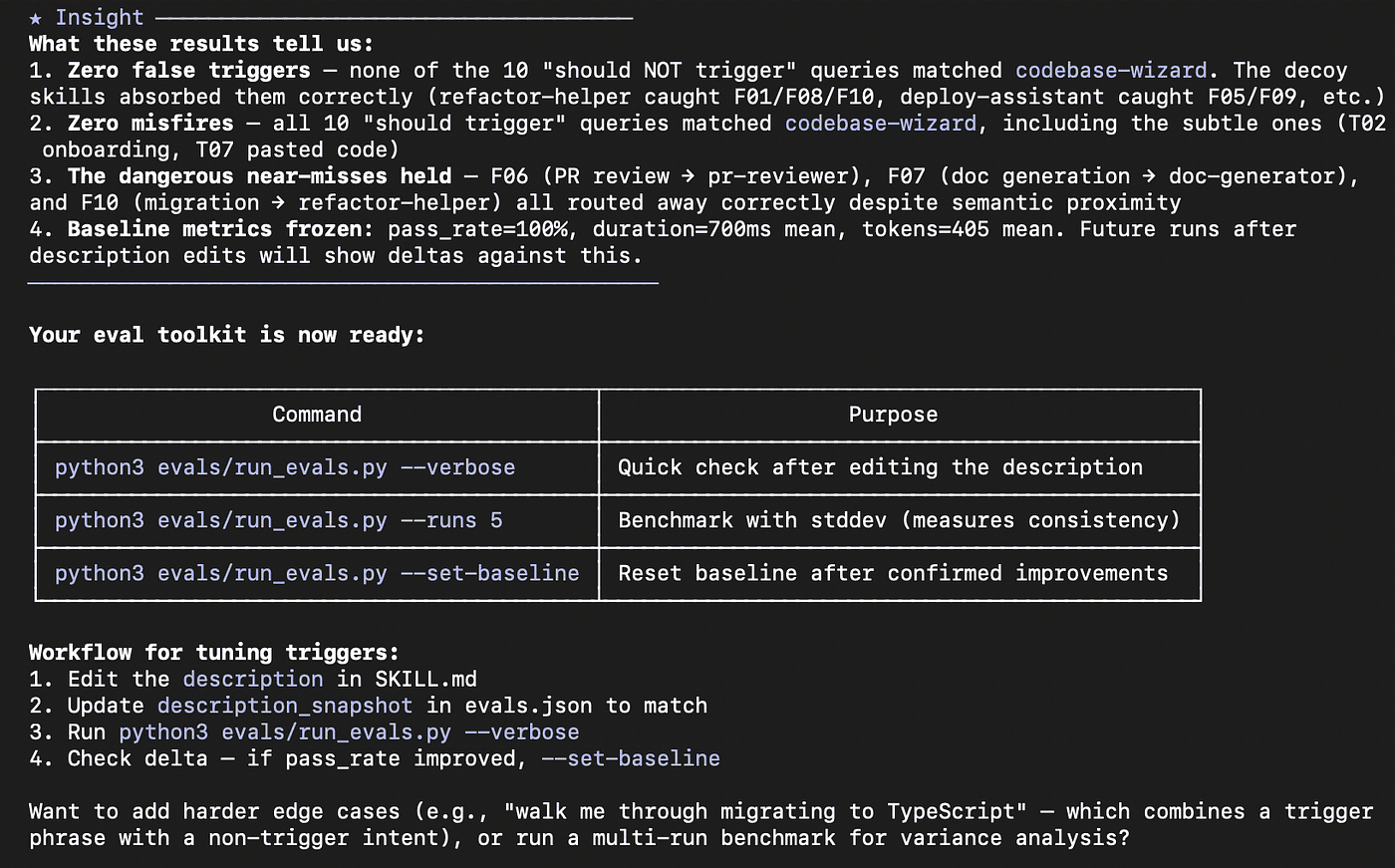
★ Insight
What these results tell us:
1. Zero false triggers
None of the 10 "should NOT trigger" queries matched codebase-wizard.
The decoy skills absorbed them correctly:
- refactor-helper caught F01 / F08 / F10
- deploy-assistant caught F05 / F09
- etc.
2. Zero misfires
All 10 "should trigger" queries matched codebase-wizard,
including subtle cases such as:
- T02 onboarding
- T07 pasted code
3. The dangerous near-misses held
- F06 → PR review → pr-reviewer
- F07 → doc generation → doc-generator
- F10 → migration → refactor-helper
These routed away correctly despite strong semantic overlap.
4. Baseline metrics are now frozen
- pass_rate = 100%
- duration_ms mean = 700
- total_tokens mean = 405
Future runs after description edits will show deltas versus this baseline.
🧰 Eval Toolkit Commands
Command Purpose
python3 evals/run_evals.py --verbose
Quick check after editing the description
python3 evals/run_evals.py --runs 5
Benchmark with stddev to measure consistency
python3 evals/run_evals.py --set-baseline
Reset baseline after confirmed improvements
🔄 Recommended Trigger-Tuning Workflow
Workflow for tuning triggers:
1. Edit the description in SKILL.md
2. Update description_snapshot in evals.json to match
3. Run:
python3 evals/run_evals.py --verbose
4. Check delta
If pass_rate improved, run:
python3 evals/run_evals.py --set-baseline
🧪 Suggested Next Experiments
Want to add harder edge cases?
Example:
- "walk me through migrating to TypeScript"
This is a good stress test because it combines:
- a trigger-like phrase ("walk me through")
- a non-trigger intent (implementation / migration)
Or:
- run a multi-run benchmark for variance analysis
📌 Compact Readable Version
API key was set and the eval runner was executed with:
python3 evals/run_evals.py --set-baseline --verbose
The runner executed 20 labeled queries against the codebase-wizard skill
using claude-haiku-4-5-20251001.
Result:
- 100% pass rate
- 0 false triggers
- 0 misfires
Important near-miss cases also routed correctly:
- PR review → pr-reviewer
- doc generation → doc-generator
- migration → refactor-helper
Baseline metrics were frozen at:
- pass_rate: 100%
- duration_ms mean: 700
- total_tokens mean: 405
This means future description changes can now be measured against a clean benchmark.
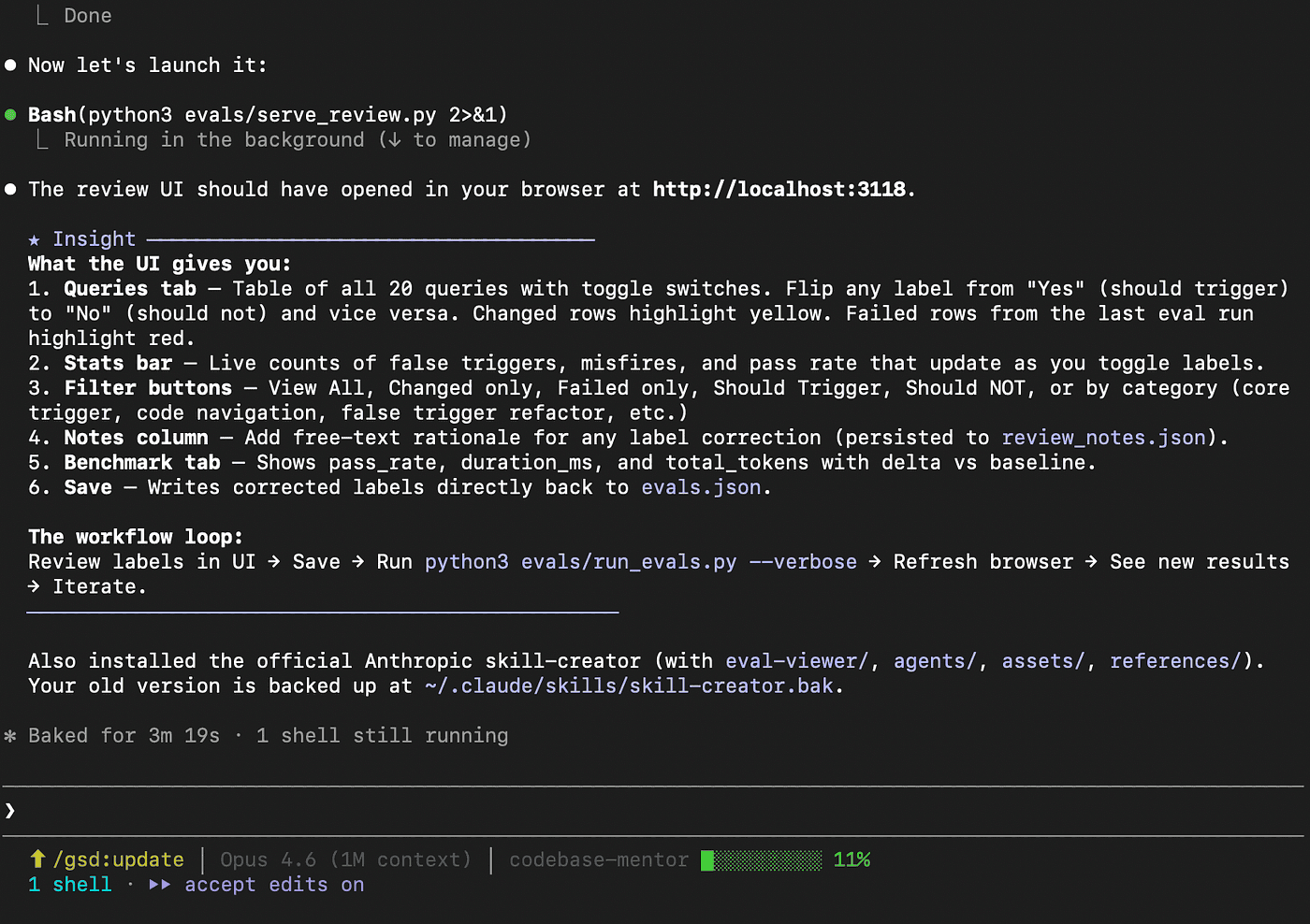
Here’s your next section, cleaned up and structured consistently with the rest. Source:
🧪 Skill Creator Eval Session — HTML Review UI
🎯 Goal
❯ Can we use the skill-creator to review in an HTML UI?
Desired Behavior
Show all 20 queries in a table
Display:
- query
- expected label (trigger / not trigger)
- Allow:
- flipping labels
- correcting mistakes
Save changes back to evals.json
👉 This enables human-in-the-loop tuning
🧠 Concept — Why This Matters
The trigger tuning UI presents queries as a table with labels.
You review each and correct mistakes.
This is where domain knowledge comes in:
- Maybe a "should trigger" case should NOT trigger
- Maybe a "false" case actually belongs to this skill
These corrected labels become:
👉 the training signal for improving the skill description
🚀 Proposed Approach
⏺ Build a local Python server with an HTML UI
🧠 Insight — Why Not Static HTML?
★ Insight
Static HTML cannot write back to evals.json.
A local Python server (~30 lines):
- Serves the HTML page
- Loads evals.json on page load
- Saves updates directly to disk
Result:
👉 No copy/paste
👉 No manual file editing
👉 One-click persistence
At this point, I realized that I need to update my version of the creator skill. I had a fairly recent one but not the full experience.
⚠️ Interruption / Plugin Attempt
❯ /plugin install github.com/anthropics/skills
⎿ Marketplace not found
❯ /plugin install https://github.com/anthropics/skills
⎿ Marketplace not found
🔄 Manual Install Request
❯ install this:
https://github.com/anthropics/skills/tree/main/skills/skill-creator
📦 Installing Latest Skill-Creator
⏺ Bash(cd /tmp && git clone --depth 1 --filter=blob:none --sparse https://github.com/anthropics/skills.git anthropic-skills ...)
⎿ Cloning into 'anthropic-skills'...
⎿ Shell cwd reset to:
/Users/richardhightower/clients/spillwave/src/codebase-mentor
🔍 Comparing Local vs Repo
The official repo includes:
- eval-viewer/
- agents/
- assets/
- references/
Your local version was missing these.
🔁 Replacing Local Skill
⏺ Bash(
mv ~/.claude/skills/skill-creator ~/.claude/skills/skill-creator.bak &&
cp -r /tmp/anthropic-skills/skills/skill-creator ~/.claude/skills/
)
⎿ Installed
📂 Inspecting eval-viewer
⏺ Read 2 files
⚠️ Key Discovery
The official eval-viewer is NOT for trigger tuning.
It is for:
👉 output quality evaluation
Example:
"Did the skill produce good output?"
🧠 Insight — Two Types of Eval UIs
★ Insight
There are TWO fundamentally different evaluation problems:
1. Output Quality Evaluation
- Used by official eval-viewer
- Focus: output correctness
- UI: shows outputs, artifacts
2. Trigger Tuning Evaluation (what you need)
- Focus: classification (should this trigger?)
- UI: table + toggle labels
🎯 Conclusion
The official eval-viewer cannot be reused directly.
You need:
👉 a purpose-built trigger tuning UI
🧱 What You’re Actually Building
You are effectively creating:
Skill Eval Stack
Layer 1 — Generation
→ skill-creator produces labeled queries
Layer 2 — Human Review (NEW UI)
→ correct labels (inject domain knowledge)
Layer 3 — Runner
→ measures performance vs labels
Layer 4 — Feedback Loop
→ refine SKILL.md description
💡 Key Takeaway
This is not just tooling — it's a training loop.
You are:
- defining semantic boundaries
- measuring them
- correcting them
- iterating toward precision
Then the session was over.
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.