Claude Code Verification: How to verify AI-written code so the bugs get caught before they ship…
Part 12 Verification: Make verification a thing that happens automatically, not a thing you have to remember, so AI-written bugs get caught…
Originally published on Medium.
Part 12 Verification: Make verification a thing that happens automatically, not a thing you have to remember, so AI-written bugs get caught…
The bug your AI shipped was not unlucky. It was unverified. Your AI Wrote the Code. Who Checked It? How to verify AI-written code so the bugs get caught before they ship, not after.
In this article: AI coding tools are fast, confident, and occasionally wrong. The fix is not a smarter model. It is a verification system that runs automatically, so the bugs get caught before they ship, not after.
Part 12 of "Claude Code, Day-to-Day," a 19-part guide to mastering Claude Code for working engineers.
There is a sentence every developer using an AI coding tool has heard, and learned to distrust: "This should work." The model is not lying. The model is reporting that the code is plausible, that it matches patterns it has seen before, that nothing in the logic looks obviously broken. That is not the same as tested.
The honest way to read that sentence is this: the code was written, but nobody checked it. And when nobody checks, "done" and "working" mean different things.
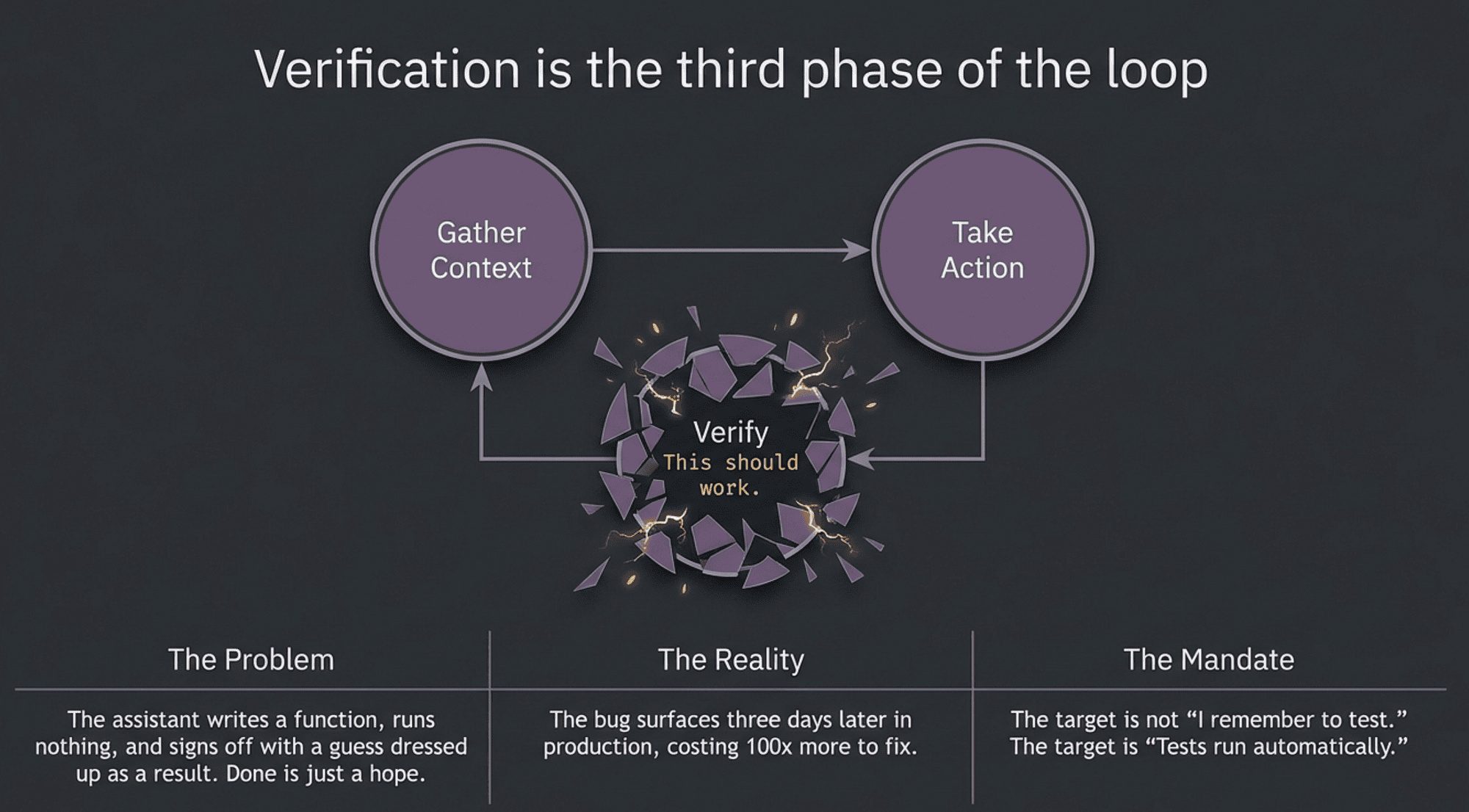
Verification is the third phase of the loop
Claude Code, the agentic coding tool from Anthropic, works in a loop with three phases: gather context, take action, verify result. That loop is how it makes progress. The verify phase is what separates "I wrote some code" from "the code works."
Most people are good at the first two and weak at the third. That weakness is expensive, because the third phase is the one that catches the bugs before users do.
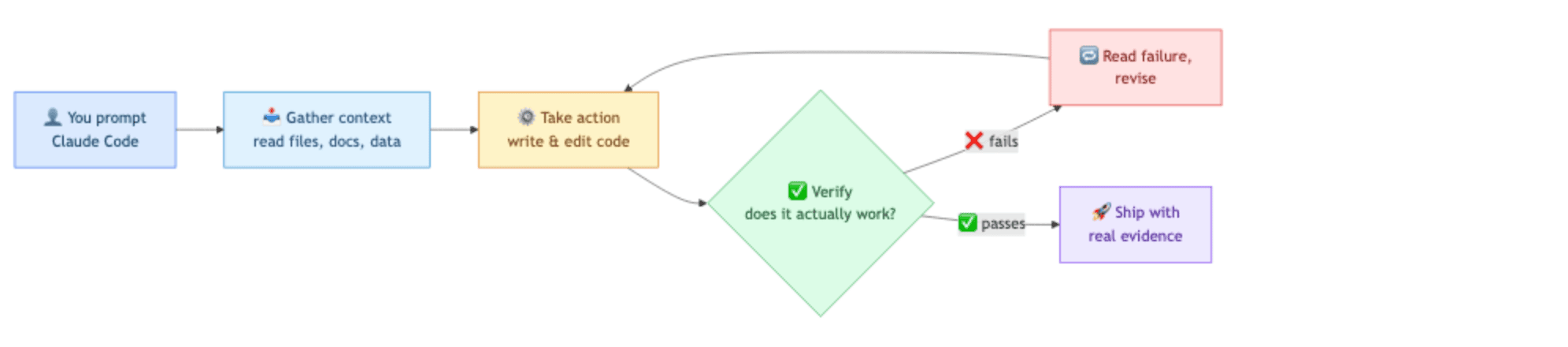
Here is the frame to carry through the rest of this article: a verifier you have to remember to run is a verifier that will sometimes not run. The goal is to make verification automatic, not optional.
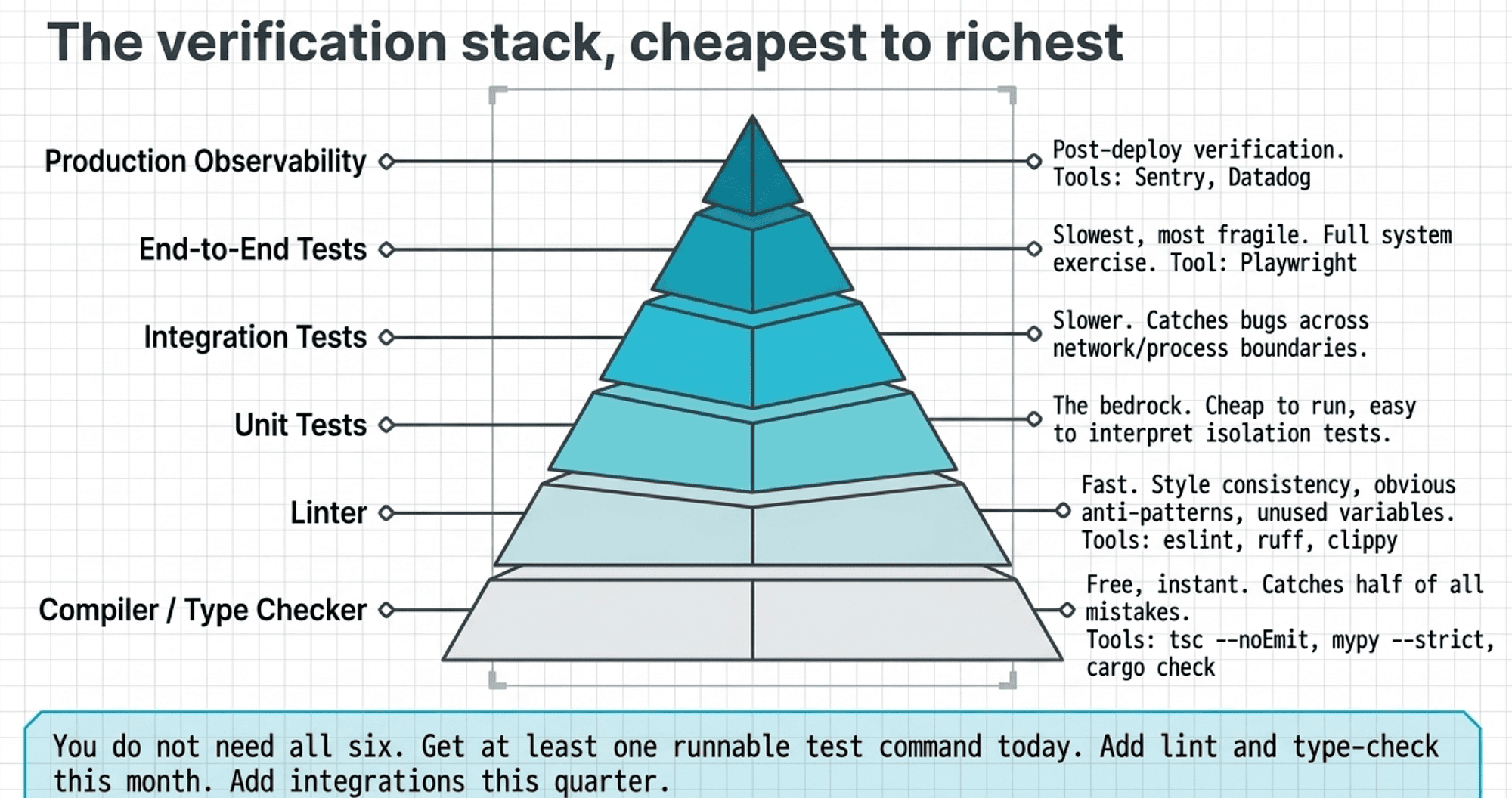
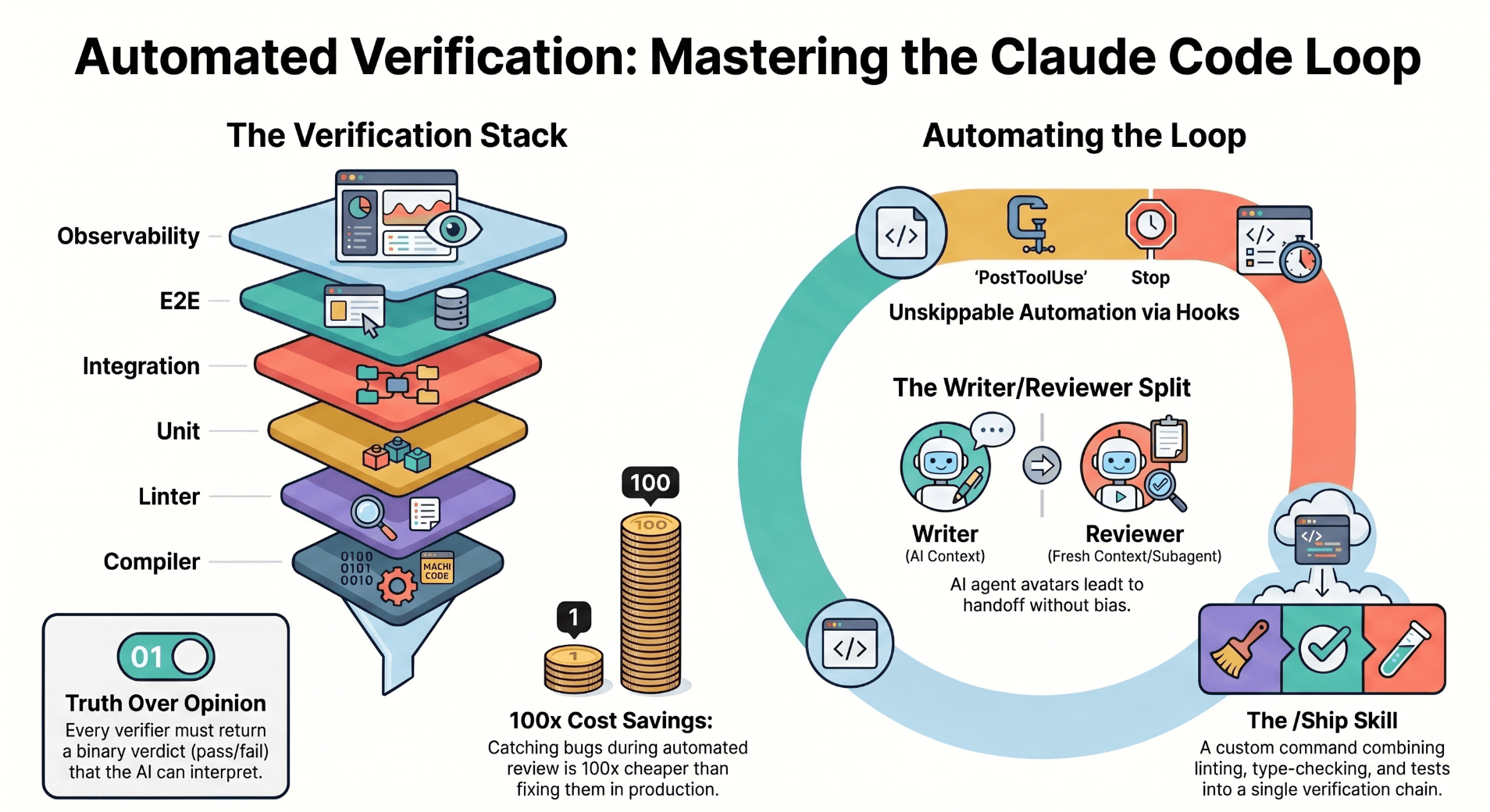
The verification stack, cheapest to richest
No single verifier catches everything. The strong move is to layer them, because each layer catches a different class of mistake, and the layers are cheap enough to run continuously.
The compiler and type checker. Free, instant, and it catches half of the dumb mistakes. Think tsc --noEmit, mypy --strict, cargo check. If your project has a type system and you are not running it on every change, that is the first thing to fix.
The linter. Style consistency, dead code, obvious anti-patterns. Think eslint, ruff, clippy. It catches what type checkers miss, and it does not argue with you about whether a pattern is problematic. --fix handles most of what it finds automatically.
Unit tests. The bedrock. They test a function in isolation, they are cheap to run, and they are easy to interpret when they fail. The failure message points at the function, not at a symptom three layers away.
Integration tests. These test the function in context, wired to its dependencies, talking to a real database or a fixture. They catch the problems unit tests cannot see, because unit tests do not talk to anything.
End-to-end tests. The full system, exercised the way a user would exercise it. Slowest, most fragile, most expensive, and the only thing that catches the class of bugs that only appear when everything is connected. Run them before merging, not before every save.
Production observability. Once code is deployed, the verifier becomes the logs and the metrics. An errors integration like Sentry or Datadog catches what tests missed. This layer does not prevent bugs from shipping, but it catches them within minutes instead of within days.

The pattern across all six layers is the same: Claude needs a tool that returns truth, not opinion. The compiler succeeds or fails. The test passes or fails. The linter reports a count. A tool that returns a definitive result is a tool Claude can act on.
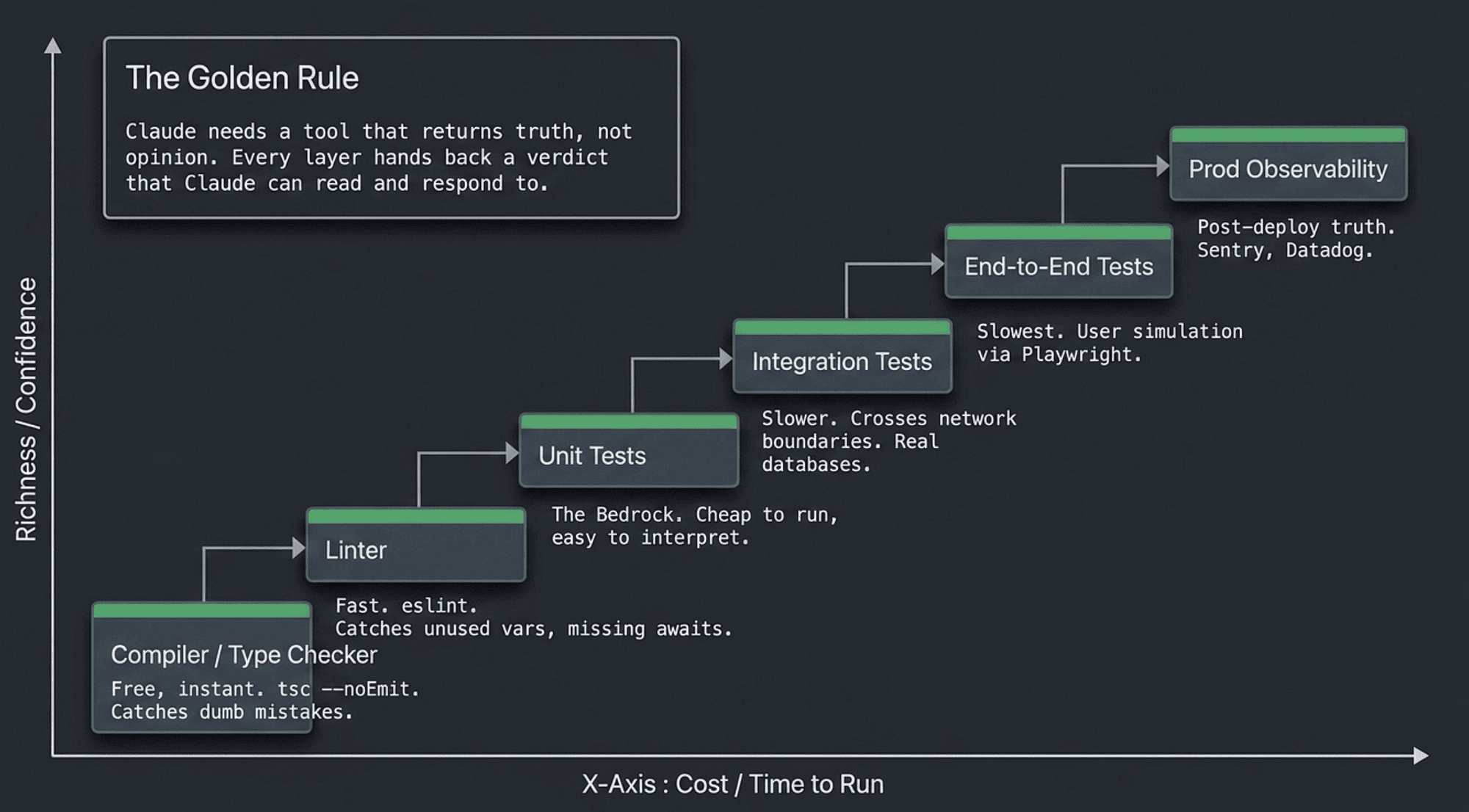
You do not need all six. Most projects get the most value from the first three, plus a sprinkle of the rest where it matters most. Pick the layers that fit your stack, wire them into the loop, and move on.
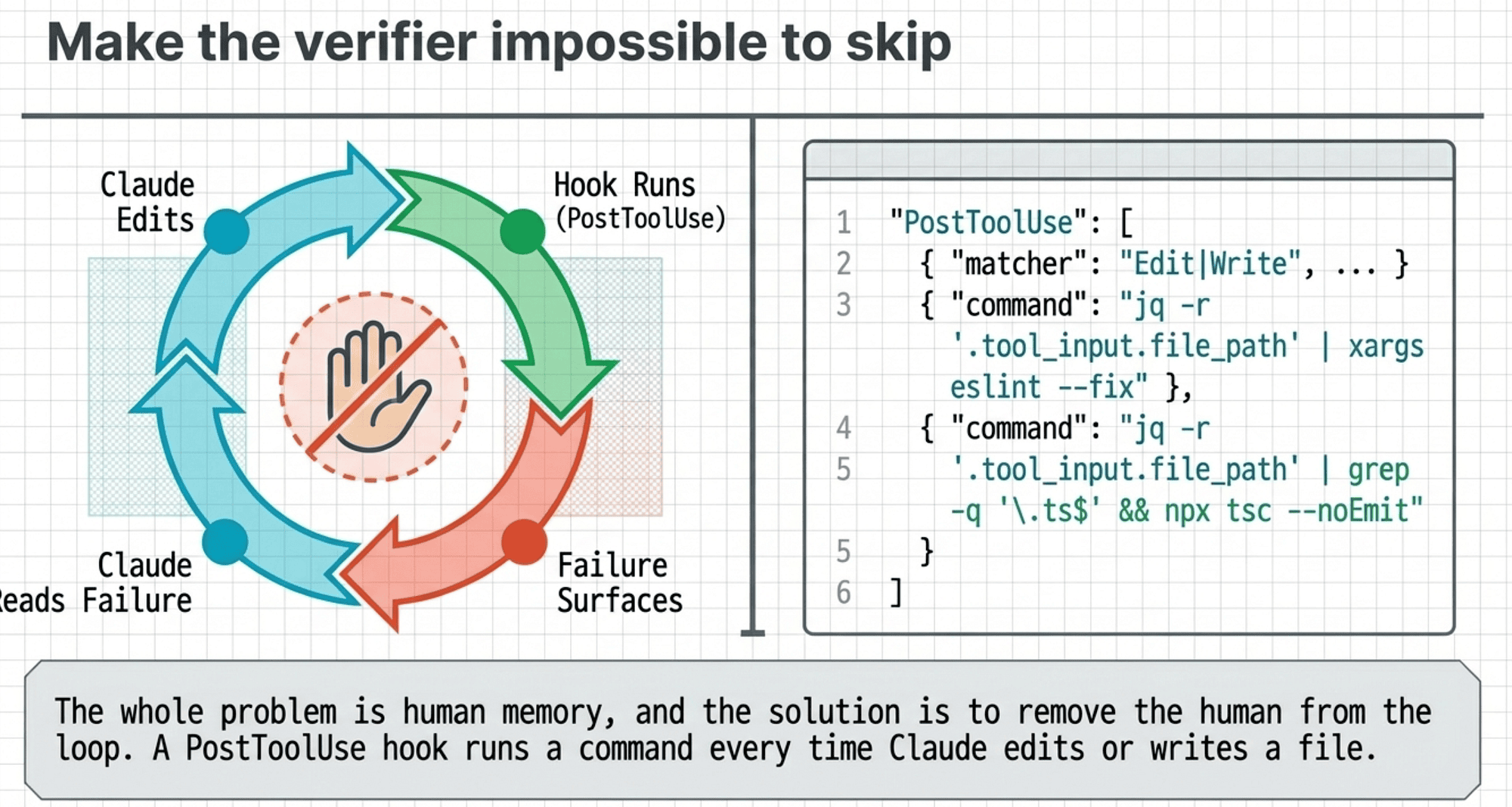
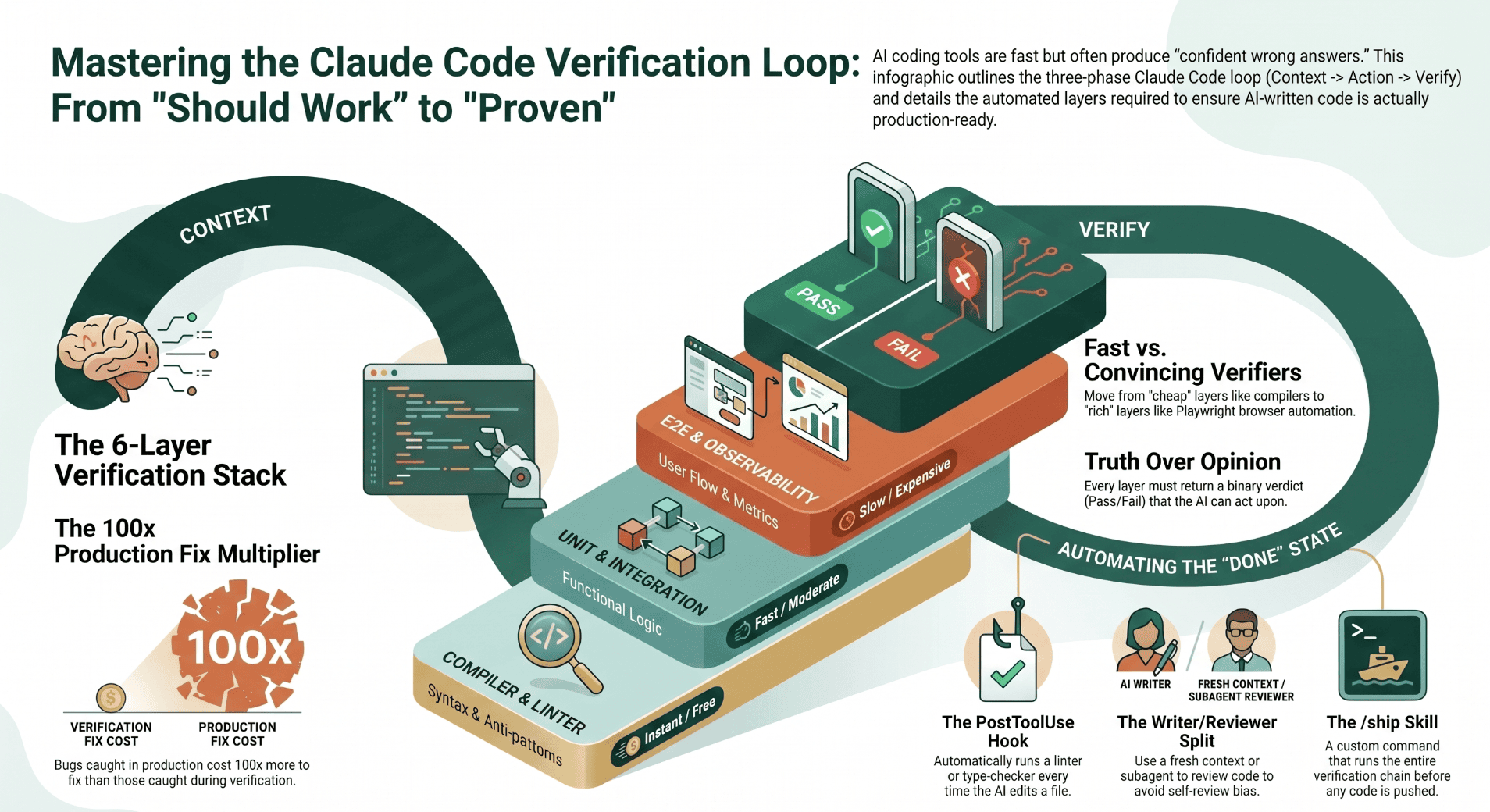
Make the verifier impossible to skip
Knowing the stack is not enough. The whole problem is human memory, and the solution is to remove the human from the loop. That is what hooks do.
A PostToolUse hook runs a command every time Claude edits or writes a file. Wire your linter or type checker into one, and it becomes impossible to skip. The verifier runs whether you thought about it or not.
Here is a PostToolUse hook that lints and type-checks every edited file:
{
"hooks": {
"PostToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{ "type": "command", "command": "jq -r '.tool_input.file_path' | xargs eslint --fix" },
{ "type": "command", "command": "jq -r '.tool_input.file_path' | grep -q '\\.ts$' && npx tsc --noEmit" }
]
}
]
}
}
The other hook worth installing is a Stop hook, which fires when Claude finishes responding. Point it at your test suite, and the tests run at the end of every turn:
{
"hooks": {
"Stop": [
{
"hooks": [
{ "type": "command", "command": "npm test --silent 2>&1 | tail -50" }
]
}
]
}
}
The tail -50 matters. Trimming hook output aggressively keeps the failure context tight and useful instead of burying the relevant line in noise.
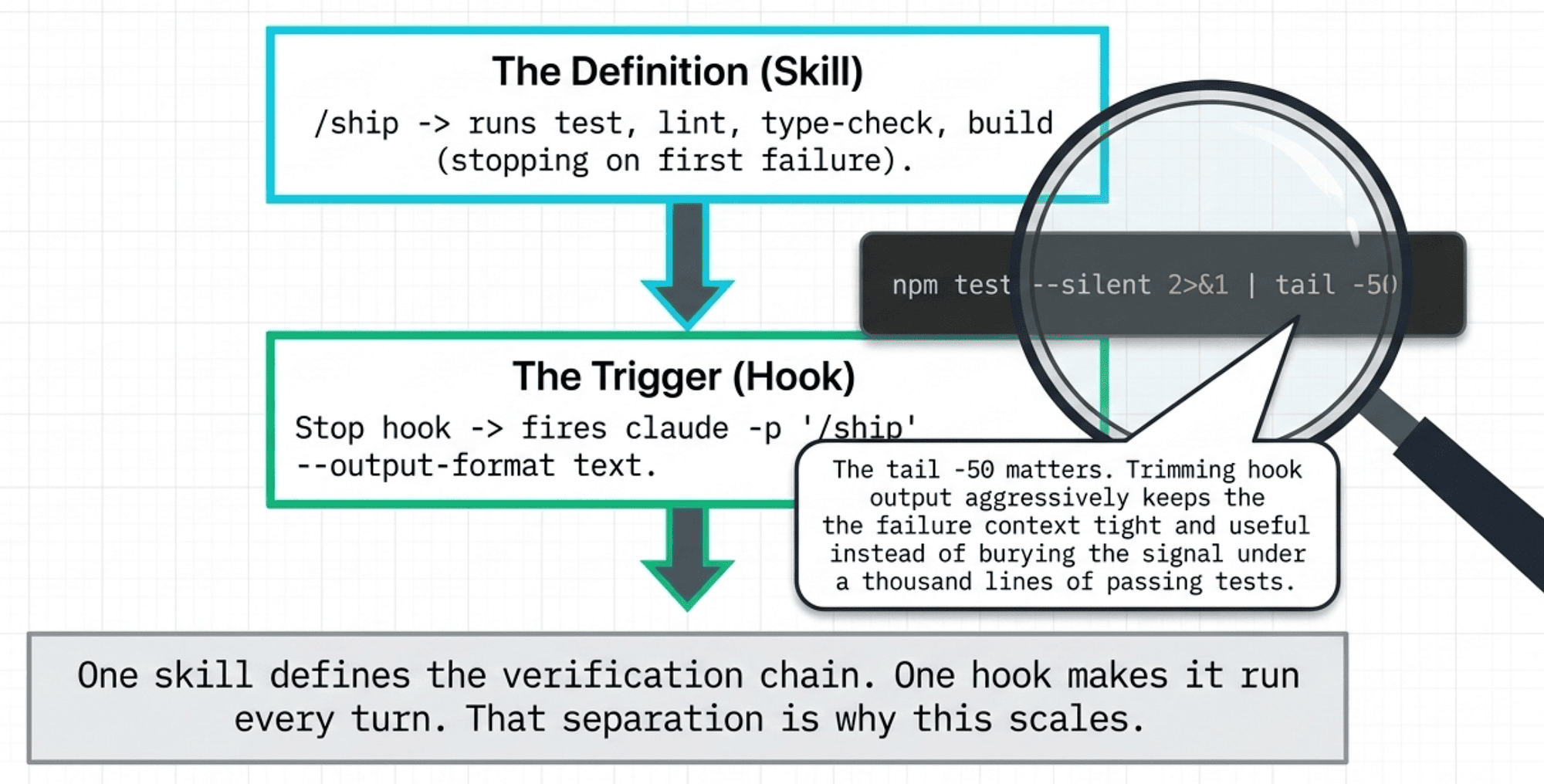
The strongest version of this combines a skill and a hook. A skill is a reusable, named command you can define once and invoke by name. A /ship skill that chains your full verification stack becomes the single source of truth for what "verified" means on this project. Then a Stop hook calls the skill automatically on every turn:
{
"hooks": {
"Stop": [
{
"hooks": [
{ "type": "command", "command": "claude -p '/ship' --output-format text" }
]
}
]
}
}
One skill defines the verification chain. One hook makes it run every turn. The two are independent: change what gets verified by editing the skill, not by editing the hook.
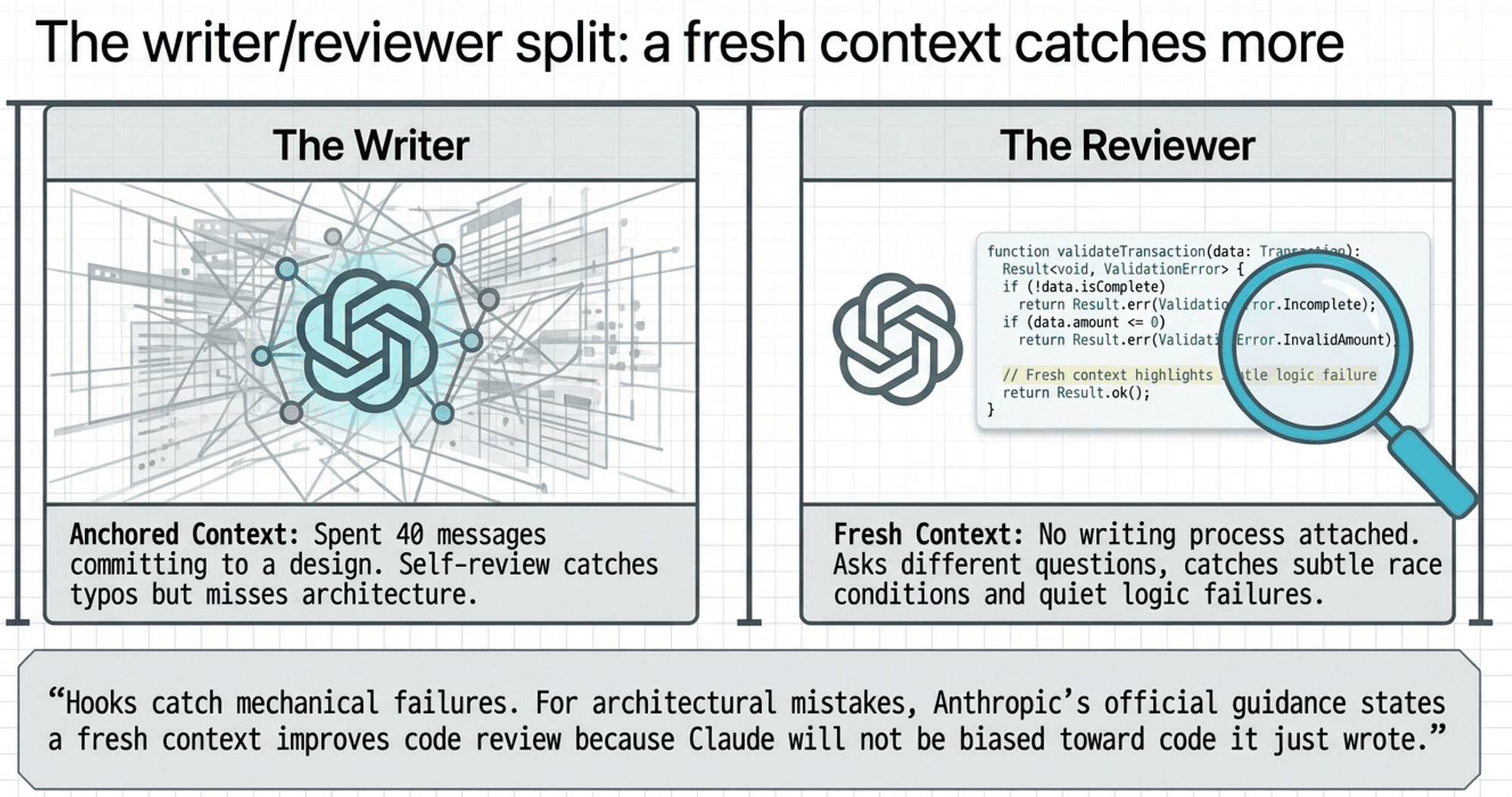
The writer/reviewer split: a fresh context catches more
Hooks catch mechanical failures: a broken type, a failing test, a lint violation. They do not catch architectural mistakes, logic errors, or the class of problems that require stepping back and reading the code as a whole.
Anthropic's official best-practices guidance makes a claim that is easy to underweight. A fresh context improves code review because it has not been anchored by the writing process. That is not a soft preference. It is a structural advantage.
The mechanism is straightforward. When Claude writes code, the writing process anchors it on the chosen approach. The second model does not have that anchor. It reads what is there, not what was intended, and that difference is where the interesting bugs live.
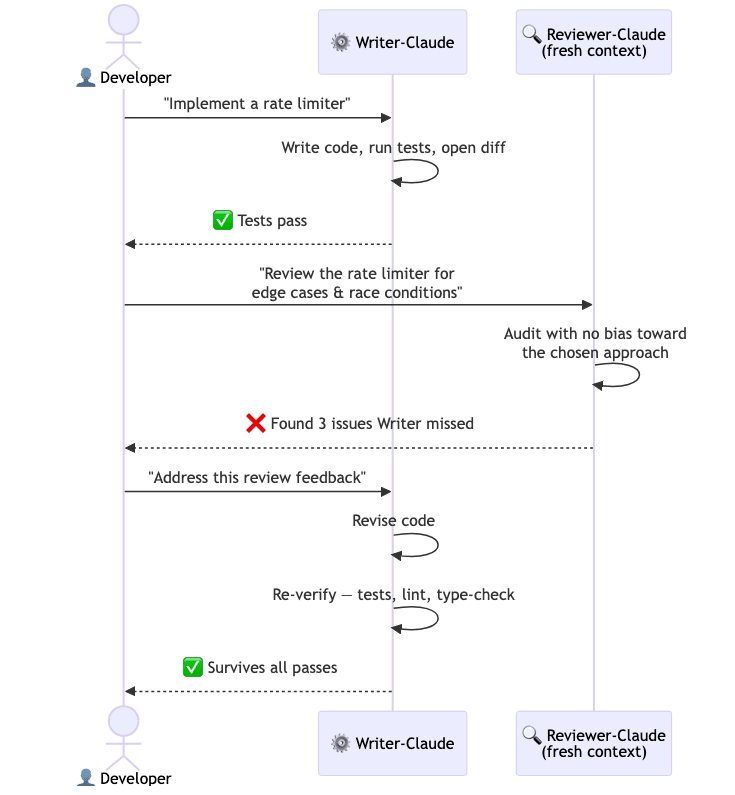
There are three ways to set this up, in increasing order of automation.
Two terminal sessions. Open a second terminal, start a fresh Claude session, and paste a review prompt: "Review the rate limiter I just wrote. Focus on edge cases and correctness." That is the manual version. It works, and it requires no setup.
A reviewer subagent. A subagent is a specialized helper with its own isolated context that Claude can delegate to. Prompt the main Claude to use a code-reviewer subagent after completing a significant change. The subagent reads the code fresh and reports what it finds.
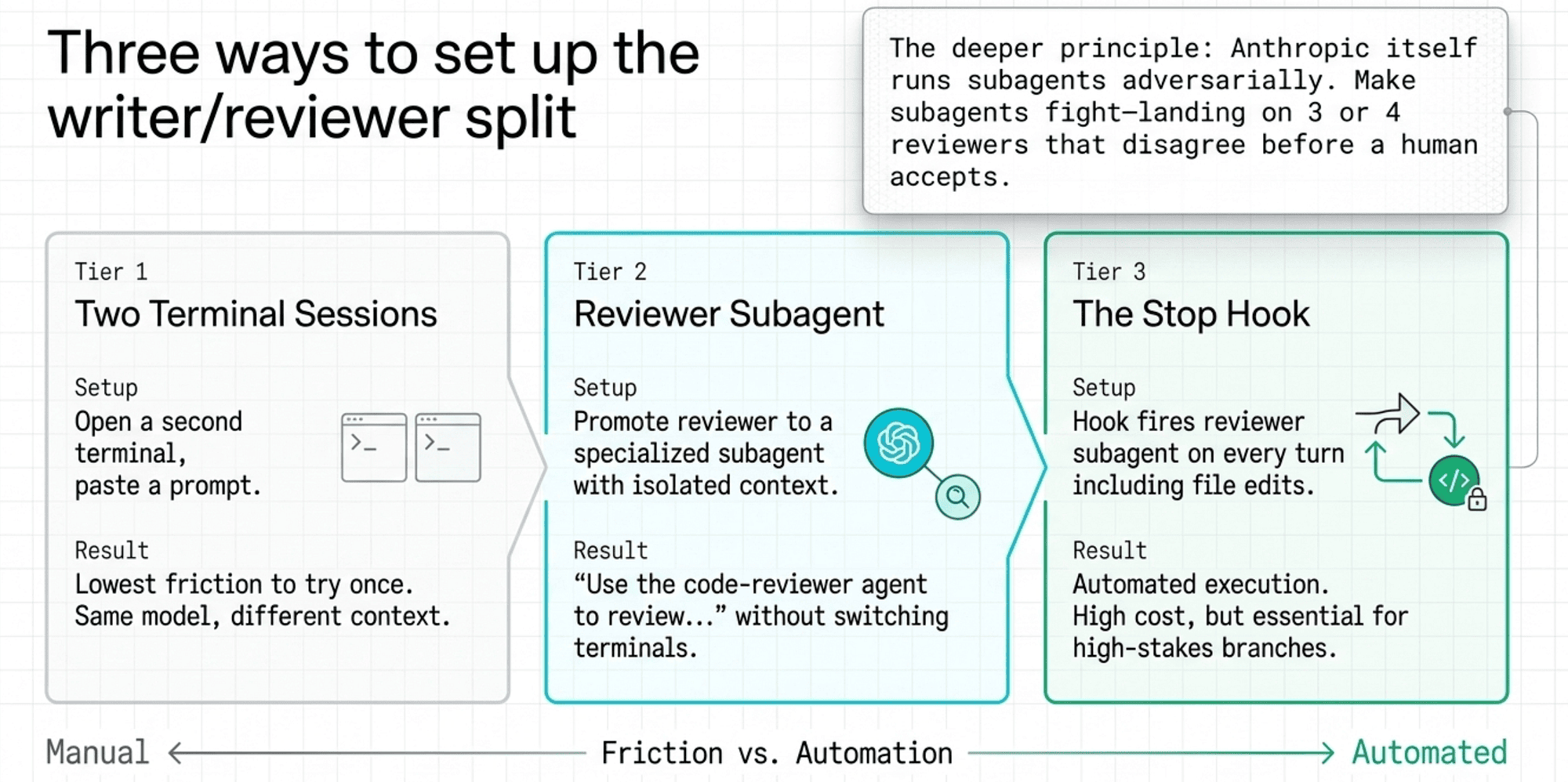
A Stop hook that fires the reviewer. When even the delegation cost is too high, automate it: a Stop hook calls the reviewer at the end of every turn. The reviewer runs whether you remembered to ask or not.
The deeper principle: the more layers of independent review you stack, the more issues you catch. Writer plus reviewer is twice as many eyes as writer alone, and the second set of eyes is cheap.
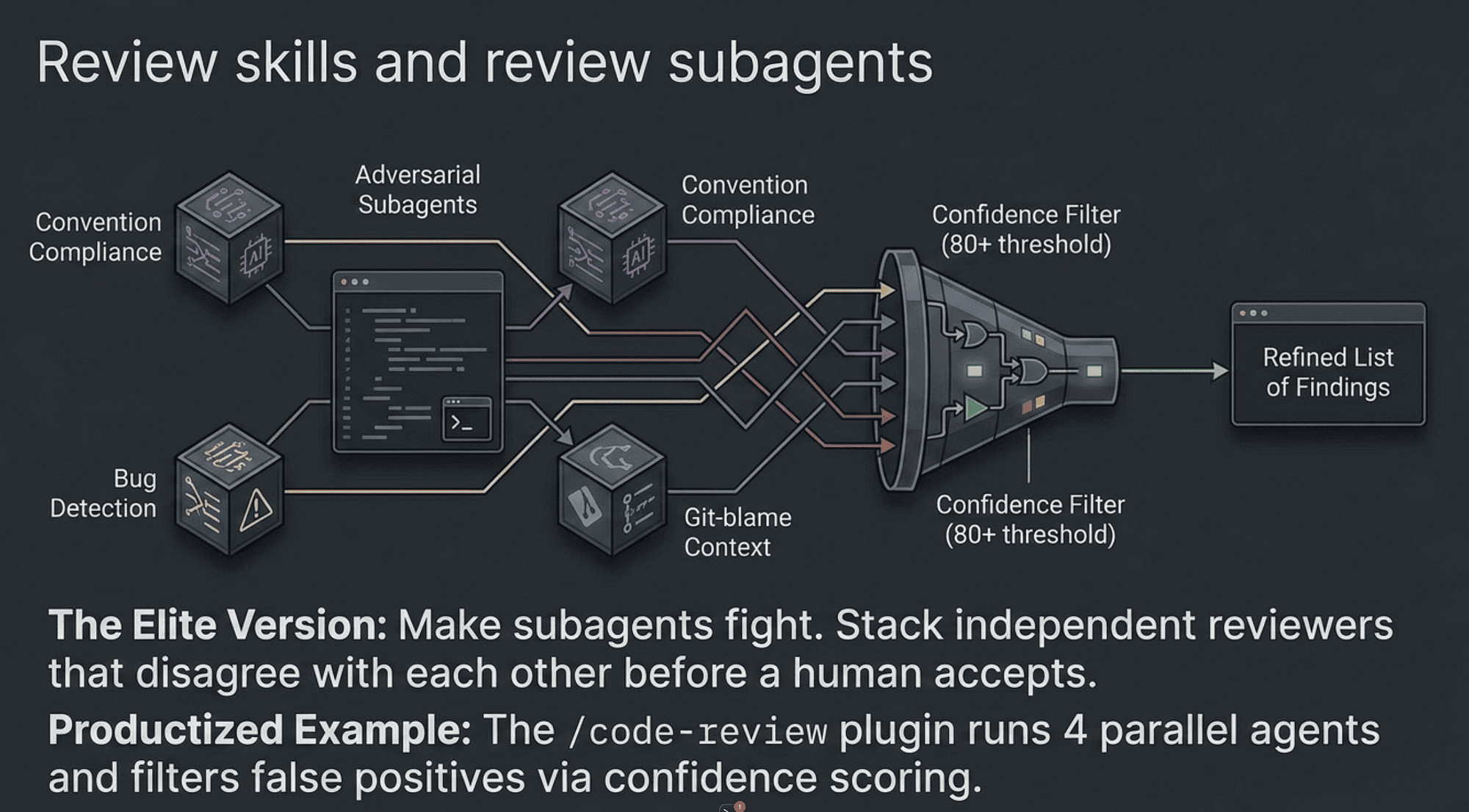
Review skills and review subagents
Two artifacts show up in most mature setups, and the difference between them is worth understanding.
A /security-review skill is a user-triggered command. You run it deliberately, before pushing, when you decide a change is sensitive enough to warrant a security pass. It is intentional and controlled.
---
name: security-review
description: Reviews code changes for security vulnerabilities
disable-model-invocation: true
argument-hint: <branch-or-path>
---
## Diff to review
!`git diff $ARGUMENTS`
Audit the changes above for:
1. Injection vulnerabilities (SQL, XSS, command)
2. Authentication and authorization gaps
3. Hardcoded secrets or credentials
4. Insecure dependencies
Report findings with severity ratings and remediation steps.
The disable-model-invocation: true line keeps Claude from triggering this on its own. A security review is something you opt into, not something that fires on every turn. The argument-hint makes the expected input clear at the call site.
A code-reviewer subagent is a delegate Claude can spawn autonomously when the work calls for review. Same review logic, different trigger: Claude decides when to invoke it, based on the task at hand.

There is also a productized version. The /code-review plugin from the official marketplace runs four parallel review agents that specialize in different dimensions: correctness, security, testing, and style. One command, four reviewers, parallel execution.
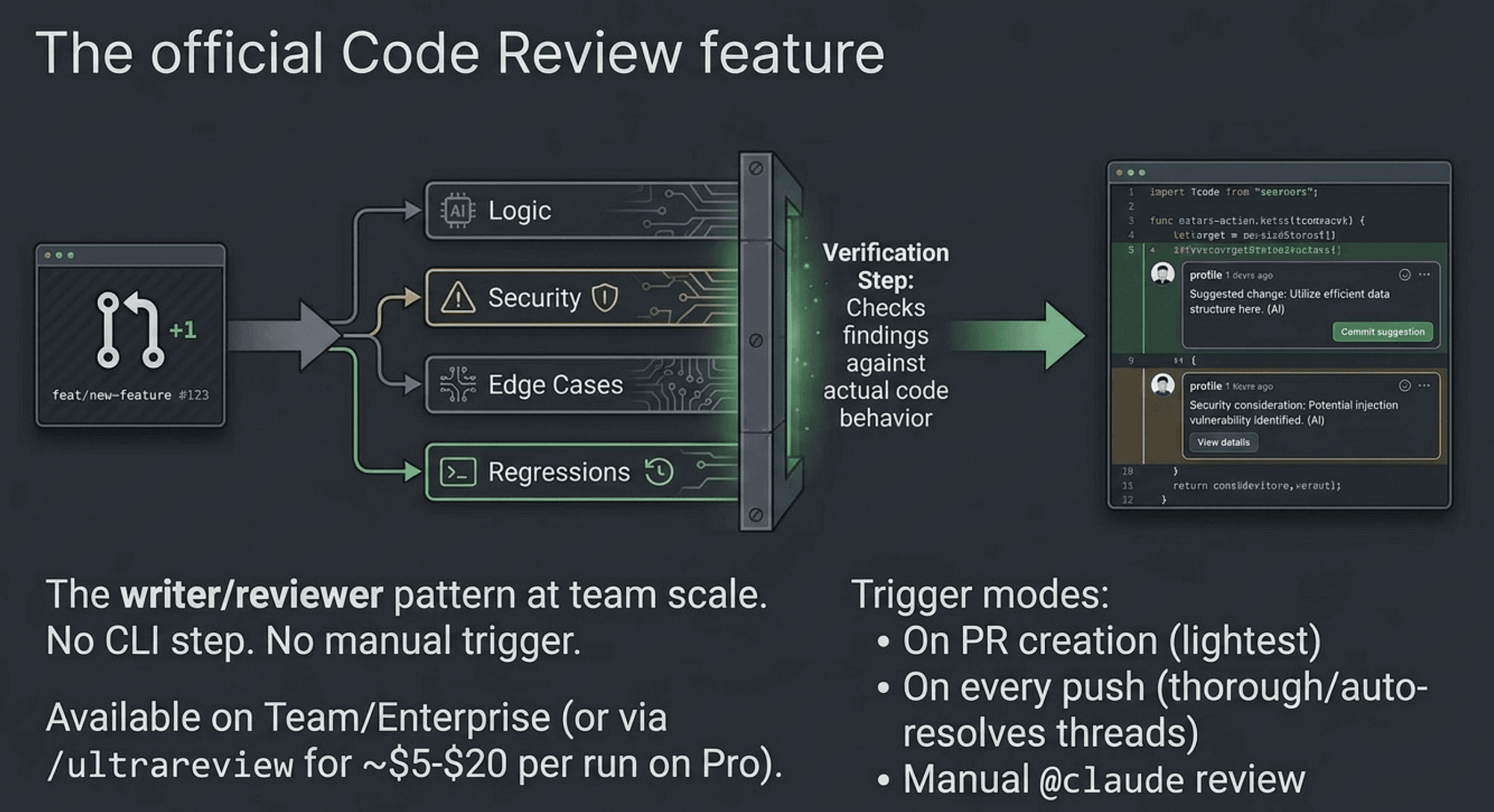
The official Code Review feature
The most automated version of code review available right now needs no CLI step and no manual trigger at all. Claude reviews pull requests automatically when it is enabled on a repository.
The feature is in research preview, available on Team and Enterprise plans, and not available for organizations with Zero Retention Mode enabled. Once activated, it connects to your GitHub repository and watches for pull request events.
When a pull request opens, Anthropic's infrastructure spins up a fleet of agents that look at the diff and the surrounding code. They check for correctness issues, security problems, test coverage gaps, and code clarity concerns. They leave comments in the pull request, the same way a human reviewer would.
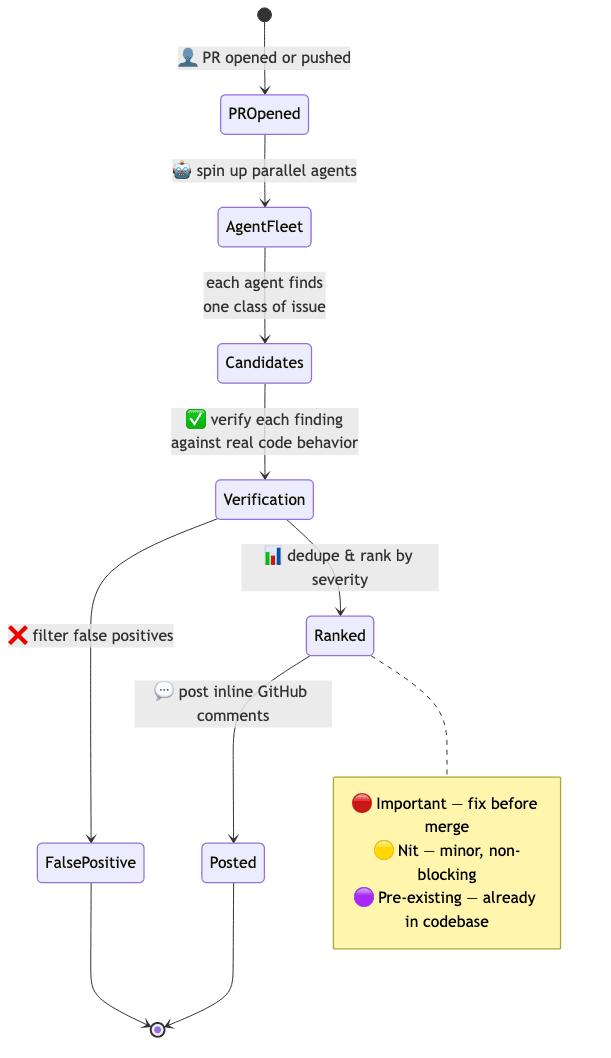
Findings carry one of three severity tags. A red Important flag is a bug that should be fixed before merging. A yellow Nice to have is a suggestion worth considering. A green Approve means the review found nothing worth flagging.

Three trigger modes are worth knowing. Run review once after pull request creation for the lightest-weight option. Run it every time a commit is pushed to keep the review current as the branch evolves. Or run it on demand, triggered by posting a comment with the @claude handle or running /review (fast, uses fewer agents) or /ultrareview (slower, thorough, uses more agents).
The cost model is pay-per-review, scaling with pull request size and completing in about 20 minutes on average. For repositories that merge frequently, that is worth evaluating against the cost of a missed bug. The /review command is available to all Claude Code users.
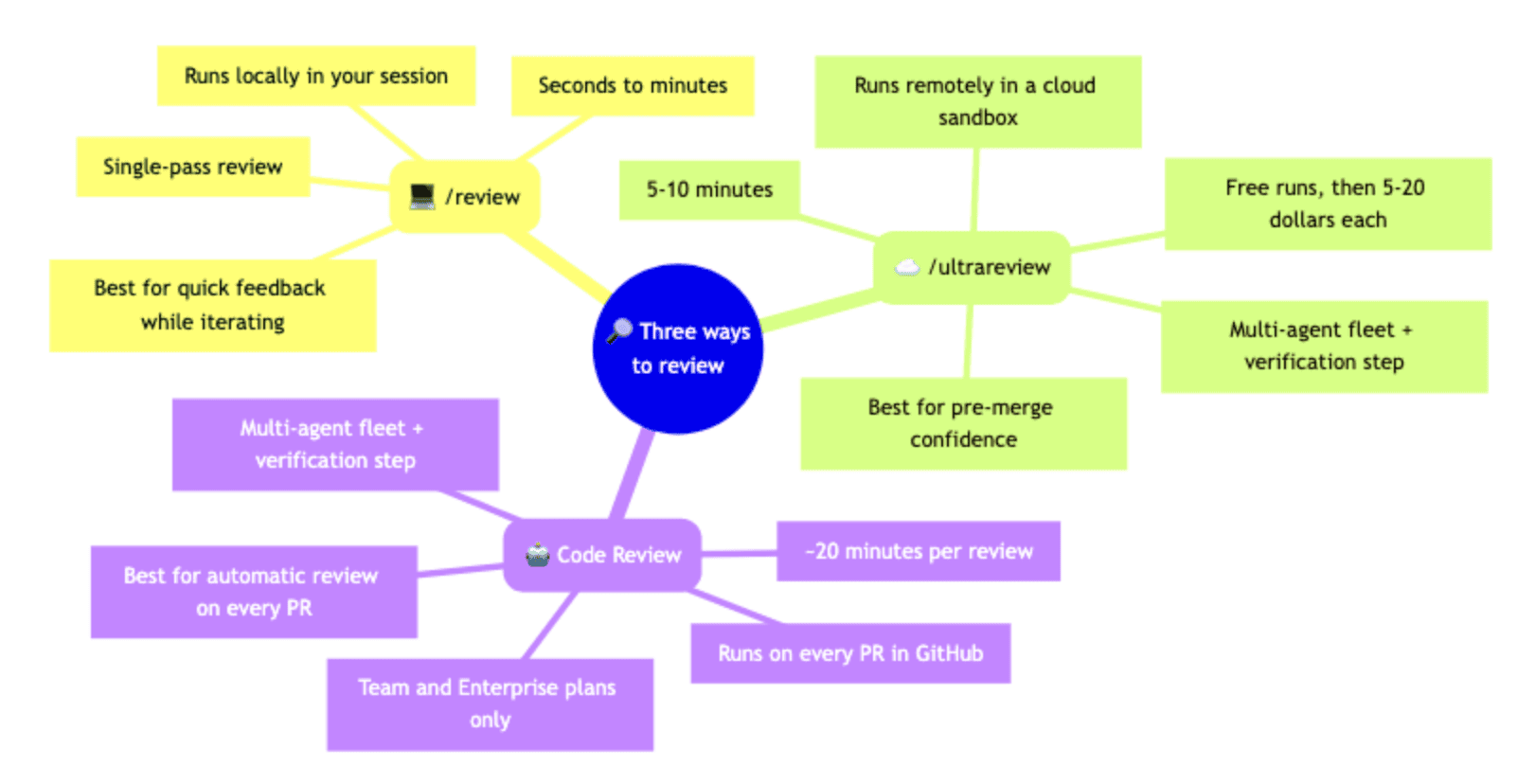
The right move for most teams: use /review during work for fast local feedback, and /ultrareview or the Code Review feature at merge time for the full pass.
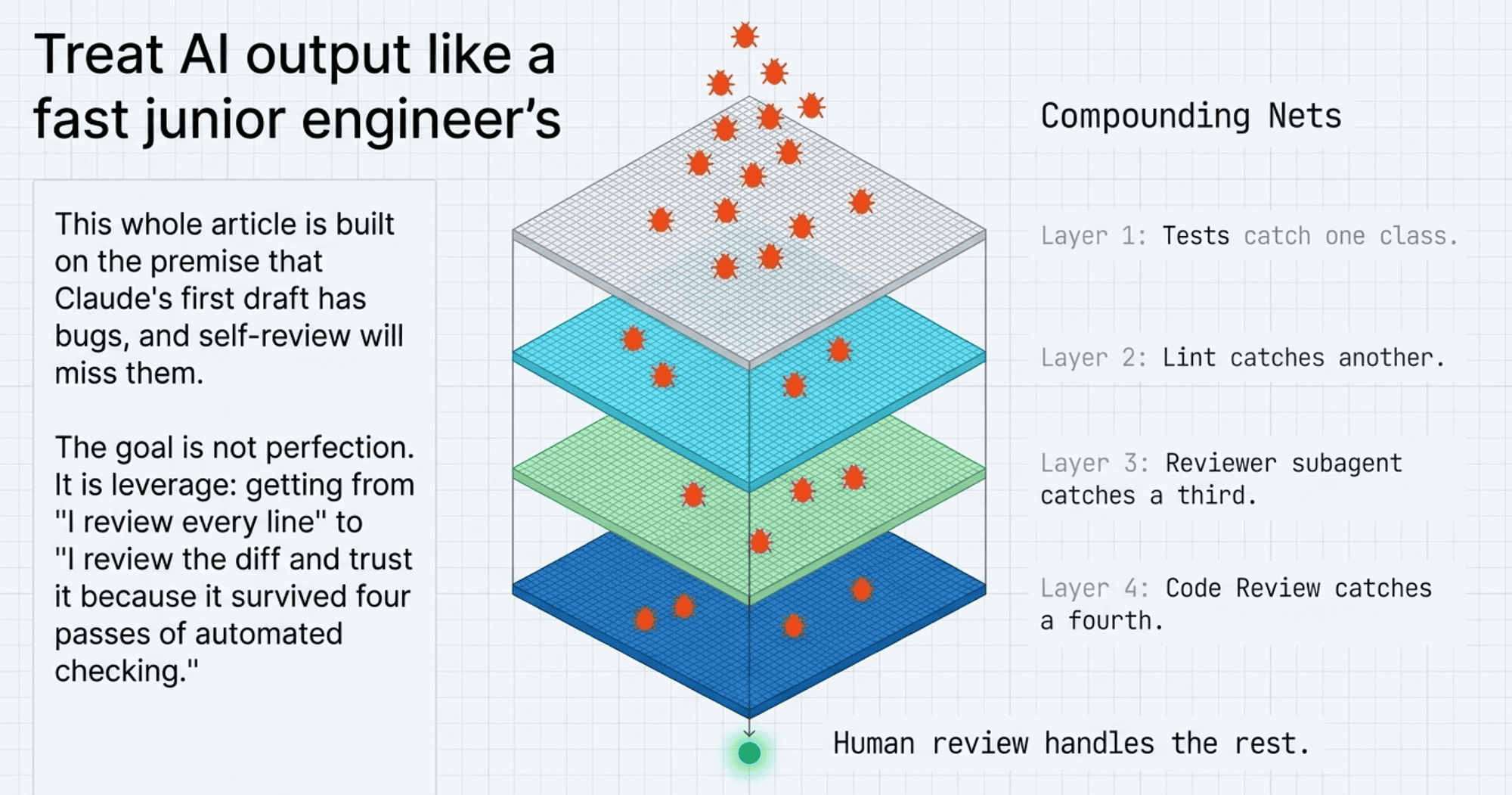
Treat AI output like a fast junior engineer's
Step back and notice the assumption underneath everything here. This whole article is built on the premise that Claude's output needs verification. That is not a criticism of Claude. It is a description of how software works.
That is a more honest framing than "prompt the AI better and it will get it right the first time." Better prompts help. They do not replace verification. No amount of prompt engineering closes the gap between "this looks plausible" and "this is confirmed to work."
So treat the output the way you would treat a fast junior engineer's output: reasonably trustworthy, often correct, and not something you ship without checking. The junior engineer does not need to be supervised on every keystroke. They do need a test suite, a reviewer, and a type checker.

This is also why the layers compound. Tests catch one class of mistake. Lint catches another. The reviewer subagent catches a third. No single layer is sufficient, and no single layer is expensive. The stack is cheap to run and expensive to skip.

Do this today
Three concrete moves, in order of payback.
Write the /ship skill. Even if the verifier chain is just npm test && npm run lint, that is enough to start. The pattern is the point: one named command, one source of truth for what "verified" means.
Add the code-reviewer subagent. Use /agents, choose Create new agent, and let Claude generate it: describe the agent in plain English, and it writes the configuration. One subagent, added once, available on every future project.
Turn on automatic review. If you are on Team or Enterprise, enable the Code Review feature on your most important repository. Let the automated reviewer run for a month. Count how many things it catches.
The bug was not unlucky. It was unverified.
Think about the compounding effect over a few months. Every layer of verification you add is one more way AI-written code gets checked before it ships. Every layer you skip is one more way it does not.
Six months in, the failure mode that used to be "the AI said it works and it does not" becomes "the test, the type checker, the reviewer, and the automatic PR review all passed." That is a different category of confidence.
The next time an AI coding tool tells you a change "should work," do not argue with it. Just make sure the answer comes from a verifier, not from the model.
This is Part 12 of "Claude Code, Day-to-Day," a 19-part guide to mastering Claude Code for working engineers.