Codex Gets Subagents: The Parallel AI Coding Pattern Is Now The De Facto Industry Standard — How does it stack up to Claude Code
Transforming AI Coding: How Codex's New Subagent System Sets De Facto Industry Standard and Comparing it to Claude Code
Originally published on Medium.

Summary: OpenAI released Codex subagents on March 16, 2026, enabling parallel execution of tasks, similar to Claude Code's model. Codex now features three roles: explorer for read-only analysis, worker for read-write execution, and default for general tasks, with up to six subagents running concurrently. The explorer/worker/orchestrator pattern is now a de facto standard across major AI coding tools, emphasizing safe parallelization of coding work. It is the baseline expectation. Key differences remain, with Codex excelling in cloud-native infrastructure and CSV batch processing, while Claude Code leads in git worktree isolation and peer-to-peer coordination (according to Anthropic demos and community reports as of yet this is not fully documented behavior.). The landscape of AI coding tools is evolving, with both tools complementing each other for different workflows.
For months, developers using both Codex and Claude Code noticed the same friction point. You'd ask Codex to review a pull request while simultaneously digging into a bug trace, and the tool would handle those tasks sequentially. One thing at a time. Meanwhile, Claude Code users were spinning up parallel agents, letting an explorer map the codebase while a worker implemented the fix. That gap became harder to ignore the longer it persisted. Then, on March 16, 2026, OpenAI shipped codex subagents to general availability, and the gap closed considerably overnight.
The reaction from Simon Willison, one of the most reliable independent observers of developer tooling, was immediate and precise. He called the Codex implementation "very similar to the Claude Code implementation, with default subagents for 'explorer', 'worker' and 'default'." That quote does a lot of work. It's not just a technical observation. It's the convergence story in a single sentence: two competing tools, developed independently, arrived at nearly identical architectural patterns. The explorer/worker/orchestrator model is no longer a Claude Code differentiator. It's an industry standard.
very similar to the Claude Code implementation, with default subagents for 'explorer', 'worker' and 'default' -- Simon Willison
Let's cover what changed in Codex on March 16, how the subagent system actually works, where the two tools are now genuinely equivalent, and where real differences still exist. No winner declared. Just a clear picture of the current landscape.
Key Takeaways:
- OpenAI shipped codex subagents to general availability on March 16, 2026, closing the parallel execution gap with Claude Code.
- Three built-in roles ship out of the box: explorer (read-only analysis), worker (read-write execution), and default (general purpose).
- Up to six parallel subagents run concurrently by default, configurable via max_threads in TOML.
- The explorer/worker/orchestrator pattern is now standard across every major AI coding tool, including Gemini CLI, VS Code, Cursor, Claude Code, and Codex.
- Real differences remain: Codex leads on cloud-native infrastructure and CSV batch processing; Claude Code leads on git worktree isolation and peer-to-peer agent coordination.
Table of Contents
- What Changed on March 16, 2026
- How Codex Subagents Work in Parallel
- The TOML Configuration Model
- Batch Processing via CSV (Experimental)
- The Token Cost Reality
- The Pattern That Won
- Codex vs. Claude Code: Parallel Capabilities Compared
- What's Now Equal
- Where Codex Has the Edge
- Where Claude Code Has the Edge
- The Full Comparison
- One Caveat Worth Stating
- Choosing Your Tool
- The Gap Narrowed. The Race Continues.
- References
What Changed on March 16, 2026
Before this release, Codex was a capable but strictly sequential tool. You gave it a task, it worked through that task, and when it finished you could give it another. There was no mechanism for parallel work within a session, no specialized agent roles, no way to say "have one agent read the code while another writes the tests."
After March 16, the picture looks substantially different.
Codex now supports concurrent parallel subagents, with up to six running simultaneously by default. That default is controlled by the max_threads setting in your configuration, and it is configurable, not a hard ceiling. The official documentation does not specify an upper bound, though the platform is designed around the assumption that most teams will stay near the default for cost reasons.
Three specialized agent roles ship out of the box:
- explorer: Read-only analysis. Maps codebases, traces execution paths, gathers evidence. Configured with read-only sandbox access so it cannot accidentally modify anything.
- worker: Read-write execution. Implements changes, applies fixes, writes code. This is the agent that actually touches your files.
- default: General-purpose fallback for tasks that don't fit neatly into explorer or worker territory.
Each subagent runs in parallel. Each subagent runs as its own isolated Codex-managed session in OpenAI's cloud. The parent agent orchestrates the work: spawning subagents, routing tasks, waiting for results, and consolidating outputs back into a single response. You don't manage infrastructure. You describe what you need and Codex handles the rest.
One important behavioral detail: Codex only spawns a new subagent when you explicitly ask it to do so. This is not a tool that automatically decides to parallelize work without your input. You direct the orchestration.
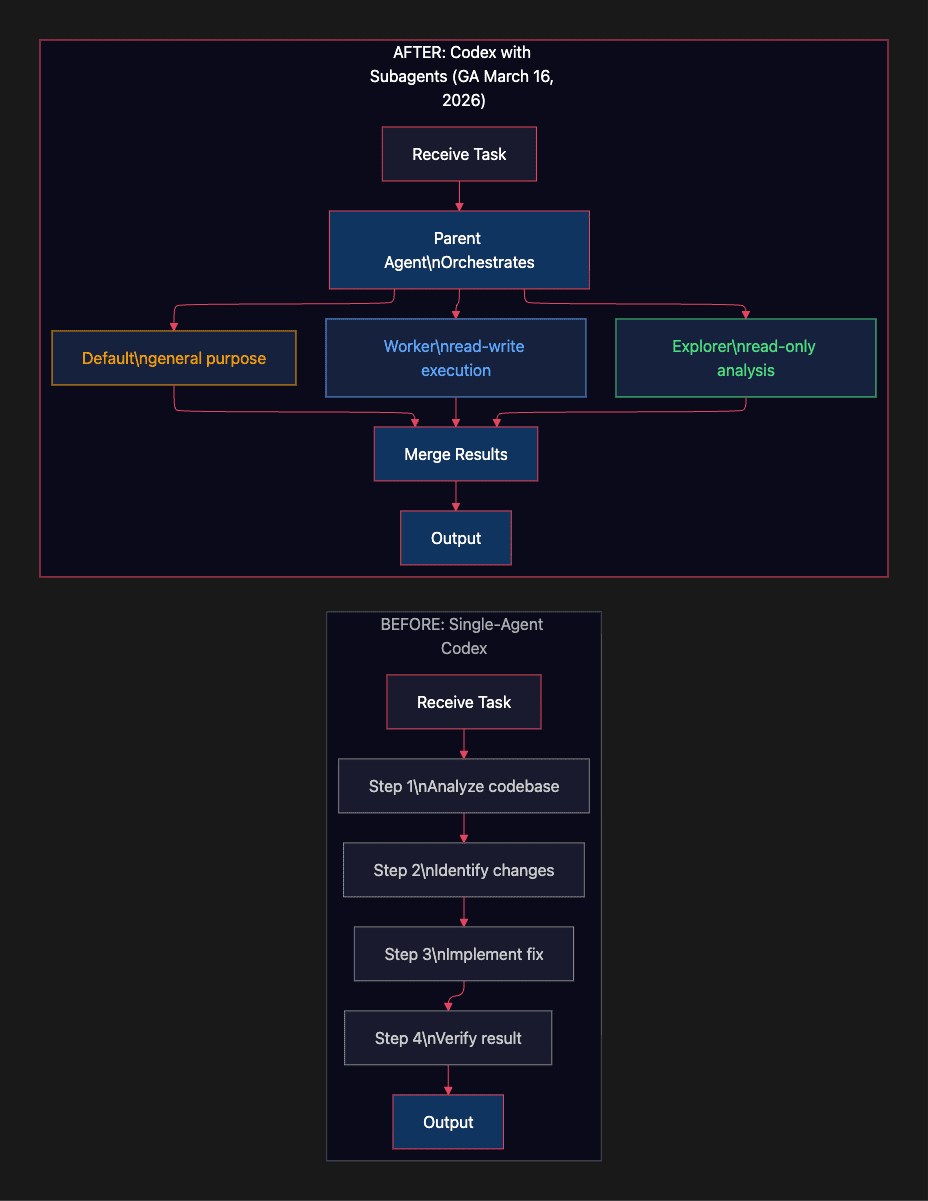
Figure 1: Codex before March 16 processed tasks sequentially. After the codex subagents GA on March 16, 2026, the parent agent spawns specialized parallel subagents (explorer, worker, default) that execute simultaneously and return consolidated results.
How Codex Subagents Work in Parallel
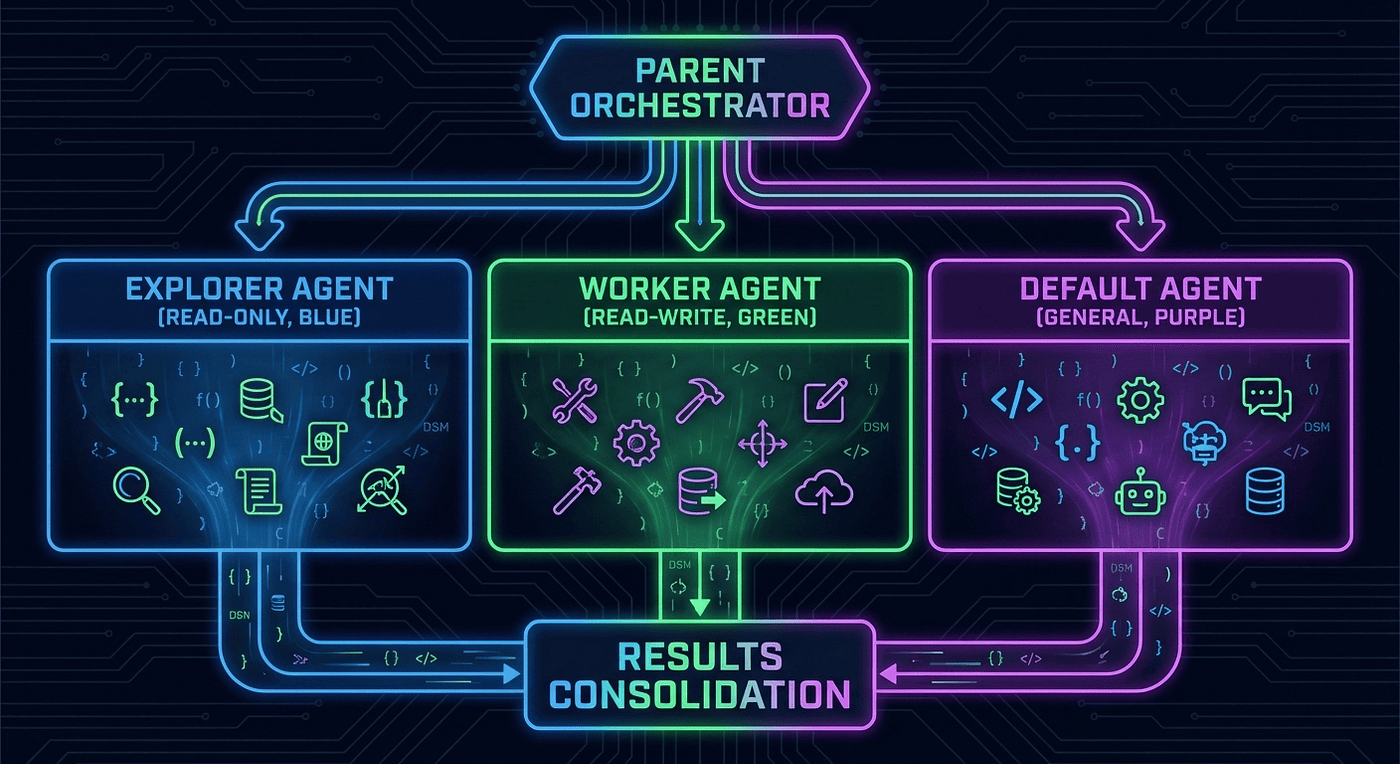
The best way to understand the system is to see it in a real scenario.
Suppose you want to review a pull request properly. Not a surface-level diff check. You want someone to map the affected code paths, someone to find real security or correctness risks, and someone to verify that the framework APIs being used actually work the way the PR assumes. With single-agent Codex, you'd do those things sequentially and hope the context window held everything together. With subagents, you write one prompt:
Review this branch against main. Have pr_explorer map affected code paths,
reviewer find real risks, and docs_researcher verify framework APIs.
Codex spawns three agents in parallel. pr_explorer runs read-only, mapping the codebase. reviewer checks for correctness, security gaps, and test coverage. docs_researcher hits external documentation via MCP tools to verify API behavior. The parent agent waits, collects results, and synthesizes a unified review.
The debugging workflow is equally clean:
Investigate why the settings modal fails to save. Have browser_debugger reproduce it,
explorer trace the responsible code path, and worker implement the smallest fix
once the failure mode is clear.
Here, the orchestration is sequential within parallel: explorer and browser_debugger work simultaneously, and worker waits for their findings before acting. The parent agent manages that dependency. You don't write coordination logic. You describe intent.
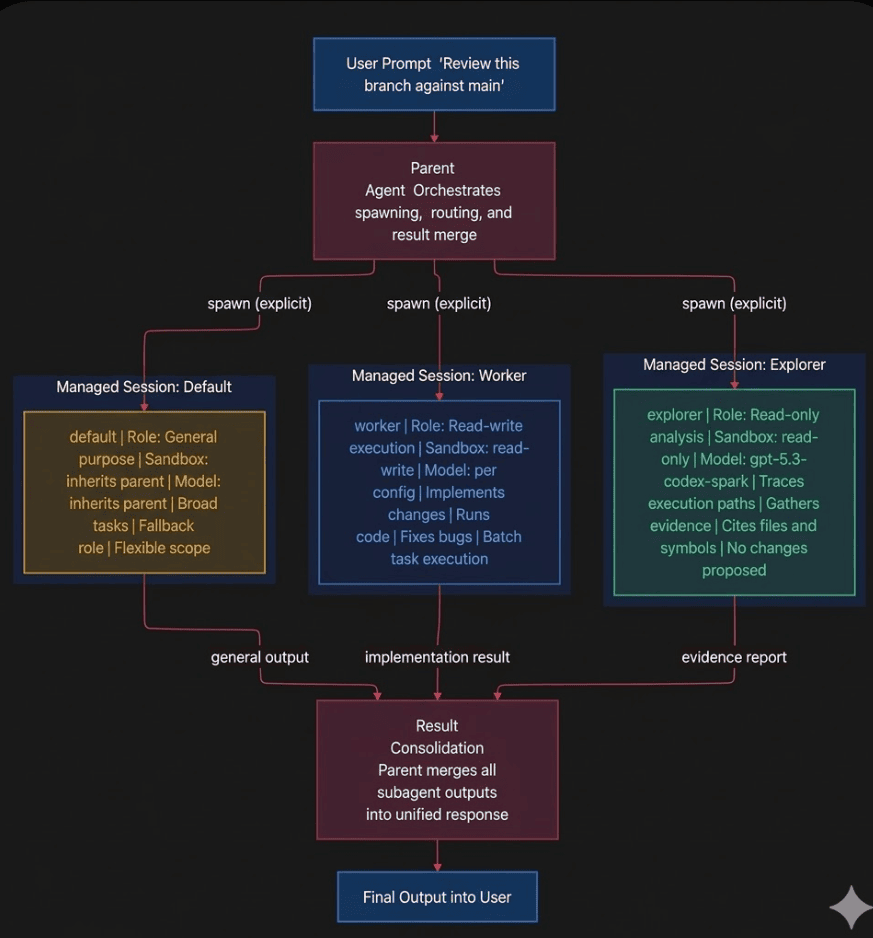
Figure 2: The codex subagents parent agent orchestrates three specialized parallel subagents. Results flow back to the parent for consolidation.
The TOML Configuration Model
Custom agent definitions live in TOML files, stored either a ~/.codex/agents/ for personal configurations or .codex/agents/ for project-scoped definitions. That per-project scoping matters: your team can commit a set of specialized agents into version control alongside the code they're designed to work with. New engineers get the full agent setup the moment they clone the repo. That's a different class of reproducibility than "I have a prompt saved somewhere."
The global config.toml file controls the session-level runtime behavior shared across all agents, including concurrency limits and nesting depth:
[agents]
max_threads = 6 # Concurrent open agent thread cap (default: 6)
max_depth = 1 # Nesting depth, root = 0 (default: 1)
job_max_runtime_seconds = 1800 # Per-CSV-worker timeout in seconds
[agents.explorer]
description = "Read-only codebase explorer for gathering evidence before changes are proposed."
config_file = "agents/explorer.toml"
The max_threads setting directly determines how many subagents run concurrently. Think of it as the width of your parallel pipeline. The max_depth = 1 setting means subagents cannot themselves spawn further subagents; the orchestration stays flat by default.
Each agent's individual TOML file then specifies the model, reasoning effort, and behavior instructions for that role:
model = "gpt-5.3-codex-spark"
model_reasoning_effort = "medium"
sandbox_mode = "read-only"
developer_instructions = """
Stay in exploration mode.
Trace the real execution path, cite files and symbols, and avoid proposing fixes unless the parent agent asks for them.
Prefer fast search and targeted file reads over broad scans.
"""
The per-agent model selection is where the cost story gets interesting. You assign a lighter, faster model like gpt-5.3-codex-spark to the explorer because exploration is a read-only intelligence task that doesn't need heavy inference. The worker, which makes real changes, gets the more capable (and more expensive) model. Heavy reasoning for the work that requires it; fast inference for the work that doesn't. This is not a nice-to-have configuration option. It's a real cost-optimization lever for teams running many parallel agents.
Batch Processing via CSV (Experimental)
What capability has no documented equivalent in Claude Code's documented feature set? spawn_agents_on_csv. This experimental tool lets you point Codex at a CSV file and spawn one worker agent per row, all running in parallel under concurrency limits you set. The use case is processing large datasets, running the same analysis across many files, or applying a standard transformation to a list of inputs. Think of it as a map operation over a spreadsheet, with one agent per cell doing real work.
Each worker receives a templated instruction with column values substituted in, must call report_agent_job_result exactly once, and writes to a shared output schema. It's batch processing with an agent per job, and the concurrency limits keep the cost from spiraling.
The Token Cost Reality
OpenAI is direct about this in their documentation: "Because each subagent does its own model and tool work, subagent workflows consume more tokens than comparable single-agent runs. Use judiciously for genuinely parallel work."
That warning deserves emphasis. Subagents are not free parallelism. Every agent you spawn does its own inference, its own tool calls, its own context management. A three-agent PR review costs more than a single-agent PR review. The value proposition is speed and specialization, not cost reduction. Know what you're optimizing for before you build a workflow around six concurrent agents.
The Pattern That Won
Here's what makes the March 16 announcement bigger than a single feature release: the explorer/worker/orchestrator pattern is now the convergent architecture across the entire industry.
Simon Willison documented this directly. Subagents are now common across Gemini CLI, Mistral Vibe, OpenCode, Visual Studio Code (multi-agent, shipped February 2026), and Cursor. Claude Code's Agent Teams came in early 2026. Codex arrived on March 16. The tools got there via different engineering paths, but they landed in essentially the same place.
When an architectural pattern appears independently across competing systems from Google, Anthropic, Microsoft, Mistral, and OpenAI within the same quarter, that pattern has won. The explorer/worker/orchestrator model is now table stakes, not a differentiator. It's the thing a serious AI coding tool has, not the thing that makes one tool special.
The read/write separation is the key insight behind the pattern's success. An explorer agent with read-only sandbox access cannot break your codebase. It can spend as much time as it needs mapping, tracing, and analyzing without any blast radius. You only widen the blast radius when you hand the findings to a worker agent with write access. The design matches how thoughtful human developers already work: gather information before making changes. The pattern encodes a discipline that developers know they should follow but often skip under time pressure.
As of March 16, 2026, most leading AI coding tools support parallel specialized subagents. The pattern is less of a differentiator; it is table stakes. This feature has become more of an expected capability.
The timeline:
| Tool | Parallel Agent Support |
|---|---|
| Claude Code | Agent Teams Early 2026 |
| VS Code | Multi-Agent February 2026 |
| Codex | Subagents March 16, 2026 (GA) |
Codex was among the last major AI coding tool to ship this capability. The fact that the implementation is, in Willison's words, very similar to what Claude Code already had suggests OpenAI studied the existing pattern and built to it rather than reinventing the wheel. That's a reasonable engineering decision. It also means developers who've learned the pattern in one tool can transfer that knowledge directly to another. Skills travel now.
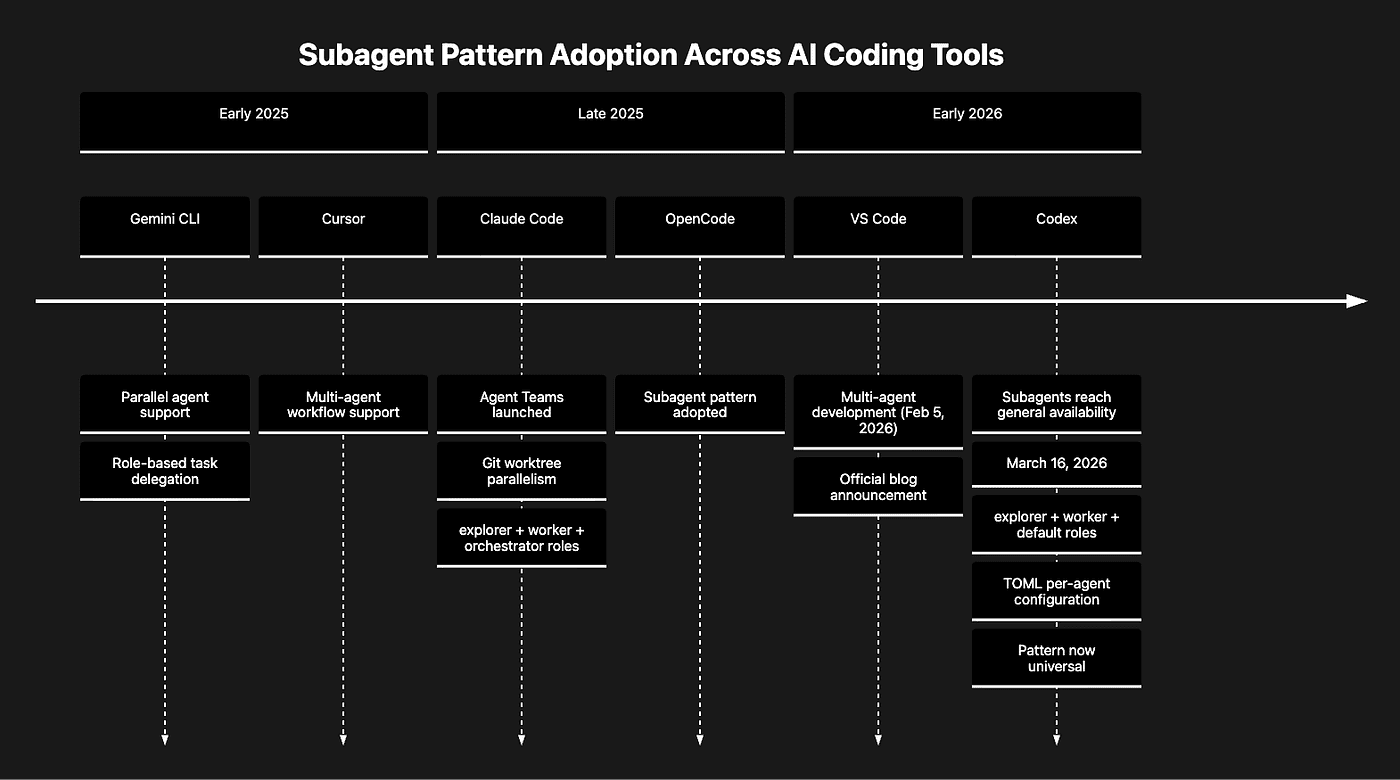
Figure 4: The explorer/worker/orchestrator parallel subagent pattern spread across AI coding tools throughout late 2025 and early 2026. Codex subagents GA on March 16, 2026 marks the point at which every major tool in the category supports the pattern.
By late 2025 and early 2026, tools like Gemini CLI, Cursor, OpenCode, and Mistral Vibe had also adopted parallel-agent patterns.
Codex vs. Claude Code: Parallel Capabilities Compared
Both tools now support parallel specialized agents. That's the headline. But "parallel specialized agents" covers a range of implementations, and the details matter for picking the right tool for a given workflow.
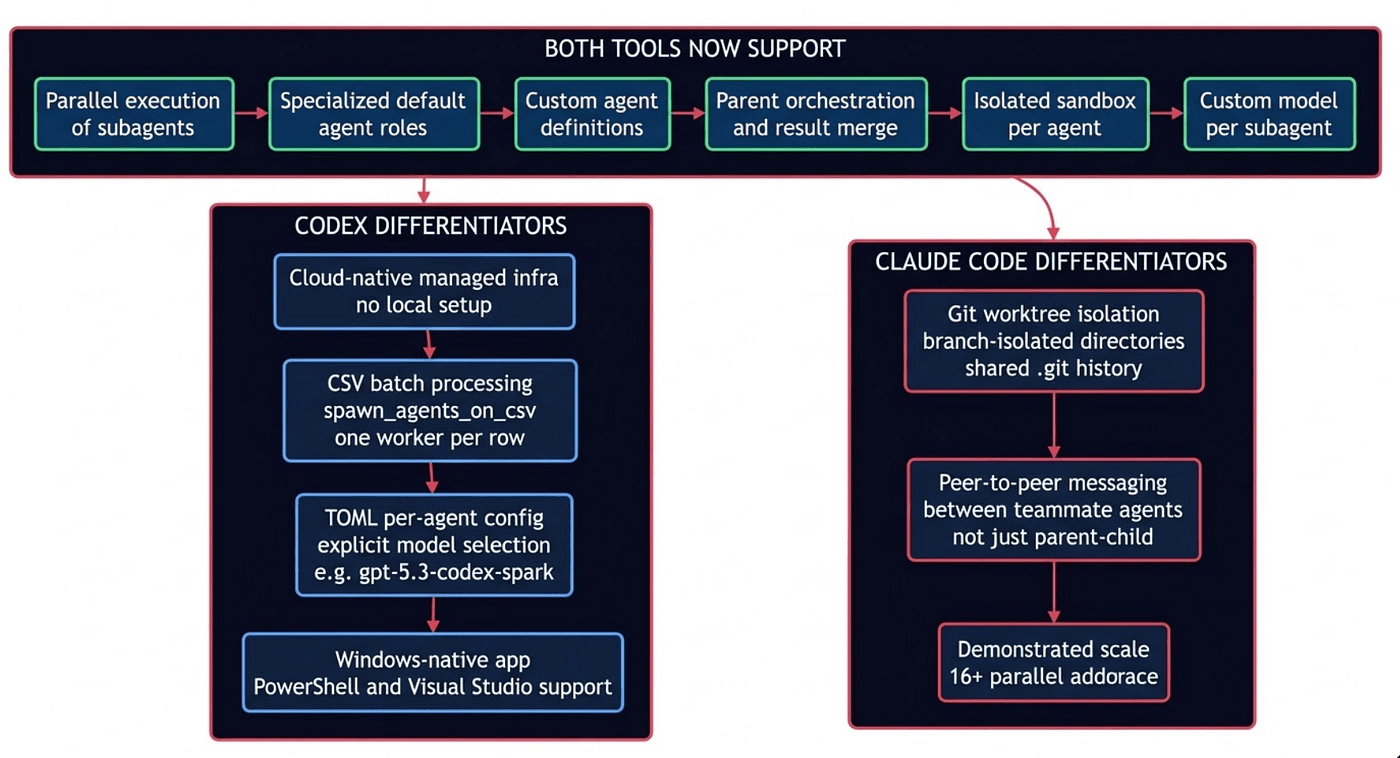
Figure 3: Both Codex subagents and Claude Code Agent Teams now share the core parallel agent architecture. Remaining differences are in infrastructure model and communication topology, not in the fundamental capability.
What's Now Equal
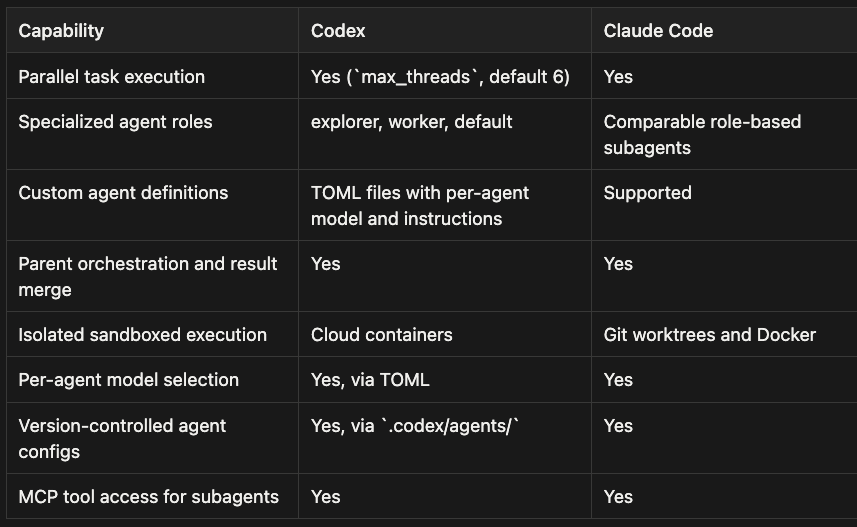
- Parallel task execution: Codex supports up to max_threads (default 6); Claude Code also supports parallel execution
- Specialized agent roles: Codex provides explorer, worker, and default roles; Claude Code offers comparable role-based subagents
- Custom agent definitions: Codex uses TOML files with per-agent model and instructions; Claude Code supports custom definitions
- Parent orchestration and result merge: Both tools support this capability
- Isolated sandboxed execution: Codex runs work in managed cloud environments, while Claude Code relies on Git worktrees and Docker for local isolation.
- Per-agent model selection: Codex enables this via TOML; Claude Code also supports it
- Version-controlled agent configs: Codex stores configs in
.codex/agents/; Claude Code also supports version-controlled configs - MCP tool access for subagents: Both Codex and Claude Code provide this capability
The parity here is real. For a substantial set of use cases, both tools will now handle parallel work similarly. Running multiple analysis passes on a codebase, reviewing a PR from multiple angles, implementing several independent bug fixes in parallel: these workflows work in both systems.
Where Codex Has the Edge
Cloud-native infrastructure. Codex subagents run in OpenAI's managed cloud. No local setup, no Docker configuration, no worktree management. You open the tool and the infrastructure is already there. For teams that don't want to think about agent infrastructure, that's a real advantage.
CSV batch processing. The spawn_agents_on_csv tool has no direct documented equivalent in Claude Code. If you need to process large datasets with one agent per row, Codex gives you a purpose-built mechanism for it.
Per-agent model selection via TOML. You can assign different models to different agents (lighter model for explorer, more capable model for worker) explicitly in Codex's TOML system. Concrete cost-optimization, not theoretical flexibility.
Enterprise scale. Fortune reports around 1.6 million Codex users as of early March 2026, with strong enterprise adoption. OpenAI's enterprise distribution, support, and compliance tooling is mature. (Fortune, March 4, 2026)
Windows-native app. Codex ships a native Windows application with PowerShell and Visual Studio integration. Claude Code is primarily a terminal-based tool. For Windows-centric teams, this is not a minor point.
Where Claude Code Has the Edge
Git worktree isolation. Claude Code uses git worktrees to give each parallel agent its own isolated working directory, all sharing a single .git history. As Anthropic's engineering team documented when they used this approach to build a C compiler, each agent clones a local copy, locks its task, works independently, then merges and pushes to a shared upstream. (Anthropic Engineering Blog: Building a C Compiler with Claude) Codex's subagent docs do not describe an equivalent mechanism for branch-isolated parallel work.
Peer-to-peer inter-agent coordination. Claude Code's Agent Teams support direct messaging between teammate agents, not just parent-child hierarchy. Agents can challenge each other's findings and self-coordinate without routing all communication through a central orchestrator. Codex's subagent system, as documented, uses a parent-child model with max nesting depth of 1 by default.
Demonstrated scale. Anthropic has showcased parallel-agent workflows with many concurrent tasks, while Codex defaults to six concurrent threads via max_threads. Codex defaults to six and the documentation does not specify a tested upper bound, though max_threads is configurable.
Complex architectural work. Zack Proser's comparative review frames the tools as complementary rather than competitive: "Codex for SDLC grunt work and maintenance; Claude Code for deeper architectural problems and complex features." (Zack Proser: OpenAI Codex Review 2026) That framing aligns with the architectural difference: Codex's cloud-native, managed approach works well for well-defined parallel tasks; Claude Code's git-integrated, locally-anchored approach handles the messier, more interconnected work where context and history matter more.
The real split isn't Codex vs Claude Code. It's well-scoped parallel jobs vs deep architectural work where history and context are the whole game. Know which one you're doing, and pick accordingly.
The Full Comparison
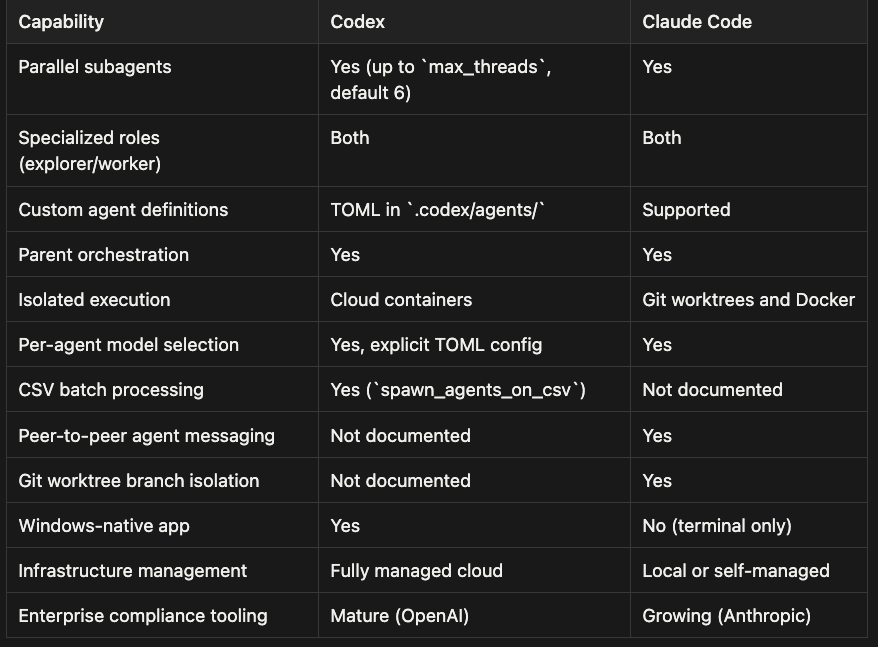
- Parallel subagents: Codex supports up to max_threads (default 6); Claude Code also supports parallel execution
- Specialized roles (explorer/worker): Both tools provide comparable role-based subagents
- Custom agent definitions: Codex uses TOML in
.codex/agents/; Claude Code supports custom definitions - Parent orchestration: Both Codex and Claude Code support parent orchestration
- Isolated execution: Claude Code uses Git worktrees and Docker
- Per-agent model selection: Codex enables this via explicit TOML config; Claude Code also supports it
- CSV batch processing: Codex provides
spawn_agents_on_csv; not documented for Claude Code - Peer-to-peer agent messaging: Not documented for Codex; Claude Code supports it
- Git worktree branch isolation: Not documented for Codex; Claude Code supports it
- Windows-native app: Codex provides a native Windows application; Claude Code is terminal only
- Enterprise compliance tooling: Codex has mature tooling from OpenAI; Claude Code's tooling from Anthropic is growing
One Caveat Worth Stating
Codex's max_threads is configurable. The default of 6 is not a hard limit. The documentation doesn't publish a maximum, so teams with high-volume workloads should test their specific configuration rather than assuming 6 is the ceiling.
Choosing Your Tool
This is not a "pick a winner" situation. These tools serve different workflows, and the right choice depends on where you're working and what kind of work you're doing.
Reach for Codex when:
- Your team doesn't want to manage local infrastructure for agent workflows
- You're on Windows and need native integration with Visual Studio and PowerShell
- You're processing large datasets and want CSV-driven batch parallelism
- You need TOML-configurable agent roles that you can commit to version control alongside your project
- You're in a large enterprise already on OpenAI's platform with existing compliance and support relationships
- The tasks are well-scoped parallel jobs with clear boundaries and defined outputs
Reach for Claude Code when:
- You're doing deep architectural work where an agent needs to navigate complex interdependencies across a large codebase
- Git worktree isolation matters because you want each agent working on a clean branch without stepping on others
- You need peer-to-peer coordination between agents, not just parent-child orchestration
- You're comfortable with (or already using) a terminal-first local workflow
- The work is the kind Proser describes: "complex features" where architectural judgment, not just parallel execution, is the differentiator
Use both:
Many teams won't have to choose. Codex for the maintenance queue, dependency updates, standard PR reviews, and repetitive tasks across a codebase. Claude Code for the feature work that requires building a mental model of system architecture and making consequential design decisions. The tools are genuinely complementary, and the skills transfer because the underlying patterns are now the same.
The Gap Narrowed. The Race Continues.
The convergence story is good news for developers, even if it makes it harder to write confident takes about which tool is winning. When the major players in a space converge on the same architectural pattern, it means the pattern works. Explorer/worker/orchestrator is not a clever trick. It's a sound model for how to parallelize coding work safely. The industry arrived at it from multiple directions and now ships it as a default.
For teams already using Codex, March 16 unlocks workflows that previously required switching tools. For teams already using Claude Code, the announcement is evidence that the architectural choices Anthropic made early are holding up under competitive pressure. For teams evaluating both: the parallel execution gap that used to be a clear differentiator has narrowed considerably, though it has not fully closed.
The next frontier is different. It's not whether a tool supports parallel agents. That question is settled. The open questions are how agents coordinate over time, how they maintain context and consistency across sessions, how they handle genuinely ambiguous or conflicting findings, and how they scale to the kinds of complex, long-running tasks where human developers still outperform autonomous systems. Both Codex and Claude Code are clearly racing toward those capabilities. The parallel subagent pattern is what enables that race, not where it ends.
Developers who understand how these systems work, who can reason about the trade-offs between cloud-managed and locally-anchored infrastructure, between parent-child orchestration and peer-to-peer coordination, are better positioned to use these tools effectively. The pattern is standard now. The skill is knowing when to use it, how to configure it, and when a single well-directed agent still beats six poorly-coordinated ones.
References
- OpenAI Codex Subagents Documentation
- Simon Willison: Codex Subagents Analysis (March 16, 2026)
- Anthropic Engineering: Building a C Compiler with Claude
- Fortune: OpenAI Codex Growth and Enterprise Adoption (March 4, 2026)
- VS Code Blog: Multi-Agent Development (February 2026)
- Zack Proser: OpenAI Codex Review 2026
I am open to clarifications and fact checking because some of these details were a bit fuzzy in the docs, release notes and press releases.
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.