Evolution: Chatbots to DeepAgents: The Natural Progression of AI Work
From Chatbots to DeepAgents: Mapping the Evolution of AI Workflows and Harness Engineering
Originally published on Medium.
From Chatbots to DeepAgents: Mapping the Evolution of AI Workflows and Harness Engineering
Discover how AI evolves from simple chatbots to powerful DeepAgents that can plan, remember, and verify long-running projects -- unlocking true labor leverage for complex research, coding, and analysis.
Summary: Dive into the evolution of AI, from simple chatbots to sophisticated DeepAgents, by exploring how each stage adds new capabilities, market value, and real-world use cases. This article breaks down the natural progression, explains why long-horizon execution demands a dedicated "harness" around the model, and shows when to choose chatbots, GenAI apps, agentic workflows, agents, or DeepAgents for maximum impact. If you're curious about building reliable, multi-step AI systems that can plan, remember, verify, and recover from errors, keep reading to discover the core concepts, architectural patterns, and practical guidelines that turn experimental agents into production-grade DeepAgents.
Ask a chatbot to answer a question, and it can be brilliant. Ask it to complete a long-running project, and the cracks appear.
It may summarize a document well, but struggles to research a market, compare vendors, write code to analyze data, check for contradictions, and produce a cited report. It forgets assumptions. It loses track of intermediate work. It waits for the user to rescue it when a tool fails.
That failure mode is giving rise to a new kind of AI architecture: the DeepAgent.
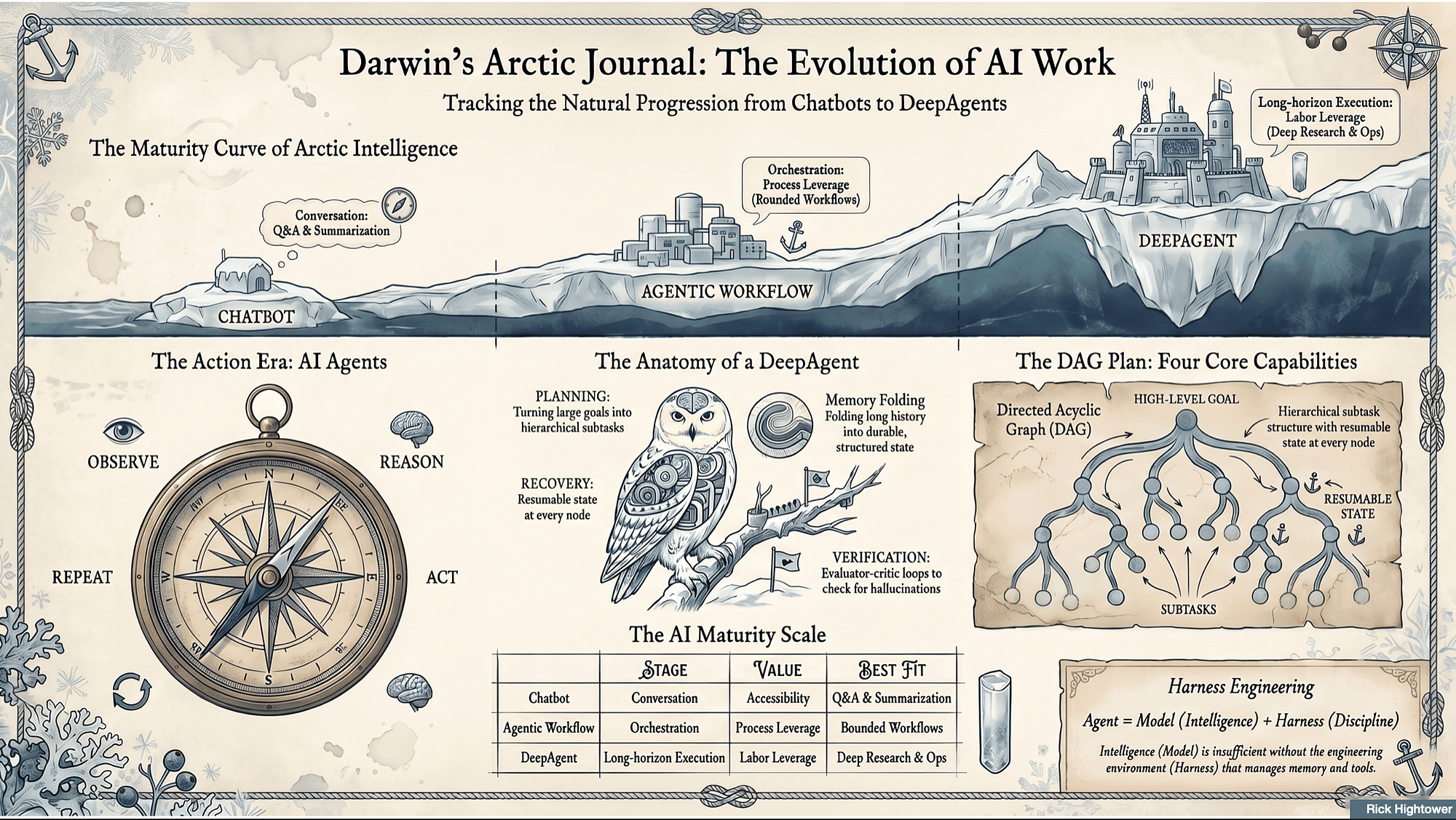
But DeepAgents did not appear out of nowhere. They are part of a natural progression in how AI systems create value:
Chatbots -> GenAI applications -> agentic workflows -> agents -> DeepAgents
Each stage adds a new layer of capability. Each also has a different market value and different use cases.

The mistake many teams make is treating these categories as interchangeable. They are not. A chatbot is not a DeepAgent. Workflow automation is not the same thing as an autonomous agent. And a DeepAgent is not merely a chatbot with more tools.
This article explains the progression: what each stage is, where it creates value, when to use it, and why the next frontier of AI is increasingly a discipline of harness engineering.
Chatbots, GenAI Applications, and Agentic Workflows: The First Three Stages
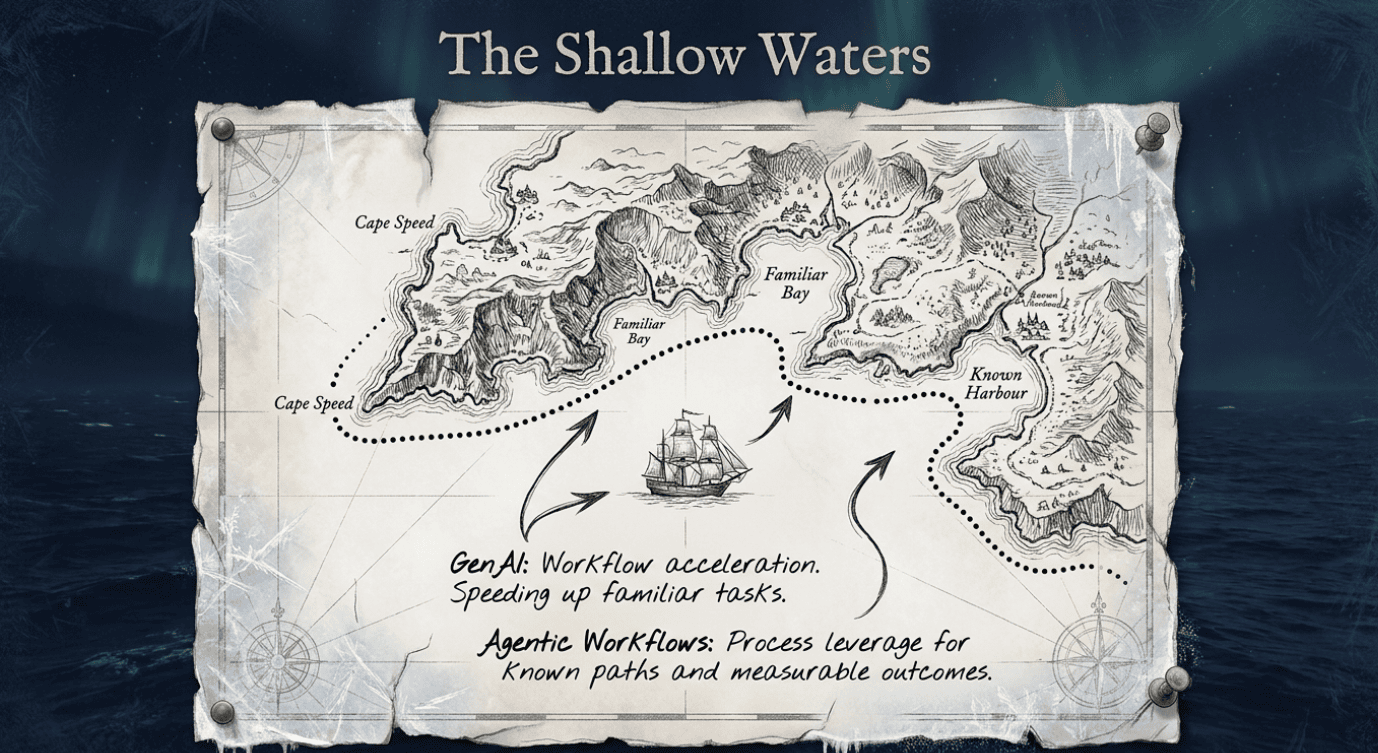
The next two stages transform AI from an interface to a product, then to a process. General AI (GenAI) applications integrate generation capabilities into specific user experiences, such as writing assistants, code copilots, meeting summarizers, image-editing tools, or contract-review applications. Their main advantage is workflow acceleration: they speed up familiar tasks without owning the entire workflow.
Agentic workflows take this a step further by coordinating multiple AI-assisted steps, including retrieval, classification, drafting, tool integration, validation, and human approval, within a defined process. The value of these workflows is their process leverage. Use GenAI applications for specific, repeatable tasks, while agentic workflows are ideal for processes with known steps, tools, handoffs, and measurable outcomes. Avoid over-developing either into a fully autonomous agent when a structured interface or a controlled workflow is sufficient.
Agents: The Action Era
The next stage is the AI agent. We will then discuss DeepAgents for the rest of the article.

An AI agent is a system that selects actions to achieve a goal. It is not limited to producing text. It can use tools, inspect results, and decide what to do next.
An agent typically has:
- a goal,
- a reasoning loop,
- access to tools,
- observations from the environment,
- and some ability to revise its next action.
The classic loop is:
- Observe.
- Reason.
- Act.
- Observe the result.
- Continue.
This is a major shift.
A GenAI application helps the user perform a task. An agent begins to perform parts of the task on the user's behalf.
Agents are useful when the path to completion cannot be fully predefined. For example, researching a topic, debugging a software issue, navigating a website, investigating an operational incident, or triaging a task queue may require adaptive decision-making.
The market value of agents is delegated.
They let users hand off bounded objectives rather than individual instructions. The user does not have to specify every step. The agent can decide which tool to invoke, which information to inspect, and how to respond if the first attempt fails.
But agents introduce new risks.
They may choose the wrong tool. They may misread a result. They may loop. They may take an action that the user did not intend. They may appear more capable than they actually are.
This is why the architecture around the agent becomes critical. The architecture to make agents or agentic workflows work well is called harness engineering.
When to use agents
Use agents when the task involves adaptive tool use and cannot be simplified into a fixed workflow. Agents are suitable for situations where the system needs to explore, make decisions, and handle uncertainty.
Avoid using agents when deterministic automation is safer, more cost-effective, and easier to maintain.
DeepAgents: The Long-Horizon Execution Era
A DeepAgent is an AI system designed for long-horizon execution.

It is not just an agent with more tools. It is an agentic system with enough planning, memory, execution control, and verification to sustain work over many steps.
A simple definition is:
A DeepAgent is an AI execution system that can plan, act, remember, use tools, recover from errors, and verify progress across a long-running task.
DeepAgents are built for tasks that require persistence.
They may need to:
- clarify intent,
- decompose a large goal into subtasks,
- spawn specialized subagents,
- search across many sources,
- inspect PDFs, websites, codebases, or datasets,
- write and run code,
- create files,
- update memory,
- verify evidence,
- recover from failed attempts,
- and produce a final artifact.
This is where the limitations of ordinary chatbots become obvious.
A chatbot can answer. A GenAI app can accelerate. An agent can act. A DeepAgent can manage a sustained body of work.
The market value of DeepAgents is a function of labor leverage.
They are aimed at work that previously required a person, or a small team, to coordinate research, analysis, execution, and verification over time. This includes software engineering, deep research, financial analysis, scientific review, legal operations, enterprise automation, and complex technical documentation.
The value is not measured only in tokens or response quality. It is measured in completed work: reports produced, pull requests opened, incidents triaged, datasets analyzed, workflows completed, and decisions supported.
When to use DeepAgents
Use DeepAgents when the task is open-ended, multi-step, tool-heavy, evidence-driven, and valuable enough to justify higher cost and latency.
Do not use DeepAgents for simple tasks. A DeepAgent is overkill for summarizing a short document, drafting a single email, or answering a simple question.
The right question is not, "Can an agent do this?"
The right question is, "Does this task require long-horizon execution?"
The Maturity Curve: Capability, Value, and Best Fit
The progression from chatbots to DeepAgents can be understood as a maturity curve.
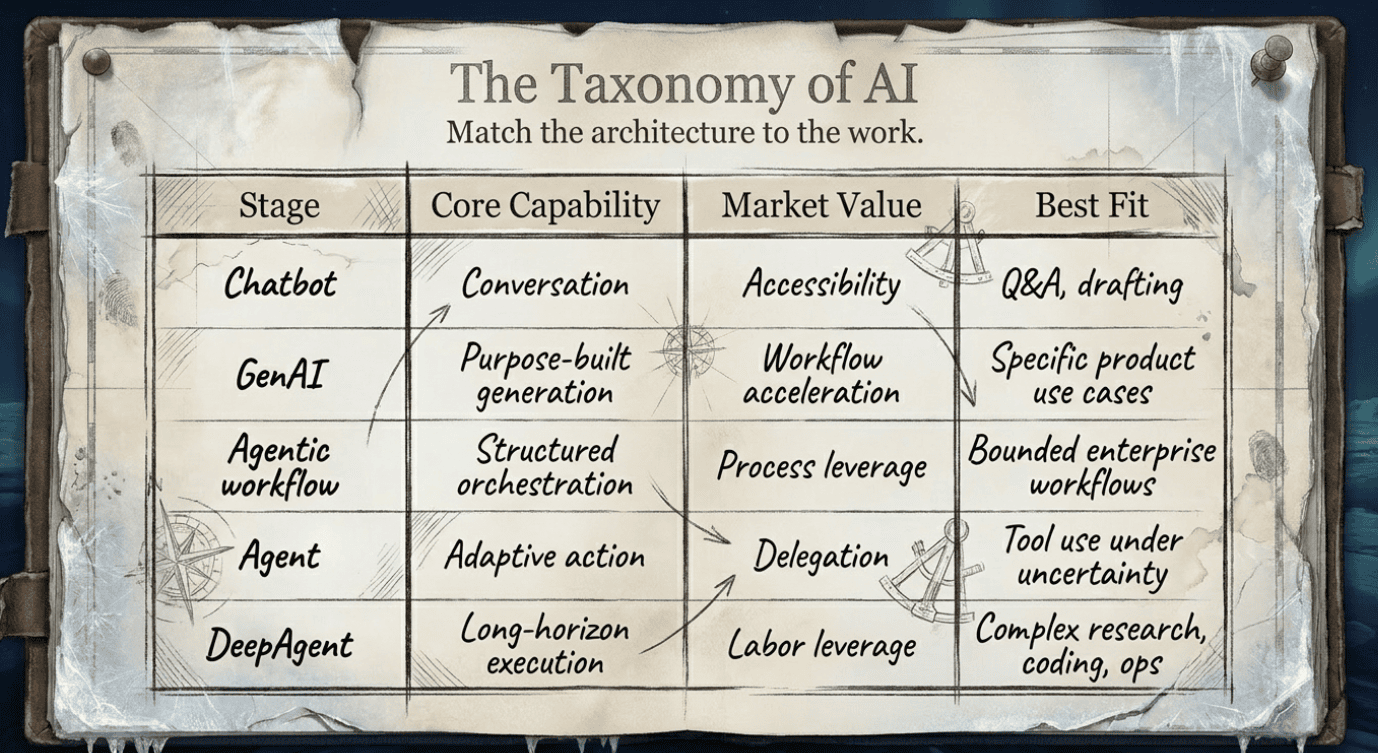
Chatbot
- Core capability: Conversation and natural-language interface (fast Q&A, drafting, summarization, brainstorming).
- Market value: Accessibility, which makes information and ideation instantly available to more people.
- Best fit: Short, self-contained tasks where the "state" lives in the user's head or the current message.
- Avoid when: The task requires durable state, multi-step execution, tool orchestration, or verification (long-horizon work).
GenAI application
- Core capability: Purpose-built generation inside a product UX (guided inputs/outputs, constraints, context injection, often with retrieval).
- Market value: Workflow acceleration, which speeds up a known task without owning the whole workflow.
- Best fit: Specific product use cases with consistent inputs/outputs (writing assistant, code copilot, meeting summary, image editing, contract review).
- Avoid when: A general chat interface (or simple template + prompt) already solves the problem; don't overbuild "an app" for ad-hoc needs.
Agentic workflow
- Core capability: Structured orchestration across multiple steps (retrieve -> classify -> draft -> call tools -> validate -> human approval), with clear handoffs.
- Market value: Process leverage, which makes a repeatable process cheaper and more scalable.
- Best fit: Bounded enterprise workflows where the steps are known and measurable, but still benefit from model flexibility in the middle.
- Avoid when: The path is unknown or highly adaptive; workflows become brittle if the task requires exploration and dynamic replanning.
Agent
- Core capability: Adaptive action selection to achieve a goal (tool use + observe results + decide next step).
- Market value: Delegation; the user can hand off a bounded objective rather than micromanaging prompts.
- Best fit: Tool use under uncertainty (research, debugging, incident investigation, navigating unfamiliar systems, triage).
- Avoid when: Deterministic automation is safer/cheaper; avoid agent autonomy where mistakes have a high blast radius without strong controls.
DeepAgent
- Core capability: Long-horizon execution with planning, memory, recovery, and verification; sustains work over many steps and across failures.
- Market value: Labor leverage; it replaces or amplifies a real chunk of coordinated human work (research + analysis + execution + verification).
- Best fit: Complex, open-ended, tool-heavy, evidence-driven work (deep research, coding, analysis, ops) where "completed artifacts" matter.
- Avoid when: The task is simple, low-value, or short-lived (a quick summary, a single email, a small one-shot question).
This curve is important because it prevents over-engineering.
Many teams jump directly to agents when they actually need a better GenAI application or a solid agentic workflow. Others build brittle workflows when the task truly requires adaptive agency. And some try to use chatbots for work that requires memory, tools, and verification.
The architecture should match the task.
Why Context Rot Forces a New Architecture
The central technical problem DeepAgents address is context rot.
Context rot is the gradual degradation of an AI system's reasoning over time as the task lengthens. The model may technically have access to earlier information, but its effective attention becomes diluted. It forgets constraints, overweights recent messages, loses track of decisions, or repeats work.

Longer context windows help, but they do not solve the problem on their own.
A giant context window is still a volatile workspace. It is not the same thing as durable memory, reliable state management, or verified execution.
DeepAgents treat the context window as a temporary cache, not the whole system.
They rely on external structures:
- task plans,
- files,
- memory stores,
- tool logs,
- checkpoints,
- evaluation gates,
- and recovery loops.
This is where DeepAgents become inseparable from harness engineering.
Harness Engineering: The Discipline Behind DeepAgents
A useful way to understand the DeepAgent shift is to separate the model from the harness.
The model provides raw intelligence: reasoning, language, coding ability, summarization, and action selection.
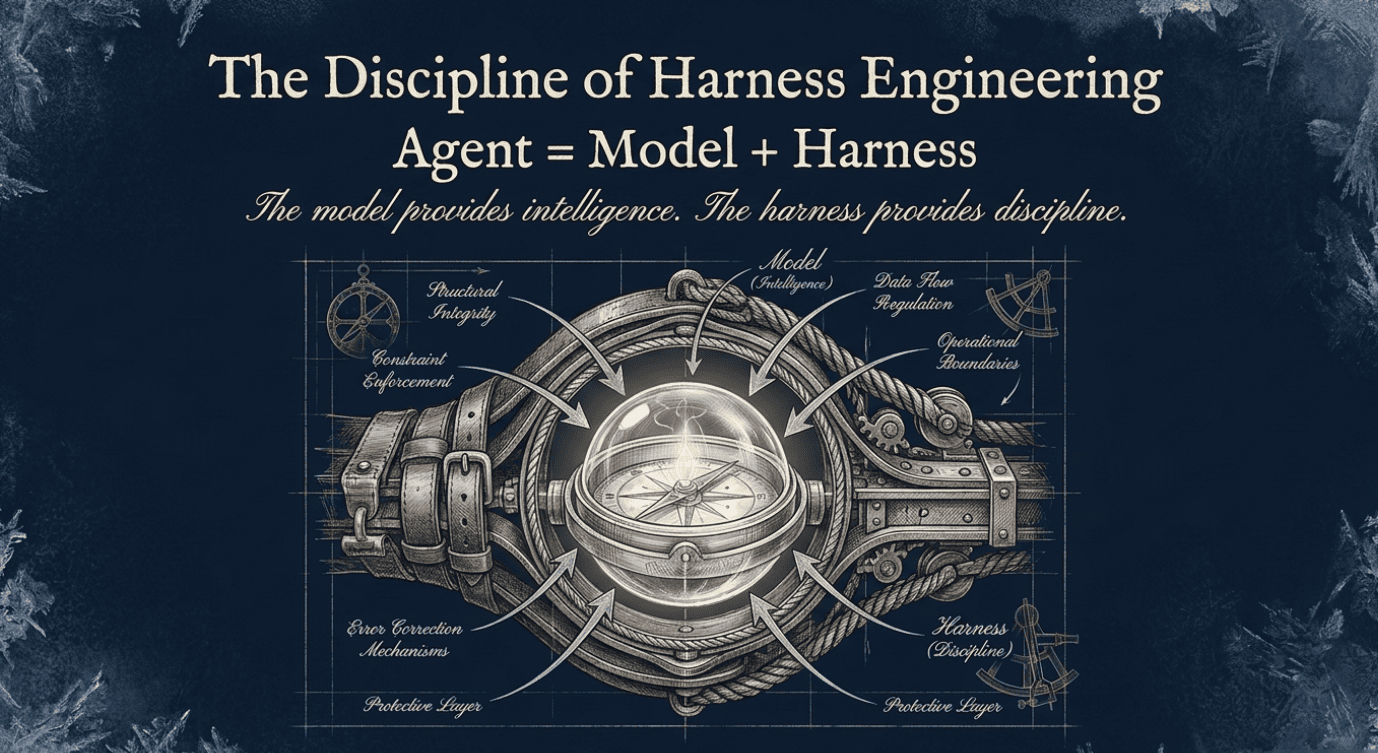
The harness is the engineering system around the model. It determines what the model sees, what tools it can use, what actions it can take, how it remembers, how it recovers, and how humans supervise it.
In this sense, DeepAgents are a form of harness engineering.
They are not created merely by prompting a model to "be autonomous." They are created by designing the operating environment around the model: context assembly, memory tiers, tool registries, file systems, sandboxes, retries, approval gates, observability, and evaluation loops.
A simple formula captures the idea:
Agent = Model + Harness
The model is necessary, but not sufficient. The harness turns a model's capabilities into reliable work.
This is why many of the most important gains in agentic AI do not come from changing the model weights. They come from changing the harness.
If an agent repeatedly makes the same mistake, a better prompt may not solve the problem. It may be a better tool, a stronger memory record, a clearer file structure, a narrower permission boundary, or a new approval checkpoint.
Harness engineering is the practice of systematically making those improvements.
The Emerging Lineage of Harness Engineering
The vocabulary around harness engineering is still young, but the practice has been developing for several years.
Early agent systems already had primitive harnesses: prompts, tools, loops, scratchpads, and memory stores. But as agents moved from demos to long-running work, the layer around the model became too important to treat as an implementation detail.
Anthropic helped establish much of the modern vocabulary. It's writing on context engineering framed context as a scarce resource that must be deliberately assembled, pruned, and managed for agents. It's later writing on long-running agent harnesses made the harness itself a first-class design object: the system that lets agents work across multiple context windows, recover from errors, and continue toward a goal.
This matters because context engineering is not just prompt engineering with a new name. Prompt engineering asks, "What instruction should I give the model?" Context engineering asks, "What information, tools, state, and constraints should be available to the model at this point in the task?" Harness engineering asks the broader question: "What environment must exist around the model so it can do reliable work?" Harness Engineering consists of prompt engineering and context engineering.
Other practitioners and organizations then sharpened the term. Mitchell Hashimoto described the discipline as improving the harness so that, when an agent makes a mistake, the same mistake is less likely to happen again. OpenAI's Codex work similarly framed the challenge of agent-first software development in terms of environments, feedback loops, control systems, and observability rather than model capabilities alone.
The emerging consensus is clear: the frontier of applied AI extends beyond model engineering. It is harness engineering.
What Goes Into a DeepAgent Harness?
A DeepAgent harness usually includes several layers.
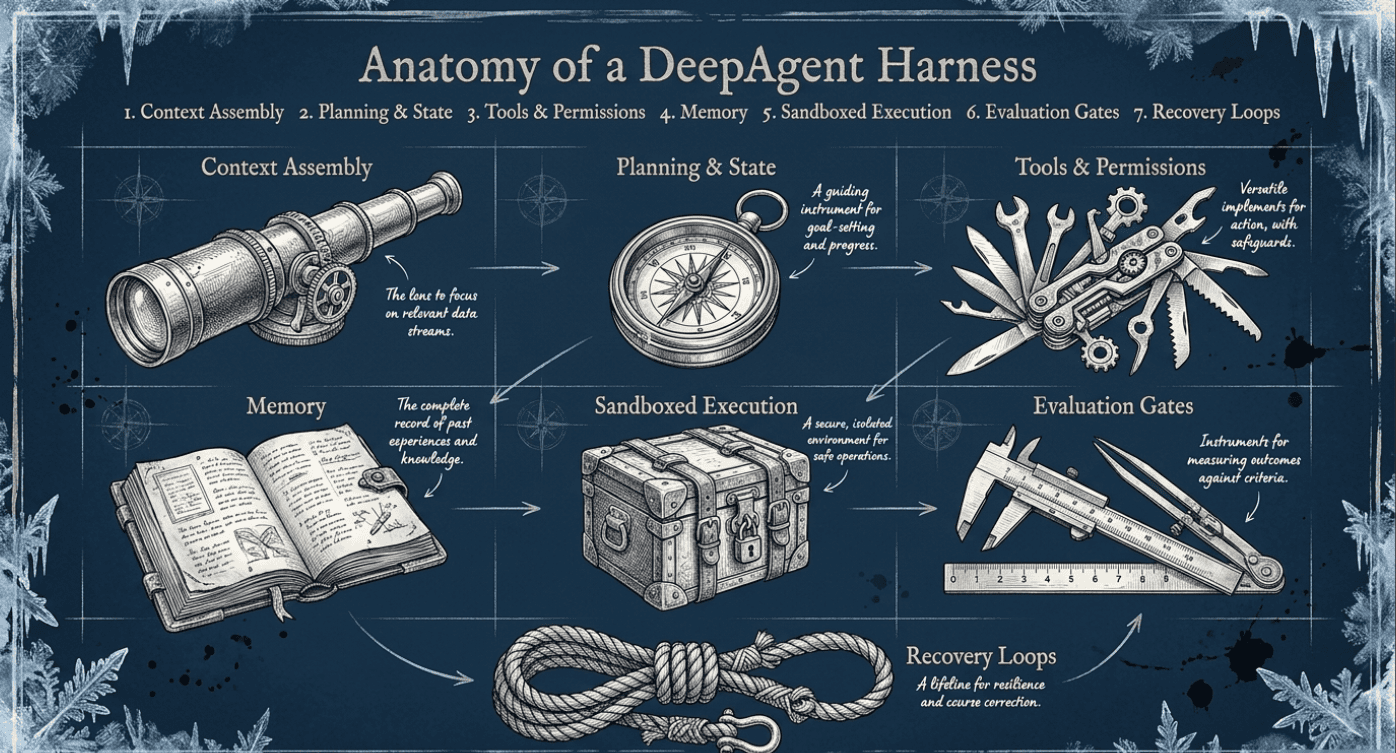
1. Context Assembly
Context assembly decides what the model sees at any given moment.
This includes the user's goal, relevant files, prior decisions, tool outputs, current constraints, and examples of the desired output.
Good context assembly reduces noise. It gives the model the information it needs without flooding it with irrelevant history.
2. Planning and Task State
The harness needs a way to represent the plan.
This might be a to-do list, a graph, a subtask tree, or a more formal state machine.
The plan gives the agent a stable frame of reference. It also gives the human a way to inspect progress.
3. Tools and Permissions
The harness defines what tools are available and what the agent is allowed to do with them.
Tools might include search, code execution, databases, calendars, email, APIs, browsers, or internal systems.
Permissions matter because tool use turns language into action.
4. Memory
The harness manages memory across time.
This may include working memory, episodic memory, tool memory, project files, vector stores, keyword lookups, and checkpoints.
A particularly important technique is memory folding: periodically compressing a long interaction history into a structured summary that the agent can use going forward.
Memory folding is not just summarization for the user. It is a summary for the agent's future self. It is designed to keep the most salient parts.
5. Sandboxed Execution
A sandbox is an isolated environment where the agent can safely run code, create files, and test ideas.
This is essential for serious agents. The more capable the agent becomes, the more important it is to contain the blast radius of mistakes.
6. Evaluation Gates
Evaluation gates check whether the agent's work is good enough to continue.
They may include tests, source checks, schema validation, code execution, citation verification, critic models, or human approval.
Without evaluation gates, autonomy can simply accelerate error.
7. Recovery Loops
Long-running agents fail. Tools break. Searches return weak evidence. Code throws errors. Plans become stale.
A DeepAgent harness needs recovery loops: ways to detect failure, revise the plan, retry intelligently, or escalate to a human.
This is one of the differences between a demo agent and a production agent.
The Four Core Capabilities of a DeepAgent
Most DeepAgent systems can be understood through four core capabilities: planning, tool use, memory, and verification.
Planning
Planning is the ability to turn a large goal into smaller steps.
This is often called hierarchical planning.
Hierarchical planning means the agent organizes work into levels: a high-level goal, intermediate subtasks, and concrete actions. Instead of treating the task as a single long text chain, the system creates a structure it can execute and revise.
Planning matters because long tasks fail when the system loses the plot.
Planning is also often described in terms of a DAG (Directed Acyclic Graph).
A DAG is a graph of work where:
- Directed means edges have an arrow (A must happen before B, or B depends on A).
- Acyclic means there are no loops (you can't depend on yourself, directly or indirectly).
- Graph means the work is not just a single list; it can branch and then rejoin (parallelizable steps, shared dependencies, fan-out/fan-in).
In agent systems, a DAG is a useful mental model because long-horizon execution usually involves dependencies:
- You can't verify before you produce an artifact.
- You can't write an implementation before you decide the approach.
- You can't decide the approach before you gather constraints and evidence.
And you often want parallel branches (e.g., "research X" and "prototype Y") that later merge into a single decision.
The DAG framing also makes a key requirement for harnessing obvious: every node needs resumable state.
At each node (task step), you want to persist:
- Inputs/dependencies: the minimal context that the step is allowed to rely on (requirements, assumptions, relevant excerpts, tool outputs).
- Outputs/artifacts: what the step produced (notes, code, draft text, computed results, citations, test results).
- Progress state: whether the node is not started/ in progress/ done/ blocked, plus retry counts, timestamps, and error summaries.
- Decision record: any decisions made, why they were made, and what alternatives were rejected.
Why this matters: the context window is not durable. If the agent crashes, encounters a tool outage, exceeds context limits, or requires human approval, it must be able to resume by reloading the DAG state, reconstructing the correct context for the next node, and continuing without redoing work or silently diverging from prior decisions.
In practice, "planning" in DeepAgents is inseparable from "checkpointing": saving the right context and progress at each point in the DAG so execution can pause, recover, and resume reliably.

Tool Use
Tool use is the ability to interact with external systems.
A tool might be a search engine, database, spreadsheet, code interpreter, email client, calendar, browser, internal API, or file system.
One important pattern in DeepAgents is CodeAct.
CodeAct means the agent uses code, often Python, as a general-purpose action language. Instead of relying only on specialized tools, the agent can write code to clean data, call APIs, parse files, generate charts, or automate repetitive work.
Another reason to generate and run code on the fly is efficiency and reliability. Many of these transformations are well within an LLM's reasoning ability, but doing them "in the model" is often (1) more expensive due to token usage and (2) less deterministic than executing a script that produces the same result. In practice, a small program can be faster, cheaper, and easier to verify than a long chain of natural-language reasoning.
Memory
Memory is the ability to preserve a useful state beyond the immediate prompt.
A typical chatbot relies primarily on the conversation window. A DeepAgent needs more durable forms of memory: working memory, episodic memory, tool memory, external files, and checkpoints.
Memory allows an agent to continue rather than constantly starting over.
Verification
Verification is the process of checking whether the work is correct.
This may include comparing sources, checking citations, running tests, validating code outputs, asking a subagent critic with a fresh context to inspect the answer, or requiring human approval before risky actions.
Verification matters because autonomy without verification is just faster error propagation.
Provenance is required for governed DeepAgent synthesis. When an orchestrator compares outputs from multiple research subagents, it needs more than final claims; it needs an auditable evidence trail containing source provenance, artifact lineage, timestamps or versions, and transformation history. This metadata lets the orchestrator's verification loop identify contradictions, resolve them when confidence is high, or route ambiguous cases to HITL approval. Without provenance-aware memory and workspace state, conflicting facts cannot be reliably resolved, trusted, or audited after the run.

Human-in-the-Loop: Autonomy With Approval Gates
DeepAgents are often described as autonomous, but autonomy should not mean unlimited permission.
Most serious DeepAgent systems need human-in-the-loop controls.
Human-in-the-loop means a person remains involved at key decision points. The agent may independently research, draft, analyze, and test, but must seek approval before taking high-risk actions.
Examples include:
- sending external email,
- making purchases,
- deploying code,
- deleting data,
- accessing sensitive information,
- changing production systems,
- or initiating financial transactions.
This changes the user's role. Instead of micromanaging each prompt, the user supervises checkpoints.
The goal is not total automation. The goal is governed autonomy.

The Verification Bottleneck
As DeepAgents become more capable, verification becomes the bottleneck.

It is one thing for an agent to generate a report. It is another thing to know whether the report is correct.
Common failure modes include:
Plan hallucination, where the agent creates irrelevant, circular, or poorly scoped subtasks.
Source hallucination, where the agent cites weak evidence, mismatches a source, or invents support that is not present.
Tool hallucination, where the agent misreads a tool result, misunderstands an error message, or assumes an action succeeded when it failed.
These problems are not solved by increasing the model's confidence. They require system-level checks.
A strong DeepAgent should be able to show its work: the sources it used, the code it ran, the tests it passed, the assumptions it made, and the points where confidence is lower.
This is why evaluator-critic patterns are becoming important.
An evaluator-critic loop uses a second process; another model, a rule-based checker, a test suite, or a human, to inspect the agent's work before it is finalized.
The future of DeepAgents is not just a better generation. It is better verification.
What Comes Next: From DeepAgents to Agentic Systems
This article has focused on the natural progression from chatbots to DeepAgents.
But the next frontier is larger.
As individual agents become more capable, the industry is exploring multi-agent systems: networks of agents that divide work among specialized roles.
This is where ideas like RecursiveMAS and Agent OS come into play.
RecursiveMAS refers to recursive multi-agent systems in which agents can spawn, coordinate, and supervise other agents. Instead of a single agent handling everything, a root agent might delegate research, coding, analysis, and verification to specialized subagents.
Agent OS is the idea that agents may eventually operate within a persistent cognitive environment: a unified workspace for files, memory, search, tools, schedules, communications, and approvals.
These ideas deserve their own deeper treatment. For now, the key point is simple: DeepAgents are the bridge between today's chatbots and tomorrow's persistent AI work environments.
Conclusion: Match the Architecture to the Work
The shift from chatbots to DeepAgents is not a single leap. It is a progression.
Chatbots made AI accessible.
GenAI applications made it useful inside products.
Agentic workflows made it operational inside bounded processes.
Agents made it capable of adaptive action.
DeepAgents enable long-horizon execution.
The practical lesson is that teams should not ask, "How do we add agents?"
They should ask, "What kind of AI system does this work require?"
If the task is conversational, use a chatbot.
If the task is a specific product feature, build a GenAI application.
If the task is structured and repeatable, design an agentic workflow.
If the task requires adaptive tool use, use an agent.
If the task requires sustained planning, memory, execution, and verification, build a DeepAgent.
The future of AI work will not be defined by models alone. It will be defined by the harnesses that turn models into reliable systems.
The model provides intelligence.
The harness provides discipline.
And DeepAgents are what emerge when both are designed together.
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company, focusing on delivering ML / AI insights to front-line applications, and a practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.

Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company
Rick created Skilz, the universal agent skill installer that supports 30+ coding agents, including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.

Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams adopting AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. Many ideas captured in the CCA and the exam prep Rick wrote echo what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code