Foundations of CCA-F Exam: 5 Battle-Tested LLM Agent Patterns (No Bloat Required)
Five Proven Patterns to Build Reliable LLM Agents and Workflows. Learn these patterns from Anthropic Research Papers that are essential for passing Claude Certified Architect Foundation Exam.
Originally published on Medium.
Five Proven Patterns to Build Reliable LLM Agents and Workflows. Learn these patterns from Anthropic Research Papers taht are essential for passing Claude Certified Architect Foundation Exam.

Unlock the secret to passing the CCA-F exam: 5 battle-tested LLM patterns that turn bloated agents into razor-sharp, production-ready workflows.
Summary: The article outlines five core LLM agent patterns — prompt chaining, routing, parallelization, orchestrator-workers, and evaluator-optimizer — explaining when to use each based on task predictability, cost, latency, and complexity, while emphasizing a "start simple" approach that favors workflows over full agents unless a fixed path is impossible, and stressing the importance of well-designed tool interfaces (ACI), clear documentation, and transparent logging to build reliable, production-ready AI systems.
Let's summarizes five composable patterns for building LLM agents and workflows that commonly appear in CCA-F study materials: prompt chaining, routing, parallelization, orchestrator-workers, and evaluator-optimizer.
Then let's highlights a practical emphasis on tool/ACI design. This includes how models: call tools, manage state, and incorporate retrieval. Those interface details often determine whether systems are reliable in production. Use the patterns below as a selection guide. Remember to start with the simplest workflow that fits the task, and add autonomy only when needed.
You will see this terminology used a lot of the test. You must be familiar with the general agentic workflow and patterns. This familiarity will help you answer effectively.
There are concepts that are not covered in the course lessons. But these concepts are listed in the study guide for the test but not elaborated on. This article covers some of this core concepts, and poins you to the source material form Anthropic Research to study further.
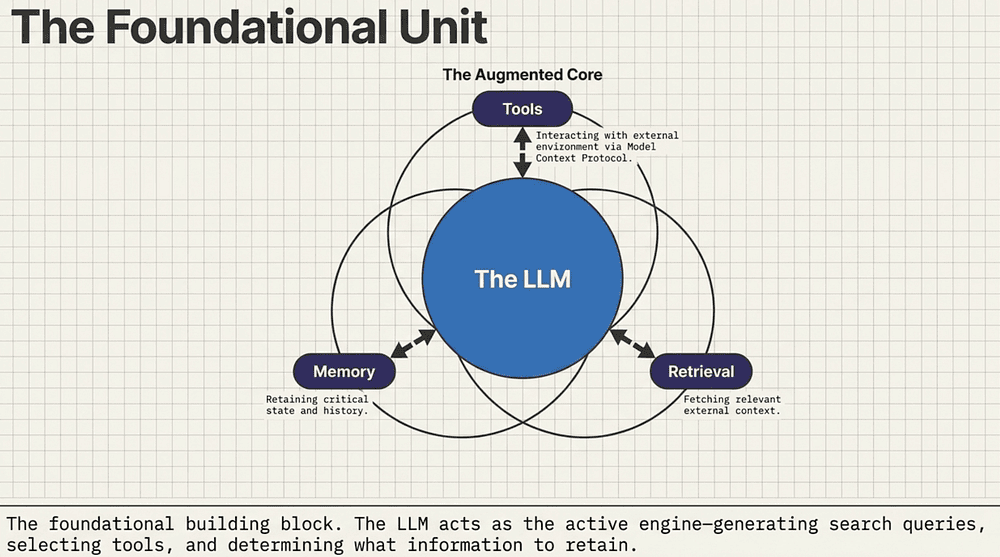
The Great Divide: Workflows vs. Agents
Before you write a single line of code, you must choose the right foundation.
Workflows: Systems where LLMs and tools are orchestrated through predefined code paths.
✅ Predictable, consistent, ideal for well-defined tasks.
✅ Optimization via retrieval and in-context examples is usually enough.
Agents: Systems where LLMs dynamically direct their own processes and tool usage in a loop.
✅ Flexible for open-ended problems.
❌ Higher latency, higher cost, and higher risk of compounding errors.
CCA-F Rule of Thumb: Start with a workflow. Only graduate to a full agent when a fixed path is literally impossible to hardcode. Most "agentic" problems on the exam are actually sophisticated workflows.
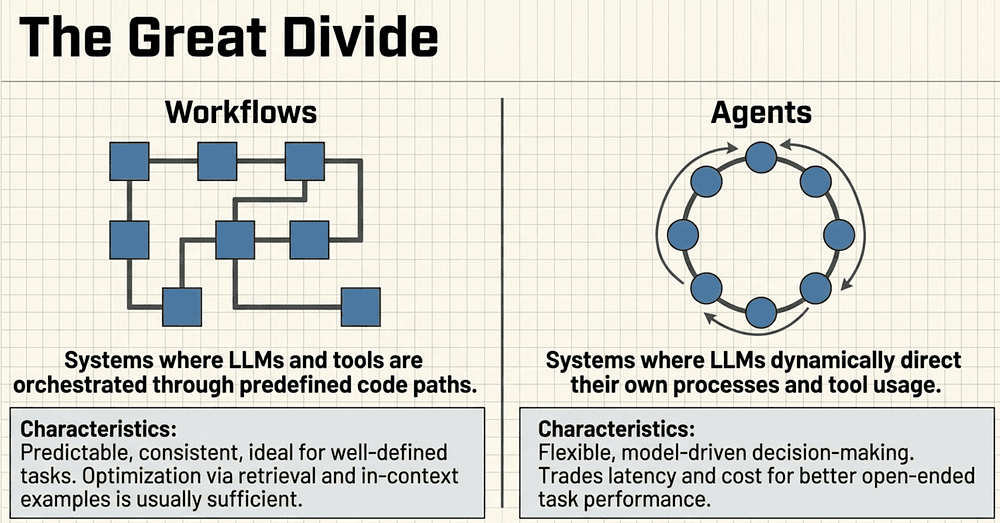
The Foundational Unit: The Augmented LLM
The "Augmented LLM" is the fundamental unit of any agentic system. It is a standard model enhanced with specific capabilities that allow it to interact with the world and manage complexity.
Retrieval: Provides access to external data sources.
- This allows the model to ground its answers in specific facts or live data rather than relying solely on its internal training.
Tools: Programmatic functions (APIs, calculators, or search engines) the model can invoke.
- Tools enable the model to transition from "thinking" to "acting" within the digital environment.
Memory: The ability to retain and manage context across interactions.
- Effective memory isn't just about total recall; it's about sophisticated context management
- Determining what information is vital to retain for multi-step task completion.
Once you have an augmented LLM, the first step in building a system is organizing these calls into a structured sequence.
Thus every effective system starts with the same core:
- The LLM — the active engine.
- Tools — interacting with the external world via a clean context protocol.
- Memory — retaining critical state and history.
- Retrieval — fetching relevant external context. This "augmented core" is the only building block you need. Everything else is just patterns layered on top.
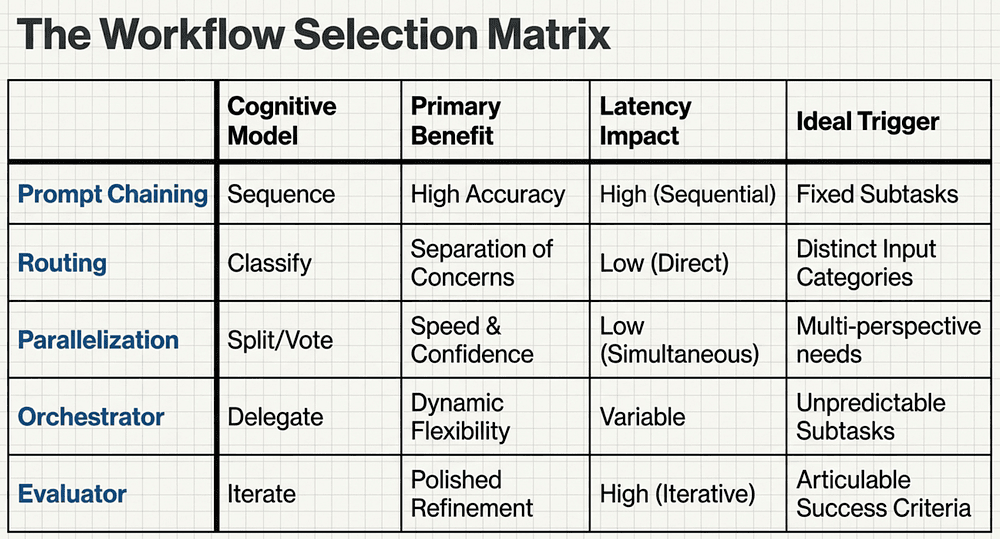
Pattern 1: Prompt Chaining (The Reliable Assembly Line)
Prompt Chaining is the baseline architectural pattern. It involves decomposing a complex task into a sequence of discrete, fixed steps where the output of one call serves as the input for the next.
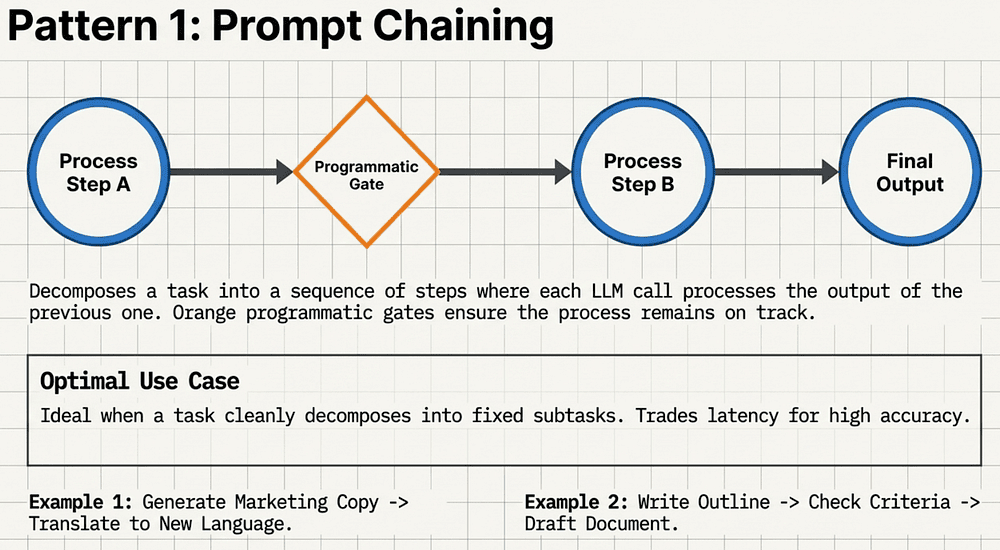
When to Use
- The task can be cleanly decomposed into static subtasks.
- You need to increase accuracy by reducing the scope of each individual LLM call.
- You require a programmatic "gate" to verify quality before moving to the next stage.
The key is to decompose a task into a fixed sequence of steps. Each LLM call processes the output of the previous one. Programmatic gates keep everything on track.
Optimal Use Case:
Tasks that cleanly break into subtasks (fixed, predictable flow). Trades a bit of latency for dramatically higher accuracy.
Examples:
- Generate marketing copy → Translate to new language
- Write outline → Check criteria → Draft document
Pattern 2: Routing (The Traffic Controller)
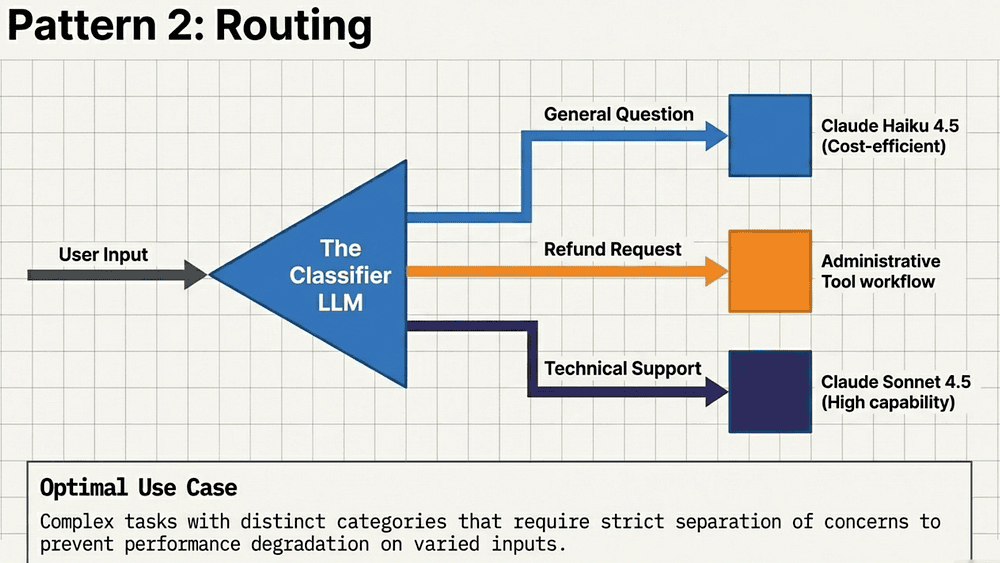
While Chaining is linear and predictable, the routing adds the ability to direct traffic based on the nature of the input.
Routing utilizes an initial LLM call to classify an input and direct it to a specialized downstream process. This enables a separation of concerns, ensuring that a prompt or toolset is perfectly tuned for a specific type of request.
Strategic Insight
Routing is your primary tool for cost and performance optimization. You can mistke proof your system by routing common, high-volume requests to smaller, faster models (like Claude Haiku) and reserving highly capable models (like Claude Sonnet) for rare, complex queries.
Example: Customer Service:
Input: "My device won't turn on."
- Router Action: Identifies as "Technical Support."
- Path: Directs to a retrieval-augmented prompt containing the technical manual.
Input: "I need to return this item."
- Router Action: Identifies as "Refund Request."
- Path: Directs to a tool-based workflow that interacts with the billing API.
Routing directs traffic to a single path, but many high-performance systems require multiple "brains" working at once.
An initial classifier LLM reads the input and sends it down the right specialized path.
Optimal Use Case:
Complex tasks with distinct categories that need strict separation of concerns.
Example:
User input → Classifier LLM
- General question → Claude Haiku (cheap & fast)
- Refund request → Administrative tool workflow
- Technical support → Claude Sonnet (high capability)
Routing is your primary lever for cost and performance on the CCA-F.
Pattern 3: Parallelization (Speed + Confidence)
Parallelization occurs when multiple LLM calls are executed simultaneously, with their outputs aggregated programmatically.
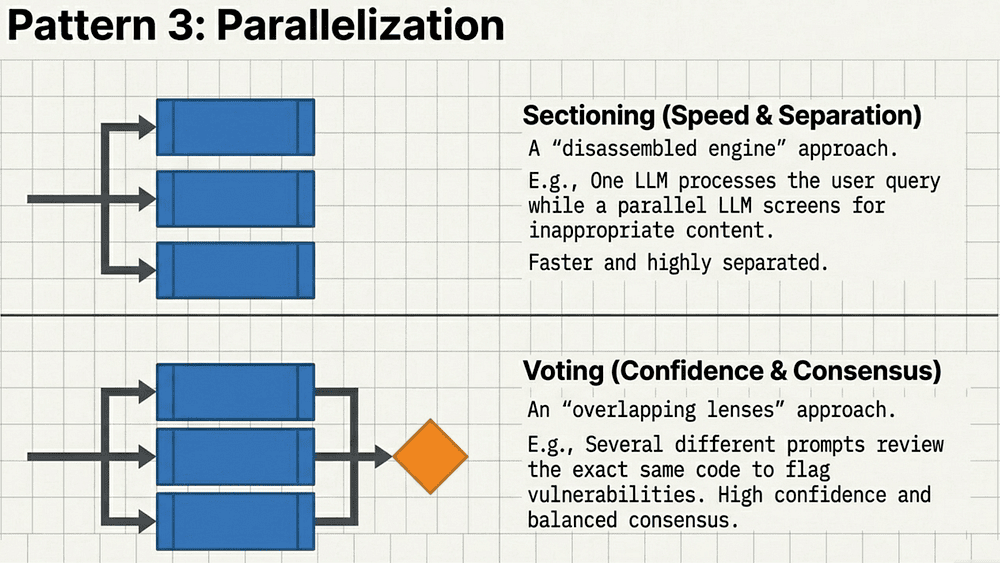
Run multiple LLM calls at the same time and combine results programmatically.
Two Flavors
- Sectioning (Speed & Separation): One model generates content while another screens for safety or policy violations.
- Voting (Confidence & Consensus): Multiple prompts review the same output (e.g., code vulnerabilities) and you take the consensus.
Strategic Benefit:
LLMs perform far better when given one focused job instead of juggling guardrails, formatting, and logic in a single call.
Pattern 4: Orchestrator-Workers (The Dynamic Project Manager)
In this workflow, a central "Orchestrator" LLM dynamically breaks down a complex task into subtasks and delegates them to "Workers." The key difference here is flexibility; the subtasks are not hardcoded but are determined on the fly based on the input. Use this pattern when you cannot predict the subtasks in advance. If the scope of work changes based on the user's request (e.g., a coding task that might involve one file or fifty), an Orchestrator is required.
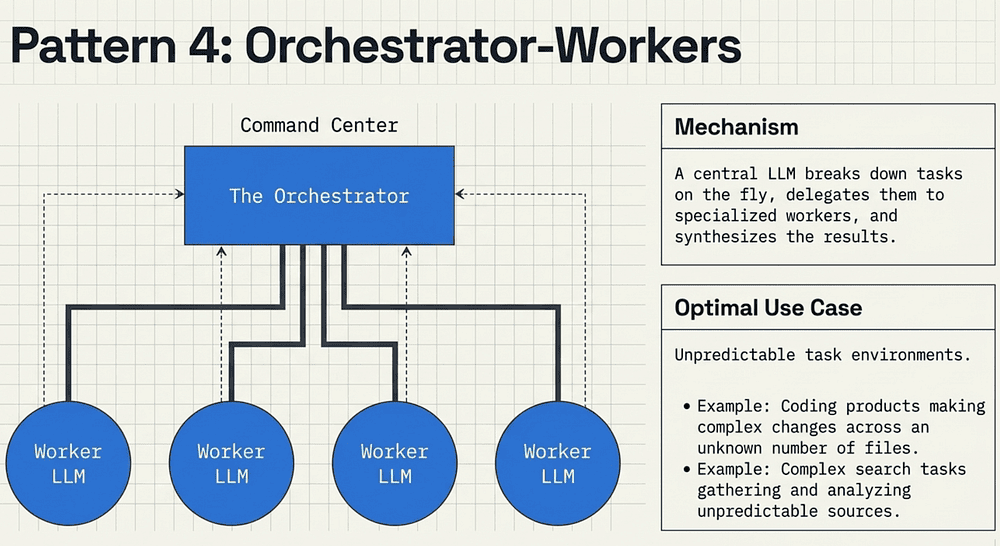
Keys to remember: A central "Orchestrator" LLM breaks down unpredictable tasks on the fly, delegates to specialized worker LLMs, and synthesizes the final result.
Optimal Use Case:
Unpredictable environments where you can't hardcode every step.
Examples
- Coding agents making complex changes across an unknown number of files
- Complex search tasks that discover new sources dynamically
Once the tasks are delegated and completed, we need a mechanism to ensure they actually meet our quality standards. This is where the next pattern comes into play.
Pattern 5: Evaluator-Optimizer (The Iterative Artist)
The Evaluator-Optimizer pattern creates a feedback loop that mimics the iterative human writing process. One LLM (the Optimizer) generates a draft, while another (the Evaluator) provides specific critiques.
Success Criteria:
This pattern is effective when:
- There are clear evaluation criteria.
- Iterative refinement provides measurable value (e.g., literary translation where nuance matters).
- The loop continues until a specific quality threshold is met, rather than just running for a fixed number of turns.
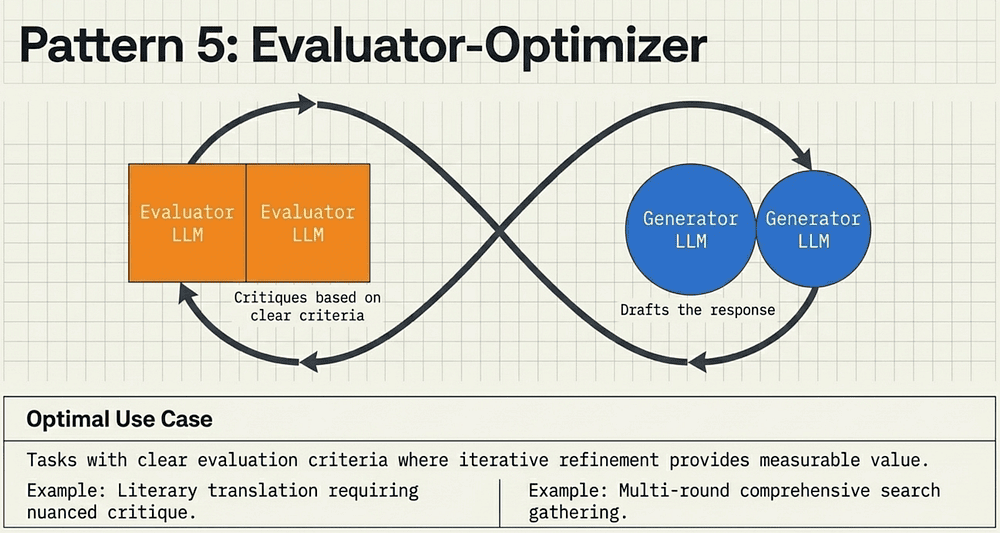
They key concepts are one LLM (Generator) drafts the output. Another (Evaluator) critiques it against clear criteria. Repeat until quality threshold is met.
Optimal Use Case:
Tasks with articulable success criteria where iteration adds measurable value (literary translation, comprehensive research, polished code).
Pro Tip:
Always give the model "tokens to think" before it commits to an action. Structured reasoning steps dramatically improve loop reliability.
The Workflow Selection Matrix
The Autonomous Leap: Agents
Autonomous Agents represent the transition from following paths to solving open-ended problems. They use reasoning and planning to operate independently over many turns.
Key Capabilities
- Reasoning and Planning: Mapping a path toward a distant goal.
- Tool Use: Interacting reliably with external environments.
- Ground Truth: This is the most critical factor. Agents must gain "ground truth" from the environment at each step (e.g., the actual result of a tool call or code execution) to assess their progress and recover from errors.
Because agents operate independently, they are susceptible to compounding errors. Always test agents in sandboxed environments and implement strict "stopping conditions" (like maximum iterations) to prevent the system from spiraling.
Example: A Coding Agent (as seen in SWE-bench) can resolve a GitHub issue by finding files, writing tests, and editing code until the tests pass — using the "ground truth" of the test results to verify its own work.
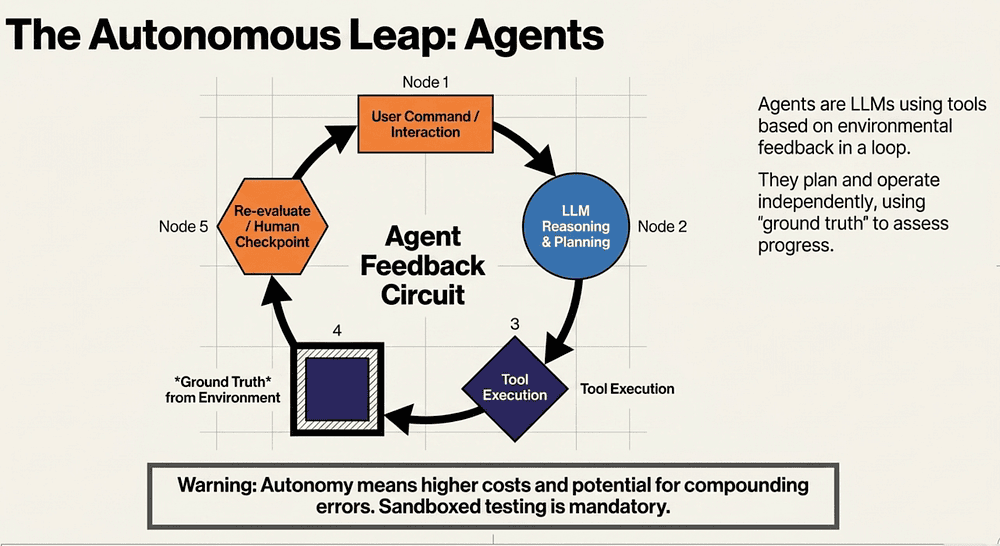
Key concepts include agents are simply workflows that close the loop with real environmental feedback ("ground truth").
Agents plan, act, observe results, and re-plan.
Warning (Exam Favorite)
- Autonomy = higher cost and risk of compounding errors.
- Sandbox everything and implement strict stopping conditions.
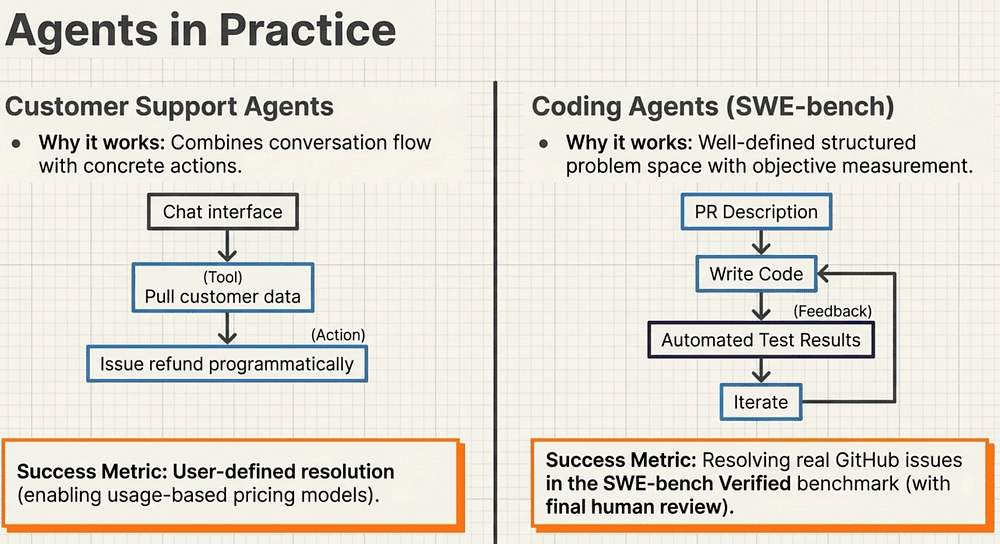
Real-World Wins:
- Customer support agents (conversation + concrete actions)
- Coding agents (SWE-bench style: PR → code → tests → iterate)
The Hidden Secret: ACI (Agent-Computer Interface)
While everyone obsesses over prompt engineering, the real differentiator is tool engineering. Three Rules for Designing Great ACI
- Give Tokens to "Think" Let the model reason in natural language before outputting structured calls. Avoid forcing heavy JSON escaping.
- Write Docstrings for the LLM Treat every tool description like documentation for a junior developer: examples, edge cases, boundaries between similar tools.
- Poka-yoke the Arguments (Mistake-Proofing) Example from SWE-bench: Agents kept failing with relative filepaths. Forcing absolute paths eliminated the error completely. Use Markdown instead of strict JSON when possible — it's what the model saw during training.
The Blueprint for Success (Memorize These Three Principles)
1. Maintain Simplicity: Start with direct LLM APIs and simple prompts. Add complexity only when a single call demonstrably fails. Strip bloated frameworks before production.
2. Prioritize Transparency: Explicitly log every intermediate planning step and ground-truth evaluation. You must be able to see the data flow.
3 Engineer the ACI: Obsess over tool documentation, parameter design, and environmental feedback loops. Build systems that are powerful, reliable, and trusted, not by adding magic, but by applying rigorous engineering patterns.
Read the Source
This material was taken from Building Effective Agents which is a research paper written by Anthropic and has strong overlap with vocabulary used quite often on the test.
"Consistently, the most successful implementations use simple, composable patterns rather than complex frameworks." — Building Effective Agents, Anthropic
If you have not done so already, go read Building Effective Agents by Anthropic Research and come back here to review.
Review Key Ideas
- What is the fundamental architectural distinction between a "workflow" and an "agent" in an agentic system? In a workflow, LLMs and tools are orchestrated through predefined code paths where the sequence of operations is fixed. In contrast, agents are systems where the LLM dynamically directs its own processes and tool usage, maintaining control over how tasks are accomplished.
- When should a developer prioritize using a simple workflow over an autonomous agent? Workflows should be prioritized for well-defined tasks where predictability and consistency are paramount. While agents offer flexibility and model-driven decision-making at scale, they often trade off higher latency and cost for that performance, making them less ideal for simple tasks.
- Describe the "prompt chaining" workflow and its primary benefit. Prompt chaining decomposes a complex task into a sequence of steps where each LLM call processes the output of the preceding one, often including programmatic "gates" to ensure the process remains on track. The primary benefit is trading latency for higher accuracy by making each individual LLM call a simpler, more manageable task.
- How does the "routing" workflow improve the performance of LLM applications? Routing classifies an input and directs it to a specialized follow-up task or model, allowing for a separation of concerns and the use of specialized prompts. This prevents the performance degradation that occurs when trying to optimize a single prompt for many different, distinct categories of input.
- What are the two key variations of the "parallelization" workflow? The two variations are sectioning and voting. Sectioning involves breaking a task into independent subtasks run simultaneously, while voting involves running the same task multiple times across different calls to achieve higher confidence or diverse outputs.
- What distinguishes the "orchestrator-workers" pattern from the "parallelization" pattern? While both involve multiple LLM calls, the orchestrator-workers pattern is more flexible because the subtasks are not predefined. The central orchestrator dynamically determines which subtasks are necessary based on the specific input and then synthesizes the results from the worker LLMs.
- When is the "evaluator-optimizer" workflow most effective? This workflow is most effective when there are clear evaluation criteria and when iterative refinement provides measurable value. It mimics the human writing process, where one LLM generates a response and another provides feedback loops to improve the output until it meets a specific standard.
- Why does the research suggest starting with LLM APIs directly rather than using complex frameworks? Starting with direct APIs allows developers to implement patterns in a few lines of code without the extra layers of abstraction that can obscure underlying prompts and responses. Frameworks can make systems harder to debug and may tempt developers to add unnecessary complexity to a solution.
- What are the three core principles for implementing successful agents? The three principles are: maintaining simplicity in the agent's design, prioritizing transparency by explicitly showing the agent's planning steps, and carefully crafting the agent-computer interface (ACI) through thorough tool documentation and testing.
- How can "Poka-yoke" principles be applied to tool design for LLM agents? Applying Poka-yoke involves designing tool arguments and interfaces so that it is naturally harder for the model to make mistakes. An example is requiring absolute filepaths instead of relative ones to prevent the agent from losing track of its directory during execution.
Key Concepts to Remember
- Workflows use predefined code paths; Agents dynamically direct their own processes and tool usage.
- Use workflows for well-defined tasks needing predictability; use agents only when model-driven flexibility is required at scale.
- Prompt chaining is a sequence of LLM calls where one's output is the next's input; it increases accuracy by simplifying the task for each call.
- Routing classifies inputs to send them to specialized prompts or models, ensuring optimization for one input type doesn't hurt another.
- Sectioning (running different subtasks at once) and voting (running the same task with different prompts multiple times for consensus).
- The orchestrator-workers pattern is dynamic, meaning the orchestrator decides the subtasks on the fly, whereas parallelization uses fixed, predefined subtasks.
- It is best when clear evaluation criteria exist and iterative feedback demonstrably improves the quality of the final response.
- Frameworks can obscure prompts/responses, make debugging difficult, and encourage unnecessary complexity.
- Simplicity in design, transparency in planning, and thorough ACI (Agent-Computer Interface) design.
- By changing arguments or constraints (like requiring absolute paths) to minimize the possibility of the LLM making an error.
Monday Morning Actions (CCA-F Edition)
- Audit your current tools: Are you making the model do mental math or heavy escaping? Simplify to Markdown and absolute paths.
- Pick one pattern above and refactor a single workflow this week.
- Check your logs: Can you see the raw prompt-response chain? If not, reduce abstraction layers immediately.
Further Essential Reading for CCA-F (Prioritized by Domain Weight)
These resources are all from Anthropic research, blogs or documentation. These are where a lot of these key concepts are disucssed which are on the CCA-F exam.
Domain 1 — Agentic Architecture (27%)
- Building Effective Agents
- How We Built Our Multi-Agent Research System
- Effective Harnesses for Long-Running Agents
Domain 2 — Tool Design & MCP (18%)
- Writing Effective Tools for AI Agents
- Introducing the Model Context Protocol
- Code Execution with MCP
Domain 3 — Claude Code (20%)
Domain 4 — Prompt Engineering (20%)
Domain 5 — Context Management (15%)
Conclusion
Building agentic systems is about finding the right level of complexity for the problem at hand. As you move toward production, adopt these three core principles:
Maintain Simplicity:
Always start with a single prompt. Only add multi-step workflows or agents when simpler solutions demonstrably fail. Complexity is a debt that must be justified by performance.
Prioritize Transparency:
Never let your agent be a "black box." Explicitly log and show the agent's planning steps and thought process. This makes the system maintainable and easier to debug.
Architect the ACI (Agent-Computer Interface):
Just as we design for humans (HCI), we must design for agents. Invest time in "poka-yokeing" your tools:
- Avoid complex formatting: Don't use formats like JSON that require heavy newline/quote escaping for code; use Markdown for "thinking".
- Use absolute paths: Agents often lose track of relative directories; require absolute filepaths for all tool calls.
- Provide Thinking Space: Give the model tokens to "think" before it acts to prevent it from writing itself into a logical corner.
Foundational Unit consists of the Augmented LLM: An LLM + Tools (to act), Retrieval (to ground answers in external facts), and Memory (to retain/manage state across steps). Most "agentic" systems are just different ways of sequencing this unit.
Patterns & when to use them
- Prompt Chaining: Fixed, decomposable steps; use when you want predictable flow and higher accuracy via smaller sub-tasks (often with programmatic gates).
- Routing: Inputs fall into distinct categories; use to send requests to the right prompt/toolchain/model (great for cost + latency optimization).
- Parallelization: Independent subtasks can run simultaneously; use for speed (sectioning) or higher confidence (voting/consensus).
- Orchestrator-Workers: Subtasks are not knowable in advance; use when the work plan must be generated dynamically and delegated, then synthesized.
- Evaluator-Optimizer: Clear quality criteria and iteration materially improves outcomes; use for critique→revise loops until a threshold is met.
The most successful AI architects don't build the most complex systems; they build the most reliable ones. Start with the building blocks, master the simple workflows, and only reach for full autonomy when the environment provides the ground truth necessary for the agent to succeed. Happy building! Good luck on your CCA-F exam if you choose to take it.
About the Author

Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.
Rick created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code