Foundations of CCA-F Exam Part 2: Engineering Lessons from Prototype to Production
Learn key agentic patterns from a Battle-Tested Multi-Agent Research Systems paper to master the Claude Certified Architect -- CCA-F exam.
Originally published on Medium.
Learn key agentic patterns from a Battle-Tested Multi-Agent Research Systems paper to master the Claude Certified Architect -- CCA-F exam.
Five proven architectural patterns and hard-won production lessons for building reliable multi-agent research systems. Learn the exact terminology and frameworks from Anthropic's "How we built our multi-agent research system" paper that are essential for passing the Claude Certified Architect Foundation Exam (CCA-F exam).
Summary: This article outlines the core concepts for multi-agent research systems, the Orchestrator-Worker pattern, Research Loop, Agent Steering Framework, Multi-Dimensional Parallelization, Tool Self-Improvement Loop, and End-State Evaluation, while emphasizing the shift from linear pipelines to dynamic, parallel agentic systems. It highlights practical production realities such as token scaling, deterministic safeguards, Filesystem Handoff, Rainbow Deployment, synchronous vs asynchronous tradeoffs, and when multi-agent systems are (and are not) the right choice.

Introduction: Why This Blueprint Matters
If you're serious about passing CCA-F (and building real systems, not demo scripts), you need more than buzzwords, you need the production mental model behind multi-agent research. Anthropic's multi-agent setup didn't win by being "more agentic." It won because it scaled reasoning with parallel token budgets, preserved provenance, and treated synthesis as a first-class engineering problem.
This guide distills the exact patterns and terms you'll see on the exam:
- Orchestrator-Worker,
- the Research Loop,
- Agent Steering,
- Filesystem Handoff, and
- End-State Evaluation
Then you can translates them into the practical lessons that prevent multi-agent systems from quietly failing in production, and also pass your CCA-F exam.
You will see this exact terminology used heavily on the test. You must be familiar with these agentic patterns and how to apply them to pass the exam.
Some concepts are not covered in the course lessons but are listed in the study guide. This article is designed to close those gaps.
The Core Problem with Linear AI
Research work involves open-ended problems, making it difficult to predict the required steps in advance. You can't hardcode a fixed path for exploring complex topics, as the process is inherently dynamic and path-dependent. When people conduct research, they continuously update their approach based on discoveries, following leads that emerge during the investigation.
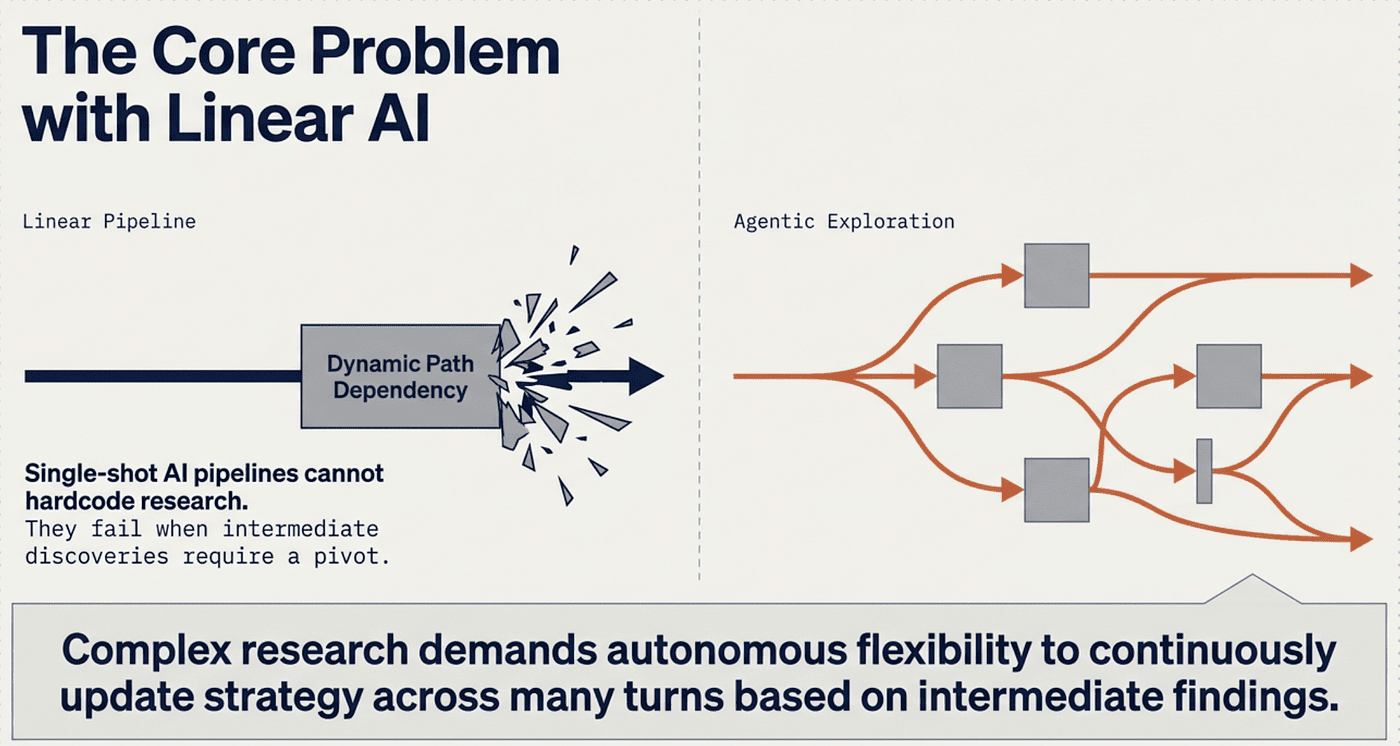
This unpredictability makes multi-agent systems particularly well-suited for research tasks. A linear, one-shot pipeline cannot handle these tasks. Multi-agent research systems give agents the flexibility to pivot or explore tangential connections as the investigation unfolds.
Important Constraint: Multi-agent systems are not the right choice for every task. They are less effective when tasks require all agents to share the same context, involve many tight dependencies between steps, or fall in domains like coding, where parallelization opportunities are limited. Agents are not yet good at coordinating and delegating to each other in real time.
CCA-F Rule of Thumb: Start with a workflow for well-defined tasks. Only move to full autonomous agents when a fixed path is literally impossible to hardcode. Most "agentic" problems on the exam are actually sophisticated workflows.
The Engine of Intelligence: Token Scaling
The "Augmented LLM" is the fundamental unit of any agentic system. Performance is driven almost entirely by token scaling.
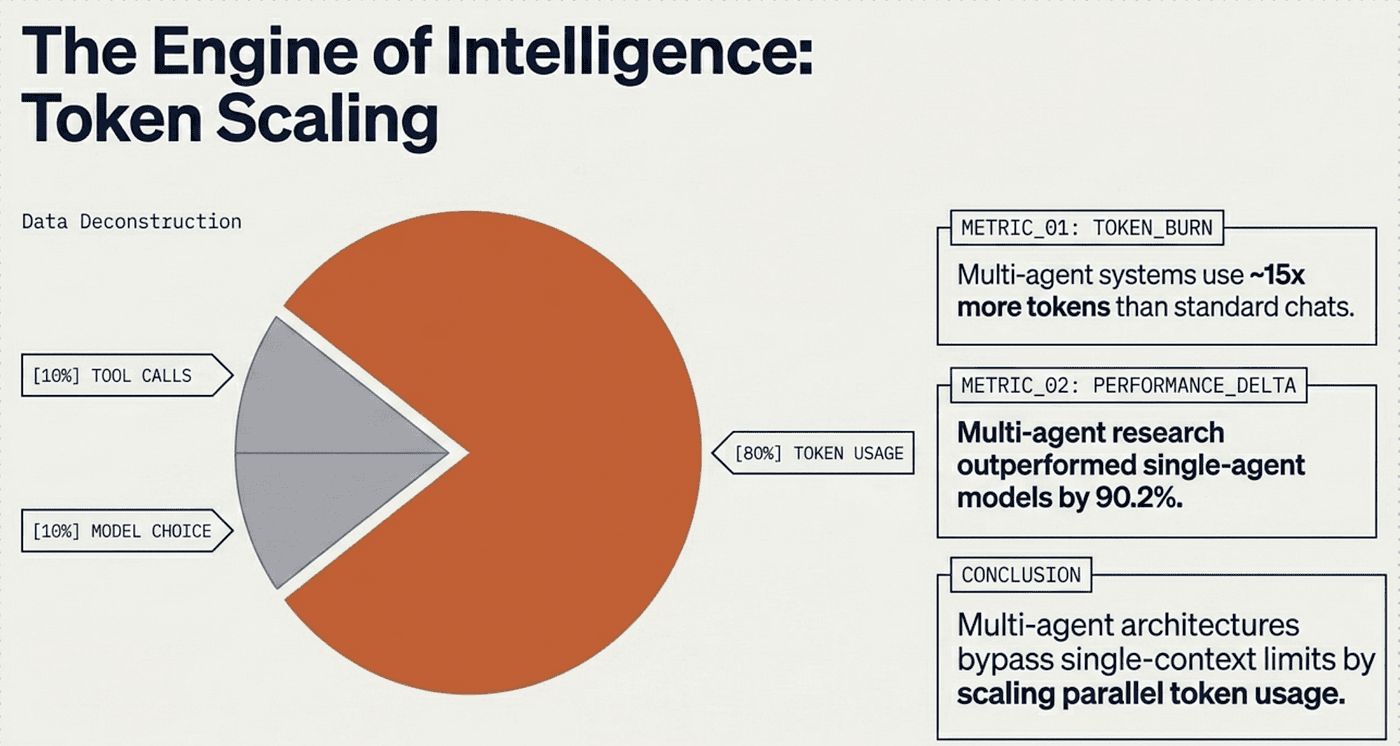
In Anthropic's BrowseComp evaluation, three factors explained 95% of the variance in performance: token usage (80%), the number of tool calls, and model choice. Multi-agent architectures scale this capacity by distributing work across agents with separate context windows, enabling parallel token usage and parallel context windows.
Internal evaluations showed that a multi-agent system with Claude Opus 4 as the lead agent and Claude Sonnet 4 subagents outperformed single-agent Claude Opus 4 by 90.2%. For example, when asked to identify all board members of IT companies in the S&P 500, the multi-agent system succeeded, whereas the single-agent approach failed due to slow sequential searches.
Subagents act as compression engines. The essence of search is compression: they reduce token entropy by distilling insights from a vast corpus before feeding high-signal summaries back to the Lead Agent.
In practice, multi-agent loops typically use about 15x more tokens than standard chat interactions (and 4x more than single-agent systems). For economic viability, reserve them for high-value tasks where the performance gain justifies the cost.
Architectural Shift: Static vs. Dynamic Retrieval
Traditional approaches using Retrieval Augmented Generation (RAG) rely on static retrieval; fetching chunks most similar to the query. In contrast, multi-agent research uses a dynamic, multi-step search that adapts to new findings and analyzes results to formulate high-quality answers.
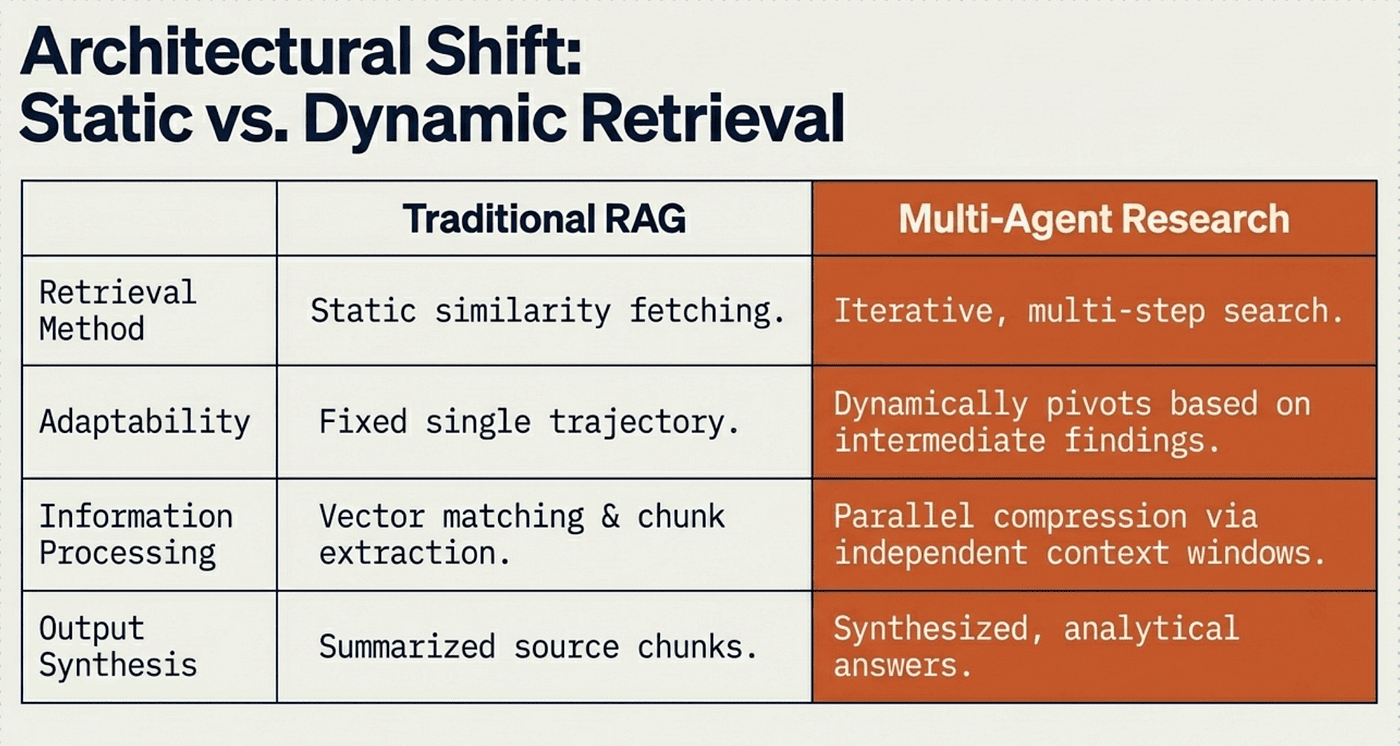
Subagents act as intelligent filters: they explore different aspects simultaneously, condense insights, and provide separation of concerns with distinct tools, prompts, and trajectories.
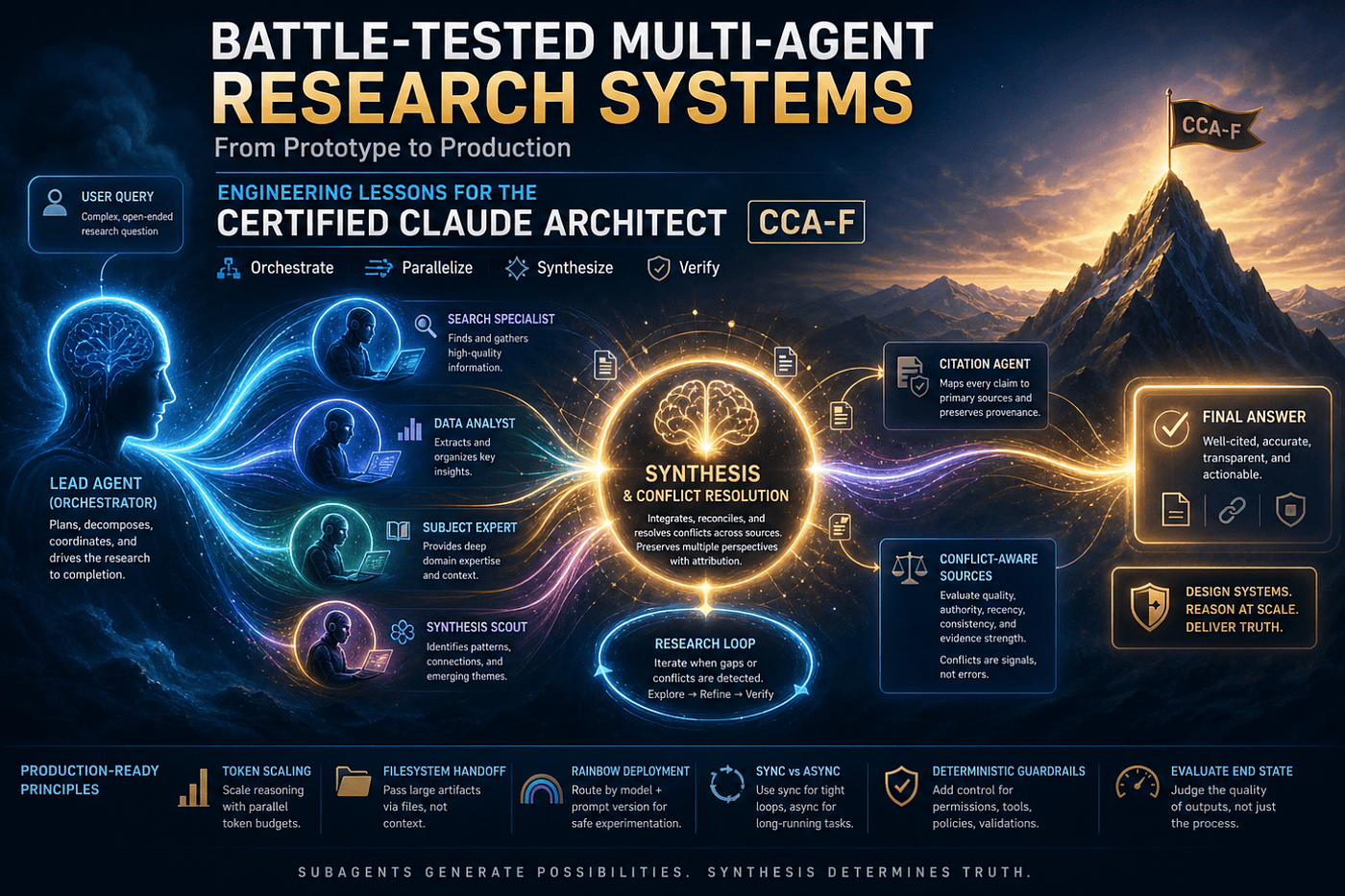
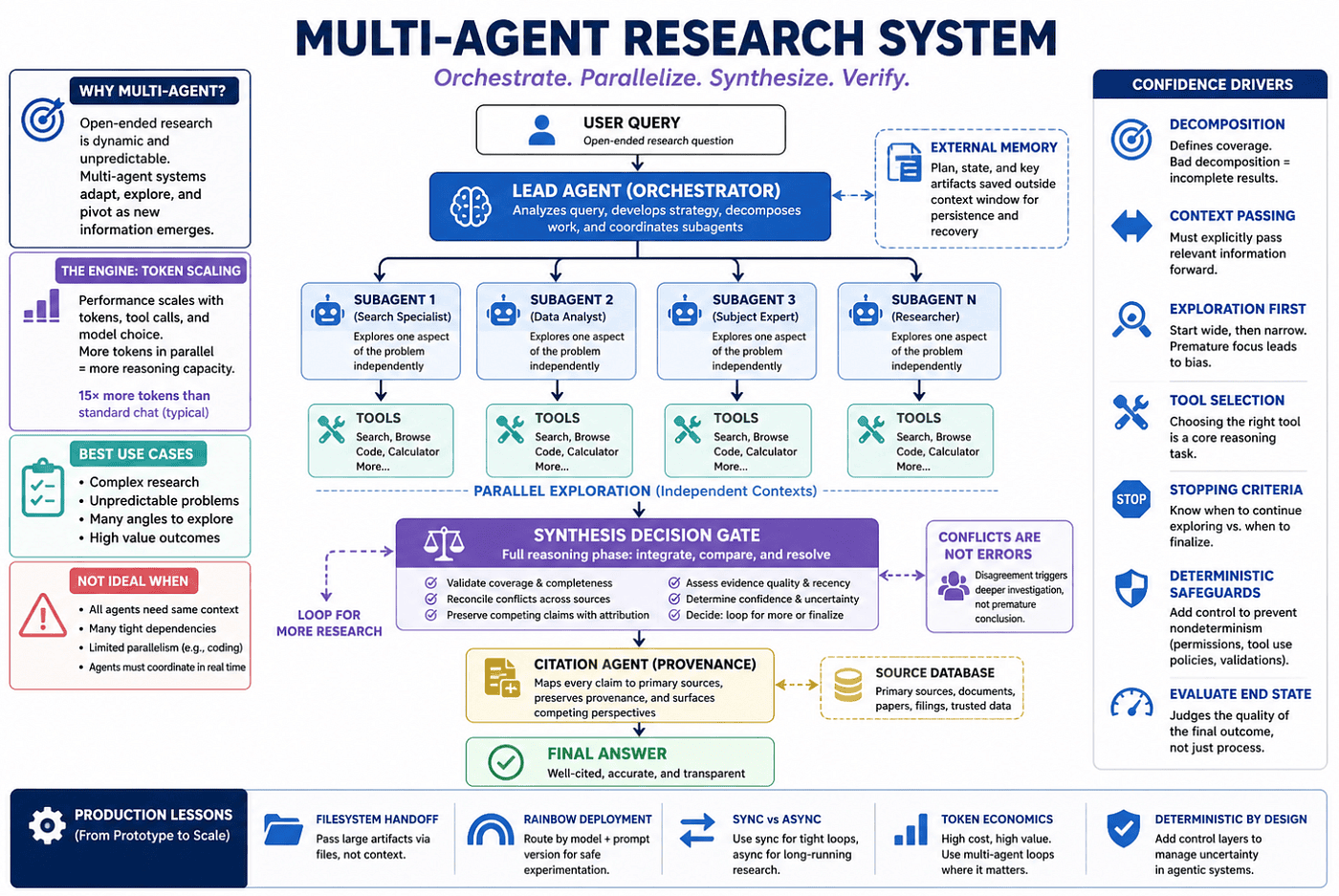
Pattern: The Orchestrator-Worker Blueprint
The most effective framework is the Orchestrator-Worker pattern (also called the orchestrator-worker architecture).
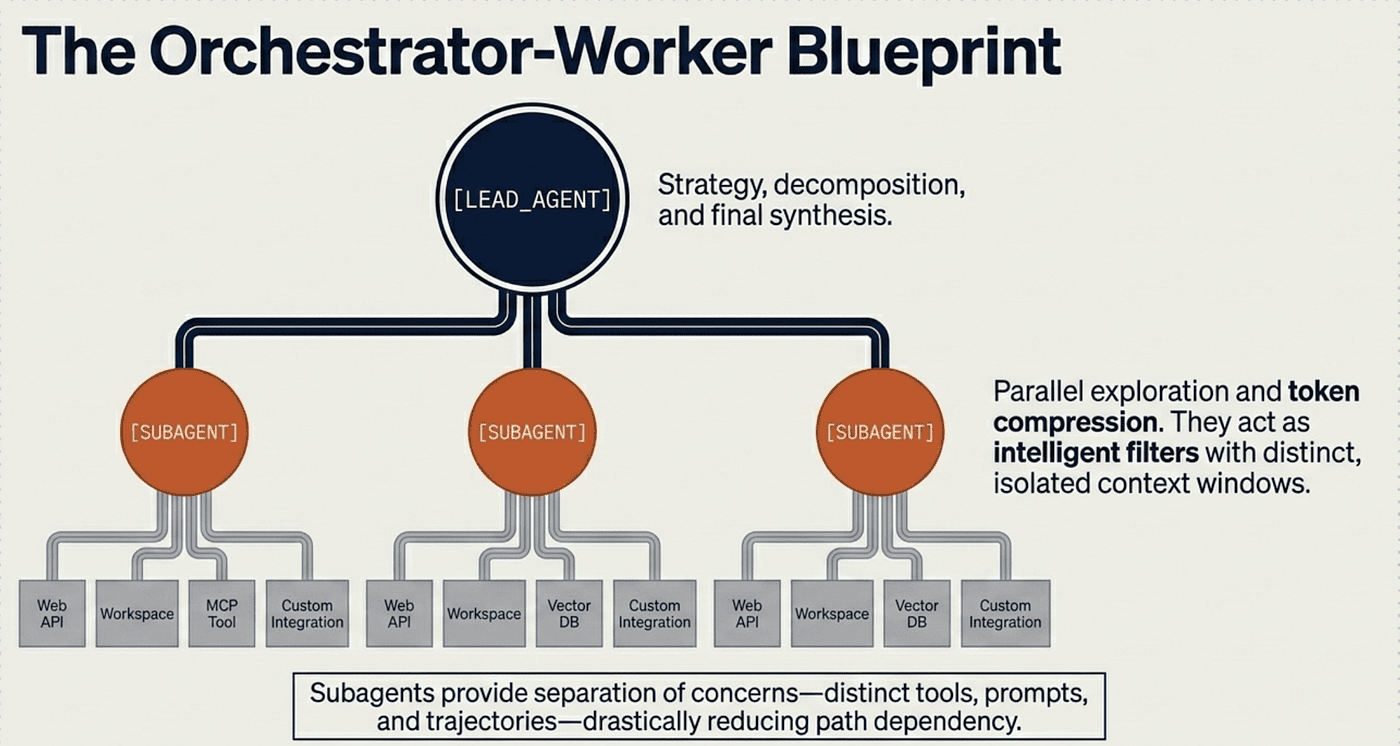
A central Lead Agent (LeadResearcher) analyzes the query, develops a strategy, and spawns specialized subagents. The subagents operate in parallel, each with its own context window, before feeding compressed findings back to the Lead Agent for synthesis.
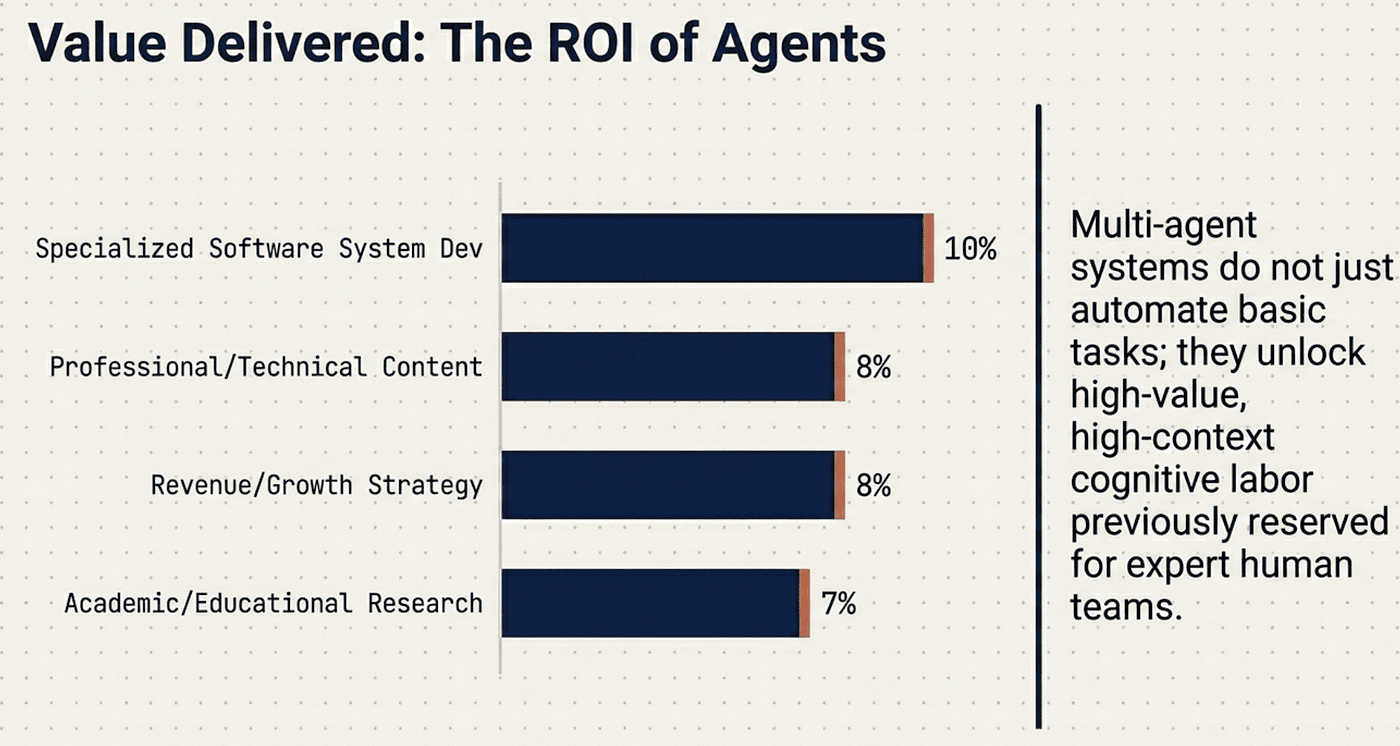
Optimal Use Case: Unpredictable environments where subtasks cannot be known in advance (complex search, software system development, business strategy, academic research).
Pattern: The Research Loop
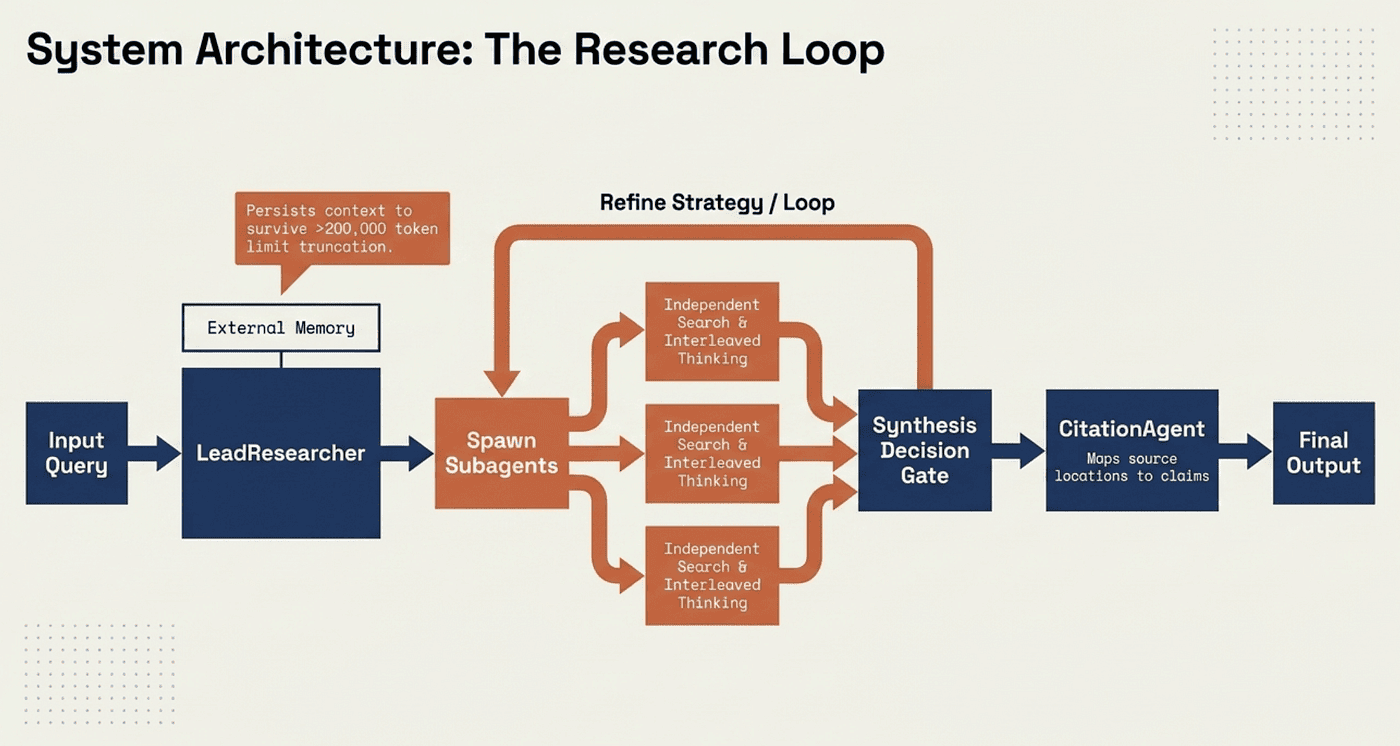
The complete system architecture is the Research Loop:
- User query -> LeadResearcher
- LeadResearcher saves plan to External Memory (to survive >200,000 token truncation)
- Spawns subagents with clear tasks
- Subagents perform an independent search with interleaved thinking
- Results flow to the Synthesis Decision Gate
- CitationAgent maps every claim to primary sources and preserves claim-to-source relationships. This is essential for synthesis because multiple agents may return conflicting or overlapping information. The system must maintain provenance so that synthesis can compare, validate, and present competing claims rather than silently resolving them.
- Loop or produce final output with citations

Synthesis and Conflict Resolution (Critical Step):
The Synthesis Decision Gate is not a simple aggregation step -- it is a full reasoning phase that integrates distributed outputs. It must:
- Validate coverage (did subagents fully explore the problem space?)
- Reconcile conflicting information across sources
- Preserve competing claims with attribution instead of collapsing them
- Trigger additional research loops when inconsistencies, low-confidence signals, or incomplete coverage are detected rather than prematurely finalizing results.
Conflicts are not errors -- they are signals of incomplete understanding. Proper synthesis treats disagreement as a reason to expand investigation, not prematurely finalize results.
Diagnosing Synthesis Failures (CCA-F Critical Skill)
Many exam scenarios describe systems where all components appear to function correctly, yet the final output is incomplete, biased, or incorrect. These are almost always synthesis failures.
Common indicators include:
- Missing information despite subagents retrieving it
- Biased or uneven coverage across topics
- Conflicting data is silently resolved or ignored
- Loss of attribution or provenance
- Over-compressed summaries that omit key details
CCA-F Rule: If subagents performed correctly but the final output is wrong, the root cause is almost always a failure in synthesis or context integration.
Pattern: The Agent Steering Framework
Prompt engineering for multi-agent systems focuses on instilling good heuristics rather than rigid rules.
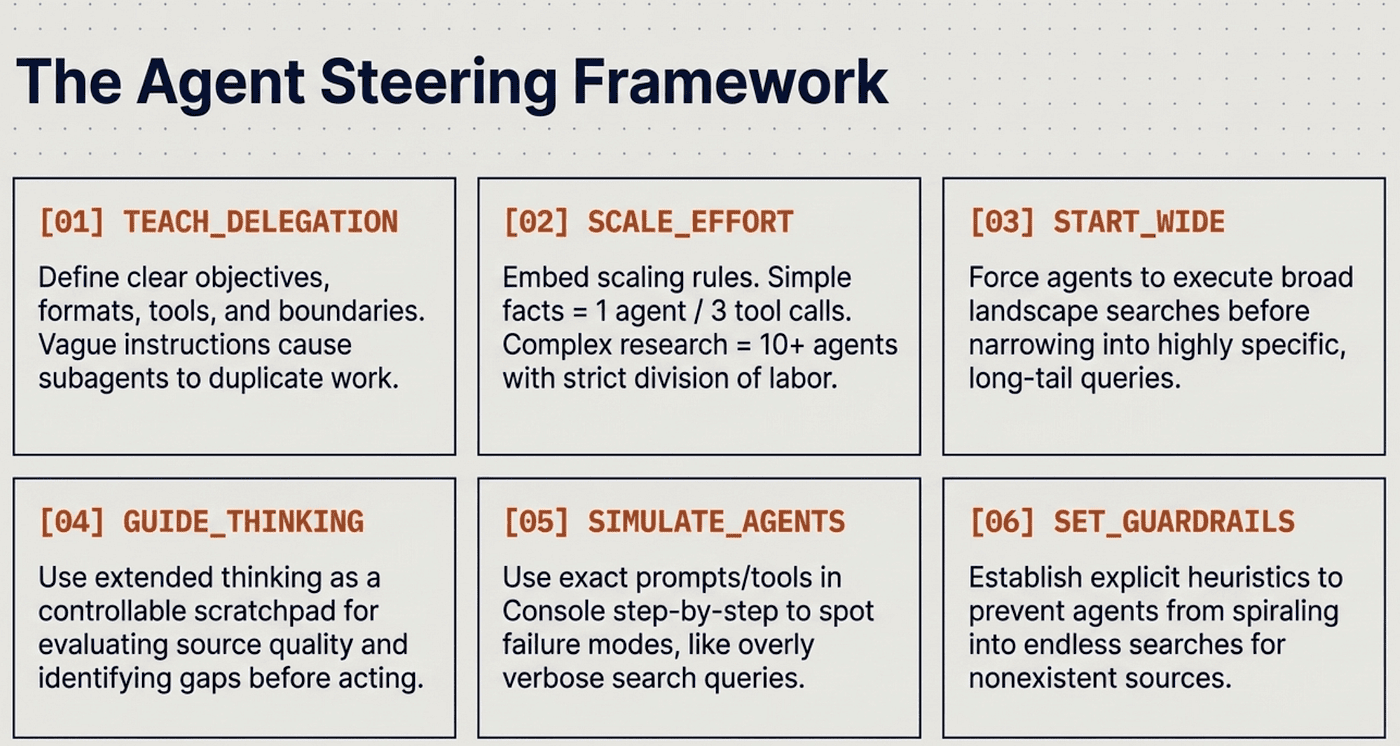
Anthropic codified the Agent Steering Framework:
- TEACH_DELEGATION -- Give each subagent a clear objective, output format, tools, and task boundaries.
- SCALE_EFFORT -- Embed scaling rules (simple facts = 1 agent; complex research = 10+ agents).
- START_WIDE -- Force broad landscape searches before narrowing into specifics.
- GUIDE_THINKING -- Use extended thinking as a controllable scratchpad.
- SIMULATE_AGENTS -- Watch agents work step-by-step in Console to spot failure modes.
- SET_GUARDRAILS -- Prevent spiraling or low-quality searches.
Early failure modes included spawning 50+ unnecessary agents, endlessly searching for nonexistent sources, duplicating work, using overly verbose queries, and selecting incorrect tools.
Pattern: The Tool Self-Improvement Loop
The agent-tool interface is as critical as the human-computer interface. Poor tool descriptions send agents down the wrong path.
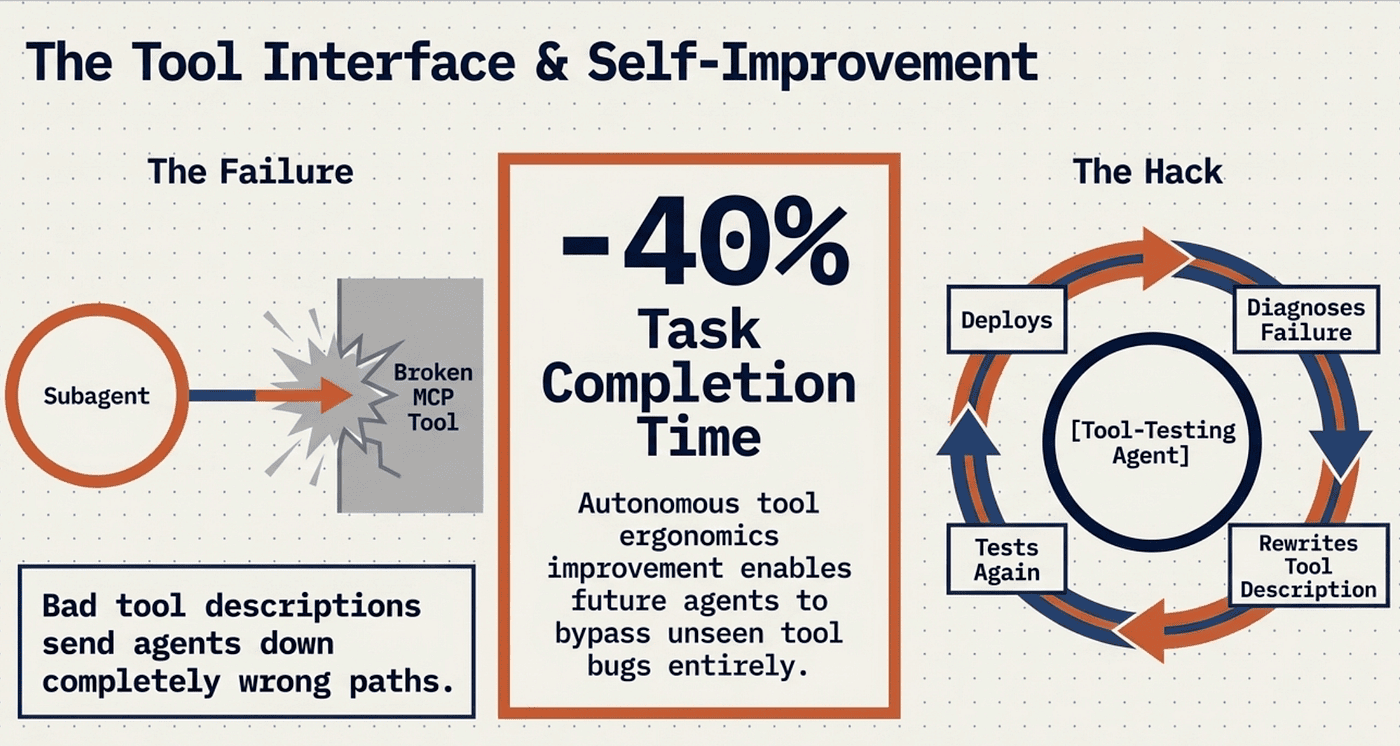
Anthropic created a Tool-Testing Agent that tests flawed MCP tools, diagnoses failures, and rewrites descriptions. This Tool Self-Improvement Loop resulted in a 40% decrease in task completion time.
Explicit tool-selection heuristics include: examine all available tools first, match tool usage to user intent, prefer specialized tools over generic ones, and never use web search for data that exists only in Slack.
Pattern: Multi-Dimensional Parallelization
Multi-Dimensional Parallelization combines two forms of parallelism: the Lead Agent spins up 3-5 subagents in parallel (orchestrator parallelism), and each subagent runs 3+ tools simultaneously (tool parallelism). These changes reduce research time by up to 90%.

Agents must balance breadth-first exploration (parallel discovery) with depth-first investigation (focused analysis), dynamically shifting between them based on intermediate findings.
The Autonomous Leap: Production Realities
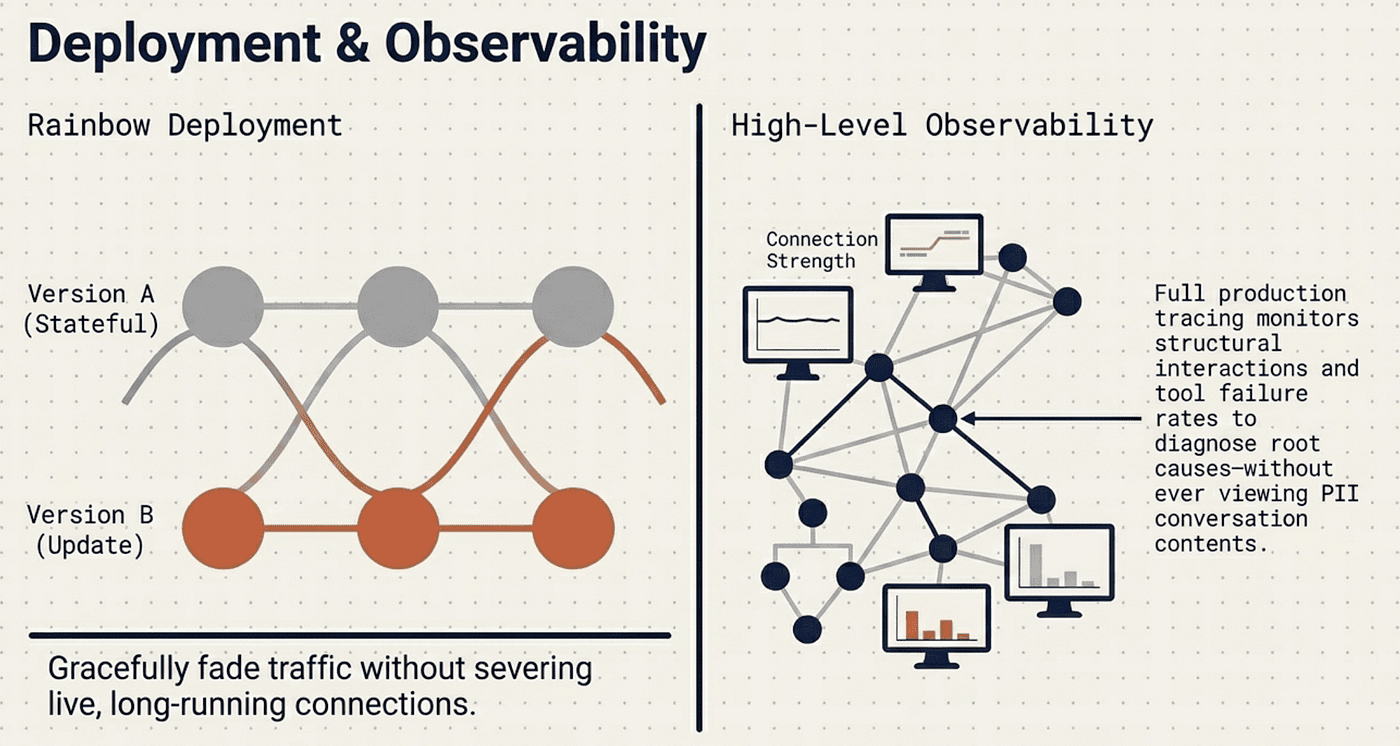
In production, agents are stateful, and compounding errors are the biggest risk. A single failure at step 45 can derail a 100-turn process. Systems must be able to resume from failure, not restart from the beginning -- restarts are expensive and frustrating for users.
Rainbow Deployment allows graceful updates without breaking live agents. High-Level Observability monitors decision patterns and interaction structures without inspecting conversation contents (preserving user privacy).
Context management uses the Filesystem Handoff (also called Artifact System): subagents write outputs directly to a persistent filesystem and pass lightweight reference pointers back to the Lead Agent. This avoids the "game of telephone" degradation, improves fidelity, performance, and token efficiency.
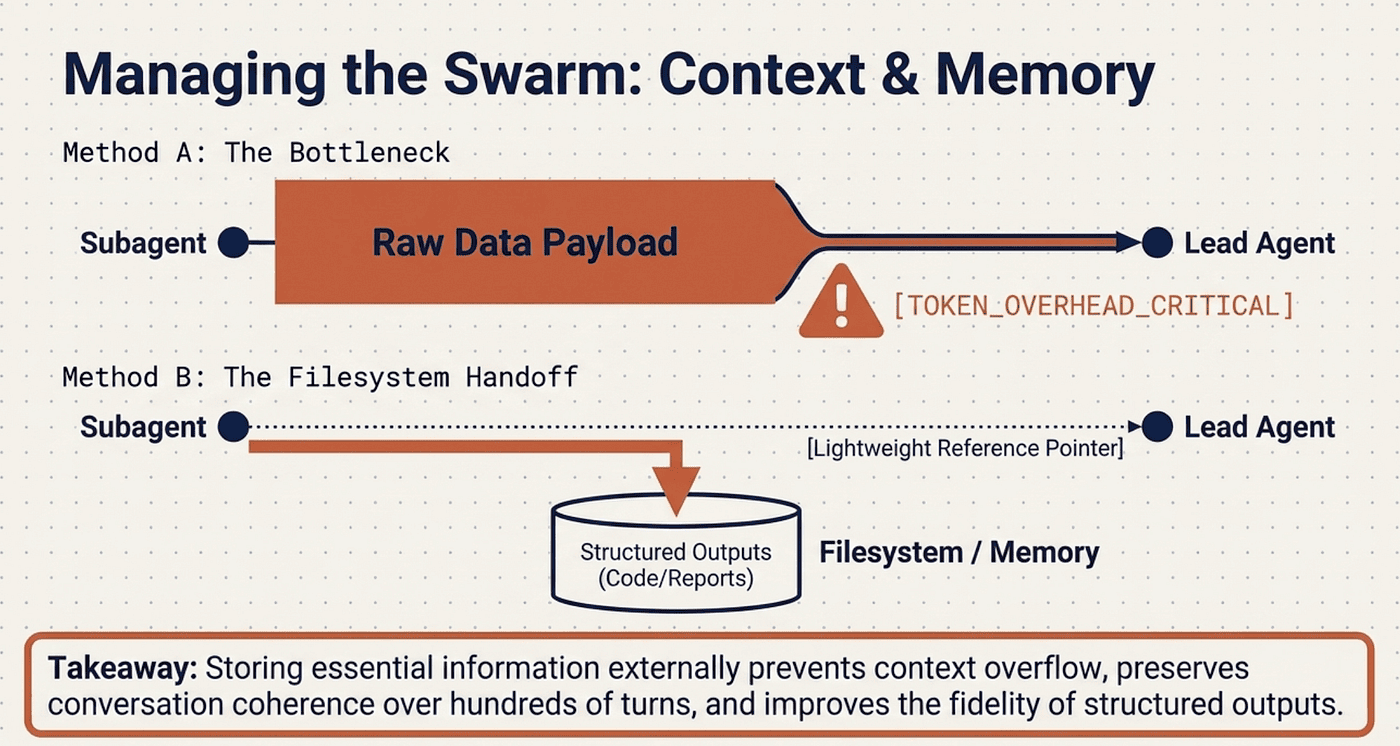
For long-horizon conversations, agents summarize completed phases, store essential information in external memory, and can spawn fresh subagents with clean contexts while retrieving stored plans later.
Synchronous execution currently creates bottlenecks (the Lead Agent waits for all subagents to complete). Asynchronous execution would enable greater power but introduces more challenging coordination and state-consistency challenges.
Coordination complexity grows rapidly in multi-agent systems. Small prompt or orchestration changes can produce nonlinear, system-wide behavioral shifts and emergent behaviors, making debugging fundamentally different from traditional software systems.
Conflict-Aware Systems (Production Requirement)
In real-world systems, conflicting information across agents is expected, not exceptional. Production systems must be designed to handle:
- Conflicting facts across sources
- Inconsistent interpretations of the same data
- Varying source quality (e.g., SEO content vs primary sources)
Systems should never silently resolve these conflicts. Instead, they must:
- Preserve multiple perspectives
- Attach source attribution
- Escalate uncertainty when necessary
- Trigger additional research when conflicts cannot be resolved
A common failure mode is premature finalization, where the system produces an answer despite unresolved conflicts or incomplete coverage. Proper systems delay finalization until sufficient consistency and evidence quality are achieved.
Evidence Prioritization in Conflict Resolution
When resolving conflicting information, systems must evaluate evidence quality across multiple dimensions:
- Source authority (primary vs secondary sources)
- Evidence strength (direct vs inferred claims)
- Consistency across independent sources
- Publication date (recency of information)
Publication date is a useful signal, particularly for time-sensitive or versioned data, but it should never override source quality. Newer information is not inherently more reliable, especially when derived from lower-quality or aggregated sources.
When high-quality sources conflict, systems should preserve both perspectives with attribution or continue gathering evidence rather than forcing convergence.
Mental Model: Subagents generate possibilities; synthesis determines truth.
Evaluating the Non-Deterministic
Multi-agent systems have emergent behaviors and non-deterministic paths. Use LLM-as-Judge for scalable automation and End-State Evaluation to judge whether the final output achieved the correct state rather than checking every intermediate step. Human evaluation catches subtle biases (e.g., agents preferring SEO-optimized content farms over authoritative academic PDFs or personal blogs).

Start with small samples (~20 real usage queries) -- dramatic improvements are visible immediately.
Deep System Insights (What the Exam Really Tests)
The exam does not just test surface-level patterns -- it tests deep system understanding drawn directly from this paper. Master these subtle but high-yield insights and you will be able to diagnose why systems fail even when individual agents succeed.
- Decomposition determines coverage. The coordinator's decomposition defines the search space explored by the system. If the decomposition is incomplete, biased, or overly narrow, synthesis will never have sufficient information to produce a correct result, regardless of subagent performance.
- Context must be explicitly passed. Subagents operate in isolated contexts and do not inherit state automatically. The coordinator must explicitly pass relevant outputs between steps. Missing information in final results is often due to context not being forwarded, not a failure in retrieval.
- Exploration must precede optimization. Agents should perform broad, parallel exploration before narrowing focus. Premature convergence on a single path leads to incomplete or biased results and is a common failure mode in both practice and exam scenarios.
- Tool selection is a reasoning task. Choosing the correct tool is not a mechanical step but a core reasoning decision. Poor tool selection leads to systematic failure even when all tools are functional. Clear tool descriptions and selection heuristics are critical to system reliability. You must specify when to use the tool and sometimes more importantly when not to use the tool.
- Stopping criteria must be explicit. Agent systems must clearly define when to continue exploration versus when to finalize results. Premature stopping leads to incomplete answers, while unbounded loops waste resources and degrade performance.
- Confidence does not imply correctness. Agent systems may produce highly confident outputs even when underlying information is incomplete or conflicting. Proper synthesis and evaluation must rely on evidence quality and coverage, not model confidence.
- Decomposition quality determines system quality. The quality of task decomposition at the coordinator level directly determines system completeness. Even perfectly functioning subagents will produce incomplete results if the decomposition is too narrow or biased.
- Subagents are independent, not collaborative. Subagents are independent execution units, not collaborative entities. They do not share state, coordinate in real time, or reconcile outputs. All integration responsibility lies with the coordinator.
- Synthesis is a separate reasoning problem and the primary determinant of correctness. Synthesis is not a trivial aggregation step; it is a distinct reasoning phase that must integrate incomplete, distributed, and often conflicting information. Even when subagents produce correct outputs, poor synthesis can result in incomplete, biased, or incorrect final answers. On the exam, if all components appear to function but the final output is wrong, the root cause is almost always a synthesis failure.
- Information must be structured before passing between agents. Raw outputs should never be passed directly between agents. Information must be structured, separating content from metadata and preserving provenance, to enable reliable downstream reasoning.
- Parallelism requires independence. Parallelization is only effective when subtasks are independent. Overlapping or interdependent subtasks lead to duplicated work, conflicting outputs, and degraded system efficiency.
- Agents fail systematically, not randomly. Agent failures are systematic rather than random, typically arising from predictable patterns such as over-delegation, poor tool selection, or unbounded search loops. These patterns can be diagnosed and corrected through prompt and orchestration design.
- Multi-agent = scaling reasoning. Multi-agent systems are fundamentally a mechanism for scaling reasoning capacity beyond the limits of a single context window by distributing cognitive workload across parallel agents.
- Coordinator is both bottleneck and single point of failure. The coordinator is both the central intelligence and the primary bottleneck of the system. It is also a single point of failure -- errors in planning, decomposition, or synthesis propagate across the entire system.
- Conflict must be surfaced, not hidden. Multi-agent systems must preserve conflicting information with attribution rather than collapsing it into a single answer. Silent conflict resolution leads to incorrect outputs and is a common failure mode tested on the exam.
CCA-F Insight: Most failures in agent systems are architectural, not prompt-related. The exam prioritizes system design decisions over prompt tuning.
The Blueprint for Success (Memorize These Three Principles)
- Maintain Simplicity -- Start with the Augmented LLM and the simplest pattern that solves the problem.
- Prioritize Transparency -- Log planning steps and ground truth.
- Engineer the ACI -- Obsess over tool documentation, poka-yoke arguments, and deterministic safeguards.
Monday Morning Actions (CCA-F Edition)
- Audit your current tools -- simplify descriptions and test with the Tool-Testing Agent mindset.
- Sketch an Orchestrator-Worker diagram for your next research task and apply the Agent Steering Framework.
- Run one query through the Research Loop simulation in Console and add External Memory and Filesystem Handoff.

For more context and patterns, read part 1 of this series on Foundations of CCA-F. Read the original paper How we built our multi-agent research system from the Anthropic Engineering Blog.
Further Essential Reading for CCA-F (Prioritized by Domain Weight)
These resources are all from Anthropic research, blogs or documentation. These are where a lot of these key concepts are discussed which are on the CCA-F exam. Some you will not find in the courseware or any course lesson. It is in the engineering blog and papers that Anthropic publishes that lays the foundation.
Domain 1 -- Agentic Architecture (27%)
- Building Effective Agents
- How We Built Our Multi-Agent Research System
- Effective Harnesses for Long-Running Agents
Domain 2 -- Tool Design & MCP (18%)
- Writing Effective Tools for AI Agents
- Introducing the Model Context Protocol
- Code Execution with MCP
Domain 3 -- Claude Code (20%)
Domain 4 -- Prompt Engineering (20%)
Domain 5 -- Context Management (15%)
About the Author

Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.

Rick created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code