Foundations of CCA-F Exam Part 3: Battle-Tested Context Engineering for AI Agents — Claude Certified Architect Foundational Prep
Originally published on Medium.

Foundations of CCA-F Exam: Maximizing the Attention Budget & Designing High-Signal Context Systems
Unlock the secret to mastering AI agents: five proven context‑engineering tactics that keep long‑horizon models sharp, focused, and exam‑ready.
Summary: This article outlines the shift from prompt engineering to context engineering, the core problem of context rot and the n² constraint, the guiding principle of curating the smallest possible set of high-signal tokens, and the three key tactics (compaction, structured note-taking/agentic memory, and sub-agent architectures) that keep agents coherent over long tasks. It emphasizes just-in-time (JIT) retrieval, progressive disclosure, metadata as a first-class signal, and the Goldilocks Zone for system prompts, while tying everything to Domain 5: Context Management & Reliability (15% of the exam).
Five proven context engineering tactics and architectural lessons for building reliable long‑horizon AI agents
This article is a faithful compression of Anthropic’s source material on effective context engineering, filtered through the lens of what matters for the Claude Certified Architect Foundation Exam CCA-F.
Five proven context engineering tactics and hard-won architectural lessons for building reliable long-horizon AI agents. Learn the exact principles from Anthropic’s research that are essential for passing the Claude Certified Architect Foundation Exam.
Key Clarification: In this context, “context” does not just mean prompt text. It includes the entire system state available to the model: system prompts, tools, file systems, metadata, memory, and interaction patterns. This broader definition is critical for both understanding the source material and answering CCA-F exam questions.
You will see this exact terminology and these exact failure modes used heavily on the test. You must be familiar with the attention budget, context rot, JIT retrieval, no-implicit context, and long-horizon tactics. This familiarity will help you answer the CCA-F exam effectively.
Some concepts are not covered in the course lessons but are listed in the study guide. This article covers those core concepts and points you to the source material from Anthropic Research to study further.
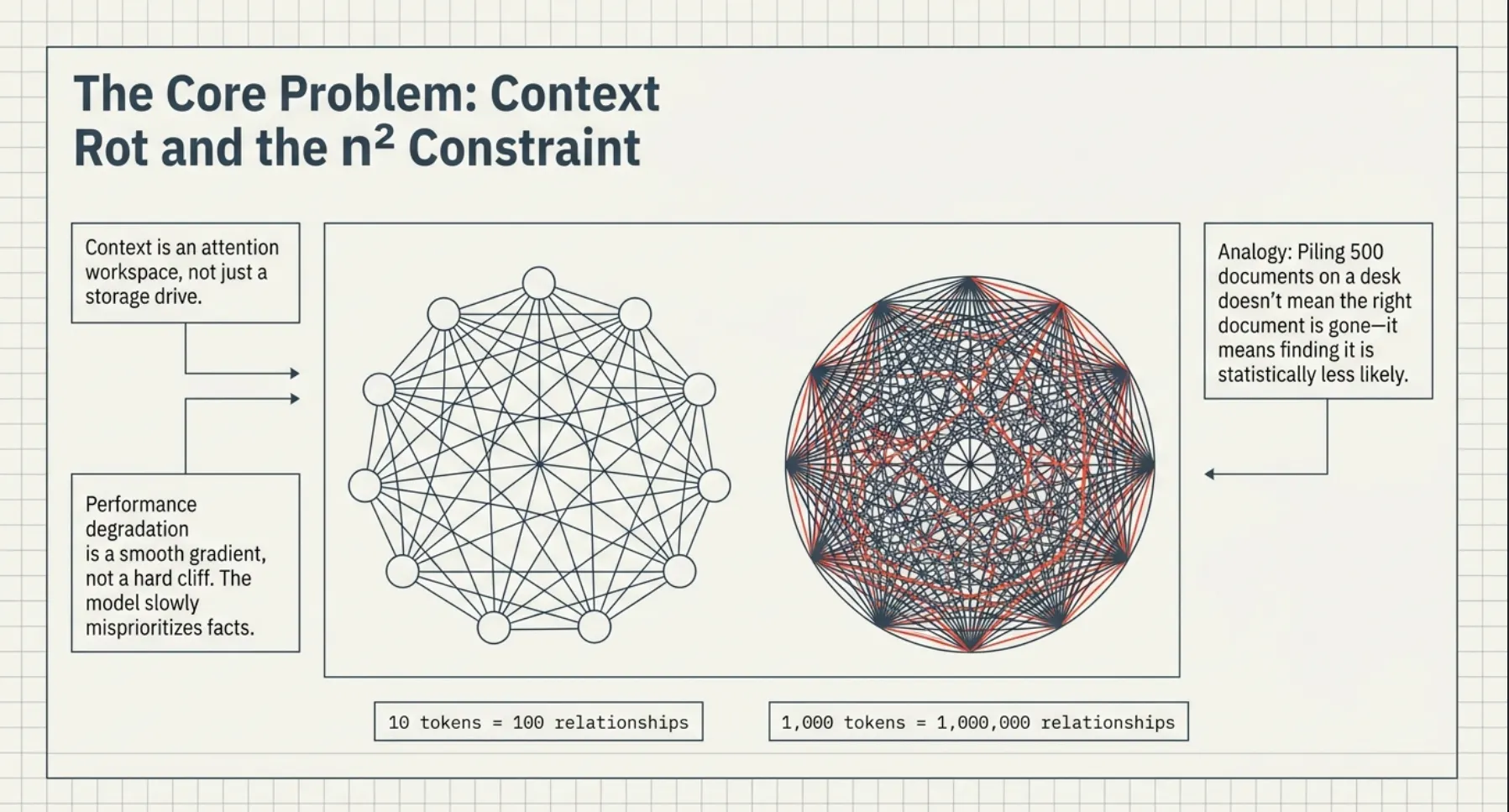
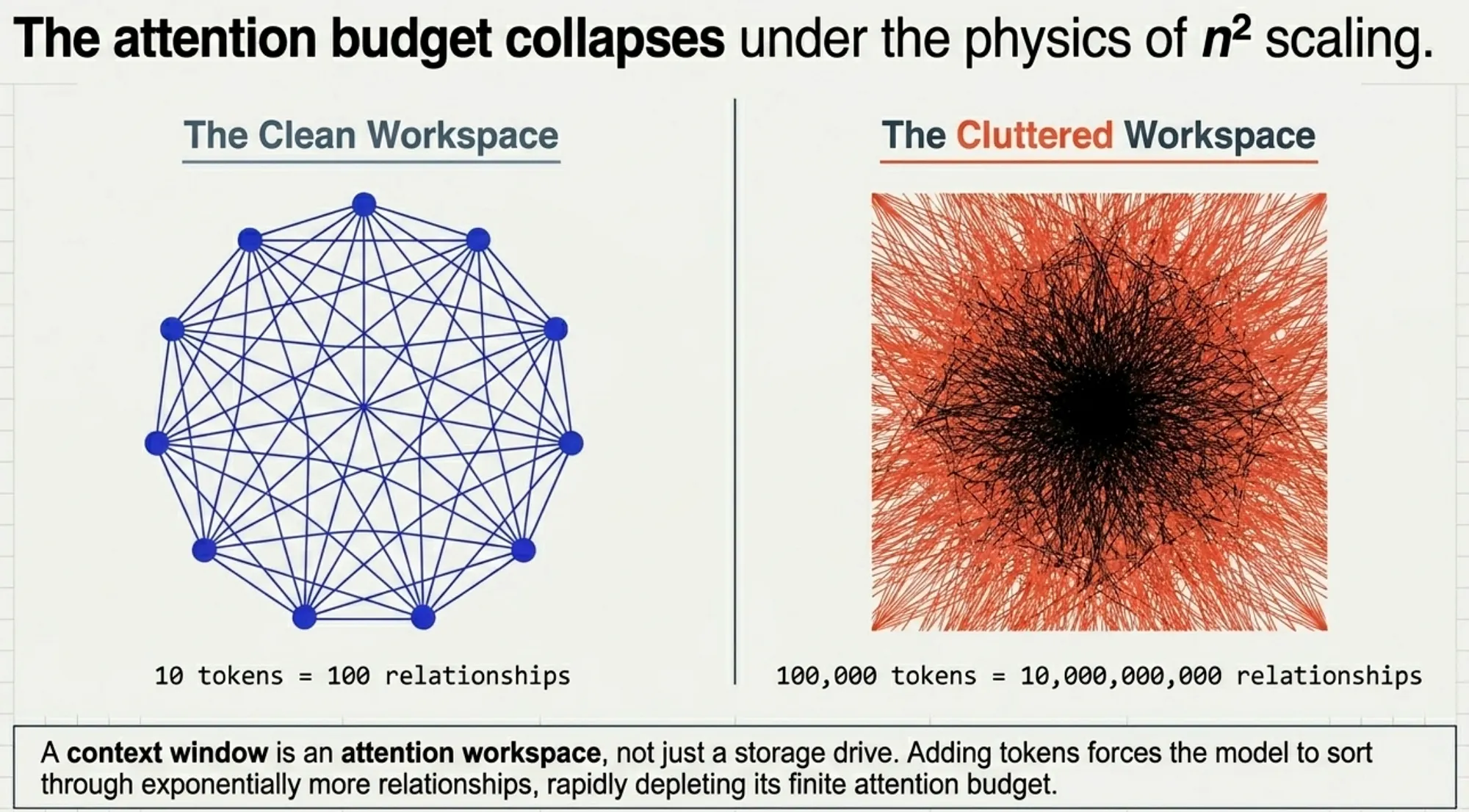
The Core Problem: Context Rot and the n² Constraint
LLMs have a finite attention budget. Models develop attention patterns based on training distributions where shorter sequences are more common. Each new token introduced depletes this budget, leading to context rot.
You can think of an AI’s context window like your own working memory or the physical space on your desk. Pile too much on it, and the model starts losing focus; exactly like a super cluttered desk where you can’t find that one specific sticky note. This leads to a very real, very frustrating phenomenon called context rot: as you pile more tokens onto the desk, the model’s ability to actually find and recall that information decreases.
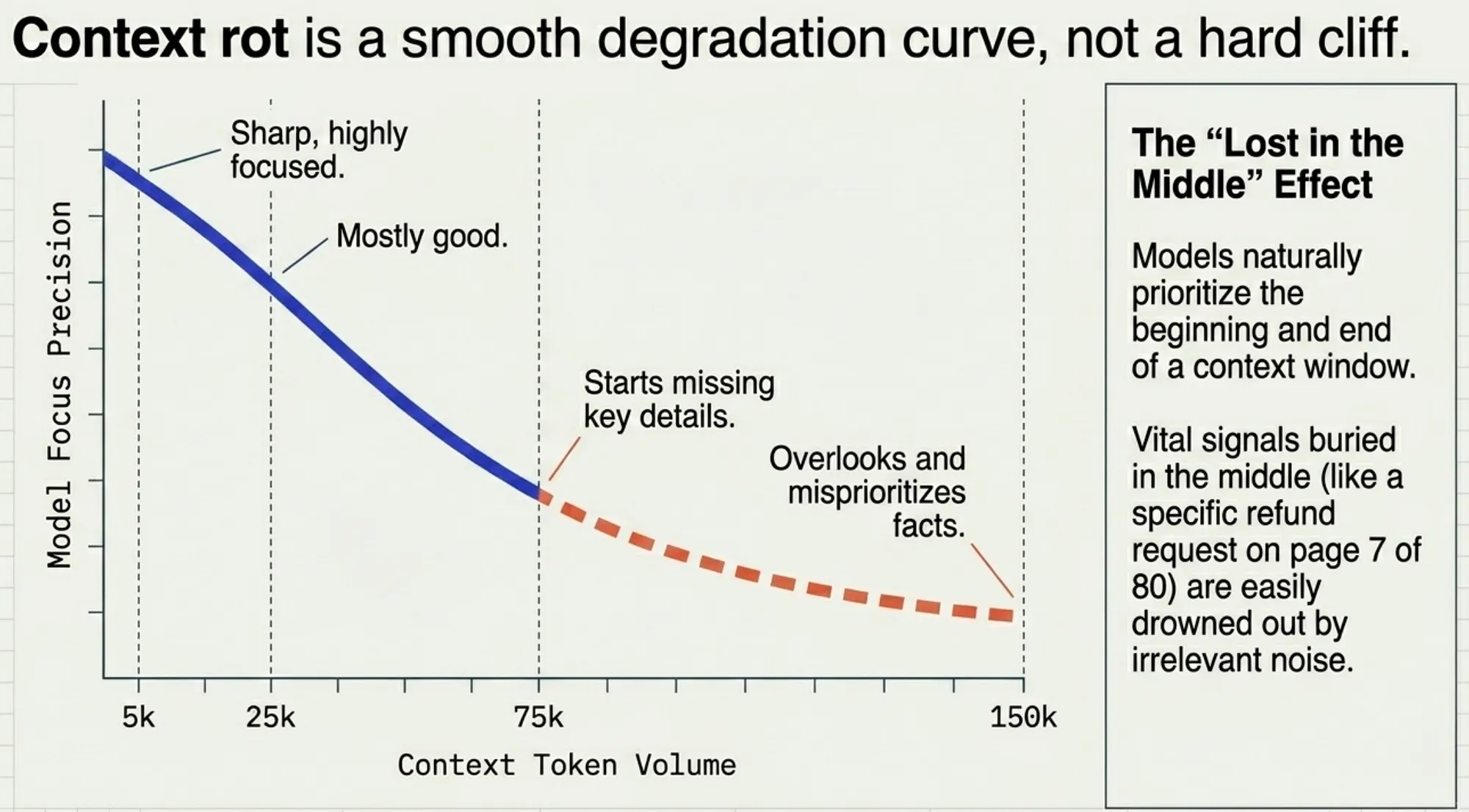
The transformer architecture imposes an n² constraint: each token must attend to every other token, resulting in n² pairwise relationships. As the context window fills, the model’s recall and focus precision degrade in a smooth performance gradient rather than a hard cliff. This is why more context is not always better.
Let’s break this down, as understanding this concept will help you focus your efforts.
Think of a transformer like a meeting where every word/token can “look at” every other word/token before deciding what it means.
1.) What “each token attends to every other token” means:
Suppose the prompt is:
“Refund the customer only after identity verification.”
The model breaks this into tokens, roughly:
Refund / the / customer / only / after / identity / verification
When generating an answer, the model does not read tokens strictly left-to-right like a human sentence parser. Instead, through attention, each token can compare itself with other tokens:
- “Refund” connects to “customer”
- “Refund” connects to “after”
- “after” connects to “verification”
- “identity” connects to “verification”
- etc.
These relationships help the model infer meaning.
2.) Why this becomes n²
If you have 10 tokens, each token can attend to about 10 tokens.
That creates roughly:
10 × 10 = 100 relationships
If you have 1,000 tokens:
1,000 × 1,000 = 1,000,000 relationships
If you have 100,000 tokens:
100,000 × 100,000 = 10,000,000,000 relationships
That is the n² constraint.
The number of relationships grows much faster than the number of tokens.
3.) Why can more context make the model worse
A context window is not just storage. It is also an attention workspace.
Adding more tokens gives the model more information, but also more things to sort through.
So the model now has to decide:
- Which facts matter?
- Which tool result is still relevant?
- Which instruction is highest priority?
- Which earlier statement conflicts with a later one?
- Which detail was just noise?
The more you add, the harder it becomes for the model to focus on the few tokens that actually matter.
4. ) “Recall and focus precision degrade.”
This means the model may still technically have the information, but it becomes less reliable at using it.
Example:
You give it 80 pages of support history. On page 7, the customer said:
“I do not want store credit. I only want the refund to my original payment method.”
Later, on page 62, there are lots of tool results, policy notes, and irrelevant shipping history.
The model may still “have” the original refund preference in context, but it may fail to prioritize it. It might say:
“We can issue store credit.”
That is not because the context window was exceeded. It is because the key fact got buried.
5.) Why is degradation smooth, not a hard cliff
A hard cliff would mean:
Up to 99,999 tokens: perfect
At 100,000 tokens: broken
That is not usually how it works.
Instead, performance gradually gets worse as context becomes noisier:
- At 5,000 tokens: sharp, focused
- At 25,000 tokens: mostly good
- At 75,000 tokens: starts missing details
- At 150,000 tokens: more likely to overlook or misprioritize facts
The model does not suddenly fail. It becomes less precise.
6.) Simple analogy
Imagine your desk. A clean desk with five documents: easy to find the right one.
A desk with 500 documents: the important document may still be there, but finding it becomes harder.
A bigger desk helps a little, but if you keep piling papers onto it, the real problem remains:
You need organization, not just more space.
That is the point of context engineering.
7.) Exam-ready version
For CCA-F, the takeaway is:
More context is not automatically better. Better systems curate the smallest high-signal context needed for the task.
That leads to techniques like:
- JIT retrieval (just context you need when you need it)
- compaction
- structured notes
- metadata-based navigation
- subagents
- clearing irrelevant tool results
The goal is not to maximize context.
The goal is to maximize signal-to-noise inside the attention budget.
Additional Failure Mode — “Lost in the Middle”:
Models tend to prioritize information at the beginning and end of the context window, while information in the middle is more likely to be ignored. This is known as the lost in the middle effect and is a key reason why simply adding more context can degrade performance rather than improve it.
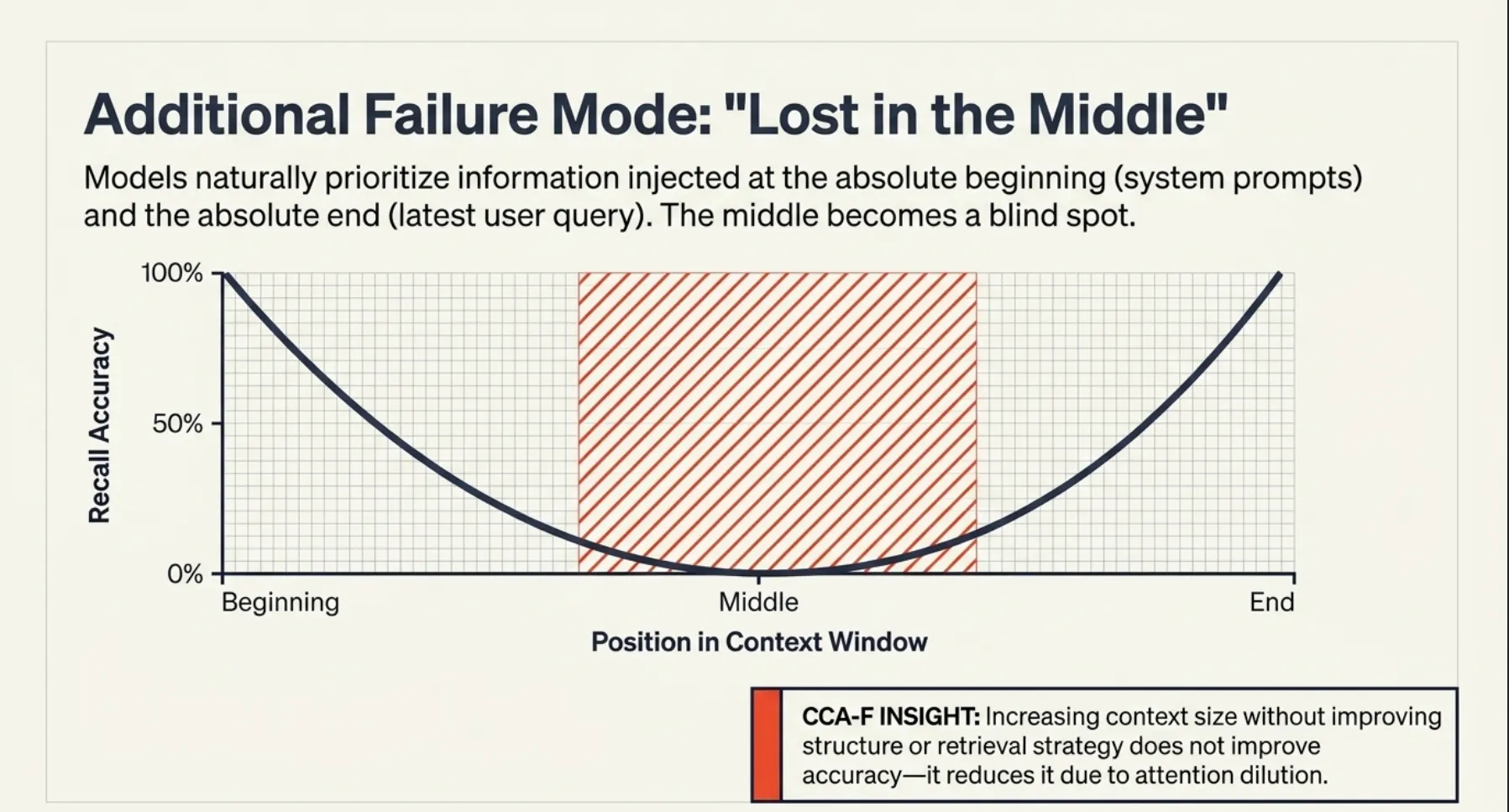
CCA-F Insight: Increasing context size without improving structure or retrieval strategy often reduces accuracy due to attention dilution; it does not improve it.
The Evolution from Prompt Engineering to Context Engineering
This section represents one of the most important conceptual shifts you need to understand for the CCA-F exam: why prompt engineering alone is no longer sufficient for building reliable AI systems. The exam guide makes it clear that real-world success depends on architectural decisions, how you design workflows, tools, memory, and context flow, not just how well you write instructions.
The Anthropic engineering blog post formalizes this shift by expanding the definition of “context” to include the entire system state: prompts, tools, retrieval strategies, memory, and interaction patterns. For exam scenarios, this distinction is critical. Many incorrect answers will focus on tweaking prompts, while correct answers typically involve changing the system design so the model cannot fail easily.
As you read this section, focus on the mindset shift: you are no longer just “writing better prompts”; you are engineering the environment in which the model operates.

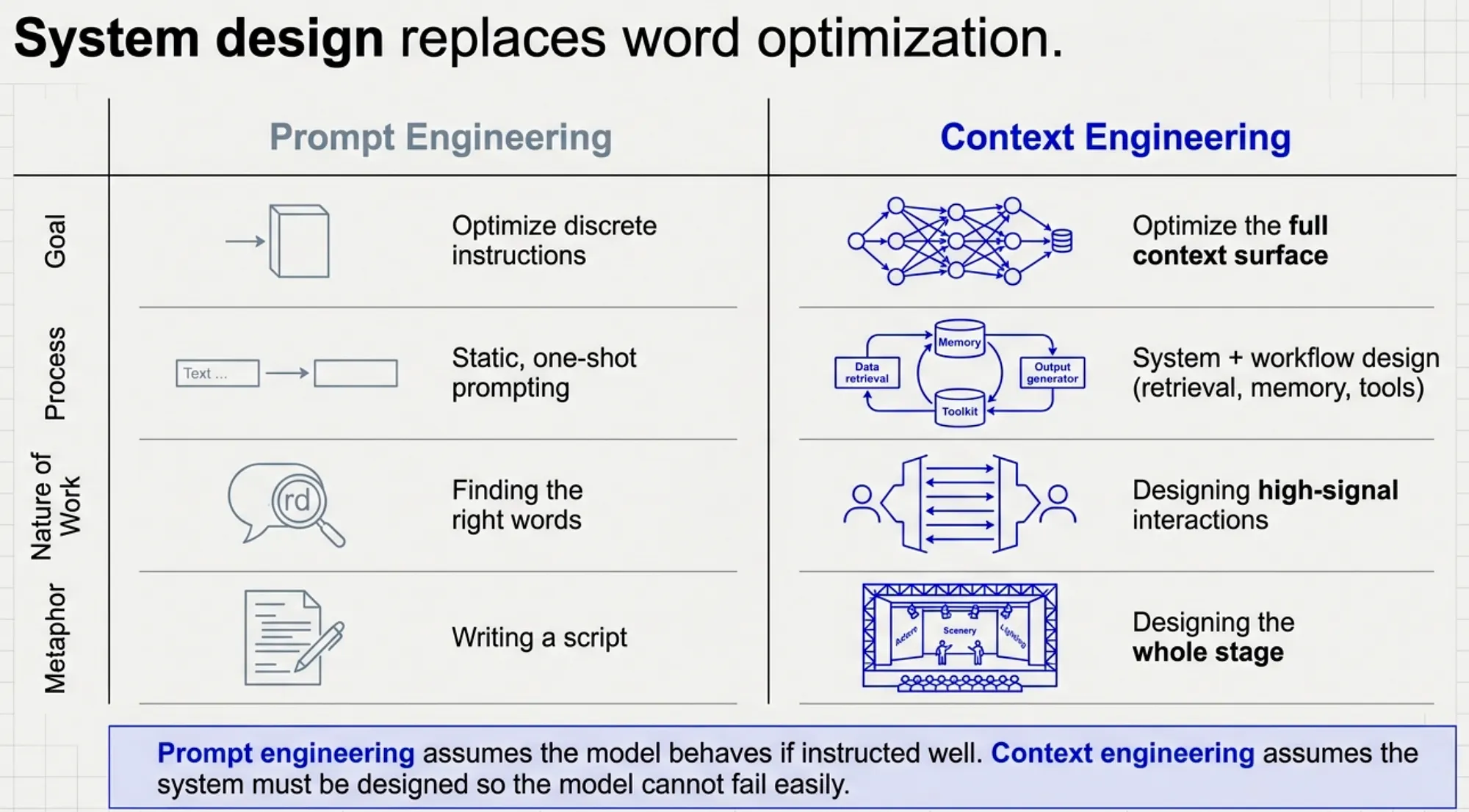
Prompt engineering vs context engineering
Goal
- Prompt engineering: Optimize discrete instructions
- Context engineering: Optimize the full context surface (what/when/how info is available)
Process
- Prompt engineering: Static, one-shot prompting
- Context engineering: System + workflow design (retrieval, memory, tools, structure)
Nature of work
- Prompt engineering: Finding the right words
- Context engineering: Designing high-signal information and interactions
Metaphor
- Prompt engineering: Writing a script
- Context engineering: Designing the whole stage
Key Shift: Prompt engineering assumes the model will behave correctly if given the right instructions. Context engineering assumes the system must be designed so the model cannot fail easily. This includes controlling what information is available, when it is available, and how it is structured.
The Guiding Principle of Context Architecture
This section introduces the core law of context engineering, which aligns directly with Domain 5: Context Management & Reliability. The study guide repeatedly emphasizes that systems must manage context deliberately, through trimming, structuring, and prioritization, to maintain accuracy over time.
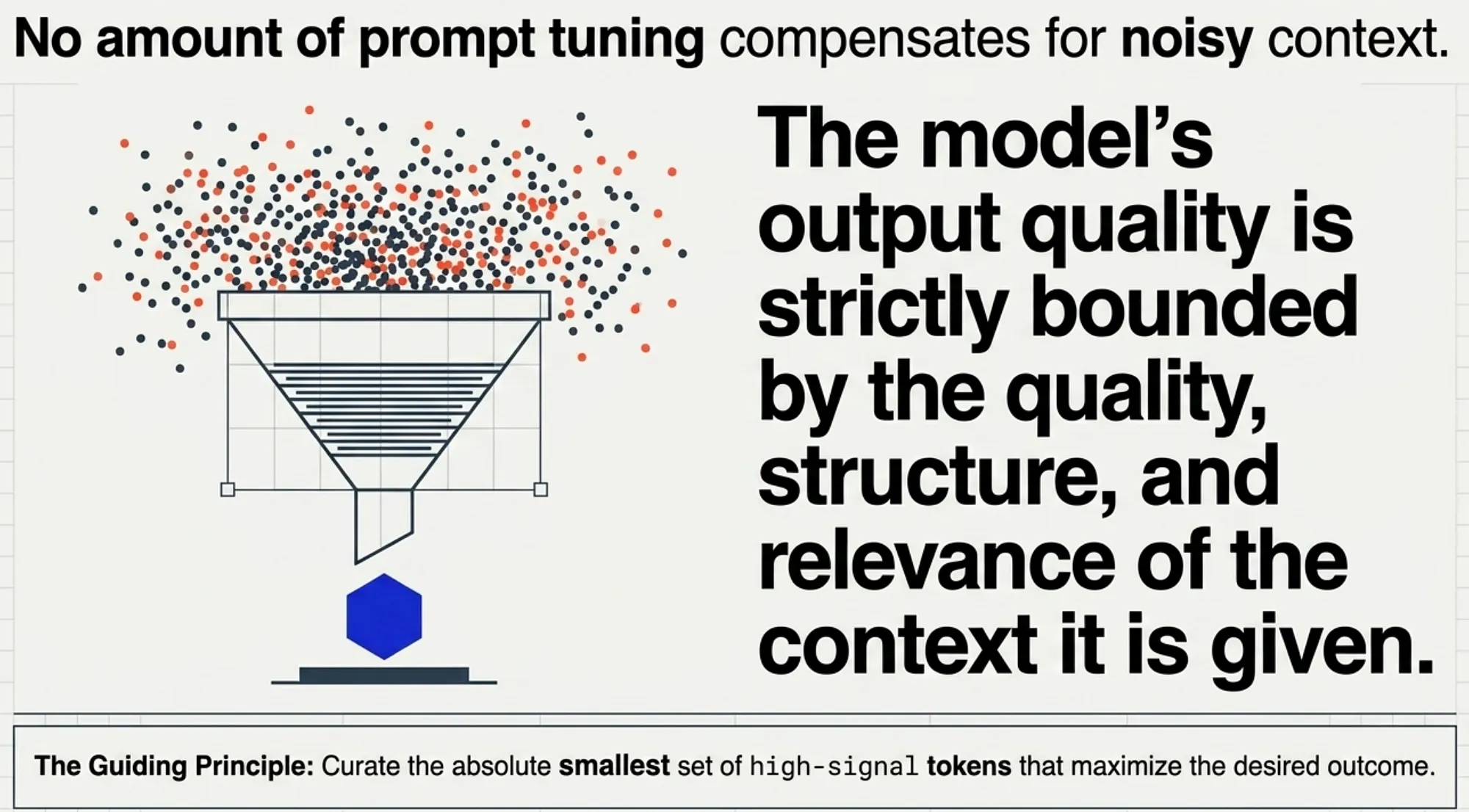
For the exam, this principle shows up in many forms: deciding what to include in prompts, how to structure tool outputs, and how to preserve critical facts across turns. The key takeaway is that output quality is bounded by context quality; not model capability alone.
Find the smallest possible set of high-signal tokens that maximize the likelihood of the desired outcome.
Core Law:
The model’s output quality is bounded by the quality, structure, and relevance of the context it is given. No amount of prompt tuning can compensate for missing, noisy, or poorly structured context.
Calibrating System Prompts to the Optimal Altitude
System prompt design is covered under both Prompt Engineering (Domain 4) and Context Management (Domain 5) in the exam guide. This section focuses on a subtle but critical skill: finding the right level of abstraction in instructions.
The Anthropic Engineering Blog introduces the “Goldilocks Zone,” which reflects a common exam theme: prompts that are too rigid reduce flexibility, while prompts that are too vague lead to inconsistent behavior. Candidates should understand that system prompts are probabilistic controls, not guarantees, and must often be paired with architectural enforcement.

System prompts must live in the Goldilocks Zone on the altitude curve:
- Too low (brittle if-else hardcoding) → creates fragility and maintenance complexity.
- Too high (vague assumptions) → fails to provide concrete signals and assumes shared context that does not exist.
The Goldilocks Zone is specific enough to guide behavior through strong heuristics while remaining flexible enough for the model to apply its intelligence. Organize prompts into precise XML-tagged sections (<background_information>, <instructions>) or Markdown headers to deliver the minimal set of information that fully outlines expected behavior.
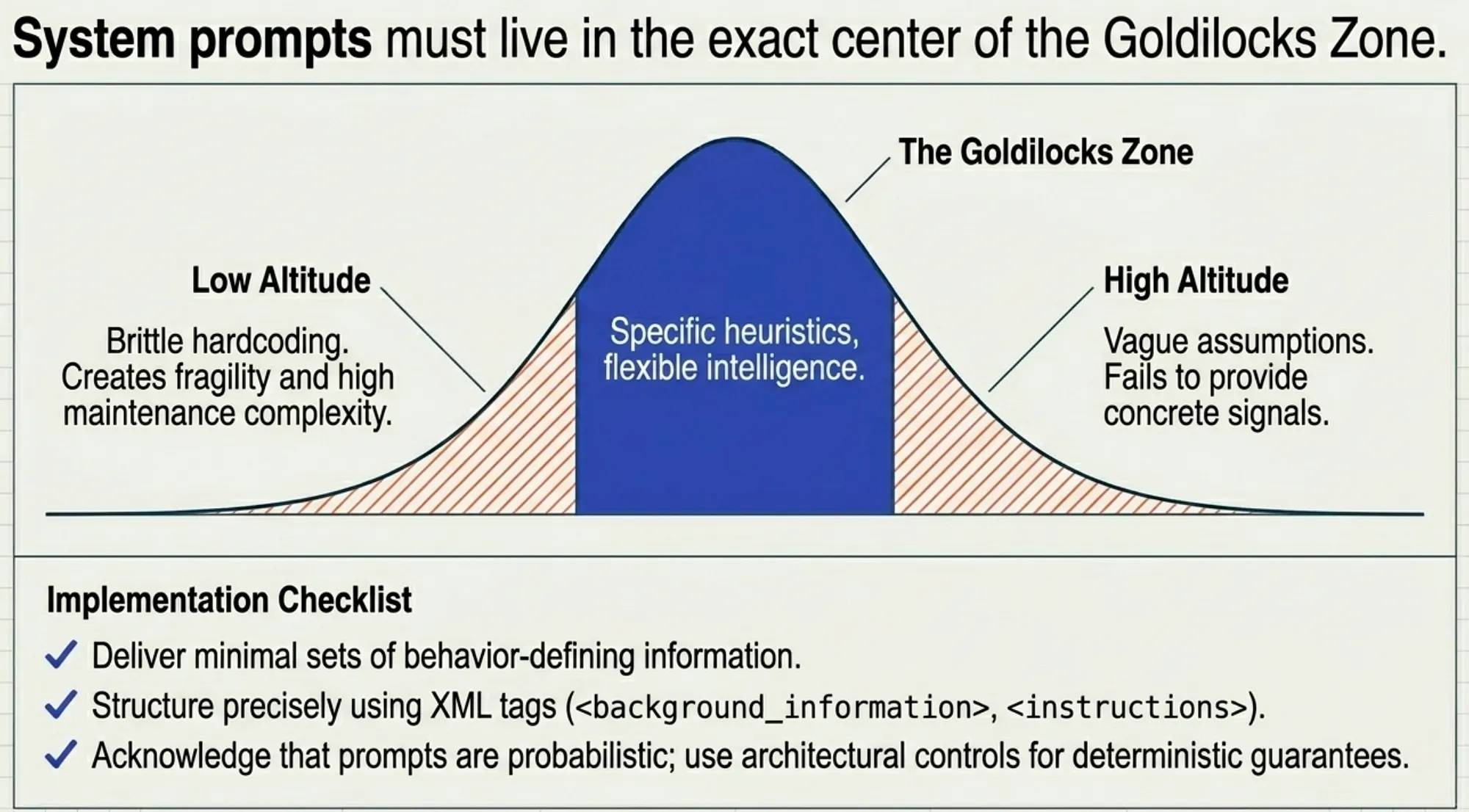
Important Limitation: Even perfectly calibrated system prompts are probabilistic controls. They guide behavior but do not guarantee it. For scenarios requiring deterministic guarantees (e.g., financial operations, compliance), architectural controls such as tool constraints or programmatic enforcement must be used instead.
Designing Interaction Spaces for Token Efficiency
This section connects directly to tool design, few-shot prompting, and context efficiency, which are heavily tested across Domains 2 and 4. The CCA-F study guide highlights that poor tool design and excessive instructions can degrade performance by increasing cognitive load on the model.
The Anthropic Engineering blog reframes tools and examples as part of the model’s “interaction surface.” For the exam, you should understand that tools and examples are not just helpers; they shape the model’s reasoning pathways and directly impact reliability. Also, specifying what a tool does not do and tool boundaries of role is important.
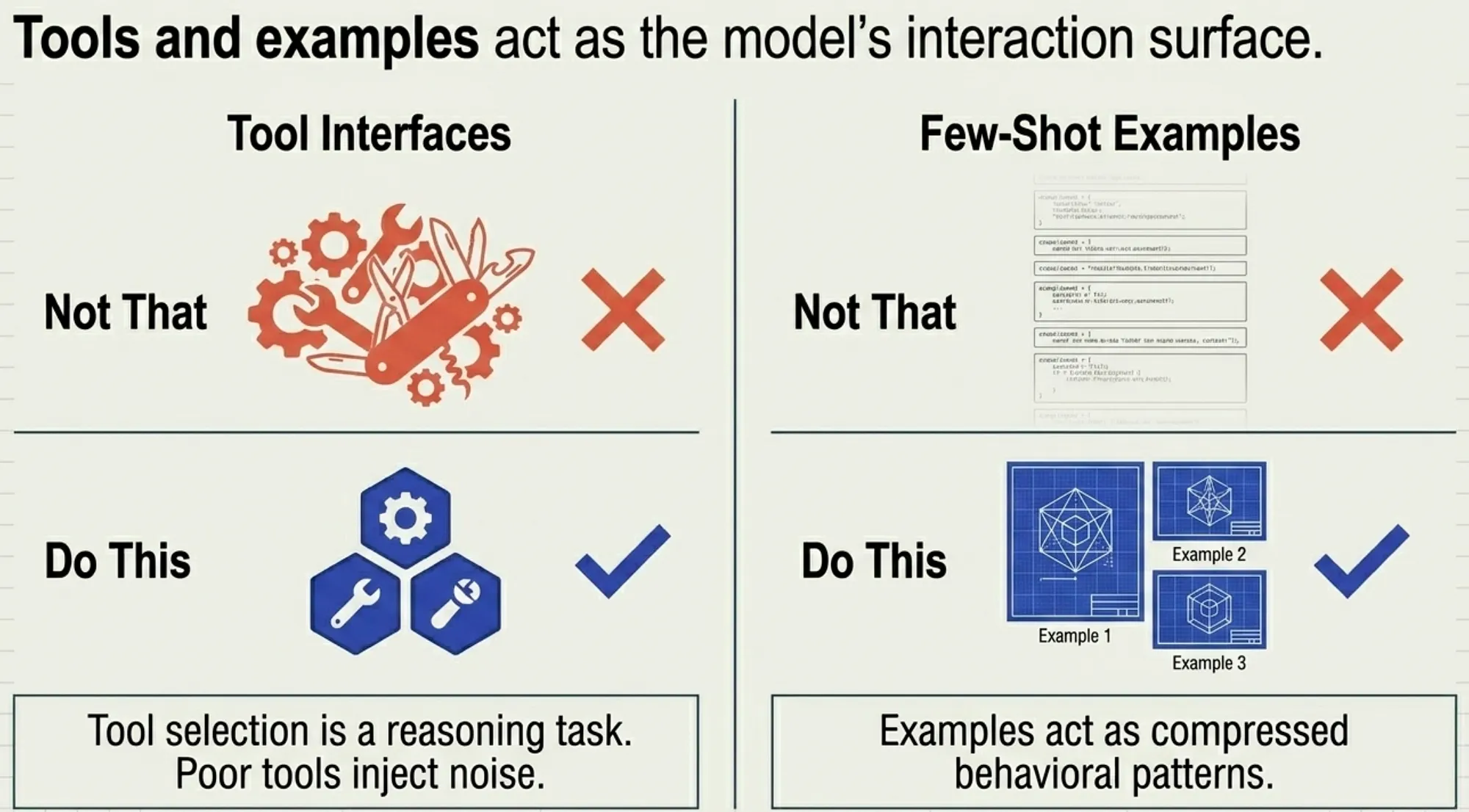
Tools:
- Not That: Bloated, overlapping functionality.
- Do This: Unambiguous, single-purpose modular tools.
Critical Insight: Tool selection is itself a reasoning task. Tools are part of the model’s context surface. Poorly designed tools effectively inject noise into the context, while well-designed tools act as structured, high-signal inputs.
Examples (Few-Shot):
- Not That: Endless lists of hyper-specific edge cases.
- Do This: 3 canonical, diverse pictures of expected success. Examples act as compressed behavioral patterns. A small number of high-quality examples often outperform long lists of rules because they demonstrate how the model should generalize.
Clear, minimal tools and a handful of high-quality examples dramatically improve token efficiency and agent reliability.
Context Retrieval Architectures for Agentic Workflows
This section maps directly to context window optimization and retrieval strategies, which are core skills in Domain 5. The exam expects you to evaluate tradeoffs between different retrieval approaches, especially in long-horizon tasks.
The blog introduces pre-inference vs JIT retrieval vs hybrid strategies. For test scenarios, you should recognize that efficient systems retrieve only what is needed, when it is needed, rather than loading large amounts of context upfront.
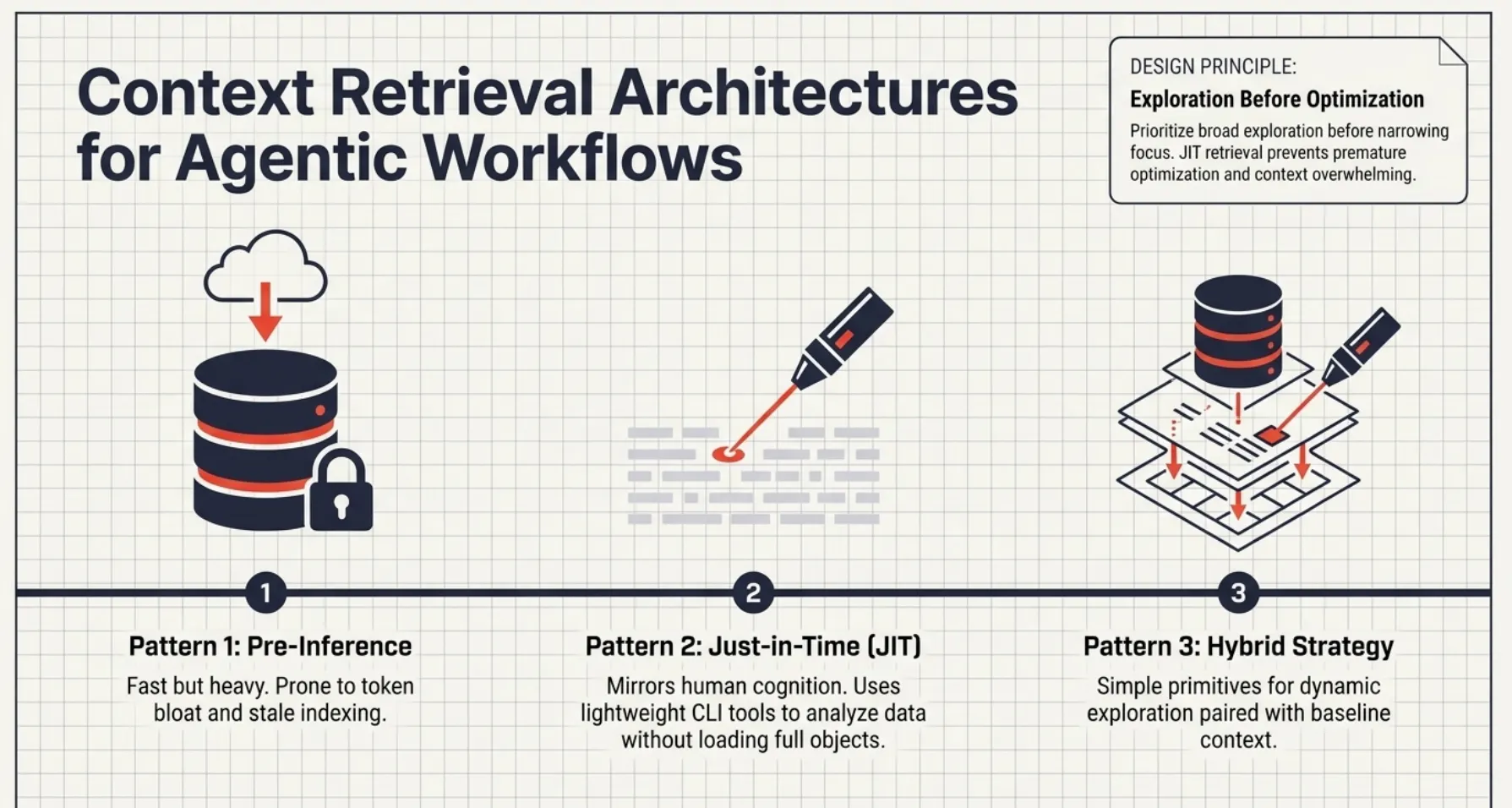
- Pre-Inference: Fast but heavy. Prone to token bloat and stale indexing.
- Just-in-Time (JIT): Mirrors human cognition. Uses lightweight tools (e.g., head, tail, grep) to analyze large volumes without loading full objects.
- Hybrid Strategy: Best of both worlds. Simple primitives for dynamic exploration paired with baseline context (e.g., CLAUDE.md).
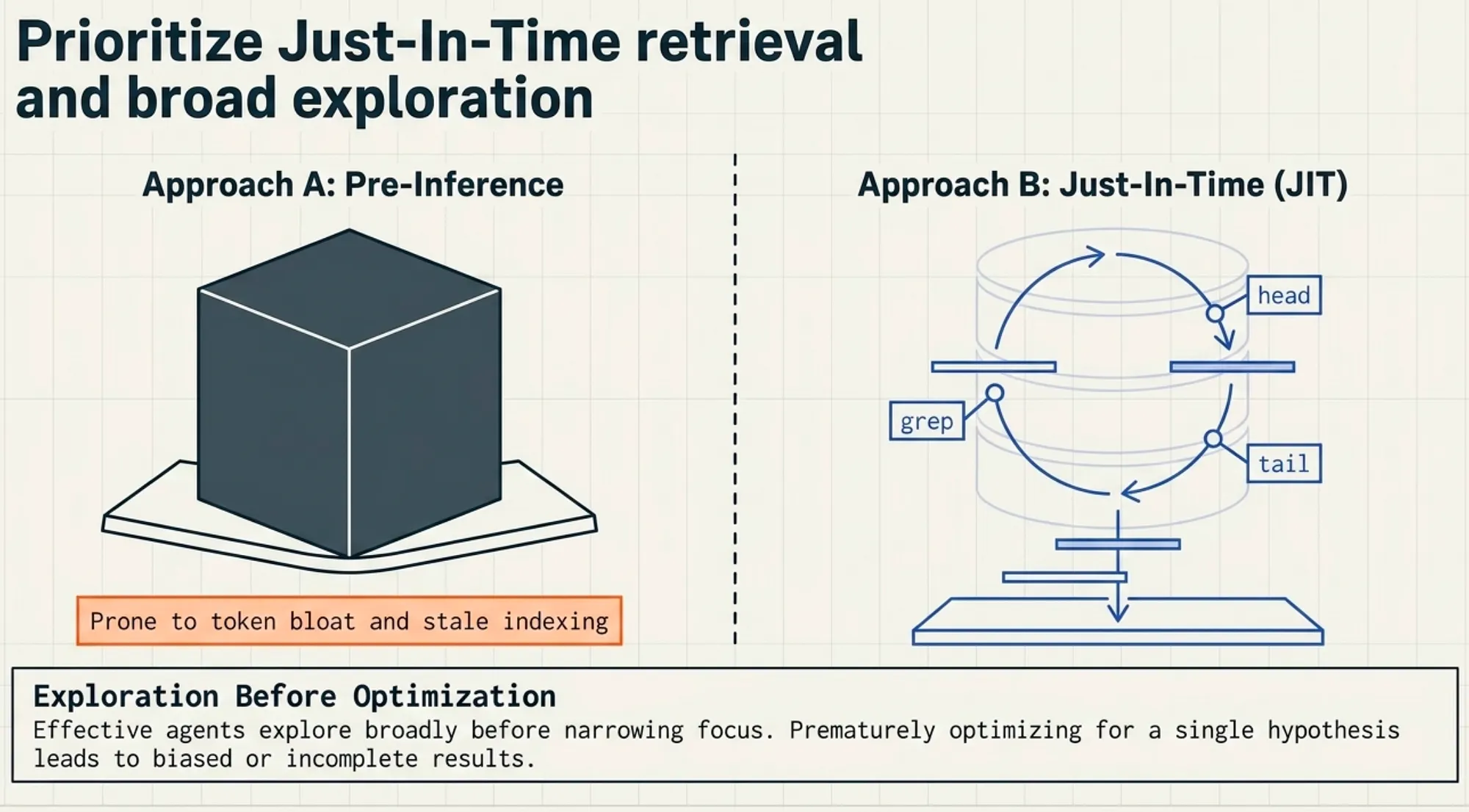
Principle — Avoid Unnecessary Context:
The goal is not just to retrieve relevant information, but to avoid loading irrelevant information entirely. High-performing systems minimize context inclusion as aggressively as they optimize retrieval.
High-performing systems minimize context inclusion as aggressively as they optimize retrieval.
Exploration Before Optimization: Effective systems prioritize broad exploration before narrowing focus. Prematurely optimizing for a single path or hypothesis often leads to incomplete or biased results. JIT retrieval enables this exploratory phase without overwhelming the context window.
The Metadata Signal and Progressive Disclosure
Metadata-driven reasoning is an advanced but important concept in the CCA-F exam. The study guide emphasizes techniques that allow models to reason over large datasets without loading full content, reducing token usage while preserving accuracy.
This section highlights how metadata acts as compressed context, enabling agents to make decisions about what to load and what to ignore. For exam purposes, this connects to efficient retrieval, tool usage, and large-scale system design.

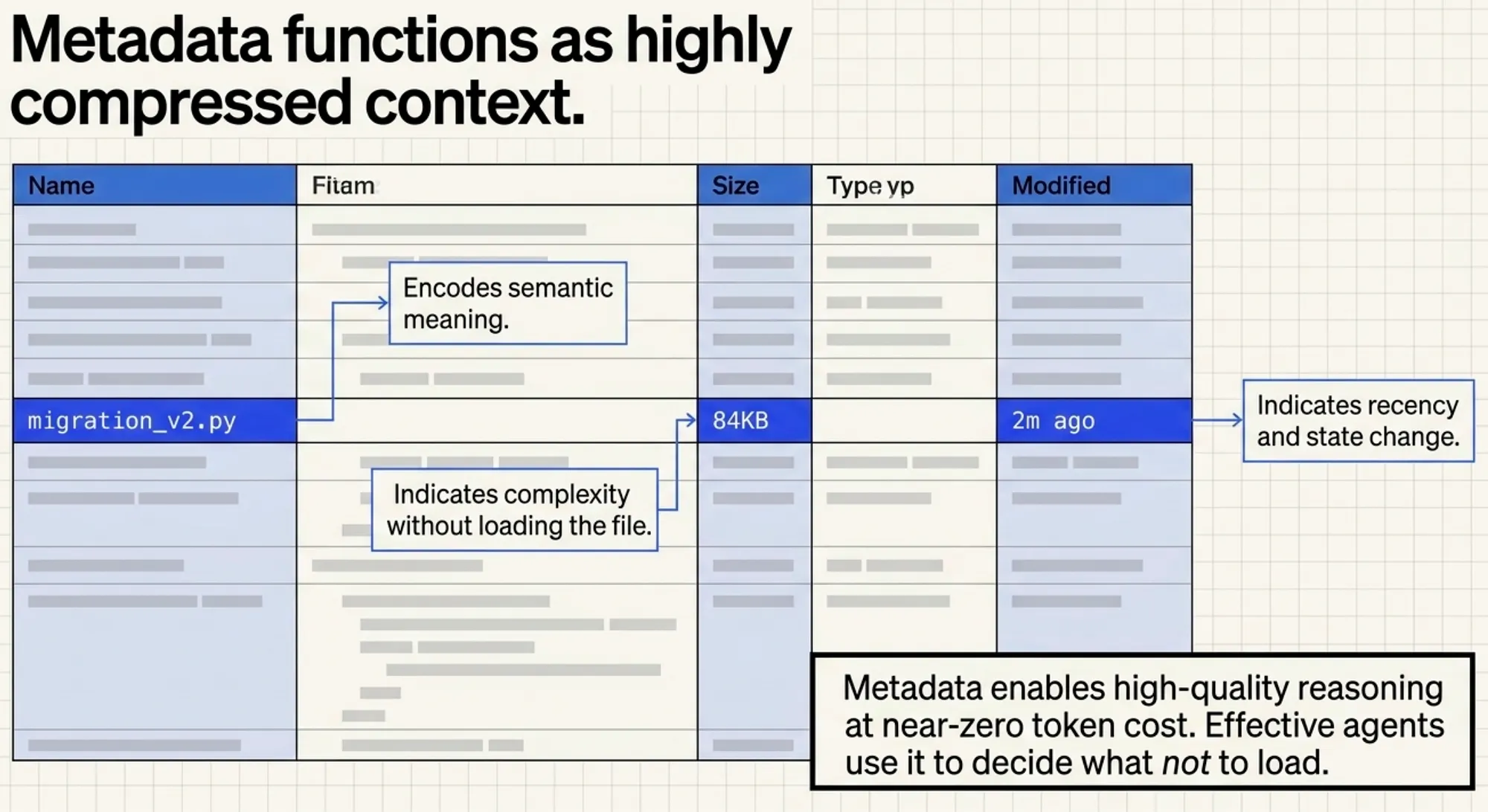
Metadata as Compressed Context
The environment itself is context. File sizes indicate complexity, timestamps indicate recency, and naming conventions encode semantic meaning. These signals allow agents to reason about large datasets without loading full content into the context window.
CCA-F Insight: Metadata enables high-quality reasoning at low token cost. Effective agents use metadata to decide what not to load, not just what to retrieve.
The Long-Horizon Challenge: When Tasks Span Hours
Long-running tasks are a central theme in the CCA-F exam, especially in scenarios involving multi-agent systems and iterative workflows. This section explains why simply increasing context size does not solve long-horizon problems.
The engineering blog emphasizes that attention dilution and context pollution accumulate over time. For the exam, you should recognize that sustained performance requires architectural strategies such as compaction, memory, and decomposition; not just larger context windows.
Complex tasks (e.g., codebase migrations) quickly hit context limits and suffer context pollution.
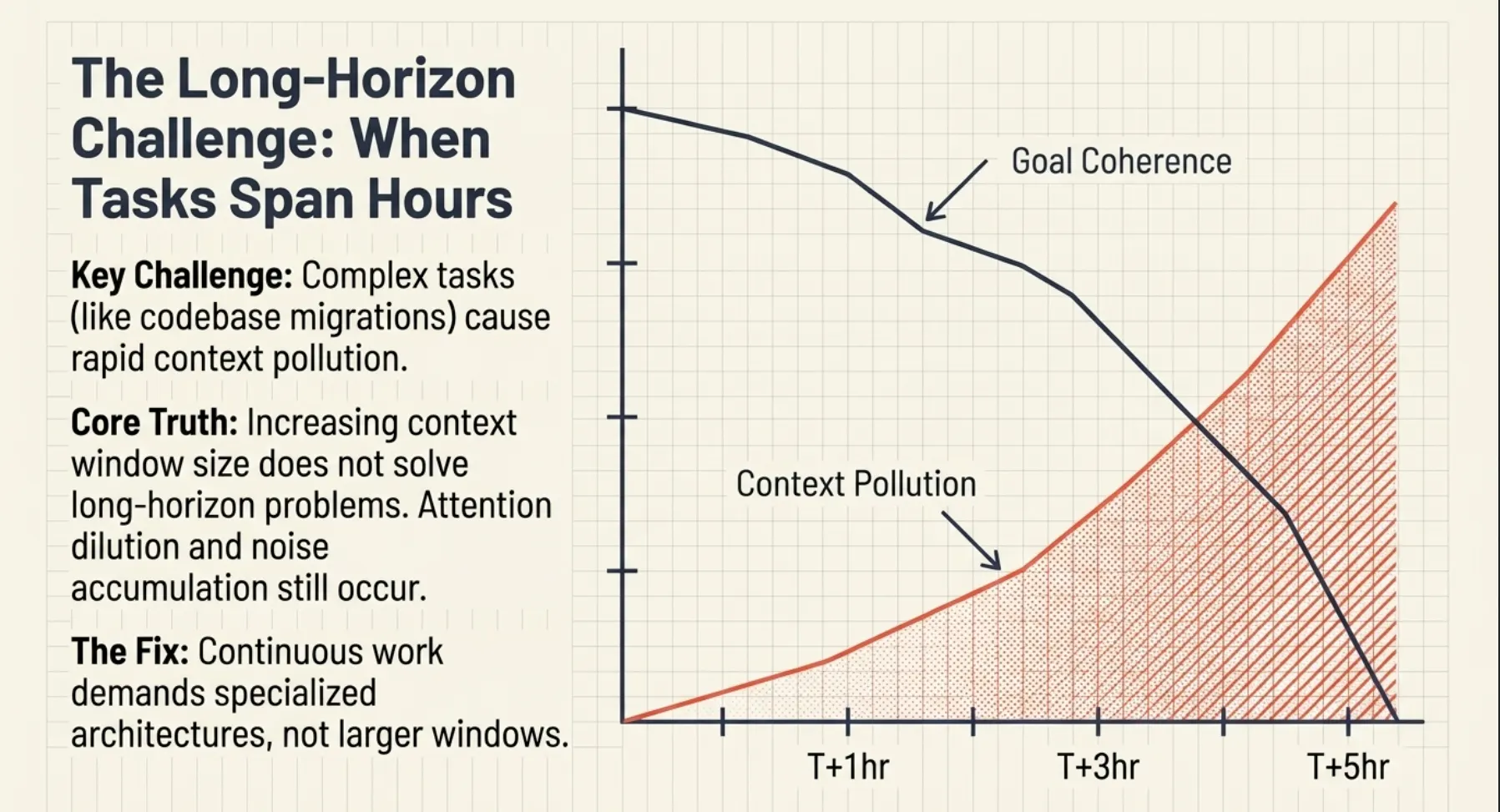
Important: Increasing context window size does not solve long-horizon problems. As context grows, attention dilution, noise accumulation, and reasoning degradation still occur. Architectural strategies, not larger windows, are required for sustained performance.
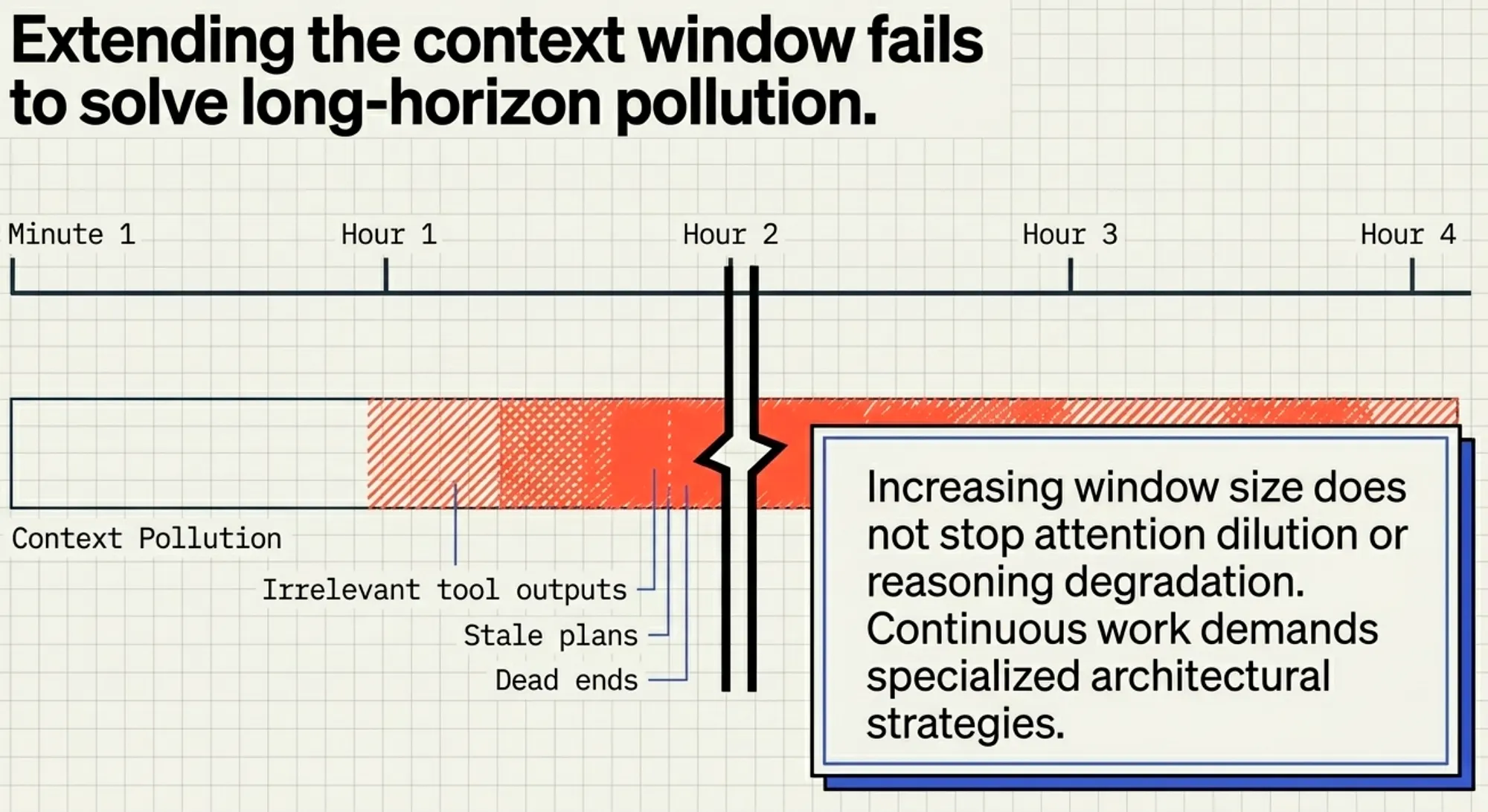
Continuous work demands specialized architectures to maintain coherence and goal-directed behavior over time.
Tactic 1: Compaction and Tool Result Clearing
Compaction directly maps to context trimming and structured summarization, which are explicitly tested skills in Domain 5. The exam often presents scenarios where excessive tool output degrades performance.
What you remove from context is just as important as what you include. Less can actually be more.
This section shows how high-performing systems distill context while preserving critical information, especially decisions and unresolved issues. The key exam takeaway is that what you remove from context is just as important as what you include.
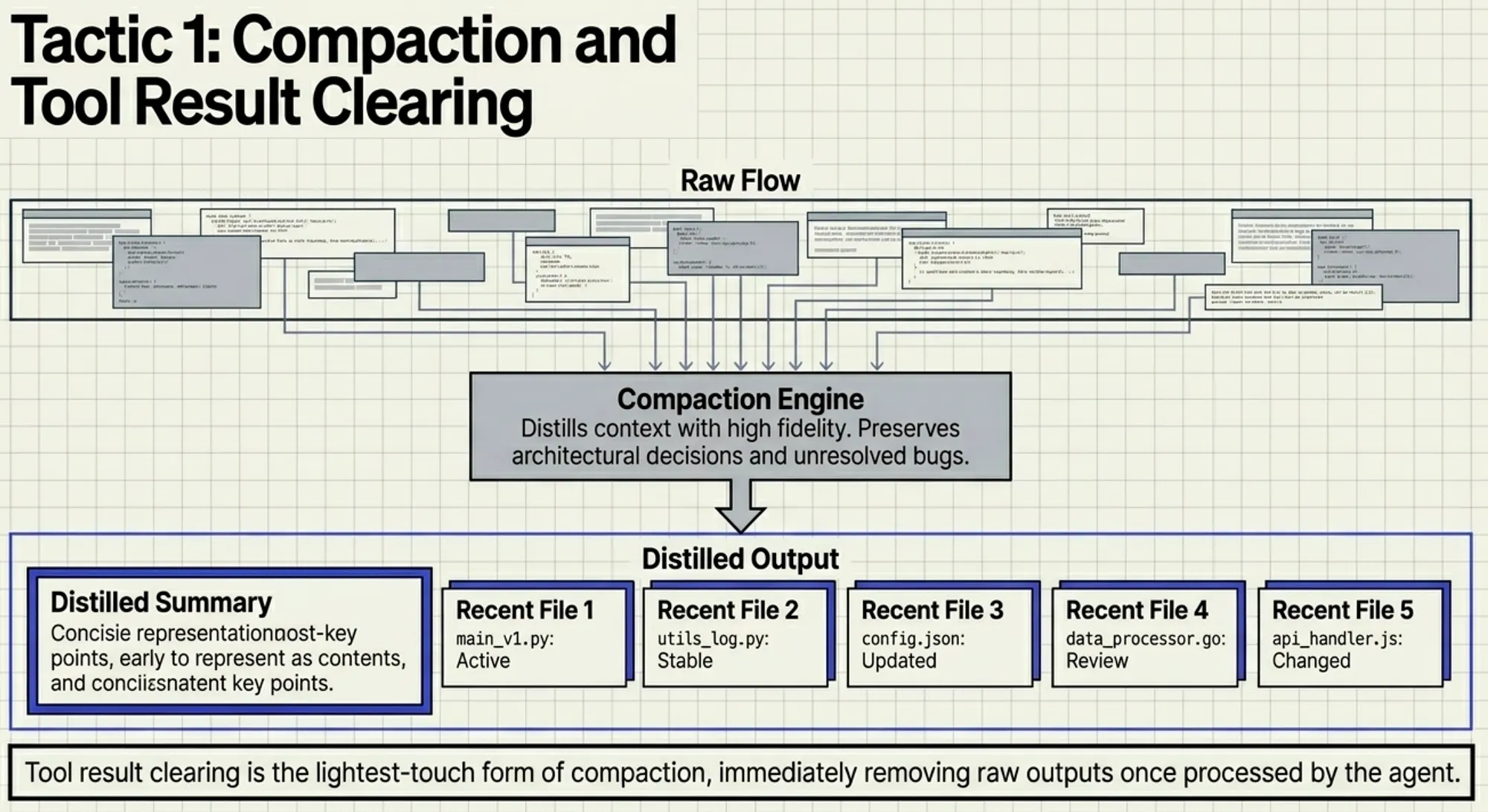
Compaction distills context with high fidelity. It discards redundant outputs while intentionally preserving architectural decisions and unresolved bugs.
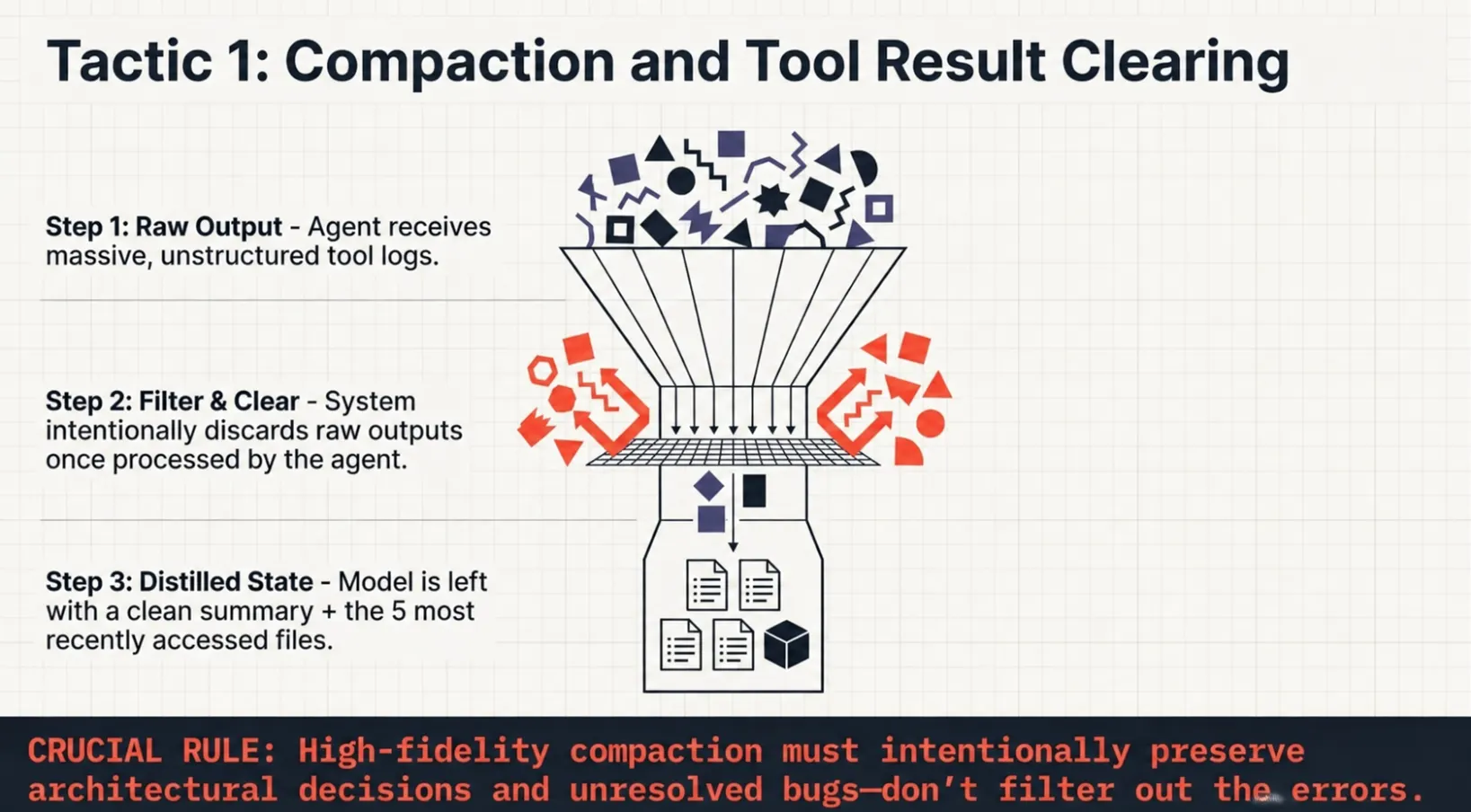
Tool Result Clearing (the lightest-touch form) removes raw tool outputs once the agent has processed them. The model then works with a clean summary + the 5 most recently accessed files.
Tactic 2: Structured Note-Taking and Agentic Memory
This section aligns with exam topics around state persistence, scratchpads, and long-session reliability. The study guide emphasizes techniques for preserving important information outside the active context window.
The engineering paper introduces external memory as a way to maintain continuity across long tasks. For the exam, you should understand that agents must explicitly store and retrieve state; nothing is implicitly remembered.
Agents write synthesized insights to an external vault (e.g., NOTES.md) that persists outside the context window. On the next loop, the agent pulls only the specific note it needs back into fresh context.
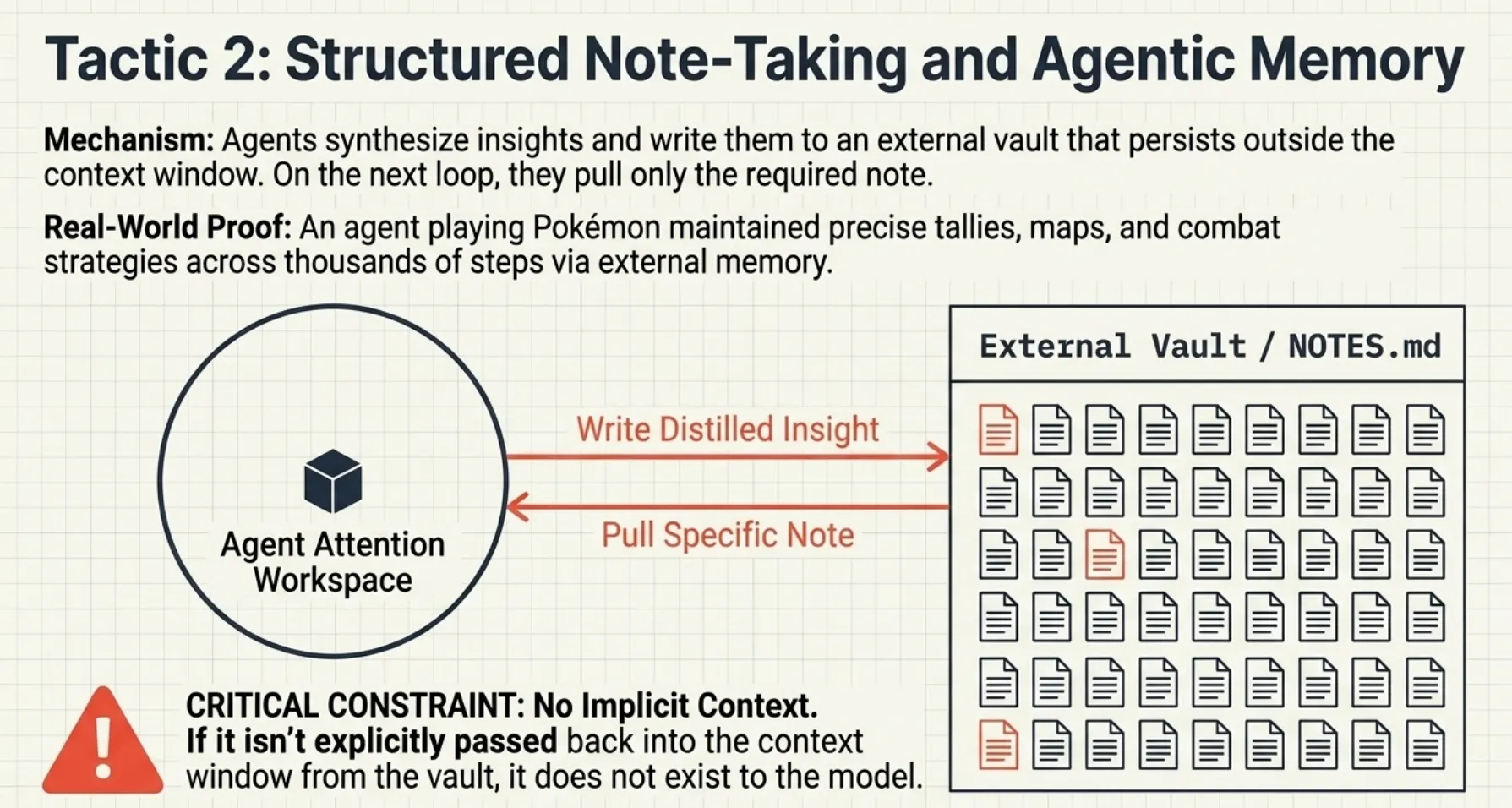
Example: An agent playing Pokémon maintained precise tallies, explored maps, and employed combat strategies across thousands of steps using external memory.
Critical Constraint — No Implicit Context:
Subagents operate in isolated contexts and do not automatically inherit information. All required context must be explicitly passed. If information is missing from outputs, it is almost always due to missing context propagation; not to a model failure.
Tactic 3: Sub-Agent Architectures for Isolated Exploration
Multi-agent orchestration is one of the highest-weighted areas on the CCA-F exam (Domain 1). This section connects context engineering principles to system-level design patterns for scalability and reliability.
The Anthropic source material emphasizes isolation, decomposition, and controlled information flow. For exam scenarios, you should recognize that subagents reduce context overload but require explicit context passing and careful task decomposition.
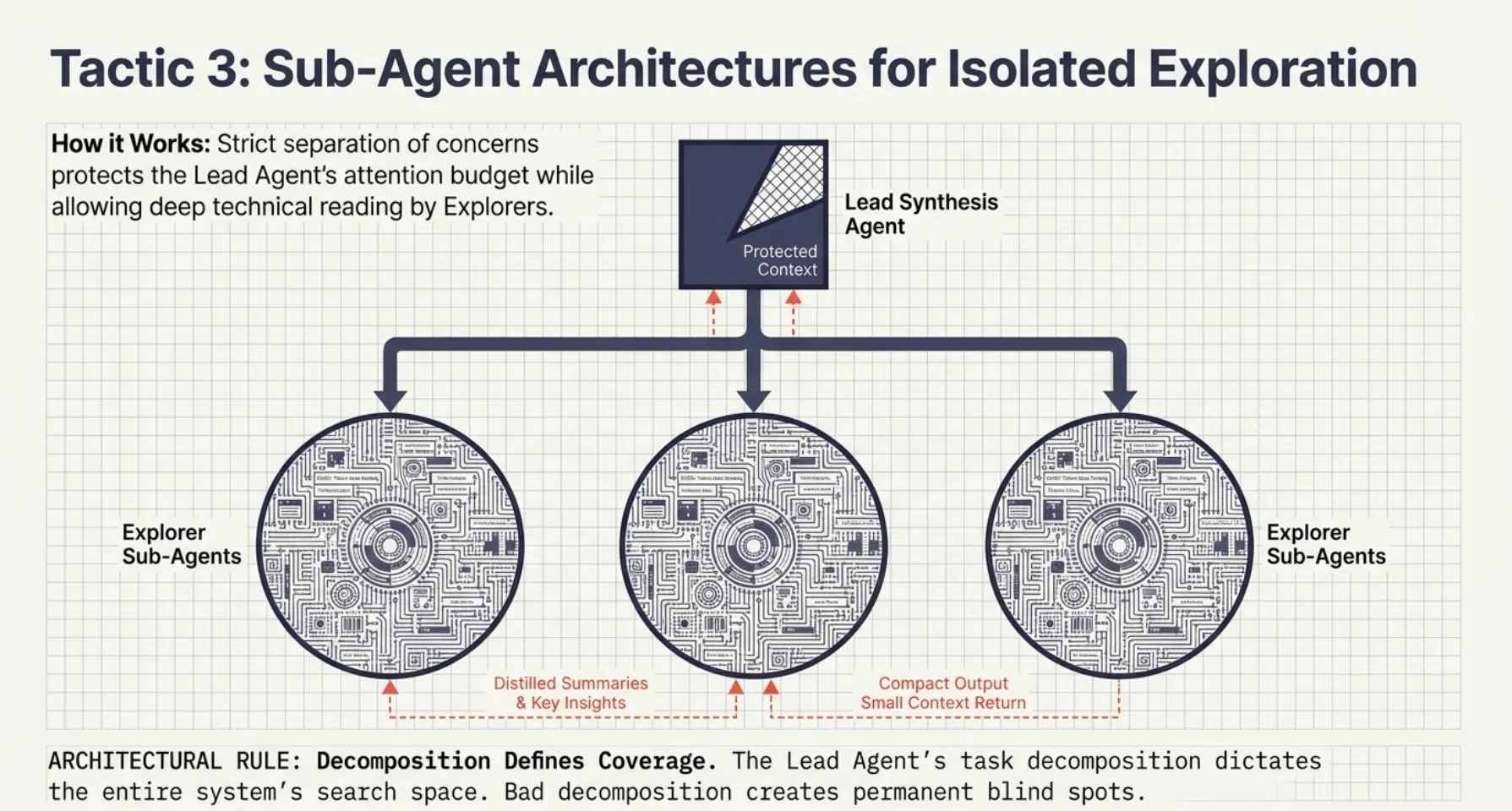
A Lead Synthesis Agent coordinates while specialized Explorer Sub-Agents perform deep technical work in isolated contexts (often 10,000+ tokens). Each sub-agent returns only a distilled 1,000-token summary. This provides strict separation of concerns and protects the lead agent’s attention budget.
Decomposition Defines Coverage: The coordinator’s task decomposition determines what the system can discover. If decomposition is too narrow or incomplete, no downstream processing can recover missing information.
This section ties heavily to the last article in this foundation series.
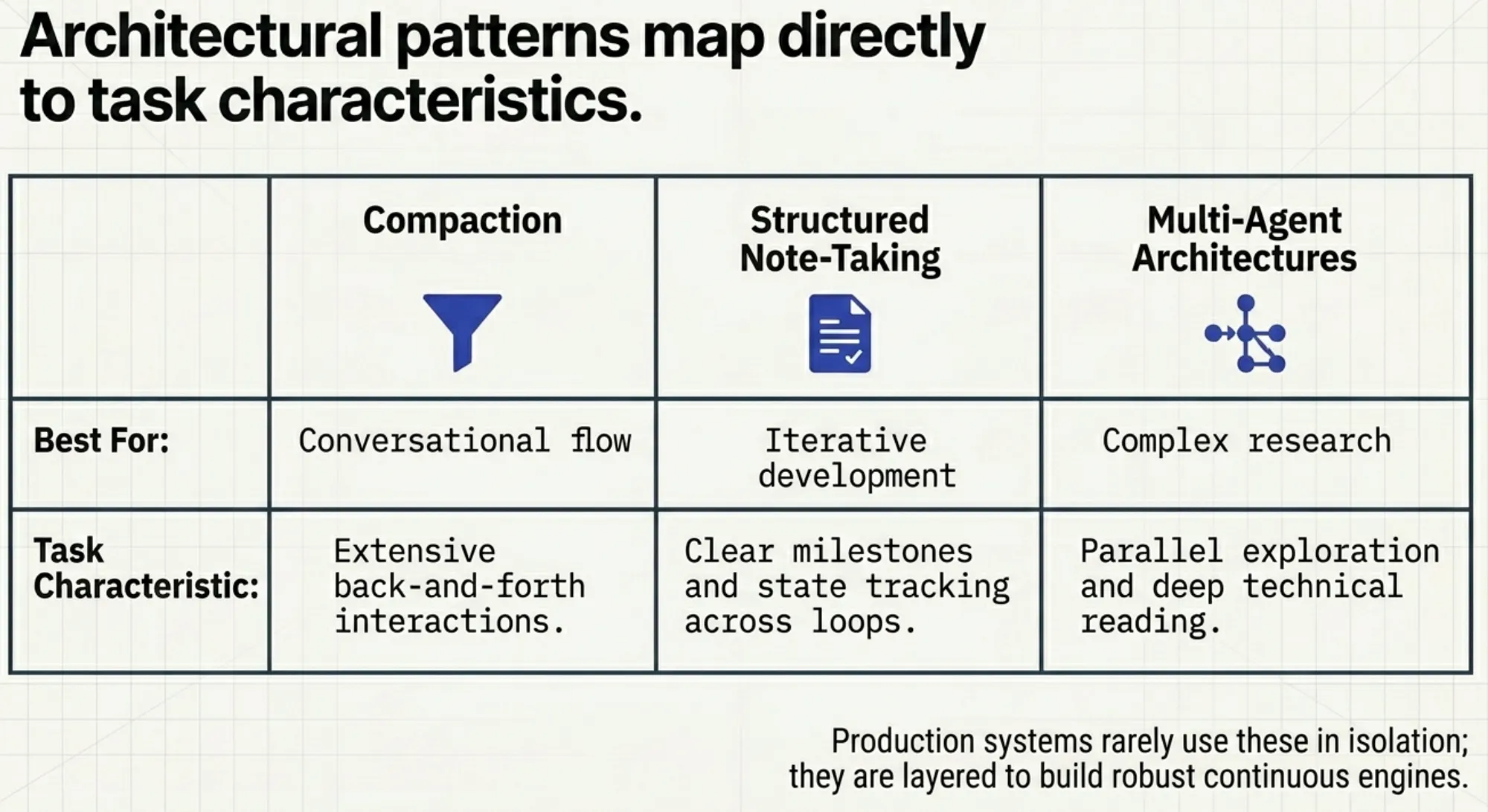
Architectural Decision Matrix for Long-Horizon Tasks
This section helps translate theory into practical decision-making, which is exactly how the CCA-F exam is structured. Questions are scenario-based and require choosing the right architectural pattern for a given problem.
The matrix presented here reinforces a key exam skill: matching the right technique (compaction, memory, multi-agent) to the task characteristics, rather than applying a single approach universally.

Architectural decision matrix:
Compaction
- Best for: Conversational flow
- Task characteristic: Extensive back-and-forth interactions
Structured note-taking
- Best for: Iterative development
- Task characteristic: Clear milestones and state tracking
Multi-agent architectures
- Best for: Complex research
- Task characteristic: Parallel exploration + deep technical reading
Note: These patterns are often combined in production systems rather than used in isolation.
The Continuous Context Loop
The continuous context loop is a direct representation of the agentic loop lifecycle, which is heavily tested in Domain 1 and reinforced in Domain 5. This loop describes how context is continuously managed across iterations.
For the exam, you should understand that reliable systems operate through cycles of injection, execution, distillation, and reinjection, ensuring the model stays within its attention budget while maintaining coherence.
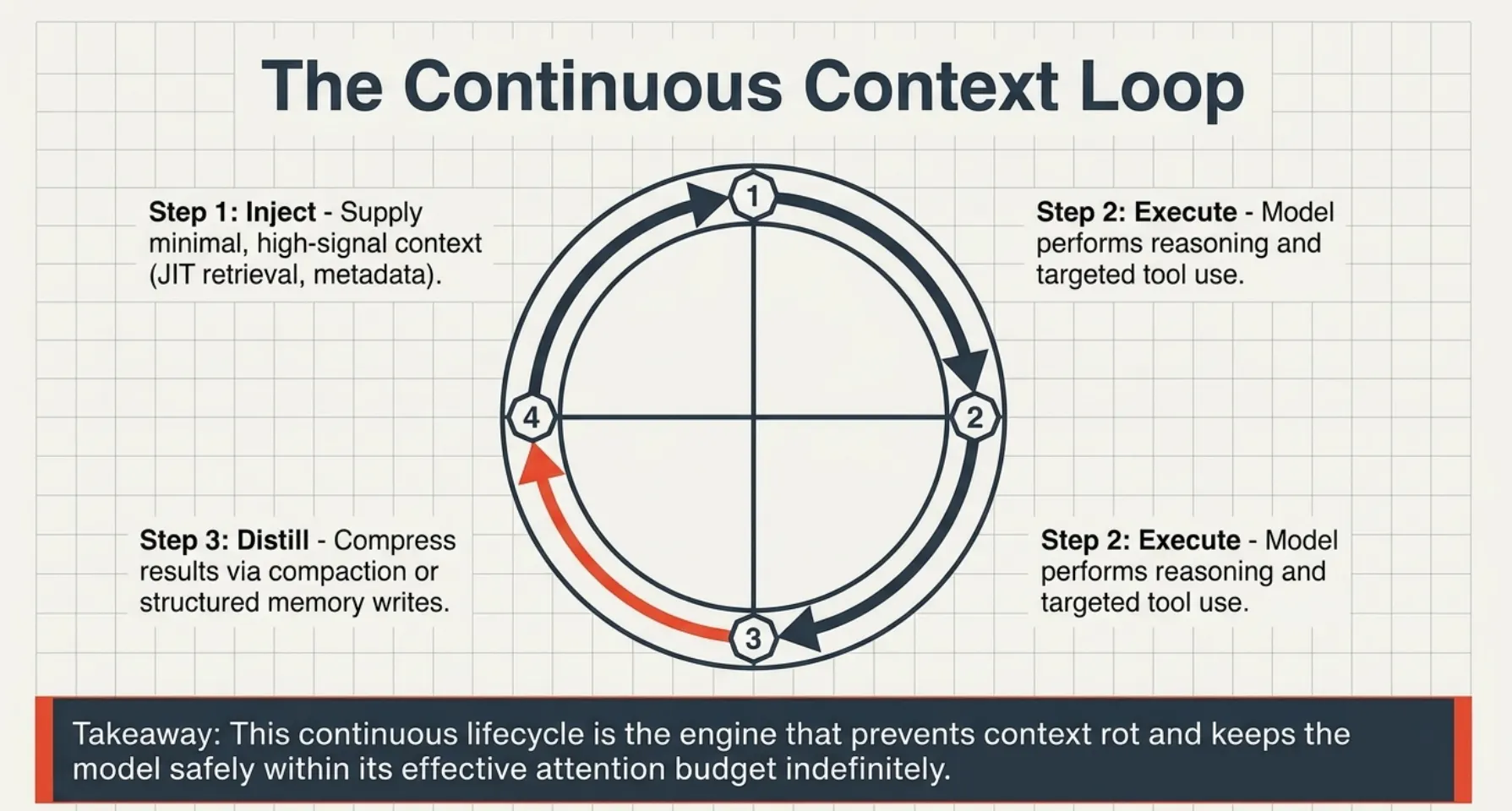
The loop consists of:
- Inject minimal, high-signal context
- Execute reasoning and tool use
- Distill results via compaction or memory
- Re-inject only what is needed for the next step
This loop repeats continuously, ensuring the model operates within its attention budget.
Deep System Insights (What the Exam Really Tests)
This section is essentially the bridge between SOURCE MATERIAL and exam expectations. The CCA-F exam is not testing memorization of terms; it is testing your ability to reason about system behavior under real-world constraints.
Each insight here corresponds to patterns that appear repeatedly in exam scenarios, especially around context boundaries, tool usage, decomposition, and reliability tradeoffs. Mastering these concepts is critical for selecting correct answers under ambiguity.
- Context = entire system state. Context is not just text — it is the entire state the model can perceive and act through, including tools, file systems, metadata, and execution environment.
- No implicit context exists. Subagents operate in isolated contexts and do not inherit state automatically. If it’s not explicitly passed, it doesn’t exist.
- Decomposition defines the solution space. The coordinator’s decomposition defines the search space explored by the system. Bad decomposition creates blind spots that no amount of prompting or synthesis can fix.
- Exploration must precede optimization. Agents should perform broad, parallel exploration before narrowing focus. Premature convergence leads to incomplete or biased results.
- Metadata is compressed context. File sizes, timestamps, and naming conventions act as powerful signals that reduce token load and enable navigation without loading full objects.
- Tool selection is a reasoning task. Choosing the correct tool is a core reasoning decision. Poor tool selection leads to systematic failure even when the model understands the problem.
- Stopping criteria must be explicit. Agent systems must clearly define when to continue exploration versus when to finalize results.
- Confidence does not imply correctness. Agent systems may produce highly confident outputs even when underlying information is incomplete or conflicting. This is especially critical in multi-agent systems where incomplete exploration can still produce confident but incorrect synthesis. Proper synthesis and evaluation must rely on evidence quality and coverage, not model confidence.
- Tools shape reasoning pathways. Poorly designed tools or excessive tool availability degrade decision quality and increase failure rates.
CCA-F Insight: Most failures in agent systems are architectural, not prompt-related. The exam prioritizes system design decisions over prompt tuning.

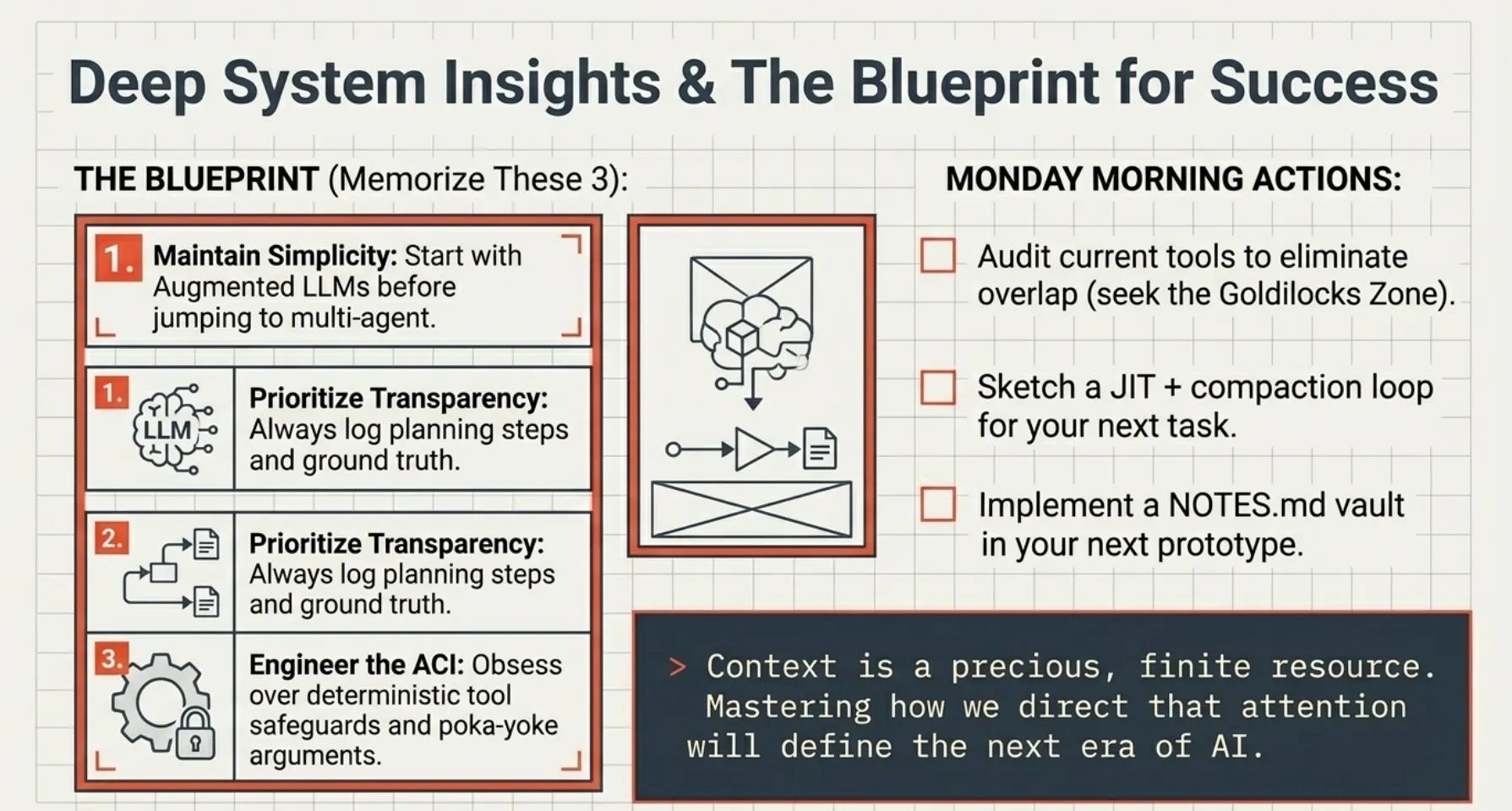
The Blueprint for Success (Memorize These Three Principles)
This section distills the article into exam-ready heuristics, which is essential given the scenario-based nature of the CCA-F test. Candidates are expected to apply principles quickly rather than derive them during the exam.
These three principles map directly to recurring themes across all domains: simplicity in architecture, transparency in reasoning, and strong tool/interface design. Treat this section as a mental checklist for evaluating answer choices.
- Maintain Simplicity — Start with the Augmented LLM and the simplest pattern that solves the problem.
- Prioritize Transparency — Log planning steps and ground truth.
- Engineer the ACI — Obsess over tool documentation, poka-yoke arguments, and deterministic safeguards.
Monday Morning Actions (CCA-F Edition)
- Audit your current tools and prompts; simplify to the Goldilocks Zone and eliminate overlap.
- Sketch a JIT retrieval + compaction loop for your next long-horizon task.
- Implement structured note-taking (NOTES.md) or a sub-agent pattern in your next agent prototype.
For more context and patterns, read part 1 of this series on Foundations of CCA-F and part 2. Read the original paper Effective Context Engineering for AI Agents from the Anthropic Engineering Blog.
Further Essential Reading for CCA-F (Prioritized by Domain Weight)
These resources are all from Anthropic research, blogs or documentation. These are where a lot of these key concepts are discussed which are on the CCA-F exam. Some you will not find in the courseware or any course lesson. It is in the engineering blog and papers that Anthropic publishes that lays the foundation.
Domain 1 — Agentic Architecture (27%)
- Building Effective Agents
- How We Built Our Multi-Agent Research System
- Effective Harnesses for Long-Running Agents
Domain 2 — Tool Design & MCP (18%)
- Writing Effective Tools for AI Agents
- Introducing the Model Context Protocol
- Code Execution with MCP
Domain 3 — Claude Code (20%)
- Effective Context Engineering for AI Agents
Domain 4 — Prompt Engineering (20%)
- The “Think” Tool: Enabling Claude to Stop and Think
- Building Agents with the Claude Agent SDK
Domain 5 — Context Management (15%)
- Equipping Agents for the Real World with Agent Skills
About the Author

Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower’s SpeakerHub.

Rick created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic’s Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain’s Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic’s Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI’s Harness Engineering Experiment: Zero Manually-Written Code