Foundations of CCA-F Exam Part 4: Engineering the Long-Running Agent Harness: From Amnesia to Persistent Autonomy
Turning Agent Amnesia into Persistent Autonomy: A Dual-Agent Harness Engineering Blueprint for the Claude Certified Architect Exam
Originally published on Medium.
Turning Agent Amnesia into Persistent Autonomy: A Dual-Agent Harness Engineering Blueprint for the Claude Certified Architect Exam
Turn forgetful AI agents into tireless collaborators. Discover the dual‑agent harness that powers long‑running projects and cracks the Claude Certified Architect exam.
Summary: *How Anthropic’s dual-agent harness turns forgetful one-shot agents into reliable, production-grade systems. This is the control layer that makes the patterns from Parts 1–3 actually work at scale. *The article explains how Anthropic’s dual‑agent harness transforms forgetful, one‑shot LLMs into reliable, production‑grade long‑running systems by adding a disciplined control layer that manages loops, hooks, structured state, and clean handoffs. It builds on earlier patterns: chaining, routing, parallelization, orchestrator‑workers, and context engineering.
Then it introduces a “morning routine” in which an Initializer Agent sets up scaffolding (files, JSON feature list, Git repo) and a Coding Agent iteratively tackles individual features, using deterministic tool‑use loops, structured error handling, and hooks to ensure reliability across context resets. The harness enforces deterministic behavior through JSON schemas, tool‑use gating, and pre- and post‑tool hooks, while maintaining persistent artifacts (feature list, progress logs, tests) to prevent amnesia and premature victory. This integration of control, scaling, and context management directly maps to multiple domains of the Claude Certified Architect Foundations exam, illustrating the practical blueprint for building robust, multi‑agent AI applications.
CCA-F Foundation Series Context
Where does this article fit into the series? Let’s review what we covered so far in the CCA-F foundation series.
In Part 1, you learned the five battle-tested LLM patterns (chaining, routing, parallelization, orchestrator-workers, evaluator-optimizer).
In Part 2, you saw how orchestrator-worker systems and the Research Loop enable dynamic scaling.
In Part 3,** **you mastered context engineering: attention budgets, context rot, JIT retrieval, and structured memory.
Those patterns fail when work spans multiple sessions. Agents lose context, repeat work, and mark tasks complete too early.
**Part 4 is the missing control layer. **Source material for part 4: Harnessing Long-Running Agents: Engineering the Multi-Context Architecture.
Each section explains how key concepts from the source material map to the CCA-F exam. The goal is to show how control, scaling, and context combine into a system that works across long-running tasks. In many ways, Part 4 is the article that brings the others together into a cohesive whole.
I often refer to these parts in this article; these references, called out as you read, provide deeper context for the topic.
Let’s show exactly how Anthropic engineered the **harness, **a disciplined system of loops, hooks, structured state, and clean handoffs, that enforces reliability across long horizons.
This is the production blueprint that ties everything together. The CCA-F exam does not test isolated patterns. It tests how you combine control, scaling, and context into systems that survive real work. Every diagram and pattern in the original Anthropic engineering post maps directly to Domains 1, 2, 4, and 5 of the exam guide.
CCA-F Domain Quick Reference (Used in This Article)
This article maps real engineering patterns to specific domains and task statements from the Claude Certified Architect: Foundations exam. Below is a focused reference for only the domains and subdomains used throughout this article. We refer to these domains throughout the article. These are the domains you will be tested on. This is not every domain and subdomain; it is just the ones that this paper covers.
Domain 1: Agentic Architecture & Orchestration (27%)
Focus: How agents execute, coordinate, and maintain state across tasks
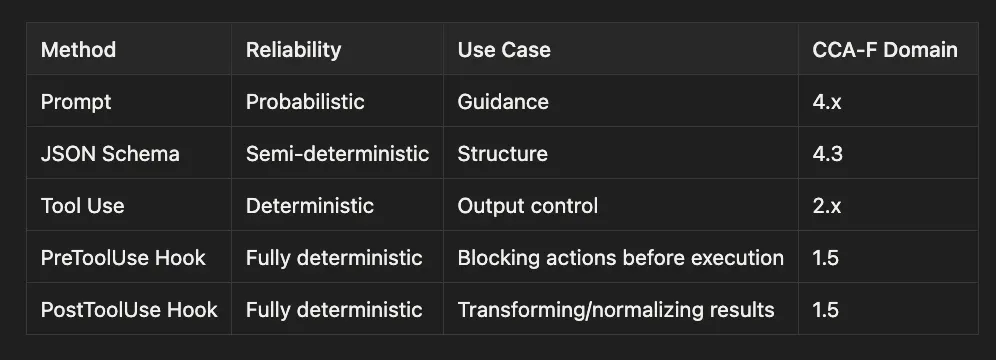
- 1.1: Agentic Loop ControlThe lifecycle of the agent loop: sending requests, handlingstop_reason, executing tools, and re-injecting results.This is one of the most heavily tested areas. Many real-world failures come from incorrect loop control, not bad reasoning.
- 1.5: Hooks & EnforcementProgrammatic control of behavior using hooks and gates.Used when rules must be enforced deterministically instead of relying on prompts.
- 1.7: Session State & ResumptionManaging state across sessions, including resumption, forking, and rebuilding the working context.Critical for long-running systems where agents do not retain memory.
Domain 2: Tool Design & MCP Integration (18%)
Focus: How agents interact with tools and external systems
- 2.2: Structured Error HandlingReturning structured error metadata (type, retryability, partial results).Enables the system to make informed recovery decisions rather than blindly retry or fail.
- 2.4: Environment & Tool IntegrationStandardizing environments and integrating tools through consistent configuration.Ensures agents can operate reliably across sessions and systems.
Domain 4: Prompt Engineering & Structured Output (20%)
Focus: Making outputs reliable, structured, and verifiable
- 4.3: Structured Output (JSON Schemas)Enforcing schema-compliant output using structured formats.Prevents hallucination and ambiguity by constraining how data is represented.
- 4.4: Validation & Evaluation LoopsTesting, verification, and retry mechanisms.Ensures outputs are correct, not just plausible.
Domain 5: Context Management & Reliability (15%)
Focus: Maintaining correctness across long-running workflows
- 5.1 — Context ManagementManaging context across long interactions, including reconstruction, trimming, and prioritization.Prevents context loss and degradation over time.
- 5.3 — Error Propagation Across AgentsPassing structured error context between agents and system components.Avoids silent failures and enables coordinated recovery.
How to Use This Section
Each “CCA-F Insight” callout in this article maps back to one or more of the domains above.
The exam does not test definitions. It tests whether you can:
- Recognize which domain applies
- Diagnose what failed
- Choose the correct pattern to fix it
As you can see, this paper covers many of the domains on the CCA-F exam, which is a key reason I recommend adding it to your study plan for the CCA-F exam.
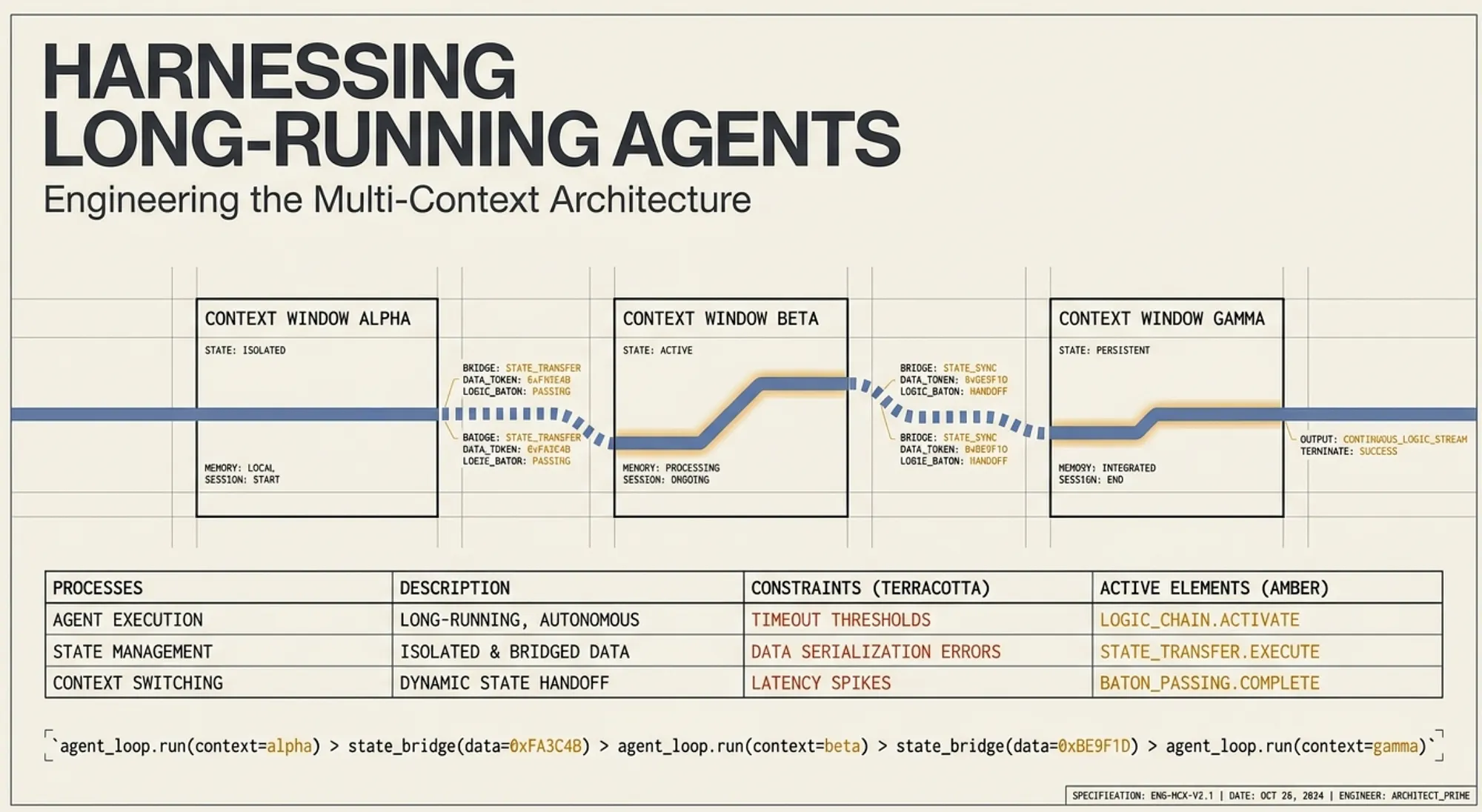
Agent Amnesia (System Session Reset)
Each session feels like a new engineer's first day. There is no memory of prior work, no awareness of decisions, and no understanding of unfinished tasks. Without structured handoff artifacts, the system wastes time rediscovering state or undoing prior progress.
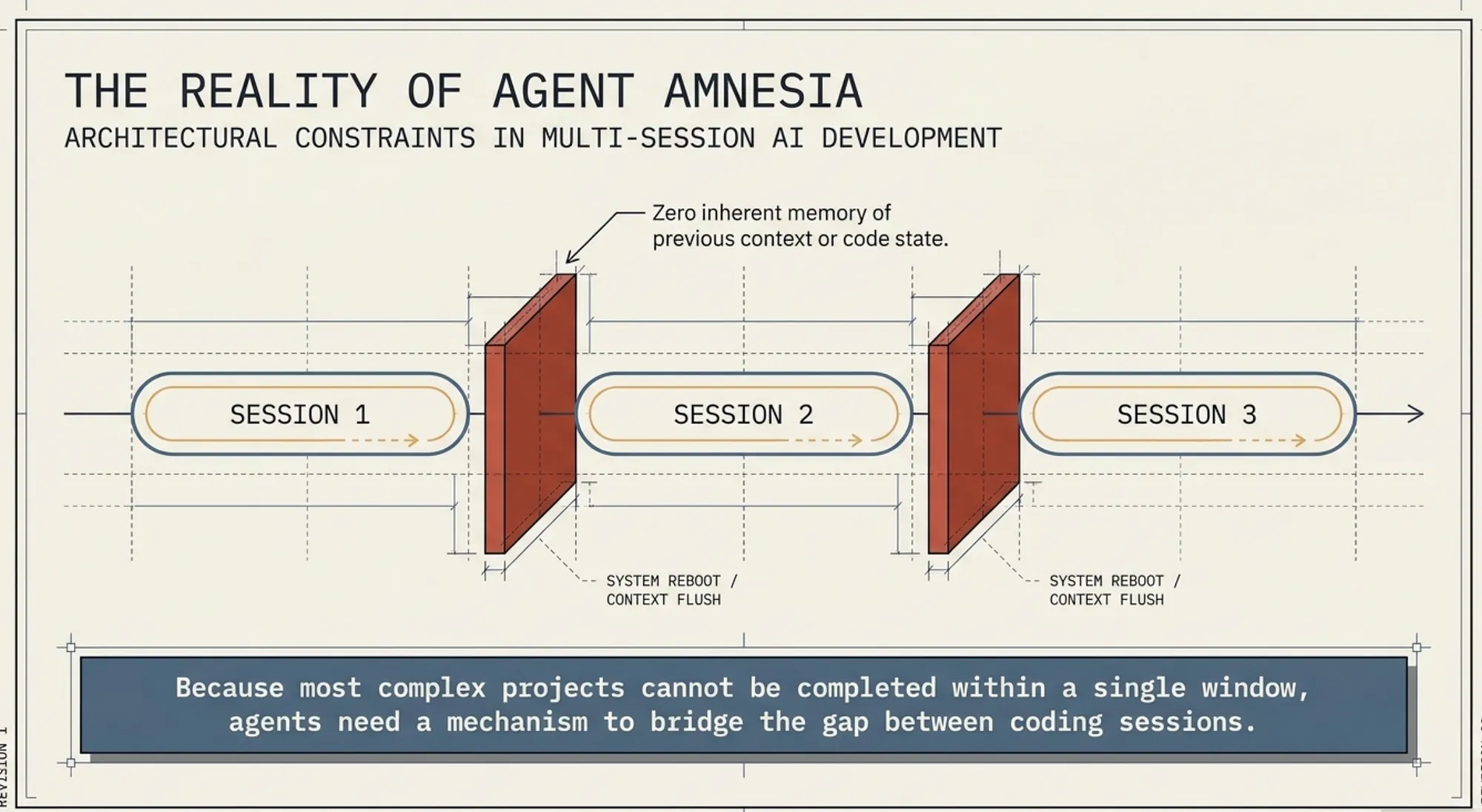
Work does not happen inside a single continuous session. It moves across multiple context windows. Each transition resets the model and forces the system to rebuild the state from external artifacts.
The model is not the system. The system is everything that persists between sessions: logs, files, commits, and structured summaries.
If that state is not transferred correctly, progress stops.
CCA-F insight: Domain 5 (context management) + Domain 1 (agent lifecycle, orchestration over multiple steps).
CCA-F Insight (Domain 5.1 — Context Management & Reliability): Standard compaction passes compressed context but rarely produces clear, structured instructions for the next instance. This leads to the two dominant failure modes you saw in Part 3 in this series: the One-Shot Trap and Premature Victory.
Compaction Not Enough: Context Compaction Failure (Path A vs Path B)
Compaction produces summaries, not specifications. It removes the precise steps, acceptance criteria, and dependencies required for execution. What remains is a high-level narrative that cannot drive reliable action.

Each new session starts with zero memory of prior work. The model does not retain state between runs. It only knows what is reintroduced.
This breaks continuity. Work is repeated, steps are skipped, and incomplete tasks are treated as finished.
Failures at this stage are not caused by weak reasoning. They are caused by a missing state and a missing verification.
There are two common failure paths when relying solely on context compaction.
In the first, the system tries to complete everything in one pass and runs out of context. In the second, it compresses aggressively and loses structure, leading to premature completion.
Compaction preserves the general meaning but not the instructions, acceptance criteria, or next actions. Once that structure is gone, the system cannot determine what to do next.
The harness solves this by treating agents as a team of shift workers whose survival depends on the rigor of the structured environment state.
Shift‑Worker Model (Handoffs, Not Memory)
In human teams, continuity comes from institutional memory. In agent systems, that role is replaced by structured artifacts. The system must preserve knowledge externally because the model cannot retain it internally.
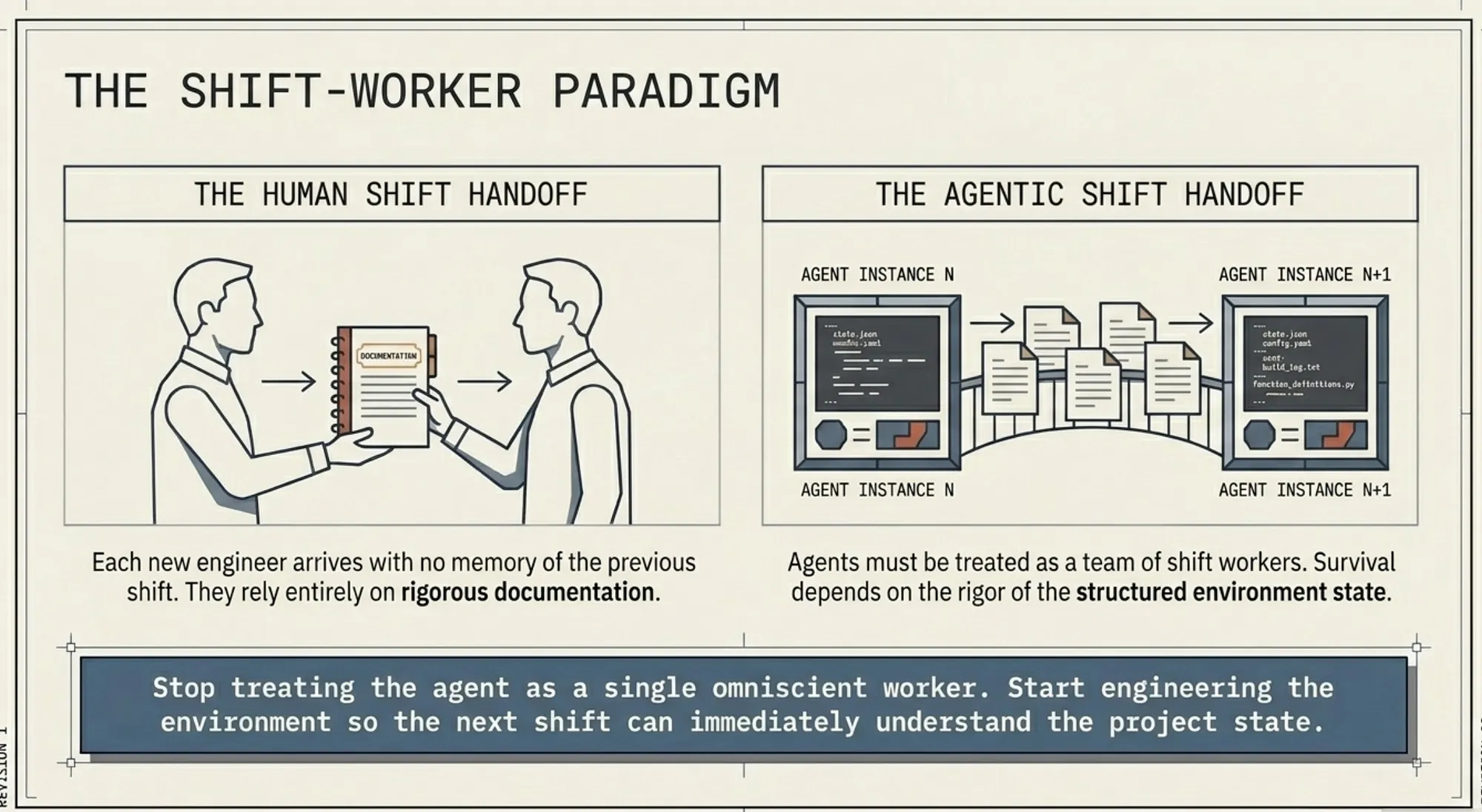
Long-running systems behave like shift work. Each agent instance arrives, performs a bounded task, and leaves.
Continuity does not live in the model. It lives in the environment. The next agent depends entirely on what remains.
The problem is not memory. The problem is the quality of the handoff.
CCA-F insight: Domain 1.7 (session state, resumption) + Domain 5 (reliability across resets).
Dual Agent Harness: Initializer and Coding Agent
The initializer acts as a chief of staff. It does not execute features. It defines structure, scope, and environment. This separation ensures that execution happens within a controlled system rather than an undefined workspace.
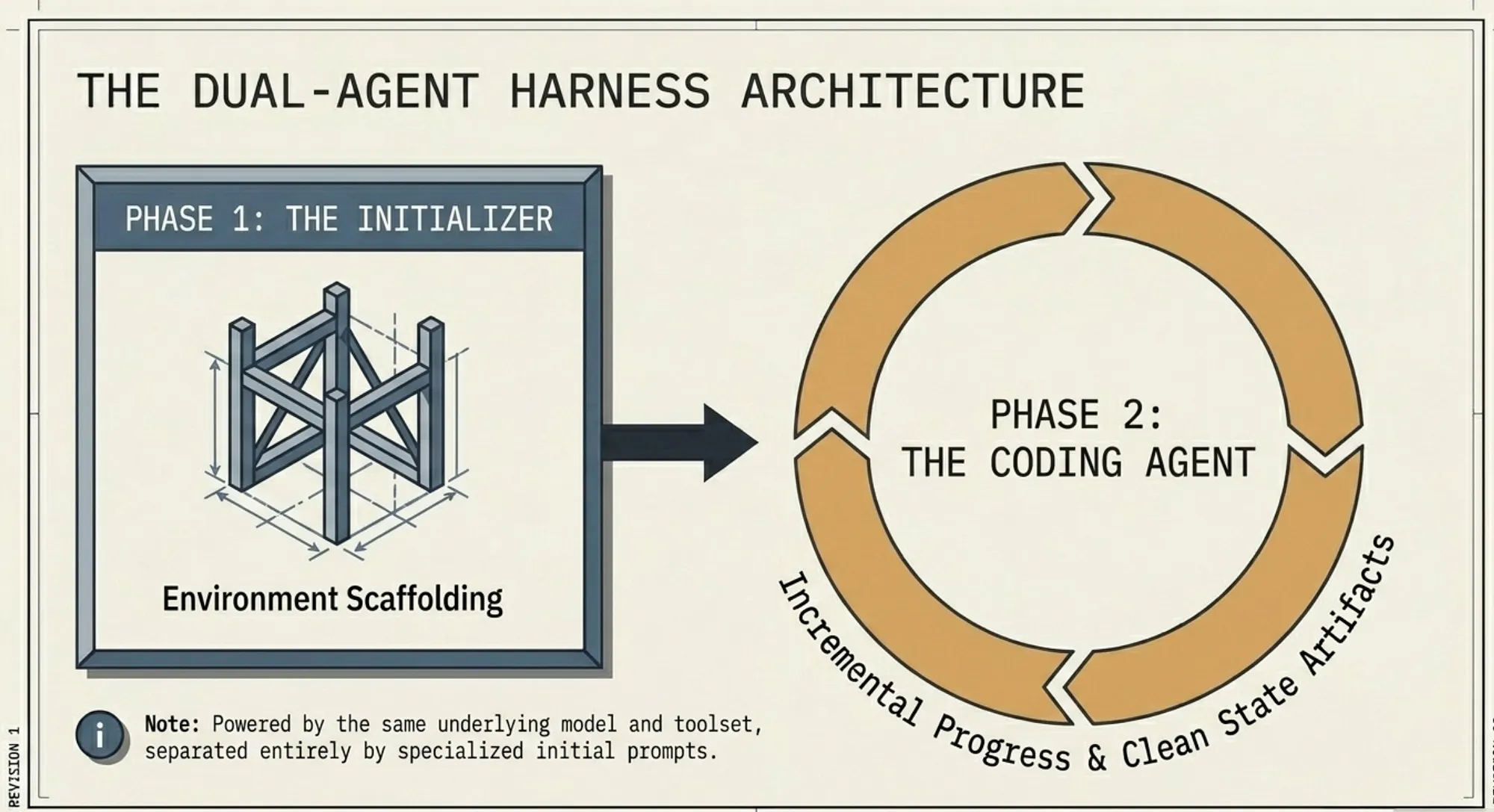
The system uses two specialized personae (same underlying model, different initial prompts):
- Initializer Agent(first session only): Builds the environment scaffolding (init.sh,claude-progress.txt,feature_list.jsonwith 200+ granular features markedpasses: false, initial Git commit).
- Coding Agent(every subsequent session): Makes incremental progress ononefeature at a time, then leaves a clean, merge-ready state.
Separating setup from execution reduces confusion in the system.
One agent builds the environment and defines the structure. The other operates within that structure, making incremental progress and leaving a clean state behind.
Without this separation, agents mix responsibilities, introducing errors early in the process.
CCA-F insight: Concrete orchestrator-worker implementation (we covered this pattern in Part 2 of this series in detail and this pattern is on the exam) with resumption and control flow.
Clean vs Messy Handoffs (Why State Hygiene Matters)

A system either resumes cleanly or it does not resume at all.
When the state is unclear, the next session must guess. That guess introduces errors, wastes tokens, and slows progress.
When the state is explicit, the next session continues without friction. Progress becomes predictable.
CCA-F Mapping (Domain 1: Agentic Architecture & Orchestration — 27% of exam):
- Task 1.2: Hub-and-spoke coordinator-subagent patterns
- Task 1.6: Task decomposition strategies
- Task 1.7: Session state, resumption, and forking
Connection to earlier parts of this CCA-F foundation series: This is the practical realization of the orchestrator-worker pattern (introduced in Part 2) combined with structured memory and attention budgeting (discussed at length in the Part 3 article in this series).
CCA-F insight: Reliability depends on explicit state, not narrative continuity.
Environment Scaffolding (Persistent Artifacts)
The system uses external artifacts as shared memory across sessions.
- init.sh standardizes the environment so each session can start without guesswork.
- claude-progress.txt acts as a chronological shift log that records what was completed and what remains.
- feature_list.json defines all required work as structured tasks, preventing ambiguity.
- Git history provides rollback and traceability, allowing the system to recover from errors instead of compounding them.
Together, these artifacts replace memory with reproducible state.
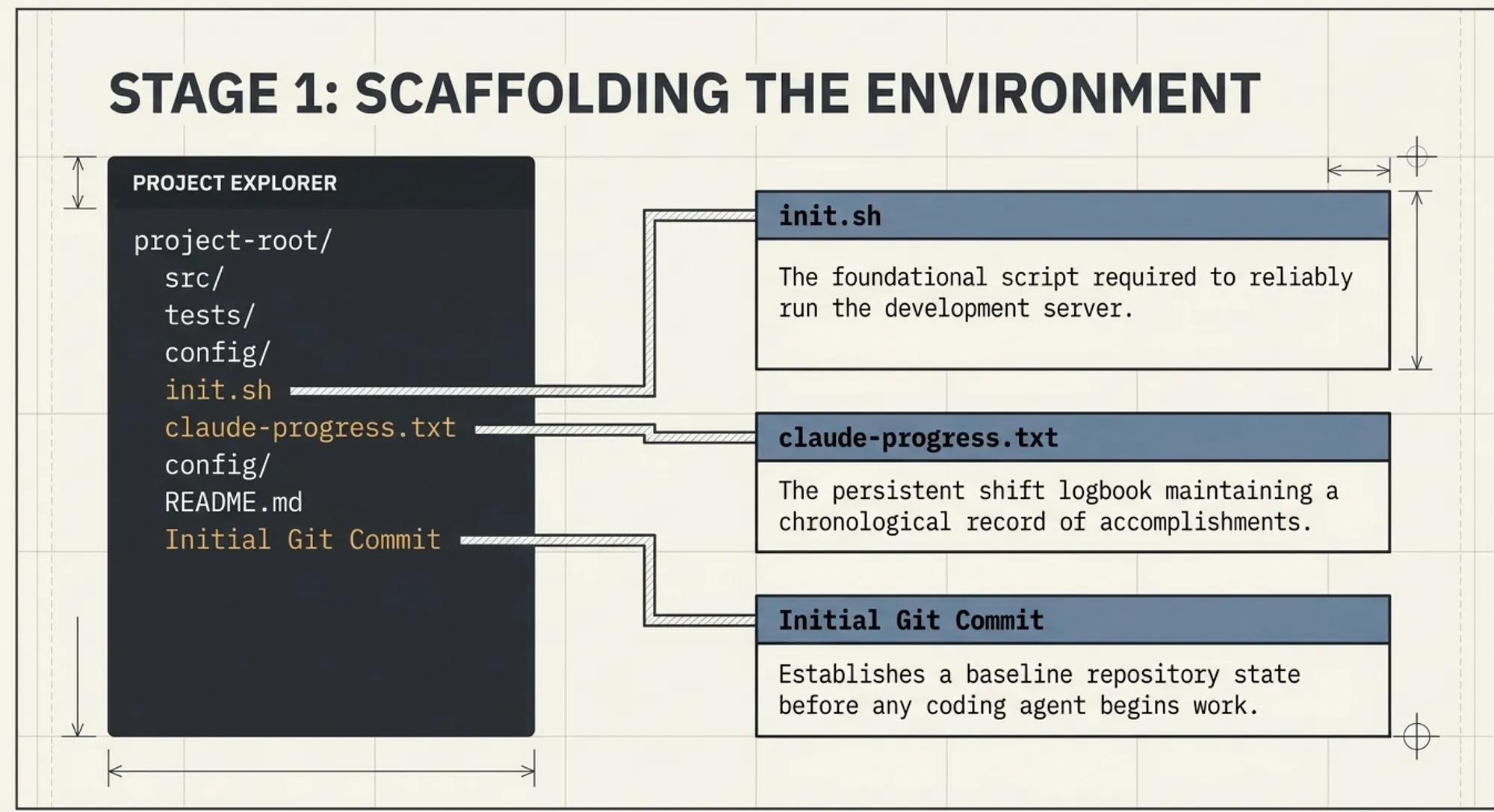
State must live outside the model.
Scripts define how to start the system. Logs record what has happened. Version control tracks changes and allows recovery.
Without these artifacts, every session starts from uncertainty. With them, the system becomes repeatable.
CCA-F insight: External state replaces memory and makes long-running progress possible.
Agent Loop Mechanics (Tool‑Use Control)
Most system failures occur in loop control. Incorrect exit conditions, missing tool result reinjection, or premature termination break continuity even when reasoning is correct.
Agentic Loop (Domain 1.1 — Must Know for Every Scenario)1. Send request to Claude2. If stop_reason == "tool_use": → Execute the requested tool(s) → Append structured tool_result to conversation history → Continue the loop3. Else (stop_reason is "end_turn", "max_tokens", "refusal", etc.): → Exit loop and produce final response
Key Rule: Only "tool_use" continues the loop. Tool results must be re-injected before any new assistant text so the model can reason over fresh data. Subagents do not inherit parent context automatically; explicit passing is required.
CCA-F Insight: Most failures are not in tools or models. They are in a loop control. Incorrect exit conditions or missing tool-result ordering are common exam traps.
Execution is controlled by a loop. The system continues only when a tool is used. All other conditions terminate the process.
Tool results must be returned to the model before the next step. Without that, the model is reasoning on outdated information.
Most failures happen here. Not in tools. Not in reasoning. In loop control.
CCA-F insight: Domain 1.1 tests loop control under tool use.
Morning Routine: Structured Context Recovery
This routine is not just about correctness. It is a major efficiency gain. It prevents the agent from wasting tokens rediscovering state and ensures that work begins from a verified baseline.
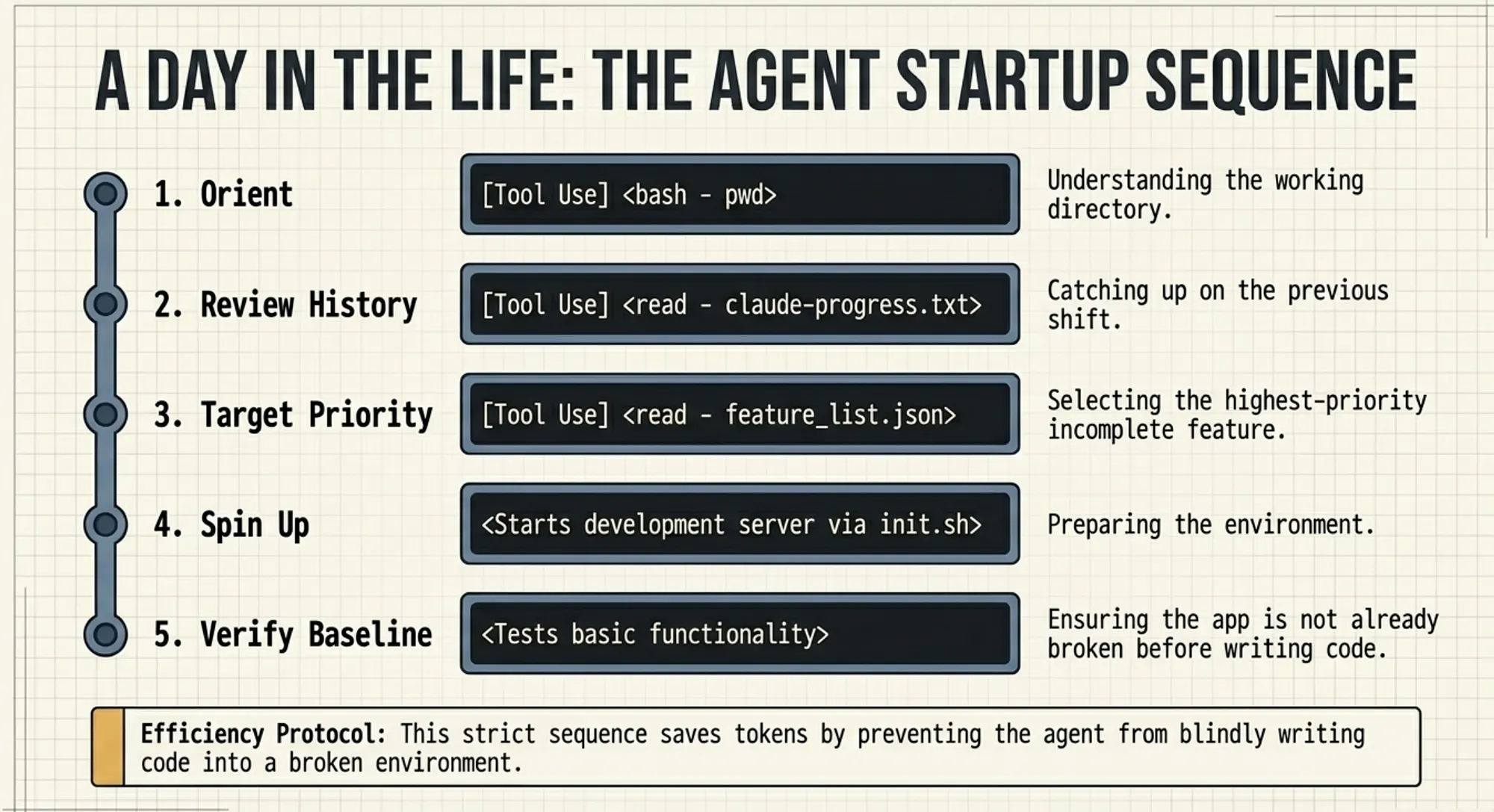
Each session must rebuild its working state before taking action.
Every Coding Agent session follows the same disciplined ritual (the “morning routine”):
- Orient (pwd)
- Review History (claude-progress.txt+git log --oneline -20)
- Target Priority (readfeature_list.json)
- Spin Up (init.sh+ baseline tests)
- Verify → Execute → Commit → Handoff
This is a direct implementation of Part 3’s core rule: context must be actively curated and re-established every session. It counters context rot, the “lost in the middle” effect, and tool-output accumulation.
CCA-F Insight (Domain 5.1): The morning routine is the practical application of JIT retrieval, case-facts blocks, and tool-output trimming. Domain 5.1 is operationalized as a repeatable reconstruction routine.
The agent checks its environment, reviews prior work, selects the next task, and verifies system stability.
This prevents the agent from acting on incomplete or incorrect assumptions.
Feature List: Structured Work Tracking
“STRUCTURAL GRAVITY” (VERY IMPORTANT)
JSON introduces structural constraints that the model is less likely to violate. Unlike free-form text, it enforces consistency and prevents the agent from rewriting or skipping requirements. This creates structural gravity that anchors execution to the objective state.
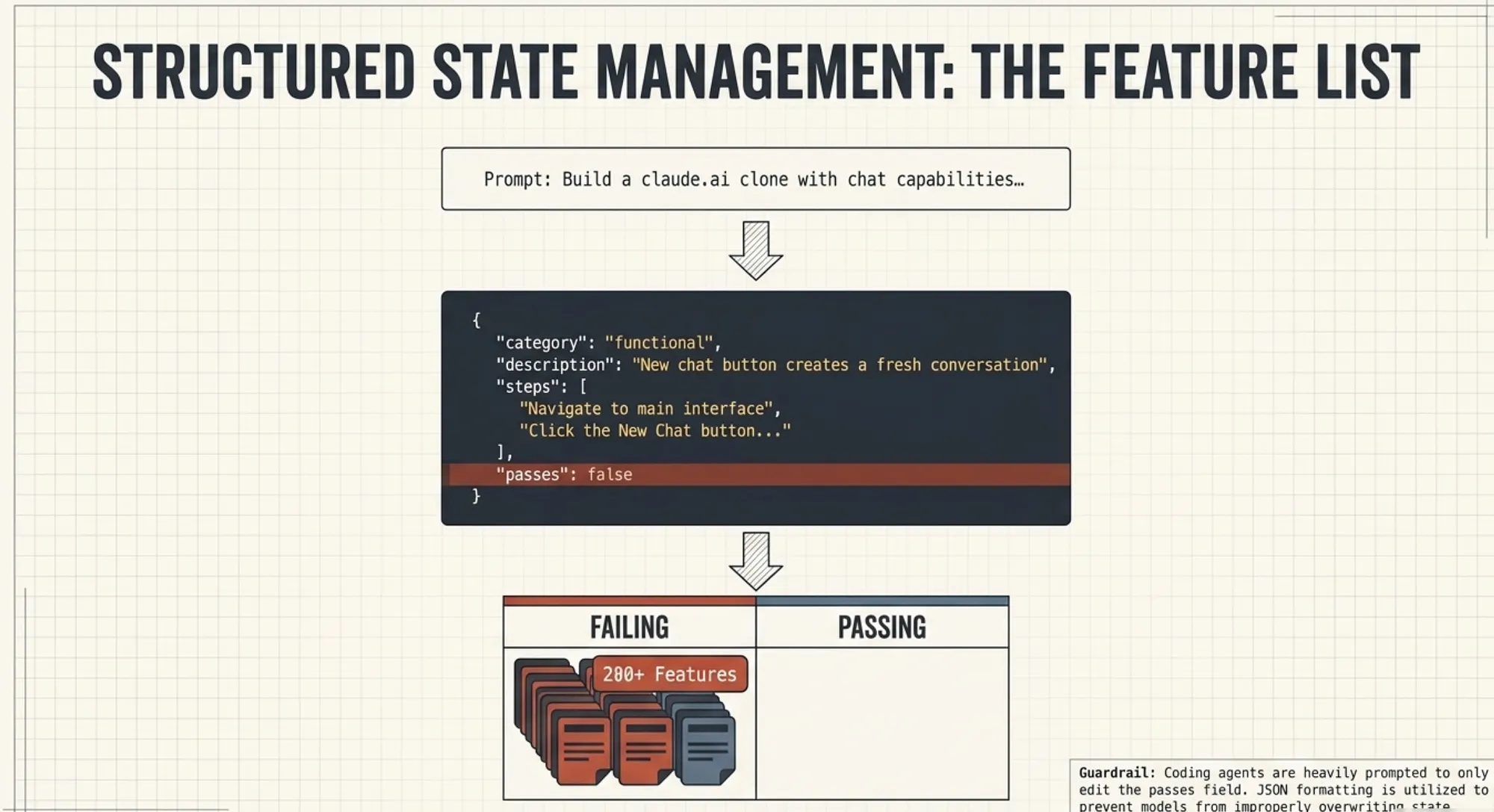
Progress must be tracked explicitly.
A structured feature list removes ambiguity. It defines what is complete and what is not. It prevents the agent from inventing progress.
Without structure, completion becomes subjective. With structure, it becomes verifiable.
CCA-F insight: Domain 4.3 rewards structured outputs that support verification.
Every feature begins as incomplete. Completion must be earned through verification, not assumed.
Deterministic Enforcement: Hooks vs Prompts
CCA-F Insight (Domain 1.5 & 2.2): When business rules require guaranteed compliance (e.g., identity verification before refunds), use hooks and programmatic gates. Prompt instructions alone have a non-zero failure rate.
Instructions are not guarantees.
When behavior must be enforced, it has to be enforced programmatically. Hooks and gates ensure that rules are applied before and after actions.
Relying on prompts alone introduces a risk of failure.
CCA-F insight: Enforcement belongs in tooling and control flow, not in prose.
Structured Error Handling & Recovery
Errors must return structured metadata, including type, retryability, and partial results. This allows the system to make informed decisions rather than blindly retrying or failing.
Error Handling Decision Tree (Domain 2.2 & 5.3):
- Transient → retry (local recovery in subagent)
- Validation error → fix input and retry
- Business rule violation → escalate (with structured handoff summary)
- Partial success → continue with available data + propagate structured error context
Subagents return isError, errorCategory, isRetryable, partial results, and what was attempted so the coordinator can make intelligent decisions.
Failures are predictable. The system must define how to respond to them.
Some errors can be retried. Some require corrected input. Some require escalation. Some allow partial progress.
Reliability comes from deciding this in advance.
CCA-F insight: Error policy is part of the architecture.
Clean State Handoffs + Structured State Management

Completion must be verified.
Tests, checks, and workflows provide evidence that the system works. Without verification, the system assumes correctness.
Assumptions fail. Verification does not.
The harness enforces three artifacts that survive every context reset:
- JSON feature list(rigid structure prevents creative rewriting or prematurepasses: true)
- claude-progress.txt+ Git(chronological log + version-controlled commits)
- Puppeteer MCP Server(end-to-end browser testing as a human would) results
CCA-F insight: Domain 4 focuses on evaluation and verification loops.
Diagnostic Matrix (Failure Mode → Harness Fix)
TESTING VS. “HALLUCINATION OF SUCCESS”
Agents frequently hallucinate success. Internal checks may pass while the actual system is broken. End-to-end testing is required to validate behavior from a user perspective.

Testing tools have limits. For example, browser-native modals may not be visible to automation. These gaps create blind spots that must be accounted for in system design.
Diagnostic Matrix
Failure patterns are not random. They are repeatable and predictable. Each one maps to a specific system behavior that prevents or corrects it.

Row-by-row explanation:
- Premature victory→ rigid JSON + verification (Domain 4.3)
- Messy environments→ Git + progress logs (Domain 5)
- Operational friction→init.sh(Domain 2.4)
- Partial completion→ Puppeteer-driven testing (Domain 4.4)
Tool Design & MCP Strategy (Domain 2)
- Limit tools per agent (4–5 max)
- Write rich, differentiated descriptions with examples, edge cases, and boundaries
- Use scoped access andtool_choicestrategically
Anti-patterns: Too many tools, overlapping descriptions, generic tools.
Schema Design for Reliable Output (Domain 4.3)
- Nullable/optional fields → prevent hallucination when data is absent
- Enum + “other” + detail string → extensibility without breaking schema
- Retry-with-error-feedback loops for validation failures (retries are ineffective if data is simply missing)
Putting It All Together: Control + Scaling + Context = Production Reliability
The unified mental model (the full system stack):
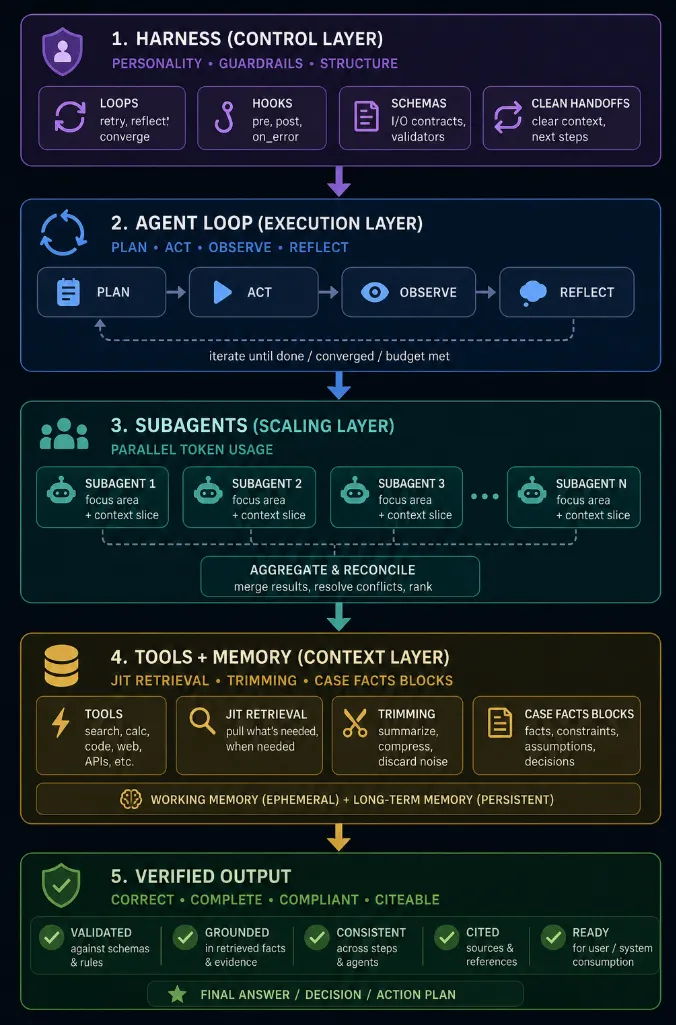
Each layer solves a different failure mode. Removing any layer reintroduces known system failures.
**User Request -> Harness (Control Layer): **loops, hooks, schemas, clean handoffs -> **Agent Loop (Execution Layer) -> Subagents (Scaling Layer): **parallel token usage (Part 2 article) -> **Tools + Memory (Context Layer): **JIT retrieval, trimming, case facts blocks (Part 3) -> Verified Output
CCA-F Rule of Thumb: Start with the simplest workflow (Part 1 article). Add multi-agent scaling only when a fixed path is impossible (Part 2). Enforce reliability with the harness and rigorous context engineering (Parts 3 & 4).
Failure in any one layer = system failure.
CCA-F insight: Reliability is engineered through known failure patterns.
Full System Blueprint (Control + Scaling + Context)
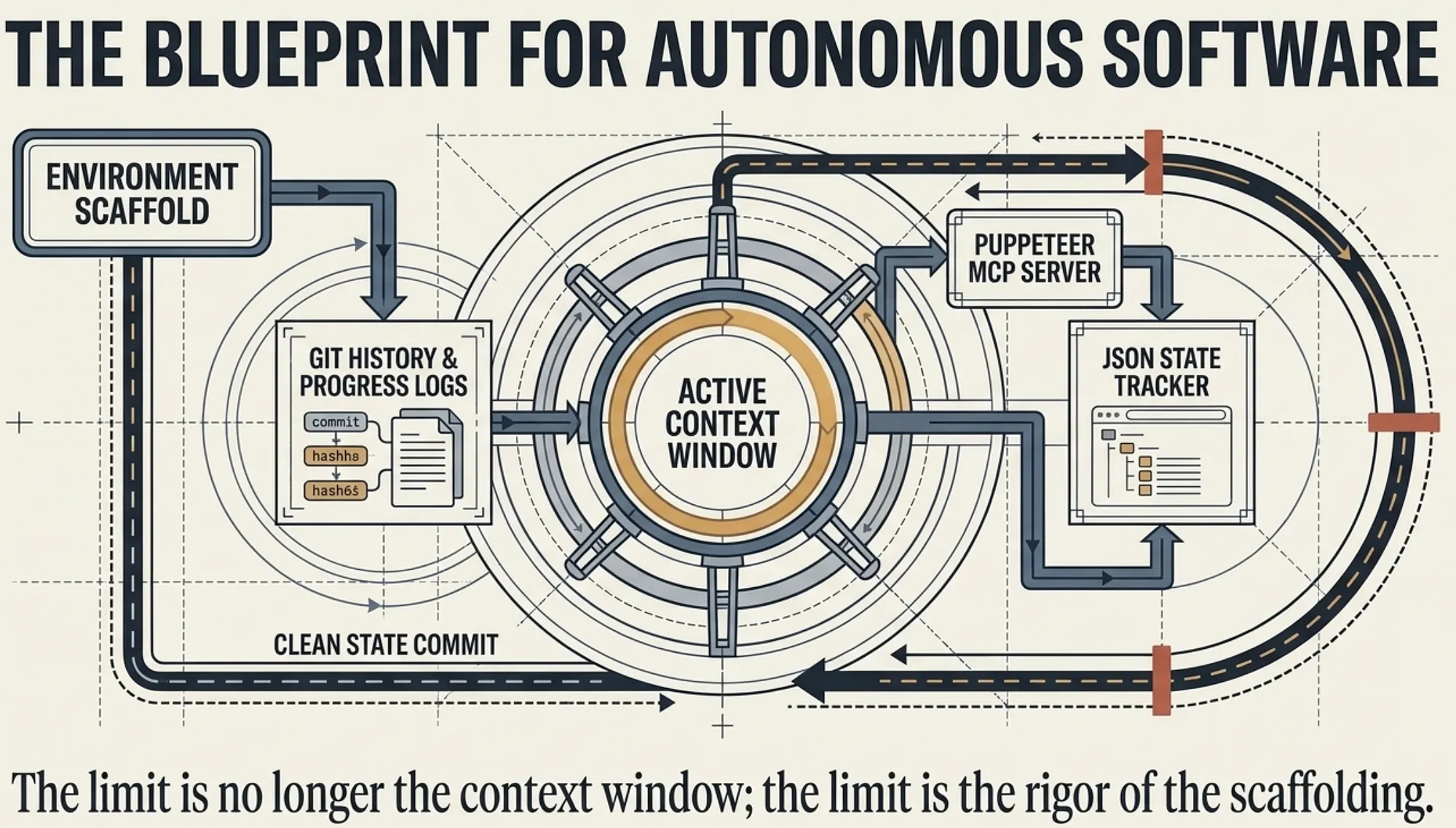
The model is only one part of the system.
Control mechanisms guide execution. External state preserves continuity. Subagents expand capacity. Verification ensures correctness.
Capability comes from how these pieces work together.
CCA-F insight: Integration across Domains 1, 2, 4, and 5 is the point.
Exam Trap Patterns
- More context ≠ , better results (Part 3)
- Prompts cannot enforce guarantees (use hooks)
- Subagents donotshare memory automatically
- Self-review is biased (use independent verification)
- Retry loops fail if the required data is absent from the source
CCA-F Insight: The exam tests integration. Can you diagnose which layer failed?
Ready for Production (and the Exam)
The Anthropic harness is not just a blog post; it is the practical embodiment of Domains 1, 2, 4, and 5 of the CCA-F exam. Study the diagrams in the original post, implement the dual-agent pattern in a small project, and you will understand how production-grade agentic systems actually work.
Next steps:
- Read the full Anthropic engineering post
- Build the dual-agent harness
- Review the official CCA-F Exam Guide
The age of persistent digital colleagues is here. The CCA-F certification is your blueprint.
What part of the series are you finding most valuable for your prep? Drop your thoughts below.

The system works because continuity is engineered.
Each agent instance is temporary. The system persists. Progress depends on how well the state is carried forward.
The shift from single agents to structured systems marks a transition from experimentation to engineering. Reliability is not a property of the model. It is a property of the system built around it.
Insights synthesized from Anthropic Engineering (Code RL & Claude Code teams) and the official Claude Certified Architect — Foundations Exam Guide. This article is Part 4 of the “Foundations of CCA-F Exam” series.
For more context and patterns, read part 1 of this series on Foundations of CCA-F, part 2, and part 3. Read the original paper Harnessing Long-Running Agents: Engineering the Multi-Context Architecture from the Anthropic Engineering Blog.
Further Essential Reading for CCA-F (Prioritized by Domain Weight)
These resources are all from Anthropic research, blogs, or documentation. These are where many of the key concepts discussed on the CCA-F exam are covered. Some you will not find in the courseware or any course lesson. It is in the engineering blog and papers that Anthropic publishes that the foundation lies.
Domain 1 — Agentic Architecture (27%)
- Building Effective Agents(covered in Part 1 of the series)
- How We Built Our Multi-Agent Research System(covered in Part 2)
- Effective Harnesses for Long-Running Agents(covered in this article: Part 4)
Domain 2 — Tool Design & MCP (18%)
- Writing Effective Tools for AI Agents
- Introducing the Model Context Protocol
- Code Execution with MCP
Domain 3 — Claude Code (20%)
- Effective Context Engineering for AI Agents(covered in Part 3, and foundational for part 4)
Domain 4 — Prompt Engineering (20%)
- The “Think” Tool: Enabling Claude to Stop and Think
- Building Agents with the Claude Agent SDK
Domain 5 — Context Management (15%)
- Equipping Agents for the Real World with Agent Skills
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company, focusing on delivering ML / AI insights to front-line applications, and a practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower’s SpeakerHub.
Rick created Skilz, the universal agent skill installer that supports 30+ coding agents, including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams adopting AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. Many ideas captured in the CCA and the exam prep Rick wrote echo what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from thisClaude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic’s Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain’s Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic’s Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI’s Harness Engineering Experiment: Zero Manually-Written Code