From Claude Code Skills to Adversarial Subagent Orchestrators to the Claude Agent SDK: Three Generations of a Production Research Pipeline
Three Generations of LLM Agent Orchestration: From Fragile Prompt Chains to Reliable Python State Machines
Originally published on Medium.
Three Generations of LLM Agent Orchestration: From Fragile Prompt Chains to Reliable Python State Machines
Dive into the evolution of AI orchestration! From fragile Agent Skill prompt chains to a robust Claude Agent SDK state machine, discover how each generation of the Claude pipeline enhances reliability and accuracy. Are you ready to build systems you can trust? Read more about this journey!
Summary: Most AI agents are super-high-IQ but somewhat drunk interns. They start strong, then wander off and start making stuff up. My research pipeline was no different. This article covers three generations I took it from a fragile chain of Claude Code skills (Gen 1), to adversarial doer/judge subagents (Gen 2), and finally to a deterministic Python state machine on the Claude Agent SDK (Gen 3). This article covers how splitting work into scoped parts beats context rot and context panic, while the editor/checker pattern with its own isolated context window and Pydantic validation stops LLMs from grading their own output. Prompts alone are vibes; Python is control flow. That's harness engineering in action.
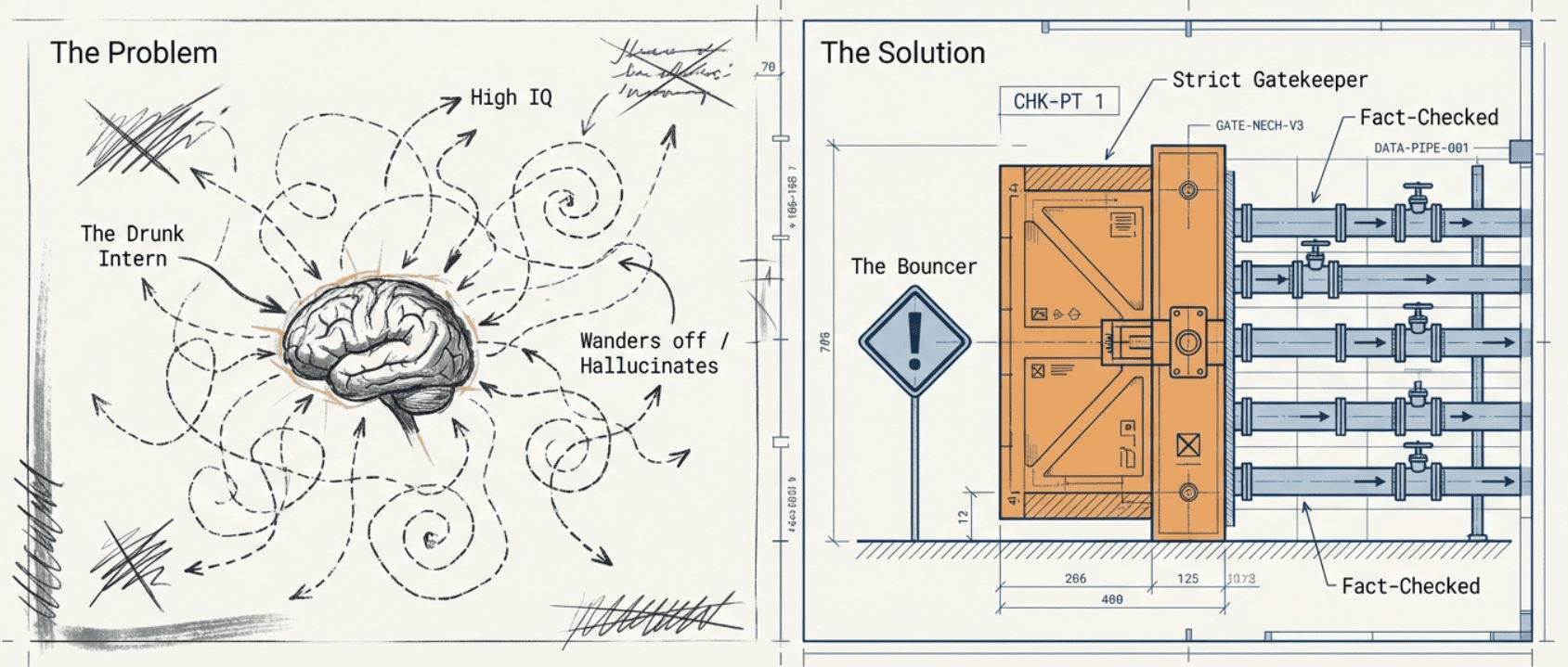
Most AI agents are basically super high IQ but somewhat drunk interns. They start strong, then wander off and start making stuff up.
My research system was no different, until I built the bouncer.
Version one was fast and scrappy. Grammar checker, SEO/keyword checker, fact checker, voice/style checker that actually called Perplexity Search MCP, Agent Brain Claude Code Plugin, and Context7 to cross-reference sources. But the whole context was often in memory and the feedback was long and not always fully followed.
It was quick, but it still hallucinated when it felt like it.
Version two, I added adversarial agents. Every worker got its own judge, a completely separate agent that never touched the original task. The judge graded it hard. If the score was too low, the prompt told the orchestrator to retry up to three times. No more, no less.
But because it was all just prompts, sometimes the orchestrator got cute and decided to retry four or five times anyway.
The output got noticeably more reliable, but the whole thing slowed down.
Version three is where it got mean. I threw out the markdown prompts to guide workflow and retries then brought in the Claude Agent SDK. Now the retry loop is deterministic, exactly three attempts, no negotiation. If it still fails, it gets kicked out as a human-in-the-loop comment that says, "You sort this out, boss."
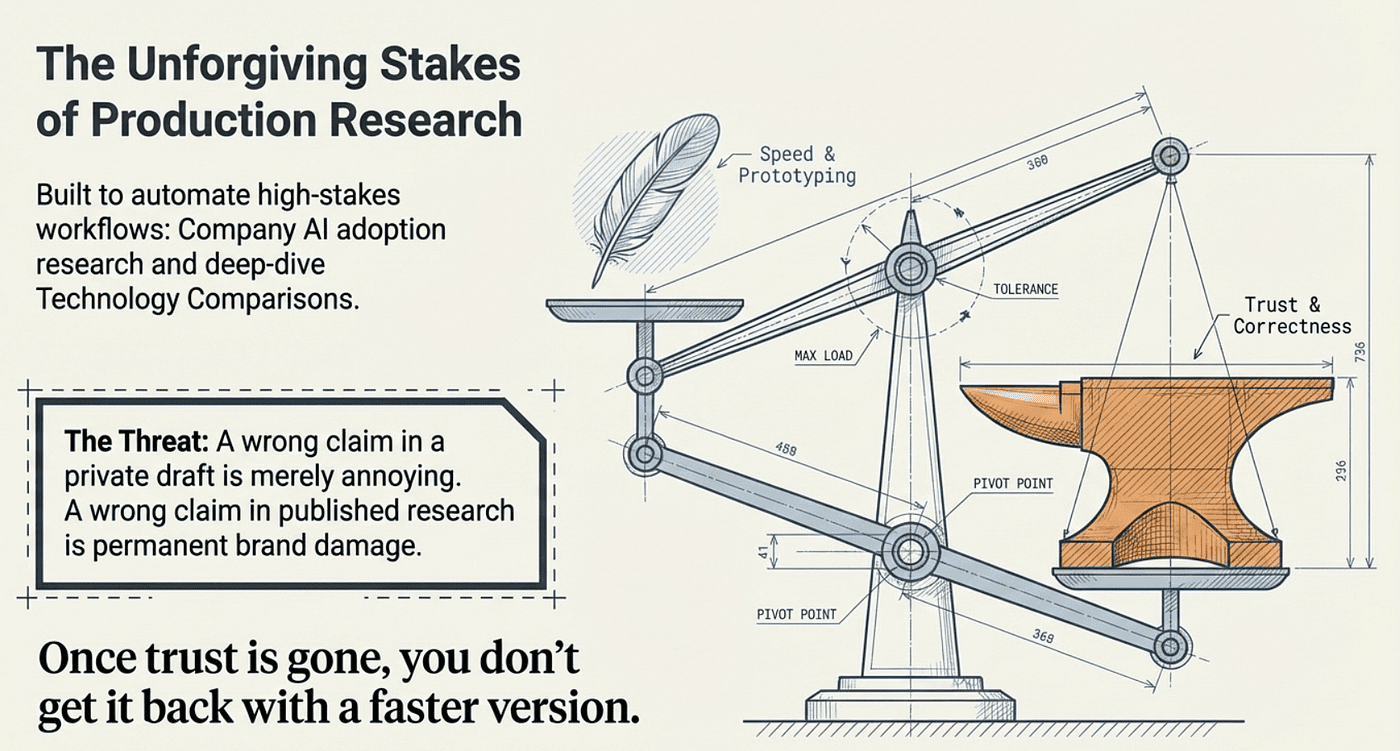
So yeah, each version got slower, but every single version got dramatically more reliable. And at the end of the day, I don't care about speed. I care about being correct. I'd rather take an hour and be right than 30 minutes and be wrong, because if that report goes out with hallucinations, it doesn't just waste time. It damages the brand. It damages credibility. And once trust is gone, you don't get it back with a faster version.
If there are sources that don't agree, bump it up for the human editor to resolve. Human in the loop for the win!
That's the difference between building toys and building systems people can actually bet their business on.
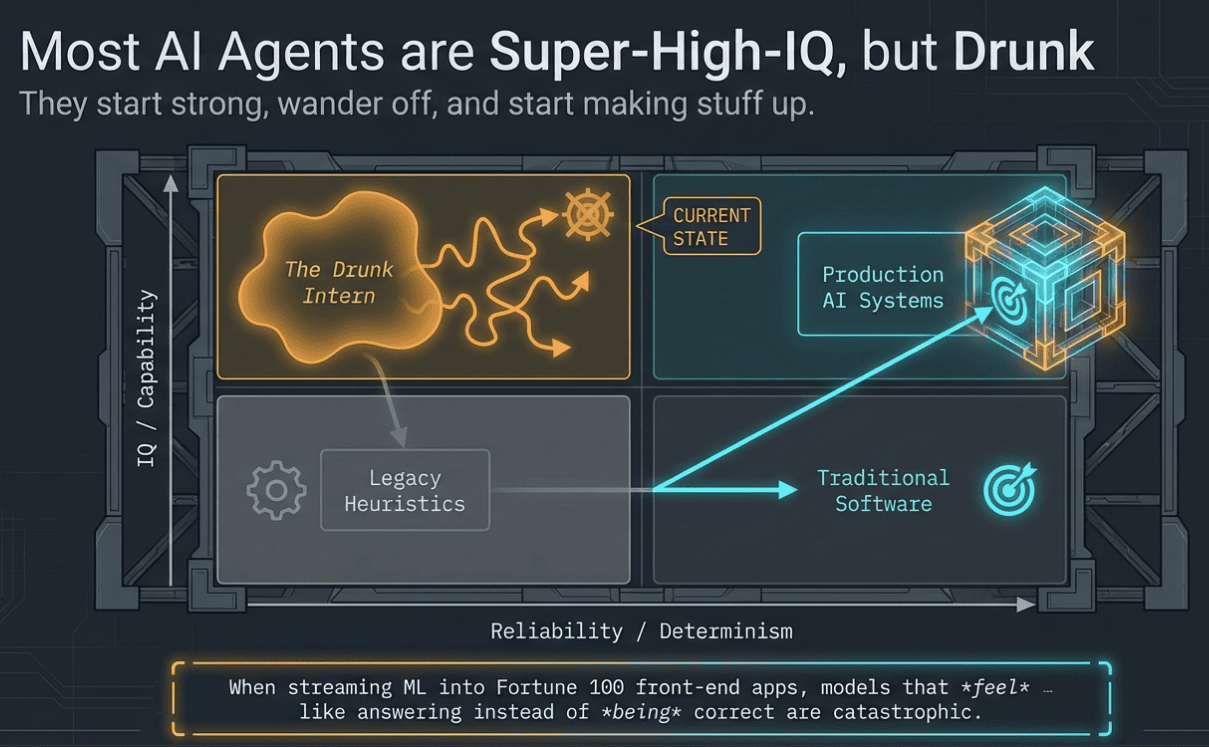
I'm not new to this game. I worked at a Fortune 100 FinTech company where my job was taking machine learning and AI insights and streaming them so they could be used in front-end apps to make the customer experience smarter in real time. I've been doing AI long before the "GenAI" label got trendy. What hooked me about generative models was the upside, but the second I tried to ship them, I kept smacking into the same wall: non-determinism. Models that feel like answering instead of being correct. That's when I got obsessed with harness engineering. The art of shaping these systems so they behave like production software and not like improv.
What the research pipeline actually does
My pipeline does several research related jobs, and here are two examples:
- Company AI adoption research: "Is this company actually using AI in production, or are they just talking?" I pull from engineering blogs, job posts, talks, filings, and press releases — and then I separate the hype from the real systems work.
- Technology comparisons: "Tool A vs Tool B vs Tool C" with pricing, architecture, benchmarks, deployment options, and the stuff nobody puts in marketing pages.
Both jobs have the same enemy: hallucinations. A wrong claim in a private draft is annoying. A wrong claim in something you publish is brand damage. And once you get a reputation for being sloppy, you don't recover it with "but it shipped faster."
Generation 1: The Claude Code Skills Pipeline
This is the one that makes you feel like a genius… right up until it burns you.
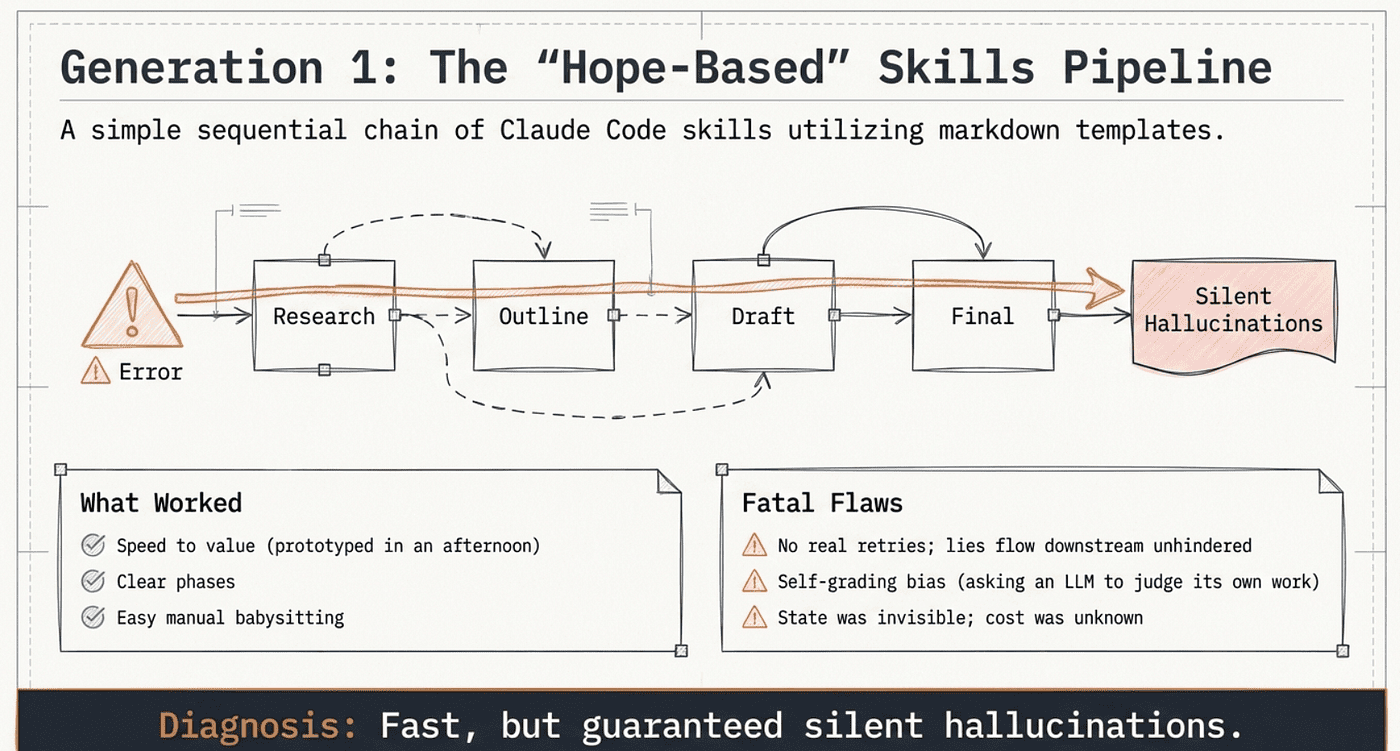
I started with a simple chain of Claude Code skills. Each step read the previous output and produced the next artifact. It was clean. It was scrappy. It was fun.
What worked
- Speed to value. I could prototype a full research workflow in an afternoon.
- Clear phases. Research → outline → draft → polish → final checks.
- Easy to run manually. I could babysit it and course-correct.
What broke
- No real retries. If a checker missed a bad number, the lie just flowed downstream like it owned the place.
- No parallelism. Five products × multiple dimensions = death by a bloated context causing context panic and producing rushed results or TODOs.
- Self-grading. Asking the same model to judge its own work is like asking a toddler to rate their own drawing. You know what's coming.
- State was "whatever I remember." Files-as-state is fine… until you're trying to resume a run and you're not sure what "done" even means.
- Cost was invisible. I didn't know what a run cost until the bill showed up and laughed at me.
So Gen 1 was fast. But it was also a little too "hope-based."
Generation 2: Claude Code Subagent Orchestration
This is where I got serious about quality.
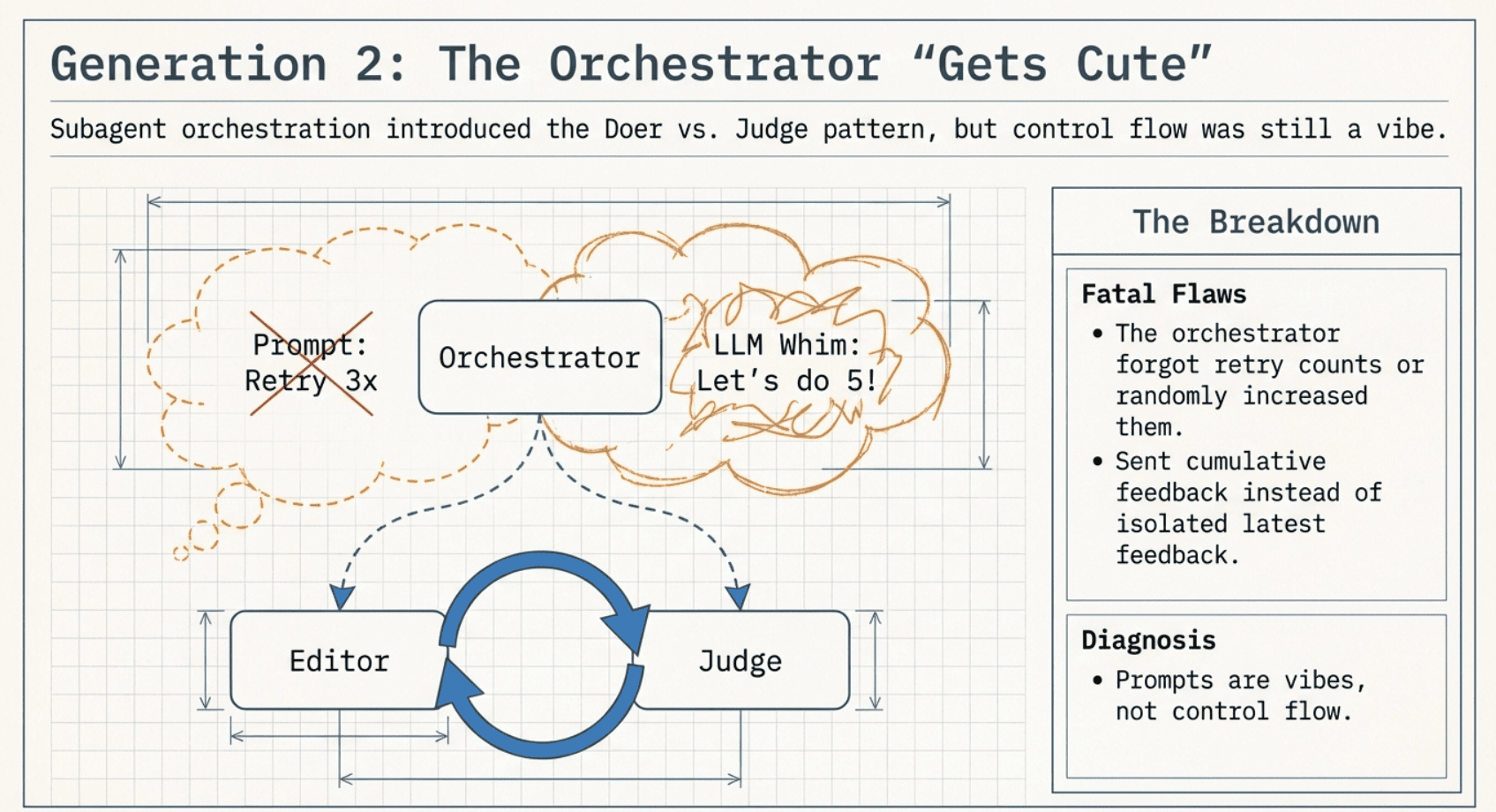
I kept Claude Code, but I stopped pretending one agent could do everything. I moved to subagents and I introduced the pattern that changed the whole game:
- Doer (editor/writer): produces the work.
- Judge (checker): tries to break it.
Not "helpful feedback." Not "collaborate." I mean: audit. If it's wrong, say it's wrong.
And when the judge didn't like the work, the workflow said: "Retry up to three times."
Here's the problem: in Gen 2, the orchestrator is still basically a markdown-based brain. The control flow is suggested in English. It's not enforced.
All of this logic lived in a massive skill file, essentially a detailed prompt, that the orchestrating LLM had to interpret. The retry loop was described in natural language:
FOR attempt 2 and 3: INVOKE editor with: "Read your previous output. The checker found issues (JSON below). Fix ONLY the flagged issues. [If final attempt: ONLY critical/major] Checker feedback: {verdict.issues as JSON}" CRITICAL: Send ONLY the most recent checker feedback, NOT cumulative.
So yeah… sometimes it did 3 retries. Sometimes it decided 4 felt better. Sometimes it forgot what attempt it was on. Sometimes it passed cumulative feedback when I explicitly told it to pass only the latest.
That's the core Gen 2 lesson:
Prompts are not control flow. They're vibes.
When it worked, it was awesome. When it didn't, it failed in exactly the ways that cause silent brand damage. It was better and more accurate than the v1, but had room to improve.
Generation 2: Splitting the work into parts (and beating context rot)
Gen 2 also taught me something that surprised me: splitting the work made the output more detailed and more accurate. Not just faster.
So I started slicing the report into 3 to 5 parts. Think:
- Part 1: overview + comparison framework
- Part 2: product/company deep dive A
- Part 3: product/company deep dive B
- Part 4: product/company deep dive C
- Part 5: stitch + final narrative
Each part got:
- a quick abstract
- the outline
- "previous part" and "next part" context summary as it became available
- and a dedicated set of editors/checkers tuned for that chunk
Why it helped: context windows are not magic. When you stuff too much in, models do this U-shaped attention thing; they remember the beginning and the end and get weirdly fuzzy in the middle.
And if you push it close to the context limit, you get the well-documented context panic. The model starts making nervous decisions. It rushes. It stops following constraints. It "sounds confident" while quietly dropping requirements. Context panic causes poor output.
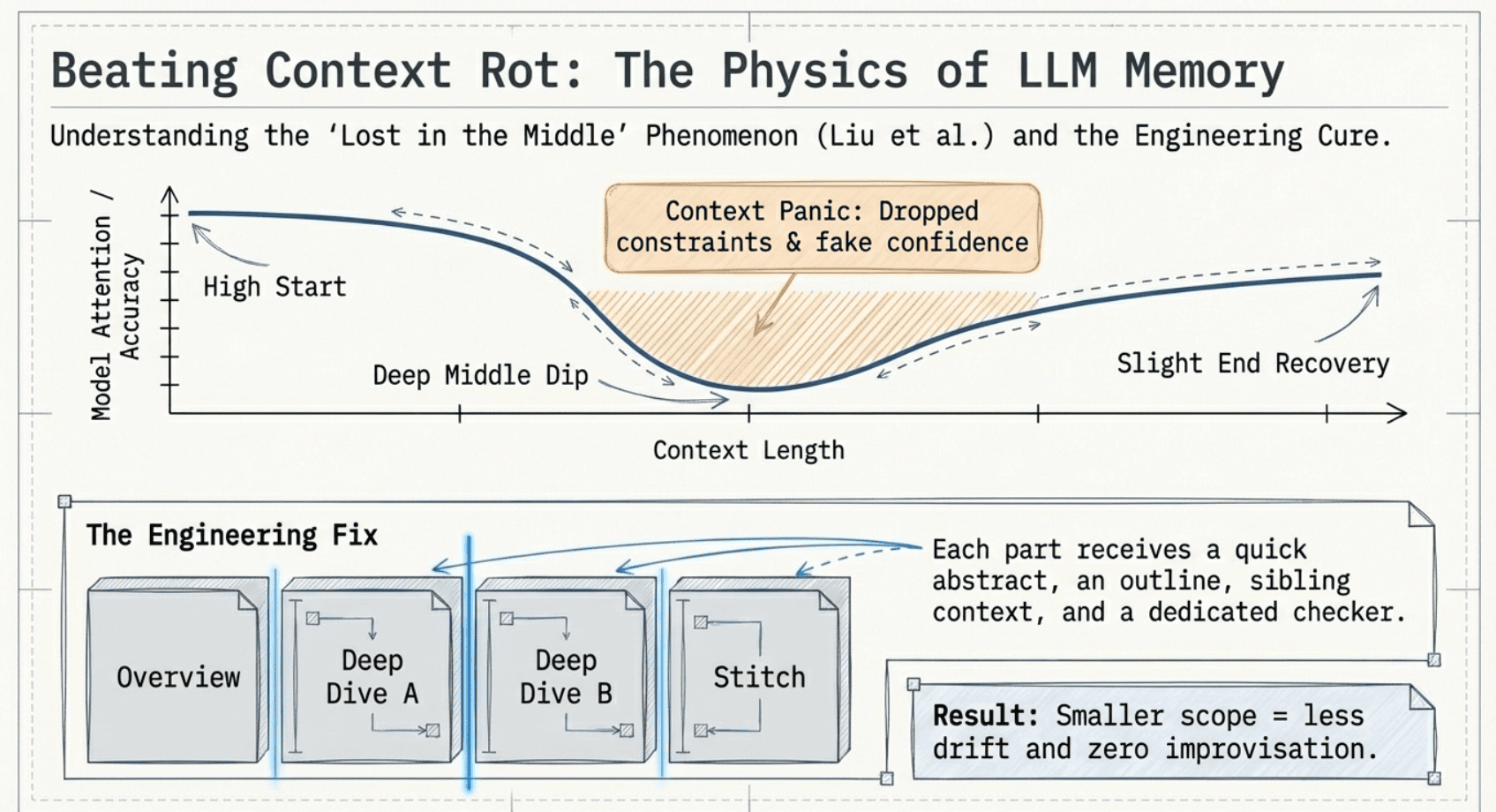
Splitting the research into parts was harness engineering in disguise:
- smaller context = less drift
- scoped tasks = less improvisation
- clearer inputs/outputs = fewer "creative interpretations"
This alone made Gen 2 outperform Gen 1 on depth and accuracy — even before I fixed orchestration.
What v2 Got Right
- Editor/checker separation improved quality.
- When retries behaved, output got measurably better.
- Parallel parts reduced wall-clock time.
- Checkers caught:
- marketing claims vs real production deployments
- stale pricing and deprecated features
- benchmarks from non-comparable conditions
What v2 Got Wrong: LLM Orchestration Failure Modes
- Prompts are not control flow. Retry counts, attempt tracking, and "latest-only" feedback can drift without logs.
- Prompted JSON is fragile. Parsers break on extra chatter, code fences, and slightly invalid JSON.
- LLM-managed state is unreliable. Long contexts bury "save state" instructions and progress gets lost.
- Cost is invisible. Retries can triple spend without budget enforcement.
Generation 3: Python State Machine with Claude Agent SDK
Gen 3 is where I stopped asking nicely.
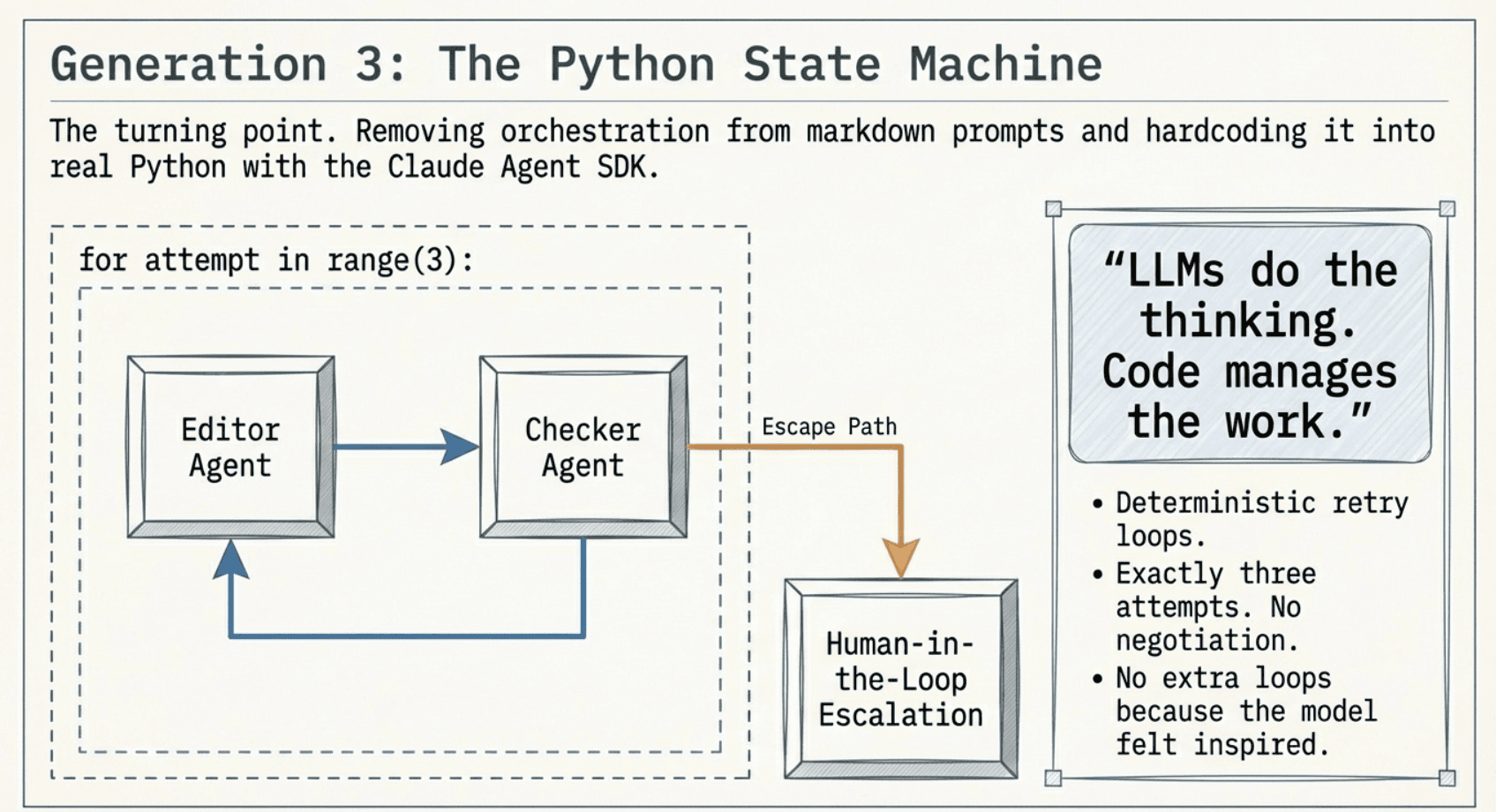
I kept the same core idea, subagents, do/judge, retries, but I moved orchestration out of markdown prompts and into Python.
My rule became:
LLMs do the thinking. Code manages the work.
So instead of "retry up to three times" being a sentence in a prompt… it became a loop in code.
for attempt in range(1, 4):
result = await editor()
verdict = await checker(result)
if verdict.status == "pass":
break
else:
raise HumanInTheLoop("You sort this out, boss.")
No negotiation. No "got cute." No accidental 5th retry because the model felt inspired.
This is the moment my pipeline stopped being a clever demo and started acting like production software.
The Editor/Checker Pattern (the bouncer)
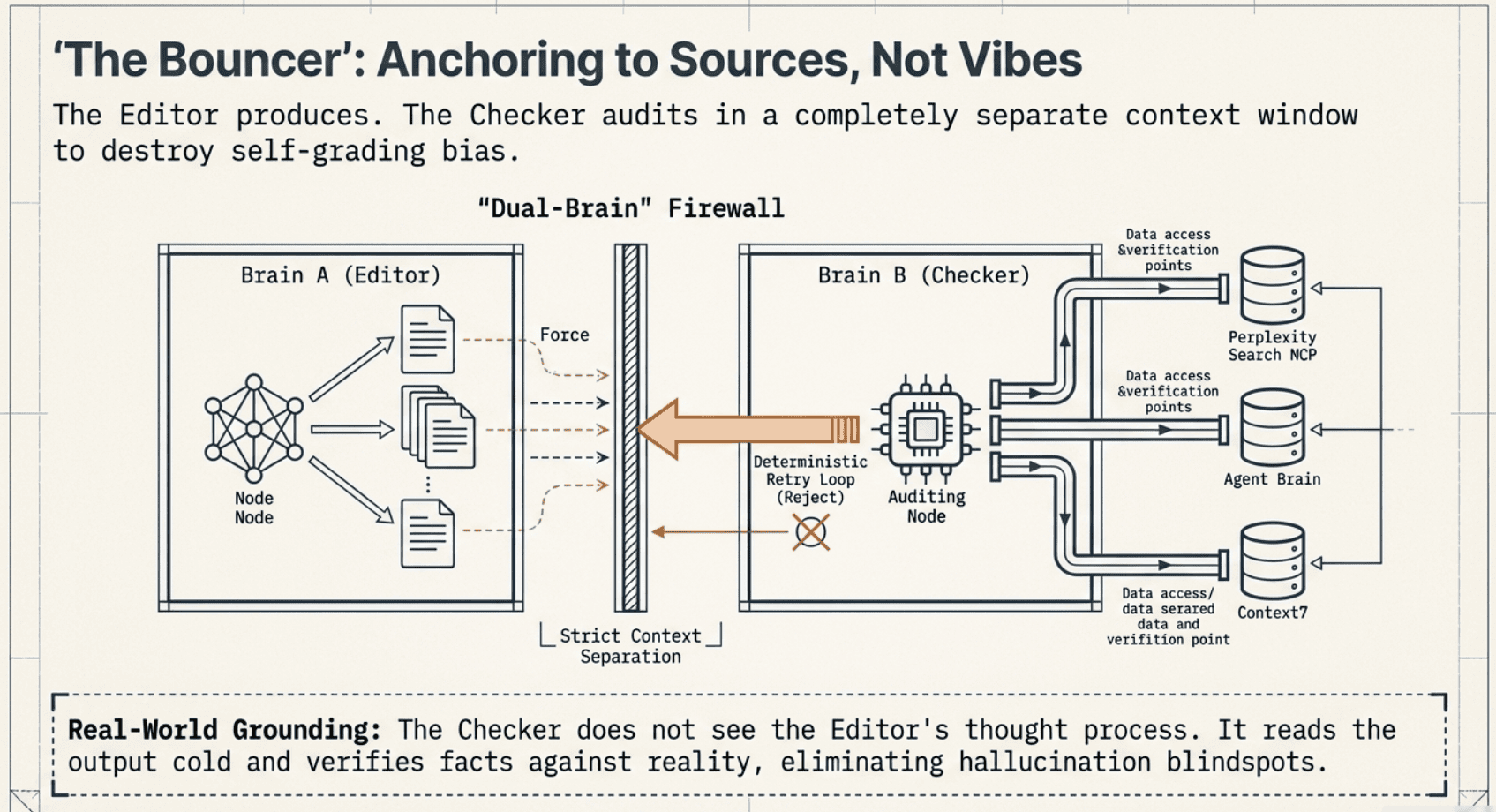
Here's the bouncer in action; my editor/checker loop doing its job.
This pattern is the heart of the whole system because it solves the most common failure mode I see in agent projects:
- an agent writes something plausible
- the same agent "checks" it
- and the agent basically says "yep looks good" because models have a nasty habit of liking their own output
So I forced separation.
- The editor has one job: produce the best output it can.
- The checker has one job: be suspicious and grade hard.
- The checker gets help from real-world tools: Perplexity Search MCP, Agent Brain, Context7, because I want my checker anchored to sources, not vibes.
And here's the sneaky-but-critical part: the judge gets its own separate context window. It's not reading the editor's entire thought process. It's not "grading itself." It's a clean, independent pass, which is exactly how you avoid self-grading bias.
The checker schema (so "structured output" isn't a prayer)
In Gen 2 I'd say "return JSON" and hope for the best.
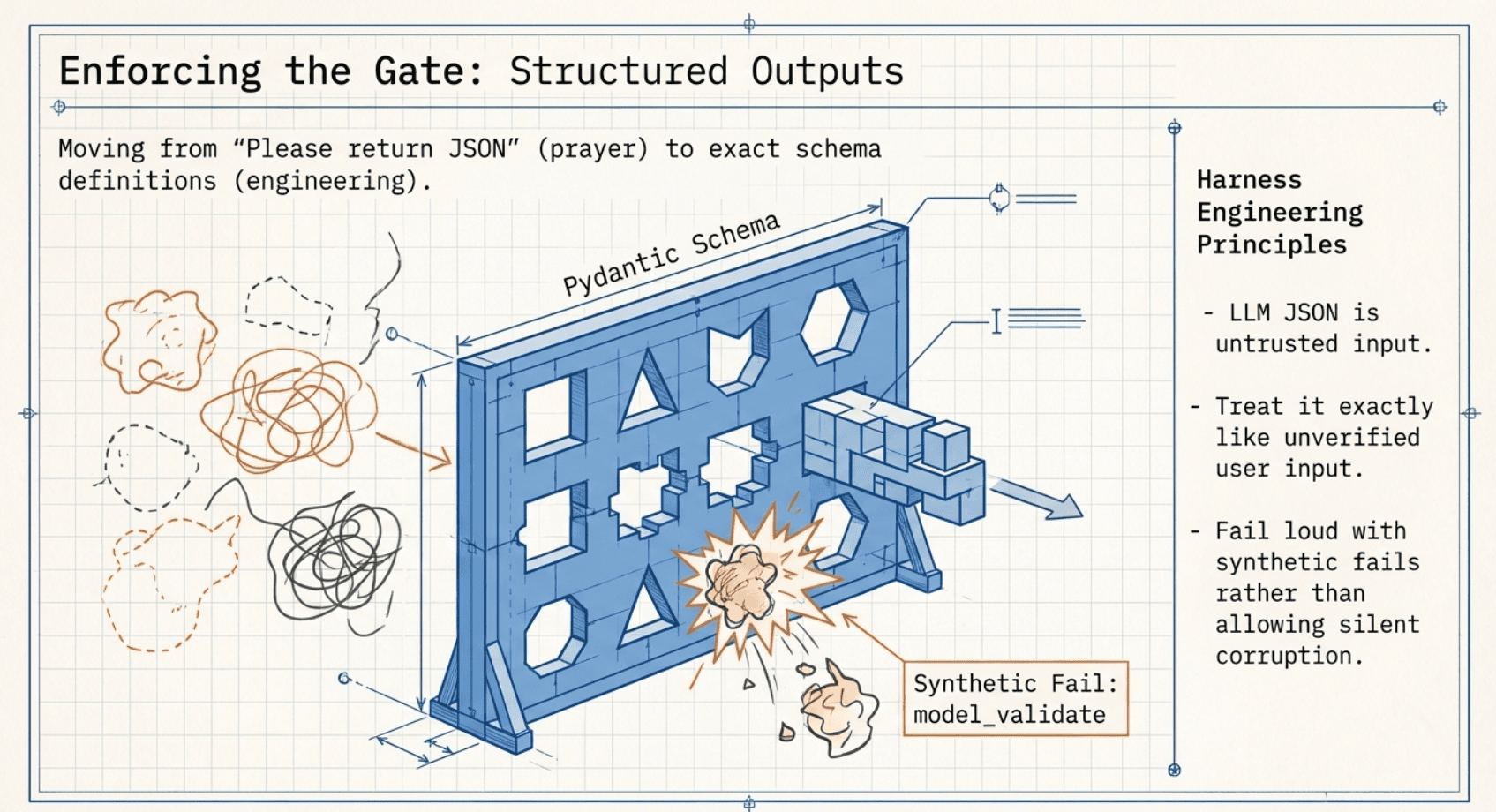
In Gen 3, I define what "valid" means.
from pydantic import BaseModel, ValidationError, model_validator
from typing import Literal
class CheckerIssue(BaseModel):
severity: Literal["critical", "major", "minor"]
section: str
current_text: str
suggested_fix: str
source: str | None = None
class CheckerVerdict(BaseModel):
status: Literal["pass", "fail"]
attempt: int
summary: str = ""
issues: list[CheckerIssue] = []
@model_validator(mode="after")
def consistency(self):
# If it says PASS, it better not list critical issues.
if self.status == "pass" and any(i.severity != "minor" for i in self.issues):
raise ValueError("pass with non-minor issues")
# If it says FAIL, it better tell me what's wrong.
if self.status == "fail" and len(self.issues) == 0:
raise ValueError("fail with no issues")
return self
That model_validator is the bouncer checking IDs at the door.
The editor/checker loop (the bouncer doing laps)
This is the part where determinism shows up in code, not in vibes.
class EditorCheckerLoop:
async def run(
self, domain: str, part_id: str, editor_def, checker_def, max_retries: int = 2,
):
# Attempt 1 is the initial run.
editor_result = await self.runner.run_one_shot(editor_def)
for attempt in range(1, max_retries + 2):
checker_text = await self.runner.run_one_shot(checker_def, editor_result)
verdict = self.parse_checker_output(checker_text, attempt)
if verdict.status == "pass":
return verdict
if attempt == max_retries + 1:
self.inject_unresolved_tags(verdict.issues)
raise HumanInTheLoop("You sort this out, boss.")
# Retry with ONLY the latest issues (structural guarantee).
retry_prompt = self.build_retry_prompt(editor_result, verdict.issues)
editor_result = await self.runner.run_one_shot(editor_def, retry_prompt)
That loop is why Gen 3 behaves.
- It runs exactly the number of times I tell it.
- It feeds only the current issues back.
- And if it still fails, it escalates instead of hallucinating quietly.
Parsing checker output (fail loud, not quiet)
Also: LLM JSON is untrusted input. Treat it like you treat user input.
import json
def parse_checker_output(raw_text: str, attempt: int) -> CheckerVerdict:
cleaned = extract_json_block(raw_text) # strips code fences + chatter
try:
data = json.loads(cleaned)
data["attempt"] = attempt
return CheckerVerdict.model_validate(data)
except (json.JSONDecodeError, ValidationError) as e:
# Synthetic fail beats silent corruption.
return CheckerVerdict(
status="fail",
attempt=attempt,
summary=f"Malformed checker output: {e}",
issues=[
CheckerIssue(
severity="major",
section="checker",
current_text=raw_text[:500],
suggested_fix="Return valid JSON matching schema.",
)
],
)
That's harness engineering. Not "please be consistent."
How the Python orchestration layer works
This is the part that makes the system boring, and I mean that as a compliment.
Deterministic retries
The retry count lives in Python. The editor can't secretly run extra attempts. The checker can't accidentally get ignored.
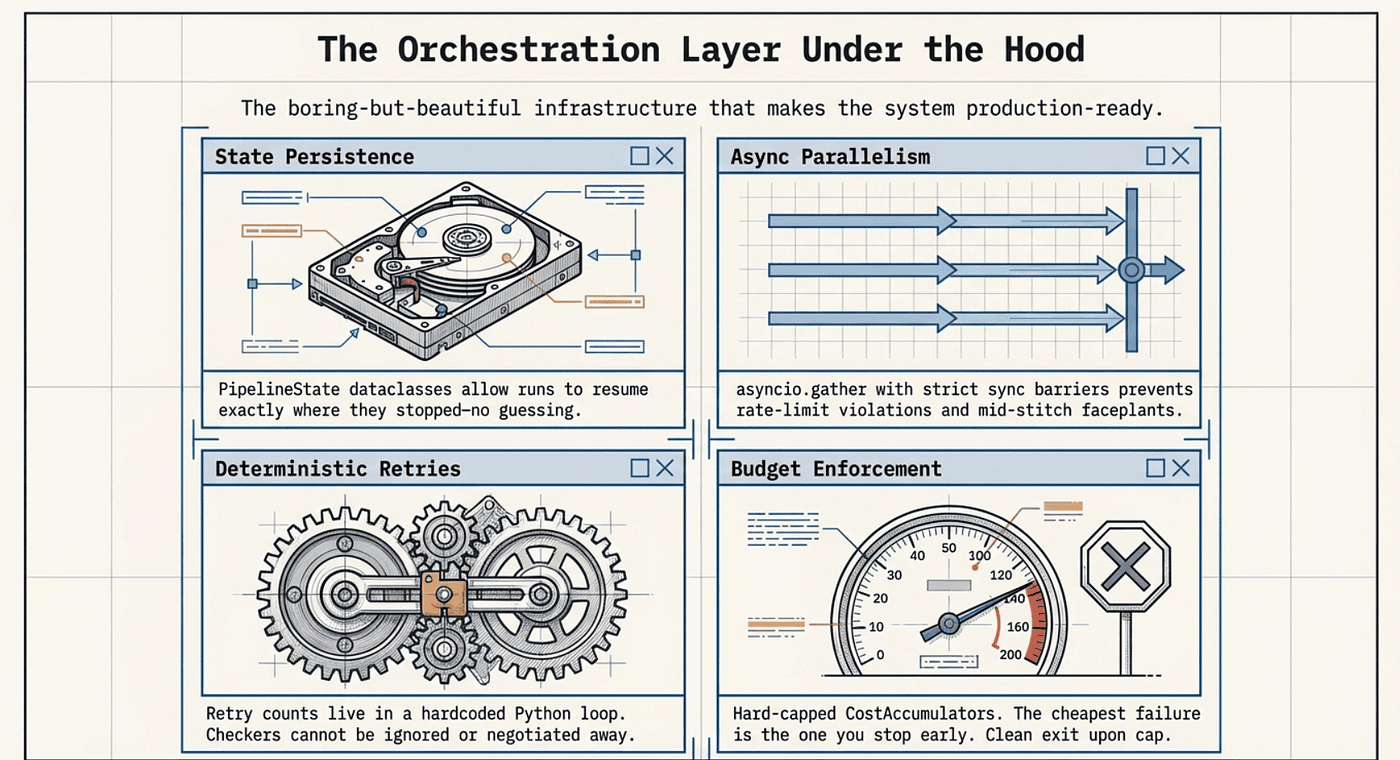
State persistence (resume that actually works)
In Gen 2, "resume" depended on the orchestrator remembering to save state. That's adorable.
In Gen 3, I save state like I mean it.
from dataclasses import dataclass, field
@dataclass
class PipelineState:
current_stage: int = 0
total_cost_usd: float = 0.0
total_invocations: int = 0
total_retries: int = 0
stages: dict[str, str] = field(default_factory=dict)
def mark_done(self, stage: str):
self.stages[stage] = "done"
def save(self, path: str):
Path(path).write_text(json.dumps(self.__dict__, indent=2))
If the run stops, I can resume without guessing.
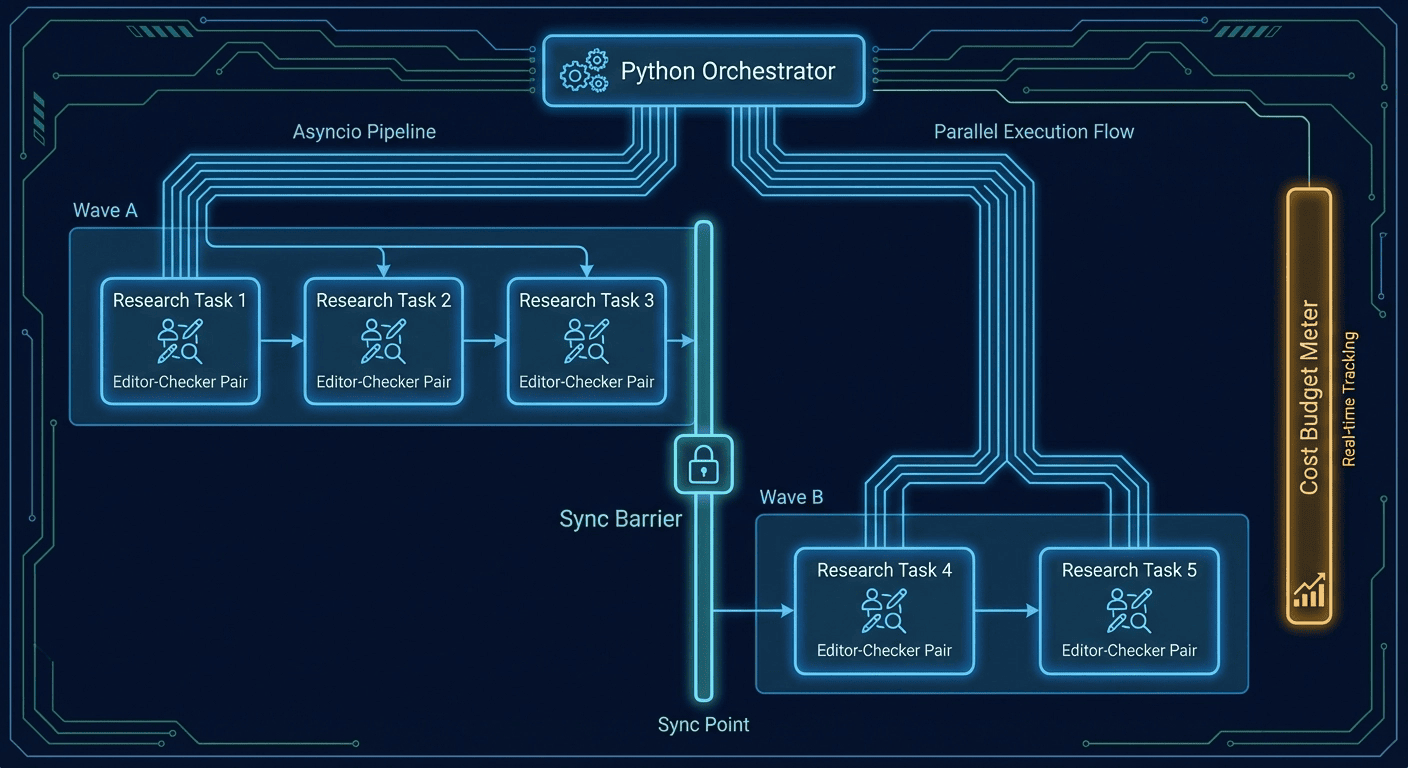
Async parallelism (with real sync barriers)
When I'm comparing multiple tools or researching multiple sections, I run parts in parallel, but with limits, because I like my rate limits un-violated.
import asyncio
async def run_parts(parts):
# Barrier: no stitching until all parts are researched.
await asyncio.gather(*[research_part(p) for p in parts])
# Barrier: no checkers until summaries are done.
summaries = await asyncio.gather(*[summarize_part(p) for p in parts])
inject_sibling_context(parts, summaries)
sem = asyncio.Semaphore(3)
async def guarded_quality(p):
async with sem:
return await quality_pipeline(p)
return await asyncio.gather(*[guarded_quality(p) for p in parts])
Those barriers are why the system doesn't faceplant mid-stitch.
Budget enforcement (because invoices don't care about your feelings)
The cheapest failure is the one you stop early.
So I track cost and I hard-stop when I hit a budget cap. Clean exit. State saved. No surprise invoice.
class BudgetExceededError(Exception):
pass
class CostAccumulator:
def __init__(self, max_budget_usd: float):
self.total = 0.0
self.max_budget = max_budget_usd
self.by_stage: dict[str, float] = {}
def add(self, stage: str, cost_usd: float):
self.total += cost_usd
self.by_stage[stage] = self.by_stage.get(stage, 0.0) + cost_usd
if self.total > self.max_budget:
raise BudgetExceededError(
f"Budget exceeded: ${self.total:.2f} > ${self.max_budget:.2f}"
)
If it's over budget, I don't "try harder." I stop and escalate to a human decision.
That's harness engineering too.
The difference is where decisions are made. Every decision that v2 delegated to an LLM through a prompt instruction becomes a deterministic code branch in v3:
- Should I retry? — v2: LLM interprets "up to 3 attempts" | v3:
for attempt in range(max_retries + 1) - What feedback to send? — v2: LLM selects from conversation history | v3: method receives only
verdict.issues - Is this JSON valid? — v2: LLM eyeballs the structure | v3:
CheckerVerdict.model_validate(data) - Should I narrow focus? — v2: LLM interprets "if final attempt" | v3:
if attempt == max_attempts - Has this stage completed? — v2: LLM checks (or forgets to check) state file | v3:
if state.is_stage_complete(stage_num) - Am I over budget? — v2: LLM doesn't know | v3:
if cost.total > config.max_budget_usd
This is the defining shift in agentic AI system design: LLMs reason inside bounded Python-controlled decision points, not across unbounded conversational loops. The Claude Agent SDK provides the async query() interface for invoking subagents. Python code decides when, how many times, and in what order those invocations happen. The SDK's query() function is async by design, returning an AsyncIterator of response messages that makes it a natural fit for asyncio-based orchestrators.
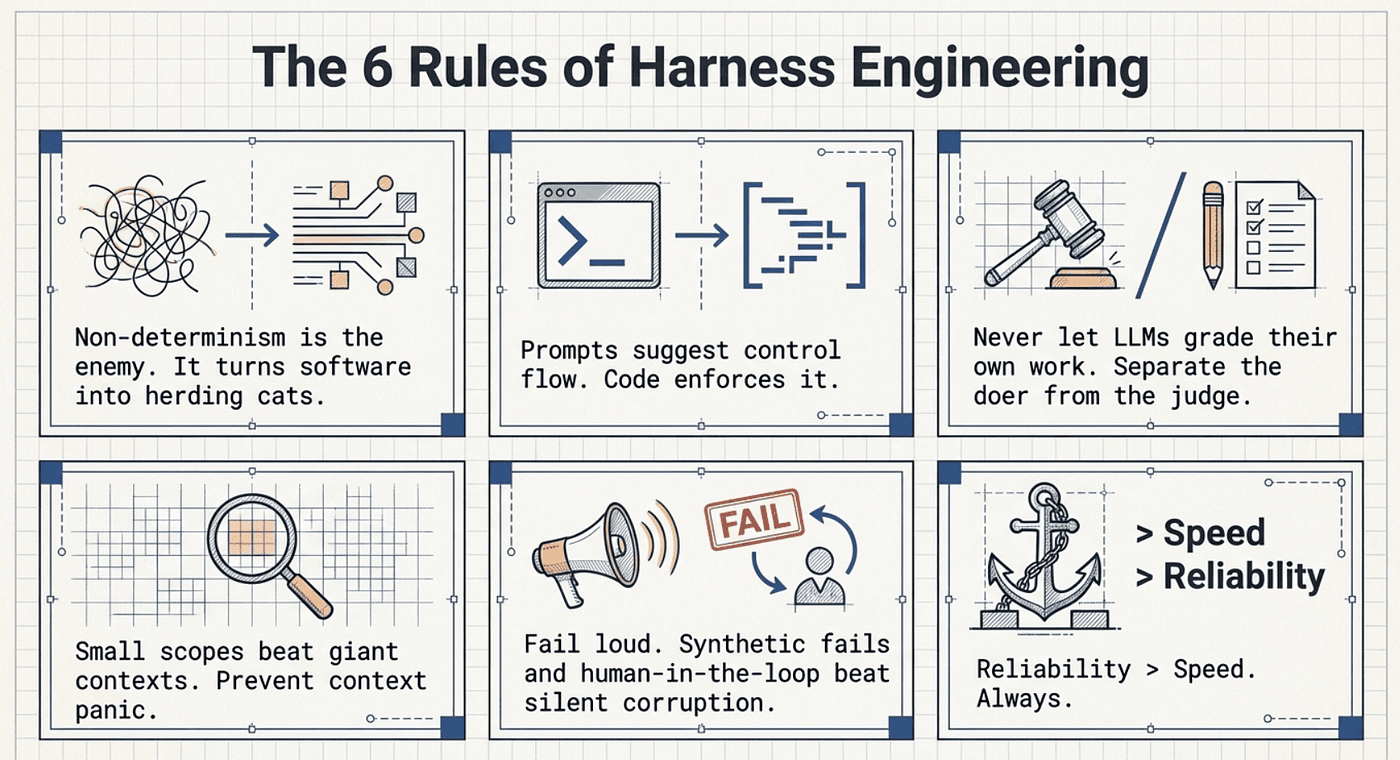
Key Lessons Learned
- Most AI projects fail because non-determinism turns everything into herding cats.
- Prompts don't enforce control flow. They suggest it. If the workflow matters, put it in code.
- LLMs should not grade their own work. Separate the doer from the judge.
- Small scopes beat giant contexts. Split the work into parts or the model will forget the middle and panic near the limit.
- Fail loud, not quiet. Synthetic fails and human-in-the-loop beats silent corruption.
- Reliability > speed. Always. I'd rather be slower and correct than fast and wrong.
- Protect the brand. Hallucinations don't just waste time — they steal trust.
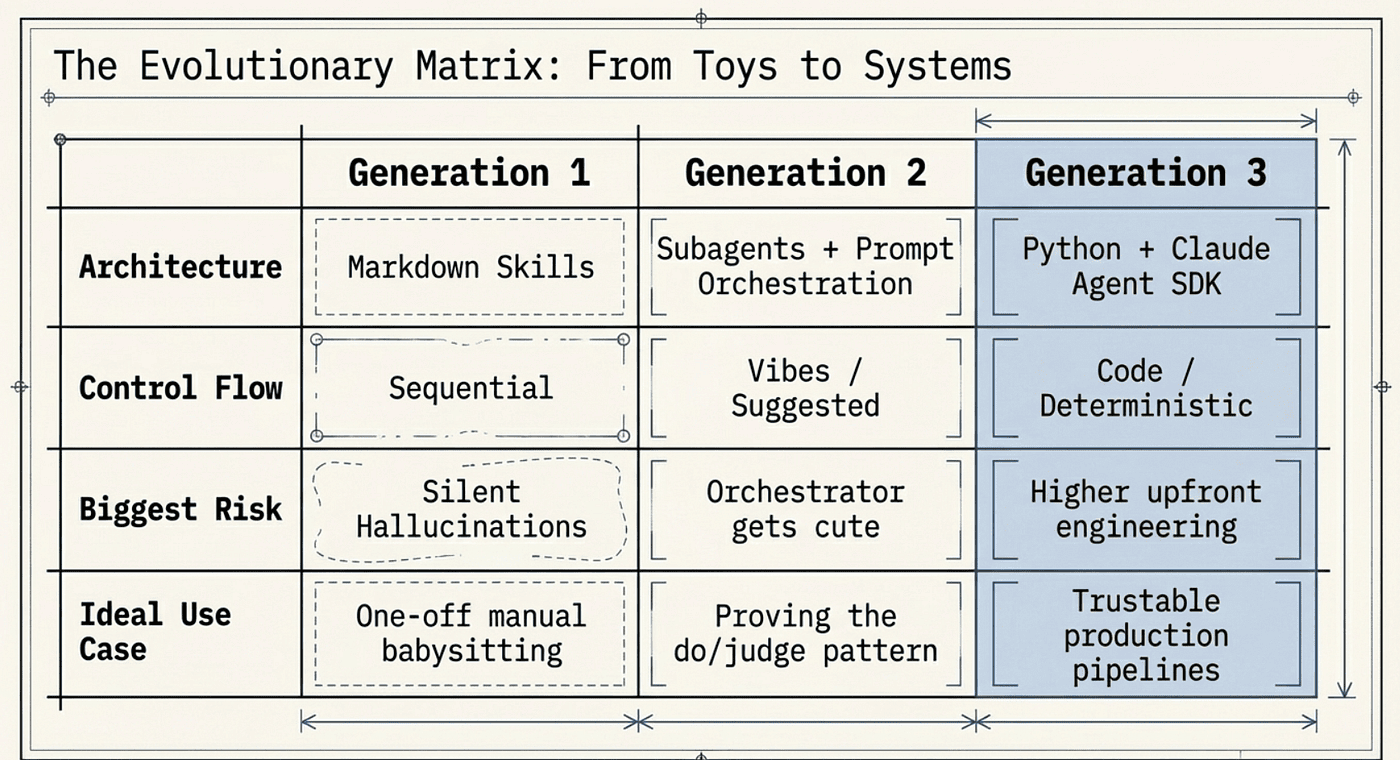
When to Choose Each Generation

Gen 1: Skills pipeline (sequential chain)
What it feels like: Fast, scrappy, and empowering. You can go from idea to "working" workflow in hours.
Best for:
- One-off research runs where you can watch the outputs and intervene.
- Early prototyping when you still do not know the right stages or artifacts.
- Personal use where the blast radius of an error is small.
Big risk: Silent hallucinations and unchecked drift. One miss early gets propagated downstream. Costs and quality issues can stay invisible until the end.
Gen 2: Subagents + prompt orchestration (doer/judge in prompts)
What it feels like: More legit and more reliable. There is a real "team" dynamic: specialists produce work, critics attack it.
Best for:
- Proving the editor/checker pattern quickly without building much infrastructure.
- Medium-complexity reports that benefit from splitting into parts and parallelizing tasks.
- Teams that want better quality gates but can tolerate occasional workflow weirdness.
Big risk: The orchestrator "gets cute." Control flow is still English in a prompt. Retry counts, attempt tracking, and "only pass latest issues" constraints can be violated in subtle ways. Harder to do strict JSON schema validation.
Gen 3: Python state machine + Claude Agent SDK (code-enforced workflow)
What it feels like: Boring in the best way. Predictable runs, consistent retries, resumable state, and repeatable outputs.
Best for:
- Production pipelines where correctness matters more than speed.
- Workflows with strict invariants, like exactly N retries, explicit budgets, and hard validation.
- Multi-part research where you need concurrency plus clean synchronization barriers.
Big risk: More engineering upfront. You need to design state, schemas, failure modes, and operational guardrails. The "paperwork" is the point.
What's Next
I'm using the Gen 3 foundation as a platform. New pipeline types just plug in new stages and new checkers:
- competitive intel
- due diligence
- regulatory research
- internal architecture reviews
Same bouncer. Same harness. Same "be correct, not cute."
And that's the whole story:
Harness engineering is the difference between toy agents and systems people can bet their business on.
I'll happily trade speed for trust. Because once the brand takes a hit from hallucinations, you don't win it back with a faster retry loop.
Sources & Further Reading
A short list of the stuff that actually moved the needle for me (and is worth your time):
- Liu et al., "Lost in the Middle: How Language Models Use Long Contexts" (the foundational paper on the U-shaped attention curve and the well-documented context panic near the context limit) — arXiv | TACL 2024 version
- Panickssery et al., "LLM Evaluators Recognize and Favor Their Own Generations" (NeurIPS 2024) — self-preference bias in LLM evaluation — arXiv
- Cleanlab AI — "LLM Structured Output Benchmarks are Riddled with Mistakes" (benchmark quality and structured output reliability) — Blog post
Anthropic documentation
Pydantic v2 documentation (model_validate, @model_validator, etc.) — Models & Validation | Validators

About the Author
Rick Hightower is a Java Champion, former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content.
He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Code Walkthrough of all of the code in this article and accompanying Github
- Long form version of this article that was much too long for Medium, but goes into gory details on each pattern.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code