From Laptop to Agent Marketplace: Deploy Google ADK Agents to Production with A2A Interoperability (Part 3/3)
Deploying Google ADK Agents with A2A Interoperability: A Comprehensive Guide to Production and Collaboration
Originally published on Medium.
Deploying Google ADK Agents with A2A Interoperability: A Comprehensive Guide to Production and Collaboration
Ready to revolutionize your AI agents? Discover how to seamlessly deploy Google ADK Agents into production and enable cross-framework communication with the A2A protocol! Dive into our latest article for the ultimate guide on turning your local agents into powerful, interoperable services. Don't miss out! #AI #GoogleADK #A2A
Summary: Deploy Google ADK agents to production using A2A interoperability, allowing agents from different frameworks to communicate. The A2A protocol standardizes agent discovery and task delegation, enhancing collaboration across systems. Two deployment paths are available: Vertex AI Agent Engine for managed services and Cloud Run for containerized control. The integration of MCP and A2A protocols enables agents to utilize tools and collaborate effectively, paving the way for a future agent marketplace where agents compete based on quality rather than framework loyalty.
This is Part 3 of a 3-part series on Google ADK.
In Part 1, we build a single agent with tools locally. In Part 2, we orchestrate multi-agent workflows. In Part 3 (this article), we ship to production and connect agents across frameworks via A2A.
Series links:
- Part 1: Google ADK Deep Dive: Building Your First Agent
- Part 2: Google ADK Deep Dive: Multi-Agent Orchestration with ADK
- Part 3 (this): Google ADK Deep Dive: A2A, MCP, and Production Deployment
💡
TL;DR: Deploy Google ADK agents to production using Vertex AI Agent Engine or Cloud Run. Use the A2A protocol (now at v1.0.0) for agent-to-agent interoperability across frameworks. MCP and A2A are complementary, not competing: MCP gives agents tools, A2A gives agents colleagues. Cross-framework communication between ADK, LangGraph, and Claude agents works today with some rough edges.
Your agent is stuck on your laptop.
This article turns it into a production service and makes it interoperable: MCP gives it tools, and A2A gives it peers -- so it can collaborate with agents built in other frameworks.
In Part 1, we built an ADK agent locally. In Part 2, we orchestrated multiple agents. Now we ship: deploy to Cloud Run or Agent Engine, then connect ADK <-> LangGraph <-> Claude-powered agents over A2A.
The A2A Protocol: Turning Agents into Services
Every web service needs a way for clients to find it, understand what it does, and call it. Why should agents be any different?
The Agent-to-Agent (A2A) protocol, launched by Google in April 2025 and now governed by the Linux Foundation at v1.0.0, answers that question. Over 50 partners have signed on: Salesforce, SAP, ServiceNow, Atlassian, LangChain, and a who's who of enterprise tech. Even the big system integrators (Accenture, Deloitte, McKinsey, PwC) are on board, which tells you something about where enterprise agent architecture is heading.
Think of A2A as HTTP for agents. It gives agents a standard way to advertise their capabilities, discover other agents, and delegate tasks across network boundaries. No custom integration required.
Agent Cards: The Business Card for Your Agent
Here's a minimal agent-card.json-style example you can use as a starting point (trimmed to the essentials):
{
"name": "research-agent",
"description": "Performs deep technical research",
"url": "https://REPLACE_ME.run.app",
"version": "1.0.0",
"skills": [
{
"id": "technical-research",
"name": "Technical Research",
"description": "Research a topic and return findings",
"inputModes": ["text"],
"outputModes": ["text"]
}
],
"authentication": {
"schemes": ["bearer"]
}
}
An Agent Card is a JSON document that tells the world what your agent can do. It lives at a well-known endpoint, just like robots.txt for web crawlers or openapi.json for REST APIs.
{
"name": "research-agent",
"description": "Performs deep research on technical topics using multiple sources",
"url": "https://my-agent.run.app",
"version": "1.0.0",
"capabilities": {
"streaming": true,
"pushNotifications": false
},
"skills": [
{
"id": "technical-research",
"name": "Technical Research",
"description": "Researches technical topics with source verification",
"inputModes": ["text"],
"outputModes": ["text"]
},
{
"id": "competitive-analysis",
"name": "Competitive Analysis",
"description": "Compares technologies and frameworks",
"inputModes": ["text"],
"outputModes": ["text"]
}
],
"authentication": {
"schemes": ["bearer"]
}
}
This card is hosted at https://my-agent.run.app/.well-known/agent-card.json (per RFC 8615). Any agent on the network can fetch it and understand what this agent offers. No custom integration. No SDK dependency. Just a JSON document at a predictable URL.
Here is what makes this powerful: the card includes skills with explicit input/output modes. A client agent can programmatically evaluate whether a remote agent can handle its task before sending a single request. It is a machine-readable API contract for agents. If you have ever written an OpenAPI spec, you already understand the concept.
Skill Discovery: How Agents Find Each Other
Discovery works through simple HTTP. A client agent fetches the Agent Card from a known endpoint, evaluates the skills listed, and decides whether this remote agent can help with its current task.
import httpx
async def discover_agent(agent_url: str) -> dict:
"""Fetch and evaluate a remote agent's capabilities."""
async with httpx.AsyncClient() as client:
response = await client.get(
f"{agent_url}/.well-known/agent-card.json"
)
card = response.json()
print(f"Agent: {card['name']}")
print(f"Skills: {len(card['skills'])}")
for skill in card['skills']:
print(f" - {skill['name']}: {skill['description']}")
return card
In production, you would combine this with a registry or directory service for agent lookup. But the protocol itself is deliberately simple: HTTP GET, JSON response, standard endpoint. If you can make an HTTP request, you can discover an A2A agent. No SDKs required. I appreciate that kind of simplicity.
Task Lifecycle: Request, Progress, Completion
Once a client agent finds a remote agent with the right skills, it delegates a task using JSON-RPC 2.0 over HTTP. The lifecycle has four stages, and each one uses a clean, predictable message format.
Stage 1: Send a task
task_request = {
"jsonrpc": "2.0",
"method": "tasks/send",
"params": {
"id": "task-001",
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "Research the current state of A2A protocol adoption across major agent frameworks."
}
]
}
}
}
Stage 2: Receive progress updates via SSE
The remote agent streams progress updates using Server-Sent Events. This matters for long-running tasks where a client needs visibility into what is actually happening:
event: task-status
data: {"id": "task-001", "status": "working", "message": "Gathering sources..."}
event: task-status
data: {"id": "task-001", "status": "working", "message": "Analyzing 12 frameworks..."}
event: task-artifact
data: {"id": "task-001", "artifact": {"type": "text", "text": "Preliminary findings..."}}
Stage 3: Get the final result
event: task-status
data: {"id": "task-001", "status": "completed"}
event: task-artifact
data: {"id": "task-001", "artifact": {"type": "text", "text": "Complete research report..."}}
Stage 4: Error handling
event: task-status
data: {"id": "task-001", "status": "failed", "error": {"code": "RATE_LIMITED", "message": "API quota exceeded"}}
Notice the pattern: every stage uses the same event-driven format. Client agents can handle all four stages with a single SSE listener. No polling. No callbacks. Just a stream of events. Clean.
Building an A2A Service with ADK
Here is where ADK genuinely surprised me. Exposing an agent as an A2A service takes exactly one function call. The to_a2a() utility wraps any ADK agent as a FastAPI application with full A2A support:
from google.adk.agents import Agent
from google.adk.a2a.utils.agent_to_a2a import to_a2a
# Define your agent (from Part 1 of this series)
research_agent = Agent(
name="research_agent",
model="gemini-3.1-pro",
description="Performs deep technical research with source verification",
instruction="""You are a technical research specialist.
When given a topic, research it thoroughly using available tools.
Always cite your sources and verify claims against multiple references.""",
tools=[web_search, document_reader]
)
# Expose it as an A2A service - one line of code
a2a_app = to_a2a(research_agent, port=8001)
Run it:
uvicorn my_agent:a2a_app --host 0.0.0.0 --port 8001
That is it. Your agent is now discoverable at http://localhost:8001/.well-known/agent.json and ready to receive A2A tasks. One import, one function call, one command. ADK auto-generates the Agent Card from your agent's name, description, and tool definitions. I have worked with enough agent frameworks to know this is unusually smooth.
ADK also provides a CLI option for serving agents from a directory:
adk api_server --a2a
This approach serves all agents in the current directory as A2A endpoints, but requires you to manually create an agent.json card for each agent. Use to_a2a() for the simpler path.
Consuming Remote A2A Agents
On the client side, ADK provides RemoteA2aAgent to consume any A2A-compatible agent as if it were a local sub-agent:
from google.adk.a2a.remote_a2a_agent import RemoteA2aAgent
from google.adk.agents import Agent
# Connect to a remote A2A agent
remote_research = RemoteA2aAgent(
name="remote_research",
description="Remote research agent accessible via A2A",
agent_card="http://research-service:8001/.well-known/agent.json"
)
# Use it as a sub-agent in your orchestrator
orchestrator = Agent(
name="orchestrator",
model="gemini-3.1-flash",
description="Orchestrates research and analysis tasks",
instruction="Delegate research tasks to the remote research agent.",
sub_agents=[remote_research]
)
The beauty of RemoteA2aAgent: it implements the same interface as a local sub-agent. Your orchestrator does not know or care whether a sub-agent is running locally or across the network. The remote agent could be running on a different server, in a different cloud, built on a different framework entirely. As long as it speaks A2A, your ADK orchestrator can use it. That is the whole point of a standard protocol.
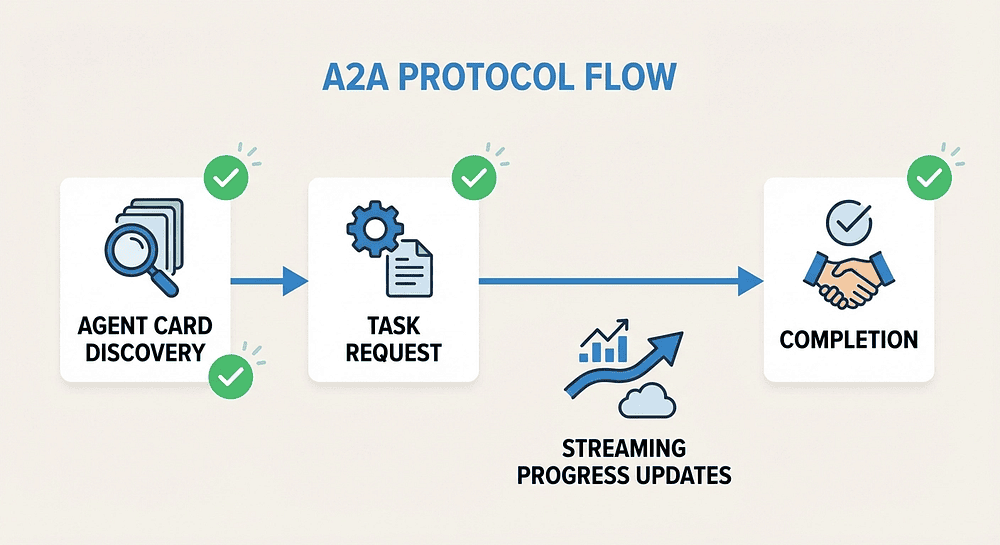
Figure 1: The A2A protocol flow from Agent Card discovery through the full task lifecycle.
MCP vs A2A: The Mental Model Most Articles Get Wrong
Here is the distinction that most articles about agent protocols miss entirely, and getting this wrong leads to confused architectural decisions. MCP and A2A do not compete. They solve fundamentally different problems at different layers of the agent stack.
MCP gives agents hands. A2A gives agents colleagues.
Once you internalize this, the entire agent protocol landscape snaps into focus. I spent weeks confused about this before the mental model clicked, and I suspect I am not alone.
MCP: Agent-to-Tool (The Vertical Layer)
The Model Context Protocol, originally created by Anthropic, standardizes how an agent connects to tools and data sources. It is the vertical layer: your agent reaches down to use capabilities.
Agent
|
| MCP Protocol
|
v
[Database] [APIs] [File System] [Search Engine]
When your agent needs to query a database, call a REST API, or search the web, it uses MCP. MCP extends what an agent can do by giving it access to external tools and data. With over 97 million downloads, it is the de facto standard for agent-to-tool communication.
A2A: Agent-to-Agent (The Horizontal Layer)
The A2A protocol standardizes how agents communicate with other agents. It is the horizontal layer: your agent reaches across to delegate work to peers.
[Research Agent] <-- A2A --> [Analysis Agent] <-- A2A --> [Writing Agent]
When your agent needs another agent to handle part of a task, it uses A2A. A2A extends what an agent can delegate by connecting it to other agents with specialized capabilities. And here is the key: agent-to-agent coordination is explicitly out of scope for MCP. A2A fills that gap.
Together: The Full Agent Stack
The real power emerges when you combine both protocols. Here is what a production multi-agent system actually looks like:
from google.adk.agents import Agent
from google.adk.a2a.remote_a2a_agent import RemoteA2aAgent
# This specialist uses MCP to access its tools
data_analyst = Agent(
name="data_analyst",
model="gemini-3.1-pro",
description="Analyzes data from multiple sources",
tools=[sql_tool, pandas_tool, chart_tool] # MCP tools
)
# This orchestrator uses A2A to delegate to remote specialists
orchestrator = Agent(
name="project_lead",
model="gemini-3.1-flash",
description="Coordinates project analysis across teams",
sub_agents=[
RemoteA2aAgent( # A2A: delegate to remote research agent
name="researcher",
agent_card="https://research.run.app/.well-known/agent.json"
),
data_analyst # Local: uses MCP for its tools
]
)
The orchestrator uses A2A to delegate research to a remote agent. That remote agent uses MCP to access its own tools. The local data analyst uses MCP directly for database queries and data visualization. Both protocols operate independently, at different layers, solving different problems. Once you see this layered model, you stop trying to pick one protocol over the other.
When to Use Which
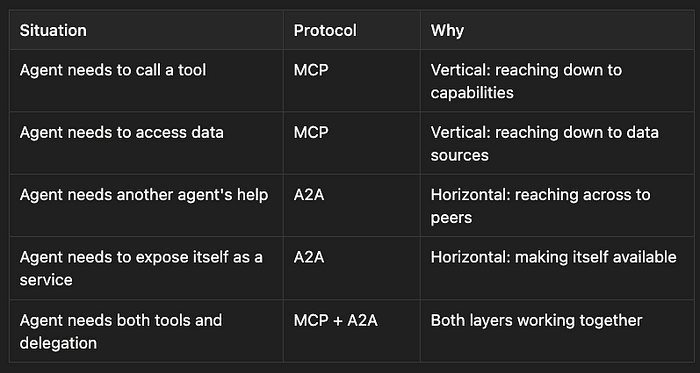
- Agent needs to call a tool -> MCP: Vertical, reaching down to capabilities
- Agent needs to access data -> MCP: Vertical, reaching down to data sources
- Agent needs another agent's help -> A2A: Horizontal, reaching across to peers
- Agent needs to expose itself as a service -> A2A: Horizontal, making itself available
- Agent needs both tools and delegation -> MCP + A2A: Both layers working together
Stop thinking of MCP and A2A as competing standards. They are complementary layers in the same stack. The most capable production systems will use both.
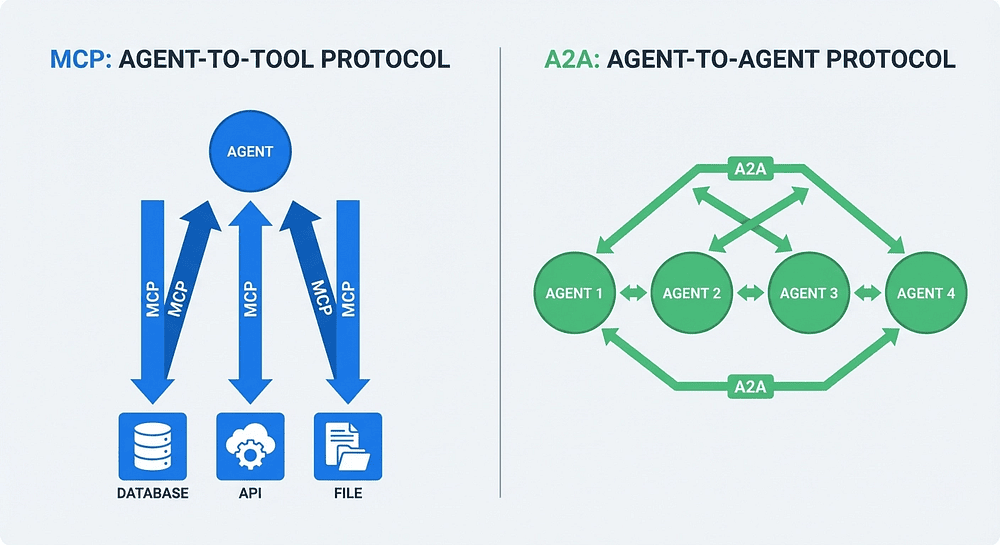
Figure 2: MCP handles vertical agent-to-tool communication; A2A handles horizontal agent-to-agent communication. Together they form the complete agent protocol stack.
Deploy to Production: Two Paths, One CLI
Building an A2A-capable agent is step one. Getting it into production is where it actually counts. I have deployed agents through both of ADK's deployment paths, and the choice comes down to a simple question: how much control do you need versus how much management do you want to offload?
Path 1: Vertex AI Agent Engine (The Managed Route)
Vertex AI Agent Engine is Google's fully managed deployment service for ADK agents. You give it your agent code; it handles packaging, scaling, monitoring, and serving. If you have ever used Cloud Functions or App Engine, the model is familiar.
Setup:
# Set your Google Cloud environment
export GOOGLE_CLOUD_PROJECT=my-project-id
export GOOGLE_CLOUD_LOCATION=us-central1
export GOOGLE_GENAI_USE_VERTEXAI=True
# Enable required APIs (one-time setup)
gcloud services enable aiplatform.googleapis.com
gcloud services enable cloudresourcemanager.googleapis.com
Deploy:
adk deploy agent_engine \
--project=$GOOGLE_CLOUD_PROJECT \
--region=$GOOGLE_CLOUD_LOCATION \
--display_name="Research Agent Production" \
research_agent
That single command packages your code, builds a container, deploys it to the managed runtime, and configures auto-scaling. Deployment typically takes a few minutes.
What you get: Auto-scaling based on request volume. Built-in monitoring through the Agent Engine UI in Cloud Console. Enterprise-grade security and authentication. Integrated logging and tracing. Zero container management.
The tradeoff: Less granular control over the runtime. No custom container configurations. You are locked to Google Cloud. For some teams, that is fine. For others, it is a dealbreaker.
Path 2: Cloud Run (The Container Route)
Cloud Run deploys your agent as a serverless container, giving you more control while still handling scaling. The --a2a flag is the key differentiator here: it automatically exposes your agent as an A2A service.
Deploy (Cloud Run + A2A):
# Minimal, copy-paste deployment (replace placeholders)
export GOOGLE_CLOUD_PROJECT="my-project"
export GOOGLE_CLOUD_LOCATION="us-central1"
adk deploy cloud_run \
--project="$GOOGLE_CLOUD_PROJECT" \
--region="$GOOGLE_CLOUD_LOCATION" \
--service_name="research-agent-service" \
--with_ui \
--a2a \
./research_agent
This single command handles four steps behind the scenes:
- Package your agent code
- Build a container image
- Push the image to Artifact Registry
- Launch the service on Cloud Run with A2A endpoints
Setting up service-to-service authentication (example):
# Create a service account for agent-to-agent communication
gcloud iam service-accounts create research-agent-sa \
--display-name="Research Agent Service Account"
# Grant the Cloud Run invoker role for A2A access
gcloud run services add-iam-policy-binding research-agent-service \
--region="$GOOGLE_CLOUD_LOCATION" \
--member="serviceAccount:research-agent-sa@${GOOGLE_CLOUD_PROJECT}.iam.gserviceaccount.com" \
--role="roles/run.invoker"
What you get: Full container control. Automatic A2A endpoint configuration. Serverless scaling that drops to zero when idle. IAM-based authentication between services. Portable containers you can run anywhere.
The tradeoff: No Agent Engine-specific monitoring dashboard. More operational responsibility. You need to know your way around containers.
Choosing Between Them

Control level
- Vertex AI Agent Engine: Managed (less)
- Cloud Run: Containerized (more)
Scaling
- Vertex AI Agent Engine: Automatic
- Cloud Run: Automatic + configurable
Cost model
- Vertex AI Agent Engine: Usage + managed premium
- Cloud Run: Pay per request
A2A support
- Vertex AI Agent Engine: Built-in
- Cloud Run: Via
--a2aflag
Best fit
- Vertex AI Agent Engine: Google-first, fast deploy
- Cloud Run: Multi-cloud, custom needs
Monitoring
- Vertex AI Agent Engine: Agent Engine UI
- Cloud Run: Cloud Run + custom
My recommendation: Start with Cloud Run and the --a2a flag. You get A2A interoperability, container portability, and enough control to customize as needs evolve. Move to Agent Engine when you need its managed features and are committed to the Google Cloud ecosystem. I have seen too many teams lock into managed services early and regret it when requirements change.
There is also a third option: adk deploy gke for teams that want full Kubernetes control. That path makes sense for organizations that already run GKE clusters and have the operational maturity to manage them.
Production Essentials
Both paths need proper observability. Here are the patterns that actually matter in production:
Structured logging for A2A interactions:
import logging
import google.cloud.logging
client = google.cloud.logging.Client()
client.setup_logging()
logger = logging.getLogger(__name__)
# Log every A2A interaction for debugging and audit
logger.info("A2A task received", extra={
"task_id": task_id,
"requesting_agent": remote_agent_name,
"skill_requested": skill_id,
"timestamp": datetime.utcnow().isoformat()
})
Health checks that verify A2A readiness:
@app.get("/health")
async def health_check():
return {
"status": "healthy",
"agent": "research-agent",
"version": "1.0.0",
"a2a_ready": True,
"skills_available": ["technical-research", "competitive-analysis"]
}
Do not skip the health checks. When an A2A agent goes down in production, the agents depending on it need to know immediately, not after a 30-second timeout on a failed task.
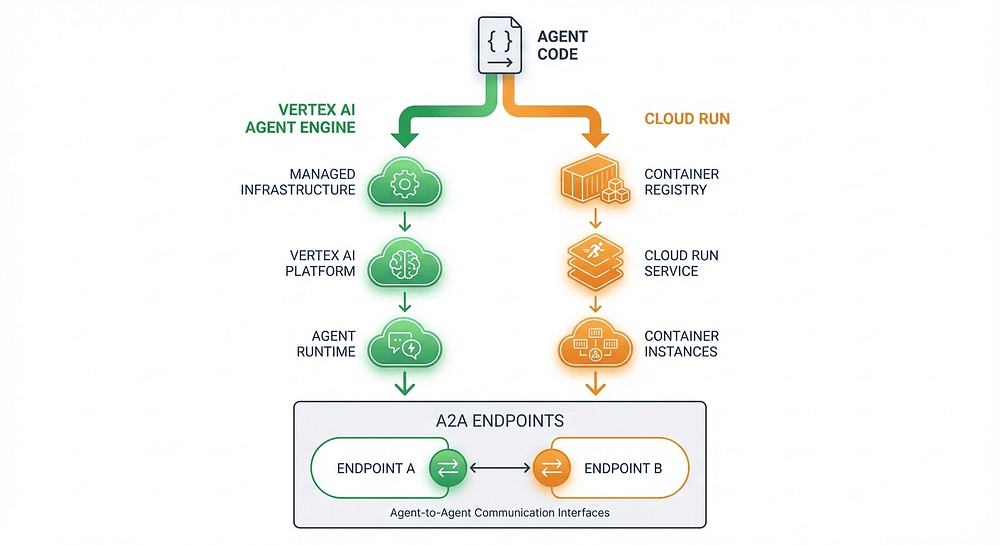
Figure 3: Two deployment paths for ADK agents. Both lead to A2A-accessible production services, with different control and management tradeoffs.
The Interoperability Test: Can These Agents Actually Talk?
Protocols look great on paper. What matters is whether agents from different frameworks can actually collaborate in practice. I tested A2A interoperability between ADK, LangGraph, and Claude-powered agents. Here is what I found, and I am going to be straight with you about what works and what does not.
Test 1: ADK Agent + LangGraph Agent via A2A
LangChain is a named A2A partner, so LangGraph has support for exposing agents via A2A endpoints. This was the test I was most optimistic about.
LangGraph side (the A2A server):
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from a2a.server import A2AServer
# Build a LangGraph agent with GPT
llm = ChatOpenAI(model="gpt-5.4")
langgraph_agent = create_react_agent(
llm,
tools=[search_tool, calculator_tool],
state_modifier="You are an analysis specialist."
)
# Expose it as an A2A service
server = A2AServer(
agent=langgraph_agent,
name="langgraph-analyst",
description="Analysis agent powered by LangGraph and GPT",
skills=[{
"id": "data-analysis",
"name": "Data Analysis",
"description": "Performs quantitative and qualitative data analysis"
}],
port=8002
)
server.run()
ADK side (the A2A client):
from google.adk.a2a.remote_a2a_agent import RemoteA2aAgent
from google.adk.agents import Agent
# Connect to the LangGraph agent via A2A
langgraph_analyst = RemoteA2aAgent(
name="langgraph_analyst",
description="Remote LangGraph analysis agent",
agent_card="http://localhost:8002/.well-known/agent-card.json"
)
# Multi-framework orchestrator
orchestrator = Agent(
name="multi_framework_lead",
model="gemini-3.1-flash",
description="Orchestrates tasks across ADK and LangGraph agents",
instruction="""You coordinate research and analysis tasks.
Use the local research agent for information gathering.
Use the remote LangGraph analyst for data analysis.
Synthesize results from both into a coherent report.""",
sub_agents=[local_research_agent, langgraph_analyst]
)
What happened:
- Agent Card discovery worked seamlessly across frameworks. No surprises.
- Task delegation through A2A succeeded on the first attempt.
- SSE streaming progress updates functioned correctly.
- Message format nuances between frameworks needed minor handling at the boundaries.
- Authentication required standard service-to-service setup (nothing exotic).
Test 2: ADK Agent + Claude Agent via A2A
The natural pattern for Claude-powered agents is MCP for tools, A2A for inter-agent communication. This is where the MCP+A2A layered model proves its value.
Claude agent as A2A server:
import anthropic
from a2a.server import A2AServer
client = anthropic.Anthropic()
async def handle_task(task_message: str) -> str:
"""Process an A2A task using Claude."""
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
messages=[{"role": "user", "content": task_message}],
system="You are a code review specialist. Analyze code for bugs, security issues, and adherence to best practices."
)
return response.content[0].text
server = A2AServer(
handler=handle_task,
name="claude-reviewer",
description="Code review agent powered by Claude",
skills=[{
"id": "code-review",
"name": "Code Review",
"description": "Reviews code for bugs, security, and best practices"
}],
port=8003
)
server.run()
The three-framework orchestrator:
# ADK orchestrator consuming agents from three different frameworks
dev_lead = Agent(
name="dev_lead",
model="gemini-3.1-pro",
description="Development lead coordinating across frameworks",
instruction="""You manage a development workflow using the best agent for each task.
1. Use the research agent for requirements gathering (ADK + Gemini)
2. Use the LangGraph analyst for technical analysis (LangGraph + GPT-4o)
3. Use the Claude reviewer for code review (Claude)
Synthesize insights from all three into actionable recommendations.""",
sub_agents=[
local_research_agent, # ADK + Gemini
langgraph_analyst, # LangGraph + GPT
claude_reviewer # Claude via A2A
]
)
What happened:
- The A2A protocol layer worked correctly regardless of underlying model.
- Claude's responses integrated cleanly into the ADK orchestrator workflow.
- The MCP+A2A hybrid pattern felt natural and effective.
- Different model response times required proper timeout configuration (Claude Sonnet is faster than Gemini Pro for some tasks; the opposite for others).
- Cost tracking across three providers needed custom instrumentation. There is no standard for this yet.
The Honest Assessment
Here is where I give you the unfiltered take, because overselling interoperability helps no one.
Production-ready right now:
- A2A protocol for agent discovery and task delegation
- ADK's
to_a2a()andRemoteA2aAgentAPIs - Basic cross-framework communication (ADK to LangGraph, ADK to Claude)
- The MCP+A2A complementary pattern
- Cloud Run deployment with automatic A2A endpoints
Still has rough edges:
- Complex multi-turn conversations across framework boundaries lose context
- Shared state and memory between cross-framework agents requires custom solutions
- Dynamic agent discovery in production still relies on static registries or manual endpoint configuration
- Error semantics vary across frameworks even with A2A standardization
- Production security patterns beyond basic authentication need more maturity
The bottom line: A2A at v1.0.0 is solid engineering. The implementations across frameworks are catching up, with ADK and LangGraph leading the pack. If you build a cross-framework system today, plan for integration glue code at the boundaries. It works. It is not yet plug-and-play. Give it six to twelve months for the rough edges to smooth out. But the direction is clear, and building on A2A today is not a bet; it is a head start.
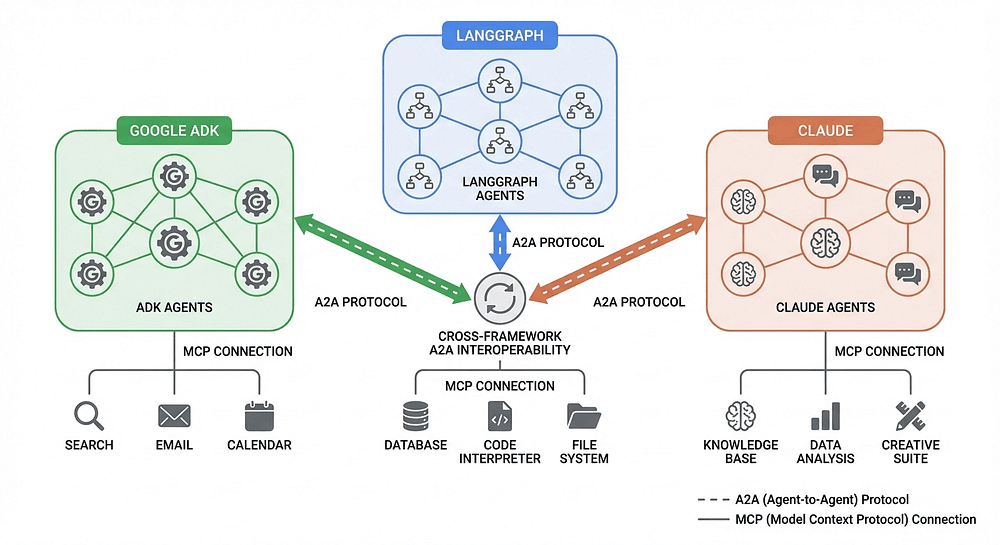
Figure 4: Three frameworks, three models, one protocol. ADK, LangGraph, and Claude agents communicate via A2A while each uses MCP for tool access.
Where ADK Fits in a Multi-Framework World
I work across LangGraph, Claude Code, and ADK regularly. Each framework has genuine strengths, and pretending any single one is the right answer for everything would be dishonest. Here is my practical assessment as someone who builds with all three.
Where ADK Excels
Google Cloud integration. If you are building on Google Cloud, ADK's deployment story is the best I have seen from any agent framework. The adk deploy command handles containerization, deployment, A2A configuration, and scaling in one step. No other framework comes close to this level of deployment integration with a major cloud provider. It just works.
A2A protocol support. ADK has first-class A2A support with to_a2a() and RemoteA2aAgent. Other frameworks support A2A, but ADK's implementation is the most polished. Google co-developed the protocol, and it shows in the developer experience.
Multi-agent orchestration. The patterns from Part 2 of this series (SequentialAgent, ParallelAgent, LoopAgent) give you clean, composable orchestration primitives. Combined with A2A for remote agents, you can build complex multi-agent systems with minimal boilerplate. I built a five-agent research pipeline in under an hour; try that with raw HTTP calls.
Gemini integration. Direct access to Gemini 2.5 Pro and Flash with native support for grounding, code execution, and multimodal capabilities.
Where ADK Falls Short
Ecosystem maturity. LangGraph has years of head start and a massive ecosystem of integrations, tools, and community examples. When you need a specific third-party integration, LangGraph almost certainly has it. ADK is catching up, but the gap is real.
Model flexibility in practice. ADK is model-agnostic on paper. In practice, the developer experience is optimized for Gemini. If Claude or GPT-4o is your primary model, their native frameworks provide a smoother path. I noticed this when trying to use Claude as the primary model in an ADK agent; it worked, but Gemini-specific features (grounding, code execution) are what make ADK shine.
Community size. LangChain's community dwarfs the ADK community in April 2026. More tutorials, more Stack Overflow answers, more battle-tested patterns. This gap is closing, but when you hit a wall at 2 AM, community size matters.
The Decision Framework
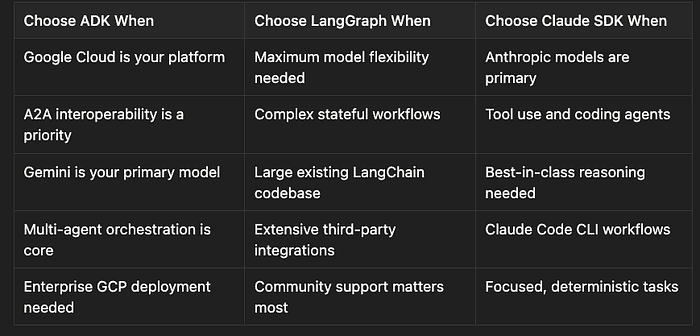
Decisions
Choose ADK when:
- Google Cloud is your platform
- A2A interoperability is a priority
- Gemini is your primary model
- Multi-agent orchestration is core
- Enterprise GCP deployment needed
Choose LangGraph when:
- Maximum model flexibility needed
- Complex stateful workflows
- Large existing LangChain codebase
- Extensive third-party integrations
- Community support matters most
Choose Claude SDK when:
- Anthropic models are primary
- Tool use and coding agents
- Best-in-class reasoning needed
- Claude Code CLI workflows
- Focused, deterministic tasks
The honest answer: Use more than one. The A2A protocol exists precisely so that you do not have to pick a single framework forever. Build your research agents in ADK with Gemini for its grounding capabilities. Build your analysis workflows in LangGraph for its state management. Build your coding agents with Claude for its reasoning strength. Connect them all through A2A.
The multi-framework approach is not a compromise. It is a strategic advantage. I learned this the hard way by trying to force one framework to do everything.
What This Means for the Agent Marketplace Vision
A2A is not just a protocol for connecting agents. It is the infrastructure layer for something much bigger: agent marketplaces where specialized agents compete on quality, not framework loyalty.
Agent Cards as Marketplace Listings
Think about what an Agent Card contains: name, description, skills with defined inputs and outputs, supported modalities, authentication requirements. That is a product listing. A2A gives every agent a standardized way to advertise itself to potential consumers. If you have ever published a package to npm or PyPI, the concept maps directly.
Skill Discovery as Marketplace Search
The A2A discovery mechanism is the foundation for marketplace search. When a client agent queries for agents with specific skills, it is browsing a catalog. Add a registry service on top of the protocol, and you have a searchable marketplace of agent capabilities.
Task Delegation as Transactions
Every A2A task request is fundamentally a transaction. A client agent identifies a need, finds a provider agent that matches, delegates the task, and receives the result. Add billing and metering on top, and you have a marketplace economy.
The Skillzwave Vision
At Skillzwave, we see A2A as the enabler for framework-agnostic agent services:
- Any developer builds an agent in their preferred framework (ADK, LangGraph, Claude, or anything else)
- Any agent registers its capabilities via standard Agent Cards
- Any client discovers and uses agents through A2A, regardless of the underlying framework
- The marketplace handles discovery, trust scoring, billing, and SLA enforcement
This is where the ecosystem is heading. Not one framework to rule them all, but an interoperable marketplace where the best agent for each job wins on merit. We have seen this pattern before with cloud services, with package registries, with API marketplaces. Agent services are next.
What is Still Missing
I want to be direct about the gaps, because the marketplace vision requires solving real infrastructure problems that nobody has solved yet:
Trust and reputation systems. Agent Cards describe capabilities, but how do you know a remote agent is reliable? There is no standard for quality ratings, uptime guarantees, or reliability metrics. This needs to be built.
SLA enforcement. A2A handles error messages, but not SLA contracts. When a remote agent fails to deliver on time or at the expected quality, the protocol has no enforcement mechanism. For enterprise adoption, this is a blocker.
Billing and metering. A2A does not specify how to charge for agent services. Marketplace economics need standardized usage tracking and payment protocols. Someone will build this; the question is who and when.
Identity verification at scale. OAuth and mutual TLS work for known partners. Open marketplaces need broader identity solutions that work at internet scale. This is a hard problem that extends well beyond agent protocols.
These are solvable problems. The Linux Foundation working on A2A governance is addressing some of them. The protocol foundation is solid. The marketplace infrastructure layer is what comes next.
Production readiness checklist
Before you call it production-ready:
- Health endpoint (
/health) and liveness checks - Structured logging for A2A task lifecycle (task id, skill id, requester, latency)
- IAM/service accounts for service-to-service auth (least privilege)
- Timeouts + retries (especially cross-provider)
- Cost/usage telemetry across providers (Gemini + OpenAI + Anthropic)
Further reading (official docs)
- Linux Foundation: Agent2Agent (A2A) Protocol overview
- Google: Announcing the Agent2Agent Protocol (A2A): https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
- Google ADK docs: Deploying A2A agents (Cloud Run / Agent Engine)
- Skillzwave: https://skillzwave.com
Wrapping Up the Series
Three articles. Three layers of agent capability.
Part 1: We built agents. Individual agents with tools, instructions, and models. The foundation.
Part 2: We orchestrated agents. Sequential pipelines, parallel processing, intelligent routing, and iterative loops. The coordination layer.
Part 3: We shipped agents. Production deployment, A2A interoperability, cross-framework communication, and the marketplace future. The production layer.
The multi-framework future is not a prediction. It is already here. A2A and MCP together create the protocol foundation for agent ecosystems that span frameworks, models, and cloud providers. ADK gives you a strong starting point, especially if you are building on Google Cloud. But the real strategic advantage comes from building systems that combine the best agents from every framework, connected through standard protocols.
Start concrete. Get an agent running on Cloud Run with the --a2a flag. Connect it to an agent from a different framework. See what works and where the gaps are. The interoperability story improves every month, and the direction is unmistakable.
Ready to let your agents talk?
- Run
adk deploy cloud_run --a2aon one of your agents. - Connect it to a LangGraph or Claude-powered A2A endpoint and watch the magic.
- Drop your results (and any rough edges you hit) in the comments -- I read every one.
Series links (start here):
- Part 1: Google ADK Deep Dive: Building Your First Agent
- Part 2: Google ADK Deep Dive: Multi-Agent Orchestration with ADK
- Part 3 (this): Google ADK Deep Dive: A2A, MCP, and Production Deployment
More agent architecture deep-dives at Skillzwave.
Your agents are ready. Let them talk to each other.
About the Author
Rick Hightower is a hands-on agent architect, AI agent engineer and technical writer who builds with LangGraph, Claude Agent SDK, CrewAI, and more.
He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems.