Giving Claude a Terminal: Inside the Claude Agent SDK
Introduction: Why the Claude Agent SDK Changes Everything
Originally published on Medium.

How Anthropic's Agent SDK transforms AI from conversational assistant to autonomous digital worker
TL;DR: The Claude Agent SDK gives AI agents terminal access, file system operations, and full network connectivity. It transforms Claude from a text synthesizer into an autonomous digital worker. The three-phase agentic loop (Gather, Act, Verify) is the key to understanding how it achieves reliability in production.
Introduction: Why the Claude Agent SDK Changes Everything
What if you could give an AI the same tools you use every day: terminal access, file system operations, and full network connectivity? That's exactly what the Claude Agent SDK does, and it changes everything about what's possible with AI.
The AI industry is witnessing a fundamental shift. Companies are moving away from specialized tools toward something far more powerful: agents that can genuinely work alongside humans on complex, multi-step tasks.
At the center of this transformation stands the Claude Agent SDK, released by Anthropic on September 29, 2025. If you've been following AI development, you know that the landscape is evolving faster than most organizations can adapt. This SDK represents not just an incremental improvement but a paradigm shift in how we think about AI capabilities.
Anthropic originally developed the SDK internally to build highly effective coding agents. These tools could write, debug, and test code with unprecedented effectiveness. But something unexpected happened during development.
Anthropic's teams quickly realized the underlying engine was so robust that they started using it for everything but coding. Research tasks. Data analysis. Complex automation workflows. Business process management.
They weren't building a Code SDK anymore. They were building an Agent SDK. This platform handles general digital work, not just software development. The Claude Code SDK became the foundation for a much broader platform.
The Core Philosophy: "Giving Claude a Computer"
The central idea behind the Claude Agent SDK is deceptively simple: give Claude a computer.
This isn't just a clever phrase. It's the fundamental insight that separates modern AI agents from traditional chatbots. Until now, most AI systems were locked in a conversation box. They could analyze text, generate responses, and even write code, but they couldn't actually do anything in the real world.
The Claude Agent SDK shatters that limitation. It gives the agent the same toolkit that any programmer or digital worker uses every day.
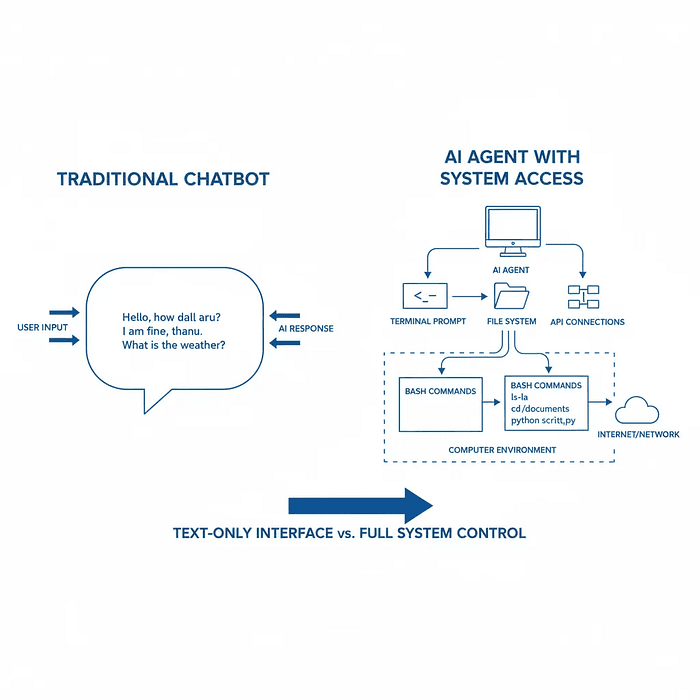
The diagram above shows a traditional chatbot with text-only interface versus AI agent with full system access including terminal, files, network, and tools.
When we say "giving it a computer," we're not talking about some sandboxed playground or browser simulation. We're talking about:
- A real terminal with full bash execution
- A persistent file system the agent can read, write, and organize
- Network access to call APIs and download data
- The ability to run any installed program or script
Think about what that means. Instead of an AI that can only describe how to fix a bug, you get an AI that fixes the bug, runs the tests, and confirms they pass. Instead of an AI that suggests a data analysis approach, you get an AI that actually analyzes the data and produces the report.
The Power of Interaction and Persistence
What does terminal access practically enable that a normal LLM can't do? Two transformative capabilities: interaction and persistence.
With terminal access, the agent can:
- Run and debug code in real-time: Execute programs, see actual error messages, and fix the real problem, not a hypothetical one
- Interact with live systems: Query databases, call APIs, read log files, monitor system state
- Persist work across sessions: Write files, maintain state, build on previous work rather than starting fresh every conversation
Bash is the universal language of computer operations. If you can use bash, you can process massive CSV files, search through gigabytes of logs, automate repetitive tasks, orchestrate complex multi-step workflows, and interface with virtually any installed tool or service.
This is what transforms Claude from a brilliant text synthesizer into a genuine digital worker. Instead of telling you what commands to run, it runs them. Instead of describing what a data pipeline should look like, it builds one.
The Security Trade-off: Utility vs. Risk
The obvious question from anyone in IT: If you're giving an AI agent terminal access to run arbitrary bash commands, isn't that a massive security risk?
Yes. The design acknowledges this explicitly. The complexity of granting that level of access safely is high. You're essentially giving the agent root access to your system, and that requires careful architectural decisions about isolation, permissions, and monitoring.
But here's the critical question: What's the alternative?
To do sophisticated, multi-step work, a human needs terminal access and a file system. If you restrict an AI to just text conversations, you're fundamentally limiting what it can accomplish. You end up with a very expensive chatbot instead of a genuine digital worker.
The bet Anthropic is making: For complex digital work, the utility of real environmental access outweighs the engineering complexity of making it safe. The SDK provides the architectural primitives, and it's on engineering teams to implement appropriate guardrails.
This is why the SDK is designed for professional development environments with proper access controls, not production systems with sensitive data. The architecture assumes you'll run agents in controlled environments, use container isolation, implement permission boundaries, and monitor agent actions.
For enterprise use cases where agents handle research, automate workflows, and manage complex data pipelines, the utility calculus clearly favors the Agent SDK approach over restricted text-only models.
What security concerns would you prioritize when deploying autonomous agents in your environment?
AI Agent Use Cases: What Claude Agent SDK Can Actually Do
The Claude Agent SDK doesn't just produce text responses. It provides the fundamental building blocks, the computational toolkit, that agents need for sophisticated real-world tasks.
Finance Agents: From Analysis to Execution
These aren't simple stock lookup bots that regurgitate market data. Finance agents built with the SDK can act as quantitative analysts with full computational power:
- Analyze entire portfolios: Load holdings, evaluate risk exposure, model scenarios
- Process real-time market data: Download feeds, apply filters, identify patterns
- Generate detailed reports: Create formatted documents with charts and analysis
- Execute complex calculations: Run Monte Carlo simulations, calculate Greeks, stress-test scenarios
- Automate regulatory workflows: Generate required filings with proper formatting and data
Why is terminal access crucial here? Because finance requires computation and persistence, not just conversation. Without these tools, you get an AI that can describe portfolio analysis. With them, you get an AI that actually does it.
It becomes a junior quant analyst that never sleeps and works at machine speed.
Deep Research Agents: Knowledge Synthesis at Scale
For research tasks involving massive amounts of data, the file system becomes a collaborative workspace. A research agent can:
- Process thousands of documents: Synthesize information across large document sets
- Maintain research state: Track what's been analyzed, what remains, what's been concluded
- Build knowledge incrementally: Each session adds to a growing structured knowledge base
- Produce structured outputs: Research reports, comparison tables, executive summaries
The entire workflow depends on the ability to load, process, and manipulate persistent data. The SDK gives the AI a computational environment where research builds over time, not just within a single context window.
This means the agent isn't starting from scratch with every query. It's building on its own previous work. It can spend hours working through a massive research task, producing increasingly refined outputs as it processes more information.
Personal Assistant Agents: Context Across Applications
These agents connect to internal data sources to handle complex coordination tasks:
- Manage calendars intelligently: Schedule meetings while respecting preferences and workload
- Handle travel logistics: Book flights that align with meeting schedules, find hotels near venues
- Assemble briefing documents: Pull relevant emails, meeting notes, and background materials
- Maintain context over time: Track ongoing projects, remember preferences, and adapt to patterns
The key advantage: state that persists beyond a single conversation. The agent can access files it created last week, remember decisions made in previous sessions, and maintain an evolving understanding of your work patterns.
Customer Support Agents: High-Touch Problem Resolution
For complex support tickets that require investigation and synthesis, these agents can:
- Gather comprehensive user context: Pull account history, previous tickets, usage patterns
- Integrate with enterprise tools: Connect to CRMs, ticketing systems, and internal knowledge bases
- Diagnose technical issues systematically: Run diagnostic scripts, analyze log files, reproduce issues
- Escalate intelligently: When human intervention is needed, provide complete context and recommended actions
These aren't chatbots reading from a script. They're support analysts that can actually investigate problems using the same tools human analysts use.
Which of these use cases resonates most with your current automation challenges? Drop a comment in the comment section of the Medium article.
Claude Code Roots
Since the Agent SDK came out of the same ecosystem that started with Claude Code, it supports the same subagents as Claude Code and the Claude Agent SDK. And, remember now it is not just Claude Code and the SDK that supports skills, but also Codex, Github Copilot, and OpenCode have all announced support for Agentic Skills. There is even a marketplace for agentic skills that support Gemini, Aidr, Qwen Code, Kimi K2 Code, Cursor (14+ and counting) and more with Agentic Skill Support via a universal installer.
The Agentic Loop: How Claude Agent SDK Processes Tasks
Once the agent has its computational environment, how does it systematically tackle complex problems? The Claude Agent SDK operates on a three-phase loop:
- Gather Context: Collect all relevant information needed to make decisions
- Take Action: Execute operations using available tools and resources
- Verify Work: Check that actions produced correct results
Then repeat until the task is complete.
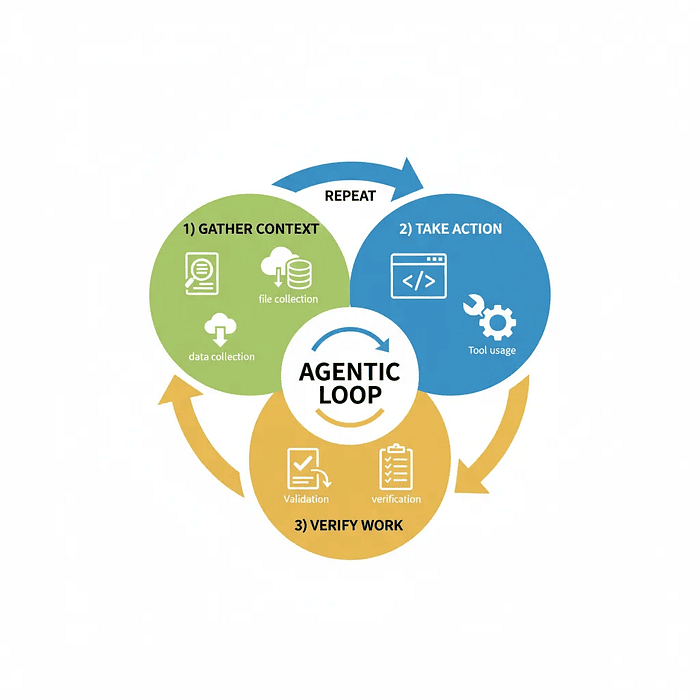
The above diagram for Claude Agent SDK shows the circular flowchart showing the agentic loop cycle with three phases: gather context, take action, verify work.
This cycle transforms a probabilistic language model into a more deterministic, reliable system. Let's examine each phase.
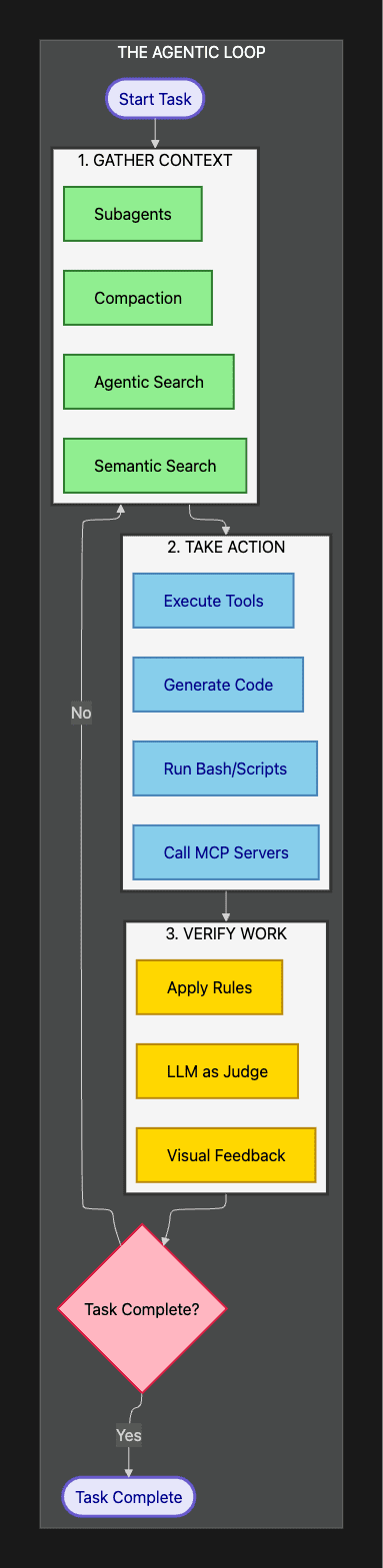
This diagram illustrates the continuous cycle that enables autonomous operation. Each iteration refines understanding, takes targeted action, and verifies results before proceeding.
Phase 1: Context Gathering in the Claude Agent SDK
This is where agent intelligence truly begins. The agent can't just rely on your initial prompt. It must actively gather the full context needed to make good decisions.
Think of it like a detective arriving at a crime scene. The initial report gives you the basics, but to solve the case, you need to examine the evidence, interview witnesses, and build a complete picture of what happened.
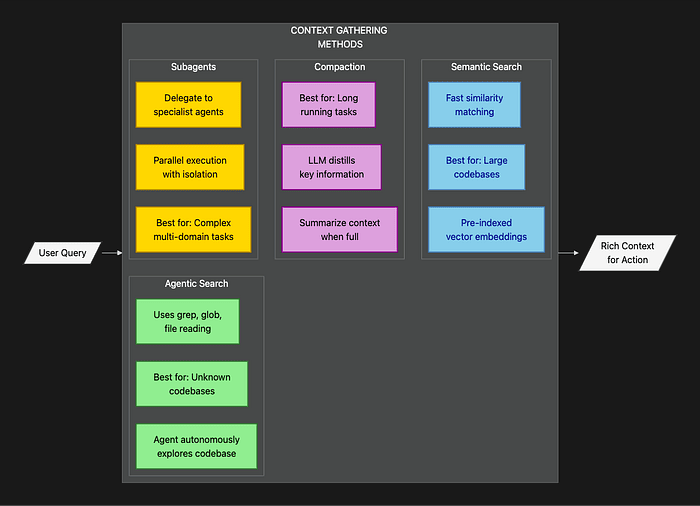
This diagram shows four complementary approaches to context gathering. Each method has specific strengths for different types of information retrieval.
Agentic Search: The File System as Navigable Memory
The key mechanism is what Anthropic calls agentic search. Here's the crucial insight: the folder and file structure of a codebase or workspace isn't just storage. It's a navigable memory system for the agent.
When an agent receives a complex query, it first examines its own file system. Imagine asking it to analyze error patterns in a large codebase. A naive approach would be to dump the entire codebase into the context window and hope the AI finds what it needs. That's slow, expensive, and often inaccurate.
Instead, it thinks like a skilled sysadmin. It uses bash tools like grep to search for specific error codes, tail to examine recent log entries, find to locate relevant configuration files, and awk to parse structured data. It navigates to exactly the information it needs.
The file system becomes the agent's external memory. It's a searchable, persistent knowledge store that the agent can navigate with precision.
Here's a real example: If you ask an agent to "fix the authentication bug in our codebase," it might:
- Use
grep -r "authentication" .to find all files mentioning authentication - Read the main auth module to understand the current implementation
- Use
git logto see recent changes that might have introduced the bug - Search test files to understand expected behavior
- Only then generate a fix with full context
This systematic exploration is impossible without file system access.
Agentic Search vs. Semantic Search: The Trade-offs
This approach differs fundamentally from the semantic search (vector database) approach that dominates most AI discussion. Both have their place, and the choice matters significantly for production reliability.

Both approaches have their place in production systems. The key insight from Anthropic's architecture is that agentic search should be your default for most enterprise applications.
Consider these guidelines when choosing between approaches:
- Use agentic search when: You need precise, auditable results; working with structured or code-like data; transparency matters; results must be explainable; data changes frequently
- Use semantic search when: You have massive document collections (millions of docs); fuzzy matching is acceptable; speed is more important than precision; natural language similarity matters
- Use both when: Semantic search can provide initial candidates, then agentic search performs precise verification and extraction
The hybrid approach often delivers the best of both worlds: semantic search for broad discovery, agentic search for precise extraction and verification.
For enterprise reliability, transparency and auditability are paramount. When an agent makes a critical decision, you need to know exactly which data it used and why. Agentic search provides that. Semantic search is inherently fuzzy.
Anthropic's recommendation: Start with agentic search. Only introduce semantic search when you absolutely need speed or scale that agentic approaches can't match.
Subagents: Parallelization and Context Isolation
For truly enormous tasks that require diverse expertise, the SDK employs subagents. These specialized workers provide two critical capabilities.
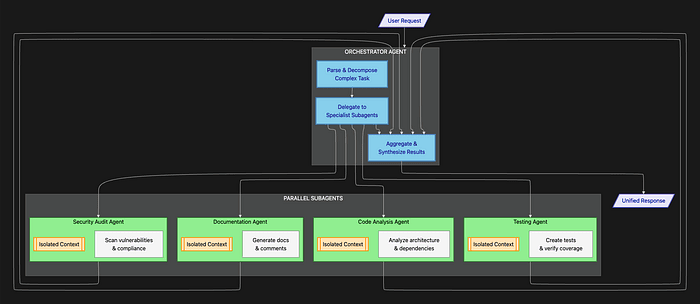
This diagram illustrates the subagent orchestration pattern. Notice how each specialist operates independently with its own isolated context window, and returns only the final, refined output to the orchestrator.
Capability 1: Massive Parallelization
Need to research 10 different technologies for a technical decision? Spin up 10 research subagents in parallel. Each one can work independently, without interfering with others. The orchestrator assigns tasks and collects results, dramatically reducing total elapsed time.
Capability 2: Context Window Isolation
This is the more subtle but equally important advantage. Each subagent operates in its own isolated context window. When a subagent is working on a complex task, it can fill its context with all the messy intermediate steps, logs, dead ends, and working notes it needs.
But when it's done, it doesn't send its entire messy work history back to the orchestrator. It only returns the final, refined output. A clean summary. A completed task. A structured result.
This architectural pattern keeps the orchestrator's context clean and high-level. It thinks strategically about task decomposition and result synthesis, not about the implementation details of each sub-task.
Think of it like managing a team. A good manager delegates specific tasks, then receives executive summaries, not hour-by-hour activity logs.
Compaction: Managing Long-Running Memory
For long-running tasks where even the orchestrator's context might fill up, the SDK includes compaction. This is automatic context management that prevents agents from running out of memory during extended work sessions.
As the context limit approaches, the agent automatically summarizes the oldest messages in its conversation history. It preserves the key decisions, important findings, and critical context, while discarding the verbose step-by-step reasoning that's no longer needed.
This is similar to how human memory works. You remember the key decisions from a meeting last month, but not every word of the discussion. Compaction gives agents the same capability.
Result: Agents can work on tasks that span hours or days without running out of context space. They maintain continuity of purpose and accumulated knowledge even as the raw conversation history grows beyond the context window limit.
Phase 2: Taking Action with Claude Agent SDK Tools
The execution phase is where gathered context transforms into concrete results. This is all about tools: the mechanisms the agent uses to take action in the world.
Tools are the core building blocks for agent capabilities, designed as the primary, most frequently used action primitives. The SDK organizes tools into four major categories, each with distinct trade-offs.
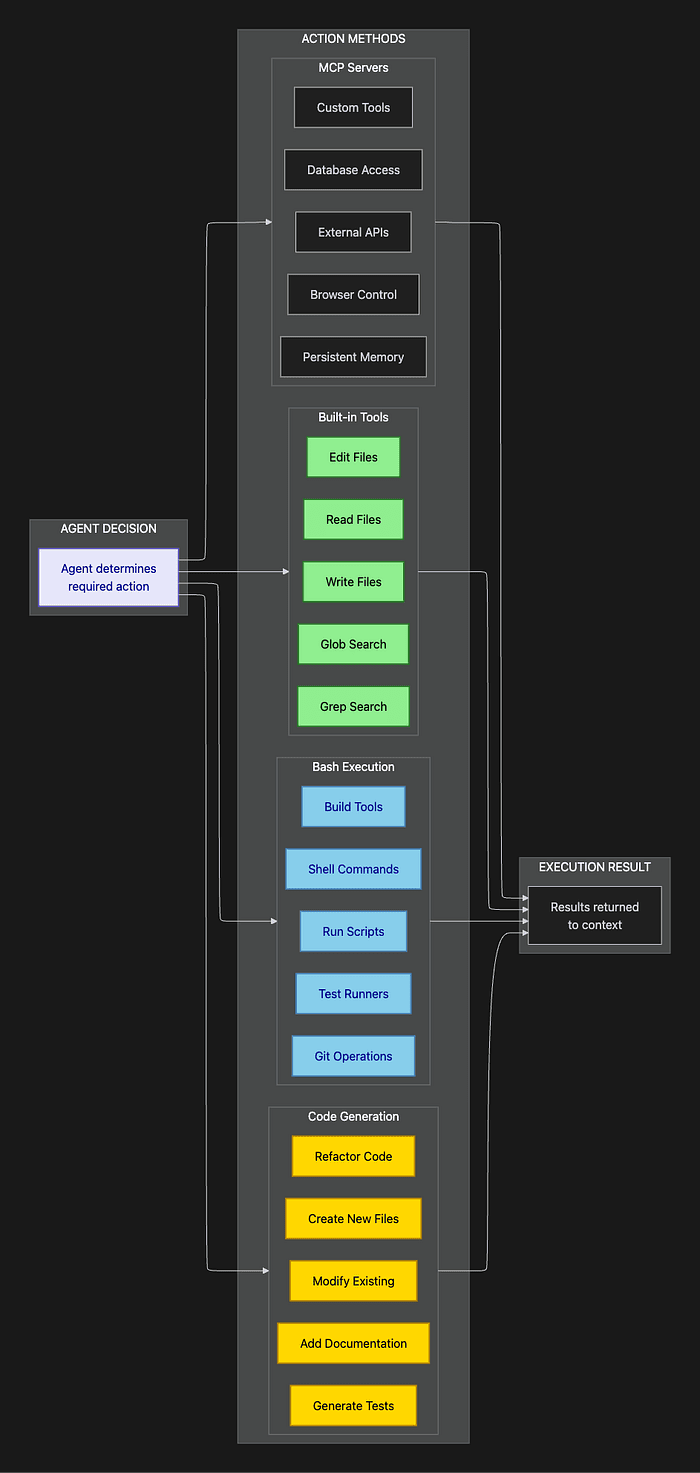

The above two diagrams shows the four categories of actions available to agents. Each serves specific use cases and offers different trade-offs in efficiency, flexibility, and complexity.
Tools: High-Efficiency Predefined Operations
You're not making Claude reinvent operations every time. You're giving it hyper-efficient, predefined macros that consume minimal tokens.
Think of defining fetchUserCalendarData as a custom tool. When the agent needs calendar information, it doesn't have to:
- Figure out which API to call
- Remember the authentication method
- Parse the response format
- Handle errors appropriately
It just invokes the tool. All the complexity is encapsulated. These become the default actions that keep the context window lean and agent behavior predictable.
Design principle: Define tools for any operation you'll use repeatedly. Each tool invocation costs far fewer tokens than asking the model to figure out the same operation from scratch.
Bash: The Universal Adapter
Bash serves as the general-purpose catch-all for operations that don't fit predefined tools. It's the escape hatch that makes the SDK infinitely flexible.
Real-world example: A finance agent needs to:
- Download an encrypted client document from cloud storage
- Decrypt it using GPG keys
- Convert from PDF to text
- Run a custom data extraction script
- Load results into a database
The agent can orchestrate all those steps using bash commands. It can even write and execute a temporary Python script if the task requires complex logic that bash can't handle elegantly.
This is computational flexibility that structured APIs can't match. Bash gives agents the ability to handle edge cases and one-off tasks that no pre-built tool anticipated.
Code Generation: Precision Beyond Data Structures
Why is writing full Python or JavaScript code often better than returning structured JSON output?
Code offers precision and composability that data structures can't match.
Consider this scenario: An agent needs to create an Excel spreadsheet with:
- Multiple worksheets with specific formatting
- Formulas that reference cells across sheets
- Conditional formatting based on value ranges
- Charts derived from table data
JSON fails here. You can't express "apply bold formatting to cells where value > 1000" or "create a pivot table summarizing by region" in a simple data structure.
But a Python script using libraries like openpyxl or pandas can guarantee consistent, complex formatting every single time.
The output becomes functional, not just informational. This is the difference between an agent that describes work and one that actually does it.
Model Context Protocol (MCP): Enterprise Integration Made Simple
MCP is the key to enterprise utility. These are standardized, pre-built integrations for services like Slack, GitHub, Notion, Asana, and dozens of other enterprise tools.
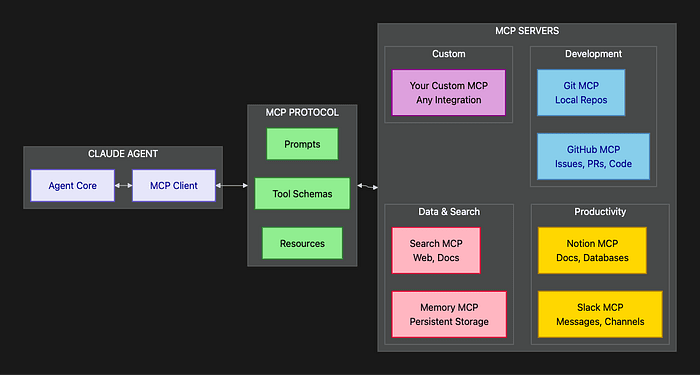
This diagram illustrates the Claude Agent SDK and the MCP ecosystem. The protocol provides a standardized interface, which means the same agent architecture works across an entire ecosystem of enterprise tools without custom integration code for each one.
No more custom integration code and OAuth nightmares. The agent can use out-of-the-box tools like:
search_slack_messagesto find relevant team discussionsget_github_pull_requeststo track code review statusquery_notion_databaseto pull project documentationlist_asana_tasksto understand current workload
This provides instant situational awareness about team context. Instead of agents working in isolation, they tap into the full fabric of enterprise communication and project management.
The difference: An agent that can only access code is limited. An agent that can also check Slack conversations, review GitHub PRs, and query project management tools can understand not just what the code does, but why it was written that way and what the team's current priorities are.
Phase 3: Verifying Work with Claude Agent SDK
This is what separates autonomous agents from sophisticated chatbots: the ability to self-correct.
Agent reliability is directly tied to verification capability. Without self-checking, agents always need human supervision for critical tasks. With robust verification, they can operate autonomously and catch their own mistakes.
The SDK provides three verification methods, ranked by robustness and appropriate use cases.
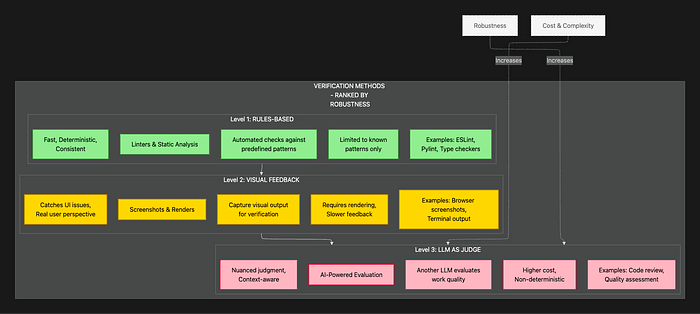
This diagram shows the three verification levels in order of increasing sophistication. The key insight: Start with rules. Add visual feedback when needed. Use LLM judges only as a last resort.
Method 1: Defining Rules (Most Robust and Preferred)
Set up clear guardrails with binary success or failure criteria. This is the gold standard for verification because it's fast, deterministic, and provides clear failure messages.
For code generation: Generate TypeScript instead of JavaScript. Why? TypeScript adds structural rules the agent must satisfy. If the TypeScript doesn't compile, the agent knows immediately and can fix the issue before delivering broken code.
For an email automation agent, define explicit rules:
- Is the email address format valid? Error (block send)
- Is the legal disclaimer present? Error (block send)
- Has user been emailed in the last 3 days? Warning (flag for review)
- Does subject line exceed 78 characters? Warning (suggest revision)
These rules give the agent fast failure points. When something's wrong, it knows immediately and can fix it before proceeding. No ambiguity, no subjective judgment.
Real-world example: A deployment agent that must verify configurations before pushing to production might check:
- All environment variables are set: Binary check
- Database connection strings are valid: Syntax validation
- No hardcoded secrets in config files: Regex pattern matching
- All required services are running: System status check
Each check either passes or fails. The agent doesn't proceed until all checks pass. This is how you achieve reliability.
Method 2: Visual Feedback (For Perceptual Validation)
For visual tasks like UI generation or document formatting, the agent becomes its own QA tester.
Using an MCP server with Playwright or similar browser automation, it can:
- Render the generated UI in a headless browser
- Take screenshots at different viewport sizes (mobile, tablet, desktop)
- Visually inspect the results using its vision capabilities
The agent then checks:
- Is the "Submit" button the correct color (matching brand guidelines)?
- Is the navigation menu properly aligned?
- Do text elements have sufficient contrast for accessibility?
- Are images loading correctly without layout shift?
- Does the footer stay at the bottom on short pages?
When it spots visual failures, it iterates on the code by adjusting CSS, fixing layout issues, and correcting color values until everything looks right.
Critical insight: This isn't just about aesthetics. Visual feedback catches real functional bugs like overlapping elements, missing content, and broken layouts that code analysis alone might miss.
Method 3: LLM as Judge (Last Resort for Subjective Criteria)
For subjective, fuzzy requirements like "ensure the email tone is friendly but professional" or "make sure code comments are clear for a junior developer," the SDK supports using a separate LLM to evaluate the output.
This judge agent receives:
- The original requirements
- The output produced by the worker agent
- Specific evaluation criteria
It then provides structured feedback: pass/fail, specific issues found, suggested improvements.
Critical warning: This is the last resort. Using another LLM for validation:
- Adds significant latency (another API call)
- Costs more (additional tokens)
- Introduces non-determinism (LLMs can be inconsistent)
- Creates potential for disagreement (two models might have different opinions)
Use rules and visual feedback whenever possible. Only employ LLM judges when the criteria are genuinely subjective and resist quantification.
When it makes sense: Evaluating creative writing quality, assessing persuasiveness of marketing copy, judging appropriateness of tone for a specific audience.
When it doesn't: Checking if code compiles, validating data formats, verifying API responses. Things with objective, measurable success criteria should always use rules.
Building Production-Ready AI Agents: Engineering for Reliability
The three-phase system of Gather, Act, and Verify transforms an agent from a sophisticated tool into a genuinely autonomous worker. But getting to production reliability requires systematic engineering discipline.
When an agent fails, developers must systematically diagnose the root cause:
Context Failure: Does the agent lack critical information?
- Is the file structure unclear? Improve workspace organization
- Are relevant files not being found? Add better search keywords or indexing
- Is context getting truncated? Use compaction or subagents to manage memory
Action Failure: Does the agent have the right tools?
- Is a required operation impossible with current tools? Define new custom tools
- Are bash commands too complex? Create helper scripts
- Are API integrations missing? Add necessary MCP servers
Verification Failure: Does the agent lack good feedback?
- Are errors not being caught? Add formal validation rules
- Are success criteria ambiguous? Define clearer acceptance tests
- Is the agent repeating mistakes? Improve error messages and retry logic
For high-stakes environments, Anthropic emphasizes building representative test sets. These are programmatic evaluations that run agents against realistic scenarios and measure their performance:
- Test scenarios that cover common tasks and edge cases
- Acceptance criteria that define what success looks like
- Performance benchmarks that track improvement over time
- Failure analysis that identifies patterns in agent mistakes
This is software engineering discipline applied to AI agents. The technology enables autonomy, but reliability comes from rigorous testing and systematic improvement.
What testing strategies have you found most effective for AI systems?
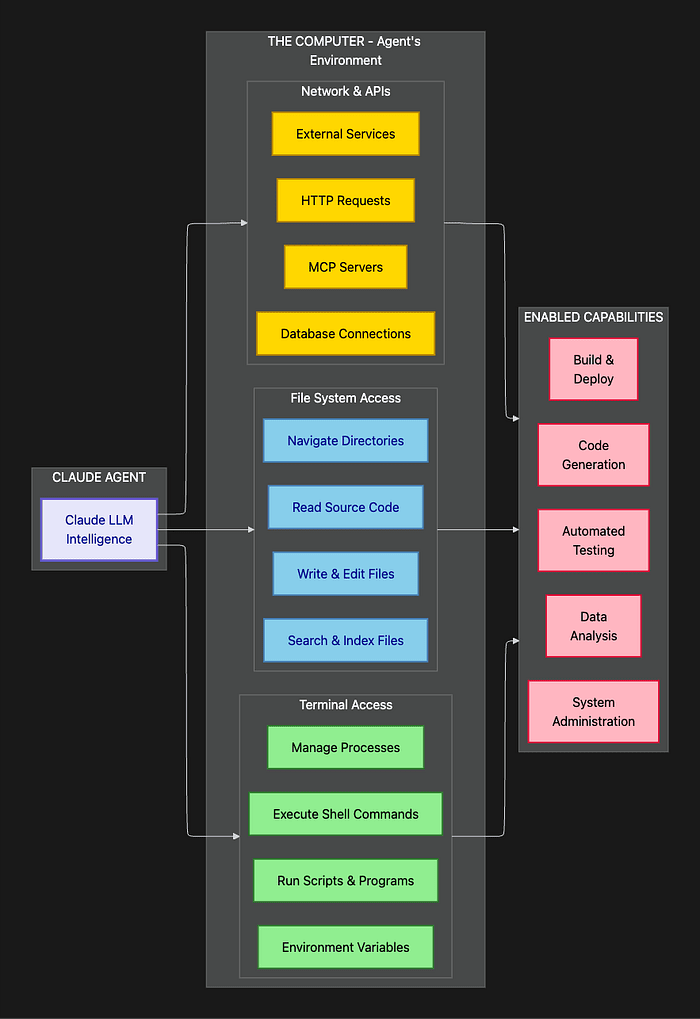
Complete Claude Agent SDK Architecture Overview
This diagram brings all the pieces together, showing how the different layers interact to create a complete agent system.
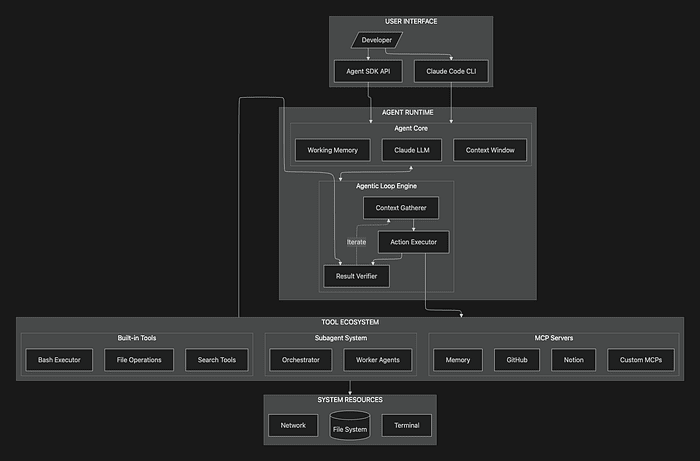
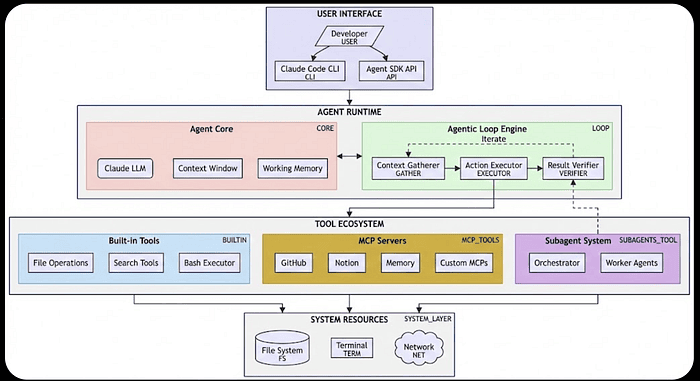
This architectural overview shows the complete stack from user interaction down to system resources. Notice how each layer builds on the one below it, with the verification phase connecting back to the action phase to create the autonomous loop.
Key Takeaways
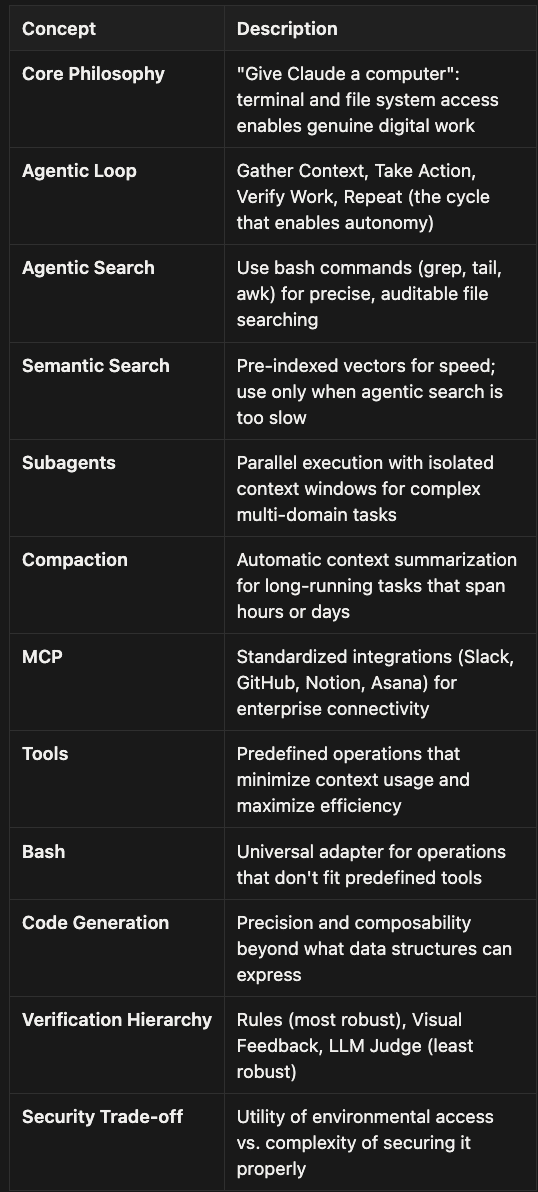
- Core Philosophy: "Give Claude a computer": terminal and file system access enables autonomous digital work
- Agentic Loop: Gather Context, Take Action, Verify Work, Repeat (the cycle that enables reliability)
- Agentic Search: Use bash commands (grep, tail, awk) for precise, auditable file system navigation
- Semantic Search: Pre-indexed vectors for speed; use only when agentic search can't scale
- Subagents: Parallel execution with isolated context windows for complex multi-step tasks
- Compaction: Automatic context summarization for long-running tasks that span hours or days
- MCP: Standardized integrations (Slack, GitHub, Notion, Asana) for enterprise tool connectivity
- Tools: Predefined operations that minimize context usage and maximize efficiency
- Bash: Universal adapter for operations that don't fit predefined tools
- Code Generation: Precision and composability beyond what data structures can express
- Verification Hierarchy: Rules (most robust), Visual Feedback, LLM Judge (least preferred)
- Security Trade-off: Utility of environmental access vs. complexity of securing it properly
The Provocative Question
If the core goal of autonomous agents is flawless, scalable reliability, how much development effort should shift away from expanding agent capabilities and toward improving their verification and self-correction mechanisms?
Current AI development emphasizes what models can do: new features, broader capabilities, more integrations. But production deployment keeps getting stuck on the same question: how do we know the agent did it correctly?
The engineering challenge of moving from what's possible to what's reliable may be where the future of AI agents is actually won or lost.
That shift in focus could transform agents from impressive demos to dependable production systems. The technology is here. The question is whether we're investing in the right problems.
Where do you think the industry should focus: more capabilities or better verification? Leave a comment below. I would love to know what you think.
Getting Started with Claude Agent SDK
The Claude Agent SDK is available today in Python and TypeScript:
# Python
pip install claude-agent-sdk
# TypeScript/JavaScript
npm install @anthropic-ai/claude-agent-sdk
Documentation and Resources:
- Official SDK Documentation
- Migration Guide (for developers moving from older Claude APIs)
- Example Agent Implementations (Python and TypeScript)
- MCP Server Registry (available integrations)
Getting Help:
For developers already building on the SDK, Anthropic provides comprehensive migration guides and backward compatibility resources to ease the transition from the Claude Code SDK to the broader Agent SDK.
The Claude Agent SDK represents a fundamental shift in how we think about AI capabilities, moving from conversational assistants to autonomous digital workers. By giving Claude a computer, Anthropic has opened the door to a new class of AI applications that can truly work alongside humans, not just talk to them.
The technology democratizes access to autonomous agents. The challenge now is engineering them to be reliable enough for production. That's the work ahead.
About the Author
Rick Hightower is an accomplished technology executive and data engineer with extensive experience at a Fortune 100 financial technology organization, where he led the development of advanced Machine Learning and AI solutions focused on enhancing customer experience metrics and fraud detection. His expertise spans both theoretical AI research and practical enterprise implementation.
And, remember now it is not just Claude Code but also Codex, Github Copilot, and OpenCode have all announced support for Agentic Skills. There is even a marketplace for agentic skills that support Gemini, Aidr, Qwen Code, Kimi K2 Code, Cursor (14+ and counting) and more with Agentic Skill Support via a universal installer.
Rick wrote the skilz universal skill installer that works with Gemini, Claude Code, Codex, OpenCode, Github Copilot CLI, Cursor, Aidr, Qwen Code, Kimi Code and about 14 other coding agents as well as the co-founder of the world's largest agentic skill marketplace.
His professional qualifications include TensorFlow certification and completion of Stanford University's Machine Learning Specialization program. Rick's technical proficiency encompasses supervised learning methodologies, neural network architectures, and enterprise-grade AI solution development. He recently earned multiple certifications from Anthropic, including Claude SDK implementation on Vertex AI and Amazon Bedrock, Claude Tools, and Model Context Protocol (MCP). His hands-on experience includes building production systems with LangChain, LlamaIndex, ChatGPT API, Lite-llm, and other frameworks across AWS, Azure, and GCP cloud platforms. Currently, his focus is on agentic AI solutions utilizing Claude Code, OpenCode, and Claude Agent SDK.
Connect with Rick Hightower on LinkedIn or Medium for insights on enterprise AI implementation and strategy.
Community Extensions & Resources
The Claude Code community has developed powerful extensions that enhance its capabilities. Here are some valuable resources from Spillwave Solutions:
Integration Skills
- Notion Uploader/Downloader: Seamlessly upload and download Markdown content and images to Notion for documentation workflows
- Confluence Skill: Upload and download Markdown content and images to Confluence for enterprise documentation
- JIRA Integration: Create and read JIRA tickets, including handling special required fields
Recently, I wrote a desktop app called Skill Viewer to evaluate Agents skills for safety, usefulness, links and PDA.
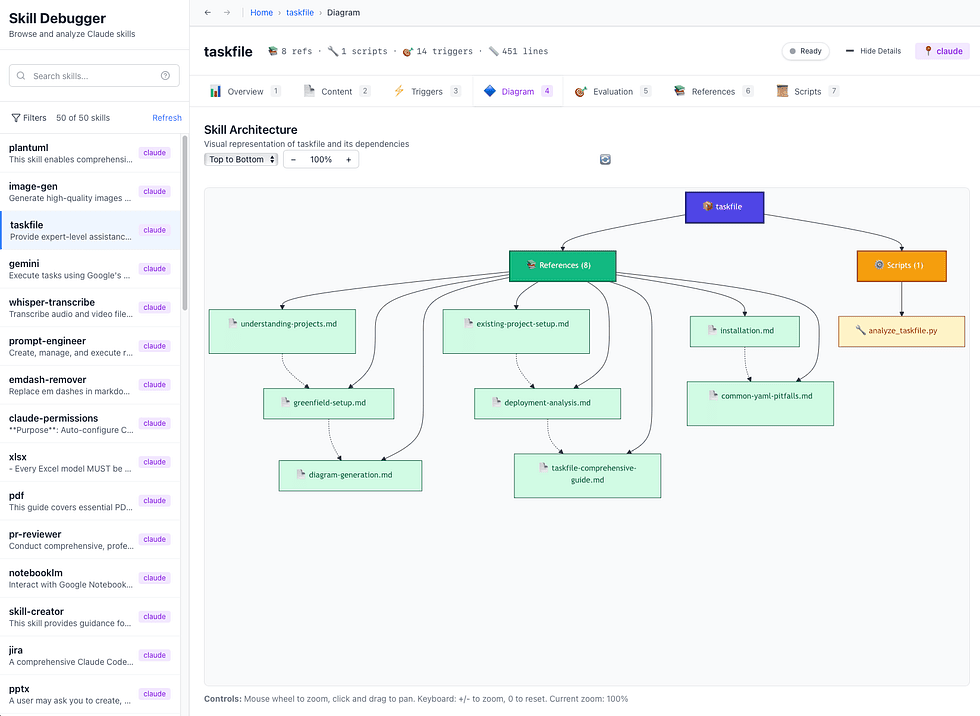
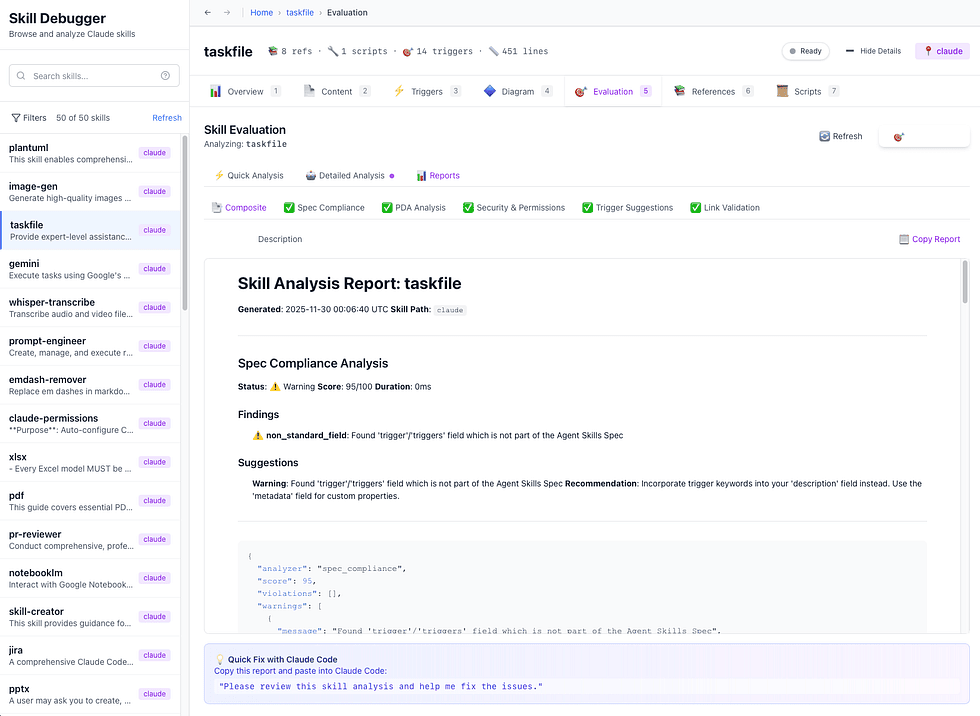
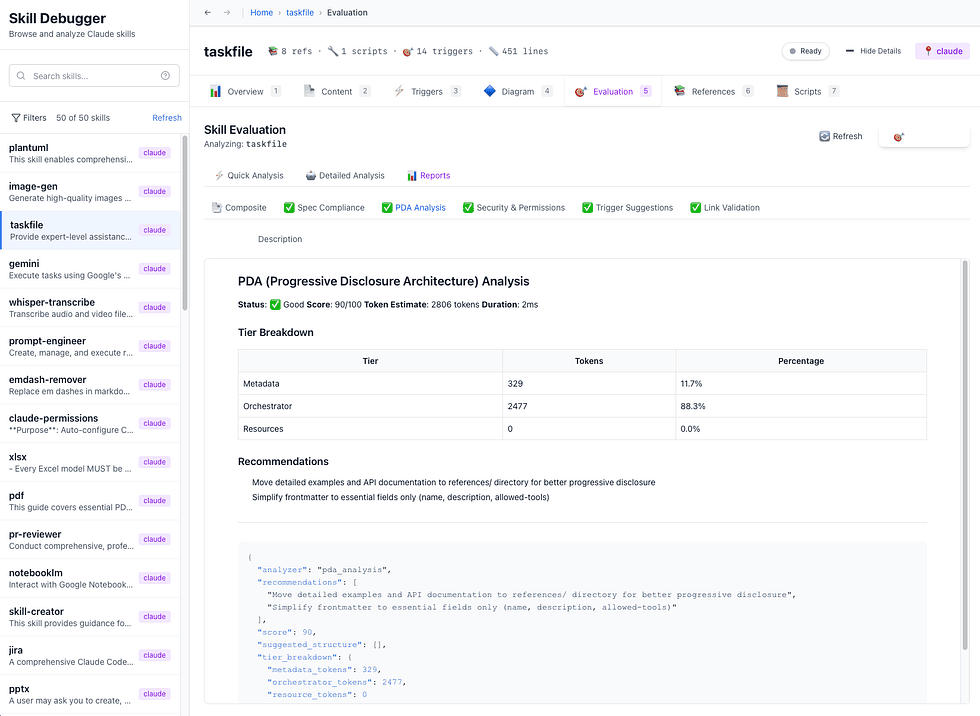
Advanced Development Agents
- Architect Agent: Puts Claude Code into Architect Mode to manage multiple projects and delegate to other Claude Code instances running as specialized code agents
- Project Memory: Store key decisions, recurring bugs, tickets, and critical facts to maintain vital context throughout software development
- Claude Agents Collection: A comprehensive collection of 15 specialized agents for various development tasks
Visualization & Design Tools
- Design Doc Mermaid: Specialized skill for creating professional Mermaid diagrams for architecture documentation
- PlantUML Skill: Generate PlantUML diagrams from source code, extract diagrams from Markdown, and create image-linked documentation
- Image Generation: Uses Gemini Banana to generate images for documentation and design work
- SDD Skill: A comprehensive Claude Code skill for guiding users through GitHub's Spec-Kit and the Spec-Driven Development methodology.
AI Model Integration
- Gemini Skill: Delegate specific tasks to Google's Gemini AI for multi-model collaboration
- Image_gen: Image generation skill that uses Gemini Banana to generate images.
Agentic Skill Explorer
Currently I am working on a tool that searches for and finds Agentic Skills and then categorizing them and grades them.
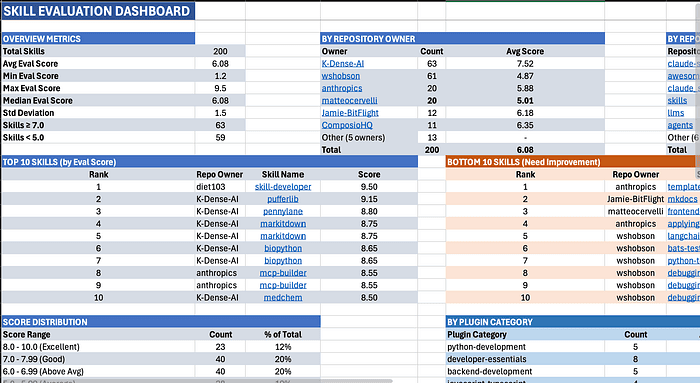
Explore more at Spillwave Solutions -- specialists in bespoke software development and AI-powered automation.