GSD vs. Superpowers vs. BMAD Handling Context Rot — Context Rot and the Memory Crisis in AI Development
Why longer context windows don't fix quality degradation, and what actually works — Context Rot Is Quietly Killing Your AI Agents; And Bigger Windows Won't Save You
Originally published on Medium.

Why longer context windows don't fix quality degradation, and what actually works — Context Rot Is Quietly Killing Your AI Agents; And Bigger Windows Won't Save You
Every model tested showed degradation as context grew. Not some models. Not older models. Every single one. Context rot is the invisible quality killer in AI development, and the best frameworks are the ones that design around it
Summary: Context rot is the progressive degradation of LLM output quality as token windows fill with conversation history and accumulated context. This article examines the research behind context degradation, including Liu et al.'s 'Lost in the Middle' findings and the Chroma Research 18-model study, then explores how frameworks like GSD, Superpowers, and BMAD solve it through fresh context isolation, micro-task decomposition, and persona switching. Includes a practical context budget calculation and seven actionable recommendations for building rot-resistant agentic workflows.
The Invisible Quality Killer
Every developer who has worked with an AI coding agent has experienced the same frustrating pattern. The first few interactions are brilliant. The agent understands your codebase, follows your constraints, and produces clean, well-structured code. Then, somewhere around the twentieth prompt, things start to slip. The agent forgets a constraint you stated ten messages ago. It generates a function signature that contradicts its own earlier output. It produces placeholder code where real implementation should be. It hallucinates an API that does not exist.
This is context rot.
Context rot is the progressive degradation of LLM output quality as the token window fills with conversation history, code snippets, tool outputs, and accumulated context. It is not a theoretical concern. It is a measurable, reproducible phenomenon that affects every language model in production today. If you are building agentic workflows that run autonomously for hours, context rot is the single biggest threat to output quality.
In earlier articles in this series, we explored how frameworks like GSD structure work through spec-driven development and how Superpowers enforces discipline through composable skills. This article examines the foundational problem that those frameworks are designed to solve: AI agents get worse the longer they work, and the most effective frameworks address this head-on.
Measuring Context Degradation
The Research That Proves Your Agent Gets Dumber the Longer It Works
The foundational research on context degradation comes from Liu et al.'s "Lost in the Middle: How Language Models Use Long Contexts," published in the Transactions of the Association for Computational Linguistics (TACL, Volume 12, pp. 157–173, 2024; originally posted to arXiv in July 2023). The researchers tested multiple LLMs on multi-document question answering and key-value retrieval tasks, systematically varying where relevant information appeared within the input context. They discovered that language model performance follows a U-shaped curve: models perform best when relevant information appears at the very beginning (primacy bias) or end (recency bias) of the input context, and performance degrades significantly when models must access information in the middle.
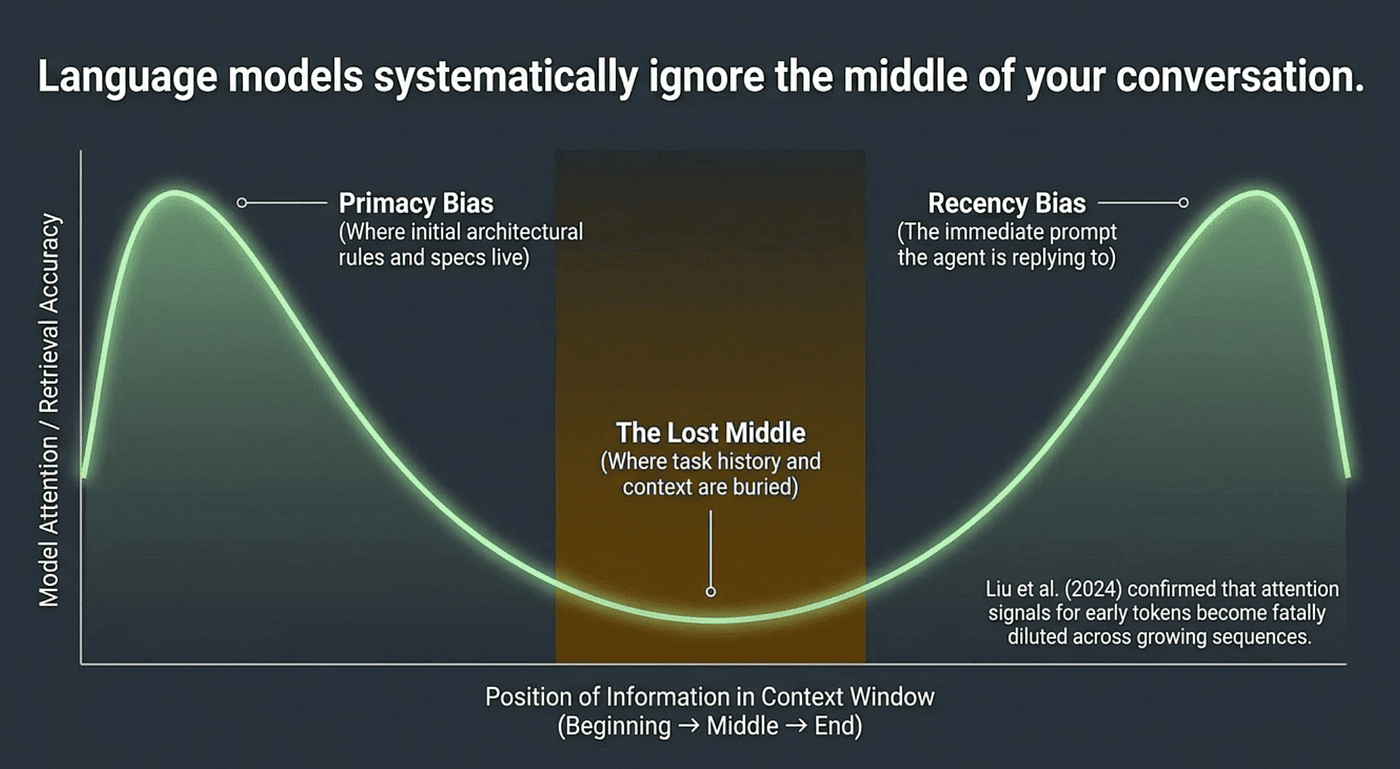
This finding has enormous implications for agentic development. When your AI agent has been working for thirty minutes and has accumulated thousands of tokens of conversation history, the constraints and specifications you provided at the beginning of the session are sitting in exactly the worst position: the middle of the context window.
Here is a concrete example. You start a session by telling your agent: "All database access must go through the repository pattern. Never create direct database queries in service classes." Twenty prompts later, the agent is deep into implementing a complex feature. Your repository constraint is now buried in the middle of a 40,000-token conversation. The agent generates a service class with inline SQL queries. It is not being defiant. It has effectively lost access to your constraint.
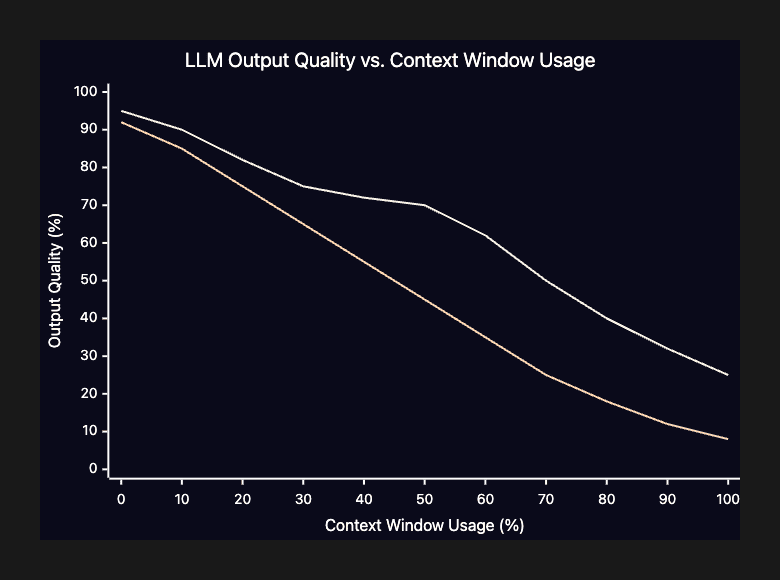
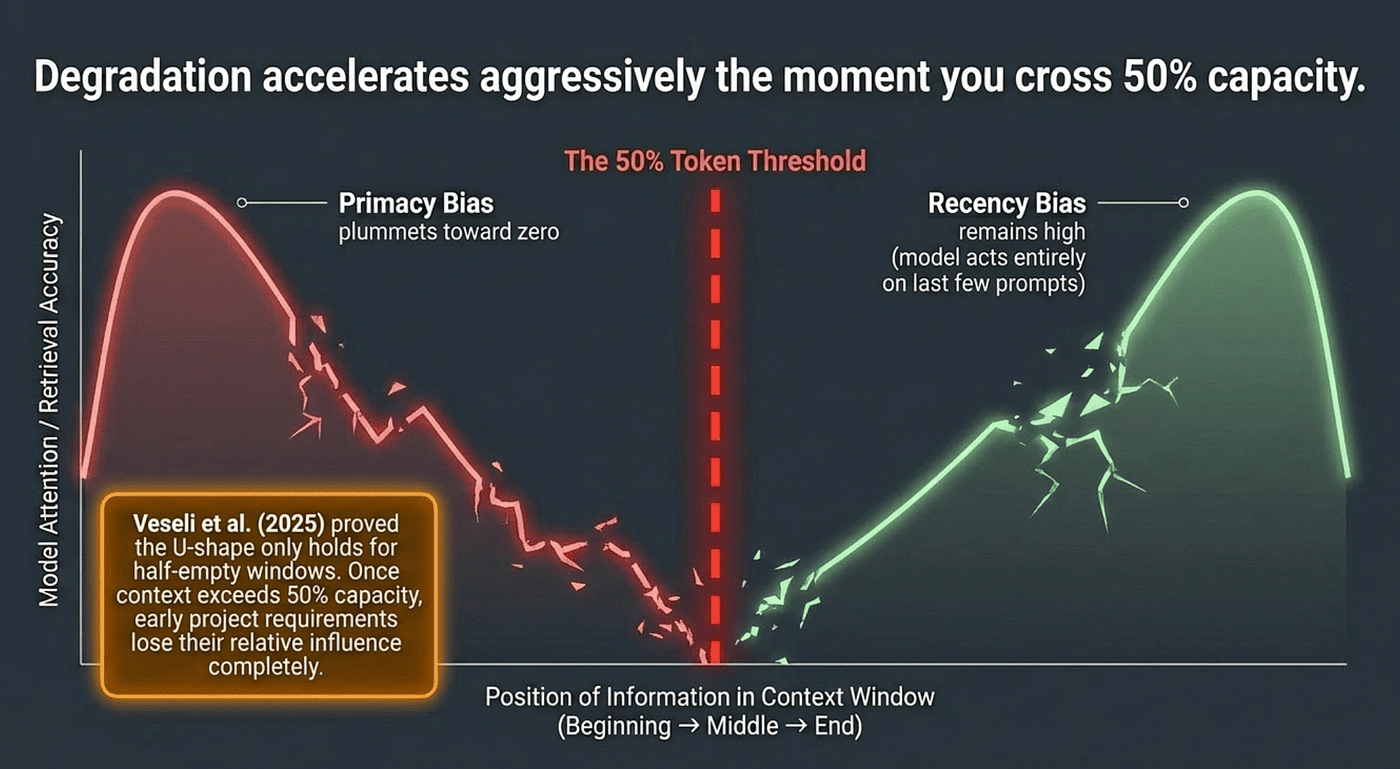
In 2025, Veseli et al. extended this research and found something even more concerning. The U-shaped pattern only persists when the context is less than 50% full. When the context exceeds 50% capacity, the pattern shifts: primacy bias weakens significantly while recency bias remains relatively stable. Your initial requirements, architectural constraints, and coding standards — which started near the beginning — gradually lose their relative influence.
The following diagram illustrates how output quality and attention to early tokens both decline as the context window fills:
The Chroma Research Study
The most comprehensive empirical study of context rot came from Chroma Research, which tested 18 models across all major providers, including Claude 4 (Opus and Sonnet variants), GPT-4.1, Gemini 2.5 (Pro and Flash), and Qwen3 models. Their findings were stark:
Every model tested showed degradation as context grew. Not some models. Not older models. Every single one.
The study revealed a counterintuitive finding: models performed better on shuffled text than on coherent text. Coherent text creates stronger positional patterns, and the model develops recency bias, attending disproportionately to passages near the end of the input while neglecting earlier content. In other words, the more logically structured your conversation with an agent is, the more susceptible it is to context rot.
Performance degradation occurred even on trivial tasks like text replication, suggesting that real-world software engineering tasks face even more pronounced impacts. If a model cannot reliably copy text from the beginning of its context window to its output, how can it reliably follow architectural constraints stated 50,000 tokens ago?

The Chroma study also found that Claude models exhibited the largest discrepancies between focused prompts (around 300 tokens) and full prompts (around 113K tokens), largely through conservative abstentions. When uncertain due to context overload, these models chose to not answer rather than hallucinate. This is arguably the safer failure mode for code generation, but it still represents lost productivity.
How Context Rot Manifests in Practice
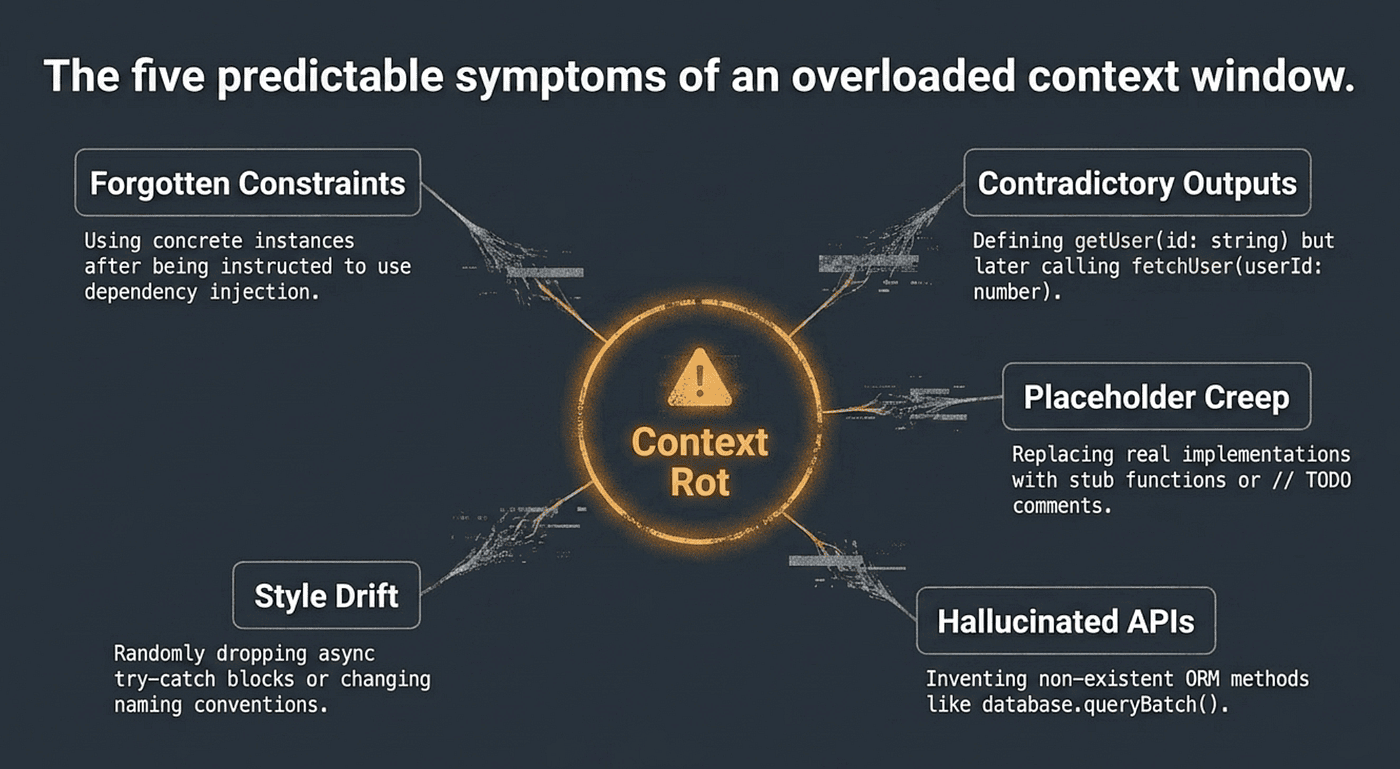
For developers working with AI coding agents, context rot shows up in predictable ways:
- Forgotten constraints. You told the agent to use dependency injection, but it starts creating concrete instances directly. You specified that all errors should return structured JSON responses, but the agent starts throwing raw exceptions. These are not random mistakes. They are symptoms of the model losing access to early-session instructions.
- Contradictory outputs. The agent produces code that conflicts with code it generated earlier in the same session. It defines a
UserServiceclass with agetUser(id: string)method in one file, then callsuserService.fetchUser(userId: number)in another, contradicting both the method name and the parameter type. - Placeholder creep. Real implementations get replaced with
// TODO: implement thiscomments or stub functions. Early in a session, the agent writes complete implementations. As context fills, it starts cutting corners, leaving placeholder code where production logic should be. - Hallucinated APIs. The agent invents function signatures, library methods, or configuration options that do not exist. It might call
database.queryBatch()when the ORM only supportsdatabase.query(), or reference aconfig.enableStrictMode()method that was never part of the library. - Style drift. The agent stops following the naming conventions, error handling patterns, or coding style it was applying earlier. It was using camelCase for variables, then switches to snake_case. It was wrapping all async calls in try-catch blocks, then stops.
I watched an agent I had been pairing with for 60 minutes suddenly invent a non-existent method because its original spec was buried in a 300K-token context. It felt like twenty-five minutes of work down the drain.
A separate study from late 2025/early 2026 on context discipline and performance correlation found that while high-capacity models like Llama-3.1–70B could maintain accuracy between 97.5% and 98.5% even with 15,000 words of irrelevant context, the operational cost was severe: a 719% increase in latency for the 70B model. The study identified a "memory wall" as the dominant bottleneck, where KV cache growth creates non-linear, quadratic scaling in processing time. Even when accuracy holds, the computational overhead of processing bloated context makes long sessions dramatically less efficient.
A Practical Context Budget Calculation
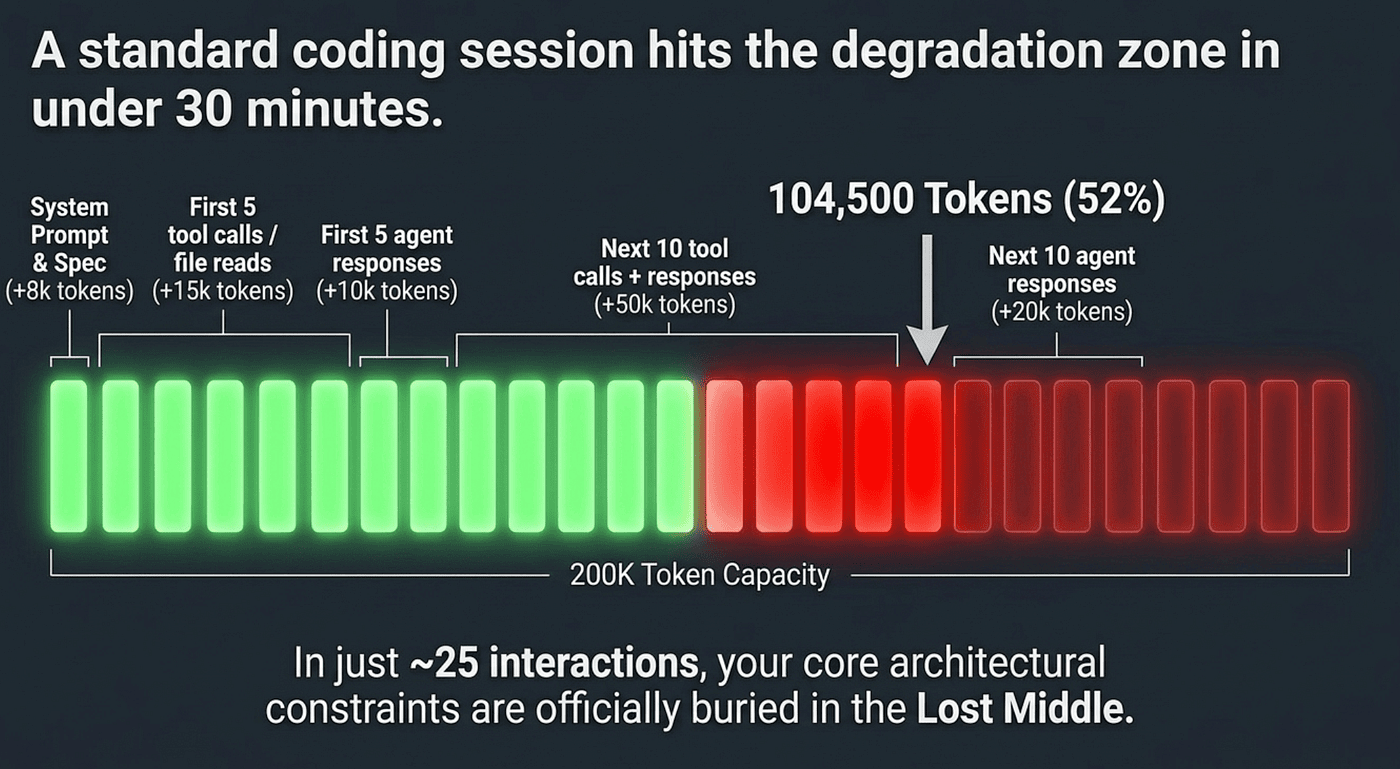
To make context rot tangible, consider a typical agentic coding session on a 200K-token model building a medium-complexity feature:
- After ~25 interactions, it's easy to cross 50% context usage, even without "huge" prompts.
- At that point, your early constraints (coding standards, architecture rules, repo patterns) sit in the lost middle, where attention weakens.
- You may have plenty of tokens left, but instruction-following quality is already sliding.

These numbers are illustrative based on typical 2025–2026 agentic coding sessions; actual token counts vary by model and implementation.
This is why "just use a bigger context window" is not a solution. Even with 200K tokens, a moderately complex task crosses the degradation threshold in under 30 minutes of active work.
Why Longer Context Windows Do Not Solve the Problem
When model providers announce 200K, 1M, or even 10M token context windows, many developers assume the problem is solved. It is not. A model with a 200K token window can start degrading at 50K tokens. The window is bigger, but the rot still sets in.
Context rot is not a capacity problem. It is an architectural one. MIT CSAIL researchers in 2025 identified the root cause in the transformer architecture itself: causal masking in the attention mechanism means each token can only attend to tokens that came before it. As the sequence grows, the attention signal for early tokens becomes diluted across an ever-growing number of positions. Techniques like Multi-scale Positional Encoding (Ms-PoE) and attention calibration can reduce the bias, but as of 2026, no production model has fully eliminated position bias.
Bigger windows delay the onset of context rot. They do not prevent it.
GSD's Aggressive Atomicity Approach
GSD (Get Stuff Done) takes the most aggressive approach to context rot of any framework in the agentic ecosystem. Rather than trying to manage a growing context window, GSD eliminates the problem entirely by giving every task its own fresh context.
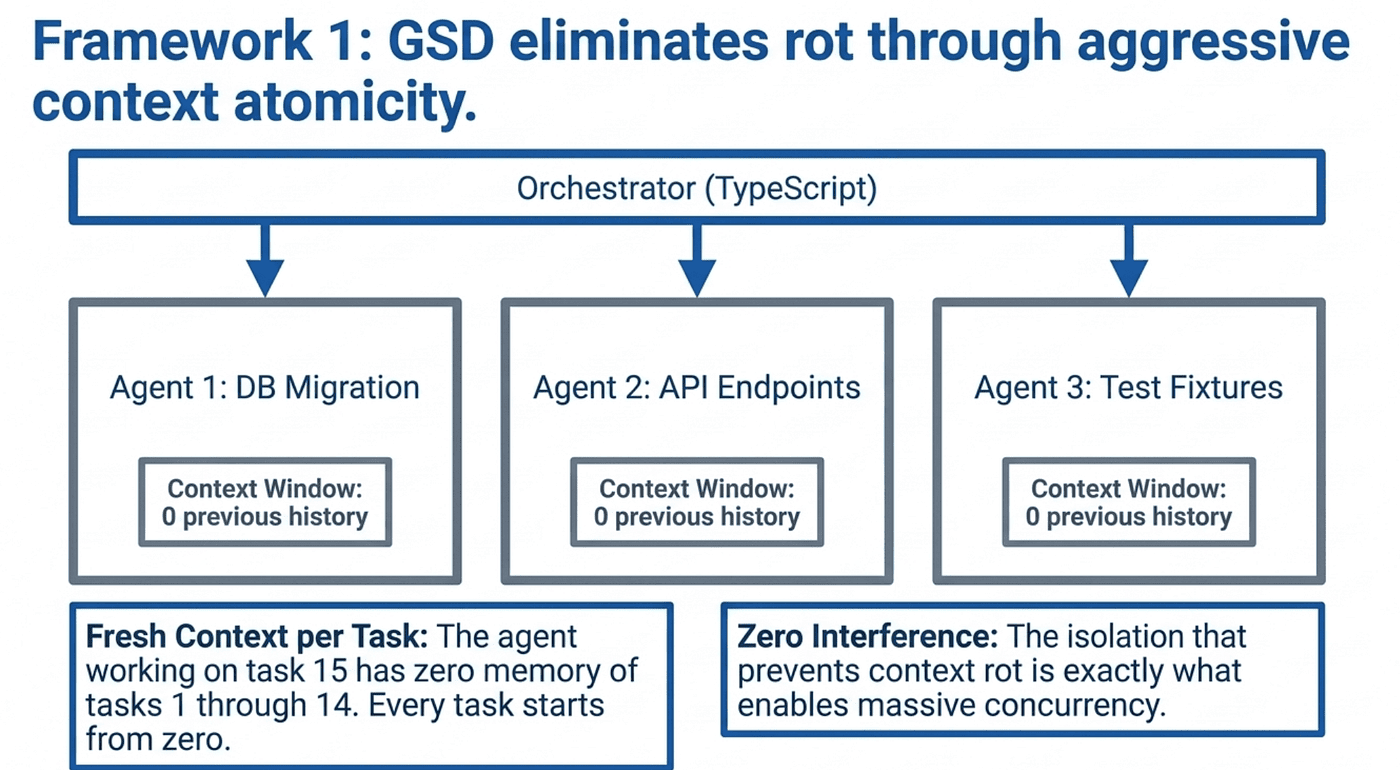
Fresh Context for Every Task
In GSD's architecture, the orchestrator (which runs as a TypeScript application controlling the agent session) breaks work into discrete units. Each unit of work is executed by a fresh agent session with a clean context window. The agent does not inherit conversation history from previous tasks. It does not accumulate context over time. Every task starts from zero.
This is a radical design choice. The agent working on task 15 has no memory of what happened during tasks 1 through 14. It cannot remember a clever solution it found earlier. It cannot recall a discussion about architectural trade-offs. Every task is isolated.
Wave-Based Parallelism
GSD extends this isolation model with wave-based parallelism. Multiple agent sessions run simultaneously on independent tasks, each in its own fresh context window. A wave might have three agents working in parallel: one implementing a database migration, one writing API endpoints, and one generating test fixtures. None of them share context with the others.
Wave 1: [Agent A: DB Migration] [Agent B: API Routes] [Agent C: Test Fixtures]
| | |
Fresh context Fresh context Fresh context
Wave 2: [Agent D: Integration] [Agent E: Validation]
| |
Fresh context Fresh context
This parallelism is only possible because each agent operates in isolation. If they shared a context window, they would interfere with each other's work. The isolation that prevents context rot also enables concurrency.
GSD's Persistent Memory System
The obvious problem with fresh context isolation is knowledge loss. If every agent starts with an empty context window, how does it know what the project is, what has already been built, and what constraints to follow?
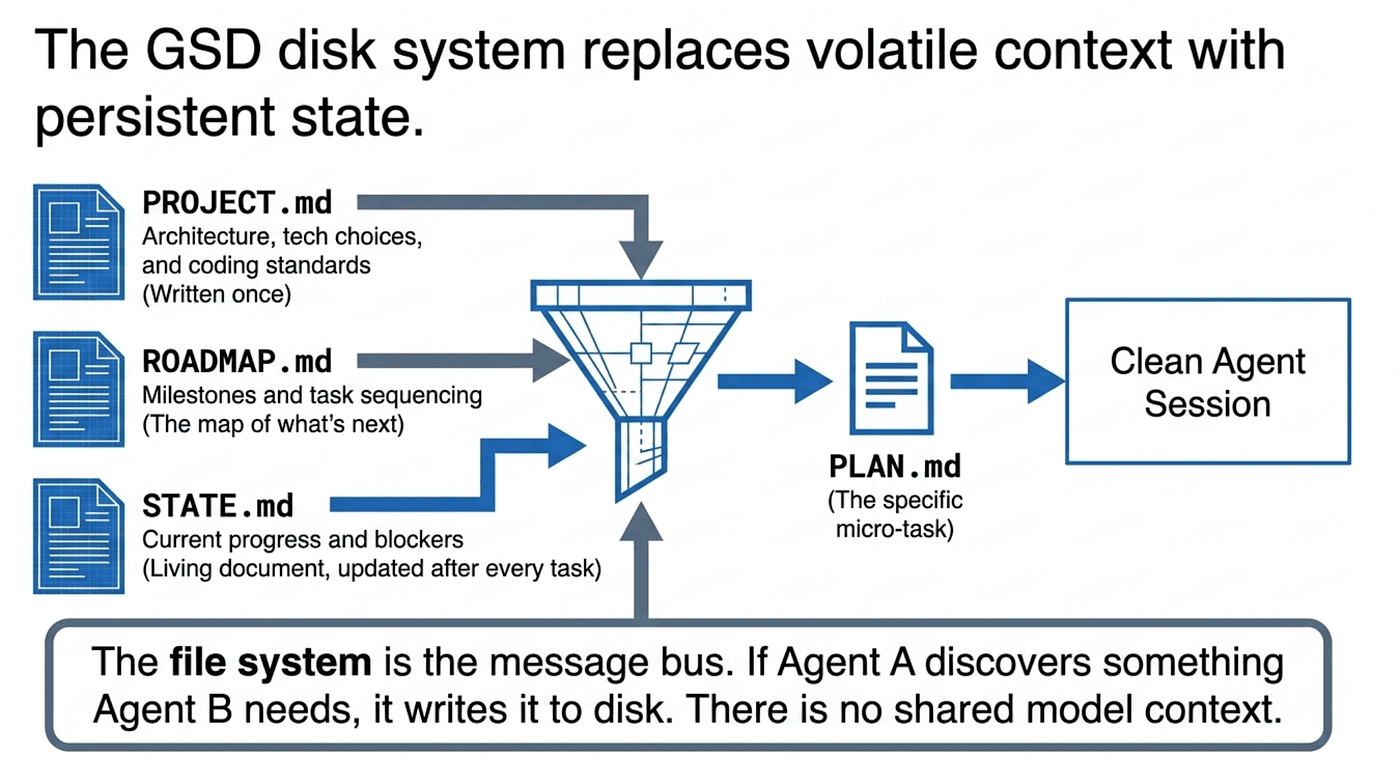
GSD solves this with what I call "memory as architecture": a system of markdown files on disk that serve as the project's external memory.
The Three Pillars of External Memory
- PROJECT.md stores the project specification, architecture decisions, technology choices, and coding standards. It is written once during project setup and updated as major decisions change.
- ROADMAP.md defines the order in which work will proceed. It breaks the project into phases, milestones, and tasks, providing a map of what comes next.
- STATE.md tracks where the project is right now. Which tasks are complete? Which are in progress? What blockers exist? STATE.md is the living document that changes with every completed task.
When GSD spawns a fresh agent session for a new task, it assembles a focused context window from these files plus the specific PLAN.md for that task. The agent reads PROJECT.md to understand the project, ROADMAP.md to understand where this task fits, STATE.md to understand current progress, and PLAN.md to understand exactly what it needs to do.
Instead of relying on the chat transcript as "memory," GSD uses a simple external-memory pattern:
- PROJECT.md (architecture + standards)
- ROADMAP.md (what comes next)
- STATE.md (what's true right now)
- PLAN.md (task-specific instructions)
Each fresh agent session reads only what it needs from these files, so core constraints never get buried mid-context.
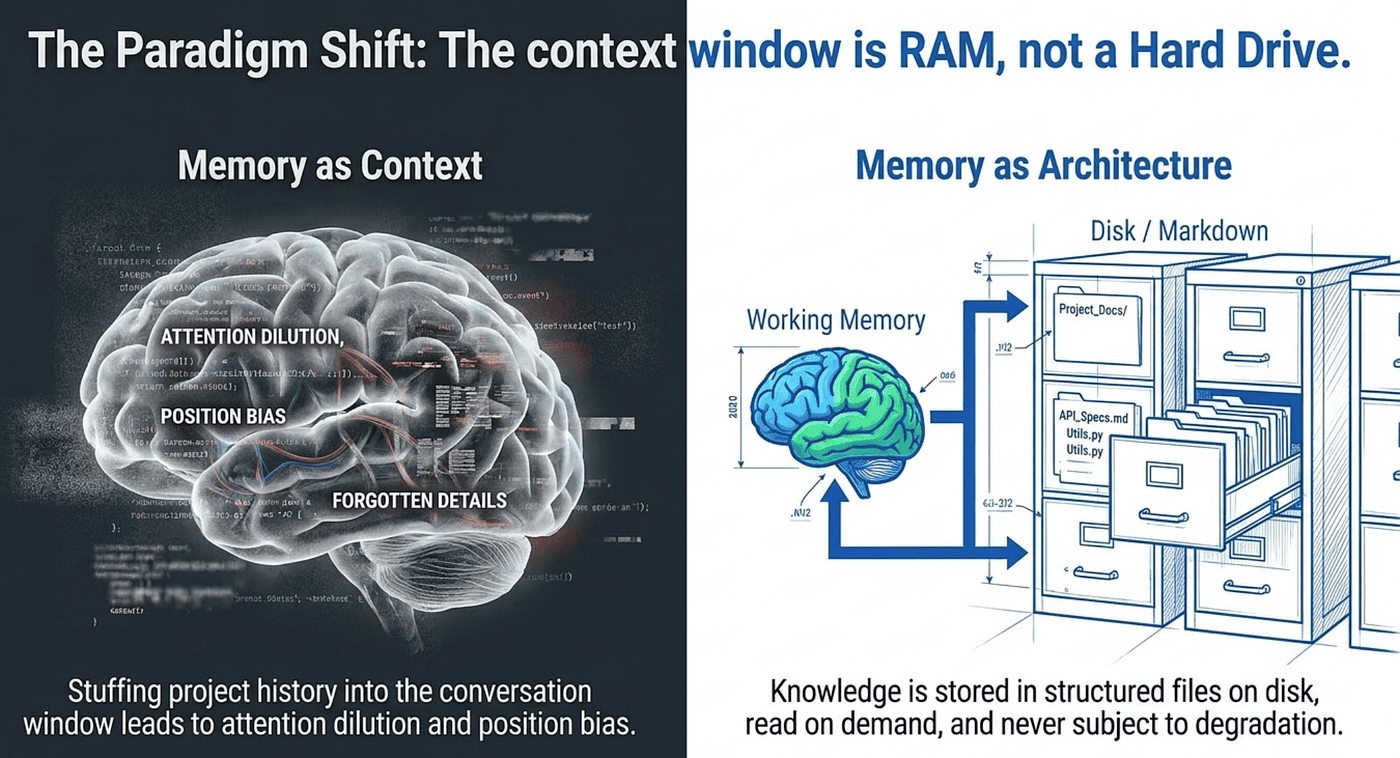
Memory as Architecture vs. Memory as Context
This distinction is crucial. Traditional AI interactions treat memory as context: everything the model needs to remember is stuffed into the conversation window. As the conversation grows, the memory degrades.
GSD treats memory as architecture: knowledge is stored in structured files on disk, read on demand, and never subject to position bias or attention dilution. The files do not degrade over time. PROJECT.md is just as readable on task 100 as it was on task 1.
Communication between agents happens exclusively through files. If Agent A discovers something that Agent B needs to know, Agent A writes it to disk (typically by updating STATE.md or a shared notes file), and Agent B reads it when it starts. There is no shared context window. There is no message passing through the model. The file system is the message bus.
Recovery and Resilience
GSD's file-based memory system also provides crash recovery. A lock file tracks the current unit of work. If a session dies from a model timeout, network failure, or context limit hit, the next /gsd auto command reads the surviving session files, synthesizes a recovery briefing from every tool call that made it to disk, and resumes with full context. Nothing is lost because nothing was stored only in a context window.
This is a subtle but important advantage. Context-only memory is volatile. If the session crashes, the memory is gone. File-based memory is durable. The project state survives any individual session failure.
Superpowers' Micro-Task Strategy
Where GSD solves context rot through architectural isolation, the Superpowers framework solves it through temporal containment. Superpowers limits the "complexity blast radius" by ensuring no task runs long enough for context rot to become a factor.

The 2–5 Minute Task Window
As we explored in Article 3, Superpowers breaks all work into tasks designed to take 2–5 minutes each. This is not arbitrary. At 2–5 minutes of active agent work, a modern coding agent will typically consume somewhere between 10,000 and 30,000 tokens of context, well below the degradation threshold identified in the research.
Every task comes with:
- Exact file paths to modify
- Complete code to write or change
- Explicit verification steps (tests to run, checks to pass)
- No ambiguity requiring the agent to make judgment calls
The implementation plan is designed so that, in Jesse Vincent's words, "an enthusiastic junior engineer with poor taste, no judgment, no project context, and an aversion to testing" could follow it. This level of prescriptive detail means each subagent needs minimal context to do its work.
Front-Loading Decisions
The key to making micro-tasks work is front-loading all decisions into the planning phase. Superpowers enforces a strict pipeline: brainstorm, then design, then plan, then execute. By the time a subagent receives a task, every architectural decision has already been made. The subagent does not need to understand the full project context. It does not need to reason about trade-offs. It needs to follow instructions.
This is why Superpowers can run autonomously for hours without deviating from the plan. Each individual task is trivial enough that context rot has no time to set in, and the planning phase has already made every decision that would require deep context understanding.
Subagent Isolation
Like GSD, Superpowers dispatches a fresh, specialized subagent for each task. The subagent receives only the context it needs: the task description, the relevant file paths, and any prerequisites. It does not inherit the parent agent's full conversation history. Even if the orchestrating agent's context is growing, the actual code-writing work happens in clean, isolated sessions.
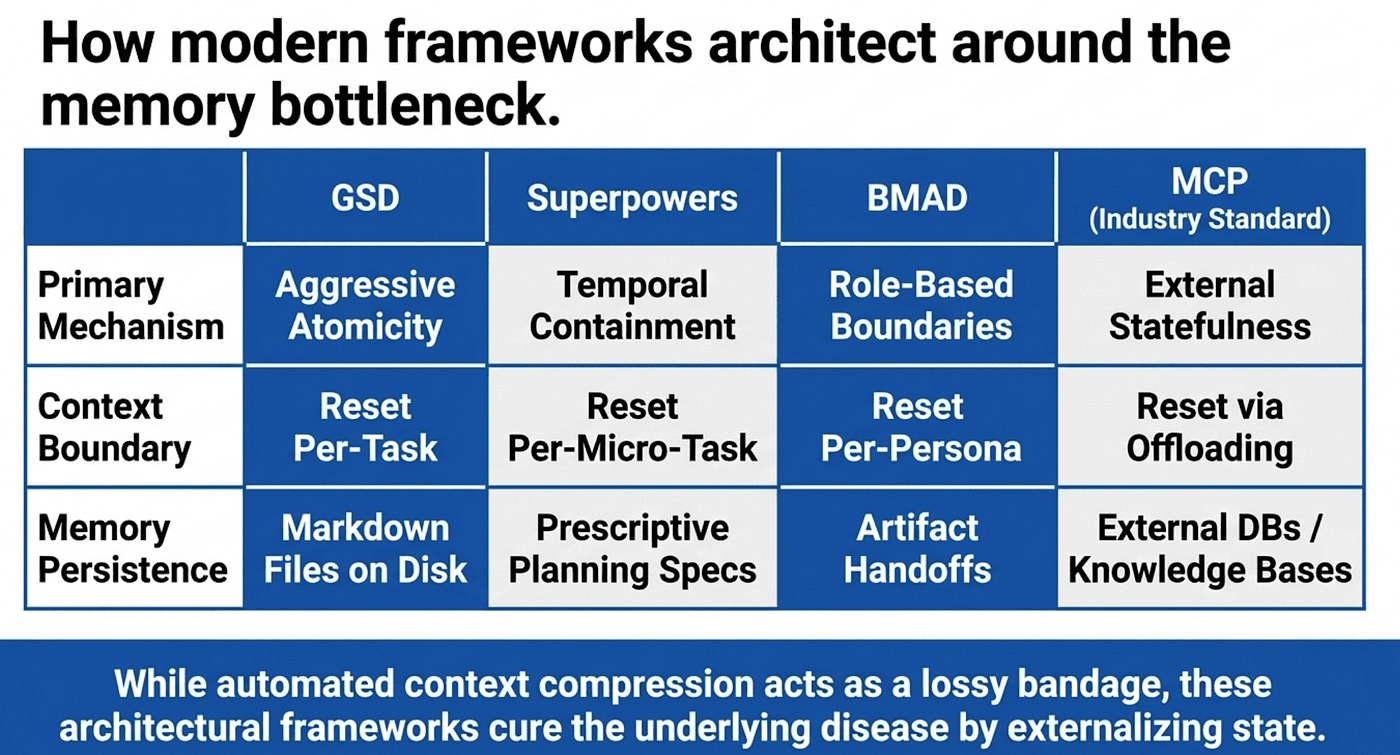
Other Approaches to Context Management
GSD and Superpowers represent two ends of a spectrum, but other frameworks have developed their own strategies for managing context degradation.
Here's the same comparison in a mobile-friendly table:

BMAD's Persona Switching
The BMAD Method (Breakthrough Method for Agile AI-Driven Development) takes an organizational approach to context management. Rather than isolating individual tasks, BMAD structures the entire development lifecycle around persona switching.
BMAD defines specialized personas: Analyst, Architect, Developer, QA, and Project Manager. Each persona is defined as an "Agent-as-Code" markdown file that specifies expertise, responsibilities, constraints, and expected outputs. When you switch from the Architect persona to the Developer persona, you are effectively resetting the context around a new set of priorities and constraints.
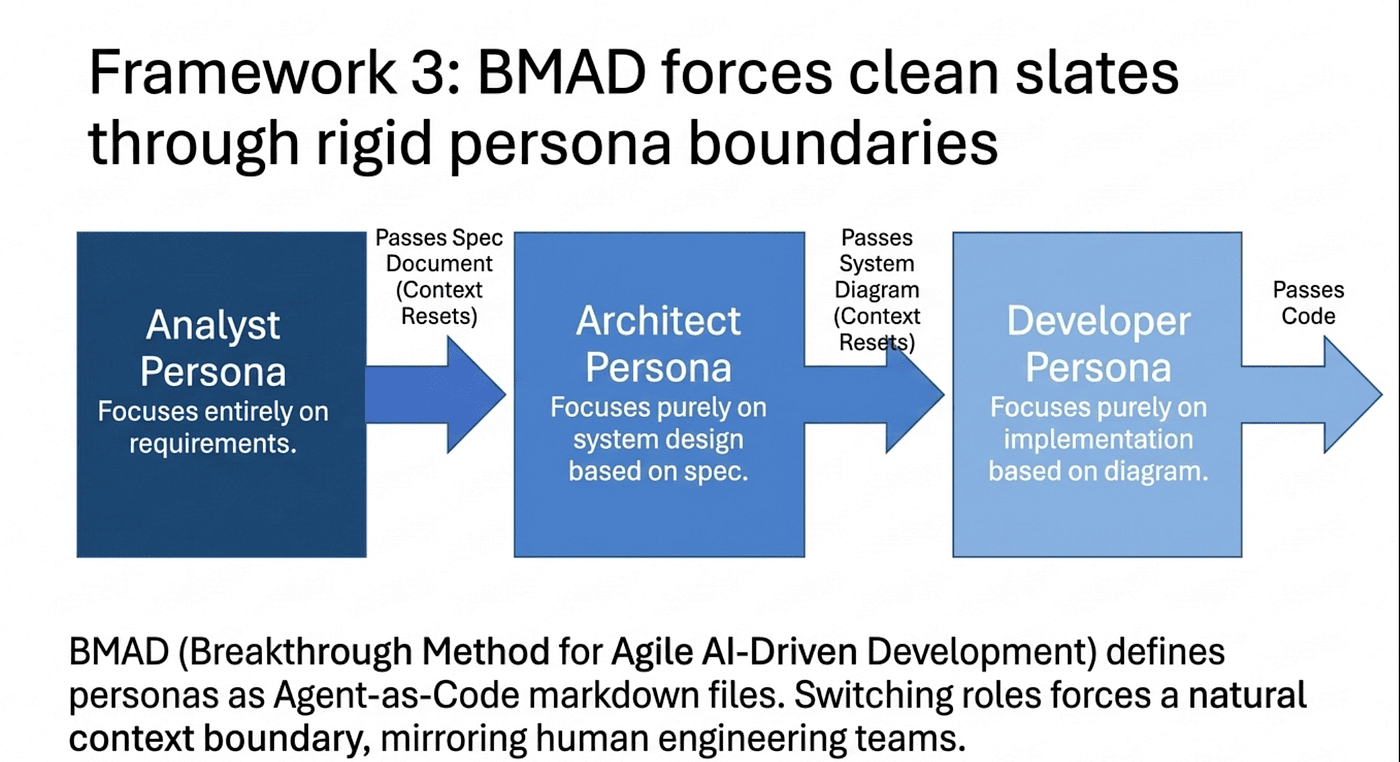
The key insight is that persona switching creates natural context boundaries. The Architect does not need to remember every line of code the Developer wrote. The QA persona does not need the full architectural discussion. Each persona receives focused context relevant to its role, with artifacts (documents, diagrams, specs) serving as the handoff mechanism between personas. This mirrors how human development teams operate: each role carries specialized knowledge, not the entire project history.
Context Compression and Summarization
Some frameworks and tools use automated context compression: periodically summarizing the conversation history and replacing the full transcript with a compressed version. Claude Code, for example, uses an auto-compact feature that triggers when context usage exceeds a threshold, compressing the conversation while preserving key information.
The trade-off is information loss. Every compression cycle loses some nuance, some detail, some constraint that might matter later. It is a lossy process applied to a domain (software specification) where precision matters. Context compression buys time, but it does not eliminate the fundamental problem. Think of it as treating symptoms rather than curing the disease.
Model Context Protocol (MCP) as External Memory
The Model Context Protocol, introduced by Anthropic in late 2024 and now adopted across the industry (including by OpenAI and Google), provides a standardized way for AI agents to interact with external tools and data sources. While MCP is broader than just memory management, it enables a powerful pattern: using external systems as persistent memory (and now widely adopted across OpenAI, Google, and most major agent frameworks).
With MCP, an agent can write intermediate results to a database, store context in a scratchpad service, or retrieve project information from a knowledge base, all through a standardized protocol. This effectively extends the agent's memory beyond its context window. The agent does not need to remember everything. It needs to know how to look things up.
MCP turns the agent's relationship with memory from "store everything in my head" to "know where to find things." This is the same philosophical shift that GSD makes with its file-based memory, but generalized to any external system. By making interactions stateful through external persistence, MCP allows agents to store context in an external repository and retrieve it later, maintaining information across turns and even across sessions.
Practical Recommendations
Based on the research and the patterns emerging from production frameworks, here are concrete strategies for minimizing context rot in your own agentic workflows.
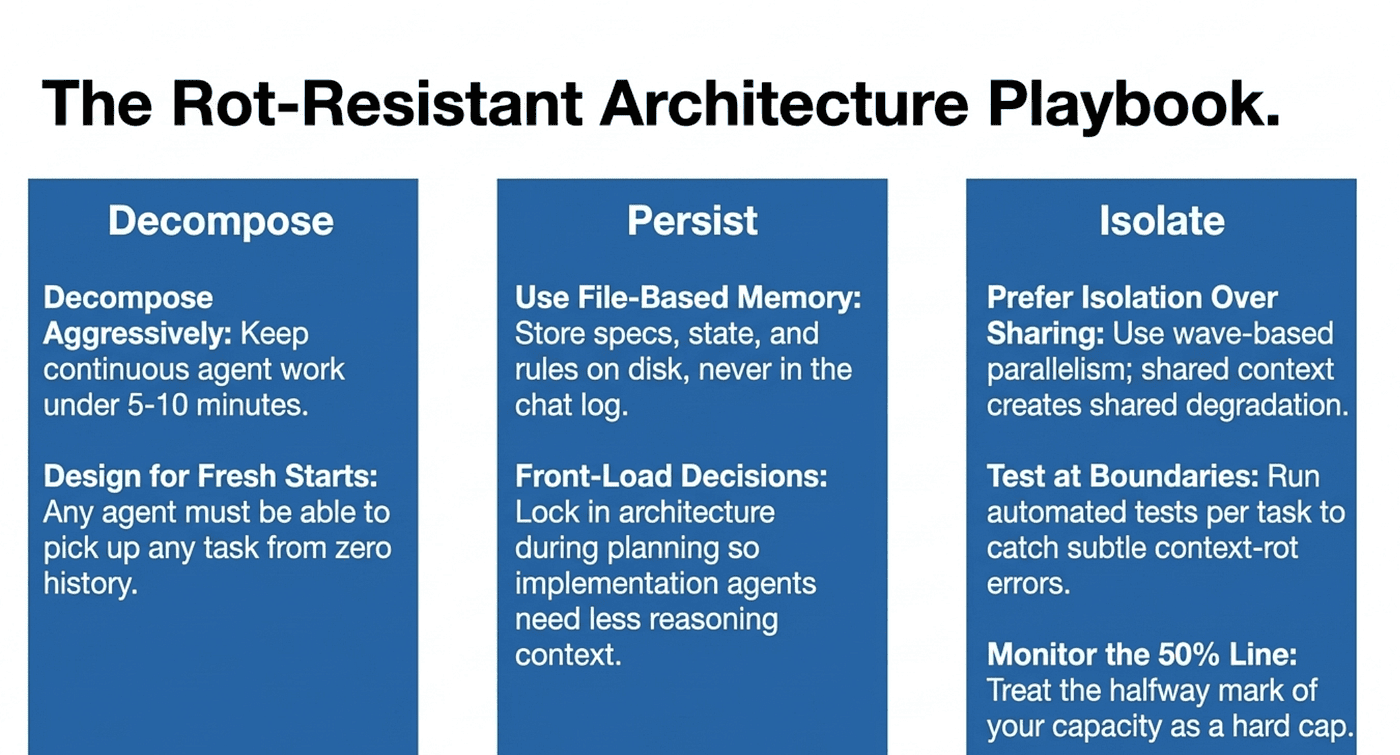
1. Decompose Aggressively
Break work into the smallest possible units. If a task takes more than 5–10 minutes of continuous agent work, it is too large. Smaller tasks mean less context accumulation, and less context accumulation means less degradation.
2. Use File-Based Memory
Do not rely on conversation history as your source of truth. Store project specifications, architectural decisions, coding standards, and current state in files on disk. Have agents read these files at the start of each session rather than depending on conversation context. GSD's PROJECT.md, ROADMAP.md, and STATE.md pattern is a proven template you can adapt to any workflow.
3. Front-Load Decisions
Make architectural decisions before the coding starts. The more decisions you can make in the planning phase, the less reasoning each implementation agent needs to do, and the less context it needs to carry.
4. Monitor Context Usage
Pay attention to how much of your model's context window is consumed. Most frameworks provide this information. When you cross 50% capacity, consider starting a fresh session or compressing the context. The research is clear: degradation accelerates past the halfway mark.
5. Design for Fresh Starts
Structure your workflow so that any agent can pick up any task with only the information in your project files. If an agent needs to read the entire conversation history to understand what to do, your memory architecture has a gap.
6. Prefer Isolation Over Sharing
When multiple tasks can run in parallel, give each its own agent session. Shared context windows create shared degradation. Isolated sessions stay clean.
7. Test at Boundaries
Context rot produces subtle errors. Automated testing becomes even more critical in agentic workflows. Run tests after every task, not just at the end of a session. Catching context-rot-induced errors early prevents them from propagating through downstream tasks.
The Path Forward
Context rot is not going away. Until transformer architectures fundamentally change how they handle long sequences, every LLM will degrade as its context window fills. The frameworks that produce the best results are not the ones that ignore this limitation. They are the ones that design around it.
GSD's radical approach gives every task a fresh context and uses files as external memory, eliminating context rot at the cost of conversational continuity. Superpowers' micro-task strategy keeps tasks small enough that rot never has time to develop. BMAD's persona switching creates natural context boundaries aligned with development phases. MCP provides the infrastructure for agents to offload memory to external systems.
The common thread across all of these approaches is the same insight: the context window is not a reliable long-term memory. Treat it as working memory. Keep it focused. Keep it fresh. Store everything important somewhere the model cannot forget it.
As of April 2026, incremental improvements in KV-cache optimization and MCP tooling have appeared, but the architectural limitations of transformer position bias — and the framework-level solutions described here — remain essential.
If you found this useful, hit Follow and turn on notifications — Article 5 drops next, and I'll share the templates and checklists I use to keep agents sharp.
Drop your worst context-rot horror story in the comments. I read every one.
In the article in this series, we explored goal-backward verification and how frameworks ensure that AI agents do not just produce output, but produce the right output, even when working autonomously for extended periods.
This is Article 4 in a five-part series on agentic software engineering. Previous articles covered spec-driven development with GSD, framework comparisons, and Superpowers' composable skills pipeline.
References
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). "Lost in the Middle: How Language Models Use Long Contexts." Transactions of the Association for Computational Linguistics, 12, 157–173. (Originally posted to arXiv in July 2023.)
- Veseli, B., et al. (2025). "Positional Biases Shift as Inputs Approach Context Window Limits." arXiv:2508.07479 (COLM 2025).
- Chroma Research. (2025). "Context Window Degradation Across 18 Production Language Models." Technical report.
- MIT CSAIL researchers. (2025). Papers on causal masking and adaptive positional encodings (e.g., PaTH Attention).

About the Author
Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content.

He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code