Harness Engineering: How Interface Design Quietly Tripled AI Coding Performance — SWE
The SWE-Agent Paper and the Birth of the Agent-Computer Interface: How a Princeton research team more than tripled AI coding benchmark performance without changing the model
Originally published on Medium.

The SWE-Agent Paper and the Birth of the Agent-Computer Interface: How a Princeton research team more than tripled AI coding benchmark performance without changing the model
Discover how a simple redesign of the AI-computer interface can triple coding performance — no new model needed.
Subject: The SWE-agent paper more than tripled AI coding benchmark performance without changing the model. Here is what the Agent-Computer Interface actually did and why it matters for anyone building or using AI Agents today. This was the birth of AI Harness Engineering.
What if more than tripling AI coding benchmark performance had nothing to do with a better model? No new training data. No architectural breakthrough. No scaling law magic. Just a better interface.
That is the core finding behind the SWE-agent research. Published by Princeton researchers (John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press) and accepted at NeurIPS 2024, it introduced a concept that quietly reshaped how the industry thinks about AI Agents: the Agent-Computer Interface, or ACI. [1] Using GPT-4 Turbo as the base model, SWE-agent achieved 12.47% pass@1 on SWE-bench (compared to 3.8% for the prior best non-interactive, retrieval-augmented approach), a more than three-fold improvement driven entirely by interface design [1].
The core insight is deceptively simple. We spend enormous energy designing user interfaces for humans. We obsess over button placement, information hierarchy, and cognitive load. But when we hand an AI agent a computer terminal, we give it raw bash and say "figure it out." The SWE-agent team asked: what if we designed the computer interface for the agent with the same care we design interfaces for humans?
The answer changed everything.
The Problem: LLM Agents on Raw Terminals Face Three Interface Failures
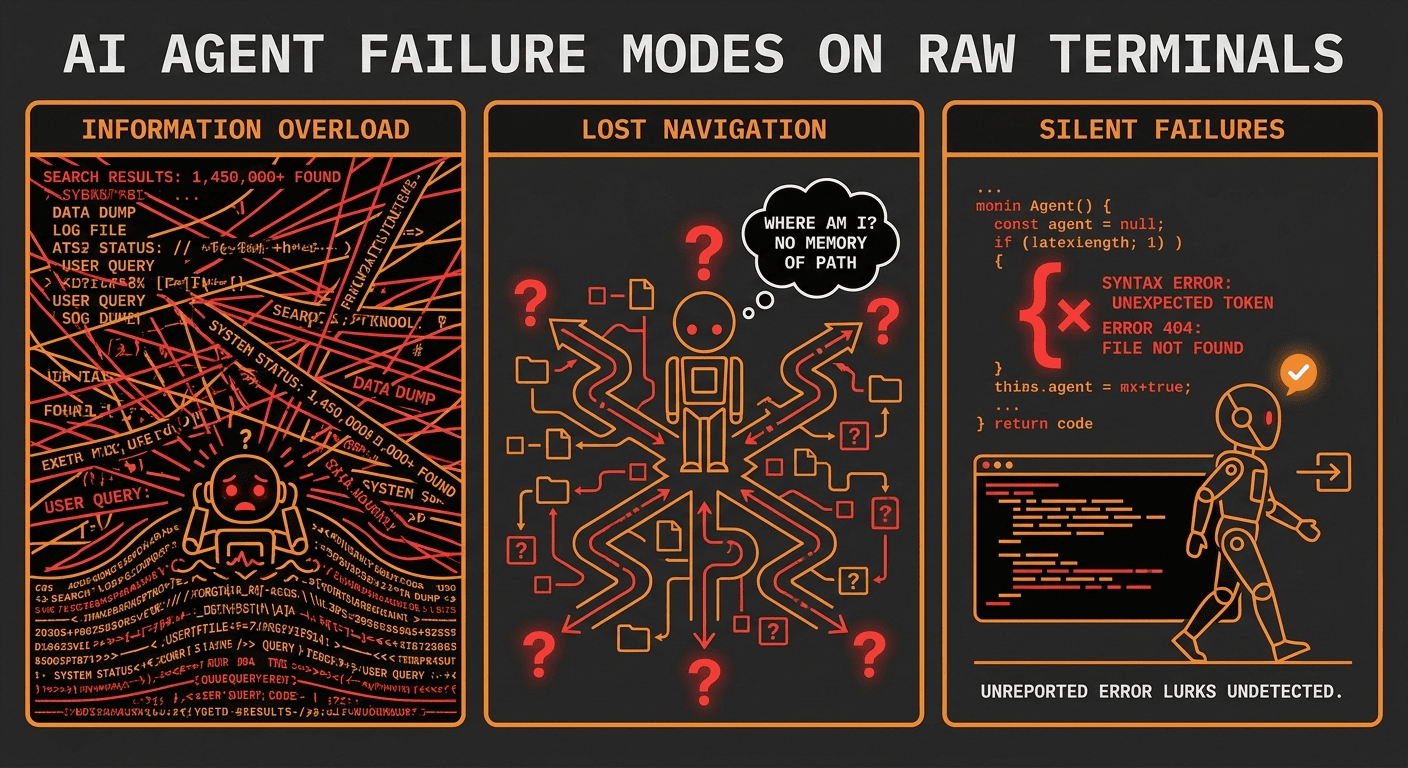
Before SWE-agent, the dominant approach to AI Agents in coding tasks was straightforward. Give the model a bash shell. Let it run commands. Parse the output. Repeat.
This works the same way that giving a new developer SSH access to a production server "works." Technically, they have everything they need. Practically, they will drown in output, lose track of where they are, and make mistakes that a better-designed environment would have prevented.
Think about what happens when a human developer runs raw grep on a large codebase. You get 500 results. You scroll through them. You lose context. You forget which file you were looking at three minutes ago. Now imagine that developer has no scrollback buffer, no syntax highlighting, and no persistent state between commands. That is what LLMs were dealing with before the ACI.
Information Overload: When LLM Agents Hit Search Result Limits
The model runs find . -name "*.py" on a large repository and gets 2,000 results. Its context window fills with filenames. It has no way to prioritize, filter, or navigate. It picks a file semi-randomly and hopes for the best.
Lost Navigation State: How Raw Terminals Break Agent Context
The model opens a file, reads some code, then runs another command. Now it has lost its place. It does not remember what line it was on, what function it was examining, or which files it has already visited. Every action resets its spatial awareness.
Silent Editing Failures: The Hidden Cost of Raw Bash Interfaces
The model writes a sed command to modify code. The command runs without error. But the regex was slightly wrong, and now there is a syntax error on line 47 that the model will not discover until five steps later, when a completely unrelated operation fails with a cryptic error message.
These are not intelligence failures. They are interface failures. The model is plenty smart enough to fix bugs. The environment just makes it unnecessarily hard.
The good news: every one of these failure modes is solvable without changing the model at all.
The Agent-Computer Interface: Designing AI Agents for LLM Cognition
The SWE-agent team's key contribution was formalizing the idea that agents need a purpose-built interface layer between themselves and the computer. They called this the Agent-Computer Interface, or ACI: a deliberate parallel to the human-computer interface (HCI) that UI designers have been refining for decades [1]. The authors explicitly argue that "LM agents represent a new category of end users" who benefit from "specially-built interfaces," drawing directly on HCI methodology, where user studies reveal insights about interface compatibility with human cognition and performance [1].
The ACI is not a prompt. It is not a tool description. It is a complete abstraction layer that reshapes how the agent perceives and interacts with the codebase. Every design decision in the ACI was driven by one question: does this match how LLMs actually process information?
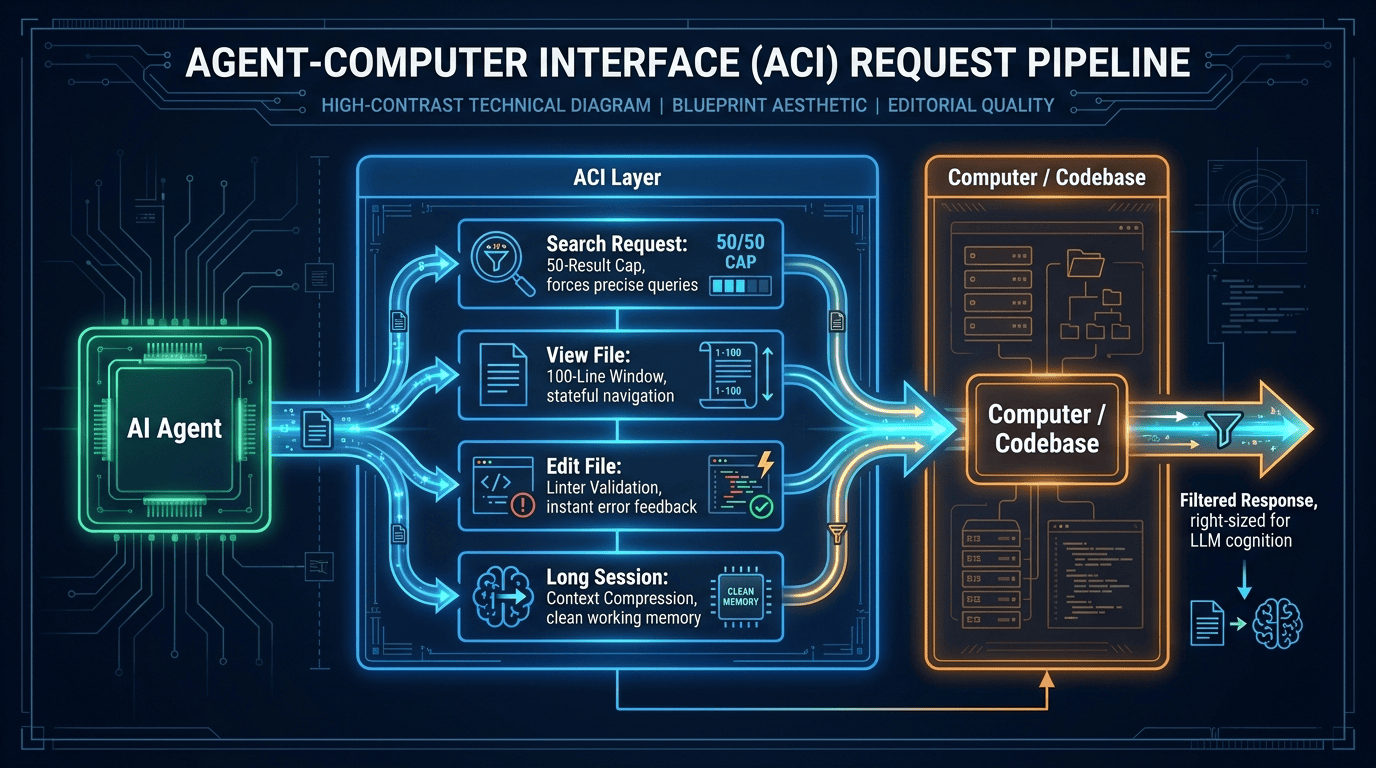
The ACI sits between the agent and the codebase. Each request type routes through a purpose-built handler:
- Search requests hit the 50-result cap, forcing precise queries instead of broad sweeps.
- File view requests go through the stateful 100-line window, preserving spatial context.
- Edit requests run through the linter before any change is applied, rejecting syntax errors immediately.
- Long sessions trigger context compression, keeping working memory lean.
Every response comes back filtered and right-sized for LLM cognition, not raw terminal output.
How LLMs Process Information: The Cognitive Case for ACI
LLMs have specific cognitive characteristics that differ from human cognition in ways that matter enormously for tooling:
- They process token sequences positionally rather than with the spatial layout awareness human readers use; transformer attention runs over a one-dimensional sequence (see general discussion of context-window mechanics in [2])
- They have a fixed context window that acts as working memory [3]
- They score higher on structured-option benchmarks than on open-ended generation tasks, a measurement gap benchmark designers explicitly flag as a bias the format introduces rather than a neutral observation about capability [4]
- They fail to reliably retrieve information from the middle of long contexts, with accuracy dropping more than 20 percentage points in the worst-case configurations as relevant content moves away from context boundaries [5]
- They are sensitive to information density; too much is as bad as too little [6]
The ACI accommodates every one of these characteristics. Not by making the model smarter, but by making the environment friendlier to how the model already thinks.
Redesigning the Environment, Not the Operator
This is the same insight that transformed aviation safety. Cockpit designers eventually stopped asking "how do we train pilots to handle more information?" and started asking "how do we redesign the cockpit so pilots do not need to?" The ACI applied that same question to AI Agents.
This reframing, from blaming the operator to redesigning the environment, is the foundational principle of human factors engineering, traced to Fitts and Jones's landmark 1947 analysis of 460 aircraft control errors, which concluded that "pilot error" was primarily a mismatch between cockpit design and human capabilities [7]. Don Norman codified the principle for software in The Design of Everyday Things: "When people err, change the system so that type of error will be reduced or eliminated" [8].
The SWE-agent team applied this principle to AI. Stop asking "is the model smart enough?" Start asking "is the environment getting in the model's way?"
The Four SWE-agent ACI Components: Each One Solves a Real Problem
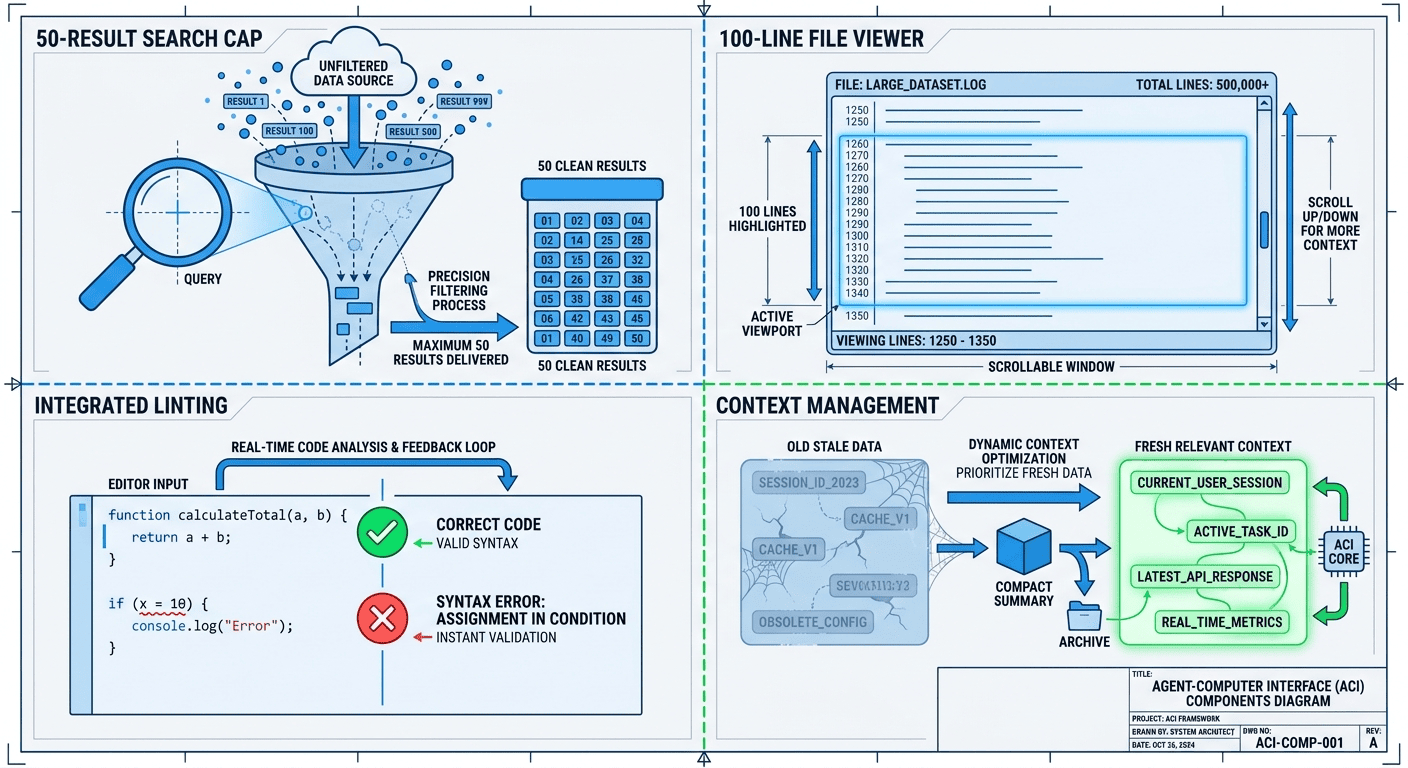
The SWE-agent ACI has four carefully designed components [1]. Each one addresses a specific cognitive limitation of LLM-based agents, and each one contributed measurably to the final performance gains [1, Table 3]. These are not academic design patterns. They are engineering decisions with measured outcomes.
Component 1: SWE-agent Search Design and the 50-Result Cap
The first design decision was brutally simple: cap all search results at 50 items.
Why 50? Because the researchers found that when agents received more than 50 results, performance degraded noticeably. The model would either fixate on the first few results or attempt to process all of them and lose track of its original goal.
The paper spells it out directly: "The search commands return at most 50 results for each search query; if a search exceeds this number, we do not report the results and instead suggest that the agent write a more specific query." [1] The project documentation gives the rationale: "showing the model more context about each match proved to be too confusing for the model." [11]
The 50-result cap does something subtle but important. It forces the agent to write better searches. Instead of grep "error" ., which might return hundreds of matches, the agent learns to write grep "ConnectionError" src/database/ because it knows it only gets 50 shots. The constraint improves the query, which improves the results, which improves the fix.
"This is a pattern you will see throughout harness engineering: intelligent constraints that make the agent more effective, not less."
The navigation system also provided structured directory listings rather than raw ls output. Instead of a flat list of filenames, the agent received a hierarchical view with file types and sizes, matching how developers actually think about codebases: by structure and purpose, not by alphabetical filename.
The ablation study on search design quantifies the stakes. Switching from SWE-agent's summarized search to iterative search (a Vim/VSCode-style approach showing results one by one) produced one of the largest single drops in the ablation study on SWE-bench Lite. Removing search tools entirely also dropped performance noticeably, though less severely than the switch to iterative search [1, Table 3]. The iterative approach actually performed worse than no search at all. That is a striking result: the wrong interface design can be more harmful than no interface.
The engineering lesson: when an agent has too many options, it makes worse choices. Constrain the option space and performance goes up. This runs counter to the intuition that "more information is always better."
Component 2: SWE-agent File Viewer: 100-Line Windowed Display with Line Numbers
The second component replaced cat with a stateful file viewer. Instead of dumping an entire file into the context window, the viewer showed 100 lines at a time with line numbers [1, §3].
The paper is specific: "The file viewer presents a window of at most 100 lines of the file at a time. The agent can move this window with the commands scroll_down and scroll_up or access a specific line with the goto command." [1, §3] [11]
This matters more than it sounds. When a model sees an entire 500-line file, it must hold all 500 lines in working context while reasoning about one specific function. That is like asking a human to keep an entire book open on their desk while writing a single footnote. The cognitive overhead is real, even for an LLM.
The 100-line window let the model focus. It could say "show me lines 200–300" and reason about just that section. Line numbers meant it could reference specific locations precisely: "the function starting at line 247" instead of "the function near the middle of the file."
Critically, the viewer was stateful. If the model scrolled to line 200, then ran a different command, and then came back to the file, it resumed at line 200. The viewer remembered where the agent was, even when the agent itself might have lost track.
This is the kind of design decision that sounds trivial until you measure it. The ablation studies confirmed it directly. Removing the windowed display in favor of showing the entire file produced one of the largest performance drops in the ablation study. Showing too few lines (30 instead of 100) also dropped performance measurably. The model did not get dumber. It just lost the environmental support that helped it stay oriented.
The engineering lesson: spatial memory is a cognitive resource. When the environment preserves it on behalf of the agent, the agent can spend that resource on reasoning instead.
Component 3: SWE-agent File Editor with Integrated Linting: Instant Error Feedback
The third component was the custom file editor with integrated linting; it turned out to be the most critical piece of the whole system.
In the shell-only baseline, editing worked like this: the model would construct a sed command or a heredoc to modify a file. If the regex was wrong, the indentation was off, or a bracket was missing, the command would succeed (sed does not check Python syntax). The model would continue working, oblivious to the error. Five or ten steps later, something would break, and the model would spend its remaining budget debugging a problem introduced much earlier.
The SWE-agent editor changed this fundamentally. Every edit passed through a linter before being applied. If the edit introduced a syntax error, the editor rejected it immediately and showed the model exactly what was wrong. The edit was not applied. The model had to fix the problem right then, while the edit was still fresh in its context.
The paper describes it this way: "a code linter integrated into the edit function alerts the agent of mistakes it may have introduced when editing a file. Select errors from the linter are shown to the agent along with a snippet of the file contents before/after the error was introduced. Invalid edits are discarded, and the agent is asked to try editing the file again." [1, §3]
# What the agent sees without the ACI linter:
$ python fix_auth.py
Traceback (most recent call last):
File "fix_auth.py", line 47, in validate_token
if token.expires > datetime.now()
^
SyntaxError: invalid syntax
# The agent is now 8 steps past the edit that introduced this error.
# It must reconstruct what it did, why, and how to fix it.
# Token budget: 40% consumed. Remaining: 60%.
# Probability of task completion: falling fast.
# What the agent sees WITH the ACI linter:
EDIT REJECTED: Syntax error on line 3 of proposed edit
if token.expires > datetime.now()
^
Missing closing parenthesis. Edit not applied.
# The agent sees this immediately, while the edit is still in active context.
# Fix is trivial. Cost: 2 tokens. Task completion: unaffected.
This is the same principle behind red-squiggly underlines in your IDE. The value is not in the detection; any linter can find syntax errors. The value is in the timing. Catching an error at the moment of introduction, rather than five steps later, reduces the debugging surface from "anything the model has done recently" to "the exact edit it just attempted."
The ablation study confirmed this. Removing linting from the editor dropped performance measurably on SWE-bench Lite. The broader file editing system (including the edit command that works in concert with the file viewer) showed the largest effect when removed entirely. That was the biggest single-component drop in the study [1, Table 3]. The paper's conclusion: "Compact, efficient file editing is critical to performance." [1, §5.1]
What really tells the story is the error data. The model made just as many initial errors with or without the linter. But with the linter, it fixed them immediately. The paper puts numbers to this: out of 2,294 task instances, 51.7% of SWE-agent trajectories had at least one failed edit. [1] Yet "any attempt at editing has a 90.5% chance of eventually being successful. This probability drops off to 57.2% after a single failed edit." [1, §5.2] Early feedback kept recovery rates high. Late feedback tanked them.
The engineering lesson: errors do not cause failures. Delayed error discovery causes failures. Build your harness to surface errors as close to their point of introduction as possible.
Component 4: LLM Context Window Management: Compression and Focus
The fourth component managed the agent's context window explicitly. As the agent worked, the ACI tracked how much context had been consumed and proactively compressed older information [1, §3].
The compression was not naive truncation. The paper describes the mechanism: "observations preceding the last 5 are each collapsed into a single line," preserving key information (file locations, error messages, successful patterns) while summarizing or removing verbose output (full directory listings, redundant search results, successful command outputs no longer relevant). [1, §3]
Think of it as garbage collection for the agent's working memory. In a raw shell session, every command output accumulates in the conversation history. By step 30, the model's context window is full of stale ls outputs and old error messages. The context management system cleaned this up, keeping the model's attention focused on what mattered right now.
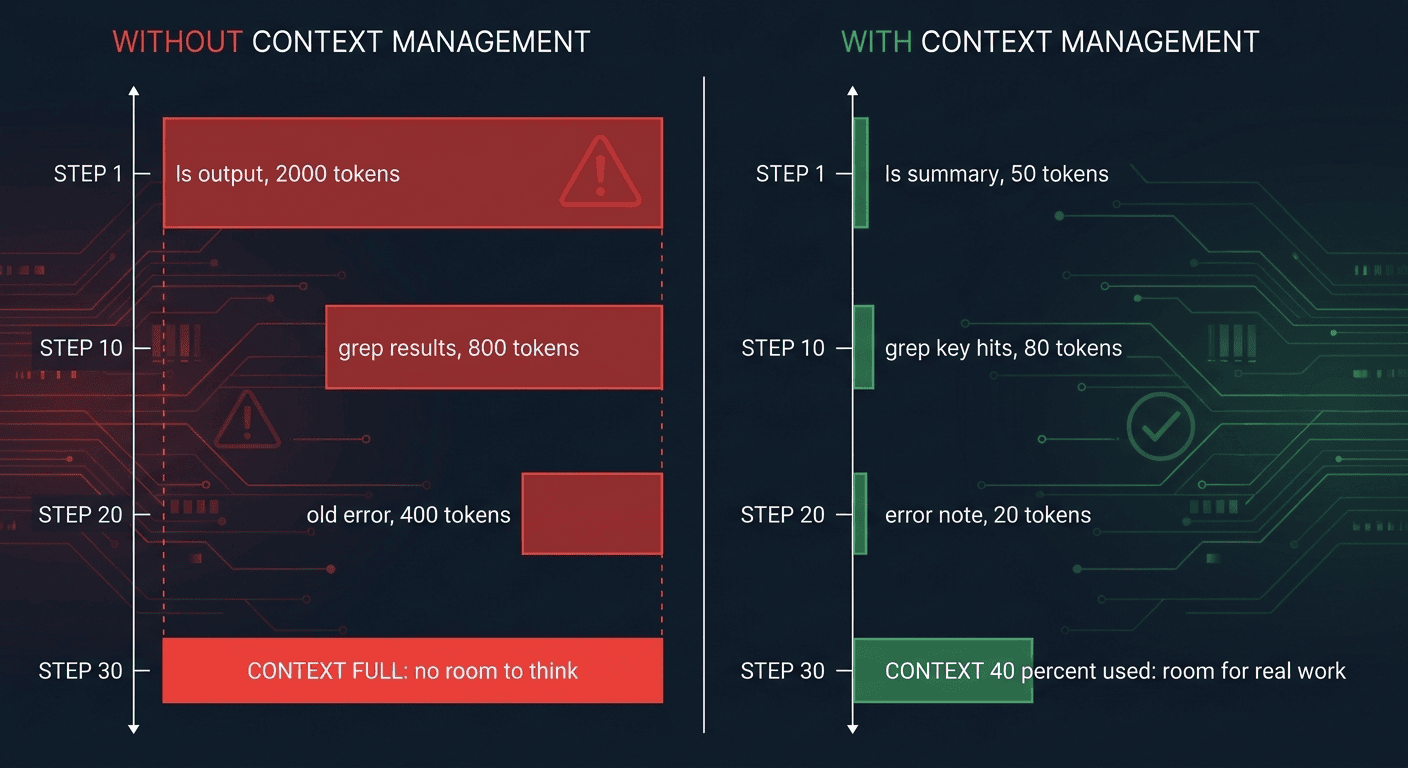
Without context management, step 30 looks like this: 2,000 tokens of stale directory listings, 800 tokens of old grep results, 400 tokens of already-handled error messages. Context full. No room to reason.
With context management, the same step 30 uses roughly 40% of the context window: summarized step records, key hits only, brief error notes. Working memory is still available for the actual problem.
The ablation study quantified this directly. Using full conversation history instead of the compressed last-5-observations approach dropped performance noticeably on SWE-bench Lite. Removing the in-context demonstration examples dropped performance by a smaller but measurable amount [1, Table 3].
The engineering lesson: the agent's context window is not a log. It is working memory. Design your harness to keep working memory clean, not comprehensive.
SWE-agent Benchmark Results: The Case in Numbers
The numbers tell the story plainly. The SWE-agent team evaluated their system on SWE-bench, the standard benchmark for AI code repair at the time [9]. SWE-bench presented agents with real GitHub issues from popular Python repositories and asked them to generate patches that resolved those issues.
💡 What SWE-bench measures: The benchmark collects 2,294 task instances by crawling pull requests and issues from 12 popular Python repositories. [10] Each task gives the AI system an issue description; the system must modify the codebase to resolve it. Correctness is checked via FAIL_TO_PASS unit tests (tests that failed before the fix and passed after) plus PASS_TO_PASS regression tests to confirm no existing functionality was broken [9].
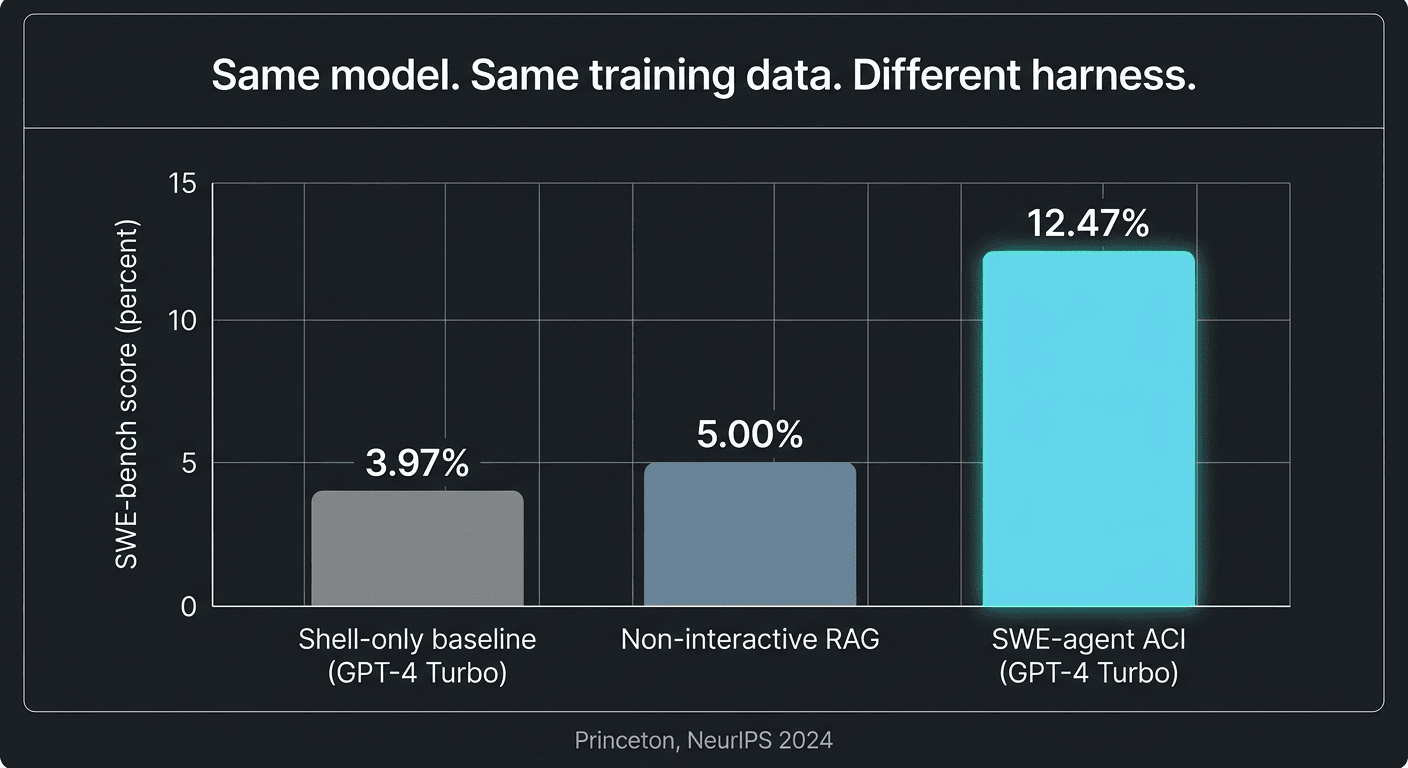
Three configurations, same GPT-4 Turbo model:
- Non-interactive RAG baseline (no agent loop): ~3.8% resolution on SWE-bench. [1]
- Shell-only agent baseline on SWE-bench Lite (GPT-4 Turbo, with demonstration): 11.00% [1, Table 1]. Without demonstration the Shell-only baseline drops to 7.33%.
- SWE-agent with the ACI harness (same model): 12.47%.
The ACI harness more than doubled the shell-only baseline and more than tripled the non-interactive approach. Same model. Same weights. Different harness.
Two comparisons matter here, and they measure different things:
- Shell-only vs. SWE-agent (same model, same split): 11.00% to 18.00% on SWE-bench Lite. The paper reports this as "a 64% relative increase compared to Shell-only, both with GPT-4 Turbo" [1]. Against the demonstration-free Shell-only baseline (7.33%), the gap widens further. Either way, the harness alone explains a large fraction of the gain.
- Prior SOTA vs. SWE-agent: approximately 3.8% to 12.47%, a ~228% relative improvement (~3.3x); this is the full system against the previous best non-interactive approach [1].
Same model. Same weights. The only variable was the four-component interface layer between the model and the codebase.
This was, to my knowledge, the first rigorous demonstration that harness design could matter more than model selection for practical coding tasks. The SWE-agent paper did not just build a better tool. It created a framework for thinking about how AI Agents should interact with computers.
Agent-Computer Interface Ablation Studies: What Actually Mattered
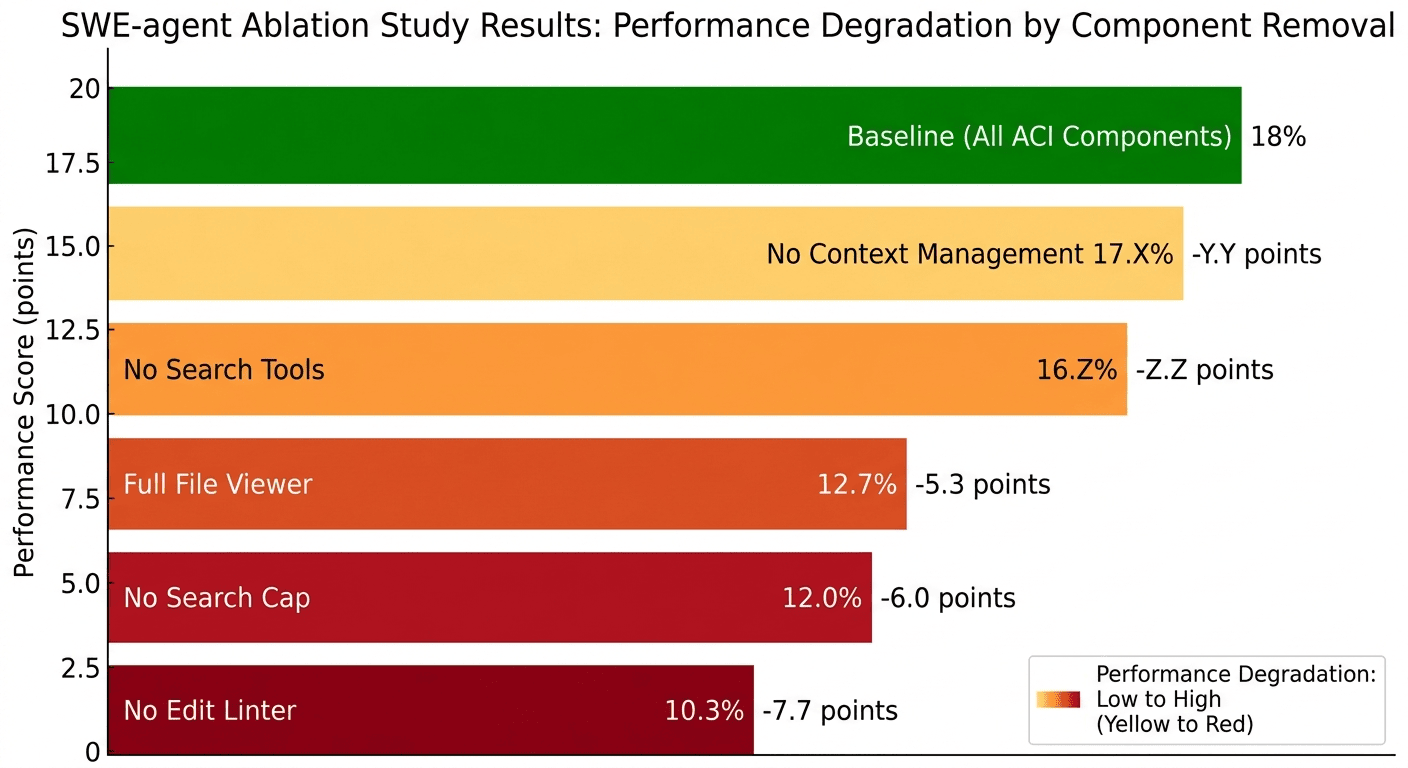
Good research does not just show that something works. It shows why. The SWE-agent team ran careful ablation studies on a 300-instance subset of SWE-bench (the Lite split) to measure each component's independent contribution [1].
Here is what they found:
The Edit Interface: The Single Biggest Factor in LLM Code Repair
Removing the edit interface (including the linter) caused the largest single drop in performance: 7.7 percentage points [1]. Without instant syntax feedback, agents would introduce errors and then spend their remaining budget chasing cascading failures.
This makes intuitive sense from the model's perspective. An LLM generating a code edit is working with probabilities. Sometimes it gets indentation wrong. Sometimes it drops a closing bracket. These are not reasoning failures. They are token-prediction noise. The linter catches that noise instantly, before it compounds.
💡 How the linter works in the paper: The ACI runs the linter when an edit command is issued and returns the result as immediate feedback in the agent's next observation. Syntax errors surface before the agent moves on to the next step [1].
How Capped Search Prevented Context Window Pollution
Removing the 50-result cap, switching from SWE-agent's summarized search to iterative search, produced one of the two largest performance drops in the ablation study [1]. When agents received unlimited search results, they showed two failure patterns:
Anchoring on early results. The model would fixate on the first few matches and ignore potentially better matches further down the list.
Context window pollution. Large result sets consumed valuable context space, leaving less room for actual reasoning about the code.
💡 From the paper: When given a large number of search results, agents tend to look through every match exhaustively, calling
nextuntil each result has been inspected. This inefficient behavior can exhaust an agent's cost budget or context window, leading to worse performance than not having additional search tools at all [1].
The cap forced agents to write precise queries, which led to more relevant results, which led to better patches. Constraint bred quality.
Stateful Viewing Preserved Spatial Awareness
The stateful file viewer contributed less than the linter or search cap, but its removal still caused a measurable decline [1]. Without persistent viewing state, agents lost track of their position in files and wasted actions re-navigating to locations they had already visited.
💡 Design detail: The paper's file viewer displays 100 lines per turn and maintains the agent's current position across steps, replacing the naive
catapproach. This reduces unnecessary context consumption while preserving spatial awareness [1].
Context Management Prevented Late-Session Collapse
The context management component's impact was most visible in longer tasks [1]. For simple one-or-two-edit fixes, context management made little difference. For complex multi-file issues requiring many steps, agents without context management showed a dramatic performance drop in the latter half of their sessions. Their context windows filled with stale information, and their later actions became increasingly confused.
Key Ablation Numbers (Table 3, Yang et al. 2024: SWE-bench Lite, GPT-4 Turbo)
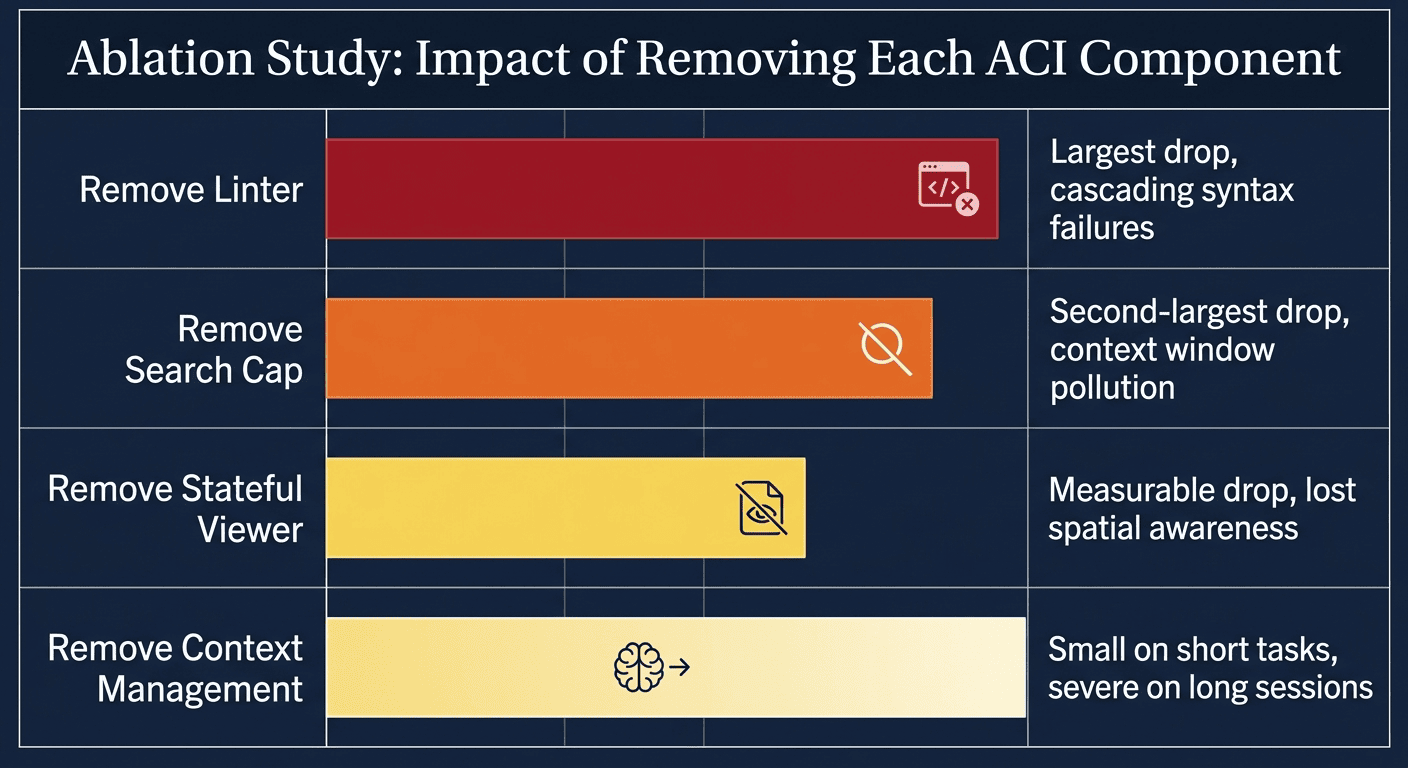
Starting from the full SWE-agent baseline of 18.0% on SWE-bench Lite (GPT-4 Turbo):
- Remove the edit interface entirely: 10.3% (down 7.7 percentage points, the largest single drop).
- Switch to iterative search instead of summarized: 12.0% (down 6.0 points).
- Show the full file instead of the 100-line window: 12.7% (down 5.3 points).
- Use a 30-line viewer instead of 100 lines: 14.3% (down 3.7 points).
- Remove linting from the editor: 15.0% (down 3.0 points).
- Use full conversation history instead of compressed last-5: 15.0% (down 3.0 points).
- Remove all search tools: 15.7% (down 2.3 points).
- Remove in-context demonstration examples: 16.3% (down 1.7 points).
The meta-lesson from the ablations is as important as any individual finding: measure component contributions independently. When you add a new component to your agent harness, run an ablation. You may find that some "improvements" are neutral or even negative. Without ablation, you will never know.
The Deeper Lesson: Cognitive Load and the Agent-Computer Interface
Here is where I want you to step back from the technical details and think about what this paper really demonstrated.
The Agent-Computer Interface did not make GPT-4 smarter. It did not give the model new capabilities. It did not teach it Python or help it understand codebases better. Every capability the model had with the ACI, it also had without it.
What the ACI did was manage the model's cognitive load. It reduced information overload (search caps). It preserved spatial context (stateful viewer). It provided immediate feedback (linter). It kept working memory clean (context management).
Every single improvement came from making the environment more compatible with how the model already processes information. This is the fundamental insight of harness engineering, and the industry is still absorbing it.
We have been treating AI models like they are bottlenecked on intelligence. "If only the model were smarter, it would solve the problem." But SWE-agent showed that in many cases, the model is bottlenecked on environment design. This is the central design challenge for Agentic AI: the intelligence is present, but the environment is working against it.
The model did not change. The training data did not change. What changed was whether the AI Agents operating in that environment had the interface support to apply their capabilities effectively.
This is not a new idea in other fields. Human factors engineering has known for decades that cockpit design matters more than pilot skill for preventing aviation accidents. Research consistently attributes 60 to 80 percent of civil and military aviation accidents to human error, with Boeing data suggesting the figure is around 80 percent [12]. Human factors engineering traces much of that error not to pilot incompetence but to environments designed without adequate regard for human cognitive limitations.
Hospital error rates drop more from checklist design than from hiring smarter doctors. Atul Gawande's research, developed with the WHO and published in The Checklist Manifesto (2009), showed that a roughly two-minute surgical checklist cut major surgical complications by more than a third and inpatient mortality by more than 40 percent, not by changing the doctors, but by redesigning the procedure environment [13, 14]. Peter Pronovost's separate ICU checklist study nearly eliminated a deadly class of central-line infections in Michigan hospital ICUs by replacing ad-hoc practice with a structured five-step procedure [15].
The SWE-agent paper brought that insight to AI agents with hard data.
From Agent-Computer Interface (ACI) to Industry Practice
The impact of the SWE-agent paper extended well beyond its benchmark scores. It gave practitioners the design vocabulary they had been missing for building reliable Agentic AI systems. The ACI framework gave the industry a vocabulary and a design methodology for thinking about agent interfaces.
Before SWE-agent, most agent builders treated the tool layer as plumbing. You needed bash access and file I/O, so you wired up some basic tools and moved on to the "real" work of prompt engineering. After SWE-agent, serious teams started treating tool design as a first-class engineering discipline for AI Agents.
You can see ACI design principles reflected in nearly every major coding agent that followed:
Claude Code's VS Code extension presents proposed changes as inline diffs that require user acceptance before being committed, directly echoing the SWE-agent linter pattern [16]. The tool validates changes before applying them and supports checkpointing so that wide-scale autonomous edits can be rewound if needed.
Cursor provides a structured IDE interface rather than raw terminal access. [17] File navigation, search, and editing all go through purpose-built interfaces that manage what the agent sees at each step. Cursor 2.0 introduced a multi-agent interface using isolated git worktrees, and Cursor 3 (released April 2026) went further with a full agent-first redesign: a new Agents Window runs parallel agents simultaneously, each in its own isolated session, and a Design Mode allows the agent to iterate directly on UI components [18].
Devin (Cognition) built an entire virtual environment designed around agent cognition, with structured browser, editor, and terminal interfaces that all manage information density. [19] Each Devin session runs in a dedicated Linux sandbox with internet access, a full file system, a web browser, a terminal, and code execution capabilities, with bidirectional file system synchronization and real-time streaming of the agent's state [19].
LangChain's deepagents-cli implemented middleware hooks that intercept agent actions for verification and correction, a pattern consistent with the ACI's edit-time linting approach [20]. In a 2025 harness engineering study, LangChain's team improved the deepagents-cli by 13.7 points on Terminal Bench 2.0 (from 52.8% to 66.5%) by modifying only the harness while keeping the underlying model fixed. The middleware stack included a PreCompletionChecklistMiddleware (forcing a verification pass before exit), a LocalContextMiddleware (mapping directory structure on startup), and a LoopDetectionMiddleware (detecting and interrupting repeated failed edit cycles) [21]. A 13.7-point gain from harness changes alone is a direct replication of the SWE-agent finding in a production context.
None of these tools cite the SWE-agent paper in their marketing materials. But the design principles are unmistakable.
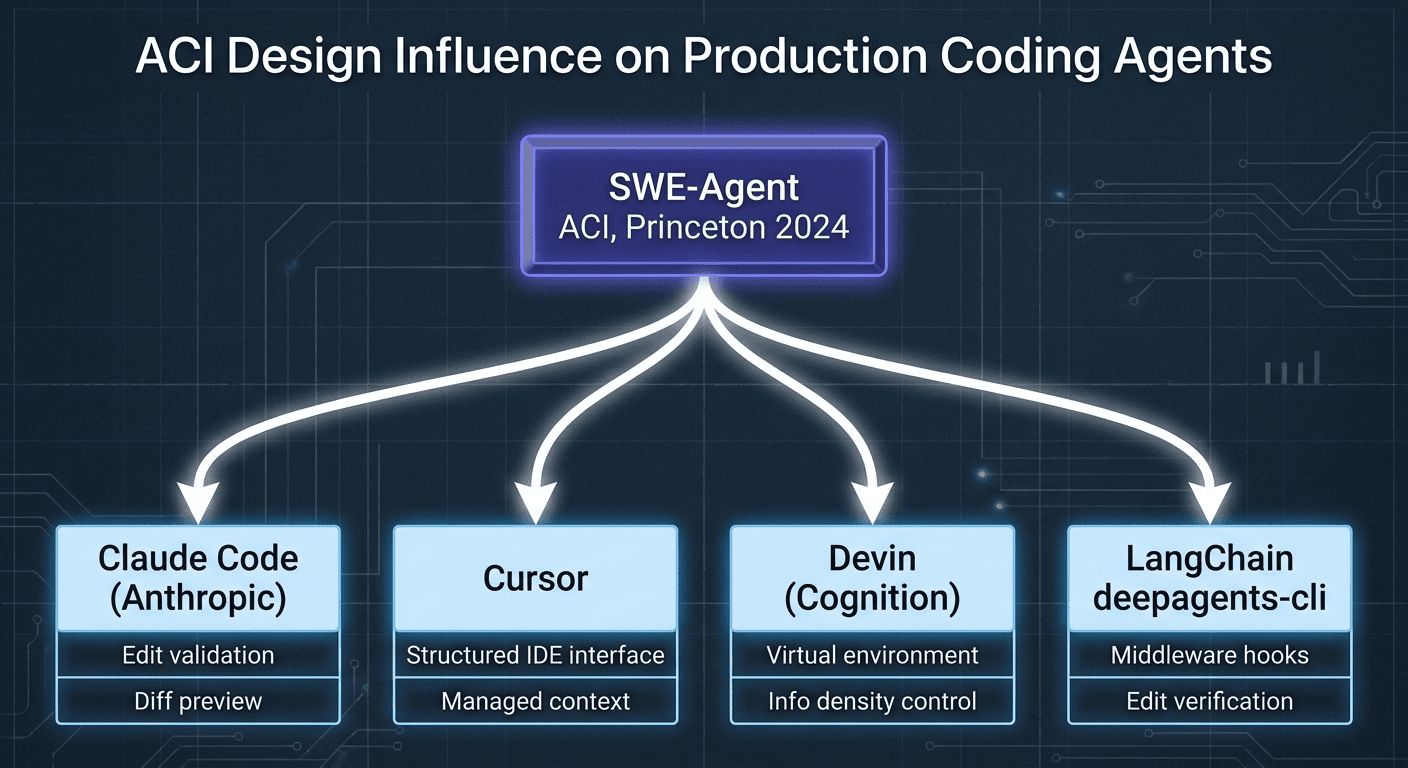
The SWE-agent ACI's design principles propagated into every major coding agent that followed:
- Claude Code adopted edit validation and inline diff preview before applying changes.
- Cursor built a structured IDE interface with managed context per agent step.
- Devin constructed a full virtual environment with deliberate information-density controls.
- LangChain deepagents-cli added middleware hooks for edit verification and loop detection.
The ACI did not just improve one agent's benchmark scores. It established the design language for an entire generation of coding agents.
What Agent-Computer Interface Design Means for Your AI Agents
If you are building or configuring AI Agents today, the SWE-agent paper gives you a concrete framework for improving performance without changing models. Here are the practical takeaways:
Cap your search results. If your agent has access to code search, grep, or any tool that returns variable-length results, set a reasonable maximum. Fifty is a good starting point. You will be surprised how much this improves the quality of the agent's queries and subsequent reasoning.
Add edit-time validation. If your agent can modify files, lint those modifications before applying them. Do not let syntax errors enter the codebase. The cost of running a linter is negligible. The cost of debugging cascading syntax errors is enormous.
Manage context window contents. Track what is in your agent's conversation history. If you see stale search results, old error messages, or verbose command outputs accumulating, implement compression or summarization. The model's attention is a finite resource. Treat it that way.
Design for the model's cognition, not yours. When you build agent tools, do not just expose your existing APIs. Ask: "Does this tool output match how the LLM processes information?" If a tool returns 2,000 lines of JSON, that is a tool designed for humans with scroll bars. The agent needs a 50-line summary with the option to drill deeper.
Measure component contributions. The ablation methodology matters as much as the results. When you add a new component to your agent harness, measure its impact independently. You may find that some "improvements" are actually neutral or negative. Without ablation, you will never know.
Think in terms of cognitive load, not capability. When your agent underperforms, the first question should not be "is this model smart enough?" It should be "is the environment making it unnecessarily hard?" In my experience, the answer is usually yes.
Looking Ahead: Harness Engineering and the Agent-Computer Interface in 2026
The SWE-agent paper was published at NeurIPS 2024 using GPT-4 Turbo, where it achieved 12.47% resolution on SWE-bench, more than triple the previous best of 3.8% set by non-interactive retrieval-augmented systems [1]. Models have improved significantly since then. But the core finding, that interface design drives agent performance, has only become more relevant as models get more capable.
Why? Because as models get smarter, the gap between "what the model can theoretically do" and "what the model actually does in a given environment" widens. A GPT-4 class model might solve 12% of SWE-bench with a good ACI. A frontier model in 2026 might solve 40% — and those AI Agents with well-designed harnesses continue to outpace their counterparts operating in raw terminal environments. But that same frontier model with a raw shell might only solve 20%. The harness multiplier does not shrink as models improve. It may actually grow.
Agentic AI systems in production now experiment with two-agent architectures (planner plus executor), explicit feature lists that anchor long-running work, and incremental progress through git commits that survive context resets. These patterns are documented across the field as of early 2026. Each of these is a direct descendant of the same insight the SWE-agent team formalized: the environment around the model matters as much as the model itself.
If you are building, evaluating, or simply choosing a coding agent in 2026, the ACI gives you a useful diagnostic question. Is the harness designed for how this model actually thinks? Or are we still handing it a raw terminal and hoping?
Discussion Questions
- The SWE-agent paper showed that a 50-result search cap improved agent performance. What other constraints in your own agent tooling might be making the agent more effective rather than limiting it?
- The linter had the single largest impact in the ablation studies because it caught errors at the moment of introduction rather than five steps later. Where else in your systems could you move error detection earlier to reduce cascading failures?
- The ACI's design was explicitly driven by the question "does this match how LLMs process information?" How would you answer that question for the agent interfaces you are building or using today?
References
- Yang, Jimenez, Wettig, Lieret, Yao, Narasimhan, Press — "SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering". NeurIPS 2024; arXiv 2405.15793.
- IBM Research — "Why larger LLM context windows are all the rage". 2024.
- IBM Think — "What is a context window?". 2024.
- Myrzakhan, Bsharat, Shen — "Open-LLM-Leaderboard: From Multi-choice to Open-style Questions for LLMs Evaluation, Benchmark, and Arena". 2024, arXiv 2406.07545.
- Liu, Lin, Hewitt, Paranjape, Bevilacqua, Petroni, Liang — "Lost in the Middle: How Language Models Use Long Contexts". TACL 2024.
- Du et al. — "Context Length Alone Hurts LLM Performance Despite Perfect Retrieval". EMNLP Findings 2025; arXiv 2510.05381.
- Fitts & Jones — "Analysis of Factors Contributing to 460 Pilot Error Experiences in Operating Aircraft Controls". USAF Aero Medical Laboratory, 1947.
- Don Norman — "The Design of Everyday Things, Revised and Expanded Edition". Basic Books, 1988/2013.
- Jimenez, Yang, Wettig, Yao, Pei, Press, Narasimhan — "SWE-bench: Can Language Models Resolve Real-World GitHub Issues?". ICLR 2024.
- SWE-bench team — "SWE-bench Original". 2024, project site.
- Princeton NLP / SWE-agent team — "ACI Background, SWE-agent Documentation". 2024.
- Shah et al. — "Role of Human Factors in Preventing Aviation Accidents: An Insight". IntechOpen, 2022.
- Atul Gawande — "The Checklist Manifesto: How to Get Things Right". Metropolitan Books, 2009.
- Haynes et al. — "A Surgical Safety Checklist to Reduce Morbidity and Mortality in a Global Population". NEJM, 2009.
- Pronovost et al. — "An Intervention to Decrease Catheter-Related Bloodstream Infections in the ICU". NEJM, 2006.
- Anthropic — "Use Claude Code in VS Code". Claude Code Docs, 2025.
- Cursor — "Changelog". 2024-2026.
- Cursor — "New Cursor Interface, Cursor 3". 2026, Cursor Changelog.
- Cognition AI — "Introducing Devin, the first AI software engineer". Cognition Blog, 2024.
- LangChain — "langchain-ai/deepagents". GitHub repository.
- LangChain — "Improving Deep Agents with Harness Engineering". LangChain Blog, 2025.
About the Author

Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications, and practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.

He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. A lot of ideas captured in the CCA and the exam prep that Rick wrote echoes what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code