Introduction: Beyond the Hype -- Architecting for Value in the AI Era
The discussion about Artificial Intelligence has fundamentally changed. It is no longer about whether organizations should adopt A
Originally published on Medium.
The discussion about Artificial Intelligence has fundamentally changed. It is no longer about whether organizations should adopt A

- Part 1: The New Frontier — An in-depth analysis of foundation models from major providers and their architectural implications
- Part 2: Architectural Patterns — Essential design patterns for building intelligent, scalable AI systems
- Part 3: Operational Excellence — Production strategies for governance, observability, and cost management
-
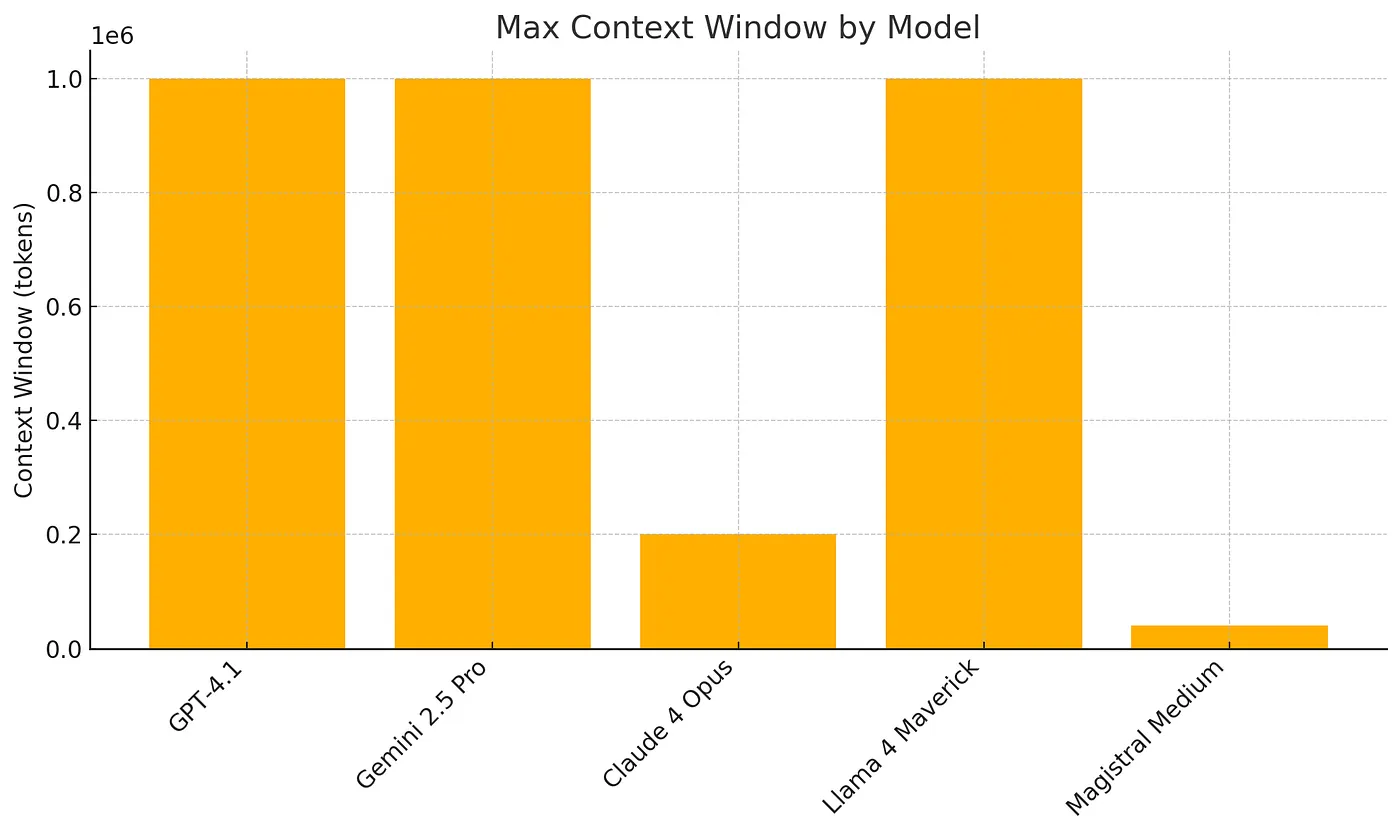
GPT-4.1 (Standard): This is the new flagship model for complex tasks, demonstrating superior coding performance (54.6% on SWE-bench) and more reliable instruction-following capabilities compared to GPT-4o. Its massive 1 million token context window is a key feature for advanced agentic applications that need to process entire codebases or extensive legal documents in a single pass.
-
GPT-4.1 Mini & Nano: These models provide cost-effective, tiered alternatives. The Mini variant matches or even exceeds GPT-4o on many benchmarks but at a significantly lower cost, making it the likely workhorse for most production API traffic. The Nano model is optimized for extremely low-latency tasks where speed is paramount, such as autocomplete or real-time classification.
-
o3 and o3-pro: These are the largest and most capable reasoning models, excelling at tasks where standard GPT models often fail, such as advanced mathematics, scientific analysis, and complex logic puzzles. The “pro” designation indicates that the model is configured to use more computational resources to “think” for longer before providing an answer.
-
o4-mini and o4-mini-high: This is a smaller, faster, and more affordable generation of reasoning models. Their existence makes these powerful reasoning capabilities more accessible for production use cases that require a balance of performance and cost.
-
Gemini 2.5 Pro: This is the most advanced offering, excelling in complex coding, scientific problems, and tasks that require deep reasoning. It features a 1 million token context window and a “Deep Think” mode.
-
Gemini 2.5 Flash & Flash-Lite: For less demanding tasks, these variants offer faster and more cost-effective alternatives, enabling architects to balance performance and budget for high-volume applications.
-
Claude 4 Opus: This is the flagship model, widely regarded as the world’s best for coding. It excels at complex, long-running agentic tasks, demonstrating the ability to work autonomously for hours on projects like refactoring entire codebases.
-
Claude 4 Sonnet: This model is designed to strike a balance between high performance and cost efficiency. It is a significant upgrade to its predecessor and is ideal for production workloads, such as automated code reviews or powering high-volume internal tools. It is also being integrated into developer platforms, such as GitHub Copilot.
-
Llama 4 Scout (109B total / 17B active parameters): Designed for accessibility, Scout can run on a single NVIDIA H100 GPU. Its standout feature is an industry-leading 10 million token context window, making it ideal for analyzing entire codebases or massive document collections in one go.
-
Llama 4 Maverick (400B total / 17B active parameters): This is Meta’s general-purpose workhorse, matching or exceeding the performance of proprietary models like GPT-4o on key benchmarks while remaining open-source.
-
Llama 4 Behemoth (~2T total / 288B active parameters): This is a massive “teacher” model used internally by Meta to distill knowledge into the smaller, publicly released models. Its existence demonstrates the immense scale of Meta’s research and development efforts.
-
Magistral Small (24B parameters): An open-weight model with strong, transparent reasoning capabilities, available under a permissive Apache 2.0 license.
-
Magistral Medium: A more powerful enterprise version that excels in multilingual, multi-step logic, making it suitable for regulated industries like law and finance, where auditability is critical.
-
Claude 4 Pricing — Anthropic
-
Open AI Pricing — OpenAI
-
Gemini 2.5 Pricing — Google Cloud
-
Llama 4 Maverick — Together AI (Official API Partner)
-
Magistral Medium — Mistral AI
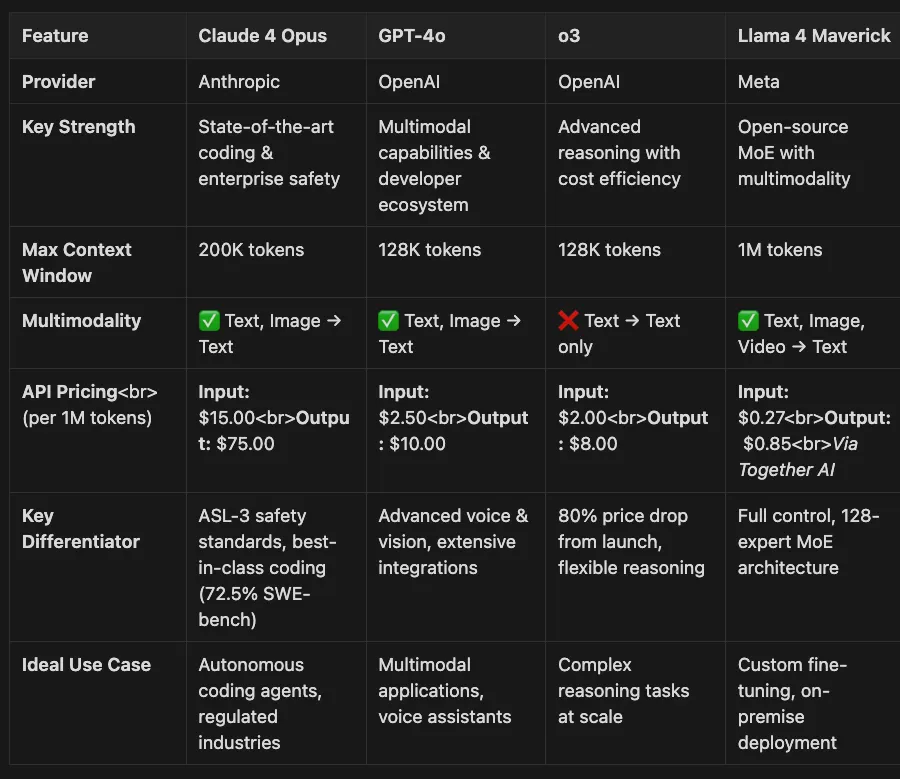
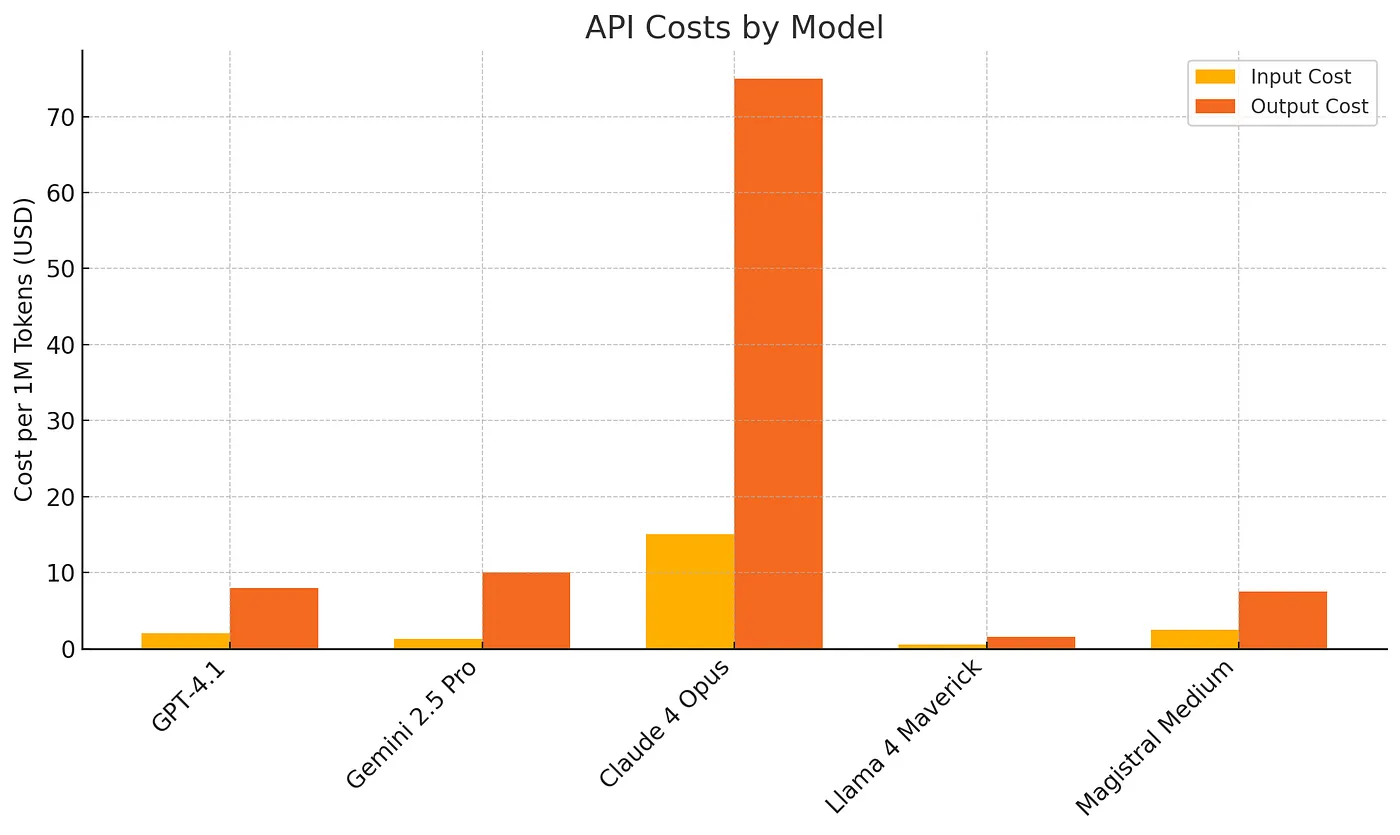
- Most Expensive: Claude 4 Opus at $15/$75 per million tokens
- Best Value Reasoning: o3 at $2/$8 per million tokens (after 80% price reduction)
- Most Affordable: Llama 4 Maverick at $0.27/$0.85 per million tokens
- Most Versatile: GPT-4o with native audio/vision capabilities
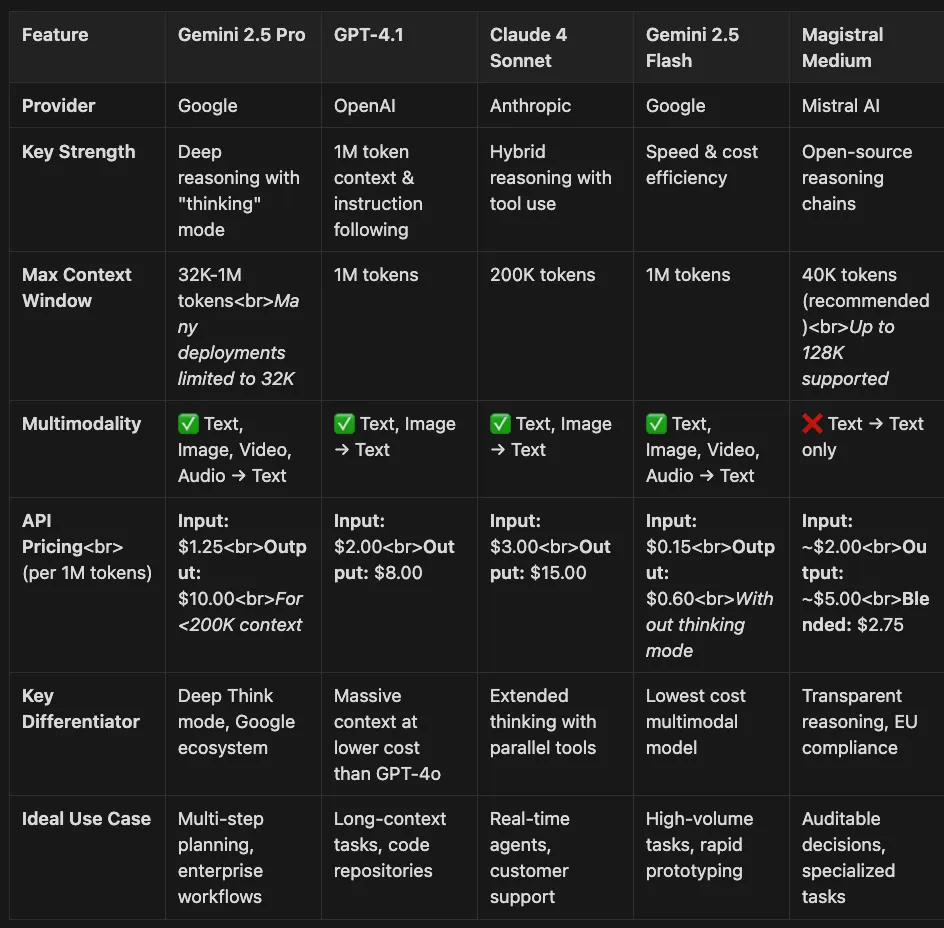
- Most Affordable: Gemini 2.5 Flash at $0.15/$0.60 per million tokens
- Best Context/Price: GPT-4.1 with 1M tokens at $2/$8
- Most Balanced: Claude 4 Sonnet at $3/$15 with hybrid reasoning
- Enterprise Choice: Gemini 2.5 Pro with Google Cloud integration
- Anthropic Claude Pricing — Claude 4 Opus & Sonnet
- OpenAI API Pricing — GPT-4o, GPT-4.1, o3
- Google Vertex AI Pricing — Gemini 2.5 Pro & Flash
- Together AI Pricing — Llama 4 Maverick
- Mistral AI Pricing — Magistral Medium
- Volume Discounts: Most providers offer enterprise agreements with custom pricing for high-volume usage.
- Caching Options: Anthropic offers up to 90% savings with prompt caching, Google offers 75% discount on cached content.
- Batch Processing: Available for most models at 50% discount for non-real-time workloads.
- Regional Variations: Prices may vary by deployment region, especially for Google Cloud services.
- Additional Costs: Consider egress charges, storage for fine-tuning, and endpoint hosting fees.
-
Gemini 2.5 Flash is suitable for multimodal tasks, but it has a much harder time following complex instructions than Gemini Pro, Claude Sonnet, or GPT4x. However, you can assign it a higher thinking budget, which could mitigate this issue. It's reasonably priced, but test it to see if it works. I have been surprised by its performance on some tasks and disappointed with it on others.
-
Llama 4 Maverick for text-heavy workloads (self-host to eliminate API costs)
-
o3 for reasoning tasks that previously required expensive models
-
Claude 4 Opus for coding and safety-critical tasks
-
Gemini 2.5 Pro for complex multi-step reasoning
-
GPT-4o for real-time multimodal interactions
-
Claude 4 Sonnet for production agents
-
GPT-4.1 for long-context applications
-
Magistral Medium for auditable workflows
-
Gemini 2.5 Pro: While Google advertises 1M tokens, many business users report being limited to 32K tokens in practice.
-
Magistral Medium: Recommended usage is 40K tokens for optimal performance, though it technically supports up to 128K.
-
Self-hosted: Infrastructure costs only
-
Via API providers: $0.27-$0.85 per 1M tokens (Together AI)
-
Robust general-purpose capabilities.
-
Extensive third-party integrations.
-
Proven reliability at scale.
-
Deep integration with Google Cloud services.
-
Advanced reasoning with transparency.
-
Multi-step planning capabilities.
-
Best-in-class coding assistance.
-
Strict safety compliance (ASL-3).
-
High-quality output worth premium pricing.
-
Complete control over your model.
-
On-premise deployment options.
-
Custom fine-tuning capabilities.
-
Cost-effective reasoning capabilities.
-
Transparent, auditable AI decisions.
-
Open-source flexibility with commercial support.
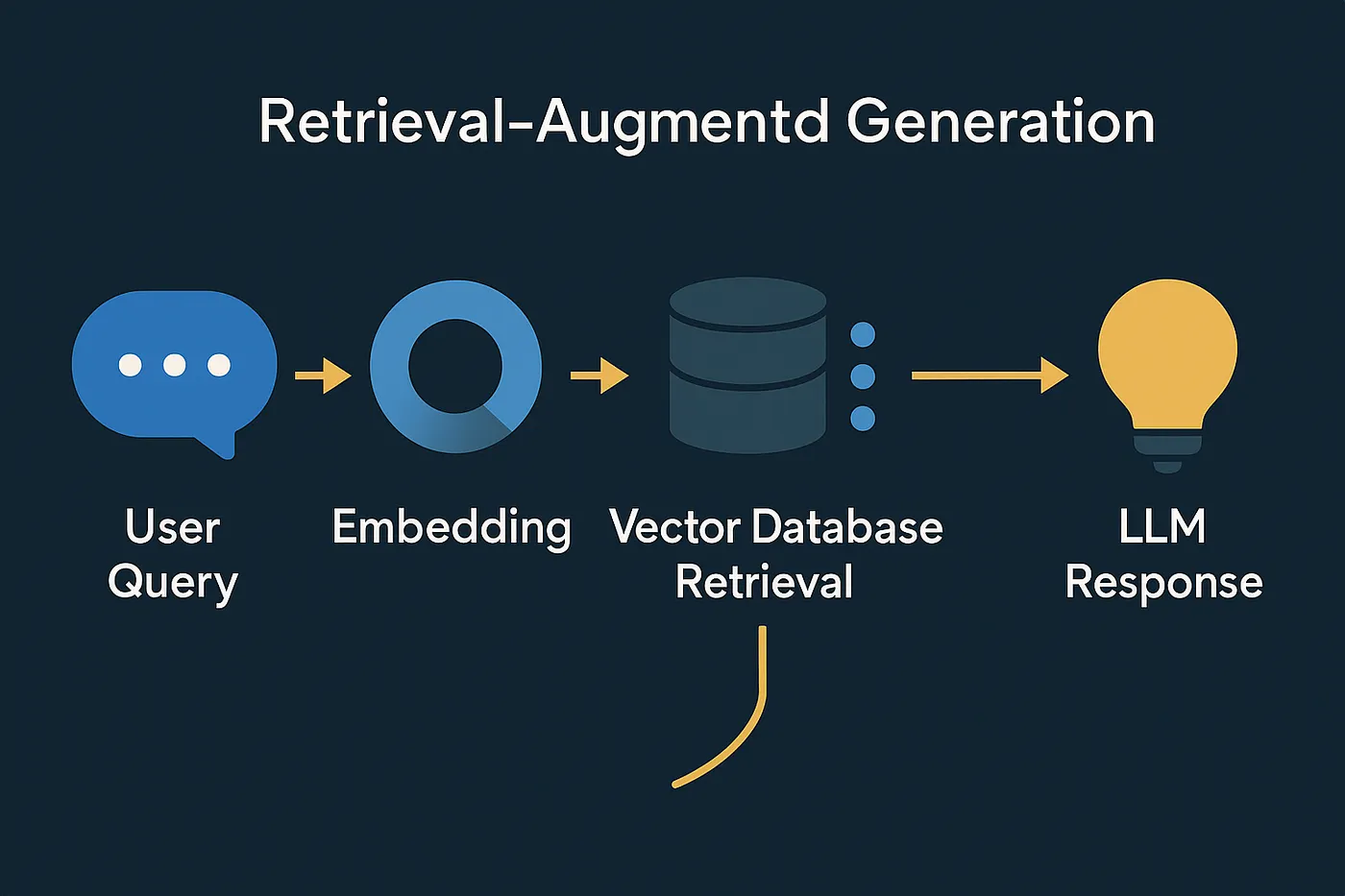
- Query Encoding: The user’s input query is converted into a numerical representation, known as a vector embedding, using a specialized model.
- Document Retrieval: This query vector is used to search a vector database, which contains pre-indexed embeddings of the company’s documents. The system identifies documents with embeddings most similar to the query vector.
- Contextual Fusion: The retrieved documents (the “context”) are appended to the original user query to form a new, augmented prompt.
- Response Generation: This combined prompt is sent to the LLM, which generates a response grounded in the provided information.
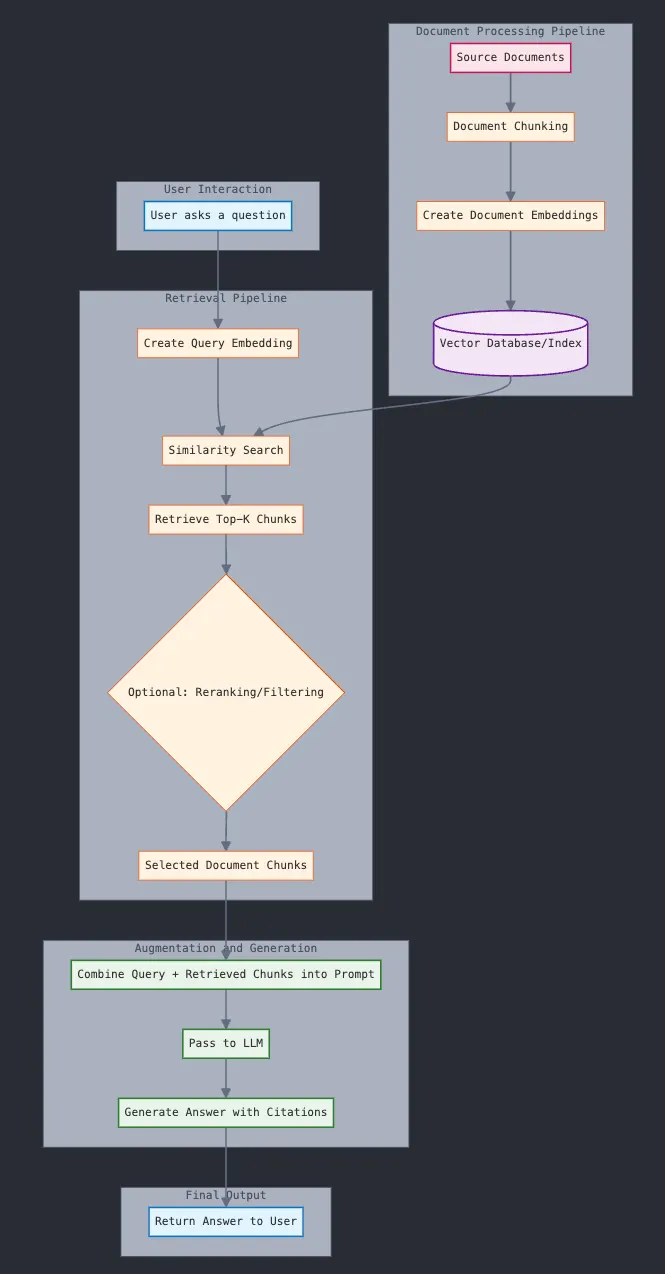
-
Agentic RAG: This pattern moves beyond simply answering questions to taking action. It combines RAG with autonomous agents that can plan and execute multi-step tasks using various tools, such as calling APIs or querying databases. This is the essential pattern for building systems that can automate business processes.
-
GraphRAG: For tasks that require high precision and an understanding of complex relationships, GraphRAG enhances the retrieval process by utilizing knowledge graphs. By representing data as a network of entities and relationships, the system can traverse these connections to find more logically sound and contextually aware information. This approach has been shown to significantly boost search precision.
-
Self-Corrective RAG (CRAG / Self-RAG): These are more sophisticated frameworks that exhibit self-reflection. It can dynamically decide whether retrieval is necessary for a given query, evaluate the relevance of the retrieved documents, and critique its own generated output for factual accuracy before presenting it to the user. This adds a crucial layer of robustness and reliability to the system.
-
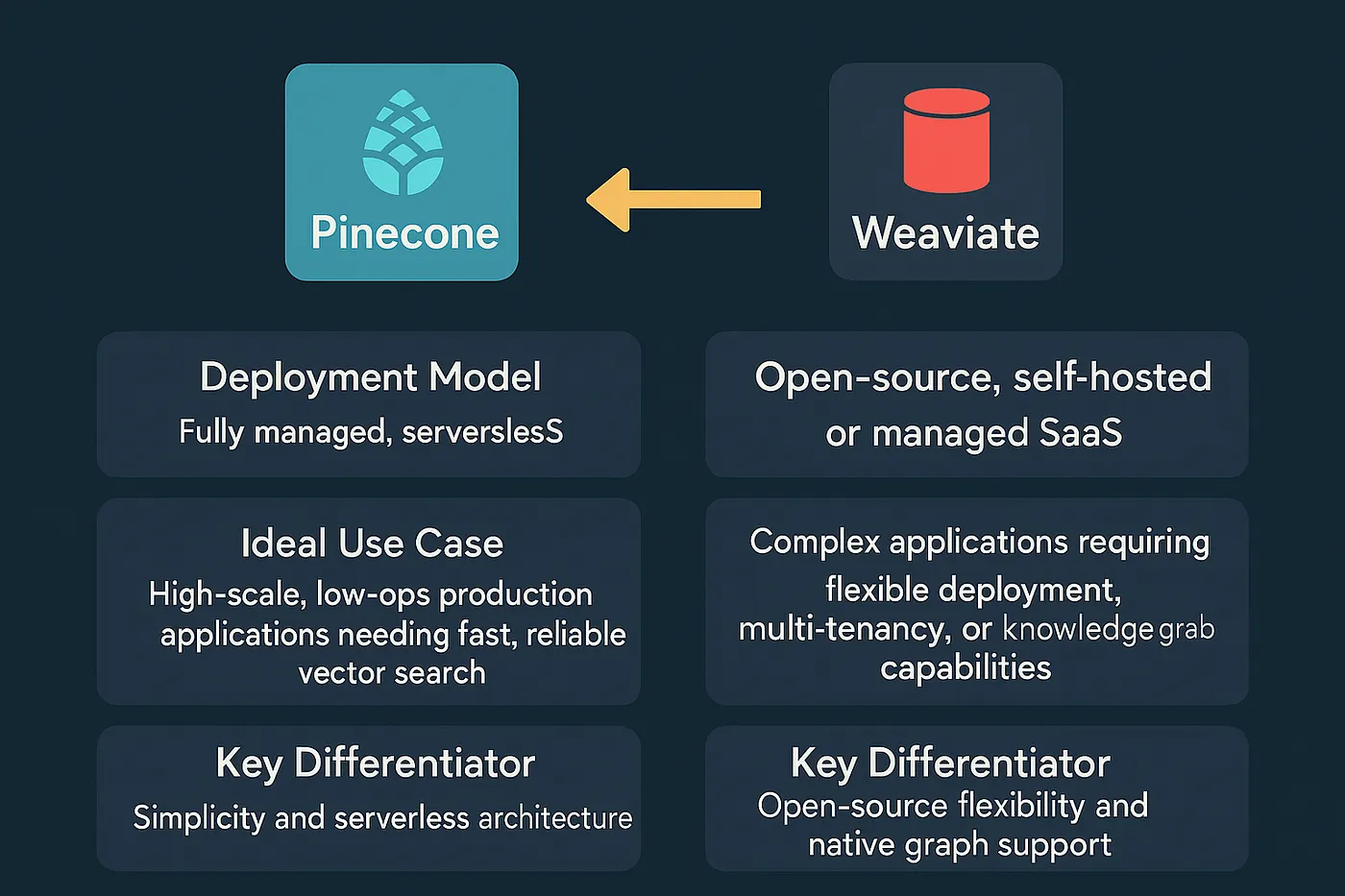
Architecture and Philosophy: Pinecone is a fully managed, serverless vector database built for ease of use and high performance at scale. Its key architectural feature is the separation of storage and compute, which allows for effortless scaling and a simple, pay-as-you-go pricing model. This makes it an attractive choice for teams that want to focus on application development without managing infrastructure.
-
Key Features: Pinecone offers advanced features like hybrid search (combining vector and keyword search), real-time indexing of new data, and enterprise-grade security, including SOC 2 and HIPAA compliance.
-
Architecture and Philosophy: Weaviate is an open-source vector database that offers maximum flexibility in deployment. It can be self-hosted, run as a managed service in the cloud, or deployed in a Kubernetes cluster. Its defining architectural features are its multi-tenant capabilities, which allow for strict data isolation, and its native support for knowledge graphs, making it a natural fit for advanced GraphRAG patterns.
-
Key Features: Weaviate provides hybrid search, a flexible GraphQL API for complex queries, and tiered storage to help enterprises optimize costs for large-scale deployments.

- PostgreSQL with pgvector: As detailed in my article Building AI-Powered Search and RAG with PostgreSQL and Vector Embeddings, PostgreSQL with the pgvector extension offers a powerful combination of vector similarity search and traditional relational capabilities. It supports multiple indexing methods (HNSW, IVFFlat) and can be combined with BM25-like keyword search for hybrid retrieval strategies. This is my personal preference. With AlloyDB and Aurora, scaling and deployment are easy.
- Elasticsearch: Now provides vector search capabilities alongside its robust BM25 text retrieval, enabling hybrid search patterns that combine semantic understanding with keyword relevance. This makes it particularly effective for document-heavy applications that need both semantic and lexical search.
- MongoDB: Has evolved into an all-in-one solution with Atlas Vector Search, supporting both document storage and vector operations. This unified approach simplifies the stack for teams already using MongoDB, while providing sophisticated similarity search capabilities.
- DuckDB: Even this lightweight analytical database now supports vector operations and similarity search, making it viable for smaller-scale RAG applications or prototyping.
-
Prompt Versioning and Regression Testing: Prompts are a form of code and must be managed as such. All prompts should be stored in a version control system like Git. Any change to a prompt should trigger an automated CI pipeline that runs a suite of regression tests to ensure the change does not degrade the model’s performance, tone, or factual accuracy.
-
RAG Pipeline Automation: The entire RAG pipeline — including the vector database schema, data ingestion jobs, and embedding model configurations — should be defined as code and deployed automatically. Tools like Terraform or GitHub Actions can be used to provision and manage this infrastructure, ensuring consistency across development, staging, and production environments.
-
Ensuring Reproducibility: To debug issues and ensure consistent behavior, every component of the AI system must be reproducible. This involves using tools like DVC (Data Version Control) to version the datasets used for fine-tuning and retrieval, and platforms like MLflow to track experiments, model parameters, and resulting artifacts.
-
Expanded Monitoring Metrics: Monitoring for LLMs must go beyond traditional software metrics like latency and uptime. It must also track AI-specific issues like model drift (performance degradation over time), bias in responses, fairness across different user groups, and the rate of hallucinations.
-
Data Governance and Security: In a RAG architecture, robust governance is essential. Organizations must implement automated systems for tracking data lineage, filtering sensitive PII from both user queries and retrieved context, and maintaining secure, authenticated access across all integrated tools and APIs. For comprehensive insights on implementing agent-based security frameworks, see my article Securing LangChain’s MCP Integration: Agent-Based Security for Enterprise AI.
-
Implementing AI Guardrails: For enterprise applications, it is often necessary to embed AI guardrails directly into the generation process. These are programmatic rules that can enforce brand tone, ensure compliance with legal or regulatory constraints, and restrict the model’s actions based on the user’s role and permissions. This is a critical layer for mitigating risk in production environments.
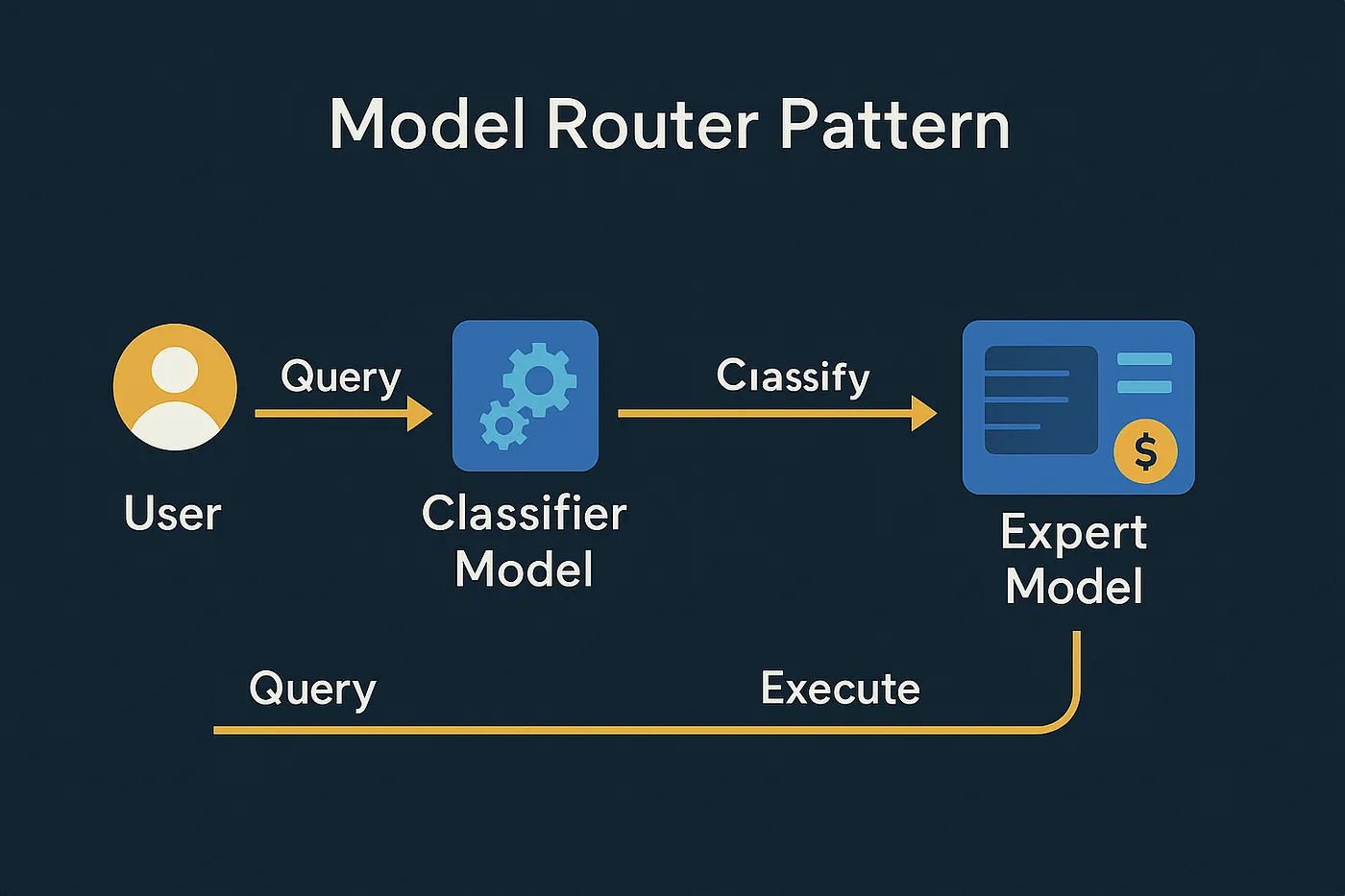
- Data Sovereignty: Keeping sensitive data on-premises is non-negotiable for many industries, such as finance and healthcare.
- Cost Predictability: Self-hosting allows organizations to shift from a variable, per-token operational expense to a more predictable, fixed infrastructure cost.
- Deep Customization: The ability to fine-tune a model on proprietary data allows a company to create a unique, defensible competitive advantage that cannot be replicated with a public API.

-
Inference Servers: Tools like vLLM, Text Generation WebUI, and Ollama are essential for serving models efficiently via an OpenAI-compatible API, simplifying integration with existing applications.
-
Containerization & Orchestration: Docker and Kubernetes are non-negotiable for managing deployments in a scalable, reproducible, and fault-tolerant manner, especially in production environments.
-
Required Engineering Skills: A successful team requires a blend of expertise:
-
ML Engineering: For model selection, quantization, performance optimization, and fine-tuning.
-
DevOps/SRE: For managing the underlying infrastructure, Kubernetes clusters, CI/CD pipelines, and monitoring.
-
Security: For implementing data governance, network security, and access control policies to protect sensitive data and the models themselves.
-
Now you have LLMOps, MLOps, AI Architects, AI Engineers, and AI Automation Engineers. Note to mention Data Engineering and Data Architects.
-
The Challenge: Rakuten, a global e-commerce and technology company, aimed to significantly reduce software development cycles and enhance the capacity of its engineering teams, particularly for large and complex projects.
-
The Architecture: The team built an agentic system using Claude 4 Opus, integrating it directly into their development workflow. This architecture represents an advanced form of Agentic RAG, where the “knowledge base” is an entire codebase. The AI agent was tasked with autonomously refactoring a massive open-source library comprising 12.5 million lines of code across multiple programming languages.
-
The Outcome: The Claude 4 agent worked independently for seven consecutive hours, completing the complex refactoring project with 99.9% numerical accuracy. This single achievement became a turning point for the company, demonstrating the power of autonomous AI. The implementation resulted in a 79% reduction in the average time-to-market for new features, from 24 days to just 5. This case validates that AI agents are no longer a futuristic concept but a practical tool for revolutionizing software engineering.
-
The Challenge: Box, a leading cloud content management platform, needed a way to help its enterprise customers extract structured, actionable information from their vast repositories of unstructured content, such as scanned PDFs, contracts, and handwritten forms.
-
The Architecture: Box developed the Box AI Enhanced Extract Agent, a system powered by Gemini 2.5 Pro. This architecture is a classic example of Enterprise RAG. The agent accesses files stored within the Box platform and leverages Gemini’s deep reasoning and multimodal capabilities to perform sophisticated key-value pair extraction. A key innovation is the use of model confidence scores to guide a human-in-the-loop review process, ensuring high reliability.
-
The Outcome: The system achieves over 90% accuracy on complex data extraction tasks, a result that significantly reduces the need for manual review and data entry. This allows Box’s customers to automate critical business workflows in finance (loan processing), legal (e-discovery), and HR (onboarding paperwork), turning their passive content archives into active, intelligent knowledge bases.
-
The Challenge: Shopify store owners need a scalable way to create unique and engaging content to drive organic search traffic, but manual content creation is time-consuming and does not scale across hundreds or thousands of products.
-
The Architecture: An automated content generation workflow was built using the automation platform n8n, orchestrating several services around GPT-4o. This showcases a Multimodal Automation Workflow. The system is triggered, pulls product data (title, description) from the Shopify API, and then uses GPT-4o’s vision capabilities to perform Optical Character Recognition (OCR) on product images to extract nutritional information. This combined data is then fed back to GPT-4o to generate a complete, SEO-rich blog post, which is automatically published back to the Shopify store.
-
The Outcome: The result is a fully automated content pipeline that can produce high-quality, unique marketing content at scale with zero manual writing. This case study perfectly illustrates how a multimodal model like GPT-4o can be the centerpiece of a sophisticated automation engine, creating tangible value for businesses by driving customer engagement and sales.
-
The Systems Orchestrator: With a fragmented market of specialized models, the architect’s primary job is to design and orchestrate a holistic system. This involves selecting the right combination of models, vector databases, and frameworks, and building the intelligent routing logic that connects them into a cohesive, high-performing application.
-
The Cost Optimizer: The immense computational cost of frontier models makes economic viability a central design challenge. The architect must be a shrewd financial steward, designing systems with cost-control built in from the ground up through techniques like model routing, caching, and batching.
-
The Risk Manager: As AI systems become more autonomous and are deployed in mission-critical and regulated environments, the architect is responsible for managing risk. This involves implementing robust MLOps practices, data governance, and safety guardrails to ensure that AI applications are not only powerful but also secure, compliant, and trustworthy.
-
GenAI for the Busy Executive: Don’t Fall Behind — Rise of MCP and A2A
-
The Executive Imperative: AI isn’t Just Tech, It’s Your Bottom Line
-
Introduction: From Hype to High Returns — Architecting AI for Real-World Value (June 2025)
-
U.S. Marine Corps’ AI Playbook: Businesses Take Note (Published in Spillwave Solutions)
-
AI Boon or Doom?: Why the Latest AI Predictions Sound Familiar (Published in Spillwave Solutions)
-
MCP: From Chaos to Harmony — Building AI Integrations with the Model Context Protocol (June 2025)
-
Anthropic’s Claude and MCP: A Deep Dive into Content-Based Tool Integration
-
DSPy Meets MCP: From Brittle Prompts to Bulletproof AI Tools
-
LangChain and MCP: Building Enterprise AI Workflows with Universal Tool Integration
-
Anthropic’s MCP: Set up Git MCP Agentic Tooling with Claude Desktop
-
OpenAI Meets MCP: Transform Your AI Agents with Universal Tool Integration
-
Securing MCP: From Vulnerable to Fortified — Building Secure HTTP-based AI Integrations
-
Securing LiteLLM’s MCP Integration: Write Once, Secure Everywhere
-
Securing DSPy’s MCP Integration: Programmatic AI Meets Enterprise Security
-
Securing LangChain’s MCP Integration: Agent-Based Security for Enterprise AI
-
Securing OpenAI’s MCP Integration: From API Keys to Enterprise Authentication
-
Why Language Is Hard for AI — and How Transformers Changed Everything
-
Build Production AI in Minutes: The Developer’s Guide to Transformers and Hugging Face
-
Transformers and the AI Revolution: The Role of Hugging Face
-
Claude 4: Why Anthropic Just Changed the Game by Abandoning the Chatbot Race
-
How Tech Giants Are Building Radically Different AI Brains: Gemini vs. Open AI vs. Claude Fight!
-
Let the battle of the AI chatbots commence: Claude2 vs ChatGPT
-
The Open-Source AI Revolution: How DeepSeek, Gemma, and Others Are Challenging Big Tech’s Language…
-
Teaching AI to Judge: How Meta’s J1 Uses Reinforcement Learning to Create Better LLM Evaluators
-
OpenAI Just Changed the Game: How Reinforcement Fine-Tuning Makes AI Learn Like a Pro
-
Beyond Fine-Tuning: Mastering Reinforcement Learning for Large Language Models
-
LangChain: Building Intelligent AI Applications with LangChain (May 2025)
-
Beyond Chat: Enhancing LiteLLM Multi-Provider App with RAG, Streaming, and AWS Bedrock
-
Your prompts are brittle. Your AI System Just Failed. Again. DSPy to the Rescue!
-
Stop Wrestling with Prompts: How DSPy Transforms Fragile AI into Reliable Software
-
Is RAG Dead?: Anthropic Says No (May 2025)
-
Beyond Basic RAG: Building Virtual Subject Matter Experts with Advanced AI
-
Building AI-Powered Search and RAG with PostgreSQL and Vector Embeddings
-
Conversation about Document Parsing and RAG (VLOG transcripts)
-
If ChatGPT and Claude are so good why do I need Amazon Textract or Unstructured?
-
The Developer’s Guide to AI File Processing with AutoRAG support: Claude vs. Bedrock vs. OpenAI
-
Implementing Retrieval-Augmented Generation (RAG) with Amazon Bedrock Knowledge Bases
-
Don’t “improve it” before you baseline it: Evaluating Foundation Models in Amazon Bedrock
-
Amazon Bedrock Foundation Models: A Complete Guide for GenAI Use Cases
-
Document Intelligence with Amazon Textract: From OCR to Structured Insights
-
Building Your First Intelligent Document Workflow with AWS Textract and Comprehend
-
Modern IT Infrastructure Management: Architecture and Strategy for Business Value