Introduction: From Hype to High Returns -- Architecting AI for Real-World Value
Introduction: From Hype to High Returns — Architecting AI for Real-World Value
Originally published on Medium.
Introduction: From Hype to High Returns — Architecting AI for Real-World Value

-
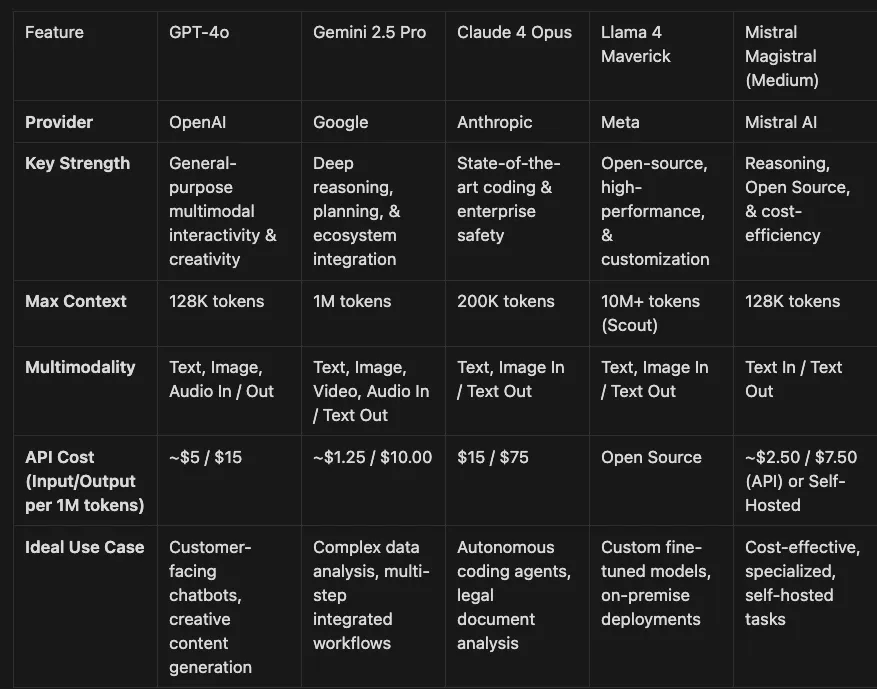
GPT-4o (“Omni”): The Multimodal Workhorse. As of mid-2025, GPT-4o is OpenAI’s flagship. Its native ability to process text, audio, and images makes it ideal for dynamic, interactive applications.
-
The Next Generation. OpenAI continues to push the frontier with models like GPT-4.1, which features a massive 1-million-token context window designed for advanced agentic applications.
-
The Claude 4 Family: Claude 4 Opus is the flagship, widely regarded as the world’s best for coding and complex agentic tasks. Claude 4 Sonnet is designed to balance high performance with cost-efficiency for production workloads.
-
Differentiators: Claude’s “Constitutional AI” approach and its extensive 200,000-token context window make it a reliable choice for regulated industries.
 Cost SnapShot
Cost SnapShot
 Basic RAG
Basic RAG
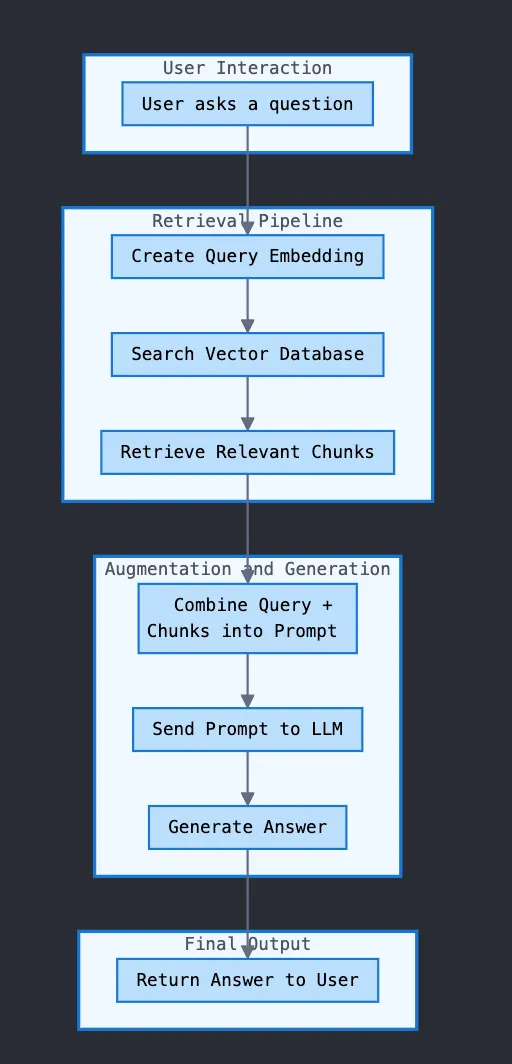
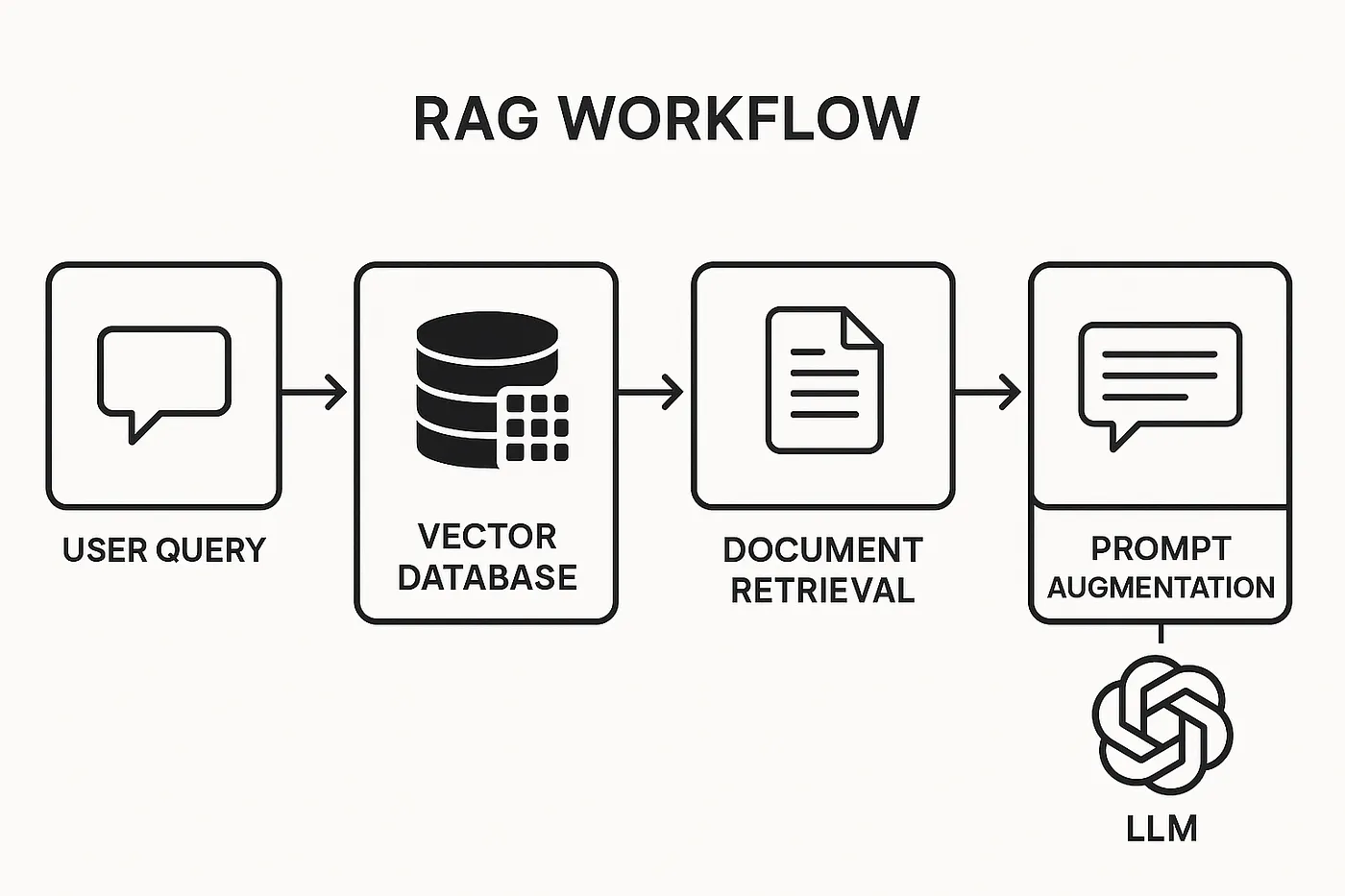
- Specialized Vector Databases (e.g., Pinecone, Weaviate): These are fully managed, purpose-built databases designed for high-performance vector search at scale. They offer features like real-time indexing and hybrid search out of the box, making them an excellent choice for teams prioritizing ease of use and low operational overhead.
- Relational Databases with Vector Extensions (e.g., PostgreSQL with
pgvector, AlloyDB): Using vector extensions is a compelling option for teams already invested in a relational database ecosystem. PostgreSQL, a workhorse of the open-source world, becomes a powerful RAG backend with thepgvectorextension. Google Cloud's AlloyDB for PostgreSQL offers a fully-managed, high-performance version of this stack, claiming significantly faster performance for vector workloads than standard PostgreSQL. This approach allows developers to keep their data and vector embeddings in a single, familiar system.
-
Hybrid Search: Blend semantic search from a vector database with traditional keyword search like BM25. This ensures you find documents that are contextually relevant and contain specific keywords. (See the articles Is RAG Dead? Anthropic Says No, The Developer’s Guide to AI File Processing, and Stop the Hallucinations: Hybrid Retrieval Techniques for more details.)
-
GraphRAG: Microsoft’s groundbreaking white paper on GraphRAG takes this further by creating a knowledge graph from data, allowing the system to understand the relationships between different pieces of information. Frameworks like LlamaIndex, which I have worked with extensively on complex data relationship projects, now offer robust support for building these sophisticated GraphRAG systems.
-
Agentic RAG: This involves creating an “agent” that can intelligently decide which tools or data sources to use, moving beyond simple Q&A to taking action.
-
LangChain is the de facto standard for developing LLM applications. As Hightower puts it in “LangChain: Building Intelligent AI Applications,” it’s a framework providing “the modular building blocks for creating sophisticated, context-aware AI applications.” Its LangGraph library is now essential for building stateful, multi-actor agents.
-
DSPy: A framework that offers a programmatic way to optimize prompts. In “Stop Wrestling with Prompts,” Hightower explains that DSPy “shifts the paradigm from fragile, hand-tuned prompts to modular, programmatic pipelines that can be optimized automatically,” turning prompt engineering into a more systematic software engineering discipline.
-
Hugging Face: The central hub for open-source models. Its Transformers library is the default for using and training LLMs in Python.
-
CI/CD for LLMs: This involves Prompt Versioning in Git, automating the entire RAG Pipeline with Infrastructure as Code, and implementing robust Monitoring & Guardrails to track AI-specific issues like model drift, bias, and hallucinations.
-
Cost Optimization & The Model Router Pattern: The most effective solution to high costs is the model router: an intelligent gateway that intercepts queries and routes them to the most cost-effective model for the job. Simple queries go to a fast, cheap model, while complex questions are escalated to a powerful, expensive one.
 The Case for Routing, Caching, and using the right model for the job
The Case for Routing, Caching, and using the right model for the job
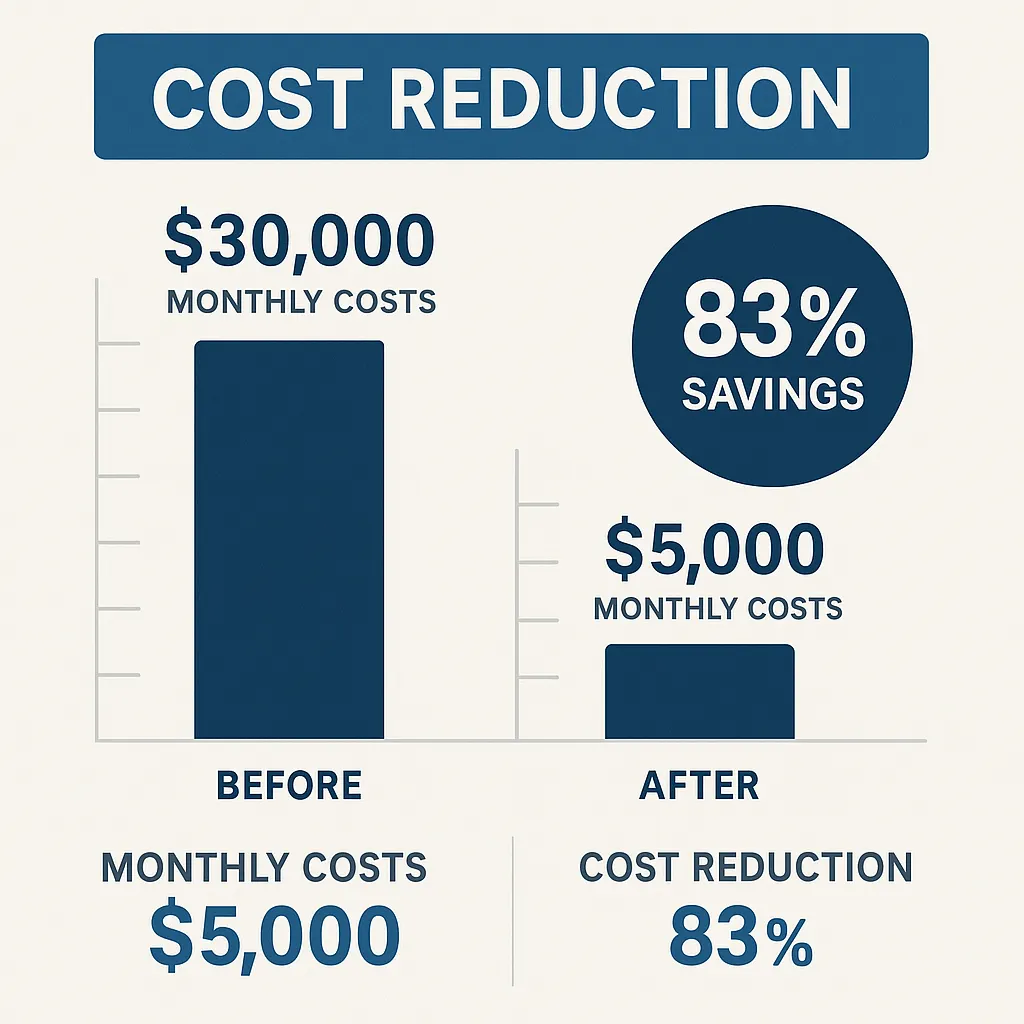
- The Challenge: FinSecure’s initial customer support system relied on a powerful proprietary LLM. As the company grew, the monthly API bill exceeded $30,000.
- The Solution: The team pivoted to a self-hosted, hybrid architecture. They created a model router that sent simple queries to a small, fine-tuned Llama model. They implemented semantic caching to handle 80% of routine queries, used offline batch processing for document analysis, and deployed model quantization to cut memory needs in half.
- The Results: The monthly run cost fell from $30,000 to around $5,000, an 83% reduction. The investment paid for itself in under five months, and KYC processing time dropped by over 90%.
 Model Routing, caching, and model quantization
Model Routing, caching, and model quantization

 What they did and how much they saved
What they did and how much they saved
-
The Challenge: Rakuten, a worldwide technology firm, aimed to shorten software development cycles significantly.
-
The Architecture: The team built an agentic system using Claude 4 Opus and tasked it with autonomously refactoring a massive open-source library.
-
The Outcome: The agent worked for seven straight hours and successfully finished the project, reducing the average time to market for new features by 79%.
-
The Challenge: Box needed to help customers extract structured information from vast unstructured content repositories like scanned PDFs and contracts.
-
The Architecture: Box developed the Box AI Enhanced Extract Agent, a classic enterprise RAG system powered by Gemini 2.5 Pro. The agent accesses files in the Box platform and uses Gemini’s reasoning to perform sophisticated key-value pair extraction.
-
The Outcome: The system achieves over 90% accuracy on complex data extraction, allowing customers to automate critical business workflows in finance, legal, and HR.
-
The Challenge: Shopify store owners needed a scalable way to create unique, engaging content to drive traffic.
-
The Architecture: An automated workflow was built using GPT-4o. The system pulls product data from the Shopify API, uses GPT-4o’s vision capabilities to perform OCR on product images, and generates a complete, SEO-rich blog post.
-
The Outcome: A fully automated content pipeline that produces high-quality marketing content at scale with zero manual writing, driving customer engagement and sales.
 Real-world Case Studies
Real-world Case Studies
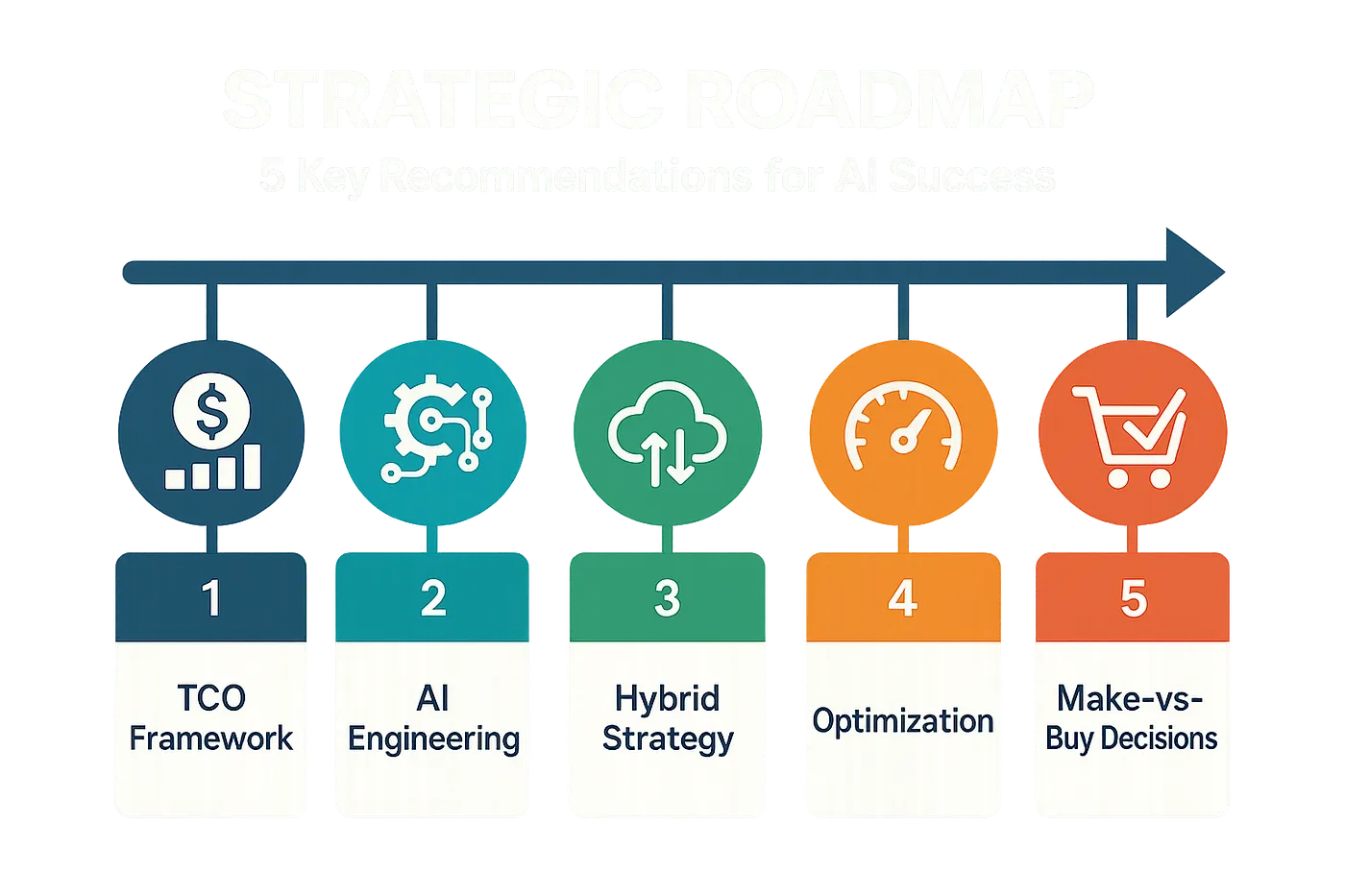
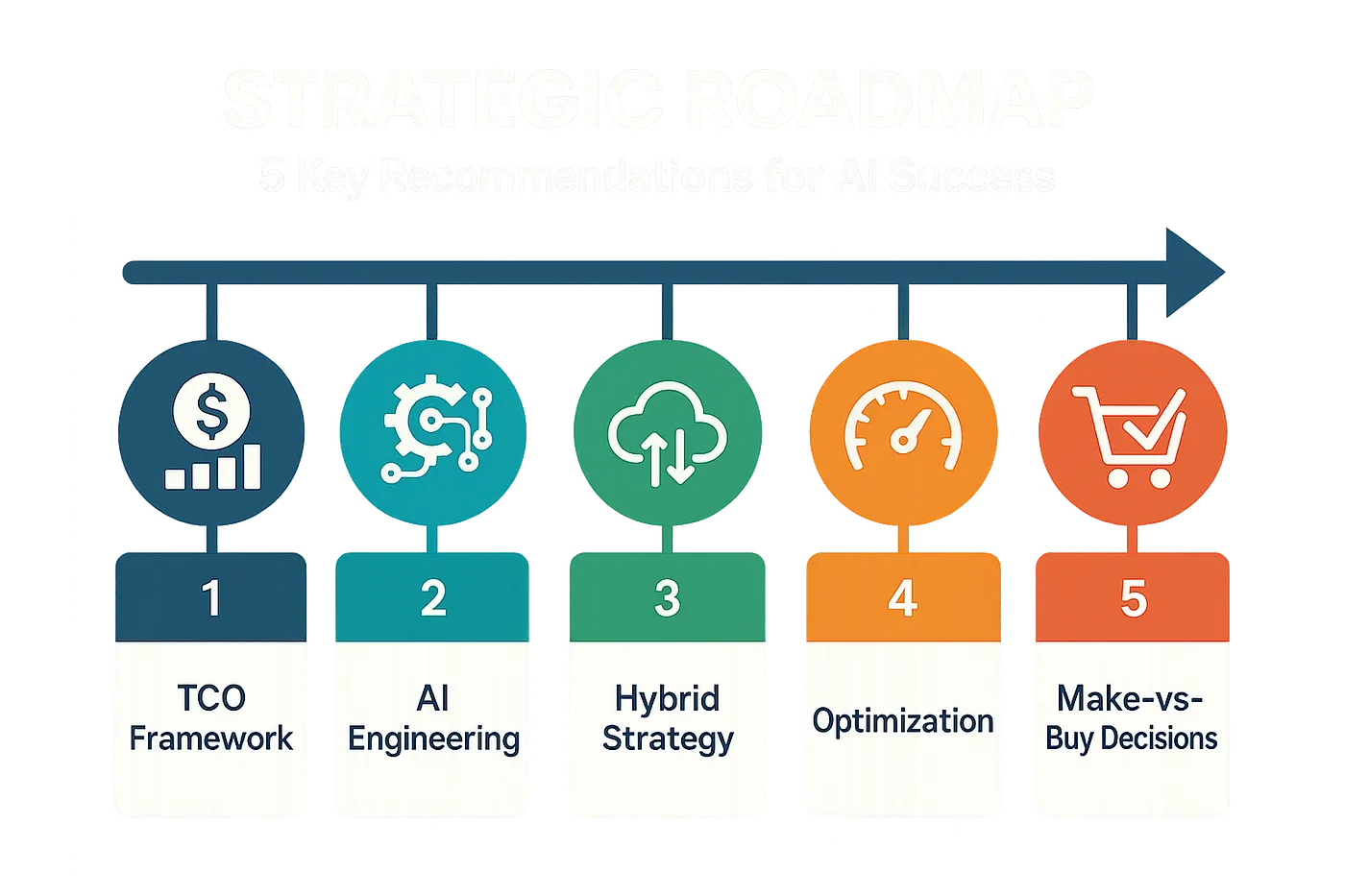
- Mandate a Full TCO Framework. Do not approve an AI project without a cost analysis that includes infrastructure, operations, development, and opportunity costs.
- Invest in AI Engineering. Your competitive advantage stems from the efficiency of your architecture, not just access to a model. Build a team capable of fine-tuning, creating intelligent routing, and enhancing performance.
- Embrace a Hybrid, Multi-Model Strategy. Use smaller, less expensive models for most of your tasks, and save the most powerful models for work that truly requires them.
- Prioritize Optimization from Day One. Integrate caching, batching, and model compression into your initial design; do not treat them as afterthoughts.
- Continuously Evaluate Make vs. Buy. The AI landscape evolves quickly. Reassess your options between API services and self-hosting at least twice a year to stay up-to-date with the market.
 Your Path Forward
Your Path Forward