Karpathy's AutoResearch: When AI Agents Become the Scientists
How 630 lines of Python and a 5-minute time budget let a single researcher run 100 ML experiments overnight
Originally published on Medium.
How 630 lines of Python and a 5-minute time budget let a single researcher run 100 ML experiments overnight
What if you could run 100 machine learning experiments overnight, on one GPU, while you sleep? Karpathy just open-sourced the tool that makes it real.
Andrej Karpathy just open-sourced a tool that lets a single researcher run 100 machine learning experiments overnight, on one GPU, while sleeping. The tool is called AutoResearch, and it changes how we think about who does the actual work of AI research.
The premise is simple but radical: instead of writing training code yourself, you write a research strategy in plain English. An AI agent reads your strategy, modifies the training code, runs the experiment, evaluates the results, and decides what to try next. If the experiment improves performance, the agent commits the code. If it regresses, the agent reverts and tries something different. This loop runs continuously, unattended, for as long as you let it.
In one widely reported case, Shopify CEO Tobi Lutke pointed AutoResearch at an internal 0.8 billion parameter model. After 37 experiments over an 8-hour overnight run, the agent achieved a 19% improvement in model quality. The optimized smaller model outperformed a manually configured 1.6 billion parameter model. A machine found what humans missed.
The Philosophy: 630 Lines and Nothing More
AutoResearch is the latest in Karpathy's lineage of deliberately minimal projects. nanoGPT gave us GPT pre-training in a single file. nanochat expanded that to the full pipeline: BPE tokenization, supervised fine-tuning, and outcome-based reinforcement learning on math benchmarks like GSM8K. AutoResearch takes the next logical step by wrapping an AI agent around the entire training loop.
The core repository is approximately 630 lines of Python. This number is not accidental. Contemporary LLMs have context windows large enough to hold the entire codebase at once. When the agent can see everything, it makes better decisions. It does not hallucinate variable names from files it cannot see. It does not generate structural errors because it lost track of a function signature three files away. The minimalism is not a limitation; it is the enabling constraint.
Karpathy has said that roughly 80% of his work is now AI-assisted. AutoResearch formalizes the remaining 20%: the experimental iteration loop that was still manual. The human writes the strategy. The agent does the science.
How It Works: Three Components, One Loop
The architecture divides the research environment into three parts.
The Strategy (program.md): A Markdown file where the human researcher defines goals and constraints. "Optimize for lower validation loss while maintaining training speed." "Explore alternative attention mechanisms." "Do not modify the tokenizer." This is the human's contribution: taste, direction, and boundaries.
The Target (train.py): The model architecture and training loop. This is the only file the agent is allowed to modify. It contains the neural network definition, the optimizer configuration, the learning rate schedule, and the training loop itself.
The Infrastructure (prepare.py): Data preparation, evaluation utilities, and scoring. This file is fixed. By holding the evaluation constant, every experiment is measured on the same terms.
The loop works like this:
- The agent reads program.md to understand what it should optimize for.
- It analyzes train.py to understand the current state of the code.
- It proposes a modification: a new normalization layer, a different attention scaling, an adjusted regularization technique.
- It applies the change and runs a training experiment.
- If performance improves, it commits the change to a git branch.
- If performance regresses, it reverts and uses the failure as context for the next attempt.
- Repeat.
The modifications are not limited to hyperparameter tuning. The agent makes architectural changes: swapping normalization strategies, restructuring attention heads, and introducing entirely new regularization techniques. This is not grid search. It is an AI scientist iterating on a theory.
The 5-Minute Rule
Every experiment in AutoResearch is capped at exactly five minutes of wall-clock training time. JIT compilation and data loading do not count. This constraint is one of the most important design decisions in the system, and it deserves attention.
Traditional ML experiments train for a fixed number of epochs or steps. AutoResearch trains for a fixed amount of time. The difference matters.
Throughput: Five-minute runs mean roughly 12 experiments per hour. Over an 8-hour overnight session, that produces approximately 100 experiments.
Hardware-aware optimization: The time cap forces the agent to find architectures that train efficiently on the specific GPU it is running on. A model that is theoretically superior but trains too slowly to converge in five minutes will score poorly. Hardware efficiency is baked into the objective.
Fair comparison: Every experiment gets the same time budget. If the agent proposes a larger model that trains more slowly, it gets fewer gradient steps. The improvement must come from genuine architectural or algorithmic superiority, not from training longer.
The scoring metric is validation bits-per-byte (val_bpb). To understand why this matters: bits-per-byte measures how many bits of information your model needs to predict each byte of text, averaged across a validation set. A lower value means the model is more confident and accurate, because it assigns higher probability to the correct next token. Concretely, even a small drop in bpb means the model is meaningfully better at predicting what comes next, which translates directly into improved generated text quality.
This metric is also tokenizer-agnostic, which is a critical property for AutoResearch. Traditional metrics like perplexity are tied to a specific tokenizer's vocabulary. If the agent changes the vocabulary, the embedding structure, or the tokenization strategy, perplexity scores become incomparable across experiments. Bits-per-byte avoids this problem by operating at the byte level rather than the token level. The agent can freely explore tokenization changes, and the metric remains a fair comparison across all of those experiments.
What It Actually Achieves
In Karpathy's initial runs, AutoResearch measurably reduced validation bits-per-byte on the nanochat baseline through autonomous code iteration. Even small improvements in bits-per-byte represent meaningful gains in language model capability.
The more striking result is the 11% reduction in the "Time to GPT-2" benchmark. Running the loop on a depth-12 model, the agent discovered roughly 20 optimizations that human researchers had missed: fixes for broken attention scaling, missing regularization components, and suboptimal learning rate schedules. When those optimizations were aggregated and applied to a larger depth-24 model, the training time to reach a specific performance tier dropped from 2.02 hours to 1.80 hours.
The Shopify case is perhaps the most telling. Tobi Lutke's team ran 37 experiments overnight. The agent-optimized 0.8B model outperformed a manually tuned 1.6B model. The implication is significant: an overnight agent run on a single GPU produced a better model than human researchers achieved with twice the parameters.
The Hardware Economics
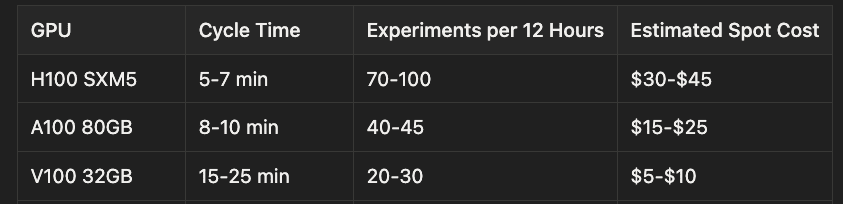
- H100 SXM5: 5-7 minute cycle time, 70-100 experiments per 12 hours, estimated spot cost $30-$45
- A100 80GB: 8-10 minute cycle time, 40-45 experiments per 12 hours, estimated spot cost $15-$25
- V100 32GB: 15-25 minute cycle time, 20-30 experiments per 12 hours, estimated spot cost $5-$10
An H100 is ideal: high memory bandwidth and 80GB of VRAM mean no gradient checkpointing penalties, so the full model fits in memory during training. But the framework runs on consumer hardware too. Community forks support Apple Silicon via MLX and consumer-grade RTX 3090/4090 GPUs.
For $30 to $45 on a cloud spot instance, you can run 70 to 100 autonomous experiments overnight. Compare that to the cost of a human researcher's time for the same number of experiments. The economics are difficult to argue with.
Why This Is Not Just Hyperparameter Tuning
There is an important distinction between AutoResearch and tools like Optuna or Ray Tune.
Traditional hyperparameter optimization (HPO) searches within a predefined space. You tell the system: "Try learning rates between 1e-5 and 1e-3." It searches that space efficiently using Bayesian optimization or random sampling. It is powerful but constrained. It cannot invent a new regularization technique. It cannot fix a bug in your attention implementation. The ceiling of what it can achieve is set by the human who defined the search space.
AutoResearch operates on the code itself. The agent reads the training script, reasons about why it might be suboptimal, and proposes structural changes. It can identify that weight decay is being incorrectly applied to bias tensors. It can discover that the learning rate scheduler is out of sync with the warm-up period. These are "silent" bugs that never crash the program but quietly prevent the model from reaching its potential.

Traditional HPO
- Search space: Predefined by human
- Mechanism: Bayesian/random search
- Can fix bugs: No
- Can invent new techniques: No
- Sample efficiency: Higher for simple searches
AutoResearch
- Search space: Open-ended code mutations
- Mechanism: LLM-based reasoning
- Can fix bugs: Yes
- Can invent new techniques: Yes
- Sample efficiency: Lower, but explores theory space
This is the key shift. AutoResearch is not an optimizer. It is an automated researcher that happens to use optimization as one of its tools.
The Bugs It Finds
One of the most immediately practical benefits is bug detection. Users have reported the agent discovering:
- Weight decay applied to bias tensors (incorrect; biases should typically be excluded from weight decay because they are low-dimensional and do not benefit from the same regularization)
- Learning rate schedulers out of sync with warm-up periods
- Broken attention scaling that silently degraded performance
- Missing regularization that prevented convergence to the theoretical optimum
These are not the kind of bugs that cause stack traces. They are the kind that cause your model to train "fine" but never quite reach the performance you expected. A human might spend weeks puzzling over why their model plateaus. The agent finds and fixes the issue in one 5-minute experiment.
The Community Response
The reception has been enthusiastic. The 630-line codebase invites modification, and the community has produced several notable forks:
- MLX AutoResearch: Runs on Apple Silicon, making overnight research loops accessible to anyone with a MacBook.
- Curriculum Learning Fork: Extends the agent's scope to modify the dataloader, experimenting with progressive sequence lengths and data difficulty.
- Multi-Agent Exploration: Community discussions describe setups where multiple agents explore different branches of the research tree simultaneously, dividing the search space for faster coverage.
The "vibe coding" connection resonates with developers who are already comfortable describing intent to AI agents rather than writing implementation details. AutoResearch extends this pattern from coding to scientific research.
The Risks Worth Understanding
AutoResearch is not without problems, and the criticisms are worth taking seriously.
Prompt quality dependency: The research loop is only as good as the strategy in program.md. Vague or poorly defined goals can send the agent into unproductive loops where it keeps trying variations that never converge on improvement. Writing a good program.md turns out to be a skill in itself.
Code generation brittleness: LLMs still occasionally produce syntactically invalid Python or structurally broken diffs. AutoResearch handles this by reverting and penalizing the agent, but each failed attempt wastes a 5-minute experiment slot.
The cheating problem: An agent optimizing for a single metric (val_bpb) might find ways to game that metric that do not generalize. Overfitting to the validation set or exploiting quirks in the loss function are real risks when the optimizer is creative enough to find loopholes. Holding out a separate test set that the agent never sees is a practical mitigation, but the broader issue of metric gaming remains an active research question.
Prompt injection via training logs: If the agent reads training log output that contains crafted text from a poisoned dataset, it could potentially interpret that text as instructions. This is a trust-boundary problem specific to agents that operate on training data. The ML community is still working through the implications.
Runaway cloud costs: An unattended agent on a cloud GPU can accumulate significant costs if it enters a loop without making progress. Cost guardrails and spending limits are essential for overnight runs. Set hard budget caps before you start.
The Bigger Picture
AutoResearch is a clean implementation of something the AI community has been theorizing about for years: recursive optimization, where an AI system improves its own training process. The current version is human-guided. The human writes the strategy. The agent executes. But the direction is clear.
The framework also points toward a future of multi-agent research organizations:
- A Literature Review Agent that monitors arXiv and summarizes relevant new papers
- A Peer Review Agent that evaluates proposed code changes before execution
- A Data Curator Agent that constructs training curricula optimized for hard reasoning tasks
Each of these is a natural extension of the pattern AutoResearch establishes: define a clear objective, give the agent the tools to pursue it, and review the results.
What This Means for Practitioners
If you work in machine learning, AutoResearch changes the calculus of your workflow.
For individual researchers: You can now run the experimentation volume of a small team. One person, one GPU, one night. The bottleneck shifts from experiment throughput to strategy quality. The question is no longer "how do I run more experiments?" It is "how do I write a better program.md?"
For teams: The tool does not replace researchers; it amplifies them. The competitive advantage moves from who can run more experiments to who can write better research strategies and who can better evaluate the agent's output.
For organizations: The strategic imperative is to define clear, measurable success metrics. AutoResearch requires a single, unambiguous objective. If your team cannot articulate what "better" means in a single number, the agent cannot optimize for it. This is a forcing function for rigor that many teams need anyway.
The human provides the taste, the boundaries, and the ethical guardrails. The agent provides the relentless, high-throughput iteration. The distance between a theoretical idea and an optimized model just got dramatically shorter.
Key Takeaways
- AutoResearch runs closed-loop ML experimentation autonomously: read strategy, modify code, train, evaluate, commit or revert.
- The 5-minute time cap is a deliberate design choice that enables roughly 100 experiments per overnight session and forces hardware-aware optimization.
- Bits-per-byte as a metric allows fair comparison across experiments that change tokenization; lower scores mean better predictive accuracy.
- The agent finds silent bugs that hyperparameter tuners cannot: incorrect weight decay, broken attention scaling, and misconfigured schedulers.
- The risks are real: prompt quality determines result quality, metric gaming is possible, and cloud cost guardrails are non-optional.
- The competitive moat is no longer experiment throughput; it is strategy quality and judgment about what the agent's results mean.
AutoResearch is available on GitHub under the MIT license. It requires Python, a single GPU, and an LLM agent (Claude Code, GPT-4, or similar) to orchestrate the research loop.
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Rick has been doing active agent development, GenAI, agents, and agentic workflows for quite a while. He is the author of many agentic frameworks and tools. He brings core deep knowledge to teams who want to adopt AI.