LangChain Deep Agents: Real-World Use Cases and the Democratization of AI Agents
Unlocking Advanced AI Capabilities for Every Developer: The Impact of LangChain Deep Agents
Originally published on Medium.
 LangChain Deep Agents: Real-World Use Cases and the Democratization of AI Agents
LangChain Deep Agents: Real-World Use Cases and the Democratization of AI Agents
Ready to revolutionize your development workflow? Discover how LangChain Deep Agents are democratizing AI capabilities, enabling anyone to build production-grade agents with just one command! Don't miss the final part of our series, where we unveil real-world use cases and the impact of open-source on AI architecture. #LangChain #AIAgents #OpenSource
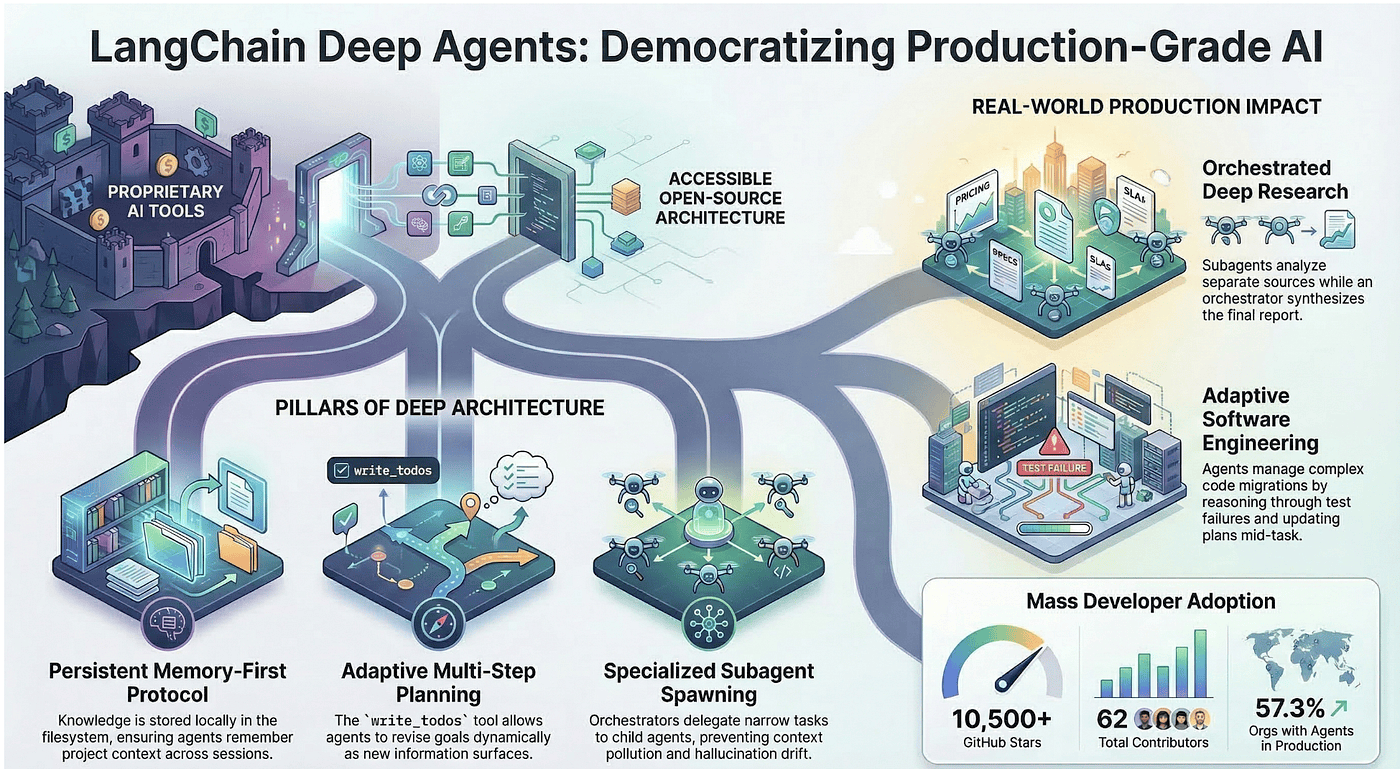
LangChain Deep Agents democratize AI agent capabilities, allowing developers to build production-grade agents easily with a single command installation. The architecture includes features like persistent memory, subagent delegation, and planning tools, enabling efficient deep research, adaptive software migrations, and incident analysis. The open-source nature of Deep Agents lowers barriers for individual developers, providing access to powerful tools previously available only through proprietary solutions. The series concludes by emphasizing the shift from complex, proprietary systems to accessible, customizable solutions for all developers.
Part 5 of 5 in the LangChain Deep Agents series
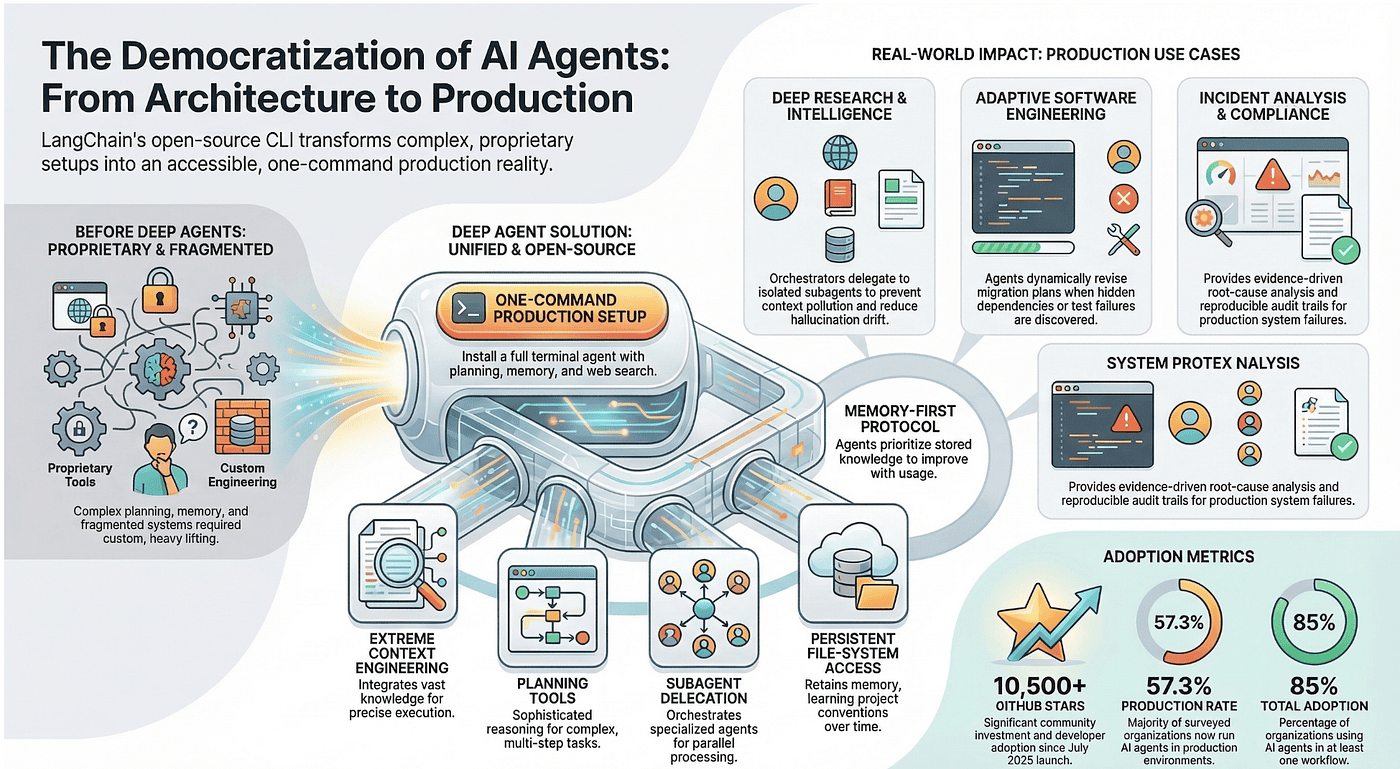
In late 2024, building a production-grade AI agent meant one of two things: paying for a proprietary tool or assembling one from scratch. The tooling existed in fragments. Planning, subagent delegation, persistent memory, and file system access each required custom engineering. The gap between what a well-funded team could ship and what an individual developer could build was enormous.
Then LangChain released Deep Agents in late 2025.
One command. One install. A terminal agent with planning, file operations, web search, MCP integration, and persistent memory, all wired together and ready to run against any LLM that supports tool calling. The proprietary playbook became an open-source blueprint.
This final article in our five-part series brings everything together. Articles 1 through 4 covered the architecture: shallow versus deep agents, open-source trade-offs, the LangGraph middleware engine, and context management with security. Now we see what that architecture does in the real world.
The Deep Agents CLI
The fastest way to experience Deep Agents is through the CLI. Install it with a single command:
uv tool install deepagents-cli
That gives you a terminal agent comparable to Claude Code or Cursor, powered by whichever LLM you choose. Set an API key, and you are running. No boilerplate code, no configuration files, no dependency wrangling.
What Ships Out of the Box
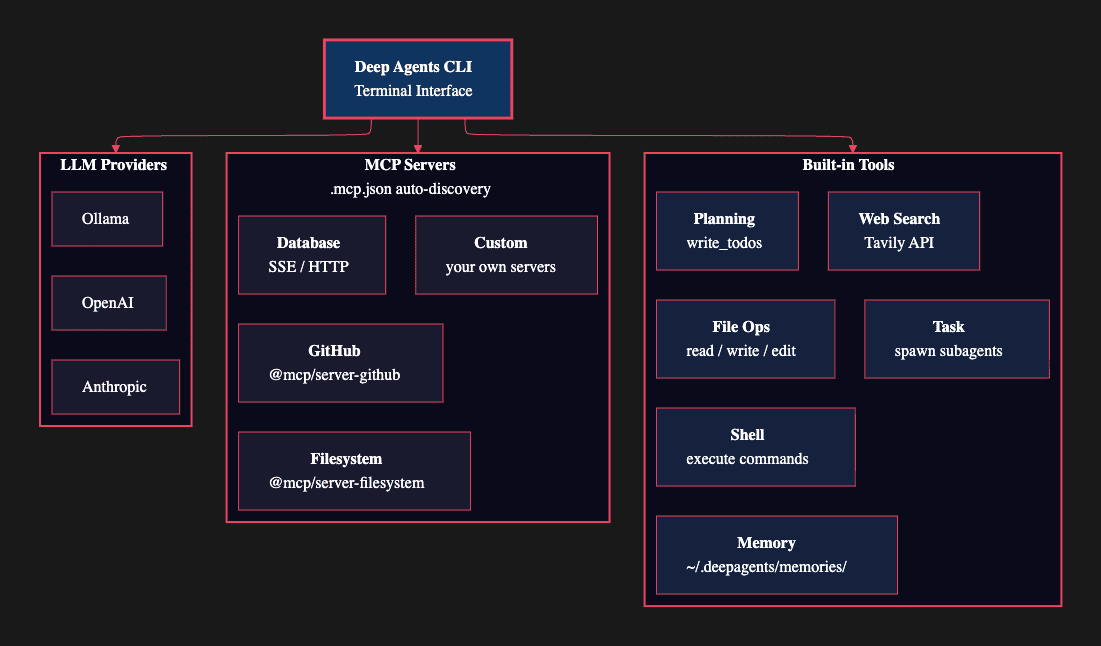
The CLI arrives with a complete toolkit that covers the four pillars of deep agent architecture discussed in Article 1:
- File operations: Read, write, and edit files in your project directory. These tools give the agent persistent memory beyond its context window, the fourth pillar that separates deep agents from shallow ones.
- Shell execution: Run commands with human approval for safety. In manual-accept mode, the agent pauses before every potentially destructive operation, giving you a chance to review. In auto-accept mode, it proceeds without interruption.
- Web search: Query the web via Tavily integration for current information. This keeps the agent grounded in real-world data rather than relying solely on its training knowledge. (Tavily is a real-time search engine and API platform built specifically for AI agents to retrieve, extract, and deliver accurate, structured web data, reducing hallucinations and enhancing decision-making in RAG workflows)
- Planning: The write_todos tool keeps the agent focused on multi-step tasks. As discussed in Article 1, this is the "no-op" planning tool that functions as context engineering, reminding the model of its goals on every iteration.
- Subagent spawning: The task tool delegates specialized work to child agents, each with its own context window and focus.
- Persistent memory: Knowledge stored at ~/.deepagents/AGENT_NAME/memories/ survives across sessions.
 LangChain DeepAgent CLI
LangChain DeepAgent CLI
Deep Agents arrives as an agent framework with batteries included. Out of the box, you get file operations for persistent memory, shell execution with safety controls, web search via Tavily, a planning system that keeps multi-step tasks on track, subagent spawning for parallel work, and a memory-first protocol that builds project knowledge across sessions. The CLI wires these capabilities together into a production-ready terminal agent that works with any LLM supporting tool calling, eliminating the need for custom engineering to assemble core agent capabilities from scratch.
LangChain DeepAgent: Memory First
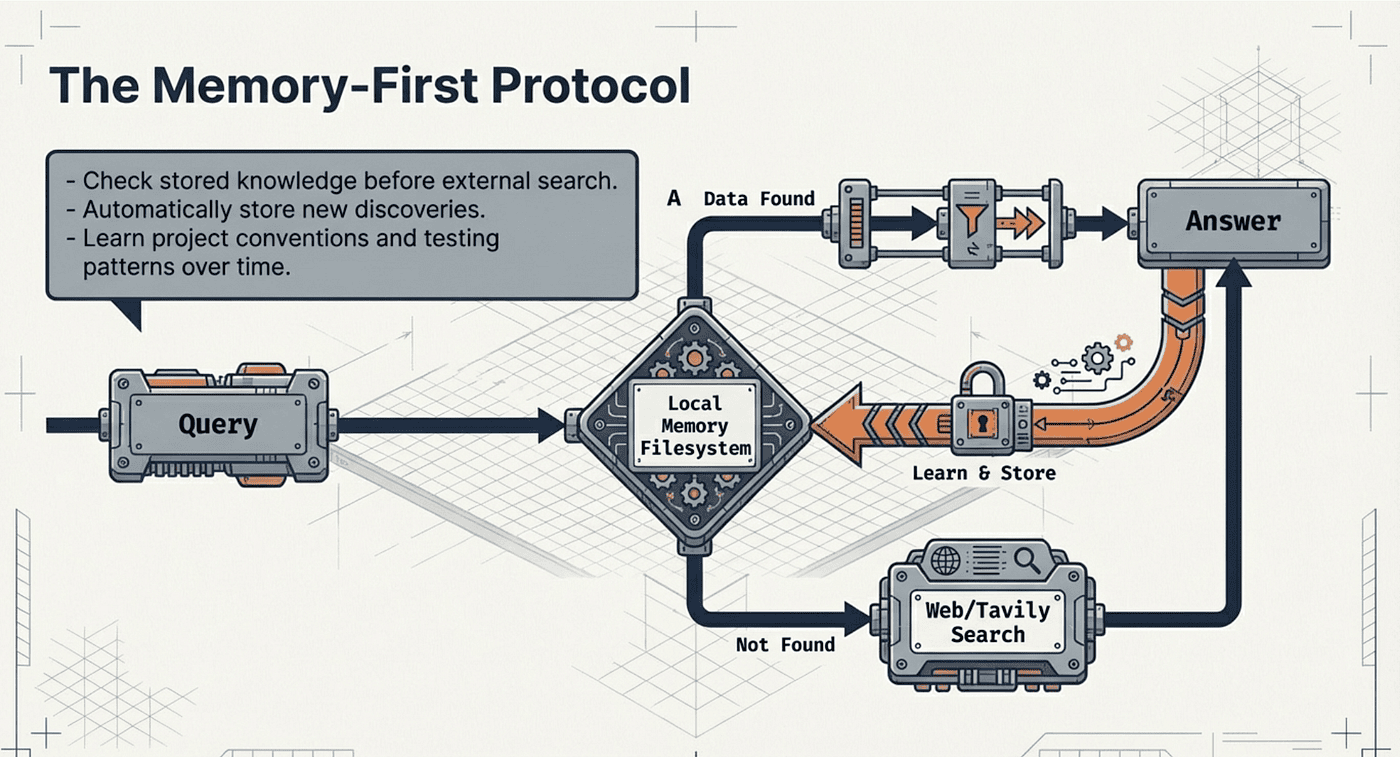 LangChain DeepAgent: Memory First Protocol
LangChain DeepAgent: Memory First Protocol
The memory system deserves special attention. The agent follows what the documentation calls a Memory-First Protocol. During research, it checks stored knowledge before searching externally. When it learns something new, it saves it automatically. When uncertain, it searches memory files first. This means an agent working on your project on Monday remembers what it learned when you pick it up again on Thursday.
In practice, the protocol creates a feedback loop: the more you use an agent, the more it knows about your project. It learns your naming conventions, your testing patterns, your deployment preferences. Over time, it becomes a specialized assistant tuned to your specific workflow.
LangChain DeepAgent CLI -- Agent Management
You can run multiple specialized agents for different projects or roles:
deepagents list
# Switch to a backend-focused agent
deepagents --agent backend-dev
# Reset an agent to default state
deepagents reset my-agent
Each agent maintains its own memories and system prompt. A "backend-dev" agent remembers your API conventions. A "docs-writer" agent remembers your style guide. A "devops" agent remembers your Kubernetes cluster topology. They operate independently, and you switch between them based on the task at hand.
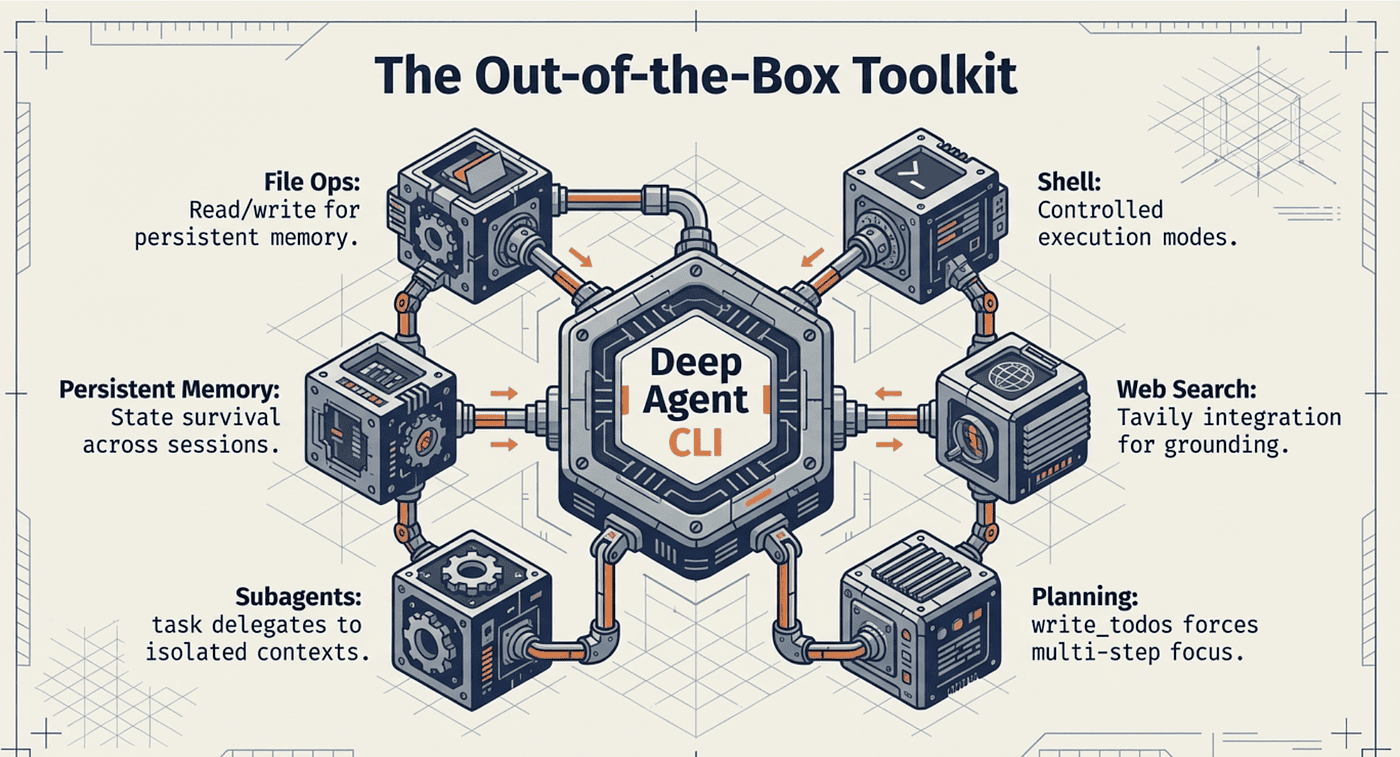 Deep Agent CLI allows management of agentic tools
Deep Agent CLI allows management of agentic tools
LangChain DeepAgent: MCP Integration: Extend Without Modifying
 LangChain DeepAgent: MCP Integration: Extend Without Modifying
LangChain DeepAgent: MCP Integration: Extend Without Modifying
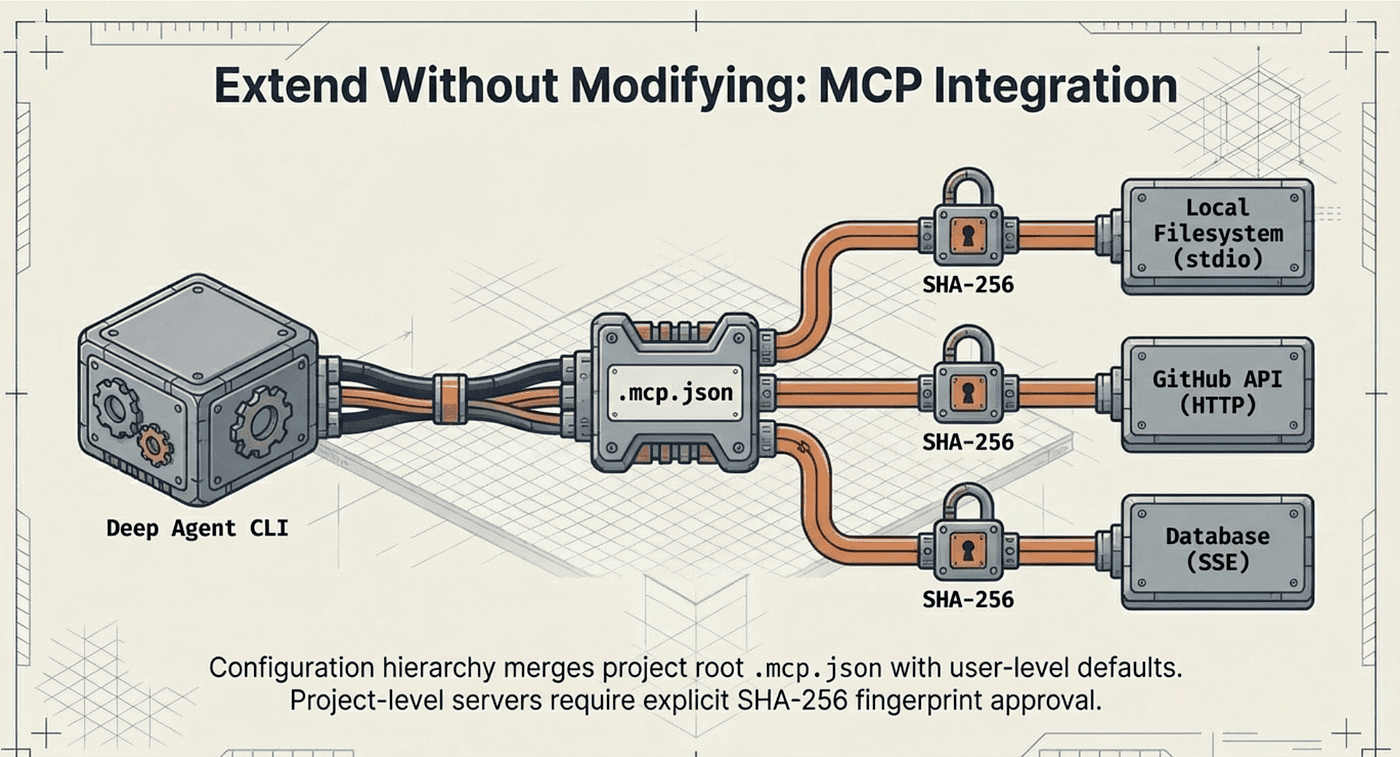
The Model Context Protocol integration is where the CLI becomes truly extensible. Create a .mcp.json file at your project root (the same format Claude Code uses), and the CLI connects to your MCP servers at startup, discovers their tools, and makes them available alongside the built-in ones.
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": ["@modelcontextprotocol/server-filesystem", "./data"]
},
"github": {
"command": "npx",
"args": ["@modelcontextprotocol/server-github"],
"env": { "GITHUB_TOKEN": "your-token" }
}
}
}
On startup, the CLI spawns each configured server, discovers its tools, and prints a confirmation: "Loaded 3 MCP tools." The tools appear in the agent's system prompt grouped by server and transport type, so the model understands which tools come from which source.
The CLI searches three locations for configuration, from highest to lowest precedence: the project root .mcp.json, a .deepagents/.mcp.json subdirectory, and a user-level ~/.deepagents/.mcp.json. Configurations merge, with project-level settings overriding user-level defaults. This mirrors the security model covered in Article 4: user-level configs are implicitly trusted, while project-level stdio servers require explicit approval before execution. Trust decisions are stored as SHA-256 fingerprints in ~/.deepagents/config.toml.
Both stdio servers (spawned as child processes) and remote servers (connecting via SSE or HTTP) are supported. This means you can connect to a local filesystem server in one project and a remote database API in another, all through the same configuration format.
Production Use Cases
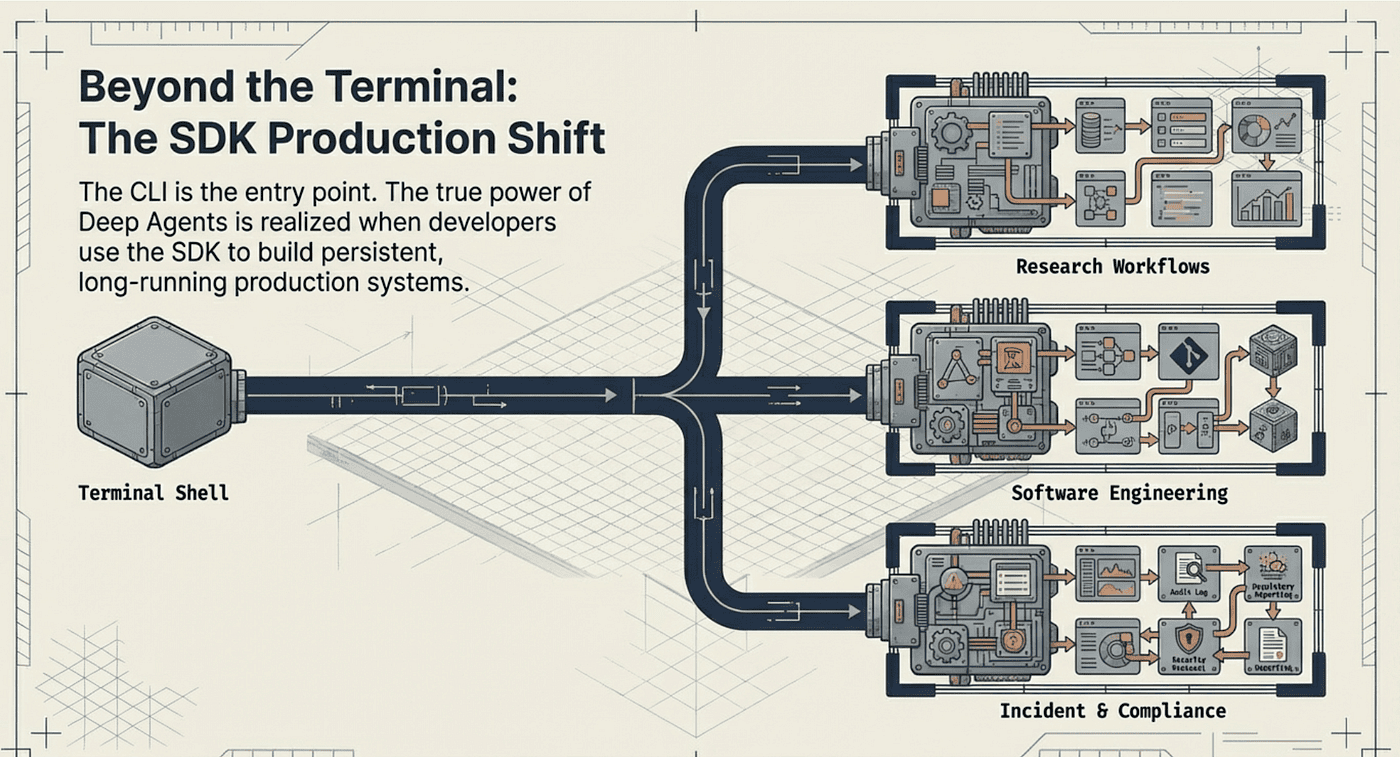
The CLI is the entry point. The real story is what developers build with the Deep Agents SDK once they move beyond the terminal. Three patterns have emerged as the strongest production use cases, each leveraging different combinations of the four architectural pillars.
 LangChain DeepAgent: Beyond the Terminal, use the SDK
LangChain DeepAgent: Beyond the Terminal, use the SDK
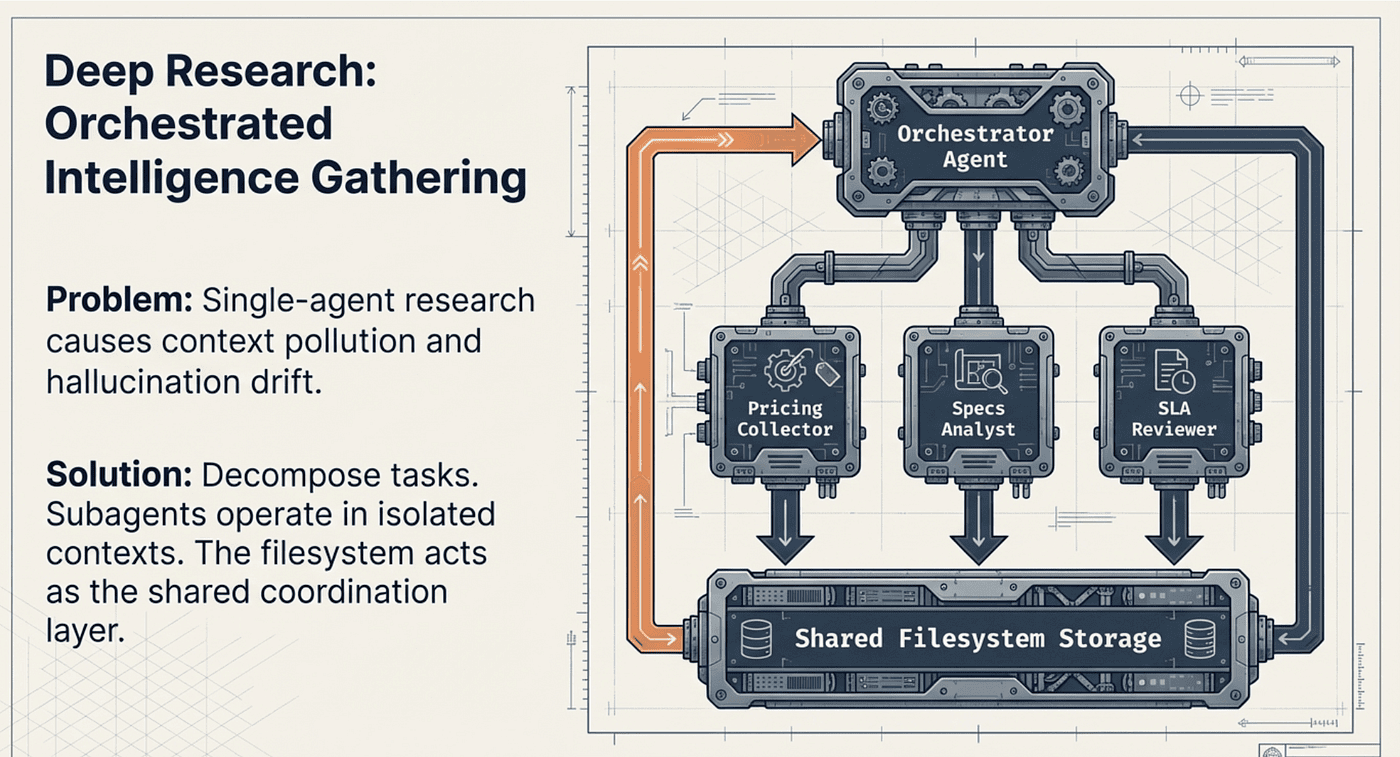
Deep Research: Orchestrated Intelligence Gathering
Manual research across dozens of sources is slow, inconsistent, and exhausting. A human researcher might spend days reading analyst reports, parsing API documentation, and cross-referencing pricing pages to produce a competitive analysis. A Deep Agent completes the same work in minutes, often with better source coverage than a human would achieve.
 LangChain DeepAgent: Deep Research: Orchestrated Intelligence Gathering
LangChain DeepAgent: Deep Research: Orchestrated Intelligence Gathering
The pattern works like this. The orchestrator agent receives a broad research question and decomposes it into focused subtasks using write_todos. Then it spawns specialized subagents via the task tool, each responsible for a narrow slice of the investigation.
Consider a concrete example: "Compare the top three cloud providers for GPU-intensive machine learning workloads." The orchestrator creates a plan and spawns three subagents:
- Pricing Collector searches the web and parses pricing pages, writing structured findings to
pricing_data.md - Specs Analyst reads documentation and benchmarks, writing GPU specifications to
gpu_specs.md - SLA Reviewer analyzes service-level agreements, writing contract comparisons to
sla_comparison.md
Each subagent operates in isolation. It has its own context window, its own tools, and its own focus. When it finishes, it writes results to the shared filesystem. The orchestrator then reads all output files, cross-references the data, resolves any conflicts between sources, and produces a final structured report with citations.
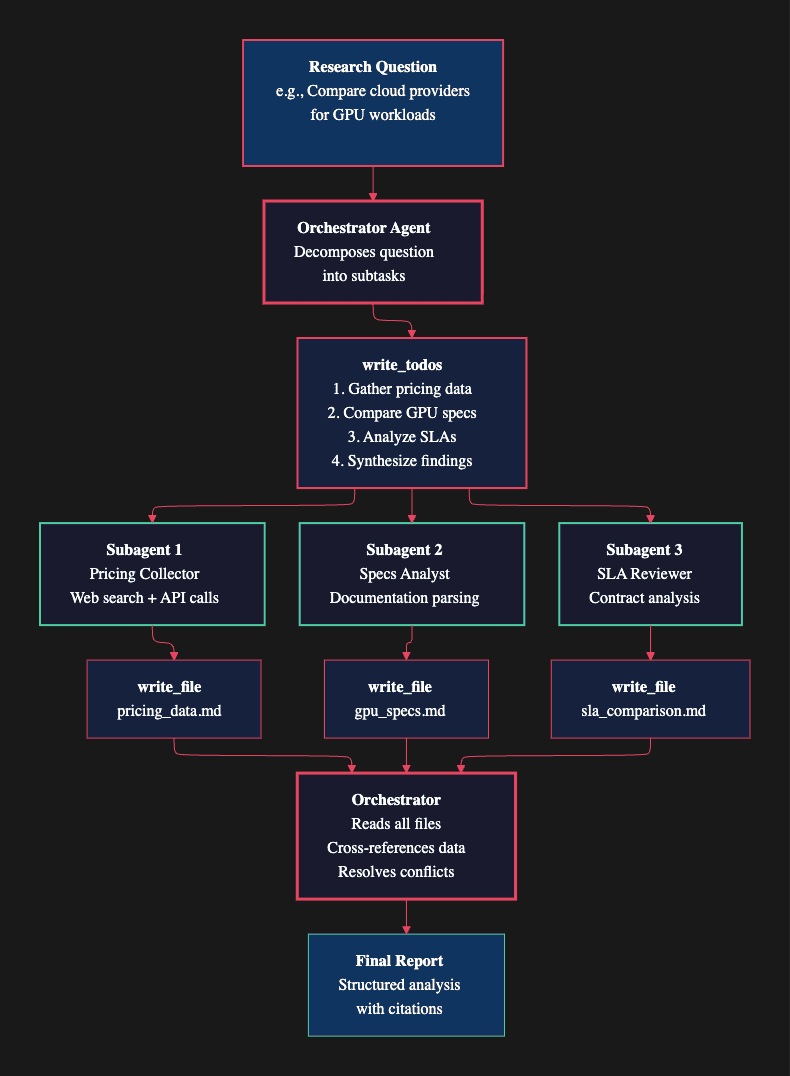
This architecture solves the two biggest problems with single-agent research. First, context pollution: when one agent handles everything, findings from early research steps consume context window space needed for later analysis. Subagents keep their contexts clean. Second, hallucination drift: a single agent working through a long task can gradually lose sight of the original question. The orchestrator's todo list anchors the process, and each subagent receives a tightly scoped prompt that prevents wandering.
The filesystem is the coordination layer. Rather than passing results through message chains (which would consume context), subagents write structured output to files. The orchestrator reads those files when it needs them. This pattern, covered in detail in Article 4's discussion of context management, is what allows Deep Agents to handle research tasks that would overwhelm a single agent's context window.
Complex Software Engineering: Adaptive Migrations with LangChain Deep Agent
 LangChain Deep Agent: Complex Software Engineering: Adaptive Migrations
LangChain Deep Agent: Complex Software Engineering: Adaptive Migrations
Large-scale code migrations are notorious for hidden complexity. You start with a clear plan, and then halfway through you discover that the authentication module depends on a deprecated library that also needs upgrading. The plan changes. Dependencies cascade.
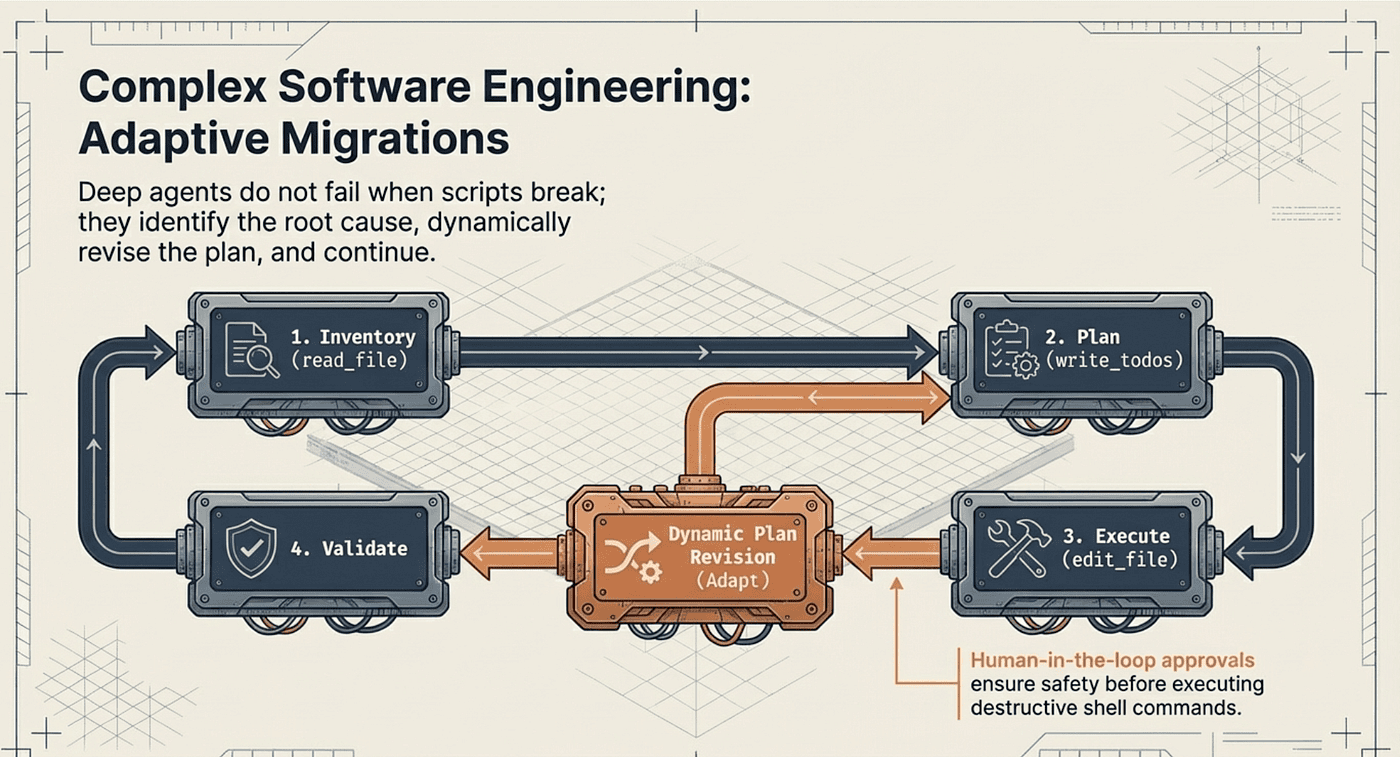
Deep Agents handle this naturally because the planning tool is not a one-time artifact. It is a living document that the agent revises as it learns. This is the "adaptive planning" capability that distinguishes deep agents from scripted automation.
Here is the pattern for a migration task. Consider upgrading from API v2 to v3 across a large codebase:
- Inventory: The agent scans the project with
lsandread_file, building a map of every file that references the v2 API. It writes this inventory tomigration_inventory.mdso it persists beyond the context window. - Plan: It creates an ordered migration sequence with
write_todos, accounting for known dependencies. Files with fewer dependencies get migrated first. - Execute: It processes each step, using
edit_fileto make changes andshellto run tests after each modification. - Adapt: When a test fails because of an undiscovered dependency, the agent reads the error output, identifies the root cause, and updates the todo list with new steps before continuing. It writes the discovery to
migration_notes.mdso it remembers the issue if context is summarized later. - Validate: After all steps complete, it runs the full test suite and integration checks.
The critical difference from a static script or a simple find-and-replace is step four. The agent does not stop when something unexpected happens. It reasons about the failure, revises its plan, and continues. This mirrors how an experienced engineer works through a migration, adapting as new information surfaces rather than abandoning the effort when the initial plan proves incomplete.
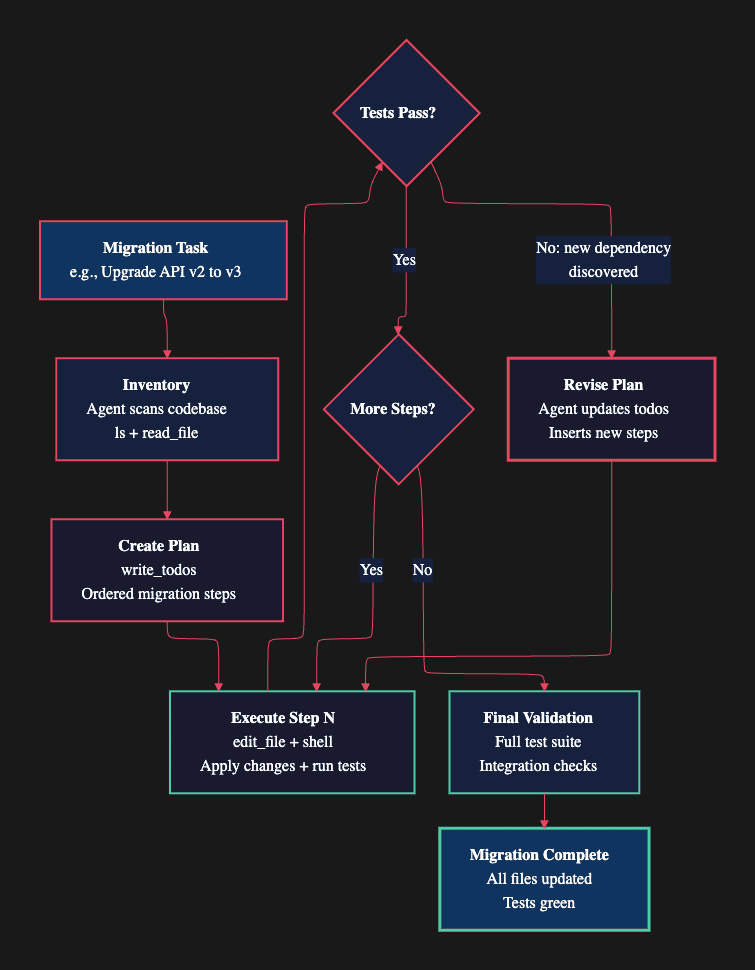
The subagent architecture helps here too. For a large migration spanning multiple services, the orchestrator can spawn separate subagents for each service, letting them work through their sections independently and writing results to the shared filesystem. The orchestrator tracks overall progress through the todo list and handles cross-cutting concerns that span multiple services, such as shared utility libraries or common configuration files.
The middleware capabilities discussed in Article 3 add another layer of safety. Human-in-the-loop approval can be configured so that the agent pauses before executing shell commands or editing critical files, giving the developer a chance to review changes before they are applied.
Incident Analysis and Compliance with LangChain DeepAgent
 Incident Analysis and Compliance
Incident Analysis and Compliance
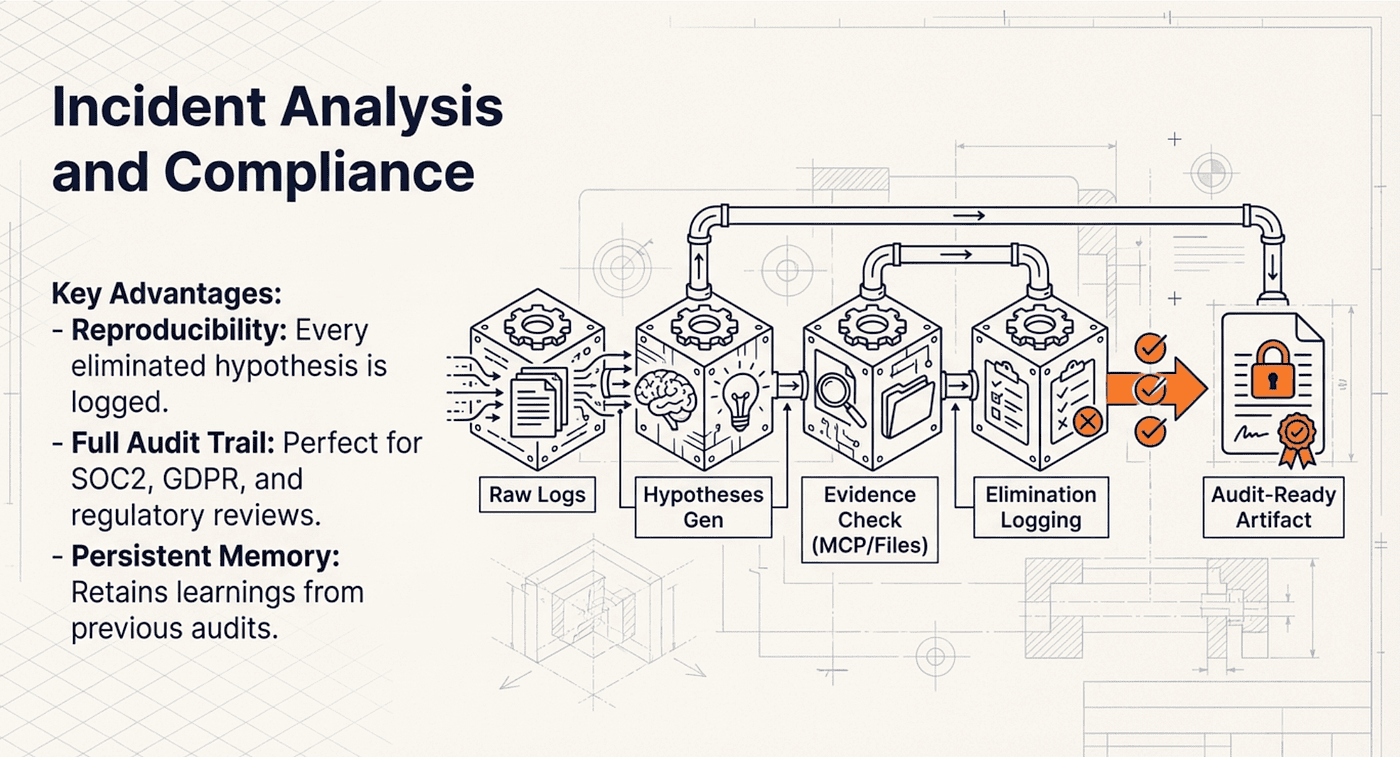
When a production system goes down at 3 AM, the incident responder's job is a textbook deep agent task: parse logs, form hypotheses, test each one against evidence, and assemble a structured timeline. The work is sequential, evidence-driven, and requires maintaining context across dozens of data points.
A Deep Agent configured for incident response works through this systematically:
- The agent reads log files from the affected time window using
read_file, extracting relevant entries toraw_evidence.md - It identifies anomalies and forms initial hypotheses, writing them to
hypotheses.mdwith confidence levels - For each hypothesis, it searches for supporting or contradicting evidence in other log sources, metrics dashboards (via MCP), and configuration files
- It eliminates hypotheses that lack evidence, updating the todo list as the investigation narrows. Each elimination is logged with reasoning.
- It assembles a root-cause analysis document with a timeline, evidence chain, and recommended fixes in
incident_report.md
The key advantage is reproducibility. Every step is documented. Every hypothesis is recorded with its supporting and contradicting evidence. When the postmortem meeting happens the next day, the agent's output provides a complete, auditable trail of the investigation.
The same pattern applies to compliance work. SOC2 audits, GDPR assessments, and regulatory reviews all follow repetitive, detail-heavy processes with strict requirements. An agent can parse policy documents, check configurations against requirements, flag gaps, and assemble audit-ready folders, all while maintaining a clear trail of what it checked, what it found, and what needs attention.
What makes Deep Agents particularly suited to these tasks is the combination of persistent memory and the todo list. The agent does not lose track of which hypotheses it has already tested or which compliance checkboxes it has already verified. The filesystem acts as an external memory store that prevents the context window from becoming a bottleneck. And because the memory persists across sessions, an agent that handled last quarter's SOC2 review remembers the findings when it starts this quarter's review.
LangChain DeepAgent -- Market Impact: The Democratizing Moment
 LangChain DeepAgent -- Market Impact: The Democratizing Moment
LangChain DeepAgent -- Market Impact: The Democratizing Moment
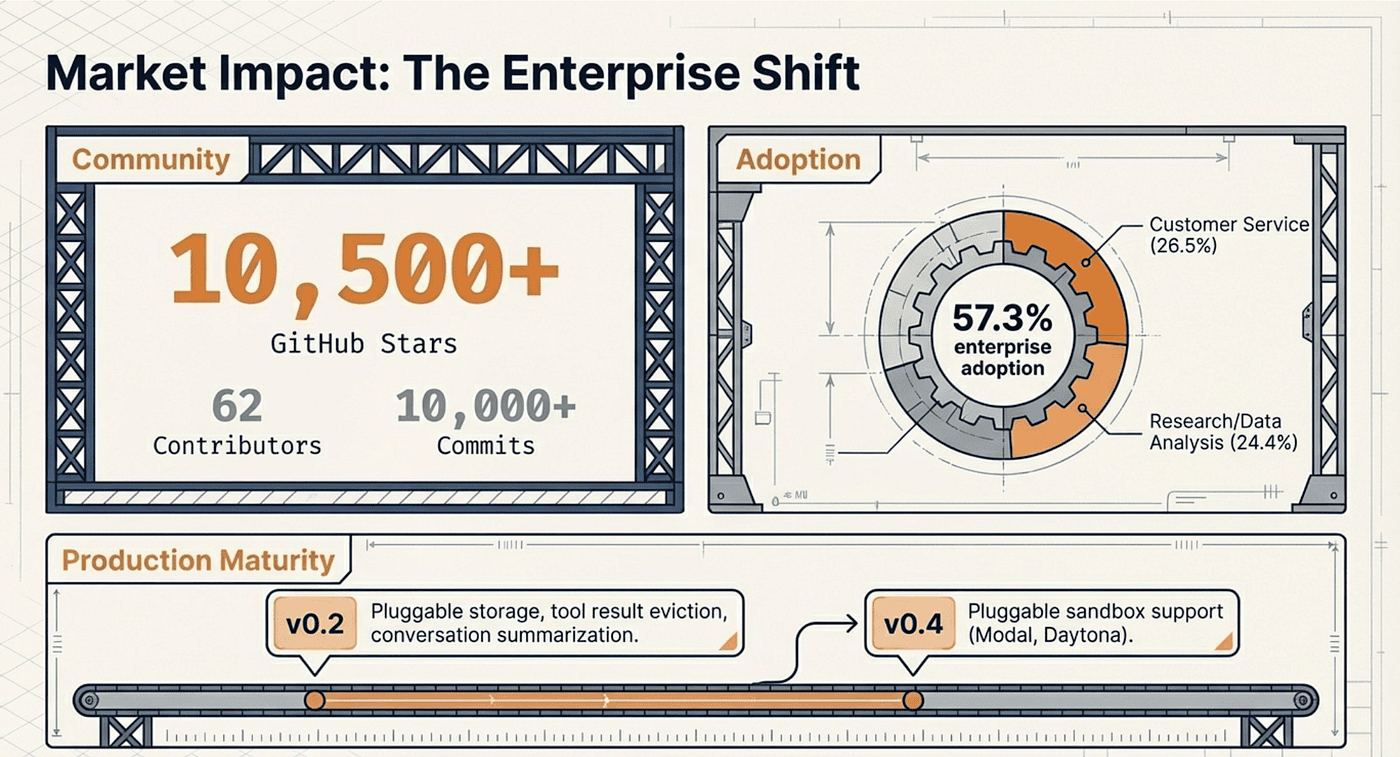
The numbers tell the story. Since its launch in July 2025, the Deep Agents repository has accumulated over 10,500 GitHub stars. The ecosystem has expanded to include a Python package (deepagents), a JavaScript/TypeScript port (deepagentsjs), a custom UI (deep-agents-ui), and a dedicated LangChain Academy training course. The project has attracted 62 contributors and over 10,000 commits, reflecting serious community investment.
But raw adoption numbers only capture part of the picture. The deeper shift is architectural.
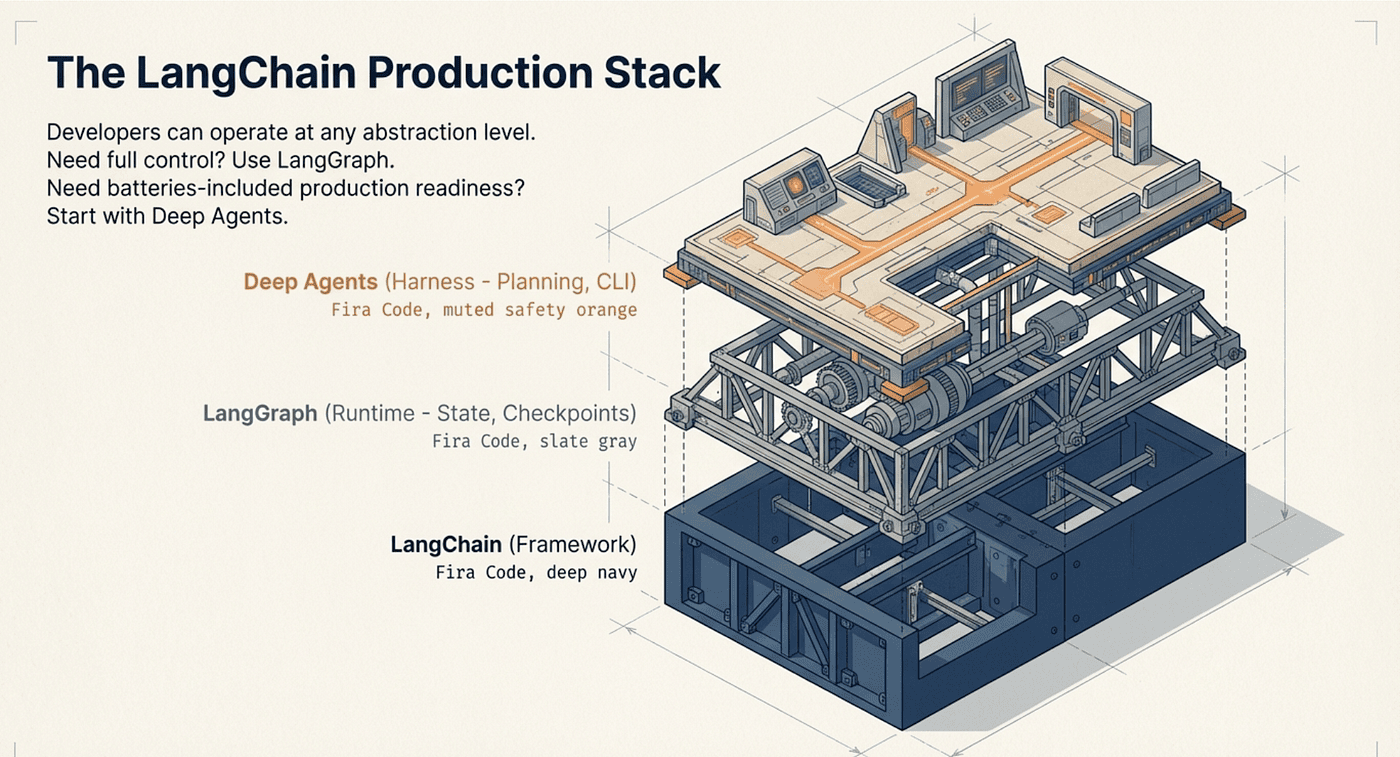
LangChain now positions three open-source libraries as a complete stack: LangChain as the agent framework, LangGraph as the agent runtime, and Deep Agents as the agent harness. This layered approach means developers can work at whatever level of abstraction fits their needs. Need a custom agent with full control over the ReAct loop? Use LangGraph directly. Need a production-ready agent with batteries included? Start with Deep Agents and customize from there. Need to integrate external tools without modifying agent code? Add MCP servers.
 LangChain DeepAgent: Production Stack with Harness Engineering
LangChain DeepAgent: Production Stack with Harness Engineering
The v0.2 release in October 2025 demonstrated the project's maturity trajectory. It introduced pluggable backends (allowing filesystem, LangGraph Store, or S3 as the persistence layer), composite backends (layering multiple storage strategies), large tool result eviction (automatically offloading oversized results to the filesystem), conversation history summarization (compressing older dialogue to free context space), and dangling tool call repair (recovering from interrupted executions). These are production-hardening features, not toys.
The v0.4 release in February 2026 added pluggable sandbox support (Modal, Daytona, Deno, Runloop) and Responses API compatibility, further expanding deployment options.
The industry context amplifies the significance. According to LangChain's State of AI Agents report, 57.3% of surveyed organizations now have agents running in production environments. Eighty-five percent have adopted agents in at least one workflow. Customer service (26.5%) and research and data analysis (24.4%) lead the deployment categories.
These are not experimental deployments. Organizations are moving past proof-of-concept into production, treating agentic systems as long-running processes with proper infrastructure, monitoring, and governance. LangSmith integration provides the observability layer, with tracing and evaluation built natively into the Deep Agents workflow.
What Deep Agents did was lower the barrier to joining that production cohort. Before its release, building an agent with planning, subagent delegation, persistent memory, and file system access required assembling those capabilities from scratch. After its release, those capabilities come pre-built, tested, and customizable. The gap between what an enterprise engineering team can build and what an individual developer can build has never been smaller.
This is the democratizing moment. The techniques that made proprietary tools like Claude Code powerful have been distilled into open-source building blocks that anyone can use, modify, and extend. A solo developer with a Tavily API key and an Anthropic account can install deepagents-cli and have a terminal agent with the same architectural foundations that power enterprise-grade systems.
LangChain DeepAgent Series: From Theory to Practice
This five-part series traced the full arc of the deep agent revolution, from identifying the problem to validating the solution in production.
Article 1: The Shift from Shallow to Deep established the problem. Shallow ReAct agents work brilliantly for simple, short-horizon tasks: look up a fact, run a query, return a result. But they break down on complex, multi-step problems. Context windows overflow. The agent loses sight of its original goal. There is no way to delegate specialized work. The shift from shallow to deep required four architectural pillars: extreme context engineering, planning tools, subagent spawning, and persistent file system access.
Article 2: Open-Source vs. Proprietary examined the tension between approaches. Claude Code proved that deep agent architecture works at scale. But its proprietary nature limited who could benefit. Deep Agents brought those same patterns to the open-source ecosystem, with trade-offs: more flexibility and transparency, but requiring more assembly and tuning. The convergence of these approaches created a healthier ecosystem where proprietary tools push innovation and open-source implementations make that innovation accessible.
Article 3: The Middleware Engine went under the hood. LangGraph provides the durable runtime that makes deep agents possible: state management, checkpointing, error recovery, and middleware hooks. The middleware system enables dynamic prompt injection, human-in-the-loop approval workflows, and model routing. Without this engine, deep agents would be fragile prototypes. With it, they are production infrastructure.
Article 4: Context Management and Security tackled the hardest operational challenges. As agents handle longer tasks, their context windows fill up. Deep Agents solve this with conversation history summarization, large tool result eviction, and filesystem-based context offloading. On the security front, runtime context injection prevents unauthorized data access, and the middleware layer enables PII masking, output filtering, and approval gates for sensitive operations.
Article 5: Real-World Use Cases (this article) brought it all together with evidence. The CLI puts the complete architecture in a developer's hands with a single install command. Deep research, software engineering, and incident analysis demonstrate that the theory works in practice. And the market adoption confirms that the developer community agrees: over 10,500 stars, 62 contributors, and integration into LangChain's three-library stack.
Article 6: The power of harness engineering. LangChain's DeepAgent coding agent improved its performance from 52.8% to 66.5% on Terminal Bench 2.0 through harness engineering techniques, including self-verification loops, loop detection middleware, and LangSmith traces. The focus was on optimizing the infrastructure around the model rather than changing the model itself. Key strategies included a structured verification process, context onboarding, and strategic reasoning depth allocation, which collectively enhanced the agent's ability to handle complex tasks effectively.
The story of Deep Agents is ultimately a story about access. Eight months ago, the four pillars of deep agent architecture were understood by a handful of teams building proprietary tools. Today, they are documented, open-source, and installable with a single command. The best ideas in AI agent architecture are no longer locked behind proprietary walls. They are open, customizable, and available to every developer who wants to build something ambitious.
One command to install. One architecture to learn. An entire ecosystem of production-ready agent capabilities at your fingertips.
uv tool install deepagents-cli
The future of AI agents is open source. Start building.
 The future of AI agents is open source. Start building.
The future of AI agents is open source. Start building.
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.
Related Articles
If you found this exploration of LangChain Deep Agents valuable, you might also enjoy these related articles that dive deeper into the topics of agent architecture, context engineering, and harness engineering:
LangChain Deep Agent Series
- The Agent Framework Landscape: LangChain Deep Agents vs. Claude Agent SDK -- Comparing architectures and capabilities of leading AI agent frameworks
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security -- A deep-dive into how Agent Brain, Agent Skills, and Agent RuleZ work together inside a LangChain agent architecture to deliver memory, security, and reusable workflows
- Under the Hood: Middleware, Sub-Agents, and Deep Agent LangGraph Orchestration -- Explores how middleware, sub-agents, and LangGraph work together as the runtime layer the harness operates within
- Introduction to LangChain Deep Agents and the Shift to "Agent 2.0" -- Frames the architectural shift from simple tool-using chatbots to Agent 2.0 systems with persistent memory, hierarchical orchestration, and harness-controlled execution
Context and Harness Engineering
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS -- Introduces the conceptual distinction between context engineering and harness engineering using the CPU/OS analogy
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage -- Navigating the challenges of AI code generation and implementing harness engineering to ensure reliability and safety
- Mastering Claude Code's /btw, /fork, and /rewind: The Context Hygiene Toolkit -- Learn how to use Claude Code's context management commands to eliminate context pollution and optimize your AI coding workflow
- Context Engineering: Agents -- Injecting the Right Rules at the Right Moment -- Covers the mechanics of dynamic rule injection -- how and when architectural constraints are delivered to an agent during execution, not just at startup
Agent Skills and Automation
- Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents -- Explains the evolution of agent skills from simple slash-command instructions to fully programmable, multi-step workflows with validation and feedback loops
- Claude Code Rules: Stop Stuffing Everything into One CLAUDE.md -- Provides a practical guide to structuring agent rules across multiple files rather than a single monolithic rules file -- the approach that Agent RuleZ formalizes
- The End of Manual Agent Skill Invocation: Event-Driven AI Agents -- Describes how agent skills can be triggered automatically by events rather than manually, eliminating a major source of inconsistency in multi-step agentic workflows
- Put Claude on Autopilot: Scheduled Tasks with /loop and /schedule built-in Skills -- Demonstrates built-in Agent Skills for scheduling and looping -- concrete examples of how harness-managed skills enable autonomous, long-running agent operation
Memory and Governance
- Claude Code's Automatic Memory: No More Re-Explaining Your Project -- Covers the automatic memory capability that ships with Claude Code and how it maintains context across sessions
- From Approval Hell to Just Do It: How Agent Skills Fork Governed Sub-Agents in Claude Code 2.1 -- Shows how Agent Skills combined with policy islands (forked sub-agents with pre-declared permissions) eliminate approval fatigue while maintaining governance