LangFuse: Why Agent Tracing Matters: You Can't Debug What You Can't See
Understanding the Importance of Trace-Based Debugging in Multi-Agent Systems
Originally published on Medium.
Understanding the Importance of Trace-Based Debugging in Multi-Agent Systems
 Agent Tracing Observability
Agent Tracing Observability
- Document Ingester: Extracts raw text from uploaded PDFs
- Entity Extractor: Identifies key entities (people, dates, organizations, monetary amounts)
- Fact Checker: Validates extracted entities against a knowledge base
- Summarizer: Generates an executive summary from validated entities and source text
- Quality Reviewer: Grades the final output for accuracy and completeness
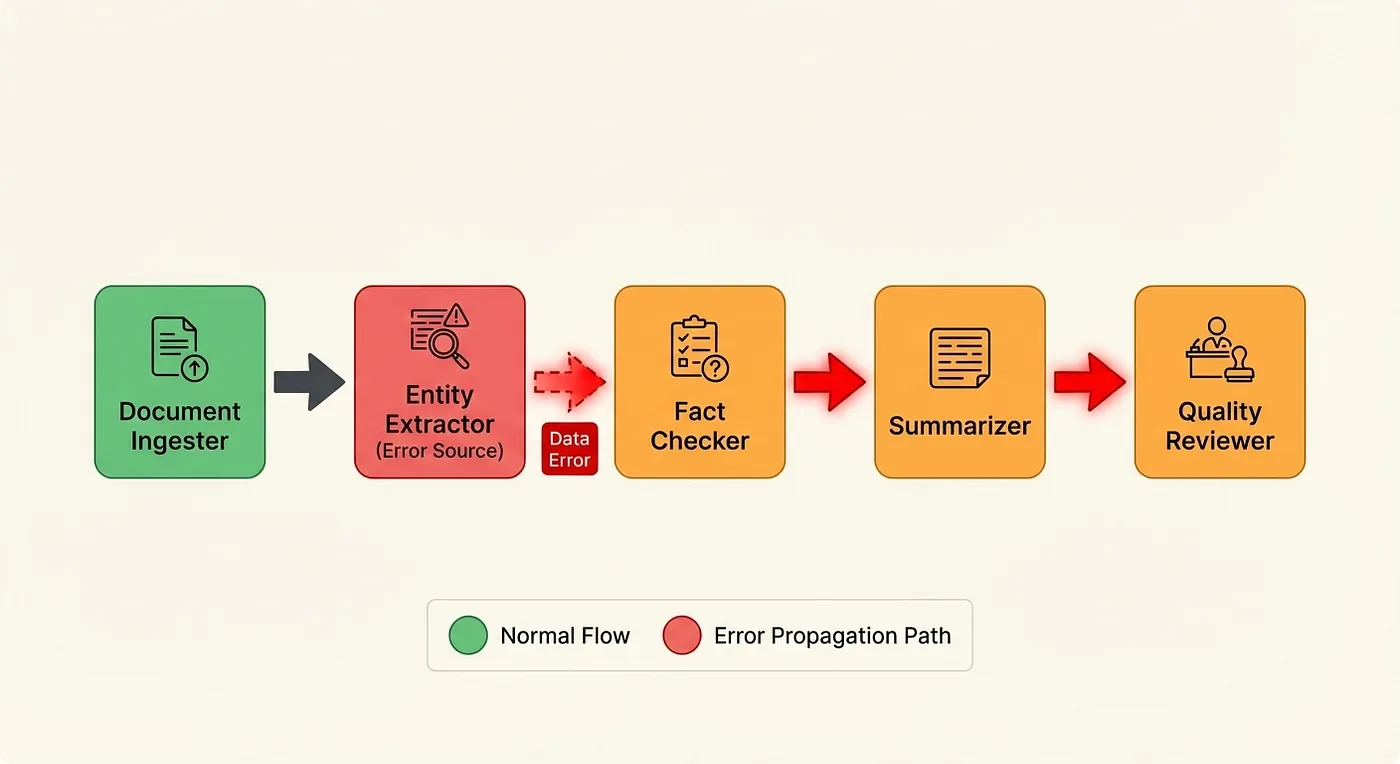 Agent Pipeline Failure Cascade
Agent Pipeline Failure Cascade
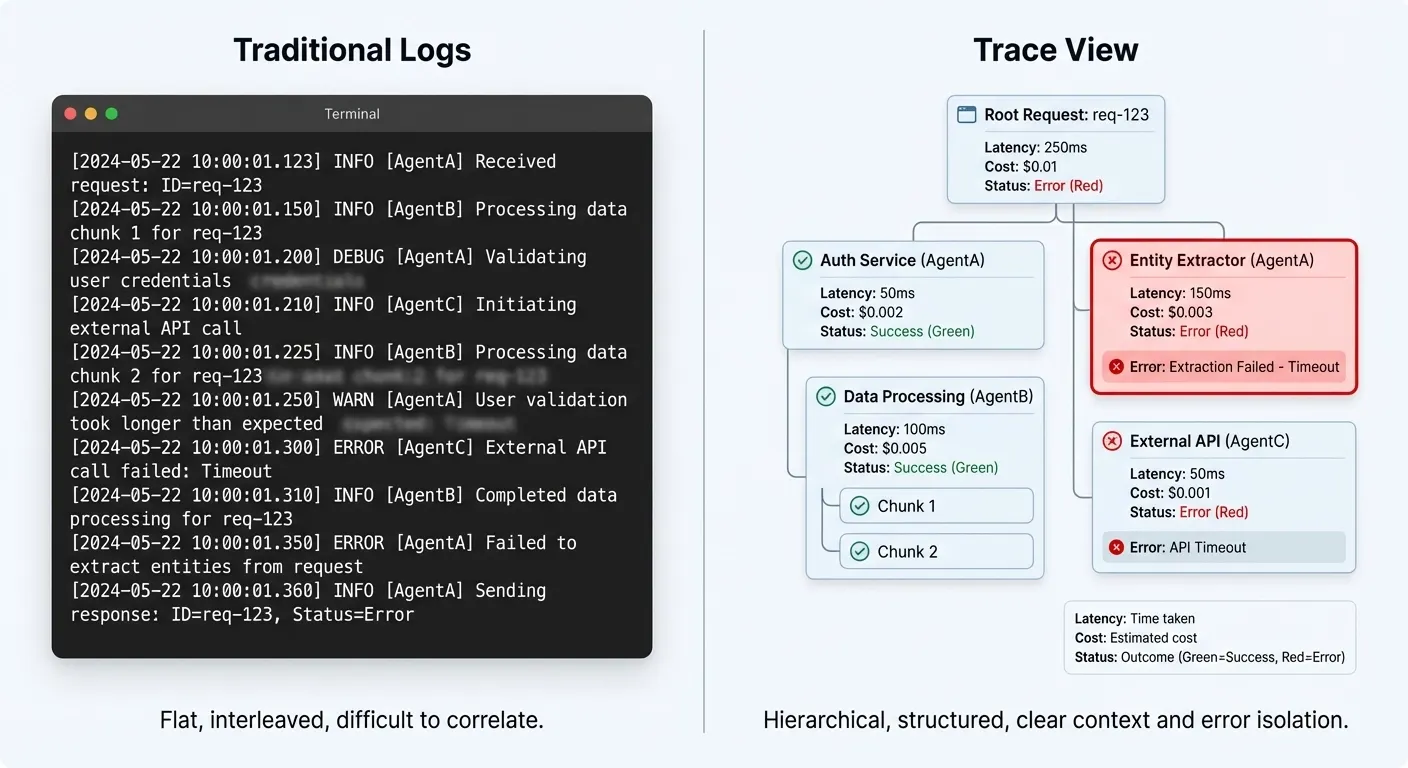 Logs vs Traces Comparison
Logs vs Traces Comparison
10:32:01.234 INFO [agent-2] Extracting entities from doc-4821
10:32:01.456 INFO [agent-3] Starting fact check for doc-4821
10:32:01.512 INFO [agent-2] Found 14 entities in doc-4821
10:32:01.789 INFO [agent-2] Entity extraction complete for doc-4821
10:32:02.101 INFO [agent-3] Validated 12 of 14 entities for doc-4821
10:32:02.345 INFO [agent-4] Generating summary for doc-4821
10:32:02.890 WARN [agent-5] Quality score 0.34 for doc-4821
Trace:
doc-4821
|
12.
4s
|
$0.47
├──
Span:
Document
Ingester
|
1.
2s
|
$0.02
|
OK
├──
Span:
Entity
Extractor
|
2.
8s
|
$0.09
|
ERROR:
wrong
date
│
├──
Generation:
GPT-5.3
Instant
(API:
gpt-5.3-chat-latest)
|
2
,134
tokens
│
├──
Tool:
entity_search()
|
0.
3s
│
└──
Retrieval:
kb_lookup
|
6
chunks
├──
Span:
Fact
Checker
|
3.
1s
|
$0.15
|
WARN:
partial
validation
│
├──
Generation:
claude-3.5
|
3
,201
tokens
│
└──
Tool:
verify_facts()
|
0.
8s
├──
Span:
Summarizer
|
3.
8s
|
$0.18
|
propagated
error
└──
Span:
Quality
Reviewer
|
1.
5s
|
$0.03
|
false
positive
(0.87
score)

- Generation: An LLM call with its prompt, completion, model, token count, and cost
- Tool call: An external function invocation with its input and output
- Retrieval: A vector search or knowledge base lookup with its query and results
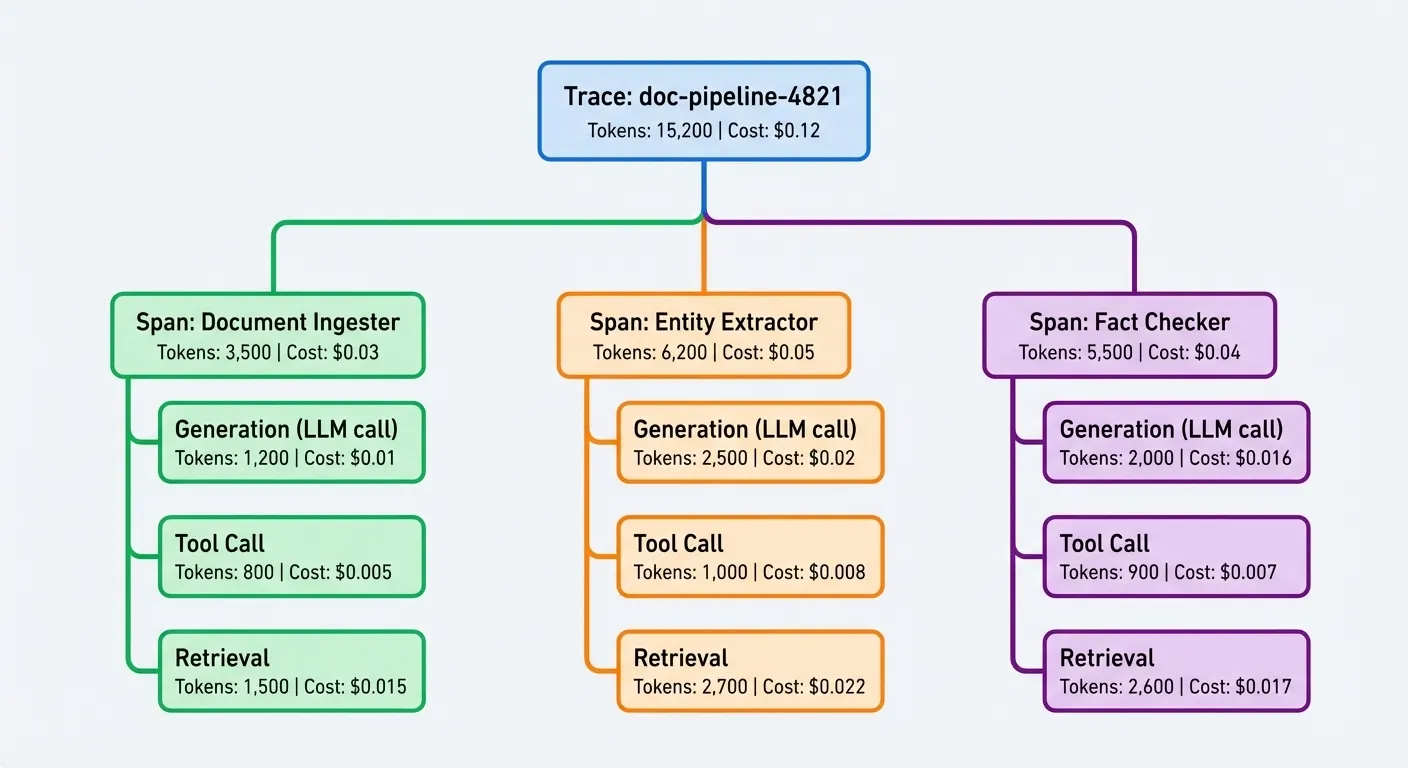 Trace Tree Visualization
Trace Tree Visualization
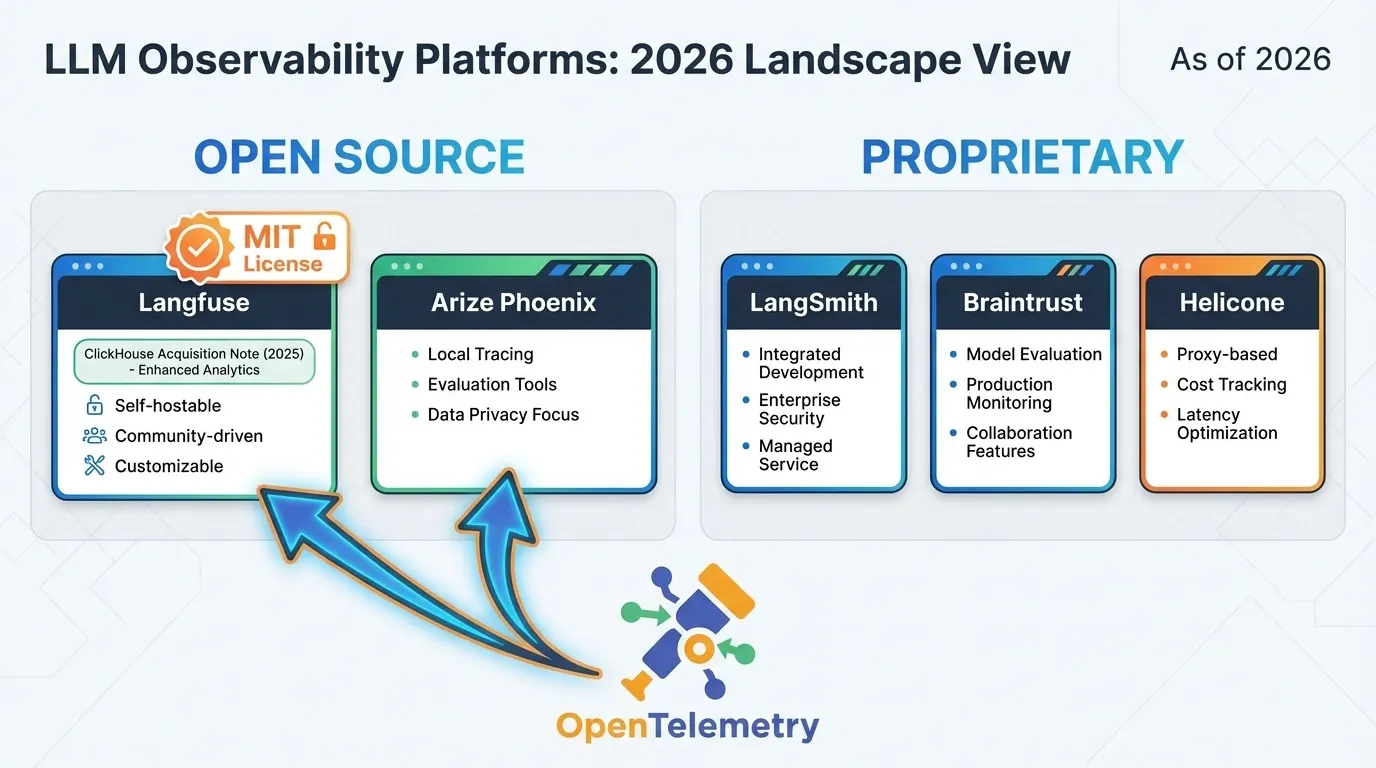 Observability Platform Comparison
Observability Platform Comparison
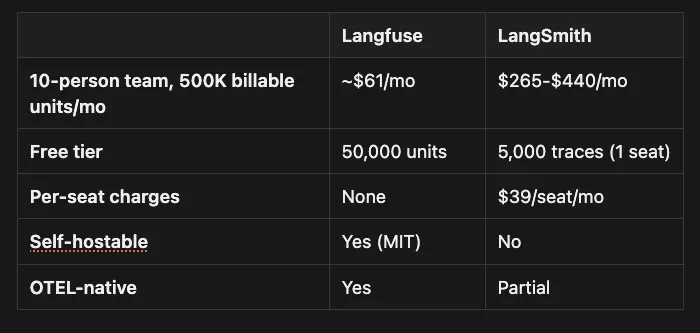
-
Multi-agent systems need traces, not logs. Log lines are flat; agent execution is hierarchical. Traces capture the causal relationships that logs miss.
-
Failures in agent pipelines are emergent, not local. A single agent can perform correctly in isolation while contributing to a system-level failure.
-
OpenTelemetry is converging as the standard for AI telemetry. Invest in OTEL-compatible tooling to avoid vendor lock-in.
-
Langfuse is the open-source, framework-agnostic choice for LLM observability. MIT-licensed, self-hostable, and now backed by ClickHouse’s $15 billion platform.
-
Agent observability is infrastructure, not a feature. We are in 2014 for agent monitoring. The teams that instrument early win.
-
Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
-
CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
-
CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
-
CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
-
The $9 Disaster: What Anthropic’s Harness Design Paper Teaches Us About Building Autonomous AI
-
Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
-
LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
-
Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
-
LangChain’s Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
-
Anthropic’s Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
-
OpenAI’s Harness Engineering Experiment: Zero Manually-Written Code