Your Mandate: AI-First Company in 90 Days: A Lead AI Architect's Playbook for Turning Every Employee Into a Force Multiplier
A 90-day roadmap to turn every employee into an AI-powered force multiplier
Originally published on Medium.
Part 2 of 2. If you haven't read Part 1 yet, start there. It defines the AI-First company and the VisiCalc analogy this playbook assumes. This piece is about how to actually become an AI-First company in 90 days.

The Mandate Reframe
You just took the job.
Head of AI.
Chief Innovation Officer.
VP of AI Platform.
Director of AI Transformation.
The title varies from company to company. The situation does not.
Friday, the CEO posted on LinkedIn that you are joining to "lead our AI transformation." By Monday, the congratulatory DMs are still rolling in, and you have not written a line of code for the company yet.
Half the engineering team already expects you to hand them a 12-month roadmap by the end of the quarter.
The marketing team wants a chatbot.
The CFO wants a cost-saving story for the next board meeting.
The VP of Engineering wants you to leave their team alone.
The CEO wants the LinkedIn post to have been true in the way investors read it.
So what is the job?
Here is what your CEO thinks you are going to do. Make the dev team ship faster. Put a chat window in the product. Hire a few ML engineers. Show up at the next board meeting with a slide deck that includes the word "copilot" and the phrase "strategic AI capability."
Here is what you should actually do, and what will get you fired in 18 months if you do not do.
You may have been hired as Head of AI, Chief Innovation Officer, or VP of AI Platform. But the job underneath the title is the same: Chief Multiplier.
But the job underneath the title is the same: Chief Multiplier.
Your mandate is not to make 80 developers ship 30 percent faster. That work matters, and you will do it, but it is a tenth of your job. Your real mandate is to turn every computer-touching employee in the company into a force multiplier. Sales. Marketing. Finance. Customer Success. Operations. The people in the warehouse generating inspection reports. The accounts-payable clerk classifying invoices. The recruiter writing a JD for the fifth time this month.
The mandate is to turn every computer-touching employee in the company into a force multiplier.
Sales.
Marketing.
Finance.
Customer Success.
Operations.
Every one of them spends their working hours in front of a screen, moving information between systems, writing the same thing in slightly different formats, making decisions that could be templated. Every one of them, with the right substrate underneath them, can become the operator of a small personal fleet of AI agents. One person plus 100 agents. That is the AI-First organization.
If you did not read Part 1, here is the VisiCalc moment in one paragraph: AI puts creation power directly into the hands of domain experts. Companies that embrace this will be AI-First companies. The point is not "AI for engineers." The point is "AI turns every computer-using employee into a solutions and innovations builder." If someone can run a business process in a spreadsheet, a CRM, a ticket queue, or an inventory system, they can use AI to automate parts of it, generate better options, and prototype new products and services, without waiting in line for engineering.
AI turns every computer-using employee into a solutions and innovations builder.
That is the VisiCalc moment Part 1 described, arriving at your company in the form of a hiring offer letter you just signed.
Your KPI is not model-eval scores. It is not commits per day. It is not "number of AI features shipped." Those are fine operational metrics for the engineering stream, but they are a tenth of the scorecard.
Your KPI is whole-company capability lift: more output, more innovation, faster learning, better customer experience, and eventually higher revenue per employee. If your engineering team is 30 percent faster but sales is still building custom decks by hand and finance is still closing the books the same way they did in 2022, the mandate collapses: you just happen to collapse slowly enough that the board does not act yet.
The only KPIs that matter is capability lift: more output, more innovation, faster learning, better customer experience, and higher revenue per employee.
Part 1 of this series made the case for why AI-First means company-wide democratization. This piece is about how you execute it in 90 days. Three parallel streams. Three 30-day phases. A dashboard you can present to the board on day 90 that survives the first three questions they ask.
You have 90 days to start a flywheel. Let us begin.
The Ownership Principle
The fastest way to kill an AI transformation is to make it feel like something being done to people.
The fastest way to make it work is to make people the authors of their own leverage.
If they own the innovation, it will succeed. Ownership is the key to motivation.
Management should facilitate the rooms, provide examples, remove blockers, and create the platform. But the ideas have to come from the people doing the work. When a finance analyst designs the close checklist agent, they own it. When a warehouse manager co-designs the inspection workflow, they defend it. When a sales rep builds the first customer-specific deck generator, the sales team believes it faster than if the AI team had delivered it from above.
Management facilitates: But the ideas have to come from the people doing the work. The domain experts. The SMEs.
IT and the development should support this sort of innovation.
People support what they help create. AI-First transformation is not a rollout. It is a transfer of creative power.
Startup vs. Established Company
This transformation is easier in a startup because you can design the operating model from day one. It is harder in an established company, but established companies have more data, more workflows, more institutional knowledge, and more leverage once the flywheel starts turning. The playbook is the same -- the pacing and politics differ.
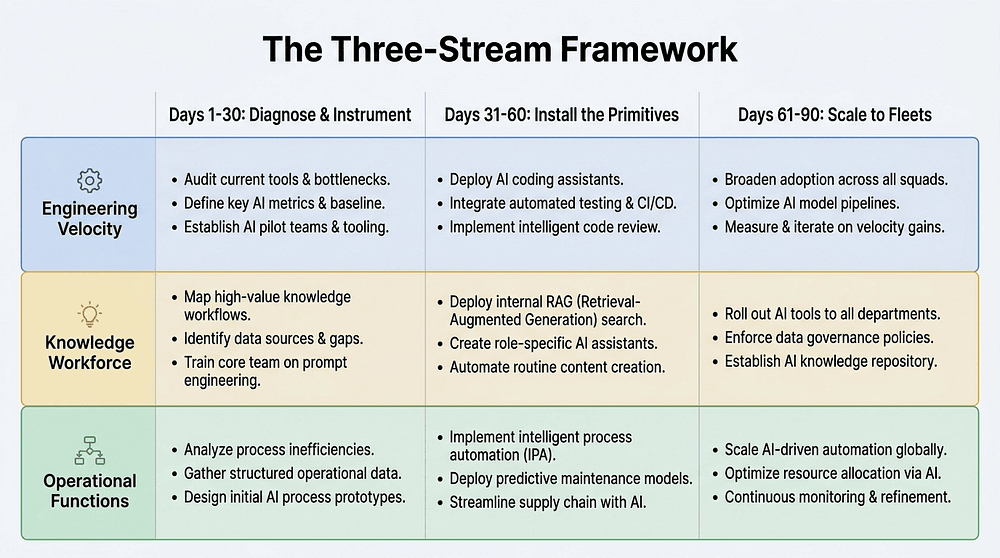
The Three-Stream Framework
The number one mistake a new Head of AI makes in their first quarter? Running their streams in series instead of in parallel. They spend the first 60 days getting engineering to AI-First shipping cadence, planning to "get to the business" in month three. They never get to the business. The transformation stalls. Or worse, they become a VPE in a different hat, and the company keeps paying Salesforce 1.4 million dollars a year for a CRM the sales team hates because nobody ever had the bandwidth to do anything about it.
Three streams. From day one. Running side by side.
Stream 1: Engineering Velocity. Get the dev team to AI-First shipping cadence. Collapse quarterly releases into weekly ones. Deploy MCP connections to the data sources engineers reach for ten times a day. Strip scaffolding debt left over from the era of weaker models (all that retry logic, all those manual to-do lists, all the prompt-engineering spaghetti written when models could not hold a plan in their head). Start running multi-agent fleets in production for code review, on-call triage, and documentation. This is the stream you were hired for. It is also the one your team can partially run without you.
Stream 2: Knowledge Workforce. Deploy AI leverage to the functions where most of your company's labor actually happens. Marketing, sales, operations, finance, HR, customer success, legal, people. These are the teams that will never hire an AI engineer of their own. They need you to bring the substrate to them. This is the stream where most architects have no playbook, and also the stream that will deliver the board-visible revenue lift within 90 days. Treat it accordingly.
Stream 3: Operational Functions. Automate the computer-touching workflows in the functions that sit outside the traditional knowledge-work bucket. Warehouse inventory reconciliation. Logistics route planning. Vendor invoice processing. Returns triage. Quality inspection documentation. Accounts-payable classification. These are the teams that have been handed the world's worst SaaS tools for a decade and made them work through sheer persistence. They will be your fiercest advocates once they see what is possible.
Three things about running these in parallel that most architects get wrong.
First, the three streams are co-equal. This is the thesis from Part 1 operationalized. If your word count in any planning document is 80 percent engineering and 20 percent everything else, you have drifted from the thesis. In this playbook, the Knowledge Workforce stream is the longest section by design, because that is where most Heads of AI have no reference material and the political lift is highest. Treat it that way internally too. When you hold your weekly stream review, the workforce stream deserves the same airtime as engineering, not a five-minute tail slot.
Second, the political window closes at day 60. The board and the CEO hired you on a vision. They will give you a free pass for the first 60 days while you "listen and learn." On day 61, the question "what have you shipped?" arrives, and if your answer is "we are still diagnosing," your runway is shorter than you think. Running all three streams in parallel means that by day 60 you have visible output from each stream. Not polished output. Visible output. A working code-review agent in engineering. Eight function workshops run with working automations in hand. Two operational pilots live with measured lift.
Third, you cannot run three streams alone. By end of week 2 you need a first lieutenant for each stream, even if it is informal. You need champions and ambassadors. An engineering manager who will own the Engineering Velocity stream while you orbit it. A Chief of Staff or Business Operations lead who will co-own the Knowledge Workforce stream with you. A frontline operations manager who will co-own the Operational Functions pilot. These people already exist inside your company. Your job in Phase 1 is to identify them and make them co-conspirators. If you try to run three streams personally, by week 8 you will be the bottleneck on all three, and the flywheel will never leave the starting line.
Run three streams. In parallel. With three co-owners. For 90 days.
Phase 1, Days 1 to 30: Diagnose and Instrument
The first 30 days are listening-and-measuring days. You will be tempted to ship something. Do not. Every piece of code you ship in month one is a piece of code written without the data you need to ship it well. This is the one month where your job is to be boring. You measure. You map. You meet people. You take notes.
The output of Phase 1 is not shipped software. It is a set of artifacts that let you defend every decision you make in Phase 2 and Phase 3 when the politics get hard. Without these artifacts, your Phase 2 decisions look like guesses. With them, every decision has a line of reasoning that traces back to an interview note, a baseline number, or a heatmap cell.
Engineering Velocity stream in Phase 1
Your first week on the engineering stream is baseline week. You need numbers, and you need them before anyone has had a chance to change behavior because they know you are watching.
Pull the git history. Baseline commits per engineer per day. Median and p90 PR cycle time. Median time from Jira ticket open to production deploy. Deploy frequency. Revert rate. Incident rate. If you have 80 engineers, you should have a one-page dashboard of current engineering velocity by end of week 1. Share it with the VPE privately, not publicly. It is a baseline, not a performance review.
Then do the AI-tool license audit. How many GitHub Copilot seats did your company buy, and how many are actually being used weekly? Same question for usage of current frontier models and tools from Anthropic, OpenAI, Google, and others: plus Cursor, Windsurf, Claude Max subscriptions, and any other tool in the stack. The number that will surprise you? It is almost never above 50 percent. Companies buy site licenses and then never operationalize them. Those unused seats are the cheapest win you will get this quarter. Activating them in Phase 2 costs nothing and moves the weekly-active AI usage number you will report in the day-90 scorecard.
Weeks 2 and 3 are scaffolding-debt weeks. Sit with your most senior engineers and walk through the codebase. Ask them to identify every feature that was built as a workaround for a weaker model. Manual to-do lists the LLM cannot maintain on its own. Heavy system prompts that try to constrain hallucinations. Retry logic built around a model that used to return malformed JSON. Extract-then-reformat pipelines that a current-generation model handles in one call. Custom chunking heuristics that pre-date long-context models. Prompt-engineering spaghetti written to squeeze the last 5 percent of reliability out of a model that is now two generations old.
Produce the Scaffolding Debt Inventory. A spreadsheet. Keep it simple. Columns: feature name, model-era it was built for, estimated lines of code, estimated maintenance cost per quarter, candidate for stripping in Phase 2, engineer who will own the stripping PR. By week 4 this document should have 20 to 40 line items in it.
By week 4, pick two engineering pilots you will announce in the all-hands. High visibility, high probability of success, short enough to demo by day 60. Do not pick three. Two is a forcing function. My default pair for most companies: a code-review agent running on every PR, and an on-call triage agent that summarizes incident context and drafts the first pass of a root-cause hypothesis. Both deliver visible value to every engineer on day one of Phase 2. Both use patterns Anthropic and other AI-First companies have already proved out, so you are not taking novel technical risk on your first public commitment.
The political move for the engineering stream in month one: tell the VPE, in private, in your first one-on-one, that you are not here to rewrite their roadmap. You are here to give every engineer a force multiplier. Say it twice. Mean it. A VPE who believes this will be your strongest ally. A VPE who thinks you are here to annex engineering will spend the next 12 months knifing you in meetings you are not invited to. If the VPE is hostile from the start, that is a CEO conversation, not a quarter-two problem.
Knowledge Workforce stream in Phase 1
This is the stream where most new Heads of AI have no playbook. You are about to meet 15 to 20 people who have never been asked the questions you are about to ask, and their answers will shape the second and third streams more than anything the engineering baseline tells you.
Book 30-minute discovery interviews with function leads. Sales ops director. CMO. Head of customer success. Finance controller. Head of people. Head of legal. Head of procurement. General counsel. Office of the COO. A frontline sales AE who closes deals. A marketing manager who runs weekly campaigns. A finance analyst who does the month-end close. A customer success manager who runs QBRs. Seven function leads and eight or so individual contributors. Aim for 15 to 20 total conversations in weeks 1 through 3.
The interview protocol, which you can use verbatim:
- Walk me through your last full workweek, hour by hour. I do not need the calendar view. I need the 'what were you actually doing' view.
- What takes you 30 minutes today that should take 30 seconds?
- Where do you duplicate information? What do you rewrite in a second format, a third format, a fourth format?
- What do you dread on your calendar?
- Who on your team is already using ChatGPT, Claude, Perplexity, or something similar on the side to get their work done?
Take notes by hand or have a notetaker capture them. Do not promise anything. Do not pitch Claude Desktop or Copilot Studio. Do not say "we are going to automate that." You are in listening mode. You are a journalist on a beat. The more you talk in these interviews, the less you learn. A good discovery interview has the function lead talking 80 percent of the time and you talking 20.
By end of week 3, synthesize the interviews into the Friction Heatmap. For each function, list the top 5 highest-friction computer workflows, ranked by hours per week burned across the team. A healthy heatmap has at least one workflow per function that is consuming 15 or more hours a week of team time. If you cannot find one, you did not dig deep enough in the interview. Go back. Ask again.
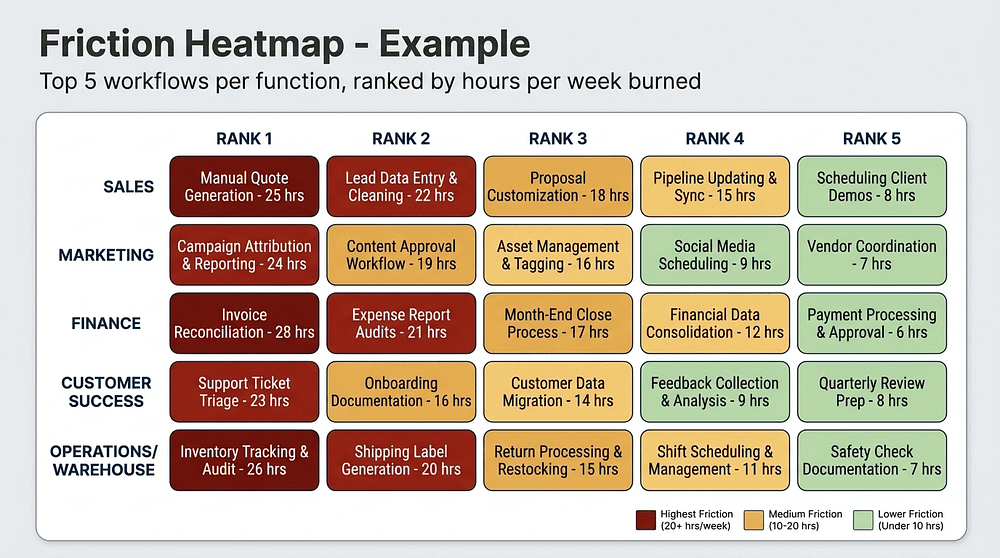
While you are building the heatmap, also build the Pilot Champion list. One name per function. The person who, when you asked "who on your team is already using ChatGPT on the side," came up with three specific examples. They already believe. Your job is to make them the internal dealer in their function during Phase 2. Invite them to coffee in week 3. Tell them explicitly that they are going to be your Champion. Some will be thrilled. A few will be nervous because they have been doing this quietly and now you are making it official. Reassure them. Give them air cover with their manager.
Last artifact for the workforce stream in Phase 1: the Workflow and SaaS Leverage Inventory. Pull the company credit card statement and the procurement contract list. List every major SaaS product the company pays for, by function, with annual spend, renewal date, and the workflows it supports. This is not a "SaaS retirement plan." It is a leverage map.
Your goal is to extend what works and retire workflows only when the AI-native version clearly creates more value. Sometimes that means replacing a tool at renewal. More often it means building AI workflows around the systems you already have.
The political move for the workforce stream in month one: do not promise anything in the discovery interviews. Listen, document, thank them. Function leads have been pitched by consultants for 15 years. The novelty of being listened to without an ask is how you build your coalition. In week 4, when you send every interviewee a one-page summary of what you heard and what you are committing to in Phase 2, that is when you cash the trust.
Operational Functions stream in Phase 1
The operational stream is the one most Heads of AI skip, and the one that most predictably delivers board-visible capability lift in the first 90 days.
In week 1, map the operational teams. Every company has them.
Warehouse and fulfillment.
Logistics.
Vendor management.
Quality.
Field service.
Back-office processing.
Compliance ops.
Data entry and annotation teams.
Accounts payable.
Returns and refunds.
Factory operations.
Farm operations.
Anywhere the work happens in front of a screen but has not traditionally been called "knowledge work." In many companies these teams sit under the COO, not under any function leader you already scheduled in the Knowledge Workforce stream. You need a second lap of scheduling here, specifically through the ops org chart.
In week 2, pick 2 pilot teams. One should have visible pain, an operational leader who has been loudly asking for help, a process that is obviously broken. The other should have quiet but measurable waste. Nobody is complaining, the process works, but the team is spending 200 hours a week on something an agent could handle in 5. Two pilots because you want one "hero story" for the narrative and one "ROI story" for the board. The hero story is what gets the CEO excited. The ROI story is what gets the CFO to defend you in the Q2 budget cycle.
In weeks 3 and 4, baseline the time trapped in each pilot workflow using the simple formula every operations leader already believes:
time-per-task x tasks-per-week = hours-per-week consumed
If you want to translate that into dollars later, you can multiply by loaded cost. But do not lead with "labor reduction." Lead with time returned to the business; and where it will be reinvested: innovation, training, collaboration, better planning, new products, and better customer service.
A worked example for a returns-triage workflow: 12 minutes per task x 400 tasks per week = 80 hours per week. You need this baseline before you intervene. Without it, Phase 2 success becomes an anecdote. With it, you have a defensible before/after story.
The political move for the operations stream: build the relationship with the frontline managers, not just the directors. The ops director will sign the pilot memo. The shift manager is who will make the pilot work or quietly kill it. Go to the warehouse. Go to the back-office floor. Shake hands. Ask what is broken. Come back with coffee next week. Managers who have been running the same process for eight years do not trust new executive hires by default. You earn trust by showing up in person more than once, in the place where the work happens.
Before you leave Phase 1, get written sign-off from the operational director on both pilots. An email will do. Preserve it. In week 7, when somebody senior asks "who approved this?" you want to be able to forward that email without hesitation.
Phase 2, Days 31 to 60: Install the Primitives
Phase 2 is the shift from listening to shipping. Every stream has to produce visible output by day 60 or your political capital evaporates. This is also the month the pattern of the transformation becomes legible to the rest of the company, and the month where adoption either catches or stalls. More of your calendar this month belongs to the workforce and operations streams than the engineering stream. Resist the pull of engineering gravity. You hired a manager for that.
Phase 2 is also the month the narrative solidifies. A story takes shape in the all-hands, in the Slack channel that just went live, in the hallway conversations. If that story is "we are making the dev team faster," you have already lost the quarter. If that story is "every function just got a force multiplier," you are on track. Every artifact you ship in Phase 2 reinforces the story you want told. Every artifact you neglect reinforces the story you do not want told.
Here is what shipping looks like in each stream during month two.
Engineering Velocity stream in Phase 2
Stand up the Evergreen Launch Room in week 5. One dedicated Slack channel. One Monday synthesis ritual, 20 minutes, where the engineering stream owner posts a bulleted summary of what shipped last week, what is internally validated and ready for external launch, and what is about to land. Marketing, docs, and DevRel join the channel as reactive consumers. They turn engineering posts into public-facing artifacts within 24 hours. No more weeks of launch coordination. No more handoff meetings. The channel is the coordination.
The Launch Room is more than a channel. It is a cadence shift. In the old model, shipping required weeks of orchestration across PM, engineering, marketing, and DevRel (with a kickoff, a docs review, a legal review, an enablement rehearsal, and a go/no-go meeting you remember fondly). In the AI-First model, shipping is continuous, and the marketing and docs functions operate on pull, not push. Engineers post. Docs responds within a day. Marketing reacts when the feature is internally antfooded. The Launch Room collapses three weeks of traditional launch coordination into three days of reactive response.
Deploy MCP connections to the 5 most-referenced internal data sources. Your defaults if you are deciding cold: the CRM (Salesforce or HubSpot), product analytics (Amplitude, Mixpanel, or equivalent), the documentation corpus (Notion, Confluence, Google Drive), the ticketing system (Jira, Linear, or Zendesk for support), and code search (GitHub, GitLab, etc.). Each MCP server is a write-up, a config, a read-only token in the right vault, and a post in the Launch Room announcing it is live. These 5 connections unlock 80 percent of the workforce stream's Phase 2 automations. Prioritize them. Every hour you spend on MCP deployment in Phase 2 returns 20 hours of workforce-stream enablement in Phase 3. Or go simpler, create a nightly job that dumps CSV files to an S3 bucket that they have access to. The point is provide the data they need to innovate.
Ship 1 to 2 research-preview features with daily visible progress. The two I pre-scoped in Phase 1 (code-review agent, on-call triage agent) are good defaults, but your pilot choices stand. Ship them as research previews. Label them as experimental, communicate that they may not be supported forever, and trade the long-term commitment for speed. The daily cadence is the point. If your research-preview feature does not have a visible change every working day of Phase 2, it is not a research preview, it is a hidden project.
Begin stripping scaffolding. Your Scaffolding Debt Inventory from Phase 1 gets actioned. Each stripping is a small PR, a short Slack post, and a line in the Scaffolding Deletion Log. By day 60 you want 6 to 10 features retired. Frame every deletion as technical-debt reduction, not as "the team was wrong to build this." The engineers who wrote the original feature should be the ones celebrating the deletion. Their name goes on the PR. Their story goes in the post. "We built this crutch for last year's models. Today's frontier models handle it natively. Killing 600 lines of prompt-engineering spaghetti." Everyone wins. The feature shrinks. The engineer looks forward-thinking. Teach development team about Agent Skills and Subagents to automate work in an LLM efficient manner.
Knowledge Workforce stream in Phase 2
This is the biggest stream in Phase 2 and the one that determines whether you get to Phase 3 at all.
The Internal FDE Layer
By week 5, you will see the same pattern across every function: people have ideas and early wins from workshops, but they hit a wall when translating those ideas into durable workflows.
This is where an internal Forward Deployed Engineering (FDE) layer becomes critical.
FDEs are embedded operators who sit between the AI platform and the business functions. They are not pure engineers, nor are they pure operators. They are translators, systems experts, architects, SMEs and builders. Often they come in pairs, one more focused on the business domain, and the other more focused on the integration, architecture and systems.
Their role is simple:
- Sit with a function and understand the workflow at a detailed level
- Translate that workflow into an AI-native pattern using MCP, agents, and internal tools
- Build the first version quickly, in partnership with the domain expert as both a mentor and co-worker
- Hand ownership back to the function, not keep it
Think of them as force multipliers for the Champions. The Champion identifies the opportunity. The FDE helps turn it into a working system in days instead of weeks.
Without this layer, the transformation stalls at the ideation stage. With it, ideas become tools, tools become patterns, and patterns become fleets.
A rough ratio that works in practice:
- 1 FDE per 2-3 functions in Phase 2
- Expanding to 1 per function (or per major domain) as the program scales
If you can only make one hire in Phase 2, make this one.
Enablement workshops
Run enablement workshops, by function, two per week for four weeks. Eight functions covered by day 60. The principle is constant: management facilitates the room. The people doing the work own the ideas. Each workshop is 90 minutes, with a format that works:
- 15 minutes of concept. What AI can do for this function today, in specific examples pulled from the Friction Heatmap for their team. Not a deck about LLMs. A walkthrough of three concrete problems from their interview notes, with live demos of how Claude, ChatGPT, Perplexity, Gemini, or the company's internal agent platform solves them.
- 45 minutes hands-on. Every participant brings one task from their actual backlog. You and a teammate walk around, pair with each person, and help them build a working automation for that specific task using an assistant, an internal agent, or an MCP-backed query. Every participant leaves with a working tool they authored.
- 30 minutes Q&A and show-and-tell. Participants demo what they built. This is where the workshop actually converts the believers. Seeing a peer get a working automation in 45 minutes is a more effective pitch than any CEO memo.
Workshop scheduling matters. Do the sales workshop first. Sales is the function most directly connected to revenue, and a sales-team success story travels faster through the company than a finance-team success story. Go finance second because the CFO is about to ask for ROI evidence. Then marketing, customer success, operations, HR, legal, people. If you have a product team adjacent to engineering, consider them a ninth function. Product managers sit in the most awkward spot in an AI-First transformation, and a dedicated PM workshop on "model-product fit" and how to strip PRDs down to prototypes is worth the extra session.
Sales is directly connected to revenue. The sales-team success story travels fast.
Provide the training in Claude Desktop, Cowork, Office Copilot, Google Workspace studio/GEMS or whatever tools you have adopted. Give the domain expert tools to do innovation. Empower them. In the workshops they learn what they do not know. Give them the tools to know.
Personalized Work Software library
Build the Personalized Work Software library (PWS library). One internal directory, accessible to everyone, where anyone who builds a useful tool can share it. Start with 3 to 5 seed examples built by you and your small team before the first workshop:
- A sales deck automator that pulls from the CRM and Gong via MCP connections, drafts a customer-specific deck in seconds. This one has been built at Anthropic and elsewhere. The pattern is public. Copy it.
- A marketing content variant generator that takes one piece of copy and produces 8 versions for different audiences, channels, and stages of funnel.
- A finance close-checklist agent that walks the controller through month-end with context from the general ledger and vendor invoices.
- A customer success renewal-risk scorer that reads ticket history, usage data, and call transcripts and flags accounts at risk before the human CSM would catch them.
- An HR JD rewriter that takes an old job description and modernizes it against recent hires in the same role and against the company's tone-of-voice guide.
Every workshop adds 5 to 10 tools to the library. By day 60 the library has 40 to 60 tools in it. Post the growth metric weekly in the Launch Room.
Identify the function AI Champions
Identify the function AI Champions. These are the Pilot Champions from Phase 1 plus the ICs who leaned in hardest during the workshops. By end of Phase 2, you want one named Champion per function. Give them a title. Give them 10 percent of their week officially dedicated to helping their function adopt AI. Give them a small recognition budget, a couple hundred dollars each to spend on gifts or meals to celebrate their function's early adopters. They are the force multipliers inside the force multipliers. Without them, your Phase 3 workforce-wide rollout plan is a deck. With them, it is a movement.
Extend or retire 1 to 2 SaaS-dependent workflows. The goal is not to kill SaaS. The goal is to create more business value than the old workflow created. Sometimes that means replacing a tool. More often it means building AI workflows around the systems you already have: CRM, docs, ticketing, finance -- and letting the value compound.
Start the Antfooding channel in Slack. Persistent, company-wide, feedback-only. Anyone can share what worked, what did not, what they built, what they wish existed. Its job is to surface bottom-up signal that the workshops alone cannot generate. Watch it every morning. The first 50 posts are the ones that tell you where the next wave of enablement needs to go. The 51st and beyond are the signal that the culture is starting to shift.
The political move for the workforce stream in Phase 2: do not pitch this as a cost-cutting program. Pitch it as capability expansion. The CFO will find the SaaS savings in the data. Your story is "every employee just got a team of 100 agents." The moment this becomes a headcount-reduction story, adoption dies. People hide their AI usage. Champions go quiet. The flywheel seizes.
Operational Functions stream in Phase 2
Ship the 2 pilots you scoped in Phase 1. Non-negotiable rule: co-design with the operators, not impose from above. The operator knows their workflow. You bring the AI plumbing. Your deal with each pilot team: you spend 5 days embedded with them, you build the first version together, you iterate weekly.
Example pattern for a returns-triage automation. The operator describes the decision tree. Does the item qualify for a refund, a replacement, or a partial credit? They have been doing this for years and have the intuition. You implement that decision tree as an agent with access to the order history, the product catalog, and the returns policy document via MCP. The agent drafts a response. The operator reviews and approves or edits. Over two weeks, the agent's suggestions get good enough that the operator is approving 80 percent of them without edits. The 20 percent that need edits are the signal for where the agent needs tuning. The operator is now doing the work of three people, in half the time, with the same accuracy.
Measure lift on every pilot, weekly. Three metrics:
- Hours saved per week. Use the Phase 1 baseline and compare.
- Error rate change. Pull a sample of pre-pilot decisions and post-pilot decisions. Have an independent reviewer (another operator, not the team that built the pilot) rate them blind. Blinding matters. The team that built the agent cannot be the team that evaluates it.
- Human Intervention Rate. What percent of agent outputs required edit or override by the operator? This is the metric that separates "full automation" from "augmented operations." A 20 percent intervention rate is healthy for most workflows in Phase 2; a 5 percent rate by Phase 3 is the stretch target.
- Worker-reported satisfaction. One-question survey after each shift: "On a scale of 1 to 10, how much is this helping?" Post weekly.
Document the pattern in a one-pager per pilot. Problem, decision tree, agent architecture, MCP connections used, human-in-the-loop checkpoints, metrics. This one-pager is what stream 3 uses in Phase 3 to scale. It is also what you hand to the next operational director who sees the first pilot working and asks "can we do that?"
If headcount allows, hire an AI Operator Enablement person in Phase 2. Job description sketch: someone with operational background (ex-warehouse manager, ex-ops analyst, ex-call-center team lead) with enough technical literacy to build simple MCP-backed agents, agent skills, GEMs, routines, prompts (depending on their stack), and enough people skills to translate between frontline operators and your AI engineers. This role is new in the market. You will be hiring against a job description nobody has written. Write it. The role pays back within 90 days because the alternative is you personally embedding with every operations team, and that does not scale past three pilots.
The political move for the operations stream in Phase 2: when you present pilot results at the exec review in week 8, bring the frontline operator to present, not yourself. Not the director. The operator. Let them tell the exec team what changed for their shift. Every exec in the room immediately understands what is possible. Every other function lead immediately wants this for their team. That is the multiplier story, live, in 15 minutes. The conference room hums differently when a warehouse shift lead in a polo shirt tells the CEO that a model gave her team back 22 hours a week and her people are using those hours to coach newer hires. No slide deck reproduces that.
Phase 3, Days 61 to 90: Scale to Fleets
Phase 3 is where the flywheel starts turning. If Phases 1 and 2 went well, adoption is now pulling you forward faster than you can push. Your calendar is booked by function leads who want their own workshop. Engineers are shipping fleet features because that is where the leverage is, not because you told them to. Operations is getting calls from adjacent teams asking when they can be next. You have a good problem: more demand than capacity. This is the month you learn to scale without losing what you built.
Your job in Phase 3 is to scale without losing what you built. That means three things. Harden the engineering fleets and move them from experiments to production. Expand workforce adoption from early adopters to function-wide coverage. Roll out the operations pattern to 3 to 5 additional teams. And prepare the day-90 accountability moment.
Engineering Velocity stream in Phase 3
Multi-agent fleet workflows move from experiments to production. The pilots from Phase 2 harden. The code-review agent is now mandatory on every PR, not an optional review. The on-call triage agent is the first responder on every incident, with a human verification layer. Add a documentation agent that keeps your internal docs in sync with code changes, and an agent that maintains the PWS library's searchable index.
Publish the Build-on-the-Edge roadmap. Frontier model providers drop new capabilities on a roughly 3 to 6 month cadence. Your roadmap lists the 3 to 5 agent products that are "almost good enough" today, where you are investing in the harness now so that when the next model jump lands, you can swap in the new intelligence and the feature becomes production-grade overnight. Do not wait for model readiness. Build the harness now, let the model catch up, swap it in.
Institute the Antfooding Gate for engineering. Every feature used externally must be used internally for a full working week first. If the team cannot use it for real work, customers cannot. Make this a written gate in your launch process. Violating it is the only engineering policy violation that stops a launch. When a PM pushes back on the gate because a customer is waiting, hold the line. Shipping broken capability to a customer costs more than a week of delay.
Artifacts by day 90: Fleet Operations Runbook, the Edge Roadmap, the Antfooding Gate policy, an updated Scaffolding Deletion Log (12+ features retired by day 90), and the next quarter's engineering stream plan. Hand these to the VPE and your engineering-stream lieutenant before the board meeting. They should be the ones presenting engineering results. You are a strategic coach at this point, not a scrum master.
Knowledge Workforce stream in Phase 3
Run the second wave of enablement. By now each function has a Champion and 3 to 5 early adopters. Function-wide adoption is the target. Ship a workshop per function that assumes the Champion runs it, not you. You are now a coach for the Champions, not the enabler for every employee. This is a delegation moment. Some Champions will nail it. Some will struggle. The ones who struggle need you in the back of the room for the first session, invisible, supporting them when they get stuck.
Weekly-active AI usage target by day 90: at least 60 percent of employees in every function. If you are below 40 percent in any function, your Champion strategy failed there and you have a Phase 4 problem to solve. Diagnose early. Three failure modes are common. The Champion does not actually have peer influence. The function lead quietly opposes. The tools require too much technical setup for non-technical users. Each has a different fix.
Update the hiring filter. Every new hire, in every function, now screens for AI fluency, AGI-pilled mindset, and product taste. Give the hiring managers actual interview questions:
- Show me a workflow you automated in the last month. Walk me through how you built it.
- What task at your last job did you wish an agent could do, and why did you not build it?
- What is a current model weakness you work around today? What changes when the next model lands?
- What is a SaaS tool you think your last company should have retired, and what would replace it?
- Describe a time you used Claude or ChatGPT and got a bad answer. What did you do next?
A candidate who cannot answer three of these five is probably not an AI-First hire. You are not looking for AI engineers in every function. You are looking for people who have internalized the multiplier mindset. The marketing manager who has never written a line of Python but has built three content automations on Claude with help from their data analyst friend? That is the hire. The marketing manager with 15 years of CMO experience who has never opened Claude? That is not.
Run the Cross-functional PWS Jam in week 11 or 12. Two days. Pair-programming across functions. Marketing with engineering. Sales with data. Ops with platform. Finance with anyone. The goal is to ship 10 to 15 new tools in 48 hours, each co-built by two functions that would not otherwise have worked together. The bonus effect is the cross-pollination. An engineer who pairs with a sales AE for two days leaves understanding the business in a way they never did before, and vice versa. Catered food helps. So does ending with live demos to the whole company on Friday afternoon. The demos are the commitment device. Nobody wants to stand up on Friday with nothing to show.
Extend or retire 0 to 3 SaaS-dependent workflows where it is obvious the AI-native workflow creates more value, and where renewal timing makes it practical. In most companies, the higher-leverage move is extending the tools you already have with AI, not rebuilding them.
Operational Functions stream in Phase 3
Take the two pilot patterns from Phase 2 and roll them out to 3 to 5 additional operational teams. The pattern is documented. The frontline operators from the Phase 2 pilots are now your rollout partners. Let them present to the new teams. The authority of a warehouse shift lead saying "this saved our team 20 hours a week" outranks any deck you can build.
Rollout sequence matters. Start with the operational team closest to the existing pilot, either organizationally (same director) or structurally (similar workflow pattern). That rollout will hit fewer surprises, confirm the pattern, and give the Operator Enablement hire (if you made it) a clean runway. Save the operational team with the most political resistance for later, after you have 3 successful rollouts under your belt.
Publish the metrics to the board. This is the accountability moment. Cost-per-task before and after, across every pilot and rollout. Error rate changes. Hours saved per team per week. If you did Phase 1 properly you have the baseline to justify every claim. Do not exaggerate. The numbers are remarkable enough without marketing spin. A 55 percent reduction in cost-per-task with a 30 percent drop in error rate is a number the board will quote to their other portfolio companies. You do not need 80 percent.
Identify the next wave of automation candidates. Go back to the Phase 1 discovery data. Which workflows survived the initial filter with 15+ hours per week burn but were not in the first two pilots? Those are your Q2 and Q3 roadmap. Share the list with the ops director. Let them pick the sequencing. The director knowing their sequencing matters more than you knowing the optimal sequence. They live with the consequences. You are leaving in 18 months.
Make the platform decision by day 90. Do you build an internal Operator AI Platform (a self-service MCP and agent-building UI for non-developers) or do you continue to build one-off solutions per team through Q2? The default for most mid-stage companies: one-offs through Q2, platform decision at the Q3 planning board. The exception: if by day 90 you have 8 or more operational pilots running with a shared pattern, the platform investment pays back faster than the one-offs. Write the one-page decision memo either way. Future you will thank present you when the Q3 planning session starts.
The Executive Scorecard: What Day 90 Looks Like
This is the dashboard you present to the CEO and the board on day 90. Five dimensions. One page. A CEO who cannot get the story of your first quarter from this one page will not remember the 20-slide deck. And honestly? If the story does not fit on one page, the story is not clear enough yet.
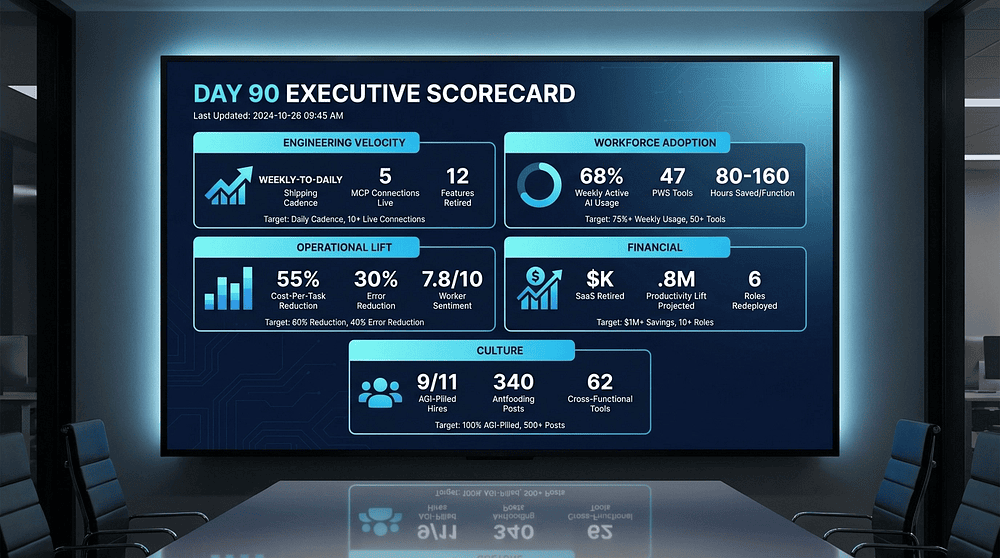
Engineering Velocity. Shipping cadence before and after (quarterly releases moved to weekly, with research previews landing daily). Number of active MCP connections in production (you want 5 by day 60 and 8 to 10 by day 90). Count of retired scaffolding features (12 to 20 is a respectable Q1 number). Median PR cycle time improvement (30 to 50 percent is realistic if you had 80 engineers to start). Include a note on the two research-preview features that shipped in Phase 2, what they did, what lift they produced for engineering itself.
Workforce Adoption. Percent of employees with weekly-active AI tool usage (target 60, stretch target 75). Number of Personalized Work Software tools in the library (40 to 80 by day 90 is respectable, north of 100 is exceptional). Hours saved per week per function (pick the top 5 functions and report the range, for example 80 to 160 hours per week saved across finance, sales, marketing, customer success, and operations). Count of Champions active across functions, one per function, ideally plus their named backup.
Operational Lift. Time-per-task and cost-per-task before and after, across pilot workflows (a 40 to 60 percent reduction is the realistic band for well-scoped pilots). Error rate change (should drop, not rise; if it is rising, your verification layer is inadequate and you need to fix that before rolling out further). Worker-reported sentiment (simple 1-to-10 score, monthly; target above 7). If sentiment is high but error rate is up, something is off. Workers like it because the agent is removing work, not because the agent is accurate. Investigate.
Financial. Revenue leverage and reinvestment capacity. Productivity-lift revenue projection (what incremental revenue does the time returned translate to, assuming freed hours get invested in higher-leverage work?). Be conservative. Cut your first-pass estimate in half, then present that. Growth capacity unlocked: work the company can now absorb without proportional headcount growth. Any SaaS savings should appear as a side benefit, not the headline.
Culture. AGI-pilled hires made in Q1, count of new hires who passed the updated hiring filter in every function. Antfooding channel activity (posts per week, engagement). Cross-functional tool shares in the PWS library. Number of function Champions active. This section is the most important and will be the one the board spends the least time on. They will not quote these metrics. They will quote the financial ones. But the cultural metrics are the leading indicators of whether the flywheel will still be turning in 18 months.
One pitfall to name here explicitly: do not present the financial section before the culture and adoption sections. If the first number the board sees is the SaaS savings, the conversation becomes a cost-cutting review and the multiplier thesis collapses. Lead with adoption. End with money.
Pitfalls: What Will Go Wrong (and How to Survive It)
Every pitfall in this section is predictable. Each one has happened to every Head of AI who has ever run a transformation of this scale. Being warned does not prevent them. Being warned shortens the recovery time from weeks to days.
1. You accidentally make AI sound like a layoff program. If the story becomes "cost savings" and "labor reduction," adoption dies. People stop sharing what they build. Rapid innovation stops. Champions go quiet. Shadow AI goes underground. The transformation stalls. Counter: lead with capability expansion and growth. Frame every win as time returned and capacity unlocked: reinvested into innovation, training, collaboration, better planning, new products, and better customer service.
Don't make AI sound like a layoff program. Rapid innovation stops. Champions go quiet. Shadow AI goes underground. The transformation stalls.
Frame every win as time returned and capacity unlocked: reinvested into innovation, training, collaboration, better planning, new products, and better customer service.
Focus on revenue growth and product innovation.
2. A function lead stonewalls you. Most likely the Head of Sales or the CMO. "We have our process. We do not need AI." The stonewalling is a status defense, not a technical argument. The function lead has spent 10 years optimizing their process and you are walking in with a claim that their process is about to become obsolete. Never mandate. Instead, find the one IC in that function who is already using ChatGPT on the side (your Phase 1 interviews identified them). Make them the internal dealer. When their peers see their output improve, the lead changes posture within 6 weeks. The workshop becomes a pull, not a push. The worst move? Escalating to the CEO. The stonewall function lead will remember it forever, and you will have won a fight you did not need to fight.
3. The engineering team resists stripping scaffolding. They built it. They are attached to it. "That retry logic is load-bearing." "That system prompt took me a week to tune." The scaffolding is their work, and retiring it feels like retiring their judgment. Counter: frame every stripping as technical-debt reduction, not as "this was built wrong." The engineer who built the original scaffolding should be the one running the retirement PR and collecting the credit. The framing is not "the model is smarter now." The framing is "we can simplify now." Give engineers credit for having built the right thing for the model generation they were on. The crutch was not a mistake. It was the correct choice for the model generation you were on. Today's frontier models handle more of it natively. That is a compliment to the model, not a correction to the engineer.
4. Your first agent fleet goes off the rails in production. A multi-agent workflow makes a mistake that costs money or customer trust. A renewal-risk agent misclassifies a healthy account as at-risk and a CS rep pulls an over-the-top intervention. An invoice-processing agent approves a duplicate payment. A code-review agent approves a PR that breaks production. This will happen. Counter: build verification layers before scale, not after. The pattern is that every agent action that costs money, affects a customer, or changes production state must have a human-in-the-loop checkpoint for the first 60 days of production, no exceptions. When the failure happens, run a blameless post-mortem. Document the fix publicly in the Launch Room. Do not abandon the pattern. An org that abandons the first agent fleet after the first public failure never deploys another one. An org that fixes it in a week builds organizational muscle you cannot buy. The first failure is also a trust milestone. Handle it well and the company trusts you more, not less.
5. The board asks for ROI before Phase 2 ends. They will. At the day-45 check-in, a board member will ask: "What is the revenue impact?" You have leading indicators, not lagging indicators. Counter: baseline early in Phase 1 exactly so you can present leading indicators credibly. Adoption percentages. Hours saved per pilot. SaaS seats unused. Workshop attendance and completion rates. Promise the lagging indicators at day 90. Commit to a quarterly revenue-per-employee review from Q2 onward. The board member asking the question is usually trying to reduce their own uncertainty, not trying to fail you. Give them a credible leading-indicator picture and a specific commit date for the lagging indicators, and the pressure lifts. Without the leading indicators, you are defensive. With them, you are the architect.
6. HR panics about layoffs. By week 3, HR will ask you privately: "Are we replacing people?" This is the hardest conversation in the quarter. Counter: you need a clear answer from the CEO before day 30. The honest answer in most companies is "we are using this to grow throughput without growing headcount proportionally." That is redeployment and hiring-pause, not layoffs. Say it out loud. Internal comms must reinforce it. If the CEO wants a layoff story, either convince them to reframe or do not take the job. The multiplier thesis dies the day the layoff memo goes out. Employees stop sharing their automations because they fear making themselves redundant. Champions go underground. The Antfooding channel dries up. The flywheel stops turning, and you will not get it started again in this company.
7. Shadow AI is a signal, not a failure. By day 45, teams are building their own AI workflows on their own credit cards. Your first instinct will be to shut this down. Counter: resist. Shadow AI is usually proof that people are trying to innovate. Your job is not to kill it. Your job is to make it visible, safe, and scalable.
Shadow AI is a signal, not a failure. Shadow AI is usually proof that people are trying to innovate. Don't kill it. Make it visible, safe, and scalable.
Set minimum guardrails and make them lightweight: approved providers, clear rules for PII/customer data, a simple way to register what exists (visibility), and logging requirements for sensitive data access. Encourage building; manage intelligently.
An eighth pitfall worth naming: the one you cannot predict. Every transformation has one failure mode nobody saw coming. A CEO who changes priorities mid-quarter. A regulatory change that locks down a data source. A sudden attrition wave in a critical function. A security incident that triggers a lockdown. Build slack into your plan. Do not commit to every artifact in this playbook. Commit to the streams. Deliver what reality lets you deliver. The playbook is a north star, not a contract.
Close: The Flywheel
The 90-day plan is not the end. It is the initial kinetic energy for a flywheel that compounds over 18 to 24 months.
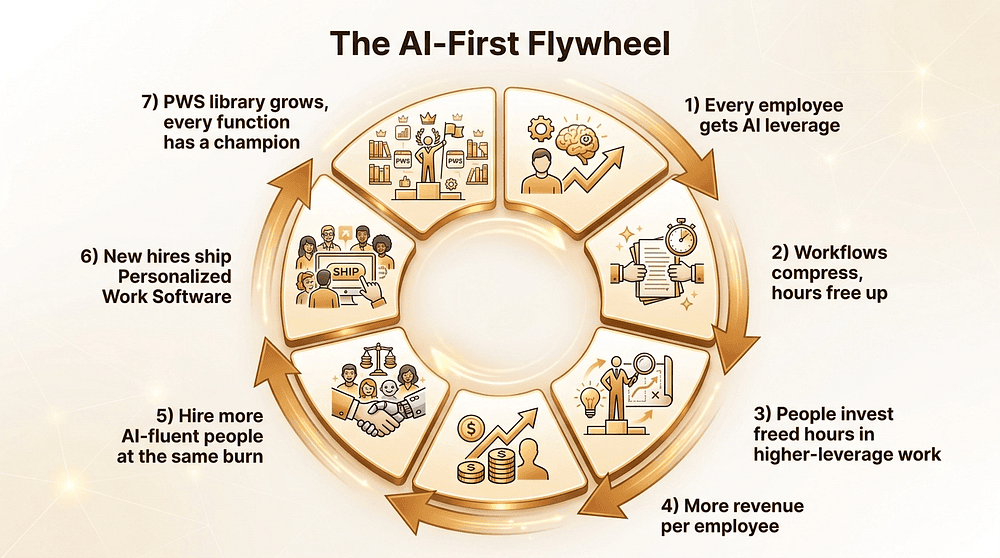
By day 90, the flywheel should be turning on its own momentum. Every new hire arrives AI-fluent, AGI-pilled, and ready to build. Every function has at least one Champion who is actively evangelizing. Every computer-touching employee is looking for their next automation to build. The PWS library is growing faster than any single team's contribution. The board is asking about Q2 expansion, not about Q1 ROI. The CFO is forwarding your Workflow and SaaS Leverage Inventory to other portfolio companies. Your calendar looks different than it did on day 1, because now the company is pulling the transformation forward instead of you pushing it.
Your measure of success is not whether you shipped everything in this plan. You will not. You will ship most of it. You will miss two or three pieces and you will discover five pieces that were more important than anything in the original plan.
Your measure of success is whether, 18 months from now, the company has structurally changed. A dramatically higher revenue-per-employee ratio. A visibly thinner SaaS stack. A culture that treats every employee as a potential software builder. A board that hires your peer in 2028 with the expectation that they will multiply the whole company, not just a team. A generation of managers across sales, ops, finance, and customer success who now intuitively know how to spec an agent, evaluate a model's fit to their workflow, and ship a custom tool without filing a ticket.
That is the AI-First company. That is what Part 1 described. And now, at day 90, you have started the flywheel.
Monday morning, you begin.
About the Author

Rick Hightower is a former Senior Distinguished Engineer at a fortune 100 focusing on delivering ML / AI insights to front line applications
Rick Hightower is a former Senior Director of Data Engineer at a fortune 100 fintech focusing on delivering ML / AI insights to intelligent front line applications. He is now a practitioner building multi-agent production systems, and advising fortune 100 companies on AI adoption and harness engineering. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower's SpeakerHub.

He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code