Multi-Agent Orchestration with Google ADK: Trees, Graphs, Crews -- Which Mental Model Wins?
Exploring the Optimal Mental Models for Multi-Agent Orchestration: Trees, Graphs, and Crews
Originally published on Medium.
Exploring the Optimal Mental Models for Multi-Agent Orchestration: Trees, Graphs, and Crews
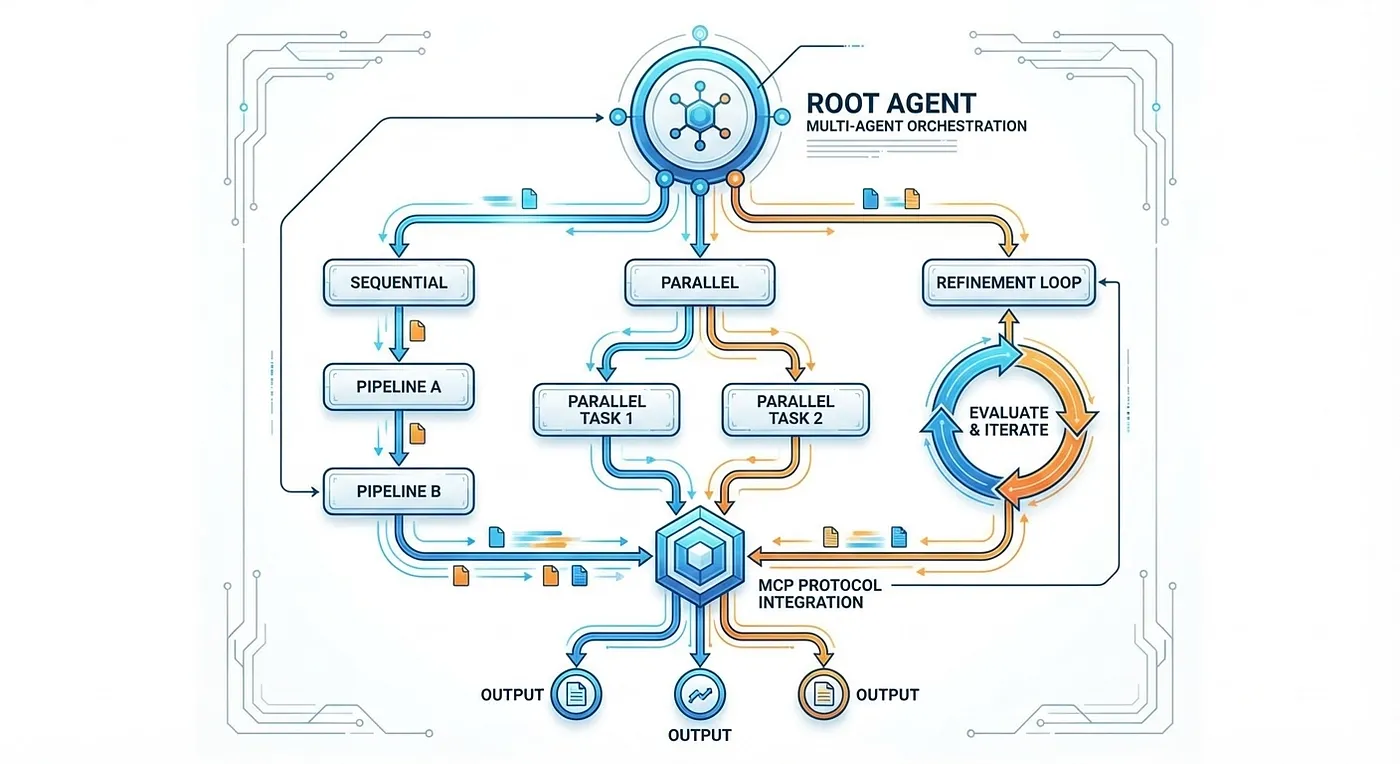 Google ADK: ADK Hierarchical Tree vs LangGraph Directed Graph vs CrewAI Crew Metaphor: three approaches to multi-agent architecture
Google ADK: ADK Hierarchical Tree vs LangGraph Directed Graph vs CrewAI Crew Metaphor: three approaches to multi-agent architecture
Dive into the world of multi-agent systems with Google ADK! Discover how the choice between trees, graphs, and crew models can make or break your orchestration strategy. Are you ready to scale your systems without the 2 AM headaches? Check out Part 2 of our deep dive series! #GoogleADK #MultiAgentSystems #AI
- Part 1: Google ADK Deep Dive: Building Your First Agent
- Part 2 (this): Multi-Agent Orchestration with Google ADK
- Part 3: Google ADK Deep Dive: A2A, MCP, and Production Deployment
- Skillzwave: skillzwave.com for more agent patterns
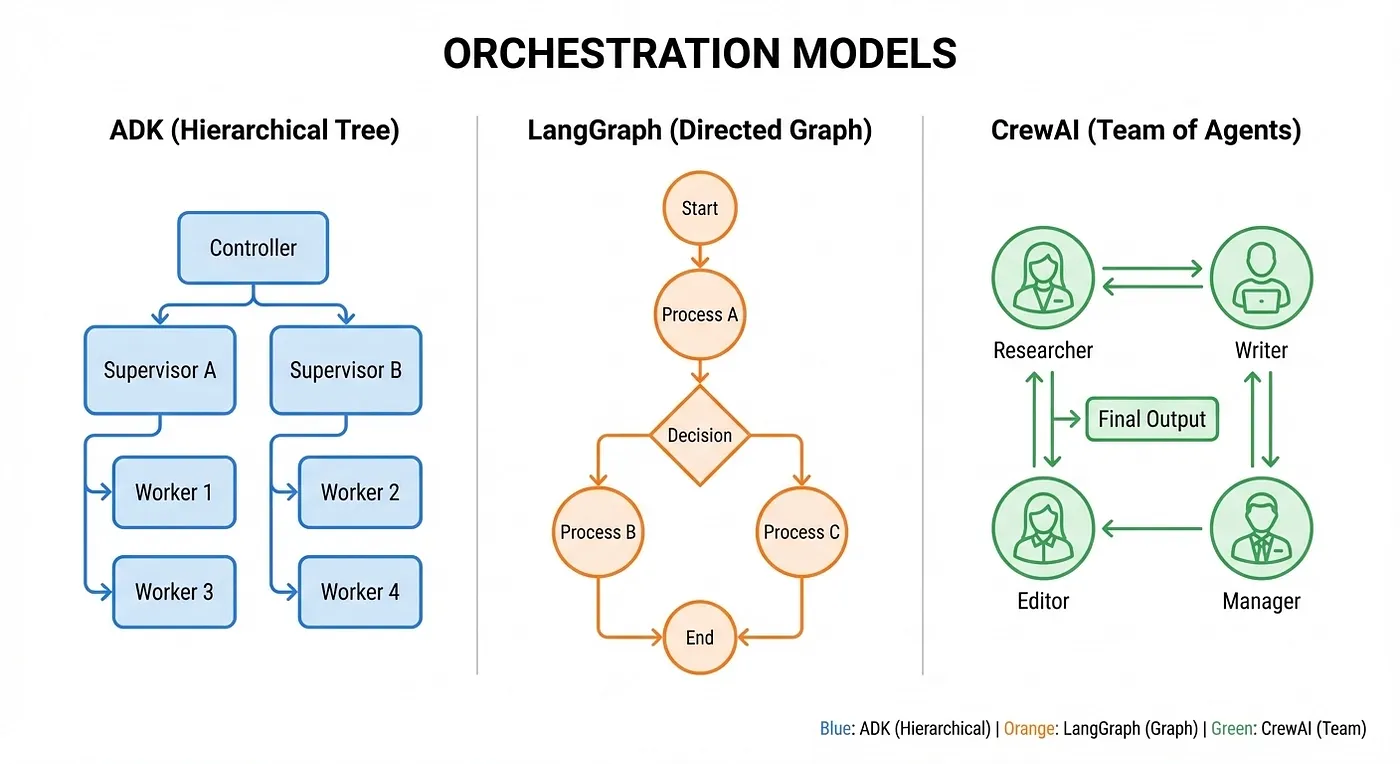 Google ADK: ADK Hierarchical Tree vs LangGraph Directed Graph vs CrewAI Crew Metaphor: three approaches to multi-agent architecture
Google ADK: ADK Hierarchical Tree vs LangGraph Directed Graph vs CrewAI Crew Metaphor: three approaches to multi-agent architecture
from google.adk.agents import SequentialAgent, ParallelAgent, LlmAgent
# Define the pipeline stages
researcher = LlmAgent(
name=
"researcher"
,
model=
"gemini-3-flash"
,
instruction=
"Research the given topic thoroughly. Provide key findings."
,
output_key=
"research_findings"
)
writer = LlmAgent(
name=
"writer"
,
model=
"gemini-3-flash"
,
instruction=
"Write a clear summary based on: {research_findings}"
,
output_key=
"draft_article"
)
reviewer = LlmAgent(
name=
"reviewer"
,
model=
"gemini-3-flash"
,
instruction=
"Review and improve: {draft_article}. Provide final version."
)
# Tree structure: root delegates sequentially
pipeline = SequentialAgent(
name=
"article_pipeline"
,
description=
"Research, write, and review articles."
,
sub_agents=[researcher, writer, reviewer]
)
from langgraph.graph import StateGraph,
END
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class
ArticleState
(TypedDict):
messages:
Annotated[list, add_messages]
research:
str
draft:
str
review:
str
def
researcher_node
(
state:
ArticleState
) ->
dict:
# Each node receives full state and returns partial updates
research = call_llm(
"Research the topic: "
+ state[
"messages"
][-
1
].content)
return
{
"research"
: research}
def
writer_node
(
state:
ArticleState
) ->
dict:
# Access previous node's output via state dict
draft = call_llm(f
"Write based on: {state['research']}"
)
return
{
"draft"
: draft}
def
reviewer_node
(
state:
ArticleState
) ->
dict:
review = call_llm(f
"Review and improve: {state['draft']}"
)
return
{
"review"
: review}
def
should_revise
(
state:
ArticleState
) ->
str:
# Conditional edge: route based on review content
if
"needs revision"
in
state[
"review"
].lower():
return
"writer"
# Loop back to writer
return
END
# Finish
# Build the graph explicitly
workflow = StateGraph(ArticleState)
workflow.add_node(
"researcher"
, researcher_node)
workflow.add_node(
"writer"
, writer_node)
workflow.add_node(
"reviewer"
, reviewer_node)
workflow.set_entry_point(
"researcher"
)
workflow.add_edge(
"researcher"
,
"writer"
)
workflow.add_edge(
"writer"
,
"reviewer"
)
workflow.add_conditional_edges(
"reviewer"
, should_revise)
app = workflow.compile()
from crewai import Agent, Task, Crew, Process
researcher = Agent(
role=
"Research Specialist"
,
goal=
"Produce thorough, accurate research on any topic"
,
backstory=
"Senior research analyst with 15 years of experience"
,
llm=
"gpt-5.4"
)
writer = Agent(
role=
"Technical Writer"
,
goal=
"Transform research into clear, engaging articles"
,
backstory=
"Published technical author and editor"
,
llm=
"gpt-5.4"
)
reviewer = Agent(
role=
"Quality Reviewer"
,
goal=
"Ensure accuracy and clarity in all content"
,
backstory=
"Editorial director with high standards"
,
llm=
"gpt-5.4"
)
# Tasks define the work; context chains outputs between tasks
research_task = Task(
description=
"Research the given topic thoroughly"
,
agent=researcher,
expected_output=
"Comprehensive research findings"
)
writing_task = Task(
description=
"Write an article based on the research"
,
agent=writer,
context=[research_task],
# Receives researcher's output
expected_output=
"Complete article draft"
)
review_task = Task(
description=
"Review and improve the article"
,
agent=reviewer,
context=[writing_task],
# Receives writer's output
expected_output=
"Publication-ready article"
)
crew = Crew(
agents=[researcher, writer, reviewer],
tasks=[research_task, writing_task, review_task],
process=Process.sequential,
memory=True
)
result = crew.kickoff()
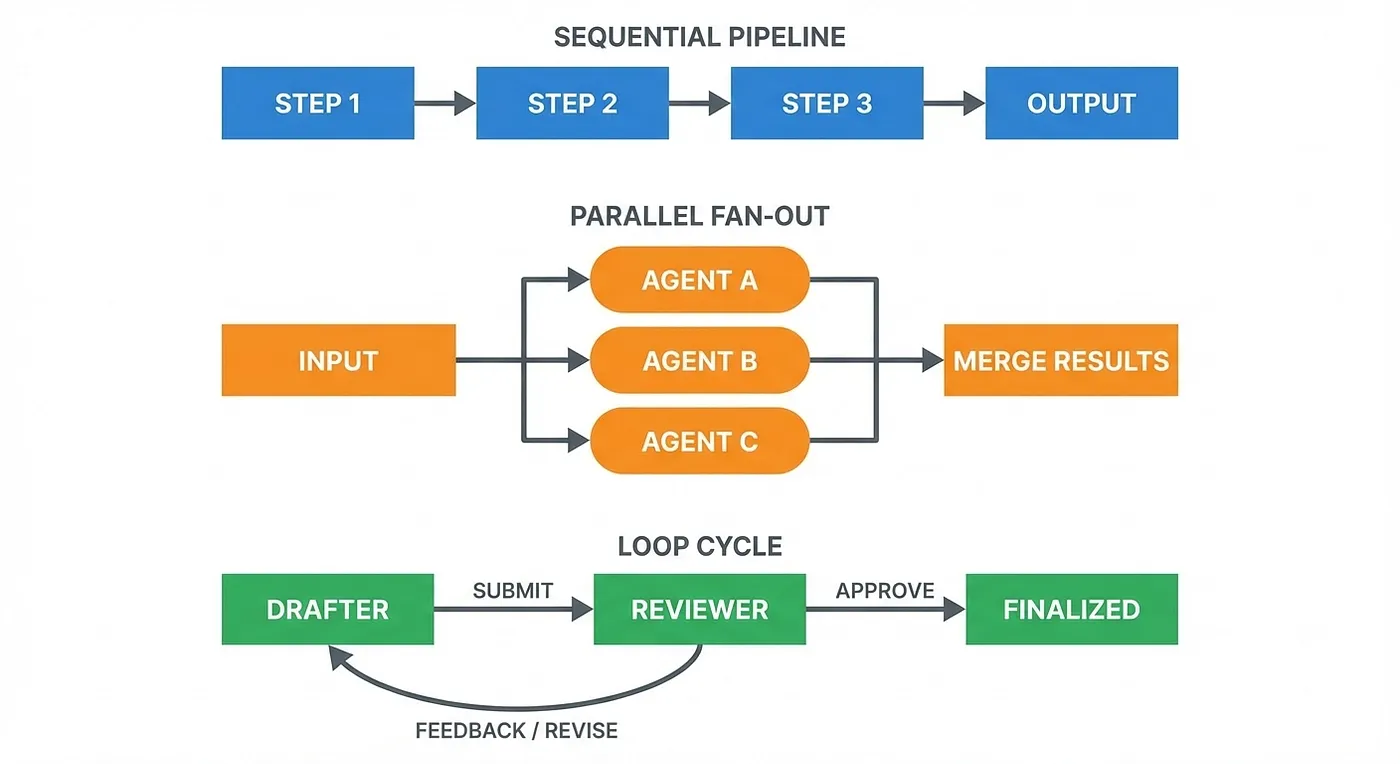 Google ADK: Workflow Agent Patterns showing Sequential, Parallel, and Loop composition for document processing pipelines
Google ADK: Workflow Agent Patterns showing Sequential, Parallel, and Loop composition for document processing pipelines
from
google.adk.agents
import
SequentialAgent, LlmAgent
# Stage 1: Extract content from raw document
extractor = LlmAgent(
name=
"content_extractor"
,
model=
"gemini-3-flash"
,
instruction=
"""Extract structured content from the raw document.
Identify: title, sections, key entities, and metadata.
Raw document: {raw_document}"""
,
output_key=
"extracted_content"
)
# Stage 2: Validate completeness
validator = LlmAgent(
name=
"content_validator"
,
model=
"gemini-3-flash"
,
instruction=
"""Validate the extracted content for completeness:
- Are all sections present?
- Are key entities identified?
- Is metadata complete?
Content: {extracted_content}
Report any gaps found."""
,
output_key=
"validation_report"
)
# Stage 3: Enrich with additional context
enricher = LlmAgent(
name=
"content_enricher"
,
model=
"gemini-3-flash"
,
instruction=
"""Enrich the validated content with additional context.
Original content: {extracted_content}
Validation notes: {validation_report}
Add: entity descriptions, category tags, summary."""
,
output_key=
"enriched_content"
)
# Assemble the pipeline
doc_pipeline = SequentialAgent(
name=
"document_processor"
,
description=
"Extracts, validates, and enriches document content."
,
sub_agents=[extractor, validator, enricher]
)
from
google.adk.agents
import
ParallelAgent, LlmAgent
# Multiple enrichment sources running concurrently
entity_extractor = LlmAgent(
name=
"entity_extractor"
,
model=
"gemini-3-flash"
,
instruction=
"""Extract all named entities from: {extracted_content}
Categorize as: people, organizations, locations, dates, amounts."""
,
output_key=
"entity_data"
)
sentiment_analyzer = LlmAgent(
name=
"sentiment_analyzer"
,
model=
"gemini-3-flash"
,
instruction=
"""Analyze sentiment of: {extracted_content}
Provide: overall sentiment, section-by-section breakdown, confidence scores."""
,
output_key=
"sentiment_analysis"
)
category_classifier = LlmAgent(
name=
"category_classifier"
,
model=
"gemini-3-flash"
,
instruction=
"""Classify the content: {extracted_content}
Assign: primary category, secondary categories, topic tags."""
,
output_key=
"category_data"
)
# All three run simultaneously
parallel_enrichment = ParallelAgent(
name=
"parallel_enrichment"
,
description=
"Runs multiple enrichment streams concurrently."
,
sub_agents=[entity_extractor, sentiment_analyzer, category_classifier]
)
from
google.adk.agents
import
LoopAgent, LlmAgent
from
google.adk.tools
import
exit_loop
# Drafter creates or improves content
summary_drafter = LlmAgent(
name=
"summary_drafter"
,
model=
"gemini-3-flash"
,
instruction=
"""Create or improve a summary of the enriched document.
Content: {enriched_content}
Entity data: {entity_data}
Sentiment: {sentiment_analysis}
Categories: {category_data}
Previous feedback: {review_feedback}
Write a comprehensive, accurate summary."""
,
output_key=
"current_summary"
)
# Reviewer evaluates and either approves or sends back
quality_reviewer = LlmAgent(
name=
"quality_reviewer"
,
model=
"gemini-3-flash"
,
instruction=
"""Review the summary for quality:
Summary: {current_summary}
Check: accuracy, completeness, clarity, conciseness.
If the summary meets all quality standards, call exit_loop.
Otherwise, provide specific feedback for improvement."""
,
tools=[exit_loop],
output_key=
"review_feedback"
)
# Loop until quality is sufficient (max 5 iterations)
refinement_loop = LoopAgent(
name=
"quality_refinement"
,
description=
"Iteratively refines summary until quality standards are met."
,
max_iterations=
5
,
sub_agents=[summary_drafter, quality_reviewer]
)
from google.adk.agents import SequentialAgent, LlmAgent
researcher = LlmAgent(
name=
"researcher"
,
model=
"gemini-3-flash"
,
instruction=
"Research the topic and return key facts + sources."
,
output_key=
"research"
)
analyst = LlmAgent(
name=
"analyst"
,
model=
"gemini-3.1-pro"
,
instruction=
"Analyze: {research}. Extract implications, risks, and a decision recommendation."
,
output_key=
"analysis"
)
writer = LlmAgent(
name=
"writer"
,
model=
"gemini-3-flash"
,
instruction=
"Write a publishable brief using: {analysis}"
,
output_key=
"draft"
)
pipeline = SequentialAgent(
name=
"research_analysis_writeup"
,
description=
"Reusable 3-step pipeline"
,
sub_agents=[researcher, analyst, writer]
)
from
google.adk.agents
import
SequentialAgent
# Complete document processing pipeline
complete_pipeline = SequentialAgent(
name=
"complete_doc_pipeline"
,
description=
"Full document processing: extract, validate, enrich, and refine."
,
sub_agents=[
extractor,
# Sequential stage 1: extract content
validator,
# Sequential stage 2: validate completeness
parallel_enrichment,
# Parallel: enrich from multiple sources
refinement_loop
# Loop: iterative quality refinement
]
)
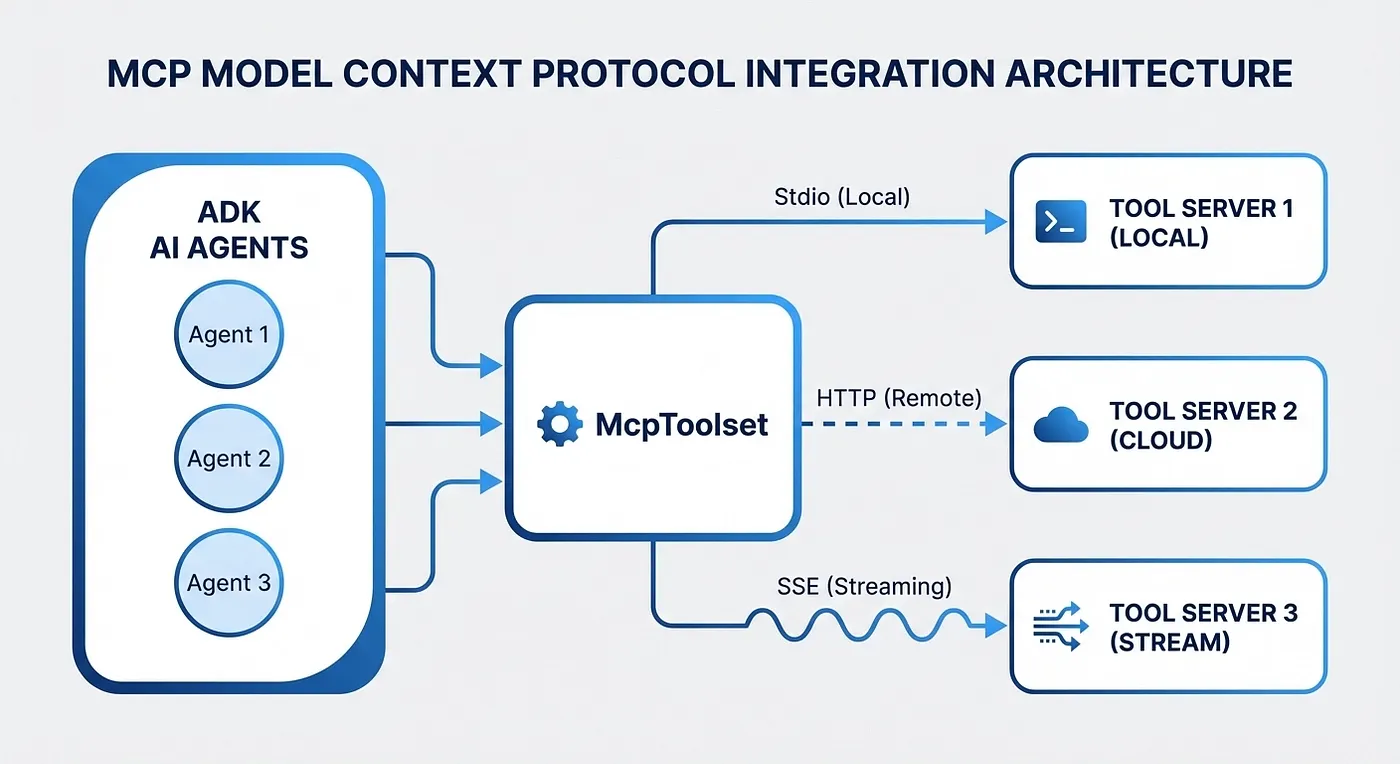 Google ADK: MCP integration architecture showing ADK agents connecting to tool servers via Stdio, HTTP, and SSE connection types through McpToolset
Google ADK: MCP integration architecture showing ADK agents connecting to tool servers via Stdio, HTTP, and SSE connection types through McpToolset
from
google.adk.agents
import
LlmAgent
from
google.adk.tools.mcp_tool
import
McpToolset
from
google.adk.tools.mcp_tool.mcp_session_manager
import
StdioConnectionParams
from
mcp
import
StdioServerParameters
file_agent = LlmAgent(
model=
"gemini-3-flash"
,
name=
"file_processor"
,
instruction=
"Process files using the available filesystem tools."
,
tools=[
McpToolset(
connection_params=StdioConnectionParams(
server_params=StdioServerParameters(
command=
"npx"
,
args=[
"-y"
,
"@modelcontextprotocol/server-filesystem"
,
"/data"
],
)
),
# Only expose these three tools (not the full MCP server surface)
tool_filter=[
"read_file"
,
"list_directory"
,
"write_file"
],
# Prefix avoids collisions with other MCP toolsets
tool_name_prefix=
"fs_"
)
]
)
from google.adk.tools.mcp_tool.mcp_session_manager
import
StreamableHTTPConnectionParams
knowledge_agent
=
LlmAgent(
model=
"gemini-3.1-pro"
,
name=
"knowledge_researcher"
,
instruction=
"Search Google developer documentation for relevant information."
,
tools=[
McpToolset(
connection_params=StreamableHTTPConnectionParams(
url=
"https://developerknowledge.googleapis.com/mcp"
,
headers={
"X-Goog-Api-Key"
: DEVELOPER_KNOWLEDGE_API_KEY}
)
)
]
)
from
google.adk.tools.mcp_tool.mcp_session_manager
import
SseConnectionParams
def
get_auth_headers
(
readonly_context
):
"""Pull auth token from session state for dynamic auth.
This function is called on every MCP request, so the token
stays fresh even in long-running sessions."""
user_token = readonly_context.state.get(
"user_token"
,
""
)
return
{
"Authorization"
:
f"Bearer
{user_token}
"
}
api_agent = LlmAgent(
model=
"gemini-3-flash"
,
name=
"api_integrator"
,
instruction=
"Integrate with external APIs via MCP tools."
,
tools=[
McpToolset(
connection_params=SseConnectionParams(
url=
"https://api.example.com/mcp"
),
header_provider=get_auth_headers,
require_confirmation=
True
# Human approves before execution
)
]
)
 Google ADK: MCPs used by various frameworks
Google ADK: MCPs used by various frameworks
from
google.adk.agents
import
LlmAgent
from
google.adk.tools
import
AgentTool
from
google.adk.tools.mcp_tool
import
McpToolset
from
google.adk.tools.mcp_tool.mcp_session_manager
import
SseConnectionParams
# Specialist sub-agent with MCP tools
research_specialist = LlmAgent(
model=
"gemini-3.1-pro"
,
name=
"research_specialist"
,
instruction=
"""You are a research specialist with access to
knowledge base tools. Answer research questions thoroughly
using your available tools."""
,
tools=[
McpToolset(
connection_params=SseConnectionParams(
url=
"http://localhost:8001/sse"
),
tool_filter=[
"search_docs"
,
"get_document"
]
)
]
)
# Root agent wraps specialist as a tool
orchestrator = LlmAgent(
model=
"gemini-3.1-pro"
,
name=
"orchestrator"
,
instruction=
"""You are a project manager. You have access to
a research specialist tool. Use it when you need to look up
information. For simple questions, answer directly."""
,
tools=[
AgentTool(agent=research_specialist)
]
)
 Google ADK: When to use each pattern
Google ADK: When to use each pattern
# Stage that dynamically consults specialists
smart_enricher = LlmAgent(
name=
"smart_enricher"
,
model=
"gemini-3.1-pro"
,
instruction=
"""Enrich the content: {extracted_content}
You have access to research and legal specialists.
Use them when the content requires expert analysis.
For straightforward content, enrich directly."""
,
tools=[
AgentTool(agent=research_specialist),
AgentTool(agent=legal_specialist),
],
output_key=
"enriched_content"
)
# Fixed pipeline with dynamic enrichment stage
pipeline = SequentialAgent(
name=
"smart_pipeline"
,
sub_agents=[extractor, validator, smart_enricher, refinement_loop]
)
sensitive_toolset
=
McpToolset
(
connection_params
=
SseConnectionParams
(
url
=
"<https://production-api.example.com/mcp>"
)
,
require_confirmation
=
True
# Every tool call pauses for approval
)
def
approval_gate
(
tool_call, agent_name
):
"""Gate expensive or destructive operations.
Auto-approve reads, require confirmation for writes."""
if
tool_call.name.startswith(
"delete_"
)
or
tool_call.name.startswith(
"write_"
):
print
(
f"[APPROVAL REQUIRED]
{agent_name}
wants to call
{tool_call.name}
"
)
print
(
f" Arguments:
{tool_call.args}
"
)
return
input
(
"Approve? (y/n): "
).lower() ==
"y"
return
True
# Auto-approve read operations
def
output_review
(
output, agent_name
):
"""Review sub-agent output before returning to parent.
Gives human opportunity to edit or override."""
print
(
f"[REVIEW]
{agent_name}
produced:
{output.content[:
200
]}
..."
)
edit =
input
(
"Edit output (or press Enter to accept): "
)
if
edit:
output.content = edit
return
output
research_tool = AgentTool(
agent=research_specialist,
before_agent_callback=approval_gate,
after_agent_callback=output_review
)
def
graduated_trust
(
tool_call, agent_name
):
"""Production-grade trust levels.
Three tiers:
- BLOCKED: Never allowed, period
- CONFIRM: Requires human approval each time
- AUTO: Approved automatically (reads, queries)
"""
BLOCKED = [
"drop_table"
,
"delete_all"
,
"reset_database"
]
CONFIRM = [
"write_file"
,
"update_record"
,
"send_email"
]
if
tool_call.name
in
BLOCKED:
print
(
f"[BLOCKED]
{tool_call.name}
is not permitted"
)
return
False
if
tool_call.name
in
CONFIRM:
print
(
f"[CONFIRM]
{agent_name}
:
{tool_call.name}
(
{tool_call.args}
)"
)
return
input
(
"Approve? (y/n): "
).lower() ==
"y"
return
True
# Auto-approve everything else (reads, queries, etc.)
from
google.adk.agents
import
SequentialAgent, LlmAgent
analyzer = LlmAgent(
name=
"analyzer"
,
model=
"gemini-3-flash"
,
instruction=
"Analyze the input and identify key requirements."
,
output_key=
"analysis_result"
# Writes to state["analysis_result"]
)
planner = LlmAgent(
name=
"planner"
,
model=
"gemini-3-flash"
,
instruction=
"""Create an action plan based on the analysis.
Analysis: {analysis_result}"""
,
# Reads from state["analysis_result"]
output_key=
"action_plan"
# Writes to state["action_plan"]
)
executor = LlmAgent(
name=
"executor"
,
model=
"gemini-3-flash"
,
instruction=
"""Execute the plan and provide results.
Plan: {action_plan}"""
# Reads from state["action_plan"]
)
pipeline = SequentialAgent(
name=
"pipeline"
,
sub_agents=[analyzer, planner, executor]
)
from langgraph.graph import StateGraph,
END
from langgraph.checkpoint.memory import MemorySaver
from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
class
PipelineState
(TypedDict):
messages:
Annotated[list, add_messages]
analysis:
str
plan:
str
result:
str
def
analyze
(
state:
PipelineState
) ->
dict:
analysis = call_llm(f
"Analyze: {state['messages'][-1].content}"
)
return
{
"analysis"
: analysis}
def
plan
(
state:
PipelineState
) ->
dict:
plan = call_llm(f
"Plan based on: {state['analysis']}"
)
return
{
"plan"
: plan}
def
execute
(
state:
PipelineState
) ->
dict:
result = call_llm(f
"Execute: {state['plan']}"
)
return
{
"result"
: result}
workflow = StateGraph(PipelineState)
workflow.add_node(
"analyze"
, analyze)
workflow.add_node(
"plan"
, plan)
workflow.add_node(
"execute"
, execute)
workflow.set_entry_point(
"analyze"
)
workflow.add_edge(
"analyze"
,
"plan"
)
workflow.add_edge(
"plan"
,
"execute"
)
workflow.add_edge(
"execute"
,
END
)
# MemorySaver enables checkpointing and state replay
app = workflow.compile(checkpointer=MemorySaver())
from crewai import Agent, Task, Crew, Process
analysis_task = Task(
description=
"Analyze the input requirements"
,
agent=analyst,
expected_output=
"Detailed analysis"
)
planning_task = Task(
description=
"Create an action plan based on analysis"
,
agent=planner,
context=[analysis_task],
# Receives analysis output automatically
expected_output=
"Action plan"
)
execution_task = Task(
description=
"Execute the plan"
,
agent=executor,
context=[planning_task],
expected_output=
"Execution results"
)
crew = Crew(
agents=[analyst, planner, executor],
tasks=[analysis_task, planning_task, execution_task],
process=Process.sequential,
memory=True
# Enables crew-level memory for cross-task recall
)
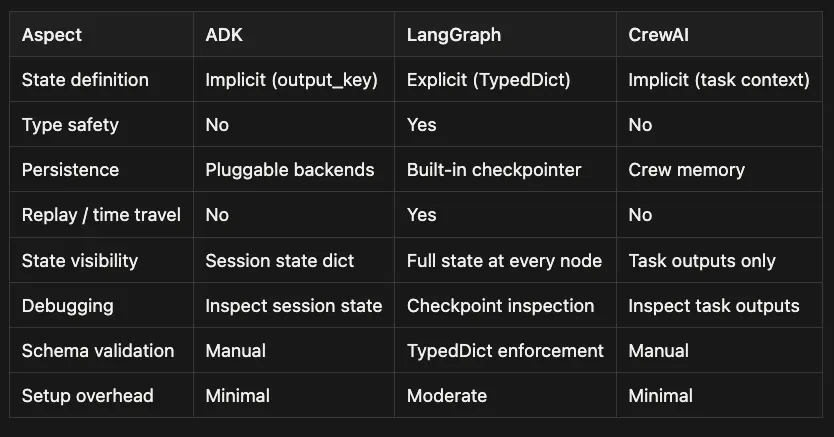 Google ADK: State Management Comparision
Google ADK: State Management Comparision
-
Hard-coding HTTP calls to each agent (you lose discoverability and can’t swap implementations cleanly)
-
Mixing orchestration logic with business logic (the pipeline becomes impossible to change without breaking everything)
-
Ignoring backpressure (parallel fan-out without limits will crush downstream services)
-
Passing raw transcripts as “state” (you inflate context and degrade quality; summarize and structure outputs)
-
Part 2 (this): Google ADK Deep Dive: Multi-Agent Orchestration with ADK
-
Part 3: Google ADK Deep Dive: A2A, MCP, and Production Deployment
-
Part 3: Google ADK Deep Dive: A2A, MCP, and Production Deployment