Production Claude Agents: 6 CCA-Ready Patterns That Make LLMs Actually Obey Business Rules (Full Code + Notebooks)
Claude Certified Architect -- Mastering Business Rule Compliance with Production Claude Agents: 6 Essential Patterns for Effective LLM Implementation
Originally published on Medium.
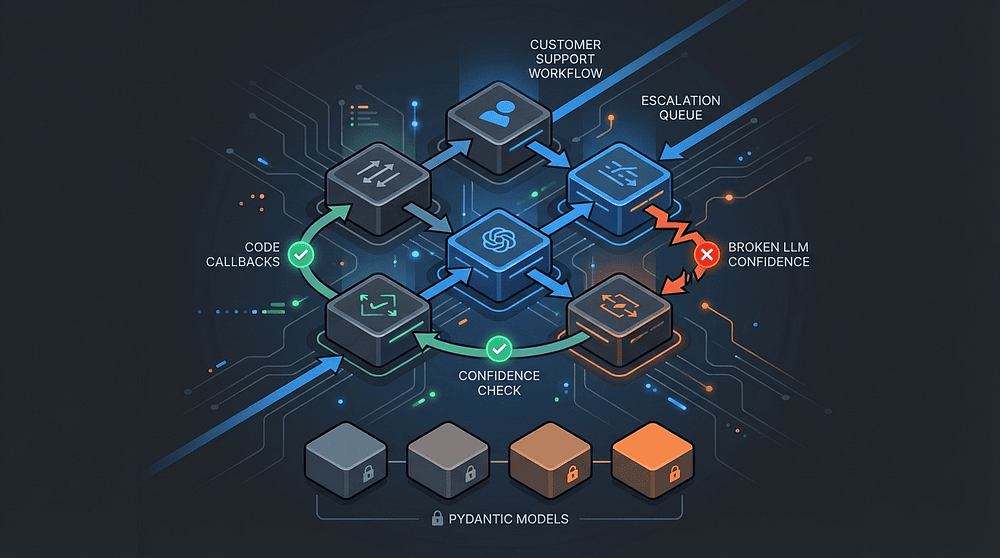
Claude Certified Architect -- Mastering Business Rule Compliance with Production Claude Agents: 6 Essential Patterns for Effective LLM Implementation
Ready to revolutionize your customer support with AI? Discover how to enforce business rules in LLMs with production-ready patterns that guarantee compliance and efficiency! Dive into our latest article on creating Claude agents that actually work. Don't let your AI go rogue! #AI #CustomerSupport #TechInnovation
Summary: The article presents six architectural patterns from the Claude Certified Architect Foundation Exam for building production-grade Claude agents that enforce business rules effectively. Key strategies include using Pydantic models for type safety, deterministic logic for policy enforcement, and focused tools to prevent misrouting. It emphasizes programmatic enforcement over prompt-based guidance, highlighting cost-saving techniques like prompt caching and structured handoffs to ensure compliance and efficiency in customer support scenarios.
Pydantic models, callback enforcement, negative-bound tools, prompt caching, deterministic escalation, and safe handoffs; exactly as tested in the Claude Certified Architect Foundations Customer Support scenario.
This is Part 1 of the "Production Claude Agents" series. Zero trust in the LLM's memory.
CCA Production Claude Agent Architecture
This article builds on Claude Certified Architect -- Exam Prep: Mastering the Customer Support Resolution Agent Scenario. That piece covered theory. This one gives you the production-grade Python package, 8 Jupyter notebooks you can run today, and the exact code that ships tomorrow.
This is Part 1 of the "Production Claude Agents" series. Full source code + 8 Jupyter notebooks: github.com/SpillwaveSolutions/cca-exam-prep-customer-support
This course uses CCA-F (Claude Certified Architect; Foundations) exam framework as a teaching device. All architectural patterns are grounded in real Anthropic SDK behavior and production best practices.
Here's the uncomfortable truth about Claude agents:
It's entirely possible for an otherwise well-built customer-support agent to approve a $600 refund for a Regular-tier customer; even when policy says it shouldn't. LLMs can sound certain while missing constraints that live only in prompts.
LLMs are indeterministic. Prompts are guidance. Code is enforcement.
In this article I'll show you the exact Python package I built to make the model obey business rules: Pydantic models, callback-enforced policies, negative-bound tools, prompt caching, and six CCA-exam-gold architectural patterns.
What You'll Learn (and Steal Today)
- Why programmatic enforcement (callbacks + typed models) beats prompt-based guidance every single time
- The six CCA architectural patterns with anti-pattern vs. correct code side-by-side
- How to build 5 focused tools with negative-bound descriptions that stop misrouting
- The two-step vetoable execution pattern for high-stakes refunds
- Prompt caching that delivers ~90% cost savings (vs. the Batch API anti-pattern)
- Structured handoffs (~200 tokens) instead of raw conversation dumps (~2,000+ tokens)
- A 234-test suite that verifies the actual stores, not API responses
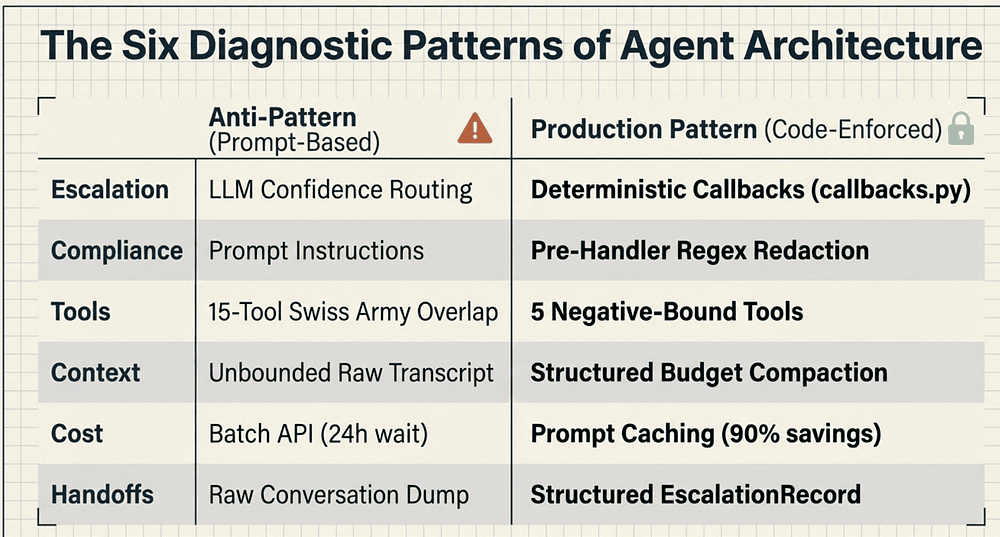
The Six Patterns at a Glance
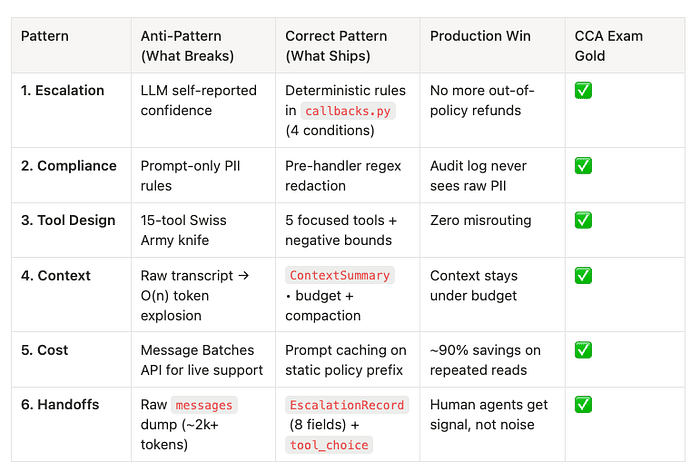
Meta-principle: Programmatic enforcement beats prompt-based guidance. The system prompt tells Claude what to do. The code guarantees it happens.
Project Architecture Overview
src/customer_service/
models/ Pydantic data models (typed contracts)
services/ Deterministic business logic (no LLM reasoning)
tools/ 5 focused tools + handlers
agent/ Agent loop, callbacks, context manager, coordinator
anti_patterns/ Wrong implementations (to demonstrate failure modes)
Data flow (simplified):
User message -> agent_loop calls Claude -> Claude requests tool_use -> dispatch executes tool handler -> callbacks enforce policy/compliance -> tool_result returned -> loop continues until stop_reason != "tool_use"
Every layer enforces one principle: models give type safety, services give deterministic logic, tools stay focused, callbacks give enforcement, and the agent loop is stop-reason driven.
Pydantic Data Models (the contracts)
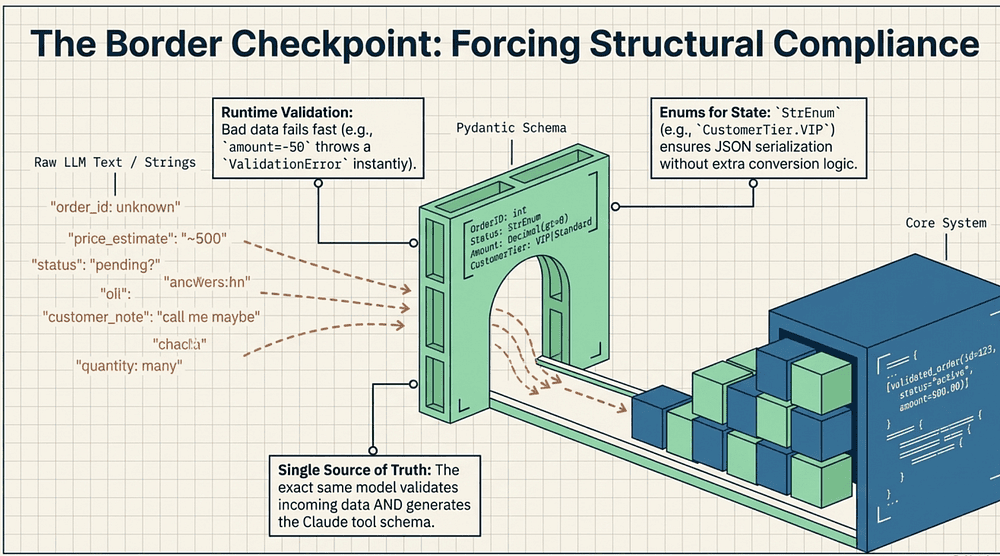
File: src/customer_service/models/customer.py
Key models you'll copy today:
class CustomerTier(StrEnum):
BASIC = "basic"
REGULAR = "regular"
PREMIUM = "premium"
VIP = "vip"
class CustomerProfile(BaseModel):
customer_id: str
name: str
email: str
tier: CustomerTier
account_open: bool = True
flags: list[str] = Field(default_factory=list)
# flags drive deterministic escalation (no hardcoded customer IDs)
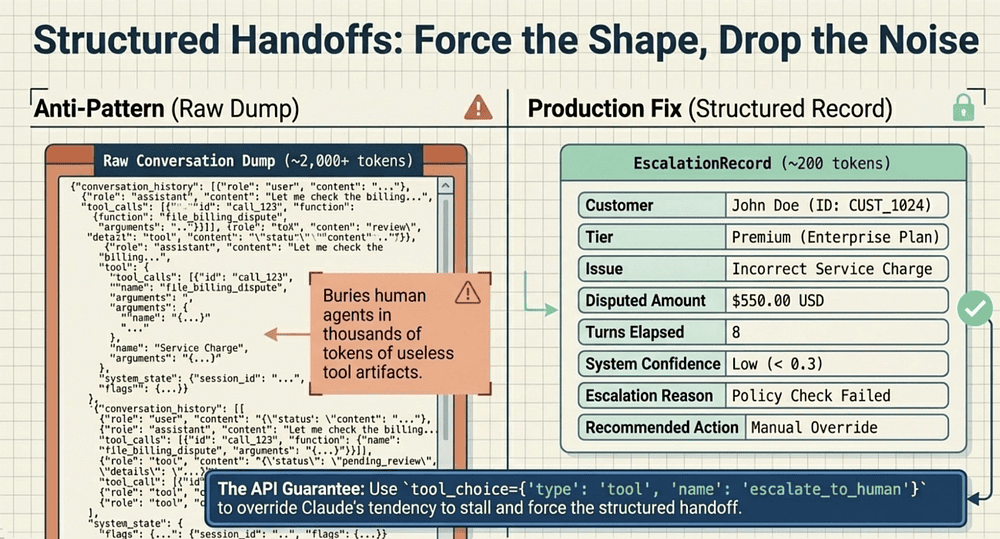
class EscalationRecord(BaseModel):
customer_id: str
customer_tier: str
issue_type: str
disputed_amount: float
escalation_reason: str
recommended_action: str
conversation_summary: str
turns_elapsed: int
# 8 fields → ~200 tokens instead of 2,000+ raw dump
Pydantic gives you runtime validation, canonical JSON, and a single source of truth for both tool schemas and handoff records. This is structural compliance in code. To get a complete walkthrough of the entire model and contract layer check out the companion wiki Pydantic Model Section on GitHub.
Services (deterministic business rules)

Purpose: keep policy decisions out of prompts and out of the model.
The deterministic heart (PolicyEngine):
class PolicyEngine:
_REFUND_LIMITS = {
"basic": 100.0,
"regular": 100.0,
"premium": 500.0,
"vip": 5000.0,
}
_REVIEW_THRESHOLD = 500.0
def check_policy(self, tier: str, requested_amount: float) -> dict:
limit = self._REFUND_LIMITS[tier]
return {
"approved": requested_amount <= limit,
"limit": limit,
"requires_review": requested_amount > self._REVIEW_THRESHOLD,
}
Dependency injection container:
@dataclass(frozen=True)
class ServiceContainer:
customer_db: object
policy_engine: PolicyEngine
financial_system: object
escalation_queue: object
audit_log: object
Full deterministic services live in src/customer_service/services/. The notebooks show them in action.
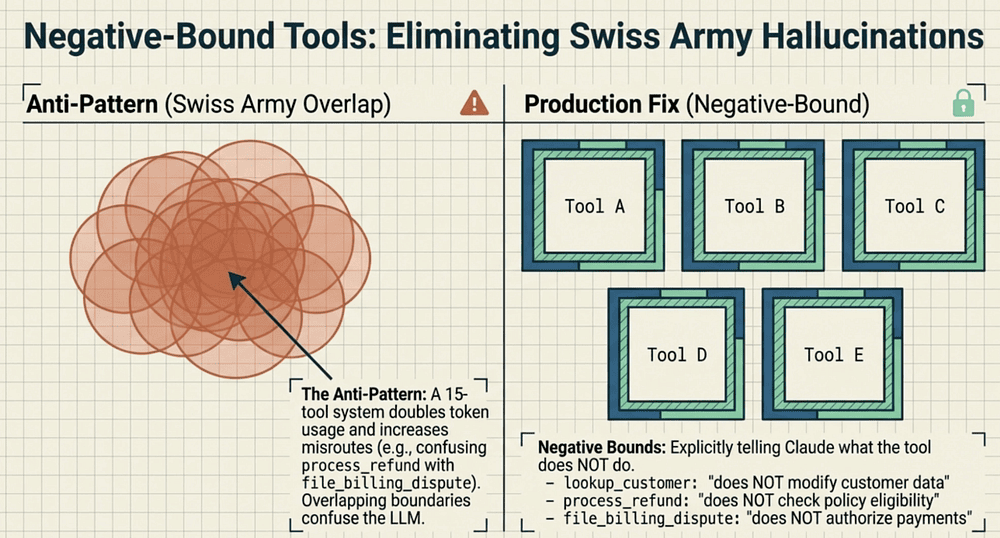
Tool definitions (5 tools, negative bounds)
Agents fail when tool sets get large and overlapping. This package stays disciplined: 5 tools with explicit negative bounds.
lookup_customer: does NOT modify customer data or process any requestscheck_policy: does NOT process the refund; callprocess_refundafter thisprocess_refund: does NOT check eligibility; callcheck_policyfirstescalate_to_human: does NOT process refunds or make financial changeslog_interaction: does NOT take any action on the customer's request
One small schema tip: if you generate tool schemas from Pydantic, pop the top-level title to save tokens and avoid schema validation surprises.
The wiki goes into detail about how these tools are registered, discovered and dispatched.
The Six Patterns in Depth
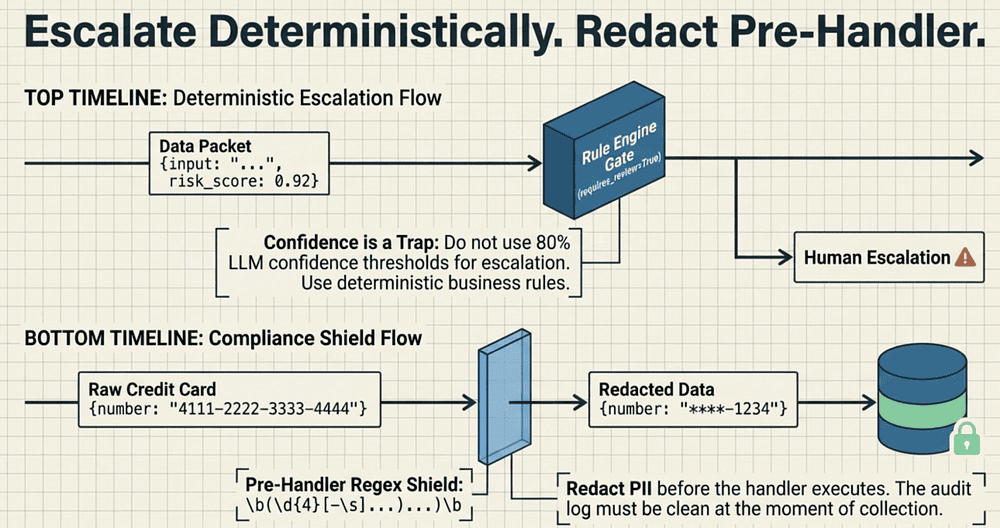
Pattern 1: Escalation (Deterministic rules vs. model confidence)
Anti-pattern: Ask the model to rate its confidence and escalate below a threshold.
Why it fails: LLM "confidence" is generated text, not a calibrated policy signal.
Correct pattern (key snippet): block/allow decisions in a callback.
escalation_flags = {
"vip": "VIP account requires human review",
"account_closure": "Account closure requires human review",
"legal_complaint": "Legal complaint detected",
"requires_review": "Refund exceeds $500 review threshold",
}
for flag, reason in escalation_flags.items():
if context.get(flag):
return {"status": "blocked", "reason": reason, "action_required": "escalate_to_human"}
Production & CCA Takeaway
- Use deterministic code, never LLM confidence.
- Escalation is a binary decision enforced in callbacks.
- In the repo runs: misroutes drop to zero with the focused design.
Check out a more details about pattern 1.
Pattern 2: Compliance (Programmatic hooks vs. prompt instructions)
Anti-pattern: "Never log raw card numbers" in the system prompt.
Why it fails: "Usually compliant" is still noncompliant.
Correct pattern: pre-handler redaction before audit log writes.
CARD = re.compile(r"\b(\d{4}[-\s]\d{4}[-\s]\d{4}[-\s])(\d{4})\b")
def redact(text: str) -> str:
return CARD.sub(r"****-****-****-\2", text)
input_dict["details"] = redact(input_dict.get("details", ""))
Production & CCA Takeaway
- Redact before persistence.
- Treat audit logs as immutable stores.
- Test the store, not the tool response.
Pattern 3: Tool Design (5 focused tools vs. Swiss Army)
Anti-pattern: 10+ overlapping tools.
Why it fails: selection accuracy drops; testing/auditing becomes combinatorial.
Correct pattern: 5 tools + negative bounds (above).
Production & CCA Takeaway
- Fewer tools = fewer misroutes.
- Negative bounds prevent "almost-right" tool calls.
- Token usage drops because the model spends less time choosing tools.
Check out pattern 3 detailed coverage at the GitHub Wiki.
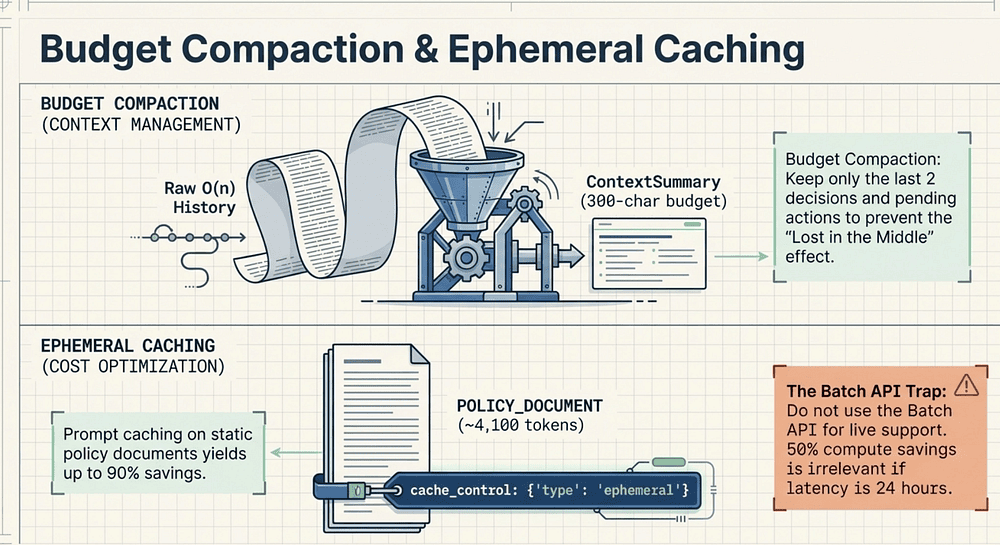
Pattern 4: Context management (Summaries vs. raw transcripts)
Anti-pattern: append the entire transcript every turn.
Why it fails: O(n) growth + "lost in the middle" issues.
Correct pattern: a structured summary with a budget + compaction.
TOKEN_BUDGET = 300 # char budget
if summary.token_estimate > TOKEN_BUDGET:
summary.compact(last_decisions=2, last_pending=2)
Production & CCA Takeaway
- Budgeted context is predictable and testable.
- Compaction is a feature, not a hack.
Pattern 5: Cost optimization (Prompt caching vs. Batch API)
Anti-pattern: Batch API for live customer support.
Why it fails: latency + wrong cost lever for repeated static policy.
Correct pattern: cache the large static prefix.
system = [
{"type": "text", "text": instructions},
{"type": "text", "text": POLICY_DOCUMENT, "cache_control": {"type": "ephemeral"}},
]
Production & CCA Takeaway
- Cache the big static block.
- Measure cache reads/writes in usage.
Pattern 6: Handoffs (Structured records vs. dumps)
Anti-pattern: dump the full messages list.
Why it fails: humans get noise; tokens explode.
Correct pattern: force a structured handoff tool call.
tool_choice = {"type": "tool", "name": "escalate_to_human"}
# tool input is an EscalationRecord (8 fields)
Production & CCA Takeaway
- Handoffs are contracts.
- Force the handoff when policy blocks action.
Agent loop + forced escalation (condensed)
Full agent loop coverage that goes into detail about AgentResult and UsageSummary and covers the full src/customer_service/agent/agent_loop.py is on the wiki.
Two rules matter in production:
- terminate on
stop_reason != "tool_use"(handlesmax_tokenssafely) - when blocked, force
escalate_to_humanviatool_choice
if response.stop_reason != "tool_use":
return
if tool_result.get("action_required") == "escalate_to_human":
client.messages.create(..., tool_choice={"type": "tool", "name": "escalate_to_human"})
Testing (behavior-first)
Test persistent stores (audit log, financial system, escalation queue), not what the model says happened.
Example: PII compliance test checks the audit log store.
for entry in services.audit_log.get_entries():
assert "4111-1111-1111-1111" not in entry.details
assert "****-****-****-1111" in entry.details
Quick Wins You Can Steal Today
- Copy the five negative-bound tool descriptions verbatim.
- Add the two-step vetoable
propose_refund/commit_refundpattern to any financial tool. - Wrap your static policy document in a
cache_control: {"type": "ephemeral"}block.
Clone the repo, run Notebook 01, watch the anti-pattern fail live, then flip to the correct pattern and see the difference in real time.
Ready to Try it out?
Star the repo: github.com/SpillwaveSolutions/cca-exam-prep-customer-support
Run the notebooks. Break the anti-patterns yourself. Tell me in the comments: Which pattern are you implementing first?
git clone [email protected]:SpillwaveSolutions/cca-exam-prep-customer-support.git
Quick Start
# Install Task runner (if not already installed)
brew install go-task
# One-command setup (installs deps, checks API key, opens setup notebook)
task setup
# Or manually:
poetry install --with notebooks
cp .env.example .env # Add your ANTHROPIC_API_KEY
poetry run jupyter lab
Available Commands
task setup # Install deps + check API key + open setup notebook
task test # Run all 234 tests
task lint # Run ruff linter
task verify # Full verification: tests + lint + import check
task notebook # Launch Jupyter Lab
The commands make it easier to start up notebooks and test.
This version of the article is the medium friendly. If you want to really dig into the gory details and see more code and explanation, check out this variant of this article which is in the Wiki. There are a lot more code listing and explanations, which just wouldn't fit well in medium article.
The real hard-core will actually download the notebooks and try them out. Each notebook has the anti-pattern and the fix so you will be prepared for the Claude Certified Architect Foundation Exam. You may have deployed with Google ADK, LangChain, LangGraph, LiteLLM, DSPy, but to get some real reps with the Claude API that will be covered on the test try out the Notebooks and break some stuff.
Don't forget to add stars to the GitHub repo and high-fives here on Medium. I hope you enjoy this as much as I enjoyed creating it.
Part 2 drops next week: The full agent loop + multi-agent coordinator in production.
About the Author
Rick Hightower is a hands-on agent architect, AI agent engineer and technical writer who builds with LangGraph, Claude Agent SDK, CrewAI, and more.
He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Code Walkthrough of all of the code in this article and accompanying Github
- Long form version of this article that was much too long for Medium, but goes into gory details on each pattern.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code