Securing LiteLLM's MCP Integration: Write Once, Secure Everywhere
OAuth 2.1, JWT validation, and TLS encryption for LiteLLM's unified client library
Originally published on Medium.

OAuth 2.1, JWT validation, and TLS encryption for LiteLLM's unified client library
Ever built an AI system only to rebuild the security layer when switching from OpenAI to Anthropic? LiteLLM addresses the provider proliferation issue by offering a single interface to over 100 language models. However, security demands careful design when this universal client interacts with the Model Context Protocol (MCP). This guide shows how to implement OAuth 2.1, JWT validation, and TLS encryption for LiteLLM's MCP integration—creating a secure setup that works with GPT-4, Claude, and beyond.
The Multi-Provider Challenge: One Client, Many Models
LiteLLM functions as a universal translator for AI providers. Write your code once, then switch between models with a configuration change—no rewrites, no breaking changes, just smooth provider flexibility. However, this flexibility creates a security challenge. How do you secure MCP tool access when your underlying model could be from any of 100+ providers? The solution is to implement security at the appropriate level—the LiteLLM client itself, not the individual providers.
Picture this scenario: Your customer service application uses LiteLLM to route simple queries to GPT-4 and complex ones to o3. Tomorrow, you switch to Claude for cost savings. Without proper architecture, you'd need to reimplement security for each provider. With our approach, security remains constant while providers change freely.

Understanding LiteLLM's Client Architecture
LiteLLM isn't a proxy or gateway — it's a client library that facilitates communication between your code and various AI providers. This distinction is important for security design.
class LiteLLMMCPClient:
"""LiteLLM client with secure MCP integration."""
def __init__(self, oauth_config: dict):
"""Initialize the LiteLLM MCP client."""
self.oauth_config = oauth_config
self.access_token = None
self.token_expires_at = 0
self.session = None
self.tools = []
self.exit_stack = AsyncExitStack()
# Configure secure HTTP client with TLS verification
ca_cert_path = oauth_config.get('ca_cert_path', None)
# Check for SSL environment variables (used by mkcert script)
ssl_cert_file = os.environ.get('SSL_CERT_FILE')
if ssl_cert_file and os.path.exists(ssl_cert_file):
ca_cert_path = ssl_cert_file
self.http_client = httpx.AsyncClient(
verify=ca_cert_path if ca_cert_path else True
)
This initialization creates a single HTTP client for all security operations. Whether you call OpenAI or Anthropic through LiteLLM, the same secure client manages OAuth and MCP communications. No duplication. No provider-specific security code.
Implementing OAuth 2.1: One Token, Many Providers
Traditional implementations might create separate OAuth flows for each provider. With LiteLLM, we implement OAuth once for MCP access, regardless of the AI provider.
async def get_oauth_token(self) -> str:
"""Obtain OAuth access token using client credentials flow."""
current_time = time.time()
# Check if we have a valid token
if self.access_token and current_time < self.token_expires_at - 60:
return self.access_token
# Request new token
response = await self.http_client.post(
self.oauth_config['token_url'],
data={
'grant_type': 'client_credentials',
'client_id': self.oauth_config['client_id'],
'client_secret': self.oauth_config['client_secret'],
'scope': self.oauth_config['scopes']
}
)
if response.status_code != 200:
raise Exception(f"OAuth token request failed: {response.text}")
token_data = response.json()
self.access_token = token_data['access_token']
# Calculate token expiration
expires_in = token_data.get('expires_in', 3600)
self.token_expires_at = current_time + expires_in
print("✅ OAuth authentication successful")
return self.access_token
- The get_oauth_token method retrieves an OAuth access token for authenticating with a protected API.
- It first checks if there's already a valid token stored (
self.access_token) and whether it's still fresh (not within 60 seconds of expiring). - If so, it returns that cached token, avoiding unnecessary network calls.
- If no valid token is available, it sends a POST request to the OAuth token URL using the client credentials flow, which is typical for machine-to-machine authentication.
- It includes the
client_id,client_secret, and desiredscopefrom a configuration object. - If the token request fails (i.e., the response status is not 200), an error with the responses' details is raised.
- If successful, it parses the token from the response and stores it for future reuse.
- It also calculates and stores the exact time the token will expire to help decide when a refresh is needed.
- Finally, it logs a success message and returns the new access token.
This design ensures efficient token reuse and reliable fallback to refresh when needed, with minimal overhead.
Notice what's missing? Provider-specific logic. This token authenticates MCP access regardless of whether LiteLLM routes to OpenAI, Anthropic, or any other model. The 60-second buffer prevents mid-request expiration, which is crucial for complex tool chains.
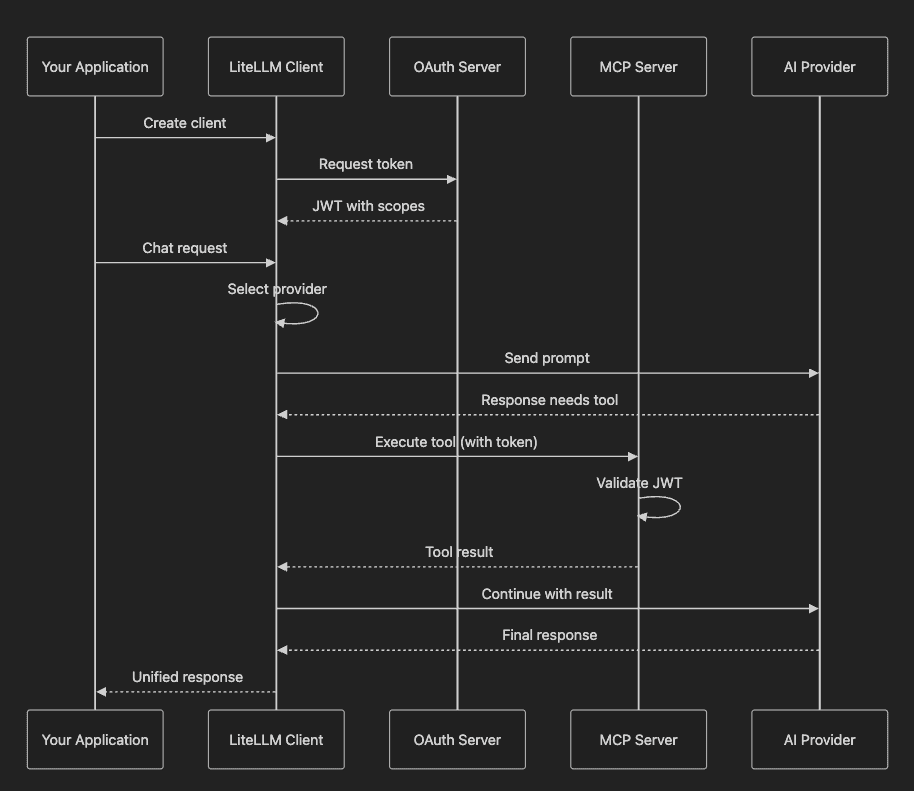
Step-by-Step Explanation:
- The application creates a LiteLLM client with OAuth configuration.
- LiteLLM Client obtains a JWT token from the OAuth server.
- The application sends a chat request without specifying a provider.
- LiteLLM selects the appropriate provider based on the configuration.
- The provider returns a response requesting tool execution.
- LiteLLM executes the MCP tool using the OAuth token.
- The MCP Server validates the JWT before executing the tool.
- The tool's result flows back through LiteLLM to the provider.
- The provider completes the response with tool data.
- The application receives a unified response format.
This flow illustrates a key point: OAuth secures MCP access, not provider communication. Provider choice stays flexible while security remains steady.
JWT Validation: Consistent Security Across Providers
JWT validation confirms that our tokens are genuine and have the correct permissions. With LiteLLM, we apply this once across all providers.
async def _verify_token_scopes(self, required_scopes: List[str]) -> bool:
"""Verify the current token has required scopes with proper JWT signature verification."""
if not self.access_token:
return False
try:
# Get the OAuth server's public key for verification
public_key_jwk = await self.get_oauth_public_key()
if public_key_jwk:
# Proper JWT verification with signature check
try:
# Convert JWK to PEM format for PyJWT
from jwt.algorithms import RSAAlgorithm
public_key = RSAAlgorithm.from_jwk(public_key_jwk)
# Verify JWT with full signature validation
payload = jwt.decode(
self.access_token,
key=public_key,
algorithms=["RS256"],
audience=self.oauth_config.get('client_id'),
issuer=self.oauth_config.get('token_url', '').replace('/token', '')
)
print("✅ JWT signature verification successful")
except jwt.InvalidTokenError as e:
print(f"❌ JWT signature verification failed: {e}")
return False
_verify_token_scopesbegins by checking ifself.access_tokenexists.- If the token is missing, it immediately returns
False, since there's nothing to validate. _verify_token_scopesthen attempts to verify the token's authenticity and integrity using the OAuth server's public key:- It calls
await self.get_oauth_public_key()to retrieve the public key in JWK format.
If a JWK is successfully retrieved:
_verify_token_scopesusesRSAAlgorithm.from_jwkto convert the JWK into a PEM-formatted key, which is required for signature verification._verify_token_scopesthen callsjwt.decode(...)with:- The
self.access_tokenas the JWT to verify. - The converted public key is used to check the signature.
- The
RS256algorithm matches the token that was signed. - An
audiencefield to ensure the token was issued for the correct client. - An
issuerfield to verify the token came from the expected authentication server (derived by removing/tokenfrom thetoken_url).
If the decode step is successful, _verify_token_scopes prints a confirmation that the JWT signature check passed.
If the JWT fails to decode or validate (e.g. wrong signature, bad audience, expired), _verify_token_scopes catches the InvalidTokenError, prints the error, and returns False.
This portion of _verify_token_scopes ensures the token was securely issued and has not been tampered with before checking the actual scopes (not shown in the provided code).
The verification continues with scope checking:
# Check scopes
token_scopes = payload.get('scope', '').split()
has_required_scopes = all(scope in token_scopes for scope in required_scopes)
if has_required_scopes:
print(f"✅ Token has required scopes: {required_scopes}")
else:
print(f"❌ Token missing scopes. Has: {token_scopes}, Needs: {required_scopes}")
return has_required_scopes
except Exception as e:
print(f"❌ Token verification error: {e}")
return False
This validation works identically whether your request goes to GPT-4o or Claude. The security layer doesn't know or care about the provider — it only validates MCP permissions.
Tool Format Standardization: One Format, All Providers
Different AI providers expect tools in other formats. LiteLLM handles this complexity, but we must prepare the MCP tools correctly.
async def setup_mcp_connection(self):
"""Set up HTTP MCP server connection."""
print("🔗 Connecting to MCP server via HTTP...")
print(f" MCP URL: {self.oauth_config['mcp_server_url']}")
try:
# Custom HTTP client factory for SSL handling
def custom_httpx_client_factory(headers=None, timeout=None, auth=None):
ssl_cert_file = os.environ.get('SSL_CERT_FILE')
verify_setting = ssl_cert_file if ssl_cert_file and os.path.exists(ssl_cert_file) else True
return httpx.AsyncClient(
headers=headers,
timeout=timeout if timeout else httpx.Timeout(30.0),
auth=auth,
verify=verify_setting,
follow_redirects=True
)
# Create HTTP MCP client with authentication
transport = await self.exit_stack.enter_async_context(
streamablehttp_client(
url=self.oauth_config['mcp_server_url'],
headers={"Authorization": f"Bearer {self.access_token}"},
httpx_client_factory=custom_httpx_client_factory
)
)
The setup_mcp_connection method starts by printing a message indicating it's attempting to connect to the MCP server over HTTP.
- It prints the MCP server URL from
self.oauth_config['mcp_server_url'] - Defines a function
custom_httpx_client_factoryto configure anhttpx.AsyncClientinstance. - Inside
custom_httpx_client_factory, it checks for an environment variableSSL_CERT_FILE. - If the cert file exists on disk, it uses it for SSL verification; otherwise, it defaults to standard verification (
True). - Returns an
httpx.AsyncClientwith optional headers, timeout, authentication, SSL verification, and redirects enabled. - Calls
streamablehttp_clientwith the MCP URL and a Bearer token in theAuthorizationheader. - Passes the custom HTTPX client factory to
streamablehttp_clientto control how the underlying HTTP client is built. - It uses await self.exit_stack.enter_async_context(...) to create and manage
transportas an async context manager.
Tool discovery and conversion happens next:
# Get available tools
list_tools_result = await session.list_tools()
print(f"📋 Found {len(list_tools_result.tools)} MCP tools")
# Convert MCP tools to OpenAI function format
self.tools = []
for tool in list_tools_result.tools:
openai_tool = {
"type": "function",
"function": {
"name": tool.name,
"description": tool.description or "",
"parameters": tool.inputSchema or {"type": "object", "properties": {}}
}
}
self.tools.append(openai_tool)
print(f"🔧 Converted {len(self.tools)} tools to OpenAI format")
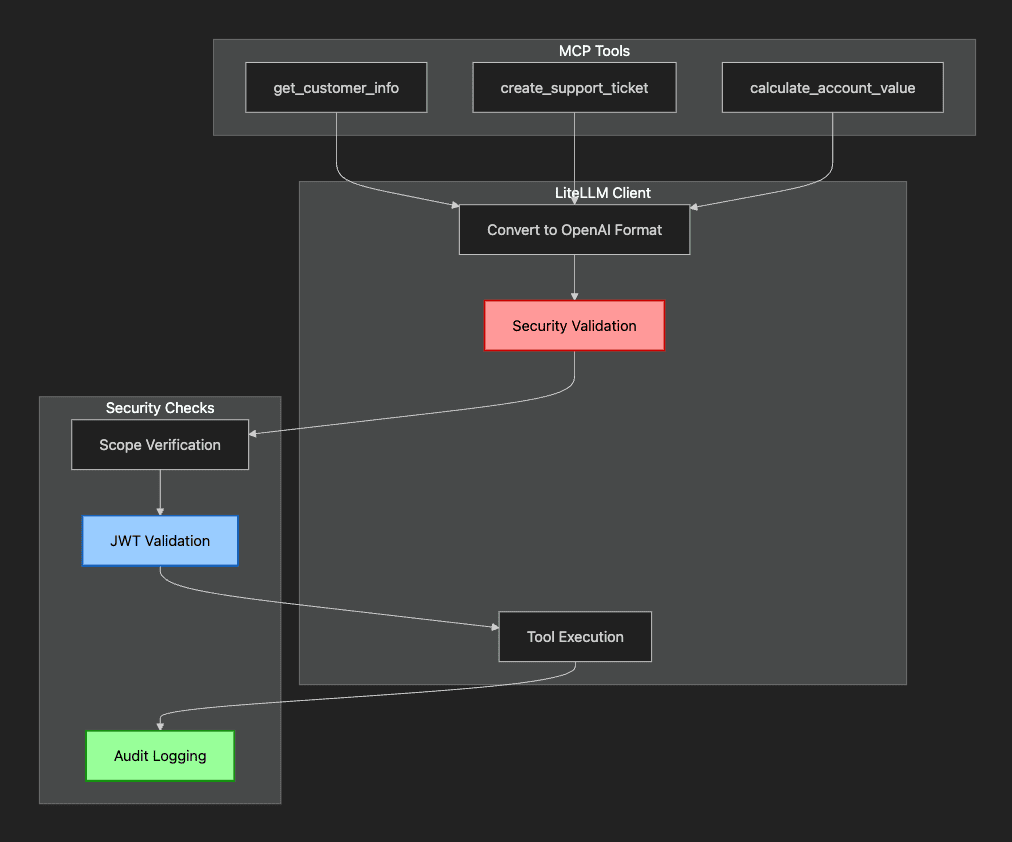
Why the OpenAI format? LiteLLM uses it as the universal standard, automatically converting to provider-specific formats internally, ensuring your security implementation remains clean and consistent.

- MCP Tools are discovered from the server.
- Convert transforms them to OpenAI function format.
- Validate checks permissions before execution.
- Scope Verification ensures token has required permissions.
- JWT Validation confirms token authenticity.
- Tool Execution happens only after security passes.
- Audit Logging records all tool usage.
Secure Tool Execution: Provider-Agnostic Implementation
When LiteLLM calls a tool, our security layer verifies permissions regardless of which AI model made the request.
async def execute_tool(self, tool_name: str, arguments: Dict[str, Any]) -> Any:
"""Execute a tool through real MCP connection with security validation."""
if not self.session:
raise Exception("MCP session not initialized")
# Verify we have required scopes for this tool
required_scopes = self._get_required_scopes(tool_name)
if not await self._verify_token_scopes(required_scopes):
raise PermissionError(
f"Insufficient permissions for {tool_name}"
)
try:
print(f" 🔧 Executing {tool_name} with {arguments}")
result = await self.session.call_tool(tool_name, arguments)
# Extract content from MCP result
if hasattr(result, 'content') and result.content:
if isinstance(result.content, list) and len(result.content) > 0:
content_item = result.content[0]
if hasattr(content_item, 'text'):
return content_item.text
else:
return str(content_item)
else:
return str(result.content)
else:
return f"Tool {tool_name} executed successfully"
except Exception as e:
print(f"❌ Tool execution failed for {tool_name}: {e}")
return f"Error executing {tool_name}: {str(e)}"
In a secure and production-ready integration between LiteLLM and MCP (Model Context Protocol), the execute_tool method functions as the operational gatekeeper, connecting intelligent function invocation with strict access control. Here's how it guarantees both smooth tool execution and airtight security:
- The method begins by enforcing that a valid MCP session (
self.session) is already initialized. If it's not, the call is halted with an immediate exception. This guards against any unauthorized or premature tool invocations. - Before any tool can be triggered, the method performs fine-grained access validation:
- It dynamically determines which OAuth scopes are required for the specified
tool_namevia_get_required_scopes(tool_name). - It then calls
_verify_token_scopesto ensure the current access token includes those scopes and that the token itself is cryptographically valid (using complete JWT signature verification). - If the token lacks the necessary permissions, a
PermissionErroris raised, stopping unauthorized access at the gate. - Once the request clears security, the method invokes the tool via
self.session.call_tool(tool_name, arguments). - It logs the execution attempt, including the tool name and its arguments, giving operators traceability and auditability.
The method gracefully parses the tool's response:
- If the result contains a
contentattribute with a non-empty list, it extracts and returns the text of the first content item. - If
contentis present but not a list or lacks atextattribute, it returns a stringified version. - If no structured content is returned, it falls back to a generic success message.
- Any unexpected errors during the tool invocation are caught, logged, and returned in a user-friendly format, ensuring system stability remains intact even during failures.
This pattern demonstrates how MCP + LiteLLM can securely and dynamically run tools in real-time, verifying access during execution, allowing detailed scopes, and safely handling various result formats. It strikes a balance between developer flexibility and enterprise-level security.
This execution path remains identical whether GPT-4o or Claude requested the tool. Security validation happens based on the tool and token, not the AI provider.
The Unified Chat Interface
LiteLLM's strength lies in its unified chat interface. One feature manages all providers while ensuring consistent security.
async def chat_with_tools(self, messages: List[Dict[str, str]], model: str = None) -> str:
"""Chat with LiteLLM using MCP tools."""
if not model:
model = Config.OPENAI_MODEL if Config.LLM_PROVIDER == "openai" else Config.ANTHROPIC_MODEL
print(f"🤖 Using model: {model}")
print(f"💬 Starting conversation with {len(self.tools)} available tools")
try:
# First call to get tool requests
response = await litellm.acompletion(
model=model,
messages=messages,
tools=self.tools if self.tools else None,
tool_choice="auto" if self.tools else None
)
# Extract the response
message = response.choices[0].message
# Check if the model made tool calls
if hasattr(message, "tool_calls") and message.tool_calls:
print(f"🔧 Model requested {len(message.tool_calls)} tool calls")
The chat_with_tools method bridges LiteLLM with MCP tools, allowing models to intelligently trigger real-world capabilities within a secure execution environment.
- If no model is specified,
chat_with_toolsselects one based on the configured provider—either OpenAI or Anthropic. - It logs which model is being used and how many tools are currently available for use in the conversation.
- The method sends a call to
litellm.acompletion, including the user messages, available tools (if any), and a dynamictool_choicesetting that lets the model decide when and what to call. - Once the response returns, it extracts the assistant's message from
response.choices[0].message. - It checks whether the model requested any tool calls by looking at the
tool_callsattribute on the message. - If tool calls are present, it logs how many tools the model attempted to use.
This architecture creates a complete feedback loop: user input goes into the model, which dynamically selects tools based on context, and execution is triggered conditionally, keeping the process both user-driven and machine-enhanced.
Tool execution follows a consistent pattern:
# Execute each tool call
for call in message.tool_calls:
print(f" ⚡ Executing {call.function.name}")
try:
# Parse arguments
arguments = json.loads(call.function.arguments)
# Execute the tool through MCP
result = await self.execute_tool(call.function.name, arguments)
# Add tool result to conversation
messages.append({
"role": "tool",
"content": str(result),
"tool_call_id": call.id
})
print(f" ✅ Tool {call.function.name} executed successfully")
except Exception as e:
print(f" ❌ Tool {call.function.name} failed: {e}")
messages.append({
"role": "tool",
"content": f"Error: {str(e)}",
"tool_call_id": call.id
})
When a model initiates tool calls through chat_with_tools, each request is securely executed and its result is injected back into the ongoing conversation:
- The method iterates over all tool calls in the model's response.
- It logs which tool is about to be executed by name.
- It parses the tool arguments from the model's response using
json.loads. - It executes the tool via
self.execute_tool, which handles permission checks and actual function invocation through MCP. - Once a tool is complete, the result is added back into the conversation as a message with role
"tool", making it available for the model in the next turn. - If the tool execution succeeds, it logs a success message.
- If execution fails for any reason (e.g., bad input, permissions issue), it logs an error and adds an error message to the conversation with the same tool call ID.
This pattern ensures a live feedback loop where models can securely trigger tool actions, observe the results, and continue the conversation, enabling real-time AI + API collaboration.
Watch the elegance: litellm.acompletion abstracts provider differences while our security layer protects tool execution. Change models freely—security remains constant.
Testing Across Providers: Verify Once, Run Anywhere
Production confidence comes from testing the same scenarios across different providers.
def _get_required_scopes(self, tool_name: str) -> List[str]:
"""Map tool names to required OAuth scopes."""
scope_mapping = {
"get_customer_info": ["customer:read"],
"create_support_ticket": ["ticket:create"],
"calculate_account_value": ["account:calculate"],
"get_recent_customers": ["customer:read"]
}
return scope_mapping.get(tool_name, [])
The _get_required_scopes method defines which OAuth scopes are needed to execute a given tool:
- It uses a dictionary called
scope_mappingto associate tool names with their required scopes. "get_customer_info"and"get_recent_customers"both require the"customer:read"scope."create_support_ticket"requires the"ticket:create"scope."calculate_account_value"requires the"account:calculate"scope.- If the provided
tool_nameisn't in the dictionary, it returns an empty list, indicating no specific scopes are required.
This scope mapping works identically for all providers. Test with GPT-4o, then switch to Claude — the same security rules apply.
Cross-Provider Testing Strategy
# Test with different models if available
models_to_test = []
if Config.LLM_PROVIDER == "openai" and Config.OPENAI_API_KEY:
models_to_test.append(Config.OPENAI_MODEL)
if Config.LLM_PROVIDER == "anthropic" and Config.ANTHROPIC_API_KEY:
models_to_test.append(Config.ANTHROPIC_MODEL)
for model in models_to_test:
print(f"\n🧪 Testing with {model}")
print("-" * 30)
for scenario in scenarios:
print(f"\n📝 Scenario: {scenario['name']}")
print(f"🙋 User: {scenario['messages'][0]['content']}")
try:
response = await self.chat_with_tools(
scenario['messages'].copy(),
model=model
)
print(f"🤖 Assistant: {response}")
except Exception as e:
print(f"❌ Error in scenario '{scenario['name']}': {e}")
This code block dynamically tests tool-based chat interactions using multiple LLM models:
- Initializes an empty list
models_to_test. - If the configured provider is
"openai"and an API key is set, it adds the OpenAI model to the test list. - If the provider is
"anthropic"and the API key is available, it adds the Anthropic model to the test list. - Iterates over each model in
models_to_testand prints a test banner with the model name. - For each model, loops through a set of predefined
scenarios. - Prints the scenario name and the user's input message.
- Calls
self.chat_with_toolsusing a copy of the scenario's messages and the current model. - Prints the assistant's response if the call succeeds.
- If an exception occurs during the test, it prints an error message specific to the scenario.
This testing loop validates that security works consistently. Each provider might format responses differently, but tool permissions remain enforced.
Production Deployment: Flexibility Without Complexity
Deploying LiteLLM with MCP security requires attention to configuration, not provider-specific code.
# OAuth configuration for production
oauth_config = {
'token_url': os.environ.get('OAUTH_TOKEN_URL', 'https://localhost:8443/token'),
'client_id': os.environ.get('OAUTH_CLIENT_ID', 'openai-mcp-client'),
'client_secret': os.environ.get('OAUTH_CLIENT_SECRET', 'openai-client-secret'),
'scopes': 'customer:read ticket:create account:calculate',
'mcp_server_url': os.environ.get('MCP_SERVER_URL', 'https://localhost:8001/mcp/'),
'ca_cert_path': os.environ.get('TLS_CA_CERT_PATH', None)
}
Notice the configuration doesn't mention providers? That's the point. Security configuration remains constant while you switch between models through environment variables.
Provider Switching Architecture
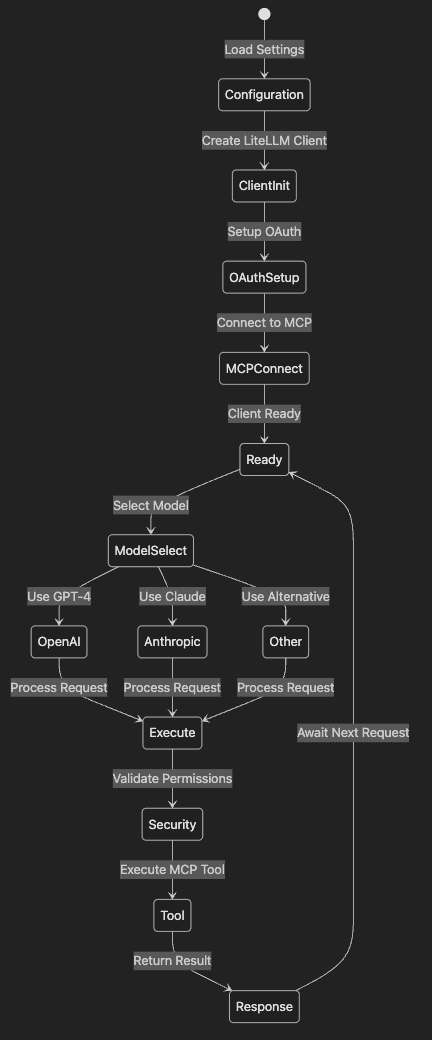
This diagram represents the end-to-end flow of how an AI assistant securely handles tool-augmented conversations using LiteLLM and MCP integration.
The process begins with configuration, where environment settings, API keys, and model options are loaded. Once configured, a LiteLLM client is initialized and OAuth authentication is set up to ensure all future actions are authorized and secure. After obtaining valid credentials, the assistant connects to the MCP server, establishing a live channel for interacting with tools.
Once connected, the assistant enters a ready state and waits for user input. When a request comes in, it selects the appropriate large language model based on the configuration, whether GPT-4, Claude, or another provider.
The selected model processes the user's message. If the model determines that a tool needs to be used, the assistant validates whether the current session has the required permissions to access that tool. This includes checking OAuth scopes and verifying the token's integrity.
The assistant executes the tool through the MCP connection if access is granted. The result of the tool's execution is then returned as part of the model's response. After completing the interaction, the assistant resets to a ready state, prepared to handle the next request.
This flow enables secure, context-aware, and interactive tool usage, tightly coupled with modern LLMs and grounded in enterprise-grade access control.
Step-by-Step Explanation:
- System starts with Configuration loading
- ClientInit creates LiteLLM client with security settings
- OAuthSetup obtains authentication token
- MCPConnect establishes secure MCP connection
- Ready state awaits requests
- ModelSelect chooses provider based on config
- Provider selection leads to Execute state
- Security validates all tool requests identically
- Tool execution happens after validation
- Response returns through same secure path
This architecture shows how provider switching happens at runtime without affecting security flow.
Advanced Patterns: Provider Failover with Security
LiteLLM enables sophisticated patterns like automatic provider failover while maintaining security.
async def run_demo(self):
"""Run a comprehensive demo of LiteLLM with MCP tools."""
print("🚀 Starting LiteLLM MCP Demo")
print("=" * 50)
try:
# Set up OAuth authentication
await self.get_oauth_token()
# Connect to real MCP server
await self.setup_mcp_connection()
# Test scenarios
scenarios = [
{
"name": "Customer Account Calculation",
"messages": [
{
"role": "user",
"content": "Customer CUST67890 recently made purchases of $150, $300, $13 and $89. Calculate their total account value and check if they qualify for premium status (>$500)."
}
]
},
{
"name": "User Information Lookup",
"messages": [
{
"role": "user",
"content": "Look up information for customer 'JOHNDOE123' and tell me about their account status."
}
]
}
]
The run_demo method orchestrates a comprehensive demonstration of using LiteLLM with MCP-integrated tools in a secure, end-to-end workflow.
It begins with clear logging to indicate the start of the demo, helping users and developers understand that the system is entering its full lifecycle test. The method initiates OAuth authentication by calling get_oauth_token, which ensures that all subsequent actions are securely authorized with a valid access token.
Next, it connects to the MCP server using setup_mcp_connection, establishing the necessary communication channel for tool execution. Once the environment is authenticated and connected, it defines a set of demo scenarios designed to test real-world use cases:
- The first scenario simulates a customer account value calculation, where the assistant processes transaction data to determine premium status.
- The second scenario tests a user lookup flow, in which the assistant retrieves and interprets customer account information.
These scenarios illustrate how natural language input can dynamically trigger secure, model-driven interactions with business tools, demonstrating the power and flexibility of combining LiteLLM, OAuth, and MCP into one cohesive assistant experience.
Real-World Benefits: The Provider Migration Story
Consider this scenario from production experience:
The Challenge: A financial services company built their customer service system using GPT-4. After six months, they needed to switch to Claude for compliance reasons. Their original implementation had OpenAI-specific security code throughout.
Traditional Approach Problems:
- Rewrite security layer for Anthropic's API
- Update all tool definitions to Claude's format
- Retest entire security implementation
- Risk introducing new vulnerabilities
LiteLLM Solution:
- Change one environment variable
- Security implementation unchanged
- Tool definitions unchanged
- Testing confirms identical behavior
The migration took hours instead of weeks. Security remained bulletproof throughout.
Performance Considerations
Does abstraction add overhead? Let's examine the metrics:
# Check for SSL environment variables
ssl_cert_file = os.environ.get('SSL_CERT_FILE')
if ssl_cert_file and os.path.exists(ssl_cert_file):
ca_cert_path = ssl_cert_file
self.http_client = httpx.AsyncClient(
verify=ca_cert_path if ca_cert_path else True
)
This configuration creates one HTTP client for all operations. Connection pooling and session reuse minimize overhead.
The abstraction cost proves minimal compared to network latency and model processing time.
Best Practices for Secure LiteLLM Deployment
Based on production experience, follow these guidelines:
Single Security Implementation: Implement OAuth, JWT, and TLS once at the LiteLLM client level. Resist the temptation to add provider-specific security.
Configuration-Driven Provider Selection: Use environment variables or configuration files to select providers. Keep provider logic out of security code.
Consistent Error Handling: LiteLLM normalizes provider errors. Handle them uniformly rather than checking provider types.
Test with Multiple Providers: Always test security scenarios with at least two providers to verify consistency.
Monitor Provider-Agnostic Metrics: Track security events without provider attribution. Patterns matter more than which model triggered them.
Conclusion: Security Through Simplification
LiteLLM's promise of "write once, run anywhere" extends beautifully to security. By implementing OAuth 2.1, JWT validation, and TLS encryption at the client library level, we create security that transcends provider boundaries.
The key insight? Security belongs with your application logic, not scattered across provider integrations. LiteLLM enables this separation, making your code both more secure and more maintainable.
As you build AI applications, remember that provider lock-in extends beyond APIs — it includes security implementations. LiteLLM breaks these chains, giving you freedom to choose providers based on performance, cost, or compliance while maintaining enterprise-grade security.
For complete implementations and runnable examples, explore the mcp_security repository. The patterns shown here provide a foundation for building AI systems that are secure, flexible, and future-proof.
Securing MCP: From Vulnerable to Fortified
The foundational security guide for MCP that this DSPy integration builds upon.
Securing LangChain's MCP Integration: Agent-Based Security for Enterprise AI
Compare agent-based security approaches with DSPy's programmatic model.
Complete Implementation Repository
The repository includes all code examples, Docker configurations, test suites, and LiteLLM, LangChain, and DSPy implementations for comparison.
Other articles by Rick Hightower
- LangChain and MCP: Building Enterprise AI Workflows
- The LLM Cost Trap and the Playbook to Escape It
- Stop Wrestling with Prompts: How DSPy Transforms Fragile AI
- Is RAG Dead?: Anthropic Says No
About the Author
Rick Hightower brings extensive enterprise experience as a former executive and distinguished engineer at a Fortune 100 company, where he specialized in Machine Learning and AI solutions to deliver intelligent customer experiences. His expertise spans both theoretical foundations and practical applications of AI technologies.
As a TensorFlow-certified professional and graduate of Stanford University's comprehensive Machine Learning Specialization, Rick combines academic rigor with real-world implementation experience. His training includes mastery of supervised learning techniques, neural networks, and advanced AI concepts, which he has successfully applied to enterprise-scale solutions.
With a deep understanding of both business and technical aspects of AI implementation, Rick bridges the gap between theoretical machine learning concepts and practical business applications, helping organizations leverage AI to create tangible value.
Follow Rick on LinkedIn or Medium for more enterprise AI and security insights.