Superpowers: From Hope It Works to 'Prove It Works': The Verification Fix for AI Code
Superpowers/GSD: Goal-Backward Verification and the End of AI Hallucinations — Revolutionizing AI Development: From Trusting Outputs to Proving Correctness
Originally published on Medium.
Superpowers/GSD: Goal-Backward Verification and the End of AI Hallucinations — Revolutionizing AI Development: From Trusting Outputs to Proving Correctness
Article 5 of 5 in the Agentic Engineering series
Your AI agent just marked the ticket 'Done.' The commit message is perfect. The code compiles. But when you run the app… the bug is still there. That's the verification gap — and you can close it.
Summary: AI coding agents can complete tasks confidently while still shipping code that compiles but doesn't solve the real problem. This article shows how modern agentic frameworks close the verification gap with systematic debugging, goal-backward verification, two-stage review, and MCP-powered autonomous testing; shifting AI-assisted development from 'hope it works' to 'prove it works.'"
Your AI agent just marked the ticket Done.
The commit message is perfect.
The code compiles.
But when you run the app… the bug is still there.
That's the verification gap: AI can produce changes that look correct (and even pass a quick skim) without ever proving the goal was achieved.
This article is a practical tour of the verification layer modern agentic frameworks add — so "done" means verified, not "I changed some files and it compiled." Throughout this series, we have explored how agentic engineering frameworks transform AI chatbots into disciplined engineering partners. We have covered Superpowers' structured workflow, the framework showdown between competing approaches, context engineering strategies that prevent context rot, and GSD's spec-driven development methodology. All of those innovations share one critical dependency: none of them matter if the AI's work is not actually verified.
This final article examines how modern agentic frameworks close the verification gap, moving from "trust the AI" to "prove the AI's work is correct."
The Placeholder Problem
AI language models exhibit a category of failure that software engineers have learned to dread: confident incorrectness. The model does not say "I don't know how to implement this." It generates something that looks right. It compiles. It might even pass a superficial review. But it does not actually work.
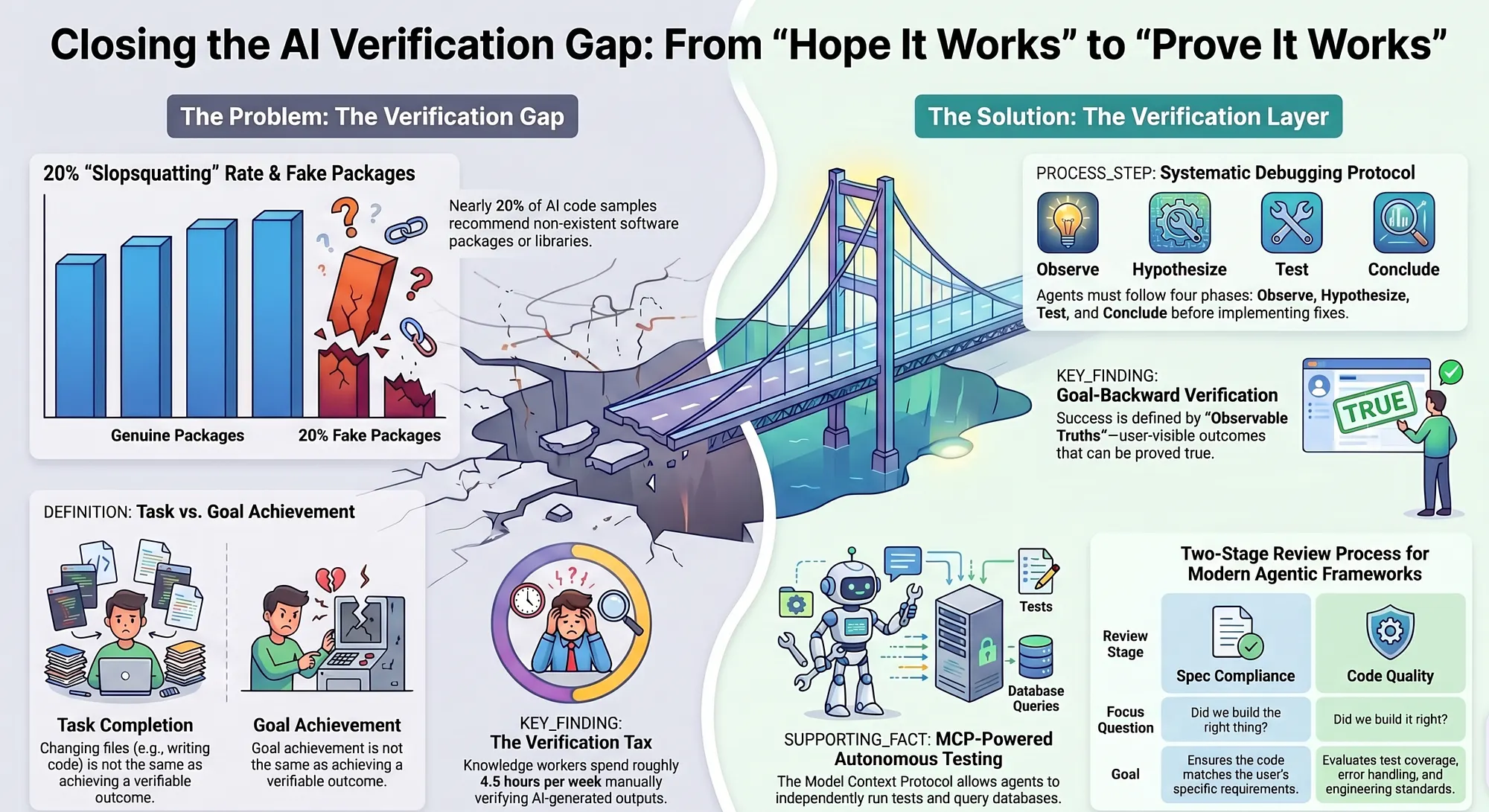
The most visible form is the placeholder problem. Ask an AI to implement a complex function, and you may get back code that includes comments like // rest of the implementation here or // TODO: handle edge cases. The model fills in the easy parts and leaves stubs where the hard logic should go. In a 2025 study of 16 code-generation models across 576,000 code samples, researchers found that nearly 20% of samples recommended packages that do not exist, a phenomenon now called "slopsquatting." The model generates a plausible-looking import statement for a library it hallucinated.

But placeholders are just the most obvious symptom. The deeper problem is that AI models can fabricate function calls to internal APIs that do not exist. They can generate test cases that do not actually test the behavior described in the test name. They can write documentation that describes behavior the code does not implement. And they can do all of this with high confidence and zero indication that anything is wrong.
These failures share a common root: the model optimizes for plausibility, not correctness. A model trained on code examples learns that functions are usually followed by implementations, that imports reference real packages, and that test assertions match test names. It generates code that matches these statistical patterns. It does not verify whether the generated code actually works.
Knowledge workers spend approximately 4.3–4.5 hours per week verifying AI outputs, according to a 2024 MIT survey. That's an entire workday lost to catching AI mistakes — and this figure comes from teams that are already aware of the problem and actively checking. Teams that trust AI output without verification are shipping bugs at a much higher rate.
The Verification Gap in Traditional AI Workflows
Traditional AI coding workflows operate on a task-completion model. The developer describes a task. The AI generates code. The developer reviews the code and, if it looks reasonable, merges it. The workflow is designed to produce code, not to verify that the code works.
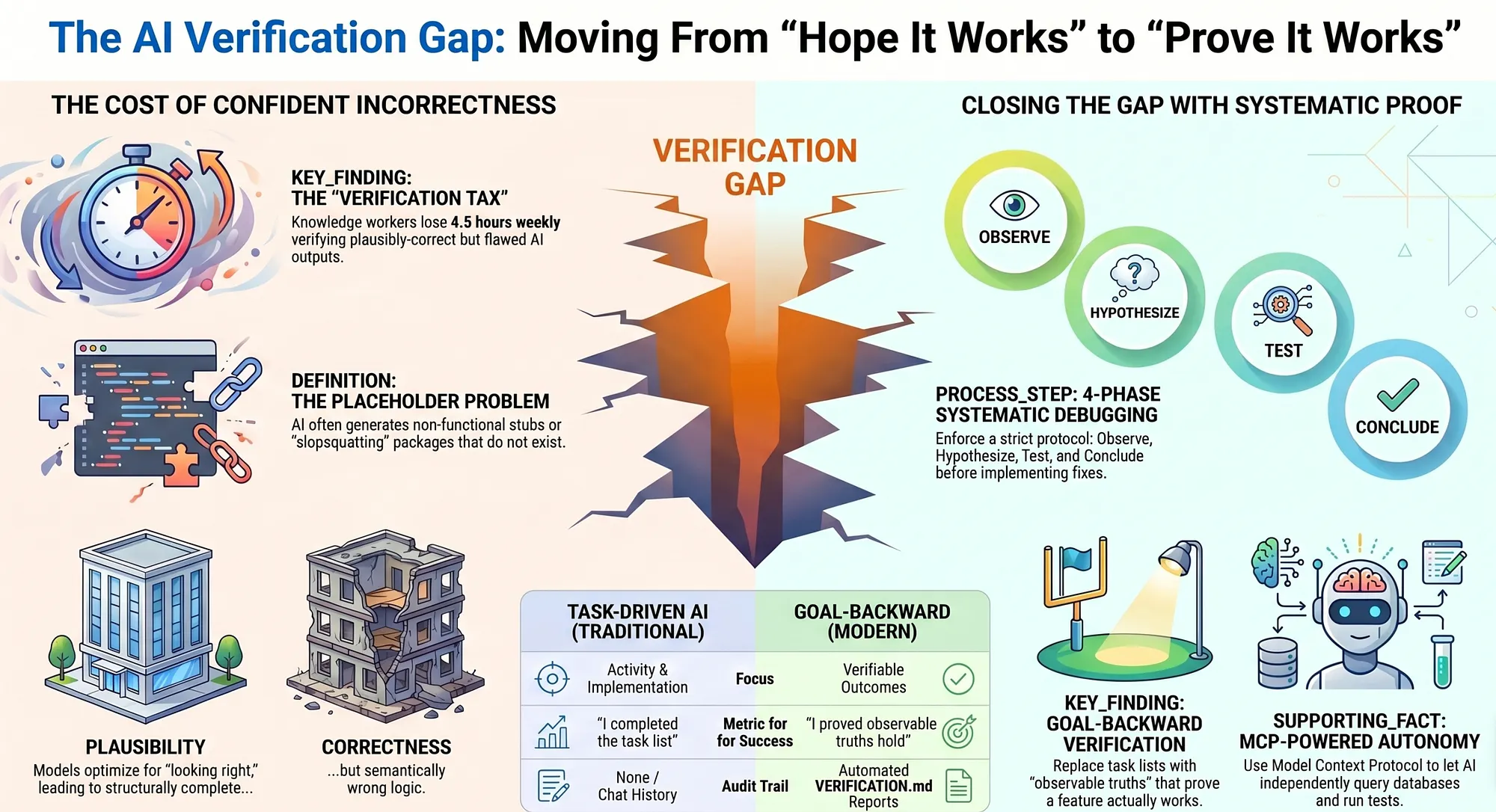
This model has a fundamental flaw: task completion and goal achievement are not the same thing. An AI agent can complete every item on a task list while still failing to achieve the underlying goal.
Consider a feature request: "Add user authentication with email and password." An AI agent might complete tasks like "create a User model," "add a login endpoint," "add a registration endpoint," and "add JWT token generation." Every task is done. The code compiles. The tests pass.
But does authentication actually work? Can a user register, receive a confirmation email, log in, maintain a session across requests, and log out securely? Can the system handle incorrect passwords, expired tokens, and concurrent login attempts? These are the questions that matter, and they are not answered by a task list.

The task list cannot answer these questions because the tasks describe implementation steps, not observable behaviors. A task like "add JWT token generation" is complete as soon as the code exists, regardless of whether the tokens are correctly signed, properly scoped, or actually validated on protected endpoints.
The verification gap is not a theoretical concern. In academic publishing, GPTZero found that AI-generated content had a 35% error rate for citations and references. In software development, the gap manifests as code that compiles but has logic errors, tests that pass but don't actually test the specified behavior, and integrations that work in isolation but fail in production.

The frameworks examined in this series address this gap through two complementary approaches: preventing agents from applying unverified fixes (the systematic debugging protocol) and requiring agents to define and check observable behaviors before declaring work complete (goal-backward verification).
Superpowers' Systematic Debugging Protocol
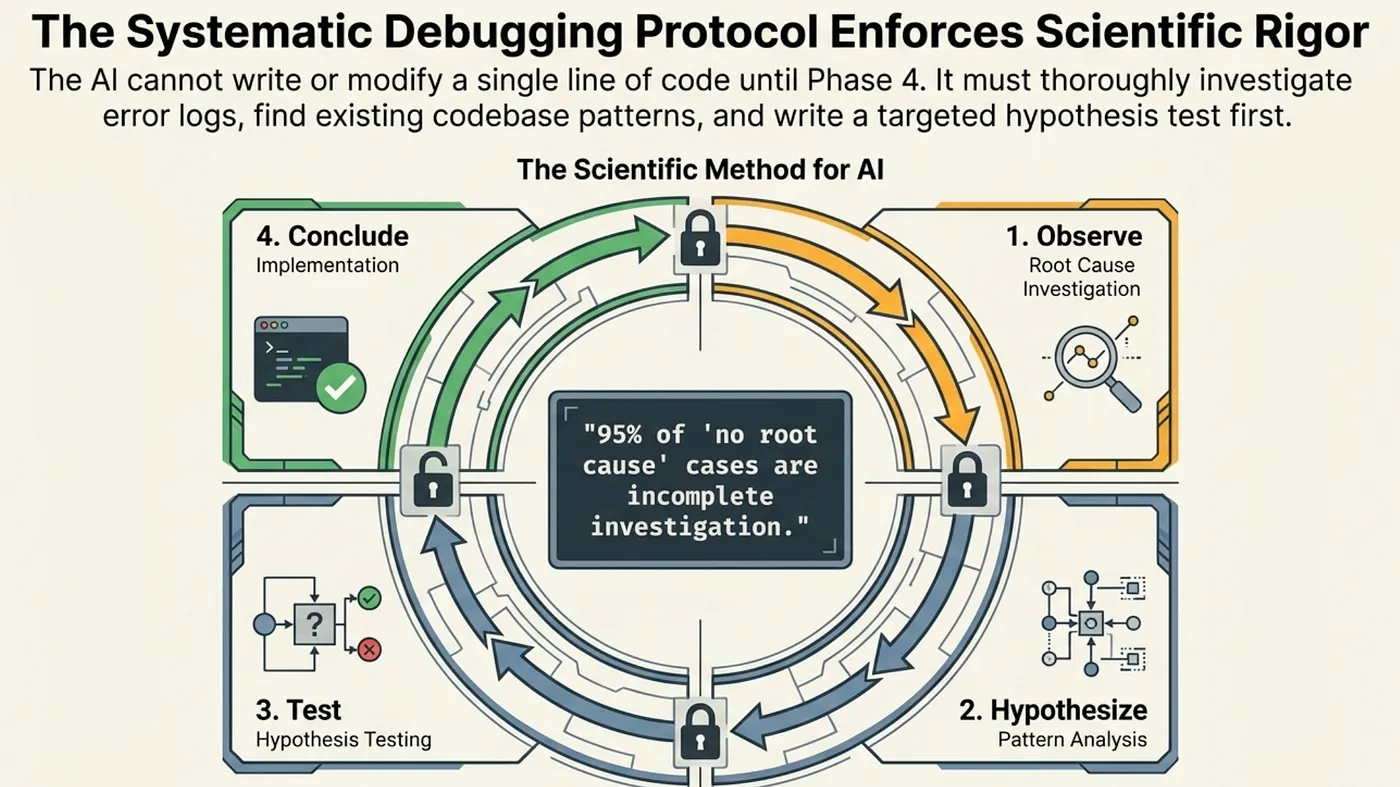
The first line of defense against AI hallucinations is preventing the agent from applying speculative fixes. Superpowers enforces a four-phase scientific debugging protocol that requires the agent to understand a bug before attempting to fix it.
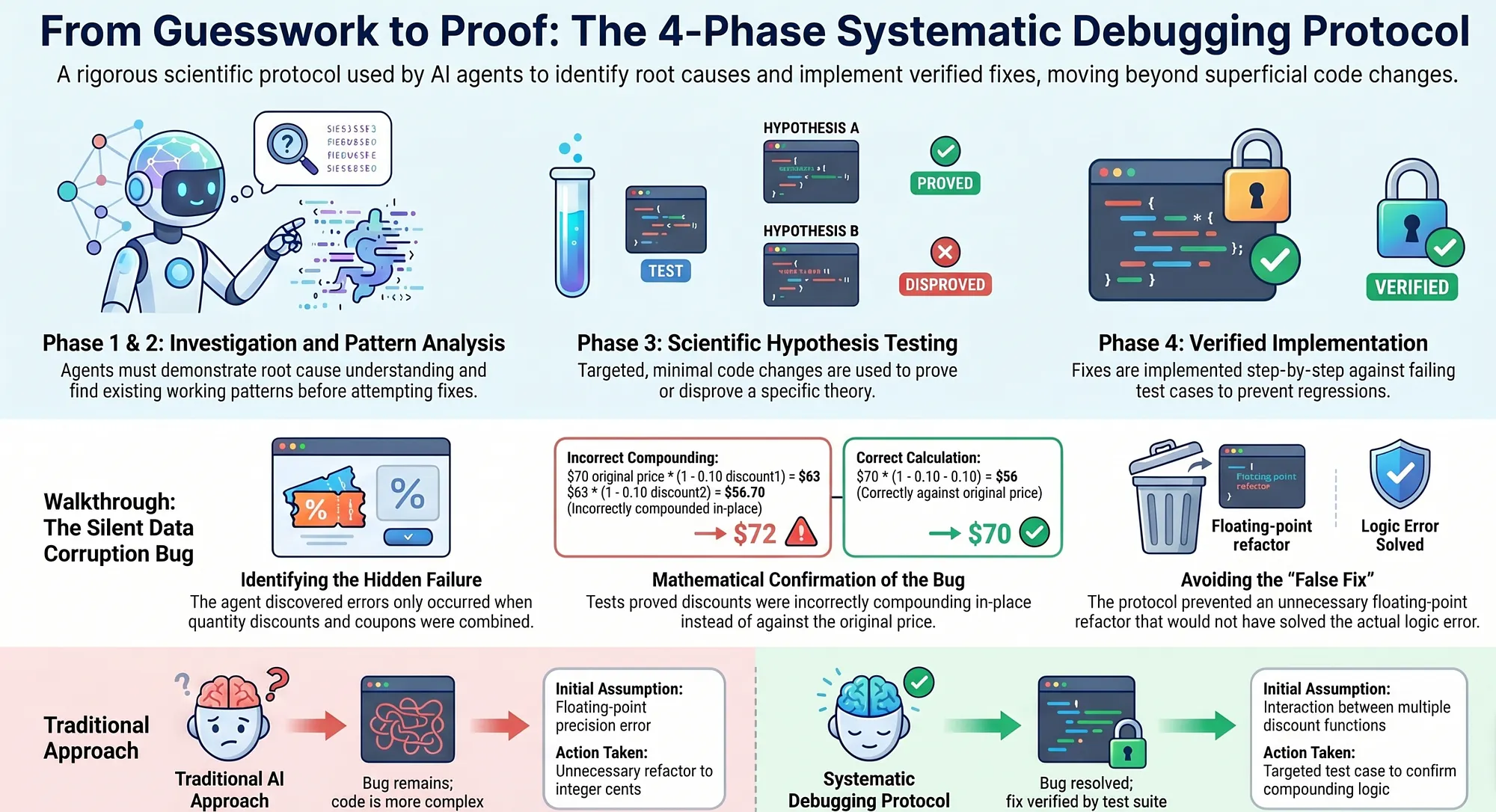
The four phases are:
Phase 1: Root Cause Investigation (Observe). The agent reads the error message, stack trace, and surrounding context. It reproduces the failure with a specific test case. It does not hypothesize. It gathers data.
Phase 2: Pattern Analysis (Hypothesize). The agent searches the codebase for similar patterns. It identifies all code paths that could produce the observed failure. It forms a ranked list of hypotheses.
Phase 3: Hypothesis Testing (Test). The agent forms a specific theory about the root cause and tests it. This might mean writing a minimal reproduction case, adding temporary logging, or tracing the execution path. The agent must confirm the hypothesis before proceeding.
Phase 4: Implementation (Conclude). Only after the root cause is confirmed does the agent modify production code. The fix targets the confirmed root cause, not the symptom.
A Debugging Walkthrough: The Silent Data Corruption Bug
To see why this protocol matters, consider a real-world scenario. A team's e-commerce platform has a bug: order totals are occasionally incorrect. The bug is intermittent and difficult to reproduce.
A bare AI agent, given the bug report "order totals are sometimes incorrect," would likely search for the most common cause of calculation errors in e-commerce systems: floating-point precision. It would find a discount calculation and "fix" it by replacing floating-point arithmetic with decimal arithmetic. The tests pass. The bug report is closed.
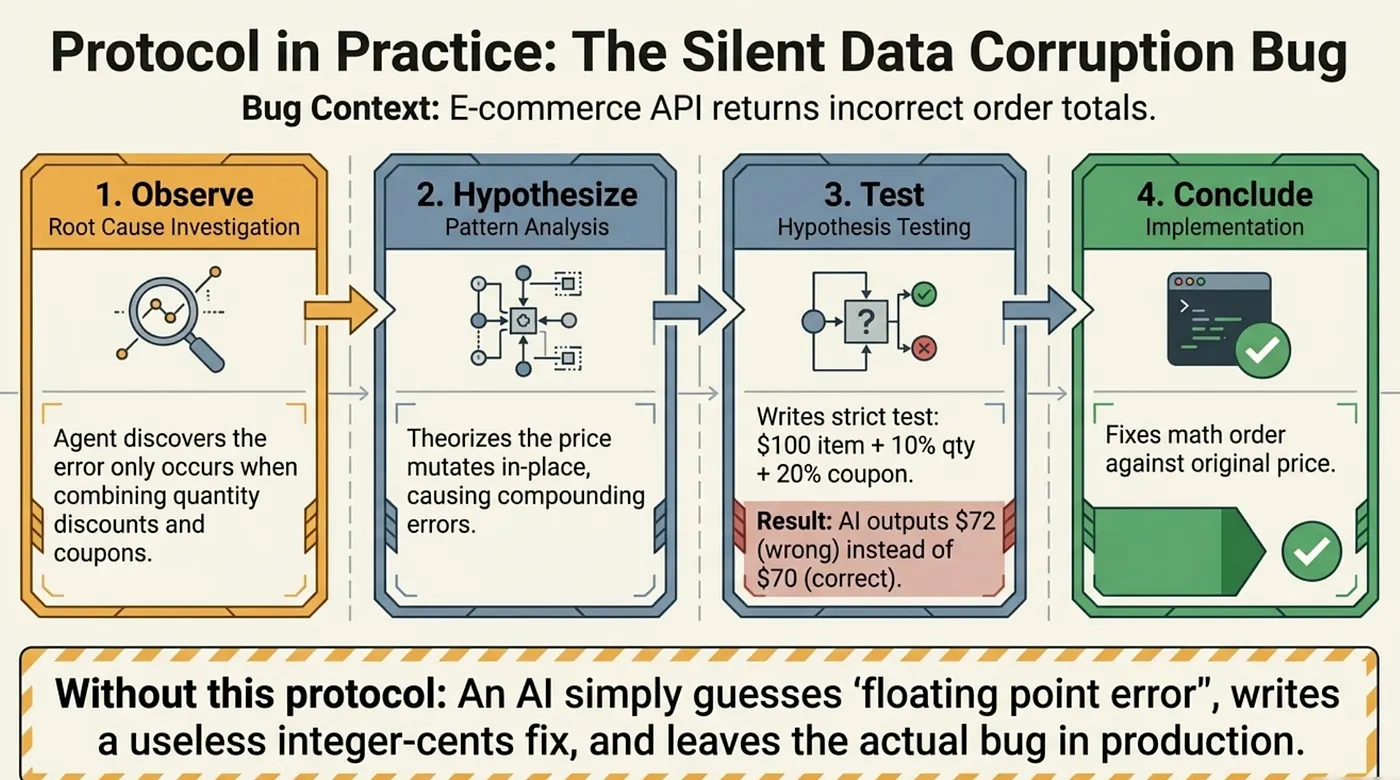
But the actual bug has nothing to do with floating-point precision. Here is how the protocol would discover the real root cause:
Observe: The agent reproduces the failure with specific test cases. It discovers that incorrect totals only occur when both a percentage discount and a quantity discount are applied to the same order. It documents the exact inputs that trigger the failure.
Hypothesize: The agent searches the codebase and finds two discount functions: applyPercentageDiscount and applyQuantityDiscount. It identifies three possible causes: the functions are applied in the wrong order, one function does not account for the other's calculation, or there is a rounding error at the combination step.
Test: The agent writes a minimal test case with a $100 item, a 10% quantity discount, and a 15% percentage discount. Applied in order A, the total is $76.50. Applied in order B, the total is $75.65. The production code applies them in order B, but the business rule requires order A. The hypothesis is confirmed.
Conclude: The agent fixes the discount application order to calculate both discounts correctly, adds regression tests for all discount combinations, and documents the business rule in the function comments.
Without the protocol, the agent would have shipped a floating-point "fix" that changed nothing about the bug while introducing subtle rounding behavior in the discount system. The original bug would have continued to produce incorrect totals. The "fix" would have made future debugging harder.
The framework enforces these phases sequentially. The agent must complete each phase before proceeding to the next. It cannot skip "Observe" and jump to "Conclude." This is not just good practice — it is a hard constraint that prevents the most common failure mode in AI-assisted debugging.
GSD's Goal-Backward Verification
While Superpowers prevents false fixes during debugging, GSD (Get "Stuff" Done) addresses a different but related problem: how do you know that a completed feature actually works?
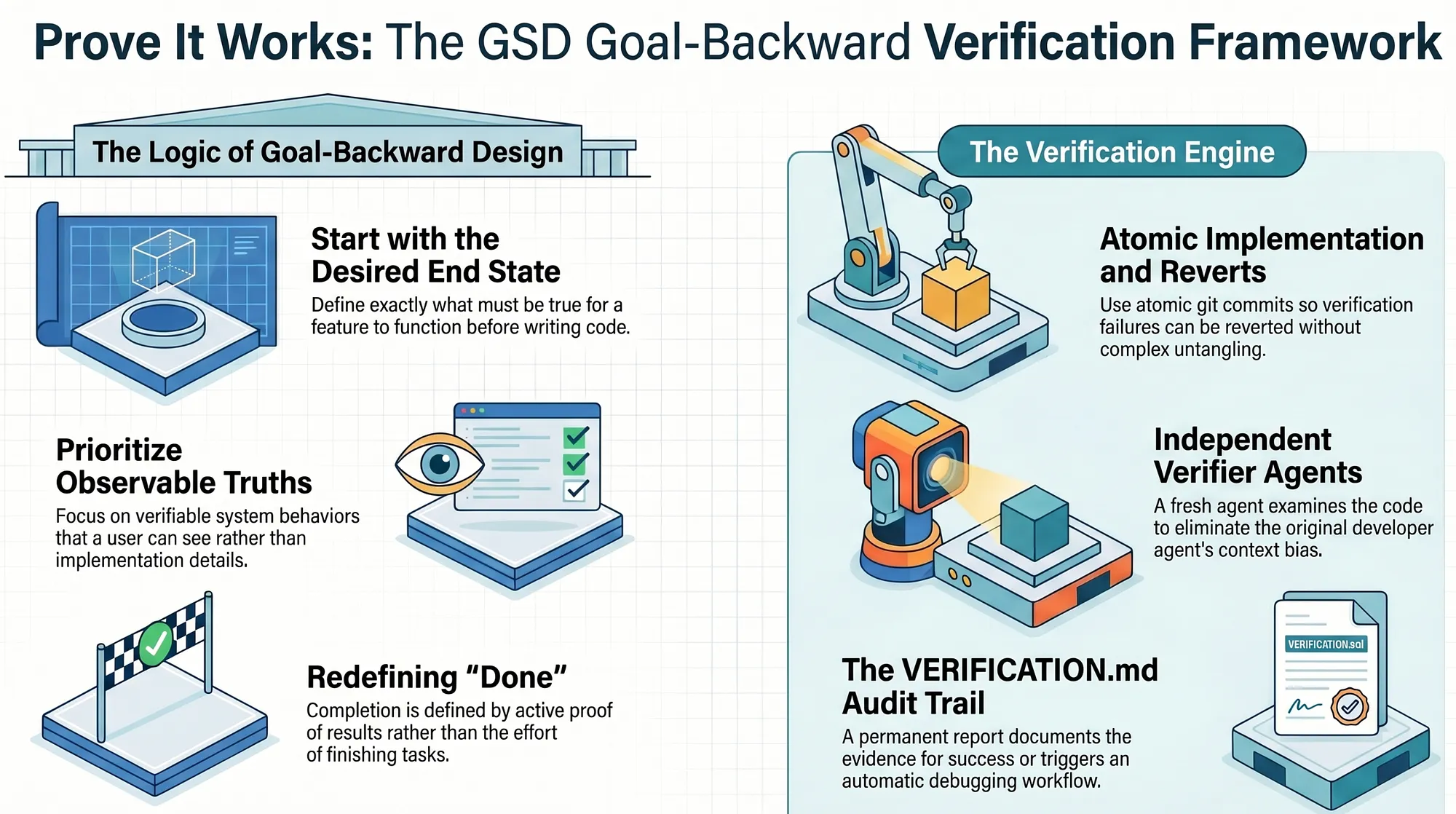
GSD's answer is goal-backward verification, a methodology that inverts the traditional task-forward approach. Instead of starting with "what needs to be built" and working forward to completion, goal-backward verification starts with "what must be observable if this goal is achieved" and works backward to implementation.
The process begins with a single question: "What must be TRUE for this goal to be achieved?" This is not a question about tasks or implementation steps. It is a question about observable reality. For the user authentication feature, the answer might include: "A user can register with a valid email and password and receive a confirmation," "A user with valid credentials can log in and receive a session token," "A user with a session token can access protected resources," and "A session token expires after the configured timeout."
For each goal, the GSD planner generates three to seven "observable truths," statements about the world that can be verified through direct observation. These are distinct from tasks (which describe actions) and from tests (which describe code behavior). An observable truth describes user-visible, system-measurable outcomes.
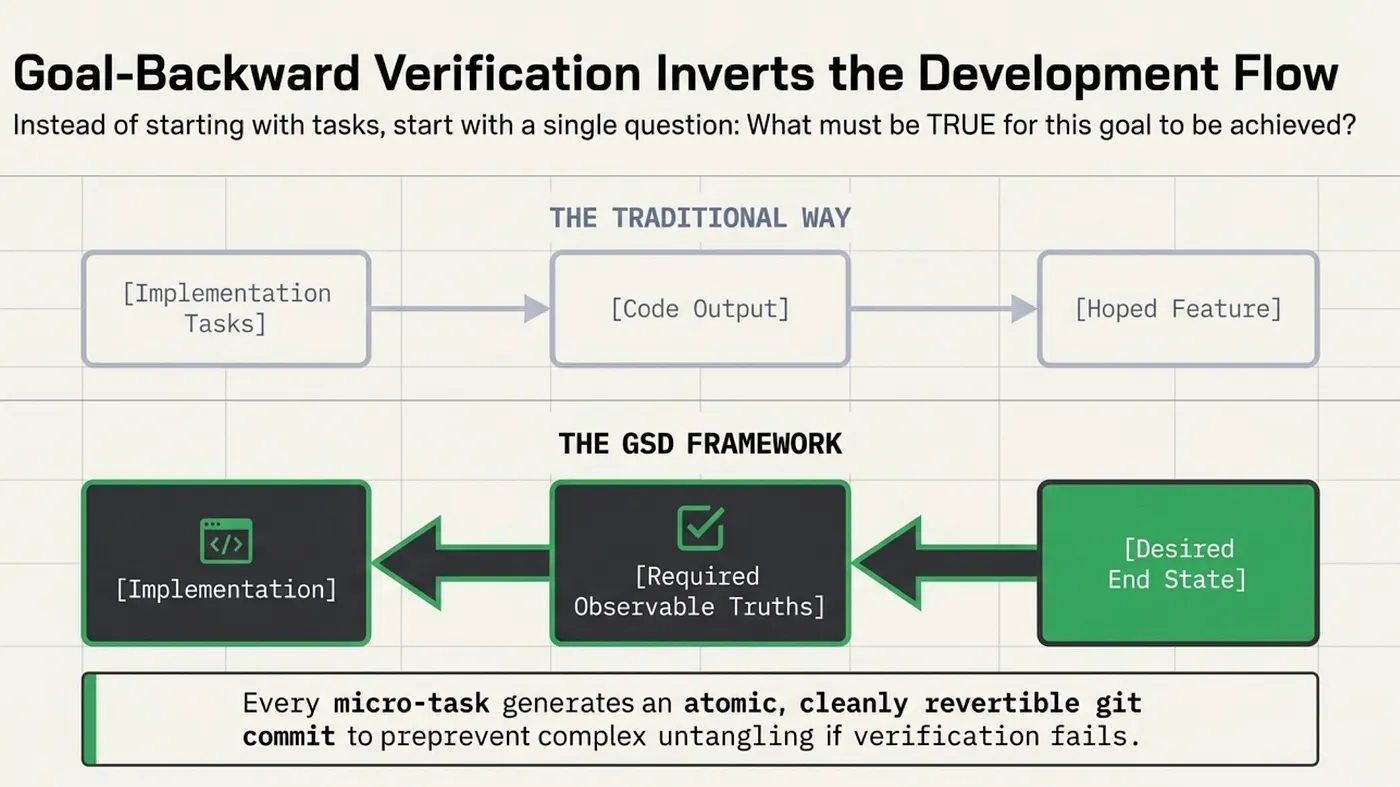
This distinction matters because observable truths are inherently verifiable. You can check whether a user can register by attempting registration. You can check whether a token expires by waiting for the timeout and attempting access. You cannot "check" whether a task was completed without running the code.
GSD's verification system operates at multiple levels. During execution, each milestone includes a verification step that confirms the agent's work against the observable truths defined at planning time. This is not optional post-processing — it is part of the execution loop.
After execution, a dedicated verifier agent checks the codebase against the phase goal. The verifier agent is separate from the implementation agent, providing independent review. It reads the observable truths, executes verification steps, and produces a structured report.
If verification passes, the verifier creates a VERIFICATION.md file that documents what was verified, how it was verified, and the result of each verification step. This file becomes the audit trail for the feature.
VERIFICATION.md: The Audit Trail
Here is what a GSD verification report looks like in practice:
# VERIFICATION.md - User Authentication Feature
## Phase Goal
Users can register, log in, maintain sessions, and log out securely.
## Observable Truths Verified
### Truth 1: Registration creates a valid user account
- **Method**: POST /api/auth/register with valid email and password
- **Evidence**: HTTP 201 response, user record exists in database
- **Result**: PASS
- **Commit**: a3f8b2c
### Truth 2: Login returns a valid session token
- **Method**: POST /api/auth/login with registered credentials
- **Evidence**: HTTP 200 response with JWT token, token decodes with correct claims
- **Result**: PASS
- **Commit**: d7e1f4a
### Truth 3: Invalid credentials are rejected
- **Method**: POST /api/auth/login with wrong password
- **Evidence**: HTTP 401 response, no token issued, attempt logged
- **Result**: PASS
- **Commit**: d7e1f4a
### Truth 4: Sessions expire after configured timeout
- **Method**: Use token after TTL expiration
- **Evidence**: HTTP 401 response with "token expired" message
- **Result**: PASS
- **Commit**: b2c9e5f
### Truth 5: Rate limiting prevents brute force attacks
- **Method**: Send 10 login attempts in 5 seconds
- **Evidence**: HTTP 429 after 5th attempt, 60-second lockout confirmed
- **Result**: PASS
- **Commit**: f1a3d8e
## Verification Summary
- **Truths Verified**: 5/5
- **Tests Added**: 12 unit tests, 5 integration tests
- **Verifier Agent**: gsd-verifier-auth-2026-03-11
- **Verification Date**: 2026-03-11T14:32:00Z
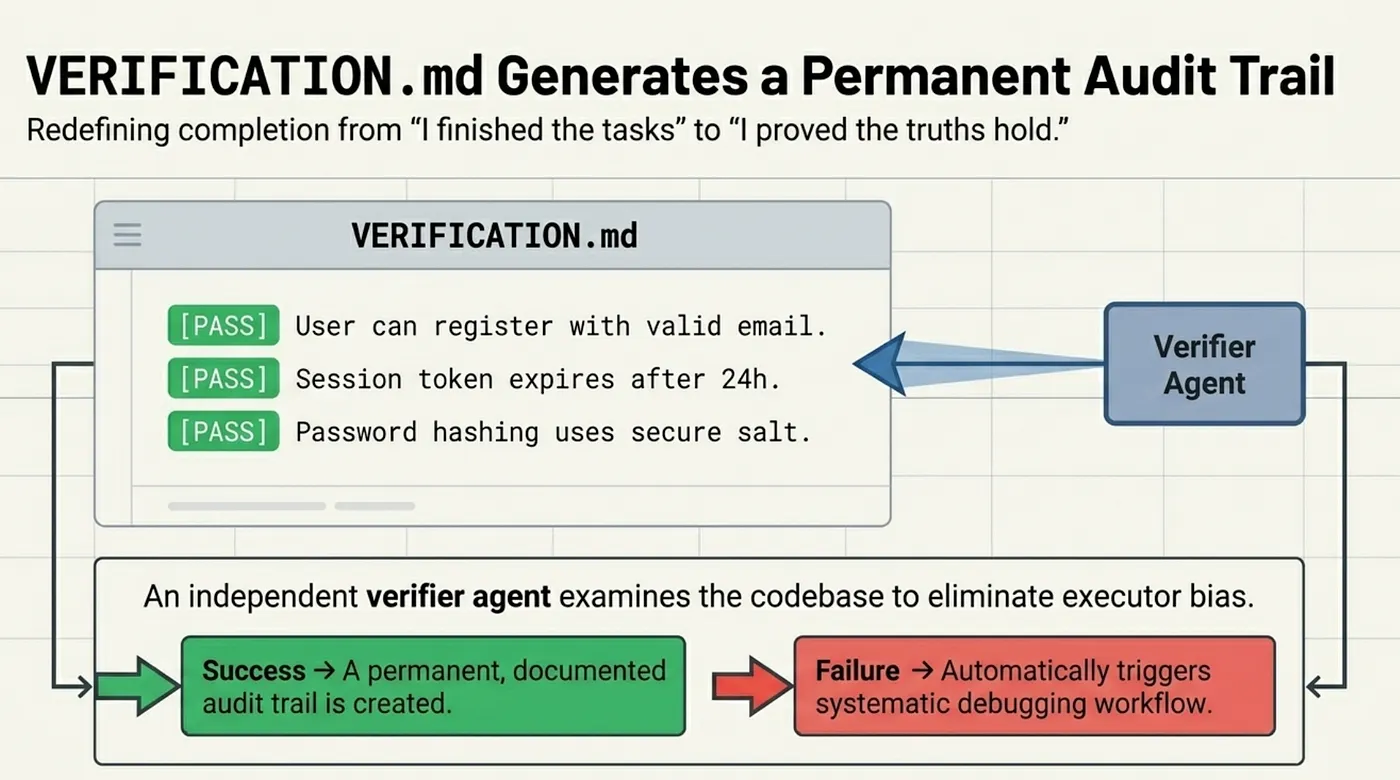
The goal-backward approach fundamentally changes what "done" means. In a task-driven workflow, "done" means all tasks are checked off. In goal-backward verification, "done" means all observable truths have been confirmed through direct verification. The difference is the difference between "I wrote the code" and "I proved the code works."
Model Context Protocol as Verification Infrastructure
Verification requires more than methodology. It requires infrastructure. An AI agent that must verify its work needs the ability to run tests, query databases, send HTTP requests, inspect logs, and parse the results — all within a single execution context.
This is where the Model Context Protocol (MCP) transforms verification from a manual process to an autonomous one.
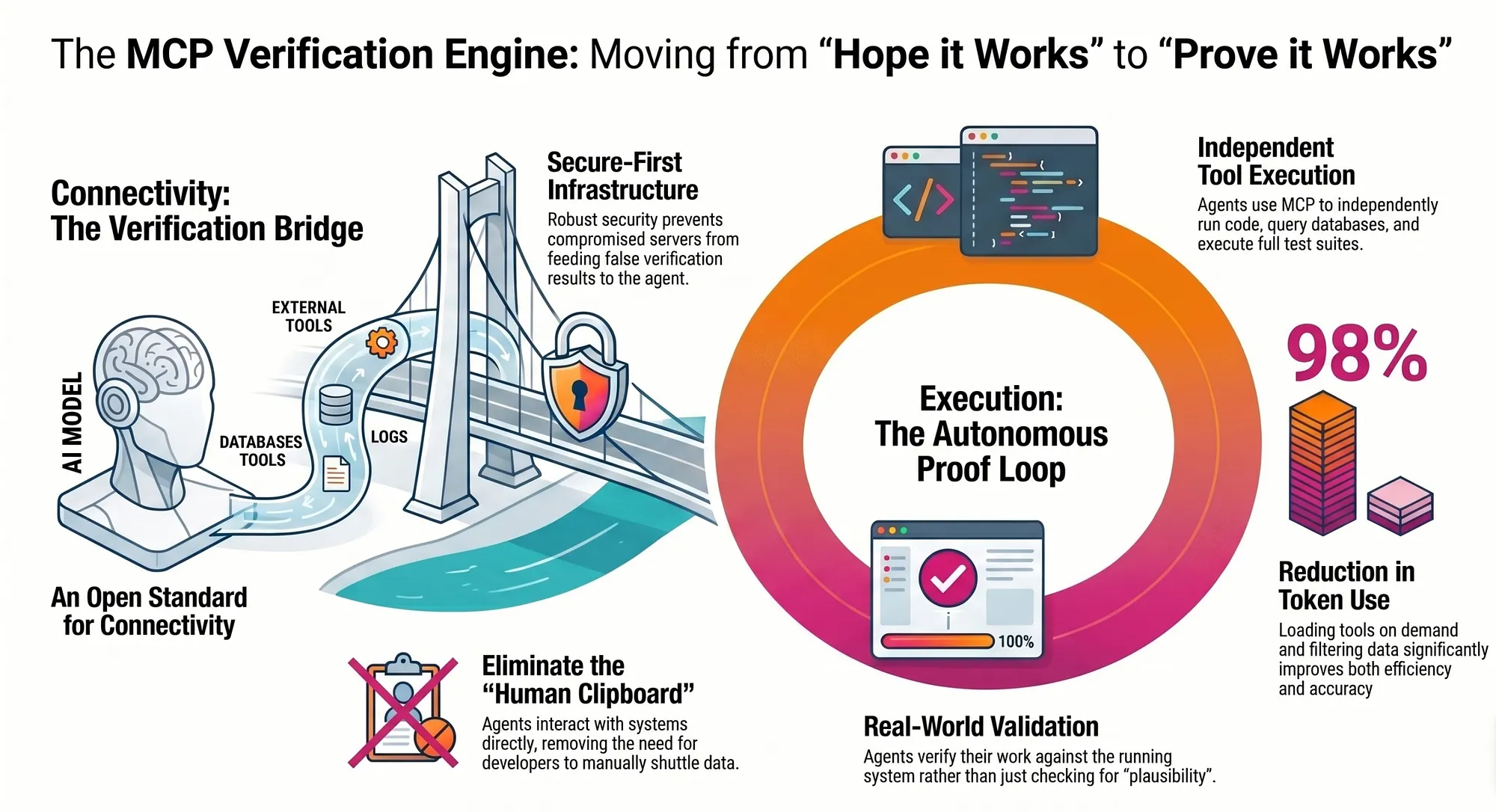
MCP, introduced by Anthropic in November 2024 and donated in December 2025 to the Linux Foundation as an open standard, provides a standardized interface for AI agents to interact with external tools and services. Before MCP, an AI agent that needed to run a test suite had to generate a command, present it to the developer, wait for the developer to run it, and receive the output through some out-of-band channel (usually a copy-paste in the chat). This is slow, error-prone, and inherently non-autonomous.
For verification, MCP matters because it gives AI agents the ability to execute verification steps directly, observe results, and iterate without human involvement in the loop. An agent with MCP access to a test runner can run the test suite, parse the results, identify failing tests, hypothesize causes, make changes, and run the suite again — all in a single execution.
MCPs can be combined with Agent Skills that can describe how to perform certain operations. Agent Skills are added to the context on how to use MCP effectively and carry out tasks in a standard manner.
Configuring MCP for Verification
A typical verification-focused MCP configuration connects the agent to the tools it needs:
{
"mcpServers": {
"test-runner": {
"command": "npx",
"args": ["-y", "@mcp/test-runner"],
"env": {
"TEST_FRAMEWORK": "jest",
"COVERAGE_THRESHOLD": "80"
}
},
"database": {
"command": "npx",
"args": ["-y", "@mcp/postgres-server"],
"env": {
"DATABASE_URL": "postgresql://localhost:5432/dev"
}
},
"http-client": {
"command": "npx",
"args": ["-y", "@mcp/http-client"],
"env": {
"BASE_URL": "http://localhost:3000",
"TIMEOUT_MS": "5000"
}
},
"log-analyzer": {
"command": "npx",
"args": ["-y", "@mcp/log-analyzer"],
"env": {
"LOG_PATH": "./logs/app.log",
"ERROR_PATTERNS": "ERROR,FATAL,PANIC"
}
}
}
}
With this configuration, an agent implementing a REST API endpoint can:
- Start the development server
- Send HTTP requests to the new endpoint with various payloads
- Inspect the response status codes, headers, and body content
- Query the database to confirm records were created or modified correctly
- Check application logs for errors or warnings
- Run the full test suite and parse the results
Without MCP, each of these verification steps requires the developer to run commands, copy-paste output into the chat, and wait for the agent to process the results. With MCP, the agent completes the entire verification loop autonomously.
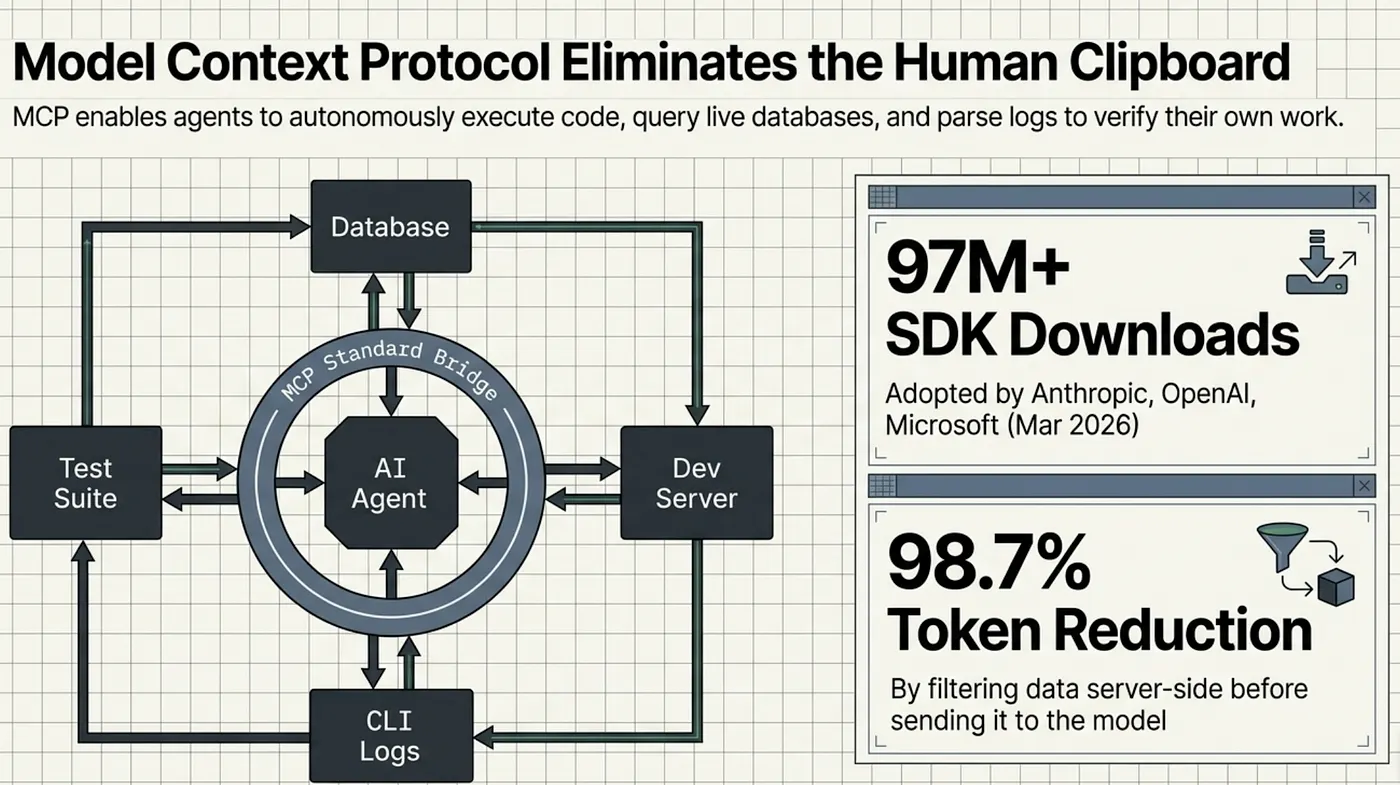
MCP servers can also execute code to filter and transform data before sending it to the agent. A log-analyzer MCP server can parse thousands of log lines and return only the errors relevant to the current task. A test-runner MCP server can execute a subset of tests related to the current file and return structured pass/fail results rather than raw terminal output. This is important because it keeps the agent's context focused on relevant information.
Anthropic's engineering team has demonstrated that this approach dramatically reduces context usage. Agents using MCP for verification can complete complex multi-step verification workflows without exhausting their context window, because each MCP call returns precisely the information needed rather than raw tool output.
The security implications are significant. The November 2025 MCP specification update introduced OAuth 2.0 resource server support and formal threat modeling guidelines. These additions reflect the recognition that MCP is not just a convenience tool — it is infrastructure that AI agents use to take real actions in real systems. The specification now includes explicit guidance on preventing prompt injection through MCP tools, a critical consideration when agents are using MCP to run code in production-adjacent environments.
The Two-Stage Review in Superpowers
Even with systematic debugging and goal-backward verification, there remains a class of failure that point-in-time verification misses: code that passes all specified tests but violates implicit quality standards or architectural constraints.
Superpowers addresses this with a two-stage review process that runs after every implementation cycle. The two stages are explicitly separated to prevent one from contaminating the other.
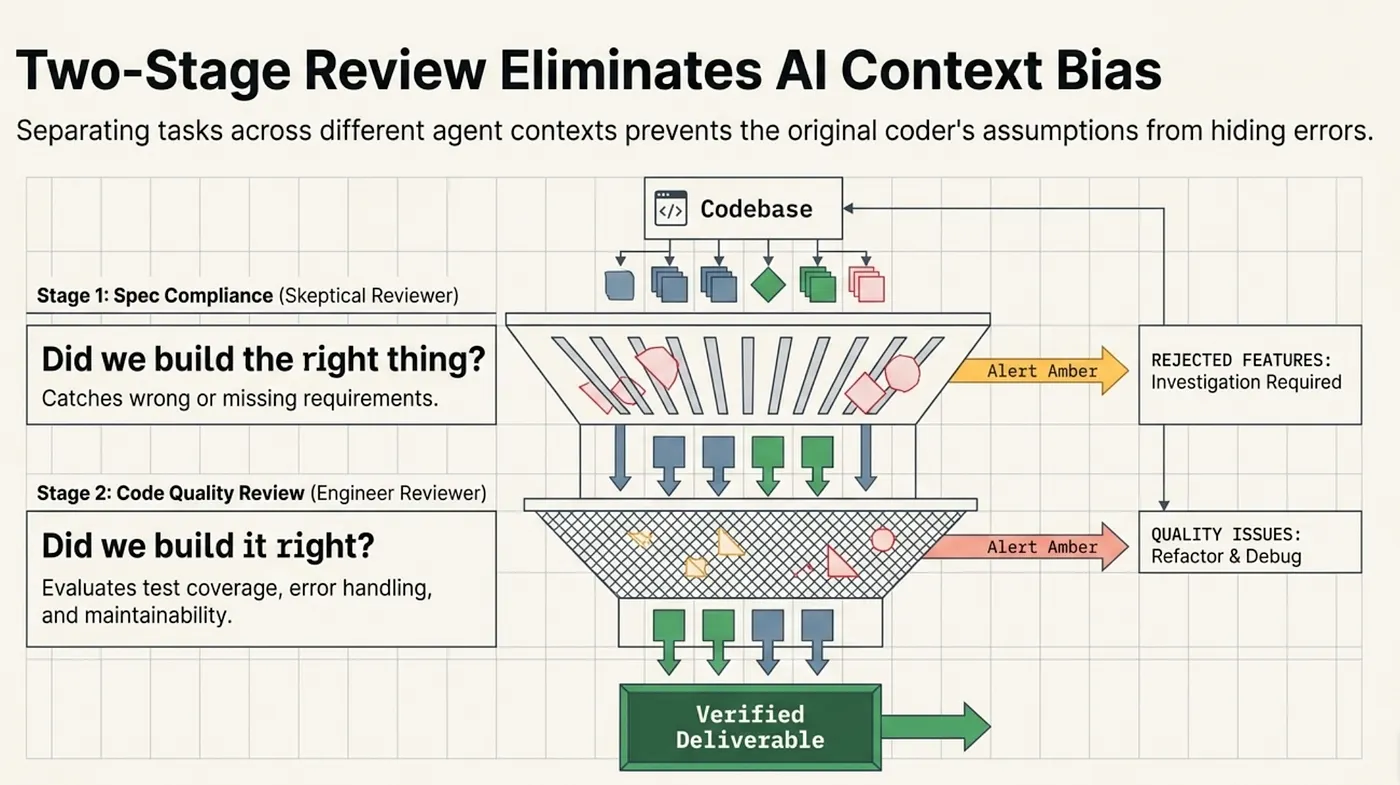
Stage 1: Spec Compliance Review. A dedicated reviewer agent, separate from the implementation agent, checks the code against the specification. The reviewer does not evaluate code quality, performance, or style. It answers one question: does this code implement what was specified? Specifically, it checks for incomplete implementations (placeholders, stubs, missing edge case handling), deviations from the spec (behavior that differs from the specified behavior, even if it "seems better"), and missing requirements (specified features that were not implemented).
Stage 2: Code Quality Review. Only after spec compliance passes does the code quality review begin. This stage evaluates the implementation's quality: test coverage and test quality, error handling completeness, security considerations, performance implications, and maintainability.
The two-stage separation is deliberate. It catches two distinct failure modes that a single-pass review tends to conflate:
- "Wrong thing built right": The code is clean, tested, and well-structured, but it does not implement the specified behavior. A quality-first reviewer would approve this code. A spec-first reviewer would reject it.
- "Right thing built wrong": The code implements the correct feature, but it is brittle, untested, or insecure. A spec-first reviewer would approve this code. A quality-first reviewer would reject it.
By using separate reviewer agents for each stage, Superpowers prevents the cognitive bias that causes human reviewers to approve technically correct code that doesn't meet the spec, or to reject well-specified code because of stylistic disagreements.
This pattern mirrors established software engineering practice. Professional teams use acceptance testing (does it work as specified?) separate from code review (is the code good?). Superpowers applies the same separation to AI-assisted development, where the need is arguably greater because AI-generated code is more likely to look correct while containing subtle deviations from the specification.
From Trust to Verify
The frameworks examined in this series represent a fundamental shift in how developers should think about AI-assisted development. Early AI tools asked developers to trust the output. Modern agentic frameworks ask developers to verify the output through systematic, automated processes.
Consider the verification chain that emerges when these approaches are combined:
- Before coding begins, Superpowers' brainstorming skill forces the agent to understand the problem, identify constraints, and surface ambiguities. Misunderstandings are caught before code is written.
- During planning, GSD's goal-backward methodology defines observable truths that must hold for the goal to be achieved. Success criteria are defined before implementation begins.
- During implementation, TDD enforcement ensures every piece of code has a corresponding test written before implementation. The test suite grows with the codebase.
- When bugs appear, systematic debugging prevents the agent from applying speculative fixes without understanding root causes. False fixes are caught before they enter the codebase.
- After implementation, two-stage review verifies both spec compliance and code quality using independent reviewer agents. Incomplete implementations and quality violations are caught before merge.
- At the feature level, goal-backward verification proves that observable behaviors match the spec. The feature is verified end-to-end, not just unit-tested.
- Throughout the process, MCP provides the infrastructure for the agent to execute tests, query databases, and check logs autonomously. Verification is continuous, not a one-time gate.
Each layer catches failures that the others miss. TDD catches logic errors. The debugging protocol catches speculative fixes. Two-stage review catches spec deviations and quality violations. Goal-backward verification catches end-to-end failures. MCP infrastructure makes all of this automation possible.
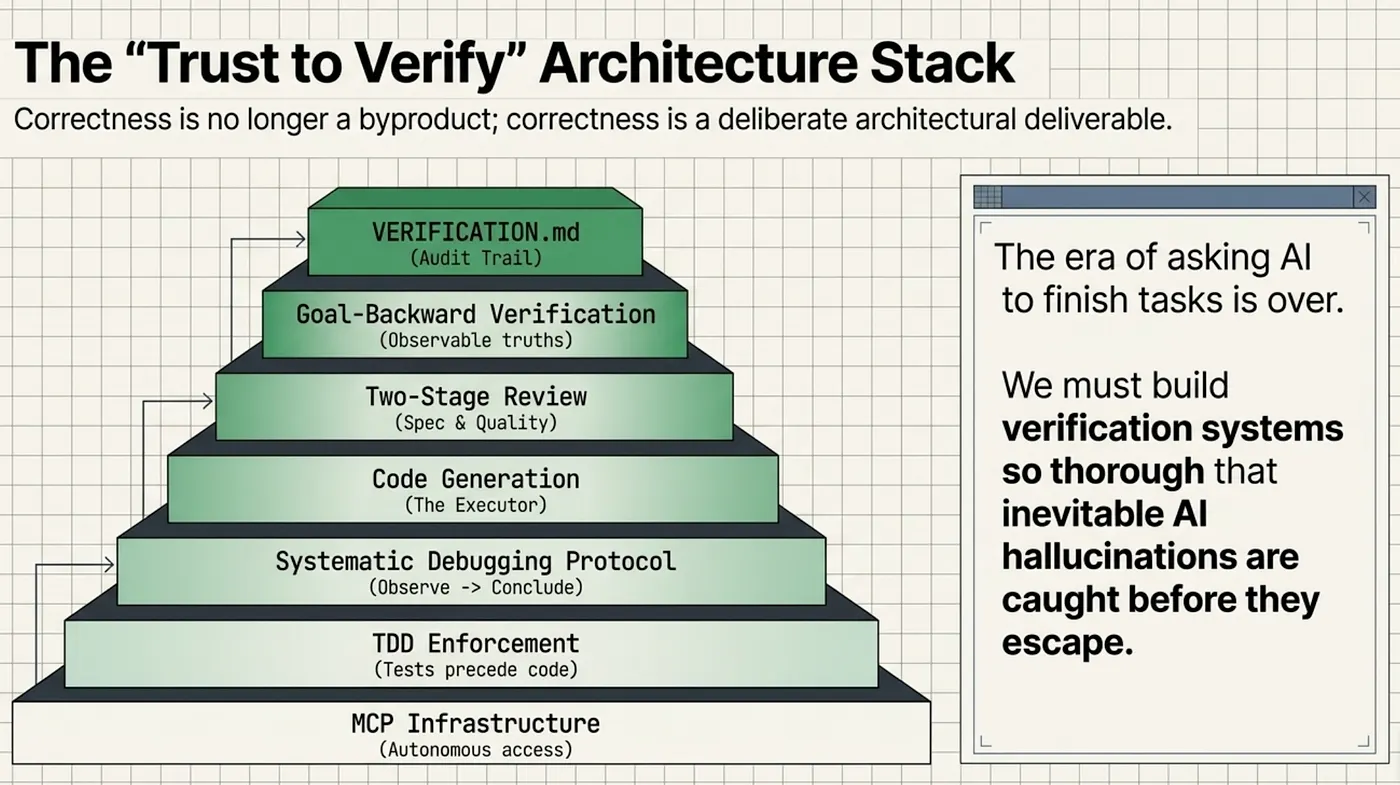
This layered approach acknowledges a truth that the AI industry has been slow to accept: AI models are not reliable enough to use as the final word on whether code works. They are powerful tools for generating and transforming code, but they need verification infrastructure around them to be production-safe.
The trajectory is clear. Early AI coding tools asked developers to trust the output. Current frameworks like Superpowers and GSD ask developers to verify the output through systematic process. Future tools will make this verification autonomous, continuous, and invisible — the AI will prove its work as part of generating it.
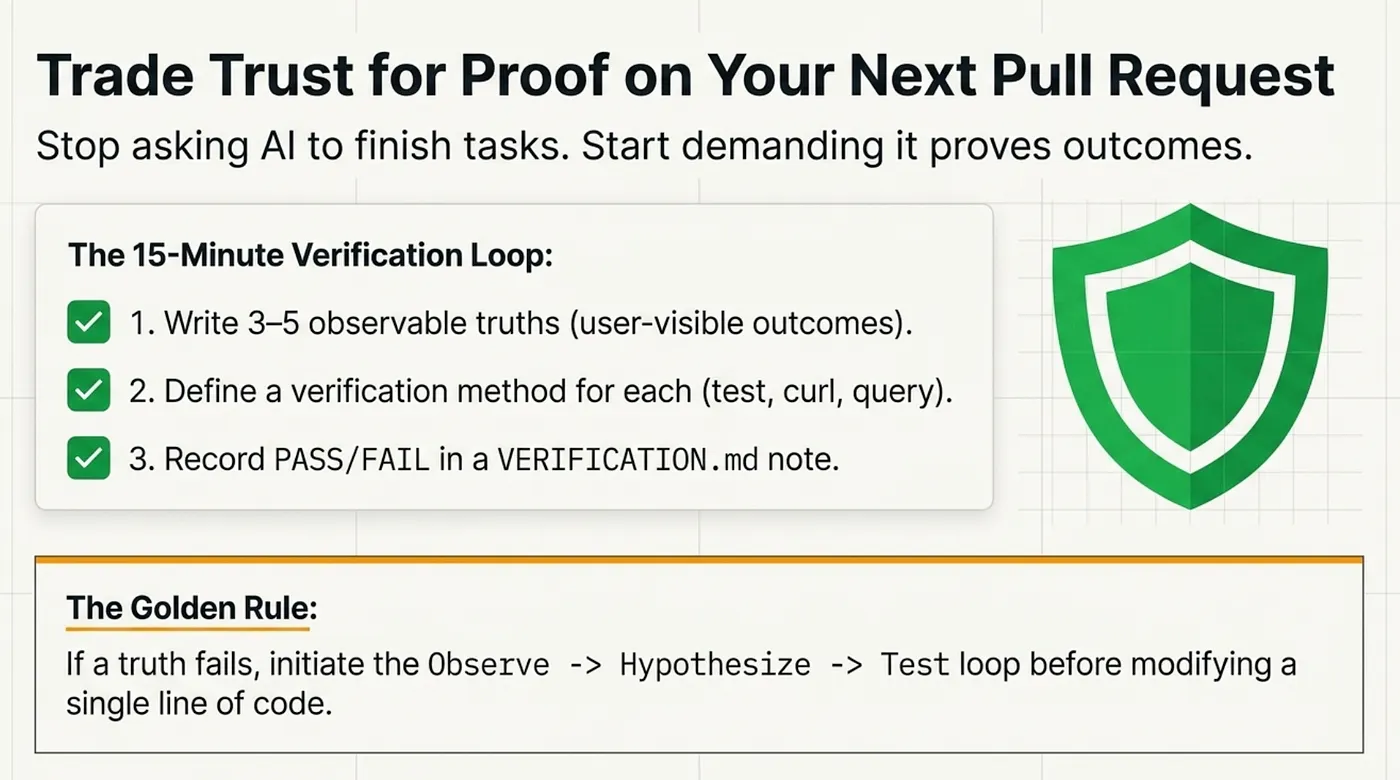
Try this today (15 minutes)
Pick one recent "AI-fixed" PR (or one agent-generated change) and run this mini-audit:
- Write 3–5 observable truths the change must satisfy (user-visible outcomes, not implementation tasks).
- For each truth, define a verification method (test, curl command, query, trace, screenshot, etc.).
- Run the verifications and record PASS/FAIL in a small
VERIFICATION.mdnote.
If any truth fails, don't "fix the symptom." Use a root-cause loop (observe → hypothesize → test → conclude) before touching any code.
Closing: trade trust for proof
AI isn't failing because it's "dumb." It fails because we keep asking it to finish the sentence instead of prove the answer. Every mechanism in this article, systematic debugging, goal-backward truths, two-stage review, MCP-powered autonomous testing, exists to answer a single question: did it actually work?
If you take one idea from this series, make it this: build a verification layer, not just a generation layer. Define observable truths before you write a line of code. Run them after every change. Make the AI prove its work, not just show its work.
If you try goal-backward verification this week, leave a comment with:
- the feature you verified,
- the 3–5 truths you used,
- and what surprised you.
That discussion (what actually fails, and what verification catches) is where the real learning happens.