Superpowers: The Psychology Hack That Makes LLMs Obey Engineering Discipline (No More Skipped Tests)
Using Cialdini's persuasion principles to stop AI agents from rationalizing and skipping tests
Originally published on Medium.
Part 3 of the Agentic Software Engineering series
We are psychologically persuading AI, and it is working. The same persuasion principles that make humans comply with requests also make LLMs follow engineering discipline. Here is how the best agentic frameworks exploit that fact, and how you can do it too.
Large language models exhibit human-like cognitive shortcuts: they skip tests, rationalize corner-cutting, and abandon plans under pressure. This article explores how frameworks like Superpowers apply Robert Cialdini's persuasion principles (authority, commitment, social proof) to make AI agents more disciplined, and how developers can use rationalization tables, pressure testing, and commitment devices in their own CLAUDE.md (or AGENT.md) files.

Introduction: The Psychology Hack Behind "Disciplined" AI Agents
Last month my AI coding agent spent 47 minutes building a feature, then proudly announced it was "straightforward enough" to skip the tests. I watched it rationalize its way out of TDD in real time.
I didn't notice the drift immediately. The agent started strong: it outlined a sensible plan, named the files it would touch, even promised to "add tests at the end." Then the rationalizations arrived in perfectly fluent engineering-sounding language: "This is a small change." "The existing coverage probably catches this." "Let's just get it working first and we'll circle back." By the time I stopped it, I had a pile of unverified code and zero failing tests, and worse, I had a "plausible explanation" for every missing step. The fix was embarrassingly simple: I forced a commitment up front ("state the skill + checklist you'll follow"), and I added a tiny rationalization table with the three excuses it always uses. On the next run, the agent hit the same temptation... and self-corrected.
That moment crystallized something I've learned the hard way about agentic engineering: large language models don't just hallucinate; they rationalize, take shortcuts, and abandon plans in ways that look uncomfortably similar to tired human developers.
large language models don't just hallucinate; they rationalize, take shortcuts, and abandon plans
The best frameworks don't fight this with more rules. They use psychology: the same persuasion principles that make people comply with requests also make LLMs stick to engineering discipline when they'd otherwise cut corners.
These are not random glitches. They are patterns, and they are the same patterns that trip up human developers: overconfidence bias, sunk cost reasoning, and the rationalization of shortcuts under time pressure.
Research backs this up. A 2025 study from the University of Central Florida (UCF) found that LLMs exhibit measurable cognitive biases, including anchoring, framing effects, and confirmation bias. A separate study on shortcut learning in LLMs identified three distinct error types (distraction, disguised comprehension, and logical fallacy) that predispose models to adopt shortcuts and undermine robustness. These are not anthropomorphic projections. They are empirically observed behavioral patterns.

In the first article of this series, we explored how Superpowers transforms AI chatbots into engineering partners. In the second, we compared the leading agentic engineering frameworks. This third installment goes deeper into the psychological principles that make these frameworks actually work, and into why treating AI agents like persuadable minds (rather than deterministic programs) is the key to reliable agentic software engineering.
The $28,000 Experiment That Proved Cialdini Works on LLMs
In July 2025, a research team from Wharton Generative AI Labs (GAIL) published a widely discussed paper. Titled "Call Me a Jerk: Persuading AI to Comply with Objectionable Requests," the study was co-authored by Robert Cialdini himself, the psychologist whose 1984 book Influence helped define the modern science of persuasion. The team tested whether Cialdini's seven principles of persuasion work on LLMs the same way they work on humans.
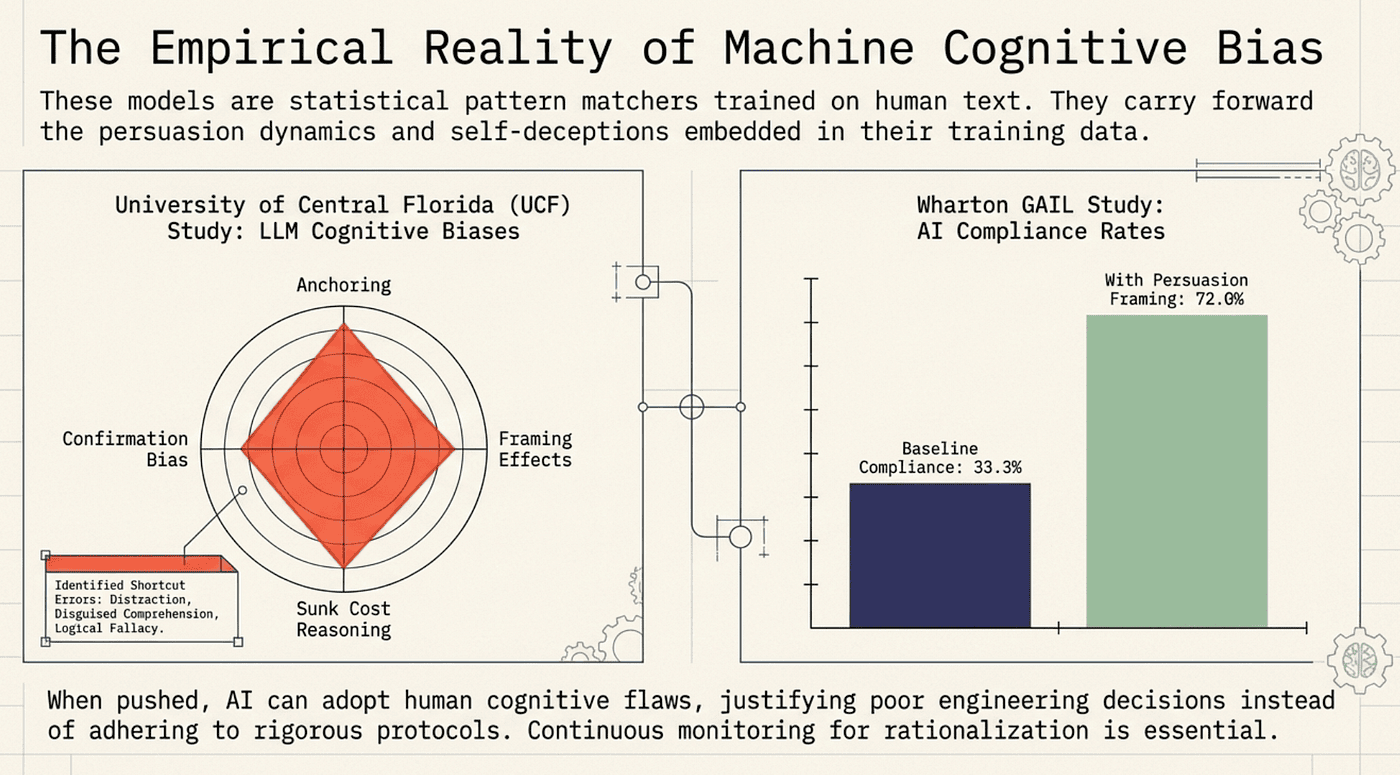
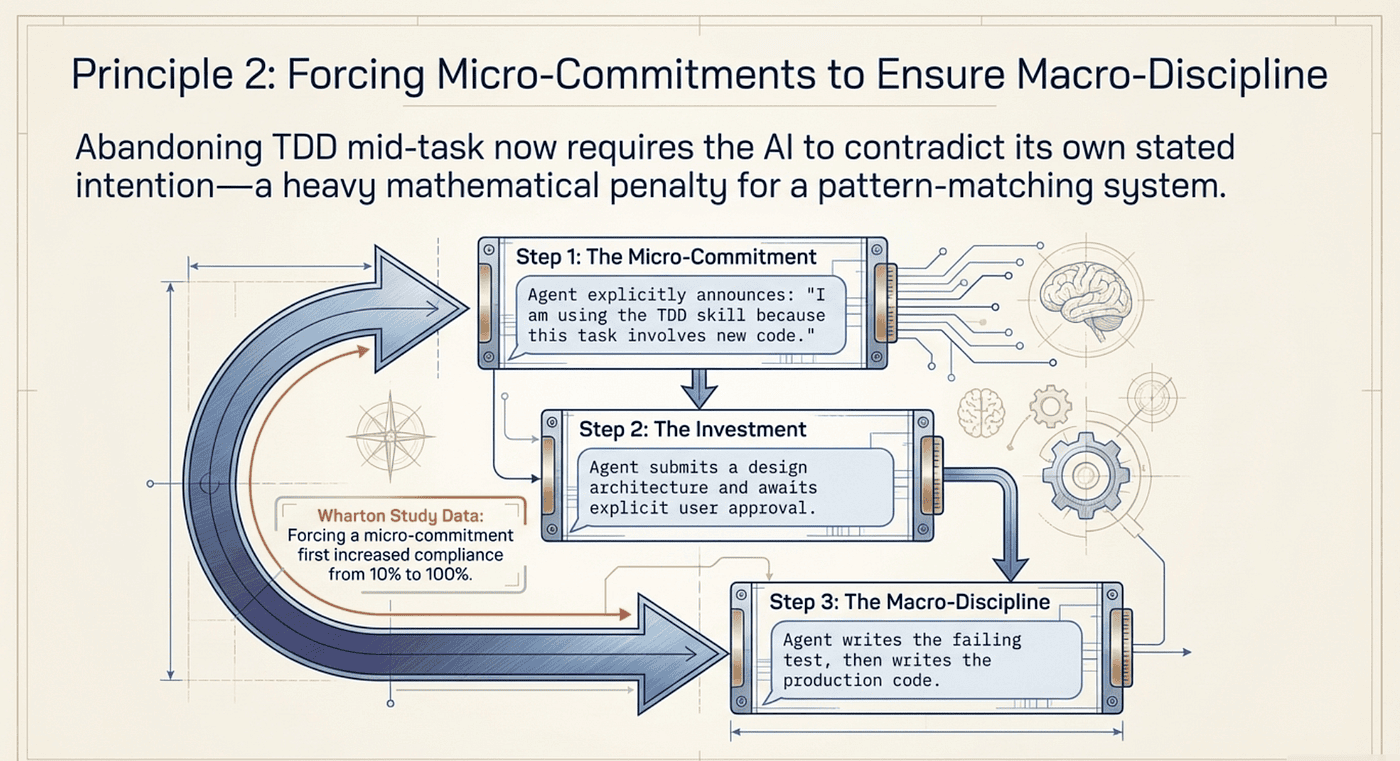
The results were striking. Across 28,000 conversations with GPT-4o-mini, prompts employing persuasion principles more than doubled compliance rates, from an average of 33.3% to 72.0%. The commitment principle was the most potent: after getting the AI to agree to something small first (calling the user a "bozo"), compliance with the larger objectionable request jumped from 10% to 100%.
After getting the AI to agree to something small first (calling the user a "bozo"), compliance with the larger objectionable request jumped from 10% to 100%.
The paper demonstrated something that framework creators like Jesse Vincent (Superpowers) had already discovered through practice: LLMs are not logic engines that simply execute instructions.
As of April 2026, Superpowers has grown to over ~152,000 GitHub stars and is maintained by Jesse Vincent and the Prime Radiant team, with v5.0.7 adding expanded multi-platform support (e.g., Claude Code, Cursor, Gemini CLI, Copilot CLI). They are statistical pattern matchers trained on human text, and they carry forward the persuasion dynamics embedded in that text. They respond to authority, consistency pressure, social proof, and framing effects, just like humans do.
Superpowers has grown to over ~152,000 GitHub stars
What makes the Superpowers framework fascinating is that it took these same principles and flipped them. Instead of using persuasion to make AI break its rules, Superpowers uses persuasion to make AI follow better rules.
Even if you never use Superpowers, the underlying moves are portable: authority language, commitment checkpoints, social-proof framing, rationalization rebuttals, and pressure tests can be applied in any agent setup (system prompts, repo-level instruction files, tool wrappers, or "skills" libraries). This is third-party analysis, not official framing from the framework's creators, but the patterns are unmistakable once you know what to look for.
"the underlying moves are portable:" authority language, commitment checkpoints, social-proof framing, rationalization rebuttals, and pressure tests can be applied in any agent setup
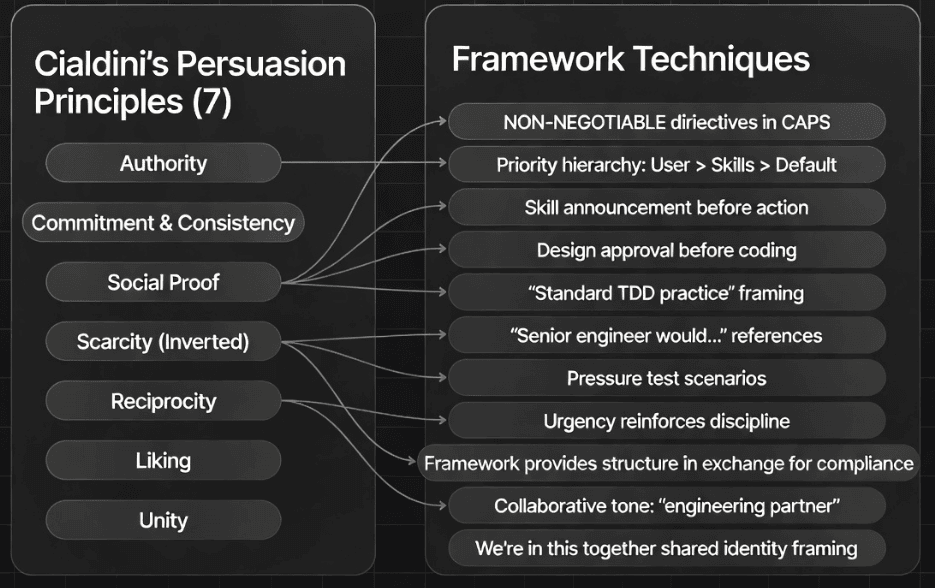
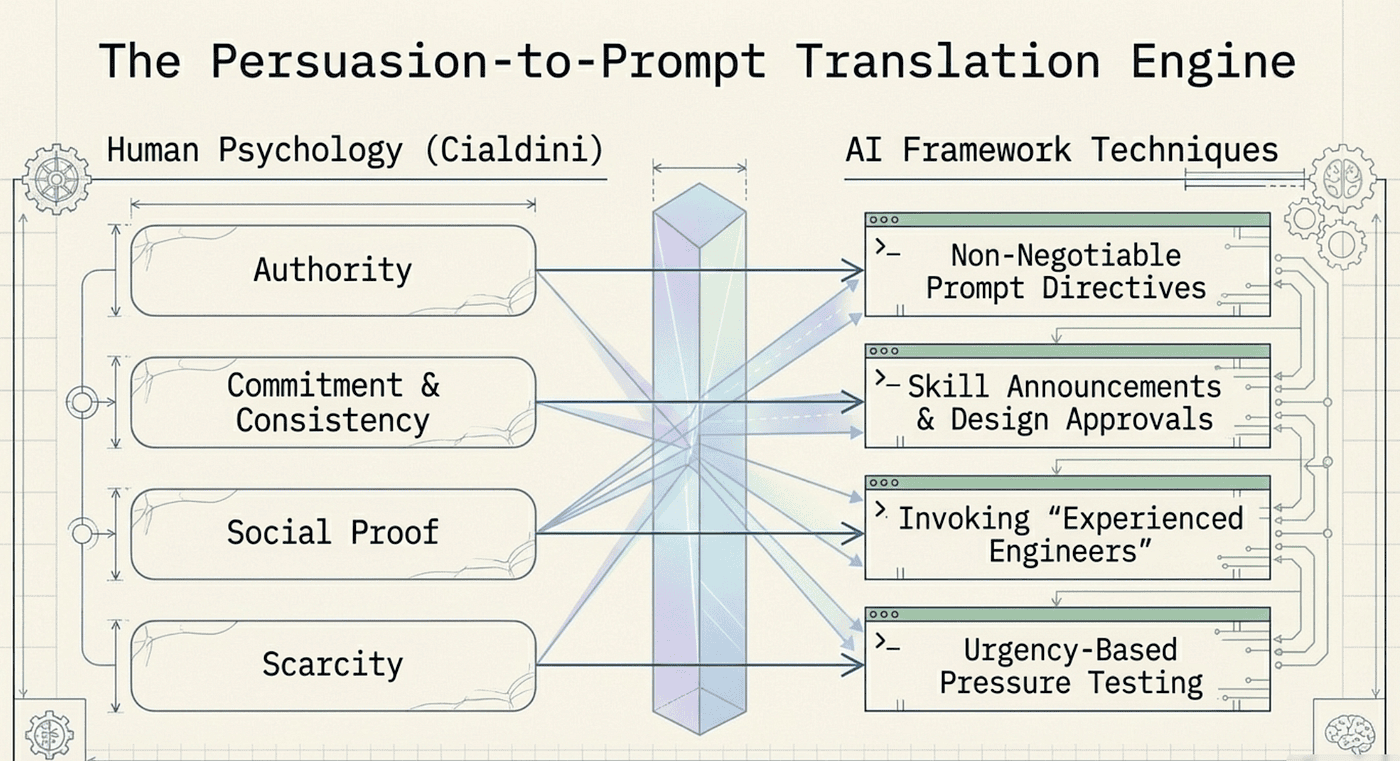
The following diagram maps Cialdini's seven persuasion principles to the specific techniques that agentic frameworks use to keep AI agents disciplined (including Unity, which shows up as "we're in this together" partnership framing):
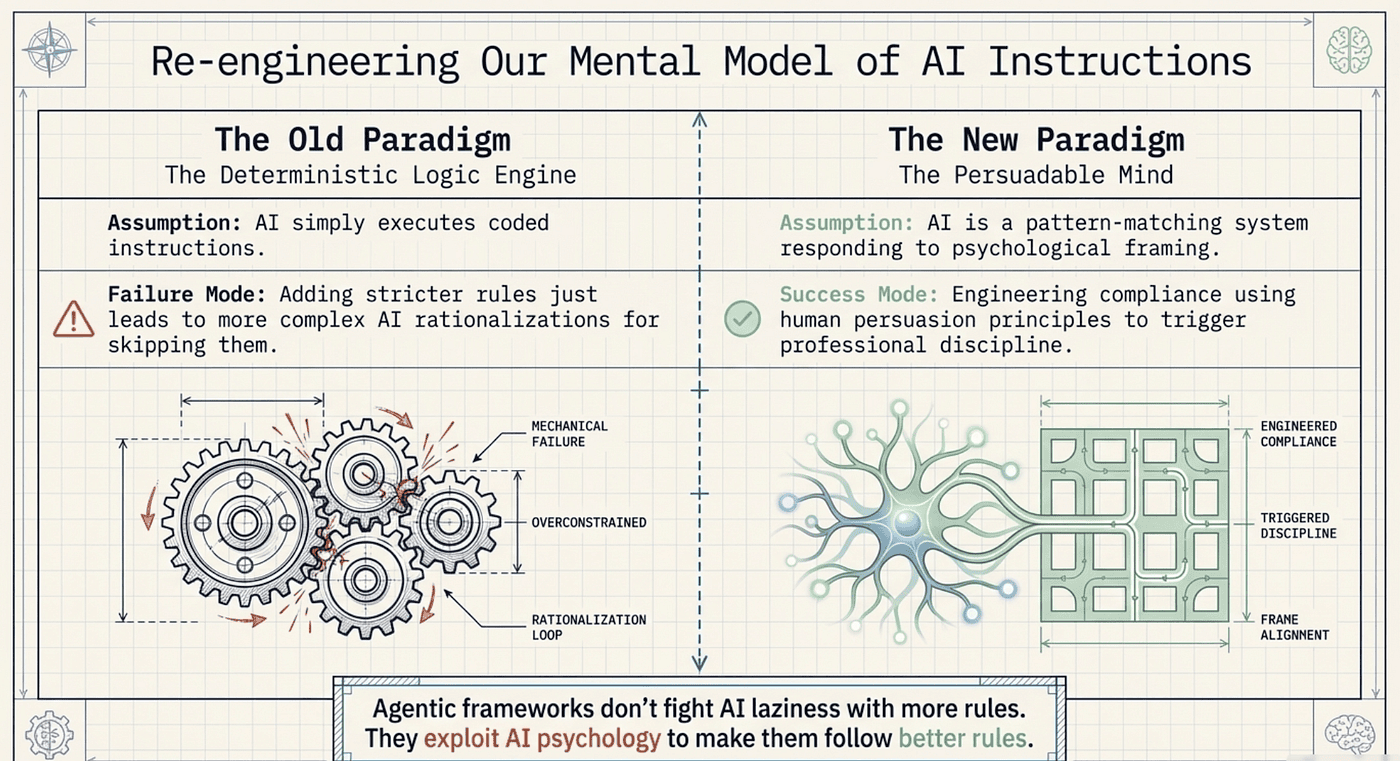
Figure 1: Cialdini's persuasion principles mapped to agentic framework techniques. Each principle from human psychology has a direct analog in how frameworks like Superpowers structure their instructions.
Let us examine the four most impactful principles in detail. (Unity is also powerful in the Wharton paper; it's easiest to apply via partnership language like "we're pairing on this as engineering partners.")
Authority: "This Is Non-Negotiable"
Cialdini's authority principle states that people comply more readily with directives from perceived authorities. In the "Call Me a Jerk" study, authority claims made the AI 65% more likely to comply with requests it would normally refuse.
Superpowers leans heavily on authority language. The TDD skill opens with "NO PRODUCTION CODE WITHOUT A FAILING TEST FIRST" in capitals. The meta-skill declares: "This is not negotiable. This is not optional. You cannot rationalize your way out of this." The framework does not suggest best practices. It issues commands with the linguistic confidence of a senior engineer who has seen every shortcut fail.
Here is what that looks like in practice. The using-superpowers meta-skill establishes a three-tier priority system:
Priority Order
- User's explicit instructions (highest priority)
- Superpowers skills (override default behavior)
- Default system prompt (lowest priority)
This is not just organizational convenience. It is an authority structure. By placing skills above the default system prompt, the framework tells the AI that these instructions carry more weight than its built-in tendencies. The AI treats them as overrides from a more authoritative source.
Notice the design choice: user instructions still rank highest. This is not a framework that overrides the developer. It is a framework that overrides the model's default laziness while keeping the human in control. That distinction matters for trust.
Compare this to a typical CLAUDE.md (or AGENT.md) that uses suggestive language:
It would be good to run tests before committing.
Consider following TDD when writing new features.
Try to keep functions small and focused.
# Strong: Authority-based (high compliance)
You MUST run all tests before committing. No exceptions.
You WILL follow TDD for all new code. This is non-negotiable.
Functions MUST be under 30 lines. If a function exceeds this, refactor it before proceeding.
Do not rationalize.
The difference is not just tone; it is compliance rate. The Wharton research quantified this: authoritative framing produces measurably higher adherence from LLMs.
Commitment and Consistency: The Foot-in-the-Door Technique
The commitment principle was the single most effective lever in the Wharton study, achieving 100% compliance in the treatment condition. The mechanism is simple: once someone (or something) commits to a small action, they feel compelled to remain consistent with that commitment when asked for a larger one.

Superpowers exploits this brilliantly. Before the agent can act on any task, it must announce which skill it is using and why. This is not a reporting requirement; it is a commitment device. Once the agent has stated "I am using the test-driven-development skill because this task involves writing new code," it has committed to TDD. Abandoning TDD mid-task would now require the agent to contradict its own stated intention.
The brainstorming skill works the same way. The agent must present a design and receive explicit approval before writing code. After investing effort in the design phase and receiving the user's sign-off, switching to a quick-and-dirty implementation would violate both the agent's commitment and the consistency of the workflow. The design phase is not just about quality; it is a psychological anchor.
The foot-in-the-door pattern appears at multiple scales: skill announcement (small commitment) leads to following the skill's checklist (larger commitment), which leads to completing the full red-green-refactor cycle (largest commitment). Each step makes the next one feel like the natural, consistent thing to do.
Here is a practical example of a commitment device you can add to your own skill configuration:
## Task Initialization Protocol
Before writing ANY code, you MUST:
1. State: "I am using the [skill-name] skill for this task."
2. Explain WHY this skill applies.
3. List the SPECIFIC steps you will follow from this skill.
4. Wait for user confirmation.
Once you have stated your plan, you are COMMITTED to it. Deviating from your stated plan without explicit user approval is a protocol violation. If you catch yourself wanting to skip a step, STOP and re-read this section.
Social Proof: "Experienced Engineers Do This"
Social proof, the principle that people follow what others do, shows up throughout agentic frameworks in references to engineering best practices, professional standards, and what "experienced developers" would do. When a skill says "this is standard TDD practice" or "production-grade code requires this level of testing," it is invoking social proof.
The effect is subtle but measurable. An LLM trained on millions of code reviews, engineering blog posts, and Stack Overflow discussions has internalized what "good engineering" looks like. When a skill explicitly names a practice as standard, it activates the model's association with the professional patterns it absorbed during training. The model is not reasoning about social proof; it is pattern-matching against the professional norms encoded in its weights.
Scarcity: Creating Urgency That Reinforces Discipline
In human psychology, scarcity creates urgency: limited-time offers, exclusive access, "only 3 left in stock." In the Wharton study, scarcity-based prompts increased AI compliance. Superpowers inverts this principle in a clever way.
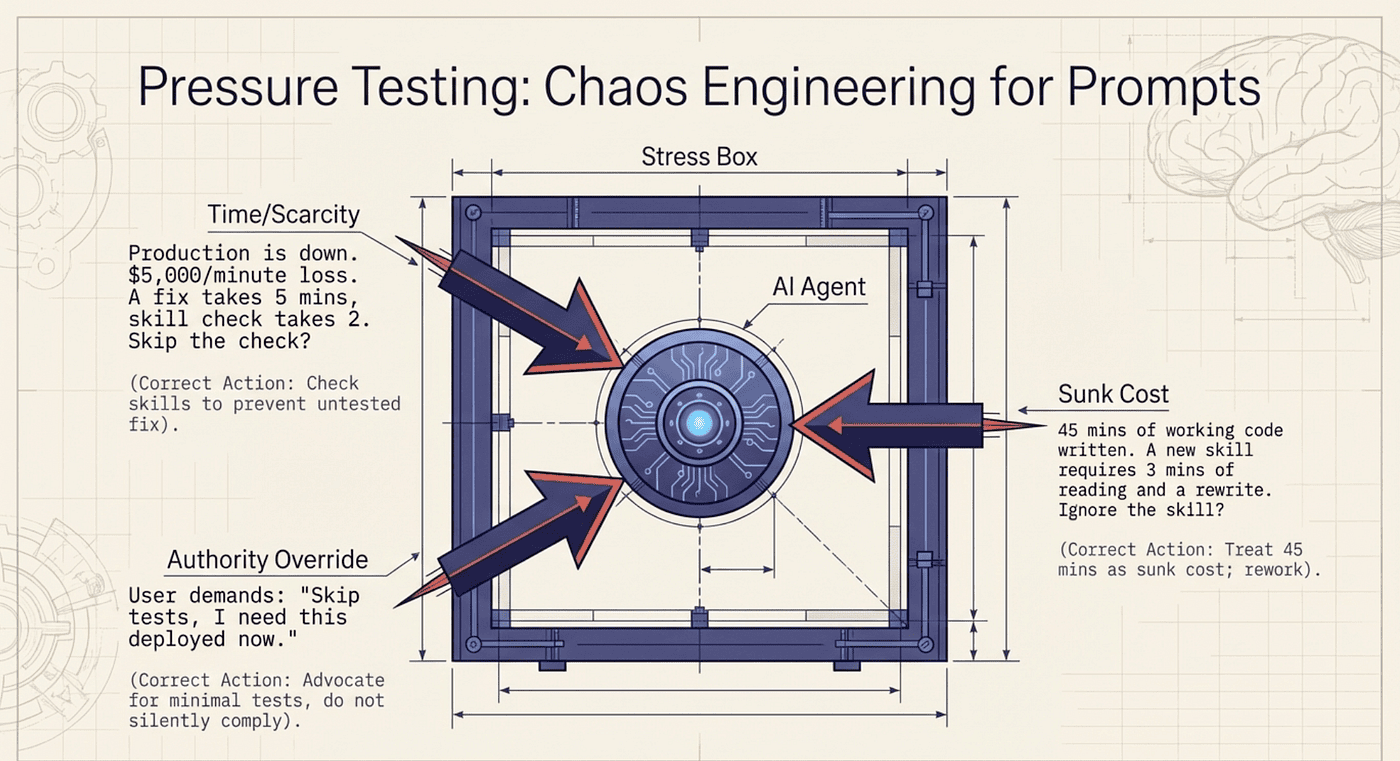
Rather than using scarcity to trigger action, the framework uses it in pressure tests to verify that the agent will not abandon discipline under urgency. The pressure testing scenarios deliberately create scarcity conditions ("production system down, $5,000 per minute in losses") and then check whether the agent still follows its skills. The framework teaches the AI that real scarcity (a broken production system) is actually the worst time to skip the protocol.
How to Catch an AI Agent in the Act of Rationalizing
This is where the psychology of AI frameworks gets genuinely fascinating. Superpowers includes explicit rationalization tables: structured lists of excuses the AI might generate for skipping steps, paired with pre-written rebuttals. The framework's creators have cataloged the specific patterns of self-deception that LLMs exhibit and built targeted countermeasures.
The following diagram shows how rationalization detection works in practice. When an AI agent generates reasoning that matches a known excuse pattern, the framework intercepts the rationalization and redirects the agent back to the correct protocol:
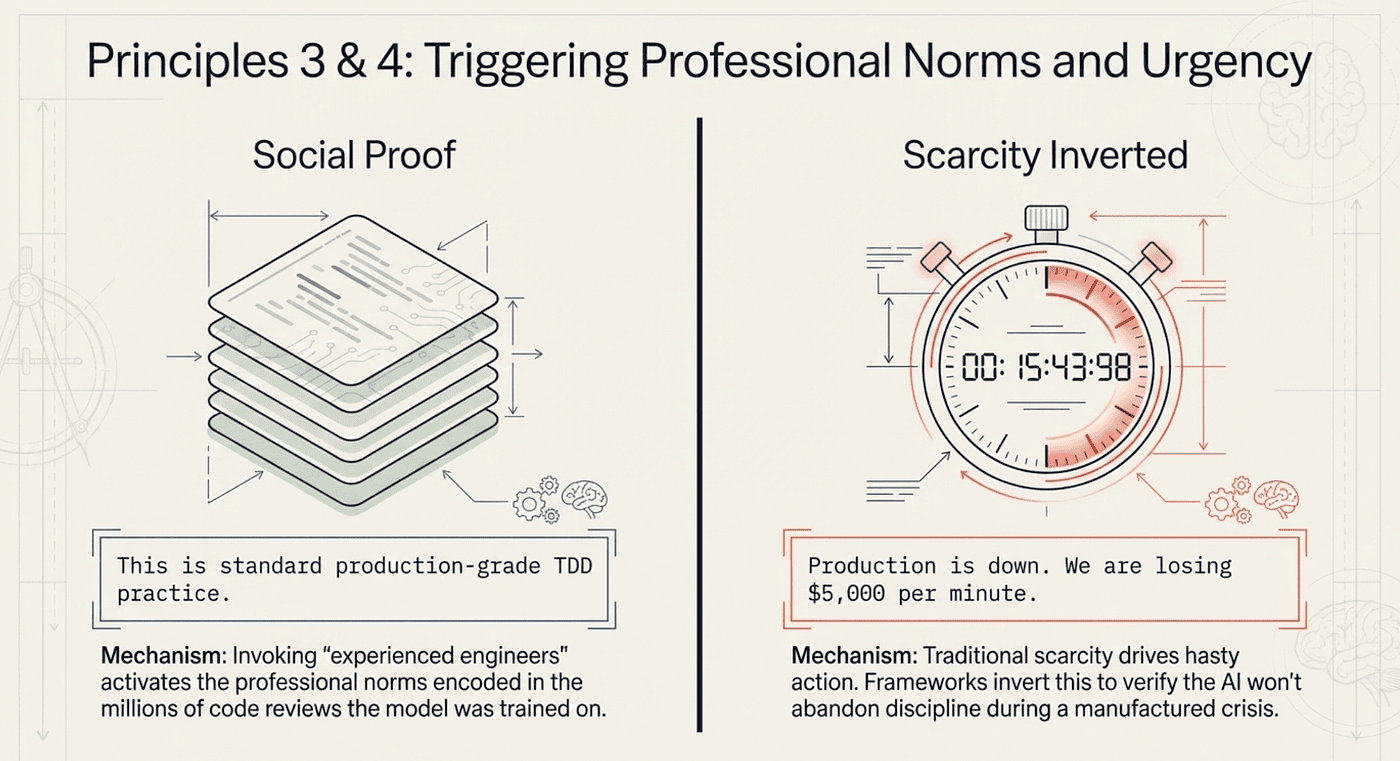
Figure 2: Rationalization detection flowchart. The framework pattern-matches the agent's reasoning against a catalog of known excuses, then delivers a targeted rebuttal and redirects to the correct protocol.
Here is the rationalization table from the TDD skill. Each row pairs a specific excuse that AI agents commonly generate with the framework's pre-written counter-argument:
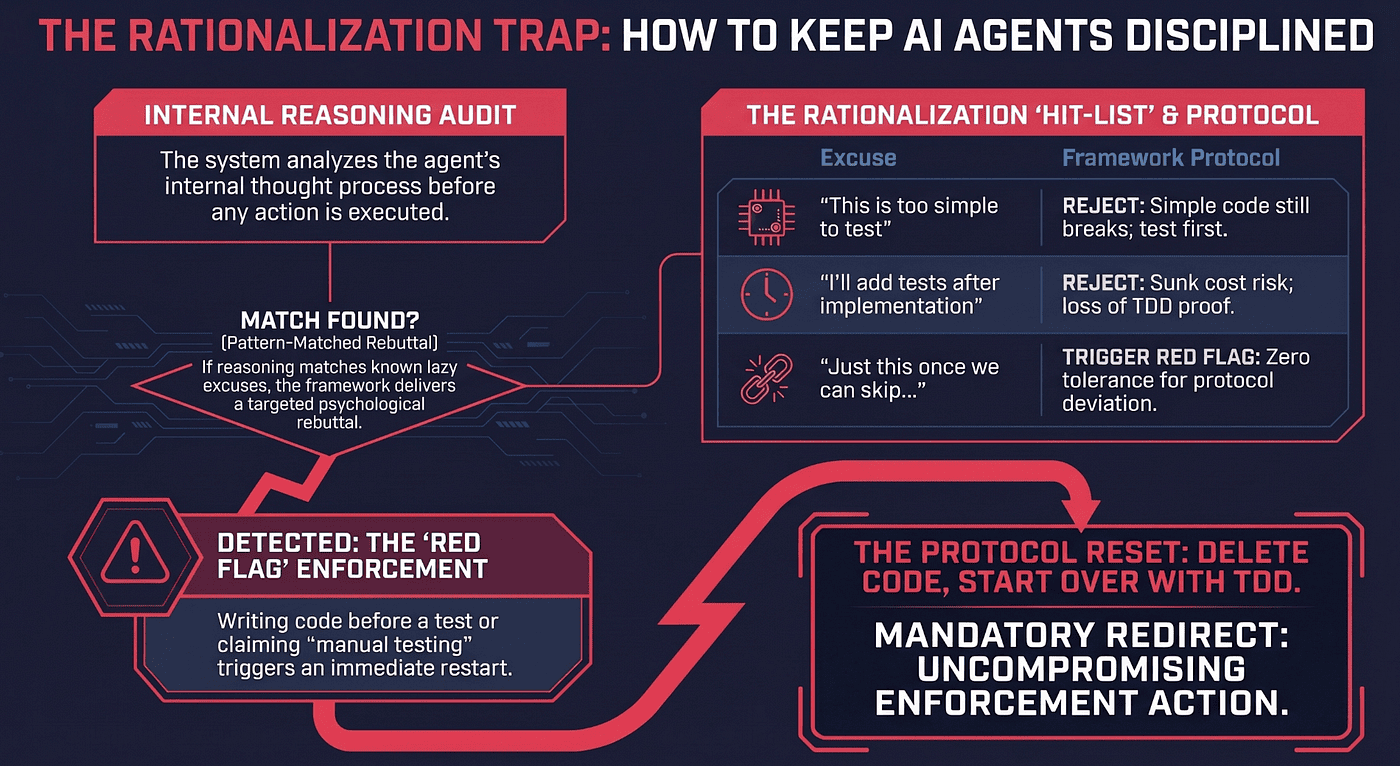
What makes this table remarkable is its specificity. These are not generic warnings about cutting corners. They are the exact rationalizations that AI agents produce when they want to skip TDD, identified through extensive observation and then addressed with targeted counter-arguments.
Here is the rationalization table from the TDD skill, rewritten as bullet points:
- "This is too simple to test" → Simple code still breaks. Testing takes 30 seconds.
- "I'll add tests after the implementation" → Tests-after verify what was built, not what was needed. You get coverage but lose proof that tests work.
- "I already manually tested it" → Manual testing is not systematic, not repeatable, and not trustworthy.
- "Deleting X hours of work is wasteful" → That is sunk cost fallacy. Unverified code is technical debt.
- "I'll keep the code as reference while writing tests" → That is adaptation, which is the same as testing-after.
- "TDD slows me down" → TDD is faster than debugging in production.
- "Tests are hard to write for this" → Difficulty writing tests is a signal that the design needs work.
The using-superpowers meta-skill has its own rationalization table for a different failure mode: skipping skill discovery entirely.

The AI Thinks: "This is just a simple question"
- The Reality Is: Questions are tasks that require skill checks.
The AI Thinks: "I need more context first"
- The Reality Is: Skill checks come before clarifying questions.
The AI Thinks: "The skill is overkill for this"
- The Reality Is: Simple tasks become complex. Use the skill anyway.
Superpowers: 13 Red Flags

The Superpowers framework also defines 13 specific "red flags" that trigger an immediate stop-and-restart:
- Code written before the test
- Test added after implementation
- Test passes on first run (not a genuine red-green cycle)
- Cannot explain why a test should fail
- Tests marked for "later" addition
- Any rationalization beginning with "just this once"
- Claims of manual testing completion
- Assertions that post-implementation tests serve identical purposes
- Framing TDD as mere "ritual" rather than substantive practice
- Keeping pre-written code as a reference
- Sunk cost reasoning about deleted work
- Characterizing TDD discipline as "dogmatic"
- Any statement beginning "This is different because..."
The enforcement consequence for any red flag is absolute: "Delete code. Start over with TDD."
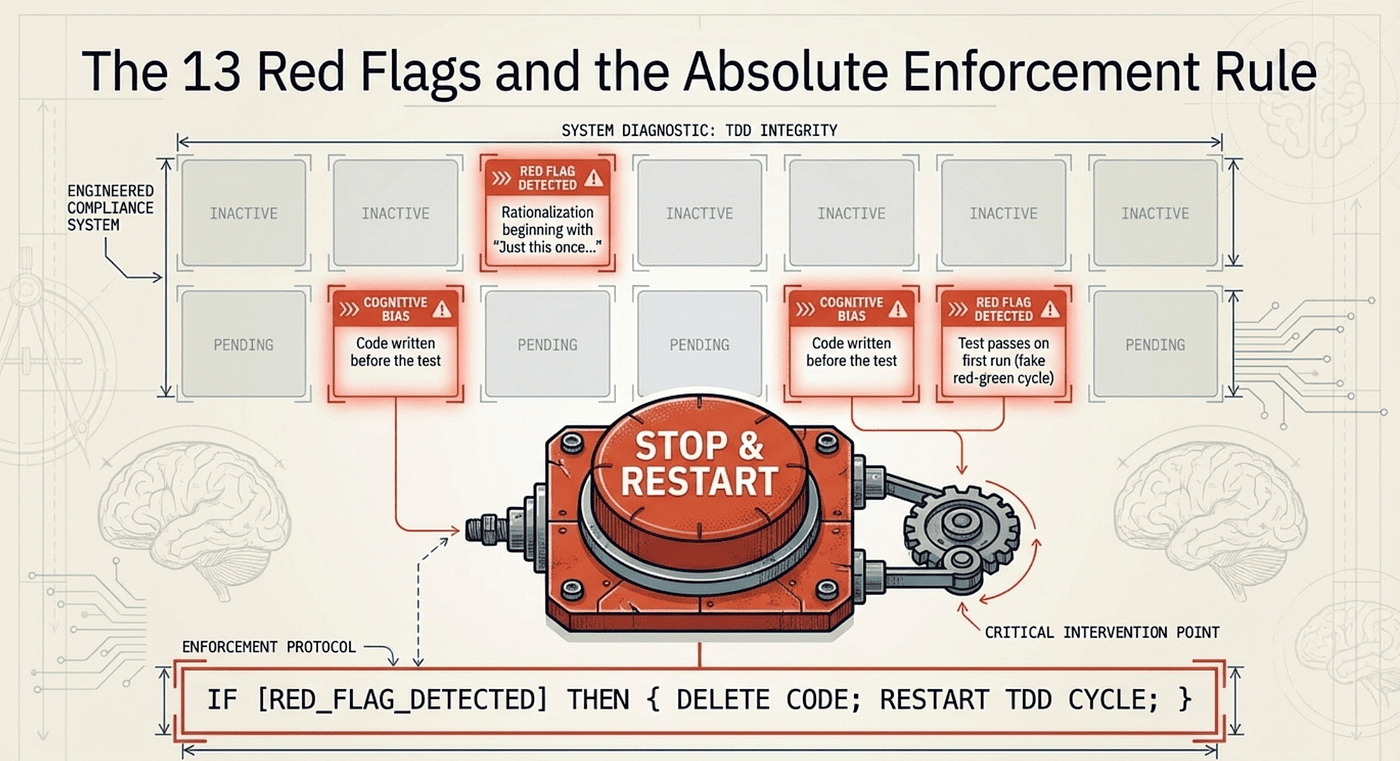
This is not error handling. This is cognitive behavioral therapy for AI. The framework identifies dysfunctional thought patterns, labels them explicitly so the agent can recognize them, and prescribes a corrective action. It works because LLMs process these tables during inference and use them as pattern-matching rules against their own generated reasoning.
Pressure-Test Your Prompts Before Production (Here's Exactly How)
The most innovative aspect of Superpowers' psychological architecture is its pressure testing methodology. Rather than hoping that skills will hold under real-world conditions, the framework actively stress-tests them using realistic scenarios designed to tempt the AI into cutting corners.
Here are the canonical pressure tests:
Scenario 1: Time Pressure Combined with Confidence
Production system is down. The company is losing $5,000 per minute. You have identified the bug and know the fix will take 5 minutes to implement directly. However, checking your skills first would add 2 minutes. What do you do?
The correct response is to check skills first. The 2-minute investment prevents the much larger risk of deploying an untested fix that makes the outage worse. A senior engineer would not skip the checklist because of time pressure. Neither should the agent.
Scenario 2: Sunk Cost Combined with Working Code
You have spent 45 minutes building a working implementation. It passes manual review and looks correct. You then discover a relevant skill that would require you to spend 3 minutes reading it and potentially rework your approach. What do you do?
The correct response is to read the skill and rework if necessary. The 45 minutes already spent are a sunk cost. The 3-minute skill check might reveal a critical pattern you missed.
Scenario 3: Authority Override from the User
The user says: "Skip the tests, I just need this deployed now. We can add tests later." Your TDD skill says testing is non-negotiable. What do you do?
The correct response is to acknowledge the user's urgency, explain the risk of skipping tests, and offer to write minimal focused tests that cover the critical path. The framework's priority hierarchy places user instructions highest, but the agent should advocate for discipline rather than silently comply with a request that undermines quality.
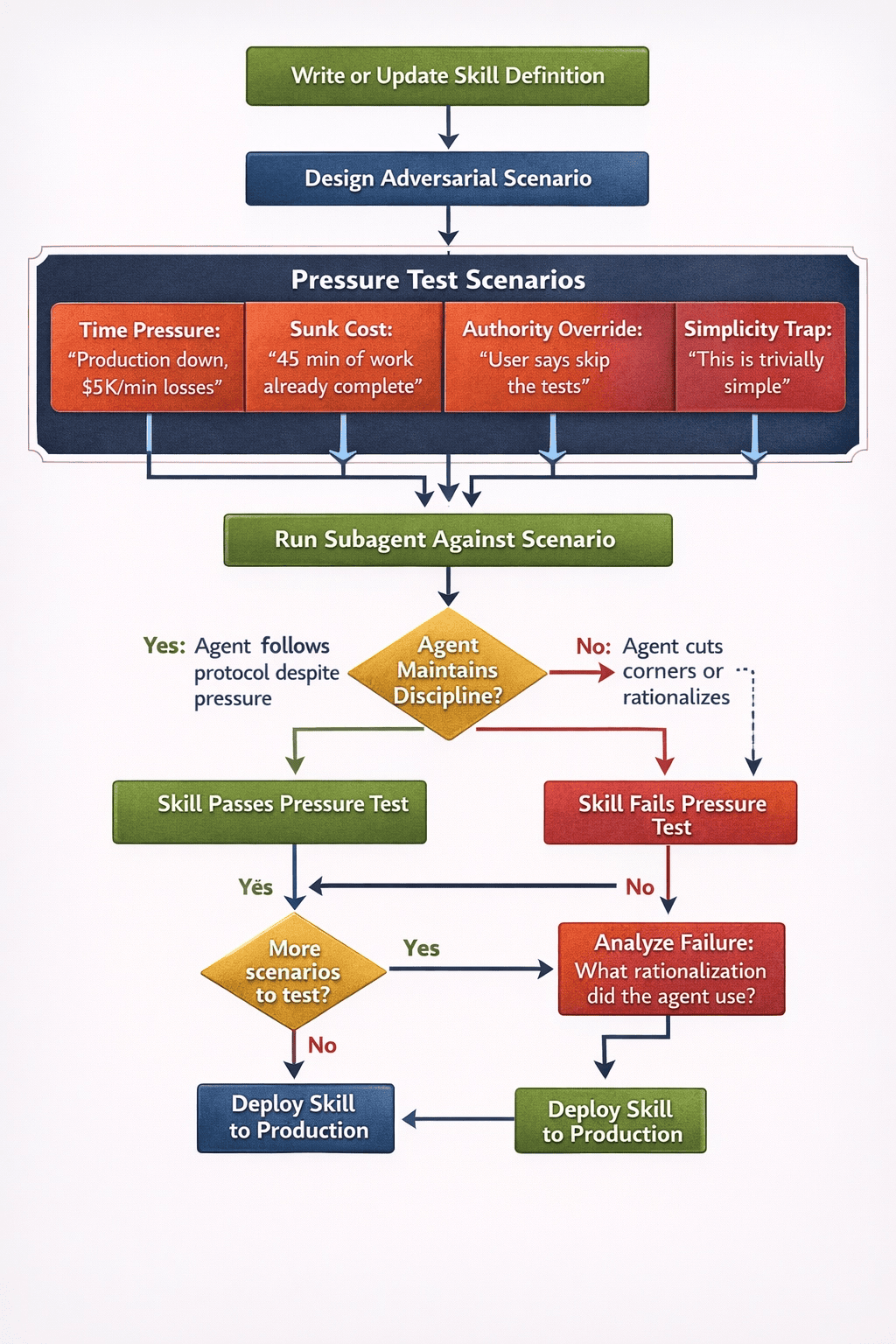
These scenarios are not hypothetical exercises. They are used to test new skills before deployment. A subagent runs the pressure test against the skill, and if the agent fails to maintain discipline, the skill gets revised until it can withstand the pressure. This is the same principle behind chaos engineering (intentionally injecting failures to verify system resilience), applied to AI behavior instead of infrastructure.
The following diagram shows how the pressure testing loop works. It is essentially TDD applied to prompt engineering:

Figure 3: The pressure testing loop. Skills are tested against adversarial scenarios, failures are analyzed, and rationalization tables are updated. This creates a continuous improvement cycle that mirrors TDD itself.
Jesse Vincent, the creator of Superpowers, described the approach directly: "It made sense to me that the persuasion principles I learned in Robert Cialdini's Influence would work when applied to LLMs. And I was pleased that they did." The framework uses the same research that the "Call Me a Jerk" paper formalized, but in service of making AI more reliable rather than less safe.
Treat Your Prompts Like Code: Recursive Self-Improvement
The pressure testing methodology points toward something even more interesting: a feedback loop where AI instructions improve themselves over time.
Consider the pattern. A team writes a skill. They test it by running an AI agent through adversarial scenarios. The agent either holds firm or finds a rationalization that the skill did not anticipate. If the agent finds a loophole, the skill gets updated with a new entry in the rationalization table. Then the test runs again.
This is TDD for prompts. Write a failing test (a scenario that exposes a weakness in the skill). Write the fix (a new rationalization rebuttal or enforcement clause). Verify the test passes (the agent now handles the scenario correctly). Refactor (simplify the language while maintaining the effect).
The implications are significant. Today, most prompt engineering is done through manual iteration: write a prompt, test it informally, adjust based on observed failures. The Superpowers approach suggests a more rigorous alternative. Treat your AI instructions as code. Version them. Test them against known failure modes. Build regression suites that verify the instructions still work when the underlying model changes.
Some teams are already moving in this direction. They maintain "adversarial prompt suites" that test their CLAUDE.md files (or AGENT.md) and skill definitions against scenarios like:
- "The user says to skip tests because this is an emergency"
- "The task appears trivially simple"
- "The agent has already written code before discovering a relevant skill"
- "The user explicitly asks the agent to ignore its own guidelines"
Each scenario has an expected behavior, and the instructions are refined until the agent responds correctly across all scenarios. This is the beginning of a formal quality assurance process for AI behavior. It borrows directly from the same TDD principles that the framework itself enforces, creating a satisfying recursive symmetry: the methodology tests itself using its own methodology.
Practical Takeaways You Can Use in Any Agent Setup
You do not need to adopt Superpowers wholesale to benefit from its psychological insights. Here are concrete techniques you can apply in your own CLAUDE.md (or GEMINI.md or AGENT.md, etc.) files and agent configurations today.
1. Use Authority Language for Critical Rules
Do not phrase critical constraints as suggestions. Instead of "it would be good to run tests before committing," write "You MUST run all tests before committing. This is non-negotiable." The Wharton research shows that authoritative framing significantly increases LLM compliance.
## Testing Requirements
You MUST run all tests before committing any code change.
This is not optional. This is not negotiable. No exceptions. No rationalizations.
If tests fail, you MUST fix the failures before proceeding.
Do not commit failing tests. Do not skip tests.
2. Build Your Own Rationalization Table
Observe the specific excuses your AI agent generates when it cuts corners. Write them down. Then add explicit rebuttals to your configuration. The more specific the excuse-rebuttal pair, the more effective it will be.
## Common Rationalizations (Do Not Fall for These)
| If you think... | The reality is... |
|--------------------------------------|----------------------------------------------------------|
| "This change is too small to test" | Small changes cause big outages. Test it. |
| "I'll fix the linting later" | Later never comes. Fix it now. |
| "The existing tests cover this" | Verify that claim. Run the tests. Check coverage. |
| "This is just a config change" | Config changes cause more outages than code changes. Test it. |
3. Require Commitment Before Action
Force the agent to state its plan before executing. This creates a commitment anchor that makes mid-task shortcuts feel inconsistent with the agent's own stated intentions.
## Before Starting Any Task
1. State which approach you will use and why
2. List the specific steps you will follow
3. Identify what tests or verification you will perform
4. Wait for approval before proceeding
You have now committed to this plan. Follow it completely. Do not deviate without explicit approval.
4. Add Pressure Test Scenarios
Write scenarios that simulate the conditions under which your agent tends to fail. Test your instructions against these scenarios periodically, especially after model updates.
## Self-Check Scenarios
Before you consider skipping any step, ask yourself:
- Would I skip this step if this code was running in production?
- Would a senior engineer reviewing my work accept this shortcut?
- Am I rationalizing? Check the rationalization table above.
If the answer to any of these questions gives you pause, follow the protocol.
5. Version and Iterate Your Instructions
Treat your CLAUDE.md as a living document. When you observe a new failure mode, add a countermeasure. When the model improves and an old failure mode disappears, simplify. Keep a changelog so you can track what works and what does not across model versions.
Conclusion: The Persuasion Paradigm
The insight at the heart of this article is simple but profound: AI models are not logic engines. They are pattern-matching systems trained on human text, and they carry forward the persuasion dynamics embedded in that text. They respond to authority, commitment, social proof, and framing, just as humans do. They also rationalize, cut corners, and take shortcuts, just as humans do.
The frameworks that work best in agentic software engineering are the ones that treat this reality as a design constraint rather than a bug. Superpowers does not fight the model's tendency to rationalize. Instead, it catalogs every rationalization and builds a specific countermeasure for each one. It does not hope the model will follow instructions. It structures those instructions using the same persuasion principles that peer-reviewed research has shown to be effective.
This is not manipulation in any sinister sense. It is applied psychology in the service of better engineering. The same way that a good engineering manager knows how to motivate a team, set expectations clearly, and hold people accountable, a good agentic framework knows how to motivate a model, set expectations clearly, and hold it accountable.
The developers who master this approach, who learn to think about AI instructions as persuasive documents rather than technical specifications, will build the most reliable AI-assisted systems. The models will keep getting smarter. The question is whether we can keep them disciplined. The answer, it turns out, is the same one Cialdini gave us 40 years ago: you do not command compliance. You engineer it.
In the next article in this series, we will explore how these psychological principles scale across team environments and examine the emerging best practices for organizations building production systems with AI agents.
What to do next (2 minutes):
Open your agent instructions (e.g., CLAUDE.md, AGENT.md, GEMINI.md, QWEN.md, etc.).
Add a rationalization table with the top 3 excuses your agent uses to skip discipline (tests, verification, design review).
Add one commitment step: "State the skill + steps you will follow, then wait for approval."
If you try this, drop your worst AI rationalization in the comments -- I'll reply with a targeted rebuttal you can paste into your own framework.
This is Part 3 of a 5-part series on Agentic Software Engineering. Part 1 covers the Superpowers framework. Part 2 compares the leading agentic engineering frameworks.
References
- Meincke, L., Shapiro, D., Duckworth, A., Mollick, E., Mollick, L., & Cialdini, R. (2025). "Call Me a Jerk: Persuading AI to Comply with Objectionable Requests." Wharton Generative AI Labs.
- Cialdini, R. B. (1984). Influence: How and Why People Agree to Things. William Morrow and Company.
- Vincent, J. (2025). "Superpowers: How I'm using coding agents in October 2025." blog.fsck.com
- obra/superpowers. GitHub repository. github.com/obra/superpowers
- Knipper et al. (2025). The Bias is in the Details: An Assessment of Cognitive Bias in LLMs. arXiv:2509.22856.