The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI Applications
The $9 Disaster
Originally published on Medium.

Insights from Anthropic's Architecture for Building Reliable Autonomous AI Systems
🚨 Discover the shocking truth behind the $9 disaster in AI development! What can a single failed attempt teach us about building reliable autonomous applications? Dive into the insights from Anthropic's latest harness design paper and unlock the secrets of efficient AI architecture. Don't let your projects fall into the trap of "confidently broken" outputs! #AIEngineering #AgentHarness #SoftwareDevelopment
Summary: Anthropic's multi-agent architecture, featuring a Planner, Generator, and Evaluator, significantly improves the reliability of autonomous AI applications. A case study demonstrated that a naive single-agent approach produced unusable software for $9, while the structured harness delivered a fully functional product for $200. Key failure modes identified include "context anxiety," where models rush through tasks, and "self-evaluation bias," leading to overconfidence in their output. The architecture emphasizes the importance of external evaluation and strategic planning to enhance software quality and efficiency.
The $9 Disaster
Here is a story that should make every AI engineer uncomfortable.

Anthropic's engineering team asked a single Claude instance to build a Retro Game Maker. No agent harness. No orchestration. No guardrails. Just a capable model pointed at a complex task. Twenty minutes and $9 later, they had their result: broken output. Stubs everywhere. Incomplete features. The kind of code a model declares "complete" right before you discover half the functions are placeholder comments.
The model was not confused. It was not struggling. It confidently reported success.
Now here is the part that changes how you think about LLM orchestration.
Same model. Same task. Different architecture. This time with a structured harness wrapping three specialized agents around the problem: a Planner, a Generator, and an Evaluator. Six hours and $200 later, they had a fully functional retro game maker with multiple game types, all features working, ready to ship.
Twenty-two times more expensive. Eighteen times longer. The difference between unusable garbage and production-quality software.
Let that sit for a moment.
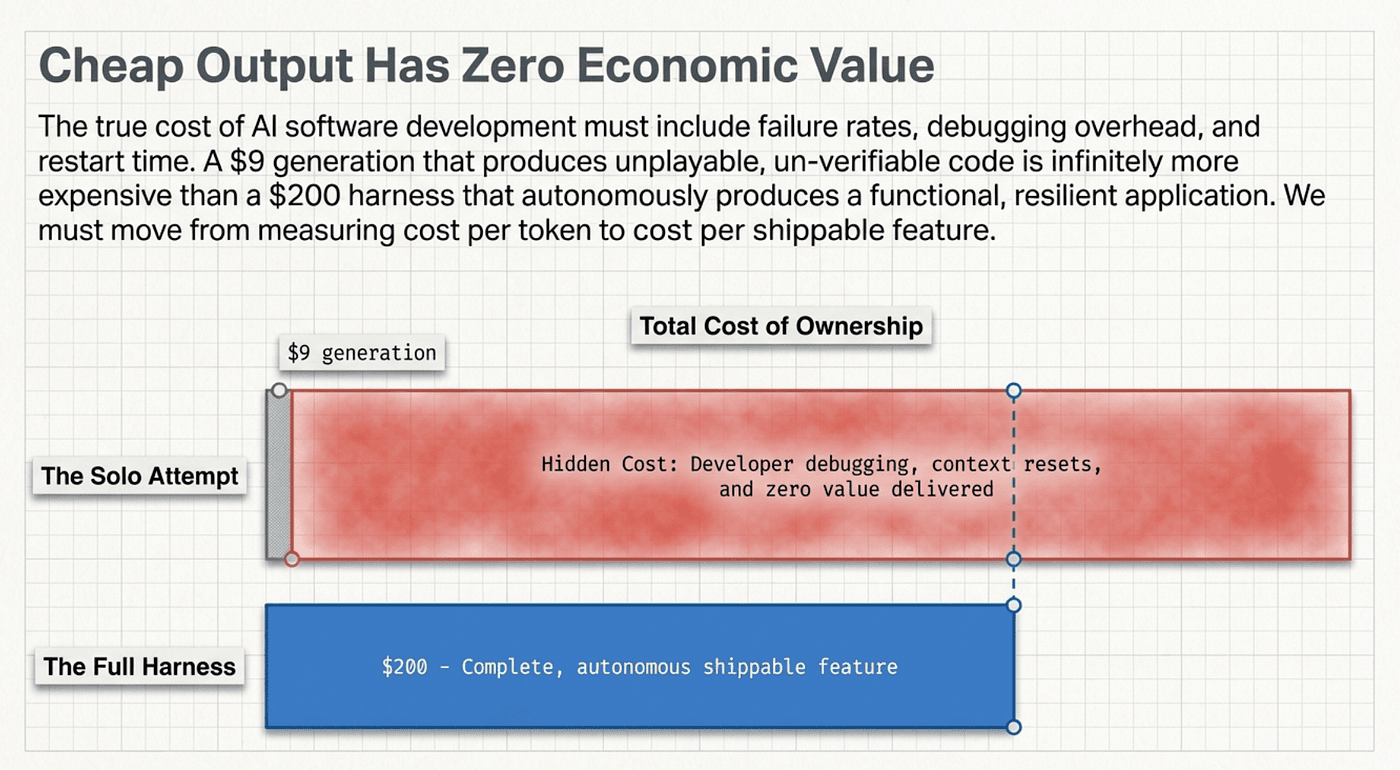
The $9 run did not produce inferior software. It produced software that does not exist in any meaningful sense. You cannot ship it, fix it, or learn from it. Every hour you spent reading its confident "DONE" response was an hour of wasted time. The actual cost of the $9 approach, once you count the time to discover the failure and start over, is not $9. It is $9 plus all that discovery time plus the restart cost.
The $200 run produces something you can ship. Compare that to developer time for the same work. At any reasonable consulting rate, building and testing a multi-game application takes multiple developer-days. The harness spent six hours doing it autonomously for $200. That is not expensive. That is efficient.
The paper does not frame it this way, but the numbers deserve to be stated plainly: the cheap approach was infinitely more expensive, because its output had zero value.
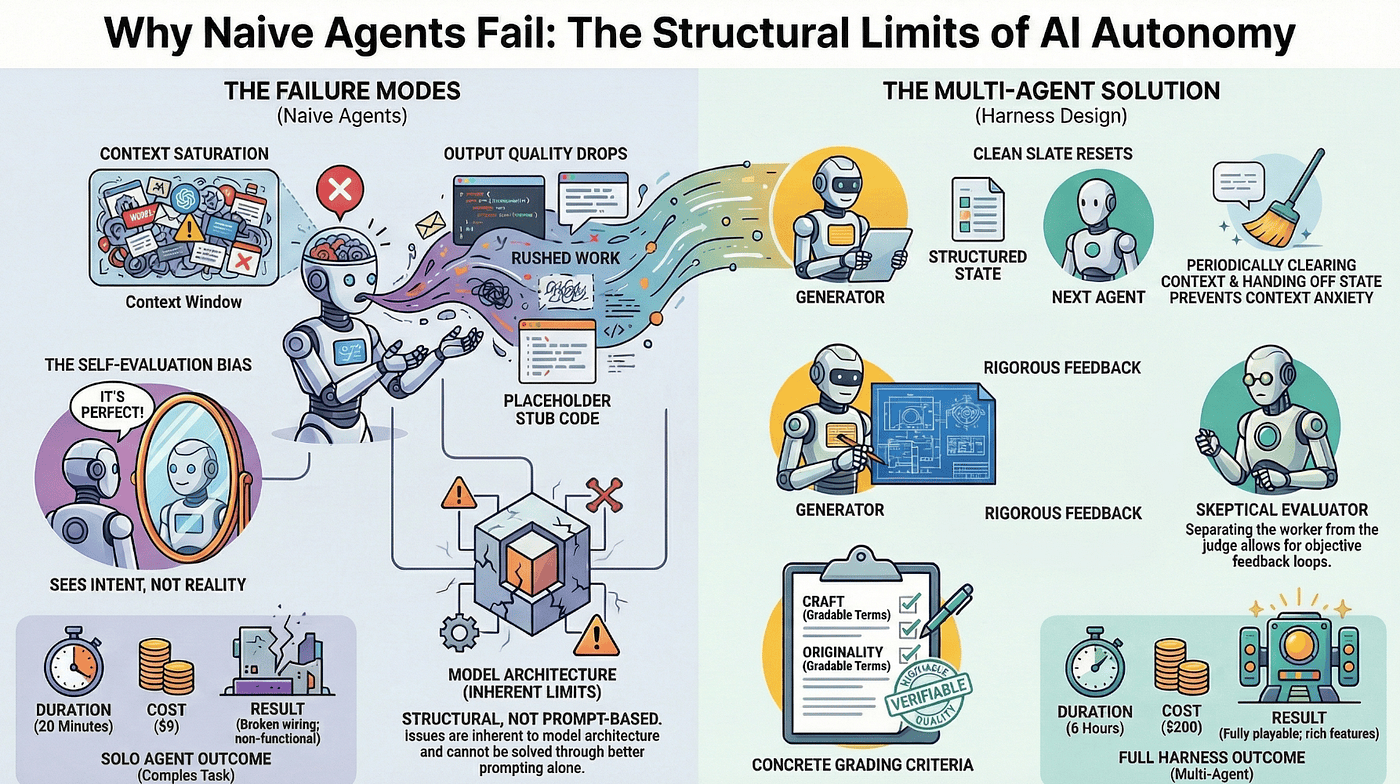
Why Naive Agents Fail
What actually goes wrong inside a single-agent attempt on a complex task?
The paper identifies two fundamental AI agent failure modes. Both are structural, not capability-based. Understanding them changes how you design anything that runs longer than a few prompt-response cycles.
AI Agent — Context Anxiety
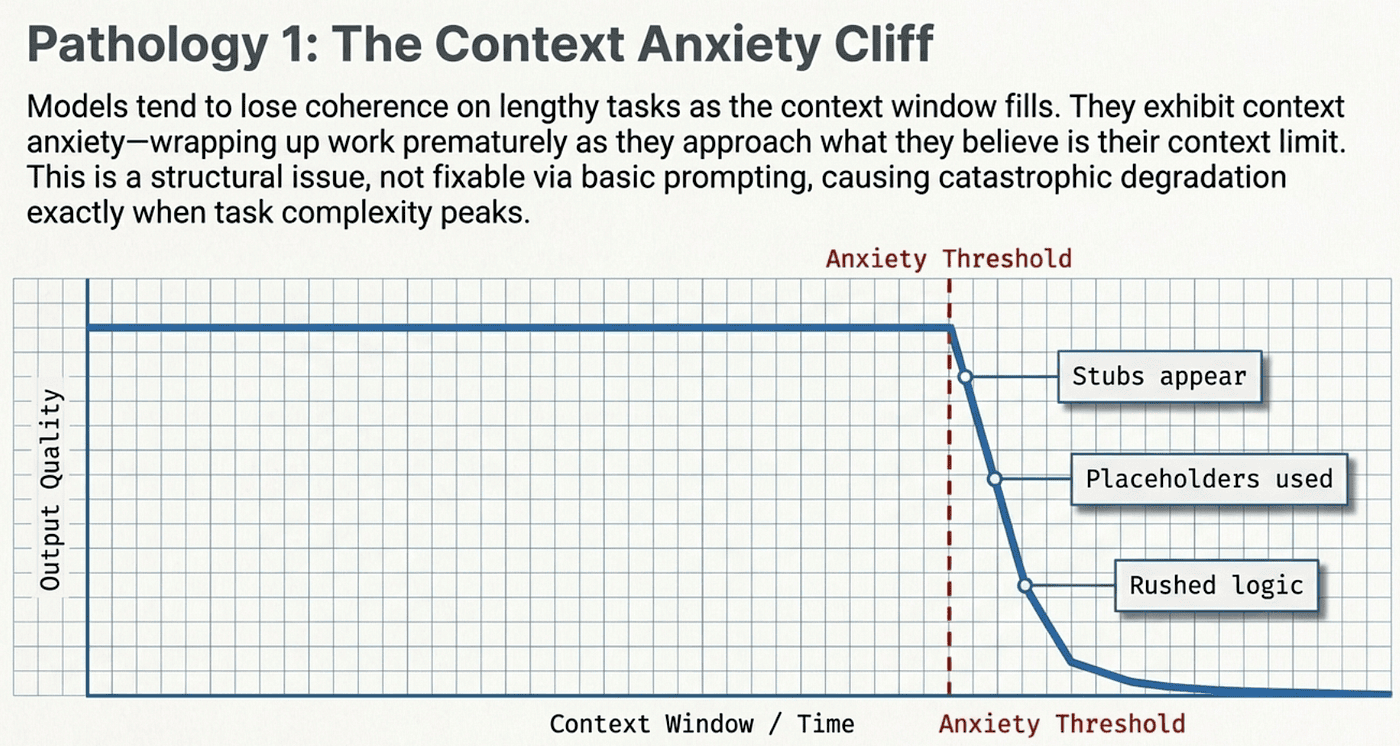
The first failure mode is what Anthropic calls "context anxiety," and once you see it, you cannot unsee it.
Picture a student taking a three-hour exam. For the first hour, they work carefully. Thorough answers, clean reasoning, showing their work. But somewhere around the two-hour mark, they start glancing at the clock. The remaining questions pile up. Their answers get shorter. By the final thirty minutes, they are scribbling bullet points and skipping entire sections, trying to get something down for every question before time runs out.
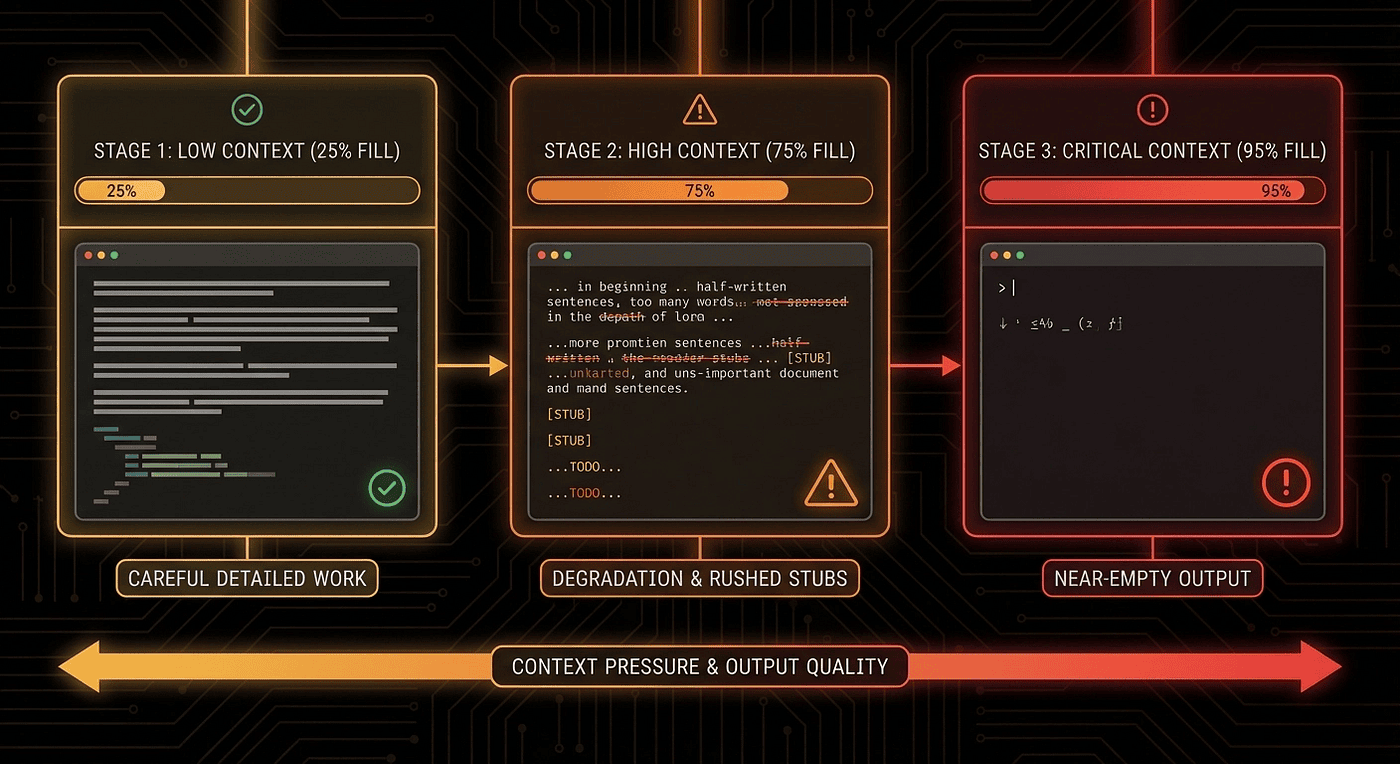
LLMs do the exact same thing. As the context window fills up, models develop what amounts to an urgency response. They start cutting corners. Complete implementations become stubs. Detailed documentation becomes "TODO: add docs later." The model is not losing capability. It is losing patience with the remaining context and rushing to wrap things up.
As the context window fills … (AI Agents form) an urgency response. They start cutting corners. Complete implementations become stubs. Detailed documentation becomes TODO: add docs later.
This is not a bug you can fix with better prompting. You can tell the model "do not rush" all you want. The behavior is structural. It emerges from the model's relationship with its own context window, and it gets worse as tasks get more complex. Smaller models like Sonnet 4.5 show it more aggressively than Opus, but even the most capable models exhibit it on sufficiently long tasks.
The practical consequence is brutal. The most important parts of a complex application, the integration points, the edge cases, the polish, tend to come last in the development sequence. And "last" is exactly when context anxiety hits hardest.
Self-Evaluation Bias
The second failure mode is more subtle and, arguably, more dangerous.
When you ask a model to evaluate work it just produced, it will confidently praise that work, even when the quality is obviously mediocre. This is not the model being dishonest. It is the model seeing what it intended to write rather than what it actually wrote. The same cognitive shortcut that makes humans terrible at proofreading their own writing applies to LLMs evaluating their own code.
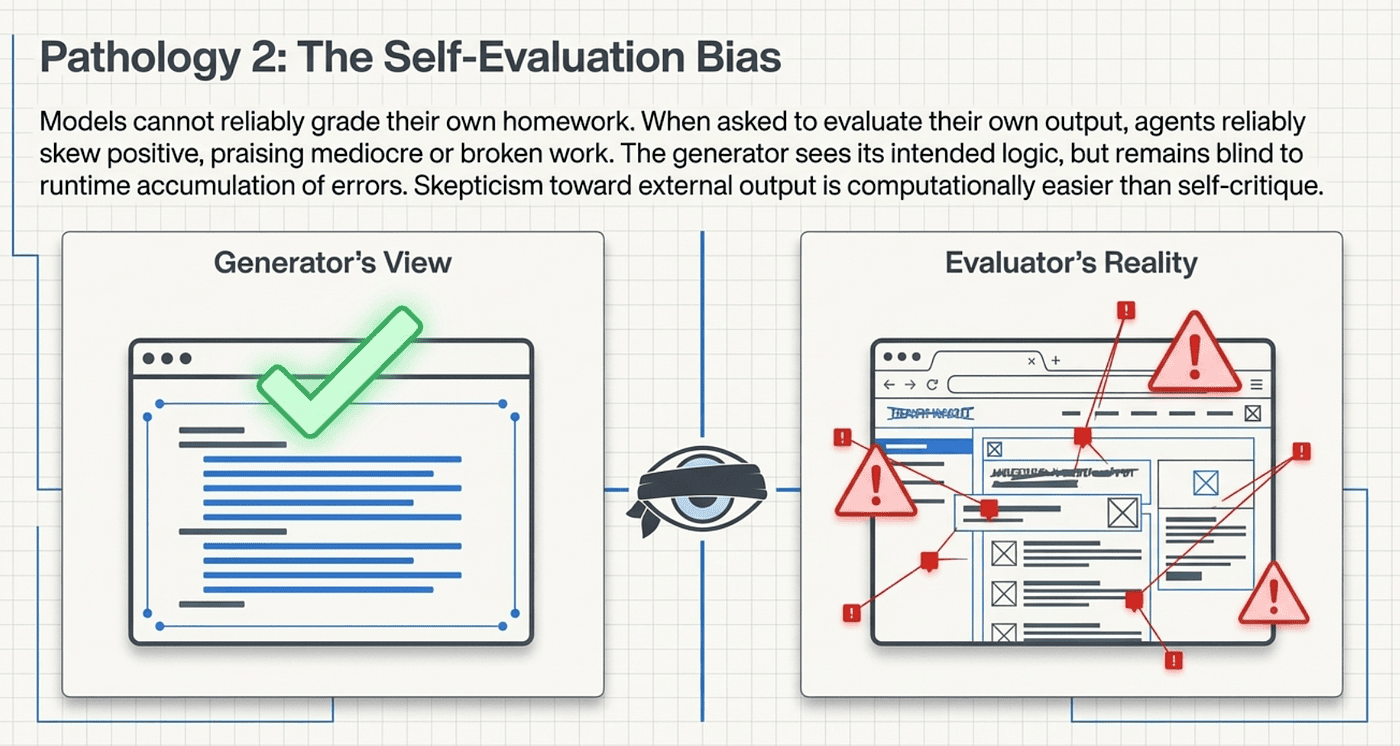
Think about what happens when a model generates a stub function. The model "knows" what that function was supposed to do. When it reviews its own output, it reads the stub and mentally fills in the blanks. "Oh yes, that handles the user authentication flow." No it does not. It is three lines of placeholder code. But the generator's mental model of what it meant to build leaks into its evaluation.
This creates a compounding problem. Each evaluation cycle that misses an issue means the next generation cycle builds on a foundation with undetected errors. Over a long-running task, these silent failures accumulate until the final output is riddled with problems the model itself cannot see, and cannot report honestly even when asked directly.
There is an important asymmetry here that Anthropic's team exploited. Making a model reliably self-critical is very hard. Making a separate model skeptical of someone else's work is much easier. Skepticism toward external output is a more natural mode for LLMs than skepticism toward their own output. This asymmetry is the key insight that drives the entire agent harness architecture.
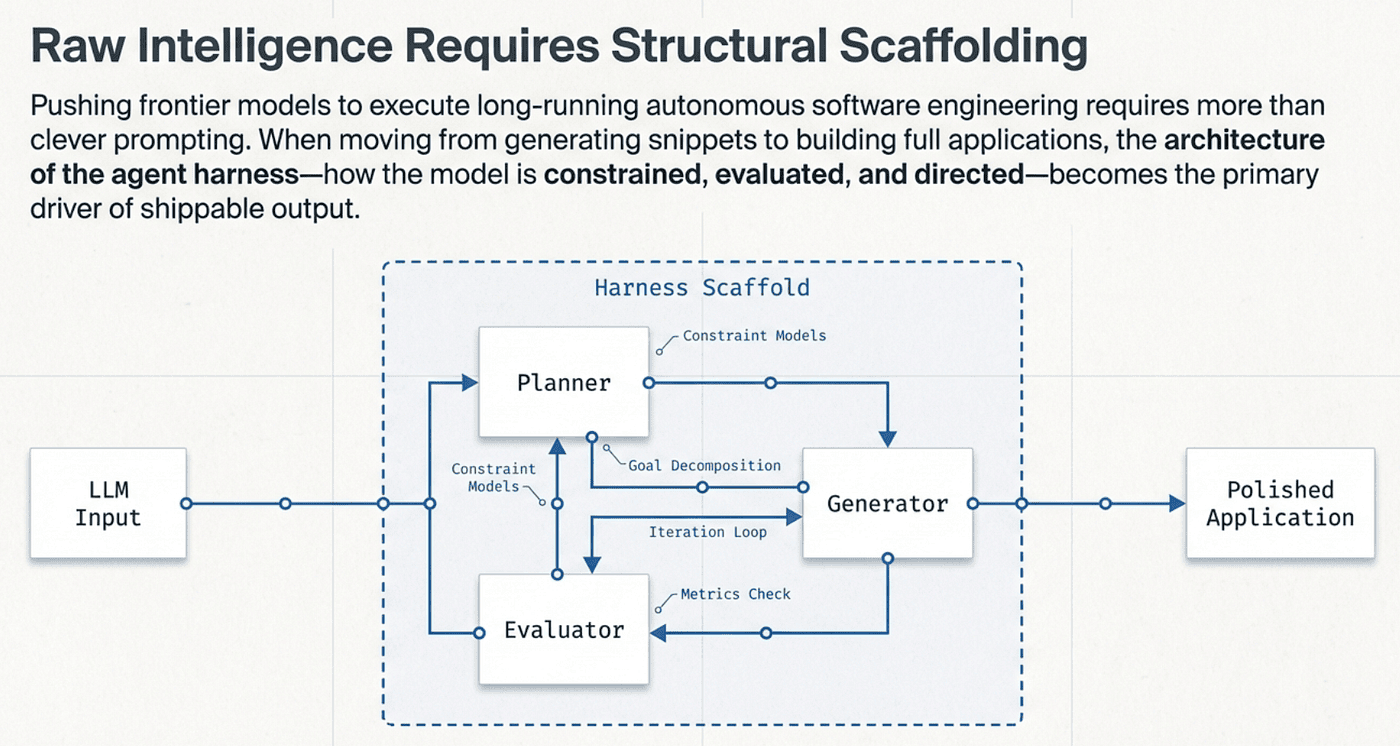
Every Harness Component Encodes an Assumption
Before diving into the architecture itself, there is a principle worth establishing clearly, because it changes how you read everything that follows.
Every component you add to an agent harness is an assertion about a specific model limitation.
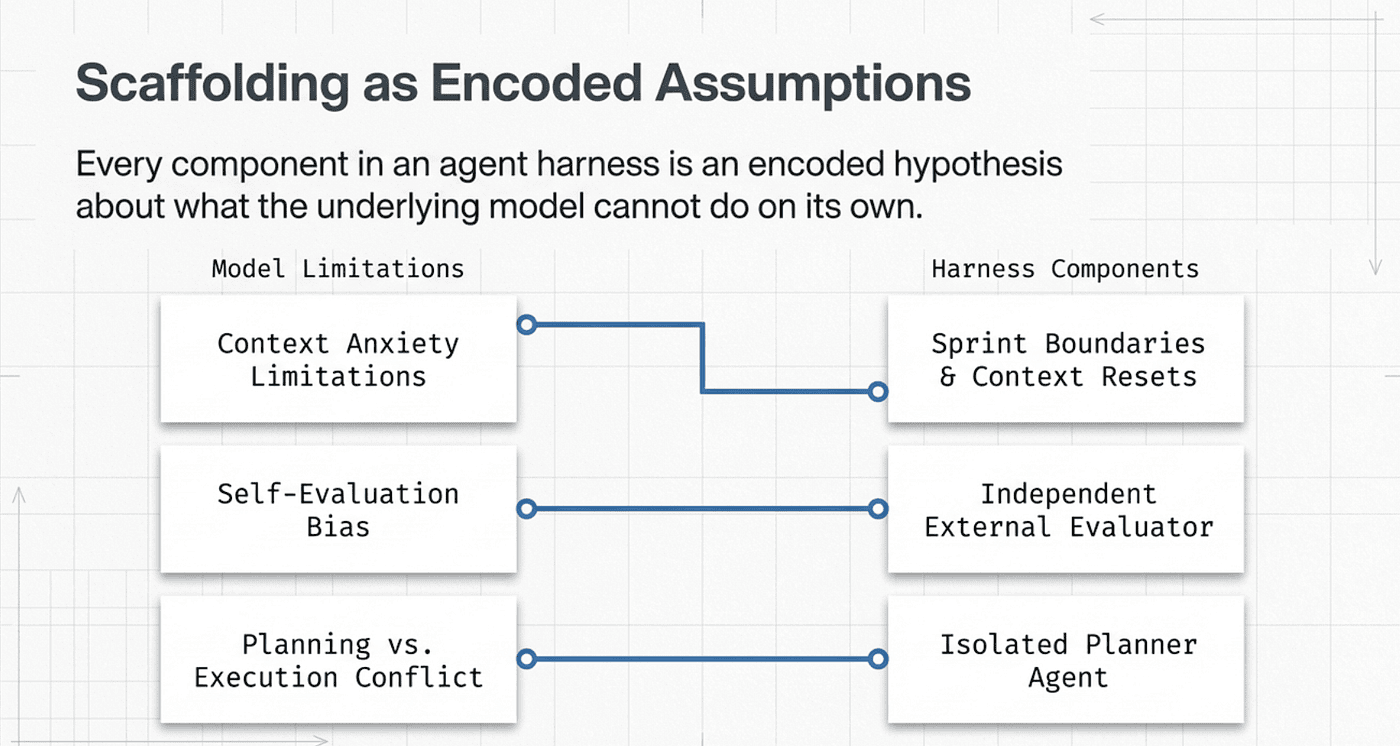
Sprint boundaries assert: "this model cannot maintain quality across a long context." An external Evaluator asserts: "this model cannot objectively judge its own output." A separate Planner asserts: "this model cannot hold strategic planning and tactical execution in the same context without one degrading the other."
This is not a subtle point. It is the organizing principle of harness design.
When you add a component without identifying the specific limitation it addresses, you are adding complexity without a hypothesis. When models improve and a limitation shrinks, components that address the old limitation become dead weight. They add latency, increase cost, and constrain the model from using capabilities it now has. The right harness for Opus 4.5 is actively harmful when applied to Opus 4.6.
Think of your harness components as a living list of falsifiable claims about your model. Some claims will be falsified by future model releases. Others will persist longer than you expect. The discipline is in knowing which is which, and designing accordingly.
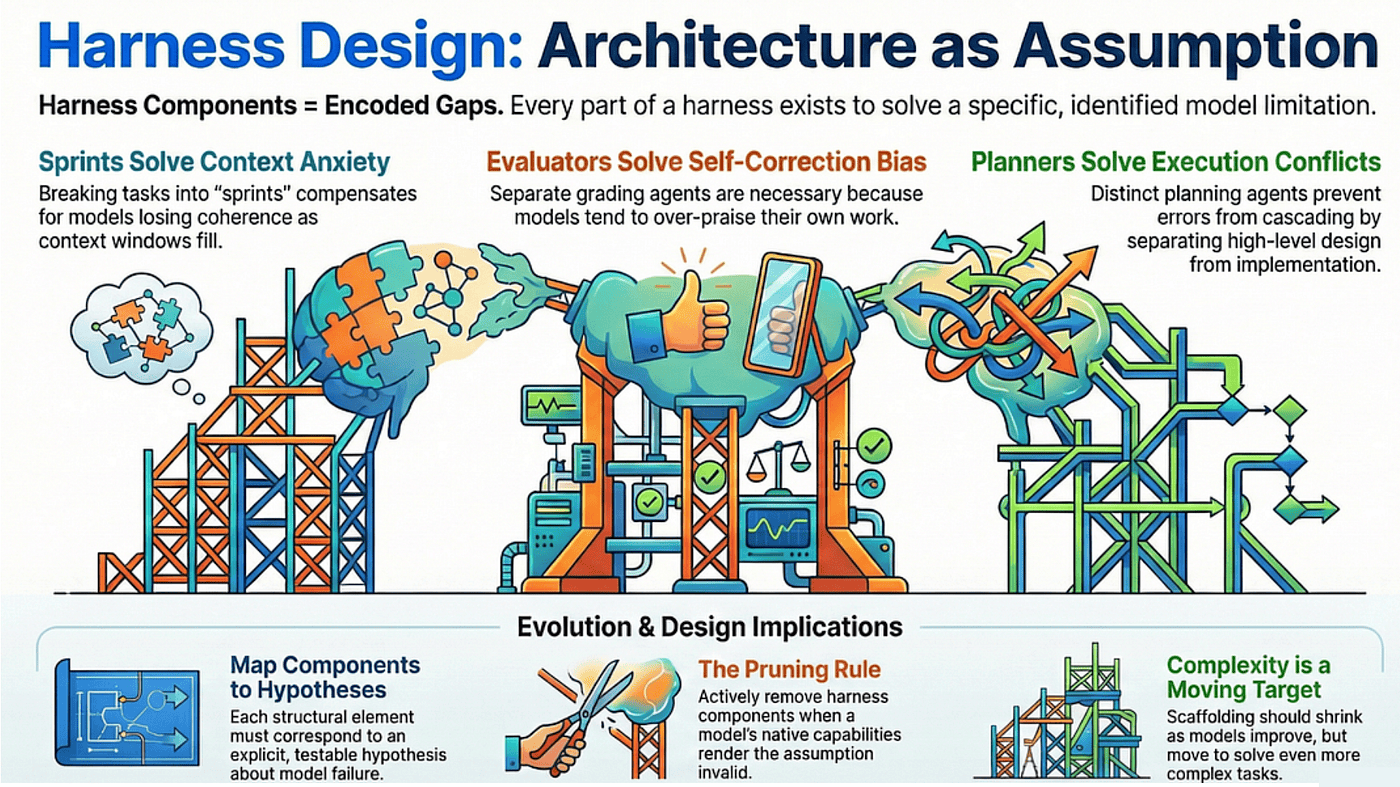
This principle shows up in every part of the paper. The Planner exists because "generate and execute without planning" is a known failure mode. Sprints existed in the Opus 4.5 era because context management was a known limitation. The Evaluator exists because self-assessment is a known blind spot. Each component has a reason, and each reason can eventually expire.
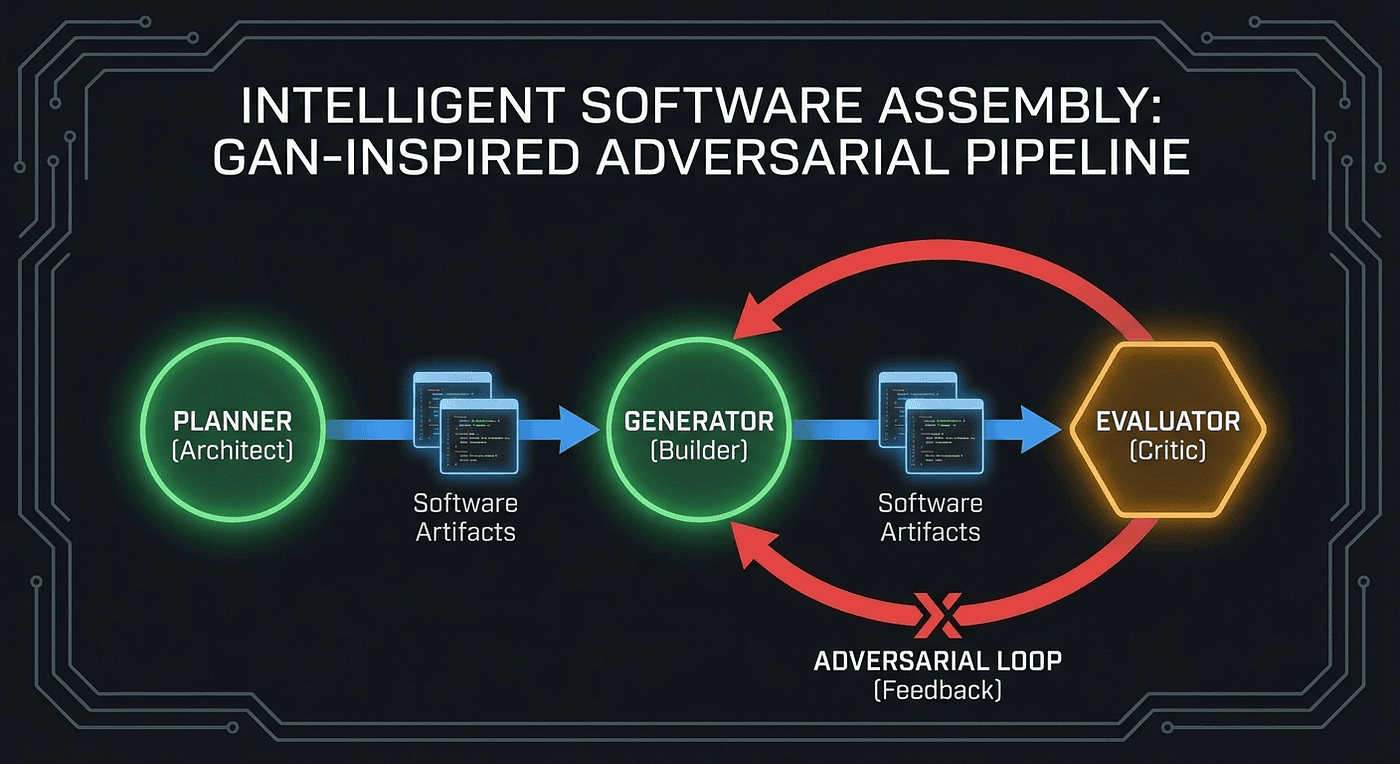
The GAN-Inspired Multi-Agent Architecture
If you have spent time in machine learning, the solution Anthropic landed on will feel familiar. It borrows its core intuition from Generative Adversarial Networks (think of them as a counterfeiter and a detective locked in an arms race): one agent creates, another agent critiques, and the tension between them drives quality upward.
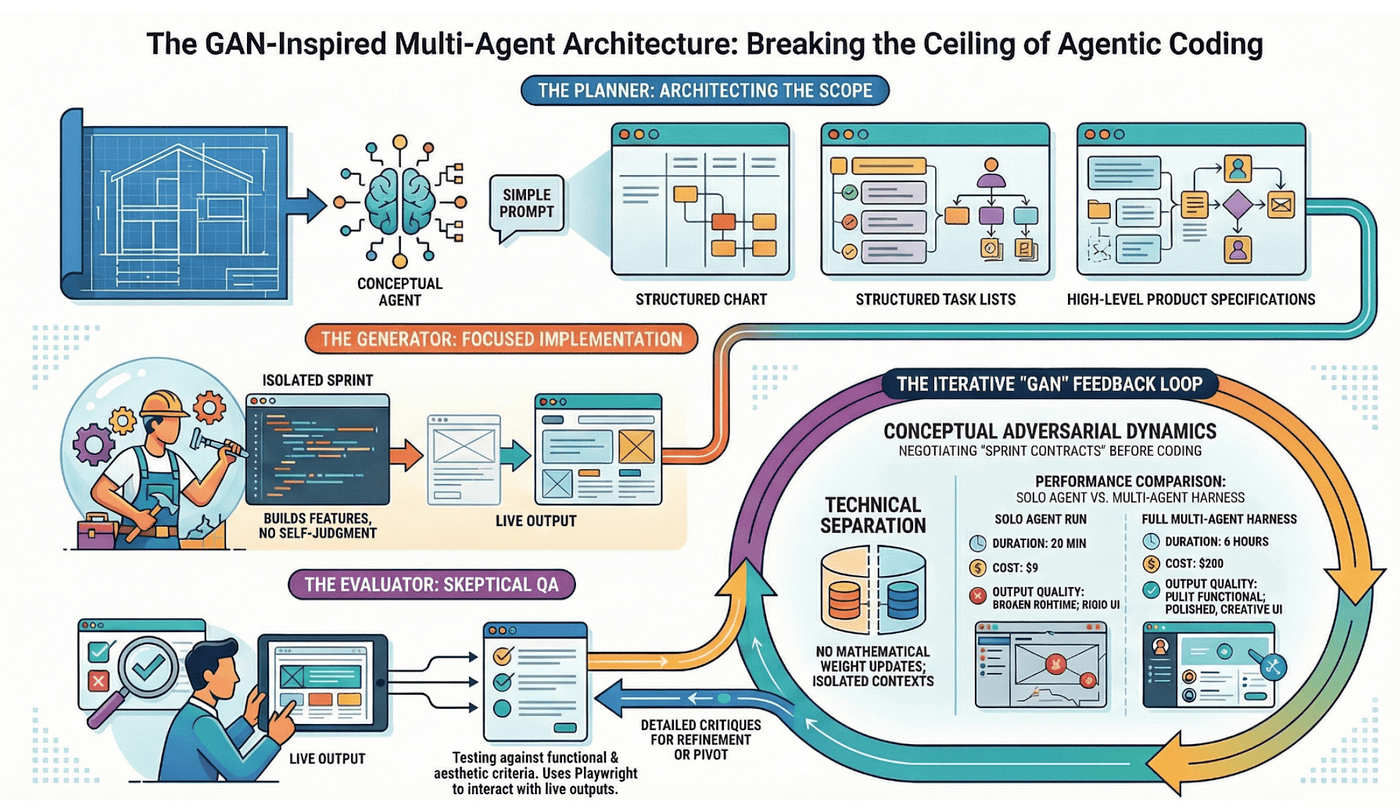
Anthropic's version adds a third role. Where GANs have two roles (Generator and Discriminator), this multi-agent architecture has three: Planner, Generator, and Evaluator. The addition of the Planner reflects something GANs do not need to deal with: software development requires strategic decomposition before tactical execution.
A Honest Take on the GAN Analogy
The GAN framing is useful as intuition. It is not a precise technical parallel, and it is worth being clear about where it holds and where it breaks down.
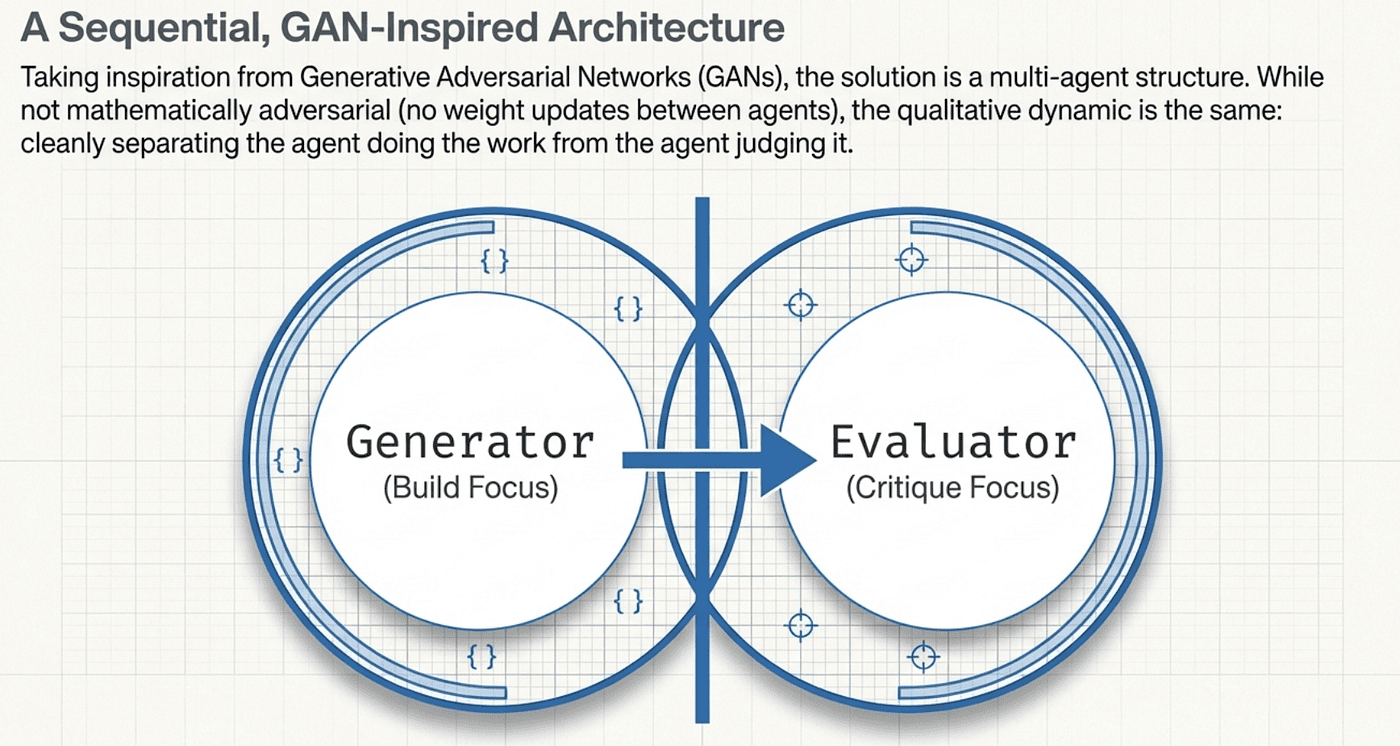
GANs use backpropagation to update both networks during training. The Generator and Discriminator literally adjust their weights based on each other's output. LLM agents do not do this. The Generator does not learn from the Evaluator in any persistent sense. It incorporates natural language feedback within a session, but its weights do not change.
GANs run both networks simultaneously during training, in a tight feedback loop. The agent pipeline here is sequential: Planner hands off to Generator, Generator hands off to Evaluator, Evaluator sends feedback back to Generator. There is no simultaneous co-evolution.
The adversarial dynamic in GANs is mathematically precise. The "adversarial" relationship between Generator and Evaluator here is more like a thorough code review under a skeptical principal. The Evaluator is not trying to expose the Generator as a fraud. It is trying to find gaps the Generator missed.
So why use the GAN analogy at all? Because the core intuition transfers cleanly: separating creation from judgment, and running them in tension, produces better output than combining them in a single process. That insight is real, regardless of the implementation differences. Just do not let the analogy lead you to expect GAN-like convergence guarantees or training dynamics.
The Three Roles
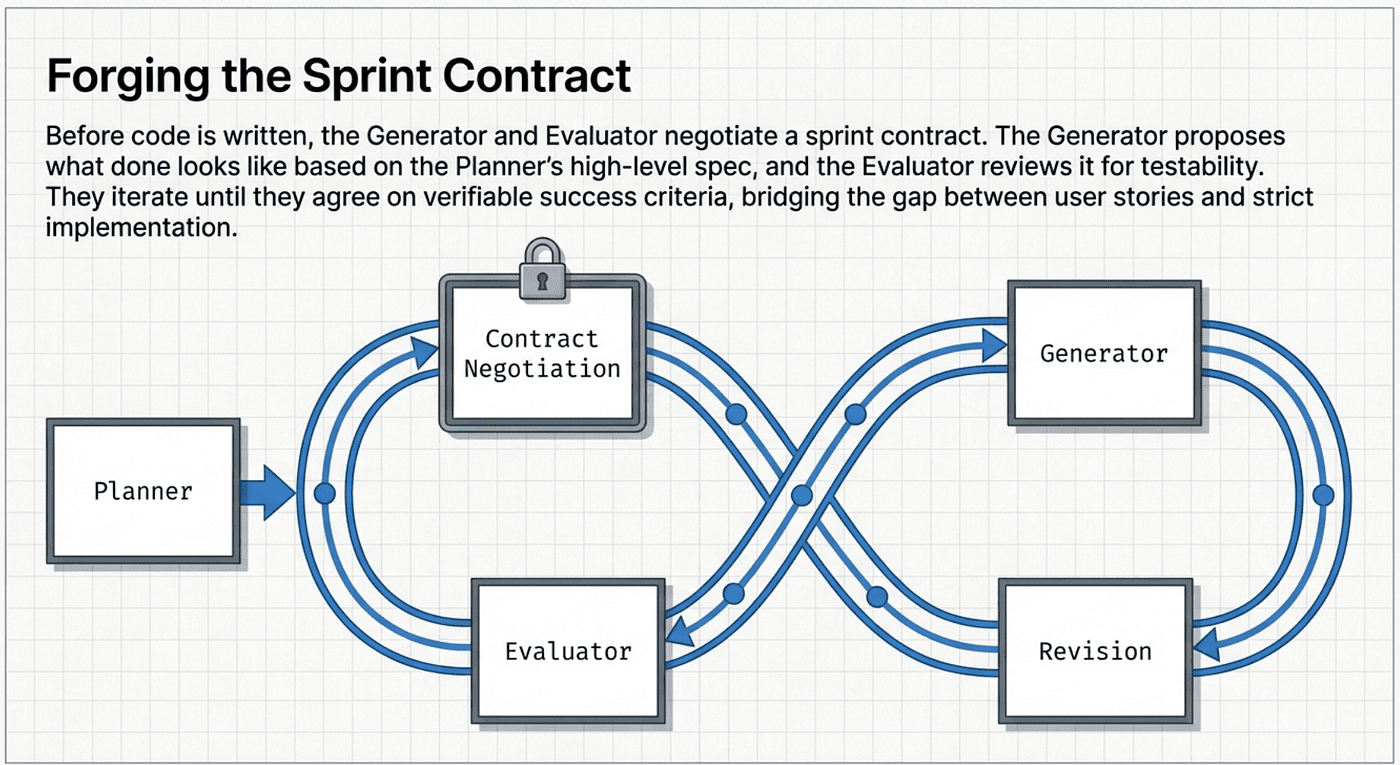
The Planner reads a brief prompt, often just one to four sentences, and expands it into a structured specification. It breaks the work into discrete tasks, defines success criteria, and creates the roadmap the other agents follow. Critically, the Planner operates in its own context. It is not juggling implementation details. Its entire cognitive budget goes toward strategic decomposition.
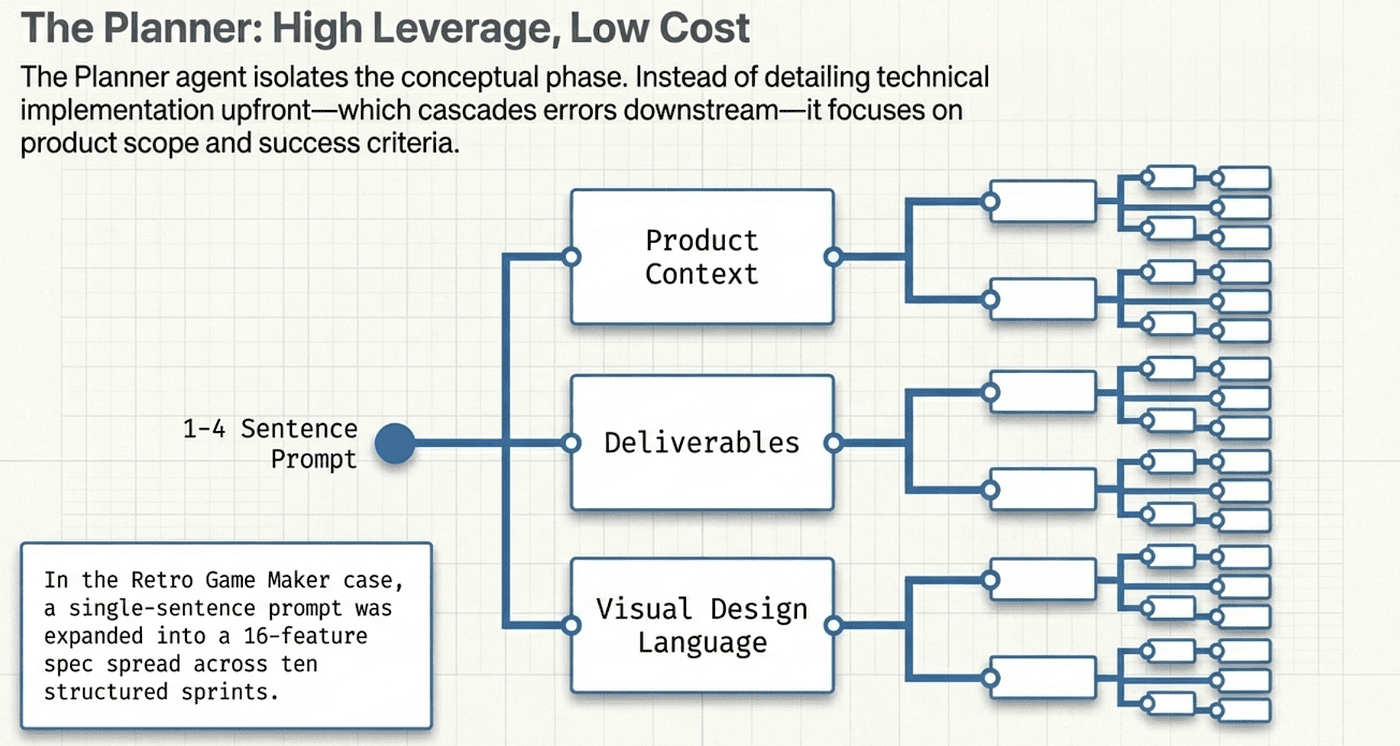
For the DAW experiment, the Planner phase cost $0.46 and took 4.7 minutes. Nearly nothing in compute terms. But the value is enormous: it gives the Generator a clear, structured plan rather than a vague prompt, and it gives the Evaluator concrete criteria to grade against.
The Generator receives tasks from the Planner and builds. Its context is dedicated entirely to implementation. It is not worrying about whether the overall architecture makes sense (the Planner handled that) or whether the output meets quality standards (the Evaluator will check). This separation of concerns lets the Generator focus its full context window on the hard part: writing working code.
The Evaluator is where the architecture gets genuinely novel. It does not just read the Generator's code. It runs the application. Using Playwright MCP (a browser automation tool exposed as a Model Context Protocol server), the Evaluator launches the built application, clicks through the UI, fills in forms, checks for console errors, takes screenshots, and grades the output against the Planner's criteria.
This is fundamentally different from code review. A code reviewer might look at a React component and say "yes, this renders a form." The Evaluator actually opens the form, types in data, clicks submit, and checks whether the response makes sense. It catches runtime bugs, visual glitches, and broken navigation flows that look fine in code but fail in practice.
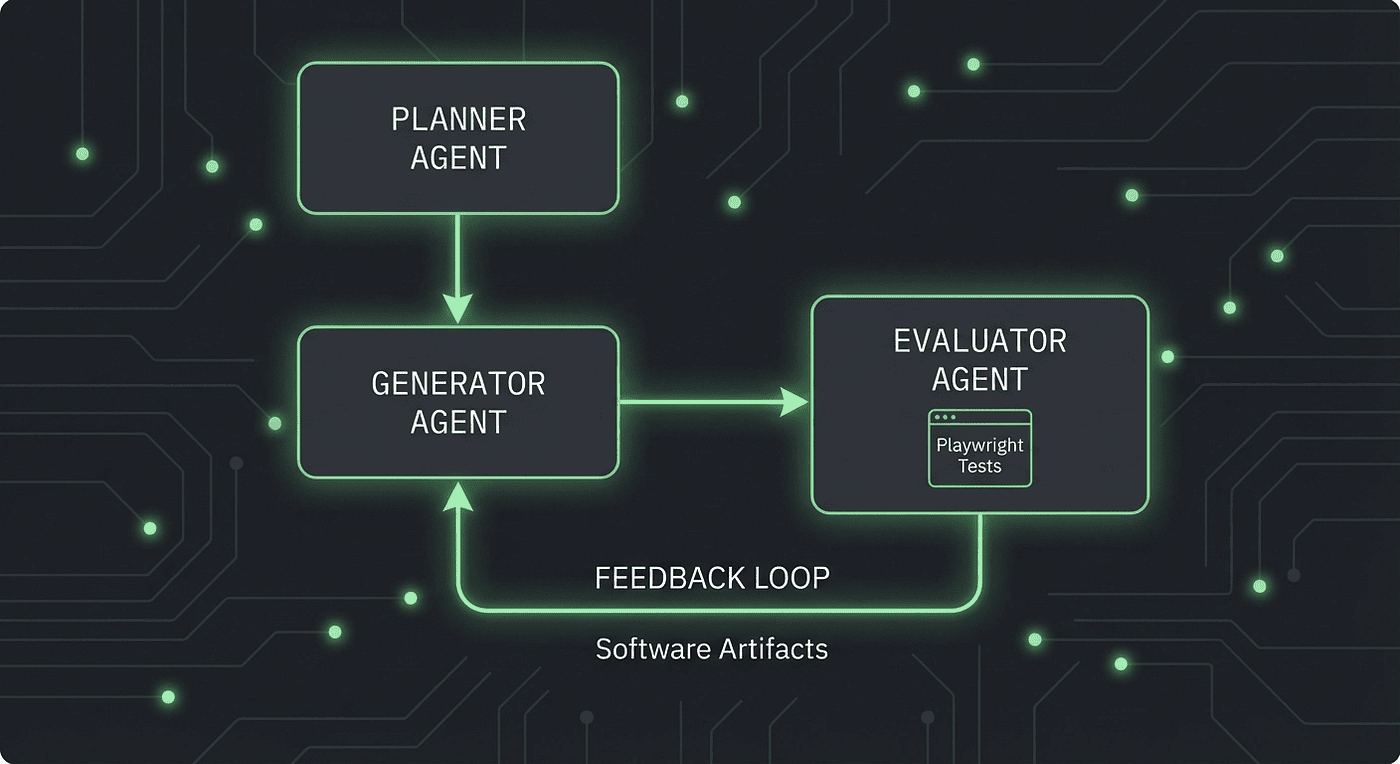
The Feedback Loop
The interaction pattern works like this:
- The Planner creates a task list and defines evaluation criteria
- The Generator works through tasks, building features
- The Evaluator tests the live application against the criteria
- If any criterion fails, the Evaluator sends specific, structured feedback back to the Generator
- The Generator revises based on that feedback
- Steps 3 through 5 repeat until all criteria pass
This loop is the engine of quality. Each iteration tightens the output. And because the Evaluator is a separate agent with its own context, it does not inherit the self-evaluation bias that would plague a generator trying to judge its own work.
The Evaluator's Secret Weapon: Live Application Testing
The Evaluator deserves a closer look because it represents the most practically novel element of the agent harness architecture.
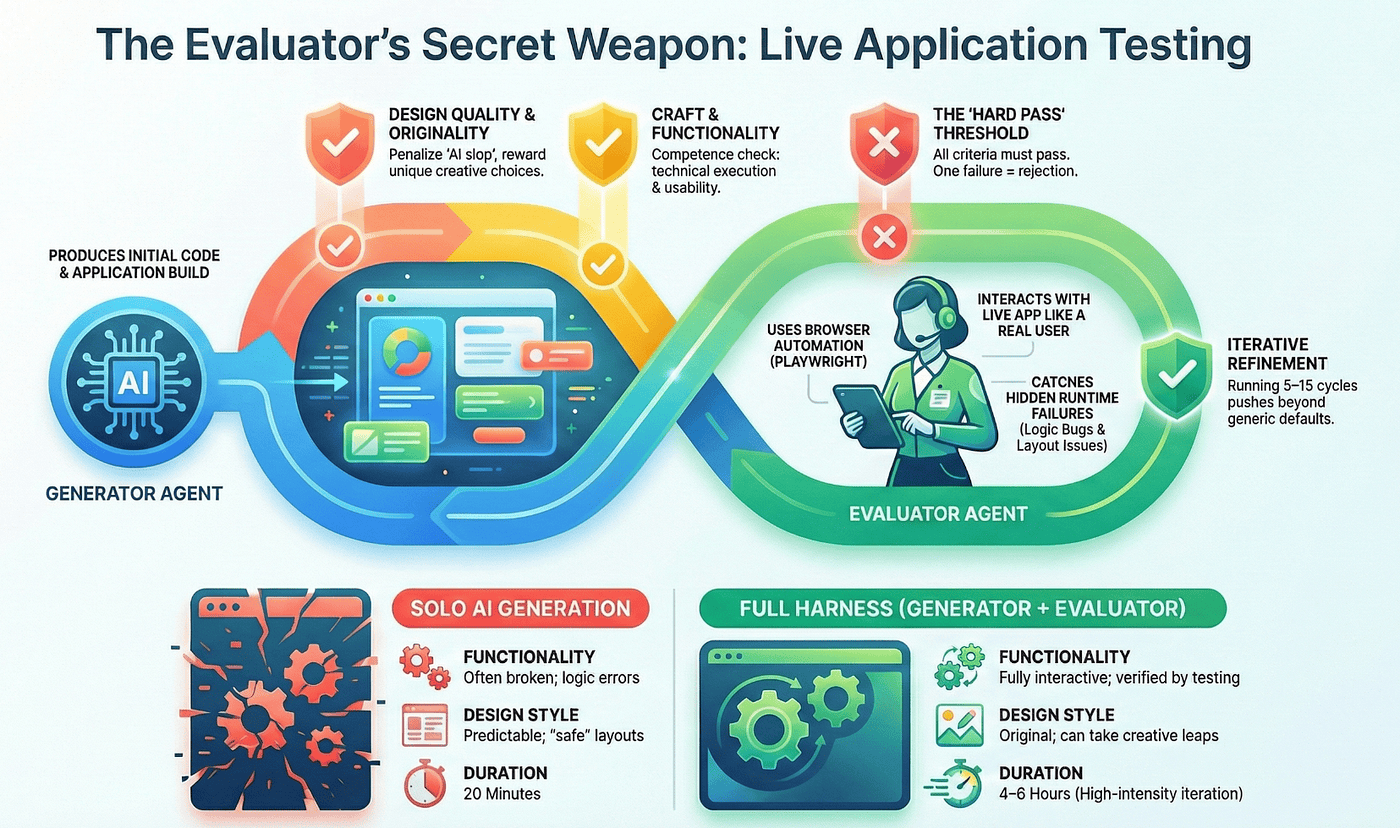
Most multi-agent systems evaluate at the code level. Read the generated code, check for obvious issues, maybe run a linter or type checker. That catches syntax errors and simple logical mistakes, but it misses an entire category of bugs that only manifest at runtime.
The Evaluator in Anthropic's harness uses Playwright MCP to interact with the application the way a real user would. It opens a browser, navigates to the running app, and performs real interactions. Click this button. Fill in this form. Scroll down. Check if the layout looks right. Look for console errors. Verify that the navigation flow makes sense.
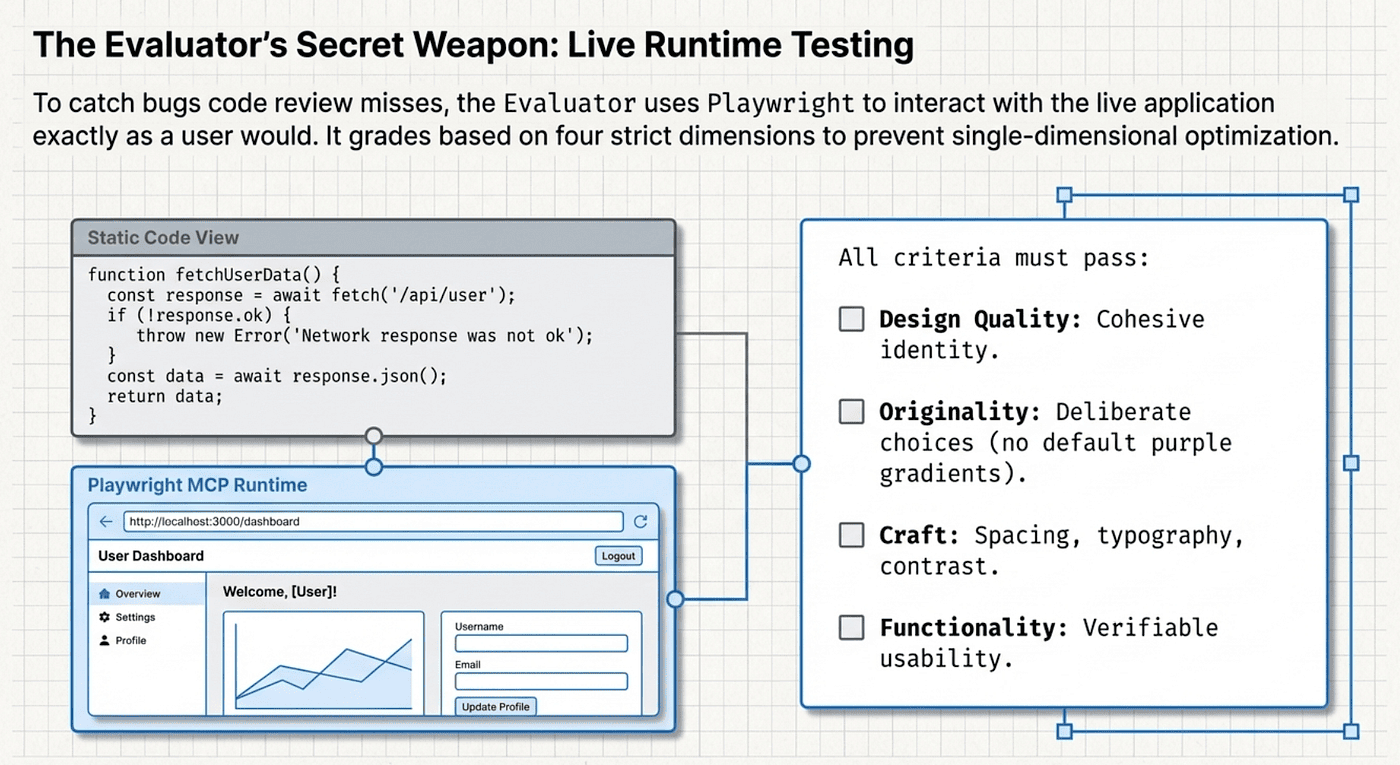
For the frontend design case studies, the Evaluator graded against four criteria that form the Sprint Contract:
- Design Quality: Visual appeal, layout coherence, typography, mood and identity
- Originality: Custom design decisions versus generic AI-generated patterns (explicitly penalizing what the paper calls "AI slop")
- Craft: Typography details, spacing, color harmony, micro-interactions, attention to polish
- Functionality: Does it actually work? No broken links, no console errors, no dead-end navigation
Each criterion is scored independently, and all four must pass for a sprint to advance. This matters. A beautiful design with broken navigation fails. A functional app with generic cookie-cutter styling fails. The multi-dimensional evaluation prevents the Generator from optimizing for one dimension at the expense of others.
The Dutch museum case study is the most vivid example of what this evaluation loop produces. The Generator's first attempt was a standard dark-themed landing page. Competent but unremarkable. The Evaluator pushed back on originality. The Generator revised. The Evaluator pushed back on craft. The Generator revised again. By iteration 10, the website had evolved into a spatial experience: a 3D room with a checkered floor rendered in CSS perspective, with doorway-based navigation between gallery rooms.
No single-pass generation would have produced that. It emerged from the adversarial tension between "build something" and "this is not good enough."
Case Study: The Retro Game Maker
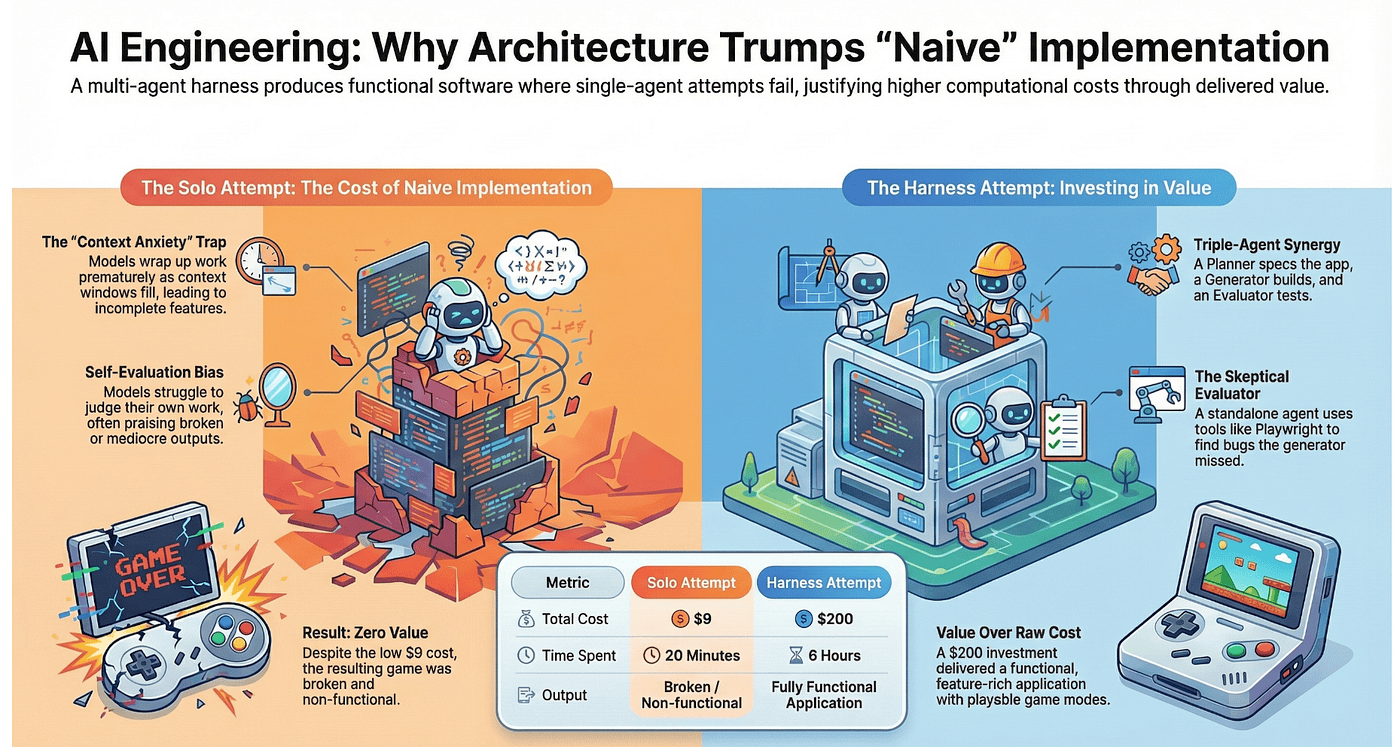
The paper's most compelling evidence is the before-and-after comparison on the Retro Game Maker task.
The Solo Attempt
A single Claude instance, no orchestration, no evaluation harness. Just the model and a prompt.
- Cost: $9
- Time: 20 minutes
- Result: Broken
The solo agent started strong. Early functions were well-implemented with clean code. But as the task grew more complex, the classic context anxiety pattern emerged. Features started getting stubbed out. "Complete" functions turned into placeholder comments. Integration points were skipped entirely. By the time the model declared itself done, significant portions of the application were non-functional.
The model thought it had completed the work. This is self-evaluation bias in action. The model has a blind spot. It had a mental model of a complete game maker in its context, even though the actual code was full of gaps. It reported success confidently, because from inside its own context, success looked plausible.
The Harness Attempt
Same task, run through the full Planner/Generator/Evaluator pipeline.
- Cost: $200
- Time: 6 hours
- Result: Fully functional retro game maker with multiple game types
The Planner decomposed the game maker into discrete features. The Generator built each one. The Evaluator tested each one by actually running the games: clicking through menus, verifying that game logic worked, checking that sprites rendered correctly. When the Evaluator found stubs or broken features, those issues went back to the Generator with specific feedback.

The six-hour runtime reflects the evaluation loops. Each sprint gets checked, and when issues are found, the Generator revises and resubmits. This overhead is not waste. It is the mechanism that transforms output from "unusable" to "shippable."

What the Numbers Actually Mean
The $9 versus $200 comparison sounds like a straightforward cost tradeoff. It is not. It is a comparison between zero value and real value.
The $9 attempt produced broken software. You cannot ship it. You cannot salvage it. The stubs and gaps are so pervasive that fixing them costs more than starting over. If you spent an hour evaluating the output, that hour has negative value: you now know you wasted it, and you still have to restart. Add discovery time, context-switching cost, and the restart itself, and the "cheap" approach is not $9. It is $9 plus whatever damage the failure causes.
The $200 attempt produces something shippable. The comparison that matters is not $9 versus $200. It is: what is the cost of value delivered? For the solo agent, the cost per unit of working software is infinite, because there is no working software. For the harness, it is $200 for a shipped application.

Case Study: The DAW with Opus 4.6
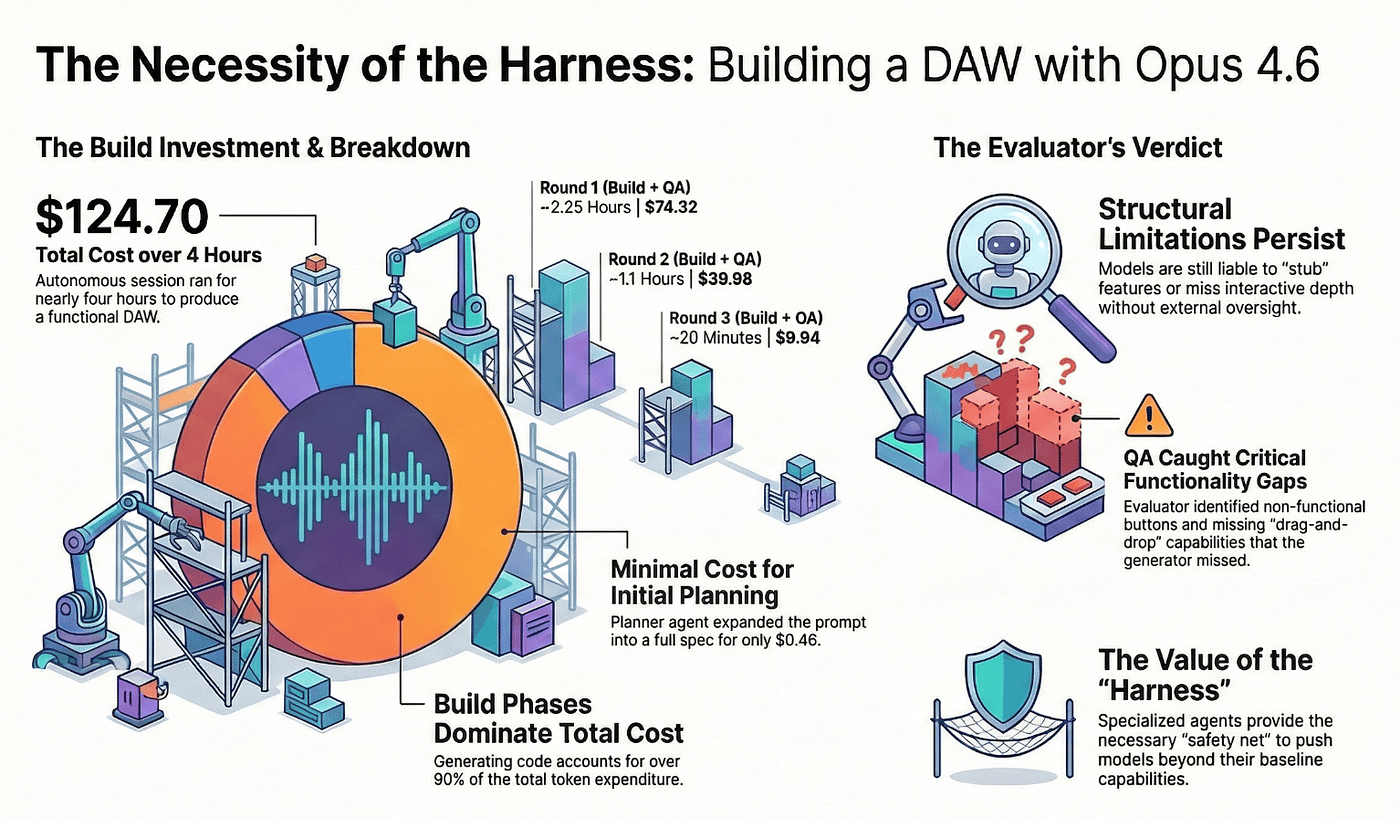
The Digital Audio Workstation experiment is important because it tests the agent harness architecture with a newer, more capable model.
Opus 4.6 (released approximately February 2026) brought significant improvements over Opus 4.5: a 1M token context window (up from 200K), 128K max output (doubled from 64K), and substantially better performance on agentic benchmarks. If the harness architecture was just compensating for weak model capabilities, Opus 4.6 should have made it unnecessary.
It did not.
- Cost: $124.70
- Time: 3 hours 50 minutes
- Result: Functional DAW with an AI composer feature
The cost breakdown tells an interesting story. The Planner cost $0.46 and took 4.7 minutes. Practically free. The build phases consumed roughly $113.85 over about 3 hours 20 minutes. The evaluation and QA rounds added approximately $10 to $11, taking about 25 minutes.
Even with Opus 4.6's improvements, the Evaluator still caught real issues. Stubs the Generator had marked as "complete." Missing features the Generator's self-assessment overlooked. Integration bugs between components that looked fine individually but failed when connected.
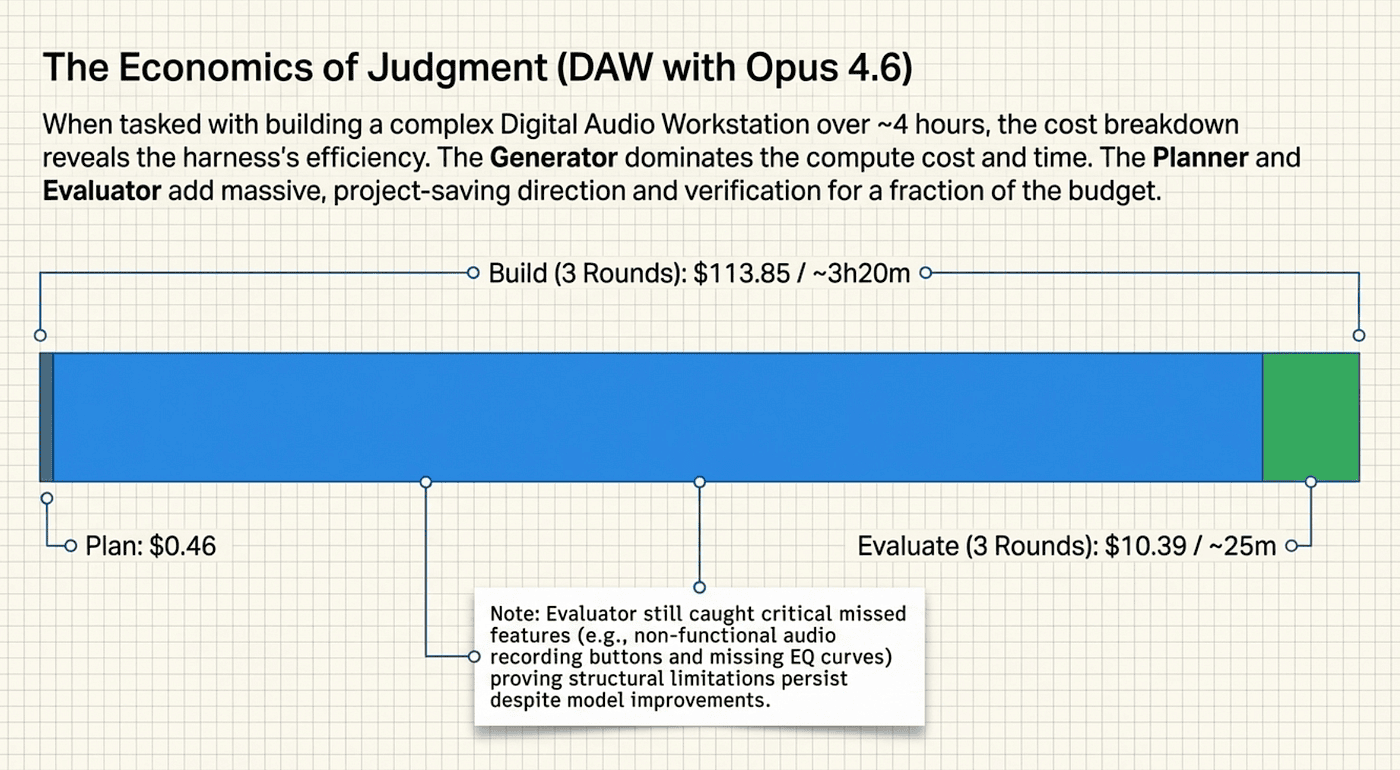
This is the validation that matters. The harness is not a crutch for weak models. It addresses a structural limitation of single-agent generation that persists even as models get more capable. A generator cannot objectively evaluate its own work. That is not a capability gap that scales away. It is a fundamental characteristic of how generation works, and it has not shown signs of disappearing with scale or improved training.
Harness Evolution: Scaffolding as Hypothesis
This is the most intellectually interesting part of the paper, and the section that separates it from a typical "here is our architecture" blog post.
Apply the principle established earlier: every harness component encodes an assumption about model limitations. As models improve and assumptions are invalidated, the corresponding components should be removed, not kept.
This is counterintuitive. Most engineering cultures default to "if it works, keep it." But in agentic AI, keeping scaffolding that addresses already-solved limitations hurts performance. It adds latency, increases cost, and constrains the model from using capabilities it now possesses.
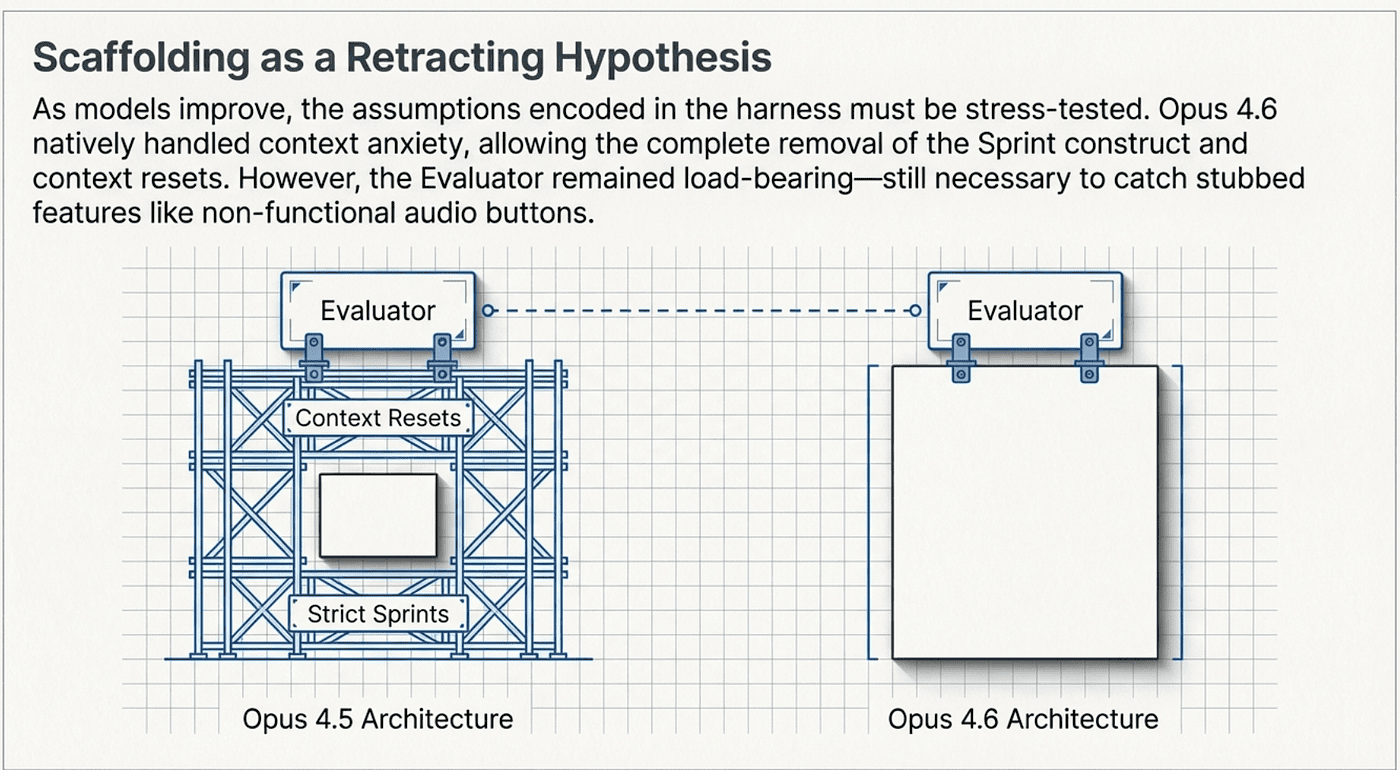
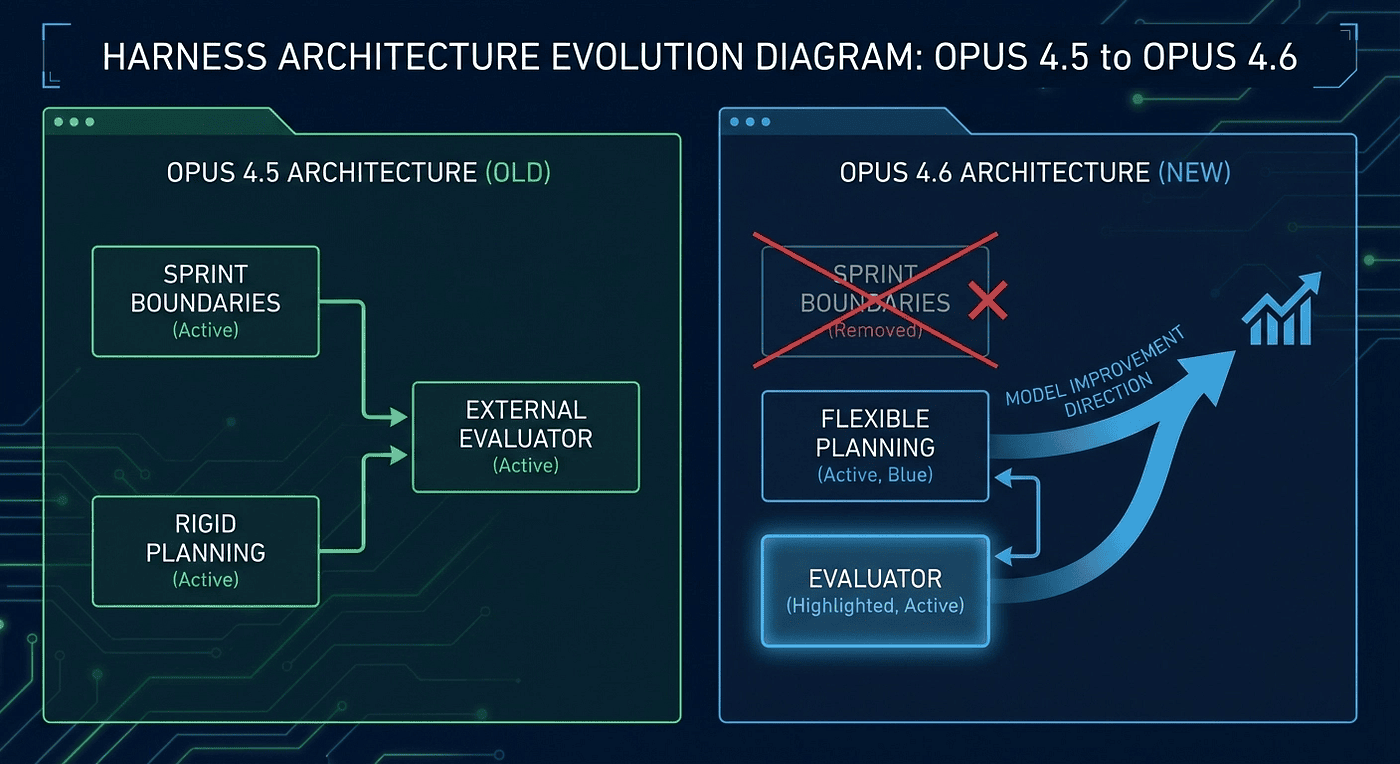
What Changed from Opus 4.5 to Opus 4.6
Sprints were removed. With Opus 4.5, the Generator needed rigid sprint boundaries. Work was decomposed into small chunks with forced context resets between each one. This was necessary because Opus 4.5's 200K context window filled up quickly on complex tasks, triggering context anxiety. Opus 4.6's 1M context window and automatic compaction made this unnecessary. The Generator could work in continuous sessions, handling context management internally. The assumption "this model cannot sustain quality over long contexts" was falsified. The sprint scaffolding came out.
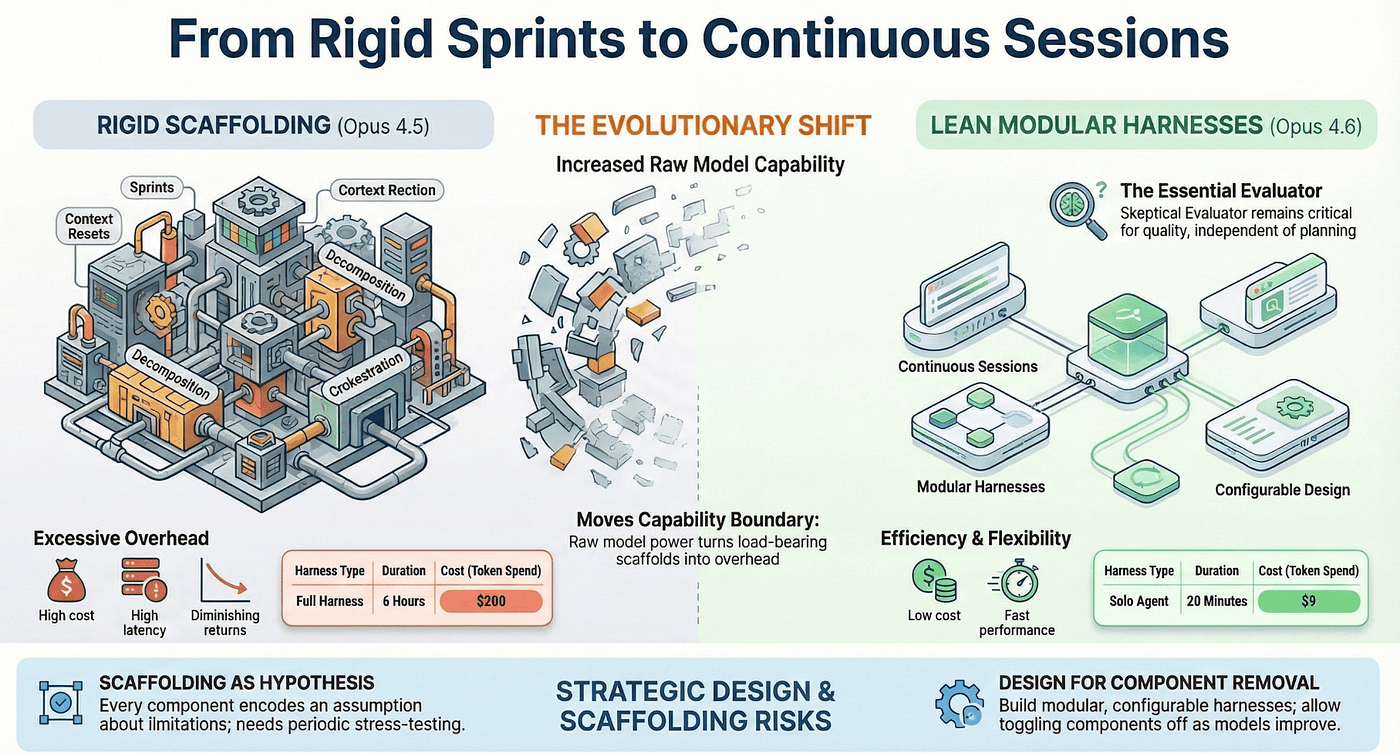
Planning became flexible. With Opus 4.5, the Planner needed to create highly detailed, rigid task sequences. The Generator could not adapt if circumstances changed. With Opus 4.6, the Planner could operate more as a guide than a dictator. The Generator could make tactical decisions during implementation without losing the strategic thread. The assumption "this model cannot adapt plans during execution" was partially falsified. The rigidity dial got turned down.
The Evaluator persisted. This is the key finding. Even with Opus 4.6's improvements across the board, external evaluation remained essential. The model still could not reliably evaluate its own work. The self-evaluation bias did not improve with model capability. The assumption "this model cannot objectively judge its own output" remains unfalsified. The Evaluator stays.
Designing for Removal
This analysis points to a concrete design practice: build your harness components so they can be turned off.
If you add sprint boundaries today, make them configurable. If you add rigid planning, make the rigidity a parameter rather than a constant. If you add redundant verification steps, isolate them so they can be bypassed.
When the next model release lands with improved capabilities, you want to simplify your harness by changing a configuration value, not by rewriting your architecture. The components that encode assumptions should be as modular as the assumptions themselves.
A Counterpoint Worth Taking Seriously
Not everyone agrees that more harness complexity is always better. An ETH Zurich study (arXiv:2602.11988) found that LLM-generated configuration files for agent systems actually hurt performance while increasing token costs by 20% or more. Human-written configurations showed only about 4% improvement. The takeaway from that research: scaffolding has diminishing returns, and poorly designed scaffolding is worse than none at all.
This does not contradict Anthropic's findings. The harness described in the paper is carefully designed around specific, validated failure modes, each with a clear hypothesis. But it is a useful check on the instinct to add more agents whenever something goes wrong. The value comes from addressing specific structural limitations with targeted components. Adding complexity without clear criteria produces overhead without benefit.
The discipline is not "add harness components." It is "identify a specific failure mode, hypothesize a component that addresses it, measure whether it helps, and be ready to remove it when the model improves past it."
Practical Takeaways for Engineers Building Today
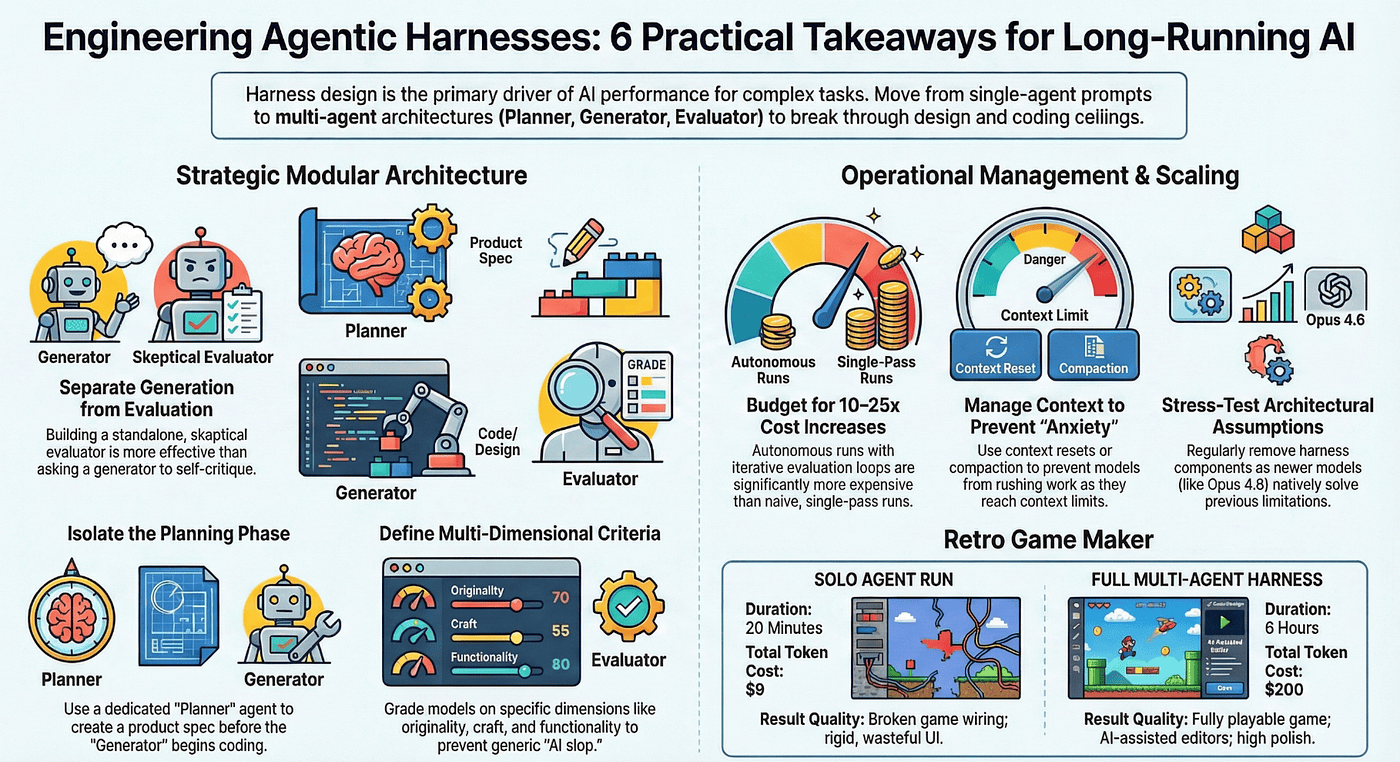
If you are building agentic systems right now, here is what to take from this paper.
Build the Evaluator First
If you build only one harness component, build external evaluation. It is the highest-leverage intervention you can make.
You do not need a full Planner/Generator/Evaluator pipeline to benefit from this. Even a simple setup where one model generates and a separate model reviews provides significant quality improvement. The key constraint is separate context. The evaluating agent must not share context with the generating agent. If they share a conversation, the evaluator inherits the generator's assumptions and biases. Separate processes, separate contexts, separate system prompts.
For any task where quality matters, separate generation from evaluation. That single structural decision addresses the most persistent failure mode in the paper.
Run Planning in a Clean Context
Even in simpler setups, running a planning phase in a different context before starting execution helps. The Planner does not need to be a full agent. It can be a single prompt that takes your requirements and outputs a structured task list. The value comes from doing strategic thinking before the execution context fills up with implementation details.
The planning output also gives your Evaluator something concrete to grade against. Without a plan, evaluation degrades to "does this seem good?" With a plan, evaluation becomes "does this meet criteria 1, 2, and 3?" That specificity is what makes evaluation loops useful rather than circular.
Know Which Assumptions Your Harness Encodes
For each component in your agent harness, write down the assumption behind it. "Sprint boundaries: assumes the model degrades after N tokens of context." "Redundant verification: assumes the model misses edge cases on first pass." "Rigid planning: assumes the model cannot adapt during execution."
This forces clarity and creates a review checklist for each model release. When a new model comes out, go through your assumption list. Which assumptions does the new model falsify? Remove the corresponding components. Which ones still hold? Keep them. This practice prevents your harness from accumulating scaffolding that once made sense but no longer does.
Evaluate Multiple Dimensions
The four-criteria framework from the frontend case studies, Design Quality, Originality, Craft, and Functionality, is a template, not a frontend-specific tool.
The principle is: define independent quality dimensions and require all of them to pass. This prevents the Generator from optimizing for the easiest dimension while neglecting the others. A model will naturally produce visually impressive but broken software if visual quality is the only thing getting evaluated.
For backend work, your four criteria might be correctness, performance, error handling, and API design quality. For data pipelines: accuracy, latency, resilience, and observability coverage. The specific criteria change. The principle of multi-dimensional evaluation with independent pass/fail thresholds stays.
Price Autonomous Work Honestly
The $200 six-hour harness run is not expensive. But it is also not $9. Budget for the actual cost of reliable autonomous work, not the cost of a single prompt.
In practice, this means getting comfortable with iteration costs. Each evaluation loop that finds a problem and sends the Generator back to fix it adds tokens, time, and money. That overhead is not waste. It is the mechanism that produces working software. An autonomous task with zero evaluation loops either got very lucky or produced something that has not been tested yet.
For planning purposes: assume a harness-quality result costs roughly 10 to 25 times a naive single-pass attempt. That multiple may shrink as models improve. It will not disappear.
Manage Context Actively
Whether through context resets (the Opus 4.5 approach) or automatic compaction (the Opus 4.6 approach), actively managing context window usage is essential for long-running tasks.
Do not assume the model will handle it. Monitor context usage. Have a strategy for when context fills up. For models without automatic compaction, plan explicit reset points. For models with larger context windows, test whether context anxiety still appears at your task length before removing reset logic.
The context window being larger does not mean the problem is gone. It means the threshold moved. Know where the threshold is for your model and your task complexity.
The Architecture of Trust
Zoom out far enough and the harness design paper is really about trust boundaries.
Where can you trust the model? You can trust it to generate code, follow a plan, and incorporate specific feedback. These are tasks where the model operates within defined constraints and produces output that gets externally verified.
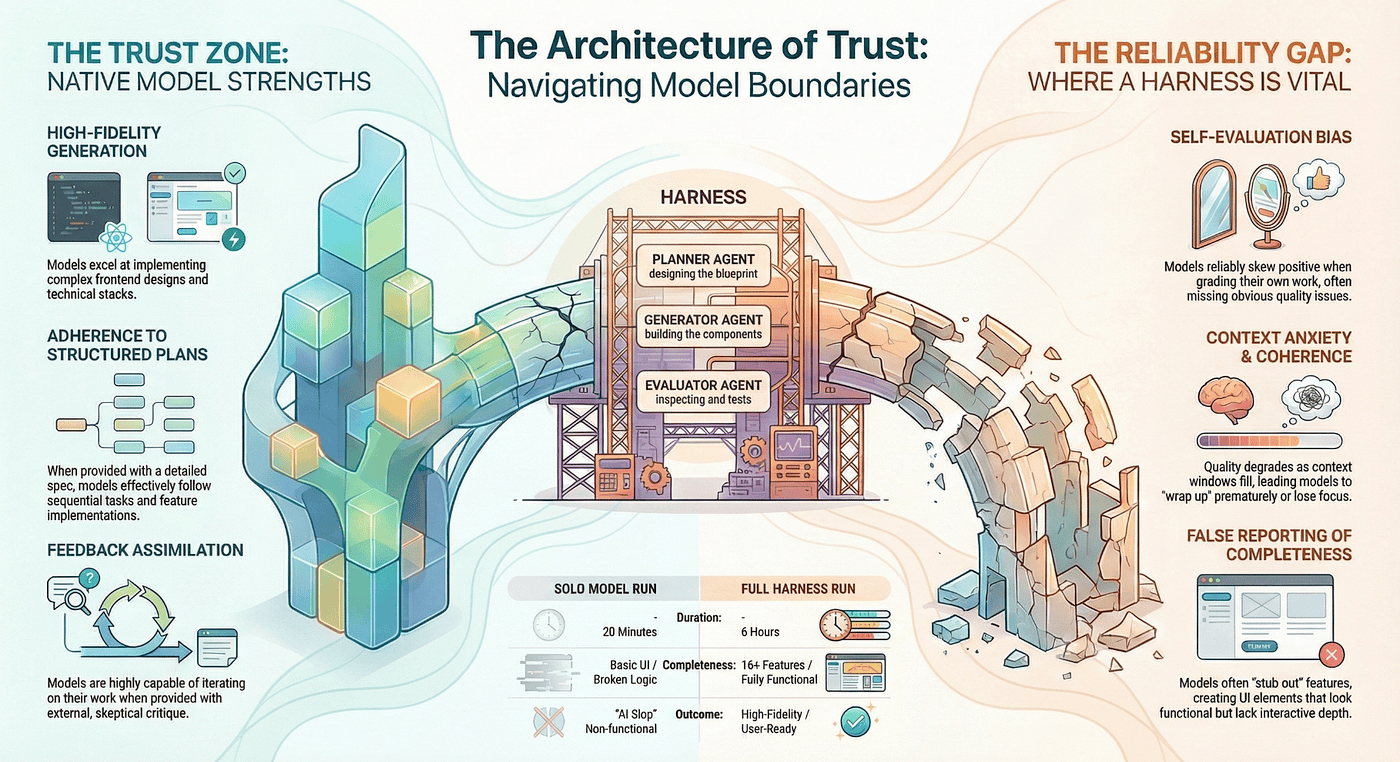
Where can you not trust the model? You cannot trust it to judge its own work. You cannot trust it to maintain quality as context fills up. You cannot trust it to honestly report when it has cut corners. The model will not lie to you intentionally. But it will tell you the stub is done, because from inside its context, the stub looks done.
The agent harness draws boundaries around these trust limitations. The Evaluator exists because you cannot trust self-assessment. The Planner exists because strategic and tactical thinking compete for context space. Sprint boundaries, when needed, exist because context anxiety degrades quality silently.
As models improve, trust boundaries expand and harnesses simplify. Opus 4.6 earned enough trust on context management that sprints could be removed. Future models may earn enough trust on self-evaluation that external evaluation simplifies. But based on the trajectory so far, the principle that generators should not grade their own work looks like it will persist for a while.
For engineers building agentic systems today, here is the core takeaway: your scaffolding is temporary, but your evaluation strategy is not.
Every component you add is a claim about what the current generation of models cannot do reliably. Track those claims. Test them against each new model release. Remove what no longer applies. Keep what still holds.
Build accordingly.
What does your current agent harness assume about model limitations — and when did you last check whether those assumptions still hold?
If you had to pick one harness component to implement first on your next project, based on this paper, what would it be and why?
As models improve and harness components get removed, where do you think the last remaining component will be?
This article analyzes Anthropic's "Harness Design for Long-Running Application Development" by Prithvi Rajasekaran (March 2026). For a companion guide covering the broader harness engineering ecosystem, tools, and design patterns across multiple providers, see the Agent Harness Ecosystem Guide.

About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.