The Agent Framework Landscape: LangChain Deep Agents vs. Claude Agent SDK
Comparing Architectures and Capabilities of Leading AI Agent Frameworks
Originally published on Medium.
 Conceptual cover image showing five AI agent framework architectures arranged across three categories: graph-based runtime, deep integration loop, and extensible platforms
Conceptual cover image showing five AI agent framework architectures arranged across three categories: graph-based runtime, deep integration loop, and extensible platforms
In Article 1 of this series, we built a Deep Agent from scratch. It planned work with TodoListMiddleware, delegated tasks through SubAgentMiddleware, prevented context overflow with SummarizationMiddleware, and maintained filesystem access across long-running sessions. The four pillars of Deep Agent architecture solved concrete problems: context overflow, hallucination drift, monolithic context pollution, and the absence of persistent memory.
Now comes the harder question.
You understand what a Deep Agent does. But the AI agent ecosystem in 2026 offers five frameworks for building one, and picking the wrong foundation means rewriting infrastructure later. Which framework should you actually build on, and why?
This article answers that question honestly, including the trade-offs each framework’s advocates rarely mention.
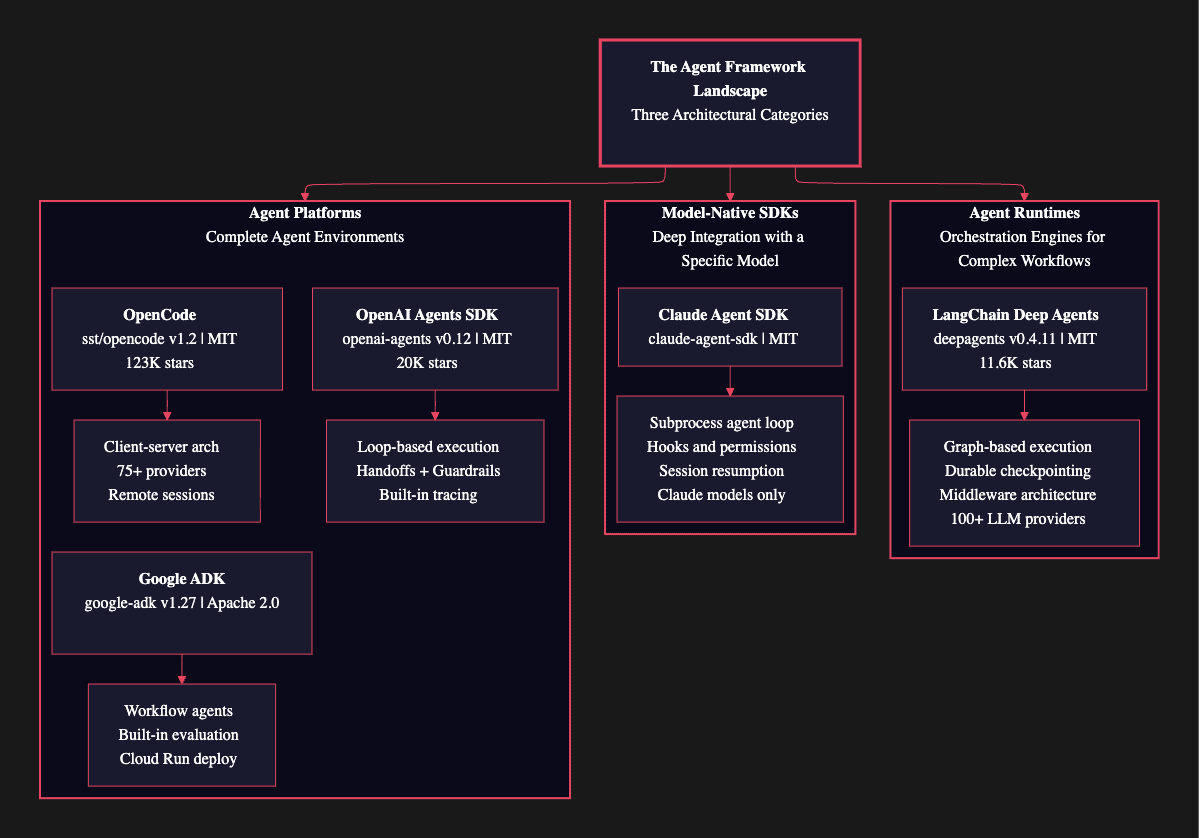
The ecosystem has matured into five major frameworks, each representing a fundamentally different philosophy about how agents should work. They share common vocabulary (tools, agents, memory, orchestration) but their architectures reflect very different design goals.
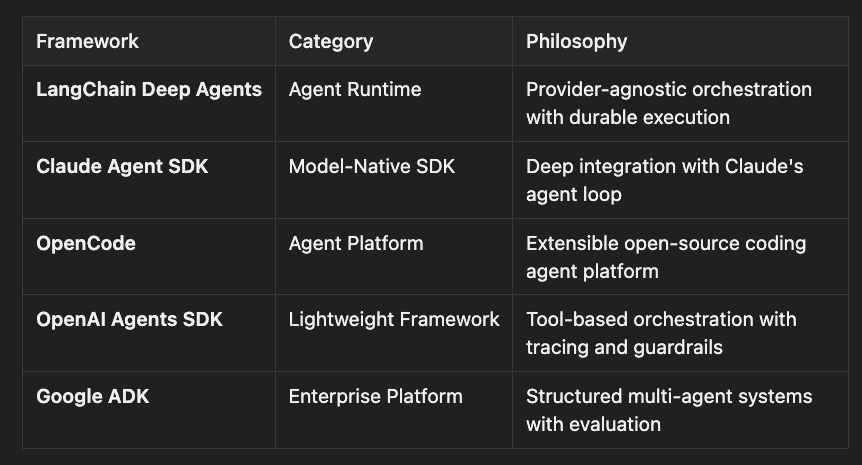
One fact worth noting immediately: all five are open source. LangChain Deep Agents, Claude Agent SDK, OpenAI Agents SDK, and OpenCode ship under MIT. Google ADK uses Apache 2.0. The “proprietary vs. open” divide that dominated the 2024 AI landscape has largely disappeared for agent frameworks.
This article is not a feature checklist. It is a strategic analysis of three architectural philosophies, five concrete implementations, and the engineering consequences of choosing one over the others.
Three Architectures for Building AI Agents
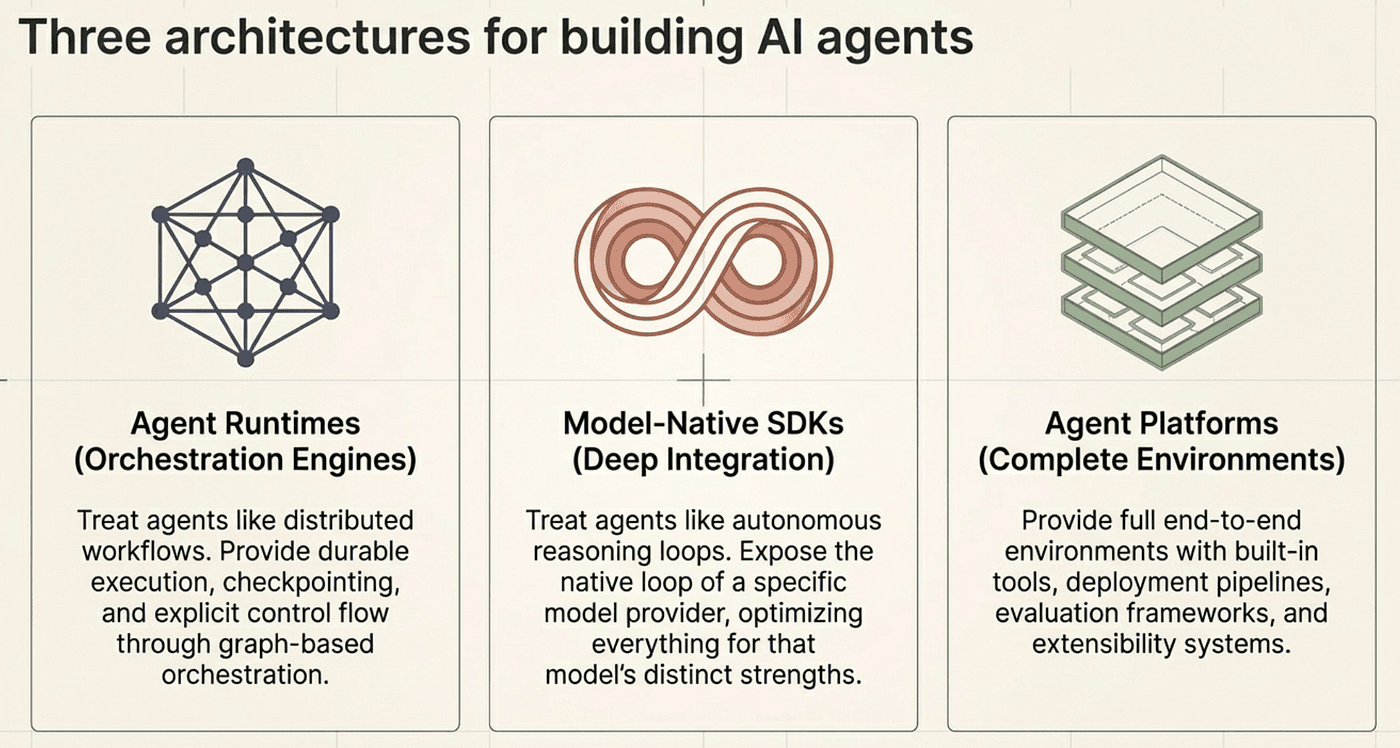
What problem should an agent framework actually solve? The five frameworks answer that question in three fundamentally different ways. Understanding those answers first makes every specific comparison easier.
 3 architectures for building AI Agents
3 architectures for building AI Agents
Agent Runtimes: Orchestration Engines
Agent runtimes treat agents like distributed systems workflows. They provide durable execution, checkpointing, and explicit control flow through graph-based orchestration.
LangChain Deep Agents is the primary example. Built on LangGraph, it models agent execution as a compiled state graph where each step is checkpointed. If the process crashes, the agent resumes from the last checkpoint. If a human needs to approve a step, the graph pauses at that node and waits. If you need to debug what went wrong, you can replay the execution from any historical state.
The mental model: if agents are programs, runtimes are operating systems for those programs.
Model-Native SDKs: Deep Integration
Model-native SDKs take the opposite approach. Instead of abstracting across providers, they expose the native agent loop of a specific model provider and optimize everything for that model’s strengths.
Claude Agent SDK is the primary example. It exposes the exact agent loop that powers Claude Code: gather context, reason, act, verify, repeat. Instead of building a generic orchestration layer, it provides hooks that intercept every tool call, a permission system that governs what the agent can do, and session management designed specifically for Claude’s context handling.
The mental model: if runtimes are cross-platform, model-native SDKs are platform-specific with deeper integration.
 OpenSource Agent Ecosystem
OpenSource Agent Ecosystem
Agent Platforms: Complete Environments
Agent platforms provide complete agent environments with built-in tools, deployment pipelines, evaluation frameworks, and extensibility systems.
OpenCode, Google ADK, and OpenAI Agents SDK fall into this category, though each emphasizes different aspects. OpenCode provides a full client-server architecture with 75+ model providers. Google ADK provides enterprise deployment and a built-in evaluation framework. OpenAI Agents SDK provides lightweight primitives designed for simplicity.
The mental model: these are closer to development environments for agents than libraries for building them.
 Agent Framework Landscape
Agent Framework Landscape
The Five Frameworks
LangChain Deep Agents: The Provider-Agnostic Runtime
LangChain Deep Agents (deepagents v0.4.11, MIT licensed, 11,600 GitHub stars) is an opinionated agent harness built on LangGraph. One function call gives you a fully capable agent with planning, file system access, subagent delegation, and context management.
The architecture centers on a middleware stack that wraps the agent’s execution loop:
- TodoListMiddleware gives the agent a write_todos tool for task decomposition and progress tracking.
- FilesystemMiddleware provides file operations (ls, read_file, write_file, edit_file, glob, grep) with pluggable storage backends.
- SubAgentMiddleware enables spawning isolated child agents through a task tool. The parent receives only the final result, keeping its context clean.
- SummarizationMiddleware compresses conversation history and manages large tool outputs to prevent context overflow.
from deepagents import create_deep_agent
from deepagents.middleware import (
TodoListMiddleware,
FilesystemMiddleware,
SubAgentMiddleware,
SummarizationMiddleware,
)
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6",
system_prompt="You are a research analyst.",
middleware=[
TodoListMiddleware(),
FilesystemMiddleware(backend="local"),
SubAgentMiddleware(),
SummarizationMiddleware(),
],
)
What this code does. create_deep_agent() compiles a LangGraph StateGraph and wraps it with each middleware component in sequence. The resulting object is a CompiledStateGraph that supports .invoke(), .stream(), and .astream_events(). Each middleware inserts its tools into the agent's available tool set and wraps the execution loop with its own pre- and post-processing logic.
Why this approach. Middleware composition separates concerns cleanly. You can add HumanInTheLoopMiddleware to any existing agent without touching other components. You can swap FilesystemMiddleware(backend="local") for a production storage backend without changing anything else. Each capability is independently testable and independently replaceable.
What you give up. The middleware stack adds conceptual overhead. You need to understand not just how each middleware works individually, but how they interact when composed. Debugging a composed stack is harder than debugging a flat loop. The LangGraph dependency is transitive, so version conflicts are possible in complex projects. With 80+ releases in 8 months, the API has moved quickly; code written against an earlier version may need updates, so disciplined version pinning is essential.
The critical design decision is provider agnosticism. That model parameter accepts any LLM provider supporting tool calling. Swap "anthropic:claude-sonnet-4-6" for "openai:gpt-5.4" or "google:gemini-3.1-pro" and the agent's tools, middleware, and streaming behavior remain identical. Internally, create_deep_agent() calls init_chat_model() to resolve the provider string, and the returned CompiledStateGraph works the same regardless of which model powers it.
One honest caveat: provider agnosticism is the capability, not the guarantee. Smaller models perform poorly with the middleware stack; GPT-4o or Sonnet-class models are required for reliable behavior. The API surface is stable enough for production use, but you should pin your deepagents version and test upgrades carefully given the rapid release pace.
The durable execution model is LangGraph’s strongest differentiator. At every super-step, the full agent state is checkpointed to a configurable backend (MemorySaver for development, DynamoDB or PostgreSQL for production). This enables crash recovery, time-travel debugging, and native human-in-the-loop workflows where the graph pauses at a checkpoint and waits for approval before continuing.
Claude Agent SDK: The Model-Native Loop
Claude Agent SDK (MIT licensed, available as @anthropic-ai/claude-agent-sdk on npm and claude-agent-sdk on PyPI) exposes the exact agent loop that powers Claude Code. Rather than building a generic orchestration engine, it provides deep integration with Claude's reasoning capabilities.
The core API is the query() function, which takes a prompt and options, then returns an async generator of structured messages:
from claude_agent_sdk import query, ClaudeAgentOptions
async for message in query(
prompt="Refactor the authentication module for better testability.",
options=ClaudeAgentOptions(
model="claude-sonnet-4-6",
allowed_tools=["Read", "Edit", "Bash", "Glob", "Grep"],
permission_mode="default",
)
):
if message.type == "result":
print(message.result)
print(f"Cost: ${message.total_cost_usd:.4f}")
What this code does. query() spawns the Claude Code CLI as a subprocess, sends the prompt over stdin as NDJSON, and yields typed message objects as they arrive over stdout. The ClaudeAgentOptions object configures which tools the agent can use and how permissions are enforced. Each yielded message has a type field: "result" contains the final answer, while intermediate messages report tool calls, tool results, and reasoning steps.
Why this approach. The subprocess model gives you identical behavior to Claude Code without requiring you to reimplement the agent loop. Every optimization Anthropic builds into Claude Code (context compaction, tool execution, reasoning patterns) becomes available automatically when the SDK updates. You are not abstracting over Claude’s behavior; you are using Claude’s actual behavior from your code.
What you give up. The subprocess architecture is a real constraint, not a minor footnote. You inherit Claude Code’s limitations: Claude models only (no provider switching), sessions stored as .jsonl files on local disk (no distributed storage), and no direct access to raw API parameters. Python has fewer hooks than TypeScript, which matters if you need the full lifecycle event set. The practical ceiling for subagent hierarchies is around three or four levels before coordination overhead hurts reliability.
For multi-turn conversations, ClaudeSDKClient maintains stateful sessions:
from claude_agent_sdk import ClaudeSDKClient, ClaudeAgentOptions
async with ClaudeSDKClient(
options=ClaudeAgentOptions(model="claude-sonnet-4-6")
) as client:
await client.query("Analyze the auth module.")
async for msg in client.receive_response():
print(msg)
await client.query("Now refactor it for dependency injection.")
async for msg in client.receive_response():
print(msg)
What this code does. ClaudeSDKClient wraps the subprocess lifecycle and maintains the session context between calls. Each query() call adds to the ongoing conversation. The client tracks the session ID and passes it to subsequent calls automatically. receive_response() is an async generator that yields messages until the current turn completes.
Why use ClaudeSDKClient over repeated query() calls. Repeated standalone query() calls start fresh conversations each time. ClaudeSDKClient preserves the full conversation history, so the agent in the second turn has full awareness of what happened in the first. For tasks that naturally break into phases (analyze, then plan, then implement), the client approach preserves context that would otherwise require manual reconstruction.
An important architectural detail that many comparisons miss: the SDK spawns the Claude Code CLI as a subprocess and communicates via JSON-lines (NDJSON) over stdin/stdout. The CLI process handles all API calls, tool execution, and context management. The SDK itself is a typed IPC layer with hook injection. This means you get the exact same behavior as Claude Code, but you also inherit its constraints: Claude models only, local session storage (.jsonl files on disk), and no direct access to raw API parameters.
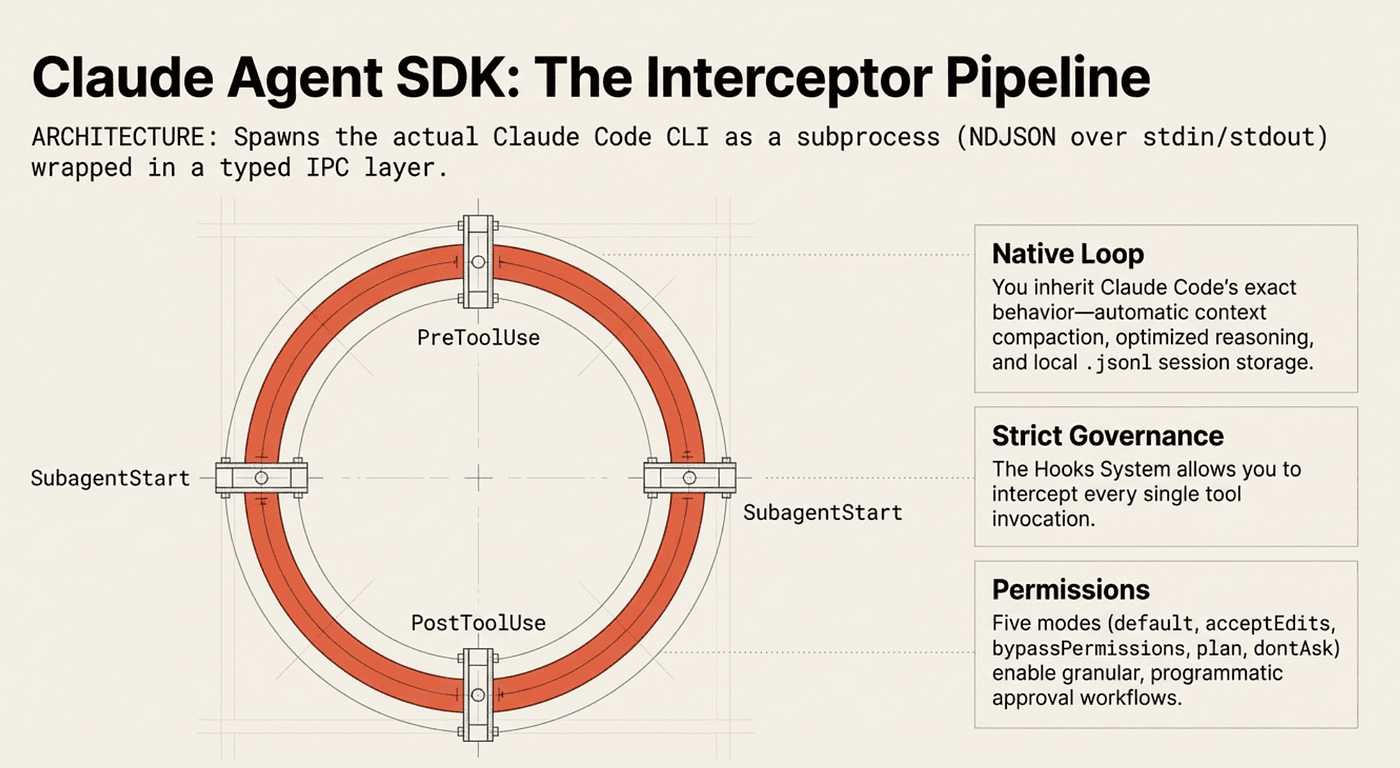
The hooks system is where Claude Agent SDK distinguishes itself. You can intercept every tool invocation:
- PreToolUse: Inspect, modify, allow, or deny a tool call before it executes
- PostToolUse: Log results, verify correctness, trigger auditing
- PermissionRequest: Handle approval workflows programmatically
- SubagentStart/SubagentStop: Monitor subagent lifecycle
 Claude Agent SDK: Hooks, Loops, Governance and Permissions
Claude Agent SDK: Hooks, Loops, Governance and Permissions
Combined with the permission system (five modes: default, acceptEdits, bypassPermissions, plan, dontAsk), this gives you governance capabilities that generic frameworks cannot match. One important warning: bypassPermissions overrides allowed_tools entirely. Teams that set bypassPermissions to avoid approval prompts during development sometimes forget to tighten permissions before production deployments. That oversight carries real consequences when agents have shell access.
OpenAI Agents SDK: The Lightweight Primitives
OpenAI Agents SDK (openai-agents v0.12.2, MIT licensed, ~20K GitHub stars) is a lightweight multi-agent framework built around four primitives. It evolved from OpenAI's "Swarm" experiment and was publicly released in March 2025.
In practice, using non‑OpenAI models requires an adapter layer so the SDK can interpret responses (including function/tool calls, handoffs, etc.) in the format it expects.
The four primitives are Agent, Tool, Handoff, and Guardrail:
from openai_agents import Agent, Runner, function_tool, handoff
@function_tool
def search_database(query: str) -> str:
"""Search the internal knowledge base."""
return f"Results for: {query}"
specialist = Agent(
name="database_expert",
instructions="You answer questions about our database schema.",
tools=[search_database],
model="gpt-4.1",
)
triage = Agent(
name="triage",
instructions="Route questions to the right specialist.",
handoffs=[specialist],
)
result = Runner.run_sync(triage, "How is the users table structured?")
What this code does. Runner.run_sync() starts the triage agent with the given prompt. The triage agent evaluates the input and, if it decides the database expert is appropriate, performs a handoff: full control transfers to the specialist, which sees the complete conversation history and responds directly. The @function_tool decorator converts a Python function into a tool, using the function signature and docstring to generate the tool definition automatically.
Why this approach. Four primitives cover a surprisingly large fraction of real multi-agent scenarios. Handoffs are elegant for routing: the triage agent does not need to summarize or reformat the question, and the specialist has full context. The decorator-based tool definition is the simplest tool registration pattern of any framework reviewed here.
What you give up. The simplicity comes at a real cost. There is no native crash recovery: if the process dies mid-run, the work is lost. Durable execution requires the external Temporal integration, which is still in Public Preview as of March 2026. Guardrails apply only at workflow boundaries by default, so intermediate steps are unguarded. Long-term memory requires separate implementation. For complex workflows with many interdependent agents, the flat loop model becomes harder to reason about than an explicit graph.
Guardrails provide input/output validation:
from openai_agents import input_guardrail, GuardrailFunctionOutput
@input_guardrail
async def block_pii(ctx, agent, input):
contains_pii = check_for_pii(input)
return GuardrailFunctionOutput(
output_info={"has_pii": contains_pii},
tripwire_triggered=contains_pii,
)
What this code does. The @input_guardrail decorator registers this function as a pre-execution check. Before the agent processes any input, block_pii runs. If tripwire_triggered is True, execution halts and the guardrail result is returned instead. The output_info dict is available for logging and debugging.
The execution model is loop-based, not graph-based. There is no DAG, no StateGraph, no checkpoint mechanism. The runner calls the LLM, handles handoffs or tool calls, and repeats until completion. This makes it dramatically simpler to understand and debug than LangGraph, but it also means there is no native crash recovery or time-travel debugging.
Google ADK: The Enterprise Platform
Google’s Agent Development Kit (google-adk v1.27.1, Apache 2.0) is designed for enterprise-grade multi-agent systems. It separates the Agent (declarative configuration) from the Runner (execution engine), giving you clean control over both.
from google.adk import Agent
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.adk.agents import SequentialAgent, ParallelAgent
researcher = Agent(
name="researcher",
model="gemini-3.1-pro",
instruction="Research the given topic thoroughly.",
tools=[search_tool],
output_key="research_findings",
)
writer = Agent(
name="writer",
model="gemini-3.1-pro",
instruction="Write a report based on: {research_findings}",
output_key="report",
)
pipeline = SequentialAgent(
name="research_pipeline",
sub_agents=[researcher, writer],
)
runner = Runner(
agent=pipeline,
app_name="research_app",
session_service=InMemorySessionService(),
)
What this code does. SequentialAgent runs its sub-agents in order, passing outputs between them via the output_key pattern. researcher writes its findings to session state under "research_findings". writer's instruction references that key with {research_findings}, so it receives the research output automatically. The Runner manages session lifecycle and routes events between agents.
Why this approach. The Agent/Runner separation is clean architecture. You can test agents independently of their execution environment, swap session backends without touching agent logic, and compose workflow agents deterministically without involving the LLM in control flow decisions. The evaluation framework is a genuine differentiator: .test.json eval files and adk eval CLI make behavioral testing first-class.
What you give up. There is no native library-level checkpointing. Persistence happens at session and turn boundaries only; there is no mid-execution checkpoint/resume like LangGraph provides. The near-weekly release cadence introduces stability risk. Non-Gemini paths were incomplete until recently: Anthropic streaming support arrived only in v1.27.0 (March 2026), so if you use ADK with Claude, verify your deployment version. Sub-agents also cannot use built-in tools except for search, a constraint fixed in v1.16.0 but worth verifying on your version.
Google ADK has three distinct multi-agent patterns. Sub-agents use LLM-driven delegation (the model decides which child to invoke via transfer_to_agent). AgentTool wraps a child agent as a callable tool, keeping the parent in control. Workflow agents (SequentialAgent, ParallelAgent, LoopAgent) provide deterministic orchestration without LLM involvement in the control flow.
The evaluation framework is ADK’s strongest unique feature. You define test cases in .test.json files and run them with adk eval or integrate with pytest:
from google.adk.evaluation import AgentEvaluator
AgentEvaluator.evaluate(
agent_module="my_agent",
eval_dataset="tests/eval.test.json",
criteria=["tool_trajectory_avg_score", "response_match_score"],
)
What this code does. AgentEvaluator.evaluate() runs the agent against each test case in the eval dataset, then scores the results against the specified criteria. tool_trajectory_avg_score measures whether the agent used the expected tools in the expected order. response_match_score measures output quality against reference answers. Results flow into either CLI output or pytest assertions, depending on how you invoke it.
OpenCode: The Agent Platform
OpenCode (sst/opencode v1.2.26, MIT licensed, ~123,000 GitHub stars) occupies a different niche. Built by the SST team (Serverless Stack), it is not a framework for building arbitrary agents. It is a coding agent platform with a programmable SDK.
The architecture is client-server: opencode serve runs a headless HTTP/SSE backend, and multiple clients connect to it (TUI, desktop app via Tauri, VS Code extension, web UI, and the SDK). Sessions persist to SQLite. You can close your laptop, reconnect from another machine, and resume where you left off.
import { OpenCode } from "@opencode-ai/sdk";
const client = new OpenCode({ baseUrl: "http://localhost:3000" });
const session = await client.sessions.create();
const response = await client.sessions.chat(session.id, {
content: "Analyze the authentication module and suggest improvements.",
});
What this code does. The SDK is a typed HTTP client for a running OpenCode server. sessions.create() allocates a new session backed by SQLite. sessions.chat() sends a message and waits for the response. The server handles model routing, tool execution, and session persistence independently of the client process. One critical constraint: this SDK requires a running opencode serve process. It is not a standalone agent framework.
Why this approach. The client-server separation enables something no other framework reviewed here provides natively: genuine remote session persistence. Close your terminal, come back hours later, reconnect from a different machine, and continue the session exactly where you left it. The 75+ provider support via Vercel AI SDK also makes it the most provider-flexible coding agent available.
What you give up. The client-server architecture adds operational overhead. You need a running server process, which changes how you deploy, monitor, and scale. It is stable enough to get meaningful work done.
OpenCode reads both AGENTS.md and CLAUDE.md configuration files, making it compatible with rules designed for other coding agents. OpenCode also works with Agent Skills as does Claude Agent SDK, OpenAI Agents SDK, and LangChain DeepAgent.
OpenCode Basic SDK Control (HTTP Client)
This mirrors what you already sketched in the article, but with streaming and error handling made explicit:
import { createOpencodeClient } from "@opencode-ai/sdk";
async function main() {
// 1) Connect to a running `opencode serve`
const client = await createOpencodeClient({
baseUrl: "<http://localhost:4096>",
directory: "/path/to/your/workspaces", // same workspace OpenCode uses
});
// 2) Create a new coding session (persisted in SQLite)
const { data: session } = await client.session.create();
// 3) Send a prompt and stream updates (tool use, diffs, final answer)
const stream = await client.session.promptStream({
path: { id: session.id },
body: {
parts: [
{
type: "text",
text: "Analyze auth.ts and suggest a better dependency injection design.",
},
],
},
});
for await (const event of stream) {
if (event.type === "message") {
process.stdout.write(event.data.text);
} else if (event.type === "file_diff") {
console.log("Changed files:", event.data);
}
}
}
main().catch(console.error);
What this does (short version for the article): createOpencodeClient gives you a typed HTTP client; session.create allocates a persisted session, and session.promptStream lets you follow OpenCode's reasoning, tool calls, and code edits in real time over SSE.
OpenCode: Re-using a Session Across Runs
To emphasize “remote, durable coding agent”:
import { createOpencodeClient } from "@opencode-ai/sdk";
async function continueSession(sessionId: string, message: string) {
const client = await createOpencodeClient({
baseUrl: "https://opencode.my-company.dev",
directory: "/srv/opencode/workspaces",
});
const { data } = await client.session.promptAsync({
path: { id: sessionId },
body: {
parts: [{ type: "text", text: message }],
},
});
return data;
}
// First call somewhere in your app:
// const { data: session } = await client.session.create();
// save session.id to your DB, then later:
await continueSession(savedSessionId, "Now write integration tests for the new auth flow.");
Here you’re showing that the server owns the state; your service can be stateless and just look up sessionId from a DB.
OpenCode: Switching Models/Providers from the SDK
To tie into the “75 providers” point in the article:
import { createOpencodeClient } from "@opencode-ai/sdk";
async function runWithModel(modelId: string) {
const client = await createOpencodeClient({
baseUrl: "http://localhost:4096",
directory: "./workspaces",
});
const { data: session } = await client.session.create({
body: {
model: modelId, // e.g. "anthropic/claude-4.6-sonnet",
"gpt-5.3-mini", "deepseek-v3"
},
});
await client.session.promptAsync({
path: { id: session.id },
body: {
parts: [{ type: "text",
text: "Refactor the payment service into hexagonal architecture." }],
},
});
return session.id;
}
Recall OpenCode sits on top of Models.dev and the Vercel AI SDK, the same SDK calls can target Claude, OpenAI, DeepSeek, or local models by changing a model identifier.
Using OpenCode as a Backend for Other Agents
If you want one tight example of “OpenCode as a tool” in the OpenAI/Claude sections:
// Pseudo-tool that calls OpenCode from another agent framework
async function runOpencodeTask(params: { sessionId?: string; prompt: string }) {
const client = await createOpencodeClient({
baseUrl: process.env.OPENCODE_URL!,
directory: "/srv/opencode/workspaces",
});
const sessionId =
params.sessionId ??
(await client.session.create()).data.id;
const { data } = await client.session.promptAsync({
path: { id: sessionId },
body: {
parts: [{ type: "text", text: params.prompt }],
},
});
return {
sessionId,
messageId: data.id,
};
}
This shows that OpenCode is an agent platform with a programmable SDK claim extremely concrete.
The Two Frameworks That Matter Most
Although all five frameworks serve valid use cases, two represent the most interesting architectural contrast: LangChain Deep Agents and Claude Agent SDK.
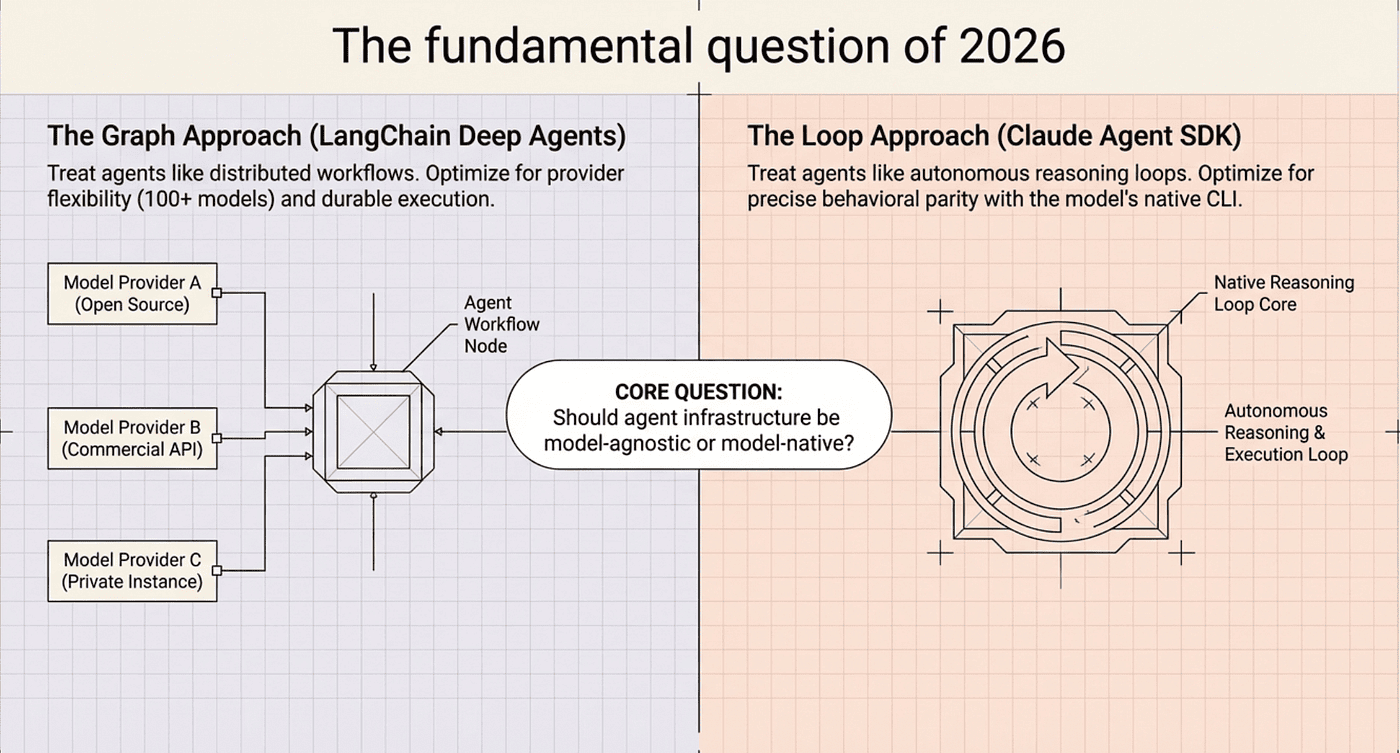
These two frameworks embody opposing philosophies about how agents should be built. The fundamental question they answer differently:
Should agent infrastructure be model-agnostic or model-native?

LangChain treats agents like distributed workflows. Claude treats agents like autonomous reasoning loops.
The rest of this article explores why that distinction matters, how Claude Code shaped both approaches, and what the difference means for your architecture.
How Claude Code Influenced Deep Agents
How did LangChain Deep Agents end up with the same five capabilities as Claude Code? The answer reveals something important about how the current generation of agent frameworks developed.
LangChain Deep Agents did not appear in isolation. Its design was heavily influenced by the success of Claude Code, which demonstrated that an agent with the right primitives could perform complex development tasks autonomously. When LangChain announced Deep Agents in July 2025, the parallels to Claude Code were not coincidental; they were intentional. Every major capability in Deep Agents traces back to a pattern that Claude Code proved in production.
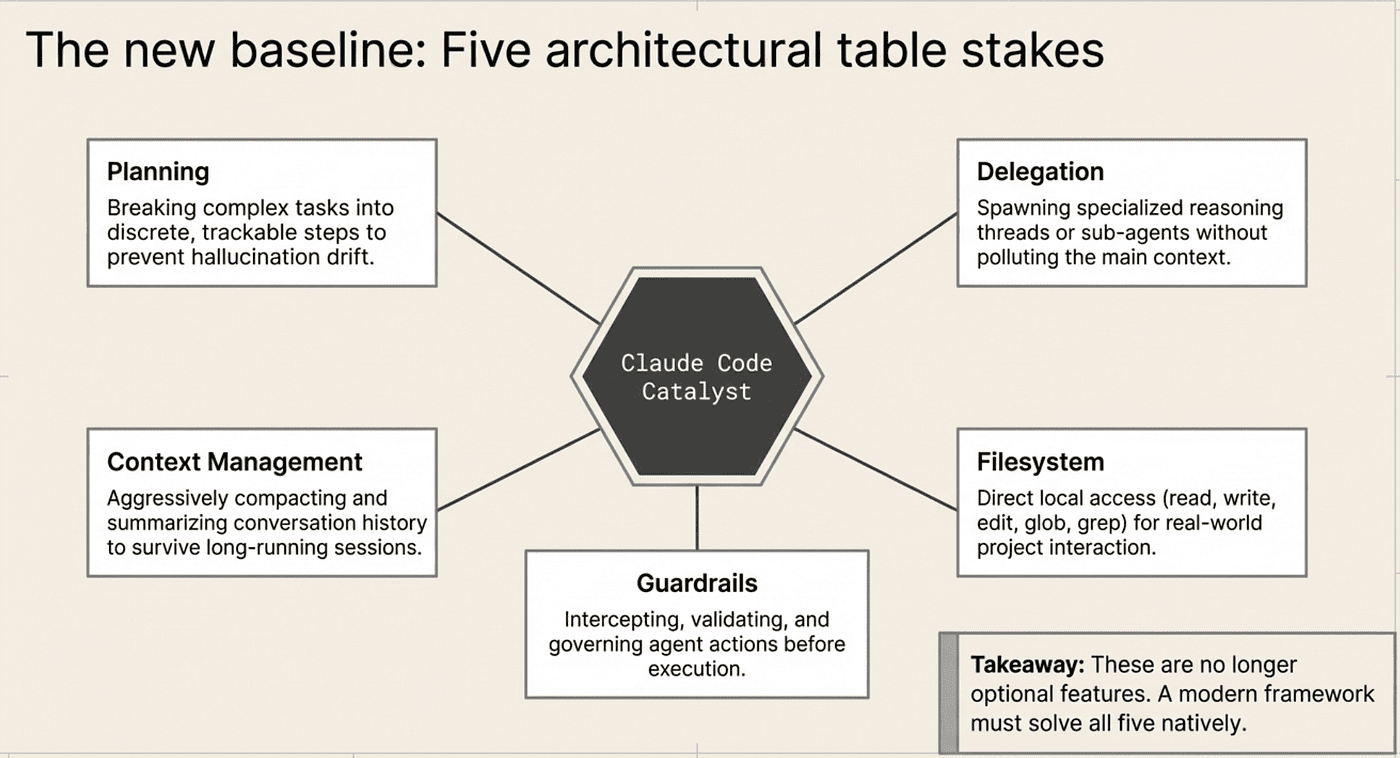 Claude Code’s influence
Claude Code’s influence
Agents Should Plan Work
Claude Code popularized the use of task planning inside agents. When Claude Code tackles a complex task, it breaks it into discrete steps, tracks progress, and adapts the plan as new information surfaces.
Deep Agents’ TodoListMiddleware performs the same function. The write_todos tool is technically a no-op from an execution perspective; it does not change external state. Its purpose is context engineering: by writing a plan into the conversation, the agent creates a reference point that reduces hallucination drift and keeps the reasoning focused.
Both approaches solve the same problem (agents losing track of multi-step work), but through different mechanisms. Claude Code’s planning is built into the model’s behavior and system prompt. Deep Agents’ planning is an explicit middleware component that any model can use. The trade-off: Deep Agents’ approach is model-agnostic and more controllable, but you lose the tight integration between planning behavior and model reasoning that Anthropic has optimized specifically for Claude.
Agents Should Delegate Work
Claude Code frequently spawns specialized reasoning threads through its Agent tool. A main agent might delegate a deep code review to a subagent, receive the summary, and continue with its primary task.
Deep Agents implements the same concept through SubAgentMiddleware. The parent agent calls a task tool, which spawns an isolated child agent that runs independently and returns only its final result.
There is an important difference in inheritance. In Claude Agent SDK, subagents can be configured with their own tools, models, and permissions through AgentDefinition. In Deep Agents, subagents do not inherit the parent's tools, system prompt, or middleware. They do inherit the model by default, but everything else must be explicitly configured. This deliberate isolation prevents context pollution. The cost is more explicit configuration: you must think carefully about what each subagent needs rather than relying on inherited behavior. For Claude Agent SDK, the practical ceiling of around three or four subagent levels is a different constraint; after that, coordination overhead starts degrading reliability.
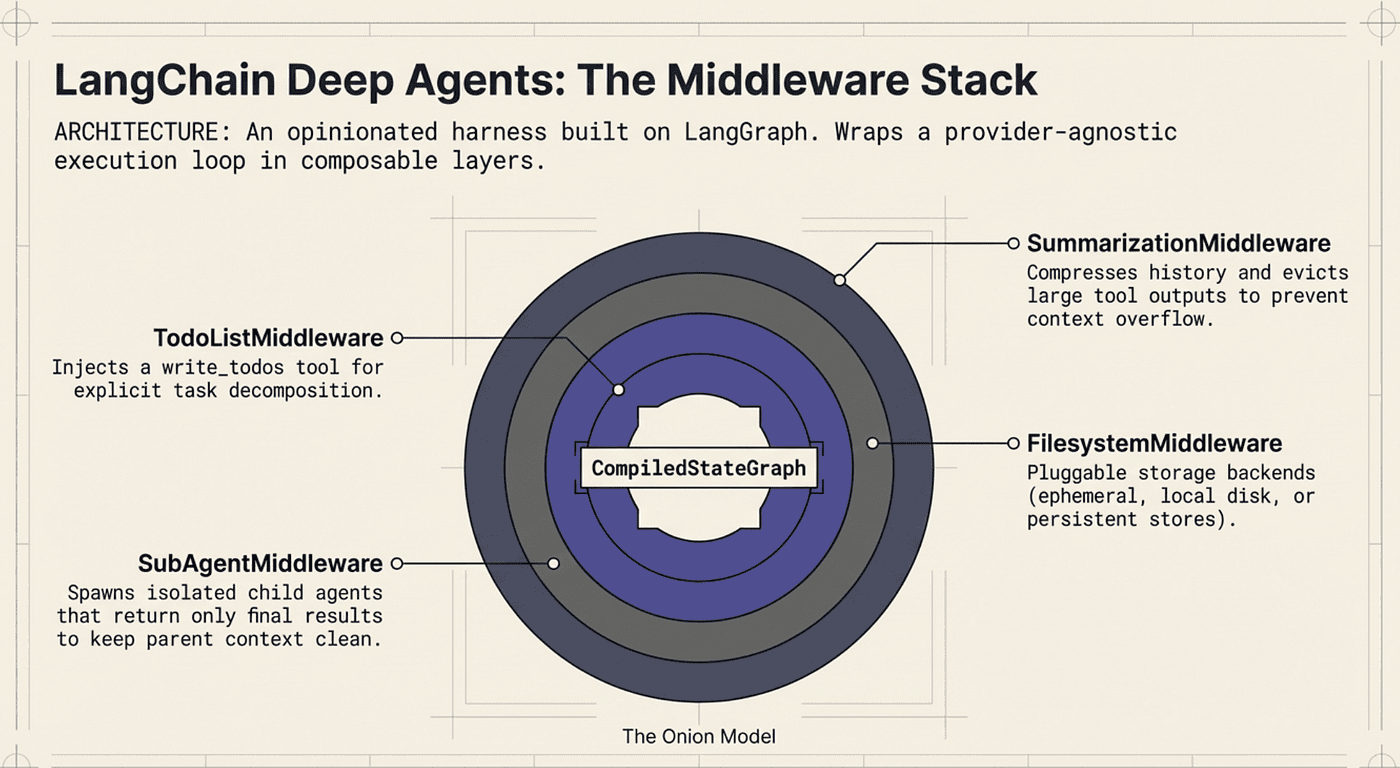 LangChain Deep Agents
LangChain Deep Agents
Agents Must Manage Context Aggressively
Claude Agent SDK aggressively manages context through automatic compaction. When a conversation approaches the context limit, the PreCompact hook fires and the system summarizes older messages to make room. This is invisible to the user but critical for long-running sessions.
Deep Agents includes SummarizationMiddleware to solve the same problem. It compresses conversation history, manages large tool results (evicting them to the filesystem when they exceed a threshold), and leverages prompt caching to reduce both latency and cost.
Both approaches recognize the same truth: agents that cannot manage their own context window will either fail catastrophically or degrade silently as conversations grow long. The difference is in control. Claude Agent SDK’s compaction is automatic and largely opaque; you can hook into PreCompact but you cannot replace the compaction logic. Deep Agents' summarization is a middleware component you can inspect, configure, and replace entirely. More control means more responsibility: if your summarization strategy is wrong, you own that failure.
Agents Need Filesystem Access
Claude Code demonstrated how powerful agents become when they can interact with the filesystem directly. Reading code, writing files, editing existing content, and navigating directory structures are fundamental capabilities for any agent that touches real projects.
Deep Agents includes FilesystemMiddleware with pluggable backends. The default StateBackend is ephemeral (stored in LangGraph state). FilesystemBackend writes to local disk. StoreBackend provides persistent cross-thread storage via LangGraph's Memory Store. CompositeBackend routes operations to different backends based on path patterns.
Claude Agent SDK ships with built-in tools (Read, Write, Edit, Bash, Glob, Grep) that provide the same capabilities but without pluggable backends. The tradeoff: Claude’s tools are simpler to use but less flexible in where and how files are stored. If your agent needs to write files to a sandboxed container environment, Deep Agents’ backend system handles that directly. Claude Agent SDK would require a custom tool or a separate storage layer.
Deep Agents has a built‑in shell capability, but it’s exposed as the execute tool rather than a literal bash tool name. The deep agent tools like ls, read_file, write_file, edit_file, glob, grep, write_todos, task, and execute, where execute runs shell commands if the backend implements a shell/sandbox backend.
Agents Need Guardrails
Claude Agent SDK introduced permission-based tool usage with its hooks system. Every tool invocation passes through a chain: hooks evaluate first (can allow, deny, or modify), then deny rules, then the permission mode, then allow rules, then a canUseTool callback. This gives you fine-grained control over every action the agent takes.
Deep Agents takes a different approach. Rather than intercepting individual tool calls, middleware wraps the entire agent execution loop. You control behavior by choosing which middleware to include and how to configure it. The HumanInTheLoopMiddleware pauses execution at checkpoints for approval, while filesystem backends can enforce sandboxing by routing code execution to Modal or Daytona containers.
The philosophy differs, but the goal is the same: constrain the agent before it causes damage. Claude Agent SDK’s approach is more granular (per-tool-call governance) but requires more hook code. Deep Agents’ approach is more structural (control what the agent can do by controlling what middleware runs) but is less effective for blocking specific calls in real time.
💡 Section Summary: How Claude Code Influenced Deep Agents
Claude Code proved five capabilities in production: planning via task decomposition, delegation via subagents, aggressive context management, filesystem access, and permission-based guardrails. LangChain Deep Agents adopted all five, implemented as composable middleware components. The key trade-off: Deep Agents’ middleware architecture makes each capability independently configurable and model-agnostic, but at the cost of tighter integration with any specific model’s reasoning. Claude Agent SDK retains that tight integration, but only for Claude.
The Key Architectural Difference
Execution model comparison showing session loop with continuous gather-reason-act-verify cycle versus graph runtime with checkpoints, crash recovery, and branching paths
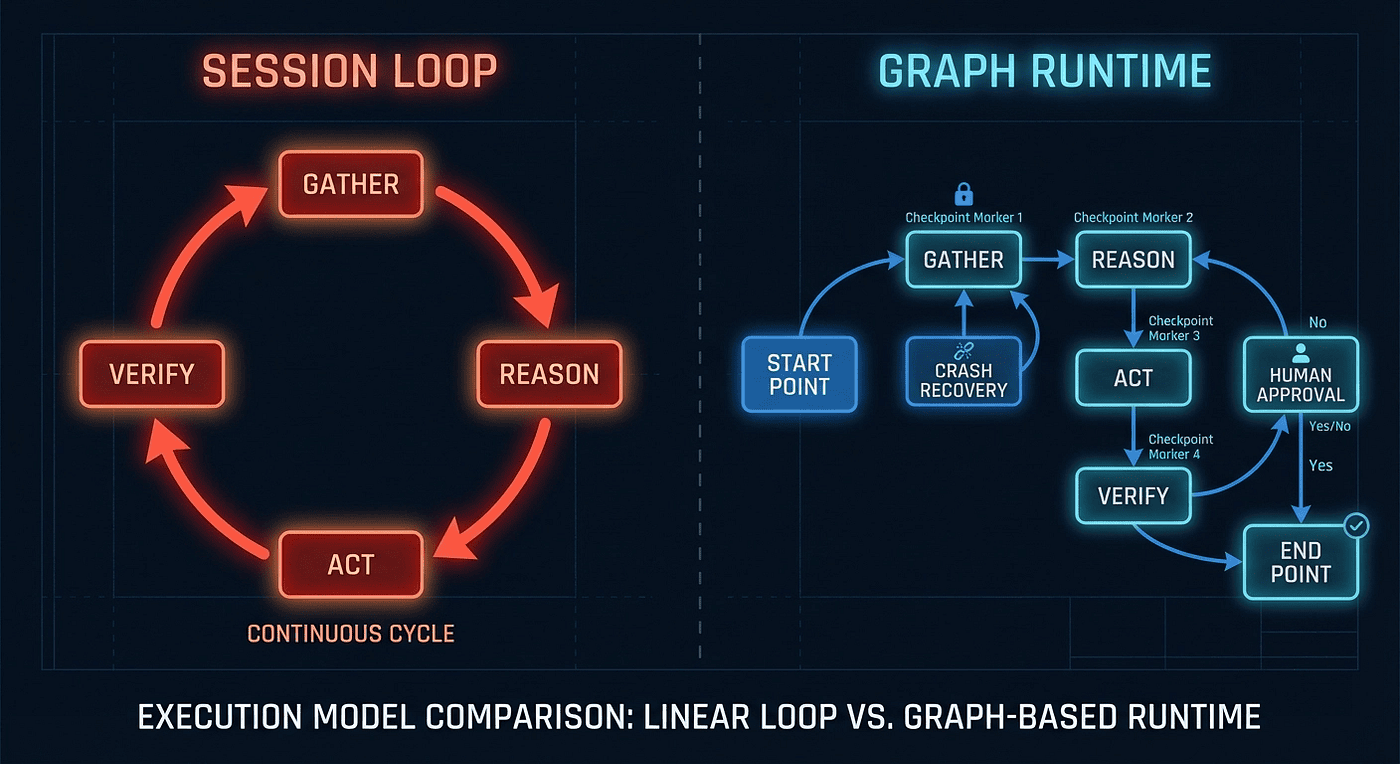 Execution model comparison showing session loop with continuous gather-reason-act-verify cycle versus graph runtime with checkpoints, crash recovery, and branching paths
Execution model comparison showing session loop with continuous gather-reason-act-verify cycle versus graph runtime with checkpoints, crash recovery, and branching paths
Despite the shared ideas, the underlying runtime models differ significantly. This is the most consequential distinction between the two frameworks. Everything else flows from it.
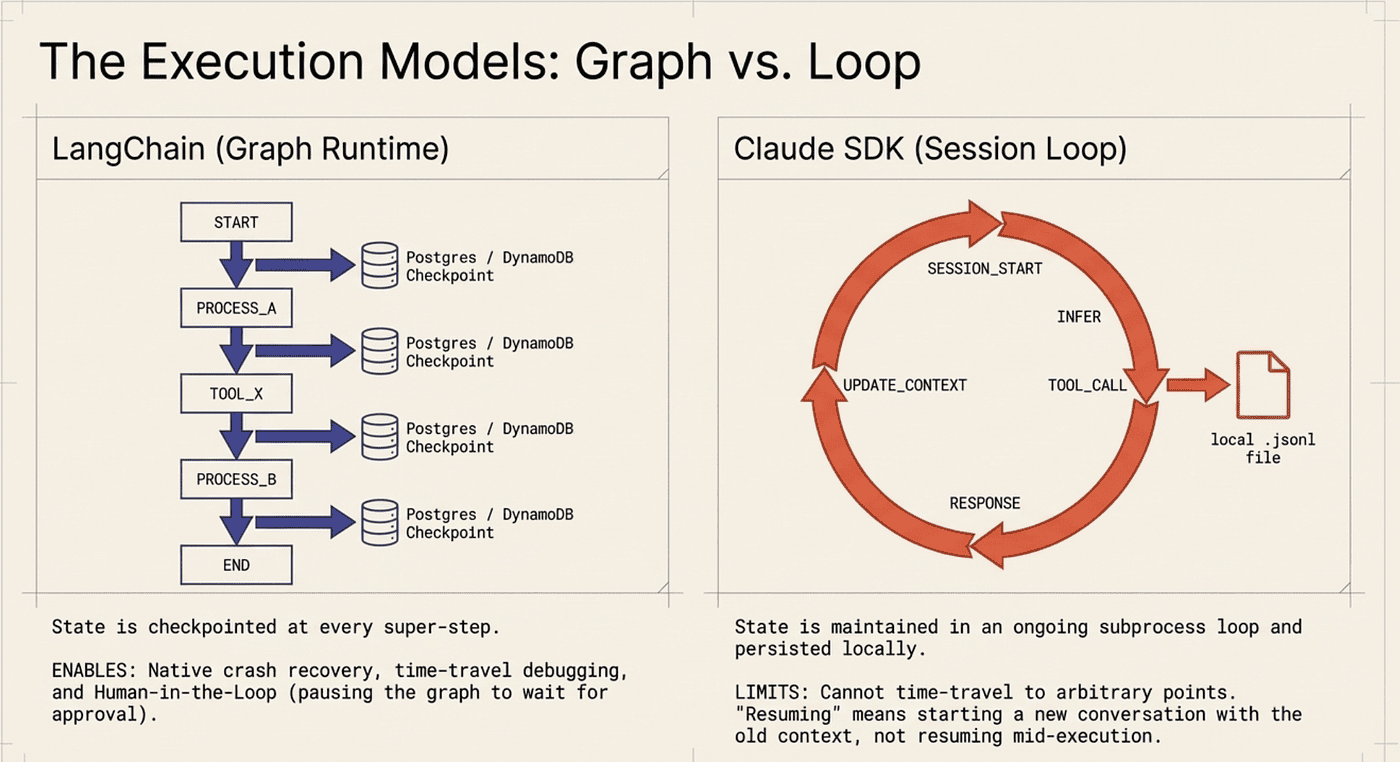 Graph vs Loop Execution Models and persistence mechanisms
Graph vs Loop Execution Models and persistence mechanisms
Claude Agent SDK: The Session Loop
Claude Agent SDK’s execution follows a feedback loop:
SDK spawns CLI subprocess
↓
Gather context (read files, search, MCP tools)
↓
Model reasoning (Claude decides next action)
↓
PreToolUse hook (allow / deny / modify)
↓
Tool execution (Read | Write | Edit | Bash)
↓
PostToolUse hook (log, verify, audit)
↓
Done? → No → gather more context
→ Yes → session saved as .jsonl
Everything happens inside a session-based loop. State persists as .jsonl files on the local machine. You can resume a session with list_sessions() to discover past sessions and pass the session ID to a new query() call. But you cannot time-travel to an arbitrary point in a session's history; you cannot swap storage backends; and you cannot distribute sessions across machines without manually copying files.
The session model has an important implication for long-running agents. If your process crashes after two hours of work, you can resume the session, but “resume” means starting a new conversation that references the old session context. It is not the same as picking up execution from the exact instruction where the crash occurred. For agents with side effects (files written, APIs called, changes committed), that distinction matters.
LangChain Deep Agents: The Graph Runtime
Deep Agents’ execution follows a graph-based model:
create_deep_agent() returns CompiledStateGraph
↓
Execute graph node (middleware-wrapped action)
↓
Checkpoint full state to configured backend
↓
Next node? → Yes → execute next node
→ HITL → pause, wait for approval, resume
→ Crash → auto-resume from last checkpoint
→ Done → final state, thread complete
At every super-step, the complete agent state is saved to a configurable backend. MemorySaver works for development. DynamoDBSaver stores metadata in DynamoDB and large payloads in S3 for production. PostgreSQL and Redis backends are also supported.
 Two different approaches
Two different approaches
This architecture enables capabilities the session model cannot match:
- Crash recovery: If the process dies, the agent resumes from the last checkpoint, not from scratch.
- Time-travel debugging: Replay execution from any historical checkpoint, inspecting state at each step.
- Human-in-the-loop: The graph pauses at a checkpoint, waits for human approval, and resumes exactly where it left off.
- Thread isolation: Each conversation gets a unique thread_id with independent checkpoint history.
- Distributed execution: Checkpoint backends can be shared across machines, enabling horizontal scaling.
The honest cost of the graph model is complexity. Building a CompiledStateGraph requires understanding LangGraph's state management, node composition, and edge definitions. Debugging a failed graph run requires LangSmith or manual checkpoint inspection. The learning curve is steeper than a simple loop, and the mental model (graph nodes, edges, state schemas) differs from how most developers initially think about agents.
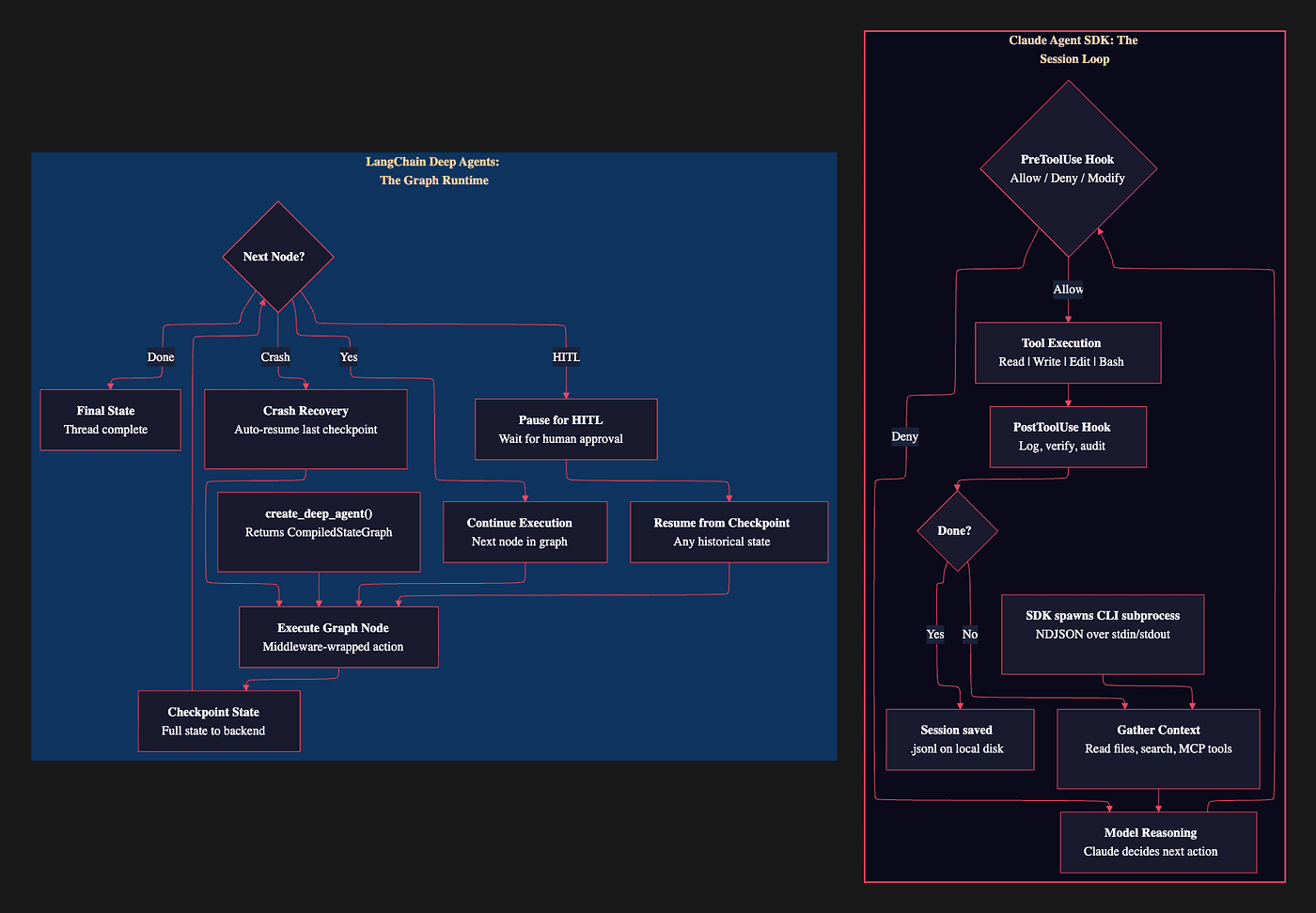 Comparing Agentic Loops and Graphs of LangChain Deep Agent and Claude Agent SDK
Comparing Agentic Loops and Graphs of LangChain Deep Agent and Claude Agent SDK
What This Means in Practice
For short-lived agents (single task, minutes of execution), both models work well. The difference is negligible.
For long-running workflows (hours, days, or workflows that pause for human approval), LangGraph’s checkpointing is significantly more capable. You get crash recovery, distributed state, and the ability to replay execution for debugging. If your agent orchestrates multi-day research tasks or batch processing jobs that touch thousands of files, the graph runtime is not optional.
For governance-sensitive environments (agents that touch production systems, execute shell commands, or modify real infrastructure), Claude Agent SDK’s hooks and permissions system is stronger. The ability to intercept and approve every tool call at a granular level is difficult to replicate in a generic middleware framework. Per-tool-call governance requires a fundamentally different architecture than LangGraph’s checkpoint-pause model.
For multi-provider deployments (organizations that want to avoid vendor lock-in or use different models for different tasks), only LangGraph supports this natively. Claude Agent SDK is Claude-only. The Bedrock and Vertex AI options change the hosting provider but not the underlying model. If a significantly better reasoning model emerges next quarter, LangChain users can switch in one line; Claude Agent SDK users cannot.
💡 Section Summary: The Key Architectural Difference
The session loop and the graph runtime both execute agents, but they answer different production needs. The session loop is simpler, gets out of your way, and provides deep per-tool governance. The graph runtime is more complex, but it makes crash recovery, distributed state, and time-travel debugging first-class capabilities. Teams choosing between them should ask: do we need per-tool-call governance, or do we need durable long-running execution? The answer shapes which framework fits.
 Same Core Capabilities
Same Core Capabilities
Choosing Your Framework
The right framework depends on your constraints, not the technology’s capabilities.
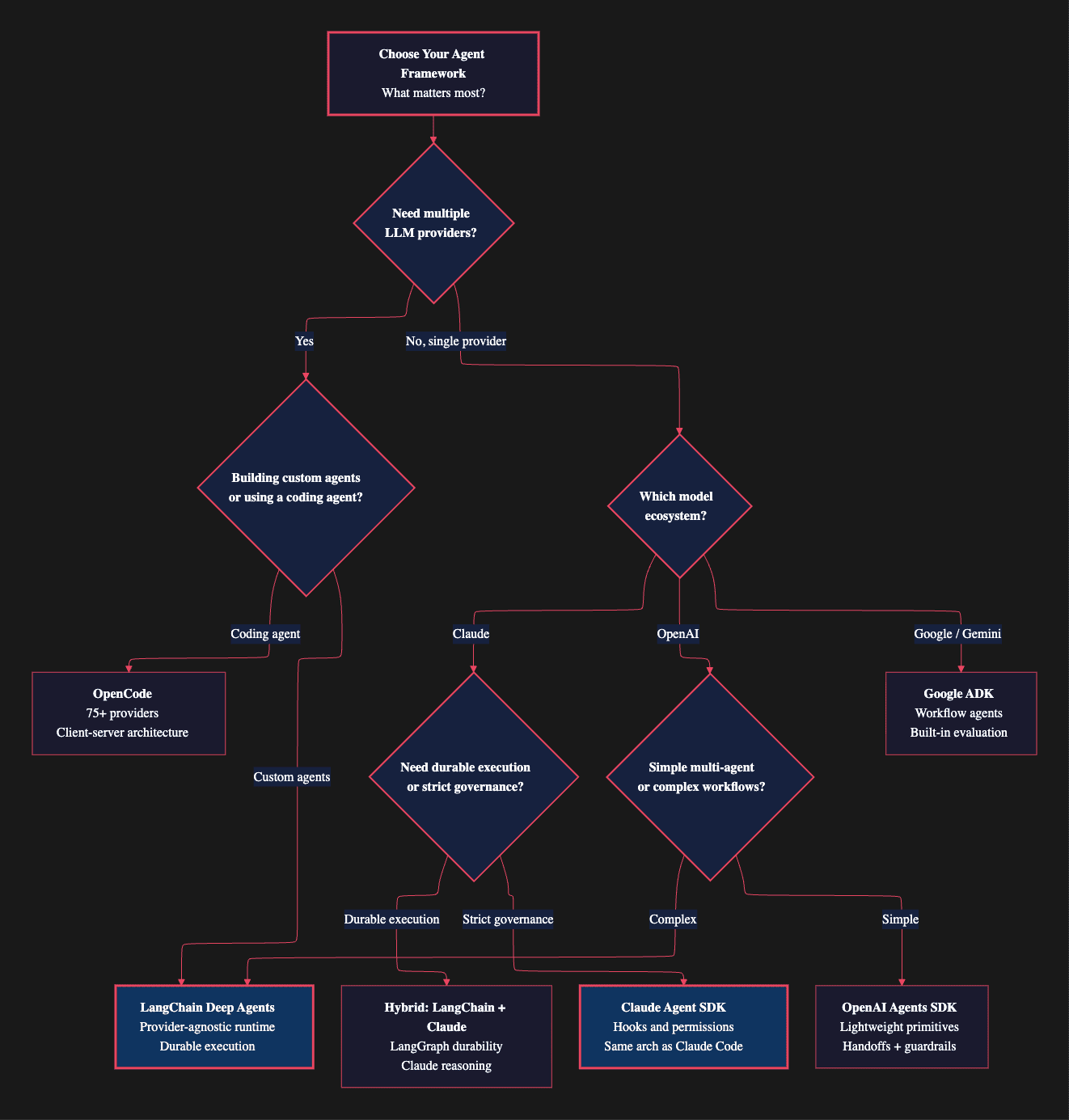 Choosing LangChain DeepAgent or Claude Agent SDK
Choosing LangChain DeepAgent or Claude Agent SDK
Choose LangChain Deep Agents when you need multi-model flexibility, durable execution with crash recovery, or long-running workflows that span hours. The middleware architecture and graph runtime make it the strongest choice for complex, production-grade agent systems. The trade-offs to accept: LangGraph has a real learning curve, the rapid release pace requires disciplined version pinning, and debugging requires LangSmith for anything beyond simple runs.
Choose Claude Agent SDK when you are committed to Claude models and need strict governance over agent behavior. The hooks and permissions system provides audit trails and approval workflows that generic frameworks cannot match. If your agents touch real infrastructure with real consequences, this governance layer matters. The trade-offs to accept: you are Claude-only, sessions live on local disk, and you inherit the subprocess architecture’s constraints. Accept those constraints knowingly, not accidentally.
Choose OpenAI Agents SDK when you want the simplest possible multi-agent setup. The four-primitive model (Agent, Tool, Handoff, Guardrail) is the easiest to learn, and handoff-based delegation is elegant for straightforward routing scenarios. The trade-offs: no native durable execution, no built-in long-term memory, and the Temporal integration for durability is still in Public Preview.
Choose Google ADK when you need enterprise deployment pipelines and built-in evaluation. The adk eval CLI and AgentEvaluator class give you testing infrastructure that other frameworks lack. Workflow agents (SequentialAgent, ParallelAgent, LoopAgent) provide deterministic orchestration. The trade-offs: no native checkpointing, Gemini-first documentation, and near-weekly releases that require active maintenance.
Choose OpenCode when you want a flexible, multi-provider coding agent with remote session support. The client-server architecture is unique and enables workflows that no other framework supports natively. The trade-offs: operational overhead of running a server.
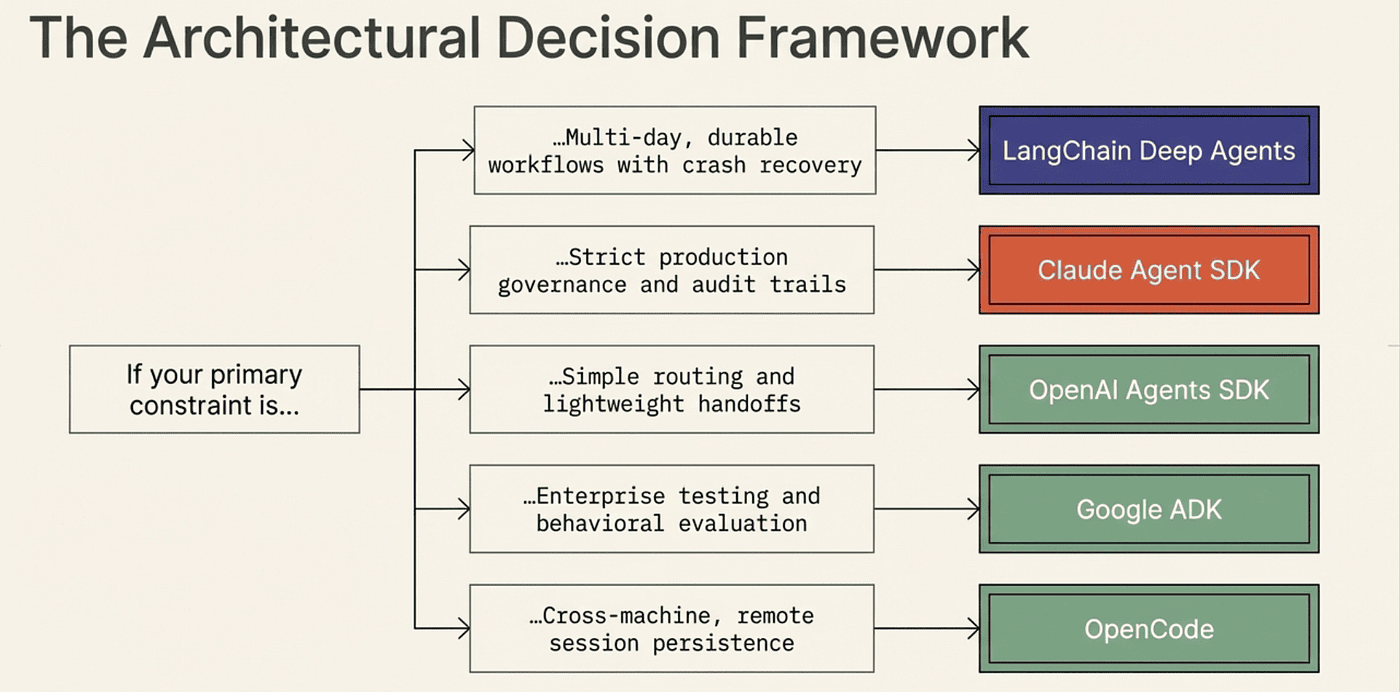 Agent Framework Decision Tree
Agent Framework Decision Tree
 Many Choices, many tradeoffs and advantages
Many Choices, many tradeoffs and advantages
The Hybrid Approach
Many teams overlook a path that combines the strengths of both leading frameworks: use LangChain Deep Agents with Claude as the model provider. You get LangGraph’s durable execution, middleware system, and provider portability while leveraging Claude’s reasoning capabilities. If Claude’s pricing changes or a better model emerges, you swap providers with a one-line change:
agent = create_deep_agent(model="anthropic:claude-sonnet-4-6")
# Switch without code changes
agent = create_deep_agent(model="openai:gpt-5.4")
# Or use Google
agent = create_deep_agent(model="google:gemini-3.1-flash")
What this code demonstrates. The model parameter uses a "provider:model_name" format that init_chat_model() resolves at runtime. All middleware, tool definitions, and graph structure remain unchanged. The only thing that changes is which LLM receives the prompts. No code refactoring, no API migration, no testing of new abstractions.
Why this matters. Provider lock-in is a real business risk in 2026. Model capabilities are changing fast, and the leading model today may not be the leading model next quarter. The hybrid approach preserves optionality at the infrastructure level.
What you give up. This hybrid approach sacrifices Claude Agent SDK’s native hooks and permissions. You lose per-tool-call governance, the permission mode system, and the automatic context compaction that Anthropic has tuned specifically for Claude. For many teams, that is the right trade-off. For teams in regulated environments or those deploying agents with shell access to production systems, it may not be.
Cross-Framework Comparison
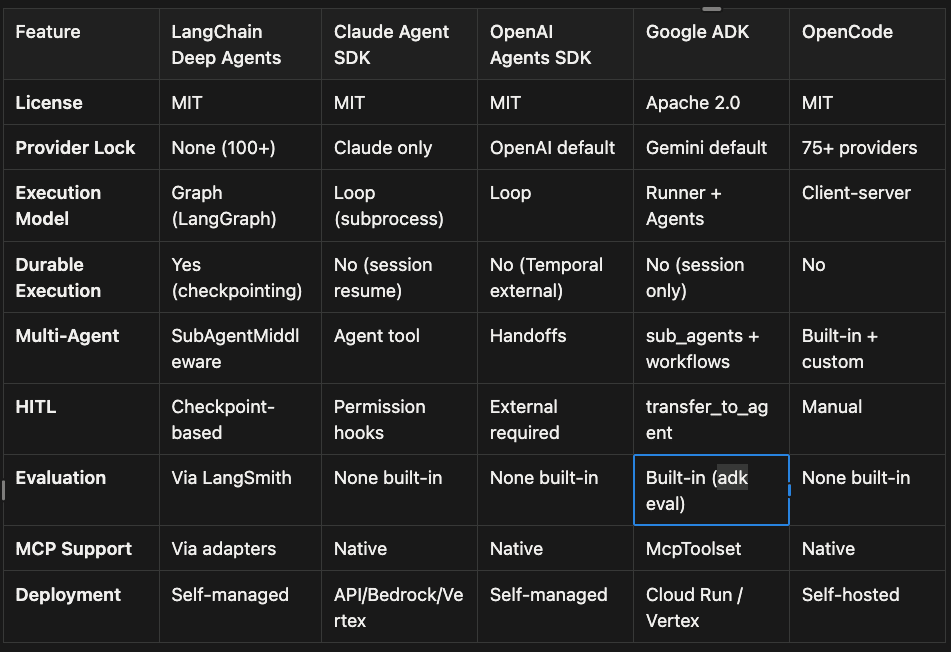
Framework Feature Comparison
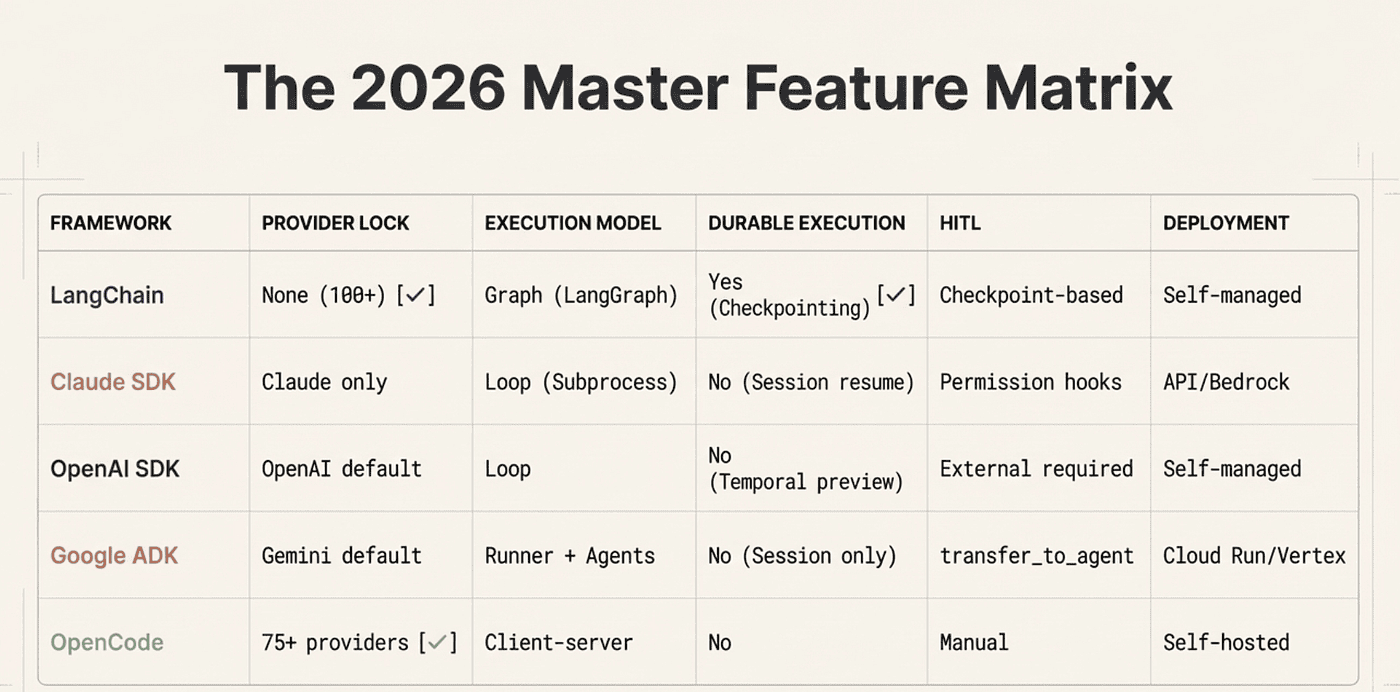 Feature Matrix
Feature Matrix
License
- LangChain Deep Agents: MIT
- Claude Agent SDK: MIT
- OpenAI Agents SDK: MIT
- Google ADK: Apache 2.0
- OpenCode: MIT
Provider Lock
- LangChain Deep Agents: None (100+)
- Claude Agent SDK: Claude only
- OpenAI Agents SDK: OpenAI default
- Google ADK: Gemini default
- OpenCode: 75+ providers
Execution Model
- LangChain Deep Agents: Graph (LangGraph)
- Claude Agent SDK: Loop (subprocess)
- OpenAI Agents SDK: Loop
- Google ADK: Runner + Agents
- OpenCode: Client-server
Durable Execution
- LangChain Deep Agents: Yes (checkpointing)
- Claude Agent SDK: No (session resume)
- OpenAI Agents SDK: No (Temporal external)
- Google ADK: No (session only)
- OpenCode: No
Multi-Agent
- LangChain Deep Agents: SubAgentMiddleware
- Claude Agent SDK: Agent tool
- OpenAI Agents SDK: Handoffs
- Google ADK: sub_agents + workflows
- OpenCode: Built-in + custom
HITL (Human-in-the-Loop)
- LangChain Deep Agents: Checkpoint-based
- Claude Agent SDK: Permission hooks
- OpenAI Agents SDK: External required
- Google ADK: transfer_to_agent
- OpenCode: Manual
Evaluation
- LangChain Deep Agents: Via LangSmith
- Claude Agent SDK: None built-in
- OpenAI Agents SDK: None built-in
- Google ADK: Built-in (adk eval)
- OpenCode: None built-in
MCP Support
- LangChain Deep Agents: Via adapters
- Claude Agent SDK: Native
- OpenAI Agents SDK: Native
- Google ADK: McpToolset
- OpenCode: Native
Deployment
- LangChain Deep Agents: Self-managed
- Claude Agent SDK: API/Bedrock/Vertex
- OpenAI Agents SDK: Self-managed
- Google ADK: Cloud Run / Vertex
- OpenCode: Self-hosted
Conclusion
The agent framework landscape is still evolving rapidly, but one pattern is already clear: Claude Code changed how developers think about agents. Planning, delegation, context management, filesystem access, and guardrails are no longer optional features. They are table stakes.
LangChain Deep Agents took those ideas and implemented them inside a provider-agnostic orchestration runtime with durable execution. Claude Agent SDK took those same ideas and exposed them through a model-native SDK with deep governance controls. The difference is not which framework has more features. The difference is which constraints you are willing to accept in exchange for which capabilities.
LangChain Deep Agents is the strongest choice for teams that need flexibility, durability, and multi-provider support. Accept the graph learning curve and the need for LangSmith. Claude Agent SDK is the strongest choice for teams committed to Claude who need the deepest possible integration and governance. Accept the Claude-only constraint and the subprocess architecture.
Neither framework is universally better. Both are good at what they were designed for. Understanding that distinction is more valuable than any feature checklist.
In Article 3, we go deeper into LangChain Deep Agents’ context management architecture: how SummarizationMiddleware decides what to compress, how SkillsMiddleware enables reusable agent behaviors, how MemoryMiddleware manages cross-thread knowledge, and what security boundaries the sandbox backends actually enforce. If you are building a production Deep Agent, Article 3 covers the architecture decisions that determine whether it stays reliable at scale.
 Choice is a good thing. Choose wisely.
Choice is a good thing. Choose wisely.
This is Article 2 in the LangChain Deep Agents series. Article 1: Introduction to Deep Agents covers the four pillars of Deep Agent architecture and the shift from Agent 1.0 to Agent 2.0. Article 3 LangChain DeepAgent: explores context management, skills, memory, and security in depth.
About the Author
Rick Hightower is a technology executive and data engineer who led ML/AI development at a Fortune 100 financial services company. He created skilz, the universal agent skill installer, supporting 30+ coding agents including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams looking to adopt AI.
Recent Articles that you might also enjoy from Rick Hightower
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security — Rick Hightower, Medium, March 17, 2026 A deep-dive into how Agent Brain, Agent Skills, and Agent RuleZ work together inside a LangChain agent architecture to deliver memory, security, and reusable workflows.
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS — Rick Hightower, Medium, March 17, 2026 — Introduces the conceptual distinction between context engineering and harness engineering using the CPU/OS analogy central to this article.
- Introduction to LangChain Deep Agents and the Shift to “Agent 2.0” — Rick Hightower, Medium, March 16, 2026 — Frames the architectural shift from simple tool-using chatbots to Agent 2.0 systems with persistent memory, hierarchical orchestration, and harness-controlled execution.
- Under the Hood: Middleware, Sub-Agents, and Deep Agent LangGraph Orchestration — Rick Hightower, Medium, March 16, 2026 — Explores how middleware, sub-agents, and LangGraph work together as the runtime layer the harness operates within.
- Claude Code Agent Skills 2.0: From Custom Instructions to Programmable Agents — Rick Hightower, Towards AI, March 9, 2026 — Explains the evolution of agent skills from simple slash-command instructions to fully programmable, multi-step workflows with validation and feedback loops.
- Claude Code Rules: Stop Stuffing Everything into One CLAUDE.md — Rick Hightower, Medium, March 10, 2026 — Provides a practical guide to structuring agent rules across multiple files rather than a single monolithic rules file — the approach that Agent RuleZ formalizes.
- Harness and Context Engineering: Agents — Injecting the Right Rules at the Right Moment — Rick Hightower, Spillwave Solutions, February 27, 2026 — Covers the mechanics of dynamic rule injection — how and when architectural constraints are delivered to an agent during execution, not just at startup.
- The End of Manual Agent Skill Invocation: Event-Driven AI Agents — Rick Hightower, Artificial Intelligence in Plain English, February 23, 2026 — Describes how agent skills can be triggered automatically by events rather than manually, eliminating a major source of inconsistency in multi-step agentic workflows.
- Put Claude on Autopilot: Scheduled Tasks with /loop and /schedule built-in Skills — Rick Hightower, Artificial Intelligence in Plain English, March 11, 2026 — Demonstrates built-in Agent Skills for scheduling and looping — concrete examples of how harness-managed skills enable autonomous, long-running agent operation.
- Claude Code’s Automatic Memory: No More Re-Explaining Your Project — Rick Hightower, Spillwave Solutions, March 9, 2026 — Covers the automatic memory capability that ships with Claude Code /memory
- From Approval Hell to Just Do It: How Agent Skills Fork Governed Sub-Agents in Claude Code 2.1 — Rick Hightower, Spillwave Solutions, February 6, 2026 — Shows how Agent Skills combined with policy islands (forked sub-agents with pre-declared permissions) eliminate approval fatigue while maintaining governance — the Layer 3 feedback and workflow pattern this article calls harness engineering.