The Economics of Deploying Large Language Models: Costs, Value, and 99.7% Savings
Every tech leader who saw ChatGPT explode asked: What will a production-grade large language model (LLM) cost us? The short answer
Originally published on Medium.
Every tech leader who saw ChatGPT explode asked: What will a production-grade large language model (LLM) cost us? The short answer

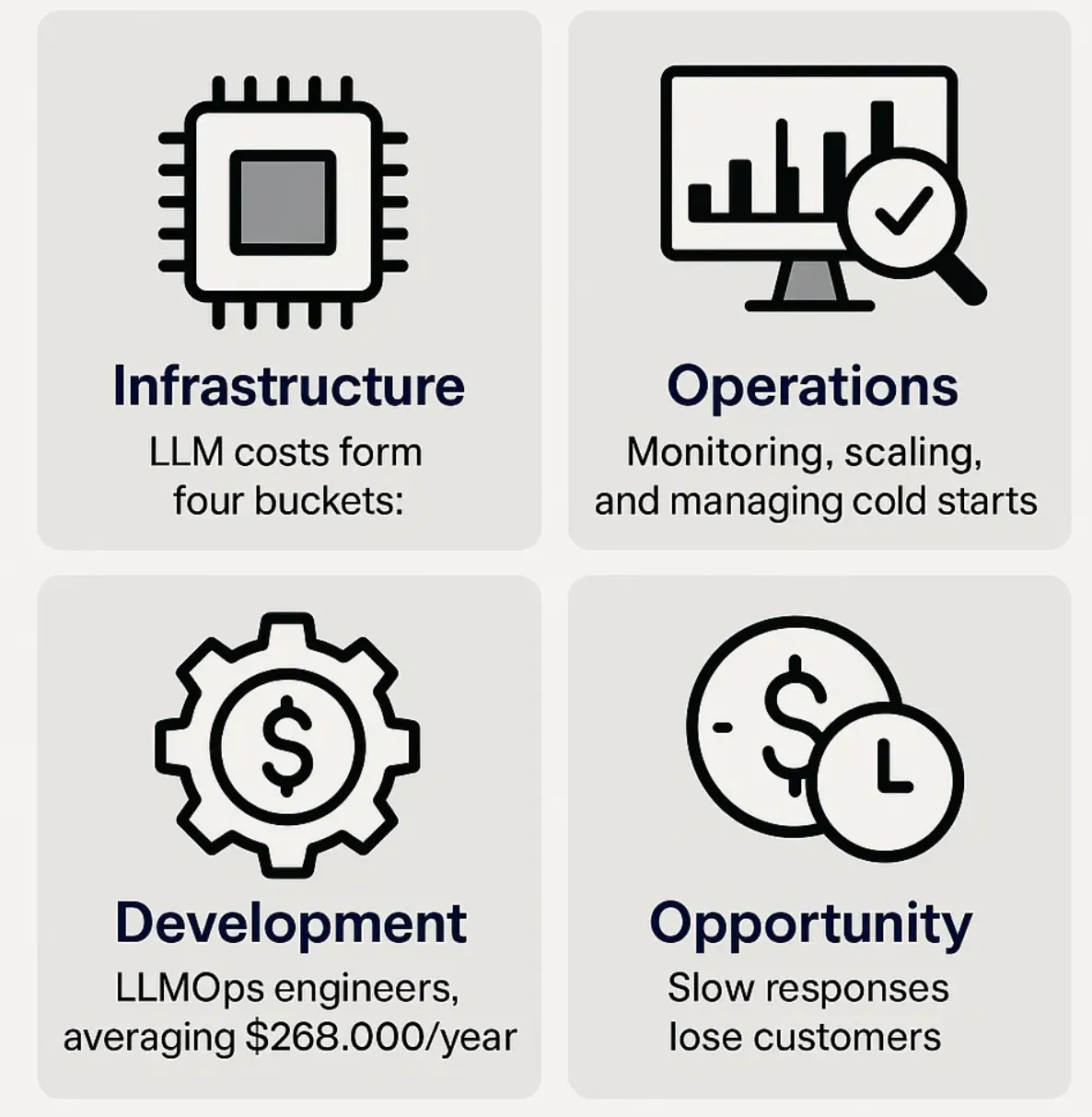
- Actual Cost Structure: LLM expenses extend far beyond API fees, encompassing infrastructure (GPUs), operations, development talent, and opportunity costs that can significantly impact ROI.
- Dramatic Optimization Potential: Strategic implementation can reduce costs by up to 99.7%, as demonstrated by our case study, where monthly expenses dropped from $937,500 to just $3,000.
- Deployment Options: The article compares API-based, self-hosted, and hybrid approaches, highlighting the tradeoffs between cost, control, and expertise requirements for each strategy.
- Talent Considerations: With LLMOps specialists commanding salaries of $ 268,000 or more and being in extremely short supply (demand up 300% since 2023), talent acquisition represents a significant hidden cost and strategic consideration.
- Practical Cost-Cutting Strategies: Specific techniques, such as request batching, caching, quantization, and hybrid routing, can deliver cost reductions of 10–90% while maintaining or improving performance.

- A $0.05 query saving $5 in labor yields a 100x return.
- For 10,000 daily queries, that’s $1.5M monthly saved.

-
Request Batching: Group queries for 10x throughput.
-
Caching: Store answers, cutting costs 50–90%.
-
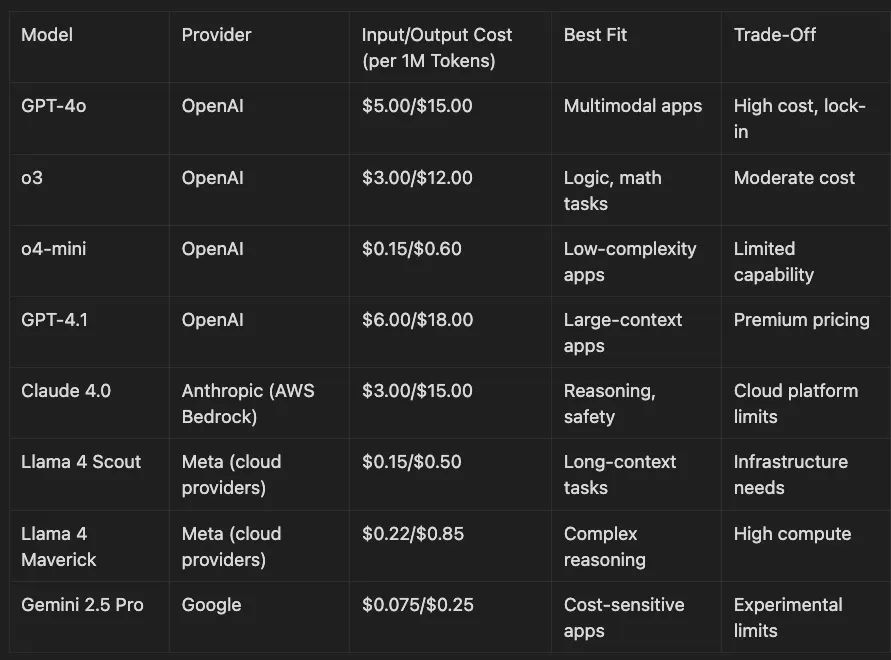
Model Selection: Scout for long contexts, Maverick or Claude 4.0 for reasoning.
-
Hybrid Routing: Route simple queries to o4-mini or Scout, leveraging LiteLLM.
-
Quantization: INT8 halves memory needs.
-
Prompt Optimization: Tools like DSPy reduce token usage and improve reliability.
-
Self-Hosting: Switched to Llama 4 Maverick on an H100 DGX, costing $5,904/month.
-
Efficiency Boost: Batching for 20x throughput; caching for 80% reuse.
-
Hybrid Routing: Scout for simple queries, Maverick for complex, using LiteLLM.
- Hightower, R. (2025). “Beyond Fine-Tuning: Mastering Reinforcement Learning for Large Language Models.” Medium.
- Hightower, R. (2025). “The Open-Source AI Revolution: How DeepSeek, Gemma, and Others Are Challenging Big Tech’s Language.” Medium.
- Hightower, R. (2025). “LiteLLM and MCP: One Gateway to Rule All AI Models.” Medium.
- Hightower, R. (2025). “Stop Wrestling with Prompts: How DSPy Transforms Fragile AI into Reliable Software.” Medium.
- AWS Pricing. (2025). Amazon Web Services., AWS EC2 Pricing
- Azure Pricing. (2025). Microsoft Azure.
- GCP Pricing. (2025). Google Cloud Platform.
- “Index.dev Blog: LLM Developer Hourly Rates.” (2025). Index.dev.
- Hightower, R. (2025). “The LLM Cost Trap — and the Playbook to Escape It.” Medium.
-
GenAI for the Busy Executive: Don’t Fall Behind — Rise of MCP and A2A
-
The Executive Imperative: AI isn’t Just Tech, It’s Your Bottom Line
-
Introduction: From Hype to High Returns — Architecting AI for Real-World Value (June 2025)
-
U.S. Marine Corps’ AI Playbook: Businesses Take Note (Published in Spillwave Solutions)
-
AI Boon or Doom?: Why the Latest AI Predictions Sound Familiar (Published in Spillwave Solutions)
-
MCP: From Chaos to Harmony — Building AI Integrations with the Model Context Protocol (June 2025)
-
Anthropic’s Claude and MCP: A Deep Dive into Content-Based Tool Integration
-
DSPy Meets MCP: From Brittle Prompts to Bulletproof AI Tools
-
LangChain and MCP: Building Enterprise AI Workflows with Universal Tool Integration
-
Anthropic’s MCP: Set up Git MCP Agentic Tooling with Claude Desktop
-
OpenAI Meets MCP: Transform Your AI Agents with Universal Tool Integration
-
Securing MCP: From Vulnerable to Fortified — Building Secure HTTP-based AI Integrations
-
Securing LiteLLM’s MCP Integration: Write Once, Secure Everywhere
-
Securing DSPy’s MCP Integration: Programmatic AI Meets Enterprise Security
-
Securing LangChain’s MCP Integration: Agent-Based Security for Enterprise AI
-
Securing OpenAI’s MCP Integration: From API Keys to Enterprise Authentication
-
Why Language Is Hard for AI — and How Transformers Changed Everything
-
Build Production AI in Minutes: The Developer’s Guide to Transformers and Hugging Face
-
Transformers and the AI Revolution: The Role of Hugging Face
-
Claude 4: Why Anthropic Just Changed the Game by Abandoning the Chatbot Race
-
How Tech Giants Are Building Radically Different AI Brains: Gemini vs. Open AI vs. Claude Fight!
-
Let the battle of the AI chatbots commence: Claude2 vs ChatGPT
-
The Open-Source AI Revolution: How DeepSeek, Gemma, and Others Are Challenging Big Tech’s Language…
-
Teaching AI to Judge: How Meta’s J1 Uses Reinforcement Learning to Create Better LLM Evaluators
-
OpenAI Just Changed the Game: How Reinforcement Fine-Tuning Makes AI Learn Like a Pro
-
Beyond Fine-Tuning: Mastering Reinforcement Learning for Large Language Models
-
LangChain: Building Intelligent AI Applications with LangChain (May 2025)
-
Beyond Chat: Enhancing LiteLLM Multi-Provider App with RAG, Streaming, and AWS Bedrock
-
Your prompts are brittle. Your AI System Just Failed. Again. DSPy to the Rescue!
-
Stop Wrestling with Prompts: How DSPy Transforms Fragile AI into Reliable Software
-
Is RAG Dead?: Anthropic Says No (May 2025)
-
Beyond Basic RAG: Building Virtual Subject Matter Experts with Advanced AI
-
Building AI-Powered Search and RAG with PostgreSQL and Vector Embeddings
-
Conversation about Document Parsing and RAG (VLOG transcripts)
-
If ChatGPT and Claude are so good why do I need Amazon Textract or Unstructured?
-
The Developer’s Guide to AI File Processing with AutoRAG support: Claude vs. Bedrock vs. OpenAI
-
Implementing Retrieval-Augmented Generation (RAG) with Amazon Bedrock Knowledge Bases
-
Don’t “improve it” before you baseline it: Evaluating Foundation Models in Amazon Bedrock
-
Amazon Bedrock Foundation Models: A Complete Guide for GenAI Use Cases
-
Document Intelligence with Amazon Textract: From OCR to Structured Insights
-
Building Your First Intelligent Document Workflow with AWS Textract and Comprehend
-
Modern IT Infrastructure Management: Architecture and Strategy for Business Value