The Eleven Patterns Behind Every Production Agentic System (And Where JSON Schemas Actually Earn Their Keep)
CCA-F: Agentic Workflow Patterns and Structured Hand-offs for Reliable Production Systems
Originally published on Medium.
CCA-F: Agentic Workflow Patterns and Structured Hand-offs for Reliable Production Systems

A field guide to the agentic workflow patterns the Claude Certified Architect curriculum tests, followed by the structured-output discipline that separates demos from production systems.
Summary: Discover the eleven essential agentic workflow patterns from prompt chaining and routing to orchestrator‑workers and structured handoffs — along with a clear, practical guide on exactly where JSON schemas belong (and where they don't) to transform fragile demos into production‑ready multi‑agent systems. This concise intro will convince you to dive deeper into the article's detailed patterns, triggers, and schema discipline for building reliable, scalable AI pipelines.
Every team building multi-agent systems eventually hits the same wall.
The individual agents work. The researcher finds sources. The synthesizer drafts prose. The evaluator scores quality. Run them in isolation and each passes its tests. Chain them together and the system becomes unreliable in ways that are hard to diagnose. Findings lose attribution somewhere between research and synthesis. The evaluator's verdict gets misread, so the refinement loop fires on the wrong gaps. A routing classifier emits Refund Request when the dispatch table expects refund, and the request silently falls into a default branch nobody owns.
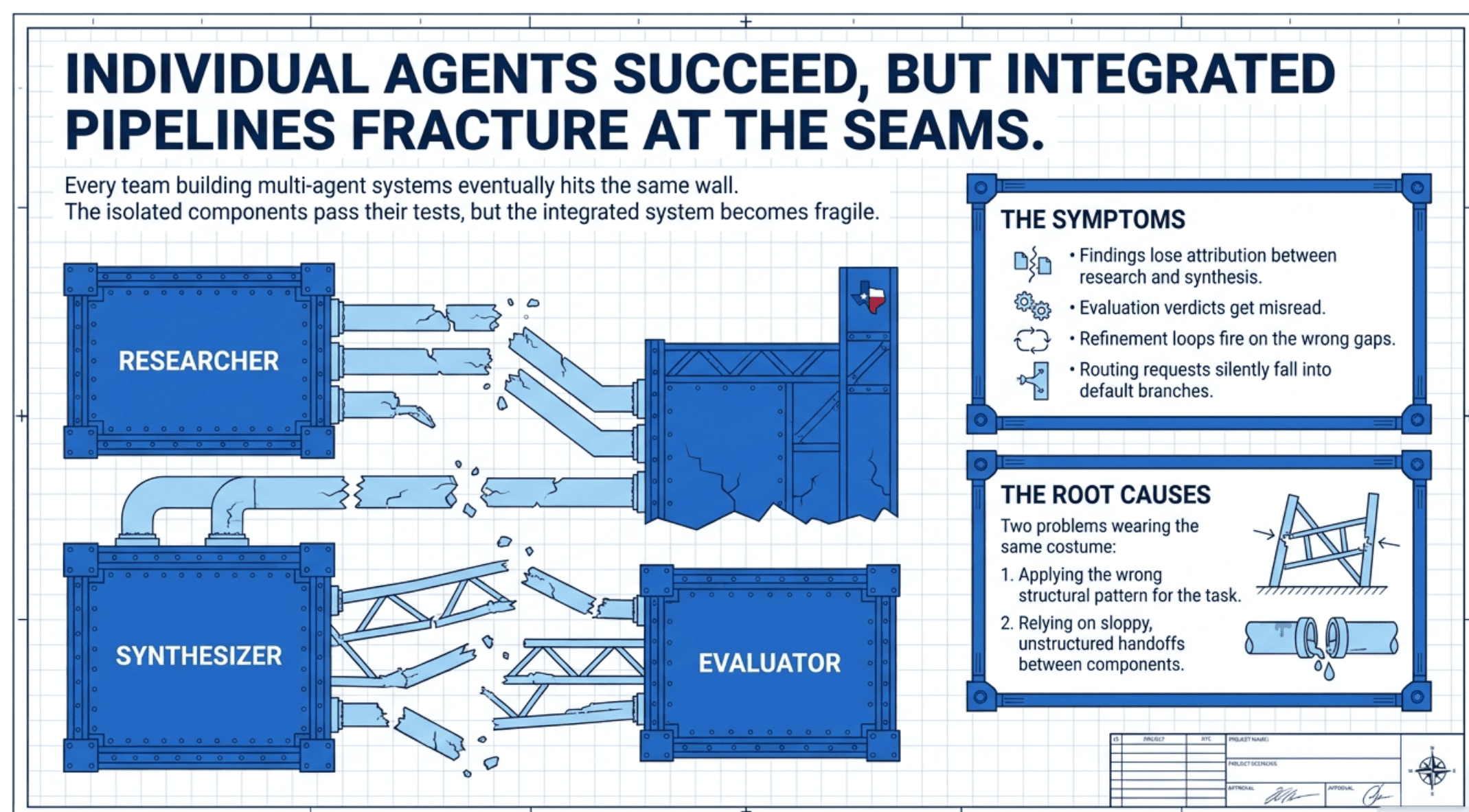
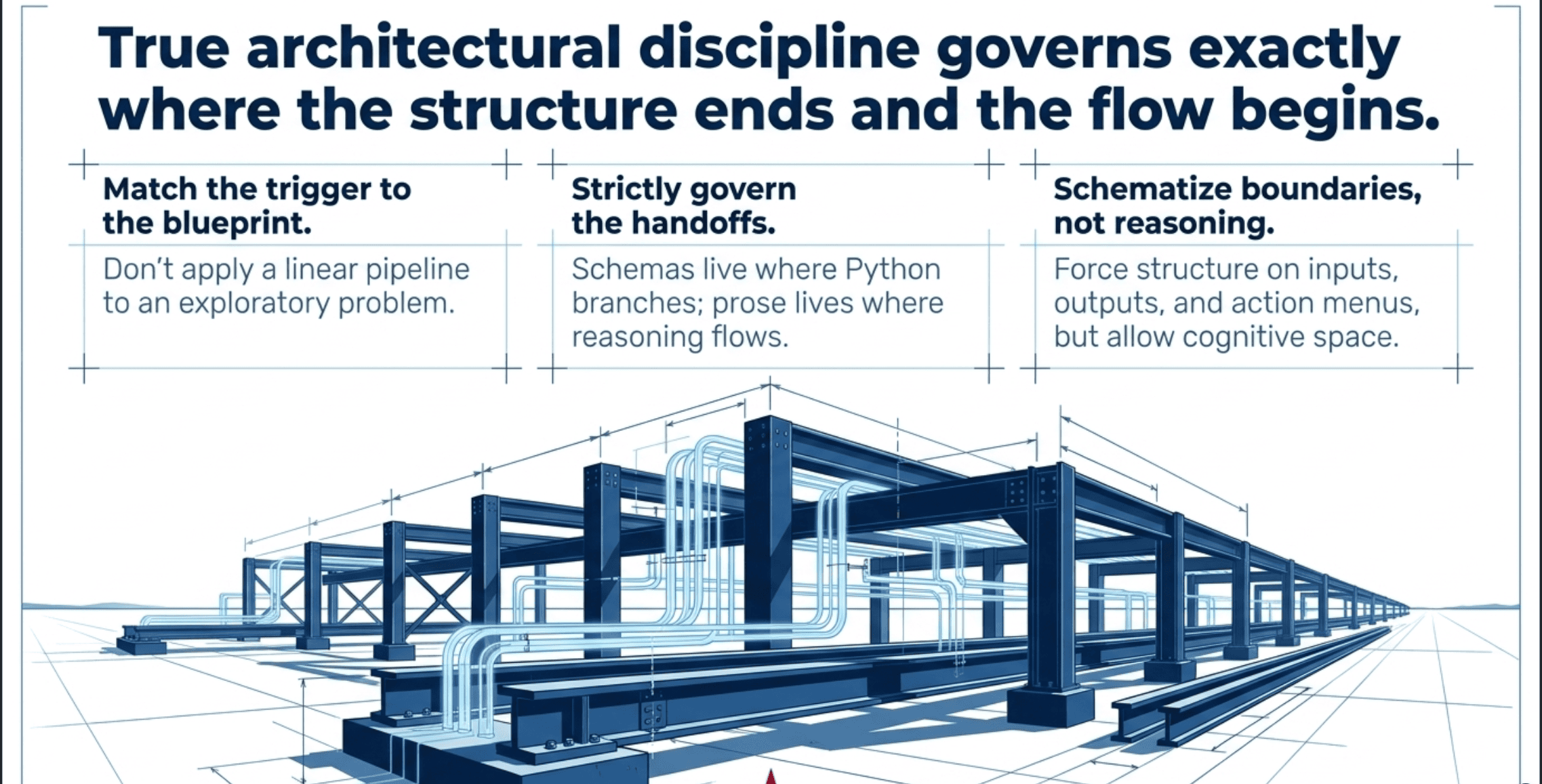
This is almost always two problems wearing the same costume. The first is that the team picked the wrong pattern for the shape of their problem. The second is that the handoffs between components are prose where they should be typed, or typed where the structure works against them.
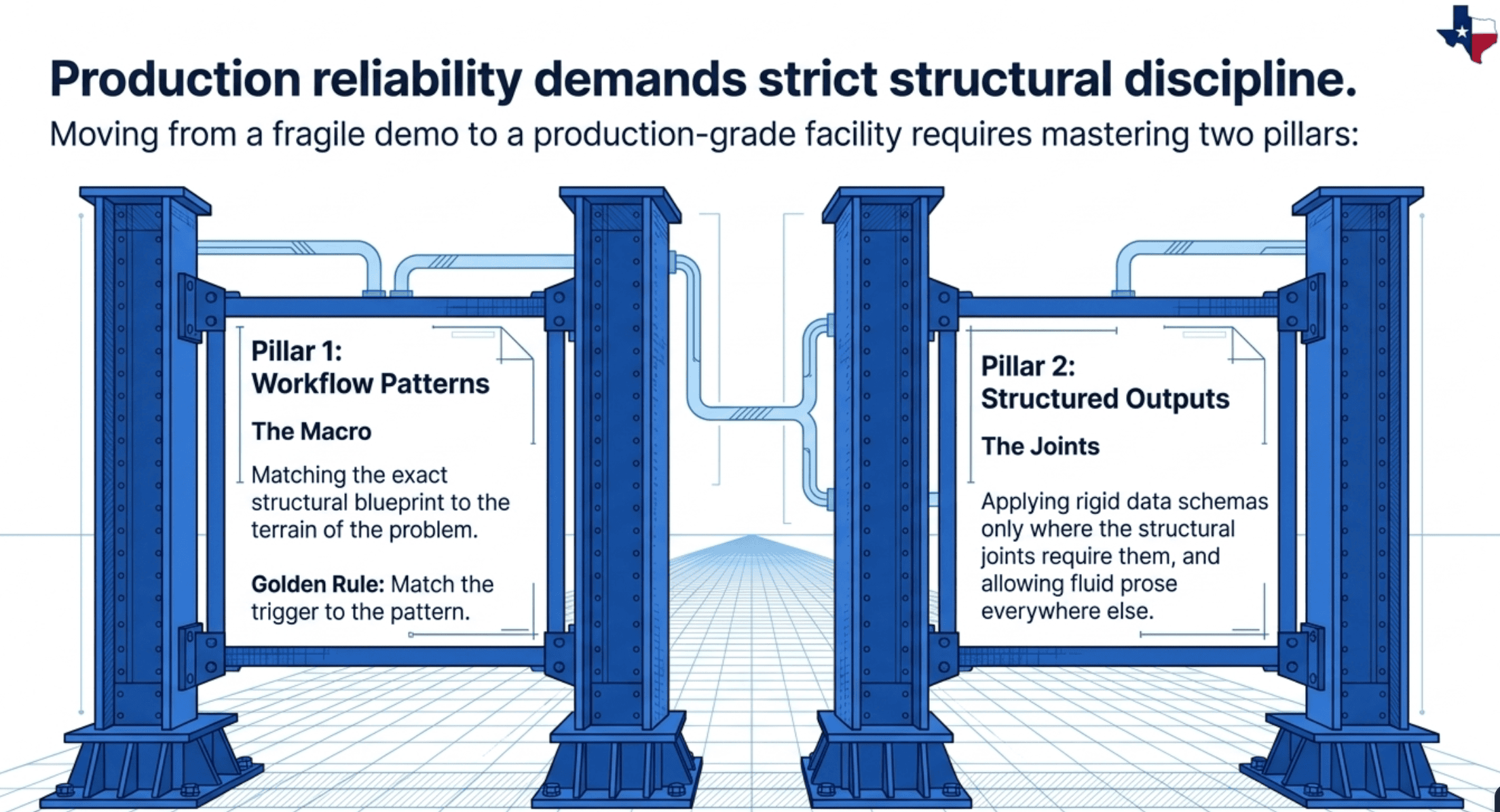
This article works through both problems in order. The first half is a tour of the eleven agentic workflow patterns, each with a trigger that tells you when to use it. The second half is a discipline for deciding exactly where JSON schemas belong in those patterns and where they do not.
If you build agentic systems and the seams between your agents feel fragile, the answer is almost certainly in one of these two places.
Part One: The Eleven Patterns
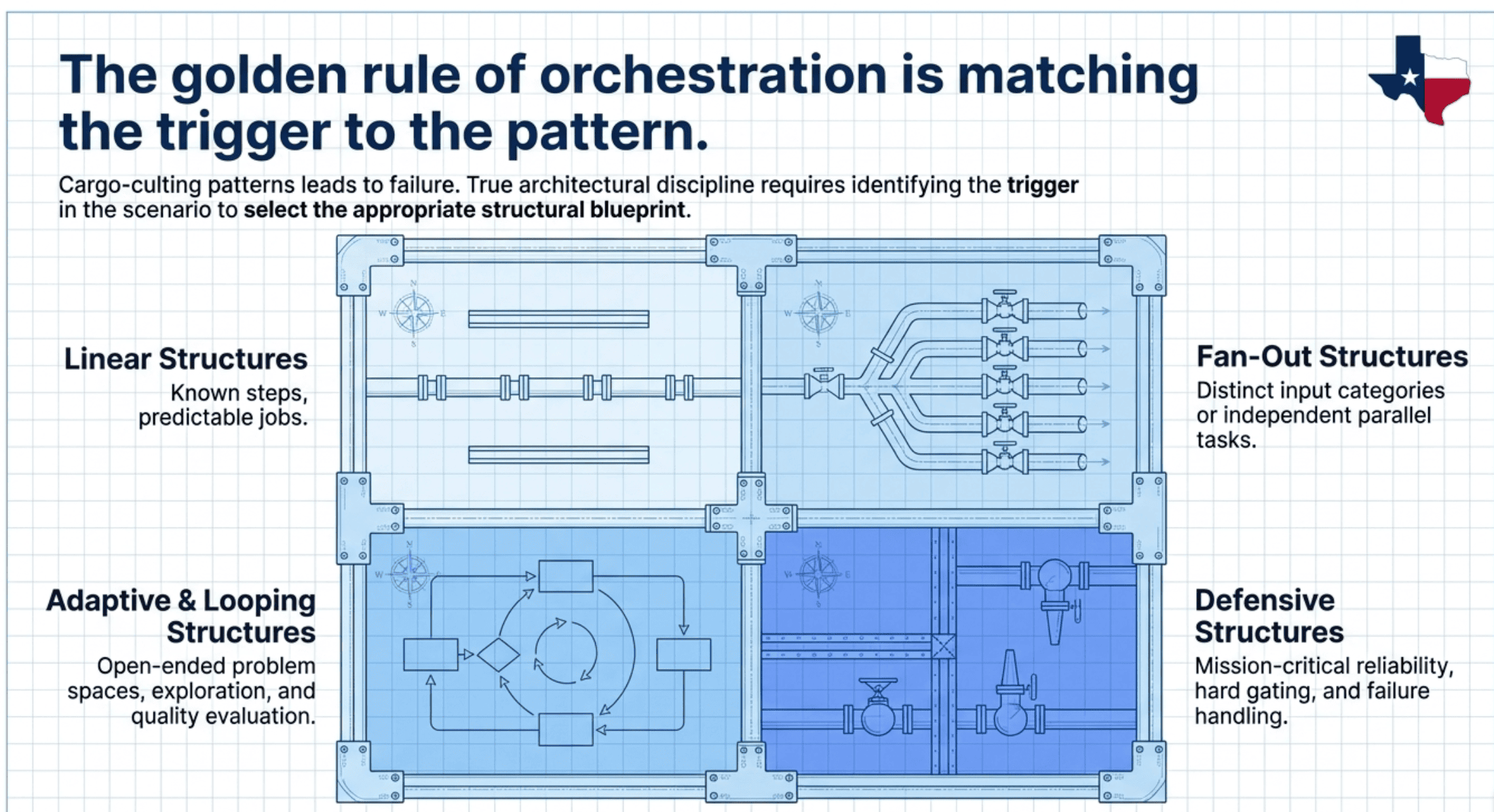
The vocabulary comes from two sources. Five canonical patterns come from Anthropic's Building Effective Agents paper. Six additional patterns are layered on by the Claude Certified Architect curriculum to handle multi-agent and production-specific concerns. Each pattern has a trigger, a signal in a scenario description that should make you reach for it. Matching trigger to pattern is the actual skill the exam tests, and the actual skill that separates production-grade design from cargo-culting.
Pattern 1. Prompt Chaining
A fixed sequence of LLM calls where each step's output feeds the next. Sometimes with programmatic checks (gate passes, format validators) between calls.
flowchart LR
A[Outline] --> B[Draft] --> C[Revise] --> D[Ship]

Canonical example. Generate marketing copy, then translate to another language. Write outline, then check criteria, then draft document. The steps are known in advance and identical for every input.
Trigger. Steps are knowable before the run starts. Each step has a simpler job than the whole task. Latency is acceptable in exchange for accuracy.
Compared to iterative refinement. Chaining is a linear pipeline; iterative refinement is a loop. Chaining's steps are fixed before execution; refinement's targeted gap-closing subtasks emerge during execution based on what the evaluator finds. The exam catches you here by offering a fixed five-step pipeline as a distractor on questions that actually call for adaptive decomposition.
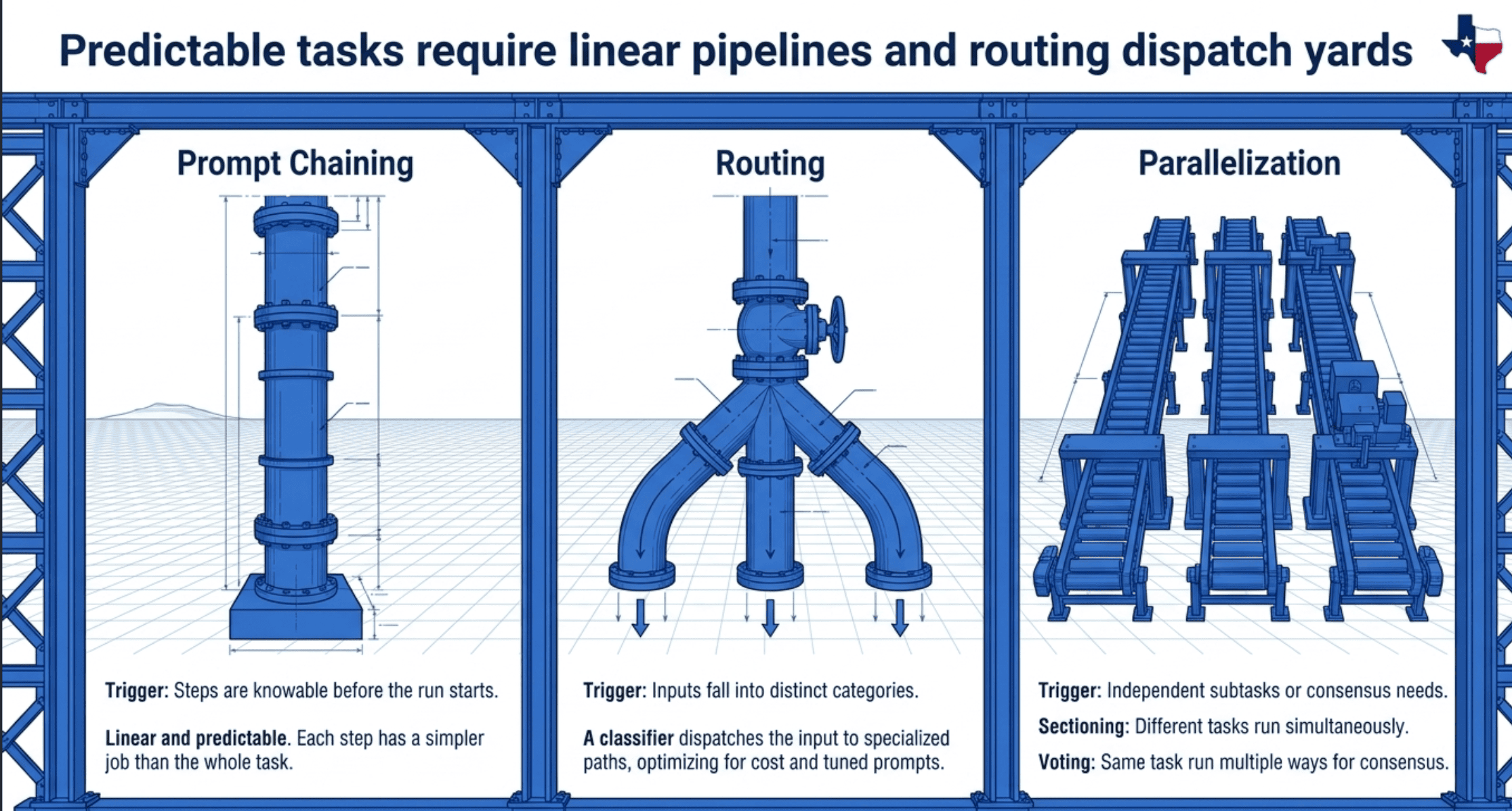
Pattern 2. Routing
A classifier reads the input and dispatches it to one of several specialized paths. Each path has its own prompt, tools, and model choice.
flowchart LR
I[User input] --> C[Classifier]
C -->|Technical| T[Tech support path]
C -->|Billing| R[Refund workflow]
C -->|General| G[Haiku, low cost]
Canonical example. Customer service intake. A device that won't turn on routes to a technical-support workflow with the manual in context. A return request routes to a billing tool path. A general question routes to Haiku to save cost.
Trigger. Inputs fall into distinct categories. One-size-fits-all prompts degrade across categories. Cost optimization matters and can be captured by sending simple cases to smaller models.
Compared to iterative refinement. Routing fans out by category; refinement loops back on quality. Routing decides which workflow runs before any real work happens. Refinement asks whether the work that ran was good enough after it happens. They compose cleanly: a real system might route on intake, and the chosen workflow might internally use iterative refinement.
Pattern 3. Parallelization
Multiple calls run concurrently, results aggregated programmatically. Two named variants.
Sectioning runs different tasks at the same time:
flowchart TD
I[Input] --> A[Draft]
I --> B[Screen]
I --> C[Tag]
A --> M[Combine outputs]
B --> M
C --> M
Voting runs the same task multiple ways and takes consensus:
flowchart TD
I[Input] --> A[Voter A]
I --> B[Voter B]
I --> C[Voter C]
A --> M[Majority verdict]
B --> M
C --> M
Canonical examples. Sectioning: one model drafts content while another screens it for policy violations. Voting: three different prompts review the same code for vulnerabilities; flag the input if any two agree.
Trigger. Independent subtasks (sectioning) or consensus needed through diverse perspectives (voting). Wall-clock latency drops to the slowest single call rather than the sum.
Compared to iterative refinement. Parallelization is a fan-out pattern; iterative refinement is a feedback loop. They compose. The initial delegation wave inside an iterative refinement coordinator is parallelization. The trap the exam tests: parallelizing dependent subtasks. Graph independence is non-negotiable for parallelization to work.
Pattern 4. Orchestrator-Workers
A central orchestrator dynamically breaks the task into subtasks at runtime, dispatches them to workers, and synthesizes the results. The orchestrator's plan is not known in advance.
flowchart TD
O[Orchestrator<br/>Plans on the fly]
O --> W1[Worker: explore module A]
O --> W2[Worker: identify untested code]
O -.->|Decided at runtime| W3[Worker future]
Canonical example. Add comprehensive tests to a legacy codebase. The orchestrator cannot list the subtasks before exploring, so it discovers them as it goes: identify untested modules, prioritize by risk, generate tests, run them, fix failures, expand coverage.
Trigger. Open-ended problems where the subtask list cannot be predefined. The orchestrator decides on the fly which subtasks are necessary based on what it has learned.
Compared to iterative refinement. Close kin. Both have a coordinator that emits subtasks dynamically. The difference is the trigger: orchestrator-workers is driven by exploration; iterative refinement is driven by quality evaluation of a synthesized output. Iterative refinement is a specialization of orchestrator-workers where the dynamic decision is "what gaps did the evaluator find?"
Pattern 5. Evaluator-Optimizer
One LLM generates an output. A second LLM evaluates it against criteria. The generator revises based on the evaluator's feedback. The loop continues until the evaluator's verdict passes or a max-iteration limit is hit.
flowchart LR
G[Generator<br/>Produces output] -->|Draft| E[Evaluator<br/>Scores against criteria]
E -.->|Revise gaps| G
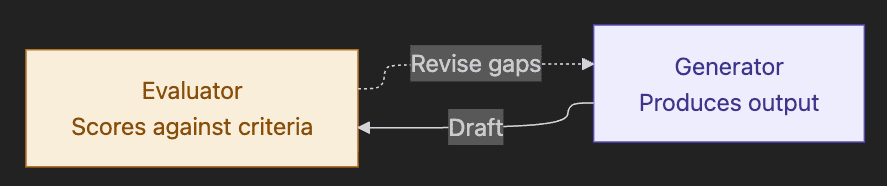
Canonical example. Translation quality. Generator produces a translation; evaluator scores it for fluency, faithfulness, and idiom; generator revises specific phrases the evaluator flagged.
Trigger. Clear evaluation criteria exist and iterative feedback measurably improves output. Mimics the human writing process of draft, critique, revise.
Compared to iterative refinement. Same structural idea, different scope. Evaluator-optimizer is a closed feedback loop applied to one generator. Iterative refinement is the same loop applied to a multi-agent coordinator. The disambiguator on the exam: does the loop revise one output, or re-orchestrate multi-agent work?
Pattern 6. Hub-and-Spoke
One central coordinator, multiple specialist subagents, all inter-agent communication routed through the hub. Subagents do not communicate with each other directly.
flowchart TD
C[Coordinator<br/>All comms through hub]
C <--> R[Researcher<br/>Isolated context]
C <--> A[Analyst<br/>Isolated context]
C <--> S[Synthesizer<br/>Isolated context]
C <--> V[Reviewer<br/>Isolated context]
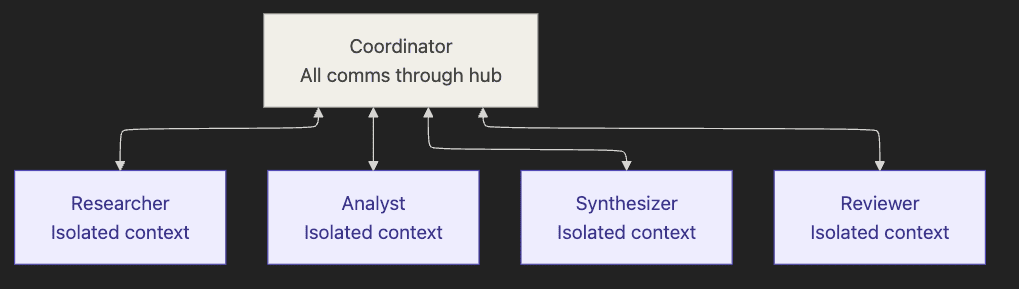
Trigger. Multi-agent work where subagents must not share context directly. The base architecture for almost every multi-agent system the curriculum tests.
Compared to iterative refinement. Hub-and-spoke is the base architecture on top of which iterative refinement adds a feedback loop. A coordinator with researchers and a synthesizer and no quality gate is hub-and-spoke. Add the evaluator subagent and the loop-back logic and you have iterative refinement.
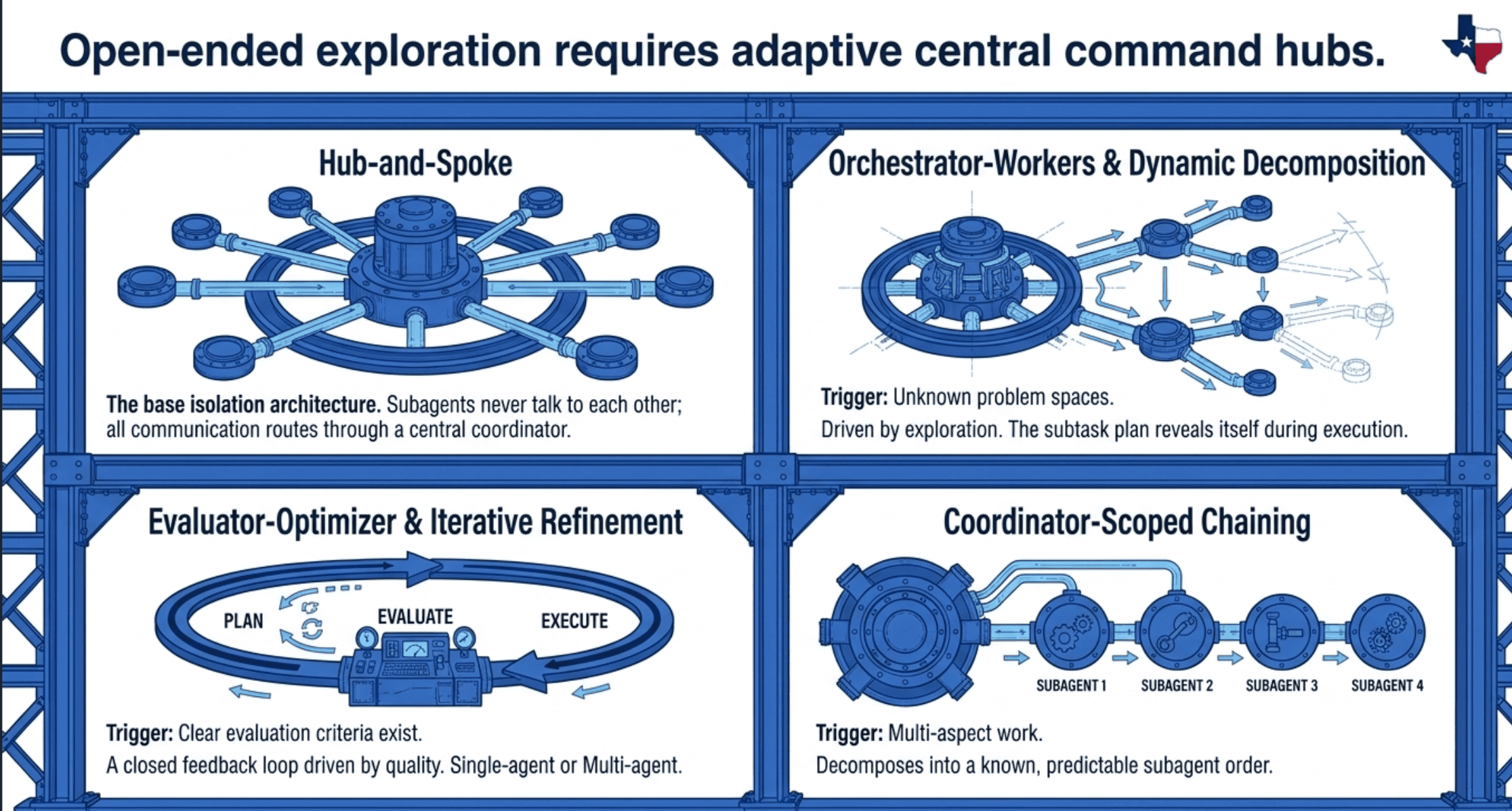
Pattern 7. Dynamic Adaptive Decomposition
The coordinator generates the next subtask based on what prior subtasks revealed. The task list is built incrementally; no step is known until the previous step's findings come back.
flowchart LR
C[Coordinator<br/>Initial query] --> S1[Subtask 1<br/>Inventory tablets]
S1 --> S2[Subtask 2<br/>Decided after S1]
S2 -.-> S3[Subtask 3<br/>Unknown now]
S3 -.-> S4[Subtask 4<br/>Decided after S3]
S4 -.-> Ship[Eventually ship]

Trigger. Unknown problem space. Investigating a newly discovered tablet collection. Adding tests to a legacy codebase you have not explored. The plan reveals itself as findings come in.
Compared to iterative refinement. Effectively the same as orchestrator-workers from the canonical five, with the trigger emphasized as exploration rather than quality evaluation. The exam pairs it with sequential prompt chaining as the two named decomposition strategies a coordinator chooses between.
Pattern 8. Sequential Prompt Chaining (Coordinator-Scoped)
The coordinator runs a fixed, predictable sequence of subagent calls. Same as canonical prompt chaining but scoped inside a multi-agent coordinator rather than at the pipeline level.
flowchart LR
C[Coordinator<br/>Fixed plan]
C --> S1[Per-file analysis]
S1 --> S2[Cross-file integration]
S2 --> S3[Final report]

Canonical example. Code review broken into per-file local analysis followed by a cross-file integration pass.
Trigger. Multi-aspect work that decomposes into a known, predictable order.
Compared to iterative refinement. Linear and fixed versus looping and adaptive. Sequential chaining works when the work is predictable; iterative refinement is needed when the output might not be good enough on the first pass.
Pattern 9. Programmatic Prerequisites and Workflow Enforcement
Hooks block downstream tool calls until prerequisite steps complete. Identity verification before account action. Payment authorization before fulfillment. Data classification before export.
flowchart LR
A[Agent<br/>Wants to act] --> H[Hook gate<br/>Deterministic check]
H -->|Pass| Y[Allow tool call<br/>Prereq complete]
H -->|Fail| N[Deny tool call<br/>Run prereq first]
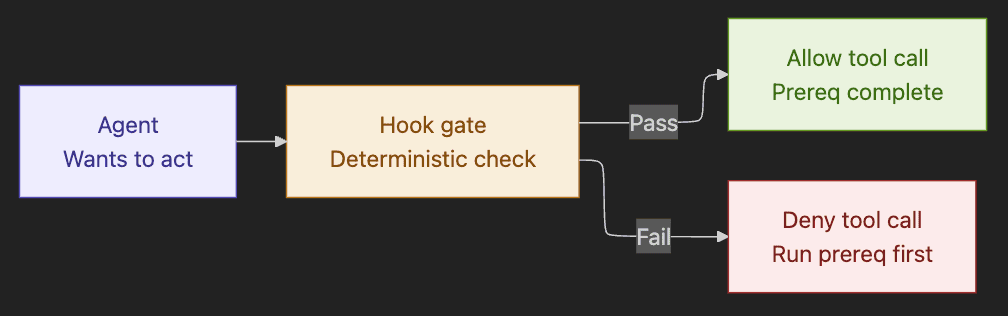
Trigger. Ordering must be guaranteed. The cost of skipping the prerequisite is unacceptable (financial transactions, identity verification, data export approvals). Prompt-based ordering has too much failure-rate variance for the stakes.
Compared to iterative refinement. Different axis entirely. Programmatic prerequisites enforce ordering via deterministic gates. Iterative refinement enforces quality via structured but probabilistic evaluation. Both close reliability gaps that pure prompt-based control leaves open. The exam treats them as complementary, not competing.
Pattern 10. Graceful Degradation with Partial Results
When a subagent fails (vendor 503, timeout, missing data), the coordinator preserves the successful work and delivers a partial result with the gap flagged rather than failing the whole pipeline.
flowchart TD
C[Coordinator] --> A[Subagent A<br/>Success]
C --> B[Subagent B<br/>Success]
C --> X[Subagent C<br/>Vendor 503]
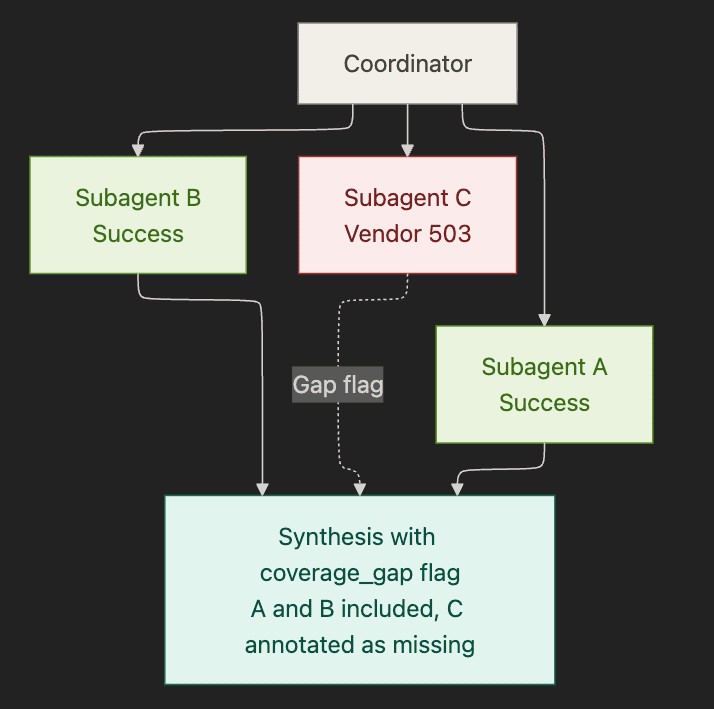
Trigger. Independent subtask failed, but successful work should not be discarded. The downstream consumer (human or system) needs to know what is missing rather than receiving a silently incomplete output.
Compared to iterative refinement. Composes directly. When iterative refinement hits its max_iterations bound without satisfying the evaluator, the coordinator ships the synthesis with the unresolved gaps annotated. That handoff is graceful degradation kicking in at the loop boundary.
Pattern 11. Structured Handoff (Human Escalation)
When an agent escalates to a human or downstream system, it compiles structured context into a typed payload before handing off. The human receives everything needed to resolve without re-reading the conversation.
flowchart LR
A[Agent<br/>Needs to escalate] --> P["Structured handoff payload<br/>customer_id<br/>root_cause<br/>recommended_action<br/>attempted_resolutions"]
P --> H[Human<br/>Resolves with context]

Trigger. Escalation to a human or downstream system that lacks conversation context. Discarding the agent's accumulated investigation by handing over only a transcript is wasteful and slow.
Compared to iterative refinement. Adjacent. Both preserve structured context across boundaries. Refinement preserves it across loop iterations in the coordinator's findings list; handoff preserves it across the agent-to-human boundary. Same discipline of typed, structured data over free-form prose.
Picking the Right Pattern: Match Trigger to Pattern
If you internalize one mental move from Part One, make it this: when you read a scenario, find the trigger phrase and let it pick the pattern.
A short reference, in the order the exam tends to test:
Steps are known in advance → prompt chaining Distinct input categories → routing Independent subtasks running together → parallelization (sectioning) Consensus through diverse perspectives → parallelization (voting) Plan emerges from exploration → orchestrator-workers / dynamic decomposition Output needs to be checked against criteria and revised → evaluator-optimizer (single-agent) or iterative refinement (multi-agent) Coordinator orchestrating specialist subagents → hub-and-spoke as the base, plus whichever decomposition fits the work Ordering must be guaranteed deterministically → programmatic prerequisites Independent failure should not waste good work → graceful degradation Handing off to a human or external system → structured handoff
Wrong-answer distractors on the exam are almost always patterns from this list applied to the wrong trigger. A "fixed five-step pipeline" is chaining applied to a problem that calls for dynamic decomposition. "Spawn more subagents" is parallelization applied to a problem that calls for iterative refinement.
Part Two: Where JSON Schemas Actually Earn Their Keep
Picking the right pattern is half the job. The other half is making the handoffs between components reliable. This is where JSON schemas live, and where most teams either underuse them (everything is prose and the system is fragile) or overuse them (schemas where they do not belong, and the system is stiff and the model's reasoning is impaired).
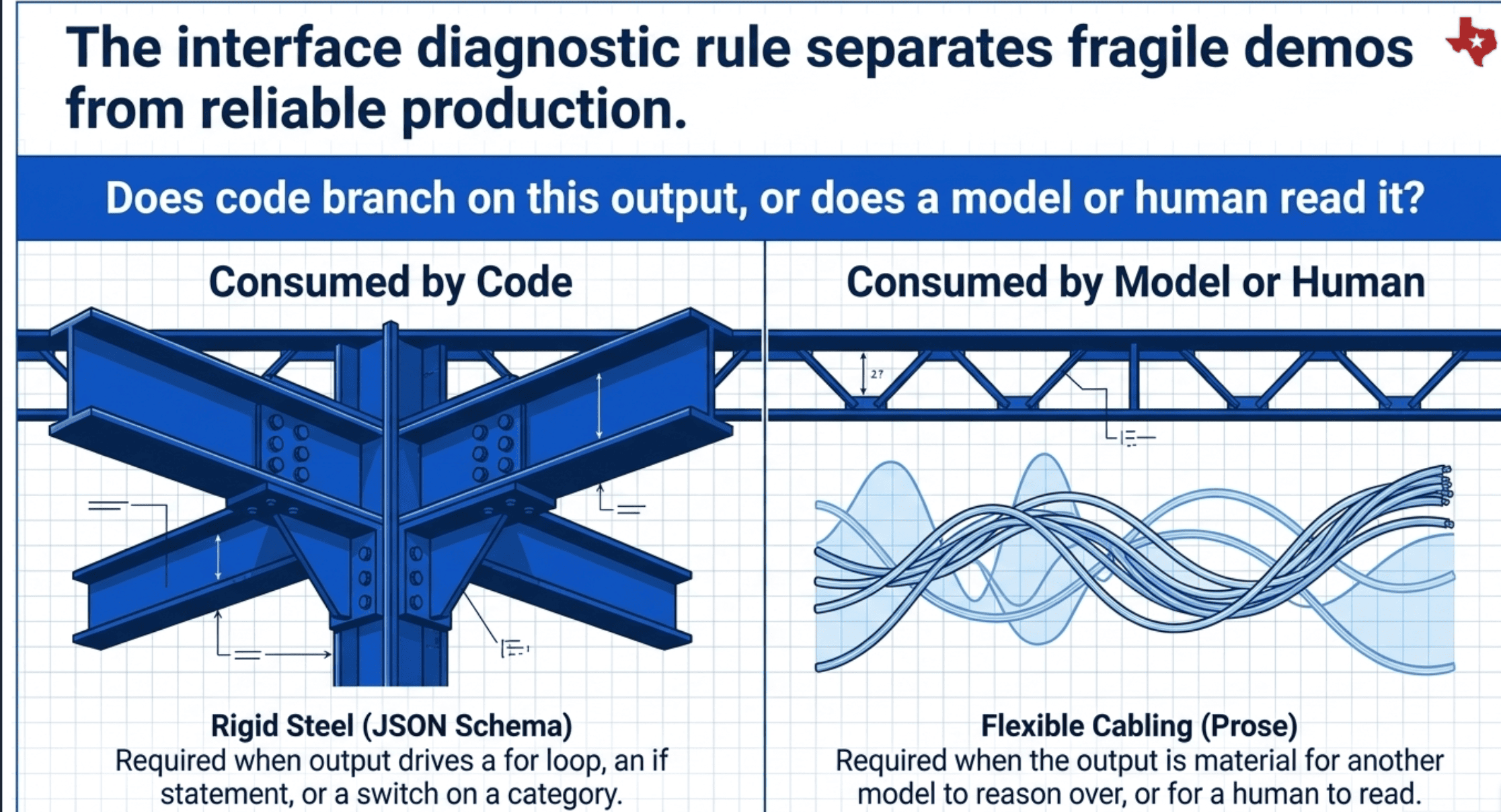
The discipline is simpler than it looks. There is exactly one diagnostic question.
Does code branch on this output, or does a model or human read it?
When the output is consumed by code (a for loop, an if statement, a switch on a category, a tally of votes), you need a schema. The schema is what makes the code possible. Without it, your branch logic has to interpret prose, which is exactly the fragility you were engineering around.
When the output is consumed by another model as material to reason over, or by a human as something to read, schemas are at best optional and at worst counterproductive. A synthesizer's job is to weave findings into prose. Forcing it to emit {"paragraph_1": "...", "paragraph_2": "..."} strips out the natural paragraph structure and gives the next model less to work with.
The rest of this section walks each pattern through that test and shows where the schema line falls.
Patterns That Require Schemas
The schema is not optional. The pattern does not work without it.
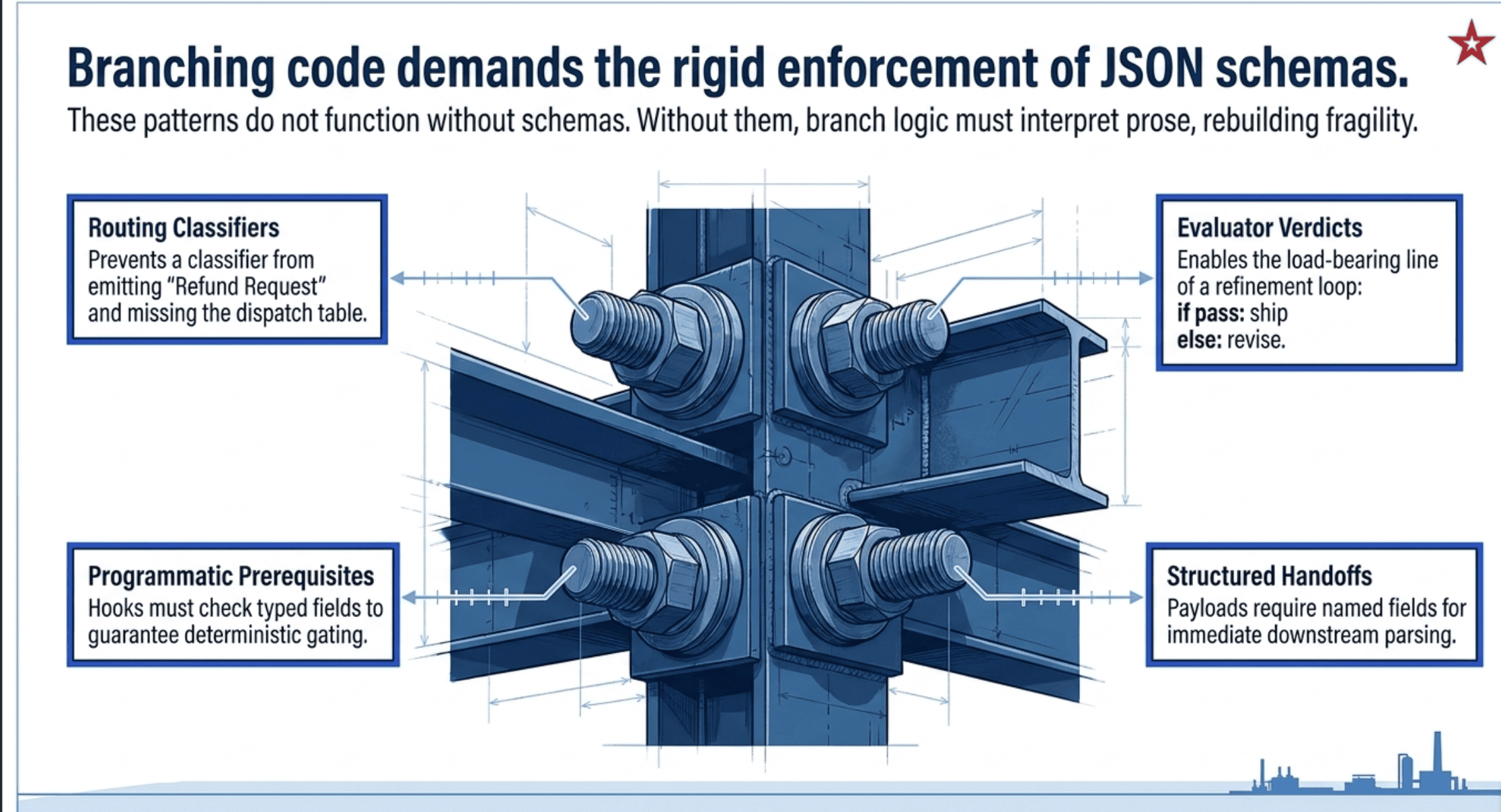
Routing. The classifier's output is a category that drives a switch statement. {"category": "refund", "confidence": 0.92} is exactly the kind of output you want typed and validated. A schema with an enum for the category field eliminates an entire class of failures where the classifier emits Refund instead of refund, or refund_request when the dispatch table expects refund.
Evaluator-optimizer (the evaluator step). The evaluator emits a verdict that the next step branches on. {"pass": false, "scores": {...}, "gaps": [...]} is read by if pass: ship else: revise. Without the schema, the branch logic becomes a prose-interpretation problem and you have rebuilt the very fragility you were engineering around.
Iterative refinement (the evaluator step). Same as evaluator-optimizer, scaled to multi-agent. The coordinator's if verdict.pass: break is the load-bearing line of the entire loop. If verdict is prose, the line cannot exist.
Programmatic prerequisites. Hooks check typed fields. if customer_verified == True: allow else: deny. The hook is a schema check. No schema, no gate.
Structured handoff. The handoff payload is the schema. A human escalation needs customer_id, root_cause, recommended_action as named fields, not as a paragraph the human has to parse.
Patterns Where Schemas Are Useful but Optional
The pattern works either way; schemas make the system more reliable, especially under load and parallelism.
Parallelization with sectioning. When multiple agents produce findings that get aggregated, schemas preserve attribution and metadata cleanly. Source URLs, page numbers, claim text, evidence strength stay typed through the merge. You can do this with prose, but attribution suffers and downstream consumers have to re-derive structure.
Parallelization with voting. Voters emit verdicts that get tallied. {"verdict": "violation", "confidence": 0.87} from three voters tallies cleanly. Prose votes can be counted, but with friction and error-rate cost.
Hub-and-spoke handoffs (researcher → coordinator → synthesizer). Structured findings between subagents are the discipline Task Statement 1.3 of the curriculum teaches. The architecture works with prose handoffs, but it works badly: provenance leaks, the synthesizer has to re-derive structure that should have been explicit.
Graceful degradation. The coverage_gap flag and partial results are easier to compose into the final output when they arrive as typed fields on a structured response. Possible without schemas; cleaner with them.
Patterns Where Schemas Are Counterproductive
These are the cases worth being most careful about, because the temptation to schema everything is strongest at the planning and synthesis layers.
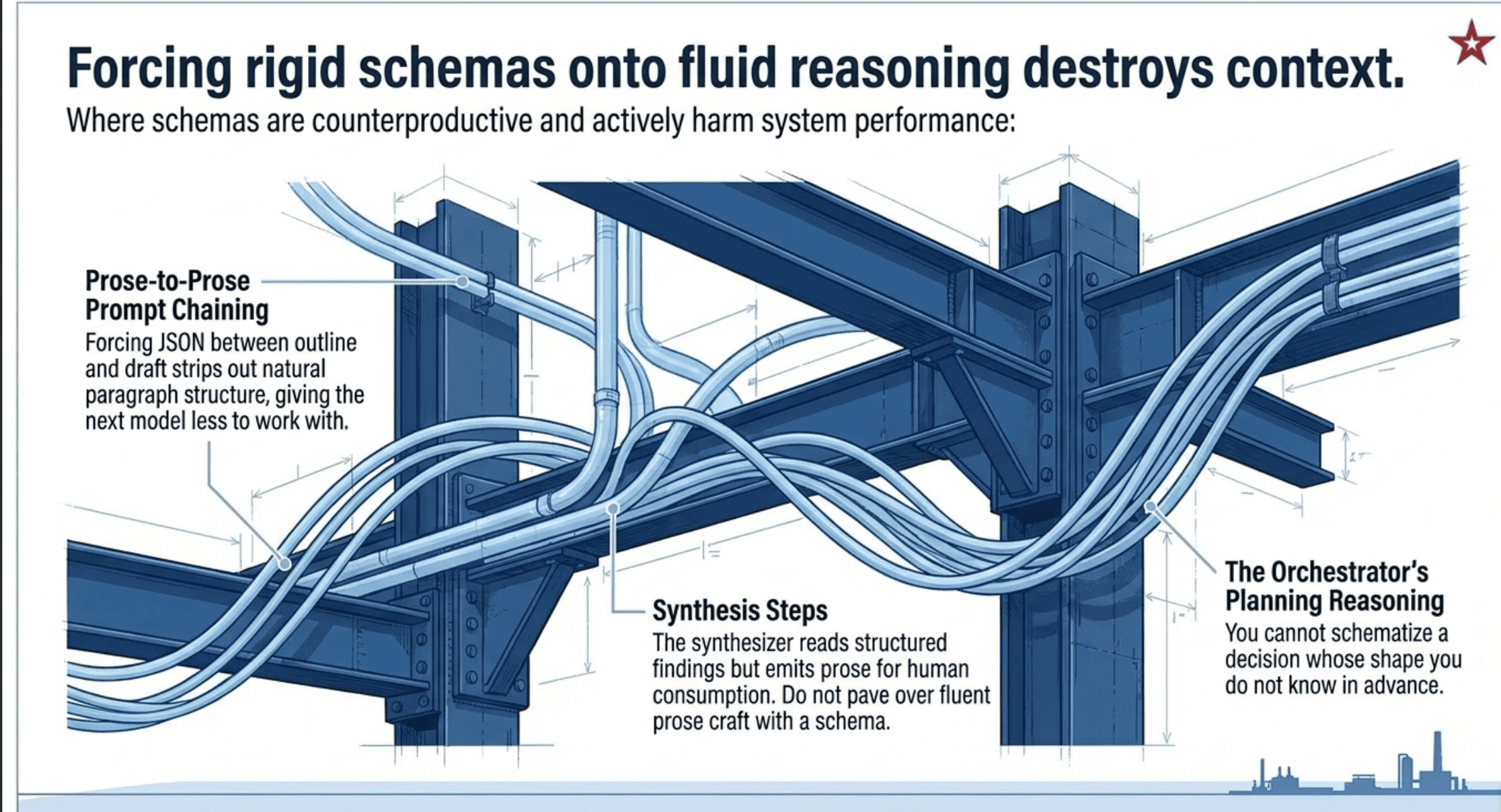
Prompt chaining where each step is prose-to-prose. Outline → draft → revise. Each step's output is material for the next, not data for code. Forcing JSON between these steps strips out the natural paragraph structure and gives the next model less to work with.
Synthesis steps in hub-and-spoke and iterative refinement. The synthesizer reads structured findings and emits prose for human consumption. JSON output here means the human or downstream model has to render it back to reading order. The synthesizer's craft is fluent prose; do not pave over that with structure.
The orchestrator's planning reasoning. This is the heart of the question that confuses most engineers. The orchestrator's next-step decision in orchestrator-workers and dynamic decomposition is reasoning over a fluid problem space. Forcing {"next_action": "...", "rationale": "..."} with a fixed schema onto that decision narrows the solution space the orchestrator can explore.
Dynamic adaptive decomposition. Same reason as orchestrator-workers. The pattern is defined by the planning step being fluid. Schematize the outputs of each spawned subtask, never the planning decision itself.
Can You Have Dynamic Decision-Making and JSON Schemas?
Yes, but the schema applies to a different layer than you might be thinking. The pattern that confuses most teams is orchestrator-workers, because they assume "dynamic" means "no schemas anywhere." It does not. The dynamic part is the planning decision. The schemas live on the boundaries around that decision.
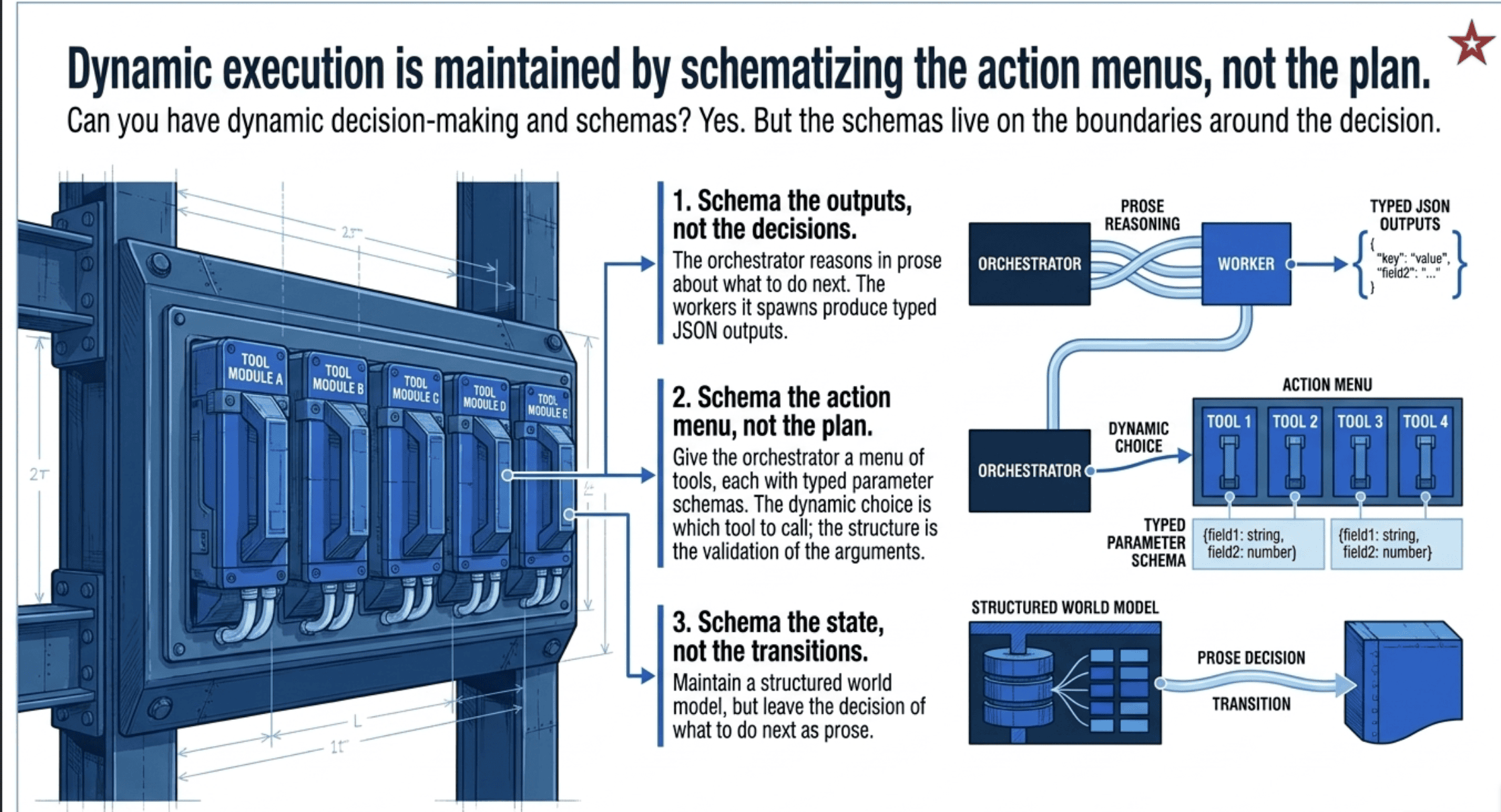
Three layers can be schematized, in order of how often you will see them:
1. Schema the outputs, not the decisions. The orchestrator reasons in prose about what to do next. Each worker it spawns produces typed output. This is what the iterative refinement pattern does: the loop logic (decide whether to loop, decide which gap queries to spawn) is prose-driven, but the research findings and evaluator verdicts are typed.
2. Schema the action menu, not the plan. Instead of giving the orchestrator a single schema for its decisions, give it a menu of tools, each with its own typed parameter schema. The orchestrator's "decision" becomes a tool call: explore_module(module_name="auth") or generate_tests(file_path="...", test_type="unit"). The schema constrains what each action does, not which action gets picked.
3. Schema the state, not the transitions. For orchestrators that maintain world models across iterations (what has been explored, what is pending, what has been found), the running state object can be typed and inspectable. The decision about what to do next stays prose. The world model is structured.
The question often hidden in "can we have dynamic-with-schemas" is whether dynamic-with-schemas is just routing in disguise. It is not, but it is worth being precise about why. Routing makes a one-shot decision against a fixed, finite set of categories. The schema enumerates the closed set. Orchestrator-workers generates subtasks against an open problem space. The difference is whether the category set is closed (routing) or open (orchestration).
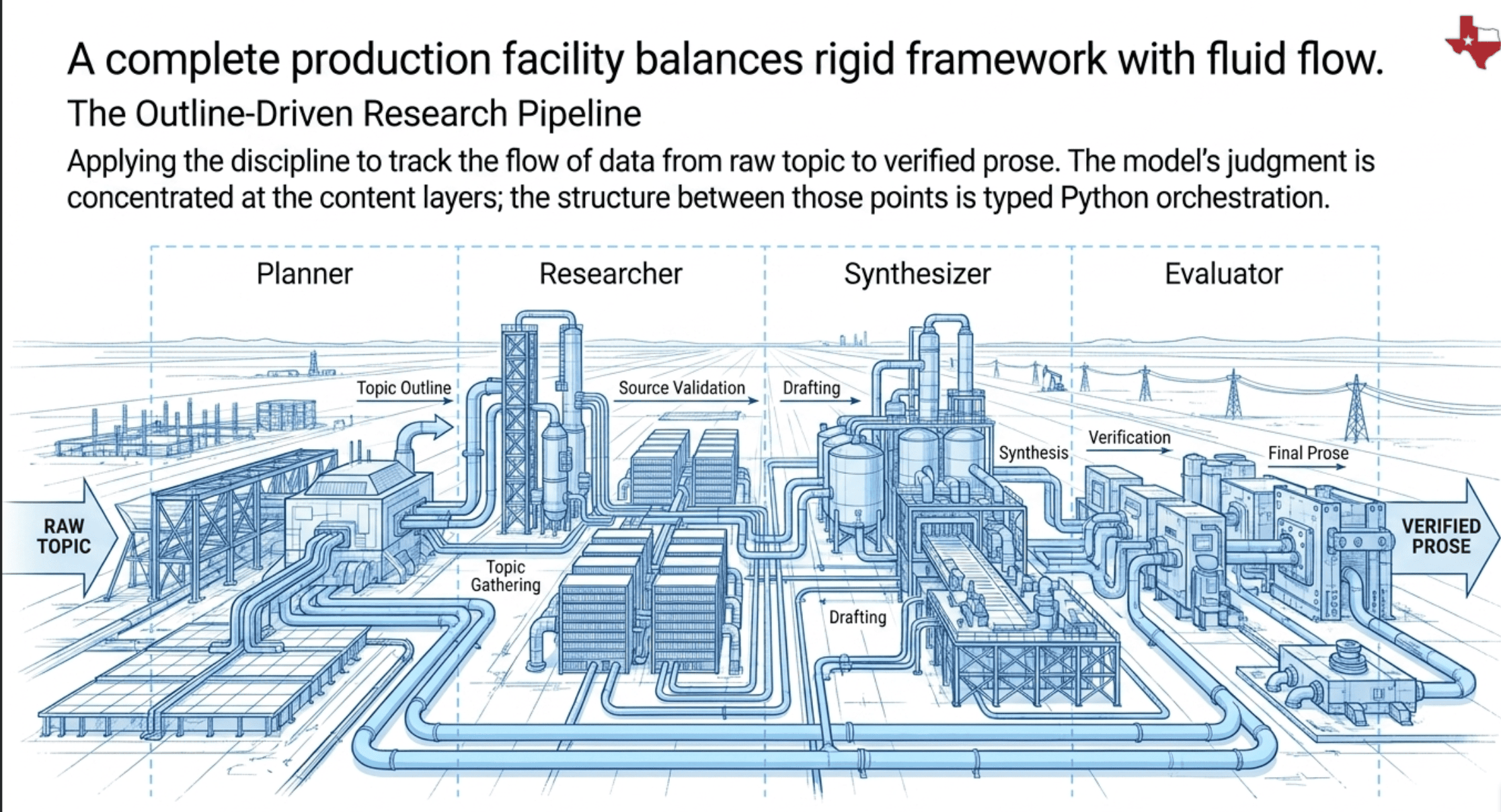
A Worked Example: The Outline-Driven Research Pipeline
To make all of this concrete, walk through a research-document pipeline that uses hub-and-spoke, parallelization, and iterative refinement, and see exactly where the schemas go.
The pipeline has four roles: a planner that generates the outline, researchers that investigate each subsection in parallel, a synthesizer that drafts prose section by section, and an evaluator that scores the draft and triggers refinement. The coordinator is Python orchestration code that owns state and loop logic.
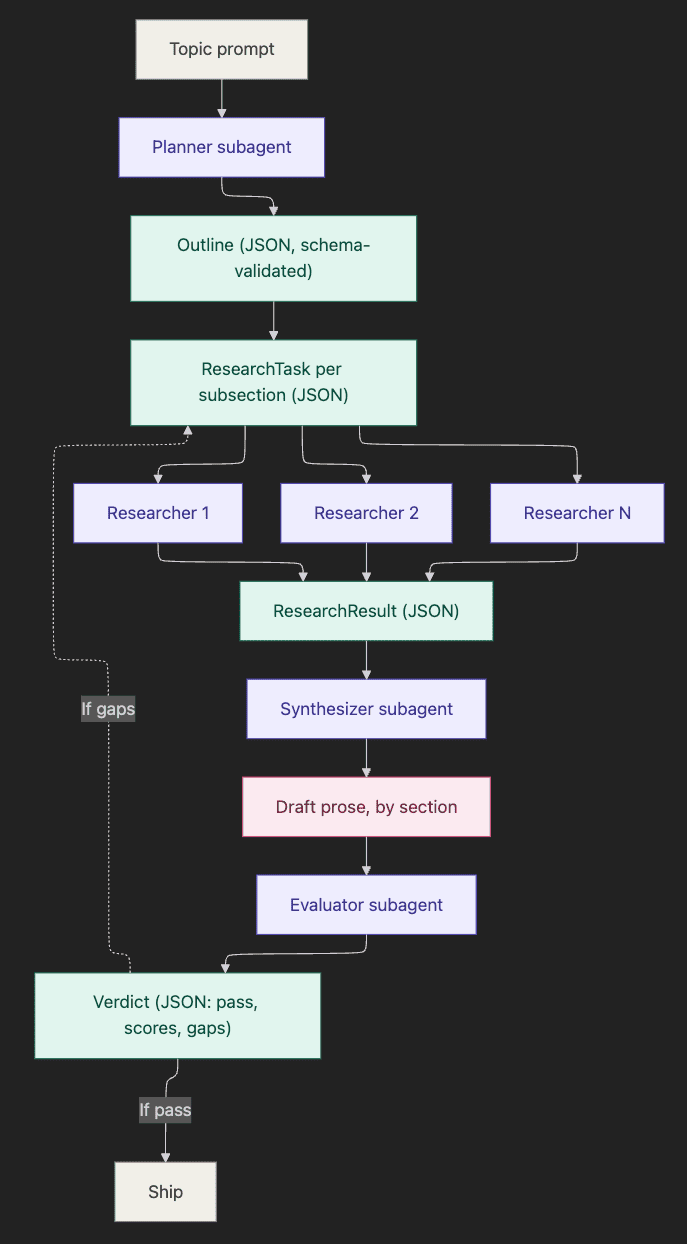
Here is the data flow:
flowchart TD
T[Topic prompt] --> P[Planner subagent]
P --> O["Outline (JSON, schema-validated)"]
O --> RT["ResearchTask per subsection (JSON)"]
RT --> R1[Researcher 1]
RT --> R2[Researcher 2]
RT --> R3[Researcher N]
R1 --> RR["ResearchResult (JSON)"]
R2 --> RR
R3 --> RR
RR --> S[Synthesizer subagent]
S --> D[Draft prose, by section]
D --> E[Evaluator subagent]
E --> V["Verdict (JSON: pass, scores, gaps)"]
V -.->|If gaps| RT
V -->|If pass| SHIP[Ship]
Notice how the diagram already partitions itself. The green nodes are the schema boundaries. The prose nodes are the model-to-model reasoning layers.
Now look at the input and output schemas, layer by layer, and ask the diagnostic question at each boundary.
The Outline: Strong Schema, Strong Win
The planner emits an outline. The outline is the structure of the whole downstream pipeline. Every section becomes a unit of work. Every subsection becomes a research subtask. The synthesizer iterates over sections. The evaluator scores coverage per section. All of that is code consuming the output.
What a weak version looks like, in prose:
Section 1: Introduction. This covers the background and motivation. Section 2: Methods. This covers how the research was conducted. Section 3: Findings. The key results.
What a strong version looks like, in Pydantic:
class Subsection(BaseModel):
number: str # "2.1", "2.2"
title: str
abstract: str # 1-2 sentences on what this covers
key_questions: list[str] # specific questions this answers
class Section(BaseModel):
number: int
title: str
abstract: str
subsections: list[Subsection]
estimated_sources_needed: int
class Outline(BaseModel):
title: str
overall_abstract: str
sections: list[Section]
target_audience: str
The schema is not just typing the data. It is forcing the planner to do work upfront that prose would defer. An abstract per subsection. Key questions per subsection. A source-count estimate. These fields exist because downstream agents need them, and forcing the planner to fill them means downstream agents do not have to derive them.
Compare what happens in the two versions when the coordinator spawns researchers.
Weak input. With prose-only outlines, the coordinator has to manually build a delegation prompt for each subsection by stitching together the section title, a guess at what the subsection should cover, and a hand-written set of research goals. The coordinator is now doing planning work that the planner should have done.
Strong input. With a schematized outline, the coordinator's loop is mechanical:
for section in outline.sections:
for subsection in section.subsections:
task = ResearchTask(
section_number=section.number,
subsection_number=subsection.number,
subsection_title=subsection.title,
subsection_abstract=subsection.abstract,
key_questions=subsection.key_questions,
style_constraints=GLOBAL_STYLE,
max_sources=section.estimated_sources_needed,
)
spawn_researcher(task)
The coordinator does no planning. It iterates and dispatches. The work is in the planner once and reused everywhere else.
This is what strong input to the subagent means in practice. The subagent receives a typed payload that contains everything it needs to do its job standalone, because the upstream agent did the work to package it.
The Researcher: Strong Input, Strong Output
The researcher receives a ResearchTask and emits a ResearchResult. Both schematized.
class ResearchTask(BaseModel):
section_number: int
subsection_number: str
section_title: str # for context only
subsection_title: str
subsection_abstract: str
key_questions: list[str]
style_constraints: list[str]
max_sources: int
class Source(BaseModel):
title: str
authors: list[str]
year: int
url: Optional[str]
citation: str # formatted per style_constraints
class Finding(BaseModel):
claim: str
evidence: str # quoted or paraphrased
evidence_strength: float = Field(ge=0, le=1)
source: Source
answers_question: Optional[str] # which key_question this addresses
counterargument_to: Optional[str] # if this is a rebuttal
class ResearchResult(BaseModel):
subsection_number: str # echoes the input
findings: list[Finding]
coverage_notes: str # what wasn't found, gaps, concerns
sources_used: int
Two design choices in these schemas are worth dwelling on.
The output echoes the input's join key. ResearchResult.subsection_number matches ResearchTask.subsection_number. Without this echo, parallel researcher results arrive as an unordered pile and the coordinator has to LLM-parse which finding belongs to which section. With it, the coordinator has a clean dict lookup.
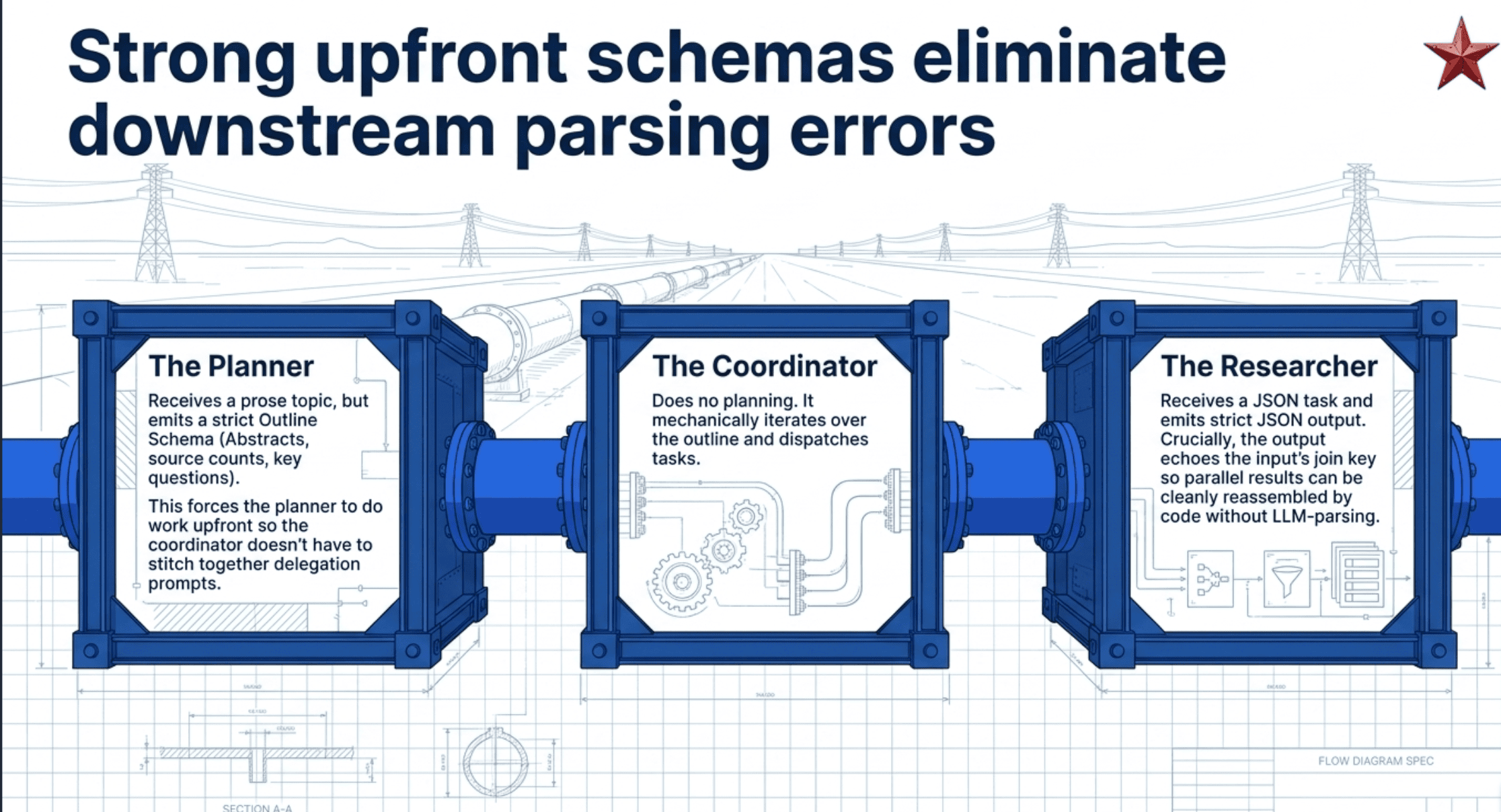
The output carries coverage_notes and answers_question fields. These exist so the evaluator can score whether each key question got at least one answer, and so the synthesizer can integrate counterarguments knowing which findings rebut which. The schema is designing for downstream consumption explicitly, not just typing the data.
Compare to a weak version where the researcher emits a paragraph: "Found three relevant sources. Smith 2019 argues X. Jones 2021 argues Y. The data on Z was inconclusive…". The downstream synthesizer has to parse that prose, the evaluator has to re-derive whether the questions were answered, and the coordinator cannot key-lookup results by subsection.
The Synthesizer: Strong Input, Prose Output
The synthesizer is where the schema discipline reverses direction. Input is strong; output is prose.
The input is a list of ResearchResult objects for the section being synthesized. The synthesizer receives findings with attribution intact, evidence strength flags visible, counterarguments tagged, and key questions linked. That is exactly the structured context that lets the synthesizer write good prose.
The output is paragraphs. A literature review. A draft chapter. Not JSON. Forcing the synthesizer to emit {"paragraph_1": "...", "paragraph_2": "..."} strips out the paragraphing skill that prose writing already handles, and forces the next consumer (the evaluator, which reads prose, and eventually the human reader) to render it back.
The schema discipline is one-directional at this layer: input is JSON because the upstream output was JSON, and that structure preserves attribution; output is prose because the downstream consumer is a model reading text or a human reading a draft.
The Evaluator: Prose Input, Strong Output
The evaluator is the mirror image of the synthesizer. Input is prose; output is JSON.
The input is the draft. The synthesizer's prose. The evaluator reads it as text, the same way a human reviewer would.
The output is a verdict that the coordinator's loop logic branches on:
class Verdict(BaseModel):
pass_: bool = Field(alias="pass")
scores: dict[str, float] # named dimensions, 0-1
gaps: list[str] # targeted refinement queries
This is the load-bearing schema in the entire pipeline. The coordinator's if verdict.pass_: break else: refine is what makes iterative refinement work. Without a structured verdict, the coordinator has to LLM-parse prose to decide whether to loop, and now the loop logic itself has a non-zero failure rate.
The targeted gaps field is what makes the refinement targeted rather than a full re-run. Each entry in gaps becomes a new ResearchTask aimed at the specific hole the evaluator found.
Enforcing the Schemas: How the SDK Actually Holds the Line
The discipline above is theoretical until you ask the next question: when a subagent is supposed to emit a ResearchResult, what stops it from emitting prose instead? "We told it to in the prompt" is the demo answer. The production answer is that the boundary has to be enforced at runtime, by code, in the framework.
The Agent SDK gives you two enforcement points, and they sit on opposite sides of the boundary.

Top-level output_format validates the final result
The first point is the output_format option on query(). You pass a JSON Schema, the SDK validates the model's final output against it, re-prompts on mismatch, and lands the parsed object on ResultMessage.structured_output. Validation, retry, and typed-data delivery are wrapped up in a single option.
class Verdict(BaseModel):
pass_: bool = Field(alias="pass")
scores: dict[str, float]
gaps: list[str]
async for message in query(
prompt=draft_text,
options=ClaudeAgentOptions(
agents={"evaluator": evaluator_subagent},
output_format={"type": "json_schema", "schema": Verdict.model_json_schema()},
),
):
if isinstance(message, ResultMessage) and message.structured_output:
verdict = Verdict.model_validate(message.structured_output)
if verdict.pass_:
break
This is the right tool when the top-level query() is the producer of the structured payload. The evaluator pattern fits cleanly: the coordinator runs a query whose entire purpose is to produce a Verdict, and output_format handles the contract.
It does not, however, apply to subagent invocations. The Agent (Task) tool that the parent uses to spawn a subagent has no output_format parameter. The only channel from parent to subagent is the prompt string; the only channel back is the final assistant message, delivered to the parent as a result string. The parent agent reads that string and may paraphrase it. output_format on the outer query() constrains what the outer query returns, not what its spawned subagents return.
PostToolUse hooks validate subagent outputs
The second enforcement point is a PostToolUse hook matched on the Agent tool. The hook fires in the parent's process the instant the subagent returns, with tool_response.result containing the subagent's verbatim final message. You parse, validate, and either accept it or push back. Crucially, returning {"decision": "block", "reason": "..."} from the hook causes the SDK to re-invoke the subagent with the reason appended, automatically, without manual retry logic in your coordinator.
The pattern, for the researcher in the outline-driven pipeline:
from pydantic import ValidationError
from claude_agent_sdk import HookMatcher, HookContext
# Where validated payloads land, keyed by tool_use_id so concurrent
# subagent calls don't stomp on each other.
research_results: dict[str, ResearchResult] = {}
async def validate_research_result(
input_data: dict[str, Any],
tool_use_id: str | None,
context: HookContext,
) -> dict[str, Any]:
if input_data["tool_input"].get("subagent_type") != "researcher":
return {}
raw = input_data["tool_response"].get("result", "")
try:
result = ResearchResult.model_validate_json(raw)
except ValidationError as e:
return {
"decision": "block",
"reason": (
"researcher returned invalid ResearchResult JSON. "
f"Validation errors:\n{e}\n"
"Re-invoke the researcher and return ONLY a JSON object "
"matching the ResearchResult schema. Do not include prose."
),
}
if tool_use_id:
research_results[tool_use_id] = result
return {}
options = ClaudeAgentOptions(
agents={"researcher": researcher_subagent, "evaluator": evaluator_subagent},
hooks={
"PostToolUse": [
HookMatcher(matcher="Agent", hooks=[validate_research_result])
],
},
)
Two implementation details are worth dwelling on, because they map directly to the article's diagnostic question.
Match on "Agent" (or "Task", the legacy alias), and filter by subagent_type inside the hook. The hook fires for every Agent tool call. If you have multiple subagent types in the same coordinator (researcher and evaluator both spawned via Agent), the hook needs to know which contract to apply. The tool input carries the subagent's prompt; parse subagent_type from it to route to the right validator.
Stash the parsed object keyed by tool_use_id. The Agent tool returns a string; the parent agent reads that string and may paraphrase it. Once you have a validated ResearchResult Pydantic object in hand, you don't want to round-trip it back through prose. Keep it in a dict keyed by tool_use_id, and retrieve it in the coordinator's post-processing step using ResultMessage.tool_use_id to look up the typed result.
Where each enforcement point lives in the pipeline
Mapping the two mechanisms onto the worked example:
Planner outputs an Outline. The planner is the top-level query(). Use output_format with the Outline schema. The coordinator gets a typed Outline on ResultMessage.structured_output without touching hooks.
Researchers output ResearchResult objects. Researchers are subagents, spawned through Agent. Use a PostToolUse hook matched on Agent, dispatching on subagent_type == "researcher", validating with the ResearchResult schema.
Synthesizer outputs prose. No schema, no validation. The boundary is model-to-model (synthesizer to evaluator) and ultimately model-to-human. Prose is the contract.
Evaluator outputs a Verdict. Two choices, depending on architecture. If the evaluator is a subagent in the same query(), use the hook pattern. If the evaluator is a separate query() call that the coordinator drives in code, use output_format and read structured_output directly. The latter is often cleaner because the coordinator's loop control (if verdict.pass_: break) wants the typed object in scope, not stashed in a dict.
The picture this leaves you with is that the SDK's two enforcement mechanisms align almost perfectly with the article's diagnostic question. output_format is for the boundary where a single query() produces output that the coordinator's code consumes. PostToolUse hooks are for the boundaries inside a query(), where subagents return results that the parent's code needs to consume.
That alignment is not accidental. The schema layer advocates and the SDK's enforcement primitives are answers to the same question, posed at the design level and at the runtime level: where does typed data cross from model output to code input, and what stops the contract from breaking at that boundary?
What the Layered Pipeline Tells You
Pull up to the pipeline as a whole and the discipline becomes a single rule:
Schemas live at boundaries where structured data crosses from "model output" to "code input." Prose lives at boundaries where data flows model-to-model as material to reason over, or model-to-human as something to read.
In the outline-driven pipeline:
Topic prompt → planner: prose in, outline JSON out. Outline → researcher: task JSON in, result JSON out. Researcher results → synthesizer: result JSON in, prose out. Draft prose → evaluator: prose in, verdict JSON out. Verdict → coordinator: JSON in, branch logic on typed fields.
Four schema layers (Outline, ResearchTask, ResearchResult, Verdict), one prose layer (synthesizer draft). Every schema layer is a place where code consumes the output. Every prose layer is a place where a model or human consumes the output.
This is what production-grade agentic systems look like when they actually work. The model's judgment is concentrated at the content layers: planning the outline, doing the research, writing the prose, scoring the draft. The structure between those judgment points is typed code. The orchestration is a Python loop, not a model.
What to Take to Production (And to the Exam)
If the CCA Foundations exam tests whether you can pick the right pattern, production tests whether you can build the right handoffs.
Three concrete moves from this article:
Match trigger to pattern, every time. Read the scenario. Find the phrase that names the trigger. Pick the pattern. Resist the temptation to apply the pattern you used last time when the trigger says something different. Most wrong-answer distractors are right-pattern-for-wrong-trigger.
Apply schemas where code branches, never where models reason. The diagnostic is a single question: does code consume this output? If yes, schema. If no (a human reads it, another model uses it as material), prose. Putting schemas everywhere makes systems stiff and overengineered. Putting them nowhere makes systems fragile and unparseable.
When a pattern's defining feature is dynamism, schematize the layer below the decision. Orchestrator-workers does not schematize the orchestrator's plan; it schematizes the outputs of the workers and the parameters of the tools the orchestrator can call. Same principle: schemas at boundaries where typed data crosses to code.
Build coordinators that check their work. Build evaluators that emit structured gap reports. Build refinement subtasks that close specific holes rather than redoing the whole sweep. Pass typed payloads between agents and reserve prose for the moments when a human is going to read the output. That is the whole discipline.
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company, focusing on delivering ML / AI insights to front-line applications, and a practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak at your event.
Rick created Skilz, the universal agent skill installer that supports 30+ coding agents, including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world's largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expert insights.
Anthropic Harness Engineering: Author Rick Hightower, AI systems practitioner and agentic frameworks developer
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams adopting AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. Many ideas captured in the CCA and the exam prep Rick wrote echo what you see in this article. If you want to improve your ability to create well-behaved AI agents and agentic systems, give this series a read.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic's Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain's Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic's Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI's Harness Engineering Experiment: Zero Manually-Written Code