The LLM Cost Trap -- and the Playbook to Escape It
Every tech leader who watched ChatGPT explode onto the scene asked the same question: What will a production‑grade large language
Rick Hightower
Originally published on Medium.
Every tech leader who watched ChatGPT explode onto the scene asked the same question: What will a production‑grade large language
 LLM Cost Trap
LLM Cost Trap
 Four Pillars of Cost
Four Pillars of Cost
 Pricing as of July 2025
Pricing as of July 2025
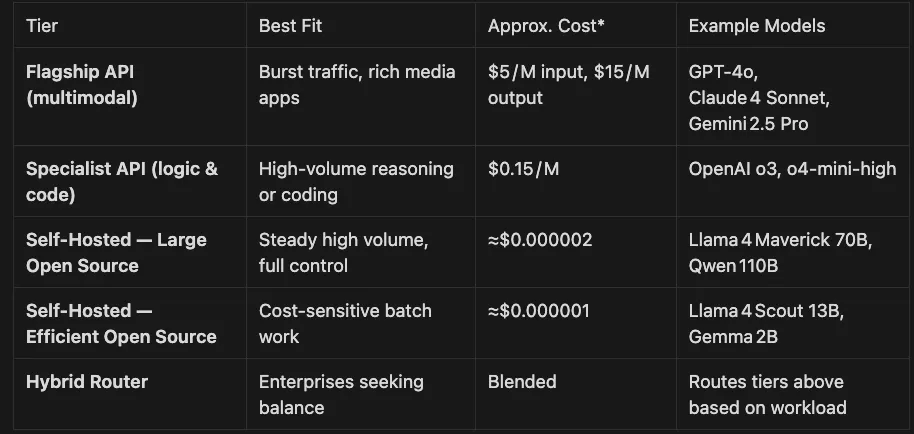 Provider Snapshot: Flagships, Specialists, and Open‑Source Contenders
Provider Snapshot: Flagships, Specialists, and Open‑Source Contenders

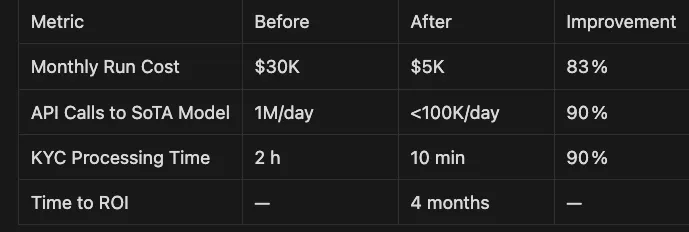
- Router Model: Fine‑tuned Llama 4 Scout 13B classifies requests.
- Main Model: Fine‑tuned Llama 4 Maverick 70B handles complex tasks.
- Semantic Cache: Redis answers eighty percent of support questions instantly.
- Batching & Quantization: GPU throughput jumped from 200 to 1,500 tokens per second.
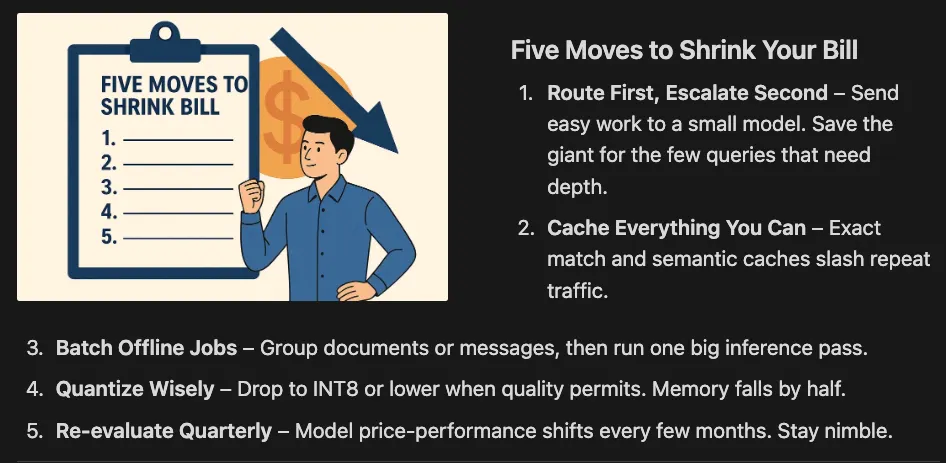
- Route First, Escalate Second — Send easy work to a small model. Save the giant for the few queries that need depth.
- Cache Everything You Can — Exact match and semantic caches slash repeat traffic.
- Batch Offline Jobs — Group documents or messages, then run one big inference pass.
- Quantize Wisely — Drop to INT8 or lower when quality permits. Memory falls by half.
- Re‑evaluate Quarterly — Model price‑performance shifts every few months. Stay nimble.

- Efficiency Gains — Shorter handle times, faster paperwork.
- Revenue Lift — Higher conversion, bigger basket size.
- Direct Savings — Fewer retries, smaller support team.
- Experience Wins — Better Customer satisfaction, lower churn.

 Escape the Cost Trap
Escape the Cost Trap
- OpenAI GPT-4.1 pricing, OpenAI Pricing Page (openai.com)
- Anthropic Claude 4 Sonnet pricing, Anthropic Pricing Page (anthropic.com)
- Google Gemini 2.5 Pro pricing, Gemini API Pricing Docs (ai.google.dev)
- AWS p4d.24xlarge hourly rate, Vantage EC2 Instance Comparison (instances.vantage.sh)
- OpenAI GPT-4o model overview, OpenAI Docs (platform.openai.com)