The Memory Leak in Your AI Strategy: Architecting for LLM Reliability at Scale
CCA-F Exam Prep Domain 5: Architecting Deterministic, Reliable LLM Systems at Scale
Originally published on Medium.
CCA-F Exam Prep Domain 5: Architecting Deterministic, Reliable LLM Systems at Scale
Discover how to turn fragile LLM demos into rock‑solid AI agents that never forget the facts. Learn the proven patterns for memory, deterministic escalation, and error‑proof architecture.
Summary: Covers CCA-F Domain 5 with examples in Claude Agent SDK (in Typescript and Python). Discover how to transform fragile LLM demos into rock‑solid, production‑ready AI agents by mastering deterministic escalation, persistent memory blocks, structured error handling, state‑driven workflows, provenance‑rich findings, and stratified evaluation. These key patterns prevent context loss, silent failures, and over‑reliance on model confidence, ensuring your LLM systems stay reliable, auditable, and scalable at any scale.

In the current AI gold rush, many organizations fall into the Trap of Domain 5: the dangerous assumption that high performance in a localized demo translates to reliability in production. Reliability is not a single performance metric; it is a cross-cutting engineering requirement that dictates whether a system is trustworthy or merely “chatty.”
The hard truth is that context is not a free resource. As conversations grow and tool outputs accumulate, information is diluted, summarized away, or lost in the noise. Your first engineering hurdle is the Progressive Summarization trap. A system reporting a 97% global accuracy score can be a dangerous lie if it masks a catastrophic failure rate on high-stakes edge cases. Building production-ready systems requires a fundamental shift: LLM Context Management and Reliability Patterns must be treated as a rigorous engineering discipline, not a collection of prompting tricks.

To build systems that scale, you must stop “hoping” the model remembers the details and start architecting environments where it is impossible for the model to forget them.
1. Persistent Memory: Beyond the “Lost-in-the-Middle” Effect
As interactions lengthen, standard memory management often relies on “Progressive Summarization.” This is a lossy compression method in which critical transactional details, such as exact order numbers, transaction dates, customer-stated expectations, and dollar amounts, are reduced to vague, unhelpful phrases like “the user asked about a refund.”
The strategic shift is from free-text history to a structured state. Instead of letting the model summarize the entire history, implement a Persistent Case Facts Block. This block lives outside the summarization loop and gets injected into every prompt, ensuring that transactional data remains immutable and visible throughout the session lifecycle. In a customer support agent processing a billing dispute, the case facts block holds the refund amount, the order ID, the escalation case number, and any commitment the agent has made. When compaction runs mid-dispute, those facts survive. Without this pattern, the agent forgets the $47.23 partial refund it just promised and has to ask the customer to restate it.
For multi-issue sessions (a single customer reporting three separate problems), the same idea extends to a separate context layer of structured issue data: order IDs, amounts, statuses, one entry per issue. Treat it like a small database living inside the prompt. The summary thread tracks the conversation; the structured layer tracks the facts.
The Physics of Context
Transformer models suffer from a measurable “Lost-in-the-Middle” effect: they attend more reliably to information at the beginning and end of an input, while content buried in the middle gets measurably less attention.
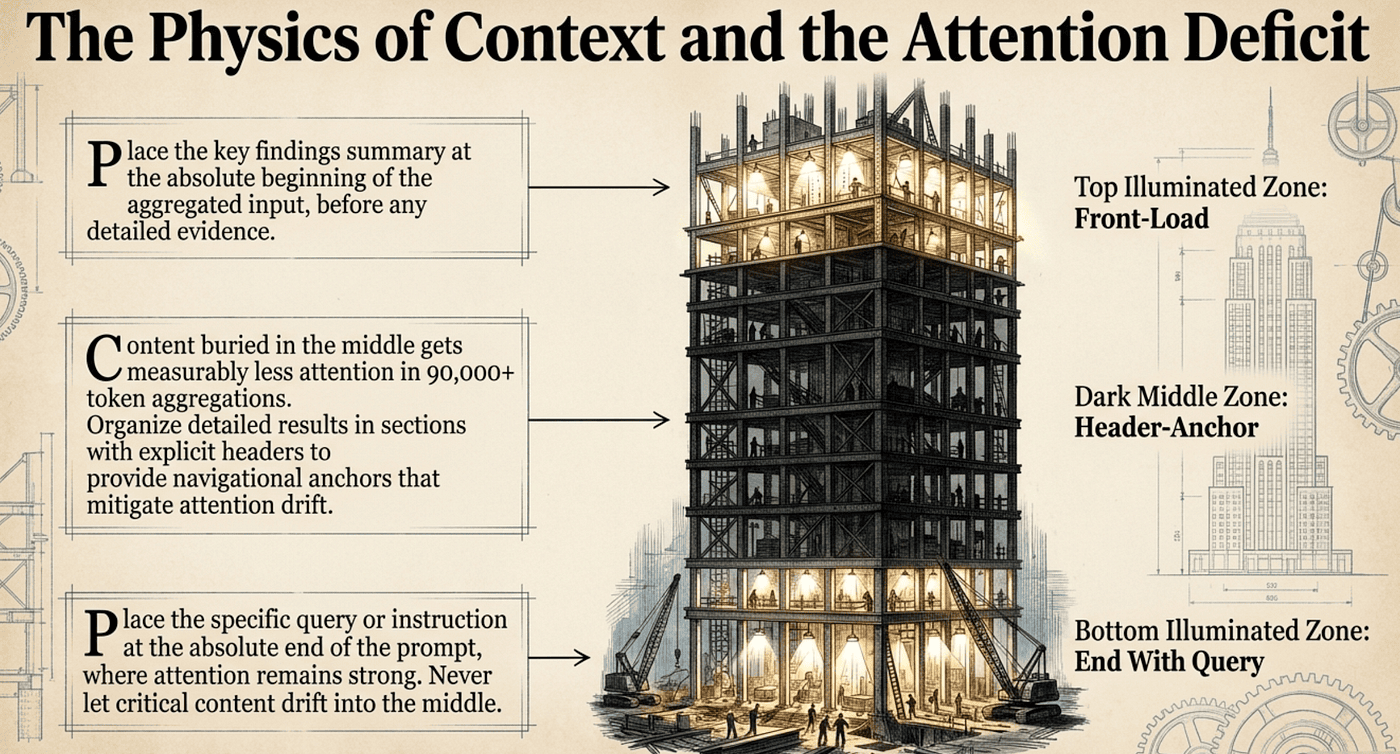
This is not theoretical; it shows up in production agent performance. The canonical case is multi-agent research aggregation. When a coordinator agent gathers findings from four subagents and the aggregated context reaches 90,000 tokens, the model reliably cites the first and last sections, while important evidence in the middle is ignored.
The structural fix is mechanical:
Front-load the key findings. Place a key findings summary at the absolute beginning of the aggregated input, before any detailed evidence.
Header-anchor the details. Organize detailed results in sections with explicit headers so the model has clear navigational anchors that mitigate attention drift.
End with the question. Place the specific query or instruction at the absolute end of the prompt, where attention is also strong.
Never let critical content drift into the middle of a long blob.
The Rule of Tool Trimming
Passing raw tool responses, which often include dozens of irrelevant backend fields, is a critical anti-pattern. A typical lookup_order MCP tool might return 40+ fields covering shipping carrier metadata, warehouse routing, internal SKUs, and audit timestamps. If the agent only needs five of those fields to make a refund decision, the other 35 are a "token bomb" that causes attention displacement and burns your budget on every subsequent turn.
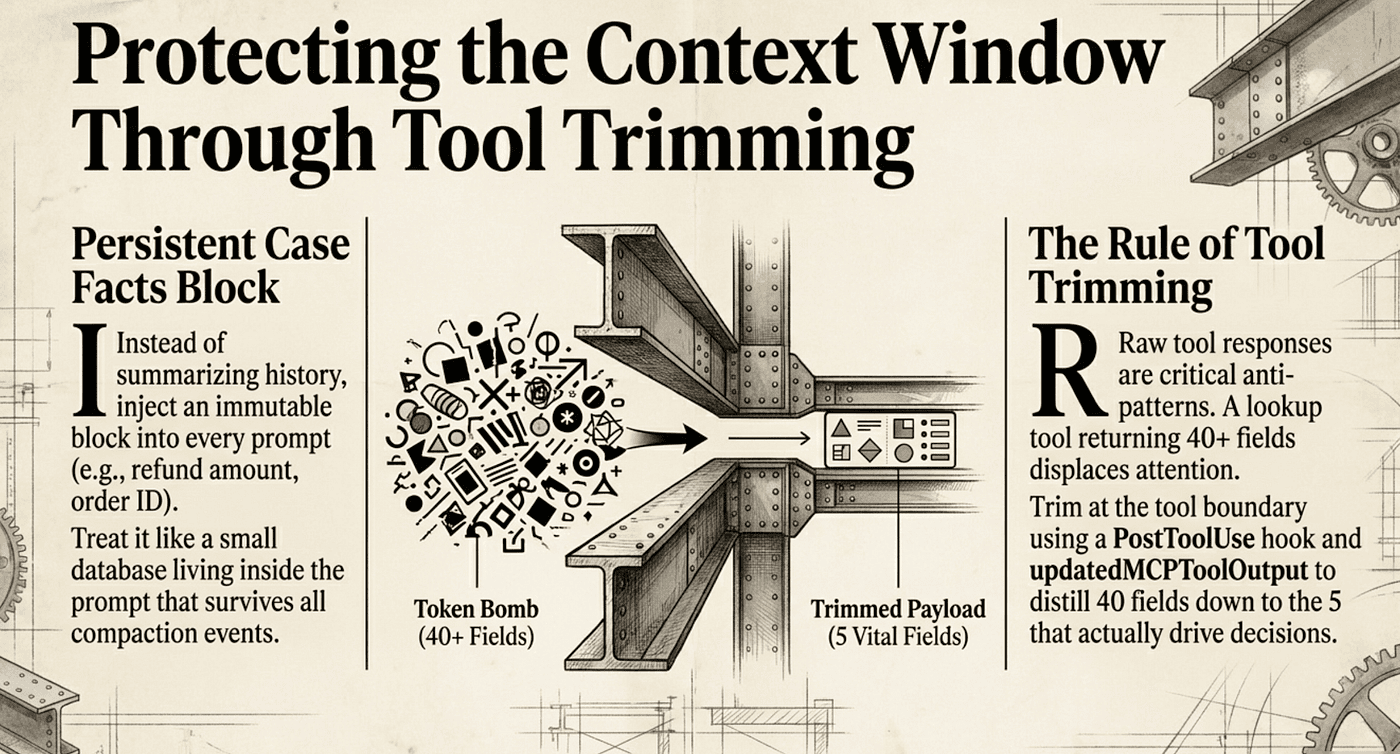
Trim tool outputs at the boundary; irrelevant metadata doesn’t just cost money. It actively makes the model dumber by burying the signal. Filter at the tool layer, not at the synthesis step. The cleaner the tool result, the more headroom you have for the actual work.
Listing 1.1: Trim Tool Output at the Boundary
The fix is to trim at the tool boundary, not at the synthesis step. A PostToolUse hook matched to the tool name intercepts the raw response and rewrites it via updatedMCPToolOutput before the agent ever sees it. The full payload is still available to the application (logging, audit, downstream services); only the agent's context gets the slim projection.
The exam-distinctive detail is the field name. updatedMCPToolOutput is the specific PostToolUse hook output that rewrites what the model sees. Returning a slimmer dict from the hook without using that field rewrites nothing.
from typing import Any
from pydantic import BaseModel
from claude_agent_sdk import (
query, ClaudeAgentOptions, HookMatcher, HookContext,
)
class SlimOrder(BaseModel):
order_id: str
status: str # placed | shipped | delivered | returned
total_cents: int
return_eligible_until: str # ISO date; agent checks vs. today
items_summary: list[str] # ["2x Widget", "1x Gadget"]
async def trim_lookup_order(
input_data: dict[str, Any],
tool_use_id: str | None,
context: HookContext,
) -> dict[str, Any]:
raw = input_data["tool_response"] # full 40-field payload
slim = SlimOrder(
order_id=raw["id"],
status=raw["fulfillment"]["status"],
total_cents=raw["totals"]["grand_cents"],
return_eligible_until=raw["policy"]["return_window_ends"],
items_summary=[f"{li['qty']}x {li['name']}"
for li in raw["line_items"]],
)
return {
"hookSpecificOutput": {
"hookEventName": "PostToolUse",
"updatedMCPToolOutput": slim.model_dump(),
}
}
options = ClaudeAgentOptions(
allowed_tools=["mcp__support__lookup_order", ...],
hooks={
"PostToolUse": [
HookMatcher(
matcher="mcp__support__lookup_order",
hooks=[trim_lookup_order],
),
],
},
)
Five fields earn their place. order_id for downstream references, status and return_eligible_until for eligibility decisions, total_cents to cap the refund amount, and items_summary because customers describe products by name, not SKU. Everything else gets dropped before the agent's context window ever sees it.
The TypeScript shape is the same hook contract:
import { query } from "@anthropic-ai/claude-agent-sdk";
import { z } from "zod";
const SlimOrder = z.object({
order_id: z.string(),
status: z.enum(["placed", "shipped", "delivered", "returned"]),
total_cents: z.number().int(),
return_eligible_until: z.string(), // ISO date
items_summary: z.array(z.string()),
});
const trimLookupOrder = async (input, _toolUseId, _ctx) => {
const raw = input.tool_response as any;
const slim = SlimOrder.parse({
order_id: raw.id,
status: raw.fulfillment.status,
total_cents: raw.totals.grand_cents,
return_eligible_until: raw.policy.return_window_ends,
items_summary: raw.line_items.map(
(li: any) => `${li.qty}x ${li.name}`
),
});
return {
hookSpecificOutput: {
hookEventName: "PostToolUse",
updatedMCPToolOutput: slim,
},
};
};
// ... wire into query() options.hooks.PostToolUse with matcher
The same logic that protects the case-facts block from compaction applies here. Anything in conversation history is a candidate for compaction or attention dilution. The earlier you trim, the less noise has a chance to accumulate, get half-summarized, or push the case-facts block toward the lost-in-the-middle zone of a long context window. Trimming at the boundary is the cheapest place to do it; every other layer pays for what this layer lets through.
Pass the Full Conversation History
This is a small but tested point. The API is stateless. Subsequent API requests must include the complete conversation history to maintain conversational coherence. The model has no memory between calls, and dropping prior turns to save tokens is an anti-pattern. The right way to reduce token cost is to trim verbose tool outputs and use structured fact blocks, never to drop turns.
Upstream Agents Return Structure, Not Prose
When subagents return findings to a coordinator, they should not dump verbose content and reasoning chains. If the downstream agent has a tight context budget, the upstream agent must return structured data: key facts, citations, relevance scores, and metadata (dates, source locations, methodological context). The synthesizer can always re-read the original if it needs to; what it cannot do is recover from a wall of prose that buried the citation it needed.
This is the single biggest lever in multi-agent research systems. A web search subagent that returns raw HTML, full document pages, and internal reasoning traces will blow the coordinator’s context budget before synthesis even begins. The output contract has to be: claims, evidence excerpts, source URLs, publication dates, relevance scores, gap notes. Internal reasoning stays in the subagent.
2. Deterministic Escalation: Why Sentiment Is a Trap
A common mistake in AI orchestration is relying on “AI vibes”: using sentiment analysis or self-reported model confidence as a proxy for when to involve a human. Both are unreliable proxies for case complexity.
Sentiment is not complexity. A calm user may have a complex policy gap that the agent hallucinates. A frustrated user may simply need a password reset, which the agent can handle. Routing every “angry” customer to a human floods the queue and misses the calm customer with the genuine edge case.
Self-reported model confidence is not calibrated. When the model says “I am 85% confident,” that number is not derived from a probability distribution against ground truth. It is generated text. The model can be confidently wrong, and in the cases that most need escalation, it often is.
Reliable systems use rule-based logic for escalation to preserve user trust and operational safety.
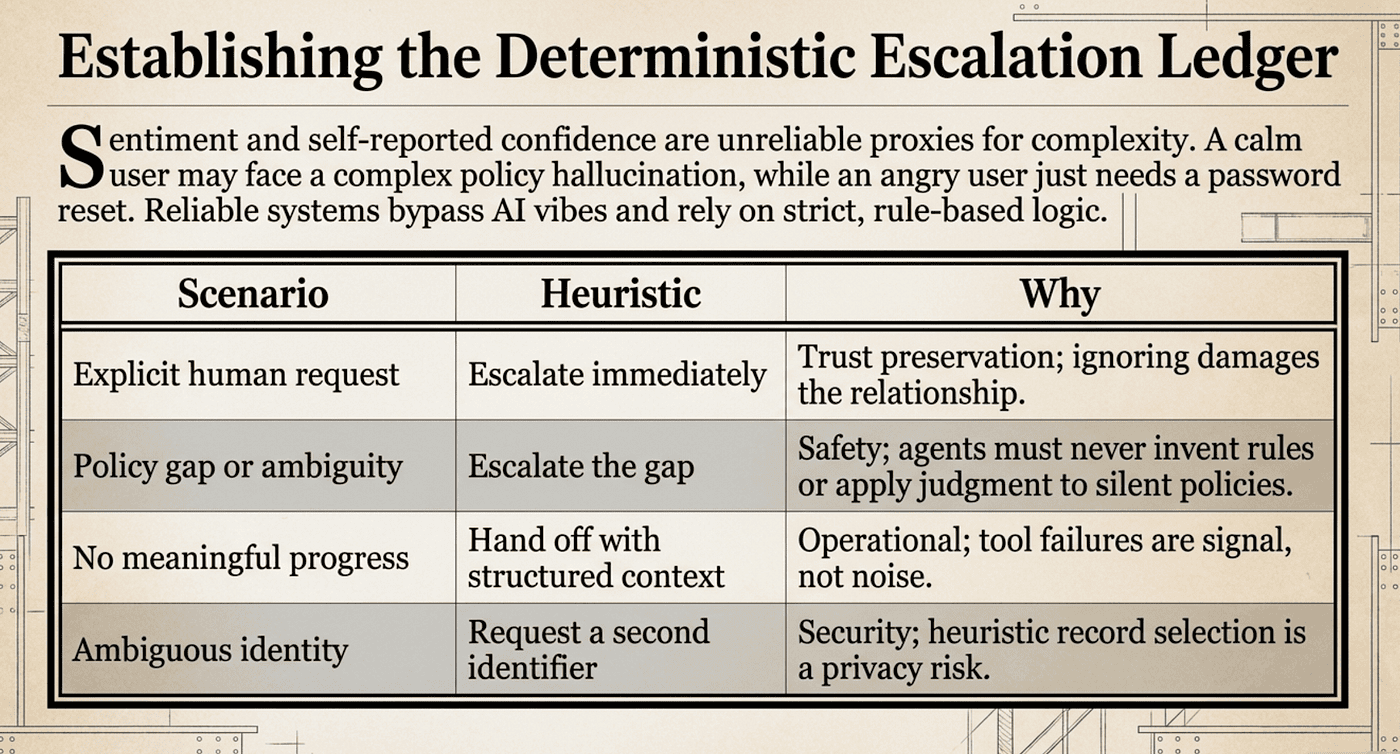
The Decision Matrix
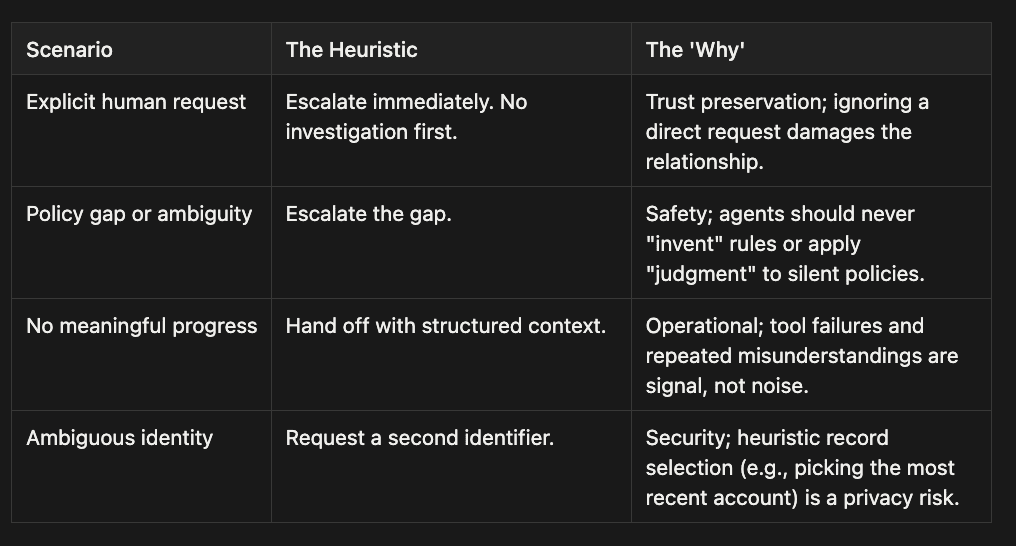
Decision Matrix in Detail: The table above breaks down four escalation triggers across three dimensions. Each row corresponds to one scenario the agent must recognize, the action it should take, and the reasoning that grounds the rule.
Explicit human request:
Heuristic: escalate immediately, no investigation first.
Why: trust preservation; ignoring a direct request damages the relationship.
Policy gap or ambiguity:
Heuristic: escalate the gap.
Why: safety; agents should never “invent” rules or apply “judgment” to silent policies. Example: a customer asks for competitor price matching when the policy only addresses own-site adjustments. The policy doesn’t say “no,” it says nothing, and inventing an answer in either direction is an unauthorized policy decision.
No meaningful progress:
Heuristic: hand off with structured context.
Why: operational; tool failures and repeated misunderstandings are signal, not noise.
Ambiguous identity:
Heuristic: request a second identifier.
Why: security; heuristic record selection, such as picking the most recent account, is a privacy risk.
Multi-Match Disambiguation in Practice
The “ambiguous identity” row hides a subtle exam trap that’s worth pulling out. Imagine a customer says, “There are two Alex Lees on my family account; refund the one from Chicago.” The lookup returns two plausible customer records, and the agent has only a name and a city. The right move is to ask for an additional identifier (email, phone, or order number) and let the customer disambiguate.
The trap answers are all heuristic shortcuts: pick the most recent activity, the most lifetime orders, by name similarity, and by address match. Each of those poses a privacy and accuracy risk. Heuristic record selection on consequential account actions (refunds, cancellations, address changes) is a documented anti-pattern. The user is the only authority on which record is theirs.
Frustration vs. Demand
The distinction matters, and the exam tests it directly. User frustration should be acknowledged and a resolution offered when the issue falls within the agent’s capabilities. Only if the customer reiterates the preference for a human does the agent escalate.
A customer saying, “This is the worst experience I have ever had, fix my order,” is expressing frustration, not demanding a handoff. Acknowledge, offer to resolve, escalate only on reiteration. A customer saying, “I do not want more troubleshooting. Please transfer me to a human manager,” is a hard escalation trigger. Do not run two more diagnostics first to “give the human more information.” The explicit request is the signal. Honor it.
Build the Rules Into the Prompt With Few-Shot Examples
The right way to ship deterministic escalation is to include explicit escalation criteria in the system prompt, with few-shot examples that show when to escalate versus resolve autonomously. One example: explicit demand → immediate escalation. One showing frustration → acknowledge and resolve. One showing a policy gap → escalate. One showing a multi-match lookup → ask for a second identifier. The examples make the rules from abstract policy into reliable behavior.
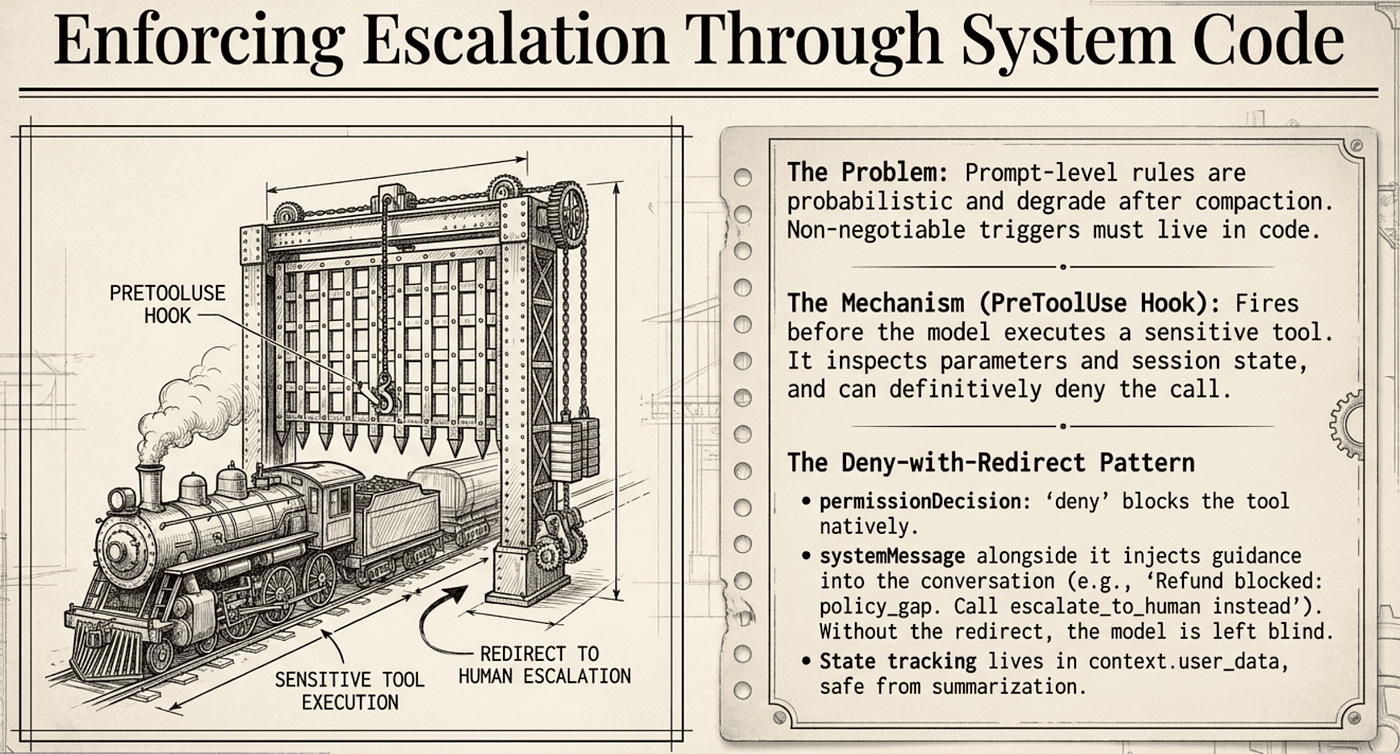
Listing 2.1: The Escalation Gate
Prompt-level escalation rules are probabilistic. The same conversation that escalates correctly on Monday may not escalate on Friday after the context has been compacted twice, and the system prompt’s escalation criteria has been summarized into a vague “be helpful.” For cases where escalation is required (explicit demands, policy gaps), the rule needs to live in code, not in the prompt.
A PreToolUse hook on the sensitive tool is the deterministic mechanism. The hook fires before the model's tool call executes, inspects the call's parameters and the session's state, and can deny the call. Deny also takes precedence over all other permission outcomes, so a single gate is enough.
The exam-distinctive surface is the pair of fields the hook returns. permissionDecision: "deny" inside hookSpecificOutput blocks the tool call. systemMessage at the top level injects guidance into the conversation so the model knows on its next turn to call escalate_to_human instead of retrying the refund. Denying without systemMessage blocks the action but leaves the model without a redirect; the pair is what makes the gate teach the model where to go next.
from typing import Any
from pydantic import BaseModel
from claude_agent_sdk import HookContext, HookMatcher
class EscalationReason(BaseModel):
code: str # "explicit_human_request" | "policy_gap" | ...
detail: str # one-line explanation for the model
def explicit_human_request_recent(
state: dict[str, Any],
) -> EscalationReason | None:
"""Return a reason if the customer asked for a human; else None."""
...
def policy_gap_flagged(
state: dict[str, Any],
) -> EscalationReason | None:
"""Return a reason if a prior policy lookup was silent; else None."""
...
async def escalation_gate(
input_data: dict[str, Any],
tool_use_id: str | None,
context: HookContext,
) -> dict[str, Any]:
state = context.user_data.get("session_state", {})
reason = (
explicit_human_request_recent(state)
or policy_gap_flagged(state)
)
if reason is None:
return {} # pass through; refund proceeds
return {
"systemMessage": (
f"Refund blocked: {reason.code}. {reason.detail} "
f"Call escalate_to_human with a structured handoff "
f"instead of retrying the refund."
),
"hookSpecificOutput": {
"hookEventName": "PreToolUse",
"permissionDecision": "deny",
"permissionDecisionReason": (
f"escalation_required: {reason.code}"
),
},
}
hooks_config = {
"PreToolUse": [
HookMatcher(
matcher="mcp__support__process_refund",
hooks=[escalation_gate],
),
],
}
Three things to notice. EscalationReason is a Pydantic model rather than a free-form string, so adding a new escalation trigger (a third predicate function) is a structural change that the hook's caller can branch on, not a string-comparison hack. The code field carries the machine-readable category; the detail field carries the prose the model needs to act on. This is the same separation 3.1's ErrorEnvelope enforces between category and user_message.
The session state lives in context.user_data, where the coordinator can track flags that persist across turns without relying on the conversation transcript. Compaction can summarize the conversation; it can't summarize a typed Python object that the coordinator maintains. The two non-negotiable triggers (explicit human request, policy gap) are in the hook because they have measurable failure rates that the business cannot accept. The softer matrix rows (no meaningful progress, ambiguous identity) belong in the system prompt with few-shot examples.
The systemMessage field is what closes the loop. Without it, the model sees a denied tool call and tries to determine next steps based solely on the denial reason. With it, the model receives an instruction in the conversation itself, naming the right next tool. The pair permissionDecision: "deny" + systemMessage is the deny-with-redirect pattern; the hook can't call escalate_to_human directly, but systemMessage tells the model that's where to go next, and the model complies because the instruction arrived inside its conversation context.
3. Legible Failures: The Architecture of Multi-Agent Errors
In a multi-agent system, a coordinator cannot recover from a generic “Operation Failed” message. For a system to be resilient, failure must be made legible through structured error propagation.

The “Error Envelope” Pattern
Instead of raw logs, subagents must return a structured envelope containing four components:
Failure Type. Categorize the error (timeout, auth error, rate limit, malformed response).
Attempted Query. What exactly was the agent trying to do?
Partial Results. What data was gathered successfully before the crash?
Alternatives. What other tools or paths should the coordinator consider?
Error Categories for Customer-Facing Tools
The same envelope shape applies to MCP tools in a customer support agent, but the categories matter more because each one drives a different user-facing behavior. A process_refund tool that returns a generic "failed" forces the agent to guess. A structured error response gives the agent everything it needs:
Validation errors. Bad input format, missing required field. Not retryable. Ask the customer for the right information.
Permission errors. Auth expired, insufficient privilege. Not retryable by the agent. Escalate to a human.
Transient errors. Timeout, rate limit, upstream service degraded. Retryable with backoff.
Business-rule errors. Refund denied by policy, order outside return window. Not retryable. Explain to the customer.
For each category, pair an isRetryable boolean with a user-facing message. The agent now retries policy denials zero times (correct), retries transient auth failures with backoff (correct), and stops asking the customer to re-enter valid information that the tool already accepted (correct). Without the categories, the agent confuses all four.
Access Failure vs. Valid Empty Result
Two outcomes look identical at the surface but require completely different responses. Distinguish them explicitly:
Access failure. The tool timed out, the API returned a 500, the rate limit was hit. The query never actually ran. Retry or fall back.
Valid empty result. The query ran successfully and returned zero matches. There is nothing more to retrieve. Report honestly.
Treating an empty result as a failure leads to wasteful retries. Treating a timeout as “no data found” leads to dangerous false negatives. Both shapes must be distinct in the envelope.
The research-system version of this rule: a patent database query returning zero results is a valid finding (report it). A separate industry-report search timing out is an access failure (retry or fall back). A coordinator that conflates the two will burn budget retrying empty queries and silently swallow real failures elsewhere.
Local Recovery First, Propagate Only What You Can’t Resolve
Subagents should handle transient failures locally (bounded retries with backoff, fallback to alternate tools, broader queries) and only propagate the errors they genuinely cannot resolve. The propagation should still include what was attempted and any partial results, so the coordinator can make an informed decision rather than starting over.
Two Symmetric Anti-Patterns
The exam tests both ends of the spectrum:
Silently suppressing errors. Returning an empty result as if the query succeeded. The system looks healthy and produces wrong answers downstream.
Terminating the entire workflow on a single failure. One subagent failure should not crash a research run with four other subagents producing good output. The coordinator should annotate the gap and proceed.
The right pattern lives in the middle: subagents handle transient failures locally, propagate only what they cannot resolve, and the coordinator decides whether to retry, route around, or report partial findings with a gap annotation.
Coverage Annotations in Synthesis Output
When the synthesis agent assembles findings from multiple subagents, the final report should not pretend that every topic got equal coverage. Annotate the gaps explicitly: which findings are well-supported, which topic areas have gaps due to unavailable sources, and what the user should treat with caution. This is the difference between an honest report and a confident lie.
A subagent that fetched four of seven planned sources does not get to write a confident report from the four and hide the gap. The synthesizer writes the report and declares which three sources failed and why. Silent omission is the canonical failure of multi-agent research; transparent gap declaration is the discipline that earns trust.
Listing 3.1: The Error Envelope
The four categories drive four distinct agent behaviors. Validation, permission, transient, and business-rule errors each have a structured shape that names the failure category and indicates whether retrying is sensible. The valid-empty-result case is the fifth shape: a successful query with zero matches is not an error and should not be encoded as one.
from typing import Any, Literal
from pydantic import BaseModel
from claude_agent_sdk import tool
Category = Literal["validation", "permission",
"transient", "business_rule"]
class ErrorEnvelope(BaseModel):
category: Category
retryable: bool
user_message: str # safe to surface to the customer
detail: str = "" # diagnostic context for the agent
class RefundOk(BaseModel):
ok: Literal[True] = True
refund: dict[str, Any]
prior_refunds: list[dict[str, Any]]
class RefundErr(BaseModel):
ok: Literal[False] = False
error: ErrorEnvelope
@tool(
"refund_for_order",
"Issue a refund. Returns RefundOk or RefundErr.",
{"order_id": str, "amount_cents": int, "reason": str},
)
async def refund_for_order(args: dict[str, Any]) -> dict[str, Any]:
try:
order = await orders_api.get(args["order_id"])
_validate_amount(order, args["amount_cents"]) # raises validation
_check_return_window(order) # business_rule
prior = await refunds_api.list_for(order.id) # [] is valid
refund = await refunds_api.create(...) # ... create call
payload = RefundOk(
refund=refund.as_dict(),
prior_refunds=[r.as_dict() for r in prior],
)
return {"content": [{"type": "text", "text": "Refund issued."}],
"structuredContent": payload.model_dump()}
except RefundError as e:
return _envelope(e.category, e.retryable,
e.user_message, e.detail)
except AuthError as e:
return _envelope("permission", False,
"I can't process this refund. Escalating.",
str(e))
except TimeoutError as e:
return _envelope("transient", True,
"The refund service is slow. Retrying.",
str(e))
def _envelope(category: Category, retryable: bool,
user_message: str, detail: str) -> dict[str, Any]:
err = RefundErr(error=ErrorEnvelope(
category=category, retryable=retryable,
user_message=user_message, detail=detail,
))
return {"content": [{"type": "text", "text": user_message}],
"structuredContent": err.model_dump(),
"isError": True}
A few things to notice. The success path returns prior_refunds: [] when the order has no prior refunds, and the inline comment names it: an empty list is a valid result, not an error. The four error paths share one envelope shape, so the agent can branch on error.category and error.retryable without parsing prose. And user_message is separated from detail: the safe-to-display string is one field, the diagnostic context the model uses for reasoning is another.
The TypeScript surface uses Zod for the same envelope shape:
import { tool } from "@anthropic-ai/claude-agent-sdk";
import { z } from "zod";
const ErrorEnvelope = z.object({
category: z.enum(["validation", "permission",
"transient", "business_rule"]),
retryable: z.boolean(),
user_message: z.string(),
detail: z.string().default(""),
});
const RefundOk = z.object({
ok: z.literal(true),
refund: z.record(z.unknown()),
prior_refunds: z.array(z.record(z.unknown())), // [] is valid
});
const RefundErr = z.object({
ok: z.literal(false),
error: ErrorEnvelope,
});
export const refundForOrder = tool(
"refund_for_order",
"Issue a refund. Returns RefundOk or RefundErr.",
{ order_id: z.string(),
amount_cents: z.number().int(),
reason: z.string() },
async (args) => {
try {
// ... order lookup, validation, business-rule checks, create call
const payload = RefundOk.parse({
ok: true, refund, prior_refunds,
});
return {
content: [{ type: "text", text: "Refund issued." }],
structuredContent: payload,
};
} catch (e) {
const { category, retryable, userMessage, detail } = classify(e);
const err = RefundErr.parse({
ok: false,
error: { category, retryable,
user_message: userMessage, detail },
});
return {
content: [{ type: "text", text: userMessage }],
structuredContent: err,
isError: true,
};
}
}
);
The envelope is the contract. Once the tool emits it, the agent has everything it needs to choose its next move: retry on transient, escalate on permission, ask the customer on validation, explain the policy on business-rule, and treat empty arrays as the legitimate answer they often are.
4. State, Not History: Managing the Context Window as an Infinite Workspace
When exploring massive codebases, LLMs suffer from Context Degradation. The model begins to ignore specific class definitions and starts speaking in “typical patterns” instead of the concrete classes and files it discovered earlier. The fix is not more prompting; it’s state management. The same patterns apply anywhere a long-running session needs to survive context pressure or outright crashes: code exploration, customer support sessions, multi-step research pipelines, and overnight compliance audits.

Scratchpad Files: A Memory Substrate Outside the Window
The first tool against context degradation is a scratchpad file: INVESTIGATION_NOTES.md, REVIEW_PROGRESS.md, whatever fits the workflow. The agent writes key findings to disk as it goes: discovered class names, file locations, dependency edges, and anomalies. Subsequent questions reference the scratchpad rather than relying on the agent to remember.
The scratchpad survives compaction, restarts, and crashes. Treat it as canonical for facts that need to outlive the current turn.
Listing 4.2: The Coordinator Scratchpad
Listing 4.1 (immediately following) covers the durable half of state management: structured agent outputs and a coordinator manifest that make crash recovery deterministic. That pattern fires at step completion. This pattern fires during the run and is what the exam guide calls “scratchpad files for persisting key findings across context boundaries.”
The coordinator’s scratchpad is a structured record maintained throughout the session. It tracks customer IDs, verified identity, the list of issues the customer raised, commitments the agent has made, and accumulated findings from subagent runs. It updates on every turn that produces a new state, and the coordinator reads it before deciding what to do next. Compaction can summarize away the conversation history; the scratchpad survives because it lives outside the summarized region of the prompt.
The pattern shape is genuinely different from 4.1’s. Scratchpad writes happen during the run, incrementally, append-mostly. Resume tombstones happen at completion, write-once. Mixing them produces a file that’s neither auditable as resume state nor reliable as running coordination.
The exam-distinctive surface is the read-before-decide loop: the coordinator reads the scratchpad at the top of every turn and treats the file, not the conversation history, as the source of truth for its knowledge. Writes occur incrementally as new facts arrive; reads occur at every coordinator decision point.
Two scenarios show the same pattern. First, a customer-support coordinator tracking a multi-issue session:
from pathlib import Path
from datetime import datetime
from pydantic import BaseModel, Field
class Issue(BaseModel):
issue_id: str
description: str
status: str # open | resolved | escalated
related_order_id: str | None = None
class Commitment(BaseModel):
made_at: datetime
text: str # "We'll refund $47.23 by Friday"
class SupportScratchpad(BaseModel):
session_id: str
customer_id: str | None = None
issues: list[Issue] = Field(default_factory=list)
commitments: list[Commitment] = Field(default_factory=list)
# ... other durable session facts
The fields look small because the schema only holds what survives compaction. Conversation pleasantries, intermediate reasoning, the model’s own narration all live in the transcript and can be summarized away without consequence. What can’t be lost is the customer’s identity, the list of issues being worked, and the commitments the agent has made. Those go in the scratchpad.
The research-coordinator variant uses the canonical Finding shape from Listing 5.1 directly:
class ResearchScratchpad(BaseModel):
run_id: str
question: str # the top-level research question
findings: list[Finding] = Field(default_factory=list)
conflicts: list[ConflictAnnotation] = Field(default_factory=list)
coverage_gaps: list[str] = Field(default_factory=list)
# ... other durable run facts
ResearchScratchpad.findings is list[Finding], not a new shape. When a subagent returns ResearchOutput from 5.1's wire-up, the coordinator's job at the boundary is scratchpad.findings.extend(output.findings). One canonical schema flows from subagent output into the scratchpad without translation.
Writes are append-mostly and need to be atomic for the same reason the manifest writes in Listing 4.1 are: a crash mid-write breaks the file. The same write-to-temp-then-os.replace pattern applies:
def append_finding(path: Path, finding: Finding) -> None:
"""Append a finding to the scratchpad atomically."""
current = ResearchScratchpad.model_validate_json(
path.read_text()
)
current.findings.append(finding)
# ... write to path.with_suffix(".tmp"), os.replace to path
The append helper is intentionally small because the entire point of the pattern is that every mutation is small and discrete: adding a finding, recording a commitment, or marking an issue resolved is one append, one atomic rewrite, no batched state machine. The same shape applies to every scratchpad field; helpers like append_commitment and append_issue are variations on the same atomic-rewrite skeleton, which is why the read example below shows the read-decide pattern with the writes elided.
The read side is what closes the loop. At the top of every coordinator turn, before the model decides what to do next:
async def coordinator_turn(scratchpad_path: Path) -> None:
state = SupportScratchpad.model_validate_json(
scratchpad_path.read_text()
)
if state.customer_id is None:
# ... call get_customer, append result to scratchpad
return
if any(issue.status == "open" for issue in state.issues):
# ... pick the next open issue, work on it
return
# ... no open issues; ask if the customer needs anything else
The decision tree branches on scratchpad fields, not on the conversation. A coordinator who asked “have I already identified this customer?” by scanning the chat transcript would be one compaction event away from re-asking the customer for their account number. A coordinator that branches on state.customer_id is None is correct after any number of compaction events, because the file survives them.
The scratchpad’s reader here is the coordinator’s application code, not the model. What the model needs from the scratchpad gets injected into prompts separately, the same way §1’s case-facts block does. The two layers address different threats: the case-facts block protects model context from compaction by re-injection; the scratchpad protects coordinator routing from compaction by living entirely outside the prompt.
The closing pattern from 5.1 (that ConflictAnnotation works for single-document extractions too) applies here in microcosm. When a customer states "I never received the package," but the order status is delivered, that disagreement goes into the scratchpad as a ConflictAnnotation with both findings preserved. The coordinator doesn't pick a side; it surfaces the conflict to a human escalation path. The discipline that 5.1 applies to multi-source research also applies within a single session here, for the same reason: disagreement is information, and silently resolving it destroys the information that human review depends on.
Subagent Delegation for Verbose Exploration
Scratchpads protect the coordinator state from compaction by living outside the prompt. The second tool against context degradation protects the coordinator state by never letting verbose work enter the coordinator’s prompt in the first place: subagent delegation. Spawn a subagent to investigate a narrow question (“find all test files,” “trace the refund flow’s dependencies,” “enumerate all the services that touch the orders table”) and have it return a short summary to the main agent. The verbose discovery output lives in the subagent’s context, never in the coordinator’s. The main agent preserves high-level coordination precisely by not doing the deep dive itself.
Phase Summaries Anchor the Next Phase
When exploration has phases (architectural sketch, then dependency trace, then test coverage), summarize the key findings from each phase before spawning subagents for the next one. Inject those summaries into the initial context of the new subagents. This anchors them in what is already known rather than forcing them to rediscover it.
Manifest-Based Crash Recovery
Long sessions crash. A 12-step compliance audit pipeline that takes 2 hours end-to-end and fails at step 9 due to a transient cloud issue should not have to restart from scratch. The exam targets a specific pattern for resuming cleanly: structured agent state exports plus a coordinator manifest.

Each agent writes its state to a known location (its findings, open questions, partial results). The coordinator loads a manifest on resume that points at each agent’s state file, then re-injects the relevant state into each agent’s prompt as it brings them back up.
The keyword is manifest. The coordinator does not rebuild from chat history. It reads a structured file describing the system state and hydrates agents from it. That is what makes recovery deterministic instead of best-effort. This pattern generalizes well beyond code exploration: any multi-step pipeline that’s expensive to repeat (audits, research runs, batch extractions) benefits from a manifest-driven resume.
Listing 4.1: Manifest-Based Crash Recovery
The pattern has two halves. Each subagent writes its findings to a known location (state/<agent_name>.json) upon completion. The coordinator maintains a manifest that lists which steps have been completed, where their states reside, and what comes next. On resume, the coordinator reads the manifest, hydrates each completed agent's state from its file, and re-injects that state into the prompt for the next agent. No chat replay; the state files are canonical.
The exam-distinctive surface is the manifest file itself. manifest.json is the contract that makes resume deterministic: it names completed steps, points at their state files, and identifies the next step. A coordinator that resumes from anything else, the conversation transcript, the database, or the model's memory, is reconstructing rather than resuming.
from pathlib import Path
from datetime import datetime
from typing import Any
from pydantic import BaseModel
class AgentState(BaseModel):
agent_name: str
completed_at: datetime
findings: dict[str, Any] # whatever this agent produced
open_questions: list[str] # anything left unresolved
class Manifest(BaseModel):
run_id: str
started_at: datetime
completed_steps: list[str] # ordered; ["code_analysis", ...]
state_files: dict[str, str] # step name -> path to AgentState JSON
next_step: str | None # None when the pipeline is complete
STATE_DIR = Path("state")
MANIFEST_PATH = STATE_DIR / "manifest.json"
def persist_agent_state(step: str, state: AgentState) -> None:
"""Called by each subagent at the end of its run."""
state_file = STATE_DIR / f"{step}.json"
state_file.write_text(state.model_dump_json(indent=2))
# ... atomic manifest update: load, append step, rewrite
Two things to notice in the state writer. AgentState is intentionally small: findings (whatever the step produced) and open questions (anything the next step might need to know). Verbose discovery output, raw tool responses, and internal reasoning chains all stay out of this file; they belong in the subagent's working context, not in the durable resume record. And the manifest update is atomic: read the current manifest, append the completed step, rewrite. A crash mid-write is the one failure mode that breaks the resume, so the implementation has to be careful. (Concretely: write to manifest.json.tmp, then os.replace to manifest.json. That's the boilerplate we're hiding behind the comment.)
The resumer is the other half of the contract:
from claude_agent_sdk import query, ClaudeAgentOptions
PIPELINE_STEPS = [
"code_analysis", "schema_review", "dependency_trace",
"test_coverage", "security_audit", "performance_review",
# ...
]
def load_manifest() -> Manifest | None:
if not MANIFEST_PATH.exists():
return None
return Manifest.model_validate_json(MANIFEST_PATH.read_text())
def load_completed_state(manifest: Manifest) -> dict[str, AgentState]:
return {
step: AgentState.model_validate_json(
Path(manifest.state_files[step]).read_text()
)
for step in manifest.completed_steps
}
async def resume_or_start() -> None:
manifest = load_manifest()
if manifest is None or manifest.next_step is None:
# ... fresh run: initialize manifest, start at step 0
return
prior = load_completed_state(manifest)
prompt = build_prompt_for_step(manifest.next_step, prior)
# prior state is injected into the prompt, not just the manifest
options = ClaudeAgentOptions(
# ... allowed_tools, hooks, mcp_servers
)
async for msg in query(prompt=prompt, options=options):
... # consume; subagent persists its own state on completion
The resume contract is one function: read the manifest, hydrate prior agents’ state from their files, build the next step’s prompt with that state pre-injected. The model never sees the conversation history from before the crash. It sees the structured outputs of the agents that have already run, in the same shape they would have arrived in if the pipeline had run straight through. That’s what makes the resume identical to a fresh run from the model’s perspective, which is what makes it deterministic.
One detail worth pinning: build_prompt_for_step is not the SDK doing anything magical. It's an application code that takes a step name and a dict of prior agent states and produces a prompt string. The reason it lives outside this listing is that the right way to write it depends entirely on what your pipeline does. A code-audit pipeline injects file lists and prior findings. A research pipeline injects sources and conflict annotations. A customer-onboarding pipeline injects account state and prior issue resolutions. The manifest pattern is what survives across all of them; the prompt assembly is the part you write per pipeline.
The same pattern protects any expensive multi-step workflow: compliance audits, research runs, batch extractions, and overnight ETL jobs. Anywhere repeating earlier work is costly, the manifest is the small investment that turns a two-hour restart into a thirty-second resume.
/compact for Verbose Discovery Output
/compact is Claude Code's command for reducing context usage by summarizing earlier turns. Reach for it when extended exploration has filled context with verbose discovery output and you want to keep going without restarting. It is not the answer for preserving facts. For that, use a scratchpad. Compact is for freeing up attention.
Optimization Tactics: Prompt Caching & Server-Side Compaction
To manage costs and latency in long-running conversations, utilize explicit caching and server-side state management:
Strategic Caching. Place cache breakpoints on the last stable content blocks (system prompts, tool definitions) before frequently changing messages.
The Beta Compaction Pattern. Modern systems use the
compact_20260112beta header. By settingpause_after_compaction: true, the system generates a summary and returnsstop_reason: "compaction". This gives the harness a clean pause point to inject updated tool results or fresh state before the conversation resumes with a high-attention summary.
One Tested Compliance Note: ZDR and Batch
A small but exam-relevant fact lives at the intersection of cost optimization and Domain 5. When a workload has Zero Data Retention requirements (regulated industries, healthcare, certain financial workflows), the Batch API is not eligible for ZDR. Even latency-tolerant overnight workloads must use the synchronous API when ZDR is required. The only cost lever remaining is Prompt Caching. The trap answer is “move it to Batch for 50% savings”; the correct answer recognizes that the compliance constraint dominates the cost optimization.
5. The Provenance Chain: Preserving the “Receipts”
Summarization is the enemy of provenance. In multi-source synthesis, the link between a claim and its source is often destroyed in the first summarization step, and once it is gone, no downstream agent can restore it.
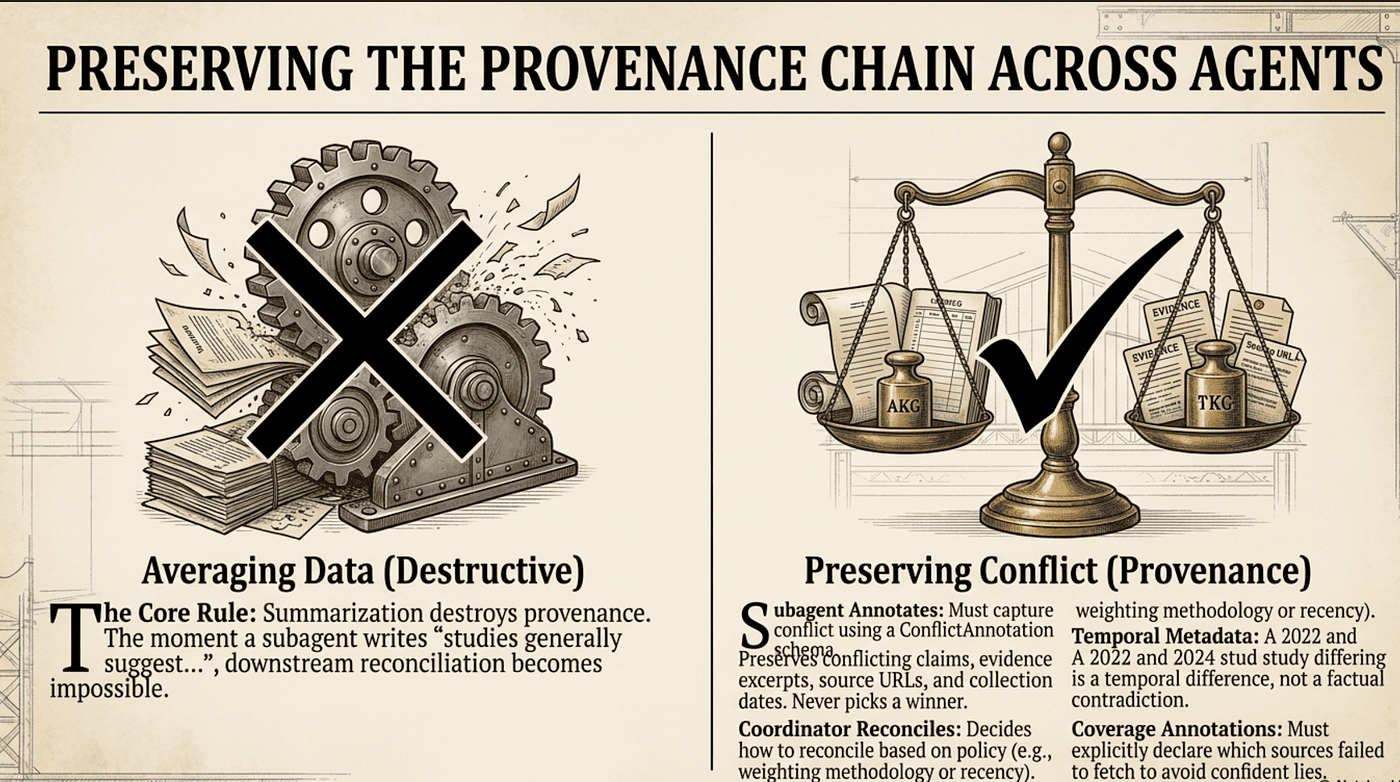
To maintain reliability, enforce the Conflict Annotation Rule: preserve the conflict, attribute the dates, and let the coordinator reconcile.
Subagent Annotates, Coordinator Reconciles
This is a separation of concerns that the exam tests directly. The subagent reading the documents is the right place to capture the conflict: both values, both sources, both excerpts, both dates. The subagent does not pick a winner. A higher-level coordinator (or the synthesis agent acting on the coordinator’s policy) decides how to reconcile before the result reaches the user.
The trap answers are “average the two values” and “pick the more recent source.” Both are silent decisions made at the wrong layer, and both hide the disagreement from the reader who might need to see it.
The Anatomy of a High-Provenance Report
Claim-Source Mappings. Every finding tagged with a source URL, document name, and relevant excerpt.
Temporal Metadata. Publication and collection dates to distinguish stale data from current contradictions. A 2022 study and a 2024 study reporting different numbers may not be contradicting each other at all. They may be measuring different time periods. Without dates, the synthesis step misreads temporal differences as factual contradictions.
Coverage Annotations. Explicit notes on which areas are well-supported and which have gaps due to tool failures.
Well-Established vs. Contested as Explicit Sections
The final synthesis report should structure findings into two explicit categories:
Well-established findings. Multiple sources agree, no significant disputes, consistent across time windows.
Contested findings. Sources disagree, with the disagreement preserved alongside the relevant excerpts and methodological context.
A finding that two studies disagree on stays a disagreement in the final report. It does not get smoothed into a confident statement by the synthesis layer.
Conflict Annotation Inside a Single Document
Provenance discipline isn’t only a multi-source concern. The same logic applies inside a single document. If an invoice has line items that sum to $91.40 but a stated total of $94.10, the line items were extracted correctly, and the source itself contains the discrepancy. The correct extraction pattern captures both: calculated_total: 91.40, stated_total: 94.10, conflict_detected: true. Route the record to human review with the conflict flagged.
The wrong pattern is to force the model to “fix” the contradiction by adjusting one value until they match. That produces incorrect data silently downstream and erases the very signal the source document is sending: this record needs human attention.
Render Content Types Appropriately
A subtle but tested point: preserve encoded information by rendering content types in formats appropriate to the content. Financial data as tables. News reporting as prose. Technical findings as structured lists. Converting everything to a uniform format, for example, bulletizing a narrative news summary, loses the structure that the original format encoded.
Listing 5.1: The Finding Schema with Conflict Annotation
The moment a subagent cites prose like “studies generally suggest the market is around $4–5 billion,” the link between any specific claim and its source is destroyed. Synthesis layers downstream can no longer be attributed, dated, or reconciled. The fix is structural: the subagent’s output schema treats every claim as a first-class record with its source attached, and conflicts are captured as conflicts rather than averaged into a single number.
Two models carry the discipline. Finding pins a single claim to its source, date, and the supporting excerpt. ConflictAnnotation captures the case where two findings disagree, preserves both, and explicitly leaves resolution to a higher layer.
The exam-distinctive surface is the separation: subagents annotate, coordinators reconcile. The schema enforces this because ConflictAnnotation.coordinator_resolution is None until a higher layer populates it. A subagent that picks a winner is violating the contract that the schema declares.
from datetime import date
from pydantic import BaseModel, Field
class Finding(BaseModel):
claim: str # the assertion, in the subagent's words
evidence_excerpt: str = Field(max_length=300)
source_url: str
document_name: str
publication_date: date | None # None when source is undated
collection_date: date # when the subagent retrieved it
relevance_score: float = Field(ge=0.0, le=1.0)
methodological_context: str | None = None
class ConflictAnnotation(BaseModel):
topic: str # what the findings disagree about
findings: list[Finding] # both (or all) sides, preserved
coordinator_resolution: str | None = None
# ^ subagents leave this None; coordinator fills it in
Six things the schema enforces. First, evidence_excerpt is required, not optional: a claim without an excerpt is unverifiable, and the subagent can't return a finding it can't quote. It's also bounded at 300 characters, which is the same discipline 1.1 applied to tool output: an unbounded excerpt field becomes a vector for the lost-in-the-middle effect, with dozens of findings each carrying paragraphs of quoted material into the coordinator's context. The cap forces the subagent to pick the sentence that grounds the claim, not the whole passage.
Second, publication_date is date | None, not just date, because some sources are genuinely undated, and a required date would tempt the model to fabricate one. collection_date is required because the subagent always knows when it ran.
Third, relevance_score is bounded [0.0, 1.0], so the coordinator can sort and threshold without having to interpret a free-form confidence string.
Fourth, methodological_context is optional and free-form, capturing things like "n=12, lab study" that turn a comparison between two findings from "they disagree" into "they're measuring different things." The softness is deliberate because attempting to enumerate methodology types creates a fake taxonomy worse than honest free-form notes.
Finally, coordinator_resolution defaults to None, which makes the subagent's contract literal: emit the conflict, do not resolve it.
The schema becomes enforceable when wired as a subagent’s output_format:
from pydantic import BaseModel
from claude_agent_sdk import query, ClaudeAgentOptions, ResultMessage
class ResearchOutput(BaseModel):
findings: list[Finding]
conflicts: list[ConflictAnnotation]
coverage_gaps: list[str] # topics the subagent couldn't source
async def run_research_subagent(question: str) -> ResearchOutput:
options = ClaudeAgentOptions(
# ... allowed_tools (web search, document fetch)
output_format={
"type": "json_schema",
"schema": ResearchOutput.model_json_schema(),
},
)
async for msg in query(prompt=question, options=options):
if isinstance(msg, ResultMessage) and msg.structured_output:
return ResearchOutput.model_validate(msg.structured_output)
raise RuntimeError("subagent produced no structured output")
output_format with type: "json_schema" converts the schema from documentation into a contract. The SDK validates the subagent's output against the schema before returning it. A subagent that returns prose, omits evidence_excerpt, or fills in coordinator_resolution itself will fail validation, and the SDK will retry. The schema is no longer a polite request; it's the wire format.
After collecting ResearchOutput from one or more subagents, the coordinator’s job is to reconcile the conflicts list. That reconciliation logic doesn't belong in this listing because it's domain-specific. A market-sizing study reconciles by weighting methodology and recency. A security-advisory aggregator reconciles by preferring vendor confirmation over third-party reports. What the schema guarantees is that the coordinator can reconcile, because every conflict arrives with both sides preserved, both excerpts intact, and both dates attached. A subagent that averaged the values or picked the more recent source would have destroyed the input the coordinator needs.
The same shape handles the single-document case earlier in this section. When a subagent extracts data from one invoice and the line items sum to a total different from the document’s stated total, both values become Finding entries on a ConflictAnnotation with topic: "invoice_total". The pattern doesn't change because the source count went from many to one; the discipline of preserving disagreement persists.
6. Stratified Truth: Calibrating Human Review
The “97% aggregate accuracy” metric is the ultimate statistical trap. A model can be 99% accurate on common document types (such as standard contracts) but crash to 60% on rare but high-value variants (such as complex multi-line-item invoices). The aggregate number obscures the local failure entirely.

A real-world version: an invoice extraction pipeline reports 97% overall accuracy. Customer complaints concentrate on credit memos. The aggregate is fine because credit memos are a minority of volume; the bad segment is dominated by the good ones in the average. Per-segment accuracy reveals the truth: 99% on invoices, 73% on credit memos. The fix does not raise the overall threshold or expand the validation sample. It is a stratified measurement.
The Calibration Workflow
Define Labeled Sets. Establish ground truth of labeled examples covering the full distribution of document types and fields.
Calibrate Confidence. Ensure that a “high confidence” score from the model correlates with actual accuracy on your labeled set. A 0.9-confidence extraction should be correct ~90% of the time. The discipline is calibration against a labeled set so that “0.85 model confidence corresponds to 92% accuracy on this document type.” Without that mapping, any routing threshold is theater. Never trust uncalibrated self-reported confidence.
Stratified Random Sampling. Audit the system by segment (document type and field) rather than global average. If one vendor’s tax extraction is failing, aggregate stats will never surface it. Stratified sampling ensures rare document types get measured and that novel error patterns become detectable as input distributions drift.
Priority Routing
Limited human reviewer hours must be focused where risk is highest. Two categories deserve priority:
Low model confidence. The system itself is signaling uncertainty.
Ambiguous or contradictory source documents. The source itself has issues the model cannot resolve (calculated total ≠ stated total, conflicting dates, missing required information).
Both are signals that the case is harder than the median. Send reviewer time there, not toward random spot-checks of high-confidence extractions that stratified sampling already validates.
Sampling High-Confidence Outputs for Drift Detection
Even after auto-approval thresholds are set for high-confidence extractions, a small percentage should still be subject to a stratified random audit. This is how you catch novel error patterns after a prompt change, a model swap, or a shift in input distribution. Without this audit, a degradation in high-confidence outputs accumulates silently in production. Reviewer attention is rationed: most goes to low-confidence and conflict-flagged records, but a measured slice goes to the apparently safe outputs precisely to prove they’re still safe.
Before You Reduce Human Review
Do not reduce human review on the basis of overall accuracy. Analyze accuracy by document type and field, and verify consistent performance across all segments. If any segment underperforms, the headline number is not yet a defensible automation signal.
Retries cannot Manufacture Absent Information
One last calibration point that crosses Domain 4 and Domain 5: validation retries can fix format mismatches and structural errors, but they cannot address missing required information from the source. If an invoice genuinely lacks a purchase order number, retrying the extraction 10 times will not generate one. The model will either fabricate to satisfy a required schema field or fail repeatedly with the same error.
The discipline is recognizing which class of failure you have. Format and structural errors get a retry with specific feedback. Absent information gets a schema fix (mark the field nullable so absence is a valid output) and a routing decision (flag the record for human review or accept null downstream). Treating these as the same failure mode produces both wasted retries and silent fabrication.
Listing 6.1: The Confidence Calibration Mapper
A model that self-reports confidence: 0.93 on virtually every extraction has told you nothing. The number is generated text, not a probability against ground truth. Routing human review on raw confidence scores means routing on the model's stylistic preference for a particular number, not on whether the extraction is actually likely to be correct.
The exam-distinctive discipline is calibration against a labeled validation set: building an empirical mapping from self-reported confidence to observed accuracy, per segment, so that “0.85 confidence on credit memos” becomes the literal statement “92% accurate on that segment in the labeled set.” Without that mapping, any threshold is theater. With it, threshold routing becomes a calibrated decision.
The pattern has three pieces. Label a validation set with ground truth. Bucket the predictions by self-reported confidence and segment. Compute observed accuracy per bucket. The mapper then turns a new extraction’s confidence score into the calibrated accuracy estimate that routing actually depends on.
from collections import defaultdict
from pydantic import BaseModel, Field
class LabeledRecord(BaseModel):
document_type: str # "invoice" | "credit_memo" | ...
field: str # "tax_amount" | "vendor_name" | ...
predicted_value: str
actual_value: str # ground truth from the labeled set
self_reported_confidence: float = Field(ge=0.0, le=1.0)
@property
def is_correct(self) -> bool:
return self.predicted_value == self.actual_value
class CalibrationBucket(BaseModel):
document_type: str
field: str
confidence_floor: float # bucket is [floor, floor + width)
sample_size: int
observed_accuracy: float # fraction correct in this bucket
def calibrate(
records: list[LabeledRecord],
bucket_width: float = 0.05,
) -> list[CalibrationBucket]:
"""Group records by (segment, confidence bucket) and compute
observed accuracy per bucket from the labeled ground truth."""
groups: dict[tuple[str, str, float], list[LabeledRecord]] = (
defaultdict(list)
)
for r in records:
# round(.., 2) handles float artifacts near bucket edges
floor = round(r.self_reported_confidence // bucket_width
* bucket_width, 2)
groups[(r.document_type, r.field, floor)].append(r)
buckets = []
for (doc_type, field, floor), recs in groups.items():
n = len(recs)
accuracy = sum(1 for r in recs if r.is_correct) / n
buckets.append(CalibrationBucket(
document_type=doc_type,
field=field,
confidence_floor=floor,
sample_size=n,
observed_accuracy=accuracy,
))
return buckets
Three things to notice. The bucket key is (document_type, field, confidence_floor), not just confidence_floor. Aggregating across segments hides the credit memo problem: a model that reports 0.85 confidence on invoices (92% actually correct) and 0.85 on credit memos (61% actually correct) gets averaged to "0.85 is roughly 85% correct" when you collapse the segment dimension. The calibration mapper has to be per-segment, or it reproduces the aggregation lie. sample_size is carried alongside observed_accuracy because a bucket with three records is not the same as one with three hundred; the downstream routing logic needs to know which buckets it can trust. And the bucketing is [floor, floor + width) Rather than rounding to the nearest, so adjacent buckets don't overlap, and every confidence score maps to exactly one bucket.
The mapper produces the calibration table. The routing logic uses it:
class Extraction(BaseModel):
document_type: str
field: str
predicted_value: str
self_reported_confidence: float = Field(ge=0.0, le=1.0)
def route(
extraction: Extraction,
calibration: list[CalibrationBucket],
bucket_width: float = 0.05,
auto_approve_accuracy: float = 0.95,
min_sample_size: int = 30,
) -> str:
"""Return 'auto_approve' or 'human_review' based on the
calibrated accuracy for this extraction's segment and
confidence, not the raw self-reported number."""
floor = round(
extraction.self_reported_confidence // bucket_width
* bucket_width, 2
)
matches = [
b for b in calibration
if b.document_type == extraction.document_type
and b.field == extraction.field
and b.confidence_floor == floor
]
if not matches or matches[0].sample_size < min_sample_size:
return "human_review" # no calibration data: default to review
return ("auto_approve"
if matches[0].observed_accuracy >= auto_approve_accuracy
else "human_review")
The routing function is what makes the calibration load-bearing. A raw-confidence router would write if extraction.self_reported_confidence >= 0.90: return "auto_approve" and ship the credit memo failure mode straight into production. The calibrated router branches on observed_accuracy for the specific (document_type, field, confidence_bucket) segment that the extraction lives in. A 0.93 self-reported confidence on a segment whose calibration table says that the bucket is 71% accurate, routes to human review; a 0.85 self-reported confidence on a segment whose bucket is 96% accurate, auto-approves. The model's preference for round numbers near 0.9 no longer matters; only the observed segment behavior does.
Two failure modes that the router explicitly defends against. min_sample_size guards against tiny buckets: a calibration bucket with 5 records can show 100% accuracy by accident, and routing on it is in the same ballpark as routing on raw confidence. Falling back to human review on under-sampled buckets is the conservative default and the right one for a calibration pipeline that's still maturing. And the empty-matches case (a (document_type, field, confidence_floor) combination the labeled set has never seen) also routes to human review rather than guessing, because an extraction in a segment with no calibration data is exactly the kind of novel case that human review exists for.
The discipline generalizes beyond extraction pipelines. Anywhere a model self-reports a quality signal and downstream code routes on it, the same pattern applies: bucket by segment, measure against ground truth, and let the routing logic branch on calibrated accuracy rather than the model’s stylistic confidence. The per-bucket measurement is what makes the discipline real, and the routing function is where the discipline starts to pay off.
7. Where Domain 5 Shows Up: Three Production Scenarios
Domain 5 is worth 15% of the scored content, the smallest slice of the CCA exam by weight. That number is a trap. Every production scenario on the exam implicitly tests Domain 5 patterns. The same six task statements show up in different costumes depending on the system you’re building. This section walks through the three scenarios where Domain 5 fingerprints are most concentrated.
Customer Support Resolution Agent
This is where Domain 5 lives in a transactional state. The agent has MCP tools (get_customer, lookup_order, process_refund, escalate_to_human), and the conversation often spans returns, billing, and account issues across many turns.
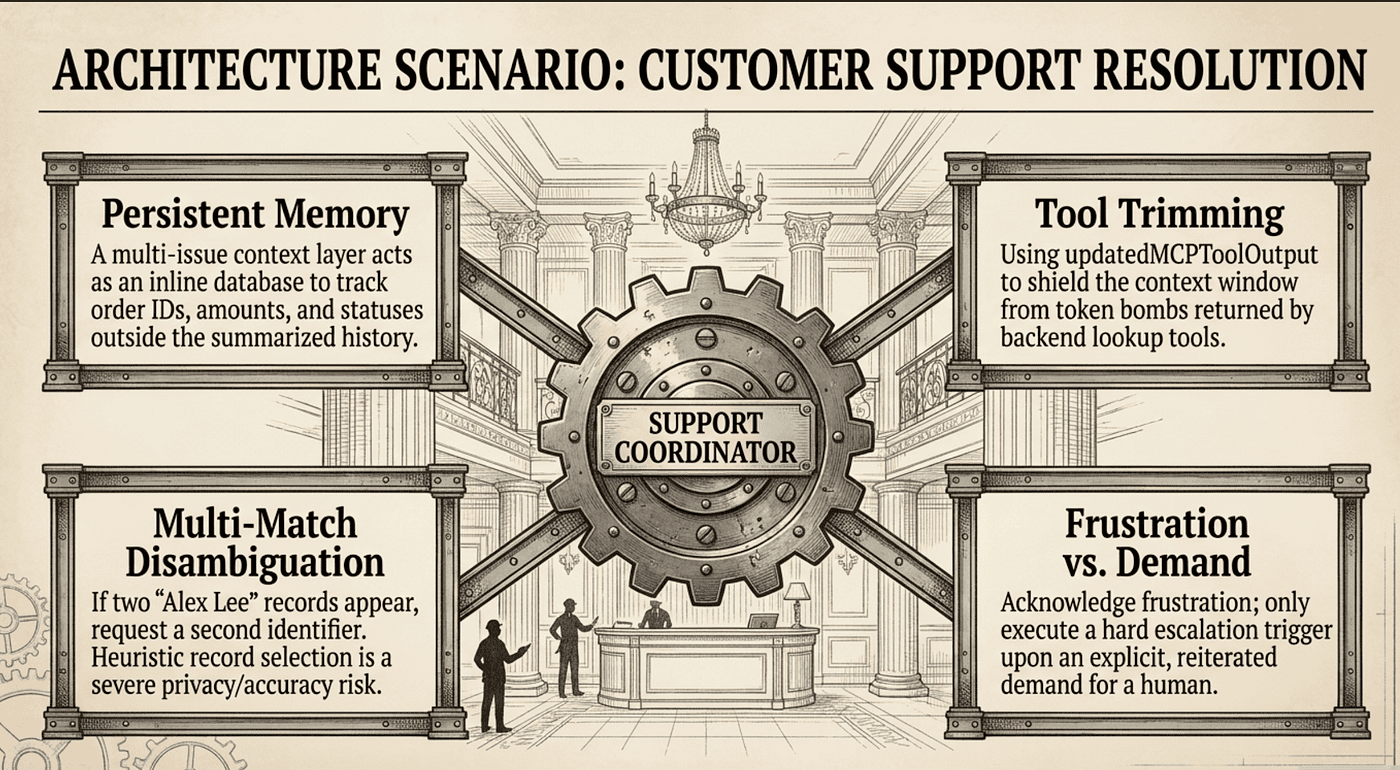
The pressure points:
Persistent case-facts block. Refund amount, order ID, escalation case ID, and any commitment the agent has made stay in a persistent block outside the summarized history. When compaction runs mid-dispute, those facts survive. (Task 5.1)
Multi-issue context layer. A customer with three concerns gets one entry per issue: order ID, amount, status, resolution path. Treat it like an inline mini-database. The summary tracks the conversation; the structured layer tracks the issues. (Task 5.1)
Tool output trimming.
lookup_orderreturning 40 fields when 5 are relevant is a token bomb. Trim at the tool boundary. (Task 5.1)
Multi-match disambiguation. Two “Alex Lee” records in the system, customer gave only name and city. Ask for a second identifier. Heuristic selection on consequential account actions is a privacy risk and an accuracy risk. (Task 5.2)
Frustration vs. demand. Acknowledge frustration and offer resolution; escalate only on an explicit demand or a reiterated preference. (Task 5.2)
Structured tool errors with categories. Validation, permission, transient, business-rule. Each drives a different agent response. Generic “failed” forces the agent to guess. (Task 5.3)
Multi-Agent Research System
This is where Domain 5 lives in provenance and aggregation. A coordinator delegates to specialized subagents (web search, document analysis, synthesis, report generation).
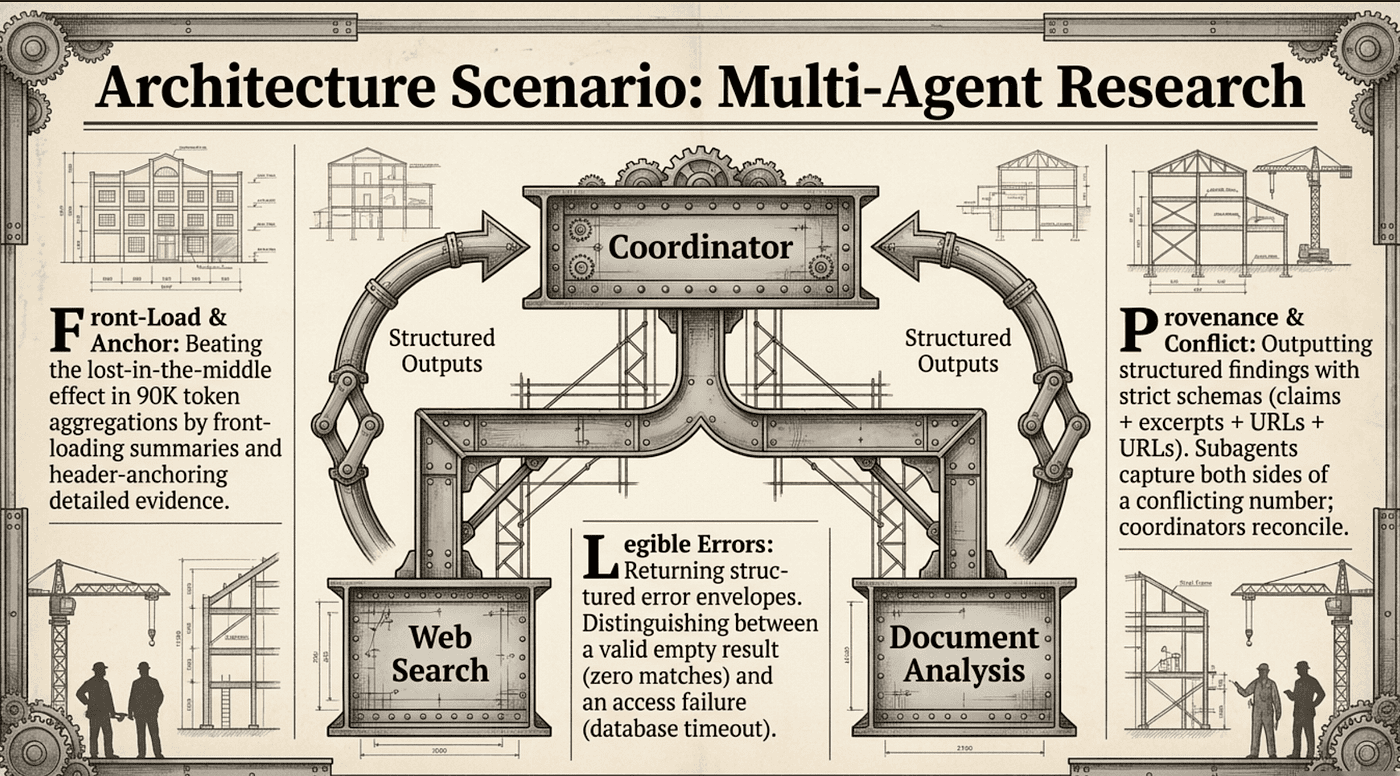
The pressure points:
Structured findings, not prose. Subagents return claims + evidence excerpts + source URLs + publication dates + relevance scores. Prose summaries with citations bolted on lose provenance the moment synthesis touches them. (Tasks 5.1, 5.6)
Front-load and header-anchor. When the coordinator aggregates 90K tokens of subagent output, the lost-in-the-middle effect bites hard. Key findings summary up top, detailed evidence in headered sections. (Task 5.1)
Distinguish timeout from empty result. Patent database returned zero matches: that’s a valid result, report it. Industry report search timed out: that’s an access failure, retry or fall back. (Task 5.3)
Structured error envelope with partial results. Web subagent finds two sources, times out on the third. Return the two it got, the failure type, the attempted query, and the alternatives. The coordinator can synthesize with what it has and annotate the gap. (Task 5.3)
Coverage gap declaration. Fetched four of seven planned sources. The synthesizer writes the report and declares which three failed and why. Silent omission is the canonical failure of multi-agent research. (Task 5.6)
Conflict annotation, not resolution. Two sources disagree on a market-size number. The subagent captures both values with attribution and dates. The coordinator decides how to reconcile. Trap answers: average them, pick the more recent. (Task 5.6)
Temporal metadata. Without publication dates on claims, the synthesis layer reads temporal differences as factual contradictions. (Task 5.6)
Structured Data Extraction
This is where Domain 5 lives in calibrated trust. The system extracts structured data from unstructured documents (invoices, contracts, claims), validates with JSON schemas, and feeds downstream systems.

The pressure points:
Stratified accuracy by document type, vendor, and field. Pipeline reports 97% overall but credit memos fail
tax_amount25% of the time. The aggregate masks the failure. Per-segment reporting is the discipline. (Task 5.5)
Field-level confidence, calibrated against a labeled set. Model self-rates 0.93 on virtually every record. That number is generated text, not a probability. Build a labeled validation set, measure what “0.85 confidence” actually corresponds to per document type, then route review against the calibrated mapping. (Task 5.5)
Priority routing for human review. Limited reviewer hours go to low-confidence extractions and to documents with internal contradictions, not random spot-checks of high-confidence outputs. (Task 5.5)
Stratified random sampling on high-confidence outputs. A measured slice of auto-approved records still goes to audit. This is how you catch drift after a prompt change or model swap before it accumulates. (Task 5.5)
Retries can’t manufacture absent information. If the PO number isn’t in the source, retrying ten times won’t conjure it. Distinguish format errors (retry with specific feedback) from absent data (schema fix: nullable; routing: human review). (Cross-cuts Tasks 4.4 and 5.5)
**calculated_totalvsstated_total,conflict_detectedbooleans.** When line items sum to $91.40 but the document states $94.10, extract both and flag the conflict. Forcing the model to reconcile produces silently wrong data. (Task 5.6 applied to single-document extraction)
ZDR + Batch API. When Zero Data Retention is required, Batch is ineligible. The cost lever that remains is Prompt Caching. (Compliance cross-cut)
8. Conclusion: The Reliability Checklist
Production readiness is not a single metric. It is a set of safeguards.

To transition from a demo to a durable agentic system, you must verify:
[ ] Deterministic Escalation. Hard rules for human handoffs beyond sentiment or self-reported confidence, with explicit criteria and few-shot examples in the system prompt, and a
PreToolUsegate on sensitive tools for the non-negotiable cases.
[ ] Structured Memory. Critical facts stored in an immutable persistent block, with a separate context layer for multi-issue sessions, and tool outputs trimmed at the boundary via
PostToolUse+updatedMCPToolOutput.
[ ] Legible Failures. Subagents return error envelopes with failure type, attempted query, partial results, and alternatives; customer-facing tools use the same envelope shape with explicit categories (validation, permission, transient, business-rule); the coordinator annotates gaps instead of crashing.
[ ] State, Not History. A coordinator scratchpad for in-session state read on every turn, subagent delegation to keep verbose work out of the coordinator’s context, phase summaries before each new phase, and a manifest for crash recovery on long-running pipelines. The scratchpad and manifest have distinct write profiles; both protect against compaction.
[ ] Provenance. Every claim traces to a specific source, date, and excerpt via a
Findingschema; subagents annotate conflicts viaConflictAnnotation; coordinators reconcile; the same logic applies inside single documents viaconflict_detectedflags.
[ ] Stratified Evaluation. Accuracy measured by segment and document type, with field-level confidence calibrated against labeled sets, a routing function that branches on observed accuracy rather than raw self-reported confidence, and a stratified random audit of high-confidence outputs to catch drift.
The evolution from “chatbots” to “reliable agents” is a structural evolution, not a linguistic one. It requires moving away from the hope that the model will behave and toward an architecture that ensures it must.
Ask yourself: in your current context management strategy, are you relying on the model to remember the receipts, or have you architected a system that refuses to lose them?
About the Author
Rick Hightower is a former Senior Distinguished Engineer at a Fortune 100 company, focusing on delivering ML / AI insights to front-line applications, and a practitioner building multi-agent production systems. Follow him on Medium for more hands-on agent engineering content. You can also book him to speak and train your team: Check out Rick Hightower’s SpeakerHub.
Rick created Skilz, the universal agent skill installer that supports 30+ coding agents, including Claude Code, Gemini, Copilot, and Cursor, and co-founded the world’s largest agentic skill marketplace. Connect with Rick Hightower on LinkedIn or Medium. Check out SpillWave, your source for AI expertise.
Rick has been actively developing generative AI systems, agents, and agentic workflows for years. He is the author of numerous agentic frameworks and developer tools and brings deep practical expertise to teams adopting AI. He enjoys writing about himself in the 3rd person.
Rick also wrote a Claude Certified Architect (CCA) series of articles that have a lot of useful information on writing agentic AI systems. Many ideas captured in the CCA and the exam prep Rick wrote echo what you see in this article. If you want to improve your ability to create well-behaved AI agents, studying for the CCA Exam is a good place to start.
CCA Exam Prep on Agentic Development
- Claude Certified Architect: The Complete Guide to Passing the CCA Foundations Exam
- CCA Exam Prep: Mastering the Code Generation with Claude Code Scenario
- CCA Exam Prep: Mastering the Multi-Agent Research System Scenario
- CCA Exam Prep: Structured Data Extraction
- CCA: Master the Developer Productivity Scenario
- Claude Certified Architect: Master the CI/CD Scenario
- CCA Exam Prep: Mastering the Customer Support Resolution Agent Scenario
- Get the complete reading list for CCA-F exam prep articles from this Claude Certified Architect Exam Prep list.
Rick also wrote a series on harness engineering and how to improve agentic systems using harness engineering for feedback loops and adversarial agents. These articles also go hand in hand with this article.
Harness Engineering Articles
- The $9 Disaster: What Anthropic’s Harness Design Paper Teaches Us About Building Autonomous AI
- Harness Engineering vs Context Engineering: The Model is the CPU, the Harness is the OS
- LangChain Deep Agents: Harness and Context Engineering: Memory, Skills, and Security
- Beyond the AI Coding Hangover: How Harness Engineering Prevents the Next Outage
- LangChain’s Harness Engineering: From Top 30 to Top 5 on Terminal Bench 2.0
- Anthropic’s Harness Engineering: Two Agents, One Feature List, Zero Context Overflow
- OpenAI’s Harness Engineering Experiment: Zero Manually-Written Code