What Is Harness Engineering? The Engineering Discipline for Production AI Agents.
Harness Engineering: Designing Reliable AI Agent Runtime for Production Systems
Originally published on Medium.

Harness Engineering: Designing Reliable AI Agent Runtime for Production Systems
Discover why the runtime around an LLM can outshine the model itself. And how "harness engineering" is turning AI agents into reliable, production-grade powerhouses.
Summary: Discover how "harness engineering," the emerging discipline that treats the runtime surrounding large language models as a first-class engineering artifact, transforms AI agents from fragile prototypes into reliable, production-grade systems. This article traces the concept's roots from a 1947 cockpit study and the 2024 SWE-agent breakthrough to the recent developments in 2025 and 2026. It explains why the engineered harness (context assembly, tool contracts, memory, observability, recovery, and orchestration) is now recognized as essential as the model itself, and showcases the recent convergence of terminology, open standards, and industry adoption that makes harness engineering the key to building scalable, long-running AI applications.
The model is the easy part
The model is not the hard part. It hasn't been for a while.
We were building harnesses at Spillwave before the term existed, and before we incorporated. So were a lot of teams I worked with as a consultant, even if none of us called it that. We hit walls. We hit a lot of walls.

We had long-running agentic workflows that ran for hours, produced correct results, and resumed cleanly after interruption; before "long-running agent" was a published term. We had programmatic validation of DAX queries, feedback loops, and LLM-as-judge before the papers showed up. I wrote about drift detection on Medium over a year ago, arguing that drift had to be tracked and retested whenever a model version changed, a prompt changed, or a tool contract shifted. None of these had names yet. We pulled them out of necessity, not literature. We read a blog here or there, but the knowledge was disjointed and lacked cohesion.
Except that this is the part I keep coming back to: they were not really walls. Walls stop you. We were not stopped. We were on the cutting edge, and the cutting edge cuts. We ran into a sliding glass door that we didn't see until we were already through it. We got cut. We have the battle scars.
The frustrating part, as a consultant, was that the demo worked. Stakeholders could not see why the scaffolding mattered. Why all this overhead? It works in dev. The problem is if it stops working. What happens when drift occurs six weeks later in production, even though it hadn't occurred yet or been caught yet, and nobody knows how to reproduce the issues in dev. The work felt improvised even when it was not.
Adding a few shots to prompts for a new use case, or more tools, or more subagent decomposition, without drift detection, is like nailing Jell-O to a wall. Non-deterministic behavior plus "just one more feature" without drift detection is like swimming in a pool of alcohol while covered in paper cuts. That isn't "the bleeding edge." It's deliberate self-destruction.

Naming things is what puts a handle on the door. Once we have shared terminology, the next team does not have to run through the glass. They can see the door, find the handle, and walk through. That is what harness engineering gives the field. It is not validation for the people who were already doing this work. It is a way to talk about getting agentic workflows into production without re-explaining the ground floor every time.
The work itself now has a name. The engineered runtime that wraps a large language model and turns its raw text output into reliable system behavior is the harness, and the discipline of designing, building, and operating it is harness engineering. This article explains where that name came from, what the harness actually is, and why the discipline is 12 months old as a named thing while being roughly 3 years old as a practice.
What a harness is, in one paragraph
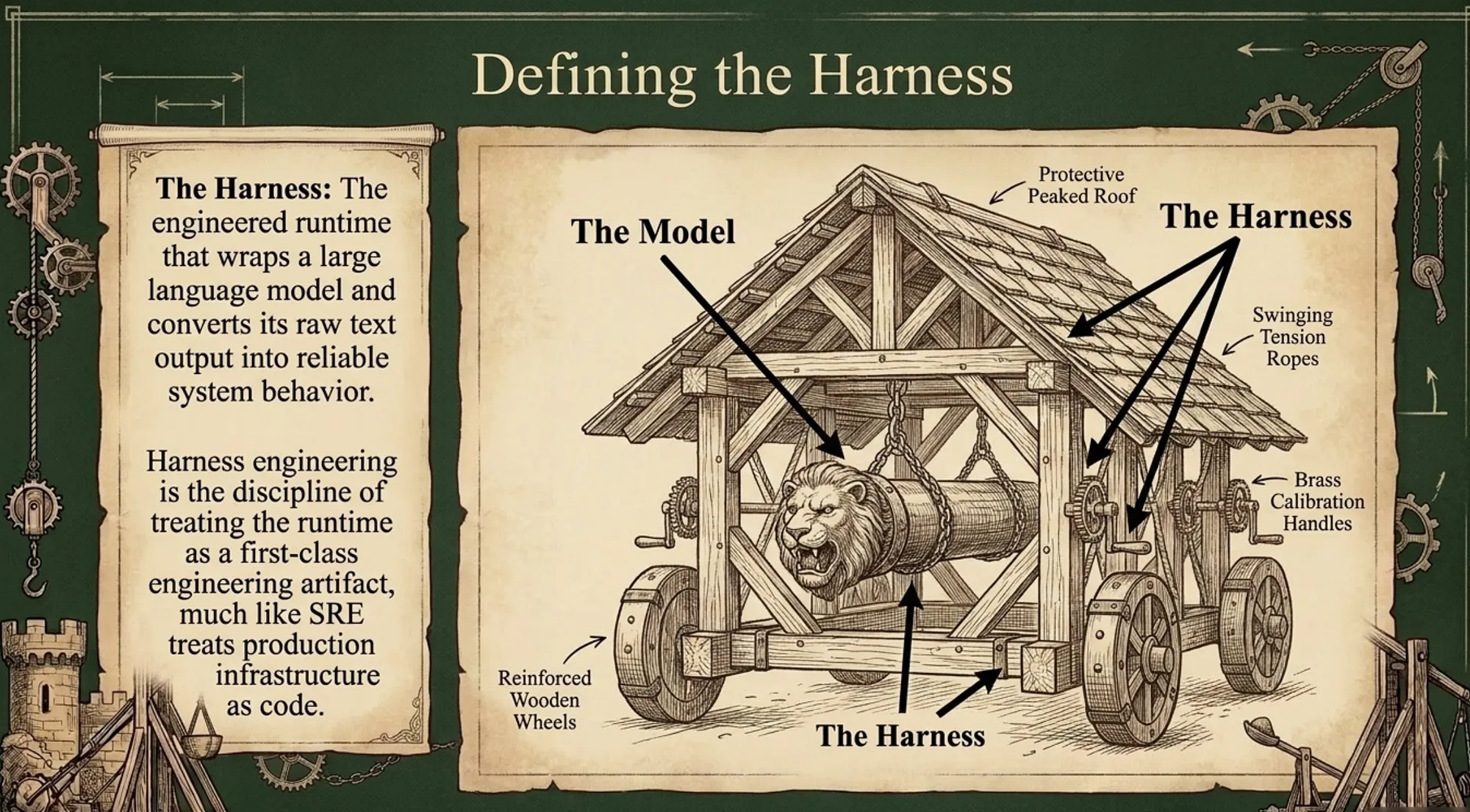
The harness is the engineered runtime that wraps a large language model and converts its raw text output into reliable system behavior. Specifically, the harness does six things the model cannot do on its own. It shapes what the model sees on each call (context assembly). It decides what the model is allowed to do (tool contracts and validators). It remembers what happened across calls (memory and durable state). It watches what the model produced (observability spans, drift detection, and evaluation gates).

It recovers when something went wrong (rollback, retry, replay). And it coordinates when multiple models or agents are involved (orchestration and protocol handling). Harness engineering is the discipline of treating the runtime as a first-class engineering artifact, much like SRE treats production infrastructure as code. Many of these are just a given, built into the tools that develop and deploy agents.
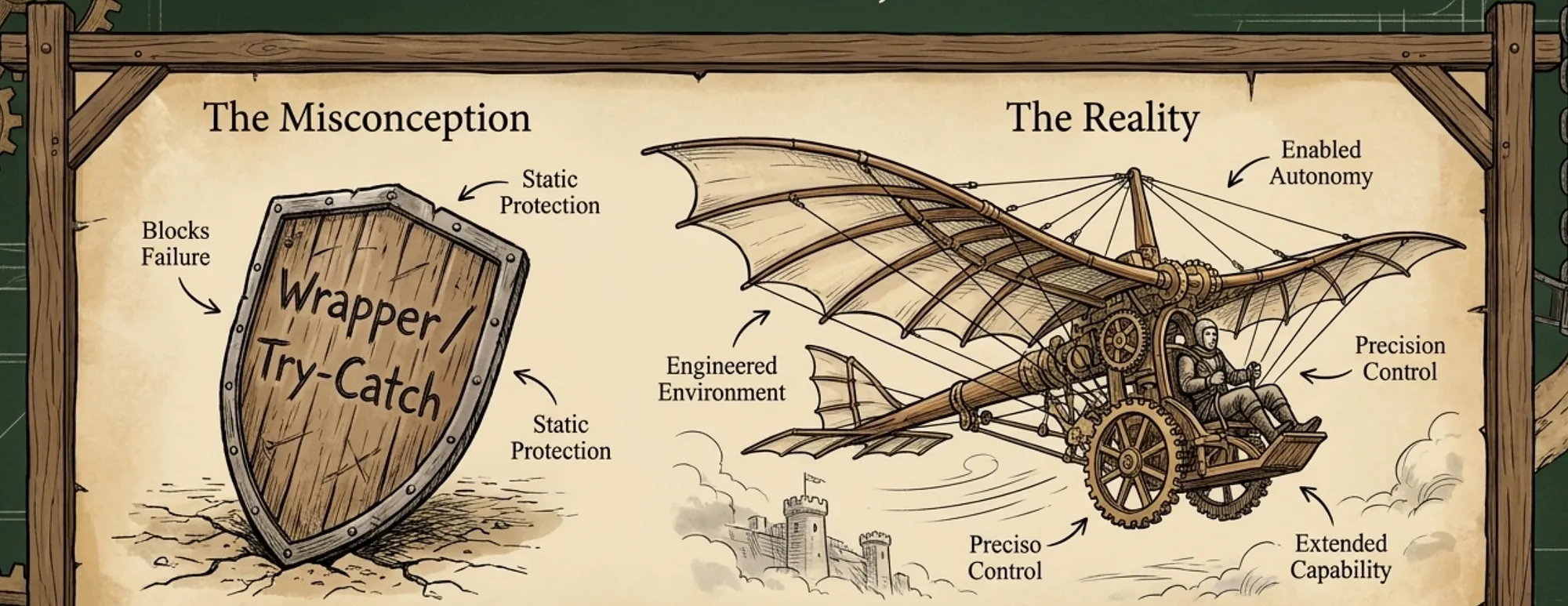
A harness is not a try-catch wrapper that prevents the model from failing. It is the engineered environment that enables a capable model to perform larger, longer, and more autonomous work than it could do on its own. A good cockpit does not just keep a pilot from crashing. It lets the pilot fly missions that a worse cockpit could not survive. Hold onto that distinction; it is the one most people get wrong when first encountering the term.
The discipline has a documented birth date
Most engineering disciplines do not. Harness engineering does, and the date is May 2024.
A team at Princeton (Yang, Jimenez, Wettig, Lieret, Yao, Narasimhan, and Press) published a paper called SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. It would later appear at NeurIPS 2024 as arXiv 2405.15793. The paper did something that, in retrospect, looks obvious and at the time looked like a category error.

They held the model fixed. GPT-4 Turbo, no fine-tuning, no prompt tricks. Then they built a small layer between the model and the codebase, called it the Agent-Computer Interface (ACI), and changed only that layer. The ACI had four parts: a cap of fifty results on file searches, a stateful file viewer that showed one hundred lines at a time and remembered position across calls, a linter that ran at edit time and rejected syntactically broken patches before they were applied, and a context window manager that compressed older observations as the trace grew.
That was it. Same model, same weights, same benchmark.
SWE-bench performance increased from 3.8 percent (previous best) to 12.47 percent. A more than three-fold gain, driven entirely by interface design.
The number is striking. The interpretation is more striking. What the SWE-agent team had demonstrated, deliberately and measurably, was that the runtime around the model can matter more than the model itself. Up to that point, the implicit assumption in agent research had been that better agents required better models. The ACI ablation showed that better agents could come from better interfaces, holding the model constant.
That paper is the foundational design document for the discipline. Everything that comes after, the harness patterns, the workflow patterns, the four-protocol stack, the production retrospectives, is a generalization of what SWE-agent demonstrated.
The 1947 cockpit study that the SWE-agent paper drew on
The SWE-agent authors did not invent the principle. They named it explicitly: human-factors engineering. The lineage is older than computing.

In 1947, Paul Fitts and Richard Jones published Analysis of Factors Contributing to 460 Pilot Error Experiences in Operating Aircraft Controls, a study commissioned by the USAF Aero Medical Laboratory after a wave of post-war crashes that the Air Force had been classifying as pilot error. Fitts and Jones interviewed the pilots and looked at the cockpits. What they found was not pilot error. They found that the same controls were laid out differently in different aircraft, that visually identical levers performed wildly different functions, and that under stress, experienced pilots reliably reached for the wrong control because the environment had been designed without regard for how humans actually behave.
Their conclusion reframed the entire field. Stop trying to train better operators. Redesign the environment. The cockpit is the variable.
That conclusion seeded human-factors engineering, was propagated through Don Norman's The Design of Everyday Things (1988), Atul Gawande's Checklist Manifesto (2009), and the surgical and ICU checklist literature, which has demonstrably saved lives by changing the environment rather than the operator. The SWE-agent paper put LLMs in the operator chair and applied the same logic. The ACI is a cockpit redesign for an agent.
This matters because it places harness engineering inside an eighty-year tradition with measurable outcomes. The discipline is not a fashion. It is the latest instance of a principle that has held true every time it has been applied: when an operator keeps repeating the same mistake, the environment is the variable.
Mechanical sympathy applied to a new substrate
The cockpit metaphor is one lens. The other, and the one that hits software engineers the hardest, is mechanical sympathy.

The phrase was coined by racing driver Jackie Stewart, who said you cannot drive a car fast unless you understand how it works. Martin Thompson brought it into software engineering around 2011 with the LMAX Disruptor, demonstrating that you could process millions of operations per second on commodity hardware if you wrote code that respected how the underlying machine actually behaves: CPU cache lines, branch prediction, memory hierarchy, false sharing, page faults. Mechanical sympathy is the discipline of writing software that adapts to the substrate on which it runs, rather than fighting it.
Harness engineering is mechanical sympathy applied to a new substrate. The substrate is the LLM, the context memory, and the attention budget. Like every substrate, it has named failure modes that the discipline teaches you to design around.

Mechanical sympathy vs harness engineering:
Mechanical sympathy (software)
- Write software that adapts to how the CPU works
- ...how memory works
- ...how the disk works
- Work around: cache misses, branch mispredictions, false sharing, page faults
Harness engineering (AI agents)
- Write agents that adapt to how LLMs work
- ...how context memory works
- ...how the attention budget works
- Work around: context rot, context panic, lost-in-the-middle, U-shaped attention
The four AI-side failure modes are real, named, measurable phenomena that production engineers hit constantly. Context rot is the documented decay in model performance as a context window fills with stale or low-signal tokens. Context panic is the failure mode where an agent under context pressure starts skipping steps and short-circuiting plans. Lost-in-the-middle is the now-replicated finding that information buried in the middle of a long prompt is reliably under-attended relative to the beginning and end. U-shaped attention is the broader generalization. None of these were nameable two years ago. All of them now have remediation patterns the harness can apply: context compression, working-memory discipline, retrieval ordering, structured note-taking, and sub-agent isolation.
This framing tells a tighter story about the lineage. Hardware mechanical sympathy taught software engineers to respect cache lines and memory layout around 2011. The SWE-agent paper in 2024 marked the moment when mechanical sympathy crossed from CPUs to LLMs. SWEs influenced projects such as Claude Code, OpenCode, Gemini CLI, and more. The same insight, applied to a new substrate, more than tripled coding-agent performance without changing the model. Harness engineering is the generalization of that insight to production agent systems. Three generations of the same idea, applied at progressively higher abstractions: CPUs, then agent-computer interfaces, now full agent runtimes.
How the practice became a named discipline: the late-2025 to early-2026 convergence
The practice of building harnesses is older than the name. Production teams shipping agentic systems through 2024 and 2025 were already building tool layers, context-assembly pipelines, validators, memory tiers, observability spans, and recovery loops around their models. Anyone who tried to ship Claude Code, OpenAI Codex, or Cursor on real codebases knew the model alone was not enough. The work had no shared vocabulary. Every team called it something different (the wrapper, the agent loop, the orchestration layer, the runtime), and each thought its version was custom.

Anthropic seeded the vocabulary first. Through the second half of 2025, while most teams still called the layer around the model "the wrapper" or "the agent loop," Anthropic was already publishing engineering writing that used the term "harness" as a term of art. Effective Context Engineering for AI Agents (28 September 2025) named context engineering a discrete engineering concern with its own patterns, separate from prompt engineering, and a key part of harness engineering. Effective Harnesses for Long-Running Agents (25 November 2025) went further, naming the harness itself a discrete artifact with a discrete set of design problems. By the time the rest of the industry caught up with the term in early 2026, Anthropic had been publishing about harnesses in print for months.
The credit Anthropic deserves for this discipline goes well beyond the vocabulary. The Model Context Protocol, the Agent Skills Open Standard, and the subagent design pattern. This subagent pattern was introduced by Claude Code (also in the Claude Agent SDK, derived from Claude Code) and later adopted by Codex, OpenCode, Gemini CLI, and LangChain Deep Agents. These are the load-bearing primitives that the rest of the harness ecosystem now builds on. Anthropic also chose to open these primitives rather than keep them proprietary: MCP was donated to the Linux Foundation in December 2025, and Agent Skills was released as an open standard with a public specification at agentskills.io.
The Claude Certified Architect: Foundations exam, released by Anthropic in 2025, tests practitioners on patterns that map almost one-to-one onto what this article calls harness engineering. If the certification were named today and vendor-agnostic, rather than in 2025, "Certified Harness Engineering Foundations" would not be an unreasonable title. The exam is, in substance, a certification in harness engineering.
In February 2026, Mitchell Hashimoto, co-founder of HashiCorp, wrote a blog post about his personal AI-adoption journey, in which he used the phrase "harness engineering" to describe the systematic practice of fixing agent mistakes by improving the harness rather than the prompt. Anthropic had the word; Hashimoto turned it into the name of a discipline. The framing landed.
On February 11, 2026, OpenAI followed with a formal definition in their post about building a million-line production codebase entirely with Codex agents. They described their primary engineering challenge not as model capability but as designing the environments, feedback loops, and control systems around the model. That post is what made the term institutional, in the sense that two of the three frontier labs were now using the same vocabulary in their public engineering writing.
From February to March 2026, Martin Fowler's site, LangChain, and Cobus Greyling wrote follow-up essays that distilled the discipline into formulas a working engineer could quote. Birgitta Boeckeler, writing on Fowler's site, framed the harness as the tooling and practices used to keep AI agents in check, naming three concerns specifically: context engineering (what the model sees), architectural constraints (what the model is allowed to do), and error garbage collection (continually pruning bad artifacts and drift before they propagate). LangChain compressed the whole picture into one formula:
Agent = Model + Harness
The model provides raw intelligence. The harness manages memory, tools, retries, human approvals, and observability so the model can focus on reasoning.
Then, on 23 March 2026, Anthropic published Harness Design for Long-Running Application Development, the most complete published reference design for the discipline to date. It is not a short-form essay; it is a full reference architecture covering context assembly, memory tiers, evaluation gates, recovery loops, and the operational patterns long-running agents need. If you read one document on harness design, that is the one. The post effectively closed the convergence window: the lab that first used the word "harness" in print also published the reference design that the rest of the industry now points to.
By April 2026, the term was in working use across major AI engineering teams, vendor blogs, and production retrospectives. The Hashimoto post and the OpenAI post were the moment the practice and the name converged. Anthropic's September 2025, November 2025, and March 2026 posts established the discipline's working vocabulary and reference architecture. The discipline is 12 months old as a named entity and roughly 3 years old as a practice.
What lives in the harness, and what lives in the model
Useful agent design depends on knowing exactly which dimensions of an agent are model concerns and which are harness concerns.
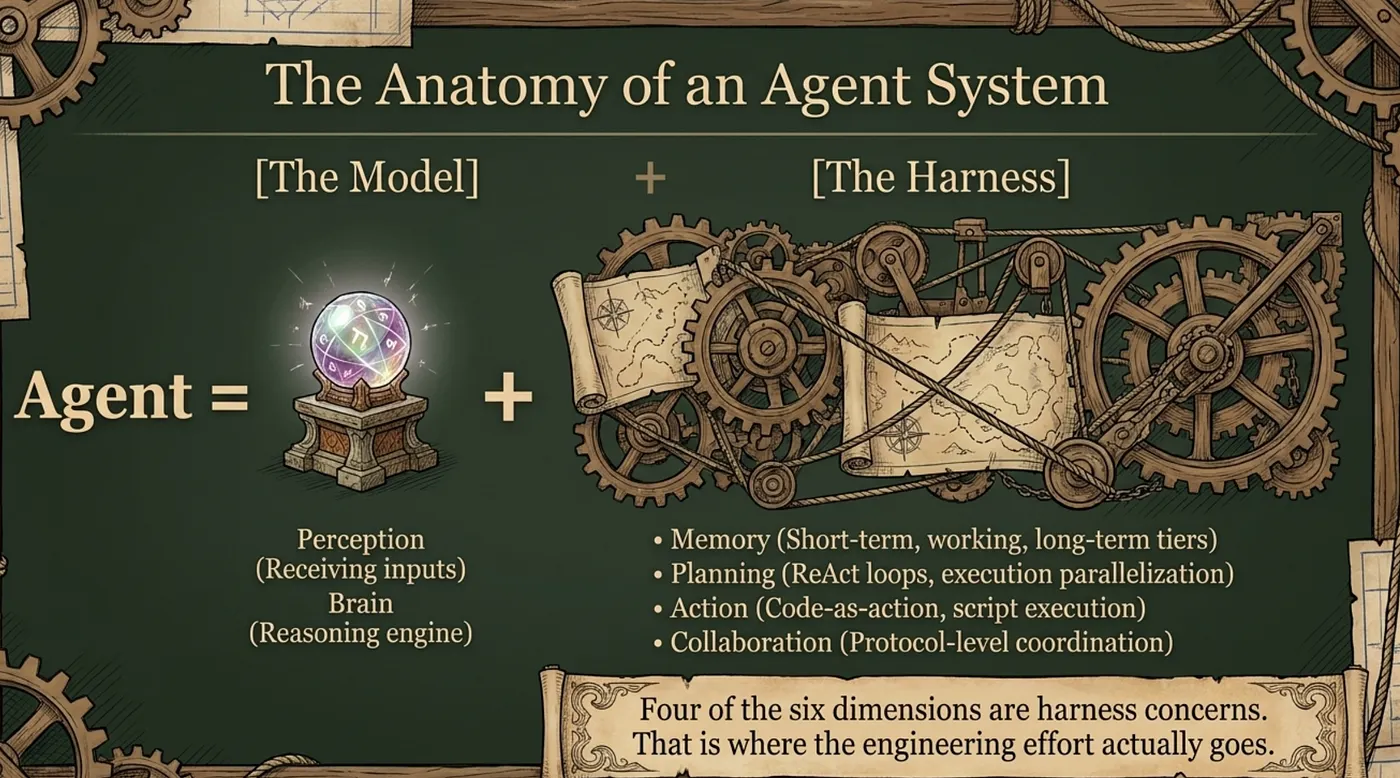
The cleanest working model I have found is six-dimensional:
Agent = Perception + Brain + Memory + Planning + Action + Collaboration
- Perception is how the agent receives and preprocesses inputs (text, images, structured data, tool responses).
- Brain is the reasoning engine, often a family of models routed by the harness (a fast model for extraction, a stronger model for orchestration, a frontier model for high-stakes decisions).
- Memory is its own engineering discipline, with short-term, working, and long-term layers, distinct from the reasoning engine.
- Planning is either a ReAct loop (reason and act at each step) or a plan-and-execute approach (decompose upfront, execute steps in parallel where possible).
- Action is increasingly code-as-action: the agent writes a short script that calls multiple tools, handles retries in code, and returns a single clean output, rather than streaming individual tool calls through a loop.
- Collaboration is now a protocol-level concern, governed by four open standards that operate at different layers. MCP (Model Context Protocol) is the vertical interface between an agent and its tools. A2A (Agent-to-Agent Protocol) is the horizontal interface between agents. Then, a quasi-standard is delegating tasks to subagents within a process to keep the main orchestrator agent's context clean. AG-UI is the frontend interface between an agent and its human user. The Agent Skills Open Standard is the capability acquisition interface.
Two of those six dimensions (Perception and Brain) are largely shaped by the model. The other four (Memory, Planning, Action, Collaboration) are largely shaped by the harness. That ratio, four to two, is the answer to "where does the engineering effort actually go?" It goes into the harness.
What a harness is not
The single most common misreading of the term comes from the failure-prevention framing. The harness is not a try/catch block around the model. It is not a guardrail in the moral-panic sense. It is not a wrapper whose purpose is to keep the model from saying something embarrassing.
The harness is what enables the model to do work it could not do alone. The cockpit metaphor is exact. A pilot in a 1944 fighter and a pilot in a modern fly-by-wire fighter have similar reflexes; the difference in what they can accomplish is overwhelmingly in the cockpit, the avionics, and the airframe. Same operator, different envelope. Harness engineering is what builds the new envelope.
The capability framing matters because it changes what you optimize for. If you treat the harness as a failure-prevention measure, you measure it by fewer bad outcomes. If you treat it as capability enabling, you measure it by larger, longer, more autonomous work successfully completed. Production teams that have made the shift in framing report that the second metric is the one that actually moves the business.
Why the timing is not a coincidence
Three forces converged in the last twelve months on top of the SWE-agent foundation, and none of them coordinated.
First, the terminology crystallized in February 2026. Hashimoto's essay, Birgitta Boeckeler's three-pillar definition on Martin Fowler's site, LangChain's "Anatomy of an Agent Harness," and Anthropic's harness design paper appeared within weeks of one another. They converged because the problem they were each solving had the same shape. AGENTS.md, an open convention that emerged from this work, has been adopted by more than 60,000 projects in under a year.

Second, the frameworks stabilized. Claude Agent SDK, LangChain Deep Agents, and the rebuilt OpenAI Agents SDK all reached general availability within the last six months. The four-protocol stack underneath them stabilized at the same time: MCP was donated to the Agentic AI Foundation under the Linux Foundation in December 2025; A2A reached version 1.0 in early 2026 with backing from more than 150 organizations; AG-UI achieved native support in Amazon Bedrock AgentCore and Microsoft Agent Framework; the Agent Skills Open Standard reached implementations across Claude Code, OpenAI Codex CLI, Cursor, GitHub Copilot, Goose, and Gemini CLI.
Third, the regulatory clock arrived on the same calendar. EU AI Act enforcement deadlines hit in 2026. NIST's AI Risk Management Framework is now a de facto standard for U.S. federal contractors. The FDA published draft guidance for AI in regulated settings. Compliance teams are now asking engineering teams to demonstrate exactly the auditability that a harness provides.

Naming, frameworks, protocols, and regulation. All four arrived atop a four-year design lineage. That is why "harness engineering" stuck, and "agent loop" did not.
What does this mean if you are building agents today
You are doing harness engineering, whether you call it that or not. The cost of doing it without shared vocabulary is real. Teams reinvent the same patterns. They miss the same failure modes. They rebuild the same infrastructure three times.
The vocabulary is now stable enough to use. The reference designs are public (Anthropic's three harness posts, the SWE-agent ACI ablation, LangChain's Deep Agents harness commentary). The pattern catalogs are converging across vendors, with no coordination, on the same shapes. The open protocols underneath the harness layer (MCP, A2A, AG-UI, Agent Skills) are stable enough to build on.
If you have been calling it the wrapper, the loop, or the runtime, this is the moment to switch. The harness is the right name. The discipline is harness engineering. And the principle, the one Fitts and Jones articulated in 1947, and the SWE-agent team applied to LLMs in 2024, is the same in every generation: when the operator keeps making the same mistake, the environment is the variable.
Coda
Twelve months ago, building production agents felt like running through a sliding glass door we did not see. We got cut. We learned. The discipline now has names for what was behind the glass: context rot, drift, the harness, the cockpit, the four protocols, and naming, which is what puts a handle on the door. The next team does not have to bleed to get through. They can see the door, find the handle, and walk through. That is what the cockpit does for the pilot. That is what the harness does for the agent. And that is what a named discipline does for the field.

References
- Yang, Jimenez, Wettig, Lieret, Yao, Narasimhan, Press. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. NeurIPS 2024; arXiv 2405.15793.
- Jimenez, Yang, Wettig, Yao, Pei, Press, Narasimhan. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? ICLR 2024.
- Fitts and Jones. Analysis of Factors Contributing to 460 Pilot Error Experiences in Operating Aircraft Controls. USAF Aero Medical Laboratory, 1947.
- Don Norman. The Design of Everyday Things, Revised and Expanded Edition. Basic Books, 1988/2013.
- Atul Gawande. The Checklist Manifesto. Metropolitan Books, 2009.
- Martin Thompson et al. LMAX Disruptor (mechanical sympathy in high-performance Java systems), circa 2011.
- Anthropic. Effective Context Engineering for AI Agents. September 2025.
- Anthropic. Effective Harnesses for Long-Running Agents. November 2025.
- Anthropic. Harness Design for Long-Running Application Development. March 2026.
- Mitchell Hashimoto. Personal blog, February 2026 (coined harness engineering as a discipline name).
- OpenAI. Building a million-line production codebase with Codex agents. February 11, 2026.
- Birgitta Boeckeler / Martin Fowler's site. Three-pillar harness definition (context engineering, architectural constraints, error garbage collection), February 2026.
- LangChain. Anatomy of an Agent Harness and Improving Deep Agents with Harness Engineering, 2026.
- Liu, Lin, Hewitt, Paranjape, Bevilacqua, Petroni, Liang. Lost in the Middle: How Language Models Use Long Contexts. TACL 2024.
- Du et al. Context Length Alone Hurts LLM Performance Despite Perfect Retrieval. EMNLP Findings 2025; arXiv 2510.05381.
Rick Hightower is co-founder and Senior AI Architect at Spillwave LLC, a Java Champion (2017), and author of five technical books, a former Senior Distinguished Engineer and Senior Technical Director at a Fortune 100 fintech. He blogs on Harness Engineering, CCA-F prep, Agent Skills, and the practitioner edge of agentic AI. If you are looking for a partner to run through glass doors with, follow the Harness Engineering series on Medium @richardhightower -- https://medium.com/@richardhightower.