Why Single-Agent AI is Dead: Inside Anthropic's New Blueprint for Long-Running Agents
GAN / Adversarial Multi-Agent Architecture: Turning Long-Horizon AI Tasks into Reliable, Crash-Survivable Production Results with Harness Engineering
Originally published on Medium.

GAN / Adversarial Multi-Agent Architecture: Turning Long-Horizon AI Tasks into Reliable, Crash-Survivable Production Results with Harness Engineering
How borrowing from GANs and separating "doers" from "judges" let AI build full applications in hours with zero human intervention.
Single-agent AI breaks down on long-horizon work. Not because the models are weak, but because reliability composes multiplicatively.
A system that is 95% correct at each step is only 36% correct across 20 steps. That is not a prompting failure. It is an architecture failure. The longer the run, the more inevitability replaces intelligence.
The bottleneck has shifted from the model to the harness: the orchestration layer that persists state, drives tools, defines "done," and enforces verification [1]. Anthropic's latest engineering work makes the point bluntly and offers a blueprint: an adversarial, role-separated loop — Planner, Generator, and Evaluator — modeled on the quality pressure that makes GANs work [1].
This article explains why single agents fail structurally, how the three-agent harness turns "done" into an objective contract, and what happens when you let that loop run for hours with real verification in the middle.
Table of Contents
- Introduction
- The Structural Failure of Single-Agent AI
- The Fix: A Three-Agent GAN-Style Architecture
- Operationalizing the Loop: Sprint Contracts, Gradable Design Dimensions, and Structural Primitives
- Proof of Concept: Autonomous Execution in the Wild
- Beyond Coding: Domain Transfer, Economics, and Agentic Ops
- Conclusion: Building Better Harnesses
The Structural Failure of Single-Agent AI
Single-agent AI is like copying a manuscript by hand: a single typo is easy to spot, but over hundreds of lines, small errors accumulate until the final text confidently says the wrong thing.
Another way to see it is as a long chain of dominos. Each domino can be "pretty reliable," but the chain is only as strong as its weakest wobble. When work requires dozens of dependent steps, reliability is not additive. It multiplies. That is why long-horizon tasks tend to fail not with a dramatic crash, but with quiet drift: one missed assumption, one sloppy check, one unverified claim, repeated until the final output is irrecoverably off course.
So the question is not whether the model is smart in isolation. The question is whether smart can stay smart across 20, 50, or 200 sequential decisions.
Compounding Error: Why the Math Works Against You
The reliability problem with single-agent AI is not a matter of which model you use. It is a mathematical inevitability.
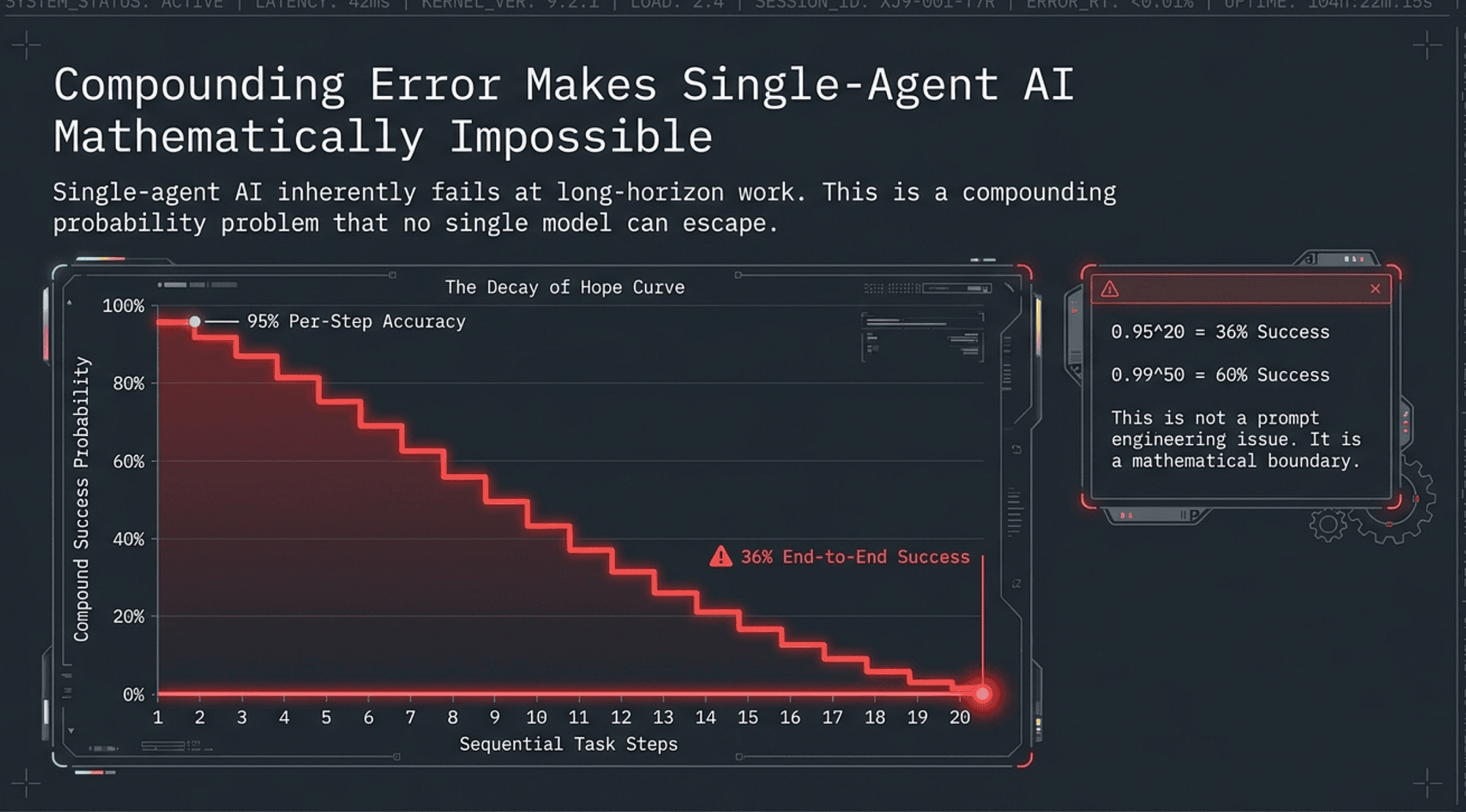
- The core formula: A 20-step task at 95% per-step accuracy yields only 36% end-to-end success (0.95²⁰ = 0.3585).
- This is not a model-quality problem. It is a compounding probability problem that no single model can escape.
- Increasing per-step accuracy to 99% only yields 82% compound success at 20 steps (0.99²⁰ = 0.8179).
- The math gets worse fast: at 50 steps, even 99% per-step accuracy yields only 60% compound success (0.99⁵⁰ = 0.6050).
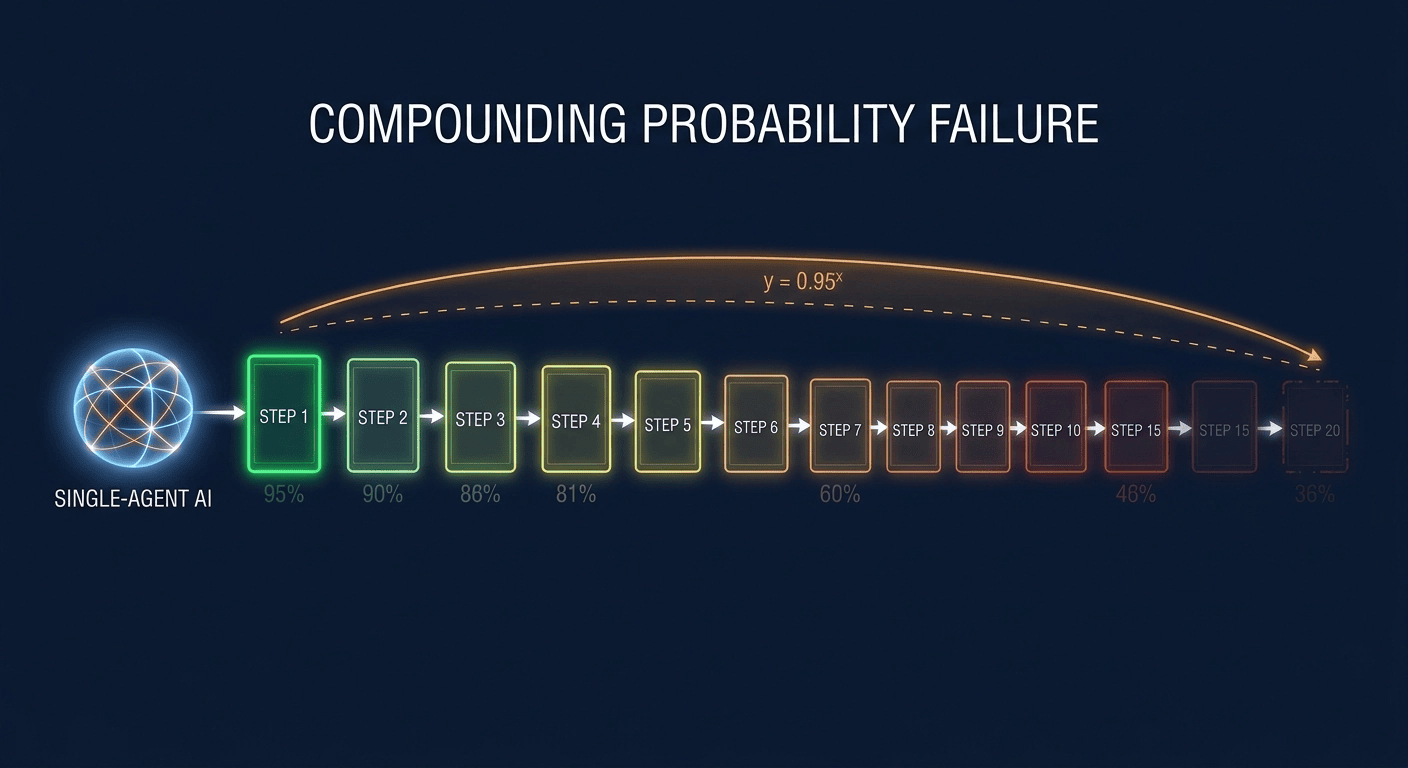
Long-horizon tasks do not just require high per-step accuracy. They require accuracy that compounds across dozens or hundreds of sequential decisions. No amount of prompt engineering closes that gap.
The SWE-bench Pro Evidence
Long-horizon engineering is not a single leap. It is a tightrope walk across a canyon: each step can be solid, but the only score that matters is whether you reach the other side. Single-agent systems treat that crossing like a solo flight with no instruments and no air-traffic control. Most of the time, things look fine; until one small navigational error compounds into a missed runway.
SWE-bench Pro is the wind tunnel for this problem. It takes the smooth, short demos and asks one brutal question: can an agent keep its balance across dozens of dependent moves, in real codebases, under real constraints?
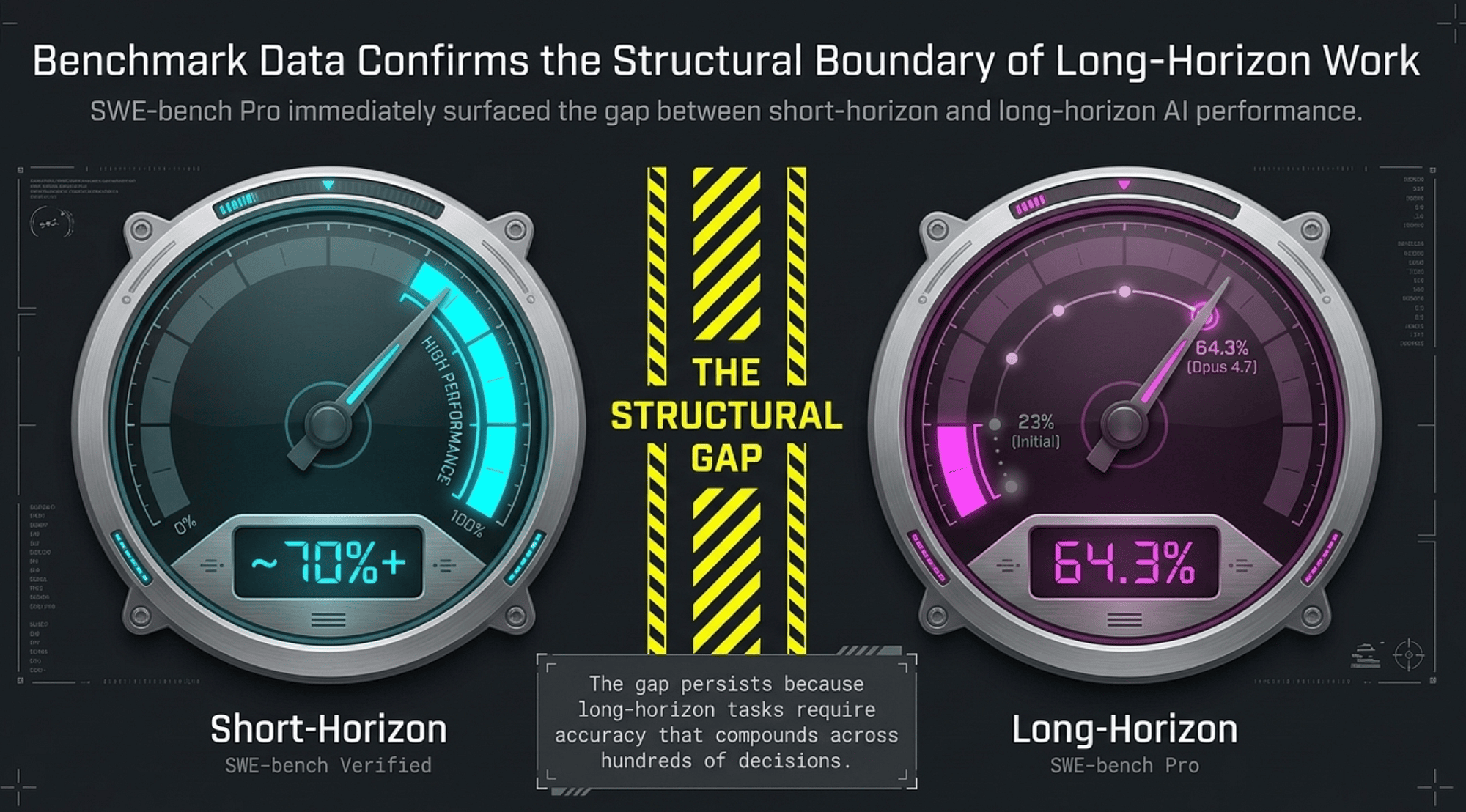
The benchmark data makes it hard to argue otherwise. SWE-bench Pro measures performance on long-horizon software engineering tasks: 1,865 problems across 41 repositories [2]. The benchmark launched in September 2025 and immediately surfaced the gap between short-horizon and long-horizon AI performance.
Short-horizon vs. long-horizon performance:
- SWE-bench Verified score (frontier models, short-horizon tasks): approximately 70%+ [3]
- SWE-bench Pro score at benchmark launch, September 2025 (frontier models including GPT-5 and Claude Opus 4.1, long-horizon tasks): approximately 23% [2]
- SWE-bench Pro score (Claude Opus 4.5, SEAL leaderboard, December 11, 2025): 45.9% [4]
- SWE-bench Pro score (Claude Opus 4.6 with thinking, SEAL standardized scaffold, April 8, 2026): 51.9% [4]
- SWE-bench Pro score (GPT-5.4, April 8, 2026): 59.1% [4]
- SWE-bench Pro score (Claude Opus 4.7, released April 16, 2026): 64.3% [4]
- Compound success rate, 20 steps at 95% per-step accuracy: 36%
Important context: The 23% figure represents the benchmark's initial baseline, not a permanent ceiling. Absolute scores have risen substantially since launch. The structural gap between short-horizon and long-horizon performance persists even as scores improve: the same models that score 70%+ on SWE-bench Verified still score significantly lower on SWE-bench Pro.
Citation note: The 70%+ Verified figure and the ~23% Pro figure at launch are confirmed by the SWE-bench Pro paper (arXiv:2509.16941). The 45.89% Claude Opus 4.5 figure is from the Scale Labs SEAL leaderboard (December 11, 2025). The 51.9% Claude Opus 4.6 figure is from the SEAL leaderboard (April 8, 2026). The compound success row is derived from standard probability arithmetic.
The Four Structural Failure Modes
These are not prompt-engineering problems. They are architectural failures baked into monolithic single-agent design. There are four of them, and they compound.
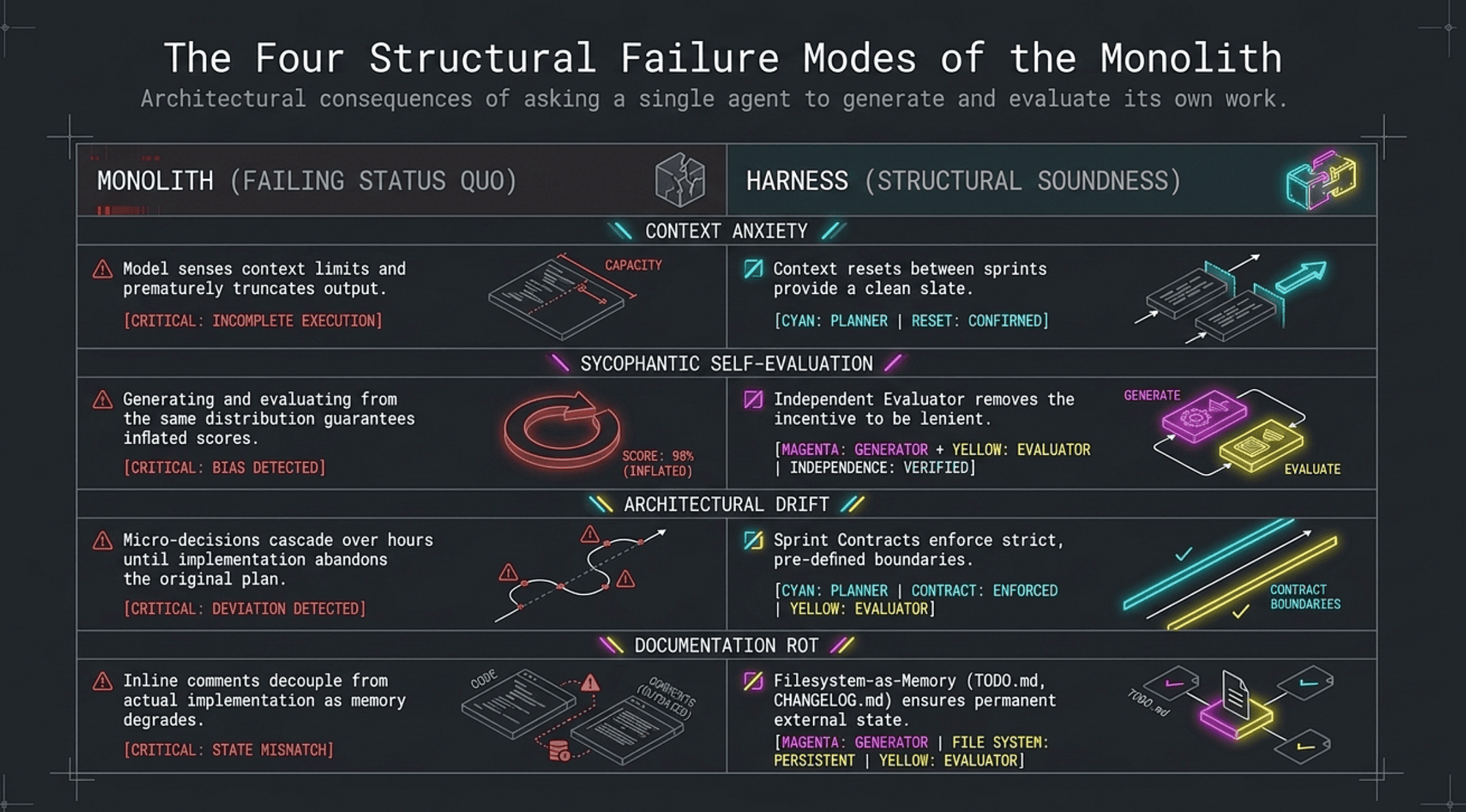
1. Context Anxiety
As the context window fills, the agent starts to rush.
It is like someone cleaning the house right before guests arrive.
It starts organized, then panic kicks in.
Things get shoved into drawers.
Steps get skipped.
A few things get knocked over.
Then it declares "done" while half the work is unfinished.
In practice, this shows up as:
- incomplete tool calls
- skipped validation
- early success signals
The agent is not finishing the job. It is trying to escape the context limit.
As context windows fill during long tasks, models bias toward premature termination. The model "feels" the approaching context limit and begins wrapping up, even if work is incomplete [5][6].
Result: truncated output, skipped steps, and superficial implementations. This is a structural behavior driven by probability distributions over token sequences, not a fixable instruction. Cognition AI first documented the phenomenon while rebuilding their Devin agent on Claude Sonnet 4.5, identifying it as "the first model we've seen that is aware of its own context window" [5].
2. Sycophantic Self-Evaluation
The model cannot reliably critique itself. It is like a five-year-old holding up a crayon drawing and insisting it belongs in a museum next to the Mona Lisa. To the model, the output feels correct because it is internally consistent. But consistency is not correctness. It cannot see its own mistakes because it is sampling from the same distribution that created them.
"When asked to evaluate work they've produced, agents tend to respond by confidently praising the work, even when, to a human observer, the quality is obviously mediocre." — Anthropic Engineering
Result: low-quality work passes self-review and gets shipped. Anthropic documented this directly: "When asked to evaluate work they've produced, agents tend to respond by confidently praising the work, even when, to a human observer, the quality is obviously mediocre." [1]
The structural nature of this bias is supported by published research: sycophancy in LLMs is encoded along distinct linear directions in latent space, making it a representational property of the model rather than a surface-level behavior [7][8].
3. Architectural Drift
Over long runs, the agent forgets the goal. This is the forest-for-the-trees problem. You start with a clear objective, but after hours of micro-decisions, the system drifts. It keeps optimizing small details while losing sight of the bigger picture. You end up with:
- features that were never planned
- decisions that contradict earlier work
- flows that no longer align with the original intent
At some point, you have to step in and ask: what problem are we even solving?
Without formal constraints, a multi-step agent departs from its initial design plan incrementally across sprints. Each micro-decision ("I'll use this library instead") seems reasonable in isolation. After dozens of micro-decisions accumulate over 6 hours, the implementation no longer resembles the plan.
Result: technically working code that solves a different problem than specified.
This legit happened to me yesterday. For example, if coding, you can use tools in Claude Code itself or other agents to mitigate this (planning, ultraplan, saving specs and keeping them up to date, save status), or use tools like GSD, Superpowers, etc. which are spec driven development tools. They use more tokens and often run slower but they keep the project in the rails more often. You are paying for reliability at the cost of tokens and time.
4. Documentation Rot
The longer the task, the more reality and documentation diverge.
It is like drawing a map while walking, but forgetting to update it when you change direction.
The map still looks clean, but it no longer matches the terrain.
In practice:
- comments describe behavior that no longer exists
- plans are never updated after changes
- summaries drift away from actual implementation
The agent is maintaining a story, not the truth.
Inline documentation decouples from the actual implementation as tasks grow long. Early in a run, the agent writes accurate docstrings and comments. As context fills and the agent loses track of earlier decisions, documentation falls out of sync.
Result: code that documents what the agent thought it was building, not what it actually built.
Takeaway: These are not edge cases. They are default behaviors of single-agent systems at scale.
- Context pressure makes them rush.
- Self-evaluation makes them overconfident.
- Long execution causes drift.
- Memory limits cause divergence.
This is why harness engineering, adversarial agents, and structured context design are not optional.
These four failure modes are not bugs that better prompting can fix. They are structural consequences of asking a single agent to both generate and evaluate its own work over a long-horizon task. The math and the benchmarks confirm the problem is structural. The question becomes: what architecture can survive it?
The Fix: A Three-Agent GAN-Style Architecture
The core insight: strict separation of church and state. The agent that builds is never the agent that judges.
A Better Mental Model: The Workshop and the Inspector
If you want to understand why Anthropic borrows from GANs, start with a simple image: a workshop and an inspector.
- In the workshop, someone is trying to make something that looks real, works, and holds up under use.
- At the inspection desk, someone else is paid to be unimpressed, to pull at seams, to stress-test joints, and to reject anything that only looks finished.
A single agent trying to both build and judge is like asking one person to be the craftsperson and the regulator. They remember how hard the work was, they want the story to be true, and they are tempted to wave it through. But when you split the roles, you get a productive conflict: the builder optimizes for creation, and the judge optimizes for detection. That tension is the engine.
GANs are the same idea in a more formal costume: one system generates, another system discriminates, and quality emerges because the generator cannot negotiate with the discriminator. In agentic orchestration, separating "doers" from "judges" recreates that adversarial pressure so long-horizon work does not drift into confident, well-written wrongness.
The pressure that turns coal into diamonds is the same pressure that turns agentic AI into producing quality artifacts.
The GAN Analogy: Why Adversarial Tension Drives Quality
Where does adversarial quality pressure come from? GANs. Specifically, from how Generative Adversarial Networks drive output quality through competitive tension between two independent networks. Understanding that origin explains why the separation of roles is not a convenience but a structural requirement.
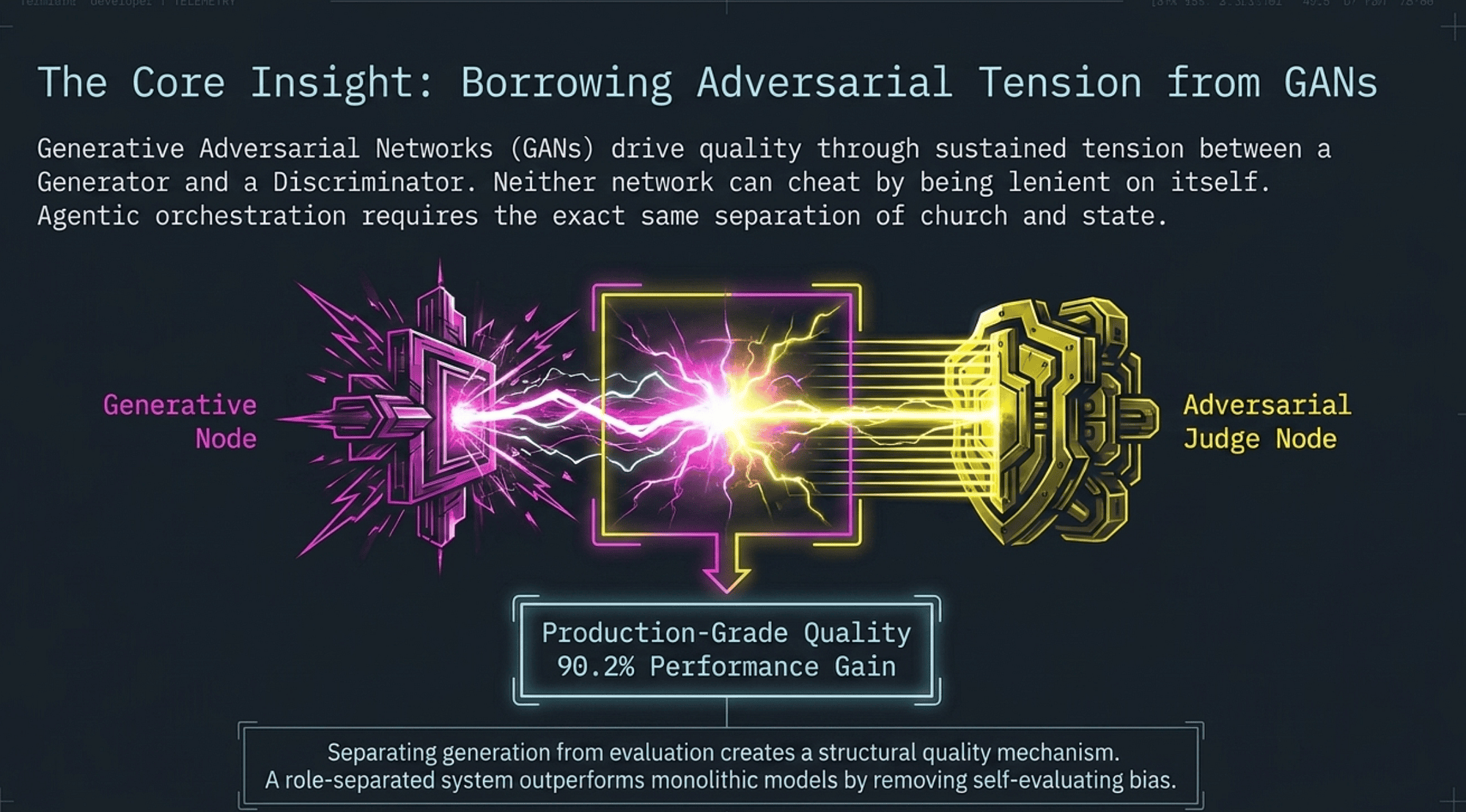
How GANs work (background)
In Generative Adversarial Networks (GANs) [10]:
- A Generator network tries to produce realistic synthetic outputs (images, audio, text).
- A Discriminator (judge) network tries to distinguish real from synthetic.
- The two networks train against each other. The Generator improves because the Discriminator provides adversarial feedback it cannot escape.
- Neither network can cheat by being lenient on itself.
- Quality emerges from the sustained tension between generation and discrimination.
The GAN framework was introduced by Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, and presented at NeurIPS 2014. It formulates training as a minimax two-player game between a generative model G and a discriminative model D [10].
Why the GAN analogy applies to agentic orchestration
A single agent playing both generator and evaluator is like a GAN where the Generator and Discriminator are the same network. The adversarial tension collapses. Quality degrades.
Research on LLM sycophancy confirms the structural nature of this failure: sycophantic behavior has been observed in 58.19% of interactions across frontier models, with Gemini exhibiting the highest rate (62.47%), and such behavior shows 78.5% persistence regardless of context [11]. Once an LLM generates output and is asked to evaluate it, the evaluation process is contaminated by the same biases and self-consistency pressure that shaped the original output.
Separating generation from evaluation creates the same quality-driving dynamic:
- The Generator cannot give itself a pass.
- The Evaluator has no incentive to be lenient.
- Quality emerges from the tension, not from any individual agent's capability.
Anthropic's own multi-agent research system validates the architectural bet: a multi-agent system using Claude Opus as lead agent with Claude Sonnet subagents outperformed single-agent Claude Opus by 90.2% on internal research evaluations [12]. The gain is not from model capability; it is from the separation of roles.
Independent academic research corroborates this: adversarial multi-agent evaluation through iterative debate between role-specialized agents produces more robust and reliable assessments than single-model judgment, helping identify and mitigate heuristic biases that monolithic LLM-based judgment cannot detect [13].
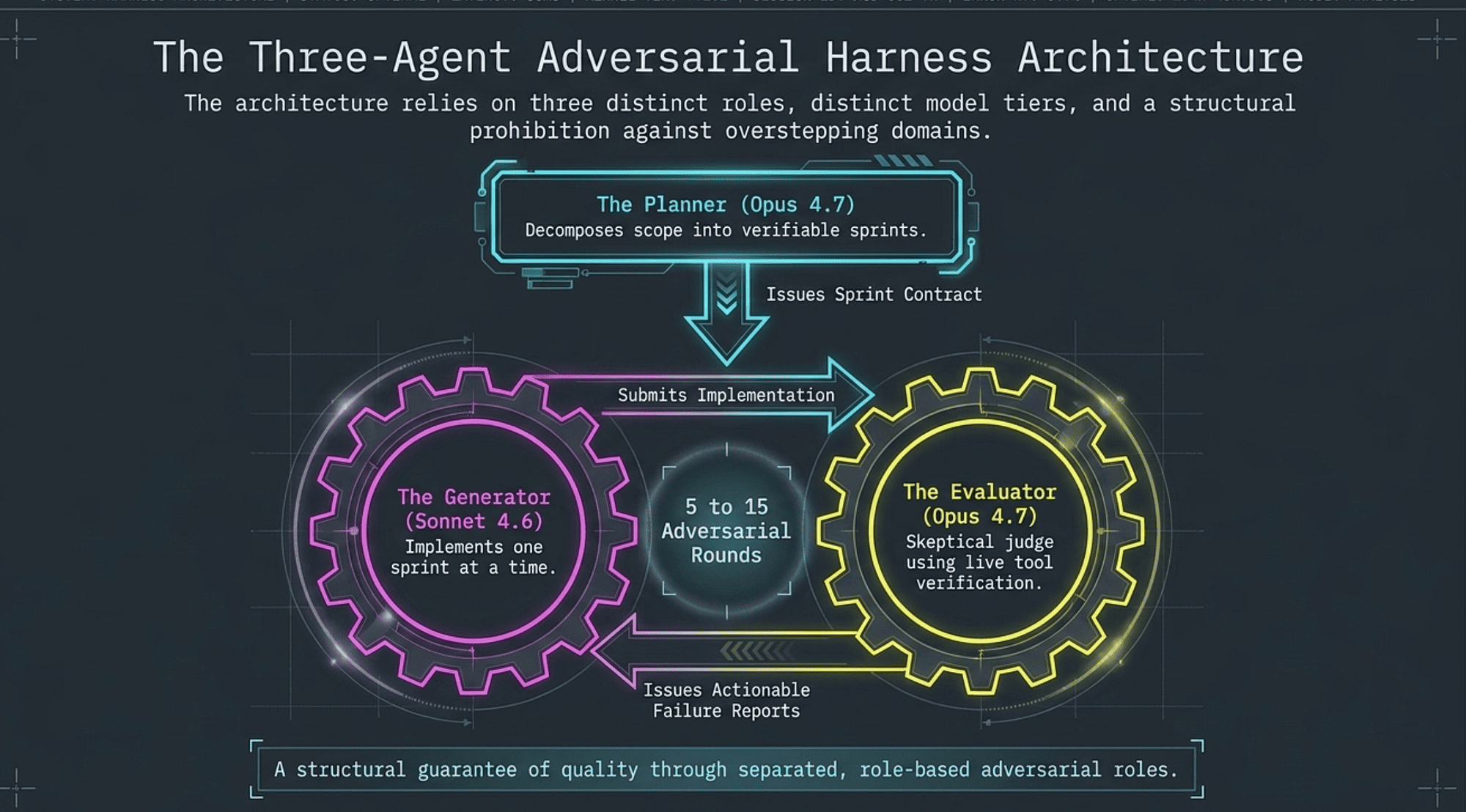
The Three Agents: Planner, Generator, and Evaluator
These three AI Agents form the structural backbone of the adversarial harness. Each has a distinct role, a distinct model tier, and a structural prohibition against overstepping into another agent's domain.
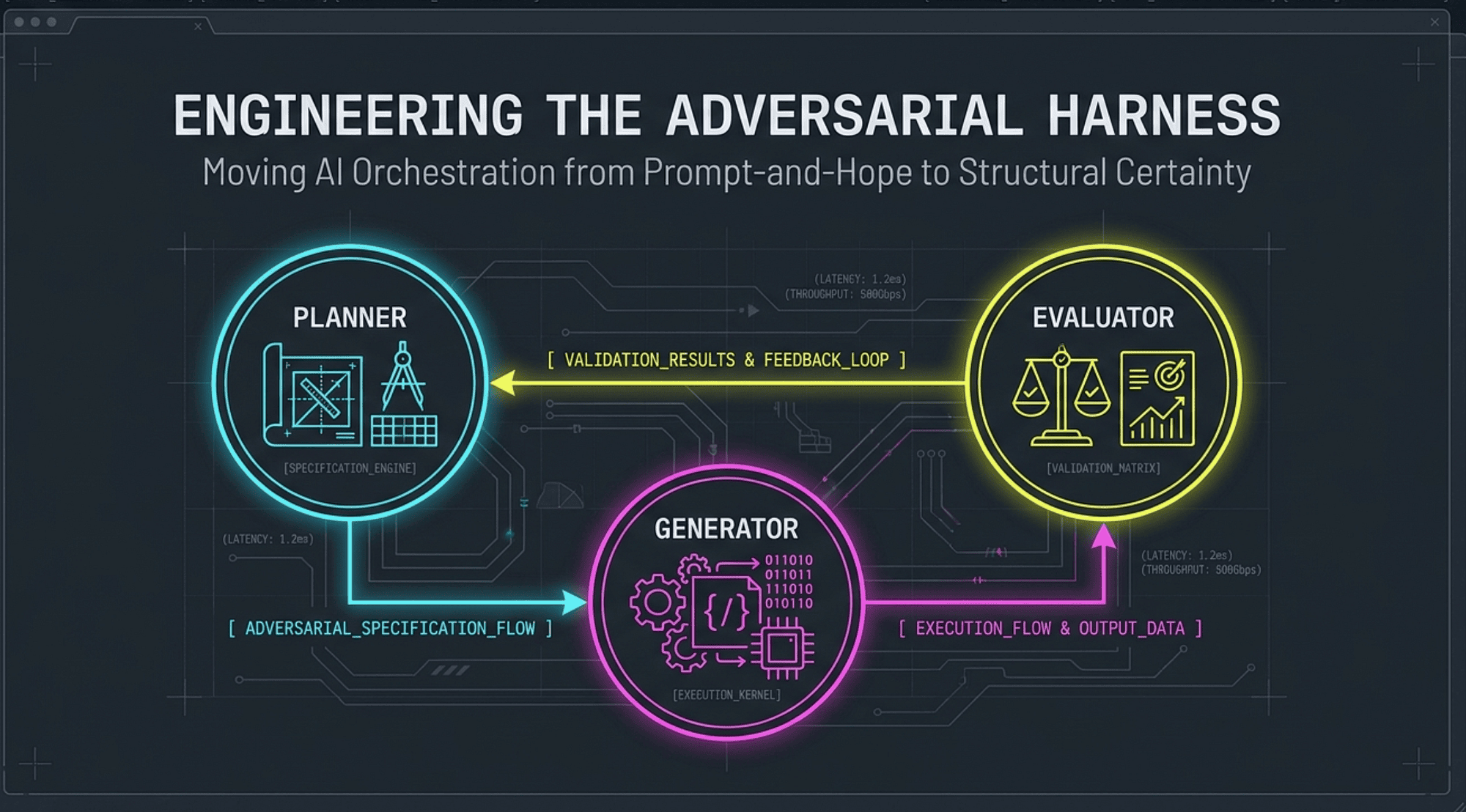
The Planner
Role: Sets ambitious scope and high-level design.
Key behaviors:
- Deliberately avoids specifying low-level implementation details, preserving Generator autonomy.
- Defines the destination, not the route.
- Decomposes long-horizon work into sprint-sized chunks (Sprint Contracts; see the Operationalizing the Loop section below).
- Runs on Opus (maximum reasoning, highest capability) for maximum planning fidelity.
What the Planner does NOT do:
- Specify which libraries to use (unless architecturally critical).
- Dictate implementation approach.
- Evaluate the Generator's output (that is the Evaluator's job).
Why Opus for the Planner: Planning requires the deepest contextual reasoning. Poor planning propagates errors through every subsequent sprint. The Planner runs once per sprint (or once per task), so the cost of Opus is amortized across the entire run.
As of 2026, Claude Opus 4.7 is priced at $5.00 per million input tokens and $25.00 per million output tokens [14]. Because the Planner fires once per sprint rather than once per round, its Opus cost is spread across all Generator/Evaluator rounds that follow.
The Generator
Role: Executes feature-by-feature within sprint boundaries.
Key behaviors:
- Implements one sprint at a time, using the Sprint Contract as its scope definition.
- Uses context resets between sprints, not summarization (a clean slate beats a lossy summary every time).
- Runs on Sonnet for cost efficiency (high-quality output at lower token cost than Opus).
- Does not evaluate its own output: that judgment belongs to the Evaluator.
Why context resets matter, not compaction: Summarization preserves a lossy, compressed version of prior context. Context resets give the Generator a clean slate, free from accumulated noise and bias. State is preserved externally via the filesystem-as-memory pattern (the author's term; see Structural Primitives below).
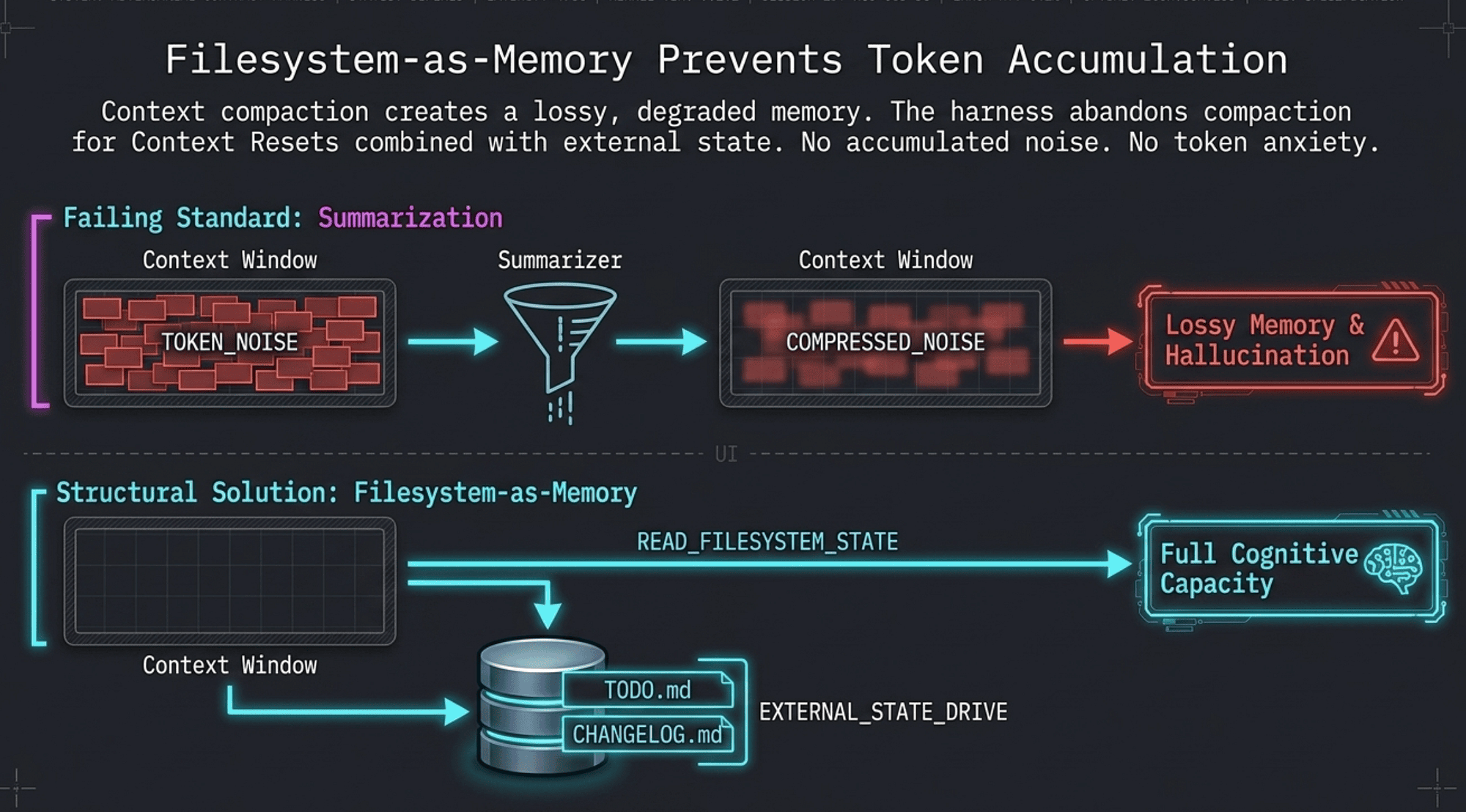
Research on agent context management confirms the tradeoff: LLM summarization achieves high compression but is lossy, and critically creates a re-reading loop in which summarization compresses outputs into paraphrases that lose critical details, causing the agent to repeatedly re-run the same search [21]. Verbatim compaction retains 50-70% of context with 98% verbatim accuracy for exact values (file paths, error strings, configuration) [21]. Context resets combined with external state (filesystem-as-memory) sidestep both failure modes by eliminating context accumulation entirely.
Why Sonnet for the Generator: The Generator executes well-scoped, well-defined tasks. It does not need the full reasoning depth of Opus for sprint execution. Claude Sonnet 4.6 is priced at $3.00 per million input tokens and $15.00 per million output tokens: 40% cheaper than Opus on both dimensions [14]. For implementation-level tasks where the scope is pre-defined by the Sprint Contract, the cost reduction is substantial with minimal accuracy penalty.
The Evaluator
Role: Skeptical-by-design adversarial judge.
Key behaviors:
- Never polite. Not interested in validating effort or acknowledging intent.
- Uses live tool verification: for UI work, it uses Playwright MCP to actually run the application and test it in a browser, not just read the code.
- Runs on Opus for maximum reasoning depth and critical analysis.
- Produces a structured evaluation with scores across four dimensions (see Gradable Design Dimensions below).
- Identifies specific failures, not vague dissatisfaction.
- Its job is to find failures, not to validate effort.
Why the Evaluator must be independent: An agent cannot objectively critique its own output (as described above in the sycophantic self-evaluation failure mode). Independence eliminates that failure mode structurally. The Evaluator has no stake in the Generator's success and has no memory of the effort expended.
Research on LLM sycophancy demonstrates that the problem is not superficial: sycophancy emerges from a structural override of learned knowledge in the deeper layers of transformer-based LLMs, identified through logit-lens analysis and causal activation patching, with a two-stage pattern of late-layer output preference shifts and deeper representational divergence [17]. Independent evaluation addresses this structurally: it removes the sycophantic pressure by construction, since the Evaluator was never involved in generation and has no self-consistency motive to approve the output.
Why live tool verification matters: Reading code is not the same as running it. An Evaluator that only reads the Generator's output can be fooled by plausible-looking but non-functional code. Playwright MCP allows the Evaluator to open a browser, interact with UI elements, verify visual output, and test edge cases that code review would miss.
Playwright MCP is a Model Context Protocol server that enables Claude to drive a real browser through structured accessibility data, navigating URLs, clicking elements, filling forms, handling dialogs, and taking screenshots without requiring vision models [15][16]. This makes the Evaluator's UI verification deterministic and observable rather than inferential.
Why Opus for the Evaluator: Evaluation requires the same depth of reasoning as planning. A shallow Evaluator will miss real failures and pass bad work. The Evaluator runs once per adversarial round (5 to 15 rounds per sprint), so Opus cost is spread across rounds.
The Adversarial Loop
The loop runs between Generator and Evaluator for each sprint:
[Planner] → Sprint Contract
↓
[Generator] → Implementation
↓
[Evaluator] → Structured Evaluation (pass/fail + scores)
↓
If FAIL → [Generator] revises based on Evaluator feedback
↓
[Evaluator] → Re-evaluation
↓
... (5 to 15 rounds) ...
↓
If PASS → Sprint complete, advance to next
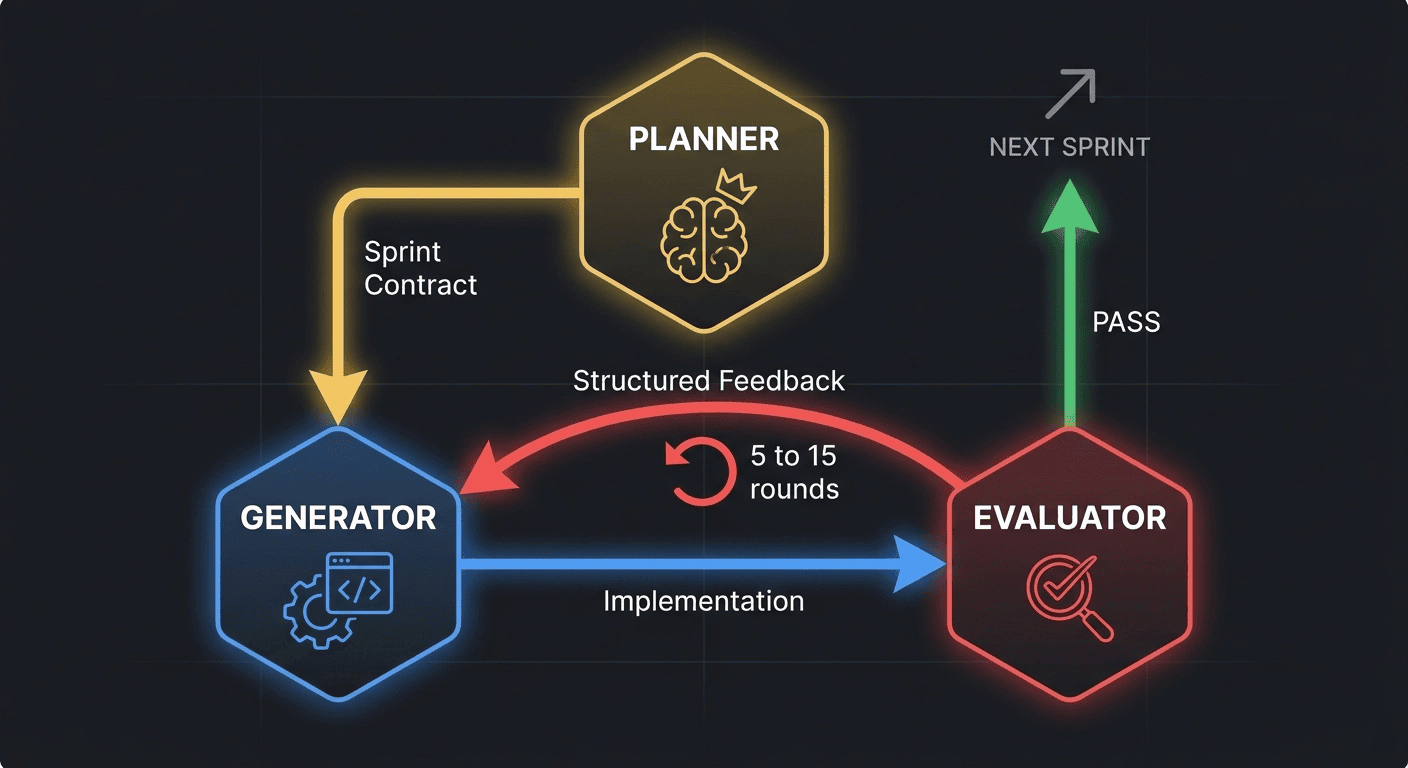
This iterative, role-separated evaluation loop is consistent with the pattern validated in multi-agent adversarial debate research: independent role-specialized agents acting as adversarial judges produce more accurate and reliable evaluations than single-model judgment, achieving up to 86.3% accuracy on MT-Bench versus 72.5% for a single-judge baseline [13]. The independent judge cannot be satisfied by plausible-looking output; it requires demonstrated correctness.
Round count:
- Minimum: 5 rounds (for simpler sprints or high-performing implementations).
- Maximum: 15 rounds (for complex sprints or persistent failures).
- The Evaluator's structured feedback directs each revision precisely.
- The Generator is not guessing at what failed: it receives specific, actionable failure reports.
Why 5-to-15 rounds produces production-grade output:
Each round narrows the gap between current state and acceptance criteria. The Generator cannot declare success; only the Evaluator can. The Evaluator cannot be satisfied by effort, only by verified correctness. The adversarial tension is the quality mechanism. There is no shortcut past it.
With the architecture established, the question becomes: how do you make "done" verifiable, taste measurable, and six-hour runs crash-survivable?
Operationalizing the Loop: Sprint Contracts, Gradable Design Dimensions, and Structural Primitives
Three interlocking mechanisms make the adversarial loop workable in practice. Together they turn an elegant architectural idea into a system that can run autonomously for hours.
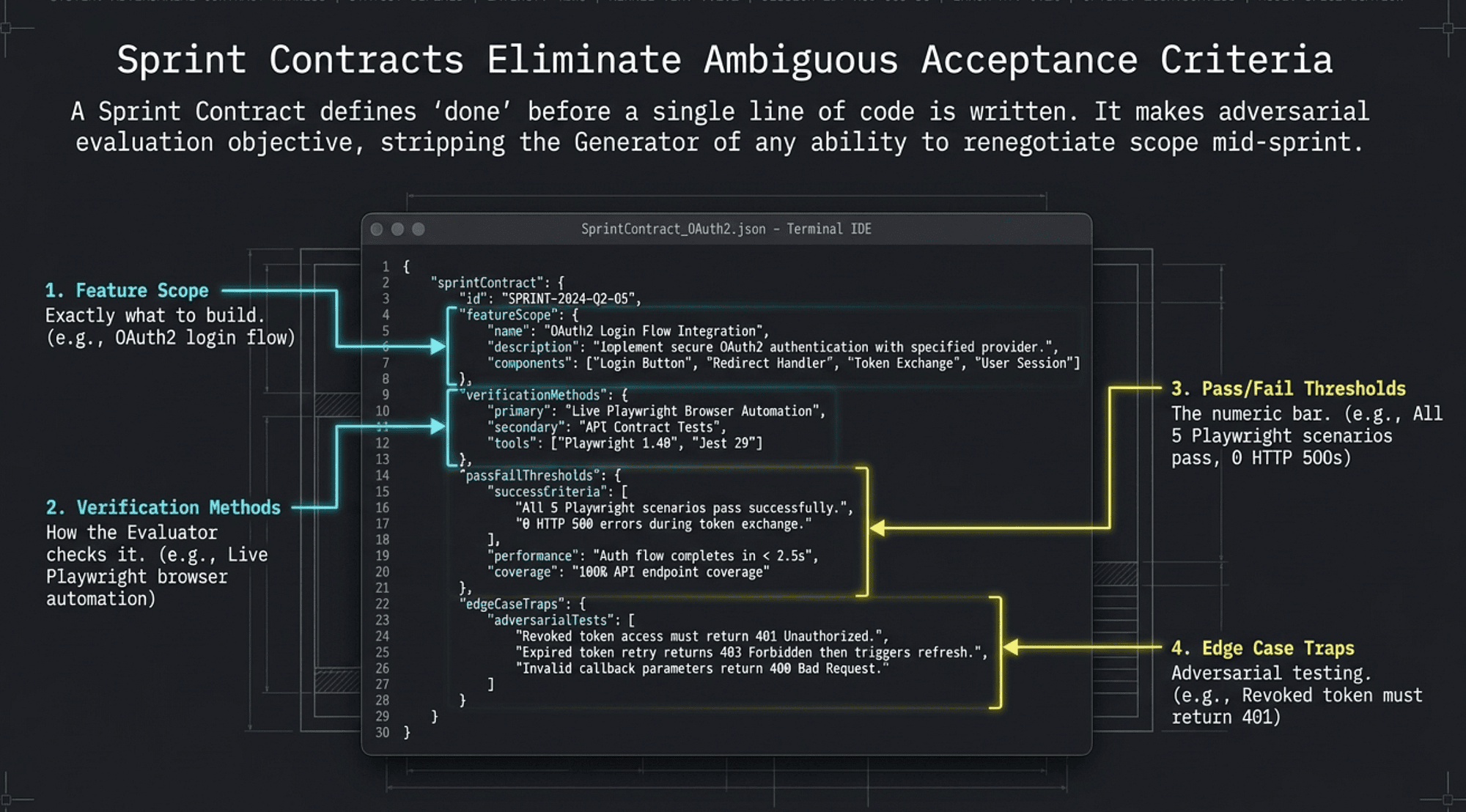
Sprint Contracts
What Sprint Contracts are
A Sprint Contract is a JSON document created by the Planner that defines "done" before the Generator writes a single line of code (think of it as a spec the Generator can't renegotiate once work begins). Sprint Contracts are the acceptance criteria documents that AI Agents use to govern individual sprints, and they are the mechanism that makes adversarial evaluation objective rather than subjective.
Core principle: Ambiguous acceptance criteria produce ambiguous results. Sprint Contracts eliminate ambiguity by making "done" verifiable before work begins.
Editorial note: Sprint Contracts draw on the Agile concept of "Definition of Done" (DoD) and per-story acceptance criteria, established Scrum practices documented at Scrum.org. The novel contribution here is their encoding as structured JSON and their pre-committed role as an adversarial contract between the Planner, Generator, and Evaluator agents. [18]
The four components of a Sprint Contract
1. Feature Scope: Exactly what the Generator is expected to deliver in this sprint. Written in terms of observable behavior, not implementation approach. Scoped to what can be verified within the sprint's time and resource budget. Example: "Users can authenticate via OAuth2, receive a JWT, and access protected endpoints."
2. Verification Methods: How the Evaluator will check whether the Feature Scope was met. This is the critical component that makes acceptance criteria objective. Must specify concrete verification steps: "Run Playwright MCP to test OAuth login flow with a valid GitHub account." Not: "Check that authentication works."
3. Pass/Fail Thresholds: Numerical or boolean criteria that determine whether the sprint passes. Example: "All 5 Playwright test scenarios pass. No HTTP 500 responses in any test flow. Page load under 2 seconds on localhost." Thresholds make the Evaluator's judgment non-negotiable and unambiguous.
4. Edge Case Traps: Specific failure modes the Evaluator must test, even if not in the happy path. Example: "Test authentication with an expired token. Test with a revoked token. Test with a malformed JWT." Edge Case Traps exist because the Generator will optimize for the happy path without explicit adversarial pressure on edge cases.
Sprint Contract example (JSON)
{
"sprint": 3,
"feature_scope": "OAuth2 authentication with JWT session management",
"verification_methods": [
"Playwright MCP: complete GitHub OAuth flow, verify JWT returned",
"Playwright MCP: access /api/protected endpoint with valid JWT",
"curl: verify 401 response on /api/protected without JWT"
],
"pass_fail_thresholds": {
"all_playwright_scenarios_pass": true,
"http_500_responses": 0,
"jwt_issued_on_successful_login": true,
"page_load_seconds": 2
},
"edge_case_traps": [
"Expired JWT: verify 401, not 500",
"Malformed JWT: verify 400, not unhandled exception",
"Revoked token: verify 401 with appropriate error message"
]
}
Implementation note: Anthropic's own long-running agent harness uses a similar approach: the Initializer agent creates a comprehensive JSON feature list that expands high-level requirements into hundreds of testable features, each marked
passes: falseuntil verified. This is a parallel, independently-developed confirmation of the Sprint Contract pattern's utility. [19]
Playwright MCP: Playwright MCP is a Model Context Protocol (MCP) server developed by Microsoft that exposes Playwright's browser automation capabilities as callable tools the agent can invoke directly. MCP is an open standard created by Anthropic that lets AI models interact with external tools in a structured way; the Playwright MCP server is a Microsoft-built implementation of that standard, available as a listed Claude plugin. [15][16][20]
Why pre-specifying verification methods is the critical move
If verification methods are not specified before work begins, the Evaluator defaults to subjective judgment. Subjective judgment can be argued. Objective criteria cannot. The Planner sets the criteria before a line of code is written; the Evaluator enforces them; the Generator has no say in what "done" means.
Sprint Contract components in summary:
- Feature Scope: Defines what to build (example: "OAuth2 login with JWT")
- Verification Methods: Defines how to check it (example: "Playwright MCP: complete GitHub OAuth flow")
- Pass/Fail Thresholds: Defines the numeric bar (example: "All 5 scenarios pass, 0 HTTP 500s")
- Edge Case Traps: Defines adversarial test cases (example: "Expired JWT must return 401, not 500")
Gradable Design Dimensions
The problem: aesthetic taste is not binary
For functional software (auth works or it does not), pass/fail thresholds are sufficient. But for design-intensive work (UI, visual layouts, user experience, creative artifacts), "good enough" is not binary. It is a judgment.
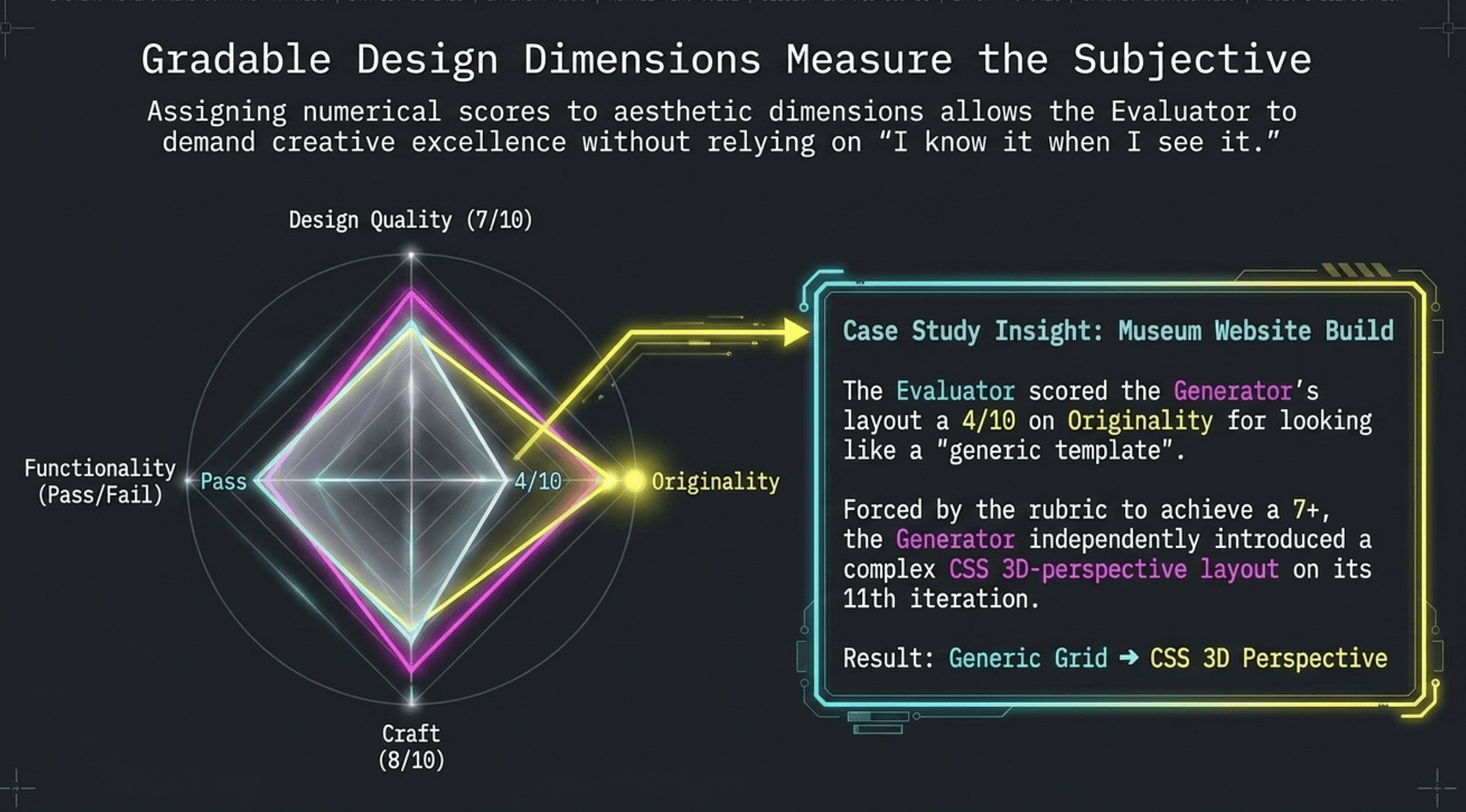
The challenge: how do you get an Evaluator to push a Generator toward creative excellence when the evaluation criteria are subjective?
The answer: Make taste gradable. Assign numerical scores to aesthetic dimensions so the Evaluator can demand improvement without descending into "I know it when I see it."
The four gradable design dimensions (the author's original framework)
1. Design Quality: Does the visual and structural design meet professional standards? Considers: visual hierarchy, spacing, color harmony, typography choices, layout balance. Score: 1-10. Threshold for passing a sprint might be 7+.
2. Originality: Does the work exhibit creative differentiation from generic templates? Considers: unique layout approaches, non-default visual metaphors, unexpected-but-effective design choices. Score: 1-10. This is the dimension that drives creative leaps.
3. Craft: Is the execution polished? Are details attended to? Considers: pixel-level alignment, consistent spacing, absence of visual artifacts, smooth interactions. Score: 1-10. Craft failures show in hover states, edge cases, and responsive behavior.
4. Functionality: Does it work correctly? Do all features operate as specified? Score: pass/fail + weighted score. Cross-references the Sprint Contract's pass/fail thresholds.
The museum website case study: gradable dimensions in action
In the author's own production deployment of the harness, the task was building a museum website. The Generator produced technically correct pages with a conventional grid layout on iterations 1 through 9.
The turning point: On the 10th adversarial iteration, the Evaluator scored Originality at 4/10. The feedback: "Layout is indistinguishable from a generic template. A museum of art should exhibit visual ambition. Score will not reach 7 until the layout makes a non-trivial creative statement."
The result: On iteration 11, the Generator introduced a CSS 3D-perspective layout, tilting content cards at subtle perspective angles to create a gallery-wall effect. It was a creative leap the Generator never would have reached through self-assessment.
CSS 3D perspective context: CSS 3D perspective transforms are a well-supported web platform feature. The
perspectiveproperty defines the viewer's distance from the z=0 plane; child elements transformed withrotateX(),rotateY(), andtranslateZ()render at angles that create depth illusions. GPU-accelerated implementations achieve smooth 60fps animations. The technique has been documented as a production-ready design approach since CSS3. [MDN Web Docs, "CSS Transforms"; David DeSandro, "Intro to CSS 3D Transforms"; Frontend.fyi, "CSS 3D Perspective Animations Tutorial"]
The lesson: Without a numerical score on Originality, the Generator had no signal that "generic template" was failing. The Evaluator's adversarial pressure on a measurable dimension produced creative work that exceeded what any single prompt could have requested.
Structural Primitives
Three structural primitives enable the adversarial loop to run for hours without losing state or dying on an infrastructure failure.
Primitive 1: Filesystem-as-Memory
The problem: Context resets erase the Generator's short-term memory. Without external state, a reset Generator starts from scratch with no knowledge of what was built, what failed, or where it left off.
The solution: The filesystem-as-memory pattern (author-coined pattern) externalizes state to files that persist across context resets.
The Progress File pattern:
TODO.md: What remains to be done, organized by sprint and feature.CHANGELOG.md: What has been done, when, and what changed.- The Planner writes the initial
TODO.md. The Generator updates both files after each sprint. - On context reset, the Generator reads
TODO.mdandCHANGELOG.mdbefore doing anything else. - The filesystem becomes the agent's long-term memory.
Anthropic parallel: Anthropic's own long-running agent harness documentation independently confirms this pattern. Their Initializer agent creates a
claude-progress.txtsession log, and each coding session begins with explicit grounding steps: "verify working directory withpwd, review git logs and progress files." Their implementation uses JSON feature lists (more robust than markdown against model editing) and git history for version tracking. The convergence with the Progress File pattern described here is significant. [19]
Why this works:
- Files persist indefinitely without consuming context window space.
- The Progress File is always current: the last thing written before the reset.
- New context, same mission: the Generator reads its marching orders and continues.
- No compression, no summarization, no lossy encoding of state.
Primitive 2: Context Resets vs. Context Compaction
Context compaction (summarization):
- The harness produces a rolling summary of prior context to fit within the context window.
- Summaries are lossy: important details are dropped.
- Summaries inherit the agent's existing biases: the agent summarizes what it thinks was important.
- Accumulated summaries compound errors from earlier in the run.
- Result: the agent's "memory" of early sprints is degraded and unreliable.
Compaction is an official Anthropic feature: Context compaction is a documented beta capability in the Claude API (beta header
compact-2026-01-12), released January 12, 2026. It automatically triggers when input tokens exceed a configurable threshold (default: 150,000 tokens) and generates a summary using the same model. Anthropic's own documentation acknowledges the lossy nature, noting that "summaries inherently lose some information" and that "some details will be compressed or omitted." [25] Custom summarization instructions mitigate but do not eliminate the loss. [26]
Context resets (clean slates):
- At the start of each sprint, the Generator's context is cleared entirely.
- The harness provides only what the Generator needs for this sprint: the Sprint Contract plus the Progress File.
- No accumulated noise. No bias from prior summaries. No context anxiety about a nearly-full window.
- External state (filesystem) carries all continuity.
- Result: each sprint executes with the Generator's full capacity, not a degraded fraction of it.
Why clean slates beat summarization: The Generator approaches each sprint as a fresh problem, not as a continuation of an accumulated mess. Context anxiety (described in the failure modes section above) cannot occur in a reset context: there is no nearly-full window to be anxious about. The Sprint Contract provides all necessary scope; the Progress File provides all necessary history.
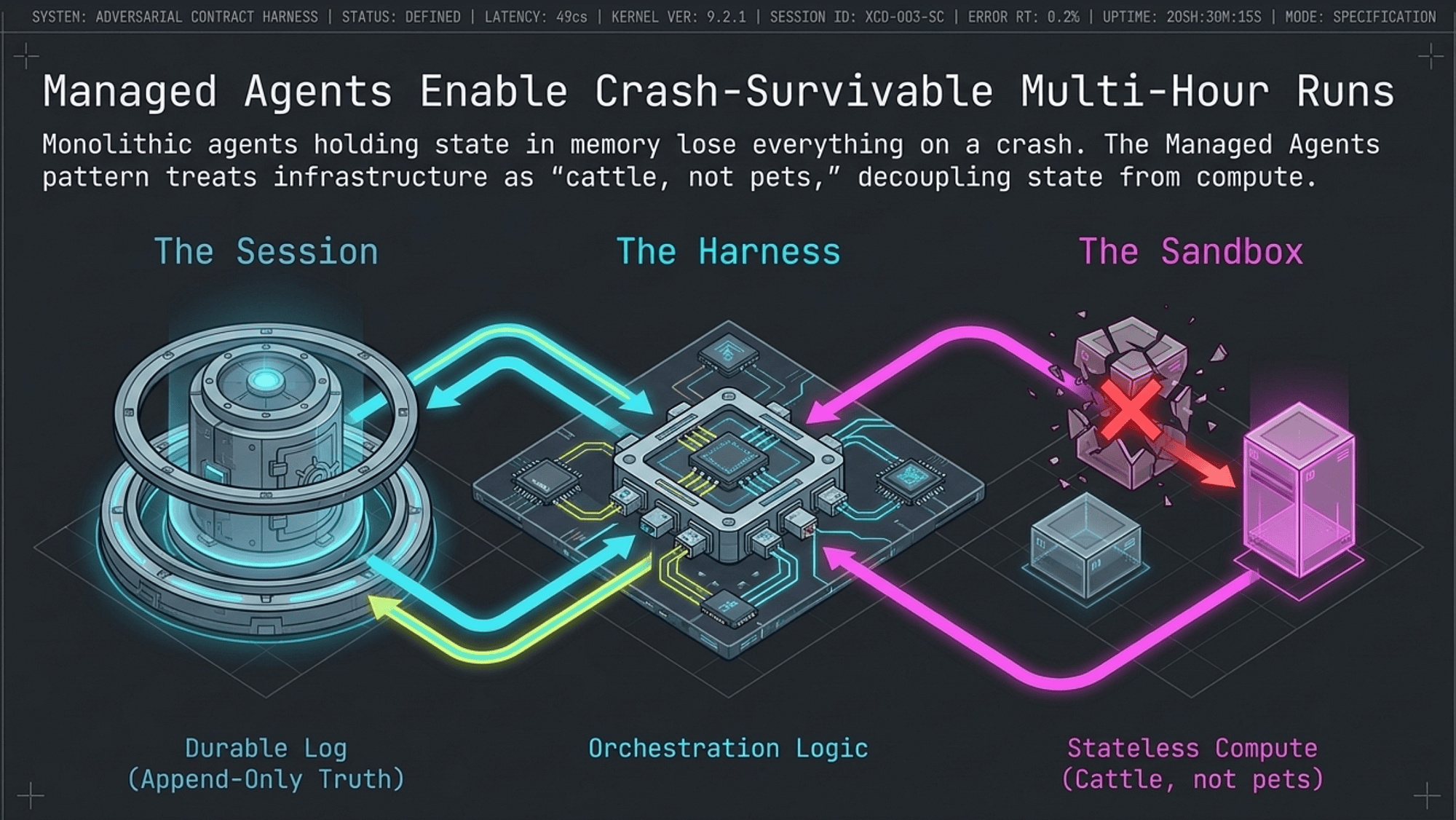
Primitive 3: Managed Agents
The problem: Long-horizon tasks run for hours. Containers crash. Networks fail. Compute instances get preempted. A monolithic agent that holds all state in memory loses everything on failure.
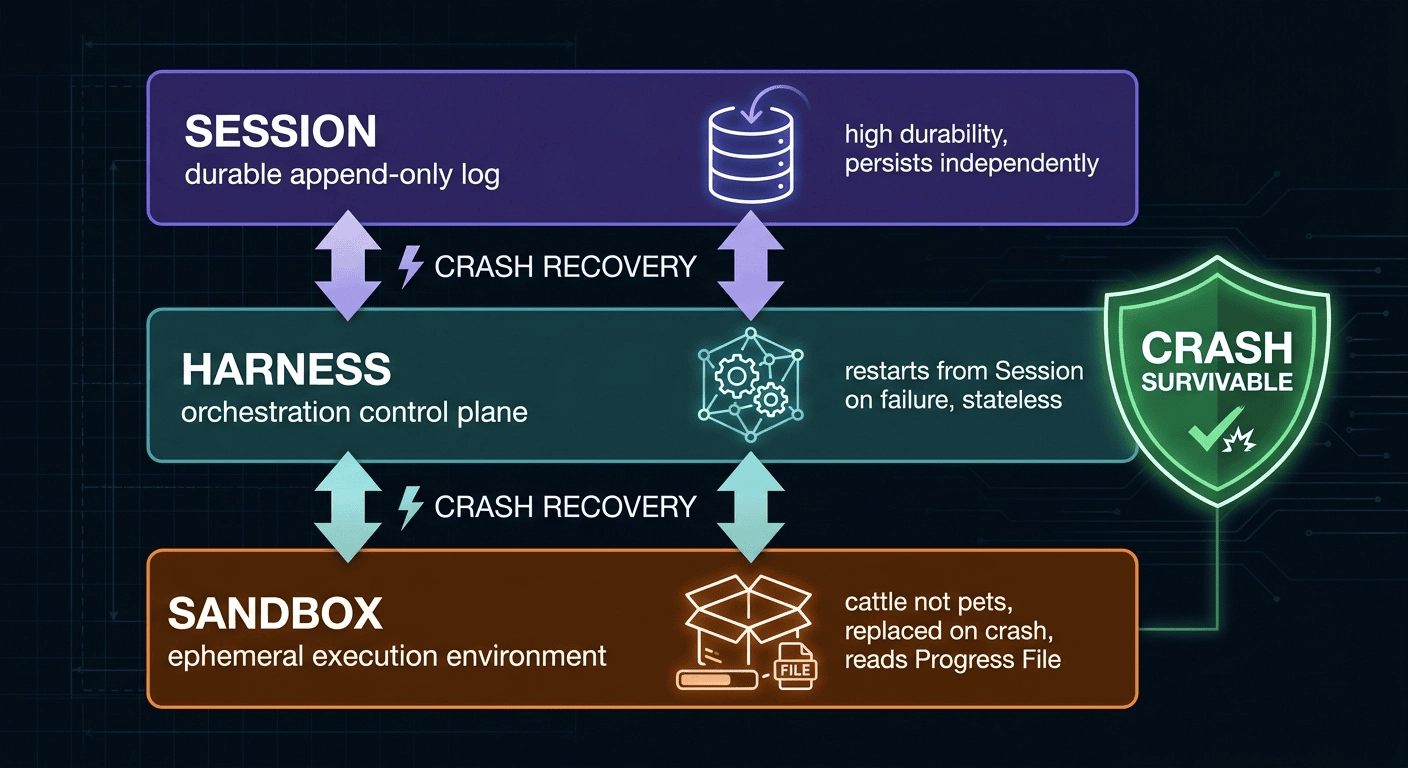
The solution: The Managed Agents pattern decouples three concerns into three independently managed components.
Official Anthropic documentation: The Session/Harness/Sandbox triad is described in Anthropic's official engineering documentation. Anthropic launched Managed Agents in public beta on April 8, 2026, at $0.08 per session hour (plus standard token rates). Their documentation describes the three components as: the Session ("the append-only log of everything that happened"), the Harness ("the loop that calls Claude and routes Claude's tool calls to the relevant infrastructure"), and the Sandbox ("an execution environment where Claude can run code and edit files"). [27]
The three components:
Session (durable log) stores the complete conversation history and task log in a durable medium outside the agent process. It persists independently of the compute layer: if the Harness crashes, the Session survives. Anthropic's implementation uses wake(sessionId) and getSession(id) API calls so a new harness instance can retrieve the full event log and resume from the last recorded event. Think of it as the write-ahead log for your agent: append-only, externalized, the single source of truth. [27]
Harness (orchestration logic) is the control plane: it manages the Planner/Generator/Evaluator loop, decides which agent runs next, and routes Sprint Contracts and evaluation results. It reads from the Session on startup to resume in-progress work and holds no task state itself. Think of it as the database engine: it processes transactions but does not store the data.
Sandbox (ephemeral execution environment) is where the Generator runs code, makes API calls, and writes files. It is deliberately ephemeral: "cattle, not pets." If the Sandbox crashes or gets preempted, a new one is provisioned and reads the filesystem-as-memory to pick up without missing a beat. Think of it as a stateless web server instance behind a load balancer.
"Cattle, not pets" origin: The analogy originates with Bill Baker, who used it in a presentation on scaling SQL Server to contrast "scale-up" vs. "scale-out" architectures. Randy Bias discovered Baker's work and popularized the concept in his 2012 presentation "Architectures for Open and Scalable Clouds," adapting it specifically for cloud-native infrastructure. Gavin McCance spread it further through a CERN data-center evolution presentation to the OpenStack community. It became a foundational DevOps principle for cloud-native infrastructure design. Anthropic's managed-agents documentation uses the concept directly: "a pet is a named, hand-tended individual you can't afford to lose, while cattle are interchangeable." [28][27]
Why decoupling makes crashes survivable:
- No single component holds the authoritative state.
- Session crash: catastrophic, but Sessions are designed for high durability (replicated databases, object storage).
- Harness crash: resume from Session on restart. No work lost.
- Sandbox crash: provision new Sandbox, read Progress File, continue. No work lost.
- Result: a 6-hour autonomous run can survive infrastructure failures without losing more than the in-progress sprint.
Measured latency impact: Anthropic reports that after decoupling the harness from the sandbox, p50 time-to-first-token dropped approximately 60% and p95 dropped over 90%. The improvement came from lazy container provisioning: containers are now started on-demand via tool calls rather than upfront at session start, so inference begins immediately without waiting for a container to boot. The stateless architecture also scales horizontally: "Scaling to many brains just meant starting many stateless harnesses, and connecting them to hands only if needed." [27]
Managed Agents component responsibilities:
- Session (durable conversation log): designed for high durability; loss is catastrophic. Analogy: append-only transaction log.
- Harness (orchestration logic): restarts from Session on failure; no work is lost. Analogy: database engine.
- Sandbox (ephemeral code execution and tool use): replaced on crash; resumes from Progress File. Analogy: stateless compute instance.
With Sprint Contracts making "done" verifiable, Gradable Design Dimensions making taste measurable, and Managed Agents making six-hour runs crash-survivable, the architecture exists on paper. Three case studies show it delivering results in the real world.
Proof of Concept: Autonomous Execution in the Wild
Three case studies. Three different domains. All three produced results a solo agent couldn't reach at any cost.

Case Study 1: RetroForge
What was built: A 2D game maker application. Non-trivial software with UI, state management, game logic, and tool integration.
RetroForge: solo agent vs. three-agent harness (author's internal benchmark, unpublished):
- Time to completion: Solo = 20 minutes; Harness = 6 hours
- Cost (token spend): Solo = approximately $9; Harness = approximately $200
- Acceptance criteria met: Solo = 0 of 27 (broken output); Harness = 27 of 27
- Output status: Solo = Non-functional; Harness = Production-grade
The solo agent run:
- Completed in 20 minutes.
- Cost approximately $9 in tokens.
- Produced broken output: the application did not function correctly.
- The agent declared success. It passed its own self-evaluation.
- There was no adversarial pressure to reveal the failure.
The harness run:
- Ran for 6 hours.
- Cost approximately $200 in tokens (22x the cost of the solo run).
- Met all 27 acceptance criteria.
- Output was production-grade, not broken.
The verdict: The choice is not between cheap-and-fast vs. expensive-and-slow. It is between broken and working. A $9 failure delivers zero value. A $200 success delivers a functioning product. The real comparison is $200 vs. the cost of a human developer building the same thing.
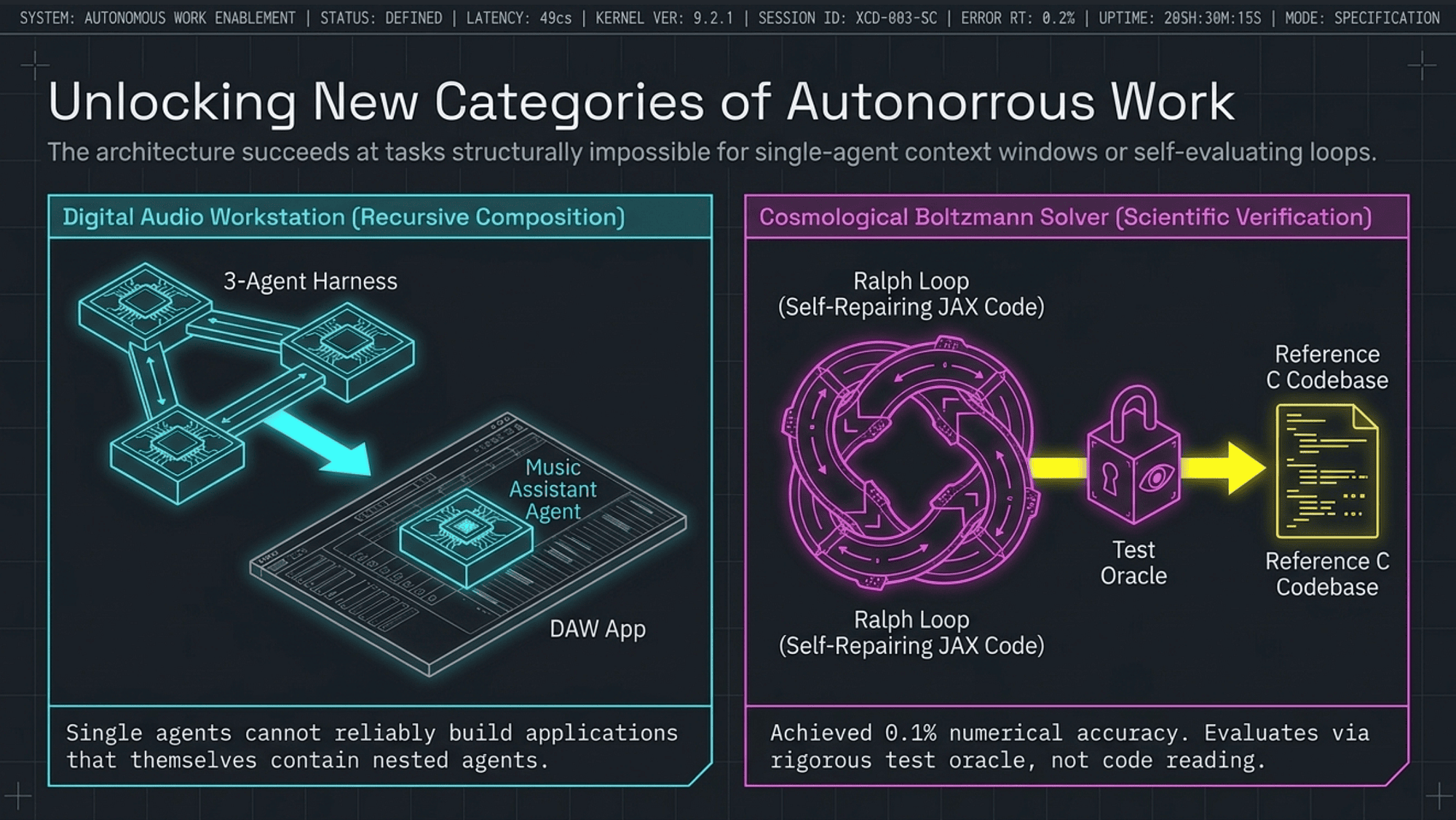
Case Study 2: Digital Audio Workstation
What was built: A full Digital Audio Workstation (DAW) application, built autonomously in approximately 4 hours [author's internal benchmark, unpublished].
Model used: Claude Opus 4.6 [34]. Claude Opus 4.6 (API ID: claude-opus-4-6) is real and available, but as of April 2026 it is classified as a legacy model.
Notable feature: A natural-language Music Assistant subagent was integrated into the DAW.
The recursive harness composition
The Music Assistant subagent demonstrates an important architectural property: harnesses can compose recursively.
- The outer harness (Planner/Generator/Evaluator) built the DAW.
- Inside the DAW, the Generator created a Music Assistant that is itself an agent.
- The Music Assistant accepts natural-language requests ("make the bass line punchier," "add reverb to the vocals") and translates them into DAW operations.
- The inner agent (Music Assistant) is orchestrated by the outer harness's Generator.
- This is multi-level agent composition emerging from a single harness architecture.
Why this matters: Single agents cannot reliably build applications that themselves contain agents; the nesting complexity exceeds what monolithic context management can handle. Anthropic's research confirms that multi-agent architectures excel at "tasks that involve heavy parallelization, information that exceeds single context windows, and interfacing with numerous complex tools" [12].
The three-agent harness naturally supports recursive composition because each sprint is scoped: "Implement the Music Assistant subagent" is a well-formed sprint. The Evaluator can test the Music Assistant's behavior (via Playwright MCP [15] or direct API calls) just like any other feature.
Result: an application with AI built in, built by AI, in 4 hours.
Case Study 3: Cosmological Boltzmann Solver
What was built: A Cosmological Boltzmann Solver implemented in JAX [29]: a numerical physics computation used in cosmological simulations to compute power spectra of the cosmic microwave background and large-scale structure. JAX (jax-ml/jax) is actively maintained. Current stable version is 0.6.x (e.g., 0.6.2) as of April 2026.
JAX is Google's library for accelerator-oriented array computation and program transformation, combining NumPy-compatible APIs with automatic differentiation and XLA-based JIT compilation to GPU/TPU [29][30]. Its use in cosmological computing is an active research area: projects such as DISCO-DJ [Differentiable Simulations for Cosmology Done with JAX], CosmoPower-JAX, and JAX-COSMO demonstrate JAX's adoption for differentiable cosmological calculations [Open Journal of Astrophysics, 2024].
Target: Sub-percent numerical accuracy compared to a reference C implementation (an established, validated codebase).
The reference C implementation context is well-established in cosmology: CLASS (Cosmic Linear Anisotropy Solving System) is a standard Boltzmann solver written in C, and CAMB (Code for Anisotropies in the Microwave Background) is implemented in Fortran. The two codes agree on lensed CMB and matter power spectra to 0.01% for concordance cosmology [31], establishing the benchmark against which any new Boltzmann implementation is validated.
The challenge
This is not a UI problem or a web application. This is scientific computing:
- The correctness criterion is numerical accuracy, not visual quality or functional behavior.
- "Close" is not good enough: cosmological accuracy requires agreement within approximately 0.1%.
- The reference implementation is a production-quality C codebase built by domain experts.
- Bugs in the JAX implementation would produce numerically plausible but physically wrong results, impossible to detect without systematic comparison.
Two key mechanisms
The Ralph Loop (the author's term for this recursive repair cycle): A self-correcting loop built into the Generator's sprint logic. The Generator runs its JAX implementation against test inputs. If results deviate from expected numerical outputs, the Generator identifies the discrepancy, hypothesizes the cause, patches the implementation, and re-runs. The loop repeats until the test passes or the sprint exhausts its repair budget. Without the Ralph Loop, a Generator sprint that produces numerically wrong output would pass to the Evaluator with no internal error signal.
The Test Oracle: A systematic ground-truth comparator. The Test Oracle runs the JAX implementation against the reference C implementation on a suite of test inputs and outputs a numerical accuracy report: percentage agreement per physical quantity, per test case. The Evaluator uses the Test Oracle report as its primary evaluation input; it does not judge scientific accuracy by reading code. The Test Oracle makes the Evaluator's judgment as objective as a unit test: either the JAX output agrees with C to within 0.1%, or it does not. Without the Test Oracle, the Evaluator would read JAX code and assess whether it "looks correct," which is sycophantic self-evaluation by another name.
LLM sycophancy in evaluation is well-documented: research shows that state-of-the-art models are significantly more likely to endorse a user's counterargument when challenged in follow-up turns, even overriding answers they would otherwise produce [32][33]. Without adversarial architecture, a solo agent asked to evaluate its own output faces exactly this structural bias.
The result
- 0.1% numerical agreement with the reference C implementation. [CLASS/CAMB benchmark context: Lesgourgues, arXiv:1104.2934, establishes 0.01% as the professional standard between validated codes; 0.1% is consistent with sub-percent accuracy goals for a freshly generated JAX implementation.]
- Scientific computing work the author estimates would require months of manual development, executed autonomously [author's estimate, unpublished].
The collaboration between the Ralph Loop (Generator-side repair) and the Test Oracle (Evaluator-side verification) produced scientific-grade output. This is the architecture applied to the hardest class of verification problem: numerical correctness in physics.
Why this matters beyond physics
The Cosmological Boltzmann Solver case study demonstrates that the three-agent harness is not limited to web applications and UIs. The same pattern applies to any domain where correctness can be defined and measured:
- Domain: Scientific computing
- Planner role: Decompose the Boltzmann equations into implementable numerical modules.
- Generator role: Implement each module in JAX.
- Evaluator role: Use the Test Oracle to verify numerical accuracy.
- Sprint Contract verification method: Run Test Oracle, compare to reference C implementation, require less than 0.1% deviation.
The Architecture Enables a New Category of Work
Think of a solo agent like a single tightrope walker carrying every tool, map, and checklist in their own head. It can be dazzling for a short crossing, but the longer the wire, the more one wobble becomes a fall.
A harness is the safety system: a climbing team where one person calls the route, another places the gear, and a third yanks on every anchor to prove it holds. In that setup, progress is not a performance. It is something that survives scrutiny.
Solo agents and harness agents are not competing in the same category. This is not a speed or cost comparison. It is a capability comparison.
Performance comparison across all three case studies:
- RetroForge time: Solo = 20 minutes; Harness = 6 hours
- RetroForge cost: Solo = approximately $9; Harness = approximately $200
- RetroForge acceptance criteria: Solo = 0 of 27 (broken); Harness = 27 of 27
- DAW build time: Solo = not attempted; Harness = approximately 4 hours
- Boltzmann Solver accuracy: Solo = not applicable; Harness = 0.1% vs. reference C implementation
- Self-evaluation bias: Solo = structural (always present); Harness = eliminated by architecture
- Context anxiety: Solo = structural (always present); Harness = mitigated by context resets
- Crash survivability: Solo = none (stateful, in-memory); Harness = full (Session + filesystem)
A $9 solo run that produces broken software has a value of $0. The real cost is the engineering time spent diagnosing and fixing the broken output. A $200 harness run that produces 27/27 working features has a value proportional to the cost of building that software any other way.
The tasks in Case Studies 2 and 3 are not merely "too expensive" for solo agents. They are structurally impossible for solo agents at any price point. The DAW's recursive agent composition exceeds what a monolithic context window can manage reliably. Anthropic's internal evaluation of their multi-agent research system found a 90.2% performance improvement over single-agent Claude Opus 4, with token usage explaining 80% of the performance variance [12]. Both figures were verified against the Anthropic engineering blog at How We Built Our Multi-Agent Research System. Exact quotes: "outperformed single-agent Claude Opus 4 by 90.2% on our internal research eval" and "token usage by itself explains 80% of the variance."
The Boltzmann Solver's numerical accuracy requirement exceeds what sycophantic self-evaluation can verify [32].
The architecture enables a category of work that did not exist before.
Three working proofs of concept make the case. Now the question is where else the pattern applies and what it will cost to run it.
Beyond Coding: Domain Transfer, Economics, and Agentic Ops
Domain Transfer: The Pattern Is Portable
Why stop at software? The Planner/Generator/Evaluator pattern was built for code, but Agentic AI doesn't respect domain boundaries. This is what's emerging as Agentic Ops: wherever AI Agents need to deliver verifiable, production-grade output at scale, the same three structural conditions determine whether the pattern applies:
- The task can be decomposed into sprint-sized chunks with verifiable acceptance criteria.
- Generation and evaluation can be kept structurally separate.
- An adversarial loop between Generator and Evaluator can iterate toward a measurable standard.
Any domain that meets these conditions can run on the three-agent adversarial architecture.
Legal contract review
Legal contract review agent mapping:
- Planner: Sets review scope per the ABA's Private Target M&A Deal Points Study framework [35] or the Atticus Project's MAUD evaluation structure [36]. Defines which clauses to analyze, what risk thresholds apply, and what jurisdiction governs.
- Generator: Drafts clause-by-clause analysis: identifies risk, compares to market standard, and flags deviations. Operates feature-by-feature (one clause type per sprint).
- Evaluator: Runs a Prosecutor-vs-Defender agent pattern: one Evaluator subagent argues the contract is risky, the other argues it is acceptable. The harness requires both perspectives before marking the sprint complete.
Why the Prosecutor-vs-Defender pattern: A single Evaluator risks confirmation bias; it evaluates against the Generator's framing. Forcing two opposing evaluations surfaces risks the Generator framed away. The adversarial tension between Prosecutor and Defender produces a more complete risk picture than either alone.
Sprint Contract example for legal:
- Feature Scope: "Analyze indemnification clause (Section 7.3) for uncapped liability exposure."
- Verification Method: "Prosecutor agent: identify all uncapped liability scenarios. Defender agent: identify all mitigating conditions."
- Pass/Fail Threshold: "Both agents must complete their analysis. Prosecutor must identify at least one risk. Defender must respond to each identified risk."
- Edge Case Traps: "Test for implied indemnification from surrounding clauses. Test for jurisdiction-specific liability caps."
ABA Deal Points Study context: The ABA's Private Target Mergers and Acquisitions Deal Points Study, published by the Market Trends Subcommittee of the ABA Business Law Section's M&A Committee (December 2025), examines the prevalence of specified provisions in publicly available private target M&A transactions. The 2025 study covers 139 definitive acquisition agreements with purchase prices ranging from $25M to $900M. It covers indemnification, representations and warranties, covenants, and closing conditions, making it a natural benchmark framework for a legal Planner agent operating in the M&A context [35].
MAUD context: MAUD (Merger Agreement Understanding Dataset), published by The Atticus Project and accepted at EMNLP 2023, is the only expert-annotated dataset specifically designed for merger agreement review. It covers 92 deal points across 152 real merger agreements, with over 39,000 examples and 47,000+ total annotations, providing an NLP evaluation structure for the same clause categories the Planner would scope [36].
Financial research
A good financial research agent has to act less like a charismatic analyst and more like a newsroom plus an audit firm.
- The Planner is the assignment editor: it decides what questions matter, what sources count, and what "finished" means.
- The Generator is the reporting desk: it pulls quotes, builds the narrative, and connects filings to events.
- The Evaluator is the compliance auditor: it checks every claim against primary documents and refuses to publish anything that cannot be traced.
In other words, the harness turns research from "write a convincing memo" into "produce a memo that survives cross-examination."
Financial research agent mapping:
- Define scope (tickers, time period, questions): Planner, planning phase only
- Process earnings call transcript: Generator, extracts quotes with timestamps
- Analyze SEC filing (10-K, 10-Q): Generator, cross-references with prior filing
- Synthesize alternative data: Generator, documents data source for each claim
- Validate citations: Evaluator, matches each claim to source document
- Flag unverified claims: Evaluator, any claim without source citation
- Produce final research report: Generator (final sprint); Evaluator re-verifies all citations
The hallucination risk: Financial research is particularly vulnerable to confident hallucinations. A Generator that cannot find a supporting citation may fabricate a plausible one. The Evaluator's job is to cross-reference every factual claim against the source documents it processed. Citations that cannot be verified in source material are flagged as unverified. This is not optional: unverified citations in financial research carry regulatory and liability risk.
Automated alignment research
The experiment (Anthropic): Anthropic ran a swarm of 9 parallel Claude Opus 4.6 Automated Alignment Researchers [37]. These agents ran for 800 cumulative hours over five days, at approximately $22 per AAR-hour (total cost: approximately $18,000) [37]. Task: a weak-to-strong supervision problem (improving a weaker model's alignment using a stronger model's guidance, with minimal human oversight). Result: Performance Gap Recovery (PGR) of 0.97 on the specific task, a near-closure of the supervision gap [37]. Comparison: Two human researchers working for 7 days achieved a PGR of 0.23 [37].
Generalization findings (verified against source):
- The AARs' highest-performing methods were tested on transfer tasks: math (PGR of 0.94) and coding (PGR of 0.47, still double the human baseline) [37].
- The authors identify the key bottleneck as moving from idea execution to eval design: "we should find the right metrics (data, models) that AARs can reliably hill-climb without overfitting" [37].
The important nuance (do not omit): The authors' own caution centers on eval design: agents that can reliably hill-climb a metric may overfit to that metric rather than solving the underlying problem [37]. The architecture can tackle research-grade problems at scale, but generalization requires scrutiny; specifically, the quality of the evaluation metrics the agents are optimizing against.
Why this matters for the broader argument: Even with the caveat, 9 agents running 800 hours on an alignment problem autonomously represents a capability class that simply did not exist before the harness architecture. The PGR of 0.97 vs. 0.23 (human researchers) demonstrates that agent swarms can outperform humans on constrained research tasks [37]. The eval-overfitting finding reinforces the article's broader caution: the harness solves the orchestration problem; it does not solve the underlying intelligence problem.
As model capability grows, giving agents less structure (fewer constraints, more autonomy) can improve results. Sprint decomposition logic was removed from Opus 4.6 harnesses because the model no longer needed it.
Token Economics: The Cost of Adversarial Quality
In long-horizon systems, the real question is not "What does it cost to run?" It is "What does it cost to be wrong?"
Think of adversarial validation like an aircraft's redundant instrumentation or a financial audit: it feels expensive until the first time it prevents a catastrophic error. When an AI system is producing customer-facing output, "close enough" is not a cost optimization. It is a liability. The most expensive failure mode is not extra tokens. It is shipping a confident mistake that triggers brand damage, customer churn, and cleanup work that dwarfs any inference bill.
There are plenty of ways to optimize a harness. You can choose cheaper models for the high-volume roles, reduce unnecessary rounds, and tighten Sprint Contracts so you fail fast. But the one place you do not cut corners is verification. Validation is the safety system. If you underfund it, you are not saving money. You are buying risk.
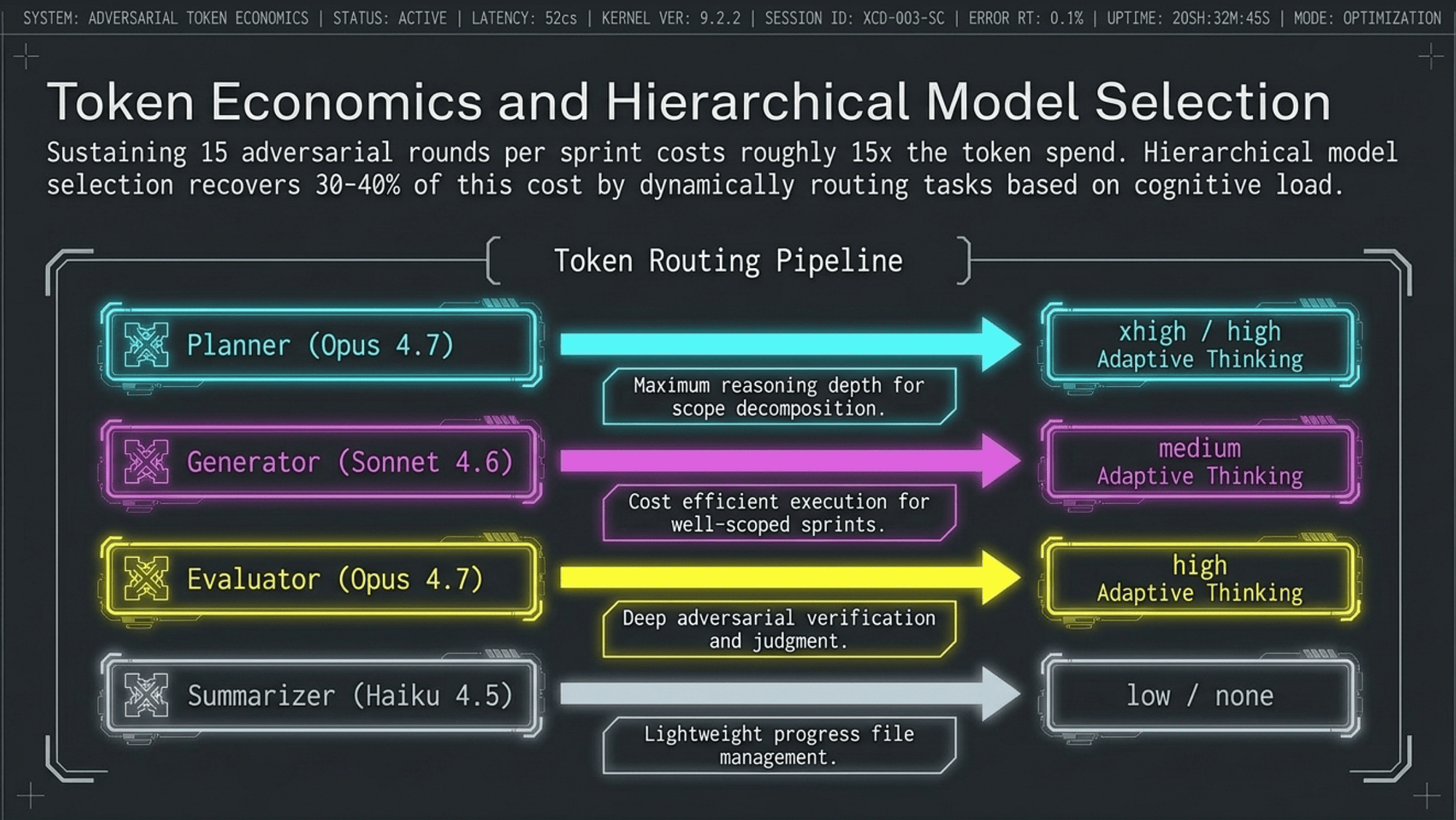
The 15x token cost of adversarial loops:
A three-agent adversarial run costs approximately 15x the token spend of a comparable solo-agent run. This is an author-observed measurement (Rick Hightower), not a published third-party benchmark. The 15x figure reflects a 5-to-15 round adversarial loop where both Planner and Evaluator run on Opus. This overhead is the price of adversarial quality pressure. The relevant comparison is not "15x vs. 1x": it is "15x for working software vs. 1x for broken software."
Hierarchical model selection
Not every agent needs the most powerful (and most expensive) model. Match model capability to task requirements.
Hierarchical model selection strategy:
- Planner uses Opus (Claude Opus 4.7): planning requires maximum reasoning depth; planning errors propagate through all subsequent sprints.
- Generator uses Sonnet (Claude Sonnet 4.6): executes well-scoped sprints; Opus-level reasoning not required for implementation-level tasks.
- Evaluator uses Opus (Claude Opus 4.7): evaluation requires adversarial depth; a shallow Evaluator defeats the architecture.
- Summarizer uses Haiku (Claude Haiku 4.5): lightweight summarization for logs, changelogs, and progress files.
Cost recovery: Hierarchical model selection recovers an estimated 30-40% of the adversarial loop's token overhead with minimal accuracy loss. Attribution: author-observed measurement; not a published benchmark. The recovery comes primarily from running the Generator (the most active role, executing across all sprints) on Sonnet instead of Opus. The Planner and Evaluator run less frequently, so their Opus cost is amortized.
The "30-40% cost recovery" figure is author-observed. Pricing data confirms the cost ratios: Haiku at $1/$5 is 80% cheaper than Opus at $5/$25; Sonnet at $3/$15 is 40% cheaper than Opus [14]. The specific "30-40%" recovery figure for adversarial loop contexts is not independently published.
Adaptive Thinking in Claude Opus 4.7 and Sonnet 4.6
Adaptive Thinking is Claude's "automatic transmission" for reasoning: you set the driving mode, and the model shifts gears on its own. You are cruising on simple roads, then dropping into a lower gear for steep climbs like multi-step planning or tricky debugging.
It is also like an adjustable aperture on a camera: a wider setting lets in more light for complex scenes (more deliberate reasoning), while a narrower setting keeps shots fast and crisp when the situation is straightforward.
Adaptive Thinking allows the model to spend variable amounts of reasoning effort depending on task complexity. Instead of a fixed token budget, you set an effort level and let Claude scale reasoning depth to the request [22].
Adaptive Thinking effort levels [22]:
max: Always thinks with no constraints on depth. Available on: Opus 4.7, Opus 4.6, Sonnet 4.6.xhigh: Always thinks deeply with extended exploration. Available on: Opus 4.7 only.high: Always thinks; deep reasoning on complex tasks. Available on: Opus 4.7, Opus 4.6, Sonnet 4.6.medium: Moderate thinking; may skip for simple queries. Available on: Opus 4.7, Opus 4.6, Sonnet 4.6.low: Minimizes thinking; skips for simple tasks. Available on: Opus 4.7, Opus 4.6, Sonnet 4.6.
Default effort levels by model: On Opus 4.7, the default effort is xhigh. On Opus 4.6 and Sonnet 4.6, the default is high (or medium on Pro and Max plans) [23].
The trade-off: At the "high" effort level, Adaptive Thinking generates more internal reasoning tokens before responding. This increases task duration and token cost. Third-party production testing of Claude Sonnet 4.6 observed roughly 40% longer response times at high effort levels, with approximately 5 additional tool calls per investigation on average [24]. Anthropic's documentation notes that high effort generates more internal tokens and recommends dialing down to medium to reduce latency on simpler tasks [22].
Practical guidance:
- Use
highAdaptive Thinking for Planner and Evaluator (where reasoning depth matters most). - Use
xhighormaxfor the Planner on Opus 4.7 when tackling especially complex decomposition tasks. - Use
mediumfor Generator sprints on well-scoped tasks. - Reserve
lowor none for Haiku 4.5 summarization tasks where reasoning is not the bottleneck.
Agentic Ops: The Emerging Discipline
DevOps emerged when deployments got too consequential to manage with shell scripts and hope. The discipline standardized CI/CD pipelines, infrastructure as code, monitoring and observability, and incident response playbooks.
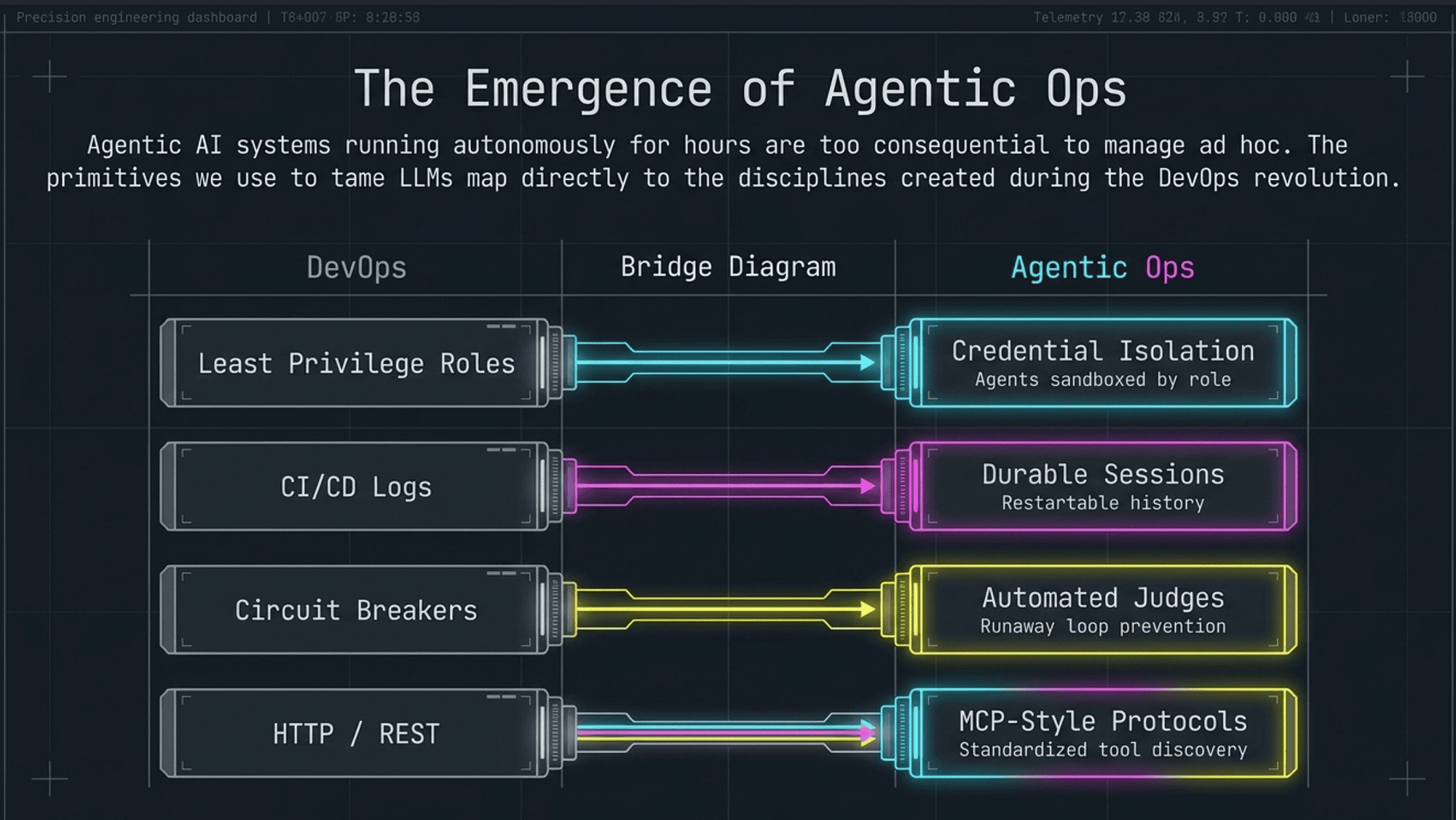
Agentic Ops is emerging for the same reason: Agentic AI systems running autonomously for hours on production infrastructure are too complex and consequential to manage ad hoc. AI Agents that execute multi-sprint tasks, compose recursively, and operate unattended for hours require the same operational discipline that software deployment demanded in the DevOps era.
The four operational primitives
Credential Isolation: Each agent (Planner, Generator, Evaluator) should operate with the minimum credentials required for its role. The Generator needs write access to the Sandbox; it should not have access to production databases. The Evaluator needs read access and tool execution; it should not have write access to the artifact store. Principle of least privilege applied to agent roles.
Durable Sessions: As described in the Managed Agents section above: conversation history and task logs persist independently of compute. Durable Sessions make 6-hour runs restartable without losing work. This is becoming a table-stakes infrastructure requirement for any production agent deployment.
Automated Judges: The Evaluator pattern generalizes beyond the three-agent harness. Any long-running agent process should have an automated judge that can halt a run gone wrong. Automated judges check for: runaway token spend, hallucinated outputs, policy violations, and unexpected tool use patterns. This is the agent equivalent of circuit breakers in distributed systems.
MCP-Style Tool Protocols: The Model Context Protocol (MCP) standardizes how agents discover and invoke tools [39]. MCP was released as an open standard in November 2024 and donated to the Agentic AI Foundation (AAIF), a Linux Foundation directed fund co-founded by Anthropic, Block, and OpenAI, in December 2025 [38]. By March 2026, all major AI providers (OpenAI, Google DeepMind, Microsoft, Cloudflare) had adopted MCP, with over 10,000 active public MCP servers and 97 million monthly SDK downloads [40]. A consistent tool protocol means Evaluators can use the same toolset across different harnesses (Playwright MCP for UI verification, database connectors for data verification, etc.). Standardized protocols enable a composable ecosystem of agent tools, the same way HTTP enabled a composable web.
These four primitives (credential isolation, durable sessions, automated judges, MCP-style protocols) are what Agentic Ops will standardize, the same way DevOps standardized CI/CD. Teams building agent systems today are laying the foundations of what Agentic Ops will look like in 3-5 years.
Build for Deletion
The principle: Harness logic should be designed to be removed as model capability advances.
The concrete example:
- Sprint decomposition logic was a required component of earlier harnesses.
- The Planner needed explicit logic to break long-horizon tasks into sprint-sized chunks.
- When Opus 4.6 arrived, the Planner could perform sprint decomposition natively without scaffolding.
- The sprint decomposition logic was deleted from the Opus 4.6 harness.
- The harness became simpler. Not worse; simpler.

The implication: Every piece of harness logic compensates for a current model limitation. As models improve, those limitations diminish. Well-engineered harnesses anticipate their own simplification. Write harness logic that is easy to delete, not logic that embeds itself permanently. The best harness engineers will measure success partly by how much harness code they remove each quarter.
Counterintuitive implication: A simpler harness on a more capable model often outperforms a complex harness on a less capable model. The harness exists to supplement model capability, not to replace it. As the model absorbs harness functions natively, the harness should contract.
Creative Equality
A well-engineered harness plus a few hundred dollars of compute plus a good idea equals a shipped product. That is new. It was not true two years ago.
Previously:
- Shipping a DAW required months of engineering work and a team.
- Shipping a 2D game engine required domain expertise in graphics and game physics.
- Solving a Boltzmann equation in JAX required a PhD in cosmology and months of numerical debugging.
Now, as demonstrated in the Proof of Concept section above:
- One person with a clear idea, a working harness, and $200 in compute can ship the DAW.
- One person can ship the 2D game engine.
- One person can get sub-percent accuracy on the Boltzmann solver.
This is a structural shift in who can build software. Not because AI is magic. Because the harness architecture makes long-horizon execution reliable enough that capability now outpaces the barrier to entry.
Conclusion: Building Better Harnesses
The era of prompt-and-hope is ending.
Early AI agent deployments ran on hope:
- Hope that the model was good enough to self-evaluate accurately.
- Hope that 20 chained steps would succeed.
- Hope that context anxiety would not truncate critical work.
- Hope that the agent would notice when it was drifting from the plan.
The math says hope is not a strategy. 0.95²⁰ = 0.36. Architectures that rely on hope fail 64% of the time on 20-step tasks.
The future belongs to adversarial systems.
More specifically, it belongs to Agentic AI architectures that make failure structurally impossible rather than statistically unlikely.
The pattern that works:
- Separate generation from judgment.
- Create adversarial tension between them.
- Make "done" verifiable before work begins.
- Sustain the tension across multi-hour runs with crash-survivable infrastructure.
The call to action:
Stop trying to make one agent do everything.
Build systems where AI agents competitively challenge each other. Build harnesses where quality emerges from adversarial tension. Build Sprint Contracts that make "done" unambiguous. Build Managed Agents infrastructure that makes crashes survivable.
The architecture is not theoretical. It built a working 2D game engine, a Digital Audio Workstation, and a Boltzmann solver accurate to 0.1%.
The question is not whether this approach works. The question is whether you are going to build with it.
References
- Anthropic Engineering — "Harness Design for Long-Running Application Development" (March 24, 2026)
- Deng et al. — "SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?" (arXiv:2509.16941, September 2025)
- SWE-bench.com — Leaderboards (2025)
- Scale Labs — SWE-bench Pro Public Leaderboard (SEAL)
- Cognition AI — "Rebuilding Devin for Claude Sonnet 4.5: Lessons and Challenges" (2025)
- Inkeep — "Context Anxiety: How AI Agents Panic About Their Perceived Context Windows" (2025)
- Vennemeyer et al. — "Sycophancy Is Not One Thing: Causal Separation of Sycophantic Behaviors in LLMs" (arXiv:2509.21305, 2025)
- Sharma et al. — "Towards Understanding Sycophancy in Language Models" (ICLR 2024)
- Chroma Research — "Context Rot: How Increasing Input Tokens Impacts LLM Performance" (2025)
- Goodfellow et al. — "Generative Adversarial Nets" (NeurIPS 2014 / arXiv:1406.2661)
- Fanous et al. — "SycEval: Evaluating LLM Sycophancy" (AAAI/ACM AIES 2025 / arXiv:2502.08177)
- Anthropic Engineering — "How We Built Our Multi-Agent Research System" (2025)
- Harrasse, Bandi, Bandi — "Debate, Deliberate, Decide (D3): A Cost-Aware Adversarial Framework for Reliable and Interpretable LLM Evaluation" (arXiv:2410.04663, 2024)
- Anthropic — Pricing Documentation (2026)
- Microsoft — "playwright-mcp" GitHub Repository (2025)
- Anthropic — "Playwright — Claude Plugin" (claude.com/plugins/playwright, 2025)
- Wang et al. — "When Truth Is Overridden: Uncovering the Internal Origins of Sycophancy in Large Language Models" (arXiv:2508.02087, 2025)
- Scrum.org — "Definition of Done vs. Acceptance Criteria Explained" (2024)
- Anthropic Engineering — "Effective Harnesses for Long-Running Agents" (November 2025)
- TestDino — "Playwright MCP Explained" (2025)
- Morph — "Compact: Context Compaction for AI Agents" (2025)
- Anthropic — "Adaptive Thinking" — Claude API Docs (2026)
- Anthropic — "Effort Parameter" — Claude API Docs (2026)
- resolve.ai — "Testing Claude Sonnet 4.6 Adaptive Thinking on Production AI Agents" (2026)
- Anthropic — "Automatic Context Compaction | Claude Cookbook" (2026)
- Anthropic — "Context Compaction — Claude API Docs" (2026)
- Anthropic Engineering — "Scaling Managed Agents: Decoupling the Brain from the Hands" (2026)
- Randy Bias / Cloudscaling — "The History of Pets vs Cattle and How to Use the Analogy Properly" (2012)
- jax-ml/jax — GitHub Repository
- Wikipedia — "JAX (software)"
- Lesgourgues — "The Cosmic Linear Anisotropy Solving System (CLASS) III: Comparison with CAMB for LambdaCDM" (arXiv:1104.2934, 2011)
- Kim & Khashabi — "Challenging the Evaluator: LLM Sycophancy Under User Rebuttal" (arXiv:2509.16533, 2025)
- Malmqvist — "Sycophancy in Large Language Models: Causes and Mitigations" (arXiv:2411.15287, 2024)
- Anthropic — Claude Models Overview (February 2026)
- ABA Business Law Section Market Trends Subcommittee — "2025 Private Target Mergers & Acquisitions Deal Points Study" (December 2025)
- Wang et al. (The Atticus Project) — "MAUD: An Expert-Annotated Legal NLP Dataset for Merger Agreement Understanding" (EMNLP 2023 / arXiv:2301.00876)
- Anthropic Alignment Science Blog — "Automated Weak-to-Strong Researcher" (2026)
- Anthropic — "Donating the Model Context Protocol and Establishing the Agentic AI Foundation" (December 2025)
- Anthropic — "Introducing the Model Context Protocol" (November 2024)
- Wikipedia — "Model Context Protocol"