One Developer, Five Ways to Make Claude Work While You Are Gone
What a real working week looks like when all five Claude Code trigger surfaces are wired up, and why trying to set them all up at once is the fastest way to end up with a graveyard of half-working integrations.
A week in the life of a setup where Claude triages, fixes, and polls without your hands on the keyboard, and the honest reason you should not build it all in one weekend.
In this article: You will see what a developer's week actually looks like when all five Claude Code trigger surfaces are wired up and working together. You will learn why setting up all five at once is the fastest path to a pile of broken integrations, how the surfaces compose into something no single one can produce, and a sober playbook for growing your setup one real friction at a time.
It is Monday morning. You sit down with coffee, open your laptop, and notice something different. Three pieces of work that used to demand your attention have already happened. Issues are triaged. A weekend PR already carries a review checklist. A briefing for your day is waiting. You did none of it, and yet it is done.
That feeling is the payoff of Claude Code automation done right. It is also the thing people chase in exactly the wrong way. The natural instinct, once you have absorbed enough new patterns, is to spend a Saturday turning everything on at once. That instinct is the trap. The developers who end up with durable leverage build slowly, one surface at a time, and let each one earn its place against a real frustration they can name.
This article shows you the destination and the road to it. First the week-in-the-life picture of all five surfaces working together. Then the honest truth about how to actually get there without burning out on tooling.
The trap worth naming first
Before the capstone picture, name the failure mode: trying to set up all five surfaces at once.
The pattern is familiar. Saturday you install every channel, configure three Routines, pair the mobile app, enable Remote Control by default, and write a loop.md. Sunday the setup is ready. Sunday night it is barely used. By the end of the next week, half of it is broken because nothing ran long enough to surface the configuration issues, and the other half is fine but is generating notifications and PRs you do not have time to review.
This is the same pattern that turns a Claude Code setup into a directory full of skills nobody uses. Artifacts earn their place only when they solve real problems. If you have not felt the specific friction a surface fixes, the surface is overhead, not leverage.
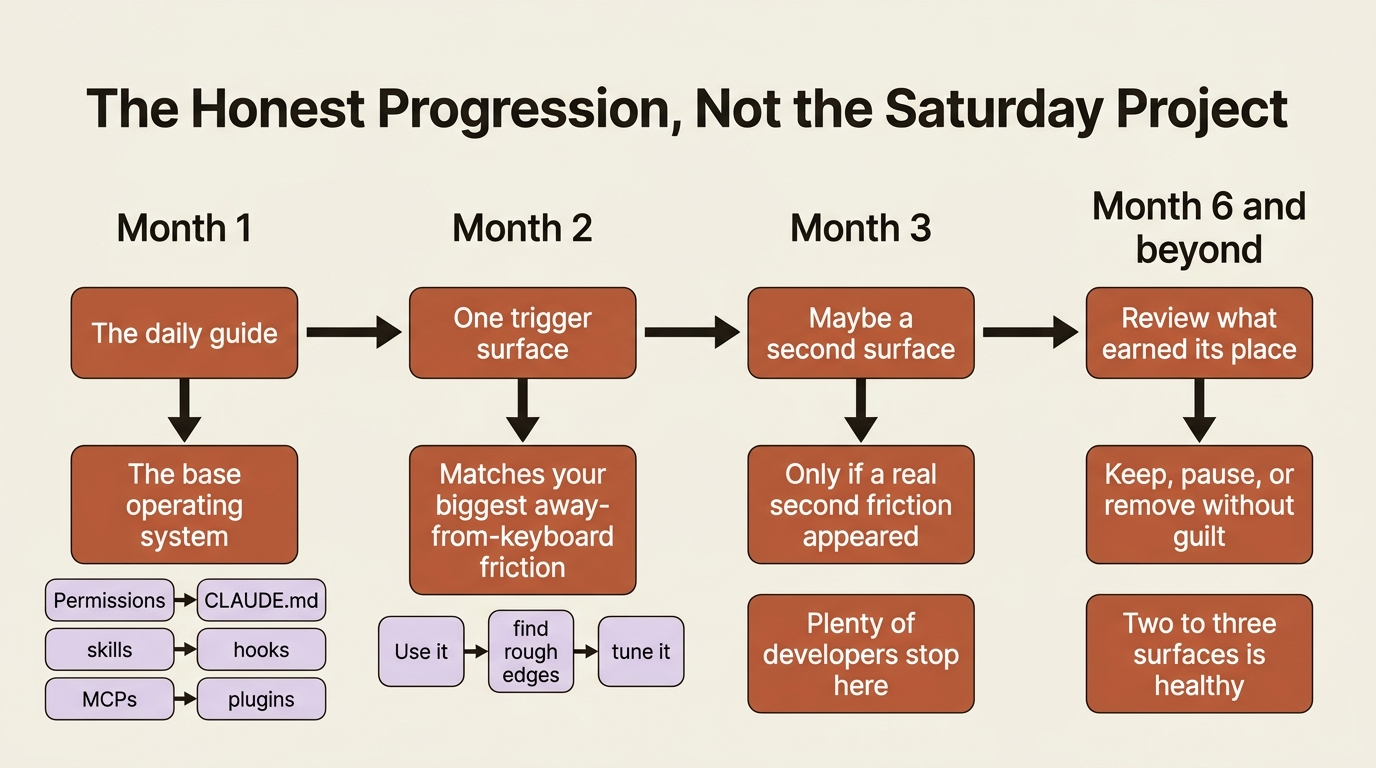
The honest progression looks more like this. Month one is the daily guide: permissions, CLAUDE.md, skills, hooks, MCPs, plugins, the base operating system. Month two is a single trigger surface, the one that matches your biggest "Claude could have done this while I was away" friction. Month three is maybe a second surface, if a genuine second friction has appeared. Plenty of strong developers run for a year on one surface plus the daily guide and never need more. By month six, the question is no longer "should I add another?" but "has my work produced a new shape of friction that an unused surface would now solve?" That question gets honest answers because there is real evidence to draw on.
The week below shows the full setup with everything in place. Read it as the long-term destination, not the Saturday project. Almost no one should aim for the full picture in a single push.
A week with all five wired up
Here is the picture, told as a week in the life.
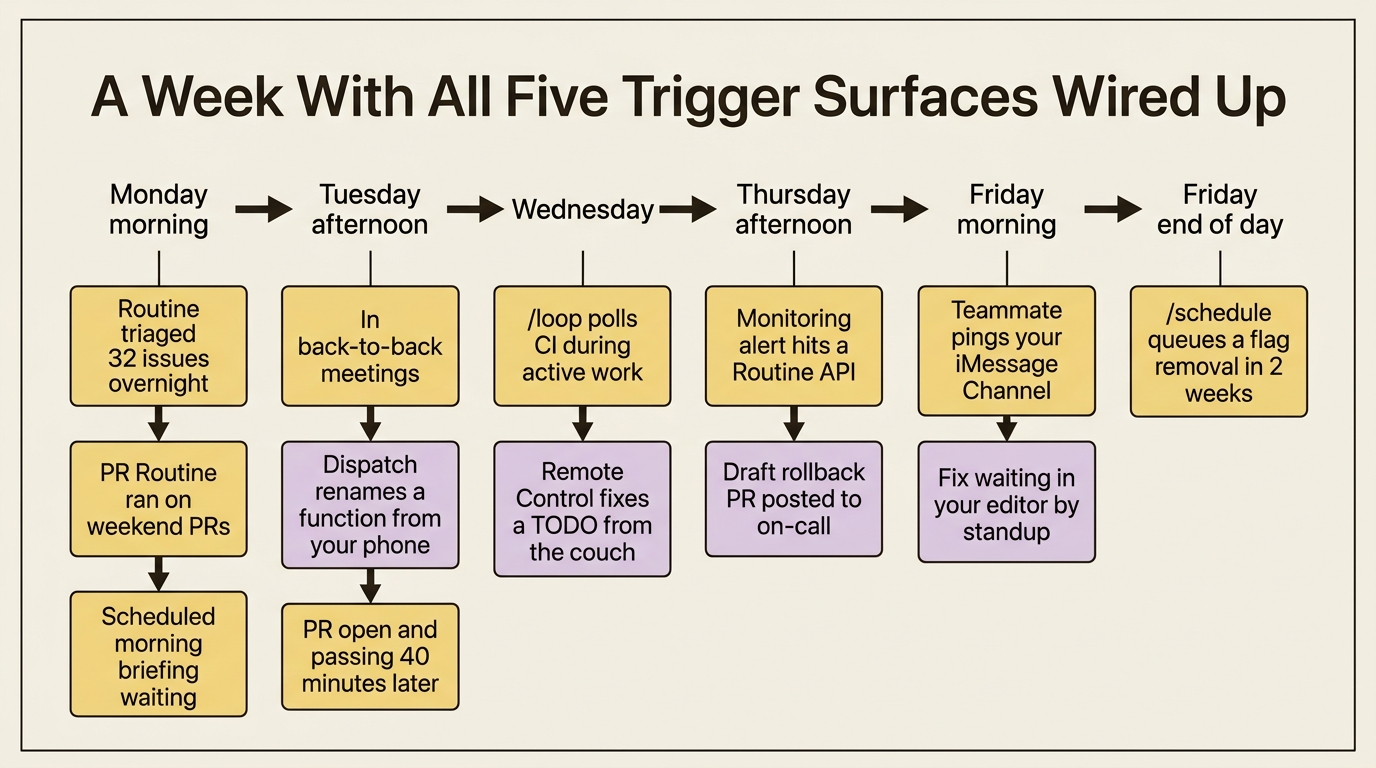
Monday morning
You sit down at 8:30. Three things have already happened without you.
A Routine ran overnight to triage the team's issue backlog. It tagged thirty-two new issues with area labels, assigned the obvious ones based on CODEOWNERS, and posted a Slack summary to #engineering at 6am: "32 issues triaged, 4 need human attention (linked below), 2 likely duplicates flagged." You click the four links over coffee and answer inside the issues themselves. The triage step was robotic. The judgment step was yours.
A pull_request.opened Routine ran on every PR opened over the weekend, applying your team's review checklist. Your reviewers see Claude's findings before they even start, so human review begins from the questions Claude could not answer rather than from scratch.
A Desktop scheduled task ran at 8am: a morning briefing. It pulled your calendar, scanned your inbox for flagged follow-ups, and surfaced a checklist for each meeting. You read it before your 9am standup.
None of these is large on its own. Together they replace forty-five minutes of "what happened while I was gone" friction. You start the day in flow instead of catching up.
Tuesday afternoon
You are in back-to-back meetings from 1 to 4. During the second one you remember: the auth-refactor branch needs a quick rename across the codebase, and you will not be free until evening.
You message Dispatch from your phone during a break: "On the auth-refactor branch, rename all instances of validateUser to validateUserCredentials. Update tests too. Open a PR."
Forty minutes later the mobile app pings. The session is done, the PR is open, the tests pass. You read the diff during a five-minute stretch and approve the merge. Total time spent in your day: about ninety seconds.
Wednesday during active work
You are debugging a flaky test and think you have a fix in progress. You need to know when CI passes or fails so you can iterate.
/loop check whether CI passed on this branch and tell me the result
You go back to writing code. Six minutes later /loop reports CI is red and pastes the error. You change something, push, and the loop catches the next run, then reports green. Two iterations later the test is fixed. The polling cost you zero attention. The result arrived where you were already working.
Wednesday evening from the couch
You ate dinner. You should be done. You remember one more small thing about the auth refactor. The laptop is on the coffee table, and the session you were in at 4pm is still running.
You open Remote Control from your phone with the session URL bookmarked: "In the JWT validation function, add a TODO comment with a link to the design doc explaining the issuer behavior. Do not change the logic." Claude does it. You see the diff on the phone and approve the change.
You did not have to walk back to your desk, sit down, lose context, write the fix, and walk back. Two minutes on the couch, and the work is done.
Thursday afternoon
It is 3:14. A monitoring alert fires for an error-rate spike. Your monitoring tool calls the API endpoint of a Routine you set up two months ago. The Routine pulls the stack trace, correlates it against commits from the last 24 hours, identifies a likely culprit (a config change that landed at 2:55), opens a draft PR with a proposed rollback, and posts to the on-call channel.
You see the post during a meeting, click through, read Claude's reasoning, and either approve the rollback or comment with the actual root cause. The triage that used to take twenty minutes of context-gathering happens in zero. You go straight to the decision.
Friday morning
A teammate sends an iMessage at 11: "Hey, the deploy script keeps failing with a permission error. Look at it?"
Your iMessage Channel is paired with your work machine, where a Claude session runs in tmux. The message arrives in the session. Claude reads the recent commits to the deploy script, runs it in dry-run mode against your local environment, finds the permission misconfiguration, and proposes a fix. By the time you walk back from standup, the fix is waiting in your editor with a one-paragraph explanation.
Your teammate did not have to wait for you. You did not have to interrupt your morning. The work happened where your project context was already loaded.
Friday end of day
It is 4:30 and you are about to leave. You remember: the feature flag for the Q2 experiment can be removed now that the rollout is complete. You do not need it now. You just need it to happen at the right time.
/schedule in 2 weeks, open a PR that removes the q2-experiment feature flag from src/ and the corresponding code paths
The Routine schedules itself for two weeks out. After it fires, it auto-disables. You did not add it to a TODO list, set a reminder, or remember at all. The work is in queue.
The compounding pattern
What this week shows is not that any one surface is transformative. It is that the combination eliminates a class of friction no single surface can.
Each surface handles a different shape of friction. Channels handle external events arriving where Claude already has context. Remote Control handles working from a different location without moving the work. Dispatch handles "I thought of this while away" tasks. Routines handle work that runs without your machine on. Scheduled tasks handle in-session polling and local recurring work.
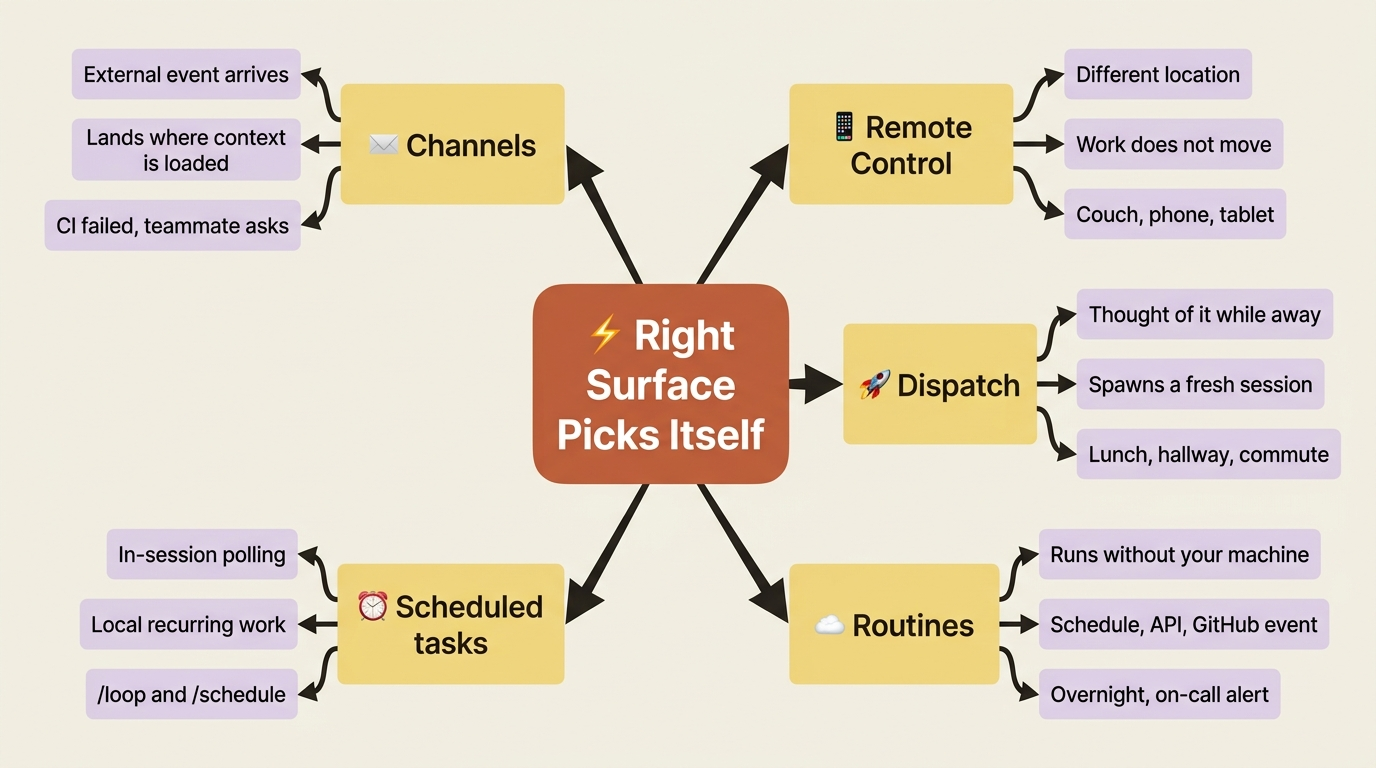
A developer with all five set up does not consciously decide which surface handles which friction. The right surface picks itself based on where the friction starts. CI failed: Channels brings it to the session you are already in. Teammate asks via Slack: Channels again. You are at lunch and think of something: Dispatch. You are at your desk watching a slow process: /loop. You are on the couch and remember a small fix: Remote Control. You want something to happen at 6am on weekdays: a Routine.
That self-selection is what produces the "three things have already happened" Monday morning. No single surface can produce that picture. All five together do.
How to actually grow your setup
Here is the honest playbook, the one that produces lasting results rather than the maximalist setup that does not.
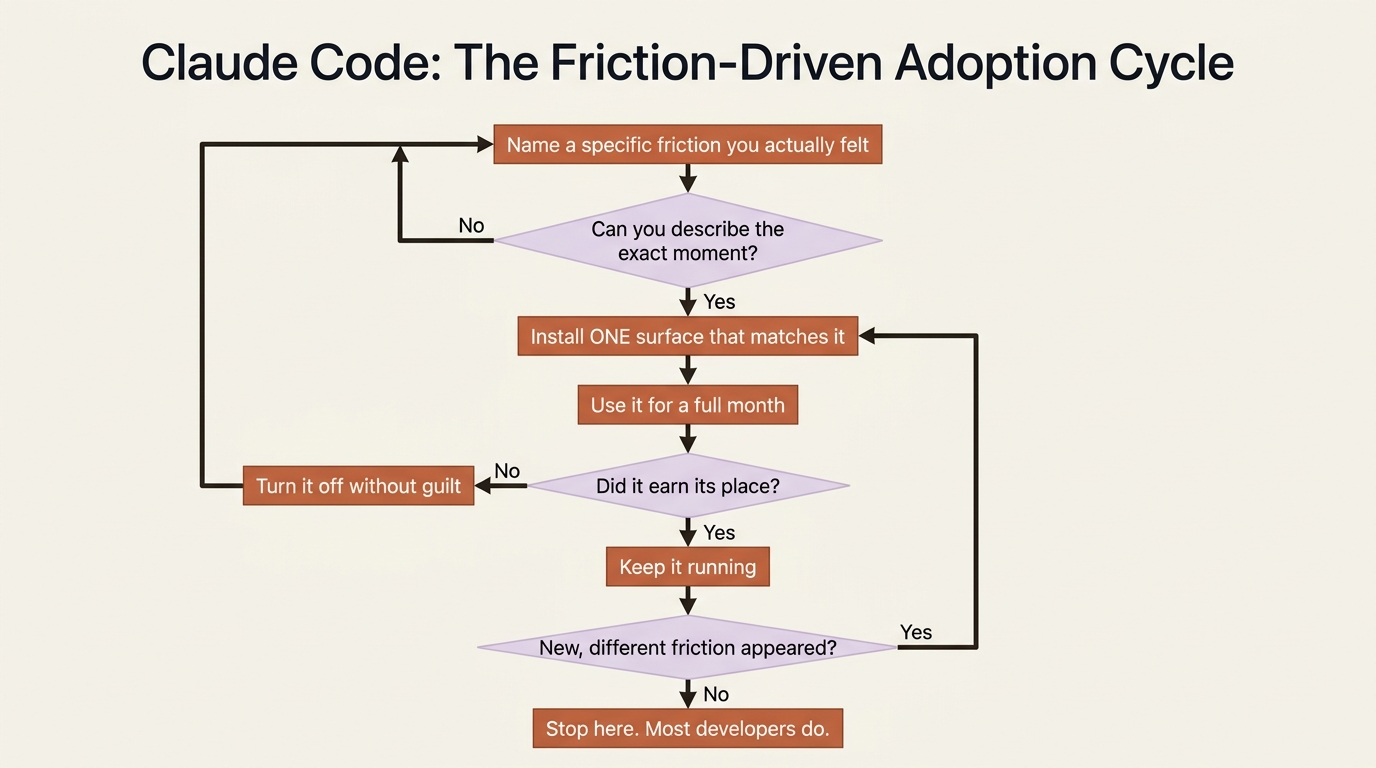
Install one surface that matches a friction you can name. Not "this seems useful." A specific frustration you can describe. "Last Friday at 8pm I wanted Claude to fix the failing build but I was already on the couch" points at Remote Control or Dispatch. "I keep forgetting the weekly dependency audit" points at Routines. Without that specificity, you are installing tools that may have no use.
Use the one surface for a month. Long enough to surface configuration issues, edge cases, real limits, and your actual usage patterns. By the end you either know the surface earned its place or you know it did not. Both outcomes are useful information.
Ask whether a second surface would solve a different friction. If yes, install it. If no, do not. The trap is the maximalist instinct: "I have one, I should set up the others." The second surface is justified by a specific second friction, not by completionism.
Review every six months. Some surfaces earn their place permanently. Some earn it for a project, then go unused; turn them off rather than let them accumulate maintenance burden. Some turn out to have been the wrong call; remove them without guilt.
The healthy long-term picture for most working developers is two to three surfaces, not five. The five-surface week above is the maximum useful setup, not the expected one. Some readers reach it because their work demands it. Most will not.
A few uncomfortable truths
Worth naming, because pretending otherwise sets you up for frustration.
Some surfaces will be wrong for your workflow forever. Not because the surface is bad, but because the friction it solves is not friction you have. If you never work from your couch, Remote Control may never matter. If your team does not use chat for technical work, Channels may not. Skip the surfaces that do not fit and do not feel inadequate about it.
The infrastructure has maintenance cost. Always-on tmux sessions for Channels need to actually stay running. Routines need checking for drift. Desktop scheduled tasks need permission approvals re-granted after some app updates. The leverage is real, but it is not free.
You will hit edges that need workarounds. Channels lose messages if the session is down. Routines can miss runs if your daily cap fills early. Desktop tasks skip if your laptop sleeps. Each surface will produce one or two workarounds you adopt over time.
Some readers will conclude they do not need any of this. That is a valid conclusion. A solid daily Claude Code setup already covers the work of being a developer who uses Claude productively. The trigger surfaces are an amplification layer that not every developer needs. The honest acknowledgment matters more than the maximalist pitch.
Do this today
Three concrete moves:
- Identify the single surface that solves your biggest "Claude could have done this while I was away" friction. Be honest about the friction. The surface that matches is the one to start with.
- Install only that one surface. Set it up properly, tune it, use it for a month. Resist the impulse to install the others "just in case."
- Schedule a review for one month from today. A calendar reminder to ask: did the surface earn its place? Would a second one solve a different friction that has shown up since? Honest answers, no completionism.
The endpoint
When the right combination is in place and earning its keep, the feeling is not "I have set up a lot of automation." It is "Claude is helping me with the parts of my work where I was not present." The work that used to require your attention but not your judgment has migrated to the right place. The work that requires your judgment has stayed where it belongs, in front of you, with the context already loaded.
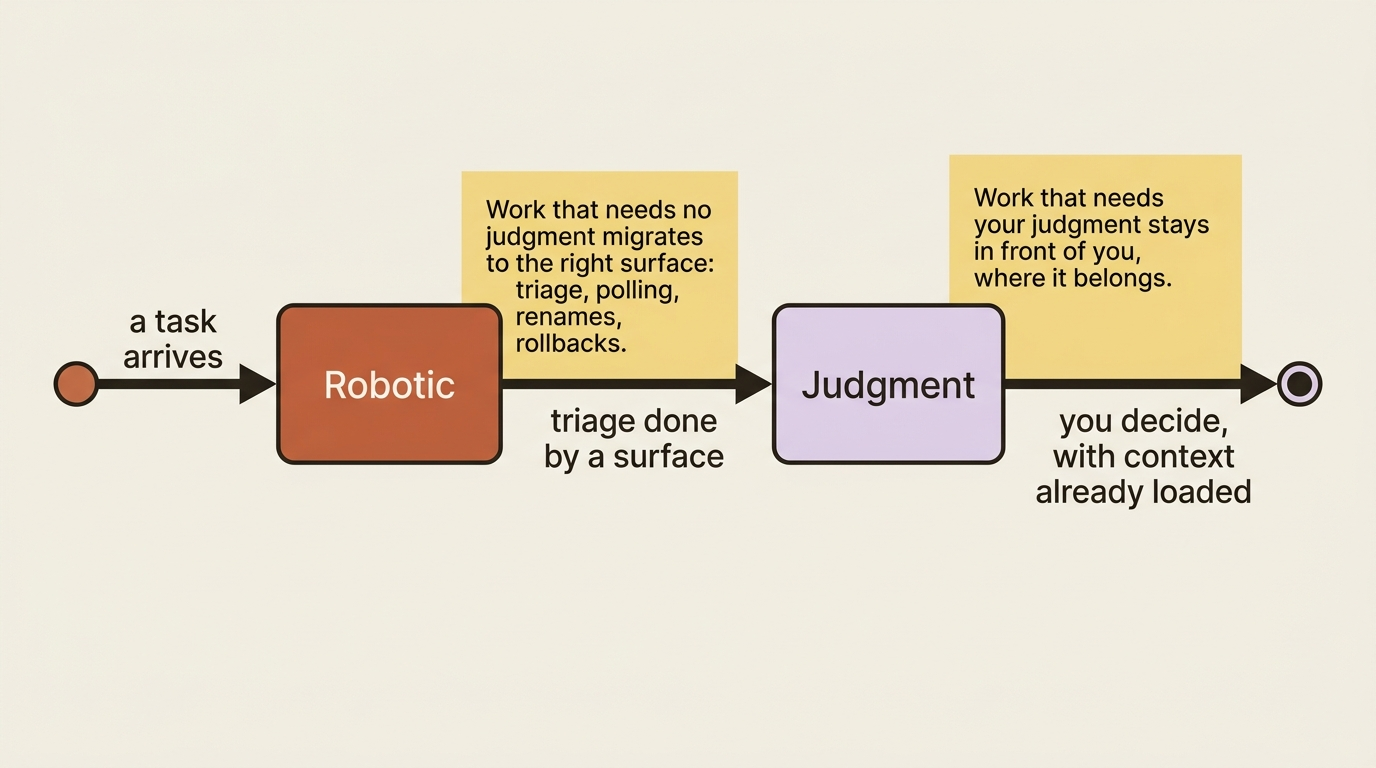
That migration is the destination. Some readers reach it in three months, some take a year, and some never need to, because a good daily setup is already enough. All three outcomes are fine. The point is not to adopt all five surfaces. It is to adopt the right ones for the right frictions, one at a time, and let them earn their place.
Six months in, the developer who did that has a setup that genuinely works without becoming maintenance overhead. The developer who installed everything at once has a graveyard of half-working integrations and the wrong instinct about what produces leverage. The choice between those two outcomes is the whole point.
This is Part 7, the capstone, of "Claude Code Away from the Terminal," a 7-part guide to making Claude work for you when you are not sitting at the terminal.