How to Build a Deep Research Agent That Composes Every Primitive at Once
A capstone build that proves the real skill is not learning agent primitives one at a time, but composing all of them into a long-running deep research agent without breaking any of them.
Most agent tutorials teach features one at a time. Real systems compose all of them at once, and the hard part is making the eleventh capability work without quietly breaking the previous ten. Here is the capstone build that proves it.
In this article: You will learn how to assemble a long-running deep research agent from the full set of Managed Agents primitives: a coordinator that plans an investigation, parallel workers that search in isolation, MCP-backed sources, rubric-graded outcomes, per-user vaults, and scheduled delivery over webhooks. By the end you will see why a research agent and an invoice reconciler are the same machine pointed at different work.
There is a gap between learning agent features and shipping an agent. Tutorials walk you through one capability at a time: here is how tool use works, here is memory, here is multi-agent delegation. Each one lands cleanly in isolation. Then you try to build something real, wire eight of them into a single agent, and discover that the actual skill was never any individual feature. It was composition. The hard part, the part no feature walkthrough teaches, is making the eleventh capability cooperate with the previous ten instead of quietly breaking them.
This article is a capstone. We stop adding features and start composing them. The vehicle is a deep research agent: you hand it a question, it plans an investigation, delegates focused research to parallel workers, synthesizes their findings into a cited report, grades its own draft against the original request, and returns a finished document. It is the agent equivalent of a final exam, because doing it well requires the event model, custom tools, permissions, MCP, skills, memory, outcomes, multi-agent orchestration, vaults, deployment, and webhooks to all work together at once.
The shape here is deliberate. It follows the deep-research pattern that has become the reference design across the agent ecosystem: an orchestrator that plans and delegates, workers that search in isolation, and a grader that holds the result to a standard. What is worth your attention is how that shape maps onto concrete Managed Agents primitives. If you can build this, you can build your own.
The Shape of the Agent
Before any code, hold the architecture in your head, because every primitive slots into it.
There is one coordinator, the main agent, and it never searches the web itself. Its job is the high-level workflow: plan the question into focused subtopics, write the original request to a memory file so it can check its work later, delegate each subtopic to a research worker, synthesize what the workers return into one report with consolidated citations, and submit that report against a rubric that judges whether it actually answered the question.
The research workers are the labor. Each takes one focused subtopic, searches and reads in its own isolated context, and returns a short cited synthesis. The coordinator stitches; the workers dig.
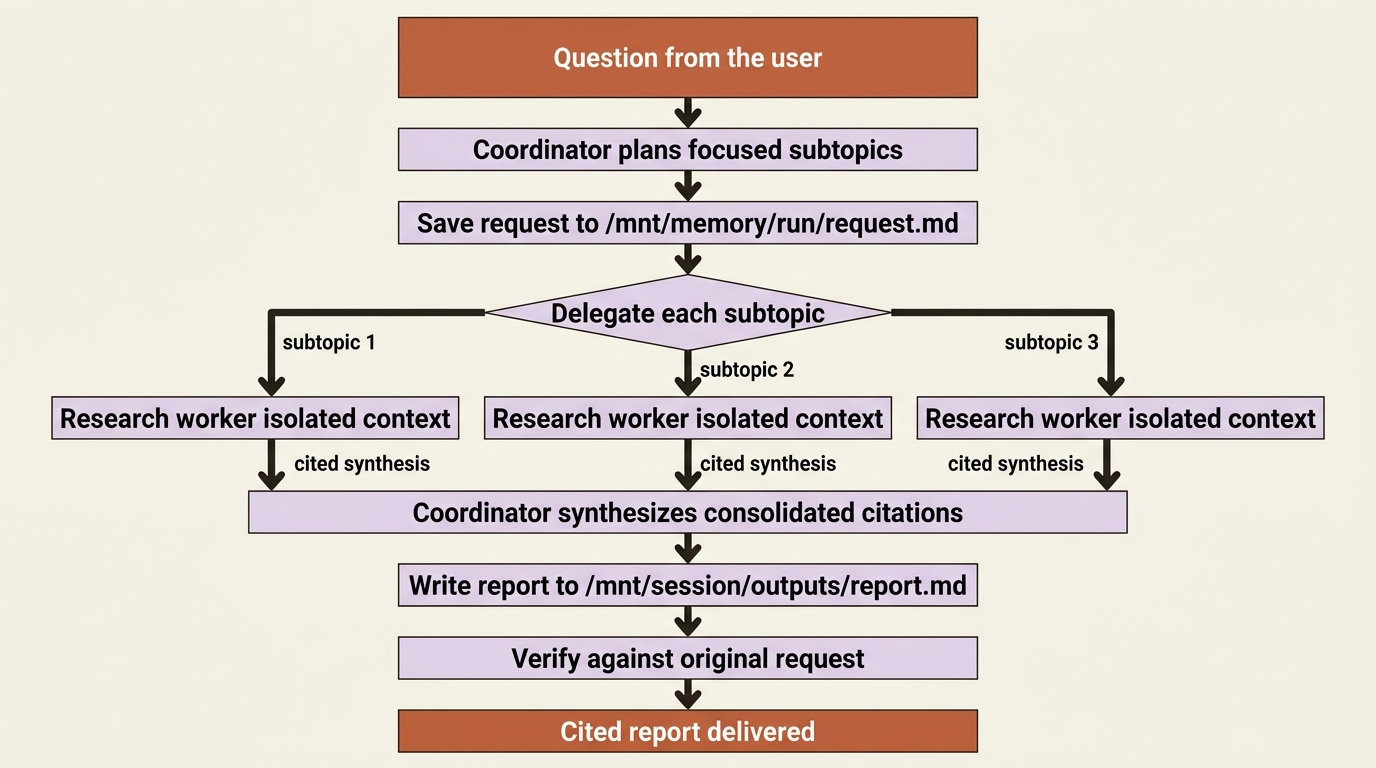
This is the multi-agent coordinator pattern doing real work: a coordinator fanning out to parallel workers, each in a context-isolated thread, with the coordinator synthesizing the results. Wrapped around it is the outcomes pattern, which turns the final "did we actually answer the question" check from a hope into a graded verdict. Two of the headline differentiators, composed into one agent, with everything else supporting them.
Step One: The Research Worker
Delegates are pre-created agents referenced by ID, not inline definitions, so the worker comes first. It is a normal agents.create call with the built-in toolset for web search and fetch, and a system prompt with one job: research one subtopic and return a short synthesis with sources, never a raw dump.
researcher = client.beta.agents.create(
name="Research Worker",
model="claude-opus-4-7",
system=(
"You research ONE focused subtopic. Search the web, read sources, and "
"return a concise synthesis: key findings plus a Sources list of title "
"and URL. Under 500 words. Never return raw search results or full page "
"text. Cite every claim."
),
tools=[{"type": "agent_toolset_20260401"}],
)
The "under 500 words, cite everything, no raw dumps" instruction is the single most important line for keeping a long research run inside its token budget. This is context isolation made concrete. A worker might read tens of thousands of tokens of web pages in its own thread, but the coordinator only ever sees the few hundred tokens of distilled findings the worker returns on the primary thread.
The worker is a disposable specialist. The coordinator can spin it up as many times as the plan needs, each instance in its own clean context.
Step Two: The Coordinator and Its Workflow
The coordinator is an agent with a multiagent block listing the worker on its roster, and a system prompt that lays out the workflow as numbered steps. The critical instruction, the one that makes this a coordinator rather than a single agent doing everything, is the rule that it always delegates research and never searches itself. That rule is what keeps its context clean: it sees plans and synthesized findings, never the raw flood of search results.
COORDINATOR_PROMPT = """You are a research coordinator. Today's date is in your
memory file at /mnt/memory/context/today.md; read it first so your research is
time-aware.
Your workflow:
1. Plan: break the question into focused subtopics.
2. Save the request: write the user's exact question to /mnt/memory/run/request.md.
3. Research: delegate each subtopic to the Research Worker. ALWAYS delegate.
NEVER search yourself. Parallelize only genuinely independent subtopics;
otherwise prefer one focused worker at a time.
4. Synthesize: consolidate findings and citations so each unique URL gets one
number across the whole report.
5. Write: write the full cited report to /mnt/session/outputs/report.md.
6. Verify: re-read /mnt/memory/run/request.md and confirm every part of the
question is addressed with citations before you consider the work done.
"""
coordinator = client.beta.agents.create(
name="Research Coordinator",
model="claude-opus-4-7",
system=COORDINATOR_PROMPT,
tools=[{"type": "agent_toolset_20260401"}],
skills=[{"type": "anthropic", "skill_id": "docx"}],
multiagent={
"type": "coordinator",
"agents": [{"type": "agent", "id": researcher.id, "version": researcher.version}],
},
)
The coordinator declaration in TypeScript, the part that differs most from a plain agent:
const coordinator = await client.beta.agents.create({
name: "Research Coordinator",
system: COORDINATOR_PROMPT,
model: "claude-opus-4-7",
tools: [{ type: "agent_toolset_20260401" }],
skills: [{ type: "anthropic", skill_id: "docx" }],
multiagent: {
type: "coordinator",
agents: [{ type: "agent", id: researcher.id, version: researcher.version }],
},
});
That single block establishes a main agent that plans, delegates, synthesizes, and verifies, with the delegation discipline baked into the prompt and the worker's version pinned for reproducibility. The docx skill is attached so the final report can be a real Word document rather than improvised Markdown. That is the specialization payoff applied to the deliverable.
Parallelization lives here too. When the plan has genuinely independent subtopics, the coordinator issues multiple delegations and the workers run in parallel threads; when the question is unified, it uses one. The bias-toward-one rule in the prompt is what keeps a broad question from fanning out into twenty concurrent threads against the 25-thread limit.
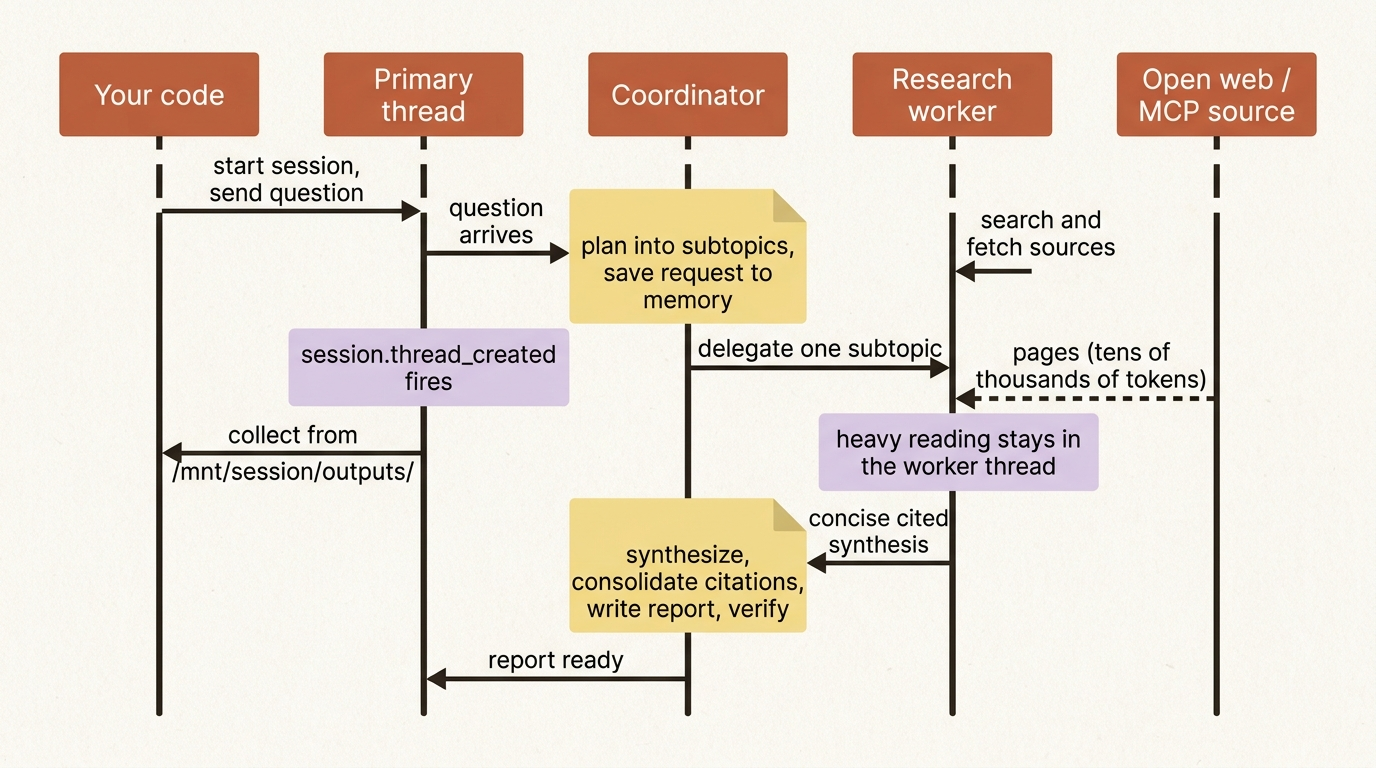
Step Three: The Filesystem and Memory as Working Storage
A long research run produces more than fits comfortably in a single context. Two different storage needs converge.
The report and the run's scratch files belong in the session container, written to /mnt/session/outputs/ so you can collect the deliverable through the session-scoped Files API. The original request, and anything the agent should carry between runs, belong in a memory store mounted under /mnt/memory/, attached at session creation.
That split is why the prompt writes the request to /mnt/memory/run/request.md and the report to /mnt/session/outputs/report.md. The request goes in memory because the verify step needs to read it back, and because a research agent that should learn a user's standing interests or recurring sources wants durable storage that outlives the session.
The 100K-token spill-to-file behavior quietly helps here too. A worker that pulls a giant page does not blow the context window, because oversized tool results land on the filesystem with a preview. The pattern to internalize: for any agent that produces a lot, the filesystem is working memory and the conversation is just talk about it.
One discipline matters more than any other here. Mount any shared reference memory read_only. This agent reads the open web, and a read_write memory store combined with untrusted web content is a prompt-injection write path into the memory that future runs will trust.
Step Four: Sources Over MCP, and Authenticating Per User
The built-in web_search and web_fetch cover the open web, but serious research often needs sources behind authentication: a paid search API, an internal document store, a licensed database. That is MCP. You declare the source server on the worker, reference it with an mcp_toolset, and scope which of its tools the worker may use.
Because MCP defaults to always_ask, a research server's tools pause for confirmation until you decide to trust them. For a high-volume research run you will want to flip the read-only search tools to always_allow while keeping anything that costs money or writes data gated.
Vaults are what make this multi-tenant: one research agent, run for many users, where each user's licensed-database access is their own credential. You register each user's credential in a vault bound to the source's mcp_server_url, and attach vault_ids at session creation so the session authenticates as that user. The agent definition never holds a secret; the user is a session-level detail. And a bad or missing credential does not crash the run. It surfaces as an MCP auth error on the stream, and the rest of the research, including the open-web workers, proceeds.
Step Five: The Verify Step Is the Outcome, and the Grader Is the Evaluator
This is the step that most improves quality, and it is where the research agent gets genuinely rigorous.
A weaker design would just instruct the coordinator to "check your work" and trust it. Outcomes do better. You run the whole research session as an outcome, with a rubric that defines what a good answer looks like, and the harness provisions a separate grader, with its own context window, to score the report against that rubric and hand gaps back for another round. The coordinator cannot grade itself into a false pass, because the grader never saw its reasoning.
You start the session and define the outcome instead of sending a plain message.
session = client.beta.sessions.create(
agent=coordinator.id,
environment_id=environment.id,
vault_ids=[user_vault.id],
resources=[{"type": "memory_store", "memory_store_id": store.id, "access": "read_write"}],
)
client.beta.sessions.events.send(
session.id,
events=[{
"type": "user.define_outcome",
"description": "Research and write a cited report answering: " + question,
"rubric": {"type": "text", "content": RESEARCH_RUBRIC},
"max_iterations": 4,
}],
)
The rubric encodes what "answered" means, in gradeable lines: every part of the question is addressed, every claim carries a citation, each unique source is numbered once, and no section is left as a stub.
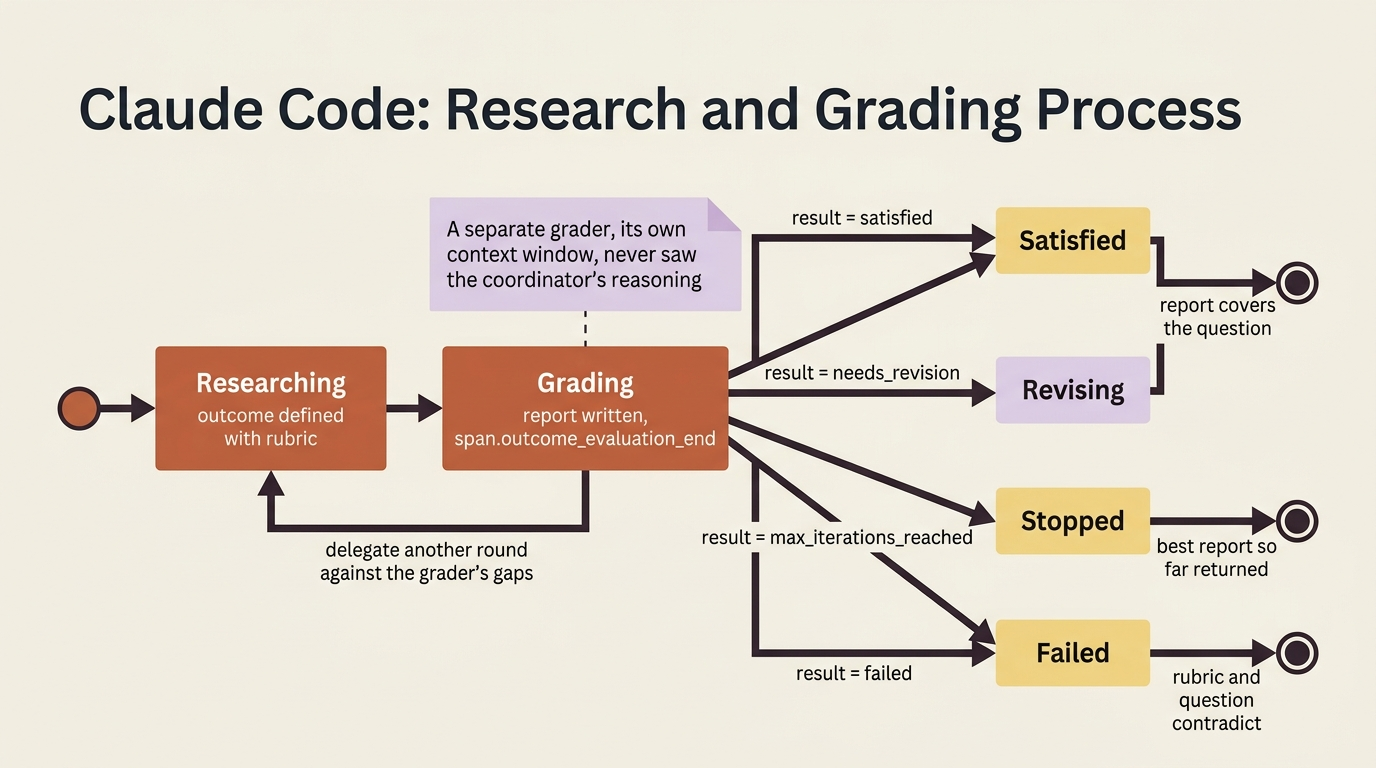
When the grader emits span.outcome_evaluation_end, its result is the verdict, and five values map cleanly onto research outcomes:
satisfiedmeans the report covers the question.needs_revisionsends the coordinator back to delegate another research round against the grader's specific gaps.max_iterations_reachedis the stopping condition that keeps an unanswerable question from looping forever, ending with the best report so far rather than burning budget.failedtells you the rubric and the question contradict each other.interruptedis emitted when auser.interruptarrives mid-evaluation, afteroutcome_evaluation_starthas fired.
That result is the closest thing Managed Agents has to a typed return value. Downstream code reads outcome_evaluations[].result off the session and knows, as data, whether the research passed, then fetches the report from /mnt/session/outputs/. The verify step is the evaluator-optimizer loop, and the grader is the evaluator.
Step Six: Watching It Run, and Keeping It on a Leash
A research run takes minutes, so the event stream is not a nicety. It is how the user knows the agent is alive. You stream the primary thread and watch the plan form, then watch session.thread_created fire for each worker the coordinator spins up, and agent.thread_message_sent and agent.thread_message_received show the delegation handoffs.
Because every worker's blocking request cross-posts to the primary thread with its session_thread_id and agent_name, you answer any confirmation on the one stream you are already watching, never racing a dozen worker threads. The span.outcome_evaluation_* events narrate the grading loop on the same stream, so you see "iteration 1: needs_revision" and know another research round is coming.
Safety scales with autonomy, and a research agent is the high-autonomy case. It reads arbitrary web content, which is untrusted input by definition. A malicious page can carry a prompt injection. The defenses are the ones you already built:
- Permissions keep the workers' dangerous tools gated while letting read-only search run free.
- Limited networking fences the container's egress to the search and source endpoints it actually needs, so a compromised worker has nowhere to exfiltrate to.
- The
read_onlymemory discipline closes the injection-into-memory path.
The throughline is that each control you turned on earlier is also a security boundary, and a web-reading agent is exactly when you choose the restrictive option at every one.
Step Seven: Shipping It on a Schedule
A long-running research agent is the textbook case for the deployment and webhook machinery, because it is stateful, slow, and far better run as a notified background job than a held-open connection.
You provision it deliberately. A deploy script stands up the environment, the worker, and the coordinator, pins the worker version into the roster, and writes a manifest of IDs. A separate run script loads the manifest and starts a session per question. The environment runs limited networking with only the search and source hosts allowed. Cost rides on the session's usage field, which matters when a single report visits twenty sources across several worker threads.
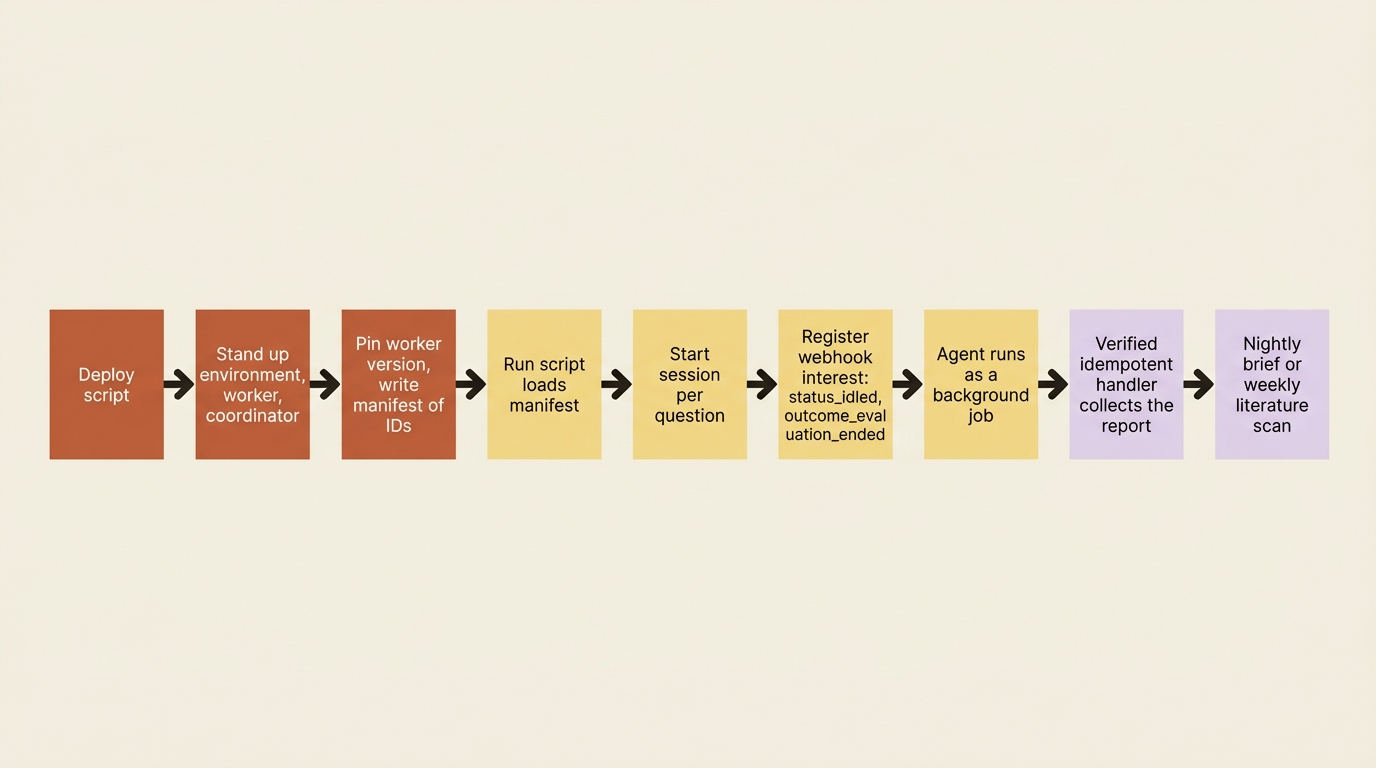
Because a research run is long and asynchronous, you do not hold a stream open through it. You use webhooks: start the session, register interest in session.status_idled and session.outcome_evaluation_ended, and let a verified, idempotent handler collect the report when the run finishes. That turns the research agent into a background job you can schedule: a nightly competitive-intelligence brief, a weekly literature scan, with the agent telling you when each report is ready rather than you watching it work. If a scheduled agent's container state must persist between runs, a periodic keep-alive message resets the 30-day checkpoint clock.
Do This Today
- Sketch the architecture before any code. One coordinator that plans and synthesizes, plus one disposable worker that searches. Draw the fan-out and the return path.
- Write the worker's prompt as a hard contract. "Under 500 words, cite everything, no raw dumps" is the single line that keeps a long run inside its token budget.
- Make the verify step a real outcome. Write a rubric in gradeable lines and run the session as an outcome so a separate grader, not the coordinator, decides whether the report passed.
- Mount reference memory
read_only. Any agent that reads the open web plus a writable memory store is a prompt-injection write path. Close it. - Plan for a background job. Register webhook interest in
session.status_idledand let an idempotent handler collect the report, instead of holding a stream open for minutes.
The Real Lesson: The Primitives Are General
Step back and look at what this one agent used. The event model, as the stream you watch and steer. Custom tools and the 100K spill, as the worker's escape valve for oversized reads. Permissions, gating the dangerous tools. MCP, reaching authenticated sources. Skills, producing a real document. Memory, holding the request and learning across runs, mounted read_only where the web could poison it. Outcomes, as the grader that holds the report to a standard. The multi-agent coordinator, fanning research out to isolated workers. Vaults, running it per user without a secret in the agent. Deployment, networking, and the threat model. And webhooks, making it a scheduled background job.
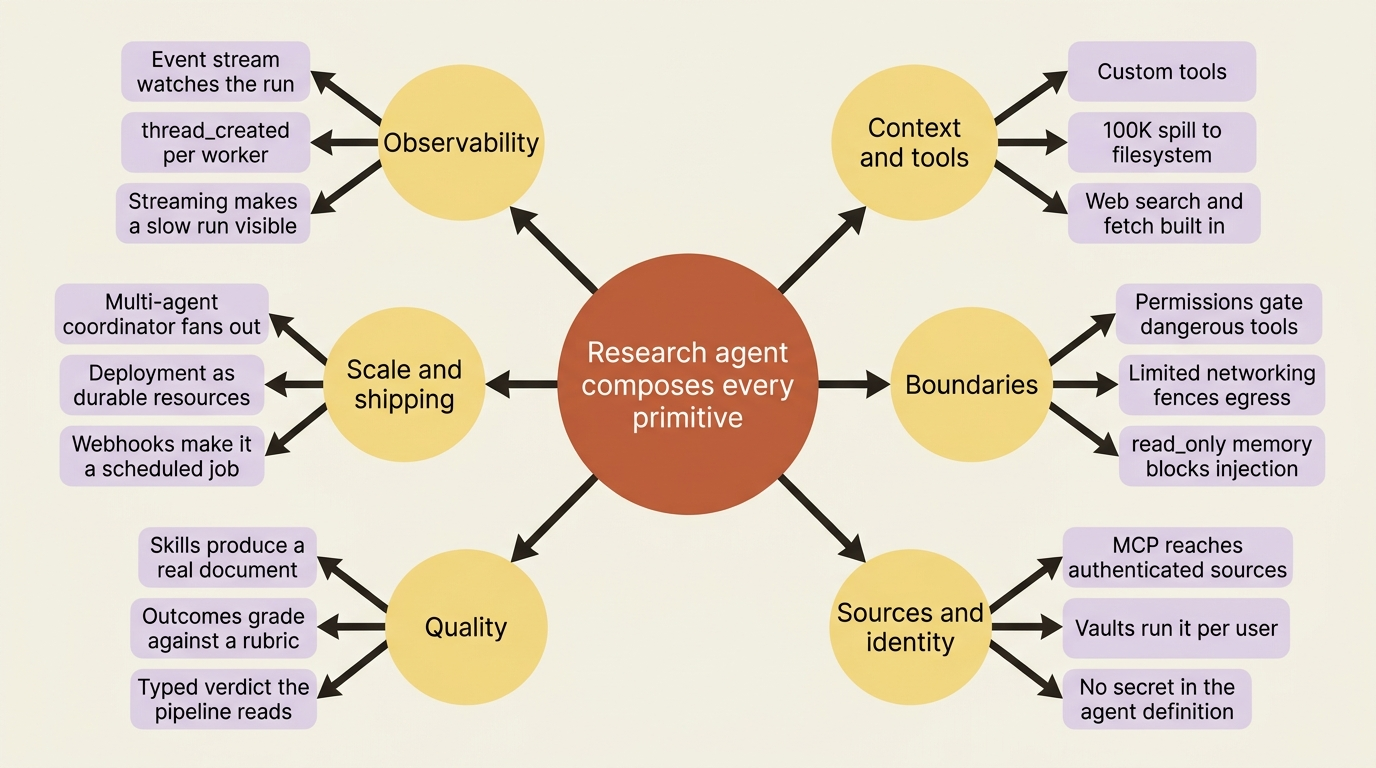
Nothing here was new. Everything here was composed.
That is the real lesson, and the reason a research agent makes a better capstone than another invoice reconciler: the primitives are general. A reconciler and a research agent look like different products, but underneath they are the same harness, the same event stream, the same coordinator-and-workers, and the same leashes, pointed at different work. Swap the worker's search tool for a SQL tool over MCP and the report for a financial summary, and you have an analyst. Swap it for a code-reading tool and you have an architecture reviewer. Swap the rubric and the deliverable, and you have something else again. The template does not change; the tools, the rubric, and the prompt do.
You can now design, build, secure, deploy, and observe an agent that plans its own multi-step research, coordinates a team of isolated workers, authenticates as any of your users, holds itself to a graded standard, defends against the injection risk of reading the open web, and ships a cited report on a schedule. And you can name, in Managed Agents' own vocabulary, exactly which primitive does each job. From here, the only agent left to build is yours.
This is Part 13 of "Building with Claude Managed Agents," a 13-part guide to building production-ready AI agents.