The Hardest Part of Building an AI Agent Is Not the Eighth Feature. It Is Keeping the First Seven Working.
Why a real production agent is never one primitive at a time but all of them composed at once, shown by building a research agent that plans, delegates, synthesizes, and reviews its own work.
Anyone can wire up planning, or subagents, or streaming, one at a time. A production agent composes all of them at once. Here is how to build a research agent that plans its own investigation, delegates to parallel workers, synthesizes a cited report, and reviews its own draft.
In this article: You will learn how to compose a complete LangChain research agent from primitives you already understand individually. We walk through a six-step orchestrator workflow, the disposable researcher subagent that keeps context clean, the filesystem as working memory, structured output your pipeline can consume, the self-review loop that separates "looks done" from "is done," and the safety leashes an autonomous web agent needs. By the end, you will see why a research agent and a bug-fixer are the same machine pointed at different work.
Most tutorials teach an agent framework one capability at a time. Planning gets its own chapter. Subagents get another. Streaming, memory, permissions, deployment, each arrives in isolation, each demonstrated on a small example that does one thing. That is the right way to learn. It is not the way you build.
Real agents do not use one primitive at a time. They compose all of them at once. And the hard part, the part no feature walkthrough can prepare you for, is making the eighth capability work without quietly breaking the previous seven. A planning tool that fights your streaming filter. A subagent that floods the orchestrator's context. A structured output schema that the verification step never populates. Composition is where agents actually get hard.
So this is a capstone. We are going to stop adding features and start composing them, and we are going to do it by building something deliberately bigger than a bug fix: a long-running LangChain research agent. You give it a question. It plans an investigation, delegates focused research to parallel workers, synthesizes their findings into a cited report, reviews its own draft against your original request, and hands you a finished document. It is the agent equivalent of a final exam, because doing it well requires planning, subagents, parallelization, structured output, memory, streaming, permissions, deployment, and observability to all cooperate. If you can build this, you can build your own.
One note on faithfulness before we start. This design follows LangChain's own deep-research reference architecture. The shape here is the shape the maintainers recommend, not one invented for an article. Where the article simplifies, it says so.
The shape of the agent: one orchestrator, many disposable workers
Before any code, hold the architecture in your head, because every primitive slots into it.
There is one orchestrator, the main agent, and it never does research itself. Its only job is to run a fixed, high-level workflow of six steps:
- Plan the investigation into a todo list.
- Save the request to a file, so it can check its own work against the request later.
- Delegate focused research tasks to subagents.
- Synthesize what the subagents return, consolidating citations so each source gets one number across all findings.
- Write a comprehensive report to a file.
- Verify that the report actually addresses the original request.
The researcher subagents are the workers. Each one takes a single focused question, searches the web in its own isolated context, and returns findings with sources. The orchestrator stitches those findings together. The workers do the digging.
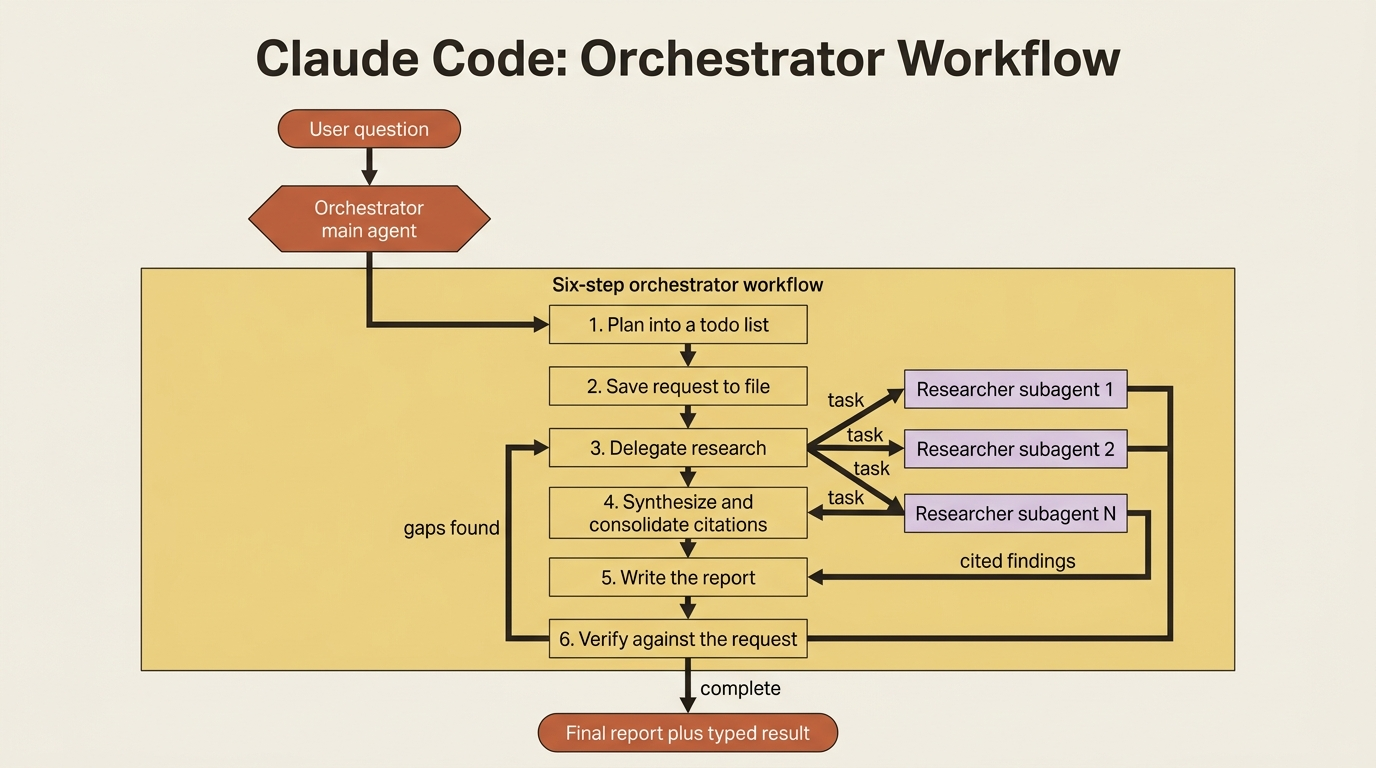
If that division of labor feels familiar, it should. This single design is orchestrator-workers, the main agent decomposing and delegating, wrapping prompt chaining, the fixed six-step sequence, with parallelization, multiple researchers running at once, and evaluator-optimizer, the verify step checking the draft against the request. Four classic agent design patterns, cooperating inside one agent. We will watch each one fall into place.
Step one: the orchestrator is a prompt, not plumbing
The orchestrator is just create_deep_agent with a system prompt that lays out the workflow as numbered steps. The prompt-chaining pattern is expressed here as plain instructions: a fixed sequence the agent follows, with the planning tool tracking progress.
The critical instruction, the one line that makes this orchestrator-workers rather than a single agent doing everything, is the rule that the orchestrator must always delegate research to subagents and never search itself. That rule is what keeps the orchestrator's context clean. The orchestrator sees plans and synthesized findings. It never sees the raw flood of search results.
from deepagents import create_deep_agent
ORCHESTRATOR_PROMPT = """You are a research orchestrator. For context, today's date is {date}.
Your workflow:
1. Plan: break the research question into focused tasks with write_todos.
2. Save the request: write the user's question to /research_request.md.
3. Research: delegate each task to a research subagent with the task() tool.
ALWAYS delegate. NEVER search yourself.
4. Synthesize: review all findings and consolidate citations (each unique URL
gets one number across all findings).
5. Write: write the full report to /final_report.md.
6. Verify: re-read /research_request.md and confirm every aspect is addressed
with proper citations.
Delegation: default to ONE subagent. Parallelize only for explicit comparisons
or genuinely independent aspects. Bias toward focused research over breadth.
""" # ①
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6", # ②
system_prompt=ORCHESTRATOR_PROMPT, # ③
subagents=[researcher], # defined next ④
)
① The system prompt encodes the entire six-step workflow as numbered instructions; this is the prompt-chaining pattern expressed as a fixed sequence the agent follows, including the "ALWAYS delegate, NEVER search yourself" rule that makes this orchestrator-workers.
② The model line is the only model choice the orchestrator needs; because it never searches, it spends its tokens on planning and synthesis.
③ Wiring the prompt in as system_prompt is what turns a plain deep agent into the orchestrator: the workflow lives in the prompt, not in plumbing.
④ Passing subagents=[researcher] gives the orchestrator a worker to delegate to, the other half of orchestrator-workers; the researcher is defined next.
That establishes a main agent that plans, delegates, synthesizes, and verifies, with delegation discipline baked into the prompt. Notice the date injection: today's date is {date}. In a real deployment that placeholder is filled by a before_model middleware that supplies the current date, so the agent's searches and report are time-aware, rather than relying on a hardcoded string that goes stale.
Step two: the researcher subagent keeps context off the orchestrator
The worker is a custom subagent with exactly one job and one tool. It searches, reads, and returns findings, and crucially it is instructed to return a concise synthesis with sources, not a raw dump of everything it read.
This is the context-isolation payoff made concrete. The researcher might read ten thousand tokens of web pages, but the orchestrator only ever sees the few hundred tokens of distilled findings the researcher returns.
researcher = {
"name": "researcher", # ①
"description": "Researches one focused question via web search and returns cited findings. Use for every research task.", # ②
"system_prompt": """You research one focused topic. For each finding, cite the
source. Return a concise synthesis (key findings plus a Sources list of title and
URL), NOT raw search results or full page text. Keep it under 500 words.""", # ③
"tools": [web_search], # your Tavily or other search tool ④
}
① The name is how the orchestrator addresses this worker when it issues a task call.
② The description is what the orchestrator reads to decide when to delegate here; "use for every research task" is the rule that keeps the orchestrator out of the search business.
③ The system prompt is the context-isolation contract: it forces a concise, cited synthesis under 500 words, so the worker can read ten thousand tokens but returns only a few hundred.
④ The single search tool is the worker's only capability; one job, one tool.
What that buys you is a disposable specialist the orchestrator can spin up as many times as the plan requires, each one in its own context, each one returning a clean result. The "under 500 words, no raw dumps" instruction is the single most important line for keeping a long research run inside its token budget. It is also the same advice the docs give for any output-heavy subagent.
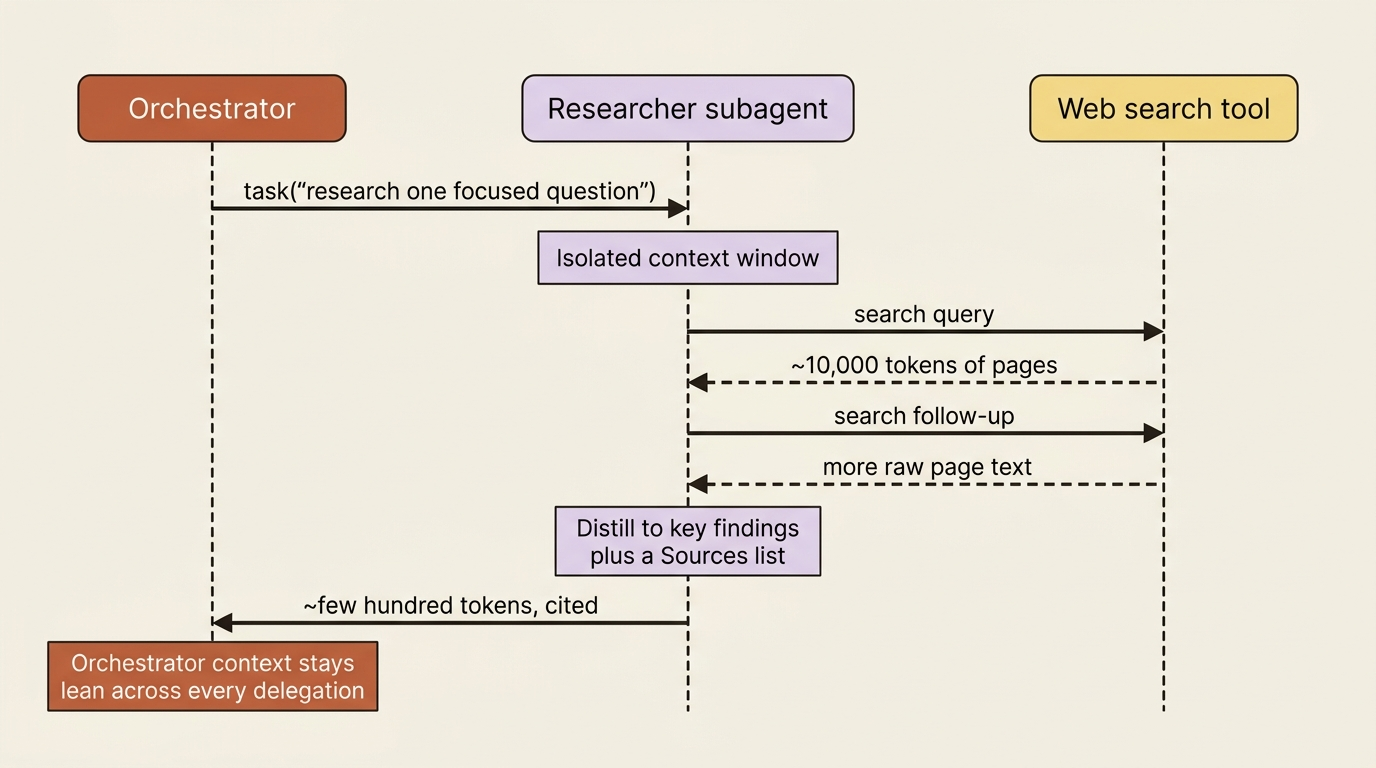
This is also where parallelization lives. When the orchestrator's plan has genuinely independent tasks, such as comparing three frameworks or surveying three regions, it issues multiple task calls to the researcher in a single turn, and they run in parallel. When the question is unified, it uses one researcher. The orchestrator decides per question, guided by the bias-toward-one discipline in its prompt. Breadth is a deliberate choice, not a default.
Step three: the filesystem is the agent's working memory
A long research run generates more than fits comfortably in a conversation. This is where a real backend stops being theoretical.
The orchestrator writes the user's request to /research_request.md and the final report to /final_report.md, and the researchers can offload long findings to files too. Three ideas converge here:
- Filesystem tools are how the agent reads and writes those files.
- The backend decides where the files live. A
StateBackendis fine for a single run. A research agent that should remember a user's past investigations wants aCompositeBackendrouting a/memories/path to durable storage. - Automatic offloading quietly moves oversized tool results to the filesystem, so the active context stays lean without you managing it by hand.
The pattern to internalize: for any agent that produces a lot, the filesystem is working memory, and messages are just the conversation about that memory. The report does not live in the chat history. It lives in a file the agent builds up and you read at the end.
Step four: a report your pipeline can actually consume
The report itself is prose, written to a file. But the orchestrator's return value should be structured, so whatever calls this agent, a UI, a pipeline, or a scheduled job, gets a typed signal rather than having to parse the agent's chatter.
from pydantic import BaseModel, Field
class ResearchResult(BaseModel): # ①
"""Outcome of a research run."""
report_path: str = Field(description="Path to the final report file") # ②
sources_count: int = Field(description="Number of unique sources cited") # ③
request_addressed: bool = Field(description="Whether verification confirmed all aspects were covered") # ④
agent = create_deep_agent(
model="anthropic:claude-sonnet-4-6",
system_prompt=ORCHESTRATOR_PROMPT,
subagents=[researcher],
response_format=ResearchResult, # ⑤
)
① The Pydantic model is the typed contract for the run's outcome, so downstream code reads data instead of parsing the agent's prose.
② report_path tells the caller where the finished report file lives, not the report text itself.
③ sources_count surfaces the citation count as a number a UI or pipeline can display or threshold on.
④ request_addressed is the evaluator-optimizer verdict as data: the verify step is the evaluator, and this boolean is its pass or fail.
⑤ Passing response_format=ResearchResult is what makes the agent populate the model; afterward your code reads result["structured_response"].
After the run, your code reads result["structured_response"] and knows, as typed data, where the report is, how many sources it cites, and whether the agent's own verification step passed. That last field, request_addressed, is the evaluator-optimizer pattern surfacing as data. The verify step is the evaluator, and the boolean is its verdict.
Step five: the verify step is an evaluator-optimizer loop the agent runs on itself
Step six of the workflow is the easiest to skim past, and it is the one that most improves quality.
After writing the report, the orchestrator re-reads /research_request.md and checks whether the draft actually addresses every part of the original question. If something is missing, the orchestrator can delegate another research round and revise. That is the evaluator-optimizer pattern, with the orchestrator playing both generator and evaluator against a clear criterion: does the report cover what was asked.
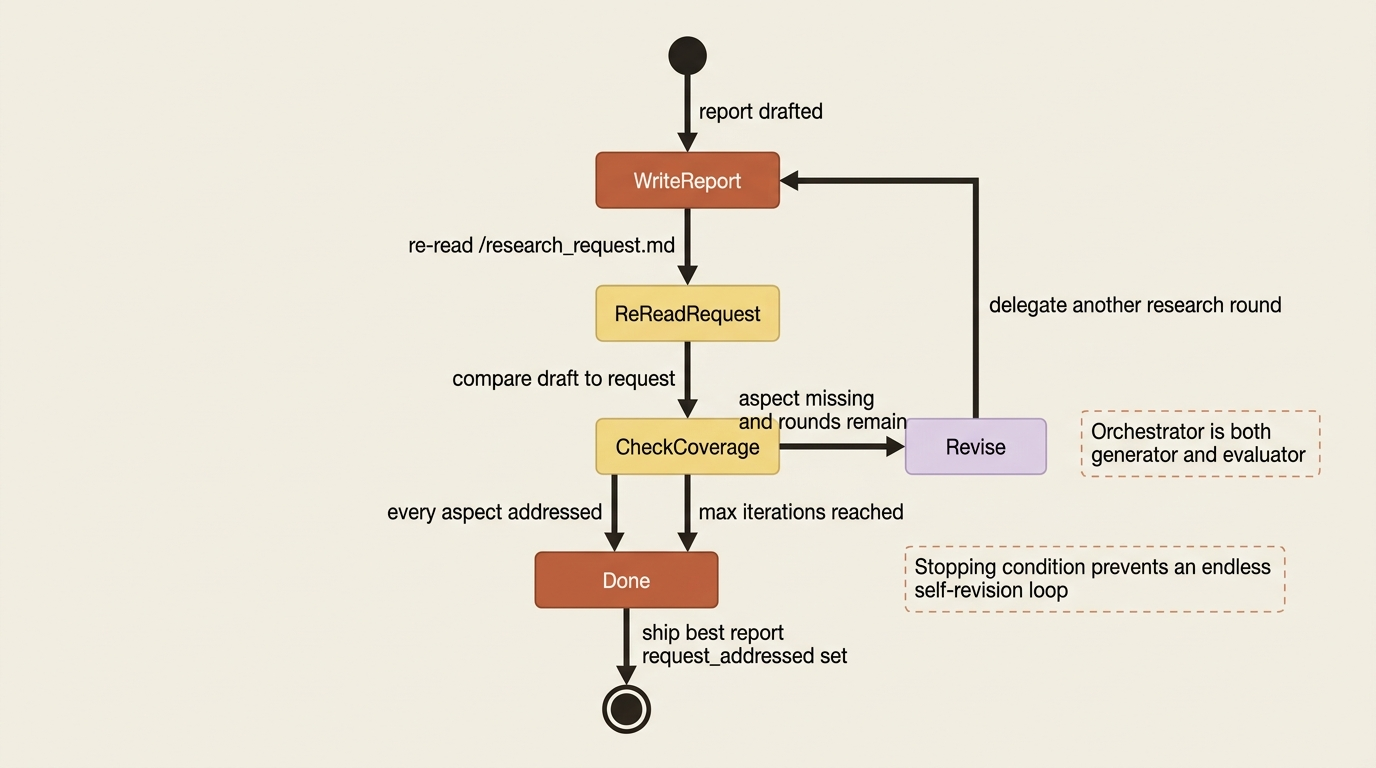
You can make this stronger by adding a dedicated reviewer subagent whose only job is to critique the draft for gaps and weak citations and return a structured verdict. Either way, one principle holds: the loop needs a stopping condition. Cap the research rounds. The reference architecture exposes a max-iterations knob for precisely this reason, so an investigation that can never fully satisfy itself ends with the best report it has rather than looping forever. An agent stuck in an endless self-revision loop is just the classic "stuck agent" failure mode wearing a research costume.
Step six: watch it run, and keep it on a leash
A research run can take minutes, so streaming is not a nicety here. It is how the user knows the agent is alive.
You stream updates to show the plan forming and each delegation firing, and you use the namespace tags to attribute streamed output to the right researcher. The user sees "researcher 2 is investigating X" rather than an undifferentiated wall of text. A summarization-token filter matters more than ever on a run this long, because it strips the noise the model emits while compacting its own context.
Safety scales with autonomy, and a research agent is autonomous by definition. It fetches arbitrary web content, which is untrusted input. The threat model is fully in play: a malicious page could carry a prompt injection. The defenses are the familiar ones:
- Permissions fence the agent to its working files, so it cannot write outside
/research_request.md,/final_report.md, and its scratch space. - Human-in-the-loop gates any tool more dangerous than search.
- Narrow write access plus memory writes confined to app-controlled paths close the door on shared memory being used as an injection channel.
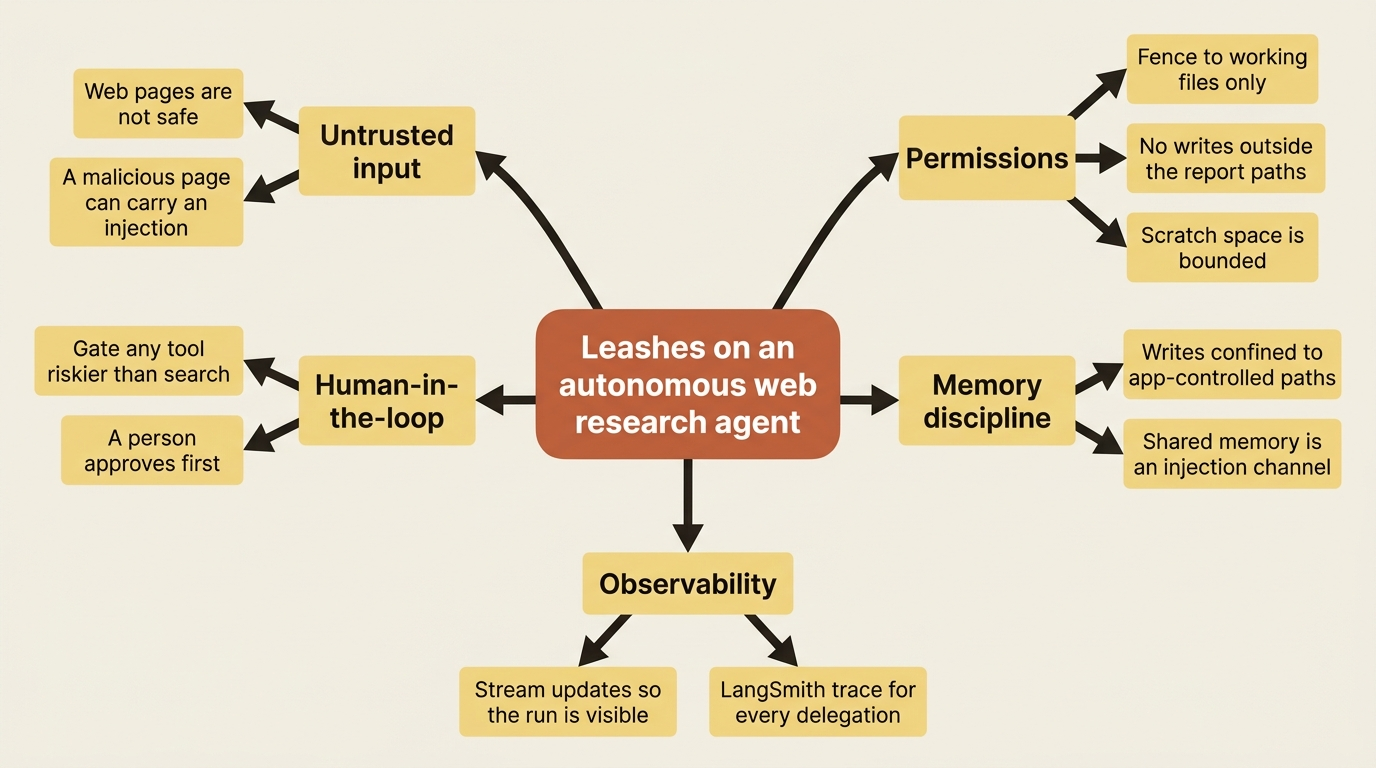
None of these are new mechanisms. They are the same leashes you use on any agent, applied to a higher-stakes one.
Step seven: ship it as a service, not a function call
A long-running research agent is a textbook case for a real deployment, because it is stateful, slow, and benefits from running as a managed service.
It is long-running, so durable execution matters. A research run that crashes at step four resumes from its last checkpoint instead of re-doing three rounds of searches. It is stateful, so it wants a real checkpointer and, for cross-run memory, a durable store. And it is the kind of thing you would run as a scheduled job or behind an API.
You would package it cleanly: the orchestrator and researcher in one module, a harness profile if you tune behavior per model, a deepagents.toml declaring any sandbox, and LangSmith tracing turned on so a multi-step research run becomes a nested trace you can actually debug. A run that visits twenty sources across five subagents is incomprehensible without that trace. With it, you can see exactly which researcher found what.
Do this today
- Sketch the six-step workflow as a system prompt for an orchestrator in your own domain. Replace "research question" with whatever your agent investigates.
- Write one researcher subagent with one tool and a hard output cap. Put "keep it under 500 words, no raw dumps" in its prompt, then watch your orchestrator's context stay flat across delegations.
- Add a
response_formatPydantic model with a singlesuccess-style boolean, and have your agent's final step populate it. That one field turns "did it work" from a guess into typed data. - Cap your self-review loop with a max-iterations limit before you ship anything that revises its own output.
- Turn on tracing for one full multi-subagent run and read the nested trace end to end. It is the fastest way to find the delegation that misbehaves.
The real lesson: the template does not change, the tools do
Step back and look at what this single agent used. Planning and the agent loop. Streaming. A backend choice. Permissions and approvals. Checkpointing and durable execution. Memory for past research. Custom search tools and researcher subagents. Date injection and audit middleware. Sandboxing and a threat model. Structured output, tracing, and packaging. And four of the five classic design patterns, cooperating in one workflow. Nothing here was new. Everything here was composed.
That is the point of building a research agent instead of yet another bug-fixer: the primitives are general. A bug-fixer and a research agent look like different products, but underneath they are the same harness, the same loop, the same delegation, and the same leashes, pointed at different work. Swap the researcher's search tool for a database query and the report for a financial summary, and you have an analyst. Swap it for a code-reading tool and you have an architecture reviewer. The template does not change. The tools and the prompt do.
You can now design, build, secure, deploy, and observe an agent that plans its own multi-step research, coordinates a team of workers, holds itself to a quality bar, and ships a cited report. More importantly, you can explain exactly which patterns it uses and why. The full reference implementation of a research agent like this lives in LangChain's examples if you want to run the complete version. Treat what you built here as the map, and the repo as the territory. From here, the only thing left to build is yours.
This is Part 13 of "Building with LangChain Deep Agents," a 13-part guide to building production-ready AI agents.