The Five Agent Patterns Everyone Cites, and the Code That Actually Is Each One
Anthropic's five canonical agent patterns are not features you build; they are mostly uses of Deep Agents primitives you already have, and seeing the mapping turns famous diagrams into runnable code.
Anthropic's "Building Effective Agents" gave the field a shared vocabulary. This is the translation layer it never shipped: each of the five patterns mapped to a concrete Deep Agents primitive you can run today.
In this article: You will learn how the five canonical agent design patterns from Anthropic's "Building Effective Agents", prompt chaining, routing, parallelization, orchestrator-workers, and evaluator-optimizer, map directly onto LangChain Deep Agents primitives. By the end, you will be able to read that essay with a translation layer running underneath, knowing exactly which line of code expresses each pattern, and you will carry the one discipline that keeps agent systems from over-engineering themselves.
If you have read one thing about agent architecture, it was probably Anthropic's "Building Effective Agents". It is the field's shared vocabulary: five composable patterns, a clean distinction between workflows and agents, and one piece of advice repeated like a mantra. The advice is that the most successful implementations use simple, composable patterns rather than complex frameworks.
That essay is deliberately framework-agnostic. That is its strength as a reference and its gap as a guide. It tells you the patterns. It does not tell you which line of code expresses each one in the stack you actually chose.
This article closes that gap for LangChain Deep Agents. For each of the five agent design patterns, we name what Anthropic means by it, show the Deep Agents primitive that implements it, and note where the Claude Agent SDK would have you build it by hand. The throughline is reassuring: most of these patterns are not features you bolt on. They are uses of primitives that Deep Agents already gives you. A deep agent is, in a real sense, the orchestrator-workers pattern already assembled.
Workflow or agent: the distinction that organizes everything
Before the patterns, hold one distinction. Anthropic is careful to separate two families, and the separation does real work.
A workflow is a system where the control flow is fixed by your code. You decide the steps. An agent is a system where the model decides the control flow at runtime. Harrison Chase's one-liner captures it: if the LLM can change your application's control flow, it is an agent; if the flow is fixed by your code, it is not.
The first three patterns lean workflow. The last two lean agent. Deep Agents can express all five, but it shines on the agent end. That is the whole reason you reach for a harness instead of writing five if statements.
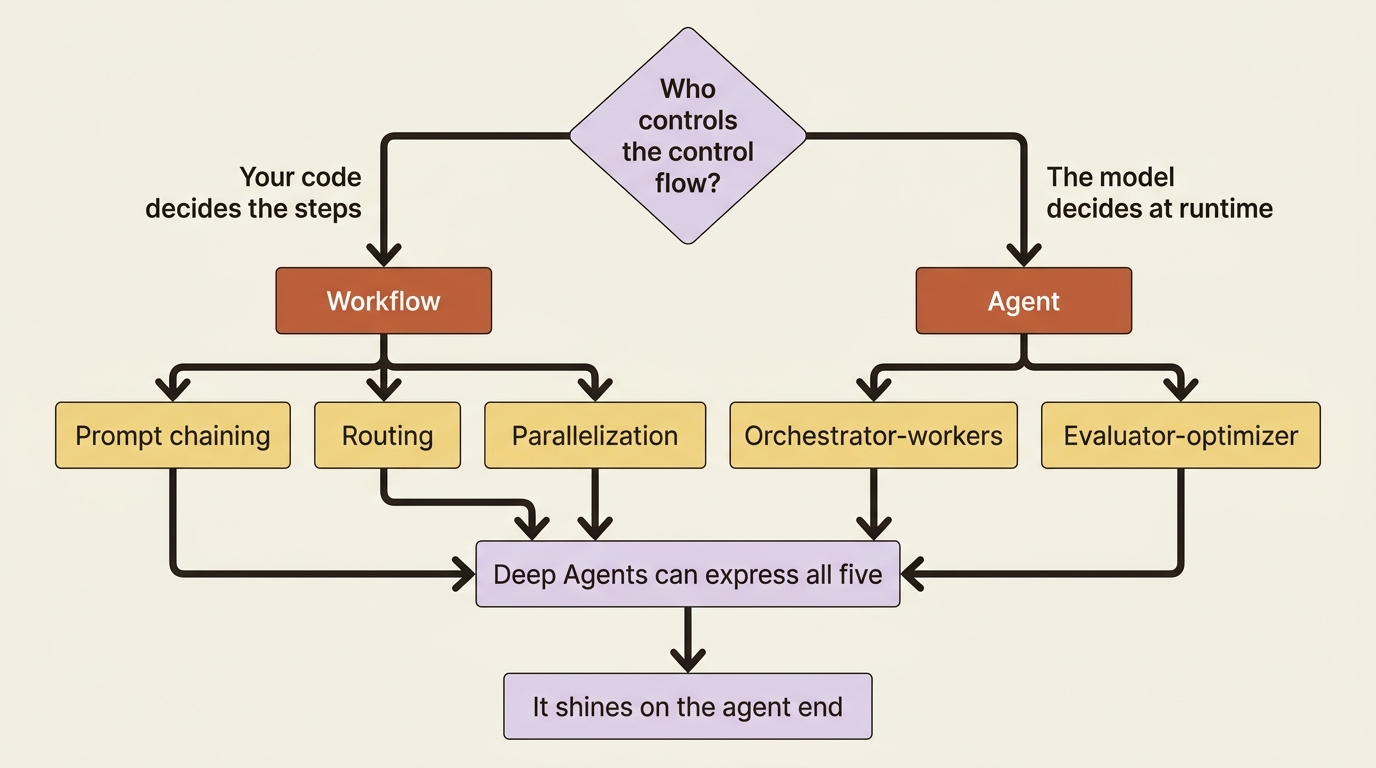
Here is the full map of the five patterns before we walk each one.
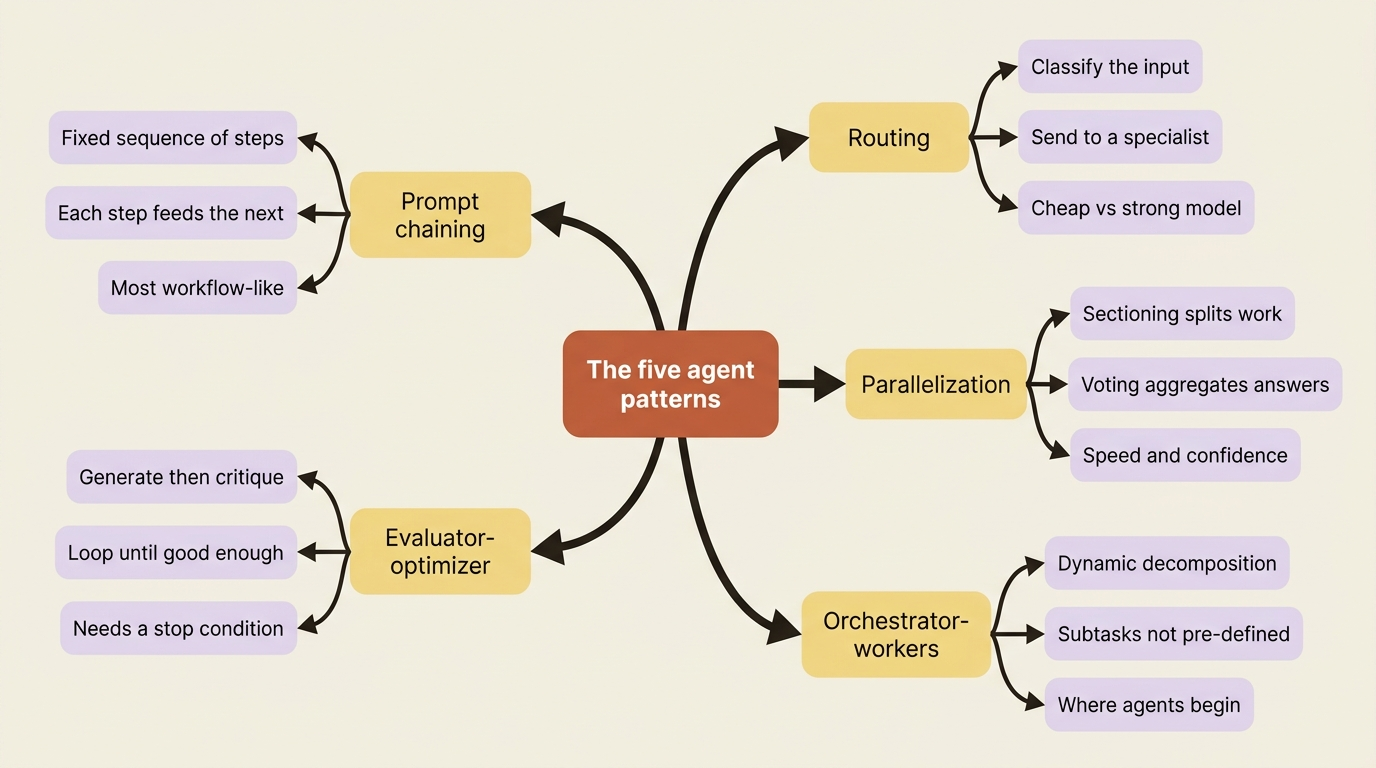
Pattern 1: Prompt chaining
Chaining decomposes a task into a fixed sequence where each step's output feeds the next. Anthropic's definition is precise: prompt chaining decomposes a task into a sequence of steps, where each LLM call processes the output of the previous one, and it is ideal when the task decomposes cleanly into fixed subtasks. Contract analysis is the classic example: extract terms, then check compliance, then summarize, with a programmatic check possible between stages.
This is the most workflow-like pattern, and that shapes how you build it. If the sequence is genuinely fixed and you want hard guarantees about order, you do not need an agent at all. You write three invoke calls in a row in your own code, passing each result to the next.
# Prompt chaining as plain code: order is guaranteed because you wrote it.
terms = invoke("Extract every term and obligation:\n" + contract_text)
compliance = invoke("Check these terms against policy:\n" + terms)
summary = invoke("Summarize the compliance findings:\n" + compliance)
That is the honest answer, and it matches Anthropic's advice to not reach for an agent when a workflow will do.
But there is a softer, more useful version inside a deep agent: a skill. A SKILL.md whose body is a numbered procedure is a chain expressed as instructions the agent follows.
# run-and-fix-tests
Follow these steps in order:
1. Run the full test suite.
2. Read the first failure and identify the failing assertion.
3. Locate the code path that produced the wrong value.
4. Apply the smallest fix that addresses the assertion.
5. Re-run the suite. If still red, return to step 2.
A skill like this is a prompt chain in skill form: a fixed sequence the agent walks, with the planning tool, write_todos, tracking progress through the steps. You get the structure of a chain with the flexibility for the agent to adapt a step when reality disagrees.
In the Claude Agent SDK, the analogue is plan mode plus skills. You use the planning step to lay out the sequence and skills to execute each step, but the orchestration of feeding step one's output into step two is still something you arrange. Same pattern, different primitives.
Pattern 2: Routing
Routing classifies an input and sends it to a specialized handler. In Anthropic's framing, it is for tasks with distinct input categories, like customer service queries, where you classify each input and send it to a specialized model, avoiding the performance issues that arise from overloading a single prompt. The win is specialization: instead of one bloated prompt trying to handle every case, each case goes to a handler tuned for it.
Deep Agents gives you two natural places to put routing logic.
The lightweight version is a custom tool that the agent calls to classify and dispatch, or simply a strong system prompt that tells the agent which subagent handles which kind of request. The model routes by delegating.
The more deterministic version is middleware: a before_model hook or a dynamic prompt that inspects the incoming request and adjusts behavior before the model even sees it.
from langchain.agents.middleware import before_model
@before_model
def route_by_difficulty(state):
request = state["messages"][-1].content
if is_simple(request):
# Steer the agent toward the cheap path.
state["system_prompt"] += "\nThis is a routine query. Answer directly."
return state
The cost-routing flavor Anthropic highlights, easy queries to a small model and hard ones to a large model, maps cleanly onto subagents with different models. A custom subagent can run a cheaper model than its parent, so the main agent routes simple delegated work to the cheap worker and keeps the expensive model for itself.
In the Claude Agent SDK, routing is typically conditional rules in CLAUDE.md that activate different behaviors based on context. The mechanism differs, file-based rules versus middleware or delegation, but the intent is identical: classify, then specialize.
Pattern 3: Parallelization
Parallelization runs independent subtasks at the same time. Anthropic splits it into two variants worth keeping distinct. Sectioning divides work among multiple agents, while voting uses several agents to tackle the same task, combining their outputs to increase confidence. Sectioning is "split the job into independent pieces and do them simultaneously." Voting is "do the same job several times and aggregate for reliability." Both are useful when speed is critical, and voting additionally buys confidence.
Deep Agents gives you parallelization two ways. The low-level form: when the model wants several independent things, it can request multiple tools in one turn and the harness runs them together. That is sectioning at the tool level, and it happens automatically when the work is genuinely independent.
The higher-level form is subagents. The main agent makes several task calls and the subagents run in parallel, each in its own isolated context, each returning a result. For sectioning, you fan out distinct pieces, such as researching three regions at once. For voting, you delegate the same question to several subagents and have the main agent reconcile their answers.
There is one caution the docs are emphatic about, and it generalizes well beyond research: bias toward fewer parallel workers than you think you need. The guidance is blunt that you should default to a single subagent and parallelize only when the task explicitly requires comparison or has genuinely independent parts, because premature decomposition wastes tokens without improving the answer. Parallelization is a speed-and-confidence tool, not a default. Reach for it when the subtasks are truly independent, not to look busy.
In the Claude Agent SDK, parallelization is subagents working in parallel with isolated contexts. This is the pattern that maps most directly across the two harnesses, because both converged on the same primitive: isolated parallel workers coordinated by a parent.
Pattern 4: Orchestrator-workers
Here is where workflows end and agents begin. An orchestrator dynamically breaks a task into subtasks it could not predict in advance and delegates them to workers. In Anthropic's words, a central LLM dynamically breaks down tasks, delegates them to worker LLMs, and synthesizes their results. The key difference from parallelization is flexibility: subtasks are not pre-defined but determined by the orchestrator based on the specific input. Anthropic points to its own coding agents, which use this approach to handle GitHub issues across multiple files without predefined subtasks. The orchestrator does not know the subtasks until it sees the problem.
This is not a pattern you assemble in Deep Agents. It is what a deep agent is.
The planning tool, write_todos, is the orchestrator decomposing the task at runtime. The task tool plus subagents is the delegation. The main agent synthesizing the workers' returned summaries is the recombination.
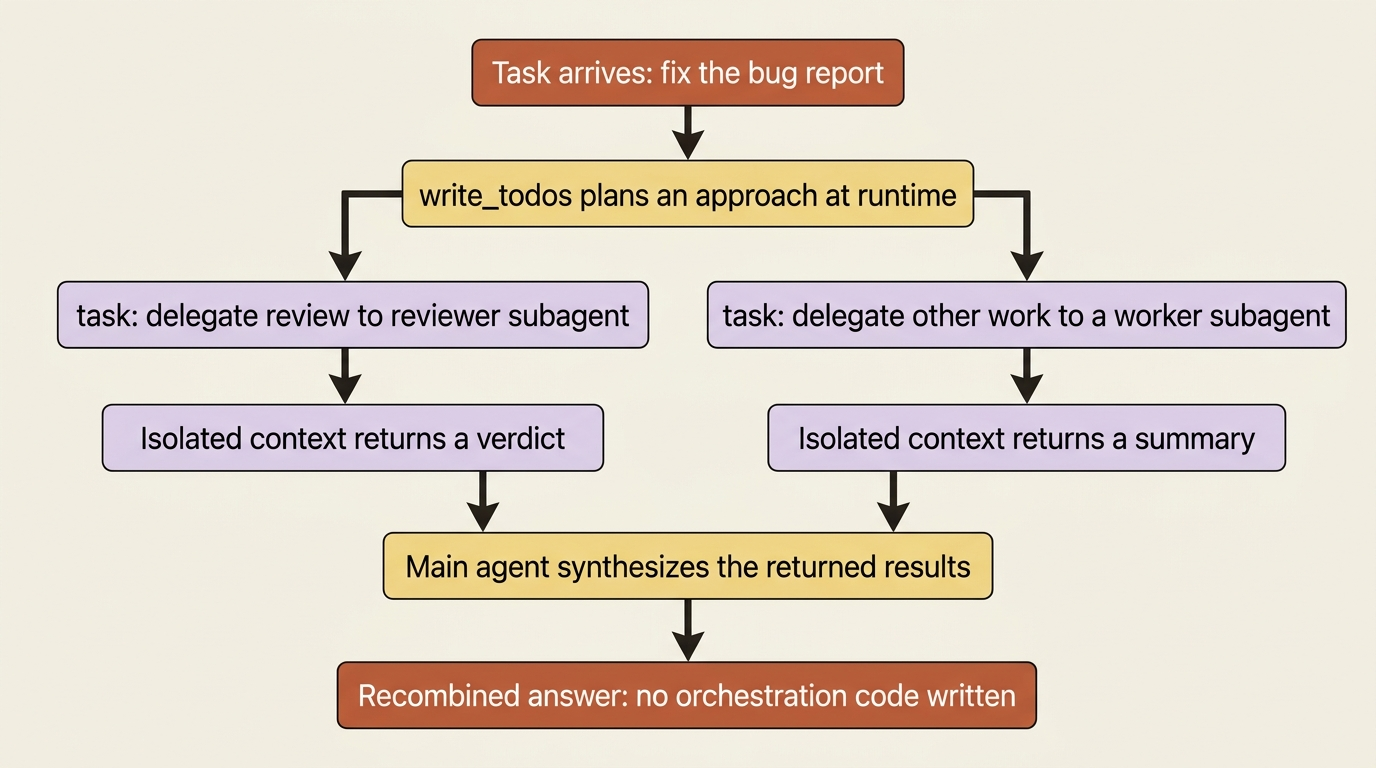
When an agent reads a bug report, plans an approach, delegates the review to its reviewer subagent, and folds the verdict back into its own work, that is textbook orchestrator-workers, and you did not write a line of orchestration logic to get it. This is the single best illustration of why a harness pays off: the pattern Anthropic describes as suitable for medium-complexity tasks where subtasks are less predictable, like multi-file coding or research, is the harness's default shape.
In the Claude Agent SDK, the analogue is also the task tool delegating to subagents. Both harnesses landed here, which is telling: orchestrator-workers is the pattern that most justifies using a harness at all, because hand-wiring dynamic decomposition and delegation is exactly the painful loop you adopted a harness to avoid.
Pattern 5: Evaluator-optimizer
The fifth pattern is a feedback loop: one LLM call generates a response while another provides evaluation and feedback in a loop. It is particularly effective when you have clear evaluation criteria and when iterative refinement provides measurable value. Generate, critique, revise, and repeat.
In Deep Agents, you build it with a reviewer subagent whose structured verdict drives whether the main agent iterates. The reviewer subagent is the evaluator: it examines the proposed fix and returns a verdict. Make that verdict structured output, a small schema, and the main agent has a clean signal to loop on.
from pydantic import BaseModel
class ReviewVerdict(BaseModel):
approved: bool
concerns: list[str]
# The reviewer subagent returns this schema.
# The main agent loops on it: if not approved, revise and resubmit.
A custom run_tests tool is a second, non-LLM evaluator in the same loop: an objective check, do the tests pass, alongside the subjective review. That combination, an objective gate plus a reasoned critique, is a strong evaluator-optimizer setup. The clear evaluation criteria Anthropic calls for are exactly "tests green and reviewer satisfied."
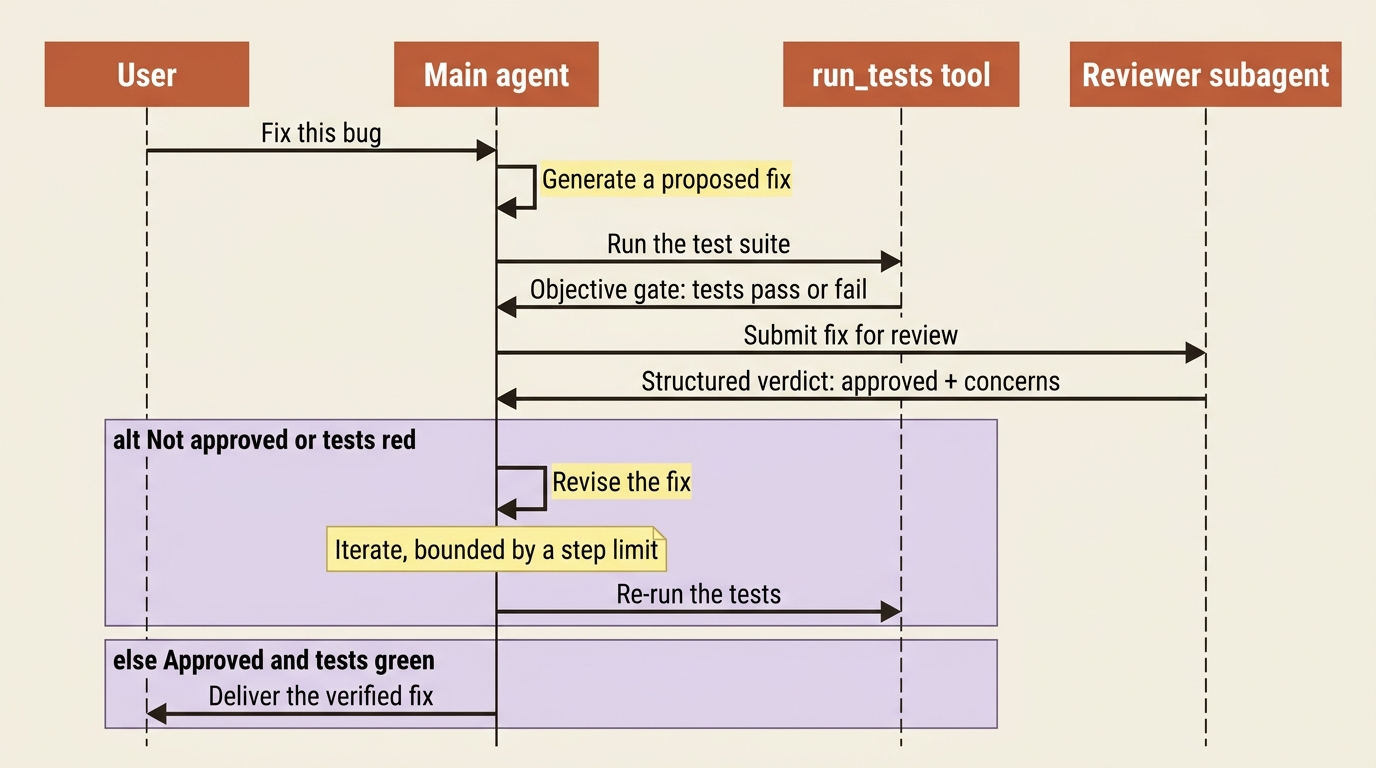
The thing to get right is the stopping condition, because an optimizer loop with no cap is a runaway agent waiting to happen. Set a sensible iteration limit so a fix that never satisfies the reviewer fails loudly instead of looping forever. Evaluator-optimizer plus a step limit is the safe version. Without the limit, you have rediscovered the "stuck" failure mode.
In the Claude Agent SDK, this is often expressed as an evaluation skill the agent invokes. The shape is the same, a separate evaluation step feeding back into generation. The difference is whether the evaluator is a subagent, which is Deep Agents' natural unit, or an invoked skill.
The pattern-to-primitive map
The five patterns collapse onto a small set of Deep Agents primitives, which is why a harness gets you most of them for free.
| Anthropic pattern | Deep Agents primitive | Claude Agent SDK analogue |
|---|---|---|
| Prompt chaining | A skill's step sequence, or plain code around invoke |
Plan mode plus skills |
| Routing | Custom tool or middleware that classifies; cheap-vs-strong model via subagents | Conditional rules in CLAUDE.md |
| Parallelization | Parallel tool calls in one turn; multiple task delegations at once |
Subagents in parallel with isolated contexts |
| Orchestrator-workers | write_todos planning plus task plus subagents (the harness default) |
Task tool delegating to subagents |
| Evaluator-optimizer | Reviewer subagent with structured-output verdict driving an iteration loop | An invoked evaluation skill |
Read across any row and the lesson repeats: the Deep Agents column is rarely new machinery. Prompt chaining is a skill or a few invoke calls. Routing is a tool or a before_model hook. Parallelization is parallel task delegations. Orchestrator-workers is the harness's resting state. Evaluator-optimizer is a reviewer subagent in a loop. The patterns are not things you add; they are things you already have.
Choosing a pattern: complexity is the dial
The patterns are not a ladder you climb. They are a menu you match to the job. Anthropic's architecture guidance ties each to a complexity tier: workflows, chaining and routing, for low-complexity tasks with predictable steps; orchestrator-workers for medium-complexity tasks where subtasks are less predictable; and multi-agent systems for high-complexity scenarios requiring specialized agents, like separating research from quality assurance. The corollary, and the essay's central warning, is to start simple. Do not deploy an orchestrator with five subagents for a task a single prompt chain would handle.
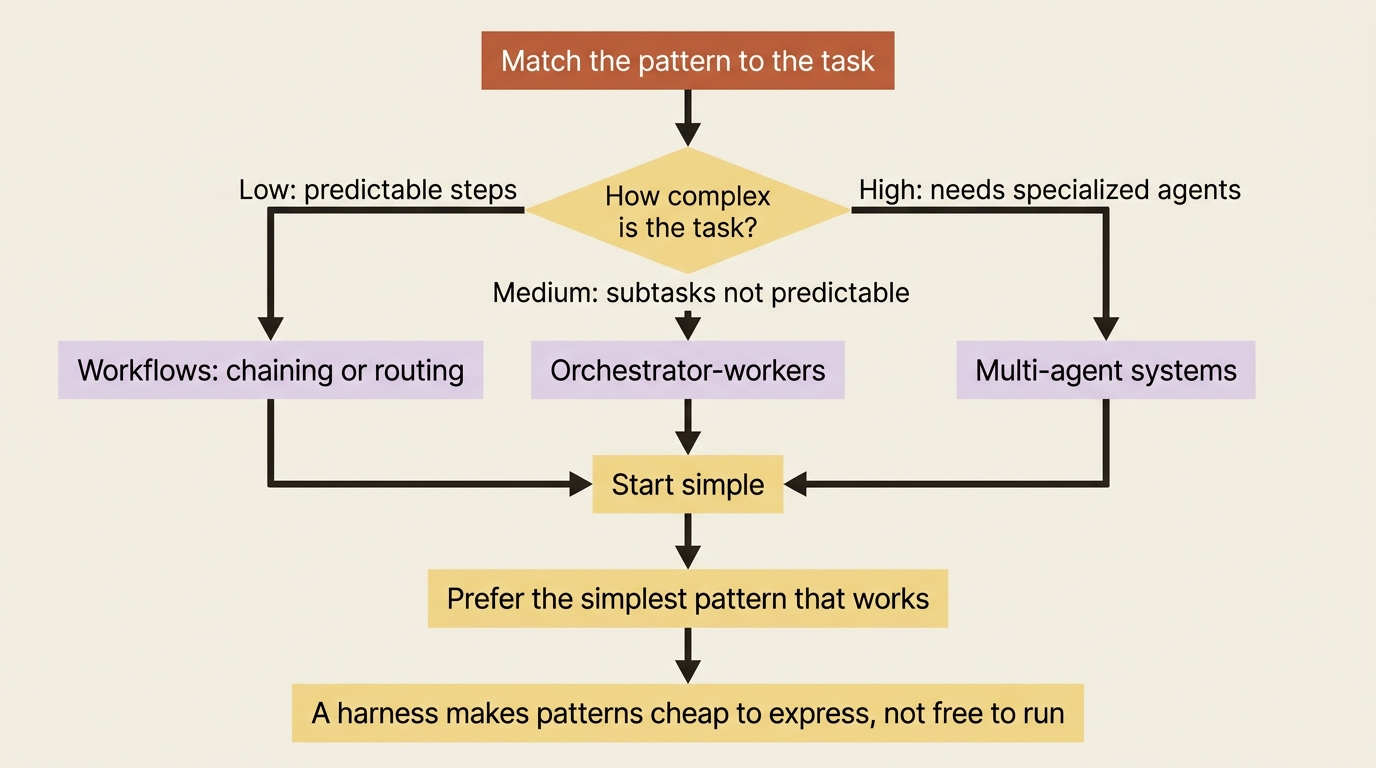
Using a harness does not suspend this rule, and it is worth saying plainly because a harness makes the powerful patterns so easy that overuse is the natural temptation. Just because subagents are one task call away does not mean every task wants them. The discipline is to reach for the simplest pattern that does the job, and to let the agent's own planning handle dynamic complexity rather than pre-building orchestration you may not need. Deep Agents makes the patterns cheap to express. It does not make them free to run, and the simplest correct pattern is still the goal.
Do this today
- Re-read "Building Effective Agents" with the map open. For each of the five patterns, name the exact Deep Agents primitive that implements it. The translation should feel automatic.
- Find the prompt chains hiding in your skills. Any
SKILL.mdwith a numbered procedure is already a chain. Decide whether each one truly needs an agent or could be plain code aroundinvoke. - Audit your subagent count. If you fan out to parallel workers, ask whether the subtasks are genuinely independent. Default to a single subagent and parallelize only when comparison or independence demands it.
- Add a stopping condition to any evaluator-optimizer loop. A reviewer-driven iteration loop without an iteration limit is a runaway agent. Set the cap before you ship.
- Match the pattern to the complexity tier. Before building, classify the task as low, medium, or high complexity, and pick the simplest pattern that fits. Resist the harness's temptation to over-engineer.
Where this leaves you
You can now read "Building Effective Agents" with a translation layer running underneath. Prompt chaining is a skill's step sequence or plain code. Routing is a classifying tool or middleware. Parallelization is parallel tool calls or fanned-out subagents. Orchestrator-workers is the harness default of planning plus delegation. Evaluator-optimizer is a reviewer subagent in an iteration loop. The Claude Agent SDK reaches most of the same patterns through its own primitives, and the two harnesses converge most tightly exactly where the patterns matter most, on orchestrator-workers and parallel subagents, because that convergence is what a harness is for.
The deepest point is the quietest one. You do not set out to implement Anthropic's patterns. You implement an agent, and the patterns fall out. A test-fixing skill is a prompt chain. A plan-and-delegate loop is orchestrator-workers. A reviewer-plus-tests cycle is evaluator-optimizer. That is the strongest possible argument for using a harness at all: the famous diagrams were never the work. They were the description of what a well-built agent already does.
Carry one thing forward above all else: match the pattern to the complexity, and prefer the simplest one that works.
This is Part 12 of "Building with LangChain Deep Agents," a 13-part guide to building production-ready AI agents.