You Can Build Any Agent. The Harder Question Is Which One You Should.
Anthropic's five agent patterns are a vocabulary for design decisions. This maps each one onto the Claude Agent SDK constructs that implement it, sorts them into workflows versus agents, and shows how to tell when you do not need an agent at all.
Anthropic's five agent design patterns are a vocabulary for design decisions. Here is how each maps onto the Claude Agent SDK constructs that implement it, which family it belongs to, and how to tell when you do not need an agent at all.
In this article: You will learn the one architectural distinction that organizes every agent design pattern, namely workflow versus agent, and the single question that sorts any pattern into the right family. We walk Anthropic's five composable patterns, map each onto a concrete Claude Agent SDK construct, and end with a decision rule that ties pattern choice to task complexity. The transformation by the end: you stop wiring features and start designing systems.
You can wire almost anything with the Claude Agent SDK. Custom tools, subagents, hooks, permissions, structured output, deployment: the mechanics are all within reach. What that fluency does not give you is the layer above the mechanics. It does not tell you how to look at a problem and decide which of those constructs to reach for. Worse, it does not tell you the most important thing of all: whether you need an agent at all.
That judgment is what separates someone who knows the SDK from someone who designs good systems with it. The SDK is a powerful hammer, and a hammer in skilled hands is still only as good as the carpenter's eye for which problems are nails.
The best vocabulary for that eye is Anthropic's own, from the "Building Effective Agents" guide. It lays out a handful of composable agent design patterns and one piece of advice that matters more than any of them. This article walks those patterns and maps each onto the SDK constructs that implement it, so the abstract names become concrete decisions about query(), subagents, and tools. We will use a small worked example throughout, a code-maintenance agent called buggy-shop, but the point is portable to anything you build.
The advice that comes before any pattern
Before a single pattern, here is the load-bearing principle: find the simplest solution possible, and only increase complexity when needed. Agentic systems trade latency and cost for better task performance, and that trade is not always worth it. For many applications, optimizing single LLM calls with retrieval and in-context examples is usually enough.
This is the thing to internalize, because the SDK makes building agents so frictionless that the temptation is to make everything an agent. Resist it. The most senior move is recognizing when the problem is not a nail. If a task has predictable, fixed steps, you may not want an agent's dynamic decision-making at all. You may want a workflow, or even just one well-prompted call.
The distinction underneath everything: workflow or agent
Anthropic draws one architectural line that organizes all the patterns. Workflows are systems where LLMs and tools are orchestrated through predefined code paths. Agents are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
The sharpest way to hold that line is to ask one question: who decides the control flow? If your code fixes the sequence of steps, it is a workflow. If the model can change the sequence at runtime, deciding which tool to call next and when to stop, it is an agent. That single test, who controls the flow, sorts every pattern into one of two families, and it is the most useful distinction in the whole essay.
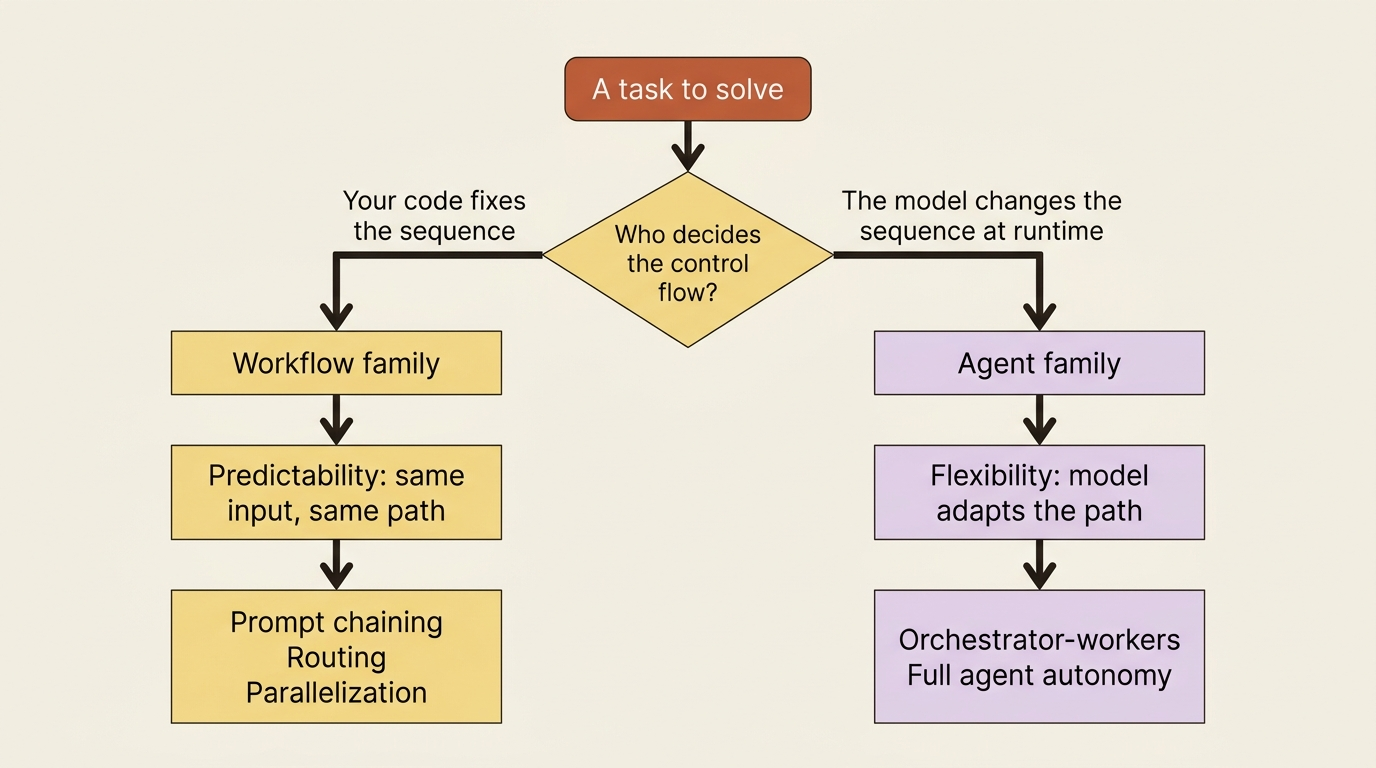
The two families matter because they have opposite strengths. Workflows give you predictability: the same input walks the same path every time, which is what you want for well-defined tasks where surprises are bugs. Agents give you flexibility: the model adapts the path to the input, which is what you want when you cannot enumerate the paths in advance. Workflows offer predictability and consistency for well-defined tasks, whereas agents are the better option when flexibility and model-driven decision-making are needed at scale.
Here is the SDK-specific twist, and it is important. The SDK sits at the agent end by default. A bare query() call hands control to the model, which decides which tools to call and when to stop. That is the opposite default from writing raw API calls, where you hold the loop. So in this SDK, building a workflow is the deliberate act. You pull control back toward your own code by chaining separate, narrowly scoped query() calls, each handling one fixed step, instead of handing the model one open-ended prompt and letting it range.
Everything that follows is either a workflow pattern, where you hold the control flow, or an agent pattern, where the model holds it. Knowing which family you are in is half the design, because it tells you whether your job is to script the steps or to describe the goal and get out of the way.
The augmented LLM: the building block
Every pattern is built from one unit, what Anthropic calls the augmented LLM: a model with access to tools, retrieval, and memory. With the Claude Agent SDK, you have been working with exactly this unit all along. A query() call with allowedTools, an MCP server, and a project CLAUDE.md is an augmented LLM. The patterns are just different ways of arranging several of these units, sequentially, in parallel, or in a loop.
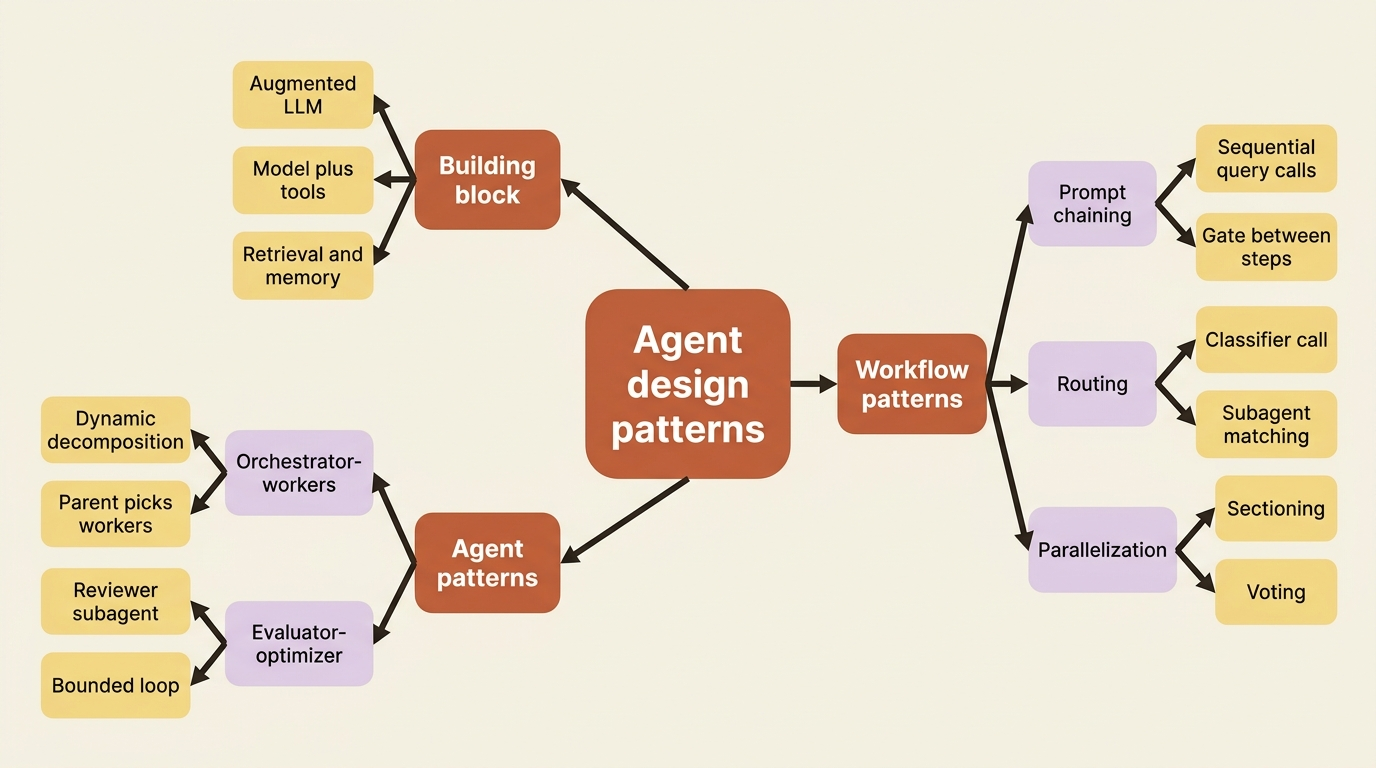
Hold that picture and the five patterns stop being a list to memorize and become five shapes you can compose.
Pattern 1: Prompt chaining (a workflow)
Prompt chaining decomposes a task into a sequence of steps, where each LLM call processes the output of the previous one. You hold the control flow, and each step is an easier, more reliable call than one giant prompt would be. The main goal is to trade off latency for higher accuracy, by making each LLM call an easier task. Use it when the task can be easily and cleanly decomposed into fixed subtasks.
In the SDK, this is sequential query() calls in your own code, optionally with a programmatic "gate" between them: a plain if that checks the first step's output before spending money on the second.
# Prompt chaining: two fixed steps with a gate in between
diagnosis = await run_query("Diagnose the failing test in buggy-shop. Report the bug as JSON.") # ①
if not diagnosis.get("bug_found"): # the gate: stop before spending more ②
raise SystemExit("No bug found; nothing to fix.") # ③
fix = await run_query(f"Write a fix for this bug:\n{diagnosis}") # ④
① Step one runs in isolation and returns structured data the next step can read. ② The gate is plain code you control, inspecting step one's output before any further spend. ③ A failed gate short-circuits the chain, so the expensive second call never happens. ④ Step two runs only past the gate, consuming the first step's output as its input.
For buggy-shop, that means one call to produce a structured diagnosis of the failing test, a gate that confirms a bug was actually found, then a second call to write the fix. The tell that you want chaining rather than one agent call: you can name the steps in advance.
Pattern 2: Routing (a workflow)
Routing classifies an input and directs it to a specialized followup task. It buys you separation of concerns: a prompt tuned for refunds does not have to also be good at technical support. Use it where there are distinct categories that are better handled separately, and where classification can be handled accurately.
The SDK gives you two ways to route. The model-driven way is subagent-description matching: define specialists with sharp description fields, and the parent agent routes work to whichever fits. The cheaper, more deterministic way is a small classifier call that picks the model or the prompt for the real work. That second option doubles as a cost lever, since you can route easy questions to a smaller model like Haiku and hard ones to a more capable model. For buggy-shop, a router might send "explain this failure" to a read-only Haiku subagent and "refactor this module" to an Opus one.
Pattern 3: Parallelization (a workflow)
LLMs can sometimes work simultaneously on a task and have their outputs aggregated programmatically. It comes in two variations. Sectioning splits a task into independent subtasks run at once. Voting runs the same task several times for diverse outputs and higher confidence. Use it when the divided subtasks can be parallelized for speed, or when multiple perspectives or attempts are needed for higher confidence.
This maps onto two SDK mechanisms. For sectioning, use concurrent subagents: a style-checker, a security-scanner, and a test-coverage agent running at the same time, with their summaries aggregated by the parent. For lighter-weight parallelism inside a single agent, use read-only tools: mark a tool readOnly and the SDK fans out concurrent calls. Voting is the same subagent mechanism pointed at one question: run three reviewers over the buggy-shop fix and merge their verdicts, which catches what any single pass would miss.
Pattern 4: Orchestrator-workers (the agent end)
In the orchestrator-workers workflow, a central LLM dynamically breaks down tasks, delegates them to worker LLMs, and synthesizes their results. The critical difference from parallelization: subtasks are not pre-defined, but determined by the orchestrator based on the specific input. You do not know the subtasks in advance; the model decides them. This is the pattern behind real coding agents, where the number of files that need to change depends on the task.
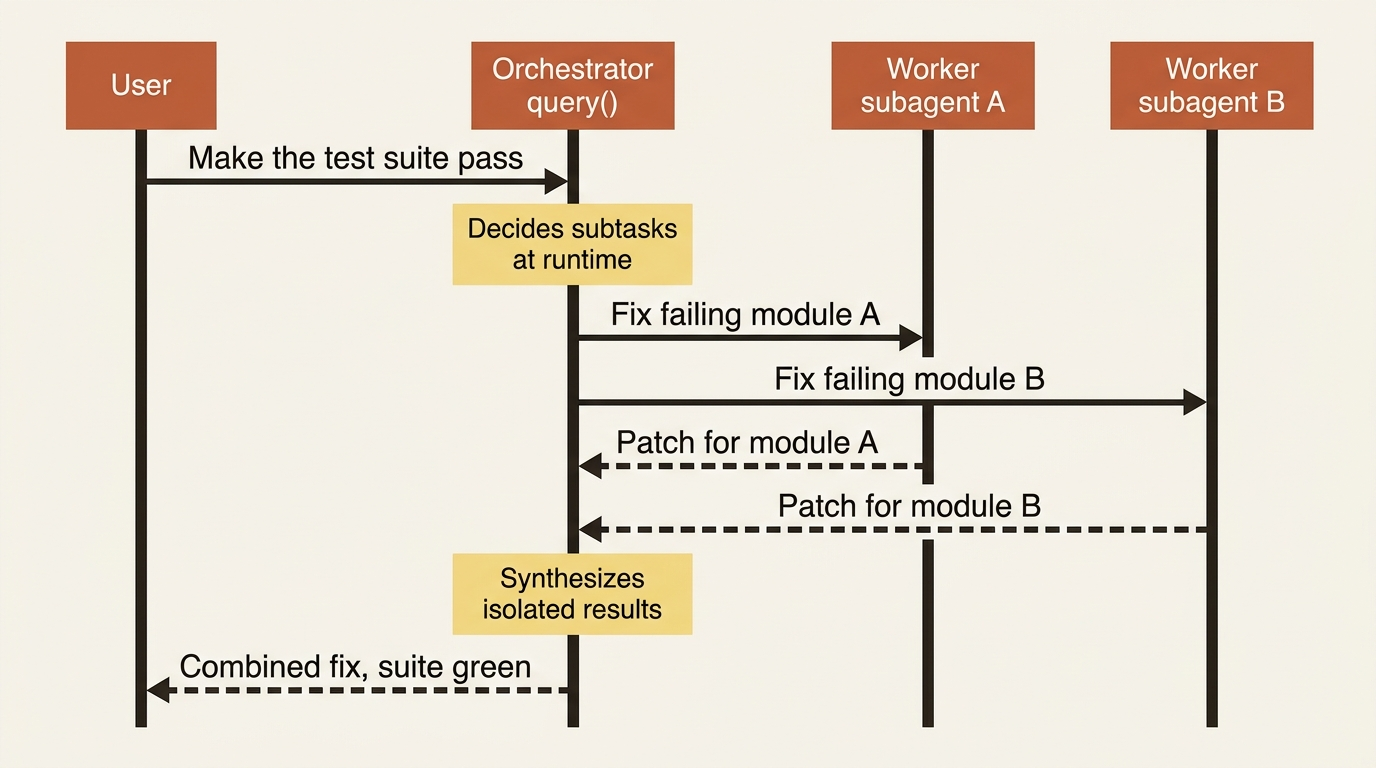
This is the most agentic of the patterns, and it maps directly onto a parent agent with the Agent tool delegating to subagents, except here you let the parent decide how many workers and what each does, rather than scripting it. For buggy-shop, an orchestrator handed "make the test suite pass" might spawn one worker per failing module, each fixing its own file, then synthesize the results.
This is also the pattern that most justifies using the SDK at all, and it is worth dwelling on why. The other four patterns you could hand-wire with raw API calls and a few if statements. The SDK saves you effort but is not strictly necessary. Orchestrator-workers is different, because hand-wiring dynamic decomposition, where the model decides the subtasks at runtime, then spawns and coordinates workers, then synthesizes their isolated results, is exactly the painful loop you adopted the SDK to avoid. Here the convenience is not incidental: a query() with subagents and the Agent tool is orchestrator-workers, assembled. You do not build the pattern; you enable it and write good subagent descriptions. When the SDK feels like it is earning its keep, this is usually the pattern doing the earning.
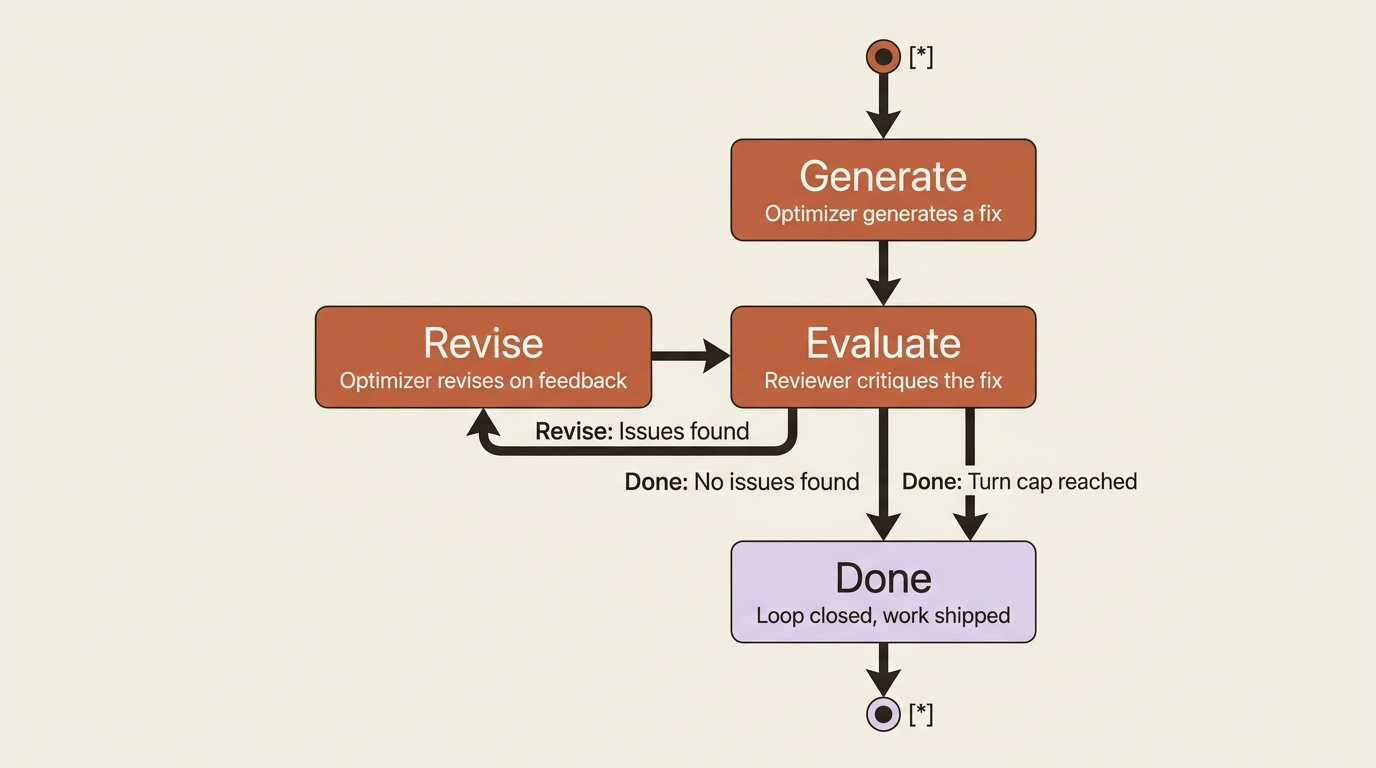
Pattern 5: Evaluator-optimizer (a loop)
In the evaluator-optimizer workflow, one LLM call generates a response while another provides evaluation and feedback in a loop. Use it when there are clear evaluation criteria, and when iterative refinement provides measurable value. The two signs are that a human's feedback would demonstrably improve the output, and that an LLM can supply that feedback.
If you have built a reviewer subagent, you have already half-built this. The reviewer is the evaluator, and the main fixer agent is the optimizer. Close the loop and you have the pattern. The fixer proposes a change, the reviewer critiques it against your criteria, and if the critique finds real issues the fixer revises, repeating until the reviewer is satisfied or you hit a turn cap.
# Evaluator-optimizer as a chain you control: generate, evaluate, revise on feedback
diagnosis = await run_query("Fix the failing test in buggy-shop.") # ①
for _ in range(3): # bounded loop, never infinite ②
review = await run_query(f"Review this fix for regressions and edge cases:\n{diagnosis}") # ③
if "no issues" in review.lower(): # ④
break
diagnosis = await run_query(f"Revise the fix given this review:\n{review}") # ⑤
① The optimizer produces the first candidate fix, before any feedback exists. ② The bounded loop caps iterations at three, so the cycle can never run forever. ③ The evaluator critiques the current fix against your criteria, regressions and edge cases. ④ The verdict gate stops the loop the moment the reviewer signals the fix is clean. ⑤ The optimizer revises using the reviewer's feedback, feeding the result back into the next round.
This is shown in Python only and deliberately schematic. The run_query helper stands in for your own query() wrapper, because the shape is the point, not the plumbing: generate, evaluate, revise, bounded by a loop you own. A turn cap is what keeps the loop from running forever. You can also let a single agent run this internally with a reviewer subagent, which trades your explicit control for less code.
The pattern-to-primitive map
Here is the whole mapping in one view: each pattern, the SDK construct that implements it, and which family it belongs to.
| Anthropic pattern | Family | SDK construct that implements it |
|---|---|---|
| Prompt chaining | Workflow | Sequential query() calls in your code, with a gate between steps; or a multi-step skill |
| Routing | Workflow | A classifier query() that picks the model or prompt; or subagent-description matching |
| Parallelization | Workflow | Concurrent subagents (sectioning or voting); read-only tools for in-turn parallel calls |
| Orchestrator-workers | Agent | A parent query() with the Agent tool delegating to subagents it chooses at runtime |
| Evaluator-optimizer | Loop | A reviewer subagent returning a verdict that drives a bounded iteration loop |
Medium does not render tables, so here is the same map in prose. Prompt chaining is a workflow, built from sequential query() calls with a programmatic gate between steps, or expressed as a multi-step skill. Routing is a workflow, built from a small classifier call that picks the model or prompt, or from subagent-description matching that lets the model route by delegating. Parallelization is a workflow, built from concurrent subagents, namely sectioning for independent pieces and voting for confidence, or from read-only tools that fan out within a single turn. Orchestrator-workers is the agent family, built from a parent query() with the Agent tool delegating to subagents it decides on at runtime. Evaluator-optimizer is a loop, built from a reviewer subagent whose verdict drives a bounded iteration. The first three are workflows where you hold the flow; the last two hand it to the model.
Choosing: match the pattern to the complexity
Anthropic's own selection rule ties each pattern to a complexity tier, and it is the most actionable guidance in the essay. Workflows, namely chaining and routing, are ideal for low-complexity tasks with predictable, well-defined steps. Orchestrator-workers suits medium-complexity tasks where subtasks are less predictable, such as multi-file coding or research. Multi-agent systems are best for high-complexity scenarios requiring specialized agents to handle different aspects of a problem. Complexity is the dial, and you turn it up only as far as the task forces you to.
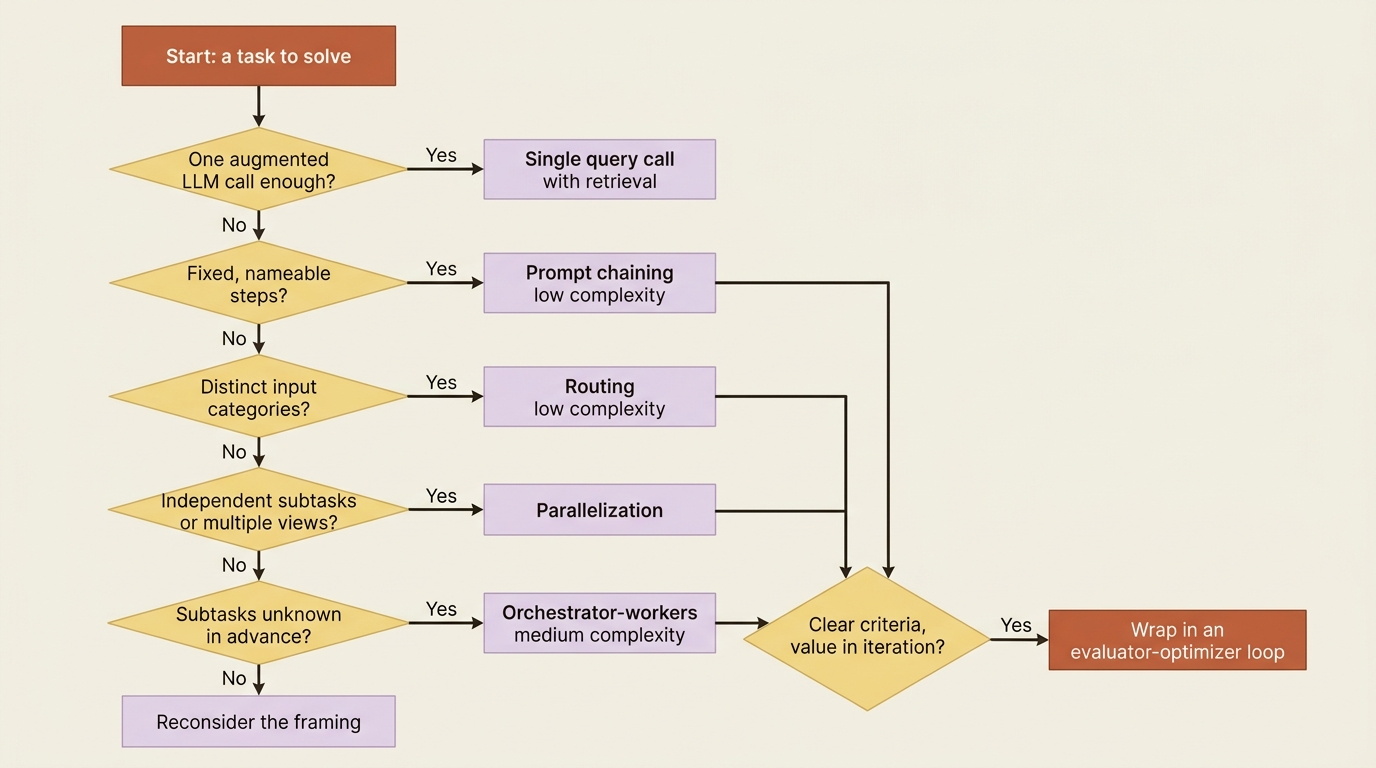
Put that together as a short walk down a list. Start at the top and stop at the first one that fits.
- A single augmented LLM call, with retrieval and good examples, handles more than you would expect. Try this first, always.
- Fixed, nameable steps? Prompt chaining (low complexity).
- Distinct input categories that deserve different handling? Routing (low complexity).
- Independent subtasks, or a need for multiple perspectives? Parallelization.
- Subtasks you cannot predict in advance? Orchestrator-workers (medium complexity, the agent end).
- Clear criteria and value in iteration? Wrap any of the above in an evaluator-optimizer loop.
The honest answer for most small, well-scoped tasks is one of the first three. Here is the discipline the SDK makes hard to keep: because subagents are one Agent call away, the powerful patterns are cheap to express, which makes overuse the natural temptation. Cheap to express is not cheap to run. Every subagent is its own context, its own token bill, and its own chance to compound an error. So reach for orchestrator-workers and full agent autonomy only when the problem genuinely cannot be scripted, let the model's own planning absorb dynamic complexity rather than pre-building orchestration you may not need, and remember that the simplest correct pattern is still the goal even when a more elaborate one is a one-liner away.
The three principles to build by
Anthropic closes its guide with three principles, and they are a good lens for every design decision. Maintain simplicity in your agent's design. Prioritize transparency by explicitly showing the agent's planning steps. Carefully craft your agent-computer interface through thorough tool documentation and testing.
Each one has shown up concretely. Simplicity is the start-with-the-simplest-thing advice above. Transparency means making the agent's reasoning visible instead of hidden, through streaming output and traces. The agent-computer interface is tool design: the SDK guide notes that teams often spend more time optimizing their tools than the overall prompt, because a tool's name, description, and parameters are how the model understands what it can do. A clear tool description is to an agent what a good docstring is to a junior developer.
Do this today
- Take an agent you have built and ask the one diagnostic question of each piece: who decides the control flow here, my code or the model? Label every piece a workflow or an agent.
- Find one place where you used a full agent and the steps were actually fixed and nameable. Rewrite it as a prompt chain of sequential
query()calls with a gate. - Pick a task you have not started and walk the decision ladder out loud, from a single augmented LLM call down. Stop at the first pattern that fits, and write down why the cheaper ones did not.
- Audit your subagent count. For each subagent, confirm the task genuinely cannot be scripted. If it can, collapse it back into a workflow.
- Open one custom tool's definition and read its
descriptionas if you were the model. Tighten it until a stranger would know exactly when to call it.
The takeaway
The SDK gives you primitives. The agent design patterns tell you how to assemble them, and the assembly is where the real design lives. Prompt chaining, routing, and parallelization are workflows where you hold the control flow, and they map onto sequential query() calls, subagent or classifier routing, and concurrent subagents or read-only tools. Orchestrator-workers and full agents hand control to the model and map onto dynamic subagent delegation. Evaluator-optimizer is a reviewer-subagent loop.
The pattern that matters most is the one before all of them: reach for the simplest thing that works, prove that complexity earns its keep before you add it, and remember that the most senior decision is often not building an agent. Keep it simple, keep it transparent, and treat your tool definitions with the same care as your prompts. You now have the vocabulary to design, not just to wire.
This is Part 12 of "Building with the Claude Agent SDK," a 14-part guide to building production-ready AI agents.