Your Claude API Demo Has Never Seen a 429. Production Will.
A demo never sees a 429. Production hits one on its first busy Monday, and the difference between a service that shrugs it off and one that falls over is a few dozen lines of retry logic you should have written first.
The error handling, backoff, and idempotency habits that separate a working integration from a deployable one, written before the support queue tells you you needed them.
In this article: You will learn the complete error surface of the Claude API, the three-axis rate-limit model behind the
429response, how to retry transient failures with exponential backoff and jitter, why honoring theretry-afterheader is non-negotiable, and how theservice_tierparameter and a small idempotency habit keep a stateless integration standing under real traffic.
Everything you have built so far works. It works in testing, it works in the demo, and it works when you are the only person using it. Then you ship it, traffic arrives in earnest, and one Monday morning the support queue triples in an hour. Suddenly, requests start coming back not with answers but with errors: 429, rate limited, plus the occasional 529, overloaded. If your code assumed every call succeeds, it is now dropping customer tickets on the floor, and you are finding out in production what you should have known in development.
This is the article that separates a working Claude API integration from a deployable one. None of it is glamorous. It is error handling, retries, backoff, and an honest understanding of the limits you are operating within. However, it is the difference between a service that degrades gracefully under load and one that simply breaks. Because the Claude API is stateless, "production" means exactly this reliability engineering rather than babysitting a long-running process. There is no server-side state to corrupt, just requests that succeed, fail, and need to be retried intelligently.
The error surface: know what can come back
Before you can handle errors, you need to know which ones exist and what they mean. The Anthropic API returns predictable HTTP status codes, and the right response to each depends on whether it is something you can fix, something the user must fix, or something that will resolve on its own if you wait.
Here is the surface, condensed:
400 invalid_request_error: your request was malformed. A bug to fix, not retry.401 authentication_error: your API key is wrong or missing. Fix the key.402 billing_error: a billing or payment problem. Check the Console.403 permission_error: your key lacks permission for that resource.404 not_found_error: the resource does not exist.413 request_too_large: the request exceeds the size limit, which is 32 MB for the Messages API. Trim it.429 rate_limit_error: you hit a rate limit. Wait and retry.500 api_error: an unexpected error inside Anthropic's systems. Retry.504 timeout_error: the request timed out while processing. Consider streaming for long requests.529 overloaded_error: the API is temporarily overloaded. Wait and retry.
The mental split is what matters. The 4xx errors in the 400 to 413 range are almost all your problem to fix and pointless to retry, because retrying a malformed or unauthorized request just fails again. The ones worth retrying are 429, 500, 504, and 529, because they are transient: the limit will refill, the overload will pass, and the blip will clear. Building retry logic that distinguishes these two camps is the core skill of the chapter.
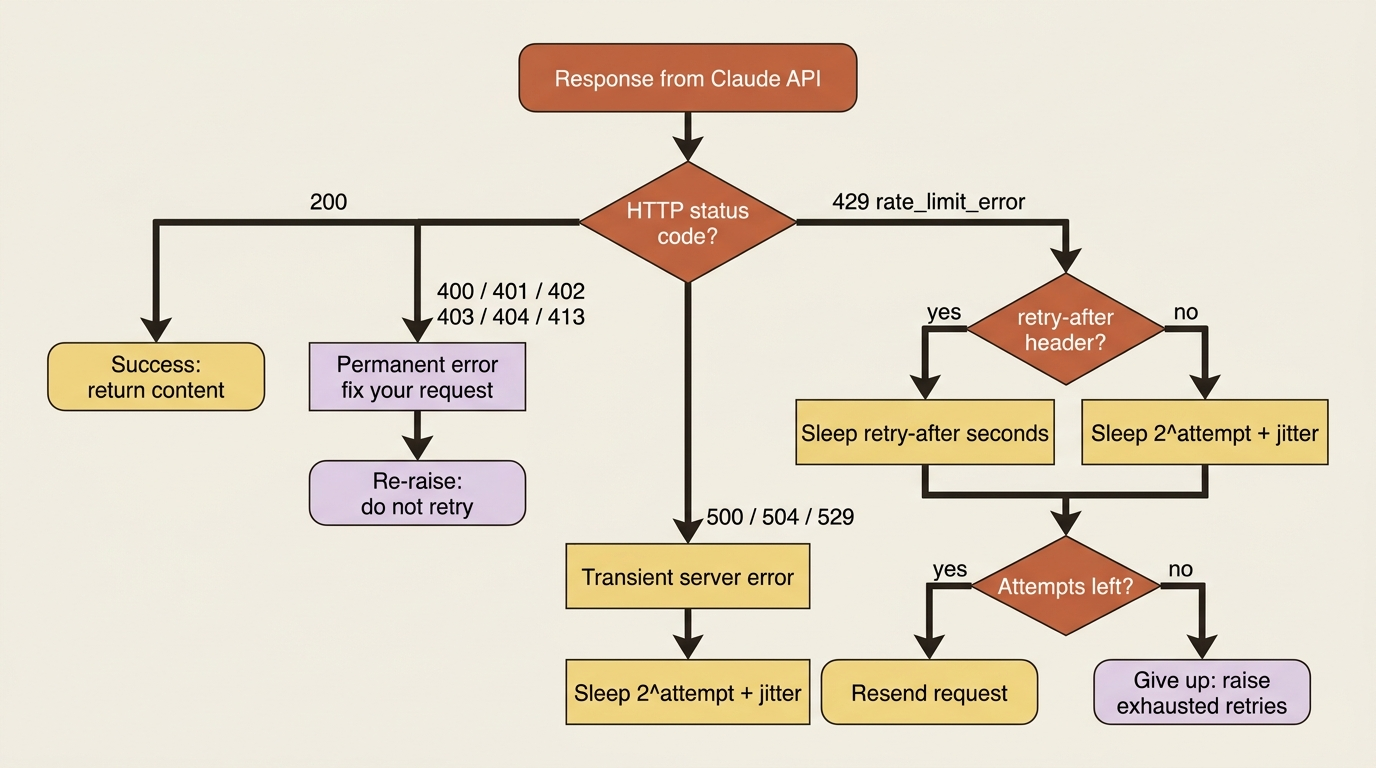
The error shape and the field you must log
Every error is returned as JSON with a top-level error object containing a type and a message, plus a request_id for tracking:
{
"type": "error",
"error": {
"type": "rate_limit_error",
"message": "Number of requests has exceeded your rate limit..."
},
"request_id": "req_011..."
}
The single most valuable habit you can build here is logging that request_id on every failed request, and ideally every request. When something goes wrong and you need to understand why, or when you contact Anthropic support, the request_id is the thread that lets anyone trace exactly what happened. A production service that does not log request IDs is one that debugs blind.
Rate limits: the model behind the 429
A 429 is not a wall. It is a speed limit, and understanding the model behind it is how you stay under it. The Messages API measures rate limits along three axes, each per minute and per model class: requests per minute (RPM), input tokens per minute (ITPM), and output tokens per minute (OTPM). You can exceed any one of them independently, and the 429 you get back tells you which. Because limits are tracked per model, you can run different models up to their separate limits at the same time, which is itself a scaling lever.
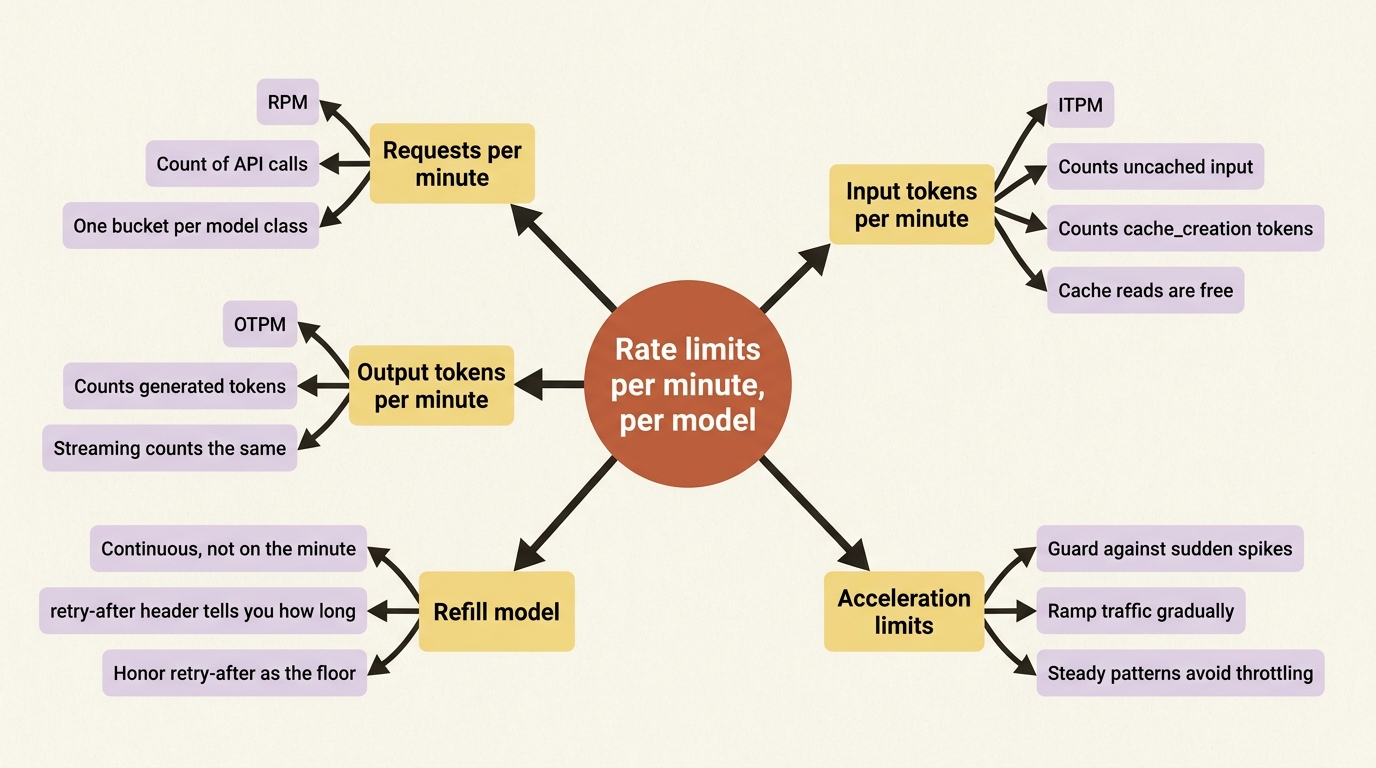
The limits do not reset in discrete chunks; they refill continuously, like a bucket that drains as you spend and refills steadily over time. This means recovery from a 429 is often a matter of seconds, not a full minute, and the API tells you exactly how long to wait through the retry-after header on the 429 response, which gives the number of seconds until you can retry successfully. Retrying earlier than that just fails again, so the correct behavior is to read retry-after and honor it.
There is one subtlety worth highlighting because it directly raises your effective ceiling: for most models, prompt cache reads do not count toward ITPM. Only uncached input_tokens and cache_creation_input_tokens are charged against the input-token limit, while cache_read_input_tokens ride free. So aggressive prompt caching is not just a cost play, it is a rate-limit play, letting you push far more total throughput through a fixed ITPM ceiling.
The acceleration-limit trap. A sudden, sharp spike in traffic can trigger 429 errors through acceleration limits even when you are nominally under your tier's rate limits, because the API guards against abrupt usage surges. The fix is counterintuitive if you are used to thinking only about steady-state limits: ramp your traffic up gradually and keep usage patterns consistent rather than slamming the API from zero to peak. A flood that arrives all at once is more likely to be throttled than the same volume eased in over a few minutes.
Retrying correctly: exponential backoff with jitter
Now the payoff. The correct way to handle a transient error is to wait and retry, but not naively. If you retry immediately you just fail again, and if every client retries on the same fixed schedule after a shared outage, they all hammer the API in synchronized waves. The standard answer is exponential backoff with jitter. Wait a little after the first failure, longer after the second, and longer still after the third. That is the exponential part. Then add a small random amount to each wait, which is the jitter, so concurrent clients spread out instead of retrying in lockstep. When a retry-after header is present, honor it as the floor.
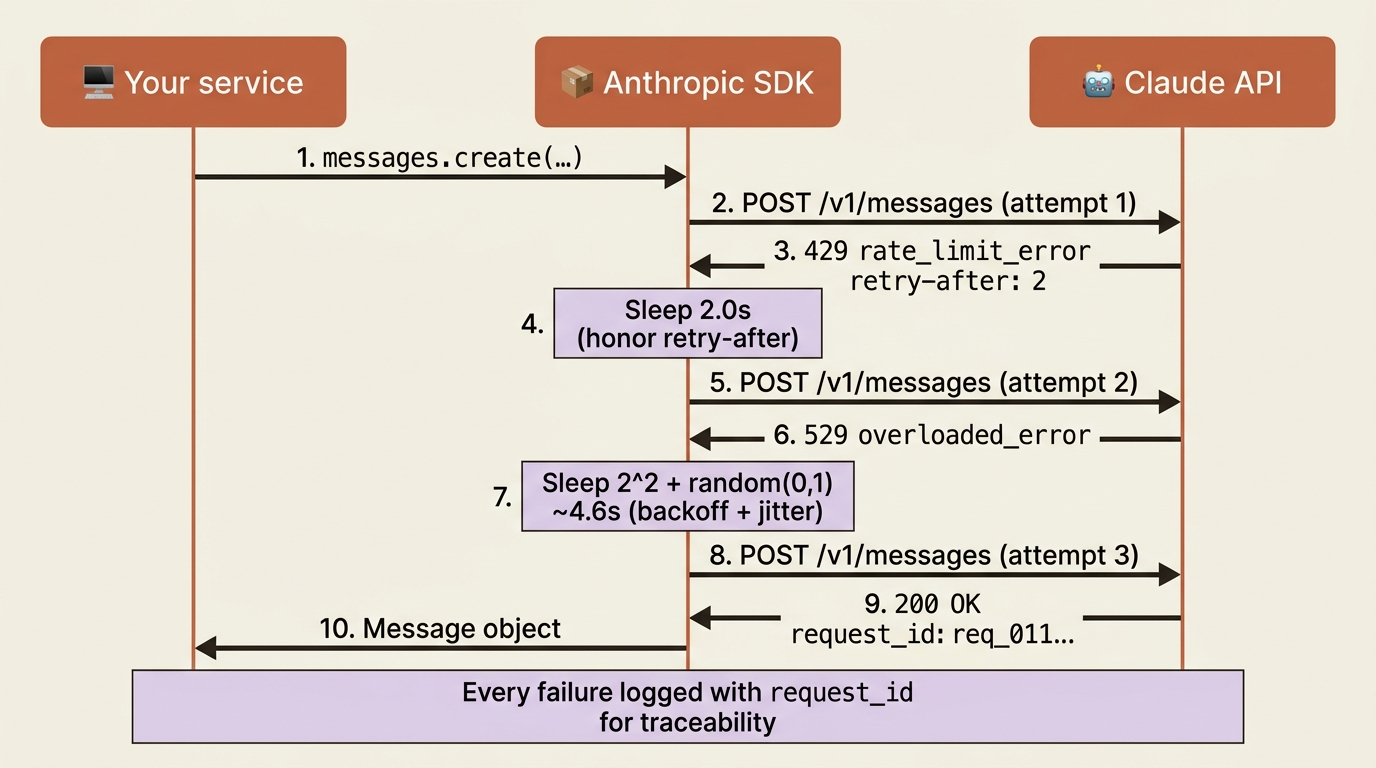
The good news is that the official Anthropic SDKs implement sensible retry logic with backoff out of the box, so for the common case you get correct behavior for free. The instructive version, written explicitly, looks like this:
import anthropic
import time
import random
client = anthropic.Anthropic()
def call_with_retry(messages, max_retries=5):
for attempt in range(max_retries):
try:
return client.messages.create(
model="claude-sonnet-4-6", max_tokens=512, messages=messages,
)
except anthropic.RateLimitError as e:
# 429: honor retry-after if present, else back off exponentially.
wait = getattr(e.response.headers, "get", lambda *_: None)("retry-after")
delay = float(wait) if wait else (2 ** attempt) + random.uniform(0, 1)
time.sleep(delay)
except anthropic.APIStatusError as e:
# Retry transient server errors (500, 529); re-raise the rest.
if e.status_code in (500, 529):
time.sleep((2 ** attempt) + random.uniform(0, 1))
else:
raise
raise RuntimeError("Exhausted retries")
Read the structure rather than the syntax. A 429 honors retry-after when present and otherwise backs off exponentially with jitter. A transient 500 or 529 backs off the same way. Anything else, a 400, a 401, or a 404, re-raises immediately, because retrying a request that is broken or unauthorized is wasted effort. This is the shape the SDK gives you by default, shown explicitly so you understand what it is doing and can tune it when your needs differ.
Idempotency and timeouts: two more production habits
Two smaller habits round out reliable behavior.
First, set a timeout on every request, so a single slow or hung call cannot block your service indefinitely. The SDKs let you configure this, and a long-running request is also a signal to consider streaming, which keeps the connection alive as tokens arrive.
Second, think about idempotency. Retries mean a request can be sent more than once, so design the surrounding logic so that a duplicate is harmless. If your triage service might process the same ticket twice because a response was lost in transit, key your downstream actions on the ticket ID so a repeat is a no-op rather than a double charge or a double reply. The API call itself returns fresh output each time, so idempotency is a property you build in your code, not one you get for free.
Service tiers: trading for availability
When availability under load matters more than anything, service tiers give you a lever. Anthropic offers a standard tier, the default with best-effort availability, and a Priority Tier that prioritizes your requests over others to minimize overloaded errors during peak times. The Priority Tier is aimed at production workflows that need predictable availability and pricing.
You control tier selection per request with the service_tier parameter, which accepts "auto", the default, which uses Priority Tier capacity when available and falls back to standard otherwise, and "standard_only", which pins to standard capacity. The "standard_only" value is useful when you want to reserve your priority commitment for other traffic.
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
service_tier="auto",
messages=[{"role": "user", "content": "Triage this ticket..."}],
)
print(response.usage.service_tier) # standard, priority, or batch
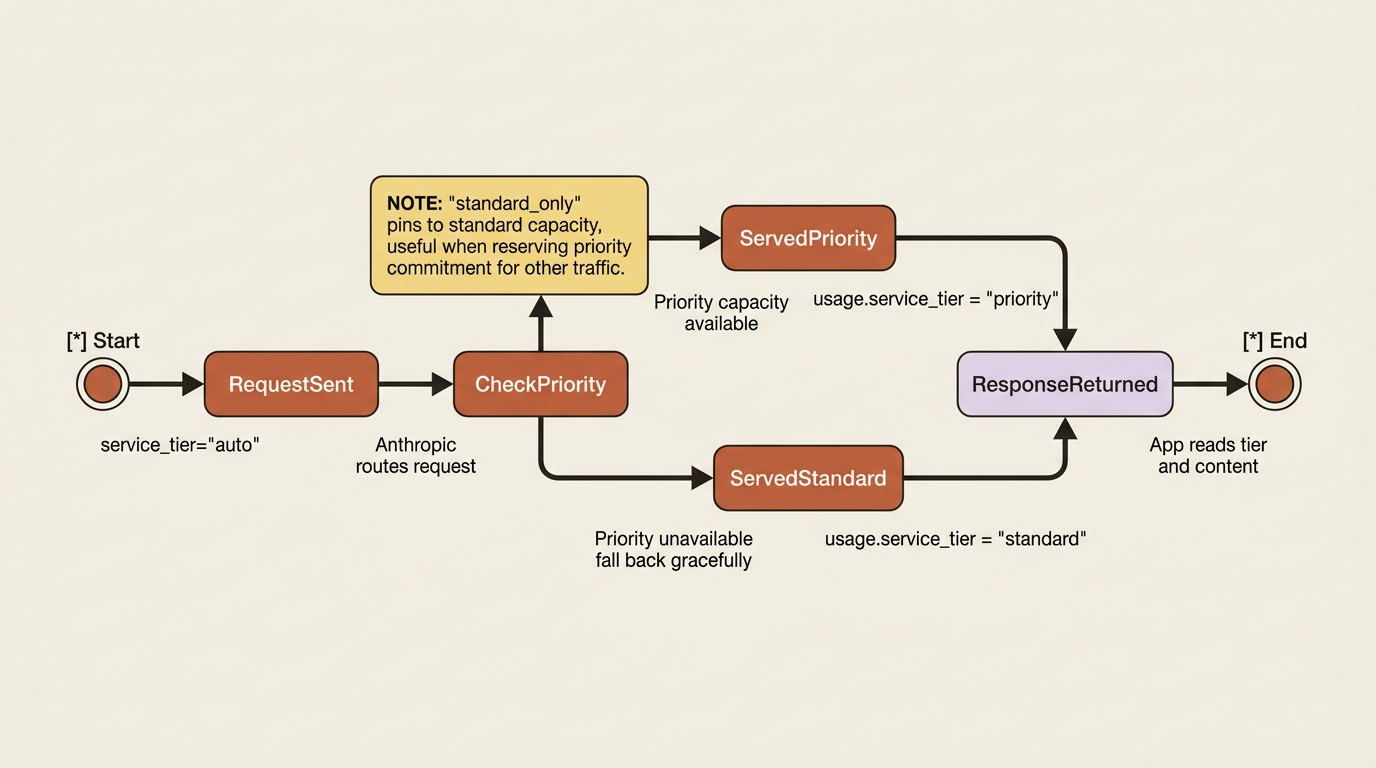
The response usage object reports the service_tier that actually served the request, so you can see whether you got priority capacity or fell back to standard. Priority Tier is a commitment you arrange with Anthropic rather than a flag you flip unilaterally, but the parameter is how your code expresses the preference once you have it. For most services, auto is the sensible default: take priority capacity when it is there, and degrade gracefully to standard when it is not.
What the SDK does and what you still own. The SDK's built-in retry logic covers the common 429-and-back-off case, but you still own the bigger decisions: how many retries before you give up, how to make your downstream actions idempotent, what timeout is right for your latency budget, and whether to commit to Priority Tier for the availability your workload needs.
A triage service that survives Monday
Let us harden a small support-triage service against the Monday-morning flood. It retries transient failures with backoff, honors retry-after, logs the request_id on every failure, uses auto service tier, and keeps its downstream action idempotent on the ticket ID so a retry never double-handles a ticket.
import anthropic
import time
import random
client = anthropic.Anthropic()
processed = set() # ticket IDs we've already acted on (idempotency guard)
def triage_resiliently(ticket_id: str, email_text: str, max_retries=5):
if ticket_id in processed:
return "already handled" # a retry must not re-handle the ticket
messages = [{"role": "user", "content": f"Classify: {email_text}"}]
for attempt in range(max_retries):
try:
resp = client.messages.create(
model="claude-sonnet-4-6", max_tokens=256,
service_tier="auto", messages=messages,
)
processed.add(ticket_id)
return resp.content[0].text
except anthropic.RateLimitError as e:
retry_after = e.response.headers.get("retry-after")
delay = float(retry_after) if retry_after else (2 ** attempt) + random.uniform(0, 1)
print(f"[{ticket_id}] 429, retrying in {delay:.1f}s (req {e.request_id})")
time.sleep(delay)
except anthropic.APIStatusError as e:
if e.status_code in (500, 529):
print(f"[{ticket_id}] {e.status_code}, backing off (req {e.request_id})")
time.sleep((2 ** attempt) + random.uniform(0, 1))
else:
print(f"[{ticket_id}] fatal {e.status_code} (req {e.request_id})")
raise
raise RuntimeError(f"[{ticket_id}] exhausted retries")
print(triage_resiliently("ticket-1001", "Where is my order 48810?"))
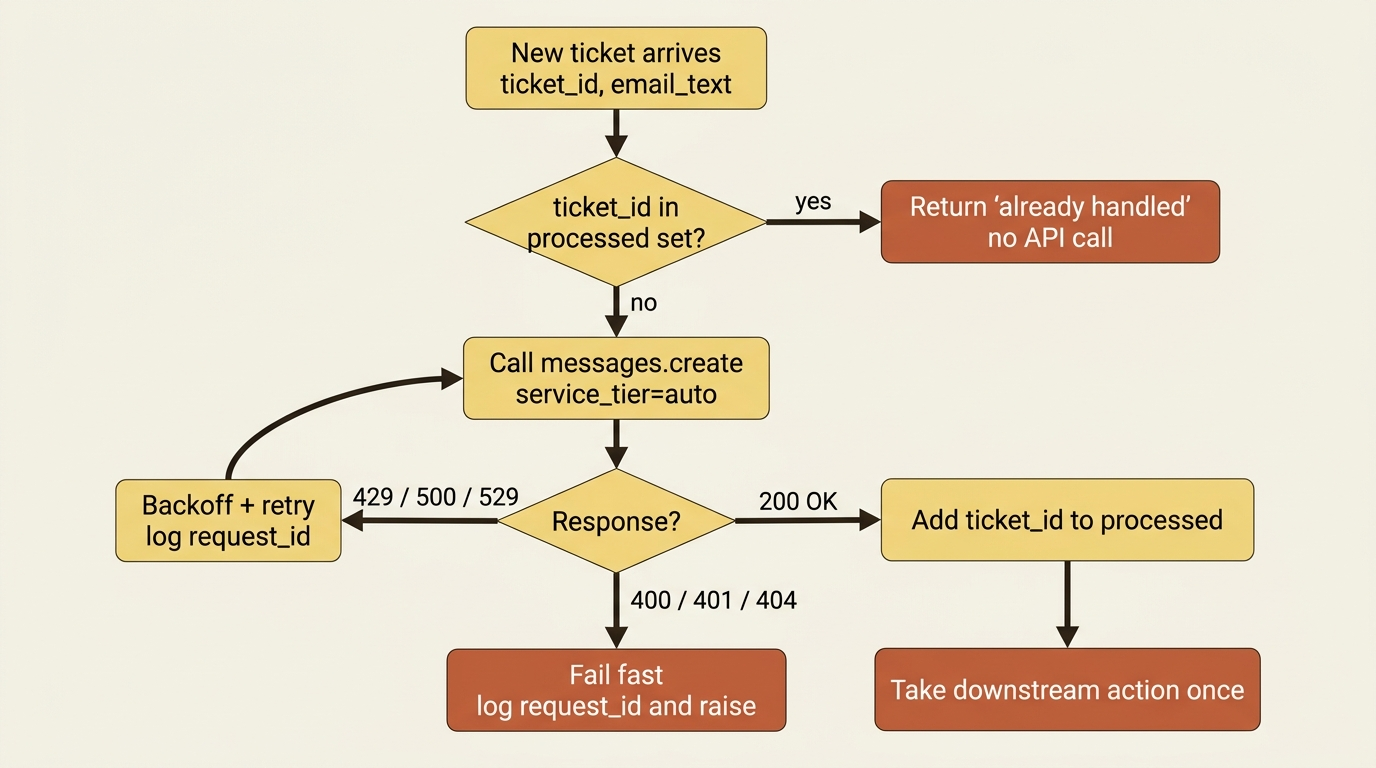
Trace how it weathers the storm. When the flood pushes you over the rate limit, each 429 is caught, the retry-after is honored, and the request is retried instead of dropped, with the request_id logged so any failure is traceable. Transient 500 and 529 errors back off the same way, while a genuine 400 or 401 fails fast rather than retrying pointlessly. The processed set means that if a response is lost and the ticket is retried, it is recognized and skipped rather than handled twice. Also, service_tier="auto" quietly takes priority capacity when it is available. The same service that dropped tickets under load now absorbs the surge and clears it.
Do this today
Whatever Claude API integration you have running right now, spend an hour adding these five habits before traffic ever stress-tests them for you.
- Log
request_idon every failure. Wrap yourmessages.createcall so any caught exception writes therequest_idto your logs. Anthropic support and your future self both need it. - Add an explicit retry block for
RateLimitErrorandAPIStatusErrorwith status500or529. Honorretry-afterwhen present, otherwise back off with(2 ** attempt) + random.uniform(0, 1). Re-raise everything else. - Set a request timeout. Pick a number that fits your latency budget and pass it to the SDK so a single hung call cannot wedge your service.
- Make one downstream action idempotent. Pick the most expensive side effect in your pipeline (a charge, a notification, a database write) and key it on a stable ID so a retried request is a no-op the second time.
- Default to
service_tier="auto"on production traffic. You get Priority Tier capacity when it is available and a clean fallback when it is not, with no code change at the call site.
Reliability is the feature
Demo code optimistically assumes the network is perfect, the service has infinite capacity, and your traffic is steady. Production is none of those things. The difference between an integration that survives the Monday-morning flood and one that becomes its own incident is, almost entirely, the few dozen lines that distinguish a fixable error from a transient one and that wait the right amount of time before trying again.
You now know the full error surface and which errors are worth retrying, the three-axis rate-limit model and the retry-after header that paces your recovery, exponential backoff with jitter (including the fact that the SDK does most of it for you), the acceleration-limit trap that punishes sudden spikes, and the idempotency, timeout, and service-tier habits that keep a deployed service standing.
The Claude API is stateless, which is what makes all of this tractable. There is no server-side session to corrupt, no long-running process to nurse. Reliability lives entirely in your client code. Write it once, write it well, and the same integration that used to drop tickets under load will absorb the surge and clear it before anyone in support notices anything went wrong. That is what production looks like.
This is Part 10 of "Building with the Claude API," an eleven-part guide to building production-grade integrations on top of the Claude API, from your first messages.create call to a hardened, observable service.