One Agent Works in Sequence. A Team Works in Parallel.
Multi-agent orchestration is not a tree of agents calling agents; it is one flat coordinator with a roster, and the rules that make it work are not the ones you would guess.
Multi-agent orchestration turns a single agent into a coordinator that delegates to a roster of specialists. The mechanics are not what you would guess: delegates are pre-built resources, delegation is exactly one level deep, and every worker's request still comes back to one stream.
In this article: You will learn how Claude Managed Agents multi-agent orchestration actually works, and why its rules differ from subagents in every other framework. We cover the shared-filesystem, separate-minds session shape, why workers are pre-built resources rather than inline definitions, the three numbers that govern a fan-out, and the single design choice that keeps coordination from becoming a nightmare. By the end you can turn a capable solo agent into a coordinated team.
A single agent is a single worker. Give it a goal and a way to verify its own work, and it will iterate to a passing result on its own. It is thorough. It is also one thing doing one thing at a time.
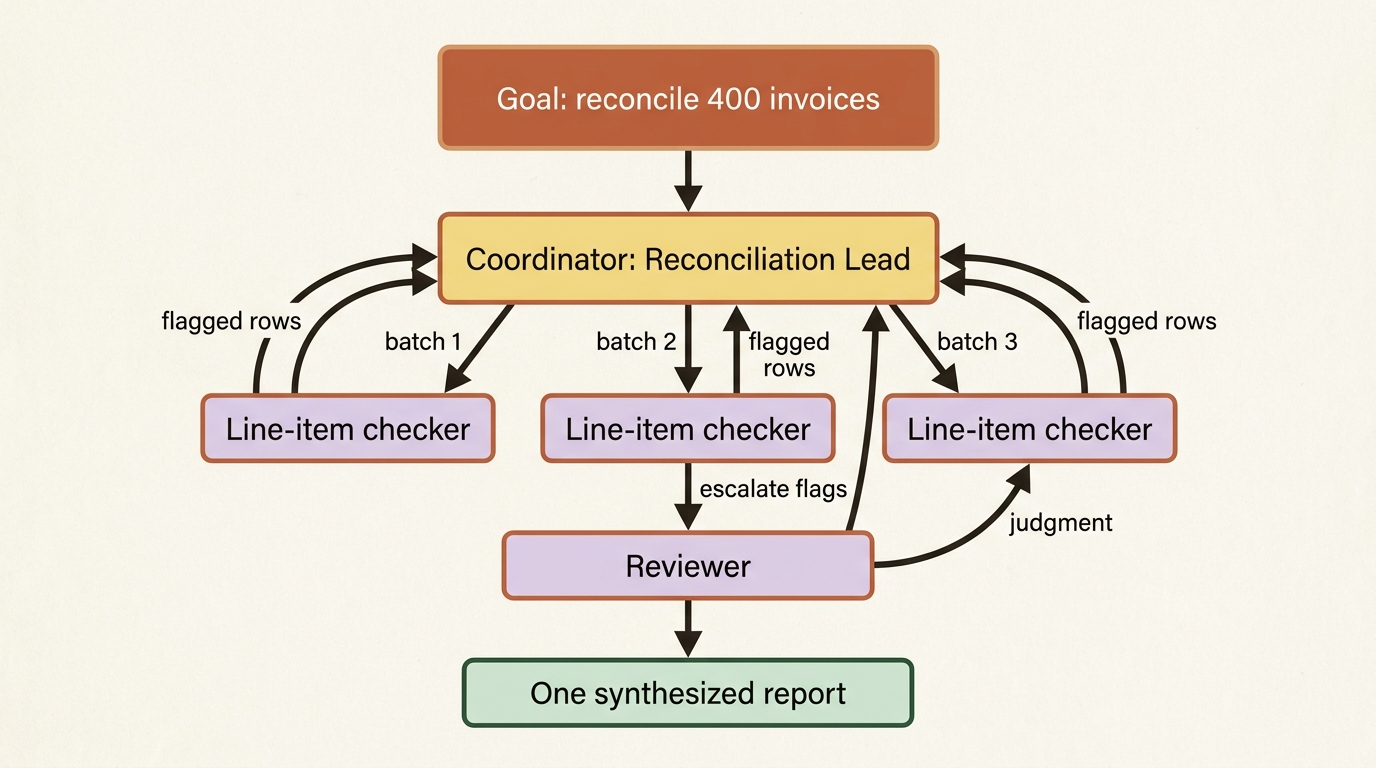
Watch it run a real job and the limit shows. An invoice agent reconciling a month of four hundred invoices works through them in sequence. One context window absorbs every invoice, every ledger lookup, and every flagged discrepancy, until that window strains under the weight of the whole job. No amount of self-evaluation fixes this. The bottleneck is not intelligence. It is that the work is serial and the memory is finite.
The fix is to stop thinking of the agent as a worker and start thinking of it as a lead. Claude Managed Agents multi-agent orchestration lets one agent become a coordinator that delegates to a roster of other agents, each running in its own isolated context, working in parallel. The coordinator breaks the job up, hands pieces to specialists, and synthesizes what comes back. Done well, this improves both quality and speed at once. Quality improves because each agent stays focused on a narrow task with a clean context. Speed improves because independent pieces run at the same time instead of in a line.
If you have used subagents in another agent framework, the idea is familiar. The mechanics are genuinely different, and the differences are exactly where people trip. This article builds the team and names every rule that is not the one you would guess. Note that multi-agent is a research-preview feature behind an access request, so plan for that gate before you build on it.
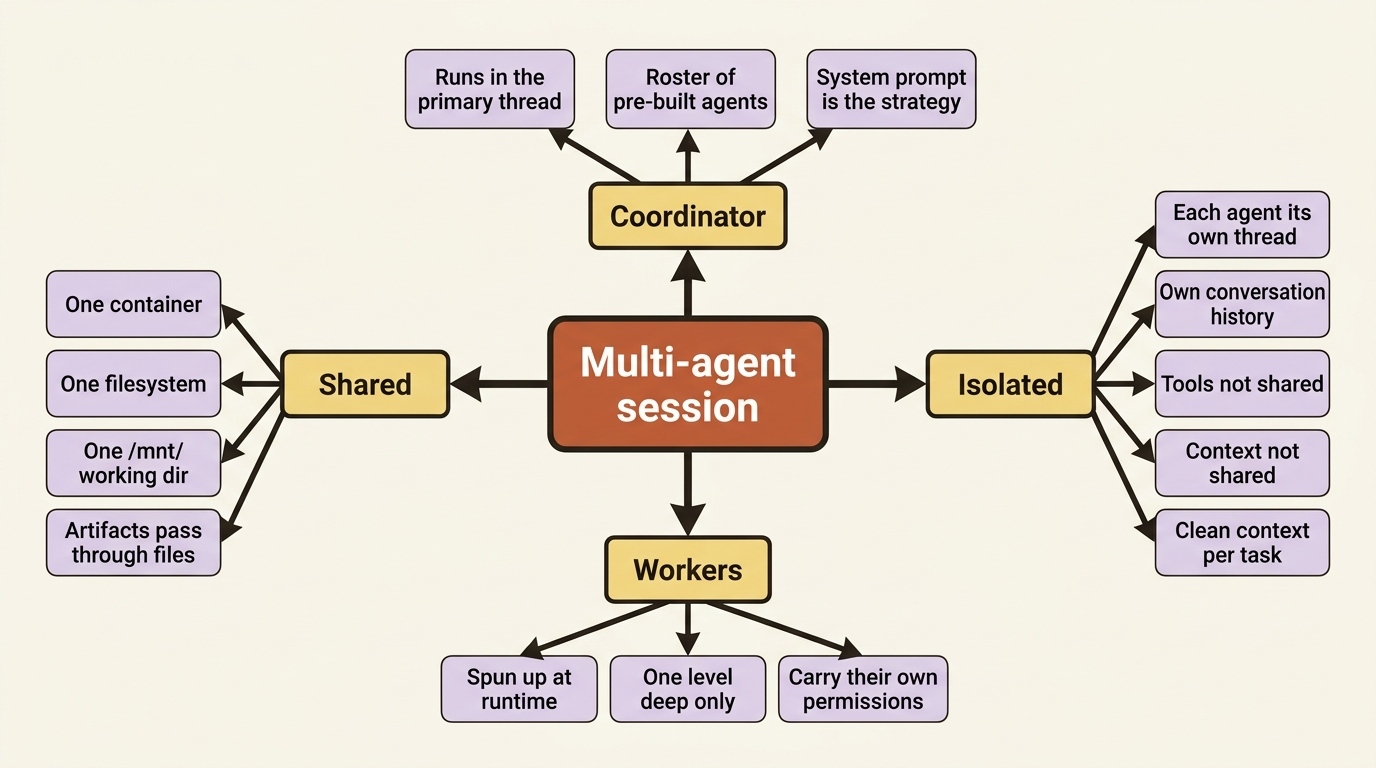
The shape: shared filesystem, separate minds
Two facts define how a multi-agent session behaves, and holding both at once is the key to reasoning about it.
All agents share the same container and filesystem. The coordinator and every agent it delegates to read and write the same /mnt/ directory. A worker that writes a partial result to a file is handing it to the others through the filesystem they all see. There is one sandbox, one set of files, and one working directory, shared across the whole team.
But each agent runs in its own session thread. A thread is a context-isolated event stream with its own conversation history. Tools and context are not shared between agents. The reviewer agent does not see what the line-item checker was reasoning about. It sees only what the coordinator passed it and what is on the shared filesystem. This isolation is the source of the quality gain: each agent gets a clean context scoped to its task, rather than one agent drowning in the combined history of everything.
So the mental model is a team sharing a workspace but not sharing a brain. They pass artifacts through files. They do not pass context through osmosis. The coordinator's own activity runs in the primary thread, the same session-level event stream you stream for any agent. Additional threads spin up at runtime each time the coordinator delegates.
Delegates are pre-built resources, not inline definitions
Here is the first place Managed Agents diverges from subagents elsewhere, and it shapes how you structure your whole deployment. You do not define a worker inline inside the coordinator. The coordinator's roster references previously created agents by ID. Each worker is its own full agent, created with its own model, system prompt, tools, MCP servers, and skills, before the coordinator ever mentions it.
That means the workers come first. For the invoice job you might create two specialists: a cheap, fast line-item checker that reconciles individual rows, and a more capable reviewer that scrutinizes the flagged discrepancies. Each one is an ordinary agents.create call. Once you have those agents and their IDs, the coordinator is an agent with a multiagent block declaring the roster.
coordinator = client.beta.agents.create(
name="Reconciliation Lead",
model="claude-opus-4-7",
system=(
"You coordinate invoice reconciliation. Split the invoices into batches "
"and delegate each batch to the line-item checker. Send anything it flags "
"to the reviewer for a closer look. Synthesize the results into one report."
),
tools=[{"type": "agent_toolset_20260401"}],
multiagent={
"type": "coordinator",
"agents": [
{"type": "agent", "id": line_item_checker.id},
{"type": "agent", "id": reviewer.id},
],
},
)
The same shape in TypeScript:
const coordinator = await client.beta.agents.create({
name: "Reconciliation Lead",
model: "claude-opus-4-7",
system:
"You coordinate invoice reconciliation. Split the invoices into batches and " +
"delegate each batch to the line-item checker. Send anything it flags to the " +
"reviewer for a closer look. Synthesize the results into one report.",
tools: [{ type: "agent_toolset_20260401" }],
multiagent: {
type: "coordinator",
agents: [
{ type: "agent", id: lineItemChecker.id },
{ type: "agent", id: reviewer.id },
],
},
});
The roster accepts three kinds of entry:
{"type": "agent", "id": ...}references an agent and defaults to its latest version.{"type": "agent", "id": ..., "version": ...}pins a specific version. You want this in production so that a roster does not silently change when someone updates a worker.{"type": "self"}lets the coordinator spawn copies of itself. This is how you fan one kind of work across many parallel instances rather than across different specialists.
You start a session against the coordinator exactly as you would any agent, and it delegates at runtime as the work demands.
Because each worker is a standalone agent, the coordinator's system prompt is doing real work: it is the delegation strategy. The agent will not magically know that flagged items go to the reviewer. You tell it, in plain language, how to use its roster. Treat the coordinator's prompt as the org chart and the routing rules combined.
The two limits that bite, and a third you will hit at scale
Three numbers govern orchestration, and the first two are the ones that surprise people.
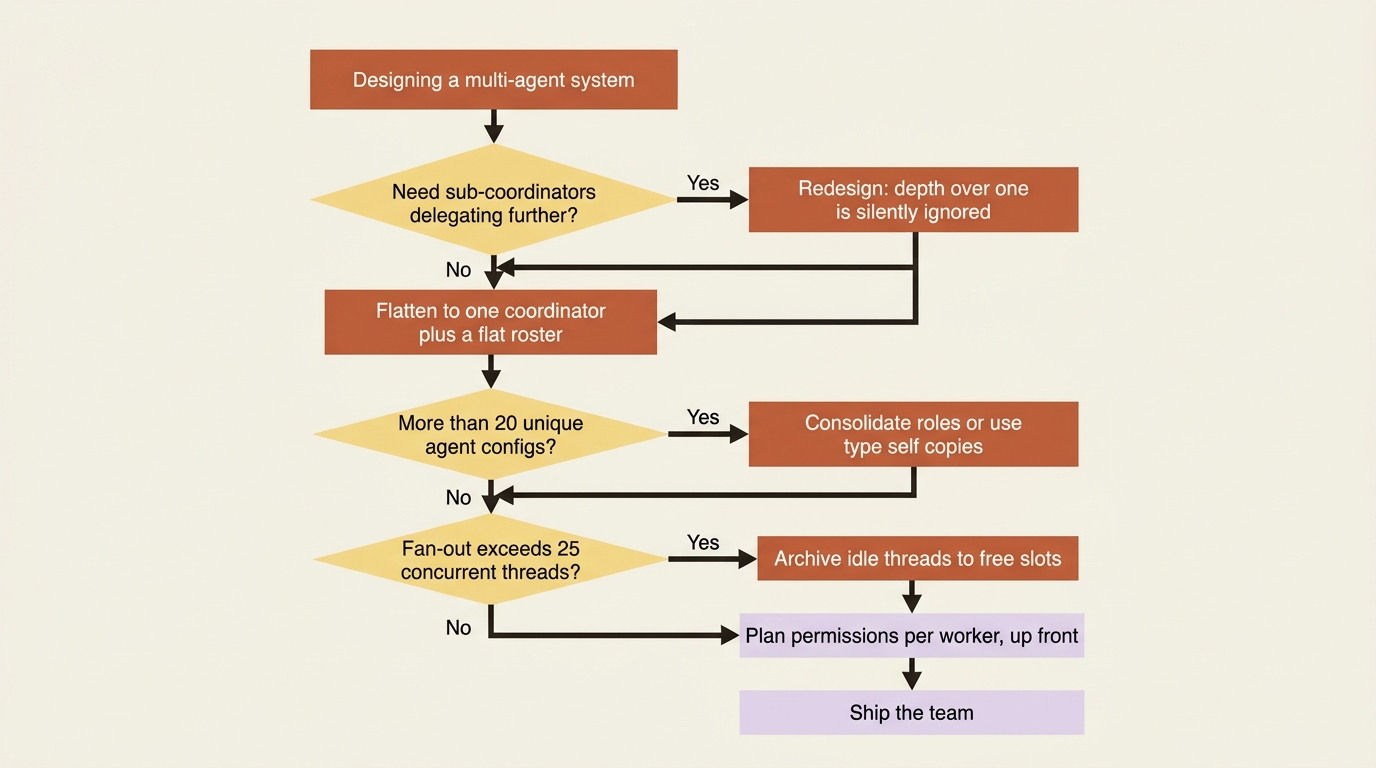
Delegation is exactly one level deep. A coordinator can delegate to its roster, but a worker cannot delegate further. Depth greater than one is silently ignored, which is the dangerous part. You do not get an error. You get a worker that simply does not fan out the way you assumed, and the work quietly collapses back onto it. If your design imagines a tree of coordinators delegating to sub-coordinators, redesign it as one coordinator with a flat roster of workers. The model is a fan-out, not a hierarchy.
The roster holds up to 20 unique agents in multiagent.agents. That is 20 distinct agent configurations, but the coordinator can call multiple copies of any one of them. A roster of two, your checker and your reviewer, can still produce many concurrent checker threads working different invoice batches. Unique agents and running threads are different budgets.
A session supports up to 25 concurrent threads. The primary thread counts, and every delegated copy counts. A coordinator fanning a batch job across many checker instances is spending against 25, not against 20. When a thread finishes its work, you can archive it to free a slot. That matters for a long batch job that would otherwise pile up idle threads against the ceiling. Archiving only succeeds on an idle thread, so interrupt a stuck one first.
Watching delegation happen
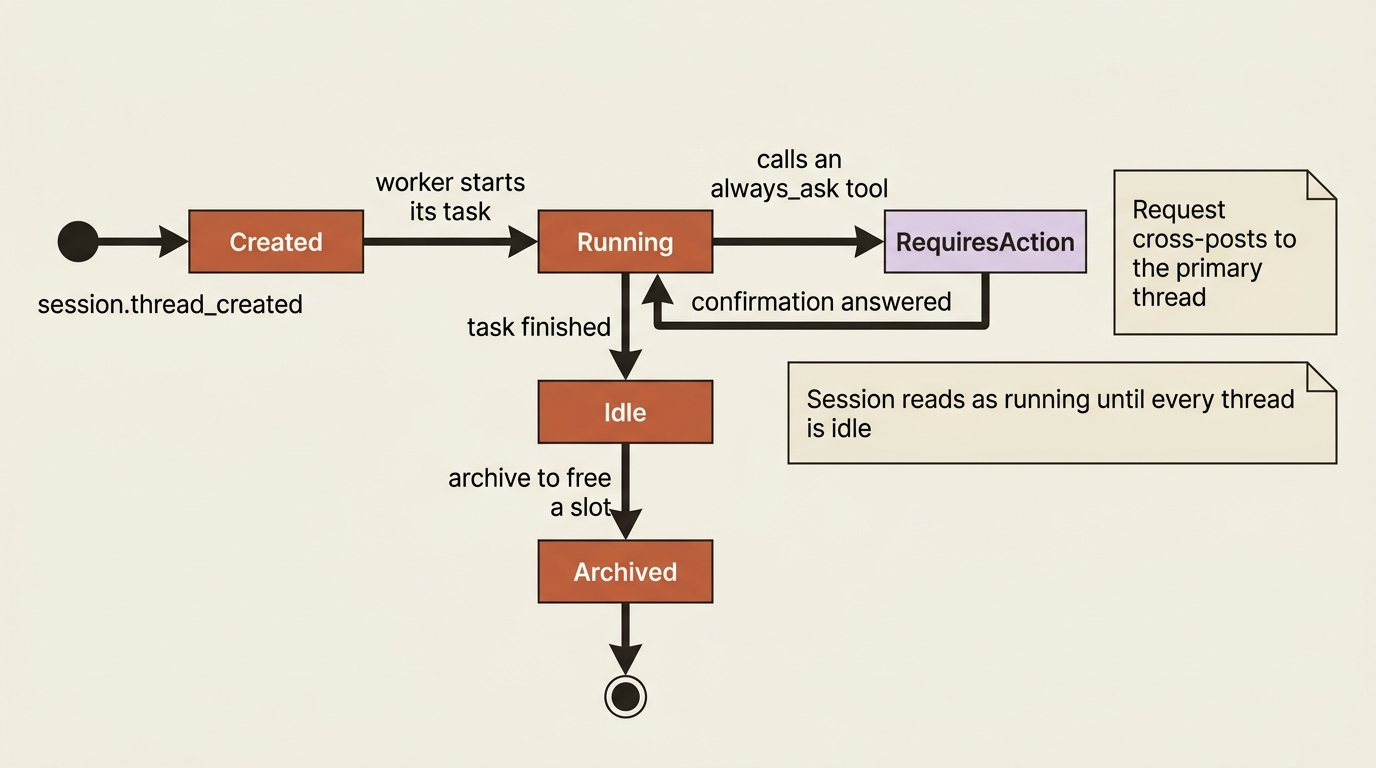
The primary thread gives you a condensed view of the whole session. You will not see every internal step of a worker on it, but you will see the shape of the delegation: when work is handed out, when results come back, and any moment a worker needs you. The events that narrate this are new ones layered on the stream you already handle.
When the coordinator delegates, a session.thread_created event marks the new thread spinning up for that worker. As the coordinator and a worker exchange instructions and results, agent.thread_message_sent and agent.thread_message_received show the handoff in each direction. The session's overall status is an aggregation: if at least one thread is running, the session reads as running. The session goes idle only when the whole team has settled.
To see inside a particular worker, you drill into its thread directly. You can list all threads on the session, each tagged with its agent name and status, and stream or list the events of any one of them. That is how you debug what a specific checker actually did rather than inferring it from the condensed primary view. The primary thread is the dashboard. The per-thread streams are the detail.
The detail that makes it usable: every request comes back to one stream
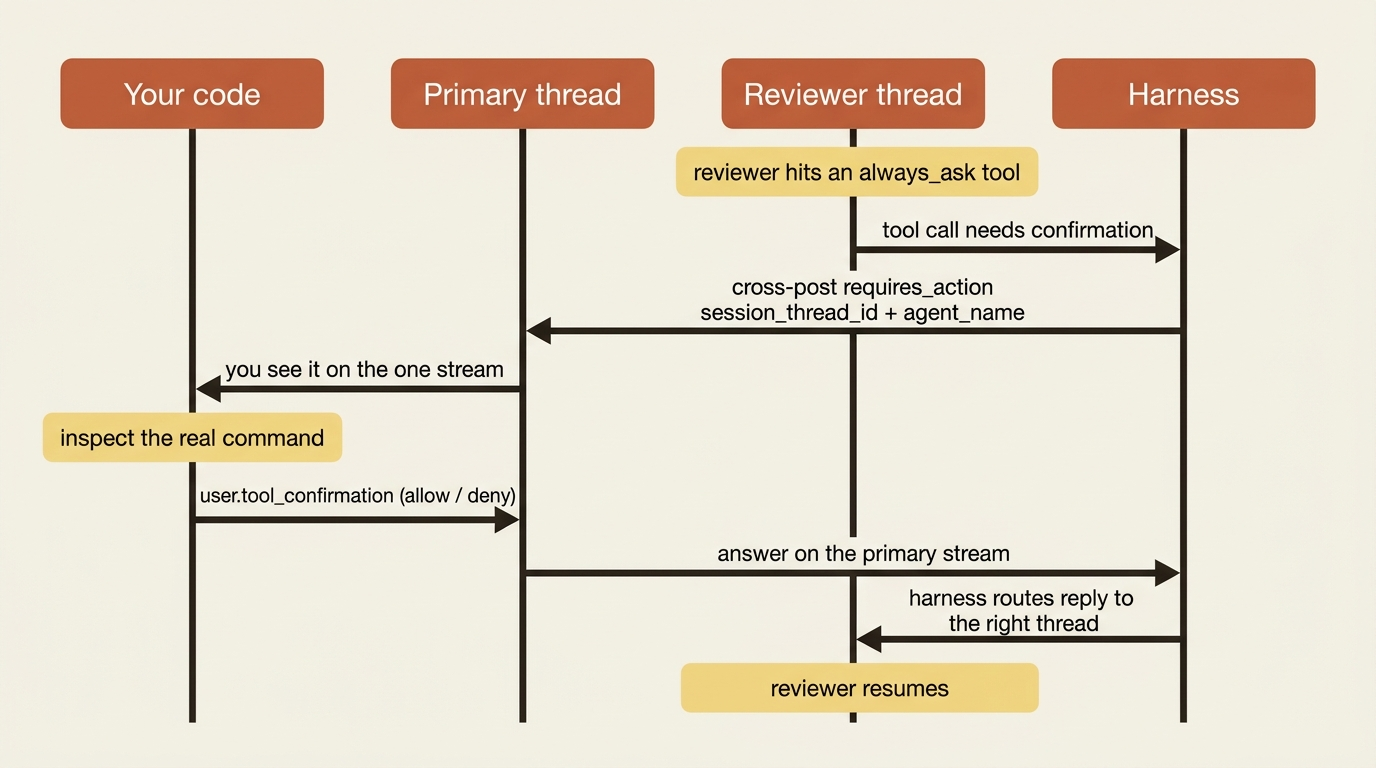
Here is the most important practical fact in the whole topic, the one that keeps multi-agent from becoming a coordination nightmare. A worker agent can hit the same blocking conditions a solo agent hits. It might call a tool gated by always_ask, or invoke a custom tool whose result only your code can produce. In a naive design you would have to listen to every worker's thread to catch those, racing dozens of streams at once.
You do not. When a non-coordinator agent needs something from your client, the request is cross-posted to the primary thread, carrying a session_thread_id that identifies which worker it came from. A worker's tool-confirmation request surfaces on the one stream you are already watching. It looks like the requires_action you handle for any single agent, just with a session_thread_id and an agent_name attached telling you who is asking:
{
"type": "session.thread_status_idle",
"id": "sevt_01ABC...",
"session_thread_id": "sth_01DEF...",
"agent_name": "reviewer",
"stop_reason": {
"type": "requires_action",
"event_ids": ["toolu_01XYZ..."]
}
}
You reply exactly as you always have. Send user.tool_confirmation with the tool_use_id, or user.custom_tool_result with the custom_tool_use_id. The server routes your answer back to the correct thread automatically. You do not address the worker. You do not manage thread routing. You answer on the primary stream and the harness delivers it. Your existing confirmation handler works here, essentially unchanged. That is the design choice that makes orchestration tractable: many workers, one place to answer.
The trap to plan for: workers do not inherit the coordinator's setup
This follows directly from delegates being independent agents, and it is the thing most likely to surprise you in practice. A worker does not inherit the coordinator's permissions, tools, or configuration. Each agent brings its own, defined when it was created.
So if your line-item checker needs the billing MCP server, the checker agent must declare it. The coordinator declaring it does nothing for the worker. If the reviewer should be allowed to run bash without asking, that policy lives on the reviewer, not the lead.
The practical consequence is that you plan permissions per agent, up front, across the whole roster. A common pattern is to set the workers' tool policies so that they do not constantly block on confirmations the coordinator cannot answer for them. You do this in one of two ways: give trusted workers always_allow on the tools they need, or be ready to handle the cross-posted requires_action requests on the primary thread for the ones you keep gated. The point is to decide deliberately rather than discover at runtime that a worker is stalled on a permission you only configured on the lead.
Do this today
- Sketch your roster before any code. List each worker as its own agent with its own model, prompt, and tools. The cheap, fast specialist and the careful, capable one are usually two different agents.
- Flatten any tree in your design. If you imagined sub-coordinators delegating further, collapse it to one coordinator with a flat roster. Depth beyond one is silently ignored.
- Write the coordinator's system prompt as a strategy. State the org chart and the routing rules in plain language: how to batch the work, who gets the flagged items, and how to synthesize the result.
- Plan permissions per worker. Decide now which tools each worker can run without asking, and which will cross-post a
requires_actionto the primary thread. - Budget your threads. Count the primary thread plus every delegated copy against the 25-thread ceiling, and archive idle threads on long batch jobs.
A team you talk to like a single agent
Multi-agent orchestration turns a capable solo agent into a coordinated team without changing how you interact with it from the outside. One session. One primary stream. One place to answer every worker's request.
The differences from subagents elsewhere are now concrete. Delegates are pre-created, versioned resources you reference by ID. Delegation is a single flat level rather than a tree. The team shares a filesystem but not a context. And each worker carries its own permissions and tools, which you plan for in advance.
The escalation-and-parallelization pattern is what the feature is built for: a cheap model for the bulk work, an expensive model for the judgment calls, and a lead to divide and combine. The same reconciliation that one agent ground through sequentially now runs as a fan-out, faster and with each agent thinking clearly in its own scoped context. The worker became a lead, and the job became a team.
This is Part 10 of "Building with Claude Managed Agents," a 13-part guide to building production-ready AI agents.